Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Privacy Preserving Data Mining:
An Overview and Examination of Euclidean
Distance Preserving Data Transformation
Chris Giannella
cgiannel AT acm DOT org
Talk Outline
●
●
●
●
Introduction
–
Privacy preserving data mining – what problem is it
aimed to address?
–
Focus of this talk: data transformation
Some data transformation approaches
My current research: Euclidean distance
preserving data transformation
Wrap-up summary
An Example Problem
●
The U.S. Census Bureau collects lots of data
●
If released in raw form, this data would provide
–
a wealth of valuable information regarding broad
population patterns
–
Access to private information regarding individuals
How to allow analysts to extract population
patterns without learning private information?
Privacy-Preserving Data Mining
“The study of how to produce valid mining
models and patterns without disclosing private
information.”
- F. Giannotti and F. Bonchi, “Privacy Preserving Data Mining,” KDUbiq Summer School, 2006.
Several broad approaches … this talk
data transformation (the “census model”)
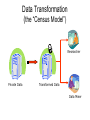
Data Transformation
(the “Census Model”)
Researcher
Private Data
Transformed Data
Data Miner
DT Objectives
• Minimize risk of disclosing private
information
• Maximize the analytical utility of the
transformed data
DT is also studied in the field of Statistical
Disclosure Control.
Some things DT does not
address…
• Preventing unauthorized access to the
private data (e.g. hacking).
• Securely communicating private data.
DT and cryptography are quite different.
(Moreover, standard encryption does not solve
the DT problem)
Assessing Transformed Data Utility
How accurately does a transformation preserve
certain kinds of patterns, e.g.:
●
data mean, covariance
●
Euclidean distance between data records
●
Underlying generating distribution?
How useful are the patterns at drawing
conclusions/inferences?
Assessing Privacy Disclosure Risk
• Some efforts in the literature to develop
rigorous definitions of disclosure risk
– no widely accepted agreement
• This talk will take an ad-hoc approach:
– for a specific attack, how closely can any
private data record be estimated?
Talk Outline
●
●
●
●
Introduction
–
Privacy preserving data mining – what problem is it aimed to address?
–
Focus of this talk: data transformation
Some data transformation approaches
My current research: Euclidean distance
preserving data transformation
Wrap-up summary
Some DT approaches
●
Discussed in this talk:
–
Additive independent noise
–
Euclidean distance preserving transformation
●
●
My current research
Others:
–
Data swapping/shuffling, multiplicative noise, microaggregation, K-anonymization, replacement with
synthetic data, etc…
Additive Independent Noise
• For each private data record, (x1,…,xn),
add independent random noise to each
entry:
– (y1,…,yn) = (x1+e1,…,xn+en)
– ei is generated independently as N(0, d*Var(i))
– Increasing d reduces privacy disclosure risk
Additive Independent Noise d = 0.5
Additive Independent Noise
• Difficult to set d producing
• low privacy disclosure risk
• high data utility
• Some enhancements on the basic idea
exist
• E.g. Muralidhar et al.
Talk Outline
●
●
●
●
Introduction
–
Privacy preserving data mining – what problem is it aimed to address?
–
Focus of this talk: data transformation
Some data transformation approaches
My current research: Euclidean distance
preserving data transformation (EDPDT)
Wrap-up summary
EDPDT – High Data Utility!
●
Many data clustering algorithms use Euclidean
distance to group records, e.g.
–
●
K-means clustering, hierarchical agglomerative
clustering
If Euclidean distance is accurately preserved,
these algorithms will produce the same clusters
on the transformed data as the original data.
EDPDT – High Data Utility!
Original data
Transformed data
EDPDT – Unclear Privacy
Disclosure Risk
●
Focus of the research ... approach
–
Develop attacks combining the transformed data
with plausible prior knowledge.
–
How well can these attacks estimate private data
records?
Two Different Prior Knowledge
Assumptions
●
Known input: The attacker knows a small
subset of the private data records.
–
●
Focus of this talk.
Known sample: The attacker knows a set of
data records drawn independently from the
same underlying distribution as the private data
records.
–
happy to discuss “off-line”.
Known Input Prior Knowledge
Underlying assumption: Individuals know
a) if there is a record for them along the private
data records, and
b) know the attributes of the private data records.
Each individual knows one private record.
A small group of malicious individuals could
cooperate to produce a small subset of the
private data records.
Known Input Attack
Given: {Y1,…,Ym} (transformed data records)
{X1,…,Xk} (known private data records)
1) Determine the transformation constraints
i.e. which transformed records came from which
known private records.
2) Choose T randomly from the set of all distance
preserving transformations that satisfy the
constraints.
3) Apply T-1 to the transformed data.
Know Input Attack – 2D data, 1
known private data record
Known Input Attack – General Case
Y = MX
●
Each column of X (Y) is a private (transformed) data record.
●
M is an orthogonal matrix.
[Ykn Yun] = M[Xknown Xunkown]
Attack:
Choose T randomly from {T an orthogonal matrix: TXknown = Ykn}.
Produce T-1(Yun).
23
Known Input Attack -- Experiments
18,000 record, 16-attribute real data set.
Given k known private data records, computed
Pk, the probability that the attack estimates one
unknown private record with > 85% accuracy.
P2 = 0.16
P4 = 1
…
P16 = 1
Wrap-Up Summary
●
●
●
Introduction
–
Privacy preserving data mining – what problem is it
aimed to address?
–
Focus of this talk: data transformation
Some data transformation approaches
My current research: Euclidean distance
preserving data transformation
Thanks to …
●
You:
– for
●
Kun Liu:
–
●
joint research & some material used in this
presentation
Krish Muralidhar:
–
●
your attention
some material used in this presentation
Hillol Kargupta:
–
joint research
Records
Attributes
Distance Preserving Perturbation
Distance Preserving Perturbation
ID
Wages
Rent
Tax
1001
-26,326
-94,502
10,151
Y
1002
-22,613
-80,324
8,432
=
-0.2507
0.4556
-0.8542
-0.9653
-0.0514
0.2559
0.0726
0.8887
0.4527
M
×
ID
Wages
Rent
Tax
1001
98,563
1,889
2,899
X
1002
83,821
1,324
2,578
Known Sample Attack
[more]
Known Sample Attack Experiments
backup
Fig. Known sample attack for Adult data with 32,561 private tuples. The attacker has
2% samples from the same distribution. The average relative error of the recovered
data is 0.1081 (10.81%).