Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Experiment Design & Analysis Reference
ReliaSoft Corporation
Worldwide Headquarters
1450 South Eastside Loop
Tucson, Arizona 85710-6703, USA
http://www.ReliaSoft.com
Notice of Rights: The content is the Property and Copyright of ReliaSoft Corporation, Tucson,
Arizona, USA. It is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0
International License. See the next pages for a complete legal description of the license or go to
http://creativecommons.org/licenses/by-nc-sa/4.0/legalcode.
Quick License Summary Overview
You are Free to:
Share: Copy and redistribute the material in any medium or format
Adapt: Remix, transform, and build upon the material
Under the following terms:
Attribution: You must give appropriate credit, provide a link to the license, and indicate if
changes were made. You may do so in any reasonable manner, but not in any way that suggests
the licensor endorses you or your use. See example at
http://www.reliawiki.org/index.php/Attribution_Example
NonCommercial: You may not use this material for commercial purposes (sell or distribute for
profit). Commercial use is the distribution of the material for profit (selling a book based on the
material) or adaptations of this material.
ShareAlike: If you remix, transform, or build upon the material, you must distribute your
contributions under the same license as the original.
Generation Date: This document was generated on April 29, 2015 based on the current state of the
online reference book posted on ReliaWiki.org. Information in this document is subject to change
without notice and does not represent a commitment on the part of ReliaSoft Corporation. The
content in the online reference book posted on ReliaWiki.org may be more up-to-date.
Disclaimer: Companies, names and data used herein are fictitious unless otherwise noted. This
documentation and ReliaSoft’s software tools were developed at private expense; no portion was
developed with U.S. government funds.
Trademarks: ReliaSoft, Synthesis Platform, Weibull++, ALTA, DOE++, RGA, BlockSim, RENO, Lambda
Predict, Xfmea, RCM++ and XFRACAS are trademarks of ReliaSoft Corporation.
Other product names and services identified in this document are trademarks of their respective
trademark holders, and are used for illustration purposes. Their use in no way conveys endorsement
or other affiliation with ReliaSoft Corporation.
Attribution-NonCommercial-ShareAlike 4.0 International
License Agreement
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public
License
By exercising the Licensed Rights (defined below), You accept and agree to be bound by the terms
and conditions of this Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
Public License ("Public License"). To the extent this Public License may be interpreted as a contract,
You are granted the Licensed Rights in consideration of Your acceptance of these terms and
conditions, and the Licensor grants You such rights in consideration of benefits the Licensor receives
from making the Licensed Material available under these terms and conditions.
Section 1 – Definitions.
a. Adapted Material means material subject to Copyright and Similar Rights that is derived
from or based upon the Licensed Material and in which the Licensed Material is translated,
altered, arranged, transformed, or otherwise modified in a manner requiring permission
under the Copyright and Similar Rights held by the Licensor. For purposes of this Public
License, where the Licensed Material is a musical work, performance, or sound recording,
Adapted Material is always produced where the Licensed Material is synched in timed
relation with a moving image.
b. Adapter's License means the license You apply to Your Copyright and Similar Rights in Your
contributions to Adapted Material in accordance with the terms and conditions of this Public
License.
c. BY-NC-SA Compatible License means a license listed at
creativecommons.org/compatiblelicenses, approved by Creative Commons as essentially the
equivalent of this Public License.
d. Copyright and Similar Rights means copyright and/or similar rights closely related to
copyright including, without limitation, performance, broadcast, sound recording, and Sui
Generis Database Rights, without regard to how the rights are labeled or categorized. For
purposes of this Public License, the rights specified in Section 2(b)(1)-(2) are not Copyright
and Similar Rights.
e. Effective Technological Measures means those measures that, in the absence of proper
authority, may not be circumvented under laws fulfilling obligations under Article 11 of the
WIPO Copyright Treaty adopted on December 20, 1996, and/or similar international
agreements.
f. Exceptions and Limitations means fair use, fair dealing, and/or any other exception or
limitation to Copyright and Similar Rights that applies to Your use of the Licensed Material.
g. License Elements means the license attributes listed in the name of a Creative Commons
Public License. The License Elements of this Public License are Attribution, NonCommercial,
and ShareAlike.
h. Licensed Material means the artistic or literary work, database, or other material to which
the Licensor applied this Public License.
Licensed Rights means the rights granted to You subject to the terms and conditions of this
Public License, which are limited to all Copyright and Similar Rights that apply to Your use of
the Licensed Material and that the Licensor has authority to license.
j. Licensor means ReliaSoft Corporation, 1450 Eastside Loop, Tucson, AZ 85710.
k. NonCommercial means not primarily intended for or directed towards commercial
advantage or monetary compensation. For purposes of this Public License, the exchange of
the Licensed Material for other material subject to Copyright and Similar Rights by digital
file-sharing or similar means is NonCommercial provided there is no payment of monetary
compensation in connection with the exchange.
l. Share means to provide material to the public by any means or process that requires
permission under the Licensed Rights, such as reproduction, public display, public
performance, distribution, dissemination, communication, or importation, and to make
material available to the public including in ways that members of the public may access the
material from a place and at a time individually chosen by them.
m. Sui Generis Database Rights means rights other than copyright resulting from Directive
96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal
protection of databases, as amended and/or succeeded, as well as other essentially
equivalent rights anywhere in the world.
n. You means the individual or entity exercising the Licensed Rights under this Public License.
Your has a corresponding meaning.
i.
Section 2 – Scope.
a. License grant.
1. Subject to the terms and conditions of this Public License, the Licensor hereby grants
You a worldwide, royalty-free, non-sublicensable, non-exclusive, irrevocable license
to exercise the Licensed Rights in the Licensed Material to:
A. reproduce and Share the Licensed Material, in whole or in part, for
NonCommercial purposes only; and
B. produce, reproduce, and Share Adapted Material for NonCommercial
purposes only.
2. Exceptions and Limitations. For the avoidance of doubt, where Exceptions and
Limitations apply to Your use, this Public License does not apply, and You do not
need to comply with its terms and conditions.
3. Term. The term of this Public License is specified in Section 6(a).
4. Media and formats; technical modifications allowed. The Licensor authorizes You to
exercise the Licensed Rights in all media and formats whether now known or
hereafter created, and to make technical modifications necessary to do so. The
Licensor waives and/or agrees not to assert any right or authority to forbid You from
making technical modifications necessary to exercise the Licensed Rights, including
technical modifications necessary to circumvent Effective Technological Measures.
For purposes of this Public License, simply making modifications authorized by this
Section 2(a)(4) never produces Adapted Material.
5. Downstream recipients.
A. Offer from the Licensor – Licensed Material. Every recipient of the Licensed
Material automatically receives an offer from the Licensor to exercise the
Licensed Rights under the terms and conditions of this Public License.
B. Additional offer from the Licensor – Adapted Material. Every recipient of
Adapted Material from You automatically receives an offer from the
Licensor to exercise the Licensed Rights in the Adapted Material under the
conditions of the Adapter’s License You apply.
C. No downstream restrictions. You may not offer or impose any additional or
different terms or conditions on, or apply any Effective Technological
Measures to, the Licensed Material if doing so restricts exercise of the
Licensed Rights by any recipient of the Licensed Material.
6. No endorsement. Nothing in this Public License constitutes or may be construed as
permission to assert or imply that You are, or that Your use of the Licensed Material
is, connected with, or sponsored, endorsed, or granted official status by, the
Licensor or others designated to receive attribution as provided in Section
3(a)(1)(A)(i).
b. Other rights.
1. Moral rights, such as the right of integrity, are not licensed under this Public License,
nor are publicity, privacy, and/or other similar personality rights; however, to the
extent possible, the Licensor waives and/or agrees not to assert any such rights held
by the Licensor to the limited extent necessary to allow You to exercise the Licensed
Rights, but not otherwise.
2. Patent and trademark rights are not licensed under this Public License.
3. To the extent possible, the Licensor waives any right to collect royalties from You for
the exercise of the Licensed Rights, whether directly or through a collecting society
under any voluntary or waivable statutory or compulsory licensing scheme. In all
other cases the Licensor expressly reserves any right to collect such royalties,
including when the Licensed Material is used other than for NonCommercial
purposes.
Section 3 – License Conditions.
Your exercise of the Licensed Rights is expressly made subject to the following conditions.
a. Attribution.
1. If You Share the Licensed Material (including in modified form), You must:
A. retain the following if it is supplied by the Licensor with the Licensed
Material:
i.
identification of the creator(s) of the Licensed Material and any
others designated to receive attribution, in any reasonable manner
requested by the Licensor (including by pseudonym if designated);
ii.
a copyright notice;
iii.
a notice that refers to this Public License;
iv.
a notice that refers to the disclaimer of warranties;
v.
a URI or hyperlink to the Licensed Material to the extent reasonably
practicable;
B. indicate if You modified the Licensed Material and retain an indication of
any previous modifications; and
C. indicate the Licensed Material is licensed under this Public License, and
include the text of, or the URI or hyperlink to, this Public License.
2. You may satisfy the conditions in Section 3(a)(1) in any reasonable manner based on
the medium, means, and context in which You Share the Licensed Material. For
example, it may be reasonable to satisfy the conditions by providing a URI or
hyperlink to a resource that includes the required information.
3. If requested by the Licensor, You must remove any of the information required by
Section 3(a)(1)(A) to the extent reasonably practicable.
b. ShareAlike.
In addition to the conditions in Section 3(a), if You Share Adapted Material You produce, the
following conditions also apply.
1. The Adapter’s License You apply must be a Creative Commons license with the same
License Elements, this version or later, or a BY-NC-SA Compatible License.
2. You must include the text of, or the URI or hyperlink to, the Adapter's License You
apply. You may satisfy this condition in any reasonable manner based on the
medium, means, and context in which You Share Adapted Material.
3. You may not offer or impose any additional or different terms or conditions on, or
apply any Effective Technological Measures to, Adapted Material that restrict
exercise of the rights granted under the Adapter's License You apply.
Section 4 – Sui Generis Database Rights.
Where the Licensed Rights include Sui Generis Database Rights that apply to Your use of the
Licensed Material:
a. for the avoidance of doubt, Section 2(a)(1) grants You the right to extract, reuse, reproduce,
and Share all or a substantial portion of the contents of the database for NonCommercial
purposes only;
b. if You include all or a substantial portion of the database contents in a database in which You
have Sui Generis Database Rights, then the database in which You have Sui Generis Database
Rights (but not its individual contents) is Adapted Material, including for purposes of Section
3(b); and
c. You must comply with the conditions in Section 3(a) if You Share all or a substantial portion
of the contents of the database.
For the avoidance of doubt, this Section 4 supplements and does not replace Your obligations under
this Public License where the Licensed Rights include other Copyright and Similar Rights.
Section 5 – Disclaimer of Warranties and Limitation of Liability.
a. Unless otherwise separately undertaken by the Licensor, to the extent possible, the
Licensor offers the Licensed Material as-is and as-available, and makes no representations
or warranties of any kind concerning the Licensed Material, whether express, implied,
statutory, or other. This includes, without limitation, warranties of title, merchantability,
fitness for a particular purpose, non-infringement, absence of latent or other defects,
accuracy, or the presence or absence of errors, whether or not known or discoverable.
Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not
apply to You.
b. To the extent possible, in no event will the Licensor be liable to You on any legal theory
(including, without limitation, negligence) or otherwise for any direct, special, indirect,
incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or
damages arising out of this Public License or use of the Licensed Material, even if the
Licensor has been advised of the possibility of such losses, costs, expenses, or damages.
Where a limitation of liability is not allowed in full or in part, this limitation may not apply
to You.
c. The disclaimer of warranties and limitation of liability provided above shall be interpreted in
a manner that, to the extent possible, most closely approximates an absolute disclaimer and
waiver of all liability.
Section 6 – Term and Termination.
a. This Public License applies for the term of the Copyright and Similar Rights licensed here.
However, if You fail to comply with this Public License, then Your rights under this Public
License terminate automatically.
b. Where Your right to use the Licensed Material has terminated under Section 6(a), it
reinstates:
1. automatically as of the date the violation is cured, provided it is cured within 30 days
of Your discovery of the violation; or
2. upon express reinstatement by the Licensor.
For the avoidance of doubt, this Section 6(b) does not affect any right the Licensor may have
to seek remedies for Your violations of this Public License.
c. For the avoidance of doubt, the Licensor may also offer the Licensed Material under
separate terms or conditions or stop distributing the Licensed Material at any time;
however, doing so will not terminate this Public License.
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public License.
Section 7 – Other Terms and Conditions.
a. The Licensor shall not be bound by any additional or different terms or conditions
communicated by You unless expressly agreed.
b. Any arrangements, understandings, or agreements regarding the Licensed Material not
stated herein are separate from and independent of the terms and conditions of this Public
License.
Section 8 – Interpretation.
a. For the avoidance of doubt, this Public License does not, and shall not be interpreted to,
reduce, limit, restrict, or impose conditions on any use of the Licensed Material that could
lawfully be made without permission under this Public License.
b. To the extent possible, if any provision of this Public License is deemed unenforceable, it
shall be automatically reformed to the minimum extent necessary to make it enforceable. If
the provision cannot be reformed, it shall be severed from this Public License without
affecting the enforceability of the remaining terms and conditions.
c. No term or condition of this Public License will be waived and no failure to comply
consented to unless expressly agreed to by the Licensor.
d. Nothing in this Public License constitutes or may be interpreted as a limitation upon,
or waiver of, any privileges and immunities that apply to the Licensor or You,
including from the legal processes of any jurisdiction or authority.
Contents
Chapter 1
DOE Overview
Chapter 2
Statistical Background on DOE
Chapter 3
Simple Linear Regression Analysis
Chapter 4
Multiple Linear Regression Analysis
Chapter 5
One Factor Designs
Chapter 6
General Full Factorial Designs
Chapter 7
Randomization and Blocking in DOE
Chapter 8
Two Level Factorial Experiments
Chapter 9
Highly Fractional Factorial Designs
Chapter 10
Response Surface Methods for Optimization
Chapter 11
Design Evaluation and Power Study
Chapter 12
Optimal Custom Designs
1
1
5
5
23
23
49
49
88
88
101
101
114
114
120
120
173
173
184
184
210
210
243
243
Chapter 13
Robust Parameter Design
Chapter 14
Mixture Design
Chapter 15
Reliability DOE for Life Tests
Chapter 16
Measurement System Analysis
Appendices
251
251
264
264
288
288
314
314
347
Appendix A: ANOVA Calculations in Multiple Linear Regression
347
Appendix B: Use of Regression to Calculate Sum of Squares
349
Appendix C: Plackett-Burman Designs
351
Appendix D: Taguchi's Orthogonal Arrays
354
Appendix E: Alias Relations for Taguchi's Orthogonal Arrays
360
Appendix F: Box-Behnken Designs
362
Appendix G: Glossary
363
Appendix H: References
368
1
Chapter 1
DOE Overview
Much of our knowledge about products and processes in the engineering and scientific disciplines is derived from
experimentation. An experiment is a series of tests conducted in a systematic manner to increase the understanding
of an existing process or to explore a new product or process. Design of experiments (DOE), then, is the tool to
develop an experimentation strategy that maximizes learning using a minimum of resources. DOE is widely used in
many fields with broad application across all the natural and social sciences. It is extensively used by engineers and
scientists involved in the improvement of manufacturing processes to maximize yield and decrease variability. Often
engineers also work on products or processes where no scientific theories or principles are directly applicable.
Experimental design techniques become extremely important in such studies to develop new products and processes
in a cost effective and confident manner.
Why DOE?
With modern technological advances, products and processes are becoming exceedingly complicated. As the cost of
experimentation rises rapidly, it is becoming increasingly difficult for the analyst, who is already constrained by
resources and time, to investigate the numerous factors that affect these complex processes using trial and error
methods. Instead, a technique is needed that identifies the "vital few" factors in the most efficient manner, and then
directs the process to its best setting to meet the ever increasing demand for improved quality and increased
productivity. DOE techniques provide powerful and efficient methods to achieve these objectives.
Designed experiments are much more efficient than one-factor-at-a-time experiments, which involve changing a
single factor at a time to study the effect of the factor on the product or process. While one-factor-at-a-time
experiments are easy to understand, they do not allow the investigation of how a factor affects a product or process
in the presence of other factors. An interaction is the relationship whereby the effect that a factor has on the product
or process is altered due to the presence of one or more other factors. Oftentimes interaction effects are more
important than the effect of individual factors. This is because the application environment of the product or process
includes the presence of many of the factors together instead of isolated occurrences of one of the factors at different
times. Consider an example of interaction between two factors in a chemical process, where increasing the
temperature alone increases the yield slightly while increasing the pressure alone has no effect. However, in the
presence of both higher temperature and higher pressure the yield increases rapidly. In this case, an interaction is
said to exist between the two factors affecting the chemical reaction.
The DOE methodology ensures that all factors and their interactions are systematically investigated. Therefore,
information obtained from a DOE analysis is much more reliable and complete than results from one-factor-at-a-time
experiments that ignore interactions and thus may lead to incorrect conclusions.
Introduction to DOE Principles
The design and analysis of experiments revolves around the understanding of the effects of different variables on
another variable. In technical terms, the objective is to establish a cause-and-effect relationship between a number of
independent variables and a dependent variable of interest. The dependent variable, in the context of DOE, is called
the response, and the independent variables are called factors. Experiments are run at different factor values, called
levels. Each run of an experiment involves a combination of the levels of the investigated factors, and each of the
combinations is referred to as a treatment. When the same number of response observations are taken for each of the
DOE Overview
treatments of an experiment, the design of the experiment is said to be balanced. Repeated observations at a given
treatment are called replicates.
The number of treatments of an experiment is determined on the basis of the number of factor levels being
investigated. For example, if an experiment involving two factors is to be performed, with the first factor having m
levels and the second having n levels, then m x n treatment combinations can possibly be run, and the experiment is
an m x n factorial design. If all m x n combinations are run, then the experiment is a full factorial. If only some of the
m x n treatment combinations are run, then the experiment is a fractional factorial. In full factorial experiments, all
the factors and their interactions can be investigated, whereas in fractional factorial experiments, at least some
interactions are not considered because some treatments are not run.
It can be seen that the size of an experiment escalates rapidly as the number of factors (or the number of the levels of
the factors) increases. For example, if 2 factors at 3 levels each are to be used, 9 (3x3=9) different treatments are
required for a full factorial experiment. If a third factor with 3 levels is added, 27 (3x3x3=27) treatments are
required, and 81 (3x3x3x3=81) treatments are required if a fourth factor with three levels is added. If only two levels
are used for each factor, then in the four-factor case, 16 (2x2x2x2=16) treatments are required. For this reason, many
experiments are restricted to two levels, and these designs are given a special treatment in this reference. Using a
fractional design further reduces the number of required treatments.
DOE Types
For Comparison: One Factor Designs
With these designs, only one factor is under investigation, and the objective is to determine whether the response is
significantly different at different factor levels. The factor can be qualitative or quantitative. In the case of qualitative
factors (e.g., different suppliers, different materials, etc.), no extrapolations (i.e., predictions) can be performed
outside the tested levels, and only the effect of the factor on the response can be determined. On the other hand, data
from tests where the factor is quantitative (such as temperature, voltage, load, etc.) can be used for both effect
investigation and prediction, provided that sufficient data is available. (In DOE++, predictions for one factor designs
can be performed using the multiple linear regression folio or free form folio.)
For Factor Screening: Factorial Designs
In factorial designs, multiple factors are investigated simultaneously during the test. As in one factor designs,
qualitative and/or quantitative factors can be considered. The objective of these designs is to identify the factors that
have a significant effect on the response, as well as investigate the effect of interactions (depending on the
experiment design used). Predictions can also be performed when quantitative factors are present, but care must be
taken since certain designs are very limited by the choice of the predictive model. For example, in two level designs
only a linear relationship can be used between the response and the factors, which may not be realistic.
• General Full Factorial Designs
In general full factorial designs, the factors can have different number of levels, and they can be quantitative or
qualitative.
• Two Level Full Factorial Designs
With these designs, all factors must have only two levels. Restricting the levels to two and running a full factorial
experiment reduces the number of treatments (compared to a general full factorial experiment), and it allows for the
investigation of all the factors and all their interactions. If all factors are quantitative, then the data from such
experiments can be used for predictive purposes, provided a linear model is appropriate for modeling the response
(since only two levels are used, curvature cannot be modeled).
• Two Level Fractional Factorial Design
2
DOE Overview
This is a special category of two level designs, where not all factor level combinations are considered, and the
experimenter can choose which combinations are to be excluded. Based on the excluded combinations, certain
interactions cannot be investigated.
• Plackett-Burman Design
This is a special category of two level fractional factorial designs, proposed by R. L. Plackett and J. P. Burman
[1946], where only a few specifically chosen runs are performed to investigate just the main effects (i.e., no
interactions).
• Taguchi's Orthogonal Arrays
Taguchi's orthogonal arrays are highly fractional designs, used to estimate main effects using only a few
experimental runs. These designs are not only applicable to two level factorial experiments, but also can investigate
main effects when factors have more than two levels. Designs are also available to investigate main effects for
certain mixed level experiments where the factors included do not have the same number of levels.
For Optimization: Response Surface Method Designs
These are special designs that are used to determine the settings of the factors to achieve an optimum value of the
response.
For Product or Process Robustness: Robust Parameter Designs
The famous Taguchi robust design is for robust parameter design. It is is used to design a product or process to be
insensitive to noise factors.
For Life Tests: Reliability DOE
This is a special category of DOE where traditional designs, such as the two level designs, are combined with
reliability methods to investigate effects of different factors on the life of a unit. In reliability DOE, the response is a
life metric (e.g., age, miles, cycles, etc.), and the data may contain censored observations (suspensions, interval
data).
For Experiments with Constraints: Optimal Custom Design
The optimal custom design tool can be used to modify the above standard designs to plan an experiment that meets
any or all of the following constraints: 1) limited availability of test samples, 2) factor level combinations that cannot
be tested, 3) factor level combinations that must be tested or 4) specific factors effects that must be investigated.
Stages of DOE
Designed experiments are usually carried out in five stages: planning, screening, optimization, robustness testing and
verification.
Planning
It is important to carefully plan for the course of experimentation before embarking upon the process of testing and
data collection. A thorough and precise objective identifying the need to conduct the investigation, an assessment of
time and resources available to achieve the objective and an integration of prior knowledge to the experimentation
procedure are a few of the goals to keep in mind at this stage. A team composed of individuals from different
disciplines related to the product or process should be used to identify possible factors to investigate and determine
the most appropriate response(s) to measure. A team-approach promotes synergy that gives a richer set of factors to
study and thus a more complete experiment. Carefully planned experiments always lead to increased understanding
of the product or process.
3
DOE Overview
Screening
Screening experiments are used to identify the important factors that affect the system under investigation out of the
large pool of potential factors. These experiments are carried out in conjunction with prior knowledge of the system
to eliminate unimportant factors and focus attention on the key factors that require further detailed analyses.
Screening experiments are usually efficient designs requiring a few executions where the focus is not on interactions
but on identifying the vital few factors.
Optimization
Once attention is narrowed down to the important factors affecting the process, the next step is to determine the best
setting of these factors to achieve the desired objective. Depending on the product or process under investigation,
this objective may be to either maximize, minimize or achieve a target value of the response.
Robustness Testing
Once the optimal settings of the factors have been determined, it is important to make the product or process
insensitive to variations that are likely to be experienced in the application environment. These variations result from
changes in factors that affect the process but are beyond the control of the analyst. Such factors as humidity, ambient
temperature, variation in material, etc. are referred to as noise factors. It is important to identify sources of such
variation and take measures to ensure that the product or process is made insensitive (or robust) to these factors.
Verification
This final stage involves validation of the best settings of the factors by conducting a few follow-up experiment runs
to confirm that the system functions as desired and all objectives are met.
4
5
Chapter 2
Statistical Background on DOE
Variations occur in nature, be it the tensile strength of a particular grade of steel, caffeine content in your energy
drink or the distance traveled by your vehicle in a day. Variations are also seen in the observations recorded during
multiple executions of a process, even when all factors are strictly maintained at their respective levels and all the
executions are run as identically as possible. The natural variations that occur in a process, even when all conditions
are maintained at the same level, are often called noise. When the effect of a particular factor on a process is studied,
it becomes extremely important to distinguish the changes in the process caused by the factor from noise. A number
of statistical methods are available to achieve this. This chapter covers basic statistical concepts that are useful in
understanding the statistical analysis of data obtained from designed experiments. The initial sections of this chapter
discuss the normal distribution and related concepts. The assumption of the normal distribution is widely used in the
analysis of designed experiments. The subsequent sections introduce the standard normal, chi-squared, and
distributions that are widely used in calculations related to hypothesis testing and confidence bounds. This chapter
also covers hypothesis testing. It is important to gain a clear understanding of hypothesis testing because this concept
finds direct application in the analysis of designed experiments to determine whether or not a particular factor is
significant [Wu, 2000].
Basic Concepts
Random Variables and the Normal Distribution
If you record the distance traveled by your car everyday, you'll notice that these values show some variation because
your car does not travel the exact same distance every day. If a variable is used to denote these values then is
considered a random variable (because of the diverse and unpredicted values can have). Random variables are
denoted by uppercase letters, while a measured value of the random variable is denoted by the corresponding
lowercase letter. For example, if the distance traveled by your car on January 1 was 10.7 miles, then:
A commonly used distribution to describe the behavior of random variables is the normal distribution. When you
calculate the mean and standard deviation for a given data set, a common assumption used is that the data follows a
normal distribution. A normal distribution (also referred to as the Gaussian distribution) is a bell-shaped curved (see
figure below). The mean and standard deviation are the two parameters of this distribution. The mean determines the
location of the distribution on the x-axis and is also called the location parameter. The standard deviation determines
the spread of the distribution (how narrow or wide) and is thus called the scale parameter. The standard deviation, or
its square called variance, gives an indication of the variability or spread of data. A large value of the standard
deviation (or variance) implies that a large amount of variability exists in the data.
Any curve in the image below is also referred to as the probability density function, or pdf of the normal distribution,
as the area under the curve gives the probability of occurrence of for a particular interval. For instance, if you
obtained the mean and standard deviation for the distance data of your car as 15 miles and 2.5 miles respectively,
then the probability that your car travels a distance between 7 miles and 14 miles is given by the area under the curve
covered between these two values, which is calculated to be 34.4% (see figure below). This means that on 34.4 days
out of every 100 days your car travels, your car can be expected to cover a distance in the range of 7 to 14 miles.
Statistical Background on DOE
6
Normal probability density function with the shaded area representing the probability of occurrence of data between 7 and 14
miles.
On
a
normal
probability
density
function, the area under the curve between
and
is
99.7% of the total area under the curve. This implies that almost all the time (or 99.7% of the
traveled will fall in the range of 7.5 miles
and 22.5 miles
covers approximately 95% of the area under
covers approximately 68% of the area under the curve.
the values of
approximately
time) the distance
. Similarly,
the curve and
Population Mean, Sample Mean and Variance
If data for all of the population under investigation is known, then the mean and variance for this population can be
calculated as follows:
Population Mean:
Population Variance:
Here,
is the size of the population.
The population standard deviation is the positive square root of the population variance.
Most of the time it is not possible to obtain data for the entire population. For example, it is impossible to measure
the height of every male in a country to determine the average height and variance for males of a particular country.
In such cases, results for the population have to be estimated using samples. This process is known as statistical
inference. Mean and variance for a sample are calculated using the following relations:
Statistical Background on DOE
7
Sample Mean:
Sample Variance:
Here, is the sample size. The sample standard deviation is the positive square root of the sample variance. The
sample mean and variance of a random sample can be used as estimators of the population mean and variance,
respectively. The sample mean and variance are referred to as statistics. A statistic is any function of observations in
a random sample. You may have noticed that the denominator in the calculation of sample variance, unlike the
denominator in the calculation of population variance, is
and not . The reason for this difference is
explained in Biased Estimators.
Central Limit Theorem
The Central Limit Theorem states that for a large sample size, :
• The sample means from a population are normally distributed with a mean value equal to the population mean,
, even if the population is not normally distributed.
What this means is that if random samples are drawn from any population and the sample mean, , calculated
for each of these samples, then these sample means would follow the normal distribution with a mean (or
location parameter) equal to the population mean, . Thus, the distribution of the statistic, , would be a
normal distribution with mean, . The distribution of a statistic is called the sampling distribution.
• The variance,
, of the sample means would be times smaller than the variance of the population,
.
This implies that the sampling distribution of the sample means would have a variance equal to
(or a
scale parameter equal to
), where is the population standard deviation. The standard deviation of the
sampling distribution of an estimator is called the standard error of the estimator. Thus the standard error of
sample mean is
.
In short, the Central Limit Theorem states that the sampling distribution of the sample mean is a normal distribution
with parameters and
as shown in the figure below.
Statistical Background on DOE
Sampling distribution of the sample mean. The distribution is normal with the mean equal to the population
mean and the variance equal to the nth fraction of the population variance.
Unbiased and Biased Estimators
If the mean value of an estimator equals the true value of the quantity it estimates, then the estimator is called an
unbiased estimator (see figure below). For example, assume that the sample mean is being used to estimate the mean
of a population. Using the Central Limit Theorem, the mean value of the sample mean equals the population mean.
Therefore, the sample mean is an unbiased estimator of the population mean. If the mean value of an estimator is
either less than or greater than the true value of the quantity it estimates, then the estimator is called a biased
estimator. For example, suppose you decide to choose the smallest observation in a sample to be the estimator of the
population mean. Such an estimator would be biased because the average of the values of this estimator would
always be less than the true population mean. In other words, the mean of the sampling distribution of this estimator
would be less than the true value of the population mean it is trying to estimate. Consequently, the estimator is a
biased estimator.
8
Statistical Background on DOE
9
Example showing the distribution of a biased estimator which underestimated the parameter in question, along
with the distribution of an unbiased estimator.
A case of biased estimation is seen to occur when sample variance,
, if the following relation is used to calculate the sample variance:
, is used to estimate the population variance,
The sample variance calculated using this relation is always less than the true population variance. This is because
deviations with respect to the sample mean, , are used to calculate the sample variance. Sample observations, ,
tend to be closer to than to . Thus, the calculated deviations
are smaller. As a result, the sample
variance obtained is smaller than the population variance. To compensate for this,
is used as the
denominator in place of in the calculation of sample variance. Thus, the correct formula to obtain the sample
variance is:
It is important to note that although using
as the denominator makes the sample variance, , an unbiased
estimator of the population variance, , the sample standard deviation, , still remains a biased estimator of the
population standard deviation, . For large sample sizes this bias is negligible.
Statistical Background on DOE
10
Degrees of Freedom (dof)
The number of degrees of freedom is the number of independent observations made in excess of the unknowns. If
there are 3 unknowns and 7 independent observations are taken, then the number of degrees of freedom is 4 (7-3). As
another example, two parameters are needed to specify a line. Therefore, there are 2 unknowns. If 10 points are
available to fit the line, the number of degrees of freedom is 8 (10-2).
Standard Normal Distribution
A normal distribution with mean
and variance
is called the standard normal distribution (see figure
below). Standard normal random variables are denoted by . If represents a normal random variable that follows
the normal distribution with mean and variance , then the corresponding standard normal random variable is:
represents the distance of
from the mean in terms of the standard deviation .
Standard normal distribution.
Statistical Background on DOE
11
Chi-Squared Distribution
If is a standard normal random variable, then the distribution of
below).
is a chi-squared distribution (see figure
Chi-squared distribution.
A chi-squared random variable is represented by
. Thus:
The distribution of the variable
mentioned in the previous equation is also referred to as centrally distributed
chi-squared with one degree of freedom. The degree of freedom is 1 here because the chi-squared random variable is
obtained from a single standard normal random variable . The previous equation may also be represented by
including the degree of freedom in the equation as:
If
,
,
...
are
independent standard normal random variables, then:
is also a chi-squared random variable. The distribution of
is said to be centrally distributed chi-squared with
degrees of freedom, as the chi-squared random variable is obtained from independent standard normal random
variables. If is a normal random variable, then the distribution of
is said to be non-centrally distributed
chi-squared with one degree of freedom. Therefore,
is a chi-squared random variable and can be represented as:
If
,
,
...
are
independent normal random variables then:
is a non-centrally distributed chi-squared random variable with
degrees of freedom.
Statistical Background on DOE
12
Student's t Distribution (t Distribution)
If is a standard normal random variable, is a chi-squared random variable with degrees of freedom, and both
of these random variables are independent, then the distribution of the random variable such that:
is said to follow the distribution with degrees of freedom.
The distribution is similar in appearance to the standard normal distribution (see figure below). Both of these
distributions are symmetric, reaching a maximum at the mean value of zero. However, the distribution has heavier
tails than the standard normal distribution, implying that it has more probability in the tails. As the degrees of
freedom, , of the distribution approach infinity, the distribution approaches the standard normal distribution.
distribution.
F Distribution
If and are two independent chi-squared random variables with and degrees of freedom, respectively, then
the distribution of the random variable such that:
is said to follow the distribution with degrees of freedom in the numerator and degrees of freedom in the
denominator. The distribution resembles the chi-squared distribution (see the following figure). This is because
the random variable, like the chi-squared random variable, is non-negative and the distribution is skewed to the
right (a right skew means that the distribution is unsymmetrical and has a right tail). The random variable is
usually abbreviated by including the degrees of freedom as
.
Statistical Background on DOE
13
distribution.
Hypothesis Testing
A statistical hypothesis is a statement about the population under study or about the distribution of a quantity under
consideration. The null hypothesis,
, is the hypothesis to be tested. It is a statement about a theory that is believed
to be true but has not been proven. For instance, if a new product design is thought to perform consistently,
regardless of the region of operation, then the null hypothesis may be stated as
Statements in
always include exact values of parameters under consideration. For example:
Or simply:
Rejection of the null hypothesis,
, leads to the possibility that the alternative hypothesis,
the previous null hypothesis, the alternate hypothesis may be:
, may be true. Given
In the case of the example regarding inference on the population mean, the alternative hypothesis may be stated as:
Or simply:
Hypothesis testing involves the calculation of a test statistic based on a random sample drawn from the population.
The test statistic is then compared to the critical value(s) and used to make a decision about the null hypothesis. The
critical values are set by the analyst.
The outcome of a hypothesis test is that we either reject
or we fail to reject
. Failing to reject
implies that
we did not find sufficient evidence to reject
. It does not necessarily mean that there is a high probability that
Statistical Background on DOE
14
is true. As such, the terminology accept
is not preferred.
For example, assume that an analyst wants to know if the mean of a certain population is 100 or not. The statements
for this hypothesis can be stated as follows:
The analyst decides to use the sample mean as the test statistic for this test. The analyst further decides that if the
sample mean lies between 98 and 102 it can be concluded that the population mean is 100. Thus, the critical values
set for this test by the analyst are 98 and 102. It is also decided to draw out a random sample of size 25 from the
population.
Now assume that the true population mean is
and the true population standard deviation is
. This
information is not known to the analyst. Using the Central Limit Theorem, the test statistic (sample mean) will
follow a normal distribution with a mean equal to the population mean, , and a standard deviation of
,
where is the sample size. Therefore, the distribution of the test statistic has a mean of 100 and a standard deviation
of
. This distribution is shown in the figure below.
The unshaded area in the figure bound by the critical values of 98 and 102 is called the acceptance region. The
acceptance region gives the probability that a random sample drawn from the population would have a sample mean
that lies between 98 and 102. Therefore, this is the region that will lead to the "acceptance" of
. On the other
hand, the shaded area gives the probability that the sample mean obtained from the random sample lies outside of the
critical values. In other words, it gives the probability of rejection of the null hypothesis when the true mean is 100.
The shaded area is referred to as the critical region or the rejection region. Rejection of the null hypothesis
when
it is true is referred to as type I error. Thus, there is a 4.56% chance of making a type I error in this hypothesis test.
This percentage is called the significance level of the test and is denoted by . Here
or
(area
of the shaded region in the figure). The value of is set by the analyst when he/she chooses the critical values.
Acceptance region and critical regions for the hypothesis test.
A type II error is also defined in hypothesis testing. This error occurs when the analyst fails to reject the null
hypothesis when it is actually false. Such an error would occur if the value of the sample mean obtained is in the
acceptance region bounded by 98 and 102 even though the true population mean is not 100. The probability of
occurrence of type II error is denoted by .
Statistical Background on DOE
15
Two-sided and One-sided Hypotheses
As seen in the previous section, the critical region for the hypothesis test is split into two parts, with equal areas in
each tail of the distribution of the test statistic. Such a hypothesis, in which the values for which we can reject
are
in both tails of the probability distribution, is called a two-sided hypothesis. The hypothesis for which the critical
region lies only in one tail of the probability distribution is called a one-sided hypothesis. For instance, consider the
following hypothesis test:
This is an example of a one-sided hypothesis. Here the critical region lies entirely in the right tail of the distribution.
The hypothesis test may also be set up as follows:
This is also a one-sided hypothesis. Here the critical region lies entirely in the left tail of the distribution.
Statistical Inference for a Single Sample
Hypothesis testing forms an important part of statistical inference. As stated previously, statistical inference refers to
the process of estimating results for the population based on measurements from a sample. In the next sections,
statistical inference for a single sample is discussed briefly.
Inference on the Mean of a Population When the Variance Is Known
The test statistic used in this case is based on the standard normal distribution. If
then the standard normal test statistic is:
where
is the calculated sample mean,
is the hypothesized population mean, is the population standard deviation and is the sample size.
One-sided hypothesis where the critical region lies in the right tail.
Statistical Background on DOE
16
One-sided hypothesis where the critical region lies in the left tail.
For example, assume that an analyst wants to know if the mean of a population, , is 100. The population variance,
, is known to be 25. The hypothesis test may be conducted as follows:
1) The statements for this hypothesis test may be formulated as:
It is a clear that this is a two-sided hypothesis. Thus the critical region will lie in both of the tails of the probability
distribution.
2) Assume that the analyst chooses a significance level of 0.05. Thus
. The significance level determines
the critical values of the test statistic. Here the test statistic is based on the standard normal distribution. For the
two-sided hypothesis these values are obtained as:
and
These values and the critical regions are shown in figure below. The analyst would fail to reject
statistic, , is such that:
if the test
or
3) Next the analyst draws a random sample from the population. Assume that the sample size,
sample mean is obtained as
.
, is 25 and the
Statistical Background on DOE
17
Critical values and rejection region marked on the standard normal distribution.
4) The value of the test statistic corresponding to the sample mean value of 103 is:
Since this value does not lie in the acceptance region
significance level of 0.05.
, we reject
at a
P Value
In the previous example the null hypothesis was rejected at a significance level of 0.05. This statement does not
provide information as to how far out the test statistic was into the critical region. At times it is necessary to know if
the test statistic was just into the critical region or was far out into the region. This information can be provided by
using the value.
The value is the probability of occurrence of the values of the test statistic that are either equal to the one obtained
from the sample or more unfavorable to
than the one obtained from the sample. It is the lowest significance level
that would lead to the rejection of the null hypothesis,
, at the given value of the test statistic. The value of the
test statistic is referred to as significant when
is rejected. The value is the smallest at which the statistic is
significant and
is rejected.
For instance, in the previous example the test statistic was obtained as
. Values that are more unfavorable to
in this case are values greater than 3. Then the required probability is the probability of getting a test statistic
value either equal to or greater than 3 (this is abbreviated as
). This probability is shown in figure below
as the dark shaded area on the right tail of the distribution and is equal to 0.0013 or 0.13% (i.e.,
). Since this is a two-sided test the value is:
Therefore, the smallest
0.0026.
(corresponding to the test static value of 3) that would lead to the rejection of
is
Statistical Background on DOE
18
value.
Inference on Mean of a Population When Variance Is Unknown
When the variance,
, of a population (that can be assumed to be normally distributed) is unknown the sample
variance, , is used in its place in the calculation of the test statistic. The test statistic used in this case is based on
the distribution and is obtained using the following relation:
The test statistic follows the distribution with
degrees of freedom.
For example, assume that an analyst wants to know if the mean of a population, , is less than 50 at a significance
level of 0.05. A random sample drawn from the population gives the sample mean, , as 47.7 and the sample
standard deviation, , as 5. The sample size, , is 25. The hypothesis test may be conducted as follows:
1) The statements for this hypothesis test may be formulated as:
It is clear that this is a one-sided hypothesis. Here the critical region will lie in the left tail of the probability
distribution.
2) Significance level,
. Here, the test statistic is based on the distribution. Thus, for the one-sided
hypothesis the critical value is obtained as:
This value and the critical regions are shown in the figure below. The analyst would fail to reject
statistic is such that:
3) The value of the test statistic,
, corresponding to the given sample data is:
if the test
Statistical Background on DOE
19
Since is less than the critical value of -1.7109,
level of 0.05 the population mean is less than 50.
4)
is rejected and it is concluded that at a significance
value
In this case the value is the probability that the test statistic is either less than or equal to
than
are unfavorable to
). This probability is equal to 0.0152.
(since values less
Critical value and rejection region marked on the distribution.
Inference on Variance of a Normal Population
The test statistic used in this case is based on the chi-squared distribution. If is the calculated sample variance and
the hypothesized population variance then the Chi-Squared test statistic is:
The test statistic follows the chi-squared distribution with
degrees of freedom.
For example, assume that an analyst wants to know if the variance of a population exceeds 1 at a significance level
of 0.05. A random sample drawn from the population gives the sample variance as 2. The sample size, , is 20. The
hypothesis test may be conducted as follows:
1) The statements for this hypothesis test may be formulated as:
This is a one-sided hypothesis. Here the critical region will lie in the right tail of the probability distribution.
2) Significance level,
. Here, the test statistic is based on the chi-squared distribution. Thus for the
one-sided hypothesis the critical value is obtained as:
Statistical Background on DOE
20
This value and the critical regions are shown in the figure below. The analyst would fail to reject
statistic is such that:
3) The value of the test statistic
if the test
corresponding to the given sample data is:
Since
is greater than the critical value of 30.1435,
significance level of 0.05 the population variance exceeds 1.
is rejected and it is concluded that at a
Critical value and rejection region marked on the chi-squared distribution.
4)
value
In this case the value is the probability that the test statistic is greater than or equal to 38 (since values greater than
38 are unfavorable to
). This probability is determined to be 0.0059.
Statistical Inference for Two Samples
Inference on the Difference in Population Means When Variances Are Known
The test statistic used here is based on the standard normal distribution. Let and represent the means of two
populations, and
and
their variances, respectively. Let
be the hypothesized difference in the population
means and
and
be the sample means obtained from two samples of sizes
the two populations, respectively. The test statistic can be obtained as:
The statements for the hypothesis test are:
and
drawn randomly from
Statistical Background on DOE
If
21
, then the hypothesis will test for the equality of the two population means.
Inference on the Difference in Population Means When Variances Are Unknown
If the population variances can be assumed to be equal then the following test statistic based on the distribution can
be used. Let
,
,
and
be the sample means and variances obtained from randomly drawn samples of
sizes
has (
and
+
from the two populations, respectively. The weighted average,
, of the two sample variances is:
-- 2) degrees of freedom. The test statistic can be calculated as:
follows the distribution with ( + -- 2) degrees of freedom. This test is also referred to as the two-sample
pooled test. If the population variances cannot be assumed to be equal then the following test statistic is used:
follows the distribution with degrees of freedom. is defined as follows:
Inference on the Variances of Two Normal Populations
The test statistic used here is based on the
distribution. If
and
are the sample variances drawn randomly
from the two populations and and are the two sample sizes, respectively, then the test statistic that can be used
to test the equality of the population variances is:
The test statistic follows the distribution with (
of freedom in the denominator.
-- 1) degrees of freedom in the numerator and (
-- 1) degrees
For example, assume that an analyst wants to know if the variances of two normal populations are equal at a
significance level of 0.05. Random samples drawn from the two populations give the sample standard deviations as
1.84 and 2, respectively. Both the sample sizes are 20. The hypothesis test may be conducted as follows:
1) The statements for this hypothesis test may be formulated as:
It is clear that this is a two-sided hypothesis and the critical region will be located on both sides of the probability
distribution.
2) Significance level
. Here the test statistic is based on the
the critical values are obtained as:
and
distribution. For the two-sided hypothesis
Statistical Background on DOE
22
These values and the critical regions are shown in the figure below. The analyst would fail to reject
statistic is such that:
if the test
or
3) The value of the test statistic
Since
corresponding to the given data is:
lies in the acceptance region, the analyst fails to reject
Critical values and rejection region marked on the
at a significance level of 0.05.
distribution.
23
Chapter 3
Simple Linear Regression Analysis
Regression analysis is a statistical technique that attempts to explore and model the relationship between two or more
variables. For example, an analyst may want to know if there is a relationship between road accidents and the age of
the driver. Regression analysis forms an important part of the statistical analysis of the data obtained from designed
experiments and is discussed briefly in this chapter. Every experiment analyzed in DOE++ includes regression
results for each of the responses. These results, along with the results from the analysis of variance (explained in the
One Factor Designs and General Full Factorial Designs chapters), provide information that is useful to identify
significant factors in an experiment and explore the nature of the relationship between these factors and the response.
Regression analysis forms the basis for all DOE++ calculations related to the sum of squares used in the analysis of
variance. The reason for this is explained in Appendix B. Additionally, DOE++ also includes a regression tool to see
if two or more variables are related, and to explore the nature of the relationship between them.
This chapter discusses simple linear regression analysis while a subsequent chapter focuses on multiple linear
regression analysis.
Simple Linear Regression Analysis
24
Simple Linear Regression Analysis
A linear regression model attempts to explain the relationship between two or more variables using a straight line.
Consider the data obtained from a chemical process where the yield of the process is thought to be related to the
reaction temperature (see the table below).
Yield data observations of a chemical process at different values of
reaction temperature.
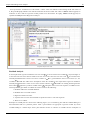
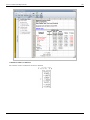
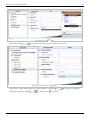
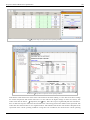
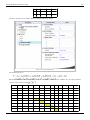
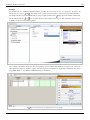
This data can be entered in DOE++ as shown in the following figure:
Simple Linear Regression Analysis
25
Data entry in DOE++ for the observations.
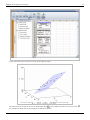
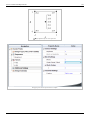
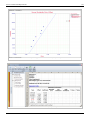
And a scatter plot can be obtained as shown in the following figure. In the scatter plot yield,
different temperature values, .
is plotted for
Simple Linear Regression Analysis
26
Scatter plot for the data.
It is clear that no line can be found to pass through all points of the plot. Thus no functional relation exists between
the two variables and . However, the scatter plot does give an indication that a straight line may exist such that
all the points on the plot are scattered randomly around this line. A statistical relation is said to exist in this case. The
statistical relation between and may be expressed as follows:
The above equation is the linear regression model that can be used to explain the relation between and that is
seen on the scatter plot above. In this model, the mean value of (abbreviated as
) is assumed to follow the
linear relation:
The actual values of (which are observed as yield from the chemical process from time to time and are random in
nature) are assumed to be the sum of the mean value,
, and a random error term, :
The regression model here is called a simple linear regression model because there is just one independent variable,
, in the model. In regression models, the independent variables are also referred to as regressors or predictor
variables. The dependent variable, , is also referred to as the response. The slope, , and the intercept, , of the
line
are called regression coefficients. The slope, , can be interpreted as the change in the
mean value of for a unit change in .
The random error term, , is assumed to follow the normal distribution with a mean of 0 and variance of . Since
is the sum of this random term and the mean value,
, which is a constant, the variance of at any given
value of is also
. Therefore, at any given value of , say , the dependent variable follows a normal
Simple Linear Regression Analysis
distribution with a mean of
The normal distribution of
27
and a standard deviation of . This is illustrated in the following figure.
for two values of . Also shown is the true regression line and the values of the random error term, , corresponding
to the two values. The true regression line and are usually not known.
Fitted Regression Line
The true regression line is usually not known. However, the regression line can be estimated by estimating the
coefficients and for an observed data set. The estimates, and , are calculated using least squares. (For
details on least square estimates, refer to Hahn & Shapiro (1967).) The estimated regression line, obtained using the
values of and , is called the fitted line. The least square estimates, and , are obtained using the following
equations:
where is the mean of all the observed values and is the mean of all values of the predictor variable at which the
observations were taken.
is calculated using
and
is calculated using
.
Once
and
are known, the fitted regression line can be written as:
where is the fitted or estimated value based on the fitted regression model. It is an estimate of the mean value,
. The fitted value, , for a given value of the predictor variable,
, may be different from the
corresponding observed value, . The difference between the two values is called the residual, :
Simple Linear Regression Analysis
Calculation of the Fitted Line Using Least Square Estimates
The least square estimates of the regression coefficients can be obtained for the data in the preceding table as
follows:
Knowing
and
, the fitted regression line is:
This line is shown in the figure below.
Fitted regression line for the data. Also shown is the residual for the 21st observation.
Once the fitted regression line is known, the fitted value of corresponding to any observed data point can be
calculated. For example, the fitted value corresponding to the 21st observation in the preceding table is:
28
Simple Linear Regression Analysis
The observed response at this point is
29
. Therefore, the residual at this point is:
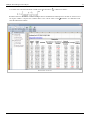
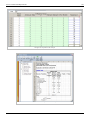
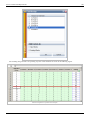
In DOE++, fitted values and residuals can be calculated. The values are shown in the figure below.
Fitted values and residuals for the data.
Hypothesis Tests in Simple Linear Regression
The following sections discuss hypothesis tests on the regression coefficients in simple linear regression. These tests
can be carried out if it can be assumed that the random error term, , is normally and independently distributed with
a mean of zero and variance of .
t Tests
The tests are used to conduct hypothesis tests on the regression coefficients obtained in simple linear regression. A
statistic based on the distribution is used to test the two-sided hypothesis that the true slope, , equals some
constant value,
. The statements for the hypothesis test are expressed as:
The test statistic used for this test is:
Simple Linear Regression Analysis
where
is the least square estimate of
30
, and
is its standard error. The value of
can be calculated
as follows:
The test statistic, , follows a distribution with
degrees of freedom, where is the total number of
observations. The null hypothesis,
, is accepted if the calculated value of the test statistic is such that:
where
and
are the critical values for the two-sided hypothesis.
is the percentile of the
distribution corresponding to a cumulative probability of
and is the significance level.
If the value of
used is zero, then the hypothesis tests for the significance of regression. In other words, the test
indicates if the fitted regression model is of value in explaining variations in the observations or if you are trying to
impose a regression model when no true relationship exists between and . Failure to reject
implies that no linear relationship exists between and . This result may be obtained when the scatter plots of
against are as shown in (a) of the following figure and (b) of the following figure. (a) represents the case where no
model exits for the observed data. In this case you would be trying to fit a regression model to noise or random
variation. (b) represents the case where the true relationship between and is not linear. (c) and (d) represent the
case when
is rejected, implying that a model does exist between and . (c) represents the case
where the linear model is sufficient. In the following figure, (d) represents the case where a higher order model may
be needed.
Possible scatter plots of against . Plots (a) and (b) represent cases when
rejected. Plots (c) and (d) represent cases when
is rejected.
is not
A similar procedure can be used to test the hypothesis on the intercept. The test statistic used in this case is:
Simple Linear Regression Analysis
where
is the least square estimate of
31
, and
is its standard error which is calculated using:
Example
The test for the significance of regression for the data in the preceding table is illustrated in this example. The test is
carried out using the test on the coefficient . The hypothesis to be tested is
. To calculate the
statistic to test
, the estimate, , and the standard error,
, are needed. The value of was obtained in
this section. The standard error can be calculated as follows:
Then, the test statistic can be calculated using the following equation:
The value corresponding to this statistic based on the distribution with 23 (n-2 = 25-2 = 23) degrees of freedom
can be obtained as follows:
Assuming that the desired significance level is 0.1, since value < 0.1,
is rejected indicating that a
relation exists between temperature and yield for the data in the preceding table. Using this result along with the
scatter plot, it can be concluded that the relationship between temperature and yield is linear.
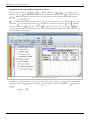
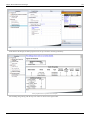
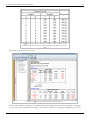
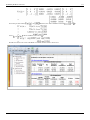
In DOE++, information related to the test is displayed in the Regression Information table as shown in the
following figure. In this table the test for is displayed in the row for the term Temperature because is the
coefficient that represents the variable temperature in the regression model. The columns labeled Standard Error, T
Value and P Value represent the standard error, the test statistic for the test and the value for the test,
respectively. These values have been calculated for in this example. The Coefficient column represents the
estimate of regression coefficients. The Effect column represents values obtained by multiplying the coefficients by
a factor of 2. This value is useful in the case of two factor experiments and is explained in Two Level Factorial
Experiments. Columns Low Confidence and High Confidence represent the limits of the confidence intervals for the
regression coefficients and are explained in Confidence Interval on Regression Coefficients.
Simple Linear Regression Analysis
32
Regression results for the data.
Analysis of Variance Approach to Test the Significance of Regression
The analysis of variance (ANOVA) is another method to test for the significance of regression. As the name implies,
this approach uses the variance of the observed data to determine if a regression model can be applied to the
observed data. The observed variance is partitioned into components that are then used in the test for significance of
regression.
Sum of Squares
The total variance (i.e., the variance of all of the observed data) is estimated using the observed data. As mentioned
in Statistical Background, the variance of a population can be estimated using the sample variance, which is
calculated using the following relationship:
The quantity in the numerator of the previous equation is called the sum of squares. It is the sum of the square of
deviations of all the observations, , from their mean, . In the context of ANOVA this quantity is called the total
sum of squares (abbreviated
) because it relates to the total variance of the observations. Thus:
The denominator in the relationship of the sample variance is the number of degrees of freedom associated with the
sample variance. Therefore, the number of degrees of freedom associated with
,
, is
. The
sample variance is also referred to as a mean square because it is obtained by dividing the sum of squares by the
respective degrees of freedom. Therefore, the total mean square (abbreviated
) is:
When you attempt to fit a regression model to the observations, you are trying to explain some of the variation of the
observations using this model. If the regression model is such that the resulting fitted regression line passes through
all of the observations, then you would have a "perfect" model (see (a) of the figure below). In this case the model
would explain all of the variability of the observations. Therefore, the model sum of squares (also referred to as the
regression sum of squares and abbreviated
) equals the total sum of squares; i.e., the model explains all of the
observed variance:
Simple Linear Regression Analysis
33
For the perfect model, the regression sum of squares,
, equals the total sum of squares,
, because all
estimated values, , will equal the corresponding observations, .
can be calculated using a relationship
similar to the one for obtaining
by replacing by in the relationship of
. Therefore:
The number of degrees of freedom associated with
is 1.
Based on the preceding discussion of ANOVA, a perfect regression model exists when the fitted regression line
passes through all observed points. However, this is not usually the case, as seen in (b) of the following figure.
A perfect regression model will pass through all
observed data points as shown in (a). Most models are
imperfect and do not fit perfectly to all data points as
shown in (b).
In both of these plots, a number of points do not follow the fitted regression line. This indicates that a part of the total
variability of the observed data still remains unexplained. This portion of the total variability or the total sum of
squares, that is not explained by the model, is called the residual sum of squares or the error sum of squares
(abbreviated
). The deviation for this sum of squares is obtained at each observation in the form of the
residuals, . The error sum of squares can be obtained as the sum of squares of these deviations:
The number of degrees of freedom associated with
,
, is
. The total variability of the
observed data (i.e., total sum of squares,
) can be written using the portion of the variability explained by the
model,
, and the portion unexplained by the model,
, as:
Simple Linear Regression Analysis
34
The above equation is also referred to as the analysis of variance identity and can be expanded as follows:
Scatter plots showing the deviations for the sum of squares used in ANOVA. (a) shows deviations for
, and (c) shows deviations for
.
, (b) shows deviations for
Mean Squares
As mentioned previously, mean squares are obtained by dividing the sum of squares by the respective degrees of
freedom. For example, the error mean square,
, can be obtained as:
The error mean square is an estimate of the variance,
Similarly, the regression mean square,
respective degrees of freedom as follows:
, of the random error term, , and can be written as:
, can be obtained by dividing the regression sum of squares by the
Simple Linear Regression Analysis
35
F Test
To test the hypothesis
, the statistic used is based on the
hypothesis
is true, then the statistic:
distribution. It can be shown that if the null
follows the distribution with degree of freedom in the numerator and
denominator.
is rejected if the calculated statistic, , is such that:
where
is the percentile of the
is the significance level.
degrees of freedom in the
distribution corresponding to a cumulative probability of (
) and
Example
The analysis of variance approach to test the significance of regression can be applied to the yield data in the
preceding table. To calculate the statistic,
, for the test, the sum of squares have to be obtained. The sum of
squares can be calculated as shown next. The total sum of squares can be calculated as:
The regression sum of squares can be calculated as:
The error sum of squares can be calculated as:
Knowing the sum of squares, the statistic to test
can be calculated as follows:
The critical value at a significance level of 0.1 is
. Since
,
is
rejected and it is concluded that
is not zero. Alternatively, the value can also be used. The value
corresponding to the test statistic, , based on the distribution with one degree of freedom in the numerator and
Simple Linear Regression Analysis
36
23 degrees of freedom in the denominator is:
Assuming that the desired significance is 0.1, since the value < 0.1, then
is rejected, implying that a
relation does exist between temperature and yield for the data in the preceding table. Using this result along with the
scatter plot of the above figure, it can be concluded that the relationship that exists between temperature and yield is
linear. This result is displayed in the ANOVA table as shown in the following figure. Note that this is the same result
that was obtained from the test in the section t Tests. The ANOVA and Regression Information tables in DOE++
represent two different ways to test for the significance of the regression model. In the case of multiple linear
regression models these tables are expanded to allow tests on individual variables used in the model. This is done
using extra sum of squares. Multiple linear regression models and the application of extra sum of squares in the
analysis of these models are discussed in Multiple Linear Regression Analysis.
ANOVA table for the data.
Confidence Intervals in Simple Linear Regression
A confidence interval represents a closed interval where a certain percentage of the population is likely to lie. For
example, a 90% confidence interval with a lower limit of and an upper limit of implies that 90% of the
population lies between the values of and . Out of the remaining 10% of the population, 5% is less than and
5% is greater than . (For details refer to the Life Data Analysis Reference Book.) This section discusses
confidence intervals used in simple linear regression analysis.
Simple Linear Regression Analysis
37
Confidence Interval on Regression Coefficients
A 100 (
) percent confidence interval on
Similarly, a 100 (
is obtained as follows:
) percent confidence interval on
is obtained as:
Confidence Interval on Fitted Values
A 100 (
) percent confidence interval on any fitted value,
, is obtained as follows:
It can be seen that the width of the confidence interval depends on the value of
and will widen as
increases.
and will be a minimum at
Confidence Interval on New Observations
For the data in the preceding table, assume that a new value of the yield is observed after the regression model is fit
to the data. This new observation is independent of the observations used to obtain the regression model. If is the
level of the temperature at which the new observation was taken, then the estimate for this new value based on the
fitted regression model is:
If a confidence interval needs to be obtained on , then this interval should include both the error from the fitted
model and the error associated with future observations. This is because represents the estimate for a value of
that was not used to obtain the regression model. The confidence interval on is referred to as the prediction
interval. A 100 (
) percent prediction interval on a new observation is obtained as follows:
Example
To illustrate the calculation of confidence intervals, the 95% confidence intervals on the response at
for the
data in the preceding table is obtained in this example. A 95% prediction interval is also obtained assuming that a
new observation for the yield was made at
.
The fitted value,
, corresponding to
The 95% confidence interval
is:
on the fitted value,
, is:
Simple Linear Regression Analysis
38
The 95% limits on
are 199.95 and 205.2, respectively. The estimated value based on the fitted regression model
for the new observation at
is:
The 95% prediction interval on
is:
The 95% limits on are 189.9 and 207.2, respectively. In DOE++, confidence and prediction intervals can be
calculated from the control panel. The prediction interval values calculated in this example are shown in the figure
below as Low Prediction Interval and High Prediction Interval, respectively. The columns labeled Mean Predicted
and Standard Error represent the values of and the standard error used in the calculations.
Simple Linear Regression Analysis
39
Calculation of prediction intervals in DOE++.
Measures of Model Adequacy
It is important to analyze the regression model before inferences based on the model are undertaken. The following
sections present some techniques that can be used to check the appropriateness of the model for the given data.
These techniques help to determine if any of the model assumptions have been violated.
Coefficient of Determination (
)
The coefficient of determination is a measure of the amount of variability in the data accounted for by the regression
model. As mentioned previously, the total variability of the data is measured by the total sum of squares,
. The
amount of this variability explained by the regression model is the regression sum of squares,
. The coefficient
of determination is the ratio of the regression sum of squares to the total sum of squares.
can take on values between 0 and 1 since
. For the yield data example,
can be calculated as:
Therefore, 98% of the variability in the yield data is explained by the regression model, indicating a very good fit of
the model. It may appear that larger values of
indicate a better fitting regression model. However,
should be
used cautiously as this is not always the case. The value of
increases as more terms are added to the model, even
if the new term does not contribute significantly to the model. Therefore, an increase in the value of
cannot be
taken as a sign to conclude that the new model is superior to the older model. Adding a new term may make the
regression model worse if the error mean square,
, for the new model is larger than the
of the older
model, even though the new model will show an increased value of
. In the results obtained from DOE++,
is
displayed as R-sq under the ANOVA table (as shown in the figure below), which displays the complete analysis
sheet for the data in the preceding table.
The other values displayed with are S, R-sq(adj), PRESS and R-sq(pred). These values measure different aspects of
the adequacy of the regression model. For example, the value of S is the square root of the error mean square,
Simple Linear Regression Analysis
40
, and represents the "standard error of the model." A lower value of S indicates a better fitting model. The values of
S, R-sq and R-sq(adj) indicate how well the model fits the observed data. The values of PRESS and R-sq(pred) are
indicators of how well the regression model predicts new observations. R-sq(adj), PRESS and R-sq(pred) are
explained in Multiple Linear Regression Analysis.
Complete analysis for the data.
Residual Analysis
In the simple linear regression model the true error terms, , are never known. The residuals, , may be thought of
as the observed error terms that are similar to the true error terms. Since the true error terms, , are assumed to be
normally distributed with a mean of zero and a variance of , in a good model the observed error terms (i.e., the
residuals, ) should also follow these assumptions. Thus the residuals in the simple linear regression should be
normally distributed with a mean of zero and a constant variance of . Residuals are usually plotted against the
fitted values, , against the predictor variable values, , and against time or run-order sequence, in addition to the
normal probability plot. Plots of residuals are used to check for the following:
1. Residuals follow the normal distribution.
2. Residuals have a constant variance.
3. Regression function is linear.
4. A pattern does not exist when residuals are plotted in a time or run-order sequence.
5. There are no outliers.
Examples of residual plots are shown in the following figure. (a) is a satisfactory plot with the residuals falling in a
horizontal band with no systematic pattern. Such a plot indicates an appropriate regression model. (b) shows
residuals falling in a funnel shape. Such a plot indicates increase in variance of residuals and the assumption of
Simple Linear Regression Analysis
41
constant variance is violated here. Transformation on may be helpful in this case (see Transformations). If the
residuals follow the pattern of (c) or (d), then this is an indication that the linear regression model is not adequate.
Addition of higher order terms to the regression model or transformation on or may be required in such cases. A plot
of residuals may also show a pattern as seen in (e), indicating that the residuals increase (or decrease) as the run
order sequence or time progresses. This may be due to factors such as operator-learning or instrument-creep and
should be investigated further.
Possible residual plots (against fitted values, time or run-order) that can be obtained from simple linear
regression analysis.
Example
Residual plots for the data of the preceding table are shown in the following figures. One of the following figures is
the normal probability plot. It can be observed that the residuals follow the normal distribution and the assumption of
normality is valid here. In one of the following figures the residuals are plotted against the fitted values, , and in
one of the following figures the residuals are plotted against the run order. Both of these plots show that the 21st
observation seems to be an outlier. Further investigations are needed to study the cause of this outlier.
Simple Linear Regression Analysis
42
Normal probability plot of residuals for the data.
Plot of residuals against fitted values for the data.
Simple Linear Regression Analysis
43
Plot of residuals against run order for the data.
Lack-of-Fit Test
As mentioned in Analysis of Variance Approach, ANOVA, a perfect regression model results in a fitted line that
passes exactly through all observed data points. This perfect model will give us a zero error sum of squares (
). Thus, no error exists for the perfect model. However, if you record the response values for the same
values of for a second time, in conditions maintained as strictly identical as possible to the first time, observations
from the second time will not all fall along the perfect model. The deviations in observations recorded for the second
time constitute the "purely" random variation or noise. The sum of squares due to pure error (abbreviated
)
quantifies these variations.
is calculated by taking repeated observations at some or all values of and
adding up the square of deviations at each level of using the respective repeated observations at that value.
Assume that there are
as shown next:
levels of and
repeated observations are taken at each the level. The data is collected
The sum of squares of the deviations from the mean of the observations at the level of ,
where
is the mean of the
repeated observations corresponding to
degrees of freedom for these deviations is (
of freedom is lost in calculating the mean, .
The total sum of square deviations (or
as shown next:
) as there are
(
, can be calculated as:
). The number of
observations at the level of but one degree
) for all levels of can be obtained by summing the deviations for all
Simple Linear Regression Analysis
44
The total number of degrees of freedom associated with
is:
If all
, (i.e., repeated observations are taken at all levels of ), then
freedom associated with
are:
and the degrees of
The corresponding mean square in this case will be:
When repeated observations are used for a perfect regression model, the sum of squares due to pure error,
, is
also considered as the error sum of squares,
. For the case when repeated observations are used with imperfect
regression models, there are two components of the error sum of squares,
. One portion is the pure error due to
the repeated observations. The other portion is the error that represents variation not captured because of the
imperfect model. The second portion is termed as the sum of squares due to lack-of-fit (abbreviated
) to
point to the deficiency in fit due to departure from the perfect-fit model. Thus, for an imperfect regression model:
Knowing
and
, the previous equation can be used to obtain
:
The degrees of freedom associated with
can be obtained in a similar manner using subtraction. For the case
when repeated observations are taken at all levels of , the number of degrees of freedom associated with
is:
Since there are
total observations, the number of degrees of freedom associated with
Therefore, the number of degrees of freedom associated with
The corresponding mean square,
is:
is:
, can now be obtained as:
The magnitude of
or
will provide an indication of how far the regression model is from the
perfect model. An
test exists to examine the lack-of-fit at a particular significance level. The quantity
follows an distribution with
degrees of freedom in the numerator and
degrees of freedom in the denominator when all
equal . The test statistic for the lack-of-fit test is:
If the critical value
is such that:
Simple Linear Regression Analysis
45
it will lead to the rejection of the hypothesis that the model adequately fits the data.
Example
Assume that a second set of observations are taken for the yield data of the preceding table [1]. The resulting
observations are recorded in the following table. To conduct a lack-of-fit test on this data, the statistic
, can be calculated as shown next.
Yield data from the first and second observation sets for the chemical process
example in the Introduction.
Calculation of Least Square Estimates
The parameters of the fitted regression model can be obtained as:
Knowing and , the fitted values,
Calculation of the Sum of Squares
, can be calculated.
Using the fitted values, the sum of squares can be obtained as follows:
Simple Linear Regression Analysis
46
Calculation of
The error sum of squares,
squares due to lack-of-fit,
and
:
, can now be split into the sum of squares due to pure error,
, and the sum of
.
can be calculated as follows considering that in this example
The number of degrees of freedom associated with
The corresponding mean square,
is:
, can now be obtained as:
can be obtained by subtraction from
as:
Similarly, the number of degrees of freedom associated with
The lack-of-fit mean square is:
Calculation of the Test Statistic
is:
Simple Linear Regression Analysis
47
The test statistic for the lack-of-fit test can now be calculated as:
The critical value for this test is:
Since
case is:
, we fail to reject the hypothesis that the model adequately fits the data. The value for this
Therefore, at a significance level of 0.05 we conclude that the simple linear regression model,
, is adequate for the observed data. The following table presents a summary of the ANOVA calculations for the
lack-of-fit test.
ANOVA table for the lack-of-fit test of the yield data example.
Transformations
The linear regression model may not be directly applicable to certain data. Non-linearity may be detected from
scatter plots or may be known through the underlying theory of the product or process or from past experience.
Transformations on either the predictor variable, , or the response variable, , may often be sufficient to make the
linear regression model appropriate for the transformed data. If it is known that the data follows the logarithmic
distribution, then a logarithmic transformation on (i.e.,
) might be useful. For data following the
Poisson distribution, a square root transformation (
) is generally applicable.
Simple Linear Regression Analysis
48
Transformations on may also be applied based on the type of scatter plot obtained from the data. The following
figure shows a few such examples.
Transformations on for a few possible scatter plots. Plot (a) may require a square root transformation, (b) may
require a logarithmic transformation and (c) may require a reciprocal transformation.
For the scatter plot labeled (a), a square root transformation (
) is applicable. While for the plot labeled
(b), a logarithmic transformation (i.e.,
) may be applied. For the plot labeled (c), the reciprocal
transformation (
) is applicable. At times it may be helpful to introduce a constant into the
transformation of . For example, if is negative and the logarithmic transformation on seems applicable, a
suitable constant, , may be chosen to make all observed positive. Thus the transformation in this case would be
.
The Box-Cox method may also be used to automatically identify a suitable power transformation for the data based
on the relation:
Here the parameter is determined using the given data such that
presented in One Factor Designs).
is minimized (details on this method are
References
[1] http:/ / reliawiki. org/ index. php/ Simple_Linear_Regression_Analysis#Simple_Linear_Regression_Analysis|
49
Chapter 4
Multiple Linear Regression Analysis
This chapter expands on the analysis of simple linear regression models and discusses the analysis of multiple linear
regression models. A major portion of the results displayed in DOE++ are explained in this chapter because these
results are associated with multiple linear regression. One of the applications of multiple linear regression models is
Response Surface Methodology (RSM). RSM is a method used to locate the optimum value of the response and is
one of the final stages of experimentation. It is discussed in Response Surface Methods. Towards the end of this
chapter, the concept of using indicator variables in regression models is explained. Indicator variables are used to
represent qualitative factors in regression models. The concept of using indicator variables is important to gain an
understanding of ANOVA models, which are the models used to analyze data obtained from experiments. These
models can be thought of as first order multiple linear regression models where all the factors are treated as
qualitative factors. ANOVA models are discussed in the One Factor Designs and General Full Factorial Designs
chapters.
Multiple Linear Regression Model
A linear regression model that contains more than one predictor variable is called a multiple linear regression model.
The following model is a multiple linear regression model with two predictor variables, and .
The model is linear because it is linear in the parameters
, and
. The model describes a plane in the
three-dimensional space of , and . The parameter is the intercept of this plane. Parameters and are
referred to as partial regression coefficients. Parameter represents the change in the mean response corresponding
to a unit change in
when
is held constant. Parameter
represents the change in the mean response
corresponding to a unit change in when is held constant. Consider the following example of a multiple linear
regression model with two predictor variables, and :
This regression model is a first order multiple linear regression model. This is because the maximum power of the
variables in the model is 1. (The regression plane corresponding to this model is shown in the figure below.) Also
shown is an observed data point and the corresponding random error, . The true regression model is usually never
known (and therefore the values of the random error terms corresponding to observed data points remain unknown).
However, the regression model can be estimated by calculating the parameters of the model for an observed data set.
This is explained in Estimating Regression Models Using Least Squares.
One of the following figures shows the contour plot for the regression model the above equation. The contour plot
shows lines of constant mean response values as a function of and . The contour lines for the given regression
model are straight lines as seen on the plot. Straight contour lines result for first order regression models with no
interaction terms.
A linear regression model may also take the following form:
A cross-product term,
, is included in the model. This term represents an interaction effect between the two
variables and . Interaction means that the effect produced by a change in the predictor variable on the response
depends on the level of the other predictor variable(s). As an example of a linear regression model with interaction,
Multiple Linear Regression Analysis
consider the model given by the equation
following two figures, respectively.
Regression plane for the model
50
. The regression plane and contour plot for this
Multiple Linear Regression Analysis
51
Countour plot for the model
Now consider the regression model shown next:
This model is also a linear regression model and is referred to as a polynomial regression model. Polynomial
regression models contain squared and higher order terms of the predictor variables making the response surface
curvilinear. As an example of a polynomial regression model with an interaction term consider the following
equation:
This model is a second order model because the maximum power of the terms in the model is two. The regression
surface for this model is shown in the following figure. Such regression models are used in RSM to find the optimum
value of the response, (for details see Response Surface Methods for Optimization). Notice that, although the
shape of the regression surface is curvilinear, the regression model is still linear because the model is linear in the
parameters. The contour plot for this model is shown in the second of the following two figures.
Multiple Linear Regression Analysis
52
Regression plane for the model
Countour plot for the model
All multiple linear regression models can be expressed in the following general form:
where denotes the number of terms in the model. For example, the model can be written in the general form using
,
and
as follows:
Multiple Linear Regression Analysis
53
Estimating Regression Models Using Least Squares
Consider a multiple linear regression model with predictor variables:
Let each of the predictor variables, , ...
, have levels. Then
represents the th level of the th
predictor variable . For example,
represents the fifth level of the first predictor variable , while
represents the first level of the ninth predictor variable, . Observations, , ... , recorded for each of these
levels can be expressed in the following way:
The system of equations shown previously can be represented in matrix notation as follows:
where
The matrix is referred to as the design matrix. It contains information about the levels of the predictor variables at
which the observations are obtained. The vector contains all the regression coefficients. To obtain the regression
model, should be known. is estimated using least square estimates. The following equation is used:
where represents the transpose of the matrix while
represents the matrix inverse. Knowing the estimates,
, the
multiple linear regression model can now be estimated as:
The estimated regression model is also referred to as the fitted model. The observations, , may be different from
the fitted values obtained from this model. The difference between these two values is the residual, . The vector
of residuals, , is obtained as:
The fitted model can also be written as follows, using
:
Multiple Linear Regression Analysis
where
54
. The matrix,
, is referred to as the hat matrix. It transforms the vector of the
observed response values, , to the vector of fitted values, .
Example
An analyst studying a chemical process expects the yield to be affected by the levels of two factors, and .
Observations recorded for various levels of the two factors are shown in the following table. The analyst wants to fit
a first order regression model to the data. Interaction between and is not expected based on knowledge of
similar processes. Units of the factor levels and the yield are ignored for the analysis.
Observed yield data for various levels of two factors.
The data of the above table can be entered into DOE++ using the multiple linear regression folio tool as shown in the
following figure.
Multiple Linear Regression Analysis
55
Multiple Regression tool in DOE++ with the data in the table.
A scatter plot for the data is shown next.
Three-dimensional scatter plot for the observed data in the table.
The first order regression model applicable to this data set having two predictor variables is:
where the dependent variable, , represents the yield and the predictor variables,
factors respectively. The and matrices for the data can be obtained as:
and
, represent the two
Multiple Linear Regression Analysis
56
The least square estimates, , can now be obtained:
Thus:
and the estimated regression coefficients are
,
model is:
The fitted regression model can be viewed in DOE++, as shown next.
and
. The fitted regression
Multiple Linear Regression Analysis
57
Equation of the fitted regression model for the data from the table.
A plot of the fitted regression plane is shown in the following figure.
Fitted regression plane
for the data from the table.
The fitted regression model can be used to obtain fitted values, , corresponding to an observed response value,
For example, the fitted value corresponding to the fifth observation is:
.
Multiple Linear Regression Analysis
The observed fifth response value is
58
. The residual corresponding to this value is:
In DOE++, fitted values and residuals are shown in the Diagnostic Information table of the detailed summary of
results. The values are shown in the following figure.
Fitted values and residuals for the data in the table.
The fitted regression model can also be used to predict response values. For example, to obtain the response value
for a new observation corresponding to 47 units of and 31 units of , the value is calculated using:
Multiple Linear Regression Analysis
59
Properties of the Least Square Estimators for Beta
The least square estimates,
random error terms,
,
,
...
, are unbiased estimators of
,
,
...
, are normally and independently distributed. The variances of the
, provided that the
s are obtained using the
matrix. The variance-covariance matrix of the estimated regression coefficients is obtained as follows:
is a symmetric matrix whose diagonal elements,
, represent the variance of the estimated th regression
coefficient, . The off-diagonal elements,
, represent the covariance between the th and th estimated
regression coefficients,
and
. The value of
is obtained using the error mean square,
. The
variance-covariance matrix for the data in the table (see Estimating Regression Models Using Least Squares) can be
viewed in DOE++, as shown next.
The variance-covariance matrix for the data in table.
Calculations to obtain the matrix are given in this example. The positive square root of
represents the estimated
standard deviation of the th regression coefficient, , and is called the estimated standard error of (abbreviated
).
Multiple Linear Regression Analysis
60
Hypothesis Tests in Multiple Linear Regression
This section discusses hypothesis tests on the regression coefficients in multiple linear regression. As in the case of
simple linear regression, these tests can only be carried out if it can be assumed that the random error terms, , are
normally and independently distributed with a mean of zero and variance of . Three types of hypothesis tests can
be carried out for multiple linear regression models:
1. Test for significance of regression: This test checks the significance of the whole regression model.
2.
3.
test: This test checks the significance of individual regression coefficients.
test: This test can be used to simultaneously check the significance of a number of regression coefficients. It
can also be used to test individual coefficients.
Test for Significance of Regression
The test for significance of regression in the case of multiple linear regression analysis is carried out using the
analysis of variance. The test is used to check if a linear statistical relationship exists between the response variable
and at least one of the predictor variables. The statements for the hypotheses are:
The test for
is carried out using the following statistic:
where
is the regression mean square and
is the error mean square. If the null hypothesis,
, is true
then the statistic
follows the distribution with degrees of freedom in the numerator and
(
)
degrees of freedom in the denominator. The null hypothesis,
, is rejected if the calculated statistic,
, is such
that:
Calculation of the Statistic
To calculate the statistic
, the mean squares
and
must be known. As explained in Simple Linear
[1]
Regression Analysis , the mean squares are obtained by dividing the sum of squares by their degrees of freedom.
For example, the total mean square,
, is obtained as follows:
where
is the total sum of squares and
is the number of degrees of freedom associated with
In multiple linear regression, the following equation is used to calculate
:
.
where is the total number of observations, is the vector of observations (that was defined in Estimating
Regression Models Using Least Squares [2]), is the identity matrix of order and represents an
square
matrix of ones. The number of degrees of freedom associated with
,
, is (
). Knowing
and
the total mean square,
, can be calculated.
The regression mean square,
degrees of freedom,
The regression sum of squares,
, is obtained by dividing the regression sum of squares,
, as follows:
, is calculated using the following equation:
, by the respective
Multiple Linear Regression Analysis
61
where is the total number of observations, is the vector of observations, is the hat matrix and represents an
square matrix of ones. The number of degrees of freedom associated with
,
, is , where
is the number of predictor variables in the model. Knowing
and
the regression mean square,
, can be calculated. The error mean square,
, is obtained by dividing the error sum of squares,
,
by the respective degrees of freedom,
, as follows:
The error sum of squares,
, is calculated using the following equation:
where is the vector of observations, is the identity matrix of order and is the hat matrix. The number of
degrees of freedom associated with
,
, is
, where is the total number of
observations and is the number of predictor variables in the model. Knowing
and
, the error
mean square,
, can be calculated. The error mean square is an estimate of the variance, , of the random
error terms, .
Example
The test for the significance of regression, for the regression model obtained for the data in the table (see Estimating
Regression Models Using Least Squares), is illustrated in this example. The null hypothesis for the model is:
The statistic to test
is:
To calculate
, first the sum of squares are calculated so that the mean squares can be obtained. Then the mean
squares are used to calculate the statistic to carry out the significance test. The regression sum of squares,
,
can be obtained as:
The hat matrix,
Knowing ,
is calculated as follows using the design matrix
and , the regression sum of squares,
from the previous example:
, can be calculated:
The degrees of freedom associated with
is , which equals to a value of two since there are two predictor
variables in the data in the table (see Multiple Linear Regression Analysis). Therefore, the regression mean square is:
Multiple Linear Regression Analysis
62
Similarly to calculate the error mean square,
The degrees of freedom associated with
, the error sum of squares,
is
, can be obtained as:
. Therefore, the error mean square,
, is:
The statistic to test the significance of regression can now be calculated as:
The critical value for this test, corresponding to a significance level of 0.1, is:
Since
,
is rejected and it is concluded that at least one coefficient out of and
is significant. In other words, it is concluded that a regression model exists between yield and either one or both
of the factors in the table. The analysis of variance is summarized in the following table.
ANOVA table for the significance of regression test.
Multiple Linear Regression Analysis
63
Test on Individual Regression Coefficients (t Test)
The test is used to check the significance of individual regression coefficients in the multiple linear regression
model. Adding a significant variable to a regression model makes the model more effective, while adding an
unimportant variable may make the model worse. The hypothesis statements to test the significance of a particular
regression coefficient, , are:
The test statistic for this test is based on the distribution (and is similar to the one used in the case of simple linear
regression models in Simple Linear Regression Anaysis):
where the standard error,
, is obtained. The analyst would fail to reject the null hypothesis if the test statistic
lies in the acceptance region:
This test measures the contribution of a variable while the remaining variables are included in the model. For the
model
, if the test is carried out for , then the test will check the significance
of including the variable
in the model that contains
and
(i.e., the model
). Hence
the test is also referred to as partial or marginal test. In DOE++, this test is displayed in the Regression Information
table.
Example
The test to check the significance of the estimated regression coefficients for the data is illustrated in this example.
The null hypothesis to test the coefficient is:
The null hypothesis to test can be obtained in a similar manner. To calculate the test statistic, , we need to
calculate the standard error. In the example, the value of the error mean square,
, was obtained as 30.24. The
error mean square is an estimate of the variance, .
Therefore:
The variance-covariance matrix of the estimated regression coefficients is:
From the diagonal elements of
, the estimated standard error for
The corresponding test statistics for these coefficients are:
and
is:
Multiple Linear Regression Analysis
64
The critical values for the present test at a significance of 0.1 are:
Considering
, it can be seen that
does not lie in the acceptance region of
. The
null hypothesis,
, is rejected and it is concluded that is significant at
. This conclusion
can also be arrived at using the value noting that the hypothesis is two-sided. The value corresponding to the test
statistic,
, based on the distribution with 14 degrees of freedom is:
Since the value is less than the significance,
can be carried out in a similar manner.
, it is concluded that
is significant. The hypothesis test on
As explained in Simple Linear Regression Analysis, in DOE++, the information related to the test is displayed in
the Regression Information table as shown in the figure below.
Regression results for the data.
In this table, the test for
is displayed in the row for the term Factor 2 because
is the coefficient that
represents this factor in the regression model. Columns labeled Standard Error, T Value and P Value represent the
standard error, the test statistic for the test and the value for the test, respectively. These values have been
calculated for in this example. The Coefficient column represents the estimate of regression coefficients. These
values are calculated as shown in this example. The Effect column represents values obtained by multiplying the
coefficients by a factor of 2. This value is useful in the case of two factor experiments and is explained in Two-Level
Factorial Experiments. Columns labeled Low Confidence and High Confidence represent the limits of the confidence
intervals for the regression coefficients and are explained in Confidence Intervals in Multiple Linear Regression. The
Variance Inflation Factor column displays values that give a measure of multicollinearity. This is explained in
Multicollinearity.
Multiple Linear Regression Analysis
65
Test on Subsets of Regression Coefficients (Partial F Test)
This test can be considered to be the general form of the test mentioned in the previous section. This is because the
test simultaneously checks the significance of including many (or even one) regression coefficients in the multiple
linear regression model. Adding a variable to a model increases the regression sum of squares,
. The test is
based on this increase in the regression sum of squares. The increase in the regression sum of squares is called the
extra sum of squares. Assume that the vector of the regression coefficients, , for the multiple linear regression
model,
, is partitioned into two vectors with the second vector, , containing the last regression
coefficients, and the first vector, , containing the first (
) coefficients as follows:
with:
The hypothesis statements to test the significance of adding the regression coefficients in
the regression coefficients in may be written as:
The test statistic for this test follows the
to a model containing
distribution and can be calculated as follows:
where
is the the increase in the regression sum of squares when the variables corresponding to the
coefficients in are added to a model already containing , and
is obtained from the equation given in
Simple Linear Regression Analysis. The value of the extra sum of squares is obtained as explained in the next
section.
The null hypothesis,
, is rejected if
. Rejection of
leads to the conclusion that at least
one of the variables in
,
...
contributes significantly to the regression model. In DOE++, the
results from the partial test are displayed in the ANOVA table.
Multiple Linear Regression Analysis
66
ANOVA Table for Extra Sum of Squares in DOE++.
Types of Extra Sum of Squares
The extra sum of squares can be calculated using either the partial (or adjusted) sum of squares or the sequential sum
of squares. The type of extra sum of squares used affects the calculation of the test statistic for the partial test
described above. In DOE++, selection for the type of extra sum of squares is available as shown in the figure below.
The partial sum of squares is used as the default setting. The reason for this is explained in the following section on
the partial sum of squares.
Partial Sum of Squares
The partial sum of squares for a term is the extra sum of squares when all terms, except the term under consideration,
are included in the model. For example, consider the model:
The sum of squares of regression of this model is denoted by
. Assume that we need to know
the partial sum of squares for . The partial sum of squares for is the increase in the regression sum of squares
when is added to the model. This increase is the difference in the regression sum of squares for the full model of
the equation given above and the model that includes all terms except . These terms are , and
. The
model that contains these terms is:
The sum of squares of regression of this model is denoted by
can be represented as
and is calculated as follows:
. The partial sum of squares for
For the present case,
and
. It can be noted that for the partial sum of squares
contains all coefficients other than the coefficient being tested.
Multiple Linear Regression Analysis
67
DOE++ has the partial sum of squares as the default selection. This is because the test is a partial test, i.e., the test
on an individual coefficient is carried by assuming that all the remaining coefficients are included in the model
(similar to the way the partial sum of squares is calculated). The results from the test are displayed in the
Regression Information table. The results from the partial test are displayed in the ANOVA table. To keep the
results in the two tables consistent with each other, the partial sum of squares is used as the default selection for the
results displayed in the ANOVA table. The partial sum of squares for all terms of a model may not add up to the
regression sum of squares for the full model when the regression coefficients are correlated. If it is preferred that the
extra sum of squares for all terms in the model always add up to the regression sum of squares for the full model then
the sequential sum of squares should be used.
Example
This example illustrates the test using the partial sum of squares. The test is conducted for the coefficient
corresponding to the predictor variable for the data. The regression model used for this data set in the example is:
The null hypothesis to test the significance of
is:
The statistic to test this hypothesis is:
where
represents the partial sum of squares for , represents the number of degrees of freedom for
(which is one because there is just one coefficient, , being tested) and
is the error mean
square and has been calculated in the second example as 30.24.
The partial sum of squares for is the difference between the regression sum of squares for the full model,
, and the regression sum of squares for the model excluding
,
. The regression sum of squares for the full model has been calculated in the second example
as 12816.35. Therefore:
The regression sum of squares for the model
is obtained as shown next. First the design
matrix for this model,
, is obtained by dropping the second column in the design matrix of the full model,
(the full design matrix, , was obtained in the example). The second column of corresponds to the coefficient
which is no longer in the model. Therefore, the design matrix for the model,
, is:
The
hat
matrix
corresponding
to
this
design
. Once
, can be calculated as:
Therefore, the partial sum of squares for
is:
matrix
is
.
It
can
be
calculated
using
is known, the regression sum of squares for the model
Multiple Linear Regression Analysis
68
Knowing the partial sum of squares, the statistic to test the significance of
The value corresponding to this statistic based on the
and 14 degrees of freedom in the denominator is:
is:
distribution with 1 degree of freedom in the numerator
Assuming that the desired significance is 0.1, since value < 0.1,
is rejected and it can be concluded
that is significant. The test for can be carried out in a similar manner. In the results obtained from DOE++, the
calculations for this test are displayed in the ANOVA table as shown in the following figure. Note that the
conclusion obtained in this example can also be obtained using the test as explained in the example in Test on
Individual Regression Coefficients (t Test). The ANOVA and Regression Information tables in DOE++ represent
two different ways to test for the significance of the variables included in the multiple linear regression model.
Sequential Sum of Squares
The sequential sum of squares for a coefficient is the extra sum of squares when coefficients are added to the model
in a sequence. For example, consider the model:
The sequential sum of squares for
is the increase in the sum of squares when
is added to the model
observing the sequence of the equation given above. Therefore this extra sum of squares can be obtained by taking
the difference between the regression sum of squares for the model after
was added and the regression sum of
squares for the model before
was added to the model. The model after
is added is as follows:
This is because to maintain the sequence all coefficients preceding
must be included in the model. These are the
coefficients , , ,
and . Similarly the model before
is added must contain all coefficients of the
equation given above except
. This model can be obtained as follows:
The sequential sum of squares for
can be calculated as follows:
For the present case,
and
. It can be noted that for the sequential sum of
squares contains all coefficients proceeding the coefficient being tested.
The sequential sum of squares for all terms will add up to the regression sum of squares for the full model, but the
sequential sum of squares are order dependent.
Multiple Linear Regression Analysis
69
Example
This example illustrates the partial test using the sequential sum of squares. The test is conducted for the
coefficient corresponding to the predictor variable for the data. The regression model used for this data set in
the example is:
The null hypothesis to test the significance of
is:
The statistic to test this hypothesis is:
where
represents the sequential sum of squares for , represents the number of degrees of freedom
for
(which is one because there is just one coefficient, , being tested) and
is the error mean
square and has been calculated in the second example as 30.24.
The sequential sum of squares for is the difference between the regression sum of squares for the model after
adding
,
, and the regression sum of squares for the model before adding
,
. The regression sum of squares for the model
is obtained as shown next. First
the design matrix for this model,
, is obtained by dropping the third column in the design matrix for the full
model,
(the full design matrix,
, was obtained in the example). The third column of
corresponds to
coefficient
which is no longer used in the present model. Therefore, the design matrix for the model,
, is:
The
hat
matrix
corresponding
to
this
design
. Once
can be calculated as:
matrix
is
.
It
can
be
calculated
using
is known, the regression sum of squares for the model
Multiple Linear Regression Analysis
70
Sequential sum of squares for the data.
The regression sum of squares for the model
variables. Therefore:
The sequential sum of squares for
is equal to zero since this model does not contain any
is:
Knowing the sequential sum of squares, the statistic to test the significance of
The value corresponding to this statistic based on the
and 14 degrees of freedom in the denominator is:
is:
distribution with 1 degree of freedom in the numerator
Assuming that the desired significance is 0.1, since value < 0.1,
is rejected and it can be concluded
that is significant. The test for can be carried out in a similar manner. This result is shown in the following
figure.
Multiple Linear Regression Analysis
71
Confidence Intervals in Multiple Linear Regression
Calculation of confidence intervals for multiple linear regression models are similar to those for simple linear
regression models explained in Simple Linear Regression Analysis.
Confidence Interval on Regression Coefficients
A 100 (
) percent confidence interval on the regression coefficient,
, is obtained as follows:
The confidence interval on the regression coefficients are displayed in the Regression Information table under the
Low Confidence and High Confidence columns as shown in the following figure.
Confidence interval for the fitted value corresponding to the fifth observation.
Confidence Interval on Fitted Values,
given by:
A 100 (
) percent confidence interval on any fitted value,
, is
where:
In the above example, the fitted value corresponding to the fifth observation was calculated as
. The
90% confidence interval on this value can be obtained as shown in the figure below. The values of 47.3 and 29.9
used in the figure are the values of the predictor variables corresponding to the fifth observation the table.
Multiple Linear Regression Analysis
72
Confidence Interval on New Observations
As explained in Simple Linear Regression Analysis, the confidence interval on a new observation is also referred to
as the prediction interval. The prediction interval takes into account both the error from the fitted model and the error
associated with future observations. A 100 (
) percent confidence interval on a new observation, , is
obtained as follows:
where:
,...,
are the levels of the predictor variables at which the new observation,
, needs to be obtained.
In multiple linear regression, prediction intervals should only be obtained at the levels of the predictor variables
where the regression model applies. In the case of multiple linear regression it is easy to miss this. Having values
lying within the range of the predictor variables does not necessarily mean that the new observation lies in the region
to which the model is applicable. For example, consider the next figure where the shaded area shows the region to
which a two variable regression model is applicable. The point corresponding to th level of first predictor variable,
, and th level of the second predictor variable, , does not lie in the shaded area, although both of these levels
are within the range of the first and second predictor variables respectively. In this case, the regression model is not
applicable at this point.
Predicted values and region of model application in multiple linear regression.
Multiple Linear Regression Analysis
73
Measures of Model Adequacy
As in the case of simple linear regression, analysis of a fitted multiple linear regression model is important before
inferences based on the model are undertaken. This section presents some techniques that can be used to check the
appropriateness of the multiple linear regression model.
Coefficient of Multiple Determination, R2
The coefficient of multiple determination is similar to the coefficient of determination used in the case of simple
linear regression. It is defined as:
indicates the amount of total variability explained by the regression model. The positive square root of
is
called the multiple correlation coefficient and measures the linear association between and the predictor variables,
, ... .
The value of
increases as more terms are added to the model, even if the new term does not contribute
significantly to the model. An increase in the value of
cannot be taken as a sign to conclude that the new model is
superior to the older model. A better statistic to use is the adjusted
statistic defined as follows:
The adjusted
only increases when significant terms are added to the model. Addition of unimportant terms may
lead to a decrease in the value of
.
In DOE++,
and
values are displayed as R-sq and R-sq(adj), respectively. Other values displayed along with
these values are S, PRESS and R-sq(pred). As explained in Simple Linear Regression Analysis, the value of S is the
square root of the error mean square,
, and represents the "standard error of the model."
PRESS is an abbreviation for prediction error sum of squares. It is the error sum of squares calculated using the
PRESS residuals in place of the residuals, , in the equation for the error sum of squares. The PRESS residual,
,
for a particular observation, , is obtained by fitting the regression model to the remaining observations. Then the
value for a new observation, , corresponding to the observation in question, , is obtained based on the new
regression model. The difference between and gives
. The PRESS residual,
, can also be obtained
using , the diagonal element of the hat matrix, , as follows:
R-sq(pred), also referred to as prediction
, is obtained using PRESS as shown next:
The values of R-sq, R-sq(adj) and S are indicators of how well the regression model fits the observed data. The
values of PRESS and R-sq(pred) are indicators of how well the regression model predicts new observations. For
example, higher values of PRESS or lower values of R-sq(pred) indicate a model that predicts poorly. The figure
below shows these values for the data. The values indicate that the regression model fits the data well and also
predicts well.
Multiple Linear Regression Analysis
Coefficient of multiple determination and related results for the data.
Residual Analysis
Plots of residuals, , similar to the ones discussed in Simple Linear Regression Analysis for simple linear
regression, are used to check the adequacy of a fitted multiple linear regression model. The residuals are expected to
be normally distributed with a mean of zero and a constant variance of . In addition, they should not show any
patterns or trends when plotted against any variable or in a time or run-order sequence. Residual plots may also be
obtained using standardized and studentized residuals. Standardized residuals, , are obtained using the following
equation:
Standardized residuals are scaled so that the standard deviation of the residuals is approximately equal to one. This
helps to identify possible outliers or unusual observations. However, standardized residuals may understate the true
residual magnitude, hence studentized residuals, , are used in their place. Studentized residuals are calculated as
follows:
where
is the th diagonal element of the hat matrix,
. External studentized (or the studentized deleted)
residuals may also be used. These residuals are based on the PRESS residuals mentioned in Coefficient of Multiple
Determination, R2. The reason for using the external studentized residuals is that if the th observation is an outlier,
it may influence the fitted model. In this case, the residual will be small and may not disclose that th observation
74
Multiple Linear Regression Analysis
75
is an outlier. The external studentized residual for the th observation, , is obtained as follows:
Residual values for the data are shown in the figure below. Standardized residual plots for the data are shown in next
two figures. DOE++ compares the residual values to the critical values on the distribution for studentized and
external studentized residuals.
Residual values for the data.
Multiple Linear Regression Analysis
76
Residual probability plot for the data.
For other residuals the normal distribution is used. For example, for the data, the critical values on the distribution
at a significance of 0.1 are
and
(as calculated in the example, Test on
Individual Regression Coefficients (t Test)). The studentized residual values corresponding to the 3rd and 17th
observations lie outside the critical values. Therefore, the 3rd and 17th observations are outliers. This can also be
seen on the residual plots in the next two figures.
Multiple Linear Regression Analysis
77
Residual versus fitted values plot for the data.
Multiple Linear Regression Analysis
78
Residual versus run order plot for the data.
Outlying x Observations
Residuals help to identify outlying observations. Outlying observations can be detected using leverage. Leverage
values are the diagonal elements of the hat matrix,
. The
values always lie between 0 and 1. Values of
greater than
are considered to be indicators of outlying observations.
Influential Observations Detection
Once an outlier is identified, it is important to determine if the outlier has a significant effect on the regression
model. One measure to detect influential observations is Cook's distance measure which is computed as follows:
To use Cook's distance measure, the
values are compared to percentile values on the distribution with
degrees of freedom. If the percentile value is less than 10 or 20 percent, then the th case
has little influence on the fitted values. However, if the percentile value is close to 50 percent or greater, the th case
is influential, and fitted values with and without the th case will differ substantially.
Multiple Linear Regression Analysis
79
Example
Cook's distance measure can be calculated as shown next. The distance measure is calculated for the first observation
of the data. The remaining values along with the leverage values are shown in the figure below (displaying Leverage
and Cook's distance measure for the data).
Leverage and Cook's distance measure for the data.
The standardized residual corresponding to the first observation is:
Cook's distance measure for the first observation can now be calculated as:
The 50th percentile value for
observations.
is 0.83. Since all
values are less than this value there are no influential
Multiple Linear Regression Analysis
80
Lack-of-Fit Test
The lack-of-fit test for simple linear regression discussed in Simple Linear Regression Analysis may also be applied
to multiple linear regression to check the appropriateness of the fitted response surface and see if a higher order
model is required. Data for replicates may be collected as follows for all levels of the predictor variables:
The sum of squares due to pure error,
Analysis as:
, can be obtained as discussed in the Simple Linear Regression
The number of degrees of freedom associated with
Knowing
, sum of squares due to lack-of-fit,
The number of degrees of freedom associated with
are:
, can be obtained as:
are:
The test statistic for the lack-of-fit test is:
Other Topics in Multiple Linear Regression
Polynomial Regression Models
Polynomial regression models are used when the response is curvilinear. The equation shown next presents a second
order polynomial regression model with one predictor variable:
Usually, coded values are used in these models. Values of the variables are coded by centering or expressing the
levels of the variable as deviations from the mean value of the variable and then scaling or dividing the deviations
obtained by half of the range of the variable.
The reason for using coded predictor variables is that many times and are highly correlated and, if uncoded
values are used, there may be computational difficulties while calculating the
matrix to obtain the
estimates,
on DOE.
, of the regression coefficients using the equation for the
distribution given in Statistics Background
Multiple Linear Regression Analysis
Qualitative Factors
The multiple linear regression model also supports the use of qualitative factors. For example, gender may need to be
included as a factor in a regression model. One of the ways to include qualitative factors in a regression model is to
employ indicator variables. Indicator variables take on values of 0 or 1. For example, an indicator variable may be
used with a value of 1 to indicate female and a value of 0 to indicate male.
In general (
) indicator variables are required to represent a qualitative factor with levels. As an example, a
qualitative factor representing three types of machines may be represented as follows using two indicator variables:
An alternative coding scheme for this example is to use a value of -1 for all indicator variables when representing the
last level of the factor:
Indicator variables are also referred to as dummy variables or binary variables.
Example
Consider data from two types of reactors of a chemical process shown where the yield values are recorded for
various levels of factor . Assuming there are no interactions between the reactor type and , a regression model
can be fitted to this data as shown next.
Since the reactor type is a qualitative factor with two levels, it can be represented by using one indicator variable. Let
be the indicator variable representing the reactor type, with 0 representing the first type of reactor and 1
representing the second type of reactor.
81
Multiple Linear Regression Analysis
82
Yield data from the two types of reactors for a chemical process.
Data entry in DOE++ for this example is shown in the figure after the table below. The regression model for this data
is:
The
and matrices for the given data are:
Multiple Linear Regression Analysis
83
Data from the table above as entered in DOE++.
The estimated regression coefficients for the model can be obtained as:
Therefore, the fitted regression model is:
Note that since
represents a qualitative predictor variable, the fitted regression model cannot be plotted
simultaneously against and in a two-dimensional space (because the resulting surface plot will be meaningless
for the dimension in ). To illustrate this, a scatter plot of the data against is shown in the following figure.
Multiple Linear Regression Analysis
84
Scatter plot of the observed yield values against
(reactor type)
It can be noted that, in the case of qualitative factors, the nature of the relationship between the response (yield) and
the qualitative factor (reactor type) cannot be categorized as linear, or quadratic, or cubic, etc. The only conclusion
that can be arrived at for these factors is to see if these factors contribute significantly to the regression model. This
can be done by employing the partial test discussed in Multiple Linear Regression Analysis (using the extra sum
of squares of the indicator variables representing these factors). The results of the test for the present example are
shown in the ANOVA table. The results show that (reactor type) contributes significantly to the fitted regression
model.
Multiple Linear Regression Analysis
85
DOE++ results for the data.
Multicollinearity
At times the predictor variables included in a multiple linear regression model may be found to be dependent on each
other. Multicollinearity is said to exist in a multiple regression model with strong dependencies between the
predictor variables. Multicollinearity affects the regression coefficients and the extra sum of squares of the predictor
variables. In a model with multicollinearity the estimate of the regression coefficient of a predictor variable depends
on what other predictor variables are included the model. The dependence may even lead to change in the sign of the
regression coefficient. In a such models, an estimated regression coefficient may not be found to be significant
individually (when using the test on the individual coefficient or looking at the value) even though a statistical
relation is found to exist between the response variable and the set of the predictor variables (when using the test
for the set of predictor variables). Therefore, you should be careful while looking at individual predictor variables in
models that have multicollinearity. Care should also be taken while looking at the extra sum of squares for a
predictor variable that is correlated with other variables. This is because in models with multicollinearity the extra
sum of squares is not unique and depends on the other predictor variables included in the model.
Multicollinearity can be detected using the variance inflation factor (abbreviated
is defined as:
where
).
for a coefficient
is the coefficient of multiple determination resulting from regressing the th predictor variable,
, on
the remaining -1 predictor variables. Mean values of
considerably greater than 1 indicate multicollinearity
problems. A few methods of dealing with multicollinearity include increasing the number of observations in a way
designed to break up dependencies among predictor variables, combining the linearly dependent predictor variables
into one variable, eliminating variables from the model that are unimportant or using coded variables.
Multiple Linear Regression Analysis
86
Example
Variance inflation factors can be obtained for the data below.
Observed yield data for various levels of two factors.
To calculate the variance inflation factor for
,
has to be calculated.
is the coefficient of determination for
the model when is regressed on the remaining variables. In the case of this example there is just one remaining
variable which is
. If a regression model is fit to the data, taking as the response variable and
as the
predictor variable, then the design matrix and the vector of observations are:
The regression sum of squares for this model can be obtained as:
where
is the hat matrix (and is calculated using
ones. The total sum of squares for the model can be calculated as:
where is the identity matrix. Therefore:
) and
is the matrix of
Multiple Linear Regression Analysis
Then the variance inflation factor for
87
is:
The variance inflation factor for ,
, can be obtained in a similar manner. In DOE++, the variance inflation
factors are displayed in the VIF column of the Regression Information table as shown in the following figure. Since
the values of the variance inflation factors obtained are considerably greater than 1, multicollinearity is an issue for
the data.
Variance inflation factors for the data in.
References
[1] http:/ / reliawiki. com/ index. php/ Simple_Linear_Regression_Analysis|
[2] http:/ / reliawiki. com/ index. php/ Multiple_Linear_Regression_Analysis#Estimating_Regression_Models_Using_Least_Squares|
88
Chapter 5
One Factor Designs
As explained in Simple Linear Regression Analysis and Multiple Linear Regression Analysis, the analysis of
observational studies involves the use of regression models. The analysis of experimental studies involves the use of
analysis of variance (ANOVA) models. For a comparison of the two models see Fitting ANOVA Models. In single
factor experiments, ANOVA models are used to compare the mean response values at different levels of the factor.
Each level of the factor is investigated to see if the response is significantly different from the response at other
levels of the factor. The analysis of single factor experiments is often referred to as one-way ANOVA.
To illustrate the use of ANOVA models in the analysis of experiments, consider a single factor experiment where the
analyst wants to see if the surface finish of certain parts is affected by the speed of a lathe machine. Data is collected
for three speeds (or three treatments). Each treatment is replicated four times. Therefore, this experiment design is
balanced. Surface finish values recorded using randomization are shown in the following table.
Surface finish values for three speeds of a lathe machine.
The ANOVA model for this experiment can be stated as follows:
The ANOVA model assumes that the response at each factor level, , is the sum of the mean response at the th
level, , and a random error term, . The subscript denotes the factor level while the subscript denotes the
replicate. If there are
levels of the factor and
replicates at each level then
and
. The random error terms, , are assumed to be normally and independently distributed with a
mean of zero and variance of . Therefore, the response at each level can be thought of as a normally distributed
population with a mean of and constant variance of . The equation given above is referred to as the means
model.
The ANOVA model of the means model can also be written using
mean and represents the effect due to the th treatment.
, where
represents the overall
Such an ANOVA model is called the effects model. In the effects models the treatment effects,
deviations from the overall mean, . Therefore, the following constraint exists on the s:
, represent the
One Factor Designs
89
Fitting ANOVA Models
To fit ANOVA models and carry out hypothesis testing in single factor experiments, it is convenient to express the
effects model of the effects model in the form
(that was used for multiple linear regression models in
Multiple Linear Regression Analysis). This can be done as shown next. Using the effects model, the ANOVA model
for the single factor experiment in the first table can be expressed as:
where represents the overall mean and represents the th treatment effect. There are three treatments in the first
table (500, 600 and 700). Therefore, there are three treatment effects, , and . The following constraint exists
for these effects:
For the first treatment, the ANOVA model for the single factor experiment in the above table can be written as:
Using
, the model for the first treatment is:
Models for the second and third treatments can be obtained in a similar way. The models for the three treatments are:
The coefficients of the treatment effects
follows:
Using the indicator variables
and
and
can be expressed using two indicator variables,
and
, as
, the ANOVA model for the data in the first table now becomes:
The equation can be rewritten by including subscripts (for the level of the factor) and (for the replicate number)
as:
The equation given above represents the "regression version" of the ANOVA model.
Treat Numerical Factors as Qualitative or Quantitative?
It can be seen from the equation given above that in an ANOVA model each factor is treated as a qualitative factor.
In the present example the factor, lathe speed, is a quantitative factor with three levels. But the ANOVA model treats
this factor as a qualitative factor with three levels. Therefore, two indicator variables, and , are required to
represent this factor.
Note that in a regression model a variable can either be treated as a quantitative or a qualitative variable. The factor,
lathe speed, would be used as a quantitative factor and represented with a single predictor variable in a regression
model. For example, if a first order model were to be fitted to the data in the first table, then the regression model
would take the form
. If a second order regression model were to be fitted, the regression
model would be
. Notice that unlike these regression models, the regression
One Factor Designs
version of the ANOVA model does not make any assumption about the nature of relationship between the response
and the factor being investigated.
The choice of treating a particular factor as a quantitative or qualitative variable depends on the objective of the
experimenter. In the case of the data of the first table, the objective of the experimenter is to compare the levels of
the factor to see if change in the levels leads to a significant change in the response. The objective is not to make
predictions on the response for a given level of the factor. Therefore, the factor is treated as a qualitative factor in
this case. If the objective of the experimenter were prediction or optimization, the experimenter would focus on
aspects such as the nature of relationship between the factor, lathe speed, and the response, surface finish, so that the
factor should be modeled as a quantitative factor to make accurate predictions.
Expression of the ANOVA Model as Y = XΒ + ε
The regression version of the ANOVA model can be expanded for the three treatments and four replicates of the data
in the first table as follows:
The corresponding matrix notation is:
where
Thus:
90
One Factor Designs
91
The matrices , and are used in the calculation of the sum of squares in the next section. The data in the first
table can be entered into DOE++ as shown in the figure below.
Single factor experiment design for the data in the first table.
Hypothesis Test in Single Factor Experiments
The hypothesis test in single factor experiments examines the ANOVA model to see if the response at any level of
the investigated factor is significantly different from that at the other levels. If this is not the case and the response at
all levels is not significantly different, then it can be concluded that the investigated factor does not affect the
response. The test on the ANOVA model is carried out by checking to see if any of the treatment effects, , are
non-zero. The test is similar to the test of significance of regression mentioned in Simple Linear Regression Analysis
and Multiple Linear Regression Analysis in the context of regression models. The hypotheses statements for this test
are:
The test for
is carried out using the following statistic:
where
represents the mean square for the ANOVA model and
is the error mean square. Note that in
the case of ANOVA models we use the notation
(treatment mean square) for the model mean square and
(treatment sum of squares) for the model sum of squares (instead of
, regression mean square, and
, regression sum of squares, used in Simple Linear Regression Analysis and Multiple Linear Regression
Analysis). This is done to indicate that the model under consideration is the ANOVA model and not the regression
model. The calculations to obtain
and
are identical to the calculations to obtain
and
explained in Multiple Linear Regression Analysis.
One Factor Designs
92
Calculation of the Statistic
The sum of squares to obtain the statistic can be calculated as explained in Multiple Linear Regression Analysis.
Using the data in the first table, the model sum of squares,
, can be calculated as:
In the previous equation, represents the number of levels of the factor, represents the replicates at each level,
represents the vector of the response values, represents the hat matrix and represents the matrix of ones. (For
details on each of these terms, refer to Multiple Linear Regression Analysis.) Since two effect terms, and , are
used in the regression version of the ANOVA model, the degrees of freedom associated with the model sum of
squares,
, is two.
The total sum of squares,
, can be obtained as follows:
In the previous equation, is the identity matrix. Since there are 12 data points in all, the number of degrees of
freedom associated with
is 11.
Knowing
and
, the error sum of squares is:
The number of degrees of freedom associated with
is:
The test statistic can now be calculated using the equation given in Hypothesis Test in Single Factor Experiments as:
One Factor Designs
The value for the statistic based on the
freedom in the denominator is:
93
distribution with 2 degrees of freedom in the numerator and 9 degrees of
Assuming that the desired significance level is 0.1, since value < 0.1,
is rejected and it is concluded that
change in the lathe speed has a significant effect on the surface finish. DOE++ displays these results in the ANOVA
table, as shown in the figure below. The values of S and R-sq are the standard error and the coefficient of
determination for the model, respectively. These values are explained in Multiple Linear Regression Analysis and
indicate how well the model fits the data. The values in the figure below indicate that the fit of the ANOVA model is
fair.
ANOVA table for the data in the first table.
Confidence Interval on the ith Treatment Mean
The response at each treatment of a single factor experiment can be assumed to be a normal population with a mean
of and variance of provided that the error terms can be assumed to be normally distributed. A point estimator
of is the average response at each treatment, . Since this is a sample average, the associated variance is
, where
is the number of replicates at the th treatment. Therefore, the confidence interval on is based on the
distribution. Recall from Statistical Background on DOE (inference on population mean when variance is unknown)
that:
One Factor Designs
94
has a distribution with degrees of freedom
on the th treatment mean, , is:
. Therefore, a 100 (
) percent confidence interval
For example, for the first treatment of the lathe speed we have:
In DOE++, this value is displayed as the Estimated Mean for the first level, as shown in the Data Summary table in
the figure below. The value displayed as the standard deviation for this level is simply the sample standard deviation
calculated using the observations corresponding to this level. The 90% confidence interval for this treatment is:
The 90% limits on
are 5.9 and 11.1, respectively.
Data Summary table for the single factor experiment in the first table.
One Factor Designs
95
Confidence Interval on the Difference in Two Treatment Means
The confidence interval on the difference in two treatment means,
, is used to compare two levels of the
factor at a given significance. If the confidence interval does not include the value of zero, it is concluded that the
two levels of the factor are significantly different. The point estimator of
is
. The variance for
is:
For balanced designs all
. Therefore:
The standard deviation for
as the pooled standard error:
can be obtained by taking the square root of
and is referred to
The statistic for the difference is:
Then a 100 (1- ) percent confidence interval on the difference in two treatment means,
, is:
For example, an estimate of the difference in the first and second treatment means of the lathe speed,
The pooled standard error for this difference is:
To test
, the statistic is:
, is:
One Factor Designs
96
In DOE++, the value of the statistic is displayed in the Mean Comparisons table under the column T Value as shown
in the figure below. The 90% confidence interval on the difference
is:
Hence the 90% limits on
are
and
, respectively. These values are displayed under the
Low CI and High CI columns in the following figure. Since the confidence interval for this pair of means does not
included zero, it can be concluded that these means are significantly different at 90% confidence. This conclusion
can also be arrived at using the value noting that the hypothesis is two-sided. The value corresponding to the
statistic
, based on the distribution with 9 degrees of freedom is:
Since value < 0.1, the means are significantly different at 90% confidence. Bounds on the difference between other
treatment pairs can be obtained in a similar manner and it is concluded that all treatments are significantly different.
Mean Comparisons table for the data in the first table.
One Factor Designs
97
Residual Analysis
Plots of residuals,
, similar to the ones discussed in the previous chapters on regression, are used to ensure that
the assumptions associated with the ANOVA model are not violated. The ANOVA model assumes that the random
error terms,
, are normally and independently distributed with the same variance for each treatment. The
normality assumption can be checked by obtaining a normal probability plot of the residuals.
Equality of variance is checked by plotting residuals against the treatments and the treatment averages, (also
referred to as fitted values), and inspecting the spread in the residuals. If a pattern is seen in these plots, then this
indicates the need to use a suitable transformation on the response that will ensure variance equality. Box-Cox
transformations are discussed in the next section. To check for independence of the random error terms residuals are
plotted against time or run-order to ensure that a pattern does not exist in these plots. Residual plots for the given
example are shown in the following two figures. The plots show that the assumptions associated with the ANOVA
model are not violated.
Normal probability plot of residuals for the single factor experiment in the first table.
One Factor Designs
98
Plot of residuals against fitted values for the single factor experiment in the first table.
Box-Cox Method
Transformations on the response may be used when residual plots for an experiment show a pattern. This indicates
that the equality of variance does not hold for the residuals of the given model. The Box-Cox method can be used to
automatically identify a suitable power transformation for the data based on the relation:
is determined using the given data such that
is minimized. The values of
are not used as is because of
issues related to calculation or comparison of
values for different values of . For example, for
all
response values will become 1. Therefore, the following relation is used to obtain
:
where
. Once all
values are obtained for a value of , the corresponding
for these
values is obtained using
. The process is repeated for a number of values to obtain a plot of
against . Then the value of corresponding to the minimum
is selected as the required transformation for the
given data. DOE++ plots
values against values because the range of
values is large and if this is not
done, all values cannot be displayed on the same plot. The range of search for the best value in the software is
from
to , because larger values of of are usually not meaningful. DOE++ also displays a recommended
transformation based on the best value obtained as per the second table.
One Factor Designs
99
Recommended Box-Cox power transformations.
Confidence intervals on the selected values are also available. Let
be the value of
corresponding to
the selected value of . Then, to calculate the 100 (1- ) percent confidence intervals on , we need to calculate
as shown next:
The required limits for are the two values of corresponding to the value
(on the plot of
against ). If
the limits for do not include the value of one, then the transformation is applicable for the given data. Note that the
power transformations are not defined for response values that are negative or zero. DOE++ deals with negative and
zero response values using the following equations (that involve addition of a suitable quantity to all of the response
values if a zero or negative response value is encountered).
Here
represents the minimum response value and
response.
represents the absolute value of the minimum
Example
To illustrate the Box-Cox method, consider the experiment given in the first table. Transformed response values for
various values of can be calculated using the equation for
given in Box-Cox Method. Knowing the hat matrix,
,
values corresponding to each of these values can easily be obtained using
.
values
calculated for values between
and for the given data are shown below:
A plot of
for various values, as obtained from DOE++, is shown in the following figure. The value of
that gives the minimum
is identified as 0.7841. The
value corresponding to this value of is 73.74. A
One Factor Designs
100
90% confidence interval on this value is calculated as follows.
can be obtained as shown next:
Therefore,
. The values corresponding to this value from the following figure are
and
. Therefore, the 90% confidence limits on are
and
. Since the confidence limits
include the value of 1, this indicates that a transformation is not required for the data in the first table.
Box-Cox power transformation plot for the data in the first table.
101
Chapter 6
General Full Factorial Designs
Experiments with two or more factors are encountered frequently. The best way to carry out such experiments is by
using full factorial experiments. These are experiments in which all combinations of factors are investigated in each
replicate of the experiment. Full factorial experiments are the only means to completely and systematically study
interactions between factors in addition to identifying significant factors. One-factor-at-a-time experiments (where
each factor is investigated separately by keeping all the remaining factors constant) do not reveal the interaction
effects between the factors. Further, in one-factor-at-a-time experiments, full randomization is not possible.
To illustrate full factorial experiments, consider an experiment where the response is investigated for two factors,
and . Assume that the response is studied at two levels of factor with
representing the lower level of
and
representing the higher level. Similarly, let
and
represent the two levels of factor that are
being investigated in this experiment. Since there are two factors with two levels, a total of
combinations exist (
,
,
,
). Thus, four runs are required for
each replicate if a factorial experiment is to be carried out in this case. Assume that the response values for each of
these four possible combinations are obtained as shown in the next table.
Two-factor factorial experiment.
Investigating Factor Effects
The effect of factor on the response can be obtained by taking the difference between the average response when
is high and the average response when is low. The change in the response due to a change in the level of a
factor is called the main effect of the factor. The main effect of as per the response values in the third table is:
Therefore, when is changed from the lower level to the higher level, the response increases by 20 units. A plot of
the response for the two levels of at different levels of is shown next. The plot shows that change in the level of
leads to an increase in the response by 20 units regardless of the level of . Therefore, no interaction exists in
this case as indicated by the parallel lines on the plot.
General Full Factorial Designs
102
Interaction plot for the data in the above table.
The main effect of
can be obtained as:
Investigating Interactions
Now assume that the response values for each of the four treatment combinations were obtained as shown next.
Two factor factorial experiment.
The main effect of
in this case is:
General Full Factorial Designs
103
It appears that does not have an effect on the response. However, a plot of the response of at different levels of
shows that the response does change with the levels of but the effect of on the response is dependent on the
level of (see the figure below).
Interaction plot for the data in the above table.
Therefore, an interaction between and exists in this case (as indicated by the non-parallel lines of the figure).
The interaction effect between and can be calculated as follows:
Note that in this case, if a one-factor-at-a-time experiment were used to investigate the effect of factor on the
response, it would lead to incorrect conclusions. For example, if the response at factor was studied by holding
constant at its lower level, then the main effect of would be obtained as
, indicating that the
response increases by 20 units when the level of is changed from low to high. On the other hand, if the response at
factor was studied by holding constant at its higher level than the main effect of would be obtained as
, indicating that the response decreases by 20 units when the level of is changed from low to
high.
General Full Factorial Designs
104
Analysis of General Factorial Experiments
In DOE++, factorial experiments are referred to as factorial designs. The experiments explained in this section are
referred to as general factorial designs. This is done to distinguish these experiments from the other factorial designs
supported by DOE++ (see the figure below).
Factorial experiments available in DOE++.
The other designs (such as the two level full factorial designs that are explained in Two Level Factorial Experiments)
are special cases of these experiments in which factors are limited to a specified number of levels. The ANOVA
model for the analysis of factorial experiments is formulated as shown next. Assume a factorial experiment in which
the effect of two factors, and , on the response is being investigated. Let there be levels of factor and
levels of factor . The ANOVA model for this experiment can be stated as:
where:
•
represents the overall mean effect
•
is the effect of the th level of factor
(
•
is the effect of the th level of factor
(
•
•
)
)
represents the interaction effect between and
represents the random error terms (which are assumed to be normally distributed with a mean of zero and
variance of )
• and the subscript denotes the
Since the effects
,
and
replicates (
)
represent deviations from the overall mean, the following constraints exist:
General Full Factorial Designs
105
Hypothesis Tests in General Factorial Experiments
These tests are used to check whether each of the factors investigated in the experiment is significant or not. For the
previous example, with two factors, and , and their interaction,
, the statements for the hypothesis tests can
be formulated as follows:
The test statistics for the three tests are as follows:
1)
where
is the mean square due to factor
and
is the error mean square.
where
is the mean square due to factor
and
is the error mean square.
2)
3)
where
is the mean square due to interaction
and
is the error mean square.
The tests are identical to the partial test explained in Multiple Linear Regression Analysis. The sum of squares for
these tests (to obtain the mean squares) are calculated by splitting the model sum of squares into the extra sum of
squares due to each factor. The extra sum of squares calculated for each of the factors may either be partial or
sequential. For the present example, if the extra sum of squares used is sequential, then the model sum of squares can
be written as:
where
represents the model sum of squares,
represents the sequential sum of squares due to factor ,
represents the sequential sum of squares due to factor and
represents the sequential sum of squares due
to the interaction
. The mean squares are obtained by dividing the sum of squares by the associated degrees of
freedom. Once the mean squares are known the test statistics can be calculated. For example, the test statistic to test
the significance of factor (or the hypothesis
) can then be obtained as:
Similarly the test statistic to test significance of factor
and the interaction
can be respectively obtained as:
General Full Factorial Designs
106
It is recommended to conduct the test for interactions before conducting the test for the main effects. This is because,
if an interaction is present, then the main effect of the factor depends on the level of the other factors and looking at
the main effect is of little value. However, if the interaction is absent then the main effects become important.
Example
Consider an experiment to investigate the effect of speed and type of fuel additive used on the mileage of a sports
utility vehicle. Three speeds and two types of fuel additives are investigated. Each of the treatment combinations are
replicated three times. The mileage values observed are displayed in the table below.
Mileage data for different speeds and fuel additive types.
The experimental design for the data is shown in the figure below.
Experimental design for the Mileage Test
In the figure, the factor Speed is represented as factor and the factor Fuel Additive is represented as factor . The
experimenter would like to investigate if speed, fuel additive or the interaction between speed and fuel additive
affects the mileage of the sports utility vehicle. In other words, the following hypotheses need to be tested:
General Full Factorial Designs
107
The test statistics for the three tests are:
1.
where
is the mean square for factor
and
is the error mean square
where
is the mean square for factor
and
is the error mean square
2.
3.
where
is the mean square for interaction
and
is the error mean square
The ANOVA model for this experiment can be written as:
where represents the th treatment of factor (speed) with =1, 2, 3; represents the th treatment of factor
(fuel additive) with =1, 2; and
represents the interaction effect. In order to calculate the test statistics, it is
convenient to express the ANOVA model of the equation given above in the form
. This can be done
as explained next.
Expression of the ANOVA Model as y = ΧΒ + ε
Since the effects
Constraints on
,
and
represent deviations from the overall mean, the following constraints exist.
are:
Therefore, only two of the effects are independent. Assuming that and are independent,
.
(The null hypothesis to test the significance of factor can be rewritten using only the independent effects as
.) DOE++ displays only the independent effects because only these effects are important to the
analysis. The independent effects, and , are displayed as A[1] and A[2] respectively because these are the
effects associated with factor (speed). Constraints on are:
Therefore, only one of the effects are independent. Assuming that is independent,
hypothesis to test the significance of factor can be rewritten using only the independent effect as
The independent effect
is displayed as B:B in DOE++. Constraints on
are:
. (The null
.)
General Full Factorial Designs
108
The last five equations given above represent four constraints, as only four of these five equations are independent.
Therefore, only two out of the six
effects are independent. Assuming that
and
are
independent, the other four effects can be expressed in terms of these effects. (The null hypothesis to test the
significance of interaction
can be rewritten using only the independent effects as
.) The effects
and
are displayed as A[1]B and A[2]B respectively in DOE++.
The regression version of the ANOVA model can be obtained using indicator variables, similar to the case of the
single factor experiment in Fitting ANOVA Models. Since factor has three levels, two indicator variables, and
, are required which need to be coded as shown next:
Factor
has two levels and can be represented using one indicator variable,
, as follows:
The
interaction will be represented by all possible terms resulting from the product of the indicator variables
representing factors and . There are two such terms here and
. The regression version of the
ANOVA model can finally be obtained as:
In matrix notation this model can be expressed as:
where:
The vector can be substituted with the response values from the above table to get:
General Full Factorial Designs
109
Knowing , and , the sum of squares for the ANOVA model and the extra sum of squares for each of the
factors can be calculated. These are used to calculate the mean squares that are used to obtain the test statistics.
Calculation of Sum of Squares for the Model
The model sum of squares,
, for the regression version of the ANOVA model can be obtained as:
where is the hat matrix and is the matrix of ones. Since five effect terms ( , ,
used in the model, the number of degrees of freedom associated with
is five (
The total sum of squares,
,
and
) are
).
, can be calculated as:
Since there are 18 observed response values, the number of degrees of freedom associated with the total sum of
squares is 17 (
). The error sum of squares can now be obtained:
Since there are three replicates of the full factorial experiment, all of the error sum of squares is pure error. (This can
also be seen from the preceding figure, where each treatment combination of the full factorial design is repeated
three times.) The number of degrees of freedom associated with the error sum of squares is:
General Full Factorial Designs
110
Calculation of Extra Sum of Squares for the Factors
The sequential sum of squares for factor
can be calculated as:
where
columns of the
and
is the matrix containing only the first three
matrix. Thus:
Since there are two independent effects (
(
).
,
) for factor
, the degrees of freedom associated with
Similarly, the sum of squares for factor
can be calculated as:
Since there is one independent effect,
one (
).
, for factor
The sum of squares for the interaction
are two
, the number of degrees of freedom associated with
is
is:
Since there are two independent interaction effects,
associated with
is two (
).
and
, the number of degrees of freedom
Calculation of the Test Statistics
Knowing the sum of squares, the test statistic for each of the factors can be calculated. Analyzing the interaction
first, the test statistic for interaction
is:
The value corresponding to this statistic, based on the
and 12 degrees of freedom in the denominator, is:
distribution with 2 degrees of freedom in the numerator
Assuming that the desired significance level is 0.1, since
value > 0.1, we fail to reject
and
conclude that the interaction between speed and fuel additive does not significantly affect the mileage of the sports
utility vehicle. DOE++ displays this result in the ANOVA table, as shown in the following figure. In the absence of
General Full Factorial Designs
111
the interaction, the analysis of main effects becomes important.
The test statistic for factor
is:
The value corresponding to this statistic based on the
and 12 degrees of freedom in the denominator is:
Since value < 0.1,
the mileage.
The test statistic for factor
distribution with 2 degrees of freedom in the numerator
is rejected and it is concluded that factor
(or speed) has a significant effect on
is:
The value corresponding to this statistic based on the
and 12 degrees of freedom in the denominator is:
distribution with 2 degrees of freedom in the numerator
Since value < 0.1,
is rejected and it is concluded that factor (or fuel additive type) has a
significant effect on the mileage. Therefore, it can be concluded that speed and fuel additive type affect the mileage
of the vehicle significantly. The results are displayed in the ANOVA table of the following figure.
General Full Factorial Designs
112
Analysis results for the experiment in the above table.
Calculation of Effect Coefficients
Results for the effect coefficients of the model of the regression version of the ANOVA model are displayed in the
Regression Information table in the following figure. Calculations of the results in this table are discussed next. The
effect coefficients can be calculated as follows:
Therefore,
,
,
etc. As mentioned previously, these coefficients are
displayed as Intercept, A[1] and A[2] respectively depending on the name of the factor used in the experimental
design. The standard error for each of these estimates is obtained using the diagonal elements of the
variance-covariance matrix .
General Full Factorial Designs
113
For example, the standard error for
Then the statistic for
is:
can be obtained as:
The value corresponding to this statistic is:
Confidence intervals on
can also be calculated. The 90% limits on
Thus, the 90% limits on
similar manner.
are
and
are:
respectively. Results for other coefficients are obtained in a
Least Squares Means
The estimated mean response corresponding to the th level of any factor is obtained using the adjusted estimated
mean which is also called the least squares mean. For example, the mean response corresponding to the first level of
factor is
. An estimate of this is
or (
). Similarly, the
estimated response at the third level of factor
is
or
or (
).
Residual Analysis
As in the case of single factor experiments, plots of residuals can also be used to check for model adequacy in
factorial experiments. Box-Cox transformations are also available in DOE++ for factorial experiments.
114
Chapter 7
Randomization and Blocking in DOE
Randomization
The aspect of recording observations in an experiment in a random order is referred to as randomization.
Specifically, randomization is the process of assigning the various levels of the investigated factors to the
experimental units in a random fashion. An experiment is said to be completely randomized if the probability of an
experimental unit to be subjected to any level of a factor is equal for all the experimental units. The importance of
randomization can be illustrated using an example. Consider an experiment where the effect of the speed of a lathe
machine on the surface finish of a product is being investigated. In order to save time, the experimenter records
surface finish values by running the lathe machine continuously and recording observations in the order of increasing
speeds. The analysis of the experiment data shows that an increase in lathe speeds causes a decrease in the quality of
surface finish. However the results of the experiment are disputed by the lathe operator who claims that he has been
able to obtain better surface finish quality in the products by operating the lathe machine at higher speeds. It is later
found that the faulty results were caused because of overheating of the tool used in the machine. Since the lathe was
run continuously in the order of increased speeds the observations were recorded in the order of increased tool
temperatures. This problem could have been avoided if the experimenter had randomized the experiment and taken
reading at the various lathe speeds in a random fashion. This would require the experimenter to stop and restart the
machine at every observation, thereby keeping the temperature of the tool within a reasonable range. Randomization
would have ensured that the effect of heating of the machine tool is not included in the experiment.
Blocking
Many times a factorial experiment requires so many runs that not all of them can be completed under homogeneous
conditions. This may lead to inclusion of the effects of nuisance factors into the investigation. Nuisance factors are
factors that have an effect on the response but are not of primary interest to the investigator. For example, two
replicates of a two factor factorial experiment require eight runs. If four runs require the duration of one day to be
completed, then the total experiment will require two days to be completed. The difference in the conditions on the
two days may introduce effects on the response that are not the result of the two factors being investigated.
Therefore, the day is a nuisance factor for this experiment. Nuisance factors can be accounted for using blocking. In
blocking, experimental runs are separated based on levels of the nuisance factor. For the case of the two factor
factorial experiment (where the day is a nuisance factor), separation can be made into two groups or blocks: runs that
are carried out on the first day belong to block 1, and runs that are carried out on the second day belong to block 2.
Thus, within each block conditions are the same with respect to the nuisance factor. As a result, each block
investigates the effects of the factors of interest, while the difference in the blocks measures the effect of the
nuisance factor. For the example of the two factor factorial experiment, a possible assignment of runs to the blocks
could be as follows: one replicate of the experiment is assigned to block 1 and the second replicate is assigned to
block 2 (now each block contains all possible treatment combinations). Within each block, runs are subjected to
randomization (i.e., randomization is now restricted to the runs within a block). Such a design, where each block
contains one complete replicate and the treatments within a block are subjected to randomization, is called
randomized complete block design.
Randomization and Blocking in DOE
In summary, blocking should always be used to account for the effects of nuisance factors if it is not possible to hold
the nuisance factor at a constant level through all of the experimental runs. Randomization should be used within
each block to counter the effects of any unknown variability that may still be present.
Example
Consider the example discussed in General Full Factorial Design where the mileage of a sports utility vehicle was
investigated for the effects of speed and fuel additive type. Now assume that the three replicates for this experiment
were carried out on three different vehicles. To ensure that the variation from one vehicle to another does not have an
effect on the analysis, each vehicle is considered as one block. See the experiment design in the following figure.
Randomized complete block design for the mileage test using three blocks.
For the purpose of the analysis, the block is considered as a main effect except that it is assumed that interactions
between the block and the other main effects do not exist. Therefore, there is one block main effect (having three
levels - block 1, block 2 and block 3), two main effects (speed -having three levels; and fuel additive type - having
two levels) and one interaction effect (speed-fuel additive interaction) for this experiment. Let represent the block
effects. The hypothesis test on the block main effect checks if there is a significant variation from one vehicle to the
other. The statements for the hypothesis test are:
The test statistic for this test is:
where
represents the mean square for the block main effect and
is the error mean square. The
hypothesis statements and test statistics to test the significance of factors (speed), (fuel additive) and the
interaction
(speed-fuel additive interaction) can be obtained as explained in the example. The ANOVA model
for this example can be written as:
where:
115
Randomization and Blocking in DOE
116
•
represents the overall mean effect
•
•
•
is the effect of the th level of the block (
is the effect of the th level of factor (
is the effect of the th level of factor (
)
)
)
•
represents the interaction effect between and
• and
represents the random error terms (which are assumed to be normally distributed with a mean of zero and
variance of )
In order to calculate the test statistics, it is convenient to express the ANOVA model of the equation given above in
the form
. This can be done as explained next.
Expression of the ANOVA Model as y = ΧΒ + ε
Since the effects
exist.
Constraints on
,
,
, and
are defined as deviations from the overall mean, the following constraints
are:
Therefore, only two of the effects are independent. Assuming that and are independent,
.
(The null hypothesis to test the significance of the blocks can be rewritten using only the independent effects as
.) In DOE++, the independent block effects, and , are displayed as Block[1] and Block[2],
respectively.
Constraints on
are:
Therefore, only two of the effects are independent. Assuming that and are independent,
The independent effects, and , are displayed as A[1] and A[2], respectively. Constraints on
Therefore, only one of the effects is independent. Assuming that
effect, , is displayed as B:B. Constraints on
are:
is independent,
.
are:
. The independent
Randomization and Blocking in DOE
117
The last five equations given above represent four constraints as only four of the five equations are independent.
Therefore, only two out of the six
effects are independent. Assuming that
and
are
independent, we can express the other four effects in terms of these effects. The independent effects,
, are displayed as A[1]B and A[2]B, respectively.
and
The regression version of the ANOVA model can be obtained using indicator variables. Since the block has three
levels, two indicator variables, and , are required, which need to be coded as shown next:
Factor
has three levels and two indicator variables,
Factor
has two levels and can be represented using one indicator variable,
The
interaction will be represented by
finally be obtained as:
and
and
, are required:
, as follows:
. The regression version of the ANOVA model can
In matrix notation this model can be expressed as:
or:
Knowing , and , the sum of squares for the ANOVA model and the extra sum of squares for each of the
factors can be calculated. These are used to calculate the mean squares that are used to obtain the test statistics.
Calculation of the Sum of Squares for the Model
The model sum of squares,
Since seven effect terms (
freedom associated with
, for the ANOVA model of this example can be obtained as:
,
, , , ,
is seven (
and
) are used in the model the number of degrees of
).
Randomization and Blocking in DOE
118
The total sum of squares can be calculated as:
Since there are 18 observed response values, the number of degrees of freedom associated with the total sum of
squares is 17 (
). The error sum of squares can now be obtained:
The number of degrees of freedom associated with the error sum of squares is:
Since there are no true replicates of the treatments (as can be seen from the design of the previous figure, where all
of the treatments are seen to be run just once), all of the error sum of squares is the sum of squares due to lack of fit.
The lack of fit arises because the model used is not a full model since it is assumed that there are no interactions
between blocks and other effects.
Calculation of the Extra Sum of Squares for the Factors
The sequential sum of squares for the blocks can be calculated as:
where
is
the
matrix
of
ones,
is
the
, and
columns of the
hat
matrix,
which
is
calculated
is the matrix containing only the first three
matrix. Thus
Since there are two independent block effects, and
is two (
).
Similarly, the sequential sum of squares for factor
, the number of degrees of freedom associated with
can be calculated as:
Sequential sum of squares for the other effects are obtained as
using
and
.
Randomization and Blocking in DOE
119
Calculation of the Test Statistics
Knowing the sum of squares, the test statistics for each of the factors can be calculated. For example, the test statistic
for the main effect of the blocks is:
The value corresponding to this statistic based on the
and 10 degrees of freedom in the denominator is:
distribution with 2 degrees of freedom in the numerator
Assuming that the desired significance level is 0.1, since value > 0.1, we fail to reject
and conclude
that there is no significant variation in the mileage from one vehicle to the other. Statistics to test the significance of
other factors can be calculated in a similar manner. The complete analysis results obtained from DOE++ for this
experiment are presented in the following figure.
Analysis results for the experiment in the example.
120
Chapter 8
Two Level Factorial Experiments
Two level factorial experiments are factorial experiments in which each factor is investigated at only two levels. The
early stages of experimentation usually involve the investigation of a large number of potential factors to discover
the "vital few" factors. Two level factorial experiments are used during these stages to quickly filter out unwanted
effects so that attention can then be focused on the important ones.
2k Designs
The factorial experiments, where all combination of the levels of the factors are run, are usually referred to as full
factorial experiments. Full factorial two level experiments are also referred to as designs where denotes the
number of factors being investigated in the experiment. In DOE++, these designs are referred to as 2 Level Factorial
Designs as shown in the figure below.
Selection of full factorial experiments with two levels in DOE++.
A full factorial two level design with factors requires runs for a single replicate. For example, a two level
experiment with three factors will require
runs. The choice of the two levels of factors used
in two level experiments depends on the factor; some factors naturally have two levels. For example, if gender is a
factor, then male and female are the two levels. For other factors, the limits of the range of interest are usually used.
For example, if temperature is a factor that varies from
to
, then the two levels used in the design for
Two Level Factorial Experiments
this factor would be
and
121
.
The two levels of the factor in the design are usually represented as
(for the first level) and (for the second
level). Note that this representation is reversed from the coding used in General Full Factorial Designs for the
indicator variables that represent two level factors in ANOVA models. For ANOVA models, the first level of the
factor was represented using a value of for the indicator variable, while the second level was represented using a
value of
. For details on the notation used for two level experiments refer to Notation.
The 22 Design
The simplest of the two level factorial experiments is the design where two factors (say factor and factor )
are investigated at two levels. A single replicate of this design will require four runs (
) The
effects investigated by this design are the two main effects, and and the interaction effect
. The treatments
for this design are shown in figure (a) below. In figure (a), letters are used to represent the treatments. The presence
of a letter indicates the high level of the corresponding factor and the absence indicates the low level. For example,
(1) represents the treatment combination where all factors involved are at the low level or the level represented by
; represents the treatment combination where factor is at the high level or the level of , while the
remaining factors (in this case, factor ) are at the low level or the level of
. Similarly, represents the
treatment combination where factor is at the high level or the level of , while factor is at the low level and
represents the treatment combination where factors and are at the high level or the level of the 1. Figure (b)
below shows the design matrix for the design. It can be noted that the sum of the terms resulting from the product
of any two columns of the design matrix is zero. As a result the design is an orthogonal design. In fact, all
designs are orthogonal designs. This property of the designs offers a great advantage in the analysis because of
the simplifications that result from orthogonality. These simplifications are explained later on in this chapter. The
design can also be represented geometrically using a square with the four treatment combinations lying at the four
corners, as shown in figure (c) below.
Two Level Factorial Experiments
122
The
design. Figure (a) displays the
experiment design, (b) displays the design
matrix and (c) displays the geometric
representation for the design. In Figure (b),
the column names I, A, B and AB are used.
Column I represents the intercept term.
Columns A and B represent the respective
factor settings. Column AB represents the
interaction and is the product of columns A
and B.
The 23 Design
The design is a two level factorial experiment design with three factors (say factors , and ). This design
tests three (
) main effects, , and ; three (
) two factor interaction effects,
,
,
; and one (
) three factor interaction effect,
. The design requires eight runs per replicate.
The eight treatment combinations corresponding to these runs are
, , , , , , and
. Note that the
treatment combinations are written in such an order that factors are introduced one by one with each new factor
being combined with the preceding terms. This order of writing the treatments is called the standard order or Yates'
order. The design is shown in figure (a) below. The design matrix for the design is shown in figure (b). The
design matrix can be constructed by following the standard order for the treatment combinations to obtain the
columns for the main effects and then multiplying the main effects columns to obtain the interaction columns.
Two Level Factorial Experiments
123
The
design. Figure (a) shows the experiment design and (b) shows
the design matrix.
Geometric representation of the
design.
The design can also be represented geometrically using a cube with the eight treatment combinations lying at the
eight corners as shown in the figure above.
Two Level Factorial Experiments
124
Analysis of 2k Designs
The designs are a special category of the factorial experiments where all the factors are at two levels. The fact
that these designs contain factors at only two levels and are orthogonal greatly simplifies their analysis even when
the number of factors is large. The use of designs in investigating a large number of factors calls for a revision of
the notation used previously for the ANOVA models. The case for revised notation is made stronger by the fact that
the ANOVA and multiple linear regression models are identical for designs because all factors are only at two
levels. Therefore, the notation of the regression models is applied to the ANOVA models for these designs, as
explained next.
Notation
Based on the notation used in General Full Factorial Designs, the ANOVA model for a two level factorial
experiment with three factors would be as follows:
where:
• represents the overall mean
•
represents the independent effect of the first factor (factor
•
represents the independent effect of the second factor (factor
•
represents the independent effect of the interaction
•
represents the effect of the third factor (factor
) out of the two effects
) out of the two effects
and
out of the other interaction effects
) out of the two effects
and
•
represents the effect of the interaction
out of the other interaction effects
•
represents the effect of the interaction
out of the other interaction effects
•
represents the effect of the interaction
and is the random error term.
and
out of the other interaction effects
The notation for a linear regression model having three predictor variables with interactions is:
The notation for the regression model is much more convenient, especially for the case when a large number of
higher order interactions are present. In two level experiments, the ANOVA model requires only one indicator
variable to represent each factor for both qualitative and quantitative factors. Therefore, the notation for the multiple
linear regression model can be applied to the ANOVA model of the experiment that has all the factors at two levels.
For example, for the experiment of the ANOVA model given above, can represent the overall mean instead of ,
and can represent the independent effect, , of factor . Other main effects can be represented in a similar
manner. The notation for the interaction effects is much more simplified (e.g.,
can be used to represent the three
factor interaction effect,
).
As mentioned earlier, it is important to note that the coding for the indicator variables for the ANOVA models of two
level factorial experiments is reversed from the coding followed in General Full Factorial Designs. Here
represents the first level of the factor while represents the second level. This is because for a two level factor a
single variable is needed to represent the factor for both qualitative and quantitative factors. For quantitative factors,
using
for the first level (which is the low level) and 1 for the second level (which is the high level) keeps the
coding consistent with the numerical value of the factors. The change in coding between the two coding schemes
does not affect the analysis except that signs of the estimated effect coefficients will be reversed (i.e., numerical
values of , obtained based on the coding of General Full Factorial Designs, and , obtained based on the new
coding, will be the same but their signs would be opposite).
Two Level Factorial Experiments
125
In summary, the ANOVA model for the experiments with all factors at two levels is different from the ANOVA
models for other experiments in terms of the notation in the following two ways:
• The notation of the regression models is used for the effect coefficients.
• The coding of the indicator variables is reversed.
Special Features
Consider the design matrix,
, for the
design discussed above. The (
Notice that, due to the orthogonal design of the
matrix, the
)
matrix is:
has been simplified to a diagonal matrix
which can be written as:
where represents the identity matrix of the same order as the design matrix,
per replicate of the
The
design, the
matrix for any
'
matrix for
. Since there are eight observations
replicates of this design can be written as:
design can now be written as:
Then the variance-covariance matrix for the
design is:
Note that the variance-covariance matrix for the design is also a diagonal matrix. Therefore, the estimated effect
coefficients ( , ,
etc.) for these designs are uncorrelated. This implies that the terms in the design
(main effects, interactions) are independent of each other. Consequently, the extra sum of squares for each of the
terms in these designs is independent of the sequence of terms in the model, and also independent of the presence of
other terms in the model. As a result the sequential and partial sum of squares for the terms are identical for these
designs and will always add up to the model sum of squares. Multicollinearity is also not an issue for these designs.
It can also be noted from the equation given above, that in addition to the matrix being diagonal, all diagonal
elements of the matrix are identical. This means that the variance (or its square root, the standard error) of all
estimated effect coefficients are the same. The standard error,
, for all the coefficients is:
Two Level Factorial Experiments
126
This property is used to construct the normal probability plot of effects in designs and identify significant effects
using graphical techniques. For details on the normal probability plot of effects in DOE++, refer to Normal
Probability Plot of Effects.
Example
To illustrate the analysis of a full factorial design, consider a three factor experiment to investigate the effect of
honing pressure, number of strokes and cycle time on the surface finish of automobile brake drums. Each of these
factors is investigated at two levels. The honing pressure is investigated at levels of 200
and 400
, the
number of strokes used is 3 and 5 and the two levels of the cycle time are 3 and 5 seconds. The design for this
experiment is set up in DOE++ as shown in the first two following figures. It is decided to run two replicates for this
experiment. The surface finish data collected from each run (using randomization) and the complete design is shown
in the third following figure. The analysis of the experiment data is explained next.
Design properties for the experiment in the example.
Design summary for the experiment in the example.
Two Level Factorial Experiments
127
Experiment design for the example to investigate the surface finish of automobile brake drums.
The applicable model using the notation for
designs is:
where the indicator variable,
represents factor (honing pressure),
represents the low level of 200
and
represents the high level of 400
. Similarly, and represent factors (number of strokes)
and (cycle time), respectively. is the overall mean, while , and are the effect coefficients for the main
effects of factors , and , respectively.
,
and
are the effect coefficients for the
,
and
interactions, while
represents the
interaction.
If the subscripts for the run ( ;
as:
1 to 8) and replicates ( ;
1,2) are included, then the model can be written
To investigate how the given factors affect the response, the following hypothesis tests need to be carried:
This test investigates the main effect of factor
where
effects,
(honing pressure). The statistic for this test is:
is the mean square for factor and
and , can be written in a similar manner.
This test investigates the two factor interaction
is the error mean square. Hypotheses for the other main
. The statistic for this test is:
where
is the mean square for the interaction
and
is the error mean square. Hypotheses for the
other two factor interactions,
and
, can be written in a similar manner.
This test investigates the three factor interaction
. The statistic for this test is:
Two Level Factorial Experiments
128
where
is the mean square for the interaction
and
is the error mean square. To calculate the
test statistics, it is convenient to express the ANOVA model in the form
.
Expression of the ANOVA Model as
In matrix notation, the ANOVA model can be expressed as:
where:
Calculation of the Extra Sum of Squares for the Factors
Knowing the matrices , and , the extra sum of squares for the factors can be calculated. These are used to
calculate the mean squares that are used to obtain the test statistics. Since the experiment design is orthogonal, the
partial and sequential extra sum of squares are identical. The extra sum of squares for each effect can be calculated
as shown next. As an example, the extra sum of squares for the main effect of factor is:
where
is the hat matrix and
is the matrix of ones. The matrix
can be calculated using
where
is the design matrix, , excluding the second column that represents
the main effect of factor
. Thus, the sum of squares for the main effect of factor
Similarly, the extra sum of squares for the interaction effect
is:
The extra sum of squares for other effects can be obtained in a similar manner.
is:
Two Level Factorial Experiments
Calculation of the Test Statistics
Knowing the extra sum of squares, the test statistic for the effects can be calculated. For example, the test statistic for
the interaction
is:
where
is the mean square for the
interaction and
is the error mean square. The value
corresponding to the statistic,
, based on the distribution with one degree of freedom in the
numerator and eight degrees of freedom in the denominator is:
Assuming that the desired significance is 0.1, since value > 0.1, it can be concluded that the interaction between
honing pressure and number of strokes does not affect the surface finish of the brake drums. Tests for other effects
can be carried out in a similar manner. The results are shown in the ANOVA Table in the following figure. The
values S, R-sq and R-sq(adj) in the figure indicate how well the model fits the data. The value of S represents the
standard error of the model, R-sq represents the coefficient of multiple determination and R-sq(adj) represents the
adjusted coefficient of multiple determination. For details on these values refer to Multiple Linear Regression
Analysis.
129
Two Level Factorial Experiments
130
ANOVA table for the experiment in the example.
Calculation of Effect Coefficients
The estimate of effect coefficients can also be obtained:
Two Level Factorial Experiments
131
Regression Information table for the experiment in the example.
The coefficients and related results are shown in the Regression Information table above. In the table, the Effect
column displays the effects, which are simply twice the coefficients. The Standard Error column displays the
standard error,
. The Low CI and High CI columns display the confidence interval on the coefficients. The
interval shown is the 90% interval as the significance is chosen as 0.1. The T Value column displays the statistic,
, corresponding to the coefficients. The P Value column displays the value corresponding to the statistic. (For
details on how these results are calculated, refer to General Full Factorial Designs). Plots of residuals can also be
obtained from DOE++ to ensure that the assumptions related to the ANOVA model are not violated.
Model Equation
From the analysis results in the above figure within calculation of effect coefficients section, it is seen that effects
, and
are significant. In DOE++, the values for the significant effects are displayed in red in the ANOVA
Table for easy identification. Using the values of the estimated effect coefficients, the model for the present
design in terms of the coded values can be written as:
To make the model hierarchical, the main effect,
is included in the model). The resulting model is:
, needs to be included in the model (because the interaction
This equation can be viewed in DOE++, as shown in the following figure, using the Show Analysis Summary icon in
the Control Panel. The equation shown in the figure will match the hierarchical model once the required terms are
selected using the Select Effects icon.
Two Level Factorial Experiments
132
The model equation for the experiment of the example.
Replicated and Repeated Runs
In the case of replicated experiments, it is important to note the difference between replicated runs and repeated runs.
Both repeated and replicated runs are multiple response readings taken at the same factor levels. However, repeated
runs are response observations taken at the same time or in succession. Replicated runs are response observations
recorded in a random order. Therefore, replicated runs include more variation than repeated runs. For example, a
baker, who wants to investigate the effect of two factors on the quality of cakes, will have to bake four cakes to
complete one replicate of a design. Assume that the baker bakes eight cakes in all. If, for each of the four
treatments of the design, the baker selects one treatment at random and then bakes two cakes for this treatment at
the same time then this is a case of two repeated runs. If, however, the baker bakes all the eight cakes randomly, then
the eight cakes represent two sets of replicated runs. For repeated measurements, the average values of the response
for each treatment should be entered into DOE++ as shown in the following figure (a) when the two cakes for a
particular treatment are baked together. For replicated measurements, when all the cakes are baked randomly, the
data is entered as shown in the following figure (b).
Two Level Factorial Experiments
133
Data entry for repeated and replicated runs. Figure (a) shows repeated
runs and (b) shows replicated runs.
Unreplicated 2k Designs
If a factorial experiment is run only for a single replicate then it is not possible to test hypotheses about the main
effects and interactions as the error sum of squares cannot be obtained. This is because the number of observations in
a single replicate equals the number of terms in the ANOVA model. Hence the model fits the data perfectly and no
degrees of freedom are available to obtain the error sum of squares.
However, sometimes it is only possible to run a single replicate of the design because of constraints on resources
and time. In the absence of the error sum of squares, hypothesis tests to identify significant factors cannot be
conducted. A number of methods of analyzing information obtained from unreplicated designs are available.
These include pooling higher order interactions, using the normal probability plot of effects or including center point
replicates in the design.
Pooling Higher Order Interactions
One of the ways to deal with unreplicated designs is to use the sum of squares of some of the higher order
interactions as the error sum of squares provided these higher order interactions can be assumed to be insignificant.
By dropping some of the higher order interactions from the model, the degrees of freedom corresponding to these
interactions can be used to estimate the error mean square. Once the error mean square is known, the test statistics to
conduct hypothesis tests on the factors can be calculated.
Two Level Factorial Experiments
134
Normal Probability Plot of Effects
Another way to use unreplicated designs to identify significant effects is to construct the normal probability plot
of the effects. As mentioned in Special Features, the standard error for all effect coefficients in the designs is the
same. Therefore, on a normal probability plot of effect coefficients, all non-significant effect coefficients (with
) will fall along the straight line representative of the normal distribution, N(
). Effect
coefficients that show large deviations from this line will be significant since they do not come from this normal
distribution. Similarly, since effects
effect coefficients, all non-significant effects will also follow a straight
line on the normal probability plot of effects. For replicated designs, the Effects Probability plot of DOE++ plots the
normalized effect values (or the T Values) on the standard normal probability line, N(0,1). However, in the case of
unreplicated designs, remains unknown since
cannot be obtained. Lenth's method is used in this case to
estimate the variance of the effects. For details on Lenth's method, please refer to Montgomery (2001). DOE++ then
uses this variance value to plot effects along the N(0, Lenth's effect variance) line. The method is illustrated in the
following example.
Example
Vinyl panels, used as instrument panels in a certain automobile, are seen to develop defects after a certain amount of
time. To investigate the issue, it is decided to carry out a two level factorial experiment. Potential factors to be
investigated in the experiment are vacuum rate (factor ), material temperature (factor ), element intensity
(factor ) and pre-stretch (factor ). The two levels of the factors used in the experiment are as shown in below.
Factors to investigate defects in vinyl panels.
With a
design requiring 16 runs per replicate it is only feasible for the manufacturer to run a single replicate.
The experiment design and data, collected as percent defects, are shown in the following figure. Since the present
experiment design contains only a single replicate, it is not possible to obtain an estimate of the error sum of squares,
. It is decided to use the normal probability plot of effects to identify the significant effects. The effect values
for each term are obtained as shown in the following figure.
Two Level Factorial Experiments
135
Experiment design for the example.
Lenth's method uses these values to estimate the variance. As described in [Lenth, 1989], if all effects are arranged in
ascending order, using their absolute values, then is defined as 1.5 times the median value:
Using , the "pseudo standard error" (
than 2.5 :
) is calculated as 1.5 times the median value of all effects that are less
Using
as an estimate of the effect variance, the effect variance is 2.25. Knowing the effect variance, the
normal probability plot of effects for the present unreplicated experiment can be constructed as shown in the
following figure. The line on this plot is the line N(0, 2.25). The plot shows that the effects , and the interaction
do not follow the distribution represented by this line. Therefore, these effects are significant.
The significant effects can also be identified by comparing individual effect values to the margin of error or the
threshold value using the pareto chart (see the third following figure). If the required significance is 0.1, then:
The statistic,
, is calculated at a significance of
number of effects
. Thus:
(for the two-sided hypothesis) and degrees of freedom
The value of 4.534 is shown as the critical value line in the third following figure. All effects with absolute values
greater than the margin of error can be considered to be significant. These effects are , and the interaction
. Therefore, the vacuum rate, the pre-stretch and their interaction have a significant effect on the defects of the vinyl
panels.
Two Level Factorial Experiments
136
Effect values for the experiment in the example.
Normal probability plot of effects for the experiment in the example.
Two Level Factorial Experiments
137
Pareto chart for the experiment in the example.
Center Point Replicates
Another method of dealing with unreplicated designs that only have quantitative factors is to use replicated runs
at the center point. The center point is the response corresponding to the treatment exactly midway between the two
levels of all factors. Running multiple replicates at this point provides an estimate of pure error. Although running
multiple replicates at any treatment level can provide an estimate of pure error, the other advantage of running center
point replicates in the design is in checking for the presence of curvature. The test for curvature investigates
whether the model between the response and the factors is linear and is discussed in Center Pt. Replicates to Test
Curvature.
Example: Use Center Point to Get Pure Error
Consider a experiment design to investigate the effect of two factors, and , on a certain response. The
energy consumed when the treatments of the design are run is considerably larger than the energy consumed for
the center point run (because at the center point the factors are at their middle levels). Therefore, the analyst decides
to run only a single replicate of the design and augment the design by five replicated runs at the center point as
shown in the following figure. The design properties for this experiment are shown in the second following figure.
The complete experiment design is shown in the third following figure. The center points can be used in the
identification of significant effects as shown next.
Two Level Factorial Experiments
138
design augmented by five center point runs.
Design properties for the experiment in the example.
Two Level Factorial Experiments
139
Experiment design for the example.
Since the present design is unreplicated, there are no degrees of freedom available to calculate the error sum of
squares. By augmenting this design with five center points, the response values at the center points, , can be used
to obtain an estimate of pure error,
. Let represent the average response for the five replicates at the center.
Then:
Then the corresponding mean square is:
Alternatively,
points:
can be directly obtained by calculating the variance of the response values at the center
Once
is known, it can be used as the error mean square,
, to carry out the test of significance for each
effect. For example, to test the significance of the main effect of factor the sum of squares corresponding to this
effect is obtained in the usual manner by considering only the four runs of the original design.
Then, the test statistic to test the significance of the main effect of factor
is:
Two Level Factorial Experiments
140
The value corresponding to the statistic,
, based on the
freedom in the numerator and eight degrees of freedom in the denominator is:
distribution with one degree of
Assuming that the desired significance is 0.1, since value < 0.1, it can be concluded that the main effect of factor
significantly affects the response. This result is displayed in the ANOVA table as shown in the following figure.
Test for the significance of other factors can be carried out in a similar manner.
Results for the experiment in the example.
Using Center Point Replicates to Test Curvature
Center point replicates can also be used to check for curvature in replicated or unreplicated designs. The test for
curvature investigates whether the model between the response and the factors is linear. The way DOE++ handles
center point replicates is similar to its handling of blocks. The center point replicates are treated as an additional
factor in the model. The factor is labeled as Curvature in the results of DOE++. If Curvature turns out to be a
significant factor in the results, then this indicates the presence of curvature in the model.
Two Level Factorial Experiments
141
Example: Use Center Point to Test Curvature
To illustrate the use of center point replicates in testing for curvature, consider again the data of the single replicate
experiment from a preceding figure(labeled " design augmented by five center point runs"). Let be the
indicator variable to indicate if the run is a center point:
If
and
are the indicator variables representing factors
experiment is:
and
, respectively, then the model for this
To investigate the presence of curvature, the following hypotheses need to be tested:
The test statistic to be used for this test is:
where
is the mean square for Curvature and
is the error mean square.
Calculation of the Sum of Squares
The
matrix and vector for this experiment are:
The sum of squares can now be calculated. For example, the error sum of squares is:
where is the identity matrix and is the hat matrix. It can be seen that this is equal to
(the sum of squares
due to pure error) because of the replicates at the center point, as obtained in the example. The number of degrees of
freedom associated with
,
is four. The extra sum of squares corresponding to the center point
replicates (or Curvature) is:
where
is the hat matrix and
is the matrix of ones. The matrix
can be calculated using
where
is the design matrix,
, excluding the
second column that represents the center point. Thus, the extra sum of squares corresponding to Curvature is:
This extra sum of squares can be used to test for the significance of curvature. The corresponding mean square is:
Two Level Factorial Experiments
142
Calculation of the Test Statistic
Knowing the mean squares, the statistic to check the significance of curvature can be calculated.
The value corresponding to the statistic,
, based on the
freedom in the numerator and four degrees of freedom in the denominator is:
distribution with one degree of
Assuming that the desired significance is 0.1, since value > 0.1, it can be concluded that curvature does not exist
for this design. This results is shown in the ANOVA table in the figure above. The surface of the fitted model based
on these results, along with the observed response values, is shown in the figure below.
Model surface and observed response values for the design in the example.
Two Level Factorial Experiments
143
Blocking in 2k Designs
Blocking can be used in the designs to deal with cases when replicates cannot be run under identical conditions.
Randomized complete block designs that were discussed in Randomization and Blocking in DOE for factorial
experiments are also applicable here. At times, even with just two levels per factor, it is not possible to run all
treatment combinations for one replicate of the experiment under homogeneous conditions. For example, each
replicate of the design requires four runs. If each run requires two hours and testing facilities are available for
only four hours per day, two days of testing would be required to run one complete replicate. Blocking can be used
to separate the treatment runs on the two different days. Blocks that do not contain all treatments of a replicate are
called incomplete blocks. In incomplete block designs, the block effect is confounded with certain effect(s) under
investigation. For the design assume that treatments
and were run on the first day and treatments and
were run on the second day. Then, the incomplete block design for this experiment is:
For this design the block effect may be calculated as:
The
interaction effect is:
The two equations given above show that, in this design, the
interaction effect cannot be distinguished from the
block effect because the formulas to calculate these effects are the same. In other words, the
interaction is said
to be confounded with the block effect and it is not possible to say if the effect calculated based on these equations is
due to the
interaction effect, the block effect or both. In incomplete block designs some effects are always
confounded with the blocks. Therefore, it is important to design these experiments in such a way that the important
effects are not confounded with the blocks. In most cases, the experimenter can assume that higher order interactions
are unimportant. In this case, it would better to use incomplete block designs that confound these effects with the
blocks. One way to design incomplete block designs is to use defining contrasts as shown next:
where the s are the exponents for the factors in the effect that is to be confounded with the block effect and the
s are values based on the level of the the factor (in a treatment that is to be allocated to a block). For designs the
s are either 0 or 1 and the s have a value of 0 for the low level of the th factor and a value of 1 for the high
level of the factor in the treatment under consideration. As an example, consider the design where the interaction
effect
is confounded with the block. Since there are two factors,
, with
representing factor and
representing factor . Therefore:
Two Level Factorial Experiments
144
The value of is one because the exponent of factor in the confounded interaction
is one. Similarly, the
value of is one because the exponent of factor in the confounded interaction
is also one. Therefore, the
defining contrast for this design can be written as:
Once the defining contrast is known, it can be used to allocate treatments to the blocks. For the design, there are
four treatments
, , and . Assume that
represents block 2 and
represents block 1. In order to
decide which block the treatment
belongs to, the levels of factors and for this run are used. Since factor
is at the low level in this treatment,
. Similarly, since factor is also at the low level in this treatment,
. Therefore:
Note that the value of used to decide the block allocation is "mod 2" of the original value. This value is obtained
by taking the value of 1 for odd numbers and 0 otherwise. Based on the value of , treatment
is assigned to
block 1. Other treatments can be assigned using the following calculations:
Therefore, to confound the interaction
with the block effect in the incomplete block design, treatments
and (with
) should be assigned to block 2 and treatment combinations and (with
) should be
assigned to block 1.
Example: Two Level Factorial Design with Two Blocks
This example illustrates how treatments can be allocated to two blocks for an unreplicated design. Consider the
unreplicated design to investigate the four factors affecting the defects in automobile vinyl panels discussed in
Normal Probability Plot of Effects. Assume that the 16 treatments required for this experiment were run by two
different operators with each operator conducting 8 runs. This experiment is an example of an incomplete block
design. The analyst in charge of this experiment assumed that the interaction
was not significant and
decided to allocate treatments to the two operators so that the
interaction was confounded with the block
effect (the two operators are the blocks). The allocation scheme to assign treatments to the two operators can be
obtained as follows.
The defining contrast for the design where the
interaction is confounded with the blocks is:
The treatments can be allocated to the two operators using the values of the defining contrast. Assume that
represents block 2 and
represents block 1. Then the value of the defining contrast for treatment is:
Therefore, treatment should be assigned to Block 1 or the first operator. Similarly, for treatment
we have:
Two Level Factorial Experiments
145
Allocation of treatments to two blocks for the
design in the example by confounding interaction of
with the blocks.
Therefore, should be assigned to Block 2 or the second operator. Other treatments can be allocated to the two
operators in a similar manner to arrive at the allocation scheme shown in the figure below. In DOE++, to confound
the
interaction for the design into two blocks, the number of blocks are specified as shown in the figure
below. Then the interaction
is entered in the Block Generator window (second following figure) which is
available using the Block Generator button in the following figure. The design generated by DOE++ is shown in the
third of the following figures. This design matches the allocation scheme of the preceding figure.
Adding block properties for the experiment in the example.
Two Level Factorial Experiments
146
Specifying the interaction ABCD as the interaction to be confounded with the blocks for the example.
Two block design for the experiment in the example.
For the analysis of this design, the sum of squares for all effects are calculated assuming no blocking. Then, to
account for blocking, the sum of squares corresponding to the
interaction is considered as the sum of
squares due to blocks and
. In DOE++ this is done by displaying this sum of squares as the sum of squares
due to the blocks. This is shown in the following figure where the sum of squares in question is obtained as 72.25
and is displayed against Block. The interaction ABCD, which is confounded with the blocks, is not displayed. Since
the design is unreplicated, any of the methods to analyze unreplicated designs mentioned in Unreplicated designs
have to be used to identify significant effects.
Two Level Factorial Experiments
147
ANOVA table for the experiment of the example.
Unreplicated 2k Designs in 2p Blocks
A single replicate of the design can be run in up to blocks where
. The number of effects confounded
with the blocks equals the degrees of freedom associated with the block effect.
If two blocks are used (the block effect has two levels), then one (
effect is confounded with the blocks.
If four blocks are used, then three (
) effects are confounded with the blocks and so on. For example an
unreplicated design may be confounded in (four) blocks using two contrasts, and . Let
and
be
the effects to be confounded with the blocks. Corresponding to these two effects, the contrasts are respectively:
Based on the values of
and
the treatments can be assigned to the four blocks as follows:
Since the block effect has three degrees of freedom, three effects are confounded with the block effect. In addition to
and
, the third effect confounded with the block effect is their generalized interaction,
. In general, when an unreplicated design is confounded in blocks, contrasts are
needed (
). effects are selected to define these contrasts such that none of these effects are the
Two Level Factorial Experiments
148
generalized interaction of the others. The blocks can then be assigned the treatments using the contrasts.
are also confounded with the blocks, are then obtained as the generalized interaction of the effects. In the statistical
analysis of these designs, the sum of squares are computed as if no blocking were used. Then the block sum of
squares is obtained by adding the sum of squares for all the effects confounded with the blocks.
Example: 2 Level Factorial Design with Four Blocks
This example illustrates how DOE++ obtains the sum of squares when treatments for an unreplicated design are
allocated among four blocks. Consider again the unreplicated design used to investigate the defects in automobile
vinyl panels presented in Normal Probability Plot of Effects. Assume that the 16 treatments needed to complete the
experiment were run by four operators. Therefore, there are four blocks. Assume that the treatments were allocated
to the blocks using the generators mentioned in the previous section, i.e., treatments were allocated among the four
operators by confounding the effects,
and
with the blocks. These effects can be specified as Block
Generators as shown in the following figure. (The generalized interaction of these two effects, interaction
,
will also get confounded with the blocks.) The resulting design is shown in the second following figure and matches
the allocation scheme obtained in the previous section.
Specifying the interactions AC and BD as block generators for the example.
The sum of squares in this case can be obtained by calculating the sum of squares for each of the effects assuming
there is no blocking. Once the individual sum of squares have been obtained, the block sum of squares can be
calculated. The block sum of squares is the sum of the sum of squares of effects,
,
and
, since
these effects are confounded with the block effect. As shown in the second following figure, this sum of squares is
92.25 and is displayed against Block. The interactions
,
and
, which are confounded with the
blocks, are not displayed. Since the present design is unreplicated any of the methods to analyze unreplicated designs
mentioned in Unreplicated designs have to be used to identify significant effects.
effects, t
Two Level Factorial Experiments
149
Design for the experiment in the example.
ANOVA table for the experiment in the example.
Two Level Factorial Experiments
Variability Analysis
For replicated two level factorial experiments, DOE++ provides the option of conducting variability analysis (using
the Variability Analysis icon under the Data menu). The analysis is used to identify the treatment that results in the
least amount of variation in the product or process being investigated. Variability analysis is conducted by treating
the standard deviation of the response for each treatment of the experiment as an additional response. The standard
deviation for a treatment is obtained by using the replicated response values at that treatment run. As an example,
consider the design shown in the following figure where each run is replicated four times. A variability analysis
can be conducted for this design. DOE++ calculates eight standard deviation values corresponding to each treatment
of the design (see second following figure). Then, the design is analyzed as an unreplicated design with the
standard deviations (displayed as Y Standard Deviation. in second following figure) as the response. The normal
probability plot of effects identifies
as the effect that influences variability (see third figure following). Based
on the effect coefficients obtained in the fourth figure following, the model for Y Std. is:
Based on the model, the experimenter has two choices to minimize variability (by minimizing Y Std.). The first
choice is that should be (i.e., should be set at the high level) and should be
(i.e., should be set at the
low level). The second choice is that should be
(i.e., should be set at the low level) and should be
(i.e., should be set at the high level). The experimenter can select the most feasible choice.
A
design with four replicated response values that can be used to conduct a variability analysis.
150
Two Level Factorial Experiments
151
Variability analysis in DOE++.
Two Level Factorial Experiments
152
Normal probability plot of effects for the variability analysis example.
Effect coefficients for the variability analysis example.
Two Level Factorial Experiments
Two Level Fractional Factorial Designs
As the number of factors in a two level factorial design increases, the number of runs for even a single replicate of
the design becomes very large. For example, a single replicate of an eight factor two level experiment would
require 256 runs. Fractional factorial designs can be used in these cases to draw out valuable conclusions from fewer
runs. The basis of fractional factorial designs is the sparsity of effects principle.[Wu, 2000] The principle states that,
most of the time, responses are affected by a small number of main effects and lower order interactions, while higher
order interactions are relatively unimportant. Fractional factorial designs are used as screening experiments during
the initial stages of experimentation. At these stages, a large number of factors have to be investigated and the focus
is on the main effects and two factor interactions. These designs obtain information about main effects and lower
order interactions with fewer experiment runs by confounding these effects with unimportant higher order
interactions. As an example, consider a design that requires 256 runs. This design allows for the investigation of 8
main effects and 28 two factor interactions. However, 219 degrees of freedom are devoted to three factor or higher
order interactions. This full factorial design can prove to be very inefficient when these higher order interactions can
be assumed to be unimportant. Instead, a fractional design can be used here to identify the important factors that can
then be investigated more thoroughly in subsequent experiments. In unreplicated fractional factorial designs, no
degrees of freedom are available to calculate the error sum of squares and the techniques mentioned in Unreplicated
designs should be employed for the analysis of these designs.
Half-fraction Designs
A half-fraction of the design involves running only half of the treatments of the full factorial design. For example,
consider a design that requires eight runs in all. The design matrix for this design is shown in the figure (a) below.
A half-fraction of this design is the design in which only four of the eight treatments are run. The fraction is denoted
as
with the "
" in the index denoting a half-fraction. Assume that the treatments chosen for the half-fraction
design are the ones where the interaction
is at the high level (i.e., only those rows are chosen from the
following figure (a) where the column for
has entries of 1). The resulting
design has a design matrix as
shown in figure (b) below.
153
Two Level Factorial Experiments
154
Half-fractions of the
design. (a) shows the full factorial
design, (b) shows the
design with the defining relation
and (c) shows the
design with the defining
relation
.
In the
design of figure (b), since the interaction
is always included at the same level (the high level
represented by 1), it is not possible to measure this interaction effect. The effect,
, is called the generator or
word for this design. It can be noted that, in the design matrix of the following figure (b), the column corresponding
to the intercept, , and column corresponding to the interaction
, are identical. The identical columns are
written as
and this equation is called the defining relation for the design. In DOE++, the present
design can be obtained by specifying the design properties as shown in the following figure.
Two Level Factorial Experiments
155
Design properties for the
The defining relation,
design.
, is entered in the Fraction Generator window as shown next.
Specifying the defining relation for the
design.
Note that in the figure following that, the defining relation is specified as
multiplying the defining relation,
, by the last factor, , of the design.
. This relation is obtained by
Two Level Factorial Experiments
156
Calculation of Effects
Using the four runs of the
where , , and
design in figure (b) discussed above, the main effects can be calculated as follows:
are the treatments included in the
design.
Similarly, the two factor interactions can also be obtained as:
The equations for and
above result in the same effect values showing that effects
in the present
design. Thus, the quantity,
estimates
and
are confounded
(i.e., both the main effect
and the two-factor interaction
). The effects, and
are called aliases. From the remaining equations
given above, it can be seen that the other aliases for this design are and
, and and
. Therefore, the
equations to calculate the effects in the present
design can be written as follows:
Calculation of Aliases
Aliases for a fractional factorial design can be obtained using the defining relation for the design. The defining
relation for the present
design is:
Multiplying both sides of the previous equation by the main effect,
gives the alias effect of
Note that in calculating the alias effects, any effect multiplied by remains the same (
multiplied by itself results in (
). Other aliases can also be obtained:
and:
:
), while an effect
Two Level Factorial Experiments
Fold-over Design
If it can be assumed for this design that the two-factor interactions are unimportant, then in the absence of
,
and
, the equations for (A+BC), (B+AC) and (C+AB) can be used to estimate the main effects, , and
, respectively. However, if such an assumption is not applicable, then to uncouple the main effects from their two
factor aliases, the alternate fraction that contains runs having
at the lower level should be run. The design
matrix for this design is shown in the preceding figure (c). The defining relation for this design is
because the four runs for this design are obtained by selecting the rows of the preceding figure (a) for which the
value of the
column is
. The aliases for this fraction can be obtained as explained in Half-fraction Designs
as
,
and
. The effects for this design can be calculated as:
These equations can be combined with the equations for (A+BC), (B+AC) and (C+AB) to obtain the de-aliased main
effects and two factor interactions. For example, adding equations (A+BC) and (A-BC) returns the main effect .
The process of augmenting a fractional factorial design by a second fraction of the same size by simply reversing the
signs (of all effect columns except ) is called folding over. The combined design is referred to as a fold-over
design.
Quarter and Smaller Fraction Designs
At times, the number of runs even for a half-fraction design are very large. In these cases, smaller fractions are used.
A quarter-fraction design, denoted as
, consists of a fourth of the runs of the full factorial design.
Quarter-fraction designs require two defining relations. The first defining relation returns the half-fraction or the
design. The second defining relation selects half of the runs of the
design to give the quarter-fraction. For
example, consider the design. To obtain a
design from this design, first a half-fraction of this design is
obtained by using a defining relation. Assume that the defining relation used is
. The design matrix
for the resulting
design is shown in figure (a) below. Now, a quarter-fraction can be obtained from the
design shown in figure (a) below using a second defining relation
. The resulting
design obtained is
shown in figure (b) below.
157
Two Level Factorial Experiments
Fractions of the
158
design - Figure (a) shows the
design with the defining relation
design with the defining relation
The complete defining relation for this
and (b) shows the
.
design is:
Note that the effect,
in the defining relation is the generalized interaction of
and
and is obtained
using
. In general, a
fractional factorial design requires
independent generators. The defining relation for the design consists of the independent generators and their - (
+1) generalized interactions.
Calculation of Aliases
The alias structure for the present
design can be obtained using the defining relation of equation
(I=ABCD=AD=BC) following the procedure explained in Half-fraction Designs. For example, multiplying the
defining relation by returns the effects aliased with the main effect, , as follows:
Therefore, in the present
design, it is not possible to distinguish between effects , ,
and
Similarly, multiplying the defining relation by and
returns the effects that are aliased with these effects:
.
Other aliases can be obtained in a similar way. It can be seen that each effect in this design has three aliases. In
general, each effect in a
design has
aliases. The aliases for the
design show that in this design the
main effects are aliased with each other ( is aliased with and is aliased with ). Therefore, this design is not
Two Level Factorial Experiments
a useful design and is not available in DOE++. It is important to ensure that main effects and lower order interactions
of interest are not aliased in a fractional factorial design. This is known by looking at the resolution of the fractional
factorial design.
Design Resolution
The resolution of a fractional factorial design is defined as the number of factors in the lowest order effect in the
defining relation. For example, in the defining relation
of the previous
design,
the lowest-order effect is either
or
containing two factors. Therefore, the resolution of this design is equal
to two. The resolution of a fractional factorial design is represented using Roman numerals. For example, the
previously mentioned
design with a resolution of two can be represented as 2
. The resolution provides
information about the confounding in the design as explained next:
1. Resolution III Designs
In these designs, the lowest order effect in the defining relation has three factors (e.g., a
design with the
defining relation
). In resolution III designs, no main effects are aliased with
any other main effects, but main effects are aliased with two factor interactions. In addition, some two factor
interactions are aliased with each other.
2. Resolution IV Designs
In these designs, the lowest order effect in the defining relation has four factors (e.g., a
design with the
defining relation
). In resolution IV designs, no main effects are aliased with any other main
effects or two factor interactions. However, some main effects are aliased with three factor interactions and the
two factor interactions are aliased with each other.
3. Resolution V Designs
In these designs the lowest order effect in the defining relation has five factors (e.g., a
design with the
defining relation
). In resolution V designs, no main effects or two factor interactions are aliased
with any other main effects or two factor interactions. However, some main effects are aliased with four factor
interactions and the two factor interactions are aliased with three factor interactions.
Fractional factorial designs with the highest resolution possible should be selected because the higher the resolution
of the design, the less severe the degree of confounding. In general, designs with a resolution less than III are never
used because in these designs some of the main effects are aliased with each other. The table below shows fractional
factorial designs with the highest available resolution for three to ten factor designs along with their defining
relations.
159
Two Level Factorial Experiments
Highest resolution designs available for fractional factorial designs with 3 to 10 factors.
In DOE++, these designs are shown with a green background in the Available Designs window, as shown next.
Two level fractional factorial designs available in DOE++ and their resolutions.
Minimum Aberration Designs
At times, different designs with the same resolution but different aliasing may be available. The best design to select
in such a case is the minimum aberration design. For example, all
designs in the fourth table have a resolution
of four (since the generator with the minimum number of factors in each design has four factors). Design has three
generators of length four (
). Design has two generators of length four (
). Design has one generator of length four (
). Therefore, design has the least number of
generators with the minimum length of four. Design is called the minimum aberration design. It can be seen that
the alias structure for design is less involved compared to the other designs. For details refer to [Wu, 2000].
160
Two Level Factorial Experiments
161
Three
designs with different defining relations.
Example
The design of an automobile fuel cone is thought to be affected by six factors in the manufacturing process: cavity
temperature (factor ), core temperature (factor ), melt temperature (factor ), hold pressure (factor ),
injection speed (factor ) and cool time (factor ). The manufacturer of the fuel cone is unable to run the
runs required to complete one replicate for a two level full factorial experiment with six factors. Instead,
they decide to run a fractional factorial design. Considering that three factor and higher order interactions are likely
to be inactive, the manufacturer selects a
design that will require only 16 runs. The manufacturer chooses the
resolution IV design which will ensure that all main effects are free from aliasing (assuming three factor and higher
order interactions are absent). However, in this design the two factor interactions may be aliased with each other. It
is decided that, if important two factor interactions are found to be present, additional experiment trials may be
conducted to separate the aliased effects. The performance of the fuel cone is measured on a scale of 1 to 15. In
DOE++, the design for this experiment is set up using the properties shown in the following figure. The Fraction
Generators for the design,
and
, are the same as the defaults used in DOE++. The
resulting
design and the corresponding response values are shown in the following two figures.
Two Level Factorial Experiments
162
Design properties for the experiment in the example.
Experiment design for the example.
The complete alias structure for the 2
design is shown next.
Two Level Factorial Experiments
163
In DOE++, the alias structure is displayed in the Design Summary and as part of the Design Evaluation result, as
shown next:
Alias structure for the experiment design in the example.
The normal probability plot of effects for this unreplicated design shows the main effects of factors
interaction effect,
, to be significant (see the following figure).
and
and the
Two Level Factorial Experiments
164
Normal probability plot of effects for the experiment in the example.
From the alias structure, it can be seen that for the present design interaction effect,
is confounded with
.
Therefore, the actual source of this effect cannot be known on the basis of the present experiment. However because
neither factor nor is found to be significant there is an indication the observed effect is likely due to interaction,
. To confirm this, a follow-up experiment is run involving only factors and . The interaction,
, is
found to be inactive, leading to the conclusion that the interaction effect in the original experiment is effect,
.
Given these results, the fitted regression model for the fuel cone design as per the coefficients obtained from DOE++
is shown next.
Two Level Factorial Experiments
165
Effect coefficients for the experiment in the example.
Projection
Projection refers to the reduction of a fractional factorial design to a full factorial design by dropping out some of the
factors of the design. Any fractional factorial design of resolution, can be reduced to complete factorial designs in
any subset of
factors. For example, consider the 2
design. The resolution of this design is four.
Therefore, this design can be reduced to full factorial designs in any three (
) of the original seven
factors (by dropping the remaining four of factors). Further, a fractional factorial design can also be reduced to a full
factorial design in any of the original factors, as long as these factors are not part of the generator in the
defining relation. Again consider the 2
design. This design can be reduced to a full factorial design in four
factors provided these four factors do not appear together as a generator in the defining relation. The complete
defining relation for this design is:
Therefore, there are seven four factor combinations out of the 35 (
) possible four-factor combinations that
are used as generators in the defining relation. The designs with the remaining 28 four factor combinations would be
full factorial 16-run designs. For example, factors , , and do not occur as a generator in the defining
relation of the 2
design. If the remaining factors, , and , are dropped, the 2
design will reduce to a
full factorial design in , , and .
Two Level Factorial Experiments
166
Resolution III Designs
At times, the factors to be investigated in screening experiments are so large that even running a fractional factorial
design is impractical. This can be partially solved by using resolution III fractional factorial designs in the cases
where three factor and higher order interactions can be assumed to be unimportant. Resolution III designs, such as
the 2
design, can be used to estimate main effects using just
runs. In these designs, the main effects are
aliased with two factor interactions. Once the results from these designs are obtained, and knowing that three factor
and higher order interactions are unimportant, the experimenter can decide if there is a need to run a fold-over design
to de-alias the main effects from the two factor interactions. Thus, the 2
design can be used to investigate three
factors in four runs, the 2
design can be used to investigate seven factors in eight runs, the 2
design can be
used to investigate fifteen factors in sixteen runs and so on.
Example
A baker wants to investigate the factors that most affect the taste of the cakes made in his bakery. He chooses to
investigate seven factors, each at two levels: flour type (factor ), conditioner type (factor ), sugar quantity
(factor ), egg quantity (factor ), preservative type (factor ), bake time (factor ) and bake temperature
(factor ). The baker expects most of these factors and all higher order interactions to be inactive. On the basis of
this, he decides to run a screening experiment using a 2
design that requires just 8 runs. The cakes are rated on a
scale of 1 to 10. The design properties for the 2
design (with generators
,
,
and
) are shown in the following figure.
Design properties for the experiment in the example.
The resulting design along with the rating of the cakes corresponding to each run is shown in the following figure.
Two Level Factorial Experiments
167
Experiment design for the example.
The normal probability plot of effects for the unreplicated design shows main effects
significant, as shown in the next figure.
Normal probability plot of effects for the experiment in the example.
However, for this design, the following alias relations exist for the main effects:
,
,
and
to be
Two Level Factorial Experiments
168
Based on the alias structure, three separate possible conclusions can be drawn. It can be concluded that effect
is
active instead of so that effects , and their interaction,
, are the significant effects. Another conclusion
can be that effect
is active instead of so that effects , and their interaction,
, are significant. Yet
another conclusion can be that effects , and their interaction,
, are significant. To accurately discover the
active effects, the baker decides to a run a fold-over of the present design and base his conclusions on the effect
values calculated once results from both the designs are available.
The present design is shown next.
Effect values for the experiment in the example.
Using the alias relations, the effects obtained from DOE++ for the present design can be expressed as:
The fold-over design for the experiment is obtained by reversing the signs of the columns
DOE++, you can fold over a design using the following window.
,
, and
. In
Two Level Factorial Experiments
169
Fold-over design window
The resulting design and the corresponding response values obtained are shown in the following figures.
Fold-over design for the experiment in the example.
Two Level Factorial Experiments
170
Effect values for the fold-over design in the example.
Comparing the absolute values of the effects, the active effects are , , and the interaction
. Therefore,
the most important factors affecting the taste of the cakes in the present case are sugar quantity, egg quantity and
their interaction.
Alias Matrix
In Half-fraction designs and Quarter and Smaller Fraction Designs, the alias structure for fractional factorial designs
was obtained using the defining relation. However, this method of obtaining the alias structure is not very efficient
when the alias structure is very complex or when partial aliasing is involved. One of the ways to obtain the alias
structure for any design, regardless of its complexity, is to use the alias matrix. The alias matrix for a design is
calculated using
where
is the portion of the design matrix,
that contains the effects for
which the aliases need to be calculated, and
those included in
.
contains the remaining columns of the design matrix, other than
To illustrate the use of the alias matrix, consider the design matrix for the 2
) shown next:
The alias structure for this design can be obtained by defining
estimates eight effects. If the first eight columns of are used then
design (using the defining relation
using eight columns since the 2
is:
design
Two Level Factorial Experiments
171
is obtained using the remaining columns as:
Then the alias matrix
is:
The alias relations can be easily obtained by observing the alias matrix as:
Two Level Factorial Experiments
172
173
Chapter 9
Highly Fractional Factorial Designs
This chapter discusses factorial designs that are commonly used in designed experiments, but are not necessarily
limited to two level factors. These designs are the Plackett-Burman designs and Taguchi's orthogonal arrays.
Plackett-Burman Designs
It was mentioned in Two Level Factorial Experiments that resolution III designs can be used as highly fractional
designs to investigate main effects using
runs (provided that three factor and higher order interaction effects
are not important to the experimenter). A limitation with these designs is that all runs in these designs have to be a
power of 2. The valid runs for these designs are 4, 8, 16, 32, etc. Therefore, the next design after the 2
design
with 4 runs is the 2
design with 8 runs, and the design after this is the 2
design with 32 runs and so on, as
shown in the next table.
Highly fractional designs to investigate main effects.
Plackett-Burman designs solve this problem. These designs were proposed by R. L. Plackett and J.P. Burman (1946).
They allow the estimation of main effects using
runs. In these designs, runs are a multiple of 4 (i.e., 4, 8, 12,
16, 20 and so on). When the runs are a power of 2, the designs correspond to the resolution III two factor fractional
factorial designs. Although Plackett-Burman designs are all two level orthogonal designs, the alias structure for these
designs is complicated when runs are not a power of 2.
As an example, consider the 12-run Plackett-Burman design shown in the figure below.
Highly Fractional Factorial Designs
174
12-run Plackett-Burman design.
If 11 main effects are to be estimated using this design, then each of these main effects is partially aliased with all
other two factor interactions not containing that main effect. For example, the main effect is partially aliased with
all two factor interactions except
,
,
,
,
,
,
,
,
and
. There are 45
such two factor interactions that are aliased with .
Due to the complex aliasing, Plackett-Burman designs involving a large number of factors should be used with care.
Some of the Plackett-Burman designs available in DOE++ are included in Appendix C.
Taguchi's Orthogonal Arrays
Taguchi's orthogonal arrays are highly fractional orthogonal designs proposed by Dr. Genichi Taguchi, a Japanese
industrialist. These designs can be used to estimate main effects using only a few experimental runs. These designs
are not only applicable to two level factorial experiments; they can also investigate main effects when factors have
more than two levels. Designs are also available to investigate main effects for certain mixed level experiments
where the factors included do not have the same number of levels. As in the case of Placket-Burman designs, these
designs require the experimenter to assume that interaction effects are unimportant and can be ignored. A few of
Taguchi's orthogonal arrays available in DOE++ are included in Appendix D.
Some of Taguchi's arrays, with runs that are a power of 2, are similar to the corresponding 2
designs. For
example, consider the L4 array shown in figure (a) below. The L4 array is denoted as L4(2^3) in DOE++. L4 means
the array requires 4 runs. 2^3 indicates that the design estimates up to three main effects at 2 levels each. The L4
array can be used to estimate three main effects using four runs provided that the two factor and three factor
interactions can be ignored. Figure (b) below shows the 2
design (defining relation
) which also
requires four runs and can be used to estimate up to three main effects, assuming that all two factor and three factor
interactions are unimportant. A comparison between the two designs shows that the columns in the two designs are
the same except for the arrangement of the columns. In figure (c) below, columns of the L4 array are marked with
the name of the effect from the corresponding column of the 2
design.
Highly Fractional Factorial Designs
175
Taguchi's L4 orthogonal array - Figure (a) shows
the design, (b) shows the
design with the
defining relation
and (c)
marks the columns of the L4 array with the
corresponding columns of the design in (b).
Similarly, consider the L8(2^7) array shown in figure (a) below. This design can be used to estimate up to seven
main effects using eight runs. This array is again similar to the 2
design shown in figure (b) below, except that
the aliasing between the columns of the two designs differs in sign for some of the columns (see figure (c)).
Highly Fractional Factorial Designs
176
Taguchi's L8 orthogonal array - Figure (a) shows the design,
(b) shows the
design with the defining relation
and (c) marks the columns of the L8 array with the
corresponding columns of the design in (b).
The L8 array can also be used as a full factorial three factor experiment design in the same way as a design.
However, the orthogonal arrays should be used carefully in such cases, taking into consideration the alias
relationships between the columns of the array. For the L8 array, figure (c) above shows that the third column of the
array is the product of the first two columns. If the L8 array is used as a two level full factorial design in the place of
a 2 design, and if the main effects are assigned to the first three columns, the main effect assigned to the third
column will be aliased with the two factor interaction of the first two main effects. The proper assignment of the
main effects to the columns of the L8 array requires the experimenter to assign the three main effects to the first,
second and fourth columns. These columns are sometimes referred to as the preferred columns for the L8 array. To
know the preferred columns for any of the orthogonal arrays, the alias relationships between the array columns must
be known. The alias relations between the main effects and two factor interactions of the columns for the L8 array
are shown in the next table.
Highly Fractional Factorial Designs
177
Alias relations for the L8 array.
The cell value in any (
) cell of the table gives the column number of the two factor interaction for the th row
and th column. For example, to know which column is confounded with the interaction of the first and second
columns, look at the value in the (
) cell. The value of 3 indicates that the third column is the same as the
product of the first and second columns. The alias relations for some of Taguchi's orthogonal arrays are available in
Appendix E.
Example
Recall the experiment to investigate factors affecting the surface finish of automobile brake drums discussed in Two
Level Factorial Experiments. The three factors investigated in the experiment were honing pressure (factor A),
number of strokes (factor B) and cycle time (factor C). Assume that you used Taguchi's L8 orthogonal array to
investigate the three factors instead of the design that was used in Two Level Factorial Experiments. Based on the
discussion in the previous section, the preferred columns for the L8 array are the first, second and fourth columns.
Therefore, the three factors should be assigned to these columns. The three factors are assigned to these columns
based on the figure (c) above, so that you can easily compare results obtained from the L8 array to the ones included
in Two Level Factorial Experiments. Based on this assignment, the L8 array for the two replicates, along with the
respective response values, should be as shown in the third table. Note that to run the experiment using the L8 array,
you would use only the first, the second and the fourth column to set the three factors.
Using Taguchi's L8 array to investigate factors affecting the surface finish of automobile brake drums.
The experiment design for this example can be set using the properties shown in the figure below.
Highly Fractional Factorial Designs
178
Design properties for the experiment in the example.
Note that for this design, the factor properties are set up as shown in the design summary.
Factor properties for the experiment in the example.
The resulting design along with the response values is shown in the figure below.
Highly Fractional Factorial Designs
179
Experiment design for the example.
And the results from DOE++ for the design are shown in the next figure.
Results for the experiment in the example.
Highly Fractional Factorial Designs
180
The results identify honing pressure, number of strokes, and the interaction between honing pressure and cycle time
to be significant effects. This is identical to the conclusion obtained from the design used in Two Level Factorial
Experiments.
Preferred Columns in Taguchi OA
One of the difficulties of using Taguchi OA is to assign factors to the appropriate columns of the array. For example,
take a simple Taguchi OA L8(2^7), which can be used for experiments with up to 7 factors. If you have only 3
factors, which 3 columns in this array should be used? DOE++ provides a simple utility to help users utilize Taguchi
OA more effectively by assigning factors to the appropriate columns. Let’s use Taguchi OA L8(2^7) as an example.
The design table for this array is:
This is a fractional factorial design for 7 factors. For any fractional factorial design, the first thing we need to do is
check its alias structure. In general, the alias structures for Taguchi OAs are very complicated. People usually use the
following table to represent the alias relations between each factor. For the above orthogonal array, the alias table is:
1
2
3
4
5
6
7
2x3 1x3 1x2 1x5 1x4 1x7 1x6
4x5 4x6 4x7 2x6 2x7 2x4 2x5
6x7 5x7 5x6 3x7 3x6 3x5 3x4
In the above table, an Arabic number is used to represent a factor. For instance, “1” represents the factor assigned to
the 1st column in the array. “2x3” represents the interaction effect of the two factors assigned to column 2 and 3.
Each column in the above alias table lists all the 2-way interaction effects that are aliased with the main effect of the
factor assigned to this column. For example, for the 1st column, the main effect of the factor assigned to it is aliased
with interaction effects of 2x3, 4x5 and 6x7. If an experiment has only 3 factors and these 3 factors A, B and C are
assigned to the first 3 columns of the above L8(2^7) array, then the design table will be:
Highly Fractional Factorial Designs
181
Run A (Column 1) B (Column 2) C (Column 3)
1
1
1
1
2
1
1
1
3
1
2
2
4
1
2
2
5
2
1
2
6
2
1
2
7
2
2
1
8
2
2
1
The alias structure for the above table is:
[I] = I – ABC
[A] = A – BC
[B] = B – AC
[C] = C – AB
This is a resolution 3 design. All the main effects are aliased with 2-way interactions. There are many ways to
choose 3 columns from the 7 columns of L8(2^7). If the 3 factors are assigned to column 1, 2, and 4, then the design
table is:
Run A (Column 1) B (Column 2) C (Column 4)
1
1
1
1
2
1
1
1
3
1
2
2
4
1
2
2
5
2
1
2
6
2
1
2
7
2
2
1
8
2
2
1
For experiments using the above design table, all the effects will be alias free. Therefore, this design is much better
than the previous one which used column 1, 2, and 3 of L8(2^7). Although both designs have the same number of
runs, more information can be obtained from this design since it is alias free.
Clearly, it is very important to assign factors to the right columns when applying Taguchi OA. DOE++ can help
users automatically choose the right columns when the number of factors is less than the number of columns in a
Taguchi OA. The selection is based on the specified model terms by users. Let’s use an example to explain this.
Example: Design an experiment with 3 qualitative factors. Factors A and B have 2 levels; factor C has 4 levels. The
experimenters are interested in all the main effects and the interaction effect AC.
Based on this requirement, Taguchi OA L16(2^6*4^3) can be used since it can handle both 2 level and 4 level
factors. It has 9 columns. The first 6 columns are used for 2 level factors and the last 3 columns are used for 4 level
factors. We need assign factor A and B to two of the first 6 columns, and assign factor C to one of the last 3
columns.
In DOE++, we can choose L16(2^6*4^3) in the following window.
Highly Fractional Factorial Designs
182
Click Taguchi Preferred Columns to specify the interaction terms of interest by the experimenters.
Based on the specified interaction effects, DOE++ will assign each factor to the appropriate column. In this case,
they are column 1, 3, and 7 as shown below.
However, for a given Taguchi OA, it may not be possible to estimate all the specified interaction terms. If not all the
requirements can be satisfied, DOE++ will assign factors to columns that result in the least number of aliased effects.
In this case, users should either use another Taguchi OA or other design types. The following example is one of
these cases.
Example: Design an experiment for a test with 4 qualitative factors. Factors A and B have 2 levels; C and D have 4
levels. We are interested in all the main effects and the interaction effects AC and BD.
Assume again we want to use Taguchi OA L16(2^6*4^3). Click Taguchi Preferred Columns in the following screen.
Specify the interaction effects that you want to estimate in the experiment.
When click on OK, you will get a warning message saying that it is impossible to clearly estimate all the main
effects and the specified interaction effect AC and BD.
This can be explained by checking the alias table of a L16(2^6*4^3) design as given below.
1
2
3
4
5
6
7
8
9
2x7 1x7 1x9 1x5 1x4 1x8 1x2 1x6 1x3
3x9 3x6 2x6 2x8 2x9 2x3 1x8 1x7 1x7
4x5 4x8 4x7 3x7 3x8 4x9 1x9 1x9 1x8
6x8 5x9 5x8 6x9 6x7 5x7 2x8 2x4 2x5
7x8 7x8 7x8 7x8 7x8 7x8 2x9 2x7 2x7
7x9 7x9 7x9 7x9 7x9 7x9 3x8 2x9 2x8
8x9 8x9 8x9 8x9 8x9 8x9 3x9 3x5 3x7
4x8 3x7 3x8
4x9 3x9 4x6
5x6 4x7 4x7
5x8 4x9 4x8
5x9 5x7 5x7
6x8 5x9 5x8
6x9 6x7 6x7
8x9 6x9 6x8
7x9 7x8
From this table, we can see that it is impossible to clearly estimate both AC and BD. Factors C and D can only be
assigned to the last three columns since they are 4 level factors. Assume we assign factor C to column 7 and factor D
to column 8. Factor B (2 level) will be in one of the columns from 1 to 6. Therefore, effect BD will be one of the
effects highlighted in the table, where the first term of the interaction is between 1 and 6 and the last term is 8 (i.e.,
factor D).
The above alias table shows factor C is aliased with one of those highlighted effects. Thus, no matter which of the
first six columns is assigned to factor B, the main effect C will be aliased with interaction effect BD. This is also true
if C is assigned to column 8 or 9. Therefore, if L16(2^6*4^3) is used, there is no way to clearly estimate all the main
effects and the interaction effects AC and BD. Another Taguchi OA or other design types such as a general level full
factorial design should be used. A more efficient way probably is to create an optimal custom design that can clearly
Highly Fractional Factorial Designs
estimate all the specified terms. For more detail, please refer to the chapter on Optimal Custom Designs.
183
184
Chapter 10
Response Surface Methods for Optimization
The experiment designs mentioned in Two Level Factorial Experiments and Highly Fractional Factorial Designs
help the experimenter identify factors that affect the response. Once the important factors have been identified, the
next step is to determine the settings for these factors that result in the optimum value of the response. The optimum
value of the response may either be a maximum value or a minimum value, depending upon the product or process in
question. For example, if the response in an experiment is the yield from a chemical process, then the objective
might be to find the settings of the factors affecting the yield so that the yield is maximized. On the other hand, if the
response in an experiment is the number of defects, then the goal would be to find the factor settings that minimize
the number of defects. Methodologies that help the experimenter reach the goal of optimum response are referred to
as response surface methods. These methods are exclusively used to examine the "surface," or the relationship
between the response and the factors affecting the response. Regression models are used for the analysis of the
response, as the focus now is on the nature of the relationship between the response and the factors, rather than
identification of the important factors.
Response surface methods usually involve the following steps:
1. The experimenter needs to move from the present operating conditions to the vicinity of the operating conditions
where the response is optimum. This is done using the method of steepest ascent in the case of maximizing the
response. The same method can be used to minimize the response and is then referred to as the method of steepest
descent.
2. Once in the vicinity of the optimum response the experimenter needs to fit a more elaborate model between the
response and the factors. Special experiment designs, referred to as RSM designs, are used to accomplish this. The
fitted model is used to arrive at the best operating conditions that result in either a maximum or minimum
response.
3. It is possible that a number of responses may have to be optimized at the same time. For example, an
experimenter may want to maximize strength, while keeping the number of defects to a minimum. The optimum
settings for each of the responses in such cases may lead to conflicting settings for the factors. A balanced setting
has to be found that gives the most appropriate values for all the responses. Desirability functions are useful in
these cases.
Method of Steepest Ascent
The first step in obtaining the optimum response settings, after the important factors have been identified, is to
explore the region around the current operating conditions to decide what direction needs to be taken to move
towards the optimum region. Usually, a first order regression model (containing just the main effects and no
interaction terms) is sufficient at the current operating conditions because the operating conditions are normally far
from the optimum response settings. The experimenter needs to move from the current operating conditions to the
optimum region in the most efficient way by using the minimum number of experiments. This is done using the
method of steepest ascent. In this method, the contour plot of the first order model is used to decide the settings for
the next experiment, in order to move towards the optimum conditions. Consider a process where the response has
been found to be a function of two factors. To explore the region around the current operating conditions, the
experimenter fits the following first order model between the response and the two factors:
Response Surface Methods for Optimization
185
The response surface plot for the model, along with the contours, is shown in the figure below. It can be seen in the
figure that in order to maximize the response, the most efficient direction in which to move the experiment is along
the line perpendicular to the contours. This line, also referred to as the path of steepest ascent, is the line along which
the rate of increase of the response is maximum. The steps along this line to move towards the optimum region are
proportional to the regression coefficients,
of the fitted first order model.
Path of steepest ascent for the model
.
Experiments are conducted along each step of the path of steepest ascent until an increase in the response is not seen.
Then, a new first order model is fit at the region of the maximum response. If the first order model shows a lack of
fit, then this indicates that the experimenter has reached the vicinity of the optimum. RSM designs are then used
explore the region thoroughly and obtain the point of the maximum response. If the first order model does not show
a lack of fit, then a new path of steepest ascent is determined and the process is repeated.
Example
The yield from a chemical process is found to be affected by two factors: reaction temperature and reaction time. The
current reaction temperature is 230 and the reaction time is 65 minutes. The experimenter wants to determine the
settings of the two factors such that maximum yield can be obtained from the process. To explore the region around
the current operating conditions, the experimenter decides to use a single replicate of the design. The range of the
factors for this design are chosen to be (225, 235) for the reaction temperature and (55, 75) minutes for the
reaction time. The unreplicated design is also augmented with five runs at the center point to estimate the error
sum of squares,
, and check for model adequacy. The response values obtained for this design are shown next.
Response Surface Methods for Optimization
The
186
design augmented with five center points to explore the region
around current operating conditions for a chemical process.
In DOE++, this design can be set up using the properties shown next.
Design properties for the
design to explore the current operating conditions.
The resulting design and the analysis results are shown next.
Response Surface Methods for Optimization
The
187
experiment design in to explore the current operating conditions.
Results for the
experiment to explore the current operating conditions.
Note that the results shown are in terms of the coded values of the factors (taking -1 as the value of the lower settings
for reaction temperature and reaction time and +1 as the value for the higher settings for these two factors). The
results show that the factors, (temperature) and (time), affect the response significantly but their interaction
does not affect the response. Therefore the interaction term can be dropped from the model for this experiment. The
results also show that Curvature is not a significant factor. This indicates that the first order model is adequate for the
experiment at the current operating conditions. Using these two conclusions, the model for the current operating
Response Surface Methods for Optimization
188
conditions, in terms the coded variables is:
where represents the yield and and are the predictor variables for the two factors, and , respectively.
To further confirm the adequacy of the model of the equation given above, the experiment can be analyzed again
after dropping the interaction term,
. The results are shown next.
Results for the
experiment after the interaction term is dropped from the model.
The results show that the lack-of-fit for this model (because of the deficiency created in the model by the absence of
the interaction term) is not significant, confirming that the model is adequate.
Response Surface Methods for Optimization
189
Path of Steepest Ascent
The contour plot for the model used in the above example is shown next.
Results for the
experiment after the interaction term is dropped from the model.
The regression coefficients for the model are
and
. To move towards the optimum, the
experimenter needs to move along the path of steepest ascent, which lies perpendicular to the contours. This path is
the line through the center point of the current operating conditions (
,
) with a slope of
.
Therefore, in terms of the coded variables, the experiment should be moved 1.1625 units in the direction for every
0.4875 units in the direction. To move along this path, the experimenter decides to use a step-size of 10 minutes
for the reaction time, . The coded value for this step size can be obtained as follows. Recall from Multiple Linear
Regression Analysis that the relationship between coded and actual values is:
or
Thus, for a step-size of 10 minutes, the equivalent step size in coded value for
is:
Response Surface Methods for Optimization
190
In terms of the coded variables, the path of steepest ascent requires a move of 1.1625 units in the direction for
every 0.4875 units in the
direction. The step-size for , in terms of the coded value corresponding to any
step-size in , is:
Therefore, the step-size for the reaction temperature,
This corresponds to a step of approximately 12
, in terms of the coded variables is:
for temperature in terms of the actual value as shown next:
Using a step of 12 and 10 minutes, the experimenter conducts experiments until no further increase is observed in
the yield. The yield values at each step are shown in the table given next.
Response values at each step of the path of steepest ascent for the experiment to investigate
the yield of a chemical process. Units for factor levels and the response have been omitted.
The yield starts decreasing after the reaction temperature of 350 and the reaction time of 165 minutes, indicating
that this point may lie close to the optimum region. To analyze the vicinity of this point, a design augmented by
five center points is selected. The range of exploration is chosen to be 345 to 355 for reaction temperature and 155
to 175 minutes for reaction time. The response values recorded are shown next.
Response Surface Methods for Optimization
191
The
design augmented with five center points to explore the region of maximum response
obtained from the path of steepest ascent. Note that the center point of this design is the new
origin.
The results for this design are shown next.
Results for the
experiment to explore the region of maximum response.
In the results, Curvature is displayed as a significant factor. This indicates that the first order model is not adequate
for this region of the experiment and a higher order model is required. As a result, the methodology of steepest
Response Surface Methods for Optimization
ascent can no longer be used. The presence of curvature indicates that the experiment region may be close to the
optimum. Special designs that allow the use of second order models are needed at this point.
RSM Designs
A second order model is generally used to approximate the response once it is realized that the experiment is close to
the optimum response region where a first order model is no longer adequate. The second order model is usually
sufficient for the optimum region, as third order and higher effects are seldom important. The second order
regression model takes the following form for factors:
The model contains
regression parameters that include coefficients for main effects (
), coefficients for quadratic main effects (
) and coefficients for two factor interaction
effects (
...
). A full factorial design with all factors at three levels would provide estimation of all
the required regression parameters. However, full factorial three level designs are expensive to use as the number of
runs increases rapidly with the number of factors. For example, a three factor full factorial design with each factor at
three levels would require
runs while a design with four factors would require
runs.
Additionally, these designs will estimate a number of higher order effects which are usually not of much importance
to the experimenter. Therefore, for the purpose of analysis of response surfaces, special designs are used that help the
experimenter fit the second order model to the response with the use of a minimum number of runs. Examples of
these designs are the central composite and Box-Behnken designs.
Central Composite Designs
Central composite designs are two level full factorial ( ) or fractional factorial (
) designs augmented by a
number of center points and other chosen runs. These designs are such that they allow the estimation of all the
regression parameters required to fit a second order model to a given response.
The simplest of the central composite designs can be used to fit a second order model to a response with two factors.
The design consists of a full factorial design augmented by a few runs at the center point (such a design is shown
in figure (a) given below). A central composite design is obtained when runs at points (
), (
), (
)
and (
) are added to this design. These points are referred to as axial points or star points and represent runs
where all but one of the factors are set at their mid-levels. The number of axial points in a central composite design
having factors is . The distance of the axial points from the center point is denoted by and is always specified
in terms of coded values. For example, the central composite design in figure (b) given below has
, while for
the design of figure (c)
.
192
Response Surface Methods for Optimization
193
Central composite designs: (a) shows the
design with center point runs, (b)
shows the two factor central composite
design with
and (c) shows the
two factor central composite design with
.
It can be noted that when
, each factor is run at five levels (
,
, , and ) instead of the three
levels of
, and . The reason for running central composite designs with
is to have a rotatable design,
which is explained next.
Rotatability
A central composite design is said to be rotatable if the variance of any predicted value of the response, , for any
level of the factors depends only on the distance of the point from the center of the design, regardless of the
direction. In other words, a rotatable central composite design provides constant variance of the estimated response
corresponding to all new observation points that are at the same distance from the center point of the design (in terms
of the coded variables).
The variance of the predicted response at any point,
, is given as follows:
The contours of
for the central composite design in figure (c) above are shown in the figure below. The
contours are concentric circles indicating that the central composite design of figure (c) is rotatable. Rotatability is a
desirable property because the experimenter does not have any prior information about the location of the optimum.
Therefore, a design that provides equal precision of estimation in all directions would be preferred. Such a design
will assure the experimenter that no matter what direction is taken to search for the optimum, he/she will be able to
estimate the response value with equal precision. A central composite design is rotatable if the value of for the
Response Surface Methods for Optimization
194
design satisfies the following equation:
where is the number of replicates of the runs in the original factorial design and is the number of replicates of
the runs at the axial points. For example, a central composite design with two factors, having a single replicate of the
original factorial design, and a single replicate of all the axial points, would be rotatable for the following value:
Thus, a central composite design in two factors, having a single replicate of the original
and with
, is a rotatable design. This design is shown in figure (c) above.
The countours of
design and axial points,
for the rotatable two factor central composite
design.
Spherical Design
A central composite design is said to be spherical if all factorial and axial points are at same distance from the center
of the design. Spherical central composite designs are obtained by setting
. For example, the rotatable
design in the figure above (c) is also a spherical design because for this design
.
Face-centered Design
Central composite designs in which the axial points represent the mid levels for all but one of the factors are also
referred to as face-centered central composite designs. For these designs,
and all factors are run at three
levels, which are
, and in terms of the coded values (see the figure below).
Response Surface Methods for Optimization
Face-centered central composite design for three factors.
Box-Behnken Designs
In Highly Fractional Factorial Designs, highly fractional designs introduced by Plackett and Burman were discussed.
Plackett-Burman designs are used to estimate main effects in the case of two level fractional factorial experiments
using very few runs. [G. E. P. Box and D. W. Behnken (1960)] introduced similar designs for three level factors that
are widely used in response surface methods to fit second-order models to the response. The designs are referred to
as Box-Behnken designs. The designs were developed by the combination of two level factorial designs with
incomplete block designs. For example, the figure below shows the Box-Behnken design for three factors. The
design is obtained by the combination of design with a balanced incomplete block design having three treatments
and three blocks (for details see [Box 1960, Montgomery 2001]).
195
Response Surface Methods for Optimization
Box-Behnken design for three factors: (a) shows the
geometric representation and (b) shows the design.
The advantages of Box-Behnken designs include the fact that they are all spherical designs and require factors to be
run at only three levels. The designs are also rotatable or nearly rotatable. Some of these designs also provide
orthogonal blocking. Thus, if there is a need to separate runs into blocks for the Box-Behnken design, then designs
are available that allow blocks to be used in such a way that the estimation of the regression parameters for the factor
effects are not affected by the blocks. In other words, in these designs the block effects are orthogonal to the other
factor effects. Yet another advantage of these designs is that there are no runs where all factors are at either the
or
levels. For example, in the figure below the representation of the Box-Behnken design for three factors clearly
shows that there are no runs at the corner points. This could be advantageous when the corner points represent runs
that are expensive or inconvenient because they lie at the end of the range of the factor levels. A few of the
Box-Behnken designs available in DOE++ are presented in Appendix F.
Example
Continuing with the example in Method of Steepest Ascent, the first order model was found to be inadequate for the
region near the optimum. Once the experimenter realized that the first order model was not adequate (for the region
with a reaction temperature of 350 and reaction time of 165 minutes), it was decided to augment the experiment
with axial runs to be able to complete a central composite design and fit a second order model to the response.
Notice the advantage of using a central composite design, as the experimenter only had to add the axial runs to the
design with center point runs, and did not have to begin a new experiment. The experimenter decided to use
to get a rotatable design. The obtained response values are shown in the figure below.
196
Response Surface Methods for Optimization
Response values for the two factor central composite design in the example.
Such a design can be set up in DOE++ using the properties shown in the figure below.
Properties for the central composite design in the example.
The resulting design is shown in the figure shown next.
197
Response Surface Methods for Optimization
Central composite design for the experiment in the example.
Results from the analysis of the design are shown in the next figure.
Results for the central composite design in the example.
The results in the figure above show that the main effects, and , the interaction,
, and the quadratic main
effects,
and
, (represented as AA and BB in the figure) are significant. The lack-of-fit test also shows that the
second order model with these terms is adequate and a higher order model is not needed. Using these results, the
model for the experiment in terms of the coded values is:
The response surface and the contour plot for this model, in terms of the actual variables, are shown in the below
figures (a) and (b), respectively.
198
Response Surface Methods for Optimization
199
Response Surface Methods for Optimization
Response surface and countour plot for the experiment in the example.
Analysis of the Second Order Model
Once a second order model is fit to the response, the next step is to locate the point of maximum or minimum
response. The second order model for factors can be written as:
The point for which the response, , is optimized is the point at which the partial derivatives,
,
,
are all equal to zero. This point is called the stationary point. The stationary point may be a point of
maximum response, minimum response or a saddle point. These three conditions are shown in the following figures
(a), (b) and (c) respectively.
200
Response Surface Methods for Optimization
201
Types of second order response surfaces and their
contour plots. (a) shows the surface with a
maximum point, (b) shows the surface with a
minimum point and (c) shows the surface with a
saddle point.
Notice that these conditions are easy to identify, in the case of two factor experiments, by the inspection of the
contour plots. However, when more than two factors exist in an experiment, then the general mathematical solution
for the location of the stationary point has to be used. The equation given above can be written in matrix notation as:
where:
Then the stationary point can be determined as follows:
Thus, the stationary point is:
The optimum response is the response corresponding to
. The optimum response can be obtained to get:
Response Surface Methods for Optimization
202
Once the stationary point is known, it is necessary to determine if it is a maximum or minimum or saddle point. To
do this, the second order model has to be transformed to the canonical form. This is done by transforming the model
to a new coordinate system such that the origin lies at the stationary point and the axes are parallel to the principal
axes of the fitted response surface, shown next.
The second order model in canonical form.
The resulting model equation then takes the following form:
where the s are the transformed independent variables, and s are constants that are also the eigenvalues of the
matrix . The nature of the stationary point is known by looking at the signs of the s. If the s are all negative,
then is a point of maximum response. If the s are all positive then is a point of minimum response. If the
s have different signs, then is a saddle point.
Example
Continuing with the example in Method of Steepest Ascent, the second order model fitted to the response, in terms
of the coded variables, was obtained as:
Then the and
matrices for this model are:
The stationary point is:
Then, in terms of the actual values, the stationary point can be found as:
Response Surface Methods for Optimization
To find the nature of the stationary point the eigenvalues of the
determinant of the matrix
:
203
matrix can be obtained as follows using the
This gives us:
Solving the quadratic equation in returns the eigenvalues
and
. Since both the
eigenvalues are negative, it can be concluded that the stationary point is a point of maximum response. The predicted
value of the maximum response can be obtained as:
In DOE++, the maximum response can be obtained by entering the required values as shown in the figure below. In
the figure, the goal is to maximize the response and the limits of the search range for maximizing the response are
entered as 90 and 100. The value of the maximum response and the corresponding values of the factors obtained are
shown in the second figure following. These values match the values calculated in this example.
Settings to obtain the maximum value of the response in the example.
Response Surface Methods for Optimization
Plot of the maximum response in the example against the factors, temperature and time.
204
Response Surface Methods for Optimization
Multiple Responses
In many cases, the experimenter has to optimize a number of responses at the same time. For the example in Method
of Steepest Ascent, assume that the experimenter has to also consider two other responses: cost of the product (which
should be minimized) and the pH of the product (which should be close to 7 so that the product is neither acidic nor
basic). The data is presented in the figure below.
Data for the additional responses of cost and pH for the example to investigate the yield of a chemical process.
The problem in dealing with multiple responses is that now there might be conflicting objectives because of the
different requirements of each of the responses. The experimenter needs to come up with a solution that satisfies
each of the requirements as much as possible without compromising too much on any of the requirements. The
approach used in DOE++ to deal with optimization of multiple responses involves the use of desirability functions
that are discussed next (for details see [Derringer and Suich, 1980]).
Desirability Functions
Under this approach, each th response is assigned a desirability function, , where the value of varies between
0 and 1. The function,
is defined differently based on the objective of the response. If the response is to be
maximized, as in the case of the previous example where the yield had to be maximized, then is defined as
follows:
where represents the target value of the th response, , represents the acceptable lower limit value for this
response and represents the weight. When
the function is linear. If
then more importance is
placed on achieving the target for the response, . When
, less weight is assigned to achieving the target for
the response, . A graphical representation is shown in figure (a) below.
205
Response Surface Methods for Optimization
206
Desirability function plots for different response optimizations: (a)
the goal is to maximize the response, (b) the goal is to minimize the
response and (c) the goal is to get the response to a target value.
If the response is to be minimized, as in the case when the response is cost,
Here
is defined as follows:
represents the acceptable upper limit for the response (see figure (b) above).
There may be times when the experimenter wants the response to be neither maximized nor minimized, but instead
stay as close to a specified target as possible. For example, in the case where the experimenter wants the product to
be neither acidic nor basic, there is a requirement to keep the pH close to the neutral value of 7. In such cases, the
desirability function is defined as follows (see figure (c) above):
Once a desirability function is defined for each of the responses, assuming that there are
desirability function is obtained as follows:
responses, an overall
where the s represent the importance of each response. The greater the value of , the more important the
response with respect to the other responses. The objective is to now find the settings that return the maximum value
of .
Response Surface Methods for Optimization
207
To illustrate the use of desirability functions, consider the previous example with the three responses of yield, cost
and pH. The response surfaces for the two additional responses of cost and pH are shown next in the figures (a) and
(b), respectively.
Response surfaces for (a) cost and (b) pH.
In terms of actual variables, the models obtained for all three responses are as shown next:
Assume that the experimenter wants to have a target yield value of 95, although any value of yield greater than 94 is
acceptable. Then the desirability function for yield is:
For the cost, assume that the experimenter wants to lower the cost to 400, although any cost value below 415 is
acceptable. Then the desirability function for cost is:
For the pH, a target of 7 is desired but values between 6.9 and 7.1 are also acceptable. Thus, the desirability function
here is:
Response Surface Methods for Optimization
Notice that in the previous equations all weights used ( s) are 1. Thus, all three desirability functions are linear.
The overall desirability function, assuming equal importance (
) for all the responses, is:
The objective of the experimenter is to find the settings of and
such that the overall desirability, , is
maximum. In DOE++, the settings for the desirability functions for each of the three responses can be entered as
shown in the next figure.
Optimization settings for the three responses of yield, cost, and pH.
Based on these settings, DOE++ solves this optimization problem to obtain the following solution:
Optimum solution from DOE++ for the three responses of yield, cost, and pH.
208
Response Surface Methods for Optimization
The overall desirability achieved with this solution can be calculated easily. The values of each of the response for
these settings are:
Based on the response values, the individual desirability functions are:
Then the overall desirability is:
This is the same as the Global Desirability displayed by DOE++ in the figure above. At times, a number of solutions
may be obtained from DOE++, and it is up to the experimenter to choose the most feasible one.
209
210
Chapter 11
Design Evaluation and Power Study
In general, there are three stages in applying design of experiments (DOE) to solve an issue: designing the
experiment, conducting the experiment, and analyzing the data. The first stage is very critical. If the designed
experiment is not efficient, you are unlikely to obtain good results. It is very common to evaluate an experiment
before conducting the tests. A design evaluation often focuses on the following four properties:
1. The alias structure. Are main effects and two-way interactions in the experiment aliased with each other? What
is the resolution of the design?
2. The orthogonality. An orthogonal design is always preferred. If a design is non-orthogonal, how are the
estimated coefficients correlated?
3. The optimality. A design is called “optimal” if it can meet one or more of the following criteria:
• D-optimality: minimize the determinant of the variance-covariance matrix.
• A-optimality: minimize the trace of the variance-covariance matrix.
• V-optimality: minimize the average prediction variance in the design space.
1. The power (or its inverse, Type II error). Power is the probability of detecting an effect through experiments
when it is indeed active. A design with low power for main effects is not a good design.
In the following sections, we will discuss how to evaluate a design according to these four properties.
Alias Structure
To reduce the sample size in an experiment, we usually focus only on the main effects and lower-order interactions,
while assuming that higher-order interactions are not active. For example, screening experiments are often conducted
with a number of runs that barely fits the main effect-only model. However, due to the limited number of runs, the
estimated main effects often are actually combined effects of main effects and interaction effects. In other words the
estimated main effects are aliased with interaction effects. Since these effects are aliased, the estimated main effects
are said to be biased. If the interaction effects are large, then the bias will be significant. Thus, it is very important to
find out how all the effects in an experiment are aliased with each other. A design's alias structure is used for this
purpose, and its calculation is given below.
Assume the matrix representation of the true model for an experiment is:
If the model used in a screening experiment is a reduced one, as given by:
then, from this experiment, the estimated
is biased. This is because the ordinary least square estimator of
As discussed in [Wu, 2000], the expected value of this estimator is:
is:
Design Evaluation and Power Study
where
211
is called the alias matrix of the design. For example, for a three factorial screening
experiment with four runs, the design matrix is:
A B C
-1 -1 1
1 -1 -1
-1 1 -1
1
1
1
If we assume the true model is:
and the used model (i.e., the model used in the experiment data analysis) is:
then
and
. The alias matrix A is calculated as:
AB AC BC ABC
Sometimes, we also put
I
0
0
0
1
A
0
0
1
0
B
0
1
0
0
C
1
0
0
0
in the above matrix. Then the A matrix becomes:
I A B C AB AC BC ABC
I 1 0 0 0
0
0
0
1
A 0 1 0 0
0
0
1
0
B 0 0 1 0
0
1
0
0
C 0 0 0 1
1
0
0
0
For the terms included in the used model, the alias structure is:
From the alias structure and the definition of resolution, we know this is a resolution III design. The estimated main
effects are aliased with two-way interactions. For example, A is aliased with BC. If, based on engineering
Design Evaluation and Power Study
212
knowledge, the experimenter suspects that some of the interactions are important, then this design is unacceptable
since it cannot distinguish the main effect from important interaction effects.
For a designed experiment it is better to check its alias structure before conducting the experiment to determine
whether or not some of the important effects can be clearly estimated.
Orthogonality
Orthogonality is a model-related property. For example, for a main effect-only model, if all the coefficients
estimated through ordinary least squares estimation are not correlated, then this experiment is an orthogonal design
for main effects. An orthogonal design has the minimal variance for the estimated model coefficients. Determining
whether a design is orthogonal is very simple. Consider the following model:
The variance and covariance matrix for the model coefficients is:
where
is the variance of the error. When all the factors in the model are quantitative factors or all the factors are 2
levels,
is a regular symmetric matrix . The diagonal elements of it are the variances of model coefficients,
and the off-diagonal elements are the covariance among these coefficients. When some of the factors are qualitative
factors with more than 2 levels,
is a block symmetric matrix. The block elements in the diagonal represent
the variance and covariance matrix of the qualitative factors, and the off-diagonal elements are the covariance among
all the coefficients.
Therefore, to check if a design is orthogonal for a given model, we only need to check matrix :
example used in the previous section, if we assume the main effect-only model is used, then
I
I 0.25
A
B
C
0
0
0
A
0
0.25
0
0
B
0
0
0.25
0
C
0
0
0
0.25
. For the
is:
Since all the off-diagonal elements are 0, the design is an orthogonal design for main effects. For an orthogonal
design, it is also true that the diagonal elements are 1/n, where n is the number of total runs.
When there are qualitative factors with more than 2 levels in the model,
matrix. For example, assume we have the following design matrix.
will be a block symmetric
Design Evaluation and Power Study
213
Run Order A B
1
-1 1
2
-1 1
3
-1 1
4
-1 2
5
-1 2
6
-1 2
7
-1 3
8
-1 3
9
-1 3
10
1
1
11
1
1
12
1
1
13
1
2
14
1
2
15
1
2
16
1
3
17
1
3
18
1
3
Factor B has 3 levels, so 2 indicator variables are used in the regression model. The
matrix for a model
with main effects and the interaction is:
I
A
B[1]
B[2]
AB[1]
AB[2]
I
0.0556
0
0
0
0
0
A
0
0.0556
0
0
0
0
B[1]
0
0
0.1111 -0.0556
0
0
B[2]
0
0
-0.0556 0.1111
0
0
AB[1]
0
0
0
0
0.1111 -0.0556
AB[2]
0
0
0
0
-0.0556 0.1111
The above matrix shows this design is orthogonal since it is a block diagonal matrix.
For an orthogonal design for a given model, all the coefficients in the model can be estimated independently.
Dropping one or more terms from the model will not affect the estimation of other coefficients and their variances. If
a design is not orthogonal, it means some of the terms in the model are correlated. If the correlation is strong, then
the statistical test results for these terms may not be accurate.
VIF (variance inflation factor) is used to examine the correlation of one term with other terms. The VIF is commonly
used to diagnose multicollinearity in regression analysis. As a rule of thumb, a VIF of greater than 10 indicates a
strong correlation between some of the terms. VIF can be simply calculated by:
For more detailed discussion on VIF, please see Multiple Linear Regression Analysis.
Design Evaluation and Power Study
214
Optimality
Orthogonal design is always ideal. However, due to the constraints on sample size and cost, it is sometimes not
possible. If this is the case, we want to get a design that is as orthogonal as possible. The so-called D-efficiency is
used to measure the orthogonality of a two level factorial design. It is defined as:
D-efficiency
where p is the number of coefficients in the model and n is the total sample size. D represents the determinant.
is the information matrix of a design. When you compare two different screening designs, the one with a
larger determinant of
is usually better. D-efficiency can be used for comparing two designs. Other alphabetic
optimal criteria are also used in design evaluation. If a model and the number of runs are given, an optimal design
can be found using computer algorithms for one of the following optimality criteria:
• D-optimality: maximize the determinant of the information matrix
determinant of the variance-covariance matrix
. This is the same as minimizing the
.
• A-optimality: minimize the trace of the variance-covariance matrix
. The trace of a matrix is the sum
of all its diagonal elements.
• V-optimality (or I-optimality): minimize the average prediction variance within the design space.
The determinant of
and the trace of
are given in the design evaluation in Version 9 of DOE++.
V-optimality is not yet included.
Power Study
Power calculation is another very important topic in design evaluation. When designs are balanced, calculating the
power (which, you will recall, is the probability of detecting an effect when that effect is active) is straightforward.
However, for unbalanced designs, the calculation can be very complicated. We will discuss methods for calculating
the power for a given effect for both balanced and unbalanced designs.
Power Study for Single Factor Designs (One-Way ANOVA)
Power is related to Type II error in hypothesis testing and is commonly used in statistical process control (SPC).
Assume that at the normal condition, the output of a process follows a normal distribution with a mean of 10 and a
standard deviation of 1.2. If the 3-sigma control limits are used and the sample size is 5, the control limits (assuming
a normal distribution) for the X-bar chart are:
If a calculated mean value from a sampling group is outside of the control limits, then the process is said to be out of
control. However, since the mean value is from a random process following a normal distribution with a mean of 10
and standard derivation of
, even when the process is under control, the sample mean still can be out of the
control limits and cause a false alarm. The probability of causing a false alarm is called Type I error (or significance
level or risk level). For this example, it is:
Similarly, if the process mean has shifted to a new value that means the process is indeed out of control (e.g., 12),
applying the above control chart, the sample mean can still be within the control limits, resulting in a failure to detect
the shift. The probability of causing a misdetection is called Type II error. For this example, it is:
Design Evaluation and Power Study
215
Power is defined as 1-Type II error. In this case, it is 0.766302. From this example, we can see that Type I and Type
II errors are affected by sample size. Increasing sample size can reduce both errors. Engineers usually determine the
sample size of a test based on the power requirement for a given effect. This is called the Power and Sample Size
issue in design of experiments.
Power Calculation for Comparing Two Means
For one factor design, or one-way ANOVA, the simplest case is to design an experiment to compare the mean values
at two different levels of a factor. Like the above control chart example, the calculated mean value at each level (in
control and out of control) is a random variable. If the two means are different, we want to have a good chance to
detect it. The difference of the two means is called the effect of this factor. For example, to compare the strength of a
similar rope from two different manufacturers, 5 samples from each manufacturer are taken and tested. The test
results (in newtons) are given below.
M1 M2
123
99
134 103
132 100
100 105
98
97
For this data, the ANOVA results are:
The standard deviation of the error is 12.4499 as shown in the above screenshot. and the t-test results are:
Design Evaluation and Power Study
216
Mean Comparisons
Contrast Mean Difference Pooled Standard Error Low CI High CI T Value P Value
M1 - M2
16.6
7.874
-1.5575 34.7575
2.1082
0.0681
Since the p value is 0.0681, there is no significant difference between these two vendors at a significance level of
0.05 (since .0681 > 0.05). However, since the samples are randomly taken from the two populations, if the true
difference between the two vendors is 30, what is the power of detecting this amount of difference from this test?
To answer this question: first, from the significance level of 0.05, let’s calculate the critical limits for the t-test. They
are:
Define the mean of each vendor as
is:
and
. Then the difference between the estimated sample means
Under the null hypothesis (the two vendors are the same), the t statistic is:
Under the alternative hypothesis when the true difference is 30, the calculated t statistic is from a non-central t
distribution with non-centrality parameter of:
The Type II error is
. So the power is 1-0.08609 =0.91391.
In DOE++, the Effect for the power calculation is entered as the multiple of the standard deviation of error. So effect
of 30 is
standard deviation. This information is illustrated below.
Design Evaluation and Power Study
and the calculated power for this effect is:
As we know, the square of a t distribution is an F distribution. The above ANOVA table uses the F distribution and
the above "mean comparison" table uses the t distribution to calculate the p value. The ANOVA table is especially
useful when conducting multiple level comparisons. We will illustrate how to use the F distribution to calculate the
power for this example.
At a significance level of 0.05, the critical value for the F distribution is:
Under the alternative hypothesis when the true difference of these 2 vendors is 30, the calculated f statistic is from a
non-central F distribution with non-centrality parameter
.
The Type II error is
. So the power is
1-0.08609 = 0.91391. This is the same as the value we calculated using the non-central t distribution.
217
Design Evaluation and Power Study
218
Power Calculation for Comparing Multiple Means: Balanced Designs
When a factor has only two levels, as in the above example, there is only one effect of this factor, which is the
difference of the means at these two levels. However, when there are multiple levels, there are multiple paired
comparisons. For example, if there are r levels for a factor, there are
paired comparisons. In this case, what is
the power of detecting a given difference among these comparisons?
In DOE++, power for a multiple level factor is defined as follows: given the largest difference among all the level
means is , power is the smallest probability of detecting this difference at a given significance level.
For example, if a factor has 4 levels and is 3, there are many scenarios that the largest difference among all the
level means will be 3. The following table gives 4 possible scenarios.
Case M1 Μ2 M3
M4
1
24
27
25
26
2
25
25
26
23
3
25
25
25
28
4
25
25 26.5 23.5
For all 4 cases, the largest difference among the means is the same: 3. The probability of detecting
(individual power) can be calculated using the method in the previous section for each case. It has been proven in
[Kutner etc 2005, Guo etc 2012] that when the experiment is balanced, case 4 gives the lowest probability of
detecting a given amount of effect. Therefore, the individual power calculated for case 4 is also the power for this
experiment. In case 4, all but two factor level means are at the grand mean, and the two remaining factor level means
are equally spaced around the grand mean. Is this a general pattern? Can the conclusion from this example be applied
to general cases of balanced design?
To answer these questions, let’s illustrate the power calculation mathematically. In one factor design or one-way
ANOVA, a level is also traditionally called a treatment. The following linear regression model is used to model the
data:
where
is the th observation at the th treatment and
First, let’s define the problem of power calculation.
The power calculation of an experiment can be mathematically defined as:
Design Evaluation and Power Study
219
where is the number of levels,
is the total samples, α is the significance level of the hypothesis testing, and
is the critical value. The obtained minimal of the objective function in the above optimization problem is the
power. The above optimization is the same as minimizing , the non-centrality parameter, since all the other
variables in the non-central F distribution are fixed.
Second, let’s relate the level means with the regression coefficients.
Using the regression model, the mean response at the ith factor level is:
The difference of level means can also be defined using the values. For example, let
, then:
Using , the non-centrality parameter can be calculated as:
where
we know:
and
is the variance and covariance matrix for
. When the design is balanced,
where n is the sample size at each level.
Third, let’s solve the optimization problem for balanced designs.
The power is calculated when is at its minimum. Therefore, for balanced designs, the optimization issue becomes:
The two equations in the constraint represent two cases. Without losing generality,
discussion.
Case 1:
example, let
for
is set to 1 in the following
, that is, the last level of the factor does not appear in the difference of level means. For
.
. The optimal solution is
,
,
. This result means that at the optimal solution,
,
,
,
.
Case 2: In this case, one level in the comparisons is the last level of the factor in the largest difference of
For example, let
The optimal solution is
, and
,
.
.
,
for
.
. This result means that at the optimal solution,
,
Design Evaluation and Power Study
220
The proof for Case 1 and Case 2 is given in [Guo IEEM2012]. The results for Case 1 and Case 2 show that when one
of the level means (adjusted by the grand mean) is
, another level mean is and the rest level means are
0, the calculated power is the smallest power among all the possible scenarios. This result is the same as the
observation for the 4-case example given at the beginning at this section.
Let’s use the above optimization method to solve the example given in the previous section. In that example, the
factor has 2 levels; the sample size is 5 at each level; the estimated
; and
. The regression model
is:
Since the sample size is 5,
. From the above discussion, we know that when
, we get the minimal non-centrality parameter
. This value is the same
as what we got in the previous section using the non-central t and F distributions. Therefore, the method discussed in
this section is a general method and can be used for cases with 2 level and multiple level factors. The previous
non-central t and F distribution method is only for cases with 2 level factors.
A 4 level balanced design example
Assume an engineer wants to compare the performance of 4 different materials. Each material is a level of the factor.
The sample size for each level is 15 and the standard deviation is 10. The engineer wants to calculate the power of
this experiment when the largest difference among the materials is 15. If the power is less than 80%, he also wants to
know what the sample size should be in order to obtain a power of 80%. Assume the significant level is 5%.
Step 1: Build the linear regression model. Since there are 4 levels, we need 3 indicator variables. The model is:
Step 2: Since the sample size is 15 and is 10:
Step 3: Since there are 4 levels, there are 6 paired comparisons. For each comparison, the optimal is:
ID Paired Comparison beta1 beta2 beta3
1
Level 1- Level2 0.5
-0.5
0
2
Level 1- Level 3
0.5
0
-0.5
3
Level 1- Level 4
0.5
0
0
4
Level 2- Level 3
0
0.5
-0.5
5
Level 2- Level 4
0
0.5
0
6
Level 3- Level 4
0
0
0.5
Step 4: Calculate the non-centrality parameter for each of the 6 solutions:
The diagonal elements are the non-centrality parameter from each paired comparison. Denoting them as , the
power should be calculated using
. Since the design is balanced, we see here that all the are the
same.
Design Evaluation and Power Study
221
Step 5: Calculate the critical F value.
Step 6: Calculate the power for this design using the non-central F distribution.
Since the power is greater than 80%, the sample size of 15 is sufficient. Otherwise, the sample size should be
increased in order to achieve the desired power requirement. The settings and results in DOE++ are given below.
Design evaluation settings.
Design evaluation summary of results.
Design Evaluation and Power Study
222
Power Calculation for Comparing Multiple Means: Unbalanced Designs
If the design is not balanced, the non-centrality parameter does not have the simple expression of
, since
will not have the simpler format seen in balanced designs. The
optimization thus becomes more complicated. For each paired comparison, we need to solve an optimization
problem by assuming this comparison has the largest difference. For example, assuming the ith comparison
has the largest difference, we need to solve the following problem:
In total, we need to solve
optimization problems and use the smallest
among all the solutions to
calculate the power of the experiment. Clearly, the calculation will be very expensive.
In DOE++, instead of calculating the exact solution, we use the optimal for a balanced design to calculate the
approximated power for an unbalanced design. It can be seen that the optimal for a balanced design also can
satisfy all the constraints for an unbalanced design. Therefore, the approximated power is always higher than the
unknown true power when the design is unbalanced.
A 3-level unbalanced design example: exact solution
Assume an engineer wants to compare the performance of three different materials. 4 samples are available for
material A, 5 samples for material B and 13 samples for material C. The responses of different materials follow a
normal distribution with a standard deviation of
. The engineer is required to calculate the power of detecting
difference of 1 among all the level means at a significance level of 0.05.
From the design matrix of the test,
and
are calculated as:
,
There are 3 paired comparisons. They are
If the first comparison
becomes:
The optimal solution is
,
and
.
has the largest level mean difference of 1
, and the optimal
, then the optimization problem
.
If the second comparison
has the largest level mean difference, then the optimization is similar to the
above problem. The optimal solution is
;
and the optimal
.
If the third comparison
has the largest level mean difference, then the optimal solution is
; {{\beta }_{2}}=0.57407\,\!</math> and the optimal
.
Design Evaluation and Power Study
223
From the definition of power, we know that the power of a design should be calculated using the smallest
non-centrality parameter of all possible outcomes. In this example, it is
. Since the
significance level is 0.05, the critical value for the F test is
. The power for this
example is:
A 3-level unbalanced design example: approximated solution
For the above example, we can get the approximated power by using the optimal
design is balanced, the optimal solution will be:
Solution ID Paired Comparison β1
of a balanced design. If the
β2
1
u1-u2
0.5 -0.5
2
u1-u3
0.5
0
3
u2-u3
0
0.5
Therefore:
Since the design is unbalanced, use
from the above example to get:
The smallest is 2.238636. For this example, it is very close to the exact solution 2.22222 given in the previous
calculation. The approximated power is:
This result is a little larger than the exact solution of 0.2162.
In practical cases, the above method can be applied to quickly check the power of a design. If the calculated power
cannot meet the required value, the true power definitely will not meet the requirement, since the calculated power
using this procedure is always equal to (for balanced designs) or larger than (for unbalanced designs) the true value.
The result in DOE++ for this example is given as:
Power Study
Degrees of Freedom Power for Max Difference = 1
A:Factor 1
2
0.2174
Residual
19
-
Power Study for 2 Level Factorial Designs
For 2 level factorial designs, each factor (effect) has only one coefficient. The linear regression model is:
The model can include main effect terms and interaction effect terms. Each
can be -1 (the low level) or +1 (the
high level). The effect of a main effect term is defined as the difference of the mean value of Y at
and
. Please notice that all the factor values here are coded values. For example, the effect of
is defined
by:
Design Evaluation and Power Study
224
Similarly, the effect of an interaction term is also defined as the difference of the mean values of Y at the interaction
terms of +1 and -1. For example, the effect of
is:
Therefore, if the effect of a term that we want to calculate the power for is
, then the corresponding coefficient
must be
. Therefore, the non-centrality parameter for each term in the model for a 2 level factorial design can
be calculated as
Once is calculated, we can use it to calculate the power. If the design is balanced, the power of terms with the
same order will be the same. In other words, all the main effects have the same power and all the k-way (k=2, 3, 4,
…) interactions have the same power.
Example: Due to the constraints of sample size and cost, an engineer can run only the following 13 tests for a 4
factorial design:
Run A B C D
1
1
1
1
1
2
1
1
-1 -1
3
1
-1 1
4
-1 1
1
5
-1 1
-1 1
6
-1 -1 1
7
-1 -1 -1 -1
8
0
0
0
0
9
0
0
0
0
10
0
0
0
0
11
0
0
0
0
12
0
0
0
0
13
0
0
0
0
-1
-1
1
Before doing the tests, he wants to evaluate the power for each main effect. Assume the amount of effect he wants to
perform a power calculation for is 2 . The significance level is 0.05.
Step 1: Calculate the variance and covariance matrix for the model coefficients. The main effect-only model is:
For this model:
The value for
is
Design Evaluation and Power Study
225
beta0
beta1
beta2
beta3
beta4
beta0 0.083333 0.020833 -0.02083 -0.02083 0.020833
beta1 0.020833 0.161458 -0.03646 -0.03646 0.036458
beta2 -0.02083 -0.03646 0.161458 0.036458 -0.03646
beta3 -0.02083 -0.03646 0.036458 0.161458 -0.03646
beta4 0.020833 0.036458 -0.03646 -0.03646 0.161458
The diagonal elements are the variances for the coefficients.
Step 2: Calculate the non-centrality parameter for each term. In this example, all the main effect terms have the same
variance, so they have the same non-centrality parameter value.
Step 3: Calculate the critical value for the F test. It is:
Step 4: Calculate the power for each main effect term. For this example, the power is the same for all of them:
The settings and results in DOE++ are given below.
Evaluation settings.
Design Evaluation and Power Study
226
Evaluation results.
In general, the calculated power for each term will be different for unbalanced designs. However, the above
procedure can be applied for both balanced and unbalanced 2 level factorial designs.
Power Study for General Level Factorial Designs
For a quantitative factor X with more than 2 levels, its effect is defined as:
This is the difference of the expected Y values at its defined high and low level. Therefore, a quantitative factor can
always be treated as a 2 level factor mathematically, regardless of its defined number of levels. A quantitative factor
has only 1 term in the regression equation.
For a qualitative factor with more than 2 levels, it has more than 1 term in the regression equation. Like in the
multiple level 1 factor designs, a qualitative factor with r levels will have r-1 terms in the linear regression equation.
Assume there are 2 factors in a design. Factor A has 3 levels and factor B has 3 levels, the regression equation for
this design is:
There are 2 regression terms for each main effect, and 4 regression terms for the interaction effect. We will use the
above equation to explain how the power for the main effects and interaction effects is calculated in DOE++. The
following balanced design is used for the calculation:
Design Evaluation and Power Study
227
Run A B Run A B
1
1 1
14
2 2
2
1 2
15
2 3
3
1 3
16
3 1
4
2 1
17
3 2
5
2 2
18
3 3
6
2 3
19
1 1
7
3 1
20
1 2
8
3 2
21
1 3
9
3 3
22
2 1
10
1 1
23
2 2
11
1 2
24
2 3
12
1 3
25
3 1
13
2 1
26
3 2
27
3 3
Power Study for Main Effects
Let’s use factor A to show how the power is defined and calculated for the main effects. For the above design, if we
ignore factor B, then it becomes a 1 factor design with 9 samples at each level. Therefore, the same linear regression
model and power calculation method as discussed for 1 factor designs can be used to calculate the power for the
main effects for this multiple level factorial design. Since A has 3 levels, it has 3 paired comparisons:
;
and
. is the average of the responses at the ith level.
However, these three contrasts are not independent, since
. We are interested in the largest
difference among all the contrasts. Let
. Power is defined as the probability of detecting a given
in an experiment. Using the linear regression equation, we get:
Just as for the 1 factor design, we know the optimal solutions are:
when
is the
largest difference ;
when
is the largest difference and
when
is the largest difference . For each of the solution, a non-centrality parameter can be calculated using
. Here
, and
is the inverse of the variance and covariance matrix obtained from
the linear regression model when all the terms are included. For this example, we have the coefficient matrix for the
optimal solution:
The standard variance matrix
for all the coefficients is:
Design Evaluation and Power Study
228
I
A[1]
A[2]
B[1]
B[2]
A[1]B[1] A[1]B[2] A[2]B[1] A[2]B[2]
0.0370
0
0
0
0
0
0
0
0
0
0.0741 -0.0370
0
0
0
0
0
0
0
-0.0370 0.0741
0
0
0
0
0
0
0
0
0
0.0741 -0.0370
0
0
0
0
0
0
0
-0.0370 0.0741
0
0
0
0
0
0
0
0
0
0.1481
-0.0741
-0.0741
0.0370
0
0
0
0
0
-0.0741
0.1481
0.0370
-0.0741
0
0
0
0
0
-0.0741
0.0370
0.1481
-0.0741
0
0
0
0
0
0.0370
-0.0741
-0.0741
0.1481
Clearly the design is balanced for all the terms since the above matrix is a block diagonal matrix.
From the above table, we know the variance and covariance matrix
Its inverse
of A is:
for factor A is:
Assuming that the
we are interested in is , then the calculated non-centrality parameters are:
=
4.5
2.25 -2.25
2.25
4.5
2.25
-2.25 2.25
4.5
The power is calculated using the smallest value at the diagonal of the above matrix. Since the design is balanced, all
the 3 non-centrality parameters are the same in this example (i.e., they are 4.5).
The critical value for the F test is:
Please notice that for the F distribution, the first degree of freedom is 2 (the number of terms for factor A in the
regression model) and the 2nd degree of freedom is 18 (the degrees of freedom of error).
The power for main effect A is:
Design Evaluation and Power Study
229
Evaluation settings.
Design Evaluation and Power Study
230
Evaluation results.
If the
we are interested in is 2 , then the non-centrality parameter will be 18. The power for main effect A is:
The power is greater for a larger
approximated power.
. The above calculation also can be used for unbalanced designs to get the
Power Study for Interaction Effects
First, we need to define what an “interaction effect” is. From the discussion for 2 level factorial designs, we know the
interaction effect AB is defined by:
It is the difference between the average response at AB=1 and AB=-1. The above equation also can be written as:
or:
From here we can see that the effect of AB is half of the difference of the effect of B when A is fixed at 1 and the
effect of B when A is fixed at -1. Therefore, a two-way interaction effect is calculated using 4 points as shown in the
above equation. This is illustrated in the following figure.
Design Evaluation and Power Study
As we discussed before, a main effect is defined by two points. For example, the main effect of B at A=1 is defined
by
and
. The above figure clearly shows that a two-way interaction effect of two-level
factors is defined by the 4 vertex of a quadrilateral. How can we define the two-way interaction effects of factorials
with more than two levels? For example, for the design used in the previous section, A and B are both three levels.
What is the interaction effect AB? For this example, the 9 design points are shown in the following figure.
231
Design Evaluation and Power Study
232
Notice that there are 9 quadrilaterals in the above figure. These 9 contrasts define the interaction effect AB. This is
similar to the paired comparisons in a one factorial design with multiple levels, where a main effect is defined by a
group of contrasts (or paired comparisons). For the design in the above figure, to construct a quadrilateral, we need
to choose 2 levels from A and 2 levels from B. There are
combinations. Therefore, we see the
following 9 contrasts.
Contrast ID
A
B
1
(1, 2) (1, 2)
2
(1, 2) (1, 3)
3
(1, 2) (2, 3)
4
(1, 3) (1, 2)
5
(1, 3) (1, 3)
6
(1, 3) (2, 3)
7
(2, 3) (1, 2)
8
(2, 3) (1, 3)
9
(2, 3) (2, 3)
Let’s use the first contrast to explain the meaning of a contrast. (1, 2) in column A means the selected levels from A
are 1 and 2. (1, 2) in column B means the selected levels from B are 1 and 2. They form 4 points:
,
,
and
. We can denote the AB effect defined by this contrast as
.
Design Evaluation and Power Study
233
In general, if a contrast is defined by A (i, j) and B(i’, j’), then the effect is calculated by:
From the above two equations we can see that the two-way interaction effect AB is defined as the difference of the
main effect of B at A = i and the main effect of B at A = j. This logic can be easily extended to three-way
interactions. For example ABC can be defined as the difference of AB at C=k and AC at C=k’. Its calculation is:
For a design with A, B, and C with 3 levels, there are
contrast for the three-way
interaction ABC.
Similarly, the above method can be extended for higher order interactions. By now, we know the main effect and
interactions for multiple level factorial designs are defined by a group of contrasts. We will discuss how the power of
these effects is calculated in the following section.
The power for an effect is defined as follows: when the largest value of a contrast group for an effect is , power is
the smallest probability of detecting this among all the possible outcomes at a given significance level.
To calculate the power for an effect, as in the previous sections, we need to relate a contrast with model coefficients.
The 9 contrasts in the above table can be expressed using model coefficients. For example:
If this contrast has the largest value
, the power is calculated from the following optimization problem:
where
, and
is the variance and covariance matrix of .
For a balanced general level factorial design such as this example, the optimal solution for the above optimization
issue is:
For all the 9 contrasts, by assuming each of the contrasts has the largest value one by one, we can get 9 optimal
solutions and 9 non-centrality parameters . The power for the interaction effect AB is calculated using the min(
). The 9 optimal solutions are:
Design Evaluation and Power Study
234
Contrast ID
A
B
1
(1, 2) (1, 2) 0.5 -0.5 -0.5 0.5
2
(1, 2) (1, 3) 0.5
3
(1, 2) (2, 3)
0
-0.5
0
0.5
0
-0.5
4
(1, 3) (1, 2) 0.5 -0.5
0
0
5
(1, 3) (1, 3) 0.5
0
0
0
6
(1, 3) (2, 3)
0
0.5
0
0
7
(2, 3) (1, 2)
0
0
0.5 -0.5
8
(2, 3) (1, 3)
0
0
0.5
0
9
(2, 3) (2, 3)
0
0
0
0.5
0
In the regression equation for this example, there are 4 terms for AB effect. Therefore there are 4 independent
contrasts in the above table. These are contrasts 5, 6, 8, and 9. The rest of the contrasts are linear combinations of
these 4 contrasts. Based on the calculation in the main effect section, we know that the standard variance matrix
for all the coefficients is:
I
A[1]
A[2]
B[1]
B[2]
0.0370
0
0
0
0
0
0
0
0
0
0.0741 -0.0370
0
0
0
0
0
0
0
-0.0370 0.0741
0
0
0
0
0
0
0
0
0
0.0741 -0.0370
0
0
0
0
0
0
0
-0.0370 0.0741
0
0
0
0
0
0
0
0
0
0.1481
-0.0741
-0.0741
0.0370
0
0
0
0
0
-0.0741
0.1481
0.0370
-0.0741
0
0
0
0
0
-0.0741
0.0370
0.1481
-0.0741
0
0
0
0
0
0.0370
-0.0741
-0.0741
0.1481
The variance and covariance matrix
Then its inverse matrix
A[1]B[1] A[1]B[2] A[2]B[1] A[2]B[2]
of AB is:
is:
Assuming that the we are interested in is , then the calculated non-centrality parameters for all the contrasts are
the diagonal elements of the following matrix.
=
Design Evaluation and Power Study
235
3.0003 1.5002 -1.5002 1.5002 0.7501 -0.7501 -1.5002 -0.7501 0.7501
1.5002 3.0003
1.5002
0.7501 1.5002 0.7501 -0.7501 -1.5002 -0.7501
1.5002 1.5002
3.0003 -0.7501 0.7501 1.5002
0.7501 -0.7501 -1.5002
1.5002 0.7501 -0.7501 3.0003 1.5002 -1.5002 1.5002
0.7501 -0.7501
0.7501 1.5002
0.7501
1.5062
0.7562
0.7501 0.7501
1.5002 -1.5002 1.5062 3.0064 -0.7501 0.7562
1.5062
1.5002 -0.7501 0.7501
1.5002 3.0064 1.5062
0.7501
1.5002 0.7501 -0.7501 3.0003
0.7501 -1.5002 -0.7501 0.7501 1.5062 0.7562
1.5002
1.5002 -1.5002
3.0064
1.5062
0.7501 -0.7501 -1.5002 -0.7501 0.7562 1.5062 -1.5002 1.5062
3.0064
The power is calculated using the smallest value at the diagonal of the above matrix (i.e., 3.0003). The critical value
for the F test is:
Please notice that for the F distribution, the first degree of freedom is 4 (the number of terms for effect AB in the
regression model) and the 2nd degree of freedom is 18 (the degree of freedom of error).
The power for AB is:
Evaluation results effect of 1
If the
is:
.
we are interested in is 2 , then the non-centrality parameter will be 12.0012. The power for main effect A
Design Evaluation and Power Study
236
The power values for all the effects in the model are:
Evaluation results for effect of 2
.
For balanced designs, the above calculation gives the exact power. For unbalanced design, the above method will
give the approximated power. The true power is always less than the approximated value.
This section explained how to use a group of contrasts to represent the main and interaction effects for multiple level
factorial designs. Examples for main and 2nd order interactions were provided. The power calculation for higher
order interactions is the same as the above example. Therefore, it is not repeated here.
Power Study for Response Surface Method Designs
For response surface method designs, the following linear regression model is used:
The above equations can have both qualitative and quantitative factors. As we discussed before, for each effect (main
or quadratic effect) of a quantitative factor, there is only one term in the regression model. Therefore, the power
calculation for a quantitative factor is the same as treating this factor as a 2 level factor, no matter how many levels
are defined for it. If qualitative factors are used in the design, they do not have quadratic effects in the model. The
power calculation for qualitative factors is the same as discussed in the previous sections.
First we need to define what the “effect” is for each term in the above linear regression equation. The definition for
main effects and interaction effects is the same as for 2 level factorial designs. The effect is defined as the difference
of the average response at the +1 of the term and at the -1 of the term. For example, the main effect of
is:
The interaction effect of
For a quadratic term
is:
, its range is from 0 to 1. Therefore, its effect is:
The quadratic term also can be thought of as:
Since there are no grouped contrasts for each effect, the power can be calculated using either the non-central t
distribution or the non-central F distribution. They will lead to the same results. Let’s use the following design to
Design Evaluation and Power Study
237
illustrate the calculation.
Run Block
A
B
C
1
1
-1
-1
-1
2
1
1
-1
-1
3
1
-1
1
-1
4
1
1
1
-1
5
1
-1
-1
1
6
1
1
-1
1
7
1
-1
1
1
8
1
1
1
1
9
1
0
0
0
10
1
0
0
0
11
1
0
0
0
12
1
0
0
0
13
2
-1.68179
0
0
14
2
1.681793
0
0
15
2
0
-1.68179
0
16
2
0
1.681793
0
17
2
0
0
-1.68179
18
2
0
0
1.681793
19
2
0
0
0
20
2
0
0
0
21
3
-1
-1
-1
22
3
1
-1
-1
23
3
-1
1
-1
24
3
1
1
-1
25
3
-1
-1
1
26
3
1
-1
1
27
3
-1
1
1
28
3
1
1
1
29
3
0
0
0
30
3
0
0
0
31
3
0
0
0
32
3
0
0
0
33
4
-1.68179
0
0
34
4
1.681793
0
0
35
4
0
-1.68179
0
36
4
0
1.681793
0
37
4
0
0
-1.68179
Design Evaluation and Power Study
238
38
4
0
0
1.681793
39
4
0
0
0
40
4
0
0
0
The above design can be created in DOE++ using the following settings:
Settings for creating the RSM design
The model used here is:
Blocks are included in the model. Since there are four blocks, three indicator variables are used. The standard
variance and covariance matrix
is
Const
BLK1
BLK2
BLK3
A
B
C
AB
AC
BC
0.085018 -0.00694 0.006944 -0.00694
0
0
0
0
0
0
-0.02862 -0.02862 -0.02862
0.00694
0.067759 -0.02609 -0.01557
0
0
0
0
0
0
0.000843 0.000843 0.000843
0.006944 -0.02609 0.088593 -0.02609
0
0
0
0
0
0
-0.00084 -0.00084 -0.00084
0.00694
0
0
0
0
0
0
0.000843 0.000843 0.000843
-0.01557 -0.02609 0.067759
AA
BB
CC
0
0
0
0
0.036612
0
0
0
0
0
0
0
0
0
0
0
0
0
0.036612
0
0
0
0
0
0
0
0
0
0
0
0
0
0.036612
0
0
0
0
0
0
0
0
0
0
0
0
0
0.0625
0
0
0
0
0
0
0
0
0
0
0
0
0
0.0625
0
0
0
0
Design Evaluation and Power Study
0
0
0
239
0
0
0
0
0
0
0.0625
0
0
0
0.02862
0.000843 -0.00084 0.000843
0
0
0
0
0
0
0.034722 0.003472 0.003472
0.02862
0.000843 -0.00084 0.000843
0
0
0
0
0
0
0.003472 0.034722 0.003472
The variances for all the coefficients are the diagonal elements in the above matrix. These are:
Term Var(
)
A
0.036612
B
0.036612
C
0.036612
AB
0.0625
AC
0.0625
BC
0.0625
AA
0.034722
BB
0.034722
CC
0.034722
Assume the value for each effect we are interested in is
model coefficient is:
. Then, to get this
Term Coefficient
A
0.5
B
0.5
C
0.5
AB
0.5
AC
0.5
BC
0.5
AA
1
BB
1
CC
1
The degrees of freedom used in the calculation are:
Source
Degree of Freedom
Block
3
A:A
1
B:B
1
C:C
1
AB
1
AC
1
BC
1
AA
1
BB
1
the corresponding value for each
Design Evaluation and Power Study
240
CC
1
Residual
27
Lack of Fit
19
Pure Error
8
Total
39
The above table shows all the factor effects have the same degree of freedom, therefore they have the same critical F
value. For a significance level of 0.05, the critical value is:
When
, the non-centrality parameter for each main effect is calculated by:
The non-centrality parameter for each interaction effect is calculated by:
The non-centrality parameter for each quadratic effect is calculated by:
All the non-centrality parameters are given in the following table:
Term Non-centrality parameter ( )
The power for each term is calculated by:
They are:
A
6.828362
B
6.828362
C
6.828362
AB
4
AC
4
BC
4
AA
28.80018
BB
28.80018
CC
28.80018
Design Evaluation and Power Study
241
Source Power (
A:A
0.712033
B:B
0.712033
C:C
0.712033
AB
0.487574
AC
0.487574
BC
0.487574
AA
0.999331
BB
0.999331
CC
0.999331
)
The results in DOE++ can be obtained from the design evaluation.
Settings for creating the RSM design
Design Evaluation and Power Study
Discussion on Power Calculation
All the above examples show how to calculate the power for a given amount of effect.When a power value is given,
using the above method we also can calculate the corresponding effect. If the power is too low for an effect of
interest, the sample size of the experiment must be increased in order to get a higher power value.
We discussed in detail how to define an “effect” for quantitative and qualitative factors, and how to use model
coefficients to represent a given effect. The power in DOE++ is calculated based on this definition. Readers may find
that power is calculated directly based on model coefficients (instead of the contrasts) in other software packages or
books. However, for some cases, such as for the main and interaction effects of qualitative factors with multiple
levels, the meaning of model coefficients is not very straightforward. Therefore, it is better to use the defined effect
(or contrast) shown here to calculate the power, even though this calculation is much more complicated.
Conclusion
In this chapter, we discussed how to evaluate an experiment design. Although the evaluation can be conducted either
before or after conducting the experiment, it is always recommended to evaluate an experiment before performing it.
A bad design will waste time and money. Readers should check the alias structure, the orthogonality and the power
for important effects for an experiment before the tests.
242
243
Chapter 12
Optimal Custom Designs
Although two level fractional factorial designs, Plackett-Burman designs, Taguchi orthogonal array and other
predefined designs are enough for most applications, sometimes these designs may not be sufficient due to
constraints on available resources such as time, cost and factor values. Therefore, in this chapter, we will discuss
how to create an optimal custom design. DOE++ has two types of optimal custom designs: regression model-based
and distance-based.
Regression Model-Based Optimal Designs
Regression model-based optimal designs are optimal for a selected regression model. Therefore, a regression model
must first be specified. The regression model should include all the effects that the experimenters are interested in.
As discussed in the linear regression chapter, the following linear equation is used in DOE data analysis.
where:
• is the response
• , …, are the factors
• , , …,
• are model coefficients
• is the error term
For each run, the above equation becomes:
It can be written in matrix notation as:
where:
,
,
,
n is the total number of samples or runs. As discussed in the design evaluation chapter, the information matrix for an
experiment is:
The variance and covariance matrix for the regression coefficients is:
where
is the variance of the error . It can be either specified by experimenters from their engineering
knowledge or estimated from the data analysis. If the number of available samples is given, we need to choose the
value of
in matrix to minimize the determinant of . A small determinate means less uncertainty of the
Optimal Custom Designs
244
estimated coefficients . This is the same as maximizing the determinant of
. A design that uses the determinant as the
objective is called D-optimal design. A D-optimal design can be either selected from a standard design or created
based on the values of factors without creating a standard design first. In this chapter, we discuss how to select a
D-optimal design from a standard factorial design.
Select a D-Optimal Custom Design from a Standard Design
Assume that we need to design an experiment to investigate five factors with two levels each. To run a full factorial
design, a total of
factor combinations are needed. However, only 11 samples are available. To obtain the
most information, which of the 11 factor combinations from the total of 32 should be applied to these 11 samples?
To answer this question, we need to first decide what information we want to obtain.
The 32 runs required for a full factorial design are given in the table below.
Order A B C D E
1
-1 -1 -1 -1 -1
2
1 -1 -1 -1 -1
3
-1 1 -1 -1 -1
4
1
5
-1 -1 1 -1 -1
6
1 -1 1 -1 -1
7
-1 1
1 -1 -1
8
1
1 -1 -1
9
-1 -1 -1 1 -1
10
1 -1 -1 1 -1
11
-1 1 -1 1 -1
12
1
13
-1 -1 1
1 -1
14
1 -1 1
1 -1
15
-1 1
1
1 -1
16
1
1
1 -1
17
-1 -1 -1 -1 1
18
1 -1 -1 -1 1
19
-1 1 -1 -1 1
20
1
21
-1 -1 1 -1 1
22
1 -1 1 -1 1
23
-1 1
1 -1 1
24
1
1 -1 1
25
-1 -1 -1 1
1
26
1 -1 -1 1
1
27
-1 1 -1 1
1
28
1
1
1 -1 -1 -1
1
1 -1 1 -1
1
1 -1 -1 1
1
1 -1 1
Optimal Custom Designs
245
29
-1 -1 1
1
1
30
1 -1 1
1
1
31
-1 1
1
1
1
32
1
1
1
1
1
Since only 11 test samples are available, we must choose 11 factor value combinations from the above table. The
experiment also has the following constraints:
• Due to safety concerns, it is not allowed to set all the factors at their high level at the same time. Therefore, we
cannot use run number 32 in the experiment.
• The engineers are very interested in checking the response at A=D=1, and B=C=E=-1. Therefore, run number 10
must be included in the experiment.
• The engineers need to check the main effects and the interaction effect of AE. Therefore, the model for designing
the optimal customer design is:
Since run number 10 must be included, there are only 10 runs left to choose from the above table. Many algorithms
can be used to choose these 10 runs to maximize the determinant of the information matrix.
For this example, we first need to create a regular two level factorial design with five factors, as shown next.
A standard full factorial design.
On the Design Settings tab of the Optimal Design window, you can select which terms to include in the model and
specify the number of runs to be used in the experiment. Only main effects and AE are selected. The number of runs
is set to 11. In the Candidate Runs tab of the window, run number 10 was set to be included and run number 32 was
set to be excluded.
Optimal Custom Designs
246
Specify terms you are interested in
Optimal Custom Designs
247
Specify constraints for candidate runs
The resulting optimal custom design is shown next.
The optimal custom design
The design evaluation results for this design are given below.
Optimal Custom Designs
248
Design evaluation for the created optimal design
From the design evaluation results, we can see the generated design can clearly estimate all the main effects and the
AE interaction. The determinate of the information matrix X’X is 1.42E+7 and the D-efficiency is 0.9554. The power
for an effect of 2-standard deviation for each of the terms of interest is also given in the design evaluation.
Algorithms for Selecting Model-Based D-Optimal Designs
In DOE++, the Federov’s method, the modified Federov’s method and the k-exchange method are used to select test
runs from all the candidates. They are briefly explained below.
The Federov algorithm [Fedorov, 1972]
Assume there is an initial optimal design with number of runs of n. The initial optimal design can be obtained using
the sequential optimization method given in [Dykstra 1971, Galil and Kiefer 1980]. We need to exchange one of the
rows in the initial design with one of the rows from the candidate runs. Let’s call the initial design
and call the
design after row exchange
. The determinant of the new information matrix is:
where is the row from the current optimal design. It needs to be exchanged with , a candidate run from the
candidate set.
is the amount of change in the determinant of the information matrix. It is calculated by:
where: •
is the covariance for
and
•
and
are the variance of and calculated using the current optimal design
The basic idea
behind the Fedorov algorithm is to calculate the delta-value for all the possible exchange pairs from the current
design and the candidate runs, and then select the pair with the highest value. At each iteration, it calculates
Optimal Custom Designs
deltas (where n is the number of runs in the current design matrix and N is the number of runs in the candidate run
matrix) and chooses the best one for exchange. The algorithm stops when the change of the determinate is less than a
pre-defined small value.
The Modified Federov Algorithm [Cook and Nachtsheim, 1980]
The above Federov algorithm is very slow since it only conducts one exchange after calculating
deltas. The
modified Federov algorithm tries to improve the speed. It is a simplified version of the Fedorov method. Assume the
current design matrix is
. The algorithm starts from the 1st row in the design matrix and uses it to calculate
deltas (deltas of this design run with all the candidate runs). An exchange is conducted if the largest delta is
a positive value. The above steps are repeated until the increase of the determinant is less than a pre-defined small
value. Therefore, the modified Federov algorithm results in one exchange after calculating N deltas.
The K-Exchange Algorithm [Johnson and Nachtsheim, 1983]
This is a variation of the modified Fedorov algorithm. Instead of calculating the deltas for all the design runs in one
iteration, it calculates only the deltas for the k-worst runs. First, the algorithm uses the current design matrix to
calculate the variance of each run in the design matrix. The k runs with the lowest variances are the runs that need to
exchange. Then for each of the k worst runs, it calculates N deltas with all the N candidate runs. If the largest delta is
greater than a pre-defined small value, then this row is exchanged with the candidate row, resulting in the largest
positive delta. Once all the k points are exchanged, a new design matrix is obtained and the above steps are repeated
until no exchange can be conducted. Usually k is set to be:
where n is the number of runs in the optimal
design. 2 Distance-Based Optimal Designs
Sometimes, experimenters want the design points (runs) in an experiment to cover as large of a design space as
possible. In other words, the distance between design points is intended to be as far as possible. Distance-based
optimal designs are used for this purpose.
To create a distance-based optimal design, the candidate runs should be available. First, the average value of each
factor is calculated. This average is called the “center” of the design space. For qualitative factors, the average is
calculated for the indicator variables in the regression model. For quantitative factors, the average is calculated based
on the coded values. The distance of each candidate run to the center is calculated and sorted. The run with the
largest distance is selected to be in the optimal design. If there are multiple runs with the same largest distance, a run
is randomly selected from them. The “center” of the runs in the current optimal design is then calculated. The
distances of all the available runs to this “center” are also calculated. Based on these distances, the next run is
selected and put in the optimal design. Repeat this process until the required number of runs in the optimal design is
reached.
Example: Three factors were investigated in an experiment. Factor A is Temperature and has two levels: 50C and
90C. Factor B is Time and it has three levels: 10, 20, and 30 minutes. Factor C is Humidity with four levels: 40%,
45%, 50%, and 55%. All three factors are quantitative. A complete factorial design would require 24 runs. The
experimenters can only run 12 of them due to limitations on time and cost. The complete general full factorial design
is given below.
The generated distance-based design with 12 runs is:
From the above generated design, we can see that for each factor, only its lowest and highest values are selected. By
doing this, the distances between all the runs are maximized. Distance-based custom design can sometimes generate
a design with aliased main effects. Maximizing the distance does not guarantee that the design can estimate all the
main effects clearly. For this reason, using the D-optimal criterion is always preferred.
Reference for the Algorithms:
• Fedorov, V. V. (1972), “Theory of Optimal Experiments (Review)”, Biometrika, cvol. 59, no. 3, 697-698.
Translated and edited by W. J. Studden and E. M. Klimko.
• Dykstra, O. (1971), “The augmentation of experimental data to maximize |X’X|, Technometrics, vol. 13, no. 3,
249
Optimal Custom Designs
682-688.
• Galil, Z. and Kiefer, J. (1980), “Time and Space Saving Computer Methods, Related to Mitchell’s DETMAX, for
Finding D-Optimal Designs”, Technometrics, vol. 22, no. 3, 301-313.
• Cook, R. D. and Nachtsheim, C. J. (1980), “A Comparison of Algorithms for Constructing Exact D-Optimal
Designs,” Technometrics, vol. 22, no. 3, 315-324.
• Johnson, M. E. and Nachtsheim, C. J. (1983), “Some Guidelines for Constructing Exact D-Optimal Designs on
Convex Design Spaces,” Technometrics , vol. 25, no. 3, 271-277.
250
251
Chapter 13
Robust Parameter Design
In Response Surface Methods for Optimization, techniques used to optimize the response were discussed. Once an
optimum value of the response has been achieved, the next goal of the experimenter should be to make the optimum
response value insensitive to the noise factors so that a consistent performance is obtained at all times. For example,
if the yield from a chemical process has been optimized at 95%, then this value of yield should be obtained
regardless of the variation in factors such as the quality of reactants or fluctuations in humidity or other weather
conditions. These factors are beyond the control of the operator. Therefore, the product or process should be such
that it is not affected by minor fluctuations in these factors. The process of making a system insensitive to such
factors is referred to as robust design. Robust design was pioneered by the Japanese industrialist Dr. Genichi
Taguchi in the early 1980s. This chapter briefly discusses his approach.
Taguchi's Philosophy
Taguchi's philosophy is based on the fact that any decrease in the quality of a system leads to customer
dissatisfaction. This occurs even if the departure in quality lies within the specified limits of the system and is
considered acceptable to the customer. For example, consider the case of a laptop that develops a defect on its screen
within the warranty period. Although the customer is able to get a warranty-replacement for the screen this might
lead to a little dissatisfaction on the part of the customer. If the same laptop then develops a problem with its DVD
drive, the customer might declare the laptop "useless," even if the problem occurs during the warranty period and the
customer is able to get a free replacement. Therefore, to maintain a good reputation, the laptop manufacturer needs to
produce laptops that offer the same quality to all customers consistently. This can only be done when the required
quality is built into the laptops. Note how this approach differs from traditional quality control where it is considered
sufficient to manufacture products within certain specifications and carry out pre-shipment quality control
inspections (i.e., sampling inspections) to filter out products that fall out of specification.
Taguchi's philosophy requires that systems be designed in such a way that they are produced, not just within the
specified limits, but right on target specifications or best values. Such a proactive approach is much more fruitful and
efficient than the reactive approach of sampling inspections. The philosophy of Taguchi is summarized by his quality
loss function (see the figure below). The function states that any deviation from the target value leads to a quadratic
loss in quality or customer satisfaction. Mathematically, the function may be expressed as:
Robust Parameter Design
252
Taguchi's quality loss function.
where represents the performance parameter of the system,
represents the quality loss and is a constant.
represents the target or the nominal value of ,
Taguchi's approach to achieve a high quality system consists of three stages: system design, parameter design and
tolerance design. System design refers to the stage when ideas for a new system are used to decide upon the
combinations of factors to obtain a functional and economical design. Parameter design refers to the stage when
factor settings are selected that make the system less sensitive to variations in the uncontrollable factors affecting the
system. Therefore, if this stage is carried out successfully, the resulting system will have little variation and the
resulting tolerances will be tight. Tolerance design refers to the final stage when tolerances are tightened around the
best value. This stage increases cost and is only needed if the required quality is not achieved during parameter
design. Thus, using parameter design, it is possible to achieve the desired quality without much increase in the cost.
The tolerance design stage is discussed in detail next.
Robust Parameter Design
Taguchi divided the factors affecting any system into two categories: control factors and noise factors. Control
factors are factors affecting a system that are easily set by the experimenter. For example, if in a chemical process
the reaction time is found to be a factor affecting the yield, then this factor is a control factor since it can be easily
manipulated and set by the experimenter. The experimenter will chose the setting of the reaction time that maximizes
the yield. Noise factors are factors affecting a system that are difficult or impossible to control. For example, ambient
temperature may also have an effect on the yield of a chemical process, but ambient temperature could be a noise
factor if it is beyond the control of the experimenter. Thus, change in ambient temperature will lead to variations in
the yield but such variations are undesirable.
Robust Parameter Design
253
Control and Noise Factor Interaction
In our example, since the experimenter does not have any control on the change in ambient temperature, he/she
needs to find the setting of the reaction time at which there is minimal variation of yield due to change in ambient
temperature. Note that this can only occur if there is an interaction between the reaction time (control factor) and
ambient temperature (noise factor). If there is no such interaction, variation in yield due to changes in ambient
temperature will always occur regardless of the setting of the reaction time. Therefore, to solve a robust parameter
design problem, interaction between control and noise factors must exist. This fact is further explained by the figure
shown next.
Interaction between control and noise factors: (a) shows the
case when there is no such interaction and (b) shows the case
when the interaction exists. Robust design is only possible in
case (b).
The figure shows the variation of the response (yield) for two levels of the noise factor (ambient temperature). The
response values are plotted at two levels of the control factor (reaction time). Figure (a) shows the case where there
is no interaction between the control and noise factors. It can be seen that, regardless of the settings of the control
factor (low or high), the variation in the response remains the same (as is evident from the constant spread of the
probability distribution of the response at the two levels of the control factor). Figure (b) shows the case where an
interaction exists between the control and noise factors. The figure indicates that in the present case it is
advantageous to have the control factor at the low setting, since at this setting there is not much variation in the
response due to change in the noise factor (as is evident from the smaller spread of the probability distribution of the
response at the low level of the control factor).
Robust Parameter Design
254
Inner and Outer Arrays
Taguchi studied the interaction between the control and noise factors using two experiment designs: the inner array
and the outer array. The inner array is essentially any experiment design that is used to study the effect of the control
factors on the response. Taguchi then used an outer array for the noise factors so that each run of the inner array was
repeated for every treatment of the outer array. The resulting experiment design, that uses both inner and outer
arrays, is referred to as a cross array.
Example
To illustrate Taguchi's use of the inner and outer arrays consider the case of a chemical process where the
experimenter wants the product to be neither acidic nor basic (i.e., the pH of the product needs to be as close to 7 as
possible). It is thought that the pH of the product depends on the concentration of the three reactants, , and ,
used to obtain the product. There are three control factors here, namely the concentration of each of the three
reactants. It has also been found that the pH of the product depends on the ambient temperature which varies
naturally and cannot be controlled. Thus, there is one noise factor in this case - the ambient temperature. The
experimenter chooses Taguchi's robust parameter design approach to investigate the settings of the control factors to
make the product insensitive to changes in ambient temperature. It is decided to carry out a experiment to study
the effect of the three control factors on the pH of the product. Therefore, the design is the inner array here. It is
also decided to carry out the experiment at four levels of the ambient temperature by using a special enclosure where
the surrounding temperature of the chemical process can be controlled. Therefore, the outer array consists of a single
factor experiment with the factor at four levels. Note that, in order to carry out the robust parameter design approach,
the noise factor should be such that it can be controlled in an experimental setting. The resulting setup of the robust
parameter design experiment is shown in the following table.
Data for the experiment in the example.
The experiment requires
runs in all as each run of the inner array is repeated for every treatment of
the outer array. The above table also shows the pH values obtained for the experiment. In DOE++, this design is set
up by specifying the properties for the inner and outer arrays as shown in the following figure.
Robust Parameter Design
255
Design properties for the factors in the example.
The resulting design is shown in the next figure.
Cross array design for the example.
Robust Parameter Design
Signal to Noise Ratios
Depending upon the objective of the robust parameter design, Taguchi defined three different statistics called signal
to noise ratios. These ratios were defined as the means to measure the variation of the response with respect to the
noise factors. Taguchi's approach essentially consists of two models: a location model and a dispersion model.
Location Model
The location model is the regression model for the mean value of the response at each treatment combination of the
inner array. If
(
) represents the response values obtained at the th treatment combination of the
inner array (corresponding to the levels of the noise factors), then the mean response at the th level is:
The location model is obtained by fitting a regression model to all values, by treating these values as the response
at each of the th treatments of the inner array. As an example, the location model for an inner array with two factors
can be written as:
where:
•
is the intercept
•
•
is the coefficient for the first factor
is the coefficient for the second factor
•
•
is the coefficient for the interaction
and are respectively the variables for the two factors
The objective of using the location model is to bring the response to its goal regardless of whether this is a target
value, maximum value or minimum value. This is done by identifying significant effects and then using the least
square estimates of the corresponding coefficients,
s, to fit the location model. The fitted model is used to decide
the settings of the variables that bring the response to the goal.
Dispersion Model
The dispersion model measures the variation of the response due to the noise factors. The standard deviation of the
response values at each treatment combination, , is used. Usually, the standard deviation is used as a log function
of because
are approximately normally distributed. These values can be calculated as follows:
Thus, the dispersion model consists of using
as the response and investigating what treatment of the control
factors results in the minimum variation of the response. Clearly, the objective of using the dispersion model is to
minimize variation in the response. Instead of using standard deviations directly, Taguchi defined three signal to
noise ratios (abbreviated
) based on the objective function for the response. If the response is to be maximized,
the
ratio is defined as follows:
The previous ratio is referred to as the larger-the-better ratio and is defined to decrease variability when maximizing
the response. When the response is to be minimized, the
ratio is defined as:
256
Robust Parameter Design
This ratio is referred to as the smaller-the-better ratio and is defined to decrease variability when minimizing the
response. If the objective for the response is to achieve a target or nominal value, then the
ratio is defined as
follows:
This ratio is referred to as the nominal-the-best ratio and is defined to decrease variability around a target response
value. The dispersion model for any of the three signal to noise ratios can be written as follows for an inner array
with two factors:
where:
•
is the intercept
•
•
is the coefficient for the first factor
is the coefficient for the second factor
•
•
is the coefficient for the interaction
and are respectively the variables for the two factors
The dispersion model is fit by identifying significant effects and then using the least square estimates of the
coefficients
s. Once the fitted dispersion model is known, settings for the control factors are found that result in
the maximum value of
, thereby minimizing the response variation.
Analysis Strategy
The location and dispersion regression models are usually obtained by using graphical techniques to identify
significant effects. This is because the responses used in the two models are such that only one response value is
obtained for each treatment of the inner array. Therefore, the experiment design in the case of the two models is an
unreplicated design.
Once the location and dispersion models have been obtained by identification of the significant effects, the following
analysis strategy [Wu, 2000] may be used:
• To obtain the best settings of the factors for larger-the-better and smaller-the-better cases:
• The experimenter must first select the settings of the significant control factors in the location model to either
maximize or minimize the response.
• Then the experimenter must choose the settings of those significant control factors in the dispersion model,
that are not significant in the location model, to maximize the
ratio.
• For nominal-the-best cases:
• The experimenter must first select the settings of the significant control factors in the dispersion model to
maximize the
ratio.
• Then the experimenter must choose the levels of the significant control factors in the location model to bring
the response on target. At times, the same control factor(s) may show up as significant in both the location and
dispersion models. In these cases, the experimenter must use his judgement to obtain the best settings of the
control factors based upon the two models.
Factors that do not show up as significant in both the models should be set at levels that result in the greatest
economy. Generally, a follow-up experiment is usually carried out with the best settings to verify that the system
functions as desired.
257
Robust Parameter Design
258
Example
This example illustrates the procedure to obtain the location and dispersion models for the experiment in the
previous example.
Location Model
The response values used in the location model can be calculated using the first equation given in Location Model.
As an example, the response value for the third treatment is:
Response values for the remaining seven treatments can be calculated in a similar manner. These values are shown
next under the Y Mean column.
Response values for the location and dispersion models in the example.
Once the response values for all the treatments are known, the analysis to fit the location model can be carried out by
treating the experiment as a single replicate of the design. The results obtained from DOE++ are shown in the
figure below.
Robust Parameter Design
259
Results for the location model in the example.
The normal probability plot of effects for this model shows that only the main effect of factor
location model (see the figure below).
is significant for the
Robust Parameter Design
260
Normal probability plot of effects for the location model in the example.
Using the corresponding coefficient from the figure below, the location model can be written as:
where
is the variable representing factor
.
Dispersion Model
For the dispersion model, the applicable signal to noise ratio is given by the equation for the nominal-the-best ratio:
The response values for the dispersion model can now be calculated. As an example, the response value for the third
treatment is:
Other
values can be obtained in a similar manner. The values are under the column Signal Noise Ratio in the
data sheet shown above. As in the case of the location model, the analysis to fit the dispersion model can be carried
out by treating the experiment as a single replicate of the design. The results obtained from DOE++ are shown in
the figure below.
Robust Parameter Design
261
Results for the dispersion model in the example.
The normal probability plot of effects for this model (displayed next) shows that the interaction
significant effect for this model.
is the only
Robust Parameter Design
262
Normal probability plot of effects for the dispersion model in the example.
Using the corresponding coefficient from the figure below, the dispersion model can be written as:
where
is the variable representing factor
.
Robust Parameter Design
Following the analysis strategy mentioned in Analysis Strategy, for the nominal-the-best case, the dispersion model
should be considered first. The equation for the model shows that to maximize
, either one of the following
options can be used:
•
•
and
and
or
Then, considering the location model of this example, to achieve a target response value as close to 7 as possible, the
only significant effect for this model, , should be set at the level of
. Therefore, the first should be used for the
dispersion model's settings. The final settings for the three factors, as a result of the robust parameter design, are:
• Factor
• Factor
• Factor
is set at the low level
is set at the high level and
, which is not significant in any of the two models, can be set at the level that is most economical.
With these settings the predicted pH value for the product is:
The predicted signal to noise ratio is:
Robust Parameter Design
To make the signal to noise ratio model hierarchical,
predicted
ratio is:
263
and
have to be included in the model. Then, the
Limitations of Taguchi's Approach
Although Taguchi's approach towards robust parameter design introduced innovative techniques to improve quality,
a few concerns regarding his philosophy have been raised. Some of these concerns relate to the signal to noise ratios
defined to reduce variations in the response, and some others are related to the absence of the means to test for
higher order control factor interactions when his orthogonal arrays are used as inner arrays for the design. For these
reasons, other approaches to carry out robust parameter design have been suggested including response modeling
and the use of
in the place of the signal to noise ratios in the dispersion model. In response modeling, the noise
factors are included in the model as additional factors, along with the other control factors. Details of these methods
can be found in [Wu, 2000] and other theory books published on the subject.
264
Chapter 14
Mixture Design
Introduction
When a product is formed by mixing together two or more ingredients, the product is called a mixture, and the
ingredients are called mixture components. In a general mixture problem, the measured response is assumed to
depend only on the proportions of the ingredients in the mixture, not the amount of the mixture. For example, the
taste of a fruit punch recipe (i.e., the response) might depend on the proportions of watermelon, pineapple and
orange juice in the mixture. The taste of a small cup of fruit punch will obviously be the same as a big cup.
Sometimes the responses of a mixture experiment depend not only on the proportions of ingredients, but also on the
settings of variables in the process of making the mixture. For example, the tensile strength of stainless steel is not
only affected by the proportions of iron, copper, nickel and chromium in the alloy; it is also affected by process
variables such as temperature, pressure and curing time used in the experiment.
One of the purposes of conducting a mixture experiment is to find the best proportion of each component and the
best value of each process variable, in order to optimize a single response or multiple responses simultaneously. In
this chapter, we will discuss how to design effective mixture designs and how to analyze data from mixture
experiments with and without process variables.
Mixture Design Types
There are several different types of mixture designs. The most common ones are simplex lattice, simplex centroid,
simplex axial and simplex vertex designs, each of which is used for a different purpose.
• If there are many components in a mixture, the first choice is to screen out the most important ones. Simplex axial
and Simplex centroid designs are used for this purpose.
• If the number of components is not large, but a high order polynomial equation is needed in order to accurately
describe the response surface, then a simplex lattice design can be used.
• Simplex vertex designs are used for the cases when there are constraints on one or more components (e.g., if the
proportion of watermelon juice in a fruit punch recipe is required to be less than 30%, and the combined
proportion of watermelon and orange juice should always be between 40% and 70%).
Mixture Design
Simplex Plot
Since the sum of all the mixture components is always 100%, the experiment space usually is given by a plot. The
experiment space for the fruit punch experiment is given in the following triangle or simplex plot.
The triangle area in the above plot is defined by the fact that the sum of the three ingredients is 1 (100%). For the
points that are on the vertices, the punch only has one ingredient. For instance, point 1 only has watermelon. The line
opposite of point 1 represents a mixture with no watermelon .
The coordinate system used for the value of each ingredient ,
is called a simplex coordinate
system. q is the number of ingredients. The simplex plot can only visually display three ingredients. If there are more
than three ingredients, the values for other ingredients must be provided. For the fruit punch example, the coordinate
for point 1 is (1, 0, 0). The interior points of the triangle represent mixtures in which none of the three components is
absent. It means all
,
. Point 0 in the middle of the triangle is called the center point. In this case,
it is the centroid of a face/plane. The coordinate for point 0 is (1/3, 1/3, 1/3). Points 2, 4 and 6 are each called a
centroid of edge. Their coordinates are (0.5, 0.5, 0), (0, 0.5, 0.5), and (0.5, 0, 0.5).
265
Mixture Design
266
Simplex Lattice Design
The response in a mixture experiment usually is described by a polynomial function. This function represents how
the components affect the response. To better study the shape of the response surface, the natural choice for a design
would be the one whose points are spread evenly over the whole simplex. An ordered arrangement consisting of a
uniformly spaced distribution of points on a simplex is known as a lattice.
A {q, m} simplex lattice design for q components consists of points defined by the following coordinate settings: the
proportions assumed by each component take the m+1 equally spaced values from 0 to 1,
and the design space consists of all the reasonable combinations of all the values for each factor. m is usually called
the degree of the lattice. For example, for a {3, 2} design,
For a {3, 3} design,
and its design space has 6 points. They are:
, and its design space has 10 points. They are:
Mixture Design
267
For a simplex design with degree of m, each component has m + 1 different values, therefore, the experiment results
can be used to fit a polynomial equation up to an order of m. A {3, 3} simplex lattice design can be used to fit the
following model.
The above model is called the full cubic model. Note that the intercept term is not included in the model due to the
correlation between all the components (their sum is 100%).
Simplex lattice design includes all the component combinations. For a {q, m} design, the total number of runs is
. Therefore to reduce the number of runs and still be able to fit a high order polynomial model,
sometimes we can use simplex centroid design which is explained next.
Mixture Design
268
Simplex Centroid Design
A simplex centroid design only includes the centroid points. For the components that appear in a run in a simplex
centroid design, they have the same values.
In the above simplex plot, points 2, 4 and 6 are 2nd degree centroids. Each of them has two non-zero components
with equal values. Point 0 is a 3rd degree centroid and all three components have the same value. For a design with q
components, the highest degree of centroid is q. It is called the overall centroid, or the center point of the design.
For a q component simplex centroid design with a degree of centroid of q, the total number of runs is
runs correspond to the q permutations of (1, 0, 0,…, 0),
. The
permutations of (1/2, 1/2, 0, 0, 0, 0, …,0), the
permutations of (1/3, 1/3, 1/3, 0, 0, 0, 0,…, 0)…., and the overall centroid (1/q, 1/q, …, 1/q). If the degree of centroid
is defined as
(m < q), then the total number of runs will be
.
Since a simplex centroid design usually has fewer runs than a simplex lattice design with the same degree, a
polynomial model with fewer terms should be used. A {3, 3} simplex centroid design can be used to fit the following
model.
The above model is called the special cubic model. Note that the intercept term is not included due to the correlation
between all the components (their sum is 100%).
Mixture Design
Simplex Axial Design
The simplex lattice and simplex centroid designs are boundary designs since the points of these designs are
positioned on boundaries (vertices, edges, faces, etc.) of the simplex factor space, with the exception of the overall
centroid. Axial designs, on the other hand, are designs consisting mainly of the points positioned inside the simplex.
Axial designs have been recommended for use when component effects are to be measured in a screening
experiment, particularly when first degree models are to be fitted.
Definition of Axial: The axial of a component is defined as the imaginary line extending from the base point
,
for all
, to the vertex where
all
. [John Cornell]
In a simplex axial design, all the points are on the axial. The simplest form of axial design is one whose points are
positioned equidistant from the overall centroid
. Traditionally, points located at the half
distance from the overall centroid to the vertex are called axial points/blends. This is illustrated in the following plot.
Points 4, 5 and 6 are the axial blends.
By default, a simple axial design in DOE++ only has vertices, axial blends, centroid of the constraint planes and the
overall centroid. For a design with q components, constraint plane centroids are the center points of dimension of q-1
space. One component is 0, and the remaining components have the same values for the center points of constraint
planes. The number of the constraint plane centroids is the number of components q. The total number of runs in a
simple axial design will be 3q+1. They are q vertex runs, q centroids of constraint planes, q axial blends and 1
overall centroid.
A simplex axial design for 3 components has 10 points as given below.
269
Mixture Design
Points 1, 2 and 3 are the three vertices; points 4, 5, 6 are the axial blends; points 7, 8 and 9 are the centroids of
constraint planes, and point 0 is the overall center point.
Extreme Vertex Design
Extreme vertex designs are used when both lower and upper bound constraints on the components are presented, or
when linear constraints are added to several components. For example, if a mixture design with 3 components has
the following constraints:
•
•
•
Then the feasible region is defined by the six points in the following simplex plot. To meet the above constraints, all
the runs conducted in the experiment should be in the feasible region or on its boundary.
270
Mixture Design
The CONSIM method described in [Snee 1979] is used in DOE++ to check the consistency of all the constraints and
to get the vertices defined by them.
Extreme vertex designs by default use the vertices at the boundary. Additional points such as the centroid of spaces
of different dimensions, axial points and the overall center point can be added. In extreme vertex designs, axial
points are between the overall center point and the vertices. For the above example, if the axial points and the overall
center point are added, then all the runs in the experiment will be:
271
Mixture Design
272
Point 0 in the center of the feasible region is the overall centroid. The other red points are the axial points. They are
at the middle of the lines connecting the center point with the vertices.
Mixture Design Data Analysis
In the following section, we will discuss the most popular regression models in mixture design data analysis. Due to
the correlation between all the components in mixture designs, the intercept term usually is not included in the
regression model.
Models Used in Mixture Design
For a design with three components, the following models are commonly used.
• Linear model:
If the intercept were included in the model, then the linear model would be
However, since
(can be other constants as well), the above equation can be written as
The equation has thus been reformatted to omit the intercept.
• Quadratic model:
Mixture Design
273
There are no classic quadratic terms such as
. This is because
• Full cubic model:
• Special cubic model:
are removed from the full cubic model.
The above types of models are called Scheffe type models. They can be extended to designs with more than three
components.
In regular regression analysis, the effect of an exploratory variable or factor is represented by the value of the
coefficient. The ratio of the estimated coefficient and its standard error is used for the t-test. The t-test can tell us if a
coefficient is 0 or not. If a coefficient is statistically 0, then the corresponding factor has no significant effect on the
response. However, for Scheffe type models, since the intercept term is not included in the model, we cannot use the
regular t-test to test each individual main effect. In other words, we cannot test if the coefficient for each component
is 0 or not.
Similarly, in the ANOVA analysis, the linear effects of all the components are tested together as a single group. The
main effect test for each individual component is not conducted. To perform ANOVA analysis, the Scheffe type
model needs to be reformatted to include the hidden intercept. For example, the linear model
can be rewritten as
where
,
,
. All other models such as the quadratic, cubic and special cubic
model can be reformatted using the same procedure. By including the intercept in the model, the correct sum of
squares can be calculated in the ANOVA table. If ANOVA analysis is conducted directly using the Scheffe type
models, the result will be incorrect.
L-Pseudocomponent, Proportion, and Actual Values
In mixture designs, the total amount of the mixture is usually given. For example, we can make either a one-pound or
a two-pound cake. Regardless of whether the cake is one or two pounds, the proportion of each ingredient is the
same. When the total amount is given, the upper and lower limits for each ingredient are usually given in amounts,
which is easier for the experimenter to understand. Of course, if the limits or other constraints are given in terms of
proportions, these proportions need be converted to the real amount values when conducting the experiment. To keep
everything consistent, all the constraints in DOE++ are treated as amounts.
In regular factorial design and response surface methods, the regression model is calculated using coded values.
Coded values scale all the factors to the same magnitude, which makes the analysis much easier and reduces
convergence error. Similarly, the analysis in mixture design is conducted using the so-called L-pseudocomponent
value. L-pseudocomponent values scale all the components' values within 0 and 1. In DOE++ all the designs and
calculations for mixture factors are based on L-pseudocomponent values. The relationship between
Mixture Design
274
L-pseudocomponent values, proportions and actual amounts are explained next.
Example for L-Pseudocomponent Value
We are going to make one gallon (about 3.8 liters) of fruit punch. Three ingredients will be in the punch with the
following constraints.
,
,
Let
(i = 1, 2, 3) be the actual amount value, be the L-pseudocomponent value and
Then the equations for the conversion between them are:
,
where
,
and
are for component A,
be the proportion value.
,
,
and
are for component B, and
,
and
are for
component C.
Since components in this example have both lower and upper limit constraints, an extreme vertex design is used. The
design settings are given below.
The created design in terms of L-pseudocomponent values is:
Mixture Design
Displayed in amount values, it is:
Displayed in proportion values, it is:
275
Mixture Design
276
Check Constraint Consistency
In the above example, all the constraints are consistent. However, if we set the constraints to
,
,
then they are not consistent. This is because the total is only 3.8, but the sum of all the lower limits is 4.7. Therefore,
not all the lower limits can be satisfied at the same time. If only lower limits and upper limits are presented for all the
components, then we can adjust the lower bounds to make the constraints consistent. The method given by [Pieple
1983] is used and summarized below.
Defined the range of a component to be
.
The implied range of component i is
and
are the upper and lower limit for component i.
, where
, and
. T is
the total amount. The steps for checking and adjusting bounds are given below.
Step 1: Check if
and
are greater than 0, if they are, then these constraints meet the basic requirement to be
consistent. We can move forward to step 2. If not, these constraints cannot be adjusted to be consistent. We should
stop.
Step 2: For each component, check if
consistent. Otherwise, if
, then set
and
, and if
. If they are, then this component’s constraints are
, then set
.
Step 3: Whenever a bound is changed, restart from Step 1 to use the new bound to check if all the constraints are
consistent. Repeat this until all the limits are consistent.
For extreme vertex design where linear constraints are allowed, DOE++ will give a warning and stop creating the
design if inconsistent linear combination constraints are found. No adjustment will be conducted for linear
constraints.
Response Trace Plot
Due to the correlation between all the components, the regular t-test is not used to test the significance of each
component. A special plot called the Response Trace Plot can be used to see how the response changes when each
component changes from its reference point [John Cornell].
A reference point can be any point inside the experiment space. An imaginary line can be drawn from this reference
point to each vertex
, and
(
). This line is the direction for component i to change. Component
i can either increase or decrease its value along this line, while the ratio of other components
(
) will
keep constant. If the simplex plot is defined in terms of proportion, then the direction is called Cox’s direction, and
is the ratio of proportion. If the simplex plot is defined in terms of pseduocomponent value, then the direction
is called Pieple’s direction, and
will be the ratio of pseduocomponent values.
Assume the reference point in terms of proportion is
Suppose the proportion of component at is now changed by
Cox’s direction, so that the new proportion becomes
Then the proportions of the remaining
(
where
.
could be greater than or less than 0) in
components resulting from the change from
will be
After the change, the ratio of component j and k is unchanged. This is because
While is changed along Cox’s direction, we can use a fitted regression model to get the response value y. A
response trace plot for a mixture design with three components will look like
Mixture Design
277
The x-axis is the deviation amount from the reference point, and the y-value is the fitted response. Each component
has one curve. Since the red curve for component A changes significantly, this means it has a significant effect along
its axial. The blue curve for component C is almost flat; this means when C changes along Cox’s direction and other
components keep the same ratio, the response Y does not change very much. The effect of component B is between
component A and C.
Example
Watermelon (A), pineapple (B) and orange juice (C) are used for making 3.8 liters of fruit punch. At least 30% of the
fruit punch must be watermelon. Therefore the constraints are
,
,
Different blends of the three-juice recipe were evaluated by a panel. A value from 1 (extremely poor) to 9 (very
good) is used for the response [John Cornell, page 74]. A {3, 2} simplex lattice design is used with one center point
and three axial points. Three replicates were conducted for each ingredient combination. The settings for creating
this design in DOE++ is
Mixture Design
The generated design in L-pseudocomponent values and the response values from the experiment are
The simplex design point plot is
278
Mixture Design
279
Main effect and 2-way interactions are included in the regression model. The result for the regression model in terms
of L-pseudocomponents is
The regression information table is
Regression Information
Term
Coefficient
Standard
Error
Low
Confidence
High
Confidence
T
Value
P
Value
Variance Inflation
Factor
A: Watermelon
4.8093
0.3067
4.2845
5.3340
1.9636
B: Pineapple
6.0274
0.3067
5.5027
6.5522
1.9636
C: Orange
6.1577
0.3067
5.6330
6.6825
1.9636
A•B
1.1253
1.4137
-1.2934
3.5439
0.7960
0.4339
1.9819
A•C
2.4525
1.4137
0.0339
4.8712
1.7348
0.0956
1.9819
B•C
1.6889
1.4137
-0.7298
4.1075
1.1947
0.2439
1.9819
The result shows that the taste of the fruit punch is significantly affected by the interaction between watermelon and
orange.
The ANOVA table is
Mixture Design
280
Anova Table
Source of
Variation
Degrees of
Freedom
Standard ErrorSum of Squares
[Partial]
Mean Squares
[Partial]
F
Ratio
P
Value
5
6.5517
1.3103
4.3181
0.0061
Linear
2
3.6513
1.8256
6.0162
0.0076
A•B
1
0.1923
0.1923
0.6336
0.4339
A•C
1
0.9133
0.9133
3.0097
0.0956
B•C
1
0.4331
0.4331
1.4272
0.2439
24
7.2829
0.3035
Lack of Fit
4
4.4563
1.1141
7.8825
0.0006
Pure Error
20
2.8267
0.1413
29
13.8347
Model
Residual
Total
The simplex contour plot in L-pseudocomponent values is
From this plot we can see that as the amount of watermelon is reduced, the taste of the fruit punch becomes better.
In order to find the best proportion of each ingredient, the optimization tool in DOE++ can be utilized. Set the
settings as
Mixture Design
The resulting optimal plot is
This plot shows that when the amounts for watermelon, pineapple and orange juice are 1.141, 1.299 and 1.359,
respectively, the rated taste of the fruit punch is highest.
281
Mixture Design
Mixture Design with Process Variables
Process variables often play very important roles in mixture experiments. A simple example is baking a cake. Even
with the same ingredients, different baking temperatures and baking times can produce completely different results.
In order to study the effect of process variables and find their best settings, we need to consider them when
conducting a mixture experiment.
An easy way to do this is to make mixtures with the same ingredients in different combinations of process variables.
If all the process variables are independent, then we can plan a regular factorial design for these process variables.
By combining these designs with a separated mixture design, the effect of mixture components and effect of process
variables can be studied.
For example, a {3, 2} simplex lattice design is used for a mixture with 3 components. Together with the center point,
it has total of 7 runs or 7 different ingredient combinations. Assume 2 process variables are potentially important and
a two level factorial design is used for them. It has a total of 4 combinations for these 2 process variables. If the 7
different mixtures are made under each of the 4 process variable combinations, then the experiment has a total of 28
runs. This is illustrated in the figure below.
Of course, if it is possible, all the 28 experiments should be conducted in a random order.
Model with Process Variables
In DOE++, regression models including both mixture components and process variables are available. For mixture
components, we use L-pseudocomponent values, and for process variables coded values are used.
Assume a design has 3 mixture components and 2 process variables, as illustrated in the above figure. We can use
the following models for them.
• For the 3 mixture components, the following special cubic model is used.
• For the 2 process variables the following model is used.
• The combined model with both mixture components and process variables is
282
Mixture Design
283
The above combined model has total of 7x4=28 terms. By expanding it, we get the following model:
The combined model basically crosses every term in the mixture components model with every term in the process
variables model. From a mathematical point of view, this model is just a regular regression model. Therefore, the
traditional regression analysis method can still be used for obtaining the model coefficients and calculating the
ANOVA table.
Example
Three kinds of meats (beef, pork and lamb) are mixed together to form burger patties. The meat comprises 90% of
the total mixture, with the remaining 10% reserved for flavoring ingredients. A {3, 2} simplex design with the center
point is used for the experiment. The design has 7 meat combinations, which are given below using
L-pseudocomponent values.
A: Beef
B: Pork C: Lamb
1
0
0
0.5
0.5
0
0.5
0
0.5
0
1
0
0
0.5
0.5
0
0
1
0.333333 0.333333 0.333333
Two process variables on making the patties are also studied: cooking temperature and cooking time. The low and
high temperature values are 375°F and 425°F, and the low and high time values are 25 and 40 minutes. A two level
full factorial design is used and displayed below with coded values.
Mixture Design
284
Temperature Time
1
-1
1
1
One of the properties of the burger patties is texture. The texture is measured by a compression test that measures the
grams of force required to puncture the surface of the patty.
Combining the simplex design and the factorial design together, we get the following 28 runs. The corresponding
texture reading for each blend is also provided.
Standard Order A: Beef B: Pork C: Lamb Z1: Temperature Z2: Time Texture (
1
1
0
0
-1
-1
1.84
2
0.5
0.5
0
-1
-1
0.67
3
0.5
0
0.5
-1
-1
1.51
4
0
1
0
-1
-1
1.29
5
0
0.5
0.5
-1
-1
1.42
6
0
0
1
-1
-1
1.16
7
0.333
0.333
0.333
-1
-1
1.59
8
1
0
0
1
-1
2.86
9
0.5
0.5
0
1
-1
1.1
10
0.5
0
0.5
1
-1
1.6
11
0
1
0
1
-1
1.53
12
0
0.5
0.5
1
-1
1.81
13
0
0
1
1
-1
1.5
14
0.333
0.333
0.333
1
-1
1.68
15
1
0
0
-1
1
3.01
16
0.5
0.5
0
-1
1
1.21
17
0.5
0
0.5
-1
1
2.32
18
0
1
0
-1
1
1.93
19
0
0.5
0.5
-1
1
2.57
20
0
0
1
-1
1
1.83
21
0.333
0.3333
0.333
-1
1
1.94
22
1
0
0
1
1
4.13
23
0.5
0.5
0
1
1
1.67
24
0.5
0
0.5
1
1
2.57
25
0
1
0
1
1
2.26
26
0
0.5
0.5
1
1
3.15
27
0
0
1
1
1
2.22
28
0.333
0.333
0.333
1
1
2.6
gram)
Using a quadratic model for the mixture component and a 2-way interaction model for the process variables, we get
the following results.
Mixture Design
285
Term
Coefficient Standard Error T Value P Value Variance Inflation Factor
A:Beef
2.9421
0.1236
*
*
1.5989
B:Pork
1.7346
0.1236
*
*
1.5989
C:Lamb
1.6596
0.1236
*
*
1.5989
A•B
-4.4170
0.5680
-7.7766
0.0015
1.5695
A•C
-0.9170
0.5680
-1.6146
0.1817
1.5695
B•C
2.4480
0.5680
4.3099
0.0125
1.5695
Z1 • A
0.5324
0.1236
4.3084
0.0126
1.5989
Z1 • B
0.1399
0.1236
1.1319
0.3209
1.5989
Z1 • C
0.1799
0.1236
1.4557
0.2192
1.5989
Z1 • A • B
-0.4123
0.5680
-0.7260
0.5081
1.5695
Z1 • A • C
-1.0423
0.5680
-1.8352
0.1404
1.5695
Z1 • B • C
0.3727
0.5680
0.6561
0.5476
1.5695
Z2 • A
0.6193
0.1236
5.0117
0.0074
1.5989
Z2 • B
0.3518
0.1236
2.8468
0.0465
1.5989
Z2 • C
0.3568
0.1236
2.8873
0.0447
1.5989
Z2 • A • B
-0.9802
0.5680
-1.7258
0.1595
1.5695
Z2 • A • C
-0.3202
0.5680
-0.5638
0.6030
1.5695
Z2 • B • C
0.9248
0.5680
1.6282
0.1788
1.5695
Z1 • Z2 • A
0.0177
0.1236
0.1433
0.8930
1.5989
Z1 • Z2 • B
0.0152
0.1236
0.1231
0.9080
1.5989
Z1 • Z2 • C
0.0052
0.1236
0.0422
0.9684
1.5989
Z1 • Z2 • A • B
0.0808
0.5680
0.1423
0.8937
1.5695
Z1 • Z2 • A • C
0.2308
0.5680
0.4064
0.7052
1.5695
Z1 • Z2 • B • C
0.2658
0.5680
0.4680
0.6641
1.5695
The above table shows that all the terms with
have very large P values, therefore, we can remove these
terms from the model. We can also remove other terms with P values larger than 0.5. After recalculating with the
desired terms, the final results are
Term
Coefficient Standard Error T Value
P Value
Variance Inflation Factor
A:Beef
2.9421
0.0875
*
*
1.5989
B:Pork
1.7346
0.0875
*
*
1.5989
C:Lamb
1.6596
0.0875
*
*
1.5989
A•B
-4.4170
0.4023
-10.9782 6.0305E-08
1.5695
A•C
-0.9170
0.4023
-2.2792
0.0402
1.5695
B•C
2.4480
0.4023
6.0842
3.8782E-05
1.5695
Z1 • A
0.4916
0.0799
6.1531
3.4705E-05
1.3321
Z1 • B
0.1365
0.0725
1.8830
0.0823
1.0971
Z1 • C
0.2176
0.0799
2.7235
0.0174
1.3321
Mixture Design
286
Z1 • A • C
-1.0406
0.4015
-2.5916
0.0224
1.5631
Z2 • A
0.5910
0.0800
7.3859
5.3010E-06
1.3364
Z2 • B
0.3541
0.0875
4.0475
0.0014
1.5971
Z2 • C
0.3285
0.0800
4.1056
0.0012
1.3364
Z2 • A • B
-0.9654
0.4019
-2.4020
0.0320
1.5661
Z2 • B • C
0.9396
0.4019
2.3378
0.0360
1.5661
The regression model is
The ANOVA table for this model is
ANOVA Table
Source of Variation Degrees of Freedom Sum of Squares [Partial] Mean Squares [Partial]
F Ratio
P Value
Model
14
14.5066
1.0362
33.5558
6.8938E-08
Linear
2
4.1446
2.0723
67.1102
1.4088E-07
A•B
1
3.7216
3.7216
120.5208 6.0305E-08
A•C
1
0.1604
0.1604
5.1949
0.0402
B•C
1
1.1431
1.1431
37.0173
3.8782E-05
Z1 • A
1
1.1691
1.1691
37.8604
3.4705E-05
Z1 • B
1
0.1095
0.1095
3.5456
0.0823
Z1 • C
1
0.2290
0.2290
7.4172
0.0174
Z1 • A • C
1
0.2074
0.2074
6.7165
0.0224
Z2 • A
1
1.6845
1.6845
54.5517
5.3010E-06
Z2 • B
1
0.5059
0.5059
16.3819
0.0014
Z2 • C
1
0.5205
0.5205
16.8556
0.0012
Z2 • A • B
1
0.1782
0.1782
5.7698
0.0320
Z2 • B • C
1
0.1688
0.1688
5.4651
0.0360
13
0.4014
0.0309
13
0.4014
0.0309
27
14.9080
Component Only
Component • Z1
Component • Z2
Residual
Lack of Fit
Total
The above table shows both process factors have significant effects on the texture of the patties. Since the model is
pretty complicate, the best settings for the process variables and for components cannot be easily identified.
The optimization tool in DOE++ is used for the above model. The target texture value is
acceptable range of
grams.
grams with an
Mixture Design
The optimal solution is Beef = 98.5%, Pork = 0.7%, Lamb = 0.7%, Temperature = 375.7, and Time = 40.
References
1. Cornell, John (2002), Experiments with Mixtures: Designs, Models, and the Analysis of Mixture Data, John Wiley
& Sons, Inc. New York.
2. Piepel, G. F. (1983), “Defining consistent constraint regions in mixture experiments,” Technometrics, Vol. 25, pp.
97-101.
3. Snee, R. D. (1979), “Experimental designs for mixture systems with multiple component constraints,”
Communications in Statistics, Theory and Methods, Bol. A8, pp. 303-326.
287
288
Chapter 15
Reliability DOE for Life Tests
Reliability analysis is commonly thought of as an approach to model failures of existing products. The usual
reliability analysis involves characterization of failures of the products using distributions such as exponential,
Weibull and lognormal. Based on the fitted distribution, failures are mitigated, or warranty returns are predicted, or
maintenance actions are planned. However, by adopting the methodology of Design for Reliability (DFR), reliability
analysis can also be used as a powerful tool to design robust products that operate with minimal failures. In DFR,
reliability analysis is carried out in conjunction with physics of failure and experiment design techniques. Under this
approach, Design of Experiments (DOE) uses life data to "build" reliability into the products, not just quantify the
existing reliability. Such an approach, if properly implemented, can result in significant cost savings, especially in
terms of fewer warranty returns or repair and maintenance actions. Although DOE techniques can be used to
improve product reliability and also make this reliability robust to noise factors, the discussion in this chapter is
focused on reliability improvement. The robust parameter design method discussed in Robust Parameter Design can
be used to produce robust and reliable product.
Reliability DOE Analysis
Reliability DOE (R-DOE) analysis is fairly similar to the analysis of other designed experiments except that the
response is the life of the product in the respective units (e.g., for an automobile component the units of life may be
miles, for a mechanical component this may be cycles, and for a pharmaceutical product this may be months or
years). However, two important differences exist that make R-DOE analysis unique. The first is that life data of most
products are typically well modeled by either the lognormal, Weibull or exponential distribution, but usually do not
follow the normal distribution. Traditional DOE techniques follow the assumption that response values at any
treatment level follow the normal distribution and therefore, the error terms, , can be assumed to be normally and
independently distributed. This assumption may not be valid for the response data used in most of the R-DOE
analyses. Further, the life data obtained may either be complete or censored, and in this case standard regression
techniques applicable to the response data in traditional DOEs can no longer be used.
Design parameters, manufacturing process settings, and use stresses affecting the life of the product can be
investigated using R-DOE analysis. In this case, the primary purpose of any R-DOE analysis is to identify which of
the inputs affect the life of the product (by investigating if change in the level of any input factors leads to a
significant change in the life of the product). For example, once the important stresses affecting the life of the
product have been identified, detailed analyses can be carried out using ReliaSoft's ALTA software. ALTA includes
a number of life-stress relationships (LSRs) to model the relation between life and the stress affecting the life of the
product.
Reliability DOE for Life Tests
289
R-DOE Analysis of Lognormally Distributed Data
Assume that the life, , for a certain product has been found to be lognormally distributed. The probability density
function for the lognormal distribution is:
where represents the mean of the natural logarithm of the times-to-failure and represents the standard deviation
of the natural logarithms of the times-to-failure [Meeker and Escobar 1998, Wu 2000, ReliaSoft 2007b]. If the
analyst wants to investigate a single two level factor that may affect the life, , then the following model may be
used:
where:
•
•
represents the times-to-failure at the th treatment level of the factor
represents the mean value of for the th treatment
•
is the random error term
• The subscript represents the treatment level of the factor with
for a two level factor
The model of the equation shown above is analogous to the ANOVA model,
, used in the One Factor
Designs and General Full Factorial Designs chapters for traditional DOE analyses. Note, however, that the random
error term, , is not normally distributed here because the response, , is lognormally distributed. It is known that
the logarithmic value of a lognormally distributed random variable follows the normal distribution. Therefore, if the
logarithmic transformation of ,
, is used in the above equation, then the model will be identical to the
ANOVA model,
, used in the other chapters. Thus, using the logarithmic failure times, the model can
be written as:
where:
•
•
•
represents the logarithmic times-to-failure at the th treatment
represents the mean of the natural logarithm of the times-to-failure at the th treatment
represents the standard deviation of the natural logarithms of the times-to-failure
The random error term, , is normally distributed because the response,
, is normally distributed. Since the
model of the equation given above is identical to the ANOVA model used in traditional DOE analysis, regression
techniques can be applied here and the R-DOE analysis can be carried out similar to the traditional DOE analyses.
Recall from Two Level Factorial Experiments that if the factor(s) affecting the response has only two levels, then the
notation of the regression model can be applied to the ANOVA model. Therefore, the model of the above equation
can be written using a single indicator variable, , to represent the two level factor as:
where is the intercept term and
above equal to each other returns:
is the effect coefficient for the investigated factor. Setting the two equations
The natural logarithm of the times-to-failure at any factor level, , is referred to as the life characteristic because it
represents a characteristic point of the underlying life distribution. The life characteristic used in the R-DOE analysis
will change based on the underlying distribution assumed for the life data. If the analyst wants to investigate the
effect of two factors (each at two levels) on the life of the product, then the life characteristic equation can be easily
expanded as follows:
Reliability DOE for Life Tests
where is the effect coefficient for the second factor and is the indicator variable representing the second factor.
If the interaction effect is also to be investigated, then the following equation can be used:
In general the model to investigate a given number of factors can be expressed as:
Based on the model equations mentioned thus far, the analyst can easily conduct an R-DOE analysis for the
lognormally distributed life data using standard regression techniques. However this is no longer true once the data
also includes censored observations. In the case of censored data, the analysis has to be carried out using maximum
likelihood estimation (MLE) techniques.
Maximum Likelihood Estimation for the Lognormal Distribution
The maximum likelihood estimation method can be used to estimate parameters in R-DOE analyses when censored
data are present. The likelihood function is calculated for each observed time to failure, , and the parameters of the
model are obtained by maximizing the log-likelihood function. The likelihood function for complete data following
the lognormal distribution is given as:
where:
•
•
•
is the total number of observed times-to-failure
is the life characteristic
is the time of the th failure
For right censored data the likelihood function [Meeker and Escobar 1998, Wu 2000, ReliaSoft 2007b] is:
where:
•
•
is the total number of observed suspensions
is the time of th suspension
For interval data the likelihood function [Meeker and Escobar 1998, Wu 2000, ReliaSoft 2007b] is:
where:
•
is the total number of interval data
•
is the beginning time of the th interval
•
is the end time of the th interval
The complete likelihood function when all types of data (complete, right censored and interval) are present is:
290
Reliability DOE for Life Tests
291
Then the log-likelihood function is:
The MLE estimates are obtained by solving for parameters
so that:
Once the estimates are obtained, the significance of any parameter,
test.
, can be assessed using the likelihood ratio
Hypothesis Tests
Hypothesis testing in R-DOE analyses is carried out using the likelihood ratio test. To test the significance of a
factor, the corresponding effect coefficient(s), , is tested. The following statements are used:
The statistic used for the test is the likelihood ratio,
follows:
. The likelihood ratio for the parameter
is calculated as
where:
•
is the vector of all parameter estimates obtained using MLE (i.e.,
... )
•
is the vector of all parameter estimates excluding the estimate of
•
is the value of the likelihood function when all parameters are included in the model
•
is the value of the likelihood function when all parameters except
If the null hypothesis,
, is true then the ratio,
are included in the model
, follows the chi-squared distribution with
one degree of freedom. Therefore,
is rejected at a significance level, , if
is greater than the critical value
.
The likelihood ratio test can also be used to test the significance of a number of parameters, , at the same time. In
this case,
represents the likelihood value when all parameters to be tested are not included in the model.
In other words,
would represent the likelihood value for the reduced model that does not contain the
parameters under test. Here, the ratio
will follow the chi-squared distribution with
degrees of freedom if all parameters are insignificant (with representing the number of parameters in the full
model). Thus, if
, the null hypothesis,
, is rejected and it can be concluded that at least one of the
parameters is significant.
Reliability DOE for Life Tests
292
Example
To illustrate the use of MLE in R-DOE analysis, consider the case where the life of a product is thought to be
affected by two factors, and . The failure of the product has been found to follow the lognormal distribution.
The analyst decides to run an R-DOE analysis using a single replicate of the design. Previous studies indicate that
the interaction between and does not affect the life of the product. The design for this experiment can be set up
in DOE++ as shown in the following figure.
Design properties for the experiment in the example.
The resulting experiment design and the corresponding times-to-failure data obtained are shown next. Note that,
although the life data set contains complete data and regression techniques are applicable, calculations are shown
using MLE. DOE ++ uses MLE for all R-DOE analysis calculations.
The
experiment design and the corresponding life data for the example.
Reliability DOE for Life Tests
293
Because the purpose of the experiment is to study two factors without considering their interaction, the applicable
model for the lognormally distributed response data is:
where
is the mean of the natural logarithm of the times-to-failure at the th treatment combination (
), is the effect coefficient for factor and is the effect coefficient for factor . The analysis
for this case is carried out in DOE++ by excluding the interaction
from the analysis.
The following hypotheses need to be tested in this example:
1)
This test investigates the main effect of factor
. The statistic for this test is:
where represents the value of the likelihood function when all coefficients are included in the model and
represents the value of the likelihood function when all coefficients except are included in the model.
2)
This test investigates the main effect of factor
. The statistic for this test is:
where represents the value of the likelihood function when all coefficients are included in the model and
represents the value of the likelihood function when all coefficients except are included in the model.
To calculate the test statistics, the maximum likelihood estimates of the parameters must be known. The estimates
are obtained next.
MLE Estimates
Since the life data for the present experiment are complete and follow the lognormal distribution, the likelihood
function can be written as:
Substituting
from the applicable model for the lognormally distributed response data, the likelihood function is:
Then the log-likelihood function is:
Reliability DOE for Life Tests
294
To obtain the MLE estimates of the parameters,
differentiated with respect to these parameters:
Equating the
and
, the log-likelihood function must be
terms to zero returns the required estimates. The coefficients
as these are required to estimate
. Setting
Substituting the values of
simplifying:
and
,
Thus:
:
Thus:
Knowing
,
and
,
are obtained first
from the example's experiment design and corresponding data and
:
Setting
and
:
Thus:
Setting
,
can now be obtained. Setting
:
Reliability DOE for Life Tests
295
Thus:
Once the estimates have been calculated, the likelihood ratio test can be carried out for the two factors.
Likelihood Ratio Test
The likelihood ratio test for factor is conducted by using the likelihood value corresponding to the full model and
the likelihood value when is not included in the model. The likelihood value corresponding to the full model (in
this case
) is:
The corresponding logarithmic value is
reduced model that does not contain factor
. The likelihood value for the
(in this case
) is:
The corresponding logarithmic value is
ratio to test the significance of factor is:
The value corresponding to
. Therefore, the likelihood
is:
Assuming that the desired significance level for the present experiment is 0.1, since
cannot be rejected and it can be concluded that factor does not affect the life of the product.
The likelihood ratio to test factor
can be calculated in a similar way as shown next:
The value corresponding to
is:
,
Since
,
is rejected and it is concluded that factor affects the life of the product.
The previous calculation results are displayed as the Likelihood Ratio Test Table in the results obtained from
Reliability DOE for Life Tests
296
DOE++ as shown next.
Likelihood ratio test results from DOE++ for the experiment in the example.
Fisher Matrix Bounds on Parameters
In general, the MLE estimates of the parameters are asymptotically normal. This means that for large sample sizes
the distribution of the estimates from the same population would be very close to the normal distribution[Meeker and
Escobar 1998]. If is the MLE estimate of any parameter, , then the (
)% two-sided confidence bounds on
the parameter are:
where
represents the variance of and
is the critical value corresponding to a significance level of
on the standard normal distribution. The variance of the parameter,
, is obtained using the Fisher
information matrix. For parameters, the Fisher information matrix is obtained from the log-likelihood function
as follows:
The variance-covariance matrix is obtained by inverting the Fisher matrix
:
Reliability DOE for Life Tests
297
Once the variance-covariance matrix is known the variance of any parameter can be obtained from the diagonal
elements of the matrix. Note that if a parameter, , can take only positive values, it is assumed that the
follows the normal distribution [Meeker and Escobar 1998]. The bounds on the parameter in this case are:
Using
we get
. Substituting this value we
have:
Knowing
from the variance-covariance matrix, the confidence bounds on can then be determined.
Continuing with the present example, the confidence bounds on the MLE estimates of the parameters
and can now be obtained. The Fisher information matrix for the example is:
The variance-covariance matrix can be obtained by taking the inverse of the Fisher matrix
Inverting
returns the following matrix:
Therefore, the variance of the parameter estimates are:
:
,
,
Reliability DOE for Life Tests
298
Knowing the variance, the confidence bounds on the parameters can be calculated. For example, the 90% bounds (
) on can be calculated as shown next:
The 90% bounds on
are (considering that
can only take positive values):
The standard error for the parameters can be obtained by taking the positive square root of the variance. For
example, the standard error for is:
The statistic for
is:
The value corresponding to this statistic based on the standard normal distribution is:
The previous calculation results are displayed as MLE Information in the results obtained from DOE++ as shown
next.
Reliability DOE for Life Tests
299
MLE information from DOE++.
In the figure, the Effect corresponding to each factor is simply twice the MLE estimate of the coefficient for that
factor. Generally, the value corresponding to any coefficient in the MLE Information table should match the value
obtained from the likelihood ratio test (displayed in the Likelihood Ratio Test table of the results). If the sample size
is not large enough, as in the case of the present example, a difference may be seen in the two values. In such cases,
the value from the likelihood ratio test should be given preference. For the present example, the value of 0.8318
for , obtained from the likelihood ratio test, would be preferred to the value of 0.8313 displayed under MLE
information. For details see [Meeker and Escobar 1998].
R-DOE Analysis of Data Following the Weibull Distribution
The probability density function for the 2-parameter Weibull distribution is:
where is the scale parameter of the Weibull distribution and is the shape parameter [Meeker and Escobar 1998,
ReliaSoft 2007b]. To distinguish the Weibull shape parameter from the effect coefficients, the shape parameter is
represented as
instead of in the remaining chapter. For data following the 2-parameter Weibull distribution,
the life characteristic used in R-DOE analysis is the scale parameter,
[ReliaSoft 2007a, Wu 2000]. Since
represents life data that cannot take negative values, a logarithmic transformation is applied to it. The resulting
model used in the R-DOE analysis for a two factor experiment with each factor at two levels can be written as
follows:
where:
•
•
•
is the value of the scale parameter at the th treatment combination of the two factors
is the indicator variable representing the level of the first factor
is the indicator variable representing the level of the second factor
•
is the intercept term
•
and are the effect coefficients for the two factors
• and
is the effect coefficient for the interaction of the two factors
Reliability DOE for Life Tests
300
The model can be easily expanded to include other factors and their interactions. Note that when any data follows the
Weibull distribution, the logarithmic transformation of the data follows the extreme-value distribution, whose
probability density function is given as follows:
where the s follows the Weibull distribution,
is the location parameter of the extreme-value distribution and
is the scale parameter of the extreme-value distribution. The two equations given above show that for R-DOE
analysis of life data that follows the Weibull distribution, the random error terms, , will follow the extreme-value
distribution (and not the normal distribution). Hence, regression techniques are not applicable even if the data is
complete. Therefore, maximum likelihood estimation has to be used.
Maximum Likelihood Estimation for the Weibull Distribution
The likelihood function for complete data in R-DOE analysis of Weibull distributed life data is:
where:
•
•
is the total number of observed times-to-failure
is the life characteristic at the th treatment
•
is the time of the th failure
For right censored data, the likelihood function is:
where:
•
•
is the total number of observed suspensions
is the time of th suspension
For interval data, the likelihood function is:
where:
•
is the total number of interval data
•
•
is the beginning time of the th interval
is the end time of the th interval
In each of the likelihood functions,
is substituted based on the equation for
as:
The complete likelihood function when all types of data (complete, right and left censored) are present is:
Then the log-likelihood function is:
The MLE estimates are obtained by solving for parameters
so that:
Reliability DOE for Life Tests
Once the estimates are obtained, the significance of any parameter, , can be assessed using the likelihood ratio
test. Other results can also be obtained as discussed in Maximum Likelihood Estimation for the Lognormal
Distribution and Fisher Matrix Bounds on Parameters.
R-DOE Analysis of Data Following the Exponential Distribution
The exponential distribution is a special case of the Weibull distribution when the shape parameter
is equal to
1. Substituting
in the probability density function for the 2-parameter Weibull distribution gives:
where
of the pdf has been replaced by . Parameter is called the failure rate.[ReliaSoft 2007a] Hence,
R-DOE analysis for exponentially distributed data can be carried out by substituting
and replacing
by in the Weibull distribution.
Model Diagnostics
Residual plots can be used to check if the model obtained, based on the MLE estimates, is a good fit to the data.
DOE++ uses standardized residuals for R-DOE analyses. If the data follows the lognormal distribution, then
standardized residuals are calculated using the following equation:
For the probability plot, the standardized residuals are displayed on a normal probability plot. This is because under
the assumed model for the lognormal distribution, the standardized residuals should follow a normal distribution
with a mean of 0 and a standard deviation of 1.
For data that follows the Weibull distribution, the standardized residuals are calculated as shown next:
The probability plot, in this case, is used to check if the residuals follow the extreme-value distribution with a mean
of 0. Note that in all residual plots, when an observation, , is censored the corresponding residual is also censored.
301
Reliability DOE for Life Tests
302
Application Examples
Using R-DOE to Determine the Best Factor Settings
This example illustrates the use of R-DOE analysis to design reliability into a product by determining the optimal
factor settings. An experiment was carried out to investigate the effect of five factors (each at two levels) on the
reliability of fluorescent lights (Taguchi, 1987, p. 930). The factors, through , were studied using a
design
(with the defining relations
and
) under the assumption that all interaction effects, except
, can be assumed to be inactive. For each treatment, two lights were tested (two replicates) with the
readings taken every two days. The experiment was run for 20 days and, if a light had not failed by the 20th day, it
was assumed to be a suspension. The experimental design and the corresponding failure times are shown next.
The
The
experiment to study factors affecting the reliability of fluorescent lights: design
experiment to study factors affecting the reliability of fluorescent lights: data
The short duration of the experiment and failure times were probably because the lights were tested under conditions
which resulted in stress higher than normal conditions. The failure of the lights was assumed to follow the lognormal
Reliability DOE for Life Tests
303
distribution.
The analysis results from DOE++ for this experiment are shown next.
Results of the R-DOE analysis for the experiment.
The results are obtained by selecting the main effects of the five factors and the interaction
. The results show
that factors , , and are active at a significance level of 0.1. The MLE estimates of the effect coefficients
corresponding to these factors are
,
,
and
, respectively. Based on these
coefficients, the best settings for these effects to improve the reliability of the fluorescent lights (by maximizing the
response, which in this case is the failure time) are:
•
•
•
•
Factor
Factor
Factor
Factor
should be set at the higher level of since its coefficient is positive
should be set at the lower level of
since its coefficient is negative
should be set at the higher level of since its coefficient is positive
should be set at the lower level of
since its coefficient is negative
Note that, since actual factor levels are not disclosed (presumably for proprietary reasons), predictions beyond the
test conditions cannot be carried out in this case.
Reliability DOE for Life Tests
304
More R-DOE examples are available! See also:
Two Level Fractional Factorial Reliability Design [1]
Using R-DOE and ALTA to Estimate B10 Life
Consider a product whose reliability is thought to be affected by eight potential factors: (temperature),
(humidity), (load), (fan-speed), (voltage), (material), (vibration) and (current). Assuming that all
interaction effects are absent, a
design is used to investigate the eight factors at two levels. The generators used
to obtain the design are
,
,
and
. The design and the
corresponding life data obtained are shown next.
The 2 design to investigate the reliability of the product.
Readings for the experiment are taken every 20 hours and the test is terminated at 200 hours. The life of the product
is assumed to follow the Weibull distribution.
The results from DOE++ for this experiment are shown next.
Reliability DOE for Life Tests
305
Results for the experiment.
The results show that only factors
and
are active at a significance level of 0.1.
Assume that, in terms of the actual units, the
level of factor corresponds to a temperature of 333 and the
level corresponds to a temperature of 383 . Similarly, assume that the two levels of factor are 1000
and 2000
respectively. From the MLE estimates of the effect coefficients it can be noted that to improve
reliability (by maximizing the response) factors and should be set as follows:
• Factor
• Factor
should be set at the lower level of 333 since its coefficient is negative
should be set at the higher level of 2000
since its coefficient is positive
Now assume that the use conditions for the product for the significant factors, and , are a temperature of 298
and a fan-speed of 3000
respectively. The analysis can be taken a step further to obtain an estimate of the
reliability of the product at the use conditions using ReliaSoft's ALTA software. The data is entered into ALTA as
shown next.
Reliability DOE for Life Tests
306
Additional reliability analysis for the example, conducted using ReliaSoft's ALTA software.
ALTA allows for modeling of the nature of relationship between life and stress. It is assumed that the relation
between life of the product and temperature follows the Arrhenius relation while the relation between life and
fan-speed follows the inverse power law relation.[ReliaSoft 2007a] Using these relations, ALTA fits the following
model for the data:
Based on this model, the B10 life of the product at the use conditions is obtained as shown next. The Weibull
reliability equation is:
Substituting the value of from the ALTA model and the value of
reliability equation becomes:
Finally, substituting the use conditions (Temp
value of 90%, the B10 life is obtained:
, Fan-Speed
as obtained from ALTA, the
) and the desired reliability
Therefore, at the use conditions, the B10 life of the product is 225 hours. This result and other reliability metrics can
be directly obtained from ALTA.
Reliability DOE for Life Tests
307
Single Factor R-DOE Analyses
DOE++ also allows for the analysis of single factor R-DOE experiments. This analysis is similar to the analysis of
single factor designed experiments mentioned in One Factor Designs. In single factor R-DOE analysis, the focus is
on discovering whether change in the level of a factor affects reliability and how each of the factor levels are
different from the other levels. The analysis models and calculations are similar to multi-factor R-DOE analysis.
Example
To illustrate single factor R-DOE analysis, consider the data in the table shown next, where 10 life data readings for
a product are taken at each of the three levels of a certain factor, .
Data obtained from a single factor R-DOE experiment.
Factor could be a stress that is thought to affect life or three different designs of the same product, or it could be
the same product manufactured by three different machines or operators, etc. The goal of the experiment is to see if
there is a change in life due to change in the levels of the factor. The design for this experiment is shown next.
Reliability DOE for Life Tests
308
Experiment design.
The life of the product is assumed to follow the Weibull distribution. Therefore, the life characteristic to be used in
the R-DOE analysis is the scale parameter, . Since factor has three levels, the model for the life characteristic,
, is:
where is the intercept, is the effect coefficient for the first level of the factor ( is represented as "A[1]" in
DOE++) and is the effect coefficient for the second level of the factor ( is represented as "A[2]" in DOE++).
Two indicator variables, and
are the used to represent the three levels of factor such that:
The following hypothesis test needs to be carried out in this example:
where
where
. The statistic for this test is:
is the value of the likelihood function corresponding to the full model, and
is the likelihood
value for the reduced model. To calculate the statistic for this test, the MLE estimates of the parameters must be
obtained.
Reliability DOE for Life Tests
309
MLE Estimates
Following the procedure used in the analysis of multi-factor R-DOE experiments, MLE estimates of the parameters
are obtained by differentiating the log-likelihood function :
Substituting from the model for the life characteristic and setting the partial derivatives
parameter estimates are obtained as
,
,
and
to zero, the
.
These parameters are shown in the MLE Information table in the analysis results, shown next.
MLE results for the experiment in the example.
Likelihood Ratio Test
Knowing the MLE estimates, the likelihood ratio test for the significance of factor can be carried out. The
likelihood value for the full model,
, is the value of the likelihood function corresponding to the model
:
The likelihood value for the reduced model,
model
:
Then the likelihood ratio is:
, is the value of the likelihood function corresponding to the
Reliability DOE for Life Tests
310
If the null hypothesis,
, is true then the likelihood ratio will follow the chi-squared distribution. The number of
degrees of freedom for this distribution is equal to the difference in the number of parameters between the full and
the reduced model. In this case, this difference is 2. The value corresponding to the likelihood ratio on the
chi-squared distribution with two degrees of freedom is:
Assuming that the desired significance is 0.1, since
,
is rejected, it is concluded that,
at a significance of 0.1, at least one of the parameters, or , is non-zero. Therefore, factor affects the life of
the product. This result is shown in the Likelihood Ratio Test table in the analysis results.
Additional results for single factor R-DOE analysis obtained from DOE ++ include information on the life
characteristic and comparison of life characteristics at different levels of the factor.
Life Characteristic Summary Results
Results in the Life Characteristic Summary table, include information about the life characteristic corresponding to
each treatment level of the factor. If
is represented as
, then the model for the life characteristic can be
written as:
The respective equations for all three treatment levels for a single replicate of the experiment can be expressed in
matrix notation as:
where:
Knowing
,
and
, the predicted value of the life characteristic at any level can be obtained. For example, for
the second level:
Thus:
The variance for the predicted values of life characteristic can be calculated using the following equation:
where
is the variance-covariance matrix for
,
and
. Substituting the required values:
Reliability DOE for Life Tests
From the previous matrix,
Since
311
. Therefore, the 90% confidence interval (
the 90% confidence interval on
is:
Results for other levels can be calculated in a similar manner and are shown next.
Life characteristic results for the experiment.
) on
is:
Reliability DOE for Life Tests
312
Life Comparisons Results
Results under Life Comparisons include information on how life is different at a level in comparison to any other
level of the factor. For example, the difference between the predicted values of life at levels 1 and 2 is (in terms of
the logarithmic transformation):
The pooled standard error for this difference can be obtained as:
If the covariance between
and
is taken into account, then the pooled standard error is:
This is the value displayed by DOE++. Knowing the pooled standard error the confidence interval on the difference
can be calculated. The 90% confidence interval on the difference in (logarithmic) life between levels 1 and 2 of
factor is:
Since the confidence interval does not include zero it can be concluded that the two levels are significantly different
at
. Another way to test for the significance of the difference in levels is to observe the value. The
statistic corresponding to this difference is:
The value corresponding to this statistic, based on the standard normal distribution, is:
Since
it can be concluded that the levels are significantly different at
levels can be calculated in a similar manner and are shown in the analysis results.
. The results for other
Reliability DOE for Life Tests
References
[1] http:/ / www. reliasoft. com/ doe/ examples/ rc11/ index. htm
313
314
Chapter 16
Measurement System Analysis
An important aspect of conducting design of experiments (DOE) is having a capable measurement system for
collecting data. A measurement system is a collection of procedures, gages and operators that are used to obtain
measurements. Measurement systems analysis (MSA) is used to evaluate the capacity of a measurement system from
the following statistical properties: bias, linearity, stability, repeatability and reproducibility. Some of the
applications of MSA are:
•
•
•
•
Provide a criterion to accept new measuring equipment.
Provide a comparison of one measuring device against another (gage agreement study).
Provide a comparison for measuring equipment before and after repair.
Evaluate the variance of components in a product/process.
Introduction
MSA studies the error within a measurement system. Measurement system error can be classified into three
categories: accuracy, precision, and stability.
• Accuracy describes the difference between the measurement and the actual value of the part that is measured. It
includes:
• Bias: a measure of the difference between the true value and the observed value of a part. If the “true” value is
unknown, it can be calculated by averaging several measurements with the most accurate measuring equipment
available.
• Linearity: a measure of how the size of the part affects the bias of a measurement system. It is the difference in
the observed bias values through the expected range of measurement.
• Precision describes the variation you see when you measure the same part repeatedly with the same device. It
includes the following two types of variation:
• Repeatability: variation due to the measuring device. It is the variation observed when the same operator
measures the same part repeatedly with the same device.
• Reproducibility: variation due to the operators and the interaction between operator and part. It is the variation
of the bias observed when different operators measure the same parts using the same device.
• Stability: a measure of how the accuracy and precision of the system perform over time.
The following picture illustrates accuracy and precision.
Measurement System Analysis
315
Precision vs. accuracy.
In this chapter, we will discuss how to conduct linearity and bias study and gage R&R (repeatability and
reproducibility) analysis. The stability of a measurement system can be studied using statistical process control
(SPC) charts.
Gage Linearity and Bias Study
Gage linearity tells you how accurate your measurements are across the expected range of the measurements. It
answers the question, “Does my gage have the same accuracy for all sizes of objects being measured?”
Gage bias examines the difference between the observed average measurement and a reference value. It answers the
question, “On average, how large is the difference between the values my gage yields and the reference values?”
Let’s use an example to show what linearity is.
Example of Linearity and Bias Study
If a baby is 8.5 lbs and the reading of a scale is 8.9 lbs, then the bias is 0.4 lb. If an adult is 85 lbs and the reading
from the same scale is 85.4 lbs, then the bias is still 0.4 lb. This scale does not seem to have a linearity issue.
However, if the reading for the adult were 89 lbs, the bias would seem to increase as the weight increases. Thus, you
might suspect that the scale has a linearity issue.
The following data set shows measurements from a gage linearity and bias study.
Part Reference Reading Part Reference Reading
1
2
1.95
3
6
6.04
1
2
2.10
3
6
6.25
1
2
2.00
3
6
6.21
1
2
1.92
3
6
6.16
1
2
1.97
3
6
6.06
1
2
1.94
3
6
6.03
1
2
2.02
4
8
8.40
1
2
2.05
4
8
8.35
1
2
1.95
4
8
8.15
1
2
2.04
4
8
8.10
2
4
4.09
4
8
8.18
2
4
4.16
5
10
10.49
2
4
4.16
5
10
10.28
Measurement System Analysis
316
2
4
4.10
5
10
10.42
2
4
4.06
5
10
10.29
2
4
4.11
5
10
10.14
2
4
4.02
5
10
10.07
The first column is the part ID. The second column is the “true” value of each part, called reference or master. In a
linearity study, the selected reference should cover the minimal and maximal value of the produced parts. The
Reading column is the observed value from a measurement device. Each part was measured multiple times, and
some parts have the same reference value.
The following linear regression equation is used for gage linearity and bias study:
where:
• Y is the bias.
• X is the reference value.
•
•
and are the coefficients.
is error following a normal distribution
•
First, we need to calculate the bias for each observation in the above table. Bias is the difference between “Reading
and Reference. The bias values are:
Part Reference Reading Bias Part Reference Reading Bias
1
2
1.95
-0.05
3
6
6.04
0.04
1
2
2.1
0.1
3
6
6.25
0.25
1
2
2
0
3
6
6.21
0.21
1
2
1.92
-0.08
3
6
6.16
0.16
1
2
1.97
-0.03
3
6
6.06
0.06
1
2
1.94
-0.06
3
6
6.03
0.03
1
2
2.02
0.02
4
8
8.4
0.4
1
2
2.05
0.05
4
8
8.35
0.35
1
2
1.95
-0.05
4
8
8.15
0.15
1
2
2.04
0.04
4
8
8.1
0.1
2
4
4.09
0.09
4
8
8.18
0.18
2
4
4.16
0.16
5
10
10.49
0.49
2
4
4.16
0.16
5
10
10.28
0.28
2
4
4.1
0.1
5
10
10.42
0.42
2
4
4.06
0.06
5
10
10.29
0.29
2
4
4.11
0.11
5
10
10.14
0.14
2
4
4.02
0.02
5
10
10.07
0.07
Measurement System Analysis
317
Results for Linearity Study
Using the Reference column as X and the Bias column as Y in the linear regression, we get the following results:
Source of Variation Degrees of Freedom Sum of Squares [Partial] Mean Squares [Partial] F Ratio P Value
Reference
1
0.3748
0.3748
Residual
32
0.2964
0.0093
Lack of Fit
3
0.01
0.0033
Pure Error
29
0.2864
0.0099
Total
33
0.6712
40.4619 3.83E-07
0.3388
0.7974
The calculated R-sq is 55.84% and R-sq(adj) is 54.46%. These values are not very high due to the large variation
among the bias values. However, the p value of the lack of fit shows that the linear equation fits the data very well,
and the following plot also shows there is a linear relation between reference and bias.
Clear linearity and bias of a gage.
The estimated coefficients are:
Measurement System Analysis
318
Regression Information
Term
Coefficient Standard Error Low CI High CI T Value P Value
Intercept
-0.0685
0.0347
-0.1272
-0.0098
-1.9773
0.0567
Reference
0.0358
0.0056
0.0263
0.0454
6.361
3.83E-07
The linearity is defined by:
This means that when this gage is used for a process, the observed process variation will be
times larger than the
true process variation. This is because the observed value of a part is
times larger/smaller than the true value
plus a constant value of the intercept.
The percentage of linearity (% linearity) is defined by:
% linearity shows the percentage of increase of the process variation due to the linearity of the gage. The smaller the
linearity, the better the gage is.
If the linearity study shows no linear relation between reference and bias, you need to check the scatter plot of
reference and bias to see if there is a non-linear relation. For example, the following plot shows a non-linear
relationship between reference and bias.
No clear linearity of a gage.
Although the slope in the linear equation is almost 0 in the above plot, it does not mean the gage is accurate. The
above figure shows an obvious V-shaped pattern between reference and bias. This non-linear pattern requires further
Measurement System Analysis
319
analysis to judge whether the gage’s accuracy is acceptable.
Results for Bias Study
The bias study results are:
Reference
Bias
Average
0.1253
%Bias Std of Mean
t
p
2.09%
0.017
7.3517 0.0000
2
-0.0060 0.10%
0.0183
0.3284 0.7501
4
0.1000
1.67%
0.0191
5.2223 0.0020
6
0.1250
2.08%
0.0385
3.2437 0.0229
8
0.2360
3.93%
0.0587
4.0203 0.0159
10
0.2817
4.70%
0.0652
4.3209 0.0076
• The Average row is the average of all the bias values while other rows are the reference values used in the
study.
• The second column is the average bias for each reference value.
• The 3rd column is
. Process variation is commonly defined as 6 times
the process standard deviation. For this example, the process standard deviation is set to 1 and the process
variation is 6.
• The 4th column is the standard deviation of the mean value of the bias for each reference value. If there are
multiple parts having the same reference value, it is the pooled standard deviation of all the parts.
The T value is the ratio of the absolute value of the 2nd column and the 4th column. The p value is calculated from
the T value and the corresponding degree of freedom for each reference value. If the p value is smaller than a given
significance level, say 0.05, then the corresponding row has significant bias.
For this example, the p value column shows that bias appears for all the reference values except for the reference
value of 2. The p value for Average row is very small, which means the average bias of all the readings is significant.
In some cases, such as the figure in the previous section, non-linearity occurs. Bias values are negative for some of
the references and positive for others. Although each of the reference values can have significant bias, the average
bias of all the references may not be significant.
When there are multiple parts for the same reference value, the standard deviation for that reference value is the
pooled standard deviation of all the parts with the same reference value. The standard deviation for the average is
calculated from the variance of all the parts.
There are no clear cut-off values for what percent of linearity and bias are acceptable. Users should make their
decision based on their engineering feeling or experience. The results from DOE++ is given in the following picture.
Measurement System Analysis
320
Gage accuracy study example
Gage Repeatability and Reproducibility Study
In the previous section, we discussed how to evaluate the accuracy of a measurement device by conducting a
linearity and bias study. In this section, we will discuss how to evaluate the precision of a measurement device. Less
variation means better precision. Gage repeatability and reproducibility (R&R) is a method for finding out the
variations within a measurement system. Basically, there are 3 sources for variation: variation of the part, variation
of the measurement device, and variation of operator. Variation caused by operator and interaction between operator
and part is called reproducibility and variation caused by measurement device is called repeatability. The formal
definitions of reproducibility and repeatability are given in the introduction of this chapter. In this section, we will
briefly discuss how to calculate them. For more detail, please refer to Montgomery and Runger, 1993. The following
picture shows the decomposition of variations for a product measured by a device.
Measurement System Analysis
321
Gage R&R study - crossed design.
Depending on how an experiment was conducted, there are two types of gage R&R study.
• When each part is measured multiple times by each operator, it is called a gage R&R crossed experiment.
• When each part is measured by only one operator, such as in destructive testing, this is called a gage R&R
nested experiment.
The following picture represents a crossed experiment.
Gage R&R study - crossed design.
In the above picture, operator A and operator B measured the same three parts. In a nested experiment, each operator
measures different parts, as illustrated below.
Gage R&R study - nested design.
Measurement System Analysis
The X-bar and R chart methods and the ANOVA method have been used to provide an estimation of the variance for
each variation source in a measurements system. The X-bar and R chart methods cannot calculate the variance of
operator by part interaction. In DOE++, we use the ANOVA method as discussed by Montgomery and Runger. The
ANOVA method is the classical method for estimating variance components in designed experiments. It is more
accurate than the X-bar and R chart methods.
In order to estimate variance, each part needs to be measured multiple times. For destructive testing, this is
impossible. Therefore, some assumptions have to be made. Usually, for destructive testing, we need to assume that
all the parts within the same batch are identical enough to claim that they are the same part. Nested design is the first
option for destructive testing since each operator measures unique parts. If a part can be measured multiple times by
different operators, then you would use crossed design.
From the above discussion, we know the total variability can be broken down into the following variance
components:
In practice,
is called gage variation. It is compared to the specification or tolerance of the product measured
using this gage to get the so called precision-to-tolerance ratio (or P/T ratio), as given by:
where USL and LSL are the upper and lower specification limits of the product under study.
If the P/T ratio is 0.1 or less, this implies adequate gage capability. There are obvious dangers in relying too much on
the P/T ratio. For example, the ratio may be made arbitrarily small by increasing the width of the specification
tolerance [AIAG]. Therefore, other ratios are also often used. One is the gage to part variation ratio:
The other is the gage to total variation ratio:
The smaller the above two ratios, the higher the relative precision of the gage is. The calculations for obtaining the
above variance components for nested design and for crossed design are different.
We should be aware that gage R&R study should be conducted only when gage linearity and bias are not found to be
significant.
Gage R&R Study for Crossed Experiments
From a design of experiment point of view, the experiment for gage R&R study is a general level 2 factorial design.
Denoting the measurement by operator i on part j at replication k as
, we have the following ANOVA model:
where:
•
is the effect of the ith operator.
•
is the effect of the jth operator.
•
represents the part and operator interaction.
322
Measurement System Analysis
•
323
is the random error that represents the repeatability.
Usually, all the effects in the above equation are assumed to be random effects that are normally distributed with
mean of 0 and variance of
,
,
, and
, respectively. When the operators in the study are the only
operators who will work on the product, operator could be treated as fixed effect. However, as pointed out by
Montgomery and Runger [], it is usually desirable to regard the operators as representatives of a larger operator
population, with the specific operators having been randomly selected for the gage R&R study. Therefore, the
operator should always be treated as a random effect. The definitions of fixed and random effects are:
• Fixed Effect: An effect associated with a factor that has a limited number of levels or in which only a limited
number of levels are of interest to the experimenter.
• Random Effect: An effect associated with a factor chosen at random from a population having a large or
infinite number of possible values.
A model that has only fixed effect factors is called a fixed effect model; a model that has only random effect factors
is called a random effect model; a model that has both random and fixed effect factors is called a mixed effect
model.
For random and mixed effect models, variance components can be estimated using least squares estimation,
maximum likelihood estimation (MLE), and restricted MLE (RMLE) methods. The general calculations for variance
components and F test in the ANOVA table are beyond the discussion of this chapter. For detail, readers are referred
to Searl 1971 and 1997. However, when the design is balanced, variance components can be estimated using the
regular linear regression method discussed in the general level factorial design chapter [1]. DOE++ uses this method
for balanced designs.
When a design is balanced, the expected mean squares for each effect in the above random effect model for gage
R&R study using crossed design are:
The mean squares in the first column can be estimated using the model given at the beginning of this section. Their
calculations are the same regardless of whether the model is fixed, random, or mixed. The difference for fixed,
random, and mixed models is the expected mean squares. With the information in the above table, each variance
component can be estimated by:
;
;
For the F test in the ANOVA table, the F ratio is calculated by:
Measurement System Analysis
324
From the above F ratio, we can test whether the effect of operator, part, and their interaction are significant or not.
Example: Gage R&R Study for Crossed Experiment
A gage R&R study was conducted using a crossed experiment. The data set is given in the table below. The product
tolerance is 2,000. We want to evaluate the precision of this gage using the P/T ratio, gage to part variation ratio and
gage to total variation ratio.
Part Operator Response
1
A
405
1
A
232
1
A
476
1
B
389
1
B
234
1
B
456
1
C
684
1
C
674
1
C
634
2
A
409
2
A
609
2
A
444
2
B
506
2
B
567
2
B
435
2
C
895
2
C
779
2
C
645
3
A
369
3
A
332
3
A
399
3
B
426
3
B
471
3
B
433
3
C
523
3
C
550
3
C
520
First, using the regular linear regression method, the mean square for each term can be calculated and is given in the
following table.
Measurement System Analysis
325
Source of Variation Degrees of Freedom Sum of Squares [Partial] Mean Squares [Partial] F Ratio P Value
Part
2
105545.00
52772.00
5.0655
0.0801
Operator
2
332414.00
166207.00
15.9538 0.0124
Part * Operator
4
41672.00
10418.00
1.4924
Residual
18
125655.00
6980.85
Pure Error
18
125655.00
6980.85
Total
26
605285.00
0.2462
All the effects are treated as random effects in the above table. The F ratios are calculated based on the equations
given above. They are:
The p value column shows that the operator is the most significant effect since that has the smallest p value. This
means that the variation among all the operators is relatively large.
Second, based on the equations for expected mean squares, we can calculate the variance components. They are
given in the following table.
Source
Variance % Contribution
Part
4706.00
15.61%
Reproducibility
18455.60
61.23%
Operator
17309.89
57.43%
Operator*Part
1145.72
3.80%
Repeatability
6980.85
23.16%
Total Gage R&R 25436.46
84.39%
Total Variation
30142.46
100.00%
The above table shows:
The repeatability is
for the random error. The reproducibility is the sum of
and
. The sum of
repeatability and reproducibility is called the total gage R&R.
The last column in the above table shows the contribution of each variance component. For example, the
contribution of the operator is 57.43%, which is calculated by:
The standard deviation for each effect is:
Measurement System Analysis
326
Source
Std (SD)
Part
68.600
Reproducibility
135.851
Operator
131.567
Operator*Part
33.848
Repeatability
83.551
Total Gage R&R 159.488
Total Variation
173.616
Since the product tolerance is 2,000, the P/T ratio is:
Since P/T ratio is much greater than 10%, this gage is not adequate for this product.
The gage to part variation ratio:
The gage to total variation ratio:
Clearly, all the ratios are too large. The operators should be trained and a new gage may need to be purchased. The
pie chart plots for the contribution of each variance components are shown next.
Measurement System Analysis
327
Variance components for the gage R&R: crossed design
In the above picture, the total variation component pie chart displays the ratio of each variance to the total variance.
The gage and part variation chart displays the ratio of the gage variance to the total variance, and the ratio of the part
to the total variance. The gage R&R variance is for the percentage of repeatability and reproducibility to the total
gage variance. The gage reproducibility variance pie chart future decomposes reproducibility to operator variance,
and operator and part interaction variance.
A variation of the example that demonstrates how to obtain the results using the gage R&R folio is available in the
DOE++ Help file [2].
Gage R&R Study for Nested Experiments
When the experiment is nested, since the part is nested within each operator, we cannot assess the operator and part
interaction. The regression model is:
The estimated operator effect includes the operator effect and the operator and part interaction. For the general
calculation on the above model, please refer to [“Applied Linear Statistical Models” by Kutner, Nachtsheim, Neter
and Li]. When the nested experiment is balanced, its calculations for total sum of squares (SST), sum of squares of
operator (SSO), and sum of square of error (SSE) are the same as those for the crossed design. The only difference is
the sum of squares of part (SSP(O)). For nested designs, it is:
Measurement System Analysis
328
SSP and SSOP are the sum of squares for part, and the sum of squares for part and operator interaction. They are
calculated using a linear regression equation by including part and operator interaction in the model.
When the design is balanced, the expected mean squares for each effect in the above random effect model for gage
R&R study nested design are:
Mean Squares Degree of Freedom Expected Mean Squares
MSO
MSP(O)
MSE
With the information in the above table, each variance component can be estimated by:
;
;
For the F test in the ANOVA table, the F ratio is calculated by:
Example: Gage R&R Study for Nested Experiment
For the example in the previous section, since it is a nested design, the part i measured by one operator is different
from the part i measured by another operator. Therefore, when the design is nested, the design in fact should be:
Part Operator Response
1_1
A
405
1_1
A
232
1_1
A
476
2_1
B
389
2_1
B
234
2_1
B
456
3_1
C
684
3_1
C
674
3_1
C
634
1_2
A
409
1_2
A
609
1_2
A
444
2_2
B
506
2_2
B
567
2_2
B
435
3_2
C
895
3_2
C
779
Measurement System Analysis
329
3_2
C
645
1_3
A
369
1_3
A
332
1_3
A
399
2_3
B
426
2_3
B
471
2_3
B
433
3_3
C
523
3_3
C
550
3_3
C
520
We want to evaluate the precision of this gage using the P/T ratio, gage to part variation ratio, and gage to total
variation ratio.
First, using the regular linear regression method for nested designs [Neter’s book], all the mean squares for each term
can be calculated. They are given in the following table.
Source of Variation Degrees of Freedom Sum of Squares [Partial] Mean Squares [Partial]
F
P
0.028917
Operator
2
332414.00
166207.00
6.77396
Part(Operator)
6
147217.00
24536.17
3.514781 0.017648
Residual
18
125655.00
6980.85
Pure Error
18
125655.00
6980.85
Total
26
605285.00
The F ratios are calculated based on the equations given above.
The p value column shows that the operator and part (operator) both are significant at a significance level of 0.05.
Second, based on the equations for expected mean squares, we can calculate the variance components. They are
given in the following table.
Source
Variance
% Contribution
Repeatability
6981
24.43%
Reproducibility
15741.2037
55.09%
Operator
15741.2037
55.09%
Part (Operator)
5851.7716
20.48%
Total Gage R&R
22722
79.52%
Total Variation
28574
100.00%
The standard deviation for each variation source is:
Measurement System Analysis
330
Source
Std (SD)
Repeatability
83.551
Reproducibility
125.464
Operator
125.464
Part (Operator)
76.497
Total Gage R&R 150.738
Total Variation
169.038
Since the product tolerance is 2,000, the P/T ratio is:
Since the P/T ratio is much greater than 10%, this gage is not adequate for this product.
The gage to part variation ratio:
The gage to total variation ratio:
The pie charts for all the variance components are shown next.
Variance components for gaga R&R study: nested design.
Measurement System Analysis
331
X-bar and R Charts in Gage R&R
X-bar and R charts are often used in gage R&R studies. Although DOE++ does not use them to estimate
repeatability and reproducibility, they are included in the plot to visually display the data. Along with X-bar and R
charts, other plots are also used in DOE++. For example, the following is a run chart for the example of gage R&R
study using crossed design.
Run chart for the gage R&R study using crossed design.
Each column in the above figure is the 9 measurements of a part by all the operators. In the above plot, we see that
all readings by operator C (the blue points) are above the mean line. This indicates that operator C’s readings are
different from the calculated mean. Part 3 (the last column in the plot) has the least variation among these 3 parts.
These two conclusions also can be inferred from the following two plots.
Measurement System Analysis
332
measurement by operator for the gage R&R study using crossed design.
The above plot shows that operator C’s readings are much higher than the other two operators.
The above plot shows part 3 has less variation compared to parts 1 and 2.
Measurement System Analysis
333
measurement by part for the gage R&R study using crossed design.
Now let’s talk about X-bar and R charts. The X-bar chart is used to see how the mean reading changes among the
parts; the R chart is used to check the repeatability. When the number of readings of each part by the same operator
is greater than 10, an s chart is used to replace the R chart. The R chart is accurate only when the sample size is small
(<10). For this example, the sample size is 3, so the R chart is used, as shown next.
Measurement System Analysis
334
R chart by operator for the gage R&R study using crossed design.
In the above plot, the x-axis is operator and the y-axis is the range for each part measured by each operator.
The step-by-step calculation for the R chart (n
10) is given below.
Step 1: calculate the range of each part for each operator.
is the range of the reading for the ith part and the jth operator. k is the trial number.
Step 2: calculate the average range for each operator.
Step 3: calculate the overall average range for all the operators.
This is the central line in the R chart.
Step 4: calculate the upper control limit (UCL) and the lower control limit (LCL) for the R chart.
D3 and D4 are from the following table:
Measurement System Analysis
335
n
A2
D3
D4
d2
2
1.88
0
3.267 1.128
3
1.023
0
2.575 1.693
4
0.729
0
2.282 2.059
5
0.577
0
2.115 2.326
6
0.483
0
2.004 2.534
7
0.419 0.076 1.924 2.704
8
0.373 0.136 1.864 2.847
9
0.337 0.184 1.816
2.97
10 0.308 0.223 1.777 3.078
The calculation results for this example are:
Operator A
Part Number T1
T2
T3
1
405 232 476
244
371
2
409 609 444
200
487.3333 408.3333
3
369 332 399
67
366.6667
Operator B
1
389 234 456
222
359.6667
2
506 567 435
132
502.6667 435.2222
3
426 471 433
45
443.3333
Operator C
1
684 674 634
50
664
2
895 779 645
250
773
3
523 550 520
30
531
137.7778
656
499.8519
From the above table, we know that the three values for the R chart are:
The step by step calculation for the X-bar chart for sample size n, where n is less than or equal to 10, is given below.
Step 1: Calculate the average of the reading for part i, by operator j.
Step 2: Calculate the overall mean of operator j.
Step 3: Calculate the overall mean of all the observations:
is the central line of the X-bar chart.
Measurement System Analysis
336
The above table gives the values of
Step 4: Calculate the UCL and LCL.
,
, and
.
A2 is from the above constant value table. The X-bar chart for this example is:
X-Bar chart by operator for the crossed design example.
When the sample size (the reading of the same part by the same operator) is greater than 10, the more accurate s
chart is used to replace the R chart. The calculation for the UCL and LCL in the X-bar chart is also updated using the
sample standard deviation s.
The step by step calculations for the s chart are given below.
Step 1: Calculate the standard deviation for each part of each operator.
Step 2: Calculate the average of these standard deviations.
The above equation is only valid for balanced designs.
is the central line for the s chart.
Step 3: Calculate the UCL and LCL.
;
where:
Measurement System Analysis
337
;
For the X-bar chart, the central line is the same as before. Only the UCL and LCL need to use the following
equations when n>10.
;
From the above calculation, it can be seen the calculation for the s chart is much more complicated than the
calculation for the R chart. This is why the R chart was often used in the past, before computers were in common
use.
Gage Agreement Study
In the above sections, we discussed how to evaluate a gage’s accuracy and precision. Accuracy is assessed using a
linearity and bias study, while precision is evaluated using a gage R&R study. Often times, we need to compare two
measurement devices. For instance, can an old device be replaced by a new one, or can an expensive one be replaced
by a cheap one, without loss of the accuracy and precision of the measurements? The study used for comparing the
accuracy and precision of two gages is called a gage agreement study.
Accuracy Agreement Study
One way to compare the accuracy of two gages is to conduct a linearity and bias study for each gage by the same
operator, and then compare the percentages of the linearity and bias. This provides a rough idea of how close the
accuracies of the two gages are. However, it is difficult to quantify how close they should be in order to claim there
is no significant difference between them. Therefore, a formal statistical method is needed. Let’s use the following
example to explain how to compare the accuracy of two devices.
Example: Compare the Accuracy of Two Gages Using a Paired t-Test
There are two gages: Gage 1 and Gage 2. There are 17 subjects/parts. For each subject, there are two readings from
each gage.
Gage 1
Gage 2
Subject 1st Reading 2nd Reading 1st Reading 2nd Reading
1
494
490
512
525
2
395
397
430
415
3
516
512
520
508
4
434
401
428
444
5
476
470
500
500
6
557
611
600
625
7
413
415
364
460
8
442
431
380
390
9
650
638
658
642
Measurement System Analysis
338
10
433
429
445
432
11
417
420
432
420
12
656
633
626
605
13
267
275
260
227
14
478
492
477
467
15
178
165
259
268
16
423
372
350
370
17
427
421
451
443
If their bias and linearity are the same, then the difference between the average readings for the same subject by the
two devices should be almost the same. In other words, the differences should be around 0, with a constant standard
deviation. We can test if this hypothesis is true or not. The differences of the readings are given in the table below.
Subject
Gage 1
Gage 2
Difference Grand Average
Number of Reading Average Reading Number of Reading Average Reading
1
2
492
2
518.5
-26.5
505.25
2
2
396
2
422.5
-26.5
409.25
3
2
514
2
514
0
514
4
2
417.5
2
436
-18.5
426.75
5
2
473
2
500
-27
486.5
6
2
584
2
612.5
-28.5
598.25
7
2
414
2
412
2
413
8
2
436.5
2
385
51.5
410.75
9
2
644
2
650
-6
647
10
2
431
2
438.5
-7.5
434.75
11
2
418.5
2
426
-7.5
422.25
12
2
644.5
2
615.5
29
630
13
2
271
2
243.5
27.5
257.25
14
2
485
2
472
13
478.5
15
2
171.5
2
263.5
-92
217.5
16
2
397.5
2
360
37.5
378.75
17
2
424
2
447
-23
435.5
The difference vs. mean plot is shown next.
Measurement System Analysis
339
Difference vs Mean plot for gage agreement study
The above plot shows that all the values are within the control limits (significant level = 0.05) except for one point,
and are evenly distributed around the central 0 line.
The paired t-test is used to test if the two gages have the same bias (i.e., if the “difference” has a mean value of 0).
The paired t-test is conducted using the Difference column. The calculation is given below.
Step 1: Calculate the mean value of this column.
For this example, n is 17.
Step 2: Calculate the standard deviation of this column.
Step 3: Conduct the t-test.
Step 4: Calculate the p value.
The calculation will be summarized in the following table.
Mean (Gage 1- Gage 2)
Std. Mean
6.02941
8.053186092
Lower Bound Upper Bound
-23.101404
11.04257999
T Value
P Value
0.748698924 0.464904
Measurement System Analysis
340
Since the p value is 0.464904, which is greater than the significant level of 0.05, the two gages have the same bias.
The paired t-test is valid only when there is no trend or pattern in the difference vs. mean plot. If the points show a
pattern such as a linear pattern, the conclusion from the paired t-test may not be valid.
Example: Compare the Accuracy of Two Gages Using Linear Regression
The data set for a gage agreement study is given in the table below.
Subject
Gage 1
Gage 2
1st Reading 2nd Reading 1st Reading 2nd Reading
1
66.32
65.80
74.30
74.39
2
95.51
95.94
94.74
94.93
3
61.93
60.27
70.81
70.75
4
163.08
162.33
149.91
149.75
5
76.60
76.56
82.00
81.53
6
127.35
127.68
120.58
120.70
7
93.07
90.51
92.96
92.88
8
134.39
134.49
126.24
126.23
9
115.54
114.33
112.27
112.96
10
117.92
118.26
112.41
113.18
The differences of the readings are given in the table below.
Subject
Gage 1
Gage 2
Difference Grand Average
Number of Reading Average Reading Number of Reading Average Reading
1
2
66.06
2
74.35
-8.29
70.20
2
2
95.72
2
94.83
0.89
95.28
3
2
61.10
2
70.78
-9.67
65.94
4
2
162.70
2
149.83
12.87
156.26
5
2
76.58
2
81.77
-5.19
79.17
6
2
127.52
2
120.64
6.88
124.08
7
2
91.79
2
92.92
-1.13
92.35
8
2
134.44
2
126.24
8.20
130.34
9
2
114.94
2
112.61
2.32
113.77
10
2
118.09
2
112.79
5.30
115.44
The difference vs. mean plot shows a clear linear pattern, although all the points are within the control limits.
Measurement System Analysis
341
Difference vs Mean plot for gage agreement study with a linear trend
The paired t-test results are:
Mean (Gage 1- Gage 2) Std. Mean Lower Bound Upper Bound T Value P Value
1.218
7.3804
17.9137
-15.4777
0.5219
0.6144
Since the p value is large, we cannot reject the null hypothesis. The conclusion is that the bias is the same for these
two gages. However, the linear pattern in the above plot makes us suspect that this conclusion may not be accurate.
We need to compare both the bias and the linearity. The F-test used in linear regression can do the work.
If the two gages have the same accuracy (linearity and bias), then the average readings from Gage 1 and the average
readings from Gage 2 should be on a 45 degree line that passes the origin in the average reading plot. However, the
following plot shows the points are not very close to the 45 degree line.
Measurement System Analysis
342
Average readings comparison
We can fit a linear regression equation:
where Y is the average reading for each part from Gage 1, and X is the average reading for each part from Gage 2. If
the two gages agree with each other, then should be 0 and should be one. Using the data in this example, the
calculated regression coefficients are:
Term Coefficient Standard Error Low Confidence High Confidence T Value
22.3873
1.2471
19.5114
25.2633
17.9508 9.51E-08
0.775
0.0114
0.7487
0.8013
19.7265 4.54E-08
The p values in the above results show that
For , the t value is:
For
P Value
is not 0 and
is not 1. These tests are for each individual coefficient.
, the t value is
The p value is calculated using the above t values and the degree of freedom of error of 8.
Since we want to test these two coefficients simultaneously, using an F-test is more appropriate. The null hypothesis
for the F-test is:
Measurement System Analysis
343
Under the null hypothesis, the statistic is:
For this example:
The result for the F-test is given below.
Simultaneous Coefficient Test
Test
= 0 and
F Value
=1
P Value
200.5754 3.43E-08
Since the p value is almost 0 in the above table, we have enough evidence to reject the null hypothesis. Therefore,
these two gages have different accuracy.
This example shows that the paired t-test and the regression coefficient test give different conclusion. This is because
the t-test cannot catch the difference between the linearity of these two gages, while the simultaneous regression
coefficient test can.
Precision Agreement Study
A gage agreement experiment should be conducted by the same operator, so the gage reproducibility caused by
operator is removed. Only repeatability caused by gages is calculated and compared. Therefore precision agreement
study is comparing the repeatability of each gage. Let’s use the first example in the above accuracy agreement study
for a precision agreement study.
First, we need to calculate the repeatability of each gage. Repeatability is also the pure error which is the variation of
the multiple readings for the same part by the same operator. The result of Gage 2 is given in the following table.
Subject 1st Reading 2nd Reading Sum of Square (SS)
1
512
525
84.5
2
430
415
112.5
3
520
508
72
4
428
444
128
5
500
500
0
6
600
625
312.5
7
364
460
4608
8
380
390
50
9
658
642
128
10
445
432
84.5
11
432
420
72
12
626
605
220.5
13
260
227
544.5
14
477
467
50
15
259
268
40.5
16
350
370
200
Measurement System Analysis
344
17
451
443
32
Total SS
6739.5
Repeatability
396.4412
The repeatability is calculated by the following steps.
Step 1: For each subject, calculate the sum of square (SS) of the repeated readings for the same gage. For example,
for subject 1, the SS under this gage is:
Step 2: Add the SS of all the subjects together.
Step 3: Find the degree of freedom.
is the number of repeated reading for subject i. n is the total number of subjects.
Step 4: Calculate the variance (repeatability). For Gage 2, it is:
Repeating the above procedure, we can get the repeatability for gage 1. It is 234.2941. We can then compare the
repeatability of these two gages. If these two variances are the same, then the ratio of them follows an F distribution
with degree of freedom of
and
.
is the degree of freedom for Gage 1 (the numerator in the F ratio) and
Gage 2 (the denominator in the F ratio).
The results are:
Gage
Repeatability Variance Degrees of Freedom F Ratio Lower Bound Upper Bound P Value
Gage 1
234.2941
17
Gage 2
396.4412
17
0.591
0.22101
1.5799
0.1440
The p value in the range of (risk level)/2 = 0.025 and 1-(risk level)/2 = 0.975. Therefore, we cannot reject the null
hypothesis that these two gages have the same precision.
The bounds in the above table are calculated by:
For this example
and
. Therefore, the upper bound is 1.5799 and the lower bound
is 0.22101. Since the bounds include 1, it means the two gages have the same repeatability. The results from DOE++
are given below.
Measurement System Analysis
345
Gage agreement study results from DOE++
General Guidelines on Measurement System Analysis
The experiments for MSA should be designed experiments. The experiment should be designed and conducted based
on DOE principals. Here are some of the guidelines for preparation prior to conducting MSA [AIAG].
1. Whenever possible, the operators chosen should be selected from those who normally operate the gage. If these
operators are not available, then personnel should be properly trained in the correct usage of the gage.
2. The sample parts must be selected from the process which represents its entire operating range. This is sometimes
done by taking one sample per day for several days. The collected samples will be treated as if they represent the
full range of product variation. Each part must be numbered for identification.
3. The gage must have a graduation that allows at least one-tenth of the expected process variation of the
characteristic to be read directly. Process variation is usually defined as 6 times the process standard deviation.
For example, if the process variation is 0.1, the equipment should read directly to an increment no larger than
0.01.
The manner in which a study is conducted is very important if reliable results are to be obtained. To minimize the
possibility of getting inaccurate results, the following steps are suggested:
1. The measurements should be made in a random order. The operators should be unaware of which numbered part
is being checked in order to avoid any possible bias. However, the person conducting the study should know
which numbered part is being checked and record the data accordingly, such as Operator A, Part 1, first trial.
2. In reading the gage, the readings should be estimated to the nearest number that can be obtained. At a minimum,
readings should be made to one-half of the smallest graduation. For example, if the smallest graduation is 0.01,
then the estimate for each reading should be rounded to the nearest 0.005.
Measurement System Analysis
References
[1] http:/ / reliawiki. org/ index. php/ General_Full_Factorial_Designs
[2] http:/ / help. synthesisplatform. net/ doe9/ gage_r& r_folio__example. htm
346
347
Appendices
Appendix A: ANOVA Calculations in Multiple
Linear Regression
The sum of squares for the analysis of variance in multiple linear regression is obtained using the same relations as
those in simple linear regression, except that the matrix notation is preferred in the case of multiple linear regression.
In the case of both the simple and multiple linear regression models, once the observed and fitted values are
available, the sum of squares are calculated in an identical manner. The difference between the two models lies in the
way the fitted values are obtained. In a simple linear regression model, the fitted values are obtained from a model
having only one predictor variable. In multiple linear regression analysis, the model used to obtained the fitted values
contains more than one predictor variable.
Total Sum of Squares
Recall from Simple Linear Regression Analysis that the total sum of squares,
equation:
The first term,
, is obtained using the following
, can be expressed in matrix notation using the vector of observed values, y, as:
If J represents an n x n square matrix of ones, then the second term,
notation as:
Therefore, the total sum of squares in matrix notation is:
where I is the identity matrix of order .
, can be expressed in matrix
Appendix A: ANOVA Calculations in Multiple Linear Regression
348
Model Sum of Squares
Similarly, the model sum of squares or the regression sum of squares,
where
is the hat matrix and is calculated using
, can be obtained in matrix notation as:
.
Error Sum of Squares
The error sum of squares or the residual sum of squares,
residuals, , as:
, is obtained in the matrix notation from the vector of
Mean Squares
Mean squares are obtained by dividing the sum of squares with their associated degrees of freedom. The number of
degrees of freedom associated with the total sum of squares,
, is (
) since there are n observations in all,
but one degree of freedom is lost in the calculation of the sample mean, . The total mean square is:
The number of degrees of freedom associated with the regression sum of squares,
, is . There are (k+1)
degrees of freedom associated with a regression model with (k+1) coefficients, , , .... . However, one
degree of freedom is lost because the deviations, (
), are subjected to the constraints that they must sum to
zero (
). The regression mean square is:
The number of degrees of freedom associated with the error sum of squares is
observations in all, but
degrees of freedom are lost in obtaining the estimates of
the predicted values, . The error mean square is:
The error mean square,
, is an estimate of the variance,
,
, of the random error terms,
, as there are
... to calculate
,
.
Appendix A: ANOVA Calculations in Multiple Linear Regression
349
Calculation of the Statistic
Once the mean squares
calculated as follows:
and
are known, the statistic to test the significance of regression can be
Appendix B: Use of Regression to Calculate Sum
of Squares
This appendix explains the reason behind the use of regression in DOE++ in all calculations related to the sum of
squares. A number of textbooks present the method of direct summation to calculate the sum of squares. But this
method is only applicable for balanced designs and may give incorrect results for unbalanced designs. For example,
the sum of squares for factor in a balanced factorial experiment with two factors, and , is given as follows:
where
represents the levels of factor , represents the levels of factor , and represents the number of
samples for each combination of and . The term
is the mean value for the th level of factor ,
is the
sum of all observations at the th level of factor and
is the sum of all observations.
The analogous term to calculate
in the case of an unbalanced design is given as:
where
is the number of observations at the th level of factor and
is the total number of observations.
Similarly, to calculate the sum of squares for factor and interaction
, the formulas are given as:
Applying these relations to the unbalanced data of the last table, the sum of squares for the interaction
is:
which is obviously incorrect since the sum of squares cannot be negative. For a detailed discussion on this refer to
Searle(1997, 1971).
Appendix B: Use of Regression to Calculate Sum of Squares
350
Example of an unbalanced design.
The correct sum of squares can be calculated as shown next. The and
can be written as:
Then the sum of squares for the interaction
where
is the hat matrix and
represents the interaction effect
matrices for the design of the last table
can be calculated as:
is the matrix of ones. The matrix
can be calculated using
where
is the design matrix, , excluding the last column that
. Thus, the sum of squares for the interaction
is:
This is the value that is calculated by DOE++ (see the first figure below, for the experiment design and the second
figure below for the analysis).
Unbalanced experimental design for the data in the last table.
Appendix B: Use of Regression to Calculate Sum of Squares
Analysis for the unbalanced data in the last table.
Appendix C: Plackett-Burman Designs
12-Run Design
351
Appendix C: Plackett-Burman Designs
20-Run Design
352
Appendix C: Plackett-Burman Designs
24-Run Design
353
Appendix D: Taguchi's Orthogonal Arrays
Appendix D: Taguchi's Orthogonal Arrays
Two Level Designs
L4 (2^3)
L8 (2^7)
L12 (2^11)
354
Appendix D: Taguchi's Orthogonal Arrays
L16 (2^15)
355
Appendix D: Taguchi's Orthogonal Arrays
Three Level Designs
L9 (3^4)
L27 (3^13)
356
Appendix D: Taguchi's Orthogonal Arrays
Mixed Level Designs
L8 (2^4 4^1)
L16 (2^12 4^1)
L16 (2^9 4^2)
357
Appendix D: Taguchi's Orthogonal Arrays
L16 (2^6 4^3)
L16 (2^3 4^4)
358
Appendix D: Taguchi's Orthogonal Arrays
L18 (2^1 3^7)
359
Appendix E: Alias Relations for Taguchi's Orthogonal Arrays
Appendix E: Alias Relations for Taguchi's
Orthogonal Arrays
For L8 (2^7):
For L16 (2^15):
For L32 (2^31) - first 16 columns:
360
Appendix E: Alias Relations for Taguchi's Orthogonal Arrays
For L32 (2^31) - remaining columns:
361
Appendix F: Box-Behnken Designs
Appendix F: Box-Behnken Designs
This table indicates that all combinations of plus and minus levels are to be run. Dashed lines indicate how the
design can be separated into blocks.
362
Appendix G: Glossary
Appendix G: Glossary
Alias
Two or more effects are said to be aliased in an experiment if these effects cannot be distinguished from each other.
This happens when the columns of the design matrix corresponding to these effects are identical. As a result, the
aliased effects are estimated by the same linear combination of observations instead of each effect being estimated
by a unique combination.
ANOVA
ANOVA is the acronym for Analysis of Variance. It refers to the procedure of splitting the variability of a data set to
conduct various significance tests.
ANOVA Model
The regression model where all factors are treated as qualitative factors. ANOVA models are used in the analysis of
experiments to identify significant factors by investigating each level of the factors individually.
Balanced Design
An experiment in which equal number of observations are taken for each treatment.
Blocking
Separation of experiment runs based on the levels of a nuisance factor. Blocking is used to deal with known nuisance
factors. You should block what you can and randomize what you cannot. See also Nuisance Factors, Randomization.
Center Point
The experiment run that corresponds to the mid-level of all the factor ranges.
Coded Values
The factor values that are such that the upper limit of the investigated range of the factor becomes +1 and the lower
limit becomes -1. Using coded values makes the experiments with all factors at two levels orthogonal.
Confidence Interval
A closed interval where a certain percentage of the population is likely to lie. For example, a 90% confidence
interval with a lower limit of A and an upper limit of B implies that 90% of the population lies between the values of
A and B.
Confounding
Confounding occurs in a design when certain effects cannot be distinguished from the block effect. This happens
when full factorial designs are run using incomplete blocks. In such designs the same linear combination of
observations estimates the block effect and the confounded effects. See also Incomplete Blocks.
Contrast
Any linear combination of two or more factor level means such that the coefficients in the combination add up to
zero. The difference between the means at any two levels of a factor is an example of a contrast.
Control Factors
The factors affecting the response that are easily manipulated and set by the operator. See also Noise Factors.
Cross Array Design
The experiment design in which every treatment of the inner array is replicated for each run of the outer array. See
also Inner Array, Outer Array.
Curvature Test
The test that investigates if the relation between the response and the factors is linear by using center points. See also
Center Point.
363
Appendix G: Glossary
Defining Relation
For two level fractional factorial experiments, the equation that is used to obtain the fraction from the full factorial
experiment. The equation shows which of the columns of the design matrix in the fraction are identical to the first
column. For example, the defining relation I=ABC can be used to obtain a half-fraction of the two level full factorial
experiment with three factors A, B and C. The effects used in the equation are called the generators or words.
Degrees of Freedom
The number of independent observations made in excess of the unknowns.
Design Matrix
The matrix whose columns correspond to the levels of the variables (and their interactions) at which observations are
recorded.
Design Resolution
The number of factors in the smallest word in a defining relation. Design resolution indicates the degree of aliasing
in a fractional factorial design. See also Defining Relation, Word.
Error
The natural variations that occur in a process, even when all the factors are maintained at the same level. See also
Residual.
Error Sum of Squares
The variation in the data not captured by the model. The error sum of squares is also called the residual sum of
squares. See also Model Sum of Squares, Total Sum of Squares.
Extra Sum of Squares
The increase in the model sum of squares when a term is added to the model.
Factorial Experiment
The experiment in which all combinations of the factor levels are run.
Fractional Factorial Experiment
The experiment where only a fraction of the combinations of the factor levels are run.
Factor
The entity whose effect on the response is investigated in the experiment.
Fitted Value
The estimate of an observation obtained using the model that has been fit to all the observations.
Fixed Effects Model
The ANOVA model used in the experiments where only a limited number of the factor levels are of interest to the
experimenter. See also Random Effects Model.
Full Model
The model that includes all the main effects and their interactions. In DOE++, a full model is the model that contains
all the effects that are specified by the user. See also Reduced Model.
Generator
See Word.
Hierarchical Model
In DOE++, a model is said to be hierarchical if, corresponding to every interaction, the main effects of the related
factors are included in the model.
Incomplete Blocks
364
Appendix G: Glossary
Blocks that do not contain all the treatments of a factorial experiment.
Inner Array
The experiment design used to investigate the control factors under Taguchi's philosophy to design a robust system.
See also Robust System, Outer Array, Cross Array.
Interactions
Interaction between factors means that the effect produced by a change in a factor on the response depends on the
level of the other factor(s).
Lack-of-Fit Sum of Squares
The portion of the error sum of squares that represents variation in the data not captured because of using a reduced
model. See also Reduced Model, Pure Error Sum of Squares.
Least Squares Means
The predicted mean response value for a given factor level while the remaining factors in the model are set to the
coded value of zero.
Level
The setting of a factor used in the experiment.
Main Effect
The change in the response due to a change in the level of a factor.
Mean Square
The sum of squares divided by the respective degrees of freedom.
Model Sum of Squares
The portion of the total variability in the data that is explained by the model. See also Error Sum of Squares, Total
Sum of Squares.
Multicollinearity
A model with strong dependencies between the independent variables is said to have multicollinearity.
New Observations
Observations that are not part of the data set used to fit the model.
Noise Factors
Those nuisance factors that vary uncontrollably or naturally and can only be controlled for experimental purposes.
For example, ambient temperature, atmospheric pressure and humidity are examples of noise factors.
Nuisance Factors
Factors that have an effect on the response but are not of primary interest to the investigator.
Orthogonal Array
An array in which all the columns are orthogonal to each other. Two columns are said to be orthogonal if the sum of
the terms resulting from the product of the columns is zero.
Orthogonal Design
An experiment design is orthogonal if the corresponding design matrix is such that the sum of the terms resulting
from the product of any two columns is zero. In orthogonal designs the analysis of an effect does not depend on what
other effects are included in the model.
Outer Array
The experiment design used to investigate noise factors under Taguchi's philosophy to design a robust system. See
also Robust System, Inner Array, Cross Array.
365
Appendix G: Glossary
Partial Sum of Squares
The type of extra sum of squares that is calculated assuming that all terms other than the given term are included in
the model. The partial sum of squares is also referred to as the adjusted sum of squares. See also Extra Sum of
Squares, Sequential Sum of Squares.
Prediction Interval
The confidence interval on new observations.
Pure Error Sum of Squares
The portion of the error sum of squares that represents variation due to replicates. See also Lack-of-Fit Sum of
Squares.
Qualitative Factor
The factor where the levels represent different categories and no numerical ordering is implied. These factors are
also called categorical factors.
Random Effects Model
The ANOVA model used in the experiments where the factor levels to be investigated are randomly selected from a
large or infinite population. See also Fixed Effects Model.
Randomization
Conducting experiment runs in a random order to cancel out the effect of unknown nuisance factors. See also
Blocking.
Randomized Complete Block Design
An experiment design where each block contains one replicate of the experiment and runs within the block are
subjected to randomization.
Reduced Model
A model that does not contain all the main effects and interactions. In DOE++, a reduced model is the model that
does not contain all the effects specified by the user. See also Full Model.
Regression Model
A model that attempts to explain the relationship between two or more variables.
Repeated Runs
Experiment runs corresponding to the same treatment that are conducted at the same time.
Replicated Runs
Experiment runs corresponding to the same treatment that are conducted in a random order.
Residual
An estimate of error which is obtained by calculating the difference between an observation and the corresponding
fitted value. See also Error, Fitted Value.
Residual Sum of Squares
See Error Sum of Squares.
Response
The quantity that is investigated in an experiment to see which of the factors affect it.
Robust System
A system that is insensitive to the effects of noise factors.
Rotatable Design
366
Appendix G: Glossary
A design is rotatable if the variance of the predicted response at any point depends only on the distance of the point
from the design center point.
Screening Designs
Experiments that use only a few runs to filter out important main effects and lower order interactions by assuming
that higher order interactions are unimportant.
Sequential Sum of Squares
The type of extra sum of squares that is calculated assuming that all terms preceding the given term are included in
the model. See also Extra Sum of Squares, Partial Sum of Squares.
Signal to Noise Ratio
The ratios defined by Taguchi to measure variation in the response caused by the noise factors.
Standard Order
The order of the treatments such that factors are introduced one by one with each new factor being combined with
the preceding terms.
Sum of Squares
The quantity that is used to measure either a part or all of the variation in a data set.
Total Sum of Squares
The sum of squares that represent all of the variation in a data set.
Transformation
The mathematical function that makes the data follow a given characteristic. In the analysis of experiments
transformation is used on the response data to make it follow the normal distribution.
Treatment
The levels of a factor in a single factor experiment are also referred to as treatments. In experiments with many
factors a combination of the levels of the factors is referred to as a treatment.
Word
The effect used in the defining relation. For example, for the defining relation I=ABC, the word is ABC.
367
Appendix H: References
Appendix H: References
1. AIAG (2010), Measurement Systems Analysis (MSA), Automotive Industry Action Group, 4th edition.
2. Box, G. E. P., and Behnken, D. W. (1960), Some New Three Level Designs for the Study of Quantitative
Variables, Technometrics, Vol. 2, No. 4, pp. 455-475.
3. Box, G. E. P., and Draper, N. R. (1987), Empirical Model Building and Response Surfaces, John Wiley & Sons,
Inc., New York.
4. Box, G. E. P., Hunter, W. G., and Hunter, J. S. (1978), Statistics for Experimenters, John Wiley & Sons, Inc.,
New York.
5. Cook, R. D. and Nachtsheim, C. J. (1980), “A Comparison of Algorithms for Constructing Exact D-Optimal
Designs,” Technometrics, vol. 22, no. 3, 315-324.
6. Derringer, G., and Suich, R. (1980), Simultaneous Optimization of Several Response Variables, Journal of
Quality Technology, Vol. 12, pp. 214-219.
7. Draper, N., and Smith H. (1998), Applied Regression Analysis, John Wiley & Sons, Inc., New York.
8. Dykstra, O. (1971), “The augmentation of experimental data to maximize |X’X|," Technometrics, vol. 13, no. 3,
682-688.
9. Fisher, R. A. (1966), The Design of Experiments, Hafner Publishing Company, New York.
10. Fedorov, V. V. (1972), “Theory of Optimal Experiments (Review)”, Biometrika, cvol. 59, no. 3, 697-698.
Translated and edited by W. J. Studden and E. M. Klimko.
11. Fries, A., and Hunter, W. G. (1980), Minimum Aberration 2k-p Designs, Technometrics, Vol. 22, pp. 601-608.
12. Galil, Z. and Kiefer, J. (1980), “Time and Space Saving Computer Methods, Related to Mitchell’s DETMAX,
for Finding D-Optimal Designs”, Technometrics, vol. 22, no. 3, 301-313.
13. Guo, H., Niu, P., and Szidarovszky, F. (2012), "A Simple Method for Power Calculation in Experiments for
Treatment Comparison," The IEEE International Conference on Industrial Engineering and Engineering
Management, Dec, 2012.
14. Hamada, M., and Balakrishnan N. (1998), Analyzing Unreplicated Factorial Experiments: A Review with Some
New Proposals, Statistica Sinica, Vol. 8, pp. 1-41.
15. Johnson, M. E. and Nachtsheim, C. J. (1983), “Some Guidelines for Constructing Exact D-Optimal Designs on
Convex Design Spaces,” Technometrics , vol. 25, no. 3, 271-277.
16. Khuri, A. I., and Cornell, J. A. (1996), Response Surfaces: Designs and Analyses, Dekker, New York.
17. Kutner, M. H., Nachtsheim, C.J., Neter, J., and Li, W. (2005), Applied Linear Statistical Models,
McGraw-Hill/Irwin, New York.
18. Lenth, R. V. (1989), "Quick and Easy Analysis of Unreplicated Factorials," Technometrics, Vol. 31, pp.
469-473.
19. Meeker, William Q., and Escobar, Luis A. (1998), Statistical Methods for Reliability Data, John Wiley & Sons,
Inc., New York.
20. Montgomery, Douglas C. (2001), Design and Analysis of Experiments, John Wiley & Sons, Inc., New York.
21. Montgomery, Douglas C., and Peck, E. A. (1992), Introduction to Linear Regression Analysis, John Wiley &
Sons, Inc., New York.
22. Montgomery, Douglas C., and Runger, George C. (1991), Applied Statistics and Probability for Engineers, John
Wiley & Sons, Inc., New York.
23. Montgomery, Douglas C., and Runger, George C. (1993a), Gauge capability analysis and designed experiments.
Part I: Basic methods. Quality Engineering, 6, 1, 115-135.
24. Montgomery, Douglas C., and Runger, George C.(1993b), Gauge capability analysis and designed experiments.
Part II: Experimental design models and variance component estimation, 6, 2, 289-305.
25. Myers, R. H., and Montgomery, D. C. (1995), Response Surface Methodology: Process and Product
Optimization Using Designed Experiments, John Wiley & Sons, Inc., New York.
368
Appendix H: References
26. Plackett, R. L., and Burman, J. P. (1946), The Design of Optimum Multifactorial Experiments, Biometrika, Vol.
33, No. 4, pp. 305-325.
27. ReliaSoft Corporation (2007a), Accelerated Life Testing Reference, ReliaSoft Publishing, Tucson, AZ.
28. ReliaSoft Corporation (2007b), Life Data Analysis Reference, ReliaSoft Publishing, Tucson, AZ.
29. Ross, S. (1987), Introduction to Probability and Statistics for Engineers and Scientists, John Wiley & Sons, Inc.,
New York.
30. Sahai, Hardeo, and Ageel, Mohammed I. (2000), The Analysis of Variance, Birkhauser, Boston.
31. Searle, S. R. (1997), Linear Models, John Wiley & Sons, Inc., New York.
32. Searle, S. R. (1971), Topics in Variance Component Estimation, Biometrics, Vol. 27, No. 1, pp. 1-76.
33. Taguchi, G. (1991), Introduction to Quality Engineering, Asian Productivity Organization, UNIPUB, White
Plains, New York.
34. Taguchi, G. (1987), System of Experimental Design, UNIPUB/Kraus International, White Plains, New York.
35. Taguchi, Genichi, Chowdhury, Subir, and Wu, Yuin. (2005), Taguchi's Quality Engineering Handbook, John
Wiley & Sons, Inc., Hoboken, New Jersey.
36. Tukey, J. W. (1951), Quick and Dirty Methods in Statistics, Part II, Simple Analysis for Standard Designs,
Proceedings of the Fifth Annual Convention, American Society for Quality Control, pp. 189-197.
37. Wu, C. F. Jeff, and Hamada, Michael (2000), Experiments: Planning, Analysis and Parameter Design
Optimization, John Wiley & Sons, Inc., New York.
369