Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Microsoft Access wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Team Foundation Server wikipedia , lookup
Clusterpoint wikipedia , lookup
Relational algebra wikipedia , lookup
Database model wikipedia , lookup
Open Database Connectivity wikipedia , lookup
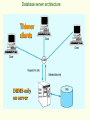
Relational Algebra & Client-Server Systems, CS263 Lectures 11 and 12 Relational Algebra Relational algebra operations work on one or more relations to define another relation leaving the original intact. Both operands and results are relations, so output from one operation can become input to another operation. Allows expressions to be nested, just as in arithmetic. This property is called closure. 5 basic operations in relational algebra: Selection, Projection, Cartesian product, Union, and Set Difference. These perform most of the data retrieval operations needed. Also have Join, Intersection, and Division operations, which can be expressed in terms of 5 basic operations. Relational Algebra Operations Selection (Restriction) predicate (R) Works on a single relation R and defines a relation that contains only those tuples of R that satisfy the specified condition (predicate). Example: List all staff with a salary greater than £10,000. salary > 10000 (Staff) Projection col1, . . . , coln(R) Works on a single relation R and defines a relation that contains a vertical subset of R, extracting the values of specified attributes and eliminating duplicates. Example: Produce a list of salaries for all staff, showing only their staffNo, fName, lName, and salary details. staffNo, fName, lName, salary (Staff) Union RS Union of two relations R and S defines a relation that contains all the tuples of R, or S, or both R and S, duplicate tuples being eliminated. R and S must be union-compatible (i.e. same attributes). Example: Produce a list of all staff that work in either of two departments (each department has a separate database), showing only their staffNo, and date of birth. staffNo, dob(Staff_DepA) staffNo, dob (Staff_DepB) Staff_DepB Staff_DepA staffNo SL10 SA51 DS40 dob 14-02-64 21-11-82 01-01-40 staffNo dob CC15 11-03-66 SA51 21-11-82 staffNo SL10 SA51 DS40 CC15 dob 14-02-64 21-11-82 01-01-40 11-03-66 Intersect RS Defines a relation consisting of the set of all tuples that are in both R and S. R and S must be union-compatible. Example: Produce a list of staff that work in both department A and department B, showing only their staffNo, and date of birth. ( staffNo, dob(Staff_DepA)) ( staffNo, dob (Staff_DepB)) Staff_DepB Staff_DepA staffNo SL10 SA51 DS40 dob 14-02-64 21-11-82 01-01-40 staffNo dob CC15 11-03-66 SA51 21-11-82 staffNo dob SA51 21-11-82 Set Difference R–S Defines a relation consisting of the tuples that are in relation R, but not in S. R and S must be union-compatible. Example: Produce a list of all staff that only work in department A (each department has a separate database), showing only their staffNo, and date of birth. staffNo, dob(Staff_DepA) Staff_DepB Staff_DepA staffNo SL10 SA51 DS40 staffNo, dob (Staff_DepB) dob 14-02-64 21-11-82 01-01-40 staffNo dob CC15 11-03-66 SA51 21-11-82 staffNo dob SL10 14-02-64 DS40 01-01-40 Cartesian product X RXS Defines a relation that is the concatenation of every tuple of relation R with every tuple of relation S. Example: Combine details of staff and the departments they work in. staffNo, job, dept (Staff) X dept, name (Dept) Staff staffNo job SL10 Salesman SA51 Manager DS40 Clerk Dept dept 10 20 20 X dept name 10 Stratford 20 Barking staffNo job SL10 Salesman SA51 Manager DS40 Clerk SL10 Salesman SA51 Manager DS40 Clerk dept 10 20 20 10 20 20 dept 10 10 10 20 20 20 name Stratford Stratford Stratford Barking Barking Barking Relational Algebra Operations Join R <join condition> <join condition> S Defines a relation that results from a selection operation (with a join predicate) over the Cartesian product of relation R and relation S. Example: Produce a list of staff and the departments they work in. ( staffNo, job, dept (Staff)) Staff staffNo job SL10 Salesman SA51 Manager DS40 Clerk Staff.dept = Dept.dept Dept dept 10 20 20 dept name 10 Stratford 20 Barking ( dept, name (Dept)) staffNo job SL10 Salesman SA51 Manager DS40 Clerk dept 10 20 20 dept 10 20 20 name Stratford Barking Barking Because the predicate operator is an ‘=‘ this is known as an Equijoin Natural Join R S This performs an Equijoin of the two relations R and S over all common attributes. One occurrence of each common attribute is eliminated from the result. Example: Produce a list of staff and the departments they work in. ( staffNo, job, dept (Staff)) Staff staffNo job SL10 Salesman SA51 Manager DS40 Clerk ( dept, name (Dept)) Dept dept 10 20 20 dept name 10 Stratford 20 Barking staffNo job SL10 Salesman SA51 Manager DS40 Clerk dept 10 20 20 name Stratford Barking Barking Left Outer Join R S Left outer join is a join in which tuples from R that do not have matching values in common columns of S are also included in the resulting relation. Example: Produce a list of all departments and associated staff that work in them. ( dept, name (Dept)) Dept dept 10 20 30 ( staffNo, job, dept (Staff)) Staff name Stratford Barking Watford staffNo job SL10 Salesman SA51 Manager DS40 Clerk dept 10 20 20 dept 10 20 20 30 name Stratford Barking Barking Watford staffNo SL10 SA51 DS40 job Salesman Manager Clerk Intersect RS Defines a relation consisting of the set of all tuples that are in both R and S. R and S must be union-compatible. Example: Produce a list of staff that work in both department A and department B, showing only their staffNo, and date of birth. ( staffNo, dob(Staff_DepA)) ( staffNo, dob (Staff_DepB)) Staff_DepB Staff_DepA staffNo SL10 SA51 DS40 dob 14-02-64 21-11-82 01-01-40 staffNo dob CC15 11-03-66 SA51 21-11-82 staffNo dob SA51 21-11-82 Division R S Defines a relation over common attributes C that consists of set of tuples from R that match a combination of every tuple in S. Example: Show all staff that use all the company’s programming languages. Staff_Prog Prog Prog Staff_Prog staffNo SL10 SA51 SA51 SE14 SE18 language COBOL BASIC COBOL BASIC BASIC language COBOL BASIC staffNo SA51 CS263 Lec. 12: Client/Server systems • • • • • • Operate in a networked environment Processing of an application distributed between front-end clients and back-end servers Generally the client process requires some resource, which the server provides to the client Clients and servers can reside in the same computer, or they can be on different computers that are networked together, usually: Client – Workstation (usually a PC) that requests and uses a service Server – Computer (PC/mini/mainframe) that provides a service. For DBMS, server is a database server Three components of application logic 1. Input – output or presentation logic component – responsible for formatting and presenting data on the user’s screen (or other output device) and managing user input from keyboard (or other input device) 2. Processing component logic – handles data processing logic (validation and identification of processing errors), business rules logic, and data management logic (identifies the data necessary for processing the transaction or query) Client/Server architectures File Server Architecture Database Server Architecture Three-tier Architecture Client does extensive processing Client does little processing File server architecture The first client/server architectures developed All processing is done at the PC that requested the data, I.e. the client handles the presentation logic, the processing logic and much of the storage logic A file server is a device that manages file operations and is shared by each of the client PCs attached to the LAN Each file server acts as an additional hard disk for each of the client PCs Each PC may be called a FAT CLIENT (most processing occurs on the client) Entire files are transferred from the server to the client for processing. Three problems with file server architecture 1. Huge amount of data transfer on network when client wants to access data whole table(s) transferred to PC – so server is doing very little work 2. Each client authorised to use DBMS when DB application program runs on that PC - one database but many concurrently running copies of DBMS (one on each PC) – heavy resource demand on clients 3. DBMS copy in each client must manage shared database integrity - must recognize shared locks, integrity checks, etc File Server Architecture FAT CLIENT Database server (2-tier) architectures Client responsible for managing user interface, I/O processing logic, data processing logic and some business rules logic (front-end programs) Database server performs data storage and access processing (back-end functions) – DBMS only on server Clients do not have to be as powerful, and server can be tuned to optimise data processing performance Greatly reduces data traffic on the network, as only records (rather than tables) that match request transmitted to client Improved data integrity as all processed centrally Stored procedures Modules of code implementing application logic – included on the database server. Advantages: Performance improves for compiled SQL statements Reduced network traffic as processing moves from the client to the server Improved security if stored procedure is accessed rather than data and code being moved to server Improved data integrity - multiple applications access same stored procedure Thinner clients (and a fatter database server) Disadvantages: Writing stored procedures takes more time than using e.g. VB + proprietary nature reduces portability + performance degrades as number of on-line users increases Database server architecture Thinner clients DBMS only on server 3-tier architectures In general, these include another server layer in addition to the client and database server This additional server may be used for different purposes Often application programs reside on the additional server (the application server) Or additional server may hold a local database whilst another server holds the enterprise database Often a thin client - PC just for user interface and a little application processing. Limited or no data storage (sometimes no hard drive) Three-tier architecture Thinnest clients Business rules on separate server DBMS only on DB server Advantages Scalability – middle tier can be used to reduce load on database sever by using a transaction processing monitor to reduce number of connections to server, and additional application servers can be added to distribute processing Technological flexibility – easier to change DBMS engines – middle tier can be moved to different platform. Easier to implement new interfaces Cost reduction – use of off-the-shelf components/services in the middle tier - also substitution of modules within application rather than whole application Improved customer service – multiple interfaces on different clients can access the same business process Competitive advantage – ability to react to business changes quickly by changing small modules of code Challenges High short-term costs – presentation component must be split from process component – this requires more programming Tools, training and experience– currently lack of development tools and training programmes, and people experienced in the technology Incompatible standards – few standards yet proposed Lack of compatible end-user tools – many end-user tools such as spreadsheets and report generators do not yet work through middle-tier services (see later discussion on middleware) Middleware Software which allows an application to interoperate with other software, without requiring the user to understand and code the low-level operations required to achieve interoperability With Synchronous systems, the requesting system waits for a response to the request in real time Asynchronous systems send a request but do not wait for a response in real time – the response is accepted whenever it is received . 6 Types of Middleware -> 1. Asynchronous Remote Procedure Calls (RPC) - client makes calls to procedures running on remote computers but does not wait for a response. If connection lost, must re-establish the connection and send again. High scalability but low recovery 2. Synchronous RPC – distributed program using this calls services available on different computers – possible to achieve this without undertaking detailed coding (e.g. RMI in Java) 3. Publish/Subscribe (push technology) - server monitors activity and sends information to client when available asynchronous, clients (subscribers) perform other activities between notifications from server. 4. Message-Oriented Middleware – asynchronous, sends messages that are collected and stored until acted upon client continues with other processing. 5. Object Request Broker (ORB) – tracks location of each object and routes requests 6. SQL-oriented Data Access - translate generic SQL into Database middleware ODBC – Open Database Connectivity - most DB vendors support this OLE-DB - Microsoft enhancement of ODBC JDBC – Java Database Connectivity - Special Java classes that allow Java applications/applets to connect to databases CORBA – Common Object Request Broker Architecture – specification of object-oriented middleware DCOM – Microsoft’s version of CORBA – not as robust as CORBA over multiple platforms Client/Server security Network environment has complex security issues. Networks susceptible to breaches of security through eavesdropping, unauthorised connections or unauthorised retrieval of packets of information flowing round the network. Specific security issues include: System-level password security – user names and passwords for allowing access to the system. Password management utilities Database-level password security - for determining access privileges to tables; read/update/insert/delete privileges Secure client/server communication - via encryption – but encryption can negatively affect performance DB access from clients Partitioning to create 2, 3 or n-tier architecture - decisions must be made about the placement of the processing logic Storage logic (the database engine) handled by server, and presentation logic handled by client Part a) of Fig. depicts possible 2-tier systems, placing processing logic on client (fat client), on server (thin client) or partitioned across both (distributed environment) Part b) depicts typical 3 and n -tier architectures Some processing logic placed on the client if Processing logic distributions a) 2-tier Processing logic could be at client, server, or both Processing logic will be at application server or Web server b) 3 and n-tier Open Database Connectivity (ODBC) An API providing common language for application programs to access/process SQL databases independent of particular RDBMS Required parameters: ODBC driver needed, Backend server name, Database name, User id and password Fig. Shows generic ODBC architecture Client application requests connection established with data source Driver manager identifies appropriate ODBC driver Driver selected processes requests from the client and submits queries to RDBMS in required version of SQL Java Database Connectivity (JDBC) similar to ODBC – built specifically for Java applications ODBC Architecture Client does not need to know anything about the DBMS Application Program Interface (API) provides common interface to all DBMSs Each DBMS has its own ODBC-compliant driver