Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Open Database Connectivity wikipedia , lookup
Microsoft SQL Server wikipedia , lookup
Oracle Database wikipedia , lookup
Ingres (database) wikipedia , lookup
Global serializability wikipedia , lookup
Relational model wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Commitment ordering wikipedia , lookup
Database model wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Clusterpoint wikipedia , lookup
ContactPoint wikipedia , lookup
Serializability wikipedia , lookup
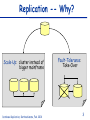
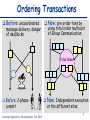
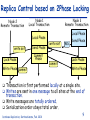
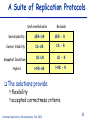
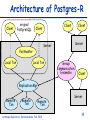
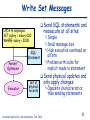
Consistent and Efficient Database Replication based on Group Communication Bettina Kemme School of Computer Science McGill University, Montreal Outline State of the Art in Database Replication Key Points of our Approach Overview of the Algorithms Implementation Issues Performance Results Ongoing Work Database Replication, Bettina Kemme, Feb. 2001 2 Replication -- Why? Scale-Up: cluster instead of bigger mainframe Database Replication, Bettina Kemme, Feb. 2001 Fault-Tolerance: Take-Over 3 Replica Control: Research and Reality UPDATE WHEN UPDATE WHERE Primary Copy Globally correct Too expensive Deadlocks Eager Placement Strategies Lazy Update Everywhere Quorum/ROWA Oracle Synchr. Repl Feasible in some applications Feasible Inconsistent reads Configuration Restrictions Inconsistent reads Reconciliation Placement Strat. Sybase/IBM/Oracle Weak Consistency Sybase/IBM/Oracle Database Replication, Bettina Kemme, Feb. 2001 4 Requirements Develop and apply appropriate techniques in order to avoid current limitations of eager update everywhere approaches Keep flexibility of update everywhere no restrictions on type of transactions and where to execute them Consistency and fault-tolerance of eager replication Good Performance response time + throughput Straightforward, Implementable Solution Easy integration in existing systems Database Replication, Bettina Kemme, Feb. 2001 5 Response Time and Message Overhead Goal: Reduce number of messages per transaction reduce response time reduce message overhead Solution local execution of transaction bundle writes and send them in a single message at the end of the transaction (as done in lazy schemes) central transaction Read Write transaction with individual remote writes transaction with local execution and write set propagation at the end Database Replication, Bettina Kemme, Feb. 2001 6 Ordering Transactions Before: uncoordinated message delivery; danger of deadlocks Now: pre-order txns by using total order multicast of Group Communication Total Order Before: 2-phasecommit Database Replication, Bettina Kemme, Feb. 2001 Now: Independent execution at the different sites 7 Group Communication Systems Group Communication: Multicast Delivery order (FIFO, causal, total, etc.) Reliable delivery: on all nodes vs. on all available nodes Membership control ISIS, Totem, Transis, Phoenix, Horus, Ensemble, ... Goal: Exploit rich semantics of group communication on a low level of the software hierarchy Database Replication, Bettina Kemme, Feb. 2001 8 Replica Control based on 2Phase Locking Node 2 Remote Transaction Local Phase write set Lock Phase Send Phase Commit Phase Write Phase commit Node 3 Remote Transaction Node 1 Local Transaction Local Phase write set commit WS Send Phase Lock Phase Write Phase Transaction is first performed locally at a single site. Writes are sent in one message to all sites at the end of transaction. Write messages are totally ordered. Serialization order obeys total order. Database Replication, Bettina Kemme, Feb. 2001 9 Concurrency Control One possible Solution: Given a transaction T Local Phase: T acquires standard local read and write locks Send Phase: Send write set using total order multicast Upon reception of write set of T on local node Commit Phase: multicast commit message Upon reception of write set of T on remote node Lock Phase: request all write locks in a single step; if there is a local transaction T’ with conflicting lock and T’ is still in local phase or send phase, abort T’. If T’ in send phase, multicast abort Write Phase: apply updates of T Upon reception of commit/abort message of T on remote node, terminate T accordingly For two transactions of same node: 2 phase locking. For concurrent transactions of different nodes: optimistic scheme with early conflict detection: when write set of one transaction is delivered the conflict is detected. Adjustment to other concurrency control schemes possible Database Replication, Bettina Kemme, Feb. 2001 10 Message Delivery Guarantees Uniform-Reliable Delivery If a site delivers a message, all non-faulty sites deliver the message Correctness on all sites (faulty or non-faulty): when a transaction commits at any site then it commits at all non-faulty sites High message delay Reliable Delivery If a non-faulty site (non-faulty for a sufficiently long time) delivers a message it is delivered at all non-faulty sites. Correctness in the failure-free case In case of failures: all non-faulty sites commit the same set of transactions a transaction might be committed at a faulty site (shortly before failure) and it is not committed at the other sites. Low message delay Database Replication, Bettina Kemme, Feb. 2001 11 A Suite of Replication Protocols Uniform Reliable Reliable SER-UR SER - R Cursor Stability CS-UR CS - R Snapshot Isolation SI-UR SI - R HYB-UR HYB - R Serializability Hybrid The solutions provide flexibility accepted correctness criteria Database Replication, Bettina Kemme, Feb. 2001 12 Implementation Integration of our replica control approach into the database system PostgreSQL Purpose - We wanted to answer the following questions Can the abstract protocols really be mapped to concrete algorithms in a relational database? How difficult is it to integrate the replication tool into a real database system? What is the performance in a real cluster environment? Database Replication, Bettina Kemme, Feb. 2001 13 Architecture of Postgres-R Client original PostgreSQL Client Client Client Server Server Postmaster Local Txn Local Txn Group Communication: Ensemble Client Replication Mgr Remote Txn Remote Txn Remote Txn Database Replication, Bettina Kemme, Feb. 2001 Server 14 Write Set Messages UPDATE employee SET salary = salary+100 WHERE salary < 2000 Parser/ Optimizer Simple Small message size High execution overhead on SQLStatement all site Problem with locks for implicit reads in statement Executor Send SQL statements and reexecute at all sites Set of physical records Database Replication, Bettina Kemme, Feb. 2001 Send physical updates and only apply changes Opposite characteristics than sending statements 15 Gain of sending and applying physical changes Scaleup for different remote update costs and update rate of 1 8 Scaleup 6 wo:0.1 wo:0.2 wo:0.5 wo:1 4 2 0 1 5 10 15 20 Number of Nodes Scaleup numberOfNodes remoteUpdateCost 1 updateRate (numberOfNodes 1) localUpdateCost Database Replication, Bettina Kemme, Feb. 2001 16 Comparison with standard distr. locking For all experiments: Database: 10 relations a 1000 tuples Transactions: 10 updates per transaction Workload: 10 transactions per second 5 concurrent clients (each submitting a transaction each 500 milliseconds) Postgres- R 800 Response Time in ms Response Time in ms Traditional 600 400 200 0 1 2 3 4 5 Number Servers Database Replication, Bettina Kemme, Feb. 2001 200 150 100 50 0 1 2 3 Number Servers 4 5 17 Response Time vs. Throughput Database Replication, Bettina Kemme, Feb. 2001 18 Scalability with fixed workload Workload: 1 update transaction per second per server 14 queries per second per server 3 clients per server Postgres-R Response Time in ms 200 150 Write Txn Read Txn 100 50 0 1 server/ 15tps 5 server/ 75tps 10 server/ 15 server/ 150tps 225tps Database Replication, Bettina Kemme, Feb. 2001 19 Differently loaded Nodes Nodes: 10 nodes 15 clients in total Database Replication, Bettina Kemme, Feb. 2001 20 Conclusions Eager, update everywhere replication is feasible (at least in clusters) by using adequate techniques As few messages as possible within transaction boundaries As few synchronization points as possible Complete transaction execution only at one site Simple to adjust to existing concurrency control mechanisms Database Replication, Bettina Kemme, Feb. 2001 21 Current Work Recovery under various failure models Development of a middleware replication tool Development of group communication protocols that better support the needs of the database system Ordering semantics Failure models Building a complete system Adding other replica control protocols System administration Partial replication functionality Database Replication, Bettina Kemme, Feb. 2001 22