Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
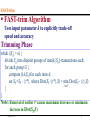
Efficient Data-Reduction Methods for On-line Association Rule Mining H. Bronnimann B. Chen P. Haas Polytechnic Univ Exilixis IBM Almaden [email protected] NGDM’02 [email protected] M. Dash, Y. Qiao, P. Scheuermann Northwestern University [email protected] {manoranj,yiqiao,peters}@ece.nwu.edu 1 Motivation Volume of Data in Warehouses & Internet is growing faster than Moore’s Law Scalability is a major concern “Classical” algorithms require one/more scans of the database Need to adopt to Streaming Data Data elements arrive on-line Limited amount of memory One Solution: Execute algorithm on a sample Lossy compressed synopses (sketch) of data NGDM’02 2 Motivation Sampling Methods Advantage: can explicitly trade-off accuracy and speed Work best when tailored to application Our Contributions Sampling methods for count datasets Base set of items & each data element is vector of item counts Application: Association rule mining NGDM’02 3 Outline Outline of the Presentation Motivation FAST Epsilon Approximation Experimental Results Data Stream Reduction Conclusion NGDM’02 4 The Problem Generate a smaller subset S0 of a larger superset S such that the supports of 1-itemsets in S0 are close to those in S minimize Dist ( S0 , S ) S0 S , S 0 n NP-Complete: One-In-Three SAT Problem | L1 ( S ) L1 ( S 0 ) | | L1 ( S 0 ) L1 ( S ) | Dist 1 | L1 (S 0 ) L1 ( S ) | Dist 2 ( f ( A; S 0 ) f ( A; S )) 2 AI1 ( S ) Dist max f ( A; S 0 ) f ( A; S ) AI1 ( S ) I1(T) = set of all 1-itemsets in transaction set T L1(T) = set of frequent 1-itemsets in transaction set T f(A;T) = support of itemset A in transaction set T NGDM’02 5 FAST-trim FAST-trim Outline Given a specified minimum support p and confidence c, FAST-trim Algorithm proceeds as follows: Obtain a large simple random sample S from D. 2. Compute f(A;S) for each 1-itemset A. 3. Using the supports computed in Step 2, obtain a reduced sample S0 from S by trimming away outlier transactions. 4. Run a standard association-rule algorithm against S0 – with Minimum support p and confidence c – to obtain the final set of Association Rules. 1. NGDM’02 6 FAST-trim FAST-trim Algorithm Uses input parameter k to explicitly trade-off speed and accuracy Trimming Phase while (|S0| > n) { divide S0 into disjoint groups of min(k,|S0|) transactions each; for each group G { compute f(A;S0) for each item A; set S0=S0 – {t*}, where Dist(S0 -{t*},S) = min Dist(S0 - {t},S) teG } } Note: Removal of outlier t* causes maximum decrease or minimum increase in Dist(S0,S) NGDM’02 7 FAST-grow FAST-grow Algorithm Select representative transactions from S and add them to the sample S0 that is initially empty Growing Phase while (|S0| > n) { divide S0 into disjoint groups of min(k,|S0|) transactions each; for each group G { compute f(A;S0) for each item A; set S0=S0 {t*}, where Dist(S0 {t*},S) = min Dist(S0{t},S) teG } } NGDM’02 8 Epsilon Approximation (EA) Epsilon Approximation (EA) Theory based on work in statistics on VC Dimensions (Vapnik & Cervonenkis’71) shows: Can estimate simultaneously the frequency of a collection of subsets VC dimension is finite Applications to computational geometry and learning theory Def: A sample S0 of S1 is an e approximation iff discrepancy satisfies Dist (S 0 , S1 ) e NGDM’02 9 Epsilon Approximation (EA) Halving Method Deterministically halves the data to get sample S0 Apply halving repeatedly (S1 => S2 => … => St (= S0)) until Dist (S 0 , S1 ) e Each halving step introduce a discrepancy e i (ni , m) where m = total no. of items in database, ni = size of sub-sample Si Halving stops with the maximum t such that e t e i ( n i , m) e i t NGDM’02 10 Epsilon Approximation (EA) How to compute halving? Hyperbolic cosine method [Spencer] 1. Color each transaction red (in sample) or blue (not in sample) 2. Penalty for each item, reflects Penalty small if red/blue approximately balanced Penalty will shoot up exponentially when red dominates (item is over-sampled), or blue dominates (item is under-sampled) 3. Color transactions sequentially, keeping penalty low Key property: no increase on penalty in average => One of the two colors does not increase the penalty globally NGDM’02 11 Epsilon Approximation (EA) Penalty Computation Let Qi = Penalty for item Ai Init Qi = 2 Suppose that we have colored the first j transactions Qi Qi( j ) (1 i ) ri (1 i ) bi (1 i ) ri (1 i ) bi where ri = ri(j) = no. of red transactions containing Ai bi = bi(j) = no. of blue transactions containing Ai i = parameter that influences how fast penalty changes as function of |ri - bi| NGDM’02 12 Epsilon Approximation (EA) How to color transaction j+1 Compute global penalty: Q ( r ) Qi( j||r ) i Q (b ) Qi( j||b ) i = Global penalty assuming transaction j+1 is red = Global penalty assuming transaction j+1 is blue Choose color for which global penalty is smaller EA is inherently an on-line method NGDM’02 13 Performance Evaluation Synthetic data set IBM QUEST project [AS94] 100,000 transactions 1,000 items number of maximal potentially large itemsets = 2000 average transaction length: 10 average length of maximal large itemsets: 4 minimum support: 0.77% length of the maximal large itemsets: 6 Final sampling ratios: 0.76%, 1.51%, 3.0%, … dictated by EA halvings NGDM’02 14 Experimental Results FAST_trim_D1 FAST_trim_D2 EA SRS Accuracy vs. Sample Ratio FAST_trim vs. EA/SRS Time vs. Sample Ratio FAST_trim vs. EA/SRS 1 Time (cpu sec) Accuracy 0.9 0.8 0.7 0.6 0.5 0.4 0 0.05 0.1 0.15 0.2 0.25 0.3 FAST_trim_D1 FAST_trim_D2 EA SRS 3.5 3 2.5 2 1.5 1 0.5 0 0 0.05 Sample Ratio 0.1 0.15 0.2 Sample Ratio 0.25 87% reduction in sample size for accuracy: EA (99%), FAST_trim_D2 (97%), SRS (94.6%) NGDM’02 15 0.3 Experimental Results Accuracy vs. Sample Ratio FAST_grow vs. EA/SRS FAST_grow_D1 FAST_grow_D2 EA SRS Time vs. Sample Ration FAST_grow vs. EA/SRS Time (cpu sec) 1 Accuracy 0.9 0.8 0.7 0.6 0.5 0.4 0 0.05 0.1 0.15 0.2 Sample Ratio 0.25 0.3 FAST_grow_D1 FAST_grow_D2 EA SRS 3.5 3 2.5 2 1.5 1 0.5 0 0 0.05 0.1 0.15 0.2 0.25 Sample Ratio FAST_grow_D2 is best for very small sampling ratio (< 2%) EA best over-all in accuracy NGDM’02 16 0.3 Data Stream Reduction Data Stream Reduction (DSR) Representative sample of data stream Assign more weight to recent data while partially keeping track of old data NS/2 mS NS/2 mS-1 NS/2 … mS-2 NS/2 Total #Transactions = ms.Ns/2 1 Bucket# To generate NS-element sample, halve (mS-k) times of bucket k NS/2 mNGDM’02 S NS/4 NS/8 mS-1 mS-2 … 1 1 Bucket# 17 Data Stream Reduction Practical Implementation To avoid frequent halving we use one buffer once and compute new representative sample when buffer is full by applying EA 0 Halving Ns 1 Halving 2 Halving NGDM’02 Empty 1 Halving 2 Halving 3 Halving 18 Data Stream Reduction Problem: Two users immediately before and after halving operation see data that varies substantially Continuous DSR: Buffer divided into chunks 2ns Next ns transactions arrive New trans ns 3ns 4ns 5ns Ns-2ns NGDM’02 Ns Oldest chunk is halved first Ns-ns Ns 19 Conclusion Two-stage sampling approach based on trimming outliers or selecting representative transactions Epsilon approximation: deterministic method for repeatedly halving data to obtain final sample Can be used in conjunction with other non-sampling count-based mining algorithms EA-based data stream reduction • We are investigating how to evaluate goodness of representative subset • Frequency information to be used for discrepancy function NGDM’02 20