Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
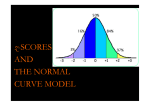
HELIA BITE / Applied Mathematics FORMULAS 30.4.2017 1 (7) Statistics Median from grouped data: n FMd 1 2 c Md f Md Md LMd LMd = lower class boundary of median class n = total number of observations FMd-1 = cumulative frequency of the class preceding median class fMd = frequency of median class cMd = width of median class Quartiles (Q1 ja Q3), deciles (Dn) and percentiles (Pn%) can be defined by applying the same principle. Arithmetic mean (=average) from ungrouped and grouped data: x x i x n xi = single observation n = total number of observations fx i i n fi = frequency of class i xi = midpoint of class i n = total number of observations Range and Range-Width (R): [min ; max] R = max - min Standard deviation from ungrouped data (with and without arithmetic mean): s x i x 2 2 s n 1 From grouped data: f x 2 s fx i 2 i i n 1 x x n i 2 n i i n 1 HELIA BITE / Applied Mathematics FORMULAS 30.4.2017 Variance (s2) and proportional variance (V): s2 = s2 (square of standard deviation) V s x Linear regression: y = a + bx b n xi y i xi y i a n xi xi 2 2 y n i b x i n Pearson’s coefficient of correlation (rxy): rxy n x n xi y i xi y i 2 i xi n yi yi 2 2 2 Spearman’s coefficient of rank correlation (rs): rs 1 6 di 2 n(n 2 1) di = difference between ranks of i n = total number of ranked items Probability Theoretical probability P( A) k n k = number of ways as event can occur n = total number of different equally likely events that can occur P(-A) = 1 – P(A) -A = “Not A” = complement of A P(A and B) = P(A) × P(B|A) P(B|A) = P(B) when A does occur 2 (7) HELIA BITE / Applied Mathematics FORMULAS 30.4.2017 3 (7) Independent events, A B : (1) P(A and B) = P(A) × P(B) P(A or B) = P(A) + P(B) – P(A and B) (2) P(A or B) = P(A) + P(B) - P(A) × P(B) Mutually exclusive events: [P(A and B) =0] P(A or B) = P(A) + P(B) Permutations and combinations: Factorial notation: n! = n × (n-1) × (n-2) × … × 3 × 2 × 1 0! = 1 In how many different ways can one put n items in order? n! Permutation: If there are n items and k are to be placed in order, the number of different ways in which this can be done is: n Pk n! (n k )! Combination: If there are n items and k are to be placed irrespective of order, the number of different ways in which this can be done is: n n n! C k k k! (n k )! Probability distributions: Binomial distribution: n P(k ) p k q n k k p = the probability of ‘success’ q = 1 - p = the probability of ’failure’ n = number of trials k = number of ‘successes’ HELIA BITE / Applied Mathematics Poisson distribution: FORMULAS 30.4.2017 P(k ) k e k! = mean number of successes [ = np ] n = number of trials k = number of ‘successes’ e = exponential constant = 2,71828 Exponential distribution: P(>T) = e-aT P(<T) = 1 - e-aT T = waiting time for the next ‘failure’ a = constant failure rate (= failures per time unit) e = exponential constant = 2,71828 Normal distribution: Standard normal distribution: x 0 , 1 See z statistic in full on the separate sheet If x ~N(,), then z x ~ N(0,1) Normal estimate of binomial and Poisson distributions: x np ( ) , npq Estimate of populations mean: is within the values x cr s n = population mean x = sample mean cr = critical factor based on the significance level (see below) s = sample standard deviation n = total number of observations in sample level of accuracy factor (cr) 95 % 99 % 1,96 2,58 99,9 % 3,30 4 (7) HELIA BITE / Applied Mathematics FORMULAS 30.4.2017 Estimation of the percentage value in population: pˆ qˆ n p is within values pˆ cr p = percentage value in population p = percentage value in sample (in decimal format) q= 1- p n = total number of observations in sample cr = critical factor based on the significance level (see the previous page) Statistical testing Critical values of the z-test: two-tailed test one-tailed test 5% 1,960 1,645 1% 2,576 2,326 0,1 % 3,291 3,090 Critical values of the t-test: See the separate sheet. Degrees of freedom f = n – 1 n = total number of observations in sample Mean test Test variable: z x t n x n x = sample mean = comparison mean = population (or sample) standard deviation n = total number of observations in sample z -test, if n 30 t -test, if n < 30 Percentage value test (only if n > 30) z x np 0 np o q 0 tai z P p0 p0 q0 n x = number of ’successes’ in sample n = total number of observations in sample p0 = comparison percentage value q0 = 1 - p0 P = x/n : percentage value of ‘successes’ in sample (in decimal format) Critical values of z-test: see above. 5 (7) HELIA BITE / Applied Mathematics FORMULAS 30.4.2017 Two sample mean test (t -test): t x1 x 2 (n1 1) s1 (n2 1) s 2 (n1 1) (n2 1) 2 where s 1 1 s n1 n 2 2 x1, s1, n1, : mean, standard deviation and number of observations in sample 1 x2, s2, n2, : mean, standard deviation and number of observations in sample 2 Degrees of freedom: f = n1 + n2 -2 Two sample percentage value test (z -test): z P1 P2 where 1 1 P (1 P ) n1 n 2 P n1 P1 n2 P2 n1 n2 P1 = percentage value of ‘successes’ in sample 1 (in decimal format) P2 = percentage value of ‘successes’ in sample 2 (in decimal format) n1 = number of observations in sample 1 n2 = number of observations in sample 2 2 –test (Chi squared –test) Critical values: see the separate sheet Distribution test: 2 (oi ei ) 2 ei oi = observed values ei = expected values : ei row total column total grand total Degrees of freedom: f = number of categories (usually = number of columns) - 1 Independency test: 2 i j (oij eij ) 2 eij oij = observed values eij = expected values : eij row total column total grand total Degrees of freedom: f = (nr. of rows -1) × (nr. of columns -1) 6 (7) HELIA BITE / Applied Mathematics FORMULAS 30.4.2017 7 (7) Queuing theory = average number of clients joining the queue within a time unit T = average number of clients that could be served within a time unit T Time unit T can be chosen freely. ’Jam factor’ : = Single line system M/M/1//FIFO defaults: (1) Number of customers in the system: n (2) Number of customers in queue: (3) Time spent in the system: w (4) Queuing time: wq 2 nq ( ) 1 ( ) Time from formulas (3) and (4) is presented in the same unit to which parameters and refer. Intervals between to consequential arrivals follow exponential distribution Number of arrivals / exits follow Poisson distribution Probability for total number of customers in system: P(n) = n(1-) P(no queue) = P(0) + P(1) P(queue) = 1 - P(no queue)
















![1 STAT 370: Probability and Statistics for y Engineers [Section 002]](http://s1.studyres.com/store/data/004155539_1-650e86b03c31606d282c23de5ae2b689-150x150.png)