Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
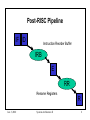
Machine Organization (CS 570) Lecture 1: Overview of High Performance Processors* Jeremy R. Johnson Wed. Sept. 27, 2000 *This lecture was derived from material in the text (HPC Chap. 1-2). Jan. 5, 2000 Systems Architecture II 1 Introduction • Objective: To review recent developments in the design of high performance microprocessors. To indicate how these features effect program performance. • An example program will be used to illustrate benchmarking techniques and the effect of compiler optimizations and code organization on performance. We will indicate how changes in software can improve performance by better utilizing the underlying hardware. Our goal for the course is to understand this behavior. • Topics – pipelining – instruction level parallelism, superscalar and out of order execution – Memory Hierarchy: cache, virtual memory Jan. 5, 2000 Systems Architecture II 2 RISC vs. CISC •CISC: instruction set made up of powerful instructions close to primitives in a high-level language such as C or FORTRAN •RISC: low level instructions are emphasized. RISC is a label most commonly used for a set of instruction set architecture characteristics chosen to ease the use of aggressive implementation techniques found in high-performance processors (John Mashey) •Prevalence began in mid-1980s (earlier example CDC 6600) when more transistors and better compilers became available. •Trade complex instructions for faster clock rate and more room for extra registers, cache and advanced performance techniques. Jan. 5, 2000 Systems Architecture II 3 Characterizing RISC • Instruction pipelining • Pipelining floating point execution • Uniform instruction length • Delayed branching • Load/Store architecture • Simple addressing modes Jan. 5, 2000 Systems Architecture II 4 Pipelining • Instruction pipelining – – – – – Instruction Fetch Instruction Decode Operand Fetch Execute Writeback IF ID F E W IF ID F E W IF ID F E W Jan. 5, 2000 Systems Architecture II 5 Branches and Hazards • If a branch is executed the pipeline may need to be flushed since the wrong instructions may have been started. IF ID F E W guess guess guess sure Jan. 5, 2000 IF ID F E W IF ID F E W IF ID F E W IF ID F E Systems Architecture II 6 Advanced Techniques • Superscalar Processors – issue more than one instruction per cycle – can’t have dependencies or hardware conflict – for example can execute an add simultaneously with a mult • Superpipeling – more stages in the pipeline • Out of order and speculative execution – maintain semantics but allow instructions to be computed in different order – may need to guess which instruction to execute – depends on difference between computation and execution Jan. 5, 2000 Systems Architecture II 7 Post-RISC Pipeline IF ID Instruction Reorder Buffer IRB E RR Rename Registers Jan. 5, 2000 Systems Architecture II R 8 Memory Hierarchy • SRAM vs. DRAM – small fast memory vs. large slow memory – principle of locality • • • • • Registers Cache (level 1) Cache (level 2) Main memory Disk Jan. 5, 2000 Systems Architecture II 9 Memory Access Speed on DEC 21164 Alpha • Clock Speed 500 MHz (= 2 ns clock rate) • Registers (2 ns) • L1 On-Chip (4 ns) • L2 On-Chip (5 ns) • L3 Off-Chip (30 ns) • Memory (220 ns) Jan. 5, 2000 Systems Architecture II 10 Cache Organization • Since cache is smaller than memory more than one address must map to same line in cache • Direct-Mapped Cache – address mod cache size (only one location when memory address gets mapped to) • Fully Associative Cache – address can be mapped anywhere in cache – need tag and associative search to find if element in cache • Set-Associative Cache – compromise between two extremes – element can map to several locations Jan. 5, 2000 Systems Architecture II 11 Virtual Memory • Decouple physical addresses (memory locations) from addresses used by a program. Programmer sees a large memory with the same virtual addresses independent of where the program is actually placed in memory. – Virtual to physical mapping performed via a page table – Since page tables can be in virtual memory, there could be several table lookups for a single memory reference. – TLB (translation lookaside buffer) is a cache to store commonly used virtual to physical maps. • Page Fault – when page is not in memory it must be brought in (from disk) – very slow (usually occurs with OS intervention) Jan. 5, 2000 Systems Architecture II 12 Improving Memory Performance • Larger and wider caches • Cache bypass • Interleaved and pipelined memory systems • Prefetching • Post-RISC effects on memory • New memory trends Jan. 5, 2000 Systems Architecture II 13