Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
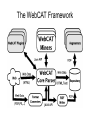
The WebCAT Framework Automatic Generation of Meta-Data from Web Resources Bruno Martins and Mário J. Silva Faculdade de Ciências da Universidade de Lisboa Outline of the Presentation • Motivation • The WebCAT framework • Overview of the components – The Core Parser – The Miners – The Augmenters • Applications and results • Conclusions and future work Motivation WWW is the largest information source in the world but... – Semantic Web is not truly deployed yet – Poorly authored HTML pages - Fuzzy and irregular input – Content and presentation heavily interlinked (not XHTML) – No meta-data standard (Dublin Core is not mandatory) – Multiple formats (Flash, PDF, …) Designing tools that reuse and remix Web content remains very difficult! Recently Proposed Semantic Web Systems Annotation of Web pages with ontology derived semantic tags – Manual or semi-automatic tagging – Laborious and error-prone task Fully automated systems can provide the means to bootstrap the Semantic Web WebCAT : Web Content Analysis Tool Extensible framework for automatically extracting/generating meta-data from present-day Web resources • Web agents and page scrappers • Web crawlers • Web mining applications Starting point for more advanced annotation systems and Semantic Web tools The WebCAT Framework WebCAT Core Parser Low-level processing related to scanning HTML and extracting information • Conversion from other file formats to HTML • Handle fuzzy, noisy, irregular input – Similar to HTML browsers, never throw syntax errors – Best effort approach to solve markup problems – Fault-tolerant parser written by hand WebCAT Core Parser: Text Content • Tokenization based on context pairs – Context given by surrounding character(s) – HTML scanning and tokenization tightly coupled • Detection of sentences and individual words • Character n-grams and collocations • Keep track of HTML markup information WebCAT Core Parser : Hyperlinks Normalization of HTML links • Discard URLs not following the syntax • Convert host names to lowercase • www.TEST.COM/ converted to www.test.com/ • Discard default port number • www.test.com:80/ converted to www.test.com/ • Normalize file information • www.test.com/d1/..// converted to www.test.com/ WebCAT Core Parser: Meta-Tags Normalization of Meta-Tag information – Dublin Core – GeoTags – GeoURL – Robots Exclusin Protocol – HTTP-Equiv Extraction of available RDF information WebCAT Miners Task specific modules that infer knowledge from the available meta-data • Machine-learning and text analytics techniques • Some examples: – – – – – Content fingerprinting algorithm (Rabin hash function) Detecting nepotistic links (Davison’00) Stemming algorithms (Snowball package) Language Identification (Martins&Silva’05) Named Entity Recognition WebCAT Miners : Language Identification Language meta-data useful to bootstrap more advanced algorithms • Existing language METATAG information • Machine learning approach based on n-grams – Comparison of most frequently occurring n-grams – Efficient similarity measure (Lin’98) – Heuristics based on HTML tags WebCAT Miners: Named Entity Recognition Named entity annotations with references to ontology • Currently handles locations and organizations with a geographical context (for use in Geo-IR) • Knowledge-based system with rules combining – Name lists (multilingual, based on language meta-data) – Context patterns (multilingual, based on language meta-data) – Capitalization • Heuristics for disambiguation + “grounding” to ontology – One reference per discourse (Gale et al’93) WebCAT Augmenters Augmenting the metadata extracted/mined from the documents • Good for simultaneous analysis of a large number of Web resources • Combination of the available meta-data WebCAT Augmenters: Assigning Geographical Scopes to Web Pages Assign each document a geographical scope • Use geo-references from the NER miner • Anchor text is propagated to other pages • Disambiguation made through: – Relations on a geographical ontology – Graph ranking algorithm (PageRank) Applications • Open source software • http://webcat.soureforge.net • In use at the tumba! Web search engine • http://www.tumba.pt • 10 million Portuguese Web pages • GREASE Project (Web-Geo-IR) • Web characterization studies • Used in participations on TREC and CLEF Experimental Results Evaluation of individual components • The Core Parser • Tokenizer achieved 95% accuracy over WSJ corpus • The Miners • Language identification achieved 91% accuracy in discriminating 11 different languages over Web pages. • NER achieved 0.89 precision and 0.68 recall on recognizing NEs on a small set of web pages • The Augmenters • Scope Assignment in DMOZ pages gave promising results Additional experiments currently under way! Experimental Results Statistics from a Crawl of the Portuguese Web Document Statistics Avg. Words per Doc. Collective Statistics Value Documents analyzed 325140 Data size 78 GB Textual data 8.8 GB External Links 243930 Web Sites Avg. Document Size Words Distinct Words Value 438 Avg. Doc Size 32.4 KB Avg. Text Size 2.8 GB Avg. Word Length 5 chars Meta-Data Statistics Value PDF Docs 1.9% DOC,XLS,PPT Docs 0.7% 131864 Description tag 17% 32.4 KB Keywords tag 18% Portuguese docs 73% English docs 17% 1652645998 7880609 Content replicas Distinct Words 15.5% 7880609 Conclusions and Future Work • Automatic meta-data generation is a pre-requisite for the deployment of the semantic Web • Large scale effort of collecting/generating meta-data for Web resources • Advantages over other existing methods (DOM parsers or regular expression tools) • Modular architecture facilitates adding new features • Some of the specific algorithms require improvements • API and documentation needs some cleaning up Thanks for your attention. [email protected] http://webcat.sourceforge.net