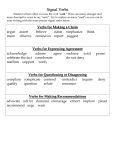
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
MASYARAKAT LINGUISTIK INDONESIA Didirikan pada tahun 1975, Masyarakat Linguistik Indonesia (MLI) merupakan organisasi profesi yang bertujuan mengembangkan studi ilmiah mengenai bahasa. PENGURUS MASYARAKAT LINGUISTIK INDONESIA Ketua Wakil Ketua Sekretaris Bendahara : : : : Faizah Sari, Universitas Katolik Indonesia Atma Jaya Rindu Parulian Simanjuntak, SIL Internasional Siti Wachidah, Universitas Negeri Jakarta Katharina Endriati Sukamto, Universitas Katolik Indonesia Atma Jaya DEWAN EDITOR Utama : Bambang Kaswanti Purwo, Universitas Katolik Indonesia Atma Jaya Pendamping : Faizah Sari, Universitas Katolik Indonesia Atma Jaya Anggota : Bernd Nothofer, Universitas Frankfurt, Jerman; Ellen Rafferty, University of Wisconsin, Amerika Serikat; Bernard Comrie, Max Planck Institute; Tim McKinnon, Jakarta Field Station MPI; A. Chaedar Alwasilah, Universitas Pendidikan Indonesia; E. Aminudin Aziz, Universitas Pendidikan Indonesia; Siti Wachidah, Universitas Negeri Jakarta; Katharina Endriati Sukamto, Universitas Katolik Indonesia Atma Jaya; D. Edi Subroto, Universitas Sebelas Maret; I Wayan Arka, Universitas Udayana; A. Effendi Kadarisman, Universitas Negeri Malang; Bahren Umar Siregar, Universitas Katolik Indonesia Atma Jaya; Hasan Basri, Universitas Tadulako; Yassir Nasanius, Universitas Katolik Indonesia Atma Jaya; Dwi Noverini Djenar, Sydney University, Australia; Mahyuni, Universitas Mataram; Patrisius Djiwandono, Universitas Ma Chung; Regina Yanti, Universitas Katolik Indonesia Atma Jaya. JURNAL LINGUISTIK INDONESIA Linguistik Indonesia diterbitkan pertama kali pada tahun 1982 dan sejak tahun 2000 diterbitkan tiap bulan Februari dan Agustus. Linguistik Indonesia telah terakreditasi berdasarkan SK Dirjen Dikti No. 040/P/2014, 18 Februari 2014. Jurnal ilmiah ini dibagikan secara cuma-cuma kepada para anggota MLI yang keanggotaannya umumnya melalui Cabang MLI di pelbagai Perguruan Tinggi, tetapi dapat juga secara perseorangan atau institusional. Iuran per tahun adalah Rp 200.000 (anggota dalam negeri) dan US$30 (anggota luar negeri). Keanggotaan institusional dalam negeri adalah Rp 250.000 dan luar negeri US$50 per tahun. Naskah dan resensi yang panduannya dapat dilihat di www.e-li.org dikirim ke Redaksi dengan mengikuti format Pedoman Penulisan Naskah di bagian belakang sampul jurnal. ALAMAT Masyarakat Linguistik Indonesia Pusat Kajian Bahasa dan Budaya Universitas Katolik Indonesia Atma Jaya JI. Jenderal Sudirman 51, Jakarta 12930, Indonesia e-mail: [email protected], Tel./Faks.: +62 (0)21 571 9560 Daftar Isi Forensic Linguistics: Forms and Processes Georgina Heydon ............................................................................. 1 A Distributed Morphology Analysis of Indonesian ke-/-an Verbs Lanny Hidajat ................................................................................... 11 Measuring Proficiency in Standard Indonesian for Enggano Speakers Rindu Parulian Simanjuntak ........................................................ 33 Akronim yang Berfonotaktik Tidak Lazim dalam Bahasa Indonesia Sariah ................................................................................................ 47 Verbs of Excretion in Taba Frederick John Bowden .................................................................. 63 The Role of Culture in the Translation Process through Think-Aloud Protocols Julia Eka Rini .................................................................................... 77 Resensi: Jan Zienkowski, Jan-Ola Östman, dan Jef Verschueren Discursive Pragmatics (Handbook of Pragmatics Highlights, volume 8) Diresensi oleh Faizah Sari .......................................................................... 93 Jelajah Linguistik: Meninjau Ulang Metodologi Kontemporer Faizah Sari .................................................................................................. 95 Bincang antara Kita dari Dunia Maya: Susunan Pengurus MLI dan Dewan Editor Linguistik Indonesia .... 99 Deklarasi dan Ikrar Anggota MLI ................................................... 100 Iuran Keanggotaan MLI dan Sumbangan Penerbitan Artikel .......... 101 Linguistik Indonesia, Februari 2014, 1-10 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 FORENSIC LINGUISTICS: FORMS AND PROCESSES Georgina Heydon* RMIT University [email protected] Abstract Following a brief introduction to the notion of forensic science and analysis, this paper will explain the different ways in which linguistics has contributed to police investigations and civil law. The paper will cover linguistic identification using spoken data and written data, and will discuss the use of discourse analysis as well as the more traditional phonetic and syntactic analysis for forensic examinations. Other applications that will be discussed include analysis for language of origin in refugee status claims, commercial applications and trademark disputes, and lie detection. Each of these applications will be considered critically and in relation to both the validity of the theories underlying them, and the statistical reliability of the analysis used to attain results. Keywords: Forensic linguistics; police investigations; credibility assessment Abstrak Menyusul pengenalan singkat pengertian ilmu dan analisis forensik, makalah ini akan menjelaskan bagaimana ilmu linguistik telah memberikan kontribusi terhadap penyelidikan polisi dan hukum perdata. Makalah ini akan mencakup identifikasi linguistik menggunakan data lisan dan data tertulis, dan akan membahas penggunaan analisis wacana serta analisis fonetik dan sintaksis yang lebih tradisional untuk pemeriksaan forensik. Aplikasi lain yang akan dibahas meliputi analisis untuk bahasa asal gugatan status pengungsi, aplikasi komersial dan sengketa merek dagang, dan deteksi kebohongan. Masing-masing aplikasi akan dipertimbangkan secara kritis dan dalam kaitannya dengan kedua validitas teori-teori yang mendasari mereka, dan keandalan statistik analisis yang digunakan untuk mencapai hasil. Kata kunci: Linguistik Forensik; penyelidikan polisi; penilaian kredibilitas INTRODUCTION When most people hear the term ‘forensics’ they immediately think of boffins in white coats performing almost magical scientific tests to provide that crucial piece of rock-solid evidence that solves a complex crime. On the rare occasion that a language expert is featured in one of the many television crime dramas, the expert is invariably able to rely on some kind of supercomputer to identify suspects by their ‘voiceprint’, irrespective of the quality or quantity of data available. Sadly, such an image is strictly limited to the realm of science fiction at this stage, as no-one has yet been able to isolate a uniquely distinguishing feature of the human voice upon which to base such a ‘voiceprint’. Nonetheless, the student of linguistics, excited by the possibilities of such a real-world application of their skills in analysing language, should not be put off by this gap between myth and reality: the truth is that forensic linguistics is a more varied and fascinating field than could ever be imagined by a lay audience. Forensic linguistics, and the study of language and the law more broadly, requires the analyst to enlist a wide variety of analytic tools and skills, drawing on almost every aspect of core linguistic study, from phonetics to pragmatics, from syntax to sociolinguistics. Forensic linguistic enquiries may form part of criminal investigations by police, or they may be initiated by the defence team on behalf of a client. They may involve trademark disputes or even non-legal concerns, such as selecting the most appropriate brand name for a product to be launched in a specific market. Georgina Heydon The International Association of Forensic Linguists and the International Association for Forensic Phonetics and Acoustics were formed in the early 1990s by specialists working in these areas and, while each organisation represents a different emphasis in the field, they are both represented by the scholarly publication, the International Journal of Speech, Language and the Law. The aim and purpose of International Association of Forensic Linguists, from the website www.iafl.org: ‘The purpose of the Association is to improve the administration of the legal systems throughout the world by means of a better understanding of the interaction between language and the law.’ AN EARLY EXAMPLE OF FORENSIC LINGUISTIC ANALYSIS The following case study will give some indication of the breadth of scholarship needed by the forensic linguist in providing expert evidence. In 1950, Timothy John Evans was hanged for the murders of his wife and child at 10 Rillington Place, London. Evans had maintained his innocence, and accused John Reginald Halliday Christie of committing the crimes, despite the fact that the police were able to produce an allegedly verbatim record of Evans confessing to the murders in his police interview. In a dramatic turn of events, Swedish linguist Jan Svartvik showed, in 1968, that the confession used to convict Evans was most likely the product of police influence and differed sharply in style and structure from the remainder of Evans’s statements. Svartvik 1968 was able to show, using linguistic analysis of the discourse structures, that the key sections of the statement, where Evans apparently confesses to the murders, are written using a formal register, typical of police texts, but most atypical of the speech of Evans and inconsistent with the remainder of the interview transcript. Evans was posthumously pardoned and, when several more bodies were discovered at 10 Rillington Place, Christie was hanged. Svartvik’s analysis of the Evans case, often cited as the original forensic linguistic investigation, involved the analysis of syntactic structure, style, register, spoken language versus written language, and knowledge of the specific police register used in statement taking. It is interesting that this landmark case did not involve the analysis of vocal qualities, which has now become the archetypal forensic linguistic application. HERE ARE SOME TYPES OF FORENSIC ANALYSIS Identification The types of analysis that are most commonly associated with the practice of forensic linguistics are those that seek to identify the source of a message. This includes the analysis of spoken and written data, and can involve some level of computer or statistical analysis. The data being used in the analysis will almost always include at least one sample of ‘known data’, where the source has been reliably identified, and one sample of ‘questioned data’, where the source is unknown. There may be some rare cases where two data samples are compared to establish whether or not they originate from the same source, without either being identified as belonging to a specific speaker. A ‘scoresheet’ may be devised, where each segment from the questioned data is rated against the known data for similarity. 2 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Spoken Data There is some debate as to whether identifying the source of spoken data should be labeled ‘voice identification’ or ‘speaker identification’, but either way, the process for this kind of analysis involves comparing samples of recorded voice data in order to establish the likelihood that they represent samples of the same voice, versus the likelihood that they represent samples of different voices. Individual sounds as well as longer stretches of talk are usually isolated for comparison across the samples. Nowadays, this is done using some form of digital sound editing software that allows the analyst to isolate very small amounts of speech data, such as one vowel sound, into separate files or segments. In this way, the analyst can collect many tokens of specific sounds or utterances which represent different aspects of the voice(s). So for example, the analyst may choose to isolate all the instances of close front unrounded vowels (the vowel in seen), and compare them across the samples using either an automated or machine-assisted process or by listening with an ‘expert ear’. This process would then be repeated for a range of individual phonemes, as well as for longer stretches of talk. The approach that is commonly known as forensic phonetics involves the automated or semi-automated processing of vocal data segments according to measurable features, such as formant values (see the box below), pitch range or the rate of speech. This computer-based analysis may be supported by the expert phonetician’s perception of the vocal features in each sample. During speech production, the air in the vocal tract vibrates at many different frequencies at once and in the production of vowel sounds, the most dominant frequencies combine and appear as bands on a spectrograph image of the air vibrations. Each of these bands is known as a formant and the different vowels are typically characterised by the different combinations of the first three formants (i.e. the three bands appearing at the lowest frequencies). When the analysis relies solely on the expert’s ‘ear’ to determine the phonetic qualities of the samples, the term used by some forensic linguists is ‘aural-perceptual analysis’ (Hollien 2002). The analyst considers the data in terms of various vocal parameters, such as perceived pitch, articulation and prosody, which can be heard and compared across samples. The aural-perceptual analysis in particular may also rely on the analyst’s knowledge of dialectology and sociolinguistics to compare the data samples. In this kind of analysis it is the presence of certain dialectal features that enables the analyst to distinguish the two speakers. For the analysis of spoken data in legal cases, the known data samples are very often drawn from a recording of the police interview with the suspect. The unknown data samples are usually some form of covert recording obtained by tapping the suspect’s phone, or from a concealed recording device, but in one case well known to the author, the questioned audio data samples were extracted from a video surveillance tape (CCTV) made during armed robberies allegedly committed by the suspect. While the video footage was of such poor quality that the person committing the crimes could not be identified visually, the audio tracks were of high quality and provided critical evidence in the case. Written Data The principles of the forensic examination of written data are essentially the same as for spoken data – that is, samples of known and questioned data are compared according to a set of linguistic parameters. In the case of written texts, the sorts of features that can be systematically analysed include punctuation, sentence structure, verb types, terms of address, spelling and grammatical errors, any idiosyncrasies of the writer, and broader patterns of discourse, such as the development of specific themes. 3 Georgina Heydon One of the problems facing prosecutors in legal cases that involve written data is how to obtain known data samples from the suspect. Very often, the questioned material, such as a threatening letter or ransom note, is readily available as it forms the basis for the complaint against the suspect. The known text, where available, often has to be drawn from personal communications signed or otherwise identified as written by the suspect. Email is becoming a major source of this kind of data, but it is important that the impact of the medium of communication is taken into account when comparing email with, say, a handwritten letter. The method of analysis might also present problems for a court. In the case described below, the court was unable to accept the results of a statistical analysis of punctuation data but instead decided to rely entirely on the qualitative analysis of specific features. This highlights the differences between courtroom rules of evidence and academic standards of validity. This issue is discussed further in the Summary of Key Issues below. Case study: A murder trial in which I gave evidence in the Bendigo Supreme Court (Victoria, Australia) involved the analysis of four anonymous letters that contained threats against both the deceased and the accused. The letters were produced as evidence of the accused man’s innocence by the defence, but were deemed suspicious by the prosecution, as explained below. The case revolved around the death by arson of a middle-aged woman living in a rural part of Australia with her husband. The couple had not been living in the area very long, and had apparently been subject to a campaign of bullying or at least social rejection and threats from the local community, and might have had some specific enemies in the town. A short time after they had arrived in the town, the wife died in suspicious circumstances as a result of a fire at the couple’s property. During the police investigation into her death, the husband was arrested and charged with her murder, but he subsequently pleaded not guilty in court. In his defence, the husband produced four short letters printed together on a single sheet of paper. He claimed that he had copied the letters from their original source although it was unclear in the trial whether this was an email source or hard copy letters. In any event, the evidence consisted of a series of four letters that were alleged to have been written to the couple by a third party or group of people who were apparently vehemently opposed to the couple residing in their community. The defence had presented these letters as evidence that there was an existing threat against the wife and it was these other people that had carried out attack that ended the life of the victim. When other evidence was gathered that suggested the husband was the perpetrator, such as crime scene evidence related to the fire, the police decided that the letters should be verified for their authorship. At the time of my analysis I was unaware of the context surrounding the evidence. I was only provided with a copy of the four letters and a collection of emails sent by the husband to his wife immediately prior to her death. These emails were used in the analysis as the ‘known data’, since their authorship was not in dispute. Despite my lack of knowledge about the case, I believe I did make some suppositions, unconsciously, about the data. For instance, I recall that I had an expectation that all the threatening letters would have been produced by the same author – either the suspect or some unidentified party. In other words, although I compared each letter to the known data set individually, I expected to find that 4 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 either all the letters would match the known data set or none of them would match the known data set. It was therefore an unexpected outcome that three of the letters did have a strong match with the known data set, but one letter, the first letter on the page, had a very weak match, or a negative match, with the known data set. The analysis of data that I carried out consisted of two main phases: the first was an analysis of syntactically classified punctuation as described in Chaski (2001). In this paper, Chaski demonstrates how punctuation marks that are quantified and classified according to their syntactic function can be used reliably to differentiate between authors of a number of written (English language) texts. The second phase was a comparative stylistic analysis of specific words and phrases used across the two sets of texts. There were a number of rather idiosyncratic spelling and grammatical choices that appeared in the known data set and the three later letters, but not in the first letter. While punctuation was analysed in the first phase for its syntactic function, in the second phase I noted some patterns of punctuation that appeared in the three later letters and the emails but not the first letter. The pattern of first person pronouns (“I” and “we”) that were used in the letters also changed between the first letter and the later three letters. Finally, I examined the use of taboo language (terms of abuse) and I found that there was a clear shift between the first letter and the later three letters in the type and strength of the abusive language that appeared. English swear words are highly sensitive to hierarchical ordering: that is, English speakers easily able to distinguish between swear words according to their level of social taboo and there are clear examples in everyday usage of certain words being banned under certain circumstances, most obviously in the media. Therefore, when a writer uses some moderate swear words but not other more offensive words, they are making a conscious choice to restrict the level of taboo language. In the evidence for this case, the first letter contained emphatic but only moderately offensive swear words. This contrasted strongly with the remaining three letters where the swear words and taboo phrases used were of the most highly offensive categories, for instance, words that are almost always banned in public television broadcasts even for an adult audience. As is typical in forensic casework, it was about two years before I was called to give evidence in court. At the Supreme Court trial in Bendigo it became clear that the case for the prosecution was consistent with my findings. Although the couple had received one threatening letter from anonymous community members, and may have received verbal threats as well, the accused was believed to have written the other three letters to exaggerate the threat and present the author/s of the original letter as the murderers. My evidence was considered along with other forensic evidence such as chemical analyses of the burnt materials in the room where the wife perished to aid the identification of the accelerants used in the fire. My evidence was presented over two days, most of which was taken up by the defense in cross examination. Naturally, a great deal was made of the differences identified between the first letter and the other three, and the defense case rested mainly on the assertion that just as authors can change their style of writing over the course of their career, an individual might change the way that they write a series of threatening letters. It is difficult to refute an assertion like this when being cross-examined in the adversarial court system, because you are confined to answering questions. The 5 Georgina Heydon counsel for the defense began by asking me if I’d read several works by Hemingway, or EM Forster or Evelyn Waugh. There ensued a rather ugly attempt to smear my professional standing on the basis that I had not read much of these early twentieth century writers. I suggested Mervyn Peake, but Peake’s books were unknown to the defense counsel, and at that point the judge interrupted this farcical cross-examination to insist that the defense counsel get to the point. Counsel then tried to have me agree to the assertion that although authors have a distinctive style, this can change over time, just like a letter writer. I refused to agree with this assertion, and forced Counsel to request that I explain my refusal. This gave me the opportunity to point out that the work of famous authors is not at all like the production of letters used in forensic linguistic analysis most obviously because, unlike famous authors, threatening letter writers do not have their work modified by an editor. Astonishingly, the counsel for the defense tried to claim that truly great authors never have their work modified by editors, but even the jury laughed at this claim. It was difficult to ignore the sarcasm and derision used by the defense counsel to emphasize his claims, but at such times it is always necessary to focus on the content and validity of the claims, and not the emotional impact of their delivery. As the cross-examination continued, I was able to explain that the analysis of syntactically classified punctuation (Chaski 2001) that I had undertaken is not just a matter of style, but can distinguish between authors on statistical grounds. The jury were quite interested in my evidence, perhaps because it was easier to understand than chemical analysis and burn marks. The two types of evidence that I gave seemed to be reasonably well understood, and although the comparative stylistic analysis was clearly more accessible to the jury than the statistical analysis of punctuation, like most researchers, I felt the quantitative punctuation analysis was more reliable. The judge, however, eventually made a decision that the evidence relating to the Chaski method of analysis could not be admitted, because Chaski’s article had only been published three or four years before I had used it in my analysis. In a courtroom, this is not considered long enough for a published method to be properly tested and accepted as reliable. This illustrates an important feature of courts, at least in an adversarial system: the main test of whether a particular kind of evidence can be admitted as part of a case is precedence. If evidence of this kind has been admitted by a judge in a higher court, or an equivalent court in another country, then it is deemed acceptable. What this means, however, is that whenever a completely new kind of expert evidence is presented to the court, the judge faces a great deal of pressure in deciding whether or not to allow the novel procedure or expert evidence. If the evidence is allowed, then it sets a legal precedent, and all other lower or equivalent courts can accept this evidence too. In the Supreme Court, the judge’s decision to allow a new type of evidence will flow on to most other courts in the country (Supreme, County and Magistrates for example). Thus, it should not have been surprising that the Bendigo Supreme Court judge was rather cautious about allowing what he saw as a novel form of analysis, namely Chaski’s syntactically classified punctuation, even though from a scientific perspective, his reservations were ill-founded. 6 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Over the last ten years, cases have been undertaken by forensic linguists that involved mobile phone text messages, and the distinctively individual nature of text messages is considered an advantage in author identification. For instance, handwriting and typeface comparison are not considered part of forensic linguistic practice, but are often carried out by the relevant experts in conjunction with the forensic linguistic analysis. Discourse Analysis The area of forensic discourse analysis is concerned with the appropriateness of interviewing techniques, the interpretation of legal texts, suspect profiling and other applications of discourse analysis to a legal case or to law enforcement more broadly. An interpretation of a legal text for a Bankruptcy case in heard in the Federal Court of Australia is described below. The expert testimony reads: The semantic interpretation of the adjectival phrase standing to the credit of rests in the aspect of the verb form standing. It is possible to expand the elliptical form of the phrase from the moneys standing to the credit of to the full, implied form the moneys [that are] standing to the credit of. The structure of standing is thus TO BE + stand + ING. This form is the present progressive and is described by Kreidler 1998 as a temporary or bounded form. Kreidler further notes that: ‘the present progressive is used for what is temporarily true’. Thus, the activity standing to the credit of is confined to a bounded period of time – it does not extend indefinitely as might be the case with the simple present stands to the credit of, which would express a durative activity, something that may continue to be true. Conclusion. According to the semantic analysis of the questioned text, the phrase the moneys standing to the credit of is highly likely to be interpreted by the addressee to mean that the moneys are those standing to the credit of the relevant accounts at the time that the words were written – that is, the date of the Order or, at the latest, the date of the Order being read by the addressee. In this case, an Order was made by a judge prohibiting the defendant from accessing money held in various bank accounts. The forensic linguistic analysis focused on a phrase used in the Order where it described the relevant funds as ‘moneys standing to the credit of [bank accounts held by the defendant and his associates]’ and considered whether or not the paragraph would be reasonably interpreted to mean that the word ‘moneys’ referred only to funds in the relevant accounts at the time that the Order was made, and not to any future funds credited to the accounts. Language of Origin Linguists may be called on to identify a speaker’s national or regional origin. This is done by analyzing features of their language such as accent, vocabulary and grammatical features. Clearly, this type of analysis has applications in establishing refugee status, where it is commonly used, but as it requires the analyst to have a thorough knowledge of both language acquisition theory and the very specific regional dialect spoken by the subject, its legitimacy is strongly contested by organizations such as the International Association of Forensic Linguists. Commercial Applications There are many commercial applications of forensic linguistics, but the most common applications are in disputes over trademarks and copyright. Very often a company will require expert testimony as to the extent to which a rival company may have infringed copyright or trademark legislation in naming or promoting a new product. 7 Georgina Heydon A case study is provided below, but names and geographic references have been changed to protect the commercial interests of the clients. Company A was introducing a new Scotch Whiskey onto the market, and had chosen the name Hoch Ay: a purely made-up name that was perhaps intended to reflect the Scottish origins of the drink. However, another company, Company B, already had a brand of Scotch Whiskey called Hawk Eye. Company B was suing Company A for copyright infringement on the basis that if the name of the product made by Company A (Hoch Ay) were to be pronounced with a Scottish accent, it would sound identical to the name of the product made by Company B (Hawk Eye). In a crowded bar or nightclub, where the drink would be sold, Company B claimed that this would cause unacceptable brand confusion. A forensic linguistic analysis was required to show whether a) the brand name Hoch Ay would indeed sound like Hawk Eye if it were pronounced with a Scottish accent and b) the target market of young Australian adults would adopt a Scottish accent to pronounce the brand name Hoch Ay. The analysis cannot be discussed in any detail because the actual case did not involve a Scottish accent, or even an English language accent. However it may be useful to make some general observations about the case, because it involves variational sociolinguistics, rather than phonetics, syntax or semantics. Part a) was a straightforward analysis of the made up words of the new brand name according to the rules of a foreign pronunciation. Part b) was a more difficult sociolinguistic analysis, because it involved research into the socioeconomic status of the target market, and then a calculation of the likelihood of this group using a foreign accent to pronounce a made up, but potentially foreign, brand name. At the time of writing this case has not gone to trial, but it may yet come before the courts at which time the results can be published in full. Lie Detection Various forms of linguistic analysis are employed by those attempting to establish the veracity of written, and sometimes spoken, statements. Often the analysis includes consideration of personal pronouns, tense, vocabulary items and sentence structure, but does not usually take account of socio-cultural and regional variation in language use. This type of analysis is only loosely classed as forensic linguistics as its validity is often the focus of disagreement among professionals and academics working in the area. It is important to emphasize that commercial methods of lie detection involving the analysis of written texts, such as Scientific Content Analysis and Criteria Based Content Analysis, have not been verified by laboratory testing. A great deal of psychological research has been conducted into verbal cues to deception (see Vrij 2008 for a comprehensive introduction), but far less attention has been paid to the linguistic methods purportedly used in for example Scientific Content Analysis (but see Heydon 2008). Identifying reliable of deception in written texts is therefore a critical area of research for scholars wishing to make a valuable contribution to forensic linguistics. SUMMARY OF KEY ISSUES A major concern for members of the international forensic linguistics community is the reliability of the evidence obtained through forensic linguistic analysis. There continues to be much controversy surrounding almost every aspect of forensic linguistics described in this paper, primarily due to questions of methodology and expertise. In many instances, the debate 8 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 focuses on whether the analytic technique is statistically valid, though in some cases, such as lie detection and language of origin analysis, the main concern is that the methods are not based on sound sociolinguistic and/or language acquisition theory in the first place, but are used uncritically by government departments and law enforcement agencies. In such cases, many linguists have considered it their professional duty to inform and educate such agencies about the pitfalls of using unreliable analytic techniques. The controversy over the statistical reliability of analytic methods, especially in the area of voice or authorship identification, is generating intense debate within the forensic linguistic community. There is a clear division between those who reject all analysis that cannot be statistically validated, and those who argue that there is a place for qualitative analysis, such as dialectology and sociolinguistic analysis, in expert testimony. In cases relating to the analysis of discourse structure, and especially where the dispute centres on the interpretation of a legal text (see the case study above) it is common for the linguistic evidence to be disregarded on the basis that such interpretation is a matter for legal experts, not linguists. In the case presented above concerning the semantic interpretation of the verb standing, the judge ruled that the matter was a point of law and therefore not the province of a linguist, irrespective of their expertise. The question of whether linguistic expertise will be recognized by courts, or whether linguistic evidence will be allowed by judges or magistrates, is further complicated by the reliance on precedence as a method for selecting evidence for inclusion. As discussed earlier, judges and magistrates are wary of allowing new kinds of evidence or expertise into their courts and thus setting a legal precedent. As members of an international community, forensic linguists have a role to play in furthering the reach of our expertise. The publication of the International Journal of Speech, Language and the Law is part of this process of improving our profile and chances of recognition as experts. However there is more that can be done by linguistic associations, such as KIMLI, simply by raising awareness of linguistics as a science. All too often, legal practitioners report that they would never think to consult a linguist about matters of language, because they believe that all their experience in writing legal cases and appearing in court makes them experts in language by default. They, like many members of the general public, are blissfully unaware of the discipline of linguistics as the scientific study of language as a system. In the bankruptcy case described above, the judge simply refused to accept that there was such a field as ‘linguistics’, which makes you wonder what we all do for a living! NOTE * I would like to thank an anonymous reviewer for very helpful comments on the earlier draft. FURTHER READING The International Journal of Speech Language and the Law is published by Equinox. ISSN (print) 1748-8885, ISSN (online) 1748-8893 See also Coulthard 1997; 2000; Danet 1980; Gibbons 1994; Hall and Collins 1980; Hammarström 1987; Jensen 1995; Kaplan, Green, Cunningham et al. 1995; Shuy 1993; Solan 1998. REFERENCES Chaski, C. 2001. Empirical evaluations of language-based author identification techniques. Forensic Linguistics: The International Journal of Speech, Language and the Law 8 (1): 1-65 9 Georgina Heydon Coulthard, Malcolm. 1997. A failed appeal. Forensic Linguistics: The International Journal of Speech, Language and the Law 4: 287-302. Coulthard, Malcolm. 2000. Whose text is it? On the linguistic investigation of authorship. In Discourse and Social Life, ed. by Malcolm Coulthard and Srikant Sarangi. Harlow: Longman. Pp. 270-87. Danet, Brenda. 1980. Language in the Legal Process. Law and Society Review 15: 445-565. Gibbons, John (ed.). 1994. Language and the Law. London: Longman. Hall, M. C. and A. M. Collins. 1980. The admission of spectographic evidence: A note of Reg v Gilmore. The Australian Law Journal 54: 21-24. Hammarström, Göran. 1987. Voice identification. The Australian Journal of Forensic Sciences 19 (3): 95-99. Heydon, Georgina. 2008. The art of deception: myths about lie detection in written confessions. In L. Smets and Aldert Vrij (Eds) Cahiers Policestudies: Special Investigative Interviewing techniques; The use of written - and oral analyses. Brussels, Politeia pp 173-186 Hollien, Harry F. 2002. Forensic Voice Identification. San Diego and London: Academic Press. Jensen, Marie-Therese. 1995. Linguistic evidence accepted in the case of a non-native speaker of English. In Language in Evidence: Issues Confronting Aboriginal and Multicultural Australia, ed. by Diana Eades. Sydney: University of NSW Press. Pp. 127- 46. Kaplan, J.P., G.M. Green, C.D. Cunningham and J.N. Levi. 1995. Bringing linguistics into judicial decision-making: semantic analysis submitted to the Supreme Court. Forensic Linguistics: The International Journal of Speech, Language and the Law 2: 81-98. Kreidler, Charles W. 1998. Introducing English Semantics. London: Routledge. Shuy, Roger W. 1993. Language Crimes: The Use and Abuse of Language in the Courtroom. Oxford: Blackwell. Solan, Lawrence M. 1998. Linguistic experts as semantic tour guides. Forensic Linguistics: The International Journal of Speech, Language and the Law 5 (2): 87-106. Svartvik, Jan. 1968. The Evans Statements: A Case for Forensic Linguistics. Gothenburg Studies in English 20. Göteborg: Göteborgs Universitet. Vrij, Aldert. 2008. Detecting Lies and Deceit: Pitfalls and Opportunities. Second Edition. Chicester: John Wiley and Sons Ltd. 10 Linguistik Indonesia, Februari 2014, 11-31 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 A DISTRIBUTED MORPHOLOGY ANALYSIS OF INDONESIAN KE-/-AN VERBSi Lanny Hidajat* Atma Jaya Catholic University [email protected] Abstract Indonesian ke-/-an verbs have a complex argument structure. Similarly to Indonesian passive di- verbs, ke-/-an verbs never have an agentive NP in the subject position and their subject NPs must be definite. However, unlike passive di- verbs, these verbs generally cannot be followed by an agentive prepositional phrase. In addition, when ke-/an verbs have two arguments, the applied argument appears in the subject position instead of the internal one. In this study, the structure of Indonesian ke-/-an verbs is analyzed by using the Distributed Morphology framework (Folli dan Harley, 2002; Kratzer, 1996; Marantz, 1997; among others). Based on the verbs’ distribution and interpretation, this study argues that of ke-/-an verbs are derived by attaching the ke-/-an circumfix, which is an overt representation of a verbalizing head, to the projection of ROOT. Keywords: ke-/-an circumfix, verbalizing head Abstrak Verba berimbuhan ke-/-an mempunyai struktur kalimat yang kompleks. Seperti verba pasif berawalan di-, subjek dari verba berimbuhan ke-/-an tidak pernah pelaku tindakan dan bersifat takrif. Tetapi, tidak seperti verba pasif berawalan di-, verba berimbuhan ke-/-an tidak bisa diikuti oleh pelaku tindakan di posisi objek. Selain itu, pada saat verba berimbuhan ke-/-an memiliki dua nomina, maka verba ini akan didahului objek tidak langsung dan diikuti oleh objek langsung, bukan sebaliknya. Dalam artikel ini, struktur verba berimbuhan ke-/-an akan dianalisis dengan kerangka teori Distributed Morphology (Folli dan Harley, 2002; Kratzer 1996; Marantz 1997; dan lain-lain). Menurut kerangka teori ini, verba berimbuhan ke-/-an dibentuk dari proses afiksasi antara imbuhan pembentuk verba ke-/-an dengan akar kata (ROOT) yang belum mempunyai kategori. Argumen ini diajukan sesuai dengan distribusi dan makna Verba berimbuhan ke-/-an. Kata kunci: sirkumfiks ke-/-an, pembentuk verba THE IDIOSYNCRASIES OF INDONESIAN KE-/-AN VERBS Little has been said in the literature about Indonesian ke-/-an verbs, presumably because the voice of ke-/-an verbs is less productive than the active voice, in which the verbs are optionally marked by the prefix meN- or N-, and the passive voice, in which the verbs are obligatorily marked by the prefix di-. In fact, the voice of ke-/-an verbs is interesting and poses problems which need to be solved because of its complex nature, as already noted in the previous studies (Dardjowidjojo 1966 and Sneddon 1996, 2000). The fact that this voice has an interesting argument structure is exemplified in the following two sentences, in which the theme role is assigned to an NP in a different position: (1) Gudang itu kebakaran Warehouse that KE-burn-AN ‘The warehouse was on fire.’ Lanny Hidajat (2) Joni kejatuhan mangga. Joni KE-fall-AN mango ‘Joni was fallen on by a mango.’ In (1), the theme role is assigned to the subject NP. On the other hand, in (2), theme is assigned to the object NP, while the subject NP is goal. Although the position of the theme NP in (1) is different from the one in (2), the form of the ke-/-an verbs in both sentences in the same. This is in contrast to the verbs in active voice which undergo a change in form when the theme NP is in a different position, as exemplified in (3): (3) a. Gambarnya udah nempel. Picture-DET already N-stick ‘The picture is already stuck.’ b. Paman nempelin gambar itu. Uncle N-stick-IN picture that ‘Uncle stuck the picture (to something).’ In (3a), the theme role is assigned to the subject DP; while, in (3b), it is assigned to the object NP. Correspondingly, unlike the N- verb in (3a), the one in (3b) is also affixed by the suffix –in. The idiosyncratic behavior of ke-/-an verbs is also indicated by the number of the NP arguments that they can take. Some ke-/-an verbs, such as: kebakaran ‘to be on fire’, keguguran ‘to miscarry’, and kebongkaran ‘to get broken into (referring to a house)’, can only have one NP argument. Other ke-/-an verbs, such as: kejatuhan ‘to be fallen on by’, kerobohan ‘to be collapsed on by’, and ketumpahan ‘to be spilled by’, must have two NP arguments. There are also ke-/-an verbs that can have either one or two NP arguments. This class of ke-/-an verbs can be categorized into three sub-classes, as follows: i. Ke-/-an verbs with an optional NP complement: As already noted by Dardjowidjojo (1978), the NP complements of some ke-/-an verbs can be optional; especially when these verbs appear in discourse. Included in this sub-class are: kecopetan ‘to have (something) stolen by a pickpocket’, kecurian ‘to have (something) stolen’, and kebagian ‘to get a share’. The ke/-an verbs of this sub-class may occur in a sentence without an object NP; however, native speakers always interpret them as if they occur with their object NP, as in (4). This fact indicates that the object NPs of the ke-/-an verbs of this sub-class are actually a verb complement. (4) Joni kecopetan (dompet). Joni KE-pick.pocket-AN wallet ‘Joni’s wallet was stolen by a pickpocket.’ ii. Ke-/-an verbs verbs with an optional NP complement with agentive flavor: The optional object NPs of this sub-class of ke-/-an verbs are different from the ones of the previous subclass because they have an agentive flavor, as exemplified in (5): (5) Aduh! Bukunya Joni kedudukan (ama) (Bobi) nih! EXCL book.DET Joni KE-sit-AN by Bobi this ‘Oh, no! Joni’s book was sat on (by Bobi)!’ The optional object NPs of this sub-class of ke-/-an verbs appear to be agentive because of the following reasons: i) the object NP is optional and can be animate, and ii) when the object NP is animate, it is optionally introduced by the preposition ama ‘by’. The agentive flavor the object NPs of this sub-class of ke-/-an verbs may mislead one to assume that they are analogous to the agentive adjunct in passive voice marked by the prefix di-. This assumption implies that the argument structure of this sub-class of ke-/-an verbs is similar to that of passive di- verbs. However, the optional object NP of this sub-class of ke-/-an verbs is actually not an agent because the ke-/-an verbs cannot be modified by subject-oriented 12 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 manner adverbials or instrumental phrases (see endnote v). This consequently means that this sub-class of ke-/-an verbs is not another type of passive voice. Included in this sub-class of are: kedudukan ‘to be sat on (by someone)’ and ketutupan ‘to be blocked (by someone)’, and kemasukan ‘to be broken into (by someone).’ iii. Ke-/-an verbs verbs with an optional NP complement with agentive flavor complement and VP complement: The following ke-/-an verbs: kelihatan ‘to be visible’ or ‘to be seen (doing something)’, kedengaran ‘to be audible’ or ‘to be heard’, ketahuan ‘to be found out (doing something)’, and kedapatan ‘to be found out/detected (doing something)’, form a sub-class because they are optionally followed by either an object NP or a VP or both, as represented in the following sentence. The optional object NPs of this sub-class of ke-/-an verbs also appear to be agentive adjunct. (6) Dia/Joni kelihatan (ama) (Wati) (lagi marahin 3sg/Joni KE-see-AN by Wati PROGRESS angry-IN ‘He/she/Joni was seen (by Wati) scolding Sita.’ Sita). Sita In this study, the argument structure of ke-/-an verbs is explained under the Distributed Morphology framework (DM) (Marantz 1997, 2001; Harley and Noyer 1999, among others). Further explanation of DM and the analysis of the argument structure of ke-/-an verbs are discussed below. Beforehand, the following sections discusses issues related to how the argument structure of ke-/-an verbs is analyzed, which are: the interpretation of ke-/-an verbs, the distribution of ke-/-an verbs in comparison to the distribution of active meN-/N-/- verbs and passive di- verbs, and the eventivity of ke-/-an verbs. ANALYZING THE ADVERSATIVE INTERPRETATION OF KE-/-AN VERBS A serious attempt to analyze the structure of ke-/-an verbs was made by Dardjowidjojo (1978). According to Dardjowidjojo (1978:117), ke-/-an verbs have the following semantic features: (i) the event or condition is unexpected, unpredicted, or unavoidable, and (ii) the effect is adversative. He classifies ke-/-an verbs based on syntactic-semantic criteria and then argues that the various derivations of ke-/-an verbs are the result of affixing the adversative feature, which is in the form of the prefix ke- and the suffix –an, to the roots, which can be verbal, adjective, or nominal (Dardjowidjojo 1978: 117). Dardjowidjojo’s analysis of the structure of ke-/-an verbs implies that all ke-/-an verbs have adversative interpretation. This means that the event described by a ke-/-an verb always negatively affects its argument, in particular the subject NP. For instance, in (7), the event ketiduran ‘to oversleep’ negatively affects the subject NP Joni because it causes Joni to come late to school. (7) Joni ketiduran jadi telat ke sekolah. Joni KE-sleep-AN so.that late to school ‘Joni overslept so that he was late to school.’ Yet, not all ke-/-an verbs are adversative. For instance, the event described by the ke-/an verb kebagian ‘to get a share of’ does not negatively affects the subject NP Joni. (8) Joni kebagian mangga. Joni KE-share-AN mango ‘Joni got a share of a mango.’ Similarly, the subject NP suaranya ‘his sound’ in (9) is not negatively affected by the ke-/-an verb kedengaran ‘to be audible’ (9) Suaranya kedengaran dari sini. Sound-DET KE-listen-AN from here ‘His voice can be heard from here.’ 13 Lanny Hidajat The fact that not all ke-/-an verbs are adversative reflects that the adversative interpretation of ke-/-an verbs is not the result of affixing the circumfix ke-/-an to the root. In this paper, I argue that it actually originates in the speakers’ real-world knowledge. This argument is based on the fact that whether or not a ke-/-an verb is adversative depends on the context in which it appears, as reflected in the interpretation of kebakaran ‘to be on fire’ in the following sentences: (10) Bangunan tua itu kebakaran structure-AN old that KE-burn-AN ‘The old building was on fire.’ In (10), it is not indicated whether or not bangunan tua ‘old building’ is owned by someone; therefore, kebakaran ‘to be on fire’ is not adversative. However, as noted by Sneddon (1996:124), in (11), kebakaran has an indirect adversative interpretation because the possessor of the entity which is on fire is indicated. (11) Rumahnya kebakaran House-3sg KE-burn-AN ‘His/her house was on fire.’ Sneddon argues that the adversative interpretation in (11) is indirect because kebakaran adversely affects the possessor of the entity which is on fire (i.e. -nya), instead of the entity itself (i.e. rumah ‘house’). As shown in (12), kebakaran will still have an indirect adversative interpretation even if the possessor of the entity which is on fire is only given in the discourse. (12) Amat kemarin beli rumah. Sekarang rumah itu kebakaran. Amat yesterday -buy house now house that KE-burn-AN ‘Amat bought a house yesterday. Now, the house is on fire.’ In (12), kebakaran still adversely affects Amat, although Amat does not appear in the sentence containing kebakaran. This is because in the earlier sentence it is stated that Amat was the owner of the house which was on fire. Interestingly, in (13), kebakaran loses its indirect adversative interpretation although it appears with the possessor of the entity which is on fire: (13) Jonii sangat senang waktu rumahnyai kebakaran, karena diai akan dapat uang asuransi. ‘Jonii was very happy when hisi house was on fire as hei would get some money from the insurance.’ -nya in rumahnya ‘his house’ refers to Joni. This means that Joni should be adversely affected by kebakaran. However, because of the context in which it appears, kebakaran even has a benefactive interpretation in (13), instead of adversely affecting Joni. The fact that kebakaran does not always have adversative interpretation, as reflected in sentences (10) to (13), shows that it is discourse and real-world knowledge that create the adversative interpretation of ke-an verbs. If adversative interpretation is the property of ke-/-an verbs, then kebakaran always have adversative interpretation, even when it appears in a context such as in (13). Similarly to kebakaran ‘to be on fire’, ketiduran ‘to oversleep’ can be either adversative, as in (7), or not adversative, as in (14), depending on the context in which it appears. The adversative interpretation in (7) emerges because, according to real-world knowledge, being late to school is not a good thing. On the other hand, in (14), ketiduran triggers a benefactive interpretation because real-world knowledge tells us that escaping from an accident is a good thing. (14) Pagi ini pesawat Garuda mengalami kecelakaan. Untungnya, Boby ketiduran sehingga ia batal naik pesawat itu. ‘Garuda airplane had an accident this morning. Fortunately, Boby overslept so that he failed to board that airplane.’ 14 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 To reiterate, not all ke-/-an verbs have an adversative interpretation. In addition, contexts can cancel the adversative interpretation of some ke-/-an verbs which appear to be adversative. These two facts contradict Dardjowidjojo’s proposal that the ke-/-an circumfix is an adversative feature; hence, raises the question of the function of this circumfix. In addition, there is still no clear explanation for the idiosyncratic argument structure of ke-/-an verbs. The answers to these two questions are discussed after discussing other issues related to how the argument structure of ke-/-an verbs is analyzed. THE INTERPRETATION OF KE-/-AN VERBS WITH TWO NP ARGUMENTS As revealed in the previous section, ke-/-an verbs do not always have an adversative interpretation. In fact, the interpretation of a ke-/-an verbs depends on the context in which it occurs. In this section, I argue that ke-/-an verbs—in particular those with two arguments—have a directional interpretation, instead of an adversative interpretation. Directional interpretation is an interpretation in which one argument of the ke-/-an verbs with two arguments is either moving closer to or going away from the other argument. The ke-/-an verb kejatuhan ‘to be fallen on by’, as in (15), is typically assumed to be adversative because it means that the fallen mango hit Joni. However, if kejatuhan is really adversative, then (15) will also be true in the situation in which Joni was negatively affected because the fall of the mango causes him not to be able to eat the mango. The fact that (15) is only relevant in a situation in which a mango fell on Joni shows that kejatuhan is directional, instead of adversative. I assume that kejatuhan is directional because the mango will end up on Joni’s body, which means that the mango is moving toward Joni. (15) Joni kejatuhan (ama) mangga. Joni KE-fall-AN by/with mango Directional: ‘Joni was fallen on by a mango.’ Adversative: *‘Joni was negatively affected by mango falling because he could not eat it.’ Other ke-/-an verbs with two NP arguments that have go toward interpretation are kebagian ‘to get a share of (something)’ and kedudukan ‘to be sat on by(someone)’, among others. Similarly to kejatuhan, kecopetan ‘to have (something) stolen by a pickpocket’ in (16) also appears to be adversative. However, kecopetan is actually not adversative because (16) is not true in the situation in which Joni was negatively affected because other person’s wallet got stolen. (16) is actually directional because it is true only in a situation in which Joni’s wallet got stolen when it was with him, and not in a situation in which the wallet was stolen in Joni’s bedroom when Joni was away. The directional interpretation of (16) is reflected in the interpretation in which Joni’s wallet is moving away from him. (16) Joni kecopetan dompet. Joni KE-pick.pocket-AN wallet Directional: ‘Joni’s wallet was stolen while it was with him.’ Adversative: *‘Joni was negatively affected by the stealing of other person’s wallet.’ Other ke-/-an verbs with two NP arguments that have go away from interpretation are kehilangan ‘to lose (something)’ and ketinggalan ‘to accidentally leave (something)’, among others. To summarize, ke-/-an verbs with two NP arguments actually have a directional interpretation, instead of adversative. The fact that native speakers generally interpret ke-/-an verbs as adversative is triggered by discourse and real-world knowledge. 15 Lanny Hidajat THE DISTRIBUTION OF KE-/-AN VERBS This section discusses the distribution of ke-/-an verbs in contrast to the distribution of active meN-/N-/- verbs and that of passive di- verbs. As will be revealed in the discussion below, ke/-an verbs are different from active meN-/N-/- verbs and passive di- verbs because they are non-agentive. Ke-/-an verbs versus meN-/N-/- verbs As exemplified in the following sentences, there are two characteristics of ke-/-an verbs that significantly distinguish them from meN-/N-/- verbs. Firstly, the subject NP of ke-/-an verbs is never agent or causer. Secondly, the subject of ke-/-an verbs with two arguments is either a goal or a source. (17) Rumah itu kebakaran. Home that KE-burn-AN ‘The house was on fire.’ *‘The house burned (something).’ (18) Joni melompat lalu lari. Joni MEN-jump past run ‘Joni jumped and then ran.’ (19) Bobi kejatuhan mangga. Bobi KE-fall-AN mango ‘Bobi was fallen on by a mango.’ *‘Bobi made the mango fall.’ (20) Joni jatuhin mangga itu (ke atas Bobi). Joni -fall-IN mango that to above Bobi ‘Joni dropped the mango (to Bobi).’ *‘(Bobi made) the mango fall on Joni.’ In (17), the NP argument in the subject position of the ke-/-an verb kebakaran ‘on fire’ cannot be interpreted as agent. This is in contrast with the NP argument in the subject position of melompat ‘to jump’ in (18). In (20), the subject NP of jatuhin ‘to drop’ must be interpreted as agent and cannot be interpreted as goal or source. On the other hand, the subject NP of the ke-/an verb kejatuhan ‘to be fallen on by’ in (19) is goal and cannot be interpreted as agent. The above two distinctions lead to the conclusion that ke-/-an verbs are not in the active voice and they are not derived in the same way as meN-/N-/- verbs. Ke-/-an verbs versus di- verbs At a glance, ke-/-an verbs and di- verbs share some characteristics. Firstly, as shown in (21) and (22), similarly to passive di- verbs, the subject NP of ke-/-an verbs can be theme: (21) Gudang itu kebakaran. Warehouse that KE-burn-AN ‘The house was on fire.’ (22) Gudang itu dibakar. Warehouse that DI-burn ‘The house was burnt.’ Secondly, the subject NP of both ke-/-an verbs and passive di- verbs can be goal, as shown in (23) and (24): (23) Joni kebagian mangga. Joni KE-share-AN mango ‘Joni got a share of a mango.’ 16 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 (24) Joni dibagiin mangga. Joni DI-share-IN mango Lit. ‘To Joni was shared the mango.’ Despite the above similarities, there are several characteristics of ke-/-an verbs which distinguish them from di- verbs. As shown in (25) and (26), unlike passive di- verbs, ke-/-an verbs cannot be followed by an optional agentive prepositional phrase. (25) Gudang itu kebakaran (*ama Joni). Warehouse that KE-burn-AN by Joni ‘The house was on fire (*by Joni).’ (26) Joni kebagian mangga *(ama Bobi). Joni KE-share-AN mango by Bobi ‘Joni got a share of a mango (*by Bobi).’ The second difference between ke-/-an verbs and di- verbs is that the subject NP of twoargument ke-/-an verbs cannot be theme, as shown in (27). In contrast, the subject NP of ditransitive passive di- verbs can be theme, as shown in (28). (27) *Mangga itu kebagian ke Mango that KE-share-AN to Lit. ‘The mango was shared (to Joni).’ (28) Mangga itu dibagiin ke Mango that DI-share-IN to ‘The mango was distributed to Joni.’ Joni. Joni Joni. Joni The above two differences reflect that ke-/-an verbs are not derived in the same way as di- verbs. The fact that ke-/-an verbs cannot co-occur with an optional agentive prepositional phrase, as discussed above, suggests that they are non-agentive. In contrast, passive di- verbs have an implicit subject, which means they are actually agentive (cf. Baker, Johnson, and Robert’s, 1989, argument for English passives.) The non-agentivity of ke-/-an verbs is also evidenced by the fact that they cannot be modified by subject-oriented manner adverbials, except tidak/gak sengaja ‘accidentally’,ii or instrumental phrases, as shown in (29) and (30), respectively (see Baker, Johnson, and Roberts 1989; Dubinsky and Simango 1996, for further explanation regarding the agentivity tests.) (29) *Joni buru-buru kebagian mangga. Joni RED.hurry KE-share-AN mango *‘Joni got a share of a mango in a hurry.’ (30) *Gudang tua itu kebakaran pake bensin. warehouse old that KE-burn-AN use gasoline *The old warehouse was on fire by using gasoline.’ In comparison, passive di- verbs can be modified by subject-oriented manner adverbials and instrumental phrases: (31) Joni buru-buru dibagiin mangga. Joni RED.hurry DI-share-IN mango Lit. ‘Joni was distributed the mango in a hurry.’ (32) Gudang tua itu dibakar pake bensin. warehouse old that DI-burn use gasoline ‘The old warehouse was burnt by using gasoline.’ To summarize, the differences in the distribution between ke-/-an verbs and meN-/N-/verbs and also between ke-/-an verbs and di- verbs reveal that ke-/-an verbs are not either in the active voice or passive voice. Unlike meN-/N-/- verbs and di- verbs, ke-/-an verbs are non- 17 Lanny Hidajat agentive. This fact implies that ke-/-an verbs are derived differently from meN-/N-/-verbs and di- verbs. THE EVENTIVITY OF KE-/-AN VERBS The fact that ke-/-an verbs do not bear an implicit agent might mislead us to assume that these verbs are stative, because non-agentivity is generally used as a diagnostic for stativity (Dowty 1979, Dubinsky and Simango 1996, Katz 2003, among others). However, the results of other “stativity” tests, which were used in Katz’s (2003; drawing on Lakoff 1966) study, show that ke-/-an verbs are actually eventive despite their non-agentivity. According to Katz (2003: 206, drawing on Dowty 1979; Sag 1973; Hinrichs 1985), “state predicates are always non-agentive, temporally homogeneous, and have a present orientation.” On the other hand, eventive predicates are agentive, can ‘move’ narrative time in discourse, and lack past orientation. One feature of ke-/-an verbs which shows that they are non-stative is the fact that they have a past orientation. According to Katz (based on work by von Stechow 1995, Ogihara 1996, and Abusch 1997), one way to check whether a predicate has past or present orientation is by inserting it into a complement clause of verbs such as believe or think. The complement clause of the matrix verb believe or think must have a present orientation with respect the matrix verb itself. Since stative verbs, such as love or know, have a present orientation, they can be the infinitival complements of the matrix verb believe or think, as shown in (33). On the other hand, eventive verbs, such as kiss, have a past orientation; therefore, it is unnatural for eventive verbs to be the infinitival complements of believe or think, as shown in (34) (33) Thelma believed Hans to love Lin. (34) ??Thelma believed Hans to kiss Lin. (Katz 2003:209) In Indonesian, when stative verbs, such as tau ‘know’, appear as an embedded verb of yakin, which corresponds to English believe, they have a present orientation, as shown in (35): (35) Gue yakin Joni tau jawabannya. 1sg certain Joni know answer-AN.DET ‘I’m sure Joni knows the answer.’ *‘I’m sure Joni knew the answer.’ In contrast, when the complement clauses of yakin ‘certain’ contain eventive verbs, such as mukul ‘to hit’, they exhibit a past orientation with respect to the matrix verb, as shown in (36): (36) Gue yakin Joni mukul temennya. 1sg certain Joni N-hit friend-3sg ‘I’m sure Joni hit his friend.’ *‘I’m sure Joni hits his friend.’ When ke-/-an verbs are inserted into the complement clause of yakin ‘certain’, they have a past orientation, as shown in (37): (37) Gue yakin Joni kejatuhan mangga. 1sg certain Joni KE-fall-AN mango ‘I’m sure a mango fell on Joni.’ *‘I’m sure a mango falls on Joni.’ The fact that ke-/-an verbs have a past orientation is one indication that they are eventive verbs. The second stativity test is that stative verbs cannot be modified by an in-adverbial phrase, such as in an hour (Katz 2003), as shown below: (38) ??He was away from home in an hour 18 (Katz, 2003:10) Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 As shown in (39) and (40), respectively, similarly to active eventive verbs, such as bagi ‘to share something to someone’, ke-/-an verbs, such as kebagian ‘to get shared something’, are compatible with the adverbial phrase dalam waktu semenit, which corresponds to in a minute. (39) Bobi bagiin makanannya ke Joni dalam Bobi -share-IN eat-AN-3sg to Joni in ‘Bobi shared his food to Joni in one minute.’ (40) Joni kebagian makanan dalam waktu Joni KE-share-AN eat-AN in time ‘Joni got shared food in one minute.’ waktu semenit. time one minute semenit. one minute In fact, Indonesian stative verbs, such as tau ‘know’, can also be modified by dalam waktu semenit ‘in a minute’. However, modifying stative verbs with an in-adverbial phrase causes them to have an inchoative interpretation, instead of the stative interpretation, as shown in (41). (41) Joni tahu jawabannya dalam waktu semenit. Joni know answer-AN-DET in time one minute *‘Joni is in the state of knowing the answer in one minute.’ (Stative) ‘Joni came to know the answer in one minute.’ (Inchoative) The fact that ke-/-an verbs do not become inchoative when modified by dalam waktu semenit shows that they are not stative. To reiterate, although ke-/-an verbs are non-agentive, they have the following two characteristics of eventive verbs. Firstly, when they are inserted into the complement clauses of yakin ‘certain’, they have past orientation. Secondly, ke-/-an verbs do not become inchoatives when modified by in a minute-type of adverbs. THE SUFFIX –KAN VS. THE CIRCUMFIX KE-/-AN To illustrate the effect of the circumfix ke-/-an on thematic role assignment and the argument structure of the based verbs to which it is affixed, I will first discuss the effect of the suffix –kan as reviewed by Cole and Son (2004). According to Cole and Son, the suffix –kan functions as syntactic licenser which serves to syntactically license an argument, which is thematically licensed by the verb, in the argument structure. Without the presence of a syntactic licenser, a thematically licensed argument is unlicensed to be in an argument structure. As a syntactic licenser, the suffix –kan can increase the valence of the base verbs. As shown in (42), attaching the suffix –kan to an intransitive and adjectival base verb, such as jatuh ‘to fall’, adds an additional NP argument. (41) Mangganya jatuh. Mango-DET fall ‘The mango fell.’ (42) Bobi menjatuhkan mangga (ke atas Joni). Bobi MEN-fall-KAN mango to top Joni ‘Bobi dropped the mango (on Joni).’ (i.e. ‘Bobi caused the mango to drop (on Joni).’) In (41), the unaccusative verb jatuh ‘to fall’ already assigns the theme role to its argument mangganya ‘the manggo’. The affixation of –kan adds the number of the NP argument of the verb. In accordance to the hierarchies of thematic relations and argument structures suggested by Grimshaw (1990), the additional NP argument is assigned a causer theta role and becomes the surface subject. As a syntactic licenser, the suffix –kan also adds the valence of transitive base verbs, as reflected in (44). In (44), the suffix –kan syntactically licenses the object NP saya ‘3sg’ in the argument structure of the transitive base verb pikir ‘think’. Although the verb pikir has assigned 19 Lanny Hidajat the theme role to the NP saya, the NP can only occur in the argument structure after the verb is affixed by the suffix –kan. In this case, the suffix –kan becomes an object marker. (43) *Dia tidak memikir saya. 3sg not meN-think 1sg ‘She does not think about me.’ (44) Dia tidak memikirkan saya. 3sg not meN-think-KAN 1sg ‘She does not think about me.’ (Cole and Son, 2004:351) When transitive base verbs that syntactically license both of their NP arguments in the argument structure are affixed to the suffix –kan, the number of their NP argument increases. As shown in (45), the transitive base verb panggang ‘bake’ assigns the agent role to the NP saya ‘1SG’ and the theme role to the NP bread ‘roti’ and also syntactically licenses them. However, it does not license and also assign a thematic role to the NP Eric. The NP Eric is an adjunct; therefore, it is optional. However, when the verb panggang ‘bake’ is affixed by –kan, Eric becomes the NP argument of panggang ‘bake’ and receives the beneficiary role; therefore, it is no longer optional, as shown in (46). In this case, the suffix –kan is a benefactive suffix. (45) Saya memanggang roti (untuk Eric). 1sg meN-bake bread for Eric ‘I baked bread for Eric.’ (46) Saya memanggangkan roti *(untuk Eric). 1sg meN-bake-KAN bread for Eric ‘I baked bread for Eric.’ (Cole and Son, 2004:343) As reflected in the above discussion, affixes can change the argument structure and the thematic role assignment of the base verbs to which they are affixed, which subsequently changes the valence of the verbs. What is the effect of the circumfix ke-/-an to the valence of the verbs to which it is affixed? As shown in (48), in some cases, ke-/-an can increase the valence of intransitive base verbs by one NP argument: (47) Joni jatuh (di tangga) Joni fall LOC stairs ‘Joni fell on the stairs.’ (48) Joni kejatuhan mangga. Joni KE-fall-AN mango ‘Joni was fallen on by a mango.’ However, attaching the circumfix ke-/-an to intransitive base verbs does not always add an additional NP argument. For example, it does not increase the valence of the intransitive base verb tidur: (49) Joni tidur (di kamarnya). Joni -sleep LOC room-DET ‘Joni is sleeping (in his room).’ (50) Joni ketiduran (di kamarnya). Joni KE-sleep-AN LOC room-DET ‘Joni overslept (in his room.)’ The presence of the circumfix ke-/-an can even decrease the valence of the verbs to which it is affixed. For example, when the ditransitive base verb bagi ‘to share’ and the transitive base verb bakar ‘to burn’ are affixed by ke-/-an, they have one less NP argument, as exemplified in (52) and (54), respectively. 20 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 (51) Joni udah bagi mangga ke Bobi. Joni already -divide mango to Bobi ‘Joni has already shared the mango to Bobi.’ (52) Bobi udah kebagian mangga (*oleh Joni). Bobi already KE-divide-AN mango by Joni ‘Bobi has already got a share of a mango (*by Joni).’ (53) Joni bakar gudang itu. Joni -burn warehouse that ‘Joni burn the warehouse.’ (54) Gudang itu kebakaran (*ama Joni). warehouse that KE-burn-AN by Joni ‘The warehouse was on fire *(by Joni).’ Similarly to the suffix –kan, the affixation of ke-/-an can also affects the thematic relations of the base verbs. As shown in (48), when the unaccusative verb ‘jatuh’ is affixed by ke-/-an, the theme theta role is assigned to the NP argument in object, instead of the one in subject. The NP argument in subject received the goal theta role. Furthermore, as illustrated in (52) and (54), transitive and ditransitive base verbs cannot assign the agent theta role when they are affixed by ke-/-an; therefore, a ke-/-an verb cannot have an agent NP as its argument. However, the circumfix ke-/-an does not always affect the thematic relations of intransitive verbs. As exemplified in (50), the unaccusative verb ‘tidur’ still have a theme subject when it is affixed by ke-/-an. To reiterate, the circumfix ke-/-an affects the argument structure of the verbs to which it is affixed by either increasing or decreasing their valence. Another notable effect of the circumfix ke-/-an is that it blocks verbs from assigning an agent theta role. THE STRUCTURE OF KE-/-AN VERBS In this paper, the structures of ke-/-an verbs are explained in terms of the Distributed Morphology framework (DM) (Marantz 1997, 2001; Harley and Noyer 1999; among others). This framework is an extension of the idea that some semantic aspects of a word are also represented in the syntax (Hale and Keyser, 1993). According to Folli and Harley (2002:5), in this structural approach, it is assumed that the interpretation of a verb is determined by “the functional/aspectual structure in which the verb is inserted” and “the syntactic positions in which its arguments are realized.” Another assumption of DM is that words are inserted into the syntactic operations as category neutral components (ROOT) (Marantz 1997). ROOTs are later categorized in accordance to their syntactic positions, or as Marantz (1997:215, based on Chomsky, 1970) puts it: When the roots are placed in a nominal environment, the result is a “nominalization”; when the roots are placed in a verbal environment, they become verbs. In other words, the derivation of verbs involves inserting ROOT into the syntax. If the ROOT is governed by a verbalizing v head, it becomes a verb. The Structure of One-Argument ke-/-an Verbs According to DM, the affixation of ke-/-an to base words is an operation in the syntax. DM also posits that ke-/-an verbs start as category neutral components in the syntactic operation. This assumption its with the fact that these verbs seem to be derived from various lexical categories, as noted by Dardjowidjojo (1978) and Sneddon (2000). In line with the notion of DM that functional heads play an important role in the derivation of verbs, I argue that ke-/-an is the overt representation of a functional head. The questions which will be answered in the 21 Lanny Hidajat discussion in this section are (i) what functional head the circumfix ke-/-an represents and (ii) where its position is in the syntax. First, I would like to address the non-agentivity of ke-/-an verbs. In recent studies, it is generally assumed that the functional head which generates the external argument is different from the one which generates the internal argument (Kratzer 1996, Marantz 1997, Folli and Harley 2002, among others). Kratzer (1996, based on Marantz 1984) proposes that the external argument is introduced in the specifier position of the voice projection, which is immediately above VP, in which the internal argument is generated. Following Kratzer’s proposal, I argue that the non-agentivity of ke-/-an verbs indicates the lack of the functional head which generates the external argument in the structure of ke-/-an verbs. This implies that there is no voice projection in the structure of ke-/-an verbs, which means that the position of the functional head represented by the circumfix ke-/-an is below the voice head. In this paper, I propose that the circumfix ke-/-an is an overt form of the v head that directly attaches to ROOT and verbalizes it. My proposal is based on several pieces of evidence; the first being the fact that ke-/-an verbs are not productive, as pointed out by Sneddon (1996). This condition corresponds to Marantz’s proposal (2001), stating that a head which attaches immediately to the ROOT is semi-productive because its selectional requirements must be satisfied by the idiosyncratic properties of the ROOT. Marantz (2001) also predicts that a head which is immediately attached to the ROOT can create an idiom. This prediction is based on the assumption that roots in combination with other elements within the locality domain may have a special meaning (Marantz 1997). Marantz (1997:8) also assumes that the functional head that projects agents is the boundary for the domain of special meanings. The fact that there exists an idiom with a ke-/-an verbs, as shown in (55), supports the assumption that the circumfix ke-/-an is a verbalizing v head. (55) Tingkahnya seperti orang/kambing kebakaran jenggot. act-3sg look.like person/goat KE-burn-AN beard ‘He acts frantically.’ (Lit. ‘He acts like a person/a goat whose beard is on fire.’) The fact that the subject NP of kebakaran jenggot in (55) can be either orang ‘person’ or kambing ‘goat’ without changing the meaning of the idiom shows that the subject NP is not part of the idiom. On the other hand, as shown in (56), the idiom orang kebakaran jenggot ‘to act frantically’ loses its idiomatic interpretation when the base verb bakar ‘to burn’ appears with the prefix di-, which is a passive marker. This shows that the verb kebakaran is part of the idiom. (56) Tingkahnya seperti orang/kambing dibakar jenggot act-3sg look.like person/goat DI-burn beard ‘He acts as if someone who is being burnt by his beard.’ Additional support for the proposal that the circumfix ke-/-an is a verbalizing v head which directly attaches to ROOT comes from the fact that ke-/-an verbs are not stative, as already discussed earlier. According to the structure of the verb phrase proposed by Marantz (2001), as shown in Figure 1, the stative head is nearer to the ROOT as compared to the verbalizing head. However, the eventivity of ke-/-an verbs suggests the absence of a stative head. Consequently, in the structure of ke-/-an verbs, it is the verbalizing v head which realizes the circumfix ke-/-an in its overt form, which immediately attaches to the ROOT. 22 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Figure 1. The Structure of the Verb Phrase (Marantz 2001:5) To reiterate, the fact that ke-/-an verbs are non-agentive postulates that there is no voice projection in the structure of ke-/-an verbs. Furthermore, several evidence indicate that the circumfix ke-/-an is an overt presentation of a verbalizing v head which directly attaches to ROOT. In line with these two assumptions, I propose that the structure of one-argument ke-/-an verbs, such as in rumah itu kebakaran ‘the house was on fire’, is as shown in Figure 2: Figure 2. The Structure of One-Argument ke-/-an verbs As shown in Figure2, the theme NP, which on the surface appears in the subject position, originates as the internal argument of ROOT. The assumption that ROOT can take a single argument is suggested by Embick (2004) to account for the structures of transitive verbs as well as unaccusative verbs. According to this assumption, the internal argument of transitive verbs and unaccusative verbs originates as the argument of ROOTs and it is interpreted as the logical object of ROOT. Following Chomsky’s (2000, 2001) Agree operation, I assume that the complement of ROOT in one-argument ke-an verbs moves to the spec of TP to satisfy the EPP feature, which is borne by T. I assume that the subject NP of the single argument ke-/-an verbs is actually the complement of ROOT because it is always assigned theme, which is relevant to its status as the logical object of the ROOT. This assumption conforms to Chomsky (1981:36)’s Theta Criterion, which is “each argument bears one and only one theta-role, and each theta-role is assigned to one and only one argument.” The Theta Criterion postulates that each argument is assigned one thematic role at the level of D-structure. Subsequently, a thematic relation remains through a derivation, even though the argument may undergo movement or raising. A piece of evidence that supports the assumption that the subject NP of one-argument ke-/-an verbs is base-generated as the complement of ROOT and move to the spec of TP is the 23 Lanny Hidajat fact that they must be definite. The two sentences in (57) are ungrammatical because the subject NPs of the ke-/-an verbs are indefinite. (57) a. *Gudang kebakaran Warehouse KE-burn-AN ‘A warehouse was on fire.’ b *Anak kejatuhan mangga. child KE-fall-AN mango ‘A boy was fallen on by a mango.’ The behavior of the subject NP of ke-/-an verbs is similar to that of the subject NP of passive diverbs. As mentioned by Sneddon (1996:254), the subject NP of passive di- verbs must be definite. In line with Guilfoyle, Hung, and Travis’s (1992) analysis of Indonesian passive construction, I assume that the restriction on the definiteness of passive subjects relates to A-movement, which is the movement of the theme NP from the complement of V to the spec of IP in order to get case. Correspondingly, the requirement for the subject NPs of ke-/-an verbs to be definite indicates that they are base-generated in a position below VP and moves to the spec of IP. The assumption that the subject NP of ke-/-an verbs undergoes A-movement to the spec of IP also gets support from the fact that a sentence can have a ke-/-an verb in conjunction with a di- verb with only one subject, as illustrated in (58): (58) Jonii kejatuhan ti tangga dan ti dikejar anjing. Joni KE-fall-AN leader and PASS-chase dog ‘Joni was fallen on by a leader and chased by a do.’ The fact that Joni can be the subject for both kejatuhan ‘to be fallen on by’ and dikejar ‘to be chased’ indicates that the subject NP of this sentence originates inside VP (McCloskey 1997, drawing on McNally 1992 and Burton and Grimshaw 1992). The Structure of Two-Argument ke-/-an verbs According to the structure represented in Figure 2, ke-/-an verbs cannot have more than one argument. The fact that these verbs can actually have two arguments indicates the presence of an applicative construction in their structure. However, where is the position of the applicative construction in the argument structure of ke-/-an verbs? As discussed earlier, I assume that the two-argument ke-/-an verbs have a directional interpretation because one of the two NP arguments either moves toward or away from the other NP argument, as already reflected in (15) and (16). The directional interpretation of twoargument ke-/-an verbs indicates the presence of a low applicative construction in the structure of the two-argument ke-/-an verbs. This notion is based on Pylkkänen’s (2002, based on Bresnan and Moshi 1990) proposal of the two types of applicative constructions: high applicatives and low applicatives. The high applicative construction attaches above the verb, as shown in Figure 3; while the low applicative attaches below the verb, as shown in Figure 4. 24 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Figure 3. The Structure of High Applicative Construction (Pylkkänen 2002:19) Figure 4. The Structure of Low Applicative Construction (Pylkkänen 2002:19) According to Pylkkänen, the difference in the syntactic positions of the high and low applicative head is reflected in two different interpretations. High applicatives denote a relation between an event and an individual, which is the applied argument, as exemplified in (59), which is an Albanian sentence with a high applicative construction. In (59), the event Agim holds my bag is related to the applied argument Drita, so that the interpretation of (59) is Agim holds my bag for the benefit of Drita. (59) Agimi i mban Drites anten A.NOM DAT.CL holds Drita.DAT bag.ACC ‘Agim holds my bag for Drita.’ time my (Pylkkänen, 2002:25) Unlike the high applicative construction, low applicatives denote a relation between two individuals, i.e. the applied argument and the internal argument. As exemplified in (60), the applied argument John is only related to the internal argument the book in the sense that the book ends up being possessed by John (60) Mary bought John the book. (Pylkkänen 2002:23) Since low applicatives denote a relation between the applied argument and the internal argument, Pylkkänen (2002) argues that low applicatives cannot appear in a structure that lacks an internal argument, such as unergative verbs. Another piece of evidence supporting the argument that the applicative construction of two argument ke-/-an verbs is a low applicative comes from the fact that only the applied argument, which is the goal/source NP, can be in the subject position of two argument ke-/-an verbs. As illustrated in (61), the internal argument, which is the theme NP, cannot be the subject of ke-/-an verbs. 25 Lanny Hidajat (61) *Mangga kejatuhan Joni. Mango KE-fall-AN Joni ‘Joni was fallen on by a mango.’ The aforementioned evidence corresponds to McGinnis’s (2001:112-113) claim that, in a structure with a high applicative construction, when the verb is passivized, either the internal argument or the applied argument can be a subject. On the other hand, in a structure with a low applicative construction, only the applied argument can be a subject. This claim is based on her analysis of the distribution of Kinyarwanda benefactives, which bear a high applicative construction, and the locatives, which bear a low applicative construction. According to her, when a Kinyarwanda benefactive verb is passivized, either the theme NP or the beneficiary NP can be in the subject. In contrast, when a Kinyarwanda locative verb is passivized, only the locative NP can occupy the subject position (see McGinnis 2001 for the discussion of the difference between the high and low applicative constructions with respect to the NP subject.) To summarize, I argue that the applicative construction in the structure of two-argument ke-/-an verbs is a low applicative. My argument is based on the following two facts: firstly, the two-argument ke-/-an verbs have a directional interpretation; and, secondly, only the applied argument can be the subject NP of two argument ke-/-an verbs. In line with the above argument, the structure of two-argument ke-/-an verbs, such as kejatuhan ‘to be fallen on by’, is as represented in Figure 5. Figure 5. The Structure of Two-Argument ke-/-an verbs As shown in Figure 5, ROOT in the two-argument ke-/-an verbs, unlike ROOT in the oneargument ke-/-an verbs, selects the low applicative construction as a complement. This implies that selection of the low applicative construction is an inherent property of ROOT. Under the assumption that the internal argument is the argument of ROOT, the low applicative construction has to be part of ROOT, so that the internal argument and the applied argument are generated at the same level. If the low applicative construction combines with and the internal argument combines with ROOT, the applied argument and the internal argument will be generated at different levels; consequently, there will not be a directional interpretation between the applied argument and the internal argument. I assume that the low applicative head of ke-/-an verbs bears [+to] and [+from] features (Legate 2001; Pylkkänen 2002). Pylkkänen (2002) argues that the low recipient and source applicatives have the following lexical entries: 26 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 (62) Low-APPL-TO (Recipient applicative): x.y.f<e<s,t>>.e. f(e,x) & theme (e,x) & to-the-possession (x,y) Low-APPL-FROM (Source applicative): x.y.f<e<s,t>>.e. f(e,x) & theme (e,x) & from-the-possession (x,y) (Pylkkänen, 2002:22) In line with the above argument, I argue that the [+to] and [+from] features borne by the low applicative head represent the direction of the internal argument with respect to the applied arguments, which are as follows: the [+to] feature means that the internal argument is heading toward the applied argument and the [+from] feature means that the internal argument is moving away from the applied argument. I assume that it is the semantic property of the ROOT that combines with the projection of the low applicative that determines which feature will be borne by the low applicative head in a particular sentence. The low applicative head bears the [+to] feature when it appears in sentences such as (63) and (64). (63) Joni kejatuhan (ama) mangga. Joni KE-fall-AN by/with mango ‘Joni was fallen on by a mango.’ (64) Joni kebagian mangga. Joni KE-share-AN mango ‘Joni got a share of a mango.’ In (63) and (64), the internal argument mangga ‘mango’ is moving toward the internal argument Joni. On the other hand, in (65), the low applicative head bears the [+from] feature because the internal argument dompet ‘wallet’ is moving away from Joni. (65) Joni kecopetan dompet. Joni KE-steal-AN wallet ‘Joni’s wallet was stolen.’ As mentioned earlier, according to Pylkkänen (2002), the low applicative construction cannot co-occur with unergative verbs. Therefore, the argument that applicative construction of the two-argument ke-/-an verbs is low applicative is somewhat problematic because there are two argument ke-/-an verbs which seem to be derived from an unergative verb; for instance, kedudukan ‘to be sat on by’, as represented in (66): (66) Aduh! Bukunya Joni kedudukan (ama) (Bobi) nih! EXCL book.DET Joni KE-sit-AN by/with Bobi this ‘Oh no! Look, Joni’s book was accidentally sat on (by Bobi)!’ This problem actually can be accounted for by assuming that kedudukan is derived from duduk ‘sit’ as the verb of spatial configuration with the simple position meaning (see Levin and Rappaport Hovav 1995 for the discussion of the possible interpretations of the verb of spatial configuration). According to Levin and Rappaport Hovav (1995), the spatial configuration verbs with the simple position meaning are unaccusative. This means that kedudukan is actually derived from duduk ‘sit’ as an accusative verb, instead of unergative. Accordingly, the structure of kedudukan can contain a low applicative construction. The argument that kedudukan is derived from duduk with the simple position meaning is supported by the following three facts: i. Goal DP, which functions as the location phrase, is mandatory in the subject position, as shown below: (67) *Aduh! kedudukan (ama) (Bobi) nih! EXCL KE-sit-AN by/with Bobi this *‘Oh no! Look, was accidentally sat on (by Bobi)!’ 27 Lanny Hidajat ii. Subject DPs of kedudukan cannot be an agent. Therefore, (68) cannot be interpreted as Bruno (the dog) was accidentally sat on by Joni. iii. Kedudukan cannot be modified by a subject-oriented manner adverbials, such as terburuburu ‘in a rush’, which shows that it has a non-agentive interpretation. To summarize, this section discusses the structure of ke-/-an verbs. Ke-an verbs are eventive, non-agentive, and can take either one or two NP arguments. To account for the fact that ke-/-an verbs are non-agentive, I argue that the structure of ke-/-an verbs lacks voice projection. In addition, the circumfix ke-/-an is an overt form of a verbalizing v head that directly attaches to ROOT and verbalizes it. The fact that there are ke-/-an verbs that take two NP arguments indicate that it structures can contain an applicative construction. I argue that the applicative construction in the structure of two-argument ke-/-an verbs is the low applicative for the following two reasons: first, two-argument ke-/-an verbs have a directional interpretation. In addition, I assume that the low applicative head bears [+to] and [+from] features, which represent the direction of the internal argument, that is, whether it is moving toward or going away from the applied argument. I also assume that it is the semantic properties of the ROOT combining with the low applicative projection that determine which feature is borne by the low applicative head in a particular sentence. A REMARK ON THE ACCIDENTAL INTERPRETATION OF KE-/-AN VERBS Ke-/-an verbs also trigger an interpretation in which the events described by the verbs happen accidentally. In line with the proposed structures of ke-/-an verbs, which are represented in Figure 2 and Figure 5, I assume that the accidental interpretation of ke-/-an verbs is due to the syntactic structures of ke-/-an verbs, instead of being semantically implicated in the circumfix ke-/-an. Ke-/-an verbs yield accidental interpretation because none of their arguments are generated above the ke-/-an v projection. This assumption corresponds to Hale and Keyser’s (1993) view that the most salient meaning of the inner VP is “change.” According to Hale and Keyser, a projection of a lexical category is associated with a structural relation of c-command and complementation and an elementary semantic relation. Following the aforementioned argument, Hale and Keyser (1993) argue that the structural relation of a causative sentence, such as the cook thinned the gravy, is as shown in Figure 6: Figure 6. The Structural Relation of a Causative Sentence (Hale and Keyser 1993:72) Each of the two v heads projected by thin contributes a subpart of the verb’s meaning. The upper v head represents a CAUSE event and the lower v head represents a BECOME event. Accordingly, the NP in the specifier of the upper v heads is regarded as the subject of the causal event and the one in the specifier of the lower v head is the subject of a ‘predicate of change’. 28 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Since the ke-/-an v head is a verbalizing head and non-agentive, I assume that the ke-/an v head corresponds to the lower v head in Figure 6, which means that it represents a BECOME event. Correspondingly, the NP argument taken by ROOT (i.e. the internal argument) in the structures of ke-/-an verbs resembles Hale and Keyser’s subject of a predicate change, i.e. it corresponds to an entity undergoing change. The accidental interpretation subsequently emerges because the internal argument is affected by ke-/-an verbs, instead of causing the event. CONCLUSION It has been shown that the idiosyncratic distribution of ke-/-an verbs can be accounted for by using the Distributed Morphology framework. The fact that ke-/-an verbs are non-agentive indicates that the structures of ke-/-an verbs lack the voice head which licenses the agent NP. Although ke-an verbs are non-agentive, they are nevertheless eventive. In the present study, I have argued that the circumfix ke-/-an is an overt form of a verbalizing v head which directly attaches to ROOT. This argument can explain why the presence of the circumfix ke-/-an does not necessarily add a new argument to the argument structure. I attributed the fact that some kean verbs take only one argument while others take two arguments to the inherent properties of the ROOT taken by the ke-/-an v head. ROOTs that take one NP argument yield one-argument ke-an verbs; while the ones that select a low applicative construction as its complement bring forth two-argument ke-an verbs. The postulation that the circumfix ke-/-an is a verbalizing v head that attaches directly to ROOT can explain why ke-/-an verbs are not productive in Indonesian. According to Marantz (2001), a functional head which attaches immediately to ROOT is less productive because its selectional restriction must be satisfied by the idiosyncratic properties of ROOT. This view implies that ke-/-an verbs are not productive because there are limited ROOTs that can satisfy the selectional restrictions of the ke-/-an verbalizing v head. This assumption raises a new question, namely, what are the inherent properties of ROOT which are required by the ke-/-an v head. I leave this question open for now. The above assumption also suggests that there is more than one verbalizing head. This brings up many questions, such as how many types of verbalizing v head there are, what makes one verbalizing v head different from other v heads, whether all languages have more than one type of verbalizing v head, and so forth. Further studies are required in order to answer these questions. The present study is only hints that the properties of a verbalizing v head can be a component which distinguishes one language from another. I would also like to point out that the proposed structures of ke-/-an verbs in this study cannot account for the ke-/-an nouns, such as kesenangan ‘happiness’, kesedihan ‘sadness’, and kebersamaan ‘togetherness’. Unlike ke-/-an verbs, ke-/-an nouns are very productive in Indonesian. This fact suggests that the circumfix ke-/-an can also be an overt form of a functional head for nominalization. This notion implies that Indonesian has two homophonous functional heads with the circumfix ke-/-an as their overt form. NOTE * I would like to thank an anonymous reviewer for very helpful comments on the earlier draft. ** Parts of the earlier version of this paper were presented at ISMIL 10, 21-23 April 2006, in the University of Delaware, Newark, DE, and AFLA XIV, 4-6 May 2007, in the McGill University, Montreal. I am indebted to Julie Anne Legate who supervised me in the process of writing this paper. I also would like to thank Gabriella Hermon, Peter Cole, and Benjamin Bruening for the invaluable comments and the inspiring discussion on the topic of this talk. My gratitude also goes to my friends in the Linguistics Dept. of the University of Delaware: Yanti, Laura Spinu, Tim McKinnon, Sean Madigan, Masahiro Yamada, and Sachie Kotani for their insightful comments and suggestions to improve the quality of this paper. I am also grateful to my friends in UNIKA Atma Jaya, Jakarta, dan the Jakarta Field Station for helping me with the language data. All errors in facts and analyses are my own responsibility. 29 Lanny Hidajat i ii The Indonesian analyzed in this paper is the colloquial register of Indonesian as spoken in Jakarta. All examples are the kind of utterances used in daily conversation by educated speakers. I assume that ke-/-an verbs can co-occur with tidak/gak sengaja because ke-/-an verbs induce an interpretation of events which happen unexpectedly. REFERENCES Baker, Mark, Kyle Johnson, and Ian Roberts. 1989. Passive Arguments Raised. Linguistic Inquiry 20: 219–251. Chomsky, Noam. 1981. Lectures on Government and Binding. Dordrecht: Foris. Chomsky, Noam. 2000. Minimalist inquiries: The framework. In Roger Martin, David Michaels, and Juan Uriagereka (eds.) Step by step: Essays on Minimalist Syntax in Honor of Howard Lasnik, (pp. 89-155). Cambridge, MA.: MIT Press. Chomsky, Noam. 2001. Derivation by Phase. In Michael Kenstowicz (ed.) Ken Hale: A Life in Language, (pp. 1-52). Cambridge, MA: MIT Press. Cole, Peter. and Min Jeong Son. 2004. The argument structure of verbs with the suffix –kan in Indonesian. Oceanic Linguistics, Volume 43.2:339-364. Dardjowidjojo, Soenjono. 1978. The semantic structures of the adversative ke-…-an verbs in Indonesian. In S. Udin (ed.) Spectrum: essays presented to Sutan Takdir Alisjahbana on his seventieth birthday (pp. 107-124). Dian Rakyat, Jakarta. Dowty, David R. 1979. Word Meaning and Montague Grammar. Dordrecht: Reidel. Dubinsky, Stanley, and Silvester Ron Simango. 1996. Passive and Stative in Chichewa: Evidence for Modular Distinctions in Grammar. Language 72:749-781. Embick, David. 2004. On the Structure of Resultative Participles in English. Linguistic Inquiry 35.3: 355-392. Folli, Raffaella and Heidi Harley. 2002. Consuming Results in Italian & English: Flavors of v. In P. Kempchinsky and R. Slabakova (eds.) Aspect. (pp. 1-26). Dordrecht: Kluwer Academic Publishers, (Manuscript is downloadable at http://dingo.sbs.arizona.edu/ ~hharley/PDFs/ FolliHarley2002Final.pdf) Grimshaw, Jane. 1990. Argument Structure. Cambridge, MA, MIT Press. Guilfoyle, Eithne, Henrietta Hung, and Lisa Travis. 1992. Spec of IP and Spec of VP: Two Subjects in Austronesian Languages. Natural Language and Linguistics Theory 10: 375-414. Hale, Kenneth and Samuel Jay Keyser. 1993. On Argument Structure and the Lexical Representation of Semantic Relations. In S.J. Keyser & K. Hale (eds.) The view from Building (pp.53-109). Cambridge, MA, MIT press. Harley, Heidi and Rolf Noyer. 1999. Distributed Morphology. Glot International, Volume 4, Issue 4, April 1999: 3 – 9. Katz, Graham. 2003. On the stativity of the English perfect. In A. Alexiadou, M. Rathert and A. von Stechow (eds.) Perfect Explorations (pp. 205-234). Mouton de Gruyter, Berlin. Kratzer, Angelika. 1996. Severing the External Argument from Its Verb. In Johan Rooryck & Laurie Zaring, (eds.). Phrase Structure and lexicon, (pp. 109-137). Dordrecht: Kluwer. 30 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Legate, Julie Anne. 2001. The Configurational Structure of a Nonconfigurational Language. In J. Rooryck and P.Pica (eds.) Linguistic Variations Yearbook 1:61-104. Levin, Beth, and Malka Rappaport Hovav. 1995. Unaccusativity: At the syntax-lexical semantics interface. Cambridge, Mass.: MIT Press. Marantz, Alec P. 1997. No escape from syntax: Don’t try morphological analysis in the privacy of your own lexicon. In A. Dimitriadis, & L. Siegel, (Eds.), University of Pennsylvania Working Papers in Linguistics, 4.2 (pp. 201-225). Philadelphia: University of Pennsylvania Working Papers in Linguistics. Marantz, Alec P. 2001. Words and Things. Handout, MIT, Cambridge, Mass. (http://dingo.sbs. arizona.edu/~hharley/Oxford/Marantz2.pdf) McCloskey. 1997. Subjecthood and Subject Positions. In L. Haegeman (ed.) Elements of Grammar, (pp. 197-235). Dordrecht: Kluwer. McGinnis, Martha. 2001. Variation in the Phase Structure of Applicatives. In J. Rooryck and P.Pica (eds.) Linguistic Variations Yearbook 1: 105-146. Pylkkänen, Liina. 2002. Introducing Arguments. Doctoral dissertation, MIT, Cambridge, Mass. Sneddon, James Neil. 1996. Indonesian: A Comprehensive Grammar. London and New York: Routledge. Sneddon, James Neil. 2000. Another Look at ke- … -an Verbs. In Bambang Kaswanti Purwo, Ed., Kajian serba linguistik: untuk Anton Moeliono, pereksa bahasa (Transl: Languages, linguistics, and civilization: festschrift in honor of Anton Moeliono, Indonesian expert in linguistics). Jakarta: Universitas Katolik Indonesia Atma Jaya, BPK Gunung Mulia. 31 Linguistik Indonesia, Februari 2014, 33-46 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 MEASURING PROFICIENCY IN STANDARD INDONESIAN FOR ENGGANO SPEAKERS Rindu Parulian Simanjuntak* SIL International, Masyarakat Linguistik Indonesia [email protected] Abstract The main purpose of study described in this paper was to measure the proficiency of Standard Indonesian spoken in Enggano Island, Bengkulu Province, Indonesia. Enggano is spoken in six villages: Malakoni, Apoho, Meok, Ka’ana, Kayapu and Banjar. Of these, two villages — Meok and Ka’ana — were selected as research sites for collecting data. The instruments used were the Indonesian Sentence Repetition Test (ISRT) (Hanawalt 2008) and a set of bilingualisms questionnaire. The results show an average bilingual proficiency in Standard Indonesian of level 2 on the ILR scale (Interagency Language Roundtable 2007) for Enggano speakers, which indicates an ability to use Indonesian limited to particular situations and domains. The analysis also shows that bilingual proficiency in Enggano varies on average between males and females and is influenced by education and age, but not by the other factors investigated. This means that bilingual proficiency in Standard Indonesian for Enggano speakers is largely the result of continuing on to higher levels of education. Even though the average proficiency of Enggano speakers in Standard Indonesian is at level 2, the attitudes of most Enggano speakers towards both the Indonesian language and the local vernacular language are strongly positive. Keywords: bilingual proficiency Abstrak Penelitian ini bertujan untuk mengukur tingkat kemahiran berbahasa Indonesia standar yang dituturkan di Pulau Enggano, Propinsi Bengkulu, Indonesia. Bahasa Enggano dituturkan di enam desa: Malakoni, Apoho, Meok, Ka’ana, Kayapu dan Banjar. Dua desa — Meok dan Ka’ana — dipilih sebagai tempat untuk mengambil data-data. Instrumen yang digunakan adalah Tes Pengulangan Kalimat (TPK) dalam bahasa Indonesia atau Indonesian Sentence Repetition Test (ISRT) (Hanawalt 2008) dan seperangkat kuesioner kedwibahasaan. Hasil penelitian mengungkapkan, rata-rata kemahiran berbahasa Indonesia standar lisan masyarakat Enggano di level 2 pada tingkat ILR (Interagency Language Roundatable 2007), mengindikasikan keterbatasan kemampuan berbahasa Indonesia dalam situasi dan ranah tertentu. Hasil analisis juga menunjukan rata-rata kemahiran kedwibahasaan antara pria dan wanita berbeda karena dipengaruhi oleh pendidikan dan usia, tetapi tidak dengan faktor-faktor lain. Artinya, hasil kemahiran kedwibahasaan bahasa Indonesia standar lisan pada penutur Enggano dapat digunakan untuk melanjutkan ke jenjang pendidikan yang lebih tinggi, dan sikap penutur Enggano pada bahasa Indonesia dan bahasa Enggano sangat positif. Kata kunci: kemahiran berbahasa Indonesia INTRODUCTION In the Indonesian context, most people use Indonesian as a medium for communication in formal situations, while vernacular languages are used in informal situations and isolated areas. The country currently faces the challenge of how to maintain both Indonesian and vernacular languages. A large number of Indonesians speak both a vernacular language (L1) and Indonesian (L2), and many also speak an international language. Thus, most people in Indonesia are bilingual or multilingual. Limited research has been conducted to quantitatively measure the Rindu Parulian Simanjuntak Standard Indonesian (hereafter BI) proficiency level of second-language speakers of Indonesian. Even though in many parts in Indonesia it is reported that people are bilingual in, little has been done to investigate the actual level of Indonesian proficiency throughout the nation. This means that more bilingualism research is necessary, especially that conducted with research tools that can quantitatively measure the proficiency level of BI in a certain speech community. The Indonesia archipelago consists of more than 17,000 islands from the island of Sumatera to Papua. Among these is Enggano, an isolated island located to the south west of Sumatra Island. Administratively, Enggano has status as a sub-district of the regency of North Bengkulu in Bengkulu Province. The population of Enggano was reported in census data at 1927 persons (Bengkulu Utara, 2000). The six villages of Enggano, located from southeast to northwest, are Kayapu, Ka’ana, Malakoni, Apoho, Meok, and Banjarsari. Figure 1. Map of South Sumatra and Bengkulu Province 34 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 According to Ethonologue (Gordon 2005:435), Enggano [eno], or Engganese (its alternate name), is classified as Enggano, Sumatera, Malayo-Polynesian, Austronesian. It is spoken on Enggano Island and on four smaller nearby islands. No other languages are reported to be closely related to it. Gumono reported in his paper, entitled Upaya Pemeliharaan Bahasa Daerah yang terancam punah: Kondisi Kebahasaan, Sikap Bahasa, dan kebutuhan bahasa masyarakat Pulau Enggano, that Indonesian and Enggano both are spoken by Enggano speakers over 40-years-old. Gumono states that Enggano people prefer to speak Indonesian to Enggano due to negative attitude towards their vernacular language. Furthermore, they feel inferior to other cultures brought from outside of the island. Despite this, Enggano people want to keep both Indonesian and vernacular language. Indonesian is seen as useful for increasing their income in the future and vernacular is seen as necessary to be maintained in order that the culture of Enggano could be passed on to the younger generation. METHODOLOGY A Sentence Repetition Test (SRT) is a type of bilingualism test for large-scale assessment of second-language (L2) proficiency. It is used to gain an objective and general assessment of a person’s proficiency in a second language, not an in-depth analysis of one person’s strengths or weaknesses in that L2 (Radloff 1991:8). The Indonesian Sentence Repetition Test (ISRT) score has been calibrated against the OPI (Oral Proficiency Interview), which is considered as one of the most reliable tests in measuring the bilingual proficiency (see Hanawalt 2008). The OPI was first used by the United States Foreign Service Institute (FSI) to evaluate an individual’s L2 proficiency (Radloff 1991: 47). In the OPI, an individual’s proficiency in L2 is described with a range of ILR (Interagency Language Roundtable) levels from 0 (No Performance) to 5 (Master Professional Performance). The correlation between ISRT score and ILR level as measured by the OPI is shown in Table 1 below. Table 1. Correlation Between ISRT Score and ILR Level (Hanawalt 2008:18) ISRT Total Score OPI (ILR) Level 0-4 0 5-7 0.6 (0+) 8-12 1 13-15 1.6 (1+) 16-20 2 21-24 2.6 (2+) 25-29 3 30-32 3.6 (3+) 33-37 4 38-40 4.6 (4+) 41-54 5 The Indonesian SRT consists of 15 sentences in Indonesian. Each sentence has an assigned point value. The total possible score on the ISRT is 54. The respondent being tested listens to the sentences one by one and repeats each sentence immediately after hearing it (Radloff 1991:7) and is scored on his or her ability to repeat the sentence exactly. Before starting the test, the respondent is allowed to practice with 3 example sentences. If the score of the respondent is low up to the 5th sentence, the interviewer does not need to continue the test. SRT tests have some advantages for assessment of community L2, such as short administration and scoring time with only a few personnel required, the fact that it can be administered even by researchers who only have rudimentary proficiency of the language being tested (provided that he/she has received proper training, and the fact that testing procedures are easy to understand. 35 Rindu Parulian Simanjuntak The test also follows the natural tendency of people to repeat what they hear, and it can eliminate cultural and social constraints (for example, the subject need not to be isolated from the group). Once developed and calibrated, an SRT can be used without further modification wherever bilingualism in that particular language is a question (Radloff 1991:6-7). Survey Procedures Two research tools were used to gather data to fulfill the research goal: a Bilingualism questionnaire, and the ISRT (Indonesian Sentence Repetition Test). The questionnaire contained a series of personal demographic questions for the respondent (see Appendix 1). Verbal consent was obtained from the respondent before the questionnaire was administered. Explanations of the questionnaire and the SRT usually took place in Indonesian. However, if the respondent was not sufficiently fluent in Indonesian to understand or reply in Indonesian, a local guide translated the explanation into the Enggano language. Sampling Random sampling was applied in each level of the sampling procedures to ensure the validity and representativeness of the collected data. At the village level, stratified random sampling was used by classifying the villages into two categories. Village Sampling The villages that were selected as research sites in Enggano are the ones where, according to the information gathered prior to the research in 2008 and confirmed afterwards, at least 75% of the residents who were native Enggano speakers. Based on this criterion, two out of six villages of Enggano were selected. They are Meok and Ka’ana. In our larger study of bilingualism in Bengkulu province, representative research site villages were randomly selected from two groups: villages located 10km or less to the nearest high school and villages located 20km or more to the nearest high school. This selection was made to see if the distance to the nearest school influences bilingual proficiency. However, there were no high schools in Meok and Ka’ana, so both villages selected as research sites where it located more than 20 km from the nearest high school. Household Sampling A systematic sampling method was used. Households were chosen by totaling the number of houses in the village of Meok and Ka’ana, and dividing that by the number of respondents needed. The total respondents were tested was 62, which 27 in Ka’ana, and 35 in Meok. For example, if there were 150 houses in a village, 150 were divided by 30 and so every 5 th house was chosen. If the residents of a household were not originally from Enggano island, the next house was chosen. Respondent Sampling A respondent between the ages of 15 to 60 was selected in each household using the KISH grid (see Appendix 3). If the respondent chosen was not originally from the Enggano language group (e.g. Javanese or Sundanese who married into the family), this person was not accepted as a respondent, and the next person indicated by the KISH grid was tested. A person was deemed an acceptable respondent if he/she met the following requirements: at least one parent was a native speaker of the local language, the local language was the respondent’s first language, the respondent was physically and mentally able to take the test, and the respondent was willing to take the test. 36 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 RESULTS Average BI Proficiency The overall average OPI or ILR levels (see Appendix 2) for BI bilingual proficiency of the Enggano is on level 2 (Limited Working Performance). According to the International Language Roundtable (2007) a person with language proficiency of level 2 is able to converse about routine or predictable subject matter, but sometimes require repetition or clarification. Table 2. Percentage of Respondents with BI Proficiency at ILR Level 3 Language Enggano Percentage of respondents at or above ILR3 21% Percentage of respondents below ILR3 79% The above table shows the percentage of Enggano respondents who are at or above ILR 3 in BI. Less than one-third of the population in all clusters is at or above ILR 3 (Professional Performance). The Enggano language group is therefore not predicted to be adequately proficient to use language materials exclusively in BI as defined in Sanders (2004): “80% or more of a cross-section of the language community (ages 20-45) speak a second language (L2) at a proficiency level of 3+ or above and this second language is used in a sustainable manner.” Thus, vernacular language materials may have benefit for the Enggano community. Social and Demographic Factors Based on information about the respondents gathered using the sociolinguistics questionnaire, ten factors were investigated as potential correlates with BI proficiency: years of education, age, exposure to literature, length of time spent outside the Enggano community, gender, distance of the respondent's village from school, frequency of travel, exposure to radio, contact with outsiders, and exposure to television. All the data were entered into electronic format, and then analyzed using the EPI software package. For most of the independent variables mentioned above, respondents were asked questions about the frequency that they engage in related activities (watching television or traveling outside of Enggano island, for example). They were then assigned by the analysts to frequency groups in the categories “never”, “seldom”, “sometimes”, and “often”. There were four exceptions. For years of education, respondents were asked how many years they had spent in school and these numerical values were used. For age, we used the respondents’ reported age. For gender there were two categories, male and female. For distance from school, we categorized respondents into two groups: those who live 10km or less to the nearest high school and those who live 20km or more to the nearest of high school. As mentioned above, all of the villages on Enggano are more than 20 km away from the nearest high school. As a last step, before statistical analysis was conducted, non-numerical data was converted to numerical codes to facilitate the analysis. The EPI software package was used to conduct multiple variable regression analysis to find the correlation between the dependent variable (ISRT score) and independent variables (years of education, age, exposure to literature, length of time spent outside the community, gender, distance from school, travel frequency, exposure to radio, contact with outsiders, and exposure to television) and also to determine which of the factors investigated had an influence on BI proficiency. As shown in Table 3 below, the factors investigated can be grouped into two categories. If the p-value resulting from the multiple variable regression analysis is less than 0.05, the factor is considered to have a statistically significant relationship with ISRT score, and if the p-value is greater than 0.05 the relationship between this factor and ISRT score is considered statistically insignificant. 37 Rindu Parulian Simanjuntak Table 3. Results of Multiple Variable Regression Analysis for Relationship with BI Proficiency Variable Coefficient Std Error F-test P-Value Years of Education 1.266 0.136 86.6471 0.000000 Age -0.086 0.036 5.6390 0.018142 Exposure to Literature 0.683 0.411 2.7689 0.097068 Contact with 0.389 0.287 1.8315 0.176882 Gender 0.503 0.828 0.3698 0.543534 Distance From School -0.035 0.093 0.1409 0.707676 Travel Frequency -0.101 0.465 0.0469 0.828677 Exposure to Radio 0.047 0.329 0.0204 0.886526 Contact with Outsiders 0.014 0.119 0.0138 0.906444 Exposure to Television 0.039 0.489 0.0062 0.937037 Statistically Significant Factors Of factors investigated, there are only two statistically significant factors which where shown to influence respondents' ISRT results: years of education and age. Years of Education The multiple regression analysis showed a positive correlation between years of education and bilingual proficiency in Indonesia. In the following presentation of the data, level of education is divided into four levels, as shown in Table 4 below. Table 4. Categories for Level of Education Level of Education Ages Years of Education Elementary 7-12 1-6 Junior High School 13-15 7-9 Senior High School 16-18 10-12 University 19 or more 13 or more Table 4 shows most children finished their education until Senior High School. Averagely, the children spent three years for the level of Elementary, Junior High School, and Senior High School. Only few students continued their studies to the higher level of education, such as college or university. Table 5. ILR Levels by Education Enggano Level of Education ILR Level Elementary 1+ Junior High 2 Senior High 2+ University * Table 5 shows ILR level of Indonesian proficiency for respondents by education in Enggano. The average proficiency level in Indonesia was level 1+ for respondents with education up to SD, level 2 for respondents with education up to SMP, and level 2+ for respondents with education up to SMU. This means that the bilingual proficiency level is apparently increasing when respondents have higher levels of education. For the people who had an opportunity to continue their studies, proficiency in Indonesian was somewhat higher;,whereas proficiency in Indonesian was lower when respondents had little or no opportunity to continue their studies. Thus in the study sample, BI proficiency increases with 38 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 increasing education. Therefore, education is very significant, and has a strong influence on Indonesian proficiency for the respondents in the study. Age In Table 6 below, the respondents were divided into two age groups: Young and Old. The Young group was defined as respondents between 15 and 35 years old. The Old group was defined as respondents between 36 and 60 years old. It is likely that the difference in BI proficiency between the two age groups is caused by variance in level of education. In general, most young people who were between ages 15 and 35 had attended school for 9 years or more, up to the SMP level (junior high school), while the older people who were between ages 36-60 had attended school for less than 9 years or had never been to school. Table 6. ILR Levels by Age Age ILR level Young 2+ Old 1+ On average individuals in the Young group are more proficient in BI than those in the Old group. The Young group had an average BI proficiency of ILR level of 2+ while the Old groups had an average BI proficiency of ILR level of 1+.. In Table 3, the coefficient value for the independent variable age is negative, meaning that higher age correlates with lower SRT score. Statistically Insignificant Factors Eight of the ten social and demographic factors investigated in this study were shown to be statistically insignificant and were not proven to influence BI bilingual proficiency in the study sample. These factors were: exposure to literature, length of time spent outside community, gender, distance from school, travel frequency, exposure to radio, contact with outsiders, and exposure to television. CONCLUSION Education plays an essential role in the life of Enggano speakers, and also has a strong factor in increasing bilingual Indonesian proficiency. In the study sample it appears that higher levels of education increase a person’s bilingual proficiency in Indonesian. Even though the average level of Indonesian proficiency for Enggano speakers can be described as Limited Working Performance (level 2), their attitudes towards both Indonesian and the local vernacular language are strongly positive. This can be seen from their motivation to still uses Indonesian in the domains of education and government while using the vernacular is mostly in the domain of home. Additionally, for Enggano speakers, Indonesian is used for continuing higher education, while the vernaculer needs to be maintained as part of Enggano culture so that it can be passed on to the younger generation. NOTE * I would like to thank an anonymous reviewer for very helpful comments on the earlier draft. ** This research was conducted when the writer worked for SIL International Indonesia from 2006-2012. *** The writer also would like to thank to the research teams that I could not mention their names one by one. They were from different institutions that helped the writer gathering the data, creating the map and doing data entry. 39 Rindu Parulian Simanjuntak BIBLIOGRAPHY Gordon, Raymond G, ed. 2005. Ethnologue, languages of the world. 15th ed. Dallas: SIL International, 435. Gumono. 2008. Upaya Pemeliharaan Bahasa Daerah yang Terancam Punah: Deskripsi Kondisi Kebahasaan, Sikap Bahasa, dan Kebutuhan Bahasa Masyarakat Pulau Enggano. FKIP Universitas Bengkulu (Accessed on http:fs.unitomo.ac.id/wp-content/uploads/2008/10/ daftar-makalah-semna-uny-2008.do), April 4, 2009 Hanawalt, Charlie. 2008. The development of the Indonesian Sentence Repetition Test. Jakarta: SIL International-Indonesia. Unpublished draft. http://www.ppmibengkulu.org/?p21. Post by admin | Wisata Bengkulu |, accessed on Sautrday, April 4, 2009 Interagency Language Roundtable. 2007. ILR skill level descriptions for interpretation performance. URL: http://www.govtilr.org/Skills/interpretationSLDsapproved.htm Sanders, Chip and IDB Academic Team. 2004. Towards an IDB policy on language project planning in multilingual settings: IDB Academic Team meeting. SIL International, Indonesian. Sugondo, Dendy., Mahsun., Inyo., Kisyani., Multamia., Nadra., and Ferry, ed. 2008. BahasaBahasa di Indonesia. Jakarta: Pusat Bahasa. Unpublished draft. Radloff, Carla F. 1991. Sentence Repetition Testing for studies of community bilingualism. Dallas: Summer Institute of Linguistics and University of Texas at Arlington. 40 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 APPENDIX 1: SOCIOLINGUISTIC QUESTIONNAIRE A. Kuesioner Penjajakan Dwibahasa #Responden Tanggal: ____/____/____ Lokasi: Desa_____________ Kec_____________ Kab_____________ Pewawancara: _______________________ Pengamat: _______________________ Penerjemah BD: _______________________ 1. Biodata Nama lengkap: ______________________ Umur: ______________________ Jenis kelamin: ______________________ Pekerjaan: ______________________ Apaka Anda sudah menikah? Y/T Pendidikan formal: Y/T Berapa lama: _____ tahun SD SMP SMA 1 2 3 4 5 6 1 2 3 1 2 3 Tempat dilahirkan: Tempat dibesarkan: Bahasa apa yang Anda gunakan pertama kali waktu kecil? Dari suku apa ayah Anda berasal? Bahasa apa yang paling sering ayah Anda gunakan dengan Anda? Dari suku apa ibu Anda berasal? Bahasa apa yang paling sering ibu Anda gunakan dengan Anda? Dari suku apa pasangan (suami/istri) Anda berasal? Bahasa apa yang digunakan pasangan Anda dengan Anda? Bahasa apa yang Anda gunakan sehari-hari di rumah? Apakah Anda bisa berbahasa yang lain? Y/T 1.18. Dari semua bahasa yang Anda bisa, apa bahasa yang paling lancar: __________________ kedua: __________________ ketiga: __________________ 2. Kontak 2.1. Tempat tinggal di luar wilayah bahasa Apakah Anda pernah tinggal di luar daerah ini? Y/T Jika ya, berapa lama? (Catat yang lebih dari 6 bulan) _____________________________________________________________________ Bahasa apa yang digunakan di daerah itu? __________________________________ 41 D3 Rindu Parulian Simanjuntak 2.2. Perjalanan (*Tulislah semua jawaban dalam tabel yang disediakan di bawah) Apakah Anda sering pergi ke luar daerah ini? Y/T Ke mana Anda pergi? Berapa sering Anda pergi ke sana? (sethar beb/mng 1x/mng 2x/bln 1x/bln <1x/bln) Bahasa apa yang digunakan di daerah itu? Apa tujuan Anda biasanya pergi ke sana? b. Lokasi c. Frekuensi d. Bahasa e.Tujuan perjalanan 2.3. Apakah Anda mempunyai tetangga atau teman yang tidak berasal dari [suku setempat]? Y/T Jika ya, bahasa apa yang Anda biasanya gunakan dengan mereka? ____________________ Seberapa sering Anda bertemu mereka? Sering Kadang-kadang Jarang 3. Media 3.1. Radio/TV Apakah Anda sering mendengarkan Radio? Y/T Jika ya, seberapa sering? Sering Kadang-kadang Jarang Siaran apa yang biasanya Anda dengarkan di radio? ________________________ Siaran-siaran tersebut biasanya dalam bahasa apa? ________________________ Apakah Anda mengerti siaran tersebut? ________________________ Apakah Anda sering menonton TV? Y/T Jika ya, seberapa sering? Sering Kadang-kadang Jarang Siaran apa yang biasanya Anda dengarkan? _______________________ Siaran-siaran tersebut biasanya dalam bahasa apa? _______________________ Apakah Anda mengerti siaran tersebut? _______________________ 3.2. Buku dan Bacaan Apakah Anda suka membaca? Y/T a. Jika ya, seberapa sering? Sering Kadang-kadang Jarang b. Jenis bacaan apa ada di rumah ini: Jenis bacaan Bahasa Mengerti (Y/T) Surat kabar, majalah Al’Quran/Alkitab Buku tentang agama Cerita (fiksi/nonfiksi) Komik Bacaan di poster, Kalendar, dll Buku petunjuk Buku kesehatan Kamus Surat, pesan, email, SMS Brosur, pengumuman Peta, sketsa/gambar Rekening atau faktur Jumlah BI_____ BD____ dll____ Ya_____ 42 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 APPENDIX 2: ILR LEVEL DESCRIPTORS (Interagency Language Roundtable 2007) ILR level 0 Attribute No Performance 0+ 1 Memorized Performance Minimal Performance 1+ Minimal Performance Plus 2 Limited Working Performance 2+ Limited Working Performance Plus 3 Professional Performance Description No functional ability to transfer information from one language to another. Unable to transfer more than isolated words. Unable to transfer more than isolated short phrases. Unable to transfer information reliably, even if familiar with the subject matter. Unable to transfer information reliably in most instances. May communicate some meaning when exchanges are short, involve subject matter that is routine or discourse that is repetitive or predictable, but may typically require repetition or clarification. Expression in the target language is frequently faulty. Able to transfer information, not always accurately and completely, during routine, everyday, repetitive exchanges in informal settings, but unable to perform adequately in the standard interpretation modes. May falter, stammer, or pause, and often resort to summarizing speech content. Idiomatic or cultural expressions may not be rendered appropriately in most instances. Language may be stilted or awkward. Able to interpret consistently in the mode (simultaneous, consecutive, and sight) required by the setting, provide renditions of informal as well as some colloquial and formal speech with adequate accuracy, and normally meet unpredictable complications successfully. Can convey many nuances, cultural allusions, and idioms, though expression may not always reflect target language conventions. Adequate delivery, with pleasant voice quality. Hesitations, repetitions or corrections may be noticeable but do not hinder successful communication of the message. Can handle some specialized subject matter with preparation. Performance reflects high standards of professional conduct and ethics. 43 Rindu Parulian Simanjuntak ILR level 3+ Attribute Professional Performance Plus 4 Advanced Professional Performance Description Able to interpret accurately and consistently in the mode (simultaneous, consecutive, and sight) required by the setting and provide generally accurate renditions of complex, colloquial and formal speech, conveying most details and nuances. Expression will generally reflect target language conventions. Demonstrates competence in the skills required for interpretation, including command of both working languages, their cultural context, and terminology in those specialized fields in which the interpreter has developed expertise. Good delivery, with pleasant voice quality, and few hesitations, repetitions, or corrections. Performance reflects high standards of professional conduct and ethics. Able to interpret in the mode (simultaneous, consecutive, and sight) required by the setting and provide almost completely accurate renditions of complex, colloquial, and idiomatic speech as well as formal and some highly formal discourse. Conveys the meaning of the speaker faithfully, including most if not all details and nuances, reflecting the style, register, and cultural context of the source language, without omissions, additions or embellishments. Demonstrates mastery of the skills required for interpretation, including command of both working languages and their cultural context, expertise in some specialized fields, and ability to prepare new specialized topics rapidly and routinely. Very good delivery, with pleasant voice quality and only occasional hesitations, repetitions or corrections. Performance reflects the highest standards of professional conduct and ethics. 44 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 ILR level 4+ Attribute Advanced Professional Performance Plus 5 Master Professional Performance Description Able to interpret in the mode (simultaneous, consecutive, and sight) required by the setting and provide accurate renditions of informal, formal, and most highly formal discourse. Conveys the meaning of the speaker faithfully and accurately, including virtually all details and nuances, reflecting the style, register, and cultural context of the source language, without omissions, additions or embellishments. Demonstrates mastery of the skills required for interpretation, including command of both working languages and their cultural context, expertise in a number of specialized fields, and ability to prepare other specialized topics rapidly and routinely. Excellent delivery, with pleasant voice quality and rare hesitations, repetitions or corrections. Performance reflects the highest standards of professional conduct and ethics. Able to excel consistently at interpreting in the mode (simultaneous, consecutive, and sight) required by the setting and provide accurate renditions of informal, formal, and highly formal discourse. Conveys the meaning of the speaker faithfully and accurately, including all details and nuances, reflecting the style, register, and cultural context of the source language, without omissions, additions or embellishments. Demonstrates superior command of the skills required for interpretation, including mastery of both working languages and their cultural context, and wideranging expertise in specialized fields. Outstanding delivery, with pleasant voice quality and without hesitations, unnecessary repetitions, and corrections. Exemplifies the highest standards of professional conduct and ethics. 45 Rindu Parulian Simanjuntak APPENDIX 3: KISH GRID FOR RANDOM SAMPLING Eligible people 1 2 3 4 5 6 7 8 9 ≥ 10 1 1 1 1 1 1 1 1 1 1 1 2 1 2 2 2 2 2 2 2 2 2 46 Household 3 4 1 1 1 2 3 1 3 4 3 4 3 4 3 4 3 4 3 4 3 4 5 1 1 2 1 5 5 5 5 5 5 6 1 2 3 2 3 6 6 6 6 6 Linguistik Indonesia, Februari 2014, 47-61 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 AKRONIM YANG BERFONOTAKTIK TIDAK LAZIM DALAM BAHASA INDONESIA Sariah* Universitas Padjadjaran [email protected] Abstrak Penelitian akronim ini bertujuan mendeskripsikan akronim yang berfonotaktik tidak lazim dalam bahasa Indonesia. Ada tiga indikator yang dapat dijadikan pedoman, yaitu (1) jajaran fonem yang fonotaktik, (2) konsonan penutup suku kata yang lazim, dan (3) jumlah suku kata yang lazim dalam bahasa Indonesia. Data yang digunakan adalah data surat kabar nasional Januari 2012—Maret 2013. Temuannya adalah akronim yang berfonotaktik tidak lazim umumnya terdapat pada bahasan penjajaran fonem, khususnya pada jajaran fonem /md/ Gakumdu, jajaran fonem /nm/ Menmud, jajaran fonem /pk/ Apkasi, dan jajaran fonem /pm/ Ipmi. Akronim dengan dua konsonan berurutan yang sama terdapat pada konsonan /pp/ Bappebti, konsonan //ss/ Kopassus, /mm/ Jamman, dan /tt/ Unpatti. Akronim dengan konsonan rangkap adalah /dh/ pada Pusbadhi, konsonan /ngg/ Unpatti, dan konsonan /nd/ pada Unand. Akronim yang menggunakan konsonan yang tidak bisa menjadi penutup suku kata umumnya adalah akronim berpenutup suku kata dengan konsonan /g/ dan /d/. Konsonan penutup suku kata/c/ tidak ditemukan dalam data akronim. Selain itu, ada akronim yang menggunakan konsonan penutup suku kata /z/ dan konsonan /v/, sedangkan dalam kata serapan pun tidak ditemukan konsonan /z/ dan konsonan /v/ sebagai penutup suku kata, seperti Baznas, Pemprov. Perulangan fonem yang sama dalam beberapa suku kata terdapat pada riskesdas. Jumlah suku kata (silabe) terdiri atas empat suku kata atau lebih, seperti Babinkumnas, Ditreskrimsus. Kata kunci: akronim, fonotaktik, suku kata Abstract This acronym research describes some uncommon phonotactic acronyms in Indonesian. Three indicators were used as guidance: (1) the list of phonotactic phonemes, (2) the common closed consonants, (3) the number of common syllables in Indonesian. The data were taken from national news papers from January 2012 thorugh March 2013. The results indicated: (1) uncommon phonotactic acronyms were usually found in the phoneme list of /md/ for Gakumdu, /nm/ for menmud, the /pk/ for Apkasi, and /pm/ for ipmi. (2) The acronyms of two identical sequenced consonants were found in the consonants /pp/ as in Bappepti, /ss/ in Kopassus, /mm/ in jamman, and /tt/ in Unpatti. (3) The acronyms of double consonant were found in the consonants /dh/ as in pusbadhi, /ngg/ in unpatti, and /nd/ in unand. The acronyms containing consonanst that were not used as word-closing acronyms were the consonants /g/ and /d/. The closing word consonant /c/ was not found in the data. Besides, acronyms using closed word consonants were found in the consonants /z/ and /v/. In borrowed words the consonants that were not found were /z/ and /v/ as word-closing acronyms, such as in baznas, pemprov. The repetition of similar phonemes in some syllables was found in riskesdas. The number of syllables commonly found in Indonesian acronyms consisted of four or more words, for example, babinkumnas, ditreskrimsus. Keywords: acronym, phonotactic, syllable PENDAHULUAN Pembentukan akronim lazimnya mengikuti beberapa pertimbangan. Pertama, pengucapan akronim yang diciptakan mudah dilafalkan dalam bahasa yang bersangkutan. Kedua, jumlah Sariah suku kata yang lazim, mengikuti kaidah fonotaktik, yaitu kaidah yang menggambarkan penjajaran fonem-fonem yang berlaku dalam suatu bahasa. Kaidah fonotaktik merupakan kaidah yang mengatur urutan atau hubungan antara fonem-fonem suatu bahasa. Fonotaktik mempunyai pola yang terkait dengan pola penyukuan kata dan pergeseran bunyi yang menimbulkan variasi bunyi satu fonem yang sama (Chaer, 2009:84). Banyak bentuk akronim yang tidak mempertimbangkan kaidah fonotaktik, misalnya akronim calhaj (calon haji). Dalam suku kata bahasa Indonesia tidak ditemukan kata yang berakhir dengan fonem /j/, kecuali dari bahasa asing. Di samping itu, akronim Unibraw (Universitas Brawijaya), Unand (Universitas Andalas) juga tidak sesuai dengan kaidah fonotaktik bahasa Indonesia karena tidak ditemukan kata bahasa Indonesia yang berakhir dengan fonem /w/ dan konsonan rangkap /nd/. Ada beberapa fonem konsonan bahasa Indonesia yang tidak dapat menjadi penutup suku kata, yaitu fonem konsonan /b/, /c/, /d/, /g/, /j/, /ny/, /w/, dan /y/ (Sudarno, 1990:31). Jika ada kata yang berakhir dengan salah satu konsonan tersebut, diduga kata itu berasal dari bahasa asing. Dengan demikian, jika ada akronim yang menggunakan konsonan yang tidak dapat menjadi penutup suku kata, berarti akronim itu tidak mengikuti kaidah fonotaktik bahasa Indonesia. Bentuk lain yang tidak fonotaktik masih banyak ditemukan, seperti caleg, penjaskes, Kopkamtib, Kemendikbud. Saat akronim sprindik mengemuka, banyak orang bertanya apa sprindik sebuah kata Indonesia atau kata asing. Umumnya orang tidak mengetahui bentuk tersebut, kecuali orang yang setiap hari membaca surat kabar. Ternyata sprindik adalah sebuah akronim dari ‘surat perintah penyidikan’. Akronim itu terkesan asing bagi penutur bahasa Indonesia karena menggunakan gugus konsonan /spr/ yang merupakan gugus konsonan asing atau serapan. Dengan demikian, gugus konsonan /spr/ pada kata sprei tidak dijadikan acuan untuk menentukan sebuah akronim yang fonotaktik. Sebenarnya secara sederhana konsep fonotaktik tidak sukar dipahami. Misalnya, kata bahasa asing phrase, psychology, business sukar dilafalkan dalam bahasa Indonesia. Oleh karena itu, orang Indonesia mengubah ejaannya menjadi frasa, psikologi, dan bisnis supaya mudah dilafalkan. Dengan demikian, kata frasa, psikologi, dan bisnis mudah diucapkan dalam pelafalan bahasa Indonesia karena susunan ejaan hurufnya (fonem) sudah sesuai dengan kaidah fonotaktik bahasa Indonesia. Sebaliknya, kata aslinya phrases, psychological, business sulit dilafalkan dengan lidah orang Indonesia karena susunan hurufnya tidak sesuai dengan kaidah tersebut. Dalam kaidah fonotaktik bahasa Indonesia tidak ada rangkaian huruf /p/ dan /h/ (phrase) dan /p/, /s/, /y/ (psychology) pada awal suku kata dan konsonan /y/ pada psycgology di akhir suku kata. Konsonan /y/ diubah menjadi vokal /i/ supaya memudahkan pelafalan. Pada kata asing business adaptasinya ke dalam bahasa Indonesia menjadi bisnis. Berdasarkan paparan pada latar belakang di atas, masalah dalam tulisan ini adalah bagaimana akronim berfonotaktik tidak lazim yang terdapat dalam surat kabar nasional? Sesuai dengan masalah yang telah disebutkan di atas, tujuan penelitian ini adalah mendeskripsikan dan menganalisis akronim berfonotaktik tidak lazim yang terdapat dalam data surat kabar nasional. Manfaat penelitian dapat ditinjau secara teori dan praktik. Secara teori, penelitian ini dapat dimanfaatkan sebagai masukan dalam melahirkan akronim berfonotaktik lazim dalam bahasa Indonesia. Di samping itu, penelitian ini dapat mengungkapkan kriteria akronim berfonotaktik tidak lazim yang didasarkan pada kaidah fonotaktik bahasa Indonesia. Penelitian akronim berfonotaktik tidak lazim dengan data yang signifikan dapat menjadi informasi mengenai akronim yang diciptakan selama ini: apakah telah sesuai atau menyimpang dari kaidah fonotaktik bahasa Indonesia. Secara praktis, penelitian ini dapat memberikan gambaran pemakaian akronim berfonotaktik tidak lazim sehingga dapat menjadi pedoman untuk menciptakan akronim baru yang mengikuti kaidah fonotaktik bahasa Indonesia, terutama bagi lembaga atau sebuah kepanitiaan yang sering melahirkan akronim baru. Di samping itu, penelitian ini juga dapat menjadi informasi kebahasaan yang penting. 48 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 KERANGKA TEORI Beberapa peneliti bahasa telah mengungkap pemakaian akronim. Di antaranya adalah Darheni, Irawati, Alaudin, dan Suratminto. Darheni (2000) meneliti pemakaian abreviasi yang berjudul “Penggunaan Singkatan dan Akronim Berbahasa Indonesia dalam Media Cetak: Ditinjau dari Segi Bentuk dan Makna”. Darheni mengamati keragaman bentuk singkatan dan akronim dalam media massa cetak dan hasilnya adalah (1) proses pembuatan singkatan dan akronim yang berupa kata tunggal, gabungan kata, berafiks, berreduplikasi, pelesapan, dan penyingkatan dalam akronim, (2) hasil pembentukan akronim yang meliputi perbedaan bentuk akronim dengan acuan sama, dan persamaan bentuk akronim berupa kata dan frasa, dan (3) acuan akronim dan/atau singkatan yang berupa kata tunggal dan jamak. Penelitian senada pernah dilakukan Irawati (2004). Penelitian itu berjudul “Singkatan dan Akronim dalam Media Chatting dan SMS: Analisis Komunikasi Teks dalam Internet dan Telepon Seluler”. Hasilnya adalah pembentukan singkatan dan akronim pada media catting dan SMS di samping menggunakan pola yang sudah ada juga menggunakan pola baru yang belum ada dalam pola pembentukan singkatan dan akronim dalam bahasa Indonesia. Pola-pola baru tersebut adalah singkatan dari angka sebagai pengganti huruf dan kata, singkatan dari gabungan huruf dan angka, singkatan yang mengubah beberapa huruf, dan singkatan yang menghilangkan unsur vokal sebuah kata. Pola yang disebutkan terakhir ini yang sering muncul dalam teks SMS. Penelitian yang berjudul “Bentuk-Bentuk Singkatan Bahasa Indonesia pada Iklan Mini (Studi Kasus pada Iklan Mini Kompas Tanggal 1—31 Agustus 2002)” pernah diteliti oleh Alaudin. Temuan pentingnya adalah bahwa tedapat singkatan pada iklan mini tersebut yang memiliki beberapa makna atau pengertian yang berbeda dari makna umum yang sudah dikenal masyarakat. Mulyati (2009) mengamati pola-pola pembentukan akronim dan fenomena akronim dalam bahasa Indonesia. Tulisannya berjudul “Menyoroti Abreviasi: Singkatan dan Akronim” Hasil yang diperoleh dari pengamatannya itu adalah (1) pola pengakroniman dalam bahasa Indonesia tidak memiliki keajekan kaidah, (2) ledakan akronim memaksa penentu kebijakan perencana dan pembaku bahasa untuk selalu jeli dan cepat tanggap dalam menangani masalah ini, paling tidak meninjau kamus secara periodik dan pengodifikasian pola-pola baru, (3) ledakan akronim juga berpengaruh terhadap pihak yang mau mempelajari bahasa Indonesia, (4) banyak yang sulit untuk dipahami, kecuali oleh kalangan tertentu sehingga bahasa Indonesia menjadi “dialek”, dan (5) banyak akronim yang dipakai secara tumpang-tindih. Lilie Suratminto (2010) meneliti “Abreviasi dan Akronim pada Batu Nisan Masa VOC di Batavia”. Simpulan yang diperoleh adalah bahwa kebiasaan untuk menggunakan abreviasi dan akronim sudah membudaya pada masyarakat VOC di Batavia pada abad ke-17 dan 18. Di samping itu, pembuatan plakat (pengumuman resmi dari pemerintah) menggunakan abreviasi dan akronim. Dengan demikian, beberapa penelitian sebelumnya dapat dikelompokkan berdasarkan kajian dan data. Penelitian akronim berdasarkan kesamaan data terdapat pada penelitian Darheni (2000), penelitian Alaudin (2002), dan Sariah (2013). Selanjutnya, peneltian akronim berdasarkan kesamaan kajian terdapat pada penelitian Darheni (2000), penelitian Irawati (2004), dan penelitian Suratminto (2010). Penelitian Sariah (2013) menggunakan teori fonotaktik. Jika dipetakan, penelitian sebelumnya dan penelitian yang akan dikaji sekarang adalah sebagai berikut. Fonotaktik mengatur bagaimana fonem-fonem dan alofonnya tersusun secara beraturan sehingga membentuk suatu kata yang bermakna. Alwi (2000:24) menegaskan bahwa fonotaktik membahas rentetan bunyi, yaitu satu bunyi diiringi bunyi yang lain. Bunyi-bunyi itu mewakili rangkaian fonem serta alofonnya. Rangkaian fonem itu tidak bersifat acak, tetapi mengikuti kaidah-kaidah tertentu. Fonem apa yang dapat mengikuti fonem yang mana ditentukan berdasarkan perjanjian oleh para pemakai bahasa itu sendiri. Kaidah yang mengatur penjajaran fonem suatu bahasa dinamakan kaidah fonotaktik. Pengertian fonotaktik menurut Parera (1985:19) dalam Fonetik dan Fonemik adalah suatu prosedur penemuan dan penentuan tata urut dalam tata hubung fonem-fonem dalam 49 Sariah sebuah bahasa. Yang dibicarakan dalam fonotaktik adalah pola urutan bunyi, distribusi fonem, pola suku kata, gugus bunyi konsonan dan vokal, jenis-jenis gugus bunyi yang mungkin dan yang tidak mungkin pada tingkat kata atau antarkata. Bahasa Indonesia juga mempunyai kaidah semacam itu. Kaidah fonotaktik itulah yang menyebabkan kita dapat merasakan secara intuitif bentuk mana yang berterima (kelihatan seperti kata Indonesia) meskipun belum pernah kita dengar/lihat sebelumnya dan mana yang tidak berterima. Pola fonotaktik adalah kaidah pergeseran bunyi dalam pelafalan kata, baik kata dasar maupun kata turunan, sebagai akibat pengaruh bunyi yang ada pada lingkungannya (baik sebelum dan sesudahnya). Pergeseran ini menimbulkan variasi bunyi dari satu fonem yang sama. Bahasa Indonesia mengizinkan jajaran, seperti /-nt-/ (untuk), /-rs-/ (bersih), dan /-st-/ (pasti), tetapi tidak mengizinkan jajaran, seperti /-pk-/ dan /-pd-/ karena tidak ada morfem bahasa Indonesia yang menjajarkan fonem seperti itu (Alwi, 2000:24). Jadi, bentuk-bentuk seperti opkir dan kapdu terasa janggal dan memang tidak ada kata dengan jajaran fonem yang demikian dalam bahasa Indonesia. Oleh karena itu, singkatan, khususnya akronim hendaknya serasi dengan kaidah fonotaktik bahasa Indonesia. Menurut Kentjono (2005:164) kaidah fonotaktik adalah aturan dalam merangkai fonem untuk membentuk satuan fonologis yang lebih besar, misalnya suku kata. Deretan fonem yang terdapat dalam bahasa Indonesia mempunyai pola fonotaktik seperti halnya deret fonem bahasabahasa lain. Deret fonem tersebut meliputi gugus vokal, deret vokal, gugus konsonan, deret konsonan, deret vokal dan deret konsonan dalam satu suku kata (silabel). (1) Gugus vokal bahasa Indonesia adalah diftong /ai/, /au/, /oi/ dan /ei masing-masing pada kata pulau, santai, asoi, survei. (2) Deret vokal bahasa Indonesia adalah sebagai berikut. /ae/ : daerah /ai/ : saing /au/ : kaum, mau /ea/ : beasiswa, kreasi /ea/ : seakan /ee/ : keenam /ee/ : seekor /ei/ : mei /ei/ : seikat /eo/ : feodal, beo, pameo /eu/ : seutas /ia/ : tiap, dia, giat /io/ : kios radio, biola /iu/ : tiup, nyiur /oa/ : soal, doa /ua/ : dua, suap /ue/ : kue. duet /ui/ : buih. kuil /uo/ : kuota (3) Gugus konsonan bahasa Indonesia terdapat di bawah ini. /bl/ : blanko, gamblang /br/ : brantas, ambruk /dr/ : drama, drakula /dw/ : dwi /fl/ : flu, flamboyan /fr/ : frustasi, fragmen /gl/ : gladi, global 50 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 /gr/ : granat, gram /kl/ : klinik, klasik /kr/ : kriminal /ks/ : ekstra, eksponen /kw : kwartet /pl/ : pleonasme, pleno /ps/ : psikologi, psikiater /sl/ : slip, slogan /sp/ : spanduk, sponsor /sr/ : sragen /sw/ : swasta, swalayan /tr/ : mitra, tragedi (4) Deret konsonan bahasa Indonesia terdapat di bawah ini /bd/ : abdi, sabda /gm/ : dogma, magma /gn/ : signal, kognisi /hb/ : sahbandar /hd/ : syahdu, syahdan /hk/ : bahkan /hl/ : ahli, tahlil /hs/ : dahsyat /ht/ : tahta, bahtera /hw/ : bahwa /hy/ : sembahyang /kd/ : takdir, bakda /kl/ : maklum, takluk /km/ : sukma /kn/ : yakni, makna, laknat /kr/ : makruf, takrif /ks/ : paksa, siksa /kt/ : bukti, bakti /kw/ : takwa, dakwa /ky/ : rukya, rakyat /lj/ : salju, aljabar /lm/ : ilmu, gulma, palma /ls/ : palsu, balsem, pulsa /lt/ : salto, sultan /mb/ : ambil, gambar /ml/ : jumlah /mp/ : empat, pimpin /mr/ : jamrut /nc/ : kunci, lancar /nd/ : indah, pandang /ngk/ : engkau, mungkin /ngs/ : angsa, bangsa, mangsa /nj/ : banjir, janji /np/ : tanpa /ns/ : insang, insan /nt/ : ganti, untuk /pt/ : sapta, baptis /rb/ : kerbau, terbang /rc/ : percaya, karcis 51 Sariah /rd/ : merdu, merdeka, kerdil /rg/ : pergi, harga, surga /rj/ : kerja, sarjana, terjang /rk/ : terka, perkara, murka /rl/ : kerlip, kerling, perlu /rm/ : cermin, derma /rn/ : warna, purnama, ternak /rs/ : gersang, bersih, /rt/ : arti, harta, serta /sb/ : asbak, asbes /sh/ : masyhur /sl/ : muslim /sm/ : basmi, asmara /sp/ : puspa, aspal /st/ : pasti, dusta Parameter yang dijadikan patokan adalah jajaran fonem yang berasal dari bahasa Indonesia sehingga jajaran fonem yang bergugus tiga konsonan tidak digunakan sebagai acuan. Gugus konsonan terdiri atas tiga fonem berderet dalam satu suku kata adalah /stra/ strategi, instruksi, /spr/ sprei, /skr/ skripsi, /skl/ sklerosis. Jumlah konsonan asli bahasa Indonesia ada delapan belas dengan ketentuan sebelas konsonan dapat menjadi penutup suku kata, yaitu konsonan /h/, /k/, /l/, /m/, /n/, /ng/, /ny/, /p/, /r/, /s/, /t/ dan ada tujuh konsonan bahasa Indonesia yang tidak bisa menjadi penutup suku kata, yaitu konsonan /b/, /c/, /d/, /g/, /j/, /w/. dan /y/ (Sudarno, 1990:46). Konsonan penutup /ny/ dalam tulisan berupa konsonan /n/ saja. Mengapa penulis berpatokan pada penjajaran fonem asli dan konsonan penutup suku kata bahasa Indonesia karena pertimbangan bahwa banyak unsur serapan yang berterima dalam bahasa Indonesia sehingga akronim yang dilahirkan masih belum mendekati kata bahasa Indonesia, seperti akronim sprindik tadi. Di samping itu, konsonan yang tidak bisa menjadi penutup suku kata di antaranya adalah /b/, /d/, dan /j/, misalnya pada kata serapan dari bahasa Arab, seperti sebab, mikraj, sujud. Dengan mengenal karakteristik kata bahasa Indonesia dan kaidah fonotaktiknya, ada tiga indikator yang dapat dijadikan pedoman, yaitu jajaran fonem yang fonotaktik, konsonan penutup suku kata yang lazim, dan jumlah suku kata yang lazim dalam bahasa Indonesia. METODE PENELITIAN Metode yang digunakan dalam penelitian ini ialah metode deskriptif. Hasil yang diperoleh berupa pemerian bahasa apa adanya secara terperinci dan mendalam (Sudaryanto, 1993:62). Berdasarkan uraian tersebut, metode deskriptif dipakai untuk memaparkan hasil temuan yang diperoleh dalam penelitian berupa penggambaran akronim yang berfonotaktik tidak lazim secara sistematik dan faktual berdasarkan data yang dikumpulkan dari Januari 2012—Maret 2013 pada suarat kabar nasional (Kompas, Media Indonesia, Republika, dan Sindo). Pendapat Sudaryanto ini sejalan dengan apa yang dinyatakan oleh Djajasudarma (2010:8) bahwa penggunaan metode deskriptif bertujuan membuat gambaran yang sistematik dan akurat mengenai data, sifat-sifat, serta hubungan fenomena-fenomena yang diteliti. Metode deskriptif dalam tulisan ini dipakai untuk memaparkan hasil temuan yang berupa pemakaian akronim yang berfonotaktik tidak lazim dalam bahasa Indonesia. Pengambilan data dilakukan dengan studi pustaka, yaitu mengumpulkan pemakaian akronim dalam surat kabar nasional. Kemudian data tersebut dicatat, diklasifikasikan, dan dianalisis. 52 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 PEMBAHASAN Berdasarkan pengamatan terhadap data, paparan dalam tulisan ini dikelompokkan menjadi (1) jajaran fonem yang tidak lazim dalam bahasa Indonesia; (2) dua konsonan berurutan yang sama dalam satu kata; (3) konsonan yang tidak bisa menjadi penutup suku kata bahasa Indonesia; (4) perulangan konsonan yang sama dalam beberapa suku kata; (5) jumlah suku kata yang terdiri atas empat suku kata lebih. Jajaran Fonem yang Tidak Lazim dalam Bahasa Indonesia Jajaran fonem bahasa Indonesia yang lazim telah disebutkan di atas. Berdasarkan telaah terhadap data, ditemukan akronim yang berfonotaktik tidak lazim. Ketidaklaziman itu mengacu pada teori fonotaktik yang telah disebutkan di atas. Dengan demikian, kefonotaktikan mengacu pada daftar gugus vokal (diftong), deret vokal, gugus konsonan, dan deret konsonan yang telah disebutkan di atas. Dalam paparan ini jajaran fonem yang berfonotaktik tidak lazim atau berbeda dengan apa yang telah dirumuskan oleh para ahli bahasa tidak disebutkan seluruhnya hanya beberapa contoh saja. No. 1 2 3 4 5 6 7 8 9 10 11 10 11 12 13 14 15 16 17 18 19 Akronim Bulcup FOBMI Balegda Dologda FAGSAM GATBI Dispendukcapil dokcil Amdal Gakumdu Jamda Kamnas Komnet Binmatkum Menmud Ranmor Kopbumi Pusdalopbang APDASI Bakopda Apkasi 20 21 22 Gapki Kopkamtib GAPMMI 23 24 Apmiso HIPMI Tabel 1. Jajaran Fonem yang Tidak Lazim Jajaran Fonem Bentuk Panjangnya /bk/ Federasi Organisasi Buruh Migran Indonesia /bm/ Badan Legislatif Daerah /gd/ Depot Logistik Daerah /gd/ Bulungan Cup /gs/ Front Antigerakan Aceh Merdeka /tb/ Gabungan Toko Buku Indonesia /kc/ Dinas Kependudukan dan Pencatatan Sipil /kc/ dokter kecil /md/ Analisis Dampak Lingkungan /md/ Penegakan Hukum Terpadu /md/ Jambore Daerah /mn/ Keamanan Nasional /mn/ Kompor megnet /nm/ Binaan Masyarakat Taat Hukum /nm/ Menteri Muda /nm/ Kendaraan bermotor /pb/ Koperasi Perlindungan Buruh Migran Indonesia /pb/ Pusat Pengendalian Operasi Pembangunan /pd/ Asosiasi Pedagang Daging Sapi Indonesia /pd/ Badan Koordinasi Pembangunan Daerah /pk/ Asosiasi Pemerintahan Kabupaten Seluruh Indonesia /pk/ Gabungan Pengusaha Kelapa Sawit Indonesia) /pk/ Komandan Operasi Keamanan dan Ketertiban /pm/ Gabungan Pengusaha Makanan dan Minuman Indonesia /pm/ Asosiasi Pedagang Bakso Indonesia /pm/ Himpunan Pengusaha Muda Indonesia 53 Sariah Jika diamati, akronim FOBMI mempunyai jajaran fonem /b/ dan /m/. fonem /b/ dan /m/ berasal dari daerah artikulasi yang sama, yaitu daerah artikulasi bilabial (bibir). Di samping itu, fonem /f/ sebagai pembuka bunyi merupakan konsonan frikatif labiodental (bunyi yang dihasilkan dengan udara menggeser alat ucap). Jika konsonan frikatif labiodental /f/ dipertemukan dengan konsonan hambat bilabial /b/ pada suku kata fob, bunyi yang dihasilkan sulit untuk diucapkan. Dengan demikian, akronim FOBMI tidak mengikuti penjajaran fonem yang lazim dalam bahasa Indonesia. Selain itu, jajaran fonem /bm/ tidak terdapat dalam jajaran fonotaktik bahasa Indonesia yang disebutkan di atas. Jajaran fonem /gd/ pada akronim balegda dan dologda tidak terdapat dalam jajaran fonem fonotaktik. Fonem /g/ dan fonem /d/ adalah fonem hambat bersuara meskipun berasal dari daerah artikulasi yang berbeda. Daerah artikulasi fonem /g/ adalah hambat velar (belakang lidah ditempelkan pada langit-langit lunak), sedangkan fonem /d/ adalah hambat alveolar (ujung lidah ditempelkan pada gusi). Jajaran fonem itu tidak ditemukan dalam kata-kata bahasa Indonesia. Akronim Bulcup merupakan akronim yang dilafalkan menjadi Bulkap. Jajaran fonem /lc/ juga tidak lazim dalam kata-kata bahasa Indonesia. Jajaran fonem /gs/ pada akronim FAGSAM juga tidak ditemukan dalam daftar jajaran fonotaktik yang telah disebutkan di atas. Selain itu, fonem /g/ umumnya tidak menjadi penutup suku kata bahasa Indonesia. Bentuk lain terdapat pada akronim GATBI. Jajaran fonem /tb/ tidak terdapat dalam daftar jajaran fonem fonotaktik. Jajaran fonem /kc/ terdapat pada akronim Dispendukcapil dan dokcil, tetapi jajaran fonem /kc/ tidak ditemukan dalam jajaran fonem fonotaktik. Fonem /k/ adalah konsonan hambat velar yang dihasilkan dengan menempelkan belakang lidah pada langit-langit lunak. Udara dihambat pada tempat tersebut dan kemudian dilepaskan. Sebaliknya, fonem /c/ adalah konsonan afrikat palatal yang dilafalkan dengan lidah ditempelkan pada langit-langit keras dan kemudian dilepas secara perlahan sehingga udara dapat lewat dengan menimbulkan bunyi desis. Konsonan /k/ bertumpuh pada lidah dengan langit-langit lunak, sedangkan konsonan /c/ bertumpuh pada lidah dengan langit-langit keras. Secara pelafalan dua konsonan itu mudah diucapkan, tetapi tidak lazim dalam kata bahasa Indonesia. Akronim amdal, Gakumdu, dan Jamdal dibentuk dengan jajaran fonem yang sama, yaitu /md/. Bentuk tersebut tidak terdapat dalam daftar jajaran fonem fonotaktik. Bahkan, tidak ditemukan kata bahasa Indonesia (melihat kamus) yang menggunakan deret konsonan /md/. Selain itu, akronim yang dihasilkan dengan jajaran fonem tersebut terasa janggal ketika dilafalkan. Berikutnya adalah jajaran fonem /mn/ yang terdapat pada akronim Kamnas dan komnet. Jajaran fonem /mn/ tidak terdapat dalam daftar jajaran fonem fonotaktik. Setelah melihat kamus, penulis belum menemukan kata bahasa Indonesia yang menggunakan jajaran fonem tersebut. Binmatkum, menmud, dan ranmor adalah akronim yang terasa aneh diucapkan. Akronim Binmatkum terdiri atas tiga suku kata. Suku kata pertama ditutup dengan fonem /n/ nasal alveolar, suku kata kedua ditutup dengan fonem /t/ hambat alveolar, dan suku kata ketiga ditutup dengan fonem /m/ nasal bilabial. Suku kata kedua dan suku kata ketiga masing-masing diakhiri dengan konsonan hambat sehingga terasa janggal diucapkan. Akronim menmud mempunyai dua suku kata. Suku kata pertama diakhiri dengan fonem /n/ nasal alveolar dan suku kata kedua dikahiri dengan fonem /d/ hambat alveolar. Jadi, dua suku kata diakhiri dengan fonem dari daerah artikulasi yang sama, yaitu alveolar maka bunyi yang dihasilkan terasa aneh. Berikutnya adalah akronim ranmor. Akronim yang diawali dengan fonem getar alveolar /r/ dan diakhiri juga dengan fonem yang sama, awal bergetar dan akhir juga bergetar. Di antara ketiga akronim tersebut, terdapat satu persamaan, yaitu ketiga akronim menggunakan jajaran fonem /nm/. Dalam daftar jajaran fonem fonotaktik tidak ditemukan jajaran fonem /nm/. 54 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Jajaran fonem /pb/ tidak lazim dalam fonotaktik bahasa Indonesia. Fonem /p/ adalah fonem hambat bilabial tak bersuara, sedangkan fonem /b/ adalah hambat bilabial bersuara. Dengan demikian, kedua fonem berasal dari daerah artikulasi yang sama. Perulangan fonem dari daerah artikulasi yang sama menimbulkan kesulitan dalam pengucapan. Akronim yang menggunakan jajaran fonem /pb/ adalah Kopbumi dan Pusdalopbang. Kedua akronim ini tampak janggal terdengar. Akronim APDASI dan Bakopda adalah akronim yang menggunakan deret konsonan /pd/. Deret konsonan tersebut tidak ditemukan dalam deret konsonan fonotaktik bahasa Indonesia. Di samping itu, tidak ditemukan kata (lema) bahasa Indonesia yang menggunakan deret konsonan /pd/, kecuali pada akronim APDASI dan Bakopda. Jika melihat daerah dan cara artikulasinya, konsonan tersebut adalah konsonan hambat. Konsonan /p/ adalah konsonan hambat bersuara yang dilafalkan dengan bibir atas dan bibir bawah terkatup rapat sehingga udara dari paru-paru tertahan untuk sementara waktu sebelum katupan itu dilepaskan. Sebaliknya, konsonan /d/ adalah hambat bersuara yang dilafalkan dengan ujung lidah ditempelkan pada gusi kemudian udara dari paru-paru dilepaskan. Tampaknya, sulit melafalkan dua konsonan hambat secara bersamaan sehingga akronim dengan deret konsonan /pd/ tidak lazim digunakan penutur bahasa Indonesia. Apkasi adalah akronim yang menggunakan deret konsonan /pk/. Adalah Akronim lain yang menggunakan deret konsonan /pk/ adalah Apkindo dan Gapki. Fonem /p/ berasal dari konsonan hambat bilabial dan fonem /k/ berasal dari konsonan hambat velar. Berarti kedua fonem merupakan konsonan hambat dan hambatnya adalah hambat tak bersuara. Jajaran fonem /pk/ tidak terdapat dalam daftar jajaran fonem fonotaktik. Di samping itu, ketiga akronim tersebut, yaitu Apkasi, Apkindo, dan Gapki agak sulit diucapkan. Jajaran fonem /pm/ terdapat pada akronim GAPMMI dan HIPMI. Fonem /p/ dan fonem /m/ berasal dari daerah artikulasi yang sama, yaitu bilabial. Jajaran fonem tersebut tidak terdapat dalam daftar jajaran fonem fonotaktik sehingga akronim GAPMMI dan HIPMI dianggap akronim yang tidak fonotaktik dalam bahasa Indonesia. Dua Konsonan Berurutan yang Sama Bahasa Indonesia tidak mengenal konsonan rangkap yang sama dalam satu kata, sedangkan bahasa Arab mengenal tasydid. Tasydid jika diindonesiakan menjadi konsonan rangkap yang jenisnya sama. Kata majalah awalnya adalah majallah, kata wasalam awalnya adalah wassalam. Dua konsonan berurutan yang sama dalam EYD tidak ditemukan, kecuali konsonan rangkap, seperti /kh/ pada akhlak, /sy/ pada syarat, /ny/ pada nyali, dan /ng/ pada ngeri (2003:3). Dengan demikian, akronim dalam bahasa Indonesia harus mengikuti fonem-fonem yang terdapat dalam EYD sehingga diharapkan bahwa akronim tidak menyimpang dari kata bahasa Indonesia. Akronim yang menggunakan dua konsonan berurutan yang sama tedapat pada beberapa contoh berikut. Tabel 2. Dua Konsonan Berurutan yang Sama No. Akronim Jajaran Fonem Bentuk Panjangnya 1 GAPMMI /mm/ Gabungan Pengusaha Makanan dan Minuman Indonsia 2 Jamman /mm/ Jaringan Masyarakat Mandiri 3 APPI /pp/ Asosiasi Pemain Profesional Indonesia atau Asosiasi Produsen Pupuk Indonesia 4 APPMI /pp/ Asosiasi Pengusaha dan Perancang Mode Indonesia 5 APPUI /pp/ Asosiasi Produsen Pakan Udang Indonesia 6 Bappebti /pp/ Badan Pengawas Perdagangan Berjangka Komoditi 7 Bappeda /pp/ Badan Perencanaan Pembangunan Daerah 55 Sariah No. 8 9 10 11 12 13 14 15 16 Akronim Bappenas Bappertal Formappi GUPPI HIPPI Noppen Perppu Kopassus Unpatti Jajaran Fonem /pp/ /pp/ /pp/ /pp/ /pp/ /pp/ /pp/ /ss/ /tt/ Bentuk Panjangnya Badan Perencanaan Pembangunan Nasional Badan Pengawas Pelaksanaan Reformasi Total Forum Masyarakat Perduli Parlemen Indonesia Gabungan Usaha Perbaikan Pendidikan Indonesia Himpunan Pengusaha Pribumi Indonesia Nomor Pokok Penduduk Peraturan Pemerintah Penggani undang Komando Pasukan Khusus Universitas Patimura Dalam EYD dan dalam jajaran fonem bahasa Indonesia tidak ditemukan dua konsonanan berurutan yang sama dalam satu kata. Akronim APPI memiliki dua makna yang berbeda, yaitu pemain profesional dan produsen pupuk. Konsonan rangkap /pp/ pada akronim tersebut termasuk menyimpang dari kelaziman karena tidak ada kata dalam bahasa Indonesia yang menggunakan bentuk tersebut. Bentuk yang sama terdapat pada akronim APPMI dan APPUI. Konsosan rangkap /pp/ pada APPMI tidak langsung bertemu vokal, tetapi masih ada konsonan lain, yakni konsonan /m/ sehingga jajaran fonemnya tersusun dari tiga konsonan sekaligus dan tidak termasuk dalam gugus konsonan atau kluster. Akibatnya, bentuk akronim APPMI agak sulit dilafalkan. Akronim APPUI hanya mempunyai dua konsonan berurutan yang sama, yaitu /pp/, tetapi vokal rangkap /ui/ di akhir suku kata tidak nyaman terdengar. Bentuk senada terdapat juga pada GAPPMI, GUPPI, HIPPI, Bappebti, Bappeda, Bappenas, Bappertal, Formappi, Noppen, dan Perppu. Tampaknya, dua konsonan berurutan yang sama dalam contoh akronim didominasi oleh fonem /p/. Namun, ada bentuk lain, yaitu konsonan /ss/ pada akronim Kopassus, konsonan /mm/ pada akronim Jamman, konsonan /tt/ pada akronim Unpatti. Tabel 3. Dua Konsonan Berurutan yang Berbeda Jajaran Fonem Bentuk Panjangnya /bh/ Pusat Bantuan dan Pengabdi Hukum Indonesia /ngg/ Sulawesi Tenggara /ph/ Asosiasi Penyelenggara Haji Umrah dan Inbound Indonesia Konphalindo /ph/ Konsorsium Perlindungan Hutan Lindung Indonesia Unand /nd/ Universitas Andalas Yapusham /sh/ Yayasan Pusat Hak Asasi Manusia No. Akronim 1 Pusbhadi 2 Sultengg 3 Asphurindo 4 5 6 Bentuk lain yang juga masih menggunakan konsonan rangkap, tetapi dengan jenis yang berbeda adalah Pusbadhi (Pusat Bantuan dan Pengabdi Hukum Indonesia), Sultengg (Sulawesi Tenggara), dan Unand (Universitas Andalas). Konsonan rangkap yang dimaksud bentuknya tidak sama karena menggunakan dua konsonan yang berbeda, seperti /dh/ pada akronim Pusbadhi, /ngg/ pada akronim Sultengg, dan /nd/ pada akronim Unand. Jadi, ada dua pengertian dalam bagian ini, yakni dua konsonan berurutan yang sama dalam satu kata dan dua konsonan berurutan yang berbeda dalam satu kata. Keduanya tidak berterima dalam EYD dan lazimnya kata dalam bahasa Indonesia. Konsonan yang Tidak Bisa Menjadi Penutup Suku Kata Bahasa Indonesia Konsonan yang tidak dapat menjadi penutup suku kata bahasa Indonesia adalah /b/, /c/, /d/, /g/, /j/, /w/, dan /y/. Fonem /b/ dalam bahasa Indonesia tidak dapat menjadi penutup suku kata pada kata bahasa Indonesia asli, tetapi ada beberapa kata serapan yang menggunakan fonem /b/, seperti kata sebab, magrib. Penulis bersikap tetap menggunakan acuan tersebut untuk menentukan akronim yang berfonotaktik tidak lazim. Dalam tulisan ini hanya beberapa data saja yang diungkap, yaitu sebagai berikut. 56 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Tabel 4. Konsonan yang Tidak Bisa Menjadi Penutup Suku Kata Bahasa Indonesia No. Akronim Jajaran Fonem Bentuk Panjangnya 1 Abnon /b/ Abang None 2 Pemkab /b/ Pemerintahan Kabupaten 3 Seskab /b/ Sekretaris Kabinet 4 jablai /b/ jarang dibelai 5 Baznas /z/ Badan Amil Zakat Nasional 6 Balegda /g/ Badan Legislatif Daerah 7 Bulog /g/ Badan Urusan Logistik 8 Caleg /g/ Calon Legislatif 9 capeg /g/ calon pegawai 10 Dologda /g/ Depot Logistik Daerah 11 Gerag /g/ Gerakan Rakyat untuk Reformasi Agraria 12 karpeg /g/ kartu pegawai 13 Kemenag /g/ Kementerian Agama 14 Disperindag /g/ Dinas Perindustrian dan Perdagangan 15 Mayjen /y/ Mayor Jenderal 16 Danlanud /d/ Komandan Pangkalan Udara 17 Kostrad /d/ Komando Strategi Angkatan Darat 18 Menmud /d/ Menteri Muda 19 Pacad /d/ Perwira Cadangan 20 Pemred /d/ Pemimpin Redaksi 21 Pidsus /d/ Pidana Khusus 22 Pemprov /v/ Pemerintah Provinsi 23 Pomad /d/ Polisi Militer Angkatan Darat 24 Puskud /d/ Pusat Koperasi Unit Desa 25 Unibraw /w/ Universitas Brawijaya 26 Unej /j/ Universitas Jember 27 Calhaj /j/ Calon Haji Konsonan /b/ dalam akronim abnon dan seskab termasuk bertentangan dengan lazimnya kata bahasa Indonesia yang tidak dapat berupa kononan /b/ meskipun ada beberapa kata yang diserap menggunakan konsonan /b/ diakhir suku kata. Akronim abnon dan Seskab jika dilafalkan terasa sulit dan terdengar janggal. Jadi, meskipun konsonan tersebut ditemukan dalam kata serapan, dalam membentuk atau menciptakan akronim diupayakan untuk menghindari bentuk tersebut. Akronim Baznas adalah akronim yang salah satu penutup suku katanya menggunakan konsonan /z/. Konsonan /z/ adalah konsonan serapan. Dalam kata bahasa Indonesia tidak ditemukan konsonan penutup suku kata yang menggunankan konsonan /z/. Konsonan /z/ termasuk konsonan frikatif alveolar yang dibentuk dengan cara menempelkan ujung lidah pada gusi dengan pita suara bergetar. Konsonan /z/ sebagai konsonan serapan pemakaiannya hanya di awal kata, terutama kata serapan. Dalam kamus tidak ditemukan konsonan penutup suku kata yang menggunakan konsonan /z/ meskipun kata itu berasal dari kata serapan. Dengan demikian, pembentukan akronim Baznas dianggap keluar dari kaidah fonotaktik bahasa Indonesia. Konsonan /v/ sebagai konsonan serapan tidak ditemukan sebagai penutup suku kata sehingga jika ada akronim pemprov, bentuk itu terasa sulit dilafalkan. Konsonan /v/ umumnya digunakan sebagai konsonan pertama pembuka suku kata, tetapi tidak bisa menjadi konsonan penutup suku kata. Beberapa kata yang menggunakan konsonan /v/ adalah varian, verba, vena, volume, dan sebagainya. 57 Sariah Konsonan berikutnya yang tidak bisa menjadi penutup suku kata dalam bahasa Indonesia adalah konsonan /d/. Akan tetapi, akronim yang menggunakan konsonan /d/ di akhir suku kata banyak ditemukan dalam data. Akronim itu antara lain adalah Menmud, paced, pemred, pidsus, Pomad, Puskud. Akronim Menmud, paced, pemred, pidsus, Pomad, dan Puskud tidak sulit untuk dilafalkan, tetapi terasa aneh terdengar. Bunyi fonem /d/ dalam kata bahasa Indonesia memang tidak lazim, kecuali kata serapan, seperti zuhud, sujud. Akronim Balegda, Bulog, caleg, dan Disperindag termasuk akronim yang menggunakan konsonan penutup suku kata yang tidak lazim dalam kata bahasa Indonesia. Konsonan /g/ di akhir suku kata menyimpang dari kaidah fonotaktik sehingga pencipta akronim diharapkan mempertimbangkan kaidah fonotaktik dalam melahirkan sebuah akronim baru. Konsonan /g/ dalam bahasa Jawa tampaknya sering berubah menjadi konsonan /k/ ketika menjadi bahasa Indonesia, misalnya kata bedug berubah menjadi beduk. Konsonan selanjutnya yang tidak bisa menjadi penutup suku kata adalah konsonan /j/, /y/, dan /w/. Akronim yang menggunakan konsonan penutup suka kata /j/, /y/, dan /w/ tidak banyak ditemukan dan termasuk langka dalam data. Akronim yang menggunakan konsonan tersebut adalah unej, calhaj, mayjen, dan Unibraw. Namun, ada satu konsonan penutup suku kata yang tidak ditemukan dalam data, yaitu konsonan /c/. Dalam kata-kata bahasa Indonesia tidak ditemukan konsonan penutup suku kata menggunakan konsonan /c/. Perulangan Fonem yang Sama dalam Beberapa Suku Kata Akronim yang menggunakan fonem yang sama dalam beberapa suku kata terdapat dalam tabel empat berikut. Tabel 5. Perulangan Fonem yang Sama dalam Beberapa Suku Kata No. Akronim Perulangan Fonem Bentuk Panjangnya 1 Bapedalda /d/ Badan Pengendalian Dampak Lingkungan Daerah 2 Ditreskrimsus /s/ Direktorat Reserse Kriminal Khusus 3 Jamkesmas /s/ Jaminan kesehatan Masyarakat 4 Kopkamtib /p/, /m/, /b/ Komandan Operasi Keamanan dan Ketertiban 5 Pangkopkamtib /p/, /m/, /b/ Panglima Komando Pemulihan Keamanan dan Ketertiban 6 Pangkopkamtibda /p/, /m/, /b/ Panglima Komando Pemulihan Keamanan dan Ketertiban Daerah 7 Paspampres /p/, /s/ Pasukan Pengaman Presiden 8 Perspebsi /p/, /s/ Persatuan Spesialis Bedah Saraf Indonesia 9 Puscadnas /s/ Pusat Cadangan Nasional 10 Pusdalobpang /b/, /p/ Pusat Pengendalian Operasi Pembangunan 11 Puskesmas /s/ Pusat Kesehatan Masyarakat 12 Puslabfor /b/, /f/ Pusat Labortorium Forensik 13 Riskesdas /s/ Riset Kesehatan Dasar 14 Perpres /p/, /r/ Peraturan Presiden 15 Perpusnas /p/, /s/ Perpustakaan Nasional 16 Propernas /p/, /s/ Program Pembangunan Nasional 17 Bapepam /p/ Badan Pengawas Pasar Modal 58 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Akronim Bapedalda menggunakan pengulangan suku kata dal dan da pada suka kata ketiga dan suku kata keempat. Kata bahasa Indonesia yang menggunakan tipe seperti itu tidak ditemukan sehingga akronim Bapedalda terdengar janggal atau terasa aneh. Bentuk yang hampir sama ditemukan pada akronim Jamkesmas, riskesdas, Prepusnas, puskesmas puscadnas, paspampres. Akronim Jamkesmas dan Prepusnas mendapat perulangan fonem /s/ pada suku kata kedua dan suku kata ketiga. Perulangan seperti itu tidak ditemukan dalam kata bahasa Indonesia. Apalagi, pengulangan fonem /s/ tiga kali berturut-turut pada akronim riskesdas dan puskesmas jelas tidak lazim dalam fonotaktik bahasa Indonesia. Sebaliknya, akronim puscadnas dan paspampres pengulangan fonem /s/ terjadi pada suku kata pertama dan suku kata kedua. Di samping itu, akronim paspampres tidak hanya mengulang fonem /s/, tetapi juga fonem /p/ di tiga tempat, yaitu suku kata pertama, suku kata kedua, dan suku kata ketiga. Dengan demikian, pengulangan atau repetisi fonem seperti itu termasuk menyimpang dari fonotaktik bahasa Indonesia. Fonem /s/ pada suku kata pertama berulang pada suku kata ketiga dan fonem /s/ pada suku kata kedua berulang pada suku kata keempat. Bentuk itu terdapat pada akronim perspebsi dan akronim Ditreskrimsus. Selain itu, kedua akronim ini sulit untuk dilafalkan. Hal itu disebabkan jajaran fonem /p/ yang berulang dan fonem penutup suku kata /b/ pada akronim perspebsi adalah sama-sama konsonan hambat bilabial, sedangkan akronim Ditreskrimsus sulit dilafalkan karena gugus konsonan /tr/ dan gugus konsonan /kr/ dipertemukan dan fonem /s/ pada suku kata kedua berulang pada suku kata keempat. Fonem /p/ pada Bapepam, Perpres, dan Propernas adalah fonem yang mengalami perulangan. Pada akronim Bapepam terjadi perulangan fonem /p/ dan perulangan daerah dan cara artikulasi, yaitu fonem /b/ dan /p/ sama-sama hambat bilabial. Akronim Perpres dan Propernas berulang fonem /p/ dan fonem /r/. Ketiga akronim itu agak sulit dilafalkan. Repetisi tidak hanya terjadi pada fonem yang sama, tetapi juga pada daerah dan cara artikulasinya. Contoh akronim yang seperti itu terdapat pada Kopkamtib, pangkopkamtib, pangkobkamtibda, pusdalobpang, puslafpor. Fonem /p/, fonem /b/, dan fonem /m/ berasal dari daerah artikulasi yang sama, yaitu bilabial dengan ketentuan fonem /p/ dan fonem /b/ hambat bilabial, sedangkan fonem /m/ nasal bilabial sehingga perulangan terjadi pada daerah artikulasi bibir (bilabial). Contoh akronim yang mengikuti tipe tersebut adalah akronim Kopkamtib, Pangkopkamtib, Pangkopkamtibda, Pusdalobpang, sedangkan akronim puslafpor pengulangan terjadi pada fonem tak bersuara /f/ dan fonem /p/. Jumlah Suku Kata yang Terdiri Atas Empat Suku Kata Lebih Jumlah suku kata bahasa Indonesia pada umumnya adalah dua meskipun ada yang lebih dari dua. Untuk keperluan telaah akronim fonotaktik, penulis mengelompokkan akronim yang terdiri atas empat suku kata ke atas. Pertimbangan akronim empat suku kata ke atas mengingat biasanya pelafalannya atau penyebutannya sulit. Dari telaah terhadap data ada beberapa akronim yang demikian (Tabel 6). Tabel 6. Jumlah Suku Kata yang Terdiri Atas Empat Suku Kata Lebih No. Akronim Jumlah Suku Kata Bentuk Panjangnya 1 Babinkumnas 4 Badan Pembinaan Hukum Nasional 2 Bapedalda 4 Badan Pengendalian Dampak Lingkungan Daerah 3 Distanbuhut 4 Dinas Pertanian Perkebunan Kehutanan 4 Ditreskrimsus 4 Direktorat Reserse Kriminal Khusus 5 Mahkumjakpol 4 Mahkamah Agung, Kementerian Hukum dan Hak Asasi Manusia, Kejaksaan Agung, dan Polri 6 Pusdalobpang 4 Pusat Pengendalian Operasi Pembangunan 59 Sariah No. 7 8 9 10 Akronim Disnakertransos Dispendukcapil Disperindagkop Ikapergabin Jumlah Suku Kata 5 5 5 5 11 Kemenkominfo 5 Bentuk Panjangnya Dinas Tenaga Kerja Transmigrasi dan Sosial Dinas Kependudukan dan Pencatatan Sipil Dinas Perindustrian dan Perdagangan Ikatan Pekerja Galian dan Bangunan Indonesia Kementerian Komunikasi dan Informatika Akronim yang terdiri atas empat suku kata ke atas dan jajaran fonem yang tidak lazim mengakibatkan akronim yang dibentuk sulit untuk dilafalkan oleh penutur bahasa Indonesia. Akronim Babinkumnas, Bapedalda, Distanbuhut, Ditreskrimsus, Mahkumjakpol, Pusdalobpang adalah akronim yang terdiri atas empat suku kata dengan penjajaran fonem yang tidak lazim. Penjelasannya akronim itu telah dipaparkan pada bagian lain, yaitu pada butir penjajaran fonem dan perulangan konsonan yang sama dalam satu akronim. Selanjutnya, akronim yang terdiri atas lima suku kata terdapat pada Disnakertransos, Dispendukcapil, Disperindagkop, Ikapergabin, Kemenkominfo. Pelafalafan atau pengucapan akronim yang terdiri atas lima suku kata tersebut tidak luwes dan penjajaran fonemnya tidak lazim, seperti Dispendukcapil dan Kemenkominfo. Penjajaran fonem /kc/ dan fonem /nk/ pada kedua contoh tersebut memang tidak terdapat dalam fonotaktik bahasa Indonesia. Di samping itu, ada beberapa hal yang perlu ditambahkan. Akronim Kowau (Korp Wanita Angkatan Udara) dan akronim Seskoau (Sekolah Staf dan Komando Angkatan Udara) adalah akronim yang sulit dilafalkan. Deret vokal /au/ yang sebelumnya didahului fonem /w/ bertemu sehingga fonem /w/ diikuti deret vokal /au/ yang juga berbunyi /w/ menjadikan pelafalan akronim tersebut menjadi sulit dan aneh. Kowau yang dilafalkan menjadi Kowaw. Padahal, kata bahasa Indonesia tidak ada yang diakhiri dengan fonem /w/. Penjelasan yang sama juga berlaku untuk akronim Seskoau yang fonem akhir yang dilafalkan dengan fonem /w/. Kondisi lain terdapat pelafalan pada huruf di tengah suku kata, misalnya pada akronim Kowal. Konsonan /w/ pada akronim itu untuk kata wanita. Konsonan itu diapit oleh vokal /o/ dan vokal /a/ (o+w+a). Kenyataannya di dalam KBBI (Kamus Besar Bahasa Indonesia) tidak terdapat satu pun lema kata yang mengandung konsonan /w/ diapit oleh vokal /o/ dan vokal /a/ (o+w+a) dan juga (u+w+a). Kalaupun ada, lema itu tentu berasal dari bahasa lain, atau merupakan bentuk tidak baku, misalny lema sowang yang merupakan bentuk tidak baku dari soang dan lema kuwalat adalah bentuk tidak baku dari kualat. Hal ini mungkin karena lafal dalam artikulasi bahasa Indonesia konsonan /w/ digolongkan sebagai semivokal atau mirip vokal, bukan konsonan murni. Akibatnya akronim Kowal dilafalkan hampir identik dengan lafal koal. Konsekuensinya konsonan /w/ pada Kowal hampir tidak dilafalkan dalam pelafalan kata bahasa Indonesia (kecuali kalau dilafalkan dengan lafal tidak baku). Kemenkeu (Kementerian Keuangan) adalah akronim yang diakhiri dengan deret vokal /eu/. Lema bahasa Indonesia tidak ditemukan suku kata yang diakhiri dengan deret vokal tersebut. Dengan demikian, akronim dengan deret vokal /eu/ di akhir suku kata tidak lazim dalam bahasa Indonesia. SIMPULAN Temuan dari akronim yang tidak fonotaktik dikelompokkan menjadi jajaran fonem yang tidak lazim; dua konsonan berurutan yang sama; konsonan yang tidak bisa menjadi penutup suku kata; perulangan konsonan yang sama dalam beberapa suku kata; jumlah suku kata yang terdiri atas empat suku kata lebih. Akronim yang berfonotaktik tidak lazim umumnya terdapat pada bahasan penjajaran fonem, khususnya pada jajaran fonem /md/ pada akronim amdal, jamda, gakumdu, dsb.; jajaran fonem /nm/ pada akronim Binmatkum, menmud, ranmor, dsb.; jajaran fonem /pk/ pada akronim Apkasi, Apkindo, Gapkindo, dsb.; jajaran fonem /pm/ pada akronim Apmiso, GAPMMI, IPMI, dsb. Akronim dengan dua konsonan berurutan yang sama terdapat 60 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 pada konsonan /pp/ Bappebti, konsonan //ss/ Kopassus, /mm/ Jamman, dan /tt/ Unpatti. Akan tetapi, konsonan berurutan yang sama didominasi oleh fonem /pp/ pada data akronim. Akronim dengan konsonan rangkap adalah /dh/ pada Pusbadhi, konsonan /ngg/ pada Sultengg, dan konsonan /nd/ pada Unand. Akronim yang menggunakan konsonan yang tidak bisa menjadi penutup suku kata umumnya adalah akronim berpenutup suku kata dengan konsonan /g/ dan /d/, seperti Balegda, FAGSAM, caleg, paced, pidsus, puskud. Akronim yang menggunakan konsonan penutup suku kata /c/ tidak ditemukan dalam data akronim. Ada akronim yang menggunakan konsonan penutup suku kata /z/ dan konsonan penutup suku kata /v/, sedangkan dalam kata serapan pun tidak ditemukan konsonan /z/ dan konsonan /v/ sebagai penutup suku kata, seperti akronim Baznas dan Pemprov. Perulangan fonem yang sama dalam beberapa suku kata tidak terdapat pada kata bahasa Indonesia, misalnya riskesdas, puskesmas, Ditreskrimsus, dan sebagainya. Jumlah suku kata (silabe) terdiri atas empat suku kata atau lebih, seperti Babinkumnas, Ditreskrimsus, Disnakertransos, Dispendukcapil. CATATAN * Penulis berterima kasih kepada mitra bebestari yang telah memberikan saran-saran untuk perbaikan makalah ini. DAFTAR PUSTAKA Alwi, Hasan et al. 2003. Tata Bahasa Baku Bahasa Indonesia. Edisi Ketiga. Jakarta: Balai Pustaka. Alwi, Hasan et al. 2003. Kamus Besar Bahasa Indonesia. Jakarta: Balai Pustaka. Chaer, Abdul. 2009. Morfologi Bahasa Indonesia (Pendekatan Proses). Jakarta:Rineka Cipta. Djajasudarma, T. Fatimah. 2010. Metode Linguistik: Ancangan Metode Penelitian dan Kajian. Bandung: Refika Aditama. Kentjono, Djoko. Ed. 2003. Dasar-Dasar Linguistik Umum. Jakarta: FSUI. Parera, Jos Daniel. 1985. Pengantar Linguistik Umum: Fonetik dan Fonemik. Ende: Flores. Pusat Pembinaan dan Pengembangan Bahasa. 2002. Pedoman Umum Pembentukan Istilah. Cetakan ke-4. Jakarta: Pusat Bahasa. Pusat Pembinaan dan Pengembangan Bahasa. 2002. Pedoman Umum Ejaan Bahasa Indonesia yang Disempurnakan. Edisi Kedua. Jakarta: Pusat Bahasa. Sudarno. 1990. Morfofonemik Bahasa Indonesia. Jakarta: Arikha Media Cipta. Sudaryanto. 1985. Linguistik: Esai tentang Bahasa dan Pengantar ke Dalam Ilmu Bahasa. Yogyakarta: Gadjah Mada University Press. Sudaryanto. 1993. Metode dan Teknik Analisis Bahasa. Yogyakarta: Duta Wacana University Press. 61 Linguistik Indonesia, Februari 2014, 63-75 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 VERBS OF EXCRETION IN TABA Frederick John Bowden* Jakarta Field Station, Max Planck Institute for Evolutionary Anthropology Universitas Katolik Indonesia Atma Jaya [email protected] Abstract This paper describes an unusual pattern of argument marking found in a small number of Taba verbs, all of which have meanings relating to excretion. The verbs concerned are sio ‘to shit’, mio ‘to piss’, sito ‘to fart’, and hantolo ‘to lay eggs’. In normal usage these occur with the excretor argument obligatorily encoded twice, once as a proclitic in the same way that Actor argument are encoded on other verbs, but also as an enclitic, similar to an Undergoer argument with other verbs. While no clear rationale for why these four verbs should be treated differently from all the other verbs in the Taba lexicon, they do all express activities that the performers are only in partial control of, and these verbs may in fact constitute something like a ‘middle voice’ in Taba. Keywords: argument marking, excretion, proclitic, enclitic, middle voice Abstrak Makalah ini mendeskripsikan sebuah pola pemarkahan argumen yang ditemukan dalam empat verba bahasa Taba. Semua verba yang dimaksud mempunyai arti yang berhubungan dengan ekskresi, yaitu sio ‘buang air besar’, mio ‘buang air kecil’, sito ‘kentut’, dan hantolo ‘bertelur’. Dalam penggunaan normal verba tersebut harus diberi dua pemarkah argumen, yaitu proklitik yang berfungsi sebagai argumen pelaku (Actor) dan enklitik sebagai argumen objek langsung (Undergoer). Meskipun tidak ada alasan yang jelas bagaimana keempat verba tersebut mempunyai pola yang berbeda dengan verba lain dalam leksikon bahasa Taba, semua verba ini menunjukkan bahwa para pelaku hanya mengendalikan sebagian dari kegiatan yang dilakukan dan keempat tersebut dapat dikategorikan sebagai middle voice dalam bahasa Taba. Kata kunci: pemarkah argumen, ekskresi, proklitik, enclitik, middle voice INTRODUCTIONi In this paper I want to discuss a small topic in Taba verbal morphosyntax (and argument structure) that remains something of a puzzle to me years after I first encountered it. There is a very small class of verbs, the meanings of which all relate to excretion, that share an unusual pattern of morphosyntactic marking, distinct from all other Taba verbs. The verbs involved are the roots sio ‘to shit’, mio ‘to piss’, sito ‘to fart’, and hantolo ‘to lay eggs’. In normal usage these occur with the excretor argument obligatorily encoded twice, once as a proclitic in the same way that Actor argument are encoded on other verbs, but also as an enclitic, similar to, but not exactly the same in all details, as an Undergoer argument. I have made exhaustive attempts to find other verbs that might be members of this class without any success: things such as bleeding, sweating, ejaculating, menstruating, etc. etc. are all expressed in a variety of different ways, but not like the class of excretion verbs discussed in this paper. I am afraid I am not able to share any startling revelations about why these four verbs should behave differently from all other verbs, but I will canvas a few ideas about possible explanations at the end of the paper. I shall approach this topic by first sketching out some basic patterns of morphosyntax found with verbs other than those referring to excretion, and then by contrasting these to the patterns found with the excretion verbs themselves. After we have examined the ‘basic’ cases, I will examine some valence-affecting affixes and what these do with different kinds of verbs in an Frederick John Bowden attempt to understand the excretion verbs themselves a little better. I will begin first of all by giving a brief introduction to the Taba language and its place in the world. Figure 1. Maluku Utara Showing Locations of Languages 64 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Taba was traditionally known in the literature as ‘East Makian’, ‘Makian Dalam’ or ‘Makian Timur’. It is classified by Blust (1978) as a South-Halmahera – West New Guinea language, along with about 40 or so other languages spoken in the North Maluku and West Papuan regions. According to Blust, these languages are the closest relations of the Oceanic subgroup of the Austronesian language family, and together they form a group known as ‘Eastern Malayo-Polynesian’. The location of the Taba language is shown in the map in Figure one. In the map, taken from Lewis, ed. (2009), Taba is referred to as ‘East Makian’. Taba speakers are Muslims and they have had a relatively long period of contact with the rest of the world. Makian (and a few other small islands off the west coast of Halmahera) were once the only source of cloves in the entire world. After Magellan’s first round the world voyage (when his ships visited Makian), Maluku Utara and its spices became a huge center of interest for would-be colonial powers out to exploit the potential spoils. Islands in this area were at the middle of a number of conflicts between various colonial powers throughout the seventeenth century and quite a few loan words from Portuguese, Spanish and Dutch are found in Taba and other nearby languages. Traditional power in North Maluku was shared between four sultanates, but after the colonial struggles had been played out, the sultanate of Ternate (with the support of the Dutch) became the dominant force, and the Ternatan language was for some time used as a local lingua franca alongside Malay. Ternatan and all of the languages spoken in the northern half of Halmahera as well as on the western side of Makian island are non-Austronesian languages. A number of typological features not common in Austronesian languages are found in Taba and presumably some of these have entered the language as a result of contact with the neighboring non-Austronesian languages. All language of the region (including these days North Maluku Malay) participate in a sprachbund with many shared features. The major reference on the Taba language is Bowden (2001). OVERVIEW OF TABA VERBAL MORPHOSYNTAX Taba is a mixed ‘split-S’ and accusative language. It has basic AVO word-order in transitive clauses, as illustrated in (1). (1) Mado npe ubang Mado n-pe ubang Mado 3sg-make fence ‘Mado is making a fence.’ Other orders are also possible. Any argument (core or otherwise) can be shifted to preverbal focus position so long as it is represented by a full NP and not just a pronoun. (2) Ubang ya Mado npe ubang ya Mado n-pe fence REC Mado 3sg-make ‘That fence, Mado is making it.’ Ellipsis of readily retrievable participants is common. (3) Npe n-pe 3sg-make ‘He’s making it.’ Taba has a split-S system for marking the non-human core arguments of verbs. Core arguments can be divided into either ‘Actors’ or ‘Undergoers’. Actors are cross-referenced by verbal proclitics agreeing in number and person with the actor they index. 65 Frederick John Bowden Table 1. Taba Pronominal Forms Free form Bound form Free form 1 sg. yakii k1pl. (incl.) tit 1pl. (excl.) am 2sg. au m2pl. meu 3sg. i n3pl. si (4) Actor = 1sg Yak kunak do yak k-unak do I 1sg-know REAL ‘I know.’ (5) Actor = 2sg Au mhan appo Tarnate au m-han ap-po Tarnate you (sg) 2sg-go ALL-down Ternate ‘You’re (singular) going to Ternate.’ (6) Actor = 1pl.excl Am atala motor lawe am a-tala motor la-we we.excl 1pl.excl-meet boat sea-ESS ‘We (exclusive) met the boat by the sea.’ Bound form tahl- Verbs may be subcategorised according to how many core arguments of each kind (either Actor or Undergoer) they take. Table 2. Sub-Classification of Taba Verbs According to Number and Type of Core Arguments Number of Actor arguments 0 1 Number of 0 Active intransitives Undergoer 1 Stative intransitives Transitives Arguments 2 Bivalent intransitives Ditransitives Active Intransitive Clauses Active intransitive clauses are distinguished by the fact that they have one core argument and that the sole argument is an Actor. (7) Wangsi lmul do. wang=si l-mul do child-pl 3pl-return REAL ‘The children have returned.’ Stative Intransitive Clauses Stative intransitive clauses are distinguished by the fact that they take a single Undergoer core argument. (8) Kutukutu nener da kutu-kutu nener da small-REDUP sp. fish MED ‘These nener (fish) are small.’ Fronting of the Undergoer is quite common with these verbs. However, the Undergoer is never cross-referenced on the verb. 66 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 (9) Nener da kutukutu nener da kutu-kutu sp.fish DIST small-REDUP ‘These nener are small.’ Basic Transitive Clauses Basic transitive clauses have verbs which take both an Actor argument and an Undergoer argument. (10) Banda not yan bakan Banda n-ot yan bakan Banda 3sg-catch fish be.big ‘Banda caught a fish that’s big.’ Note the stative intransitive relative clause (yan bakan ‘big fish’) which is not marked in any way. Bivalent Intransitive Clauses Double object intransitive clauses take two Undergoer arguments and no Actor arguments. The verbs involved in these constructions are always derived applicatives, and one of the two arguments is invariably fronted. (11) Hamasik posak niwi hamasik posa-Vk niwi rice be.boiled-APPL coconut ‘The rice is cooked with coconut.’ Ditransitive Clauses Ditransitive verbs have three core arguments: an Actor argument and two Undergoers. All ditransitive verbs are derived by applicativization. (12) Bib npunak kolai peda Bib n-pun-ak kolai peda Bib 3sg-kill-APPL snake machete ‘Bib killed the snake with a machete.’ (13) Banda notik yak Banda n-ot-ik yak Banda 3sg-catch-APPL me ‘Banda gave me some fish.’ yan yan fish VERBS OF EXCRETION As indicated in the introduction, excretion verbs normally occur with both proclitics and enclitics cross-referencing the excretor, unlike most active verbs which occur only with proclitics. The forms used to cross-reference the arguments of excretion verbs are listed in table 3. Table 3. Cross-referencing of Intransitive Excretion Verbs 1sg k—k / k—yak 1pl.incl t—tit 1pl.excl a—m 2sg m—u 2pl h—meu 3sg n—i 3pl l—si Illustrative examples are given below. 67 Frederick John Bowden (14) Buang nciwi Buang n-sio-i Buang 3sg-shit-3sg ‘Buang did a shit.' (15) Yak kmiok yak k-mio-k 1sg 1sg-piss-1sg ‘I had a piss.’ do / Yak kmioyak do yak k-mio-yak REAL 1sg 1sg-piss-1sg do do REAL (16) Si lcitosi si l-sito-si 3pl- 3pl-fart-3pl ‘They farted.’ Note the formal similarity with pronominal forms and also note that object pronouns can be (but need not be) encliticised. Note that the forms are not exactly the same as the cliticised object forms in all person and number combinations, but that they seem to be pretty obviously derived from such forms historically. VALENCE-AFFECTING MORPHOLOGY A variety of affixes are available for deriving verbs of various kinds. These affixes are listed below. We will not examine all of these in detail, but simply look at the behavior of a few, contrasting what happens with the excretion verbs and the other verbs, and seeing if there are any clues here that might help explain the aberrant nature of the excretion verbs themselves. Let us first note that although all of the affixes listed can have valence-affecting functions, they can also perform some other functions, such as marking ‘intensity’. ha- valence increasing prefix - ‘causative’ -Vk valence increasing suffix - ‘applicative’ -o valence increasing suffix - ‘applicative’ ta- valence decreasing prefix - ‘passivizing/ detransitivizing’ Table 4. Valence Affecting Affixes derives transitive verbs from active intransitives derives active intransitive verbs from stative verbs derives active verbs from a variety of other word classes ‘intensive’ marker derives ‘bivalent intransitive’ verbs from stative verbs derives transitive verbs from active intransitives derives ditransitive verbs from transitive verbs ‘intensive’ marker derives ‘bivalent intransitive’ verbs from stative verbs derives ‘process oriented’ stative verbs from unmarked statives derives transitive verbs from active intransitives derives ditransitive verbs from transitive verbs derives stative verbs from transitive verbs derives stative verbs from active intransitive verbs ‘Causative’ Prefix haThe most common functions of ha- are deriving transitive verbs from active intransitives, and deriving active intransitives from other kinds of roots. (17) a. Paramalam nmot. paramalam n-mot lamp 3sg-die ‘The lamp has gone out.’ (lit. ‘the lamp has died’). 68 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 b. I namot paramalam. i n-ha-mot paramalam 3sg 3sg-CAUS-die lamp ‘He turned the lamp off’ (lit. ‘he made the lamp die’). (18) a. Ni calana kuda POSS trousers black ‘Her trousers are black.’ b. John nakuda John n-ha-kuda John 3sg-CAUS-black ‘John is black like Jul.’ sama sama same lo Jul lo Jul as Jul Example (18) illustrates the most common non-causative use of ha- which is to derive an Actor oriented verb from an Undergoer oriented root to enable the verb to be used with a human argument. Since excretion verbs are cross-referenced by a proclitic, the Actor oriented derivation illustrated in (18) is not possible with excretion verbs, but we might imagine a truly causative derivation in which we might derive verbs which could describe situations such as a mother telling her child to go to the toilet. Causative derivations of excretion verbs are not found with this kind of meaning, as illustrated in (19). Example (20) without any crossreferencing cannot be used with a causative meaning either. (19) * Ni mamasi nasiwi ni mama-si n-ha-sio-i 3sg.POSS mother-PL 3sg-CAUS-shit-3sg ‘His mother made Buang shit.’ (20) ? Ni mamasi nasio ni mama-si n-ha-sio 3sg.POSS mother-PL 3sg-CAUS-shit * ‘His mother made Buang shit.’ Buang Buang Buang Buang Buang Buang Another function of ha- prefixation with active verbal roots is to indicate that an activity was performed with some degree of intensity. (21) a. Tit twonga tit t-wonga 1pl.incl 1pl.incl-stay.awake.all.night ‘We stayed awake all last night.’ maliling maliling night b. Tit tawonga tit t-ha-wonga 1pl.incl 1pl.incl-CAUS-stay.awake.all.night ‘We stayed awake all last night.’ ya ya up maliling maliling night ya ya up The prefix can also be used with this reading with excretion verbs. (22) Ismit nasitoi Ismit n-ha-sito-i Ismit 3sg-CAUS-fart-3sg ‘Ismit did a big fart.’ The Applicative -Vk With ‘normal’ verbs, this suffix is used to add applied objects of various kinds, most commonly instruments, but also themes and recipients. It can derive bivalent intransitives from stative verbs, transitives from active intransitives, and ditransitives from transitive stems. Example (23) 69 Frederick John Bowden shows the derivation of a bivalent intransitive verb from an Undergoer oriented intransitive verb. (23) a. Ubang bulang ubang bulang fence be.white ‘The fence is white.’ b. Ubang bulngak cet ubang bulang-k cet fence be.white-APPL paint ‘The fence was whitened with paint.’ Example (24) illustrates the derivation of an instrumental ditransitive verb from a transitive stem. (24) a. Ahmad npun kolai Ahmad n-pun kolai Ahmad 3sg-kill snake ‘Ahmad killed a snake.’ b. Ahmad npunak kolai peda Ahmad n-pun-ak kolai peda Ahmad 3sg-kill-APPL snake machete ‘Ahmad killed the snake with a machete’ In example (25) we can see the derivation of a simple transitive verb from an Actor oriented intransitive stem. (25) a. i nggaleit i n-galeit 3sg 3sg-burp ‘He burped.’ b. i nggaleitik i n-galeit-ik 3sg 3sg-burp-APPL ‘He burped up milk.’ susu susu milk Note that the applicative suffix also occasionally has an intensive reading, similar to that found with some ‘causatives’. (26) a. Kaidis k-ha-idis 1sg-CAUS-spit ‘I spit (making no noise).’ b. Kaidcik k-ha-idis-k 1sg-CAUS-spit-APPL ‘I spit (making a lot of noise).’ Spitting publically is quite common practice amongst Taba speakers, but polite spitting is always done silently. To make a large noise while spitting is seen as insulting, and the applicative form is used here to signal that spitting is performed with such an insulting noise. Of course the example in (26) can be read literally as ‘spit with noise as theme or companion’. The way the applicative suffix works with excretion verbs parallels the last couple of examples: they allow us to express whatever was excreted as an object of the verb, parallel to (25) above where -ak allows a theme to be introduced: 70 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 (27) Ksiak halua k-sio-ak halua 1sg-shit-APPL halua ‘I’m shitting halua.’ [halua = ‘toffee made from palm sugar’] The Detransitivizing Prefix taThe ‘passive’ prefix ta- most commonly derives agentless stative verbs from transitive verbs. The sole derived argument in these constructions is the root Undergoer. In this kind of derivation it could perhaps also be called a ‘resultative’ prefix, because the effect of its application is to focus semantically on the resulting state of the patient after a process of some kind has reached its end. (28) a. underived i nbes niwi i n-bhes niwi 3sg 3sg-husk coconut ‘She husked the coconut.' b. derived niwi tabhes do niwi ta-bhes do coconut DETR-crack REAL ‘The coconut has been husked.' (29) a. underived Male tcakal boa male t-sakal boa must 1pl.incl-smash door ‘We had to smash down the door.' b. derived Boa tasakal boa ta-sakal door DETR-smash ‘The door was smashed down.' (either intentionally or not) The ta- detransitivizing prefix can also be used with the verbs of excretion, but whenever it occurs, it must co-occur with the -Vk applicative. These constructions are used to indicate that the person excreting is totally incapable of not excreting, as when for instance they might have diarrhea. (30) Tasiak ta-sio-ak DETR-shit-APPL ‘I’ve got the shits.’ yak yak 1sg I have never actually heard anyone mention the theme supposedly licensed by the -Vk applicative when this construction has been used spontaneously, but it is possible to do so, and people tell me that they understand the theme as the cause of the uncontrollable excretion as in (31). (31) Tasiak yak niwi ta-sio-ak yak niwi PASS-shit-APPL 1sg coconut ‘The coconut has given me the shits.’ [lit. ‘I’m uncontrollably shitting coconut’]iii This sentence is formally a bivalent intransitive, analogous to sentence (23) above which is repeated as (32). 71 Frederick John Bowden (32) a. Ubang bulang ubang bulang fence be.white ‘The fence is white.’ b. Ubang bulngak cet ubang bulang-k cet fence be.white-APPL paint ‘The fence was whitened with paint.’ Although (31) is formally a bivalent intransitive verb, as already mentioned such sentences with excretion verbs are rarely offered with the instrumental argument overtly coded. The Applicative –o In addition to the –Vk applicative discussed above, Taba also has an applicative suffix –o which usually introduces a locative argument to the frame of the derived verb. It is illustrated in its normal use in (33). (33) a. I nyog i n-yog 3sg 3sg-jump ‘She jumps.’ b. I nyogo mesel i n-yog-o mesel 3sg 3sg-jump-APPL wall ‘She jumped on the wall.’ It appears that the excretion verbs can also be used with the –o applicative to derive transitive verbs where the object of the verb is a locative goal (or where the excretia ended up). The fact that the –o applicative is attached to excretion verbs is somewhat obscured in Taba because all of the excretion verb roots end in the segment o and thus there is no overt sign of the applicative suffix having been added part from the disappearance of the cross-referencing suffix and the possible appearance of a locative goal. In example (34) the locative goal is overt, but in (35) it is ellipsed. (34) Buang ncio ni calana Buang n-sio-o ni calana Buang 3sg-shit-APPL POSS trousers ‘Buang shitted his trousers.' (35) Q: Mesel tasakal hapwe mesel ta-sakal ha-pu-e wall DETR-collapse CAUS-what-FOC(how) ‘How come the wall collapsed?’ A: Iswan ncito Iswan n-sito-o Iswan 3sg-fart-APPL ‘Iswan farted on it.’ One further example of the locative applicative being used with an excretion verb is supplied below. In (36), the verb hantolo ‘to lay eggs’ is shown with double cross-referencing, and in (37) it is shown with the locative applicative suffix. (36) Nantoli n-han-tolo-i 3sg-INCH-egg-APPL ‘It lays / they lay an egg / eggs.’ 72 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 (37) Nantolo gut n-han-tolo-o gut 3sg-INCH-egg-APPL nest ‘It lays / they lay an egg / eggs in the nest.’ DISCUSSION Why should it be that this small class of Taba verbs is marked differently from all others in the grammar of the language? One thing that can be said about all of these verbs is that people who ‘shit’, ‘piss’, and ‘fart’ as well as the creatures which ‘lay eggs’ have a certain degree of control over the process, but to a large degree these processes are things that happen to you, and the excretor can be seen to some degree as both volitional actor and involuntary undergoer. The split-S system by which Taba clausal grammar is organized builds this semantic distinction into the core of the grammar, so perhaps we should not find it so unusual if a few verbs whose arguments are not easily distinguished in terms of their volitionality should be marked in an unusual way. A number of other languages use double agreement or something similar with small classes of verbs. Kokota, in the Solomon Islands (Palmer, 2005) has double agreement for a small set of verbs including ‘laugh’, ‘hiccup’, ‘yawn’, ‘be angry’ and ‘’be pleased’. Palmer suggests these verbs are doubly marked because their arguments are subjected to forces over which they have little control. Kemmer (1993:53ff) also notes languages which have ‘middle voice’ constructions in which ‘body action middles’ often with similar semantic elements to the Taba constructions also have peculiar properties that may derive from these same semantic elements. Finally, we can observe something similar with the standard Indonesian word tertawa ‘laugh’ or its colloquial Jakarta equivalent ketawa where the initial prefixes are generally used to signal something accidental. Why these particular verbs and not others with similar semantics are singled out in Taba must remain a mystery though. Perhaps some sort of cultural explanation is necessary. I would like to end this paper by making a few remarks about what might be called the ‘culture of excretion’ Taba speakers always appeared to be both quite discrete about their own excretion and very amused by it when excretion became the topic of a joke. Many of the examples given above were taken from natural conversations in which the speaker was making fun of someone else. The following postscript is a transcription of the telling of a Taba riddle, and the answer to it that plays with this sort of humor. It also has many naturally occuring examples of the excretion verb sio ‘shit’ and some of its derivatives. The text consists of (a) the asking of a riddle, and (b), the very detailed explanation of why the author's response (that he would elect to go to sleep first) was the wrong choice. Not transcribed are the great peals of raucous laughter from the audience as they listened to the detailed explanation of excretory catastrophe found in part (b). Postscript: A Taba Riddle (a) John ni we mhonas... nim we nalusa mhonas. Nim John ni we mhonas... ni-m we n-alusa mhonas. ni-m John POSS leg sore... POSS-2sg leg 3sg-say sick POSS-2sg pappuko me nalusa 'mhonas'. Bingo namolam. Ulo nmau nhan pappuko me n-alusa mhonas. Bingo n-amolam. ulo n-mau n-han knee well 3sg-say sick. Stomach 3sg-hungry heart 3sg-want 3sg-go Poto pope nmau nhan nciwi. Sumo nalusa 'khan'. Mto Poto po-pe n-mau n-han n-cio-i. Sumo n-alusa k-han. Mto anus down-ESS 3sg-want 3sg-go 3sg-shit-3sg mouth 3sg-say 1sg-go eye 73 Frederick John Bowden nuyak, poyo n-uyak, poyo 3sg-tired head mhonas, ulo mhonas, ulo sick heart nmau n-mau 3sg-want nhan... mtumo n-han, m-tumo 3sg-go 2sg-follow e loe? e lo-e? FOC where-FOC? ‘John, your leg is sore. Your leg says 'I’m sick'. Your knee says it’s sick. Your stomach is hungry. Your heart wants to go somewhere. Your anus down there wants to go for a shit. Your mouth says 'I'm going (I’m hungry)'. Your eyes are tired, your head is sick, your heart wants to go somewhere, which one do you follow (first)? Your anus down there is about to shit itself. Which one do you follow (first)?’ (b) Poto pope me tasiaki. John ni suka nhantuli Poto po-pe me ta-sio-ak-i. John ni suka n-han-tuli Anus down-ESS but PASS-shit-APPL-3sg John POSS desire 3sg-go.sleep sedangkan ni klolo nparenta nhan... Han akno ni sedangkan ni klolo n-parenta n-han... han ak-no ni while POSS NOM-inside 3sg-stop 3sg-go go ALL-there POSS dalawaci de ncio ni calana de namliak dawalat-si de n-sio-o ni calana de n-amlih-ak girlfriend-PL PURP 3sg-shit-APPL POSS trousers PURP 3sg-laugh-APPL 1pl.incl. tit Ncuka te. Male sio malai han. Idia. Sio okik, malai tit N-suka te. Male sio malai han. I-dia. Sio okik, malai 1pl(incl.) 3sg-like NEG must shit then go DEM-DIST shit finish then nhantuli malai nhan ronda. Tasiak nit calana? n-han.tuli malai n-han ronda. Ta-sio-ak nit calana? 3sg-go.sleep then 3sg-go walkabout PASS-shit-APPL 1pl.incl.POSS trousers Tatés! Polo tese, cio calana, cio Tatés! Polo te-se t-sio-o calana t-sio-o crazy if NEG-POT 1pl.incl-shit-APPL trousers 1pl.incl-shit-APPL mattress jok berarti masure te. jok berarti masure te. mattress means good NEG ‘But your anus down there is shitting itself! And John you want to go to sleep while your insides have stopped working? If you go to your girlfriend's place you'll shit your trousers and she'll laugh at you!!! She won't like it! You have to shit first and then you go do other things. That’s how. Once you’ve finished shitting then you go to sleep then you go for a walk. Shit our trousers? Crazy!!! If we don't shit our trousers, we'll shit on the mattress. It’s no good!’ NOTE *I would like to thank an anonymous reviewer for very helpful comments on the earlier draft. i The following abbreviations are used in this paper: 1 first person; 2 second person; 3 third person; ALL allative; APPL applicative; CAUS casusative; DETR detransitivizing; DIST distal; ESS essive; excl exclusive; FOC focus; INCH inchoative; incl. inclusive; MED medial; NEG negative; pl plural; PL plural; POSS possessive; POT potential; PURP purposive; REAL realis; REC reciprocal; REDUP reduplication; sg singular. ii Note that in some dialects (Mailoa, Kayoa, Peleri) the 1sg. independent pronoun is lak. iii Coconut is viewed locally as a cure for constipation. 74 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 REFERENCES Blust, Robert A, 1978. ‘Eastern Malayo-Polynesian: a subgrouping argument’. In S.A. Wurm and Lois Carrington, eds. Second International Conference on Austronesian Linguistics: proceedings, 181-234. Pacific Linguistics C-61. Canberra: Pacific Linguistics. Bowden, John, 2001. Taba: description of a South Halmahera language. Canberra: Pacific Linguistics. Kemmer, Suzanne, 1993. The Middle Voice. Typological Studies in Language, 23. Amsterdam: John Benjamins. Lewis, M. Paul (ed.), 2009. Ethnologue: Languages of the World, Sixteenth edition. Dallas, Tex.: SIL International. Online version:http://www.ethnologue.com/. Palmer, William Dennis, 2009. Kokota Grammar. Honolulu: University of Hawaii Press 75 Linguistik Indonesia, Februari 2014, 77-91 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 THE ROLE OF CULTURE IN THE TRANSLATION PROCESS THROUGH THINK-ALOUD PROTOCOLS Julia Eka Rini Universitas Kristen Petra [email protected] Abstract Cultural differences have been a major focus in translation. This study investigates two aspects; first, the translation process of culture-bound words and second, the strategies taken by two translators. These translators are English Department students and they have different cultural backgrounds, Moslem Javanese and Buddhist Chinese. Each of them has to translate the same four texts: one text whose cultural background both of them are familiar with, another text whose cultural background both of them are not familiar with and two other texts. Out of the two texts, only one text has a familiar cultural background to one of the translators. The method used to investigate what was happening in the translators’ mind is think-aloud protocols. Two points can be concluded from this study. One, translators’ cultures do play a role in their consideration of choosing the words they use. Two, translators generally use the strategy of cultural substitution if the culture is nearly the same, but they use the strategy of using a neutral word or paraphrasing by related words when the culture is different. Keywords: culture-bound words, translation strategy, cultural differences Abstrak Perbedaan budaya telah banyak mendapat sorotan dalam penerjemahan. Yang dikaji dalam penelitian ini ialah pertama, proses penerjemahan kata-kata yang disebabkan oleh perbedaan budaya dan kedua, strategi yang diambil oleh penerjemah. Kedua penerjemah ialah mahasiswa Jurusan Bahasa Inggris, dan keduanya mempunyai latar belakang budaya yang berbeda. Yang satu berlatar budaya Jawa dan Islam dan yang lain Tionghoa dan Budha. Masing-masing menerjemahkan empat teks yang sama: satu teks mempunyai latar belakang budaya yang dikenal keduanya, satu teks lainnya mempunyai latar belakang budaya yang tidak dikenal keduanya, dan dua teks yang lain mempunyai latar belakang budaya yang hanya dikenal salah satunya oleh masingmasing penerjemah. Penelitian ini menggunakan metode analisis protokol untuk meneliti apa yang terjadi dalam pikiran penerjemah ketika sedang menerjemahkan. Ada dua hal yang diperoleh dari penelitian ini. Pertama, latar belakang budaya penerjemah memegang peranan dalam memilih kata-kata yang mereka gunakan. Kedua, strategi yang berbeda digunakan kedua penerjemah dalam menerjemahkan kata-kata yang mengandung budaya. Jika budaya hampir sama, strategi yang digunakan ialah menggunakan kata yang mempunyai budaya yang mirip; namun, jika budaya berbeda, strategi yang digunakan adalah menggunakan kata yang netral atau memparafrasa dengan kata-kata yang masih ada hubungannya dengan kata tersebut. Kata kunci: kata-kata budaya, strategi penerjemahan, perbedaan budaya INTRODUCTION The term ‘translation’ can refer to translation as a process and also as a product. The research focus on translation product (the translation text) is already common in Indonesia, but the focus to the translation process is not that popular. However, in other countries “there has been an increasing interest in studying the translation process since the mid-1980s” (Li 2004:301). With the shift of focus to the translation process, the translators also become more important in the focus of research. The important role of translators can be seen in what experts in translation say Julia Eka Rini about it. Wills (2004:3), for example, says, “A translator is supposed to be a bridge between linguistic and cultural communities, but at the same time is different from both the source-text author and the target-text reader(ship).” Two important aspects in Will’s statement about the important role of translators in translation are in the area of language and also culture. Since the role of translators cannot be ignored in translation process, this study tries to describe how the three aspects of translation process—language, culture, and translators—are related. This study tries to describe how translators of different cultures deal with language. Culture, as defined by Beamer and Varner (2001:3), is the coherent, learned, shared view of a group of people about life’s concerns that ranks what is important, furnishes attitudes about what things are appropriate, and dictates behaviour. This general definition underlies the concept of culture in this study, but a more specific definition from Appelbaum and Chambliss (1997) is used as a guideline to choose the words or culture-bound units in this research that are taken as data because it is more systematic and concrete. According to them, sociologists and anthropologists differentiate two aspects of culture that are different but interrelated aspects of human culture, material culture and non-material culture. “Material culture includes all the physical objects made by the members of a particular society to help shape their lives” (1997: 63). This includes tools and technologies to make goods, the goods consumed, the place of worship, the offices or stores and the cities or towns where people live. “Non-material culture consists of all the nonphysical products of human interaction, that is, the ideas shared by people in a particular society. This includes languages, values, beliefs, rules, institutions and organizations” (1997: 64). This study deals with difficult words, terms, or expressions concerning culture and they are referred to as culture-bound units. Concerning culture in translation, Baker (1992) lists a number of common problems, such as: 1) the source language concepts are not lexicalized in the target language, (2) the source-language is semantically complex, (3) the source and target languages make different distinctions in meaning, (4) the target language lacks a superordinate, (5) the target language lacks a specific term, (6) differences in physical or interpersonal perspective, (7) differences in expressive meaning, (8) differences in form, (9) differences in frequency and purpose of using specific forms, (10) the use of loan words in the source text, and (11) culture-specific concepts, that is, “the source language word may express a concept which is totally unknown in the target culture. The concept in question may be abstract or concrete; it may relate to a religious belief, a social custom, or even a type of food” (1992:21). Some common strategies to overcome the problems are (1) translation by a more general word (superordinate), (2) translation by a more neutral or less expressive word, (3) translation by cultural substitution, (4) translation using a loan word plus explanation, (5) translation by paraphrase using a related word, (6) translation by paraphrase using an unrelated word, (7) translation by omission, and (8) translation by illustration. Baker (1992:42) admits that the list is not limited to what she has described, and further studies of the strategies—how translators cope with the culture-bound units—are encouraged. The solutions of dealing with special words which are ‘culturally bound,’ according to Duff (1981:26), may differ greatly, although the problems of all translators of literary, general, or technical texts are the same. Therefore, the strategies taken by the translators are worth discussing. Some common solutions, according to Duff (1981), are (1) the word is retained in its original form and no explanation is given, (2) the word is retained in its original form, with either a literal translation in brackets, an official or accepted translation in brackets, or an explanatory footnote, (3) the word is never mentioned in its original form, (4) the same with the previous, but the translator expands the text in order to convey all associations, (5) different translations of the same word are used, because the target language differentiates more than the source language, (6) part of the source language is omitted, (7) a target language expression is given, although it is not derived from anything in the text. This study, then, tries to portray 78 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 more specifically, what is happening in the minds of translators of different cultures when dealing with culture-bound units in the process of translation. What is happening in the minds of translators is worth paying attention to, since translation, according to Hatim and Munday (2004:36), happens not only linguistically, but also cognitively as the translator works on a translation. In translation theory that describes the translation process in stages, the stage that happens in the translators’ minds is the stage of transfer; the meaning or message obtained from the analysis is transferred from the Source Text (ST) to the Target Text (TT). In the translation process there are four stages (Suryawinata 2003: 19), which can happen quickly or slowly, and either once or repeatedly, depending on the intensity of the difficulties encountered by the translators. The following is the complete diagram of translation process. Figure 1. Translation Process Adapted from Nida and Taber Modified by Suryawinata In the stage of analysis, before the stage of transfer, the translators analyze the text to get the textual or contextual meaning of the text. In the stage of restructuring, translators write the TT, maintaining the equivalent content, meaning, and message of the ST. The stage of evaluation and revision is where the translators evaluate the TT (the translation) to determine whether or not it is the same as the ST. If it is not the same, then the TT is revised and the process is repeated from analysis. During the translation process, translators can pay attention to one sentence, one clause, one group of words or even one word, referred to as translation units. The units discussed in this study can be words, phrases or sentences. One of the few available means to know what happens in the translator’s mind in the stage of transfer is verbal reports or verbal protocols or think-aloud. This method was first used in psychology and cognitive science in the early twentieth (Brown and Rogers 2001:54). To explain what is verbalization or think-aloud, it is useful to use what Brown and Rogers (2001:53-54) say about it; it is like doing mental (or even written) arithmetic of 45 times 52. They explain as follows: In a simple language, verbalizing or think-aloud is saying what one is thinking so that others can hear it. Later, this method is also used in language research. Verbal protocols ask subjects to verbalize or tell their thought processes when they are involved in processing language. McKay (2006) cites from Brown and Rogers some principles that should be given attention while 79 Julia Eka Rini conducting verbal reports: 1) verbal reports should occur either while the activity is occurring or as soon as possible afterward; 2) because verbalization needs additional demands, subjects should be allowed to use their first language (p. 61); 3) researchers should be as unobtrusive as possible; researchers should take notes on both nonverbal and verbal behaviour; and 4) verbal reports cannot be used to report automatic thought processes. Some procedures to follow in conducting verbal reports in language rsearch are as follows: 1) 2) 3) 4) provide students with a practice activity; give simple directions; be as unobtrusive as possible; ask subjects to report their thought processes at particular points in the text after they have read the text; 5) do not ask leading questions; 6) record the session; 7) and pay attention to nonverbal behaviour. Beginning in 1980’s this method is also used in translation research. The name of this method is then recognized as Think-aloud protocols (TAPs) as the name of the transcriptions of verbalizations of thoughts that subjects are instructed to produce while carrying out a translation task (Bernardini 2000). Verbalization in translation means saying everything that is happening in one’s mind while translating. For example, when a translator encounters a difficult word, in her/his verbalization, he might say, “What does this word mean? Dictionary. Let’s see. First meaning. No. It’s not that. Second, third. Ah this one, yes.” What the translator is saying is recorded and later on, transcribed. The transcription is also called TAPs. The two ways of doing verbal reports are introspective and retrospective. In translation research, the retrospective one is done immediately after translation. After a translator has finished translating a text, s/he is asked to describe what was going on during the translating of the text. What s/he says about the process of translating is recorded and later on, transcribed. This method is considered less appropriate for this research because the chance of forgetting what actually happens is bigger. The one chosen for this research is the introspective report or TAPs. In this way the recording is done while the translator is translating a text. Everything that the translator is saying that s/he is thinking is by being recorded; ideally, the thinking, saying and the recording happens simultaneously. The recording is later transcribed and the transcription is also called think-aloud protocols (TAPs). However, this method, according to Bernardini (2000), has limits because it is highly influenced by individual differences in terms of personality, personal history, capacity to verbalise thoughts, and attitude towards the task. Additionally, it is not yet proven whether long complex methods could be accessed and reported on in the same way as short problem-solving tasks. However, since this is the most probable way to know what is going on inside someone’s mind, it is one good tool to use. In this research these points are already tackled in the methodology of this research. The following points were carefully considered in the methodology: the criteria for the subjects chosen for this research, the background of the subjects to determine their suitability for this research, the texts chosen to be translated by the subjects, and the training given to the subjects to make them accustomed to TAPs. According to (Bernardini (1999), the major concerns of researchers using TAPs in translation research are translation strategies, attention units, automaticity of processing and affective factors. In her review of translation strategies, Bernardini (1999) quotes eleven ‘problem indicators’ of translation problems and translation strategies according to Krings (1986): (1) the subjects’ explicit statement of problems; (2) the use of reference books; (3) the underlining of source-language text passages; (4) the semantic analysis of source –language text items; (5) hesitation phenomena in the search for potential equivalents; (6) competing potential 80 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 equivalents; (7) the monitoring of potential equivalents; (8) specific translation principles; (9) the modification of written target-language texts; (10) the assessment of the quality of the chosen translation; and (11) para-linguistic or non-linguistic features. Early TAP studies have been concerned with classification of translation strategies and differences between professional and non-professional strategies. Regarding translation units, she discusses ‘unmarked processing,’ which refers to unproblematic sections of the protocols in which a subject verbalizes fluently while reading or writing. Marked processing begins with a problem indicator and ends with a solution to the problem or an indication that the problem is temporarily abandoned. Those theories are used by the writer to conduct this research, in determining the data collection and data analysis. METHODS Participants joining this research were students who joined the translation class of English Deparment of Petra Christian University. After considering the cultural backgrounds of several students, two students were chosen to be the subjects in this research based on the ethnicity and religion. One student is a Moslem and Javanese; the other one is a Buddhist and Chinese. The two students fulfilled the criteria of the subjects in this research. The first criteria was that they had taken three translation classes. Before joining the third class of translation, they had taken all structure, reading and writing classes. It was assumed that they had had enough practice in translation so that it could be assumed that their difficulties in translation were not caused by lack of practice or lack of ways of dealing with difficulties concerning language (English) or structure. Second, they were able to explain their reasons when they were asked to explain the assignments in front of the class in the previous classes of translation; this was important in choosing the subjects because if they were not good at explaining, then it would also be difficult to verbalize their thoughts while doing the translation. Before doing the real think-aloud protocols, both students had been given a practice of translating a text with verbalization. The text used in the practice was different from the texts used in the research, but the level of difficulty was nearly the same. Before they translated the text, they were given some explanation how to do the verbalization and to record their verbalization. When each of them was doing the practice, they were also equipped with dictionaries. After they finished translating the texts and recording, the recording was checked to see whether they did it in the way they were expected, namely verbalizing what they were thinking. After the practices and the checking, the two students were asked whether they wanted to continue taking part in the research and they agreed. The two students (henceforth referred to as translators) were asked to translate the same four texts. Two stories were taken from the same book—entitled Who Is the Most Talkative of Them All? Stories for Language Teacher Education (1996)—so that the language difficulty is more or less the same. One text was of familiar culture for both translators, entitled “The Farmer and the Rice Plants.” Both translators are Indonesians and therefore, farmers and rice plants are not strange for them. Another text was of unfamiliar culture for both translators, which was entitled “How Do You Shower a Bride.” Both translators were not familiar with the culture spoken in the text (bridal shower). The other two texts were familiar to one translator and not to the other. The Buddhist text was taken from a book entitled A Still Forest Pool: The Insight Meditation of Achaan Chah, (1985); the title of the text was “The Real Magic”. The Islamic text entitled ”She Had True Faith” was taken from http://www.batkhela.com/islam/story7.shtml. In doing the translation of the four texts, they were also equipped with dictionaries. The two translators determined their own schedules. Each did the translation and recording on different days, one text at a time. The verbalization was recorded in C-90 cassettes. Each translator pushed the recording button when they were ready to translate and pushed it again 81 Julia Eka Rini when they finished translating. The C-90, not C-60, cassettes were used because one side of C90 lasted 45 minutes; this minimized the risk of the unrecorded verbalization. The following is an example of a transcript and how the analysis is done. The transcript below is an example taken from Translator A. The underlined parts are the ones he writes down; others are just what he says. The transcript below has been divided into six parts (indicated by number 1-6). Verbalization can be divided into might include utterances that are not related to the translation process of the text, but it is transcribed in the protocol (Part 1). Part 2 is the reading of the English text before the translation. The woman’s voice might be his classmate greeting him. Part 4 is the process of translating the text with dictionary checking. The example written here is shortened because the complete one is very long. Part 5 is the utterances that are not related to the translation, except when he said that he has finished translating. The last part is reading the Indonesian translation. 1) {ehmm sodok ngantuk/ tap: ndak papa/aku milih kelas 206/ b 206/ Ini aku duduk sebelahe jendela/ jadi nek bosen ngeliat ijo ijo seger/ apalagi sambil bau minyak angen/ ini aku lagi bau minyak angen/ jadi biasane nek aku nulis nek ndak pake minyak angen ya/ nek pake minyak angen ngantuke ilang/ini apa ya?/ The farmer and the rice plants/sek sek sana/ the farmer and the rice plants/ tak bacae ae sek/Mbacae sambil mba- bau minyak angin ya/} 2) {the farmer and the rice plants/there once a farmer who always wished that the rice in his field would grow more quickly/ the rice like any other crop/ takes time to grow and cannot be hurried/ the farmer lost patience with waiting/ and thought of a plan to make the rice grow more quickly/ he ran to the field and pulled every one of the rice plant /plant/ ee/just a little bit higher/he was tired out when he came home but very pleased with himself/ what of a day/ I’ve worked so hard he said to his family/ but at least I know that the rice plants are a little bit higher/ when his son heard that the rice plants had/ grown taller/he ran to the field to take a look/instead of finding taller/ healthy rice plants he found that} 3) {Woman: /halo/} 4) {bau... bau minyak angin enak/ iya, e/ the farmer and the rice plants. [clears throat] ee/seorang…petani dan...tanaman.. padi..nya. There was! Once a farmer who always wished that the rice in his fields would grow more quickly. Pada.. suatu.. ketika.. emm.. ini tangan kananku megang bolpen tangan kiriku megang minyak angin, jadi.. kadang kalo aku berhenti nulis.. aku bau minyak angin ini lagi. M enak baune. Pada suatu ketika/ ada seorang/ petani/ mm/ yang selalu/ berharap/ ee/that the rice in his fields/ agar tanaman padi/ field/ field itu apa ya?/ field itu kalo ga salah anu/ apa? lahan/ di lahannya/dapat tumbuh dengan/ lebih.. cepat] …. 5) {[sighing] ya tanaman hijau menyegarkan mata/ enak kok memang duduk sebelahe jendela/ nek mata sepet /sediluk/ ke luar./ yah selesai} 6) {sek sek sek sek sek/ cek lagi/ ee seorang petani dan tanaman padinya/ pada suatu ketika ada seorang petani yang selalu berharap agar tanaman padi di lahannya dapat tumbuh dengan lebih cepat/ akan tetapi padi seperti halnya tanaman budidaya dan/ lainnya membutuhkan waktu untuk tumbuh dan tidak dapat dipercepat/ petani tersebut kehilangan kesabarannya karena menunggu/ dan ia berpikir sebuah ide untuk membuat tanaman padi tumbuh/ lebih cepat/ dan ia memikirkan sebuah ide untuk membuat tanaman padi agar dapat/ agar dapat/ ditambahi/tumbuh lebih cepat/ petani tersebut pergi ke lahannya dan menarik setiap tanaman padinya sedikit lebih tinggi/ petani ini ke lelahan ketika ia tiba di rumahnya/ tetapi puas dengan dirinya/ dia berkata pada keluarganya/ hari yang melelahkan/ aku telah bekerja dengan keras/ tetapi setidaknya aku tahu/ bahwa tanaman padi telah tumbuh sedikit lebih tinggi/ karena anak laki-lakinya mendengar/ bahwa tanaman padi telah tumbuh lebih tinggi/ dia pergi ke luar menuju lahan padi untuk melihat/ justru bukan menemukan/ padi tersebut lebih tinggi/ dia menemukan bahwa tanaman padi yang sehat telah mulai kehilangan kekuatannya layu dan mengering/ yaah selesai/ emm mulet sek/ mulet/ mm...m/ wes mari} 82 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 All the process of translation of the four texts done by the two translators were recorded and transcribed. The transcriptions were then analyzed to find the strategies taken by the two translators and whether the different cultures have an influence in translation. The discussion of the findings below is organized according to the texts related to the cultures of the translators. To make it easy, the two translators are labeled as Translator A (Chinese Budhist) and Translator B (Javanese Moslem). CULTURE KNOWN TO BOTH TRANSLATORS The culture known to both translators was that there was a plant called rice that grew in a field. According to Baker, a type of food is culture-bound (1992:21); therefore, it could be assumed that a type of plant was also culture-bound. The text used for translation contained this type of plant and words related to it. The culture-bound words and the translations were as follows: Table 1. Culture Known to Both Translators words translator A translator B rice padi padi field lahan ladang crop tanaman budidaya tumbuhan There were apparently no difficulties of culture-bound words encountered by both translators. Both could directly translate rice into padi, and were not confused whether it should be padi or beras. The following is the example of the translation process of translator A in translating rice. A read first the English text and the example below is the one when he started writing his translation (underlined words are the translation that he wrote on his paper.) the farmer and the rice plants [clears throat] e… seorang… petani dan tanaman…padi…nya/there was/once a farmer who always wished that the rice in his fields would grow more quickly/ pada…suatu…ketika…emm/ ini tangan kananku megang bolpen tangan kiriku megang minyak angin/ jadi kadang kalo aku berhenti nulis/ aku bau minyak angin ini lagi/emm/enak baune/pada suatu ketika/ ada seorang…petani…emm yang selalu…berharap ee that the rice in his fields…agar tanaman padi… field/field itu... apa ya? Field itu kalo ga salah anu… apa? Lahan/ After reading the title once again (the farmer and the rice plants), he directly wrote the translation of the Indonesian translation. After reading the first line of the story (there was once a farmer who always wished that the rice in his fields would grow more quickly), although he commented about the herbal oil that he held in his hand—this happens in TAP—he directly wrote the translation after repeating again the clause [that the rice in his fields]. Although A thought for a while about the right translation of the word field [field itu... apa ya? (field is … what is it?) Field itu kalo ga salah anu… apa? (Field is if it is not mistaken er …what?). Lahan] he could directly solve the problem. Therefore, it was not considered a difficulty. Likewise, B also could directly translated rice as in the example below. … the farmer and the rice plant/there was once a farmer who always wish that/the rice in his field would grow more quickly/ suatu saat/pada suatu saat/there was once/pada suatu ketika ada seorang petani yang selalu berharap bahwa…padi…di…di ladang/in his field/padi di ladangnya akan tumbuh lebih cepat The word padi came directly and he did not think about it again. Checking the dictionary is only done by A for the word crop. He checked the dictionary because he wanted to preserve its specific meaning. Translator B did not check the dictionary and could directly translate the words field and crop. The strategies taken by translator B were using the general term for crop and the specific term for field, while A used a more general term as the strategy to translate field into lahan. 83 Julia Eka Rini However, both translators had difficulties in wither and droop that did not have anything to do with culture. The following is the example of translator A. had all began to wither/ and droop/ yang sehat …telah… mulai…wither itu apa? layu to… layu dan/ droop ini apa ya?Buka kamus/ini kok gatel kabeh se tanganku/ tangan kiriku gatel/ guaruk garuk terus ae ket tadi /wither/ droop eh droop seh kok wither/ droop/ abcdefghijklmno o kelewatan/opqrs/drug? jklmnoprstu/ uudoop/ 0/drop/lho?/klmnopqrs/d/op/op/droop/to sink down/hang or bent down/to lose vitality or strength/became weaken/languish/adjective/ to lose vitalityor strength/ to sink down/ hang bent down/to lose vitality or strength/ ya to lose vitalityor strength/sip emm/ berarti ketemu/ bukan layu she telah mulai layu dan coret sek. telah mulai kehilangan/kekuatannya … dan layu/iya/wither tu/ layu ya? sek sek buka kamus lagi (open dictionary)/kamus kamus kamus/ w/ wither/ absdefghi/ ini sampe piro ya kesete ya?(how long does one side of this cassette last) Cukup? (Enough?) baru dua pertiga kok/ aduh kepalaku gatel lagi (my head itches) /aneh (strange)/ kok aku kok gatel gatel se ndak kelas ini (why does my head itch in this class? onok opo se? what’s wrong with this class?)/klmn/ opqrst/ wither/ mm to dry up as/ for gravish/to lose/frigil/or freshness/layu/iya/hilang kesegaran/to wither lemah/ apa? kering/layu dan mengering/berarti/telah mulai kehilangan kekuatannya koma/ini dan ndak usah/layu dan mengering [sighing] The two words are not that easy to translate. He opened both English-English dictionary. Like translator A, translator B also checked the dictionary. The following is the example of translator B when dealing with the two words. semua tumbuhan… itu … mulai wither and droop/ wither/ wither and droop/ wwwwwww wither/ mana w ini/sebentar ya/ wither wither wither wither wither wither wither wither wither/to dry up/mengering/mana wither/wither gak pakai ed/to dry up/to weaken/languish/mengering/mm lemah atau mengering/bisa lemah atau/droop apa?/dra droop droop/droop/to sink down/hang or bent down/halah layu/terus/withering/down/ya layu/mulai mengering dan layu/wither and droop/mengering dan layu/OK/saatnya writing. Both A and B needed the dictionary to translate the two words. Besides, both translators also asked themselves the meaning of the words using apa (what). Both the dictionary and the question word apa are signals of difficulty faced by both translators Globally, the translation process is smooth in translating a text whose culture is known. Translator A translated the text without great difficulties concerning culture-bound units. He read the text first, translated every sentence and wrote it directly. After that he read it once again to check the translation as can be seen in the given example in the method above. Translator B stated explicitly in the protocol, “wah ini lebih gampang ini” (this is easier) compared to the first text he translated (How Do You Shower a Bride) The results of A and B are more or less the same, except in translating what a day. The following is the translation of both A and B. Table 2. The Indonesian Translation The Farmer and The Rice Plants English text A’s translation B’s translation “What a day! I have Dia berkata kepada keluarganya, “Hari yang menyenangkan! worked so hard, “He “Hari yang melelahkan! Aku Aku telah bekerja keras,” ujar said to his family, “but telah bekerja keras, tetapi sang petani pada keluarganya. at least I know that the setidaknya aku tahu bahwa “Namun, paling tidak, aku tahu rice plants are a little tanaman padi telah tumbuh bahwa tumbuhan padiku sudah bit higher.” sedikit lebih tinggi!” sedikit lebih tinggi!” 84 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 All sentences were more or less translated in the same way, except “What a day!” as can be seen below in the process of Translator A; he associated it with the clause after it—I’ve worked very hard. Mm dia berkata kepada keluarganya/ tanda petik/ hari yang menye/ salah tulis/ menyenangkan/ koma/ loh tanda seru bukan koma/ aku telah bekerja dengan keras. At least I know that rice plants are little bit high/ What a day/What a day ini bukane maksude hari yang melelahkan/ I’ve worked very hard/ o iya/What a day ini berarti disini bukan hari yang menyenangkan tapi hari yang melelahkan/ ini menyenangkan salah/ coret/ jadi melelahkan/ hari yang melelahkan/ On the other hand, B’s translation is different; it has the opposite meaning. In the process, first, he used the word indah, then replaced it with menyenangkan; he associated what a day with the clause before the interjection—but very pleased with himself. Different context used can result in different words chosen in the translation. CULTURE KNOWN TO ONE TRANSLATOR, BUT NOT TO THE OTHER The culture known to Translator A is the religion of Buddhism and to Translator B is the religion of Islam. Each text used for the translation was about Islam and Buddhism. It can be seen below how culture plays a role in the translation process. In translating an Islamic text, She Had True Faith, the culture of the text (Islam) is known to Translator B, who is a Moslem, but not to Translator A, who is a Buddhist. The difficult culture-bound words they encountered were (1) true faith, (2) day of judgment, (3) games of chance, (4) idols, (5) intoxicants, (6) divining arrows. B translated faith as keyakinan and did not use a specific word like iman. Below is how the subject thought about the word. Figure 2. True faith true faithkeyakinan yang benarkepercayaankeyakinan yang benarkeyakinan yang teguh True faith was translated into keyakinan yang benar and later was changed into keyakinan yang teguh because of the context; this can be seen from the transcript [judulnya di atas kayaknya salah ini...(seen from the title, this seems wrong)]. Thus, he used a more neutral strategy. After he translated all the lines and checked them again, he decided that teguh was better than benar. Although faith can be considered as a culture-bound word (since it is about religion), it is a little bit general because nearly all religions talk about faith. A more specific culture-bound word is the day of judgment and it can be seen below that culture influenced the translators’ decisions of which term to use. Figure 3. Day of Judgment the day of judgment judgment dayhari pembalasanhari penilaian pengadilanhari pengadilanhari penentuanhari pembalasan In the course of thinking, culture played a role when he said, “...opo yo? (what is it) Kalau di Islam itu hari pembalasan....” (In Islam the term is hari pembalasan). Another culture-bound word is “divining arrows.” This word was not attended by B (this is the strategy of translation by omission) because probably it is not from Javanese culture or Islam; it is probably from another culture, Middle East, with which the translator was not familiar of. Other words are culture-bound, but they are not deeply embedded in the culture and religion because all culture and religions have them, for example: intoxicating drink, games of chance, and worship idols. The word intoxicant was translated as minuman racun, while actually it should be minuman yang memabukkan. The word idols was translated as pertanda.The translator used a less expressive strategy. 85 Julia Eka Rini Some other words are culture-bound, but they did not cause difficulties. B could directly translate them. If the Moslem’s translation of those words are compared to those of the Buddhist, it can be clearly seen in the table below that culture plays a role in choosing the term. Table 3. The Non Difficult Culture-bound Words of She Had True Faith culture-bound words Moslem Buddhist prayer sholat doa chapter surat bab believers umat Islam orang percaya When translating an Islamic text, the Buddhist used general words, while the Moslem used words related to Islam. Culture known to the Buddhist, but not to the Moslem, in translating the Buddhist text, “The Real Magic” The difficult words are (1) magic, (2) disciples, (3) power, (4) clairvoyance, (5) samadhi, (6) dharma, (7) suffering, (8) freedom, (9) psychic power, (10) blessing, 11) charm, (12) spell, (13) path, (14) the way Buddha passed, (15) vipassana, (16) contemplation, (17) mental object, and (18) liberation. In the following table, the differences of word choice between the two subjects can be seen. Table 4. Difficult words of “The Real Magic” culture-bound words Moslem Buddhist magic kekuatan sihir disciples pengikut murid power kemampuan kekuatan clairvoyance kemampuan untuk melihat kemampuan untuk melihat hal-hal yang tidak kasat mata yang tidak dapat dilihat oleh mata samadhi semedi meditasi dharma dharma dharma suffering penderitaan kesengsaraan freedom kebebasan kebebasan psychic power kekuatan fisik kekuatan tubuh blessing pemberkatan pemberkatan charm mantera jimat-jimat spell aji-ajian mantera-mantera vipassana vipassana vipassana contemplation meditasi meditasi mental objects pikiran objek-objek dalam pikiran liberation kebebasan pembebasan In translating the text of a culture which was not familiar to him, he referred to his great healing power as kekuatannya untuk pulih kembali, but before he decided to use this translation, he referred to untuk kekebalan sesuatu. This was clearly from Javanese culture, where people who are good at martial arts have power to be immune from sharp weapons. [Ini cerita tentang kemampuannya untuk pulih kembali. (This story is about the ability to recover)] Also, for the phrase of his clairvoyance, before he decided to translate it as untuk melihat sesuatu yang tidak kasat mata, he used the term goib. [Of his clairvoyance..what is clairvoyance? I don’t know! clair.. clairvoyance hemm. Ini (this) clair clair clair clair clair clairvoyance ah kok dak ada? (it is not here) oh ini?! that are not in sight or that cannot be seen that cannot oh.. kemampuannya untuk membaca pikiran orang… (the abilityto read people’s mind) kemampuannya indra mosok indra ke enam (the ability of sixth sense) kemampuannya untuk melihat sesuatu yang goib (the ability to see something goib) This is paraphrasing by using related word strategy. 86 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Also, with the phrase samadhi, Translator B used semedi because his culture has it and directly related it with bertapa (meditation and fasting) [penetrating semedi..penetrating itu memasukkan.. dan memasukkan dan melakukan semedi melakukan semedi semedi itu opo yo (what is it)? dan bertapa dan bertapa dan melakukan- dan bertapa]. In translating charm and spell, he used the word aji-ajian, which is common in Javanese culture. He used the strategy of translation by cultural substitution. Magic should be translated as keajaiban not sihir, because real magic here refers to the teachings of the Dharma that can liberate the mind and put an end to suffering (English text, sentence 5). Thus, real magic should be translated keajaiban sejati, not kekuatan nyata (as B translated it) or sihir yang sesungguhnya (A). Translator A referred to Samadhi as meditasi and translated contemplation as meditasi keagamaan because meditasi is a common practice in Buddhism. Translation B, however, referred to it as semedi, which is a common practice in Javanese culture. He also used meditasi for contemplation. Culture-bound words related closely to religion were absorbed, such as dharma and vipassana by both translators. Both translators made mistakes in translating psychic power as kekuatan fisik or kekuatan tubuh (physical power) because psychic is connected more with mind than with body. Translator A said, “Aku rasa bacaan yang kedua ini...lebih gampang dingerti ya, soale mungkin memang kepercayaan yang saya pegang dengan bacaan mungkin sama jadi mungkin saja lebih mudah untuk…belajar untuk memahami.” (I think this second text is easier, because the text is the same with my belief; therefore, it is easier to comprehend). This also proves that texts containing a familiar culture are easier than those containing one that is unfamiliar. CULTURE UNKNOWN TO BOTH TRANSLATORS (How Do You Shower a Bride?) The text used for translation was a funny story in which the culture was unknown to both translator A and translator B. The story is about the bridal shower, which is very culture-specific because both in Chinese and Javanese custom, the party for a bride-to-be is without gifts. However, in Javanese custom, water is used, but it is not used in Chinese custom. The difficulties related to culture encountered by the translators in translating the English text were the word shower and groups of words containing this particular word, for example, shower a bride in the title, bridal shower in the first sentence, to the shower in the second sentence, shower the bride-to-be with gifts in the fifth sentence, and shower in the last sentence. This word or group of words is difficult to translate because the word shower is usually associated with water, such as to take a shower, which is translated in Indonesian as mandi. In the context of the story, the word shower in the phrase bridal shower is culturebound and has the meaning of giving gifts to the bride-to-be. It has nothing to do with the association of water. This double meaning makes the story funny because the character thought that it was a swimming pool party (the character associated the program with water because of the word shower, but actually it does not have anything to do with water, but with gifts). So, the translators faced two difficult tasks. One, they needed to keep the story funny; they needed to reveal the funny point bit by bit, not all at once, and certainly by not breaking the point of humor from the very beginning. Second, they needed to find a word or group of words which contain the double meaning. Although both translators checked the dictionary and knew from the dictionary that bridal shower means giving gifts to the bride-to-be, which resulted in the same translation, the association and considerations they took were different in the process, as it can be seen in the following discussion. Translator B’s (the Javanese) difficulties were translating the title How Do You Shower a Bride and later also bridal shower (1) as can be seen below. 87 Julia Eka Rini Figure 4. The Javanese Moslem Translator For (1) in the diagram, the TAPs say [Opo iki a bridal shower.(What is bridal shower) Gak ngerti istilah Indonesiae ini (I don’t understand the Indonesian term)... How do you shower a bride. Shower ini apa.. apa ya (what is it) shower. For (2), Liat di kamus dulu (see the dictionary first). After finding the meaning about ‘shower a bride’ in the dictionary, the TAPs say Ooo ini nomer empat ini (ooo this one number four)/ A party of- at which a number of gifts are presented to the guest of honor… hmm, a apaan ya?(hmm what is it?) Siraman pengantèn/ perasaan pengantèn itu ndak pake hadiah (I think of the bride, gift is not used) a party at which a number of gifts, adalah…]. At this point the Javanese translator still directly associated ‘shower’ with siraman pengantin (3); he still associates it with the Javanse tradition. In Javanese culture, brides are indeed showered with water mixed with flowers. And he said that in such kind of ritual, no gift is given (perasaan penganten ndak pakai hadiah)(5). Although the translation he wrote later on was Bagaimana cara mau memberikan kado pengantin (give a gift) (7), he had been thinking of siraman pengantin and also menyiram calon pengantin dengan kado a number of times. This was cultural substitution strategy. Bridal shower was translated as Penyiraman kado, also acara siraman pengantin, again, taking reference from the culture (4). Later, in the evaluation step, he was aware that the translation of the title is not suitable and thought again of siraman (Shower itu istilah yang paling… harus bisa diartikan /di sini?/)and compared the customs in Indonesia (with water) and in the US (with gifts) (tapi kalo dikasi siraman.. orang Indonesia siraman ya karo air, siraman pengantin, bukan.. pake kado biasanya. Lek barat, kalo di Amerika pake kado.). In the last sentence, … whenever I hear the word, shower, the Javanese translator translated the sentence into setiap kali mendengar kata siraman, referring to the customs. As it can be seen in the diagram below, different from the Javanese translator, the Chinese one, before consulting the dictionary took the meaning of bathing (mandeni) the bride (1), and after consulting the dictionary (3), he directly took the meaning of giving gifts to the bride-to-be (4). Figure 5. The Chinese Buddhist 88 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 He just took the dictionary meaning because it does not exist in his culture. However, the Chinese translator thought of words like penghormatan, penganugerahan, pemberian which have the meaning of to give a gift. This is using less expressive word strategy. In the 2nd sentence, for the phrase ‘… what she had to bring to the shower, the Javanese translator used a generic word acara, but the Chinese used acara pemberian kado and in 3rd sentence added pada saat acara memandikan mempelai wanita (bathing the bride-to-be) and in the evaluation he was aware of the funniness that he had to transfer (5). Cuma ndak jadi joke malahan (no joke then). Jadi semacam kayak (it’s like)/ apa namae..eee...apa ya (what is it called?)/ bukan joke lagi ya (no joke then)/ ya dob- ya (it’s …)/ artikel biasa kalo mau jadi joke ya harus jadi memandikan (if the joke should be there, it should be bathing)/ tapi nek memandikan pikire (but if it’s bathing, people will think that…)/ganti ya (it’s better to change it)/ bagaimana anda memberikan kado kepada seorang mempelai wanita... how do you shower a bride shower bride/ ya emm/ dirubah ae (change it). Bagaimana anda memandikan seorang mempelai wanita ya gitu... ee how do you shower a bride... emm.. bagimana! anda/ ini bingung ini aku (I’m confused) In the 5th sentence, ‘… she was supposed to “shower” the bride-to-be with gifts’ was translated by the Javanese as ‘menyiram calon pengantin dengan kado’ while the Chinese translator still used ‘bathing.’ The Chinese translator used ‘shower’ and did not translate it. In comparing the translation of the Javanese and the Chinese, some important items could be noted. Right from the first sentence, the Javanese translator used the word siraman which had something to do with water. Therefore, the context was still useful when in the third sentence, it was said that bringing a swimming suit, the character in the story was wondering about the swimming pool. It was different from the Chinese translator’s translation. Right from the very beginning, he used ‘giving gifts,’ (which does not have anything to do with water) and so suddenly at the third sentence, the character was wondering about swimming pool (which is associatd with water). Although he compensated it by adding ‘the bathing program’ in the Indonesian translation, it made the translation strange. It was even more strange when the word ‘shower’ was not translated, because the readers of the translation did not find that word in the beginning and suddenly it came up at the end. The Javanese was more consistent, translating shower into siraman, although the translation of the title using ‘giving gifts’ also makes the TT not funny. Although the Chinese translator’s translation was not as consistent or funny as the Javanese’s translation, it did not mean—after knowing the process happening in the translator’s mind—that he did not know what to do with the difficulties he encountered. He was very well aware of it and did the steps of analyzing, transferring, restructuring and also evaluating many times. He was not only thinking about finding the right word, but also trying hard to maintain the joke. This tells us that a mistake is not produced without thinking and effort to find the right translation. CONCLUSION AND SUGGESTION From the process of translation of the two translators, two points can be concluded. One, it is clear that translators’ culture does play a role in their consideration in picking up the right words. Translators will derive something from their experience of his own cultures, e.g. the Javanese translator derived something from the Javanese prewedding ceremony although he had consulted the dictionary beforehand. If the culture in the ST is not like their own culture, like the Chinese, translators rely on information taken from the dictionary or any other written text. Two, culture-bound words creates some difficulties for the translators, but some words which do not become the difficulties for the translators are translated differently by the translators, which 89 Julia Eka Rini is influenced by culture. However, text for culture known to both translators used in this research is not that difficult because the text is not too deeply embedded in the culture. Concerning the translation strategies applied by the translators, cultural substitution strategy is generally used by the translation if the culture is nearly the same. When the culture is different, translators generally use the strategy of using a more neutral word or paraphrase by related words. What people see in the product (the translation printed on paper) might not convey all the things that happened in the process (in the translator’s mind). The crucial point is what makes the translator decide to choose one word and not the other. The problem of culture is indeed difficult to cope with if the translator’s culture is really different from the text, moreover, if this difficulty occurs in a humorous text. Another important factor is time. When the translator does not have enough time to evaluate his own work, he reads his work as a translator, not as a reader. As a translator, it is difficult to see whether he can preserve the joke or not, while as a reader, he will be more sensitive to this. The ideal position to evaluate his own work is when the translator can position himself as a reader when evaluating his own work. Suggestions for further research are as follows. Concerning the problems of the research, some problems can be added for the next research, for example, translation unit in the process of translation. Concerning the materials to be translated, texts used should be short and contain only one or two difficulties. The difficulties should be center or global understanding. because the translation process of dealing with the difficulties could be seen in a better way. If there are too many difficulties and only about local understanding, the process is not striking because the strategies taken are general and translators tend to abandon difficulties. Concerning methodology, people doing the transcript should read the English text first before transcribing so that they do not have difficulties in doing the transcription. Mentioning the time for the cassettes should be emphasized so that translators understand that it is not the time for the translation, because if it is not emphasized, translators will think that it is the limit for the translation. Combination of introspective and retrospective methods can also be used. This might bring clearer explanation of what is happening in translators’ minds while translating. NOTE * I would like to thank Professor Esther Kuntjara, Ph.D., who conducted the research together with me, for her invaluable suggestion and feedback for the study. I feel very indebted to Prof. Bambang Kaswanti Purwo, who gave me feedback about the article. I am also very grateful to Angie Elaine Breneman for editing this article. REFERENCES Appelbaum, Richard P. & William J. Chambliss. 1997. Sociology. New York: Longman. Armstrong, Nigel. 2005. Translation, Linguistics, Culture: A French-English Handbook. Clevedon: Multilingual Matters Ltd. Baker, Mona. 1992. In Other Words: A Coursebook on Translation. London: Routledge and Kegan. Bassnett, Susan & André Lefevere. 1998. Constructing Cultures: Essays on Literary Translation. Clevedon: Multilingual Matters Ltd. Beamer, Linda & Iris Varner. 2001. Intercultural Communication in the Global Workplace. New York: McGraw-Hill. Bernardini, Silvia. 2001. Think-Aloud Protocols in Translation Research: Achievements, Limits, Future Prospects. Target 13 (2):241-263. 90 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Bernardini, Silvia. 2000. ‘Think-aloud Protocols in Translation Research: Achievements, Limits, Future Prospects’. A paper presented at the Conference of Process-oriented Translation Research. 28 April. Accessed 1 March 2007. Available from: http://www. art.man.ac.uk/SML/ctis/events/Conference2000/process1.htm. Bernardini, Silvia. 1999. Using Think-Aloud Protocols to Investigate the Translation Process: Methodological Aspects, in John N. Williams (Ed.). RCEAL Working papers in English and Applied Linguistics 6, pp. 179-199. Cambridge: University of Cambridge. Accessed 6 November 2006. Available from http://www.rceal.cam.ac.uk/Publications/Working/ Vol 6/Bernardini.pdf. Brown, James Dean, & Rodgers, Theodore S. 2001. Doing Second Language Research. Oxford: Oxford University Press. Duff, Alan. 1981. The Third Language. Oxford: Pergamon Press. Hatim, Basil & Jeremy Munday. 2004. Translation: An Advanced Resource Book. London and New York: Routledge. Kornfield, Jack & Paul Bleiter (Eds.). 1985. A Still Forest Pool: The Insight Meditation of Achaan Chah. Illinois: The Thesophical Publishing House. Li, Defeng. 2004. “Trustworthiness of Think-Aloud Protocols in the Study of Translation Processes.” International Journal of applied Linguistics 14.3:301-313. McKay, Sandra Lee. 2006. Researching Second Language Classrooms. Mahwah, New Jersey: Lawrence Erlbaum Associates. Rajan, B.R. Sundara & George. M. Jacobs (Eds.). 1996. Who Is the Most Talkative of Them All?: Stories for Language Teacher Education. Singapore: SEAMEO RELC. Suryawinata, Zuchridin & Sugeng Hariyanto. 2003. Translation: Bahasan Teori dan Penuntun Praktis Menerjemahkan. Yogyakarta: Kanisius. ‘She Had True Faith’. Accessed 12 December 2006. Available from http://www.batkhela.com/ islam/story7.shtml Wills, Wolfram. 2004. “Translation Studies-The State of the Art.” Meta, 49.4:777-785, retrieved on November 11, 2006. 91 Linguistik Indonesia, Februari 2014, 93-94 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 Resensi Buku Judul ISSN Penyunting Penerbit Tebal : : : : : Discursive Pragmatics (Handbook of Pragmatics Highlights, volume 8) 1877-654X Jan Zienkowski, Jan-Ola Östman, dan Jef Verschueren Amsterdam: John Benjamins B.V. 2011 307 halaman Faizah Sari Surya University [email protected] Buku ini merupakan koleksi atas lima belas artikel komprehensif yang disunting secara teliti dan yang membahas beraneka ragam topik menarik dalam analisis wacana dan pragmatik. Kelima belas artikel itu dipaparkan dalam gaya bahasa yang sederhana namun jelas. Dalam Appraisal (hlm. 14-36), Peter R.R. White dari University of Birmingham membahas kajian mengenai kerangka teoretis penggunaan bahasa penilaian (appraisal) yang relatif masih baru pada penelitian linguistik umum. Dalam artikel ini dibahas parameter-parameter penilaian, seperti pengaruh (affect), keputusan (judgement), penghargaan (appreciation), cara langsung atau tersirat (direct or implied modes of activation), kriteria tipologis (typological criteria), saling pengaruh antarcara bersikap (the interplay between the attitudinal modes), kedudukan intersubjektif (intersubjective stance), penilaian sikap (attitudinal assessment), dan keterlibatan (engagement). Dalam Cohesion and Coherence (hlm. 37-49), Wolfram Bublitz dari University of Augsburg mengkaji hubungan antara kepaduan (cohesion) dan kelekatan (coherence) dalam wacana yang membedakan sudut pandang peneliti yang lebih berorientasi pada bentuk dan struktur (form and structure oriented linguists) daripada pada fungsi (function oriented linguists). Dalam Critical Linguistics and Critical Discourse Analysis (hlm. 50-70) Ruth Wodak dari University of Lancaster mengkaji kesimpangsiuran terminologis dan pemahaman komunitas linguistik mengenai Critical Discourse Analysis (CDA). Wodak menelaah pendekatan-pendekatan yang mampu membentuk Critical Discourse Analaysis menjadi bagian dari kajian linguistik yang benar-benar berdasarkan pemahaman intelektual sosiopolitik yang kuat. Dalam Énonciation: French Pragmatic Approaches (hlm. 71-101), Marjut Johansson dan Eija Suomela-Sami dari University of Turku membahas pendekatan teoretis mengenai pragmatik enunsiatif (enunciative pragmatics), yaitu produksi pengucapan penutur dalam situasi tertentu, terutama dalam bahasa Prancis, dengan menjelajahi sejarah pragmatik enunsiatif bahasa Prancis dan tipe-tipe modalitas enunsiatif. Dalam Figures of Speech (hlm. 102-118), Manfred Kienpointner dari University of Innsbruck mengemukakan ungkapan kiasan (figures of speech/FSP) berdasar pada kerangka retorika kuno (ancient rhetoric) dan menguraikan ikhtisar upaya kontemporer dalam mendefinisikan dan mengklasifikasikan FSP dalam berbagai disiplin ilmu, misalnya, kajian komunikasi lisan, linguistik, kritik sastra, filsafat, dan psikologi. Dalam Genre (hlm. 119-134), Anna Solin dari University of Jyväskylä mengkaji konsep genre dalam wacana. Dengan memformulasikan teori genre awal dari Bakhtin (1953, 1986), Solin menggarisbawahi genre sebagai konsep penting interaksi antara tipe-tipe wacana dan antara interaksi pengguna dan penyusun teks. Dalam Humor (hlm. 135-155), Salvatore Attardo dari Texas A&M University, Commerce membahas pendekatan linguistik dalam mengkaji humor, terutama dalam humor referesial dan lisan, semantik, prinsip-prinsip kerja sama lisan (the cooperative principles), analisis percakapan (conversation analysis), termasuk di antaranya humor berdasarkan situasi (canned jokes) atau lelucon percakapan, dan sosiolinguistik humor (the sociolinguistics of Resensi Buku humor). Dalam Intertextuality (hlm. 156-175), Stef Slembrouck dari University of Ghent memaparkan telaah intertekstual dalan analisis percakapan melalui pandangan teoritis Bakhtin, Volosinov, dan Bordieu. Dalam Manipulation (hlm. 176-189) Paul Chitton dari University of Lancaster membahas manipulasi sebagai pengendali pemikiran (thought control) yang tidak melekat pada struktur bahasa. Dalam Narrative (hlm. 190-207), Alexanda Georgakopoulou dari King’s College London mengemukakan narasi sebagai alat komunikasi yang diperoleh dan dipraktikkan melalui pendekatan kontekstual. Dalam Polyphony (hlm. 208-222), Eddy Roulet dari University of Ghent mengkaji dialogisme dalam wacana yang kerap dikenal dalam kajian pragmatik sebagai polyphony. Dalam Pragmatic Markers (hlm. 223-247), Karin Aijmer dan Anne-Marie SimonVandenbergen dari University of Gothenburg dan University of Ghent membahas pendekatan kontemporer dan lintas-bahasa atas kajian pemarkah pragmatik (pragmatic markers) bahasabahasa yang bermunculan melalui pembahasan pragmatik (Aijmer & Simon-Vandenbergen, 2006). Aijmer dan Simon-Vandenbergen juga mengulas problematika terjemahan dan semantik atas penggunaan pemarkah pragmatik dalam percakapan. Dalam Public Discourse (hlm. 248265), Srikant Sarangi dari Cardiff University menelaah model-model dominan dalam pragmatik sosial. Dalam Text and Discourse Linguistics (hlm. 266-285), Jan-Ola Östman dan Tuija Virtanen dari University of Helsinki dan Åbo Akademi University memberikan gambaran luas pada linguistik teks dan wacana, yang di dalamnya terhimpun beraneka ragam topik yang telah dibahas secara khusus berdasarkan data individual oleh penulis-penulis sebelumnya pada Handbook of Pragmatic Highlights ini dan mengupas perihal keumuman dan kekhususan kajian yang ada pada lingkup wacana. Dalam Text Linguistics (hlm. 286-296), Robert de Beaugrande dari University of Vienna menyimpulkan bahwa linguistik teks merupakan kajian yang dinamis, di antaranya, tidak hanya mencakup unit linguistik tetapi juga interaksi. Menurutnya, penelitian kontemporer mesti berdasar pada data yang otentik, yaitu data yang berasal dari naturally occurring texts and discourse. Ditambah lagi, peneliti harus ‘melekat’ pada konteks wacana dan memiliki motif pengembangan hubungan antara teks dan masyarakat. Dengan demikian pada akhirnya, linguistik teks merupakan kajian yang interdisipliner. Buku ini baik sekali digunakan sebagai bahan acuan bagi penelitian bermetodologi analisis wacana dan berdata bahasa lisan alami, Systemic Functional Linguistics, Functional Grammar, dan Critical Discourse Analysis. Walaupun kajian di bidang pragmatik sudah cukup banyak, penelitian bersifat spesifik, misalnya partikel pragmatik, analisis wacana, analisis percakapan, dan sejenisnya, masih bergantung banyak pada publikasi khusus mengenai bidangbidang ini. Jilid kedelapan Handbook of Pragmatic Highlights ini merupakan salah satu publikasi yang konsisten memaparkan dan memopulerkan kajian-kajian spesifik di bidang pragmatik yang luas namun sedang berkembang. Artikel-artikel dalam jilid ini secara eksplisit juga menjelaskan medan penelitian yang masih dapat dikembangkan, sehingga para peneliti yang tertarik akan pendekatan linguistik ini dapat berkontribusi memperluas diskusi penting atas topik ini. DAFTAR PUSTAKA Aijmer, Karin & Simon-Vandenbergen, Anne-Marie (Ed.). 2006. Pragmatic markers in contrast. Studies in pragmatics 2. Amsterdam: Elsevier. Bakhtin, Mikhail Mikhailovich. 1986. [1953]. The problem of speech genres. In Speech genres and other late essays: 60–102. (translated by V. McGee; ed. by C. Emerson & M. Holquist.) University of Texas Press. 94 Linguistik Indonesia, Februari 2014, 95-98 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 JELAJAH LINGUISTIK Rubrik ini membuka peluang untuk saling berbagi di antara kita tentang beberapa kemungkinan topik ini: a. pencanangan metode penelitian linguistik yang belum lazim digunakan b. daur-ulang metodologi penelitian linguistik c. persoalan data yang – meskipun barangkali belum ditemukan pemecahannya – penelusurannya berpeluang membuka sesuatu yang baru yang belum pernah menjadi perhatian peneliti terdahulu d. penerapan teori linguistik tertentu untuk menjelaskan data bahasa seperti bahasa Indonesia yang membuat peneliti mempersoalkan teori yang bersangkutan MENINJAU ULANG METODOLOGI KONTEMPORER Faizah Sari Surya University [email protected] Hampir seratus tahun yang lalu kumpulan catatan kuliah Ferdinand de Saussure pertama dipublikasikan oleh mahasiswanya dalam Course in General Linguistics (1916) dan telah menjadi sumber rujukan bagi peneliti linguistik dan pada kelas-kelas linguistik di institusi pendidikan di seluruh dunia bahkan sampai di putaran milenia baru ini. Sejak itu begitu banyak aspek-aspek bahasa dan penggunaan bahasa terutama pada konsep kalimat yang telah diteliti dan dipublikasikan. Namun, pertanyaan klasik selalu muncul setiap kali penelitian bahasa dilakukan oleh seseorang: dengan mengaitkan teori A dan/atau teori B dengan data yang saya miliki, apakah sebenarnya yang akan digali dari sistem linguistik sebagai objek penyelidikan (object of inquiry) ini? Apa yang ingin saya capai saat penuntasan penelitian melalui pembedahan suatu kalimat? Beaugrande (2011) memberi ulasan singkat bagaimana peneliti bahasa dapat mempertajam eksplorasi pada kalimat sebagai unit berstruktur (a grammatical or syntactic unit) dengan melihat secara makro ”perjalanan” kajian linguistik secara umum agar peneliti bahasa kontemporer dapat menciptakan metodologi yang lebih kritis dan meluas sehingga ‘potret’ penelitian linguistik dapat terlihat lebih terfokus. Beaugrande menawarkan cara melihat pembatas-pembatas (constraints) di sekeliling suatu kalimat dengan lebih jauh lagi yang berefek pada “struktur (grammar), misalnya kepaduan (cohesion), kelekatan (coherence), penderetan topik (topic progression), penarasian (narrativity) dan perubahan keadaan (situationality)” (2011, hlm. 288). Dengan kata lain, tantangan penelitian kontemporer jatuh pada kemampuan peneliti melihat lebih dalam lagi melampaui konvensi yang biasa pada aspek-aspek kerangka wacana, proses berwacana, pendekatan sintaksis lewat pragmatik dan semantik khususnya pada aktivitas komunikasi, dan gaya bahasa. Dengan demikian kerangka teoritis yang digunakan untuk menganalisis bentuk-bentuk kalimat. Sampai saat ini Beaugrande berpendapat bahwa cara-cara menjaring data dapat dikelompokkan menjadi dua polar umum, yakni “kumpulan data asli berupa rekaman tersimpan dalam korpus dan penciptaan kalimat-kalimat tak berkonteks (isolated sentences), hanya berdasarkan intuisi” (2011, hlm. 286). Namun, keduanya memiliki ruang untuk perbaikan. Pertama, menurut Beaugrande, pada saat mengkaji rekaman atau contoh bahasa yang dipakai dalam tindak komunikasi (naturally-occurring language sample), peneliti bahasa terbiasa untuk mengkontekstualisasi perkataan, sanggahan, dan ucapan yang diproduksi oleh penutur dan ini justru menjadikan pembatas bagi penyelidikan yang lebih dalam. Dalam kenyataan yang sesungguhnya “suatu teks tidak dapat menampung semua aspek komunikasi, termasuk keinginan dan strategi penutur” (hlm. 289). Kedua, pengamatan berdasarkan intuisi terhadap suatu kalimat ciptaan sendiri telah lama diketahui sebagai hal buatan yang kurang andal sebagai Jelajah Linguistik data karena, selain tidak berdasarkan bukti empiris, suatu contoh kalimat buatan dapat saja menyesatkan dan terpolarisasi oleh latar belakang kebahasaan dan pemahaman subjektif peneliti, bukan dari fakta yang objektif. Ringkasnya, kedua polar di atas masih dapat dikembangkan seperti halnya metodologi yang terus-menerus berpedoman pada jalur menuju ke arah komprehensif melalui kritisi yang relevan dan konstruktif. Pelajaran bagi peneliti adalah kenyataan bahwa tatanan suatu metodologi dapat terus digoyang sehingga menjadi tugas utama peneliti untuk terus memperbarui metodologi. Satu hal imperatif yang perlu kita perhatikan adalah bahwa bentuk pokok semua analisis dan penyelidikan ilmiah yang kita lakukan akhirnya dituangkan dalam publikasi yang dibaca sesama kolega peneliti, calon peneliti, dan pemelajar bahasa yang akan menelaah publikasi tersebut untuk mencari contoh-contoh yang mudah dipahami. Bagi pemelajar bahasa, misalnya, contoh bahasa yang sederhana dan masuk akal dapat memberikan informasi akurat mengenai struktur kalimat atau arti kata. Contoh sederhana, bergantung pada tingkat kemahiran berbahasa, seorang pemelajar bahasa Indonesia sebagai bahasa asing perlu mengetahui bahwa bahasa Indonesia membedakan pronomina pertama jamak kami (eksklusif) dan kita (inklusif), sebagaimana yang umumnya terdapat pada buku-buku teks pelajaran bahasa Indonesia bagi penutur asing. Akan tetapi, dapat dijumpai pemakaian kita di antara sesama penutur bahasa Indonesia yang dalam pengertian eksklusif, yakni tidak mengikutsertakan kawan bicara (addressee), misalnya dalam kalimat kita suka nonton bola bareng. Keanekaragaman ini dapat membingungkan pemelajar pemula bahasa Indonesia sebagai bahasa asing, terutama bagi penutur asing berbahasa pertama bahasa Inggris atau bahasa-bahasa Eropa lainnya. Masih pada pronomina, mari kita lihat satu contoh yang relevan bagi sesama kolega peneliti bahasa-bahasa Indonesia tanpa memperhatikan kebangsaan atau bahasa pertama. Keanekaragaman pronomina pada bahasa-bahasa di Indonesia, representasi pronomina pertama tunggal saya dan jamak kami digunakan longgar dan tidak ada pembatas tunggal/jamak dan tidak perlu inklusif, misalnya torang dan kitorang dalam bahasa Melayu Maluku; awak dalam bahasa Ocu, Melayu Riau; dan urang dalam bahasa Sunda. Seluruh keanekaragaman ini memberikan cara baru melihat struktur bahasa karena pentingnya mengikutsertakan proses wacana untuk menentukan pengaruh arti dan konteks. Lalu, bagaimana cara kita menyikapi ruang untuk perbaikan pada kedua metode ini? Aijmer dan Simon-Vandenbergen (2011) dan Beaugrande (2011) merangkumkan celah yang terdapat pada metodologi linguistik kontemporer, bahwa peneliti (a) menggunakan sumber data asli, bukan rekaan; (b) terus berhubungan dengan data, bukan alih-alih memisahkan diri sebagai peneliti; (c) tidak superior atas data karena struktur komunikasi merupakan hal yang kompleks dan menyangkut pengetahuan dan masalah tentang masyarakat penutur. Intinya, kemajuan metodologi bertumpu pada kemampuan peneliti berkolaborasi, meninjau ulang, dan meluaskan jangkauan penyelidikan. Memang halnya, tekanan yang jelas berada di depan mata tiap peneliti adalah hasil penelitian yang akurat dan dapat dipublikasikan paling tidak secara nasional. Sementara disiplin ilmu bahasa di belahan “dunia pertama” telah berkembang begitu pesat sehingga peneliti bahasa di belahan dunia mana pun cenderung berpedoman pada konsep-konsep teori bahasa dari dunia pertama, antara konsep parole dan langue (Saussure, 1916), konsep linguistik historis komparatif (Bloomfield, 1933; cf. Salverda, 1985), konsep bahasa universal sebagai struktur bahasa yang cukup deskriptif (Chomsky, 1957), sampai pada linguistik fungsional (Halliday & Hasan, 1976). Namun, penelitian bahasa-bahasa di Indonesia pun patut dibanggakan. Sampai tahun 1988 di Indonesia terdapat 95 kamus bahasa Indonesia dan bahasa-bahasa daerah telah didokumentasikan (Idayu, 1988). Publikasi kamus ini terutama kamus bahasa-bahasa mayoritas, misalnya kamus bahasa Indonesia (hampir 50%), bahasa Sunda (5,3%), bahasa Bali dan bahasa 96 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 Jawa (4%), bahasa Minang (3%), dan bahasa Batak dan bahasa Melayu-Jakarta (2%). Dari sudut geopolitik daerah, sampai tahun 1988 ini pula upaya penulisan kamus bahasa daerah, termasuk bahasa-bahasa minoritas di Indonesia telah didokumentasikan, misalnya kamus bahasa-bahasa di Aceh (3%; bahasa Aceh, Alas, dan Gayo), Sumatra Utara (24%; bahasa Batak, Deli, MelayuLangkat, Karo, Angkola, Dairi Pakpak, Mentawai, dan Nias), Sumatra Barat-Riau-Sumatra Selatan (3%; bahasa Minang, Kerinci, dan Sakai), Kalimantan Barat-Tengah (3%; Melayu Banjar dan Bakumpai), Sulawesi Utara-Barat-Tengah-Tenggara-Selatan (3%; Bahasa Manado, Gorontalo, Tondano, Mandar, Suwawa, Muna, Tolaki, Wolio, Melayu Makasar, dan Bugis), Papua (3%; bahasa Biak), Nusatenggara Barat (bahasa Bima dan Sasak), dan Timor Leste (3%; bahasa Tetun). Pasca 1988 dapat merupakan titik penting di saat upaya pendokumentasian bahasa melalui penelitian bahasa dan pembuatan kamus bertemu dengan revolusi teknologi. Pada titik ini dunia menyaksikan derasnya informasi mengenai bahasa-bahasa di seluruh dunia, dan Indonesia turut menikmati sorotan atas diversifikasi bahasanya. Bentuk-bentuk publikasi terdahulu melibatkan percetakan non-digital, misalnya stensil atau dimuat pada bahan kertas yang mudah rusak apabila tidak disimpan dengan baik. Sekarang publikasi telah bertransformasi, termasuk dalam bentuk pangkalan data (database) dan dapat leluasa diakses melalui jaringan internet. Peneliti Indonesia pun tertolong dengan revolusi informasi ini dan dapat dengan cepat menjelajah informasi mengenai bahasa-bahasa di Indonesia. Contohnya, The World Atlas of Language Structures (WALS) menyediakan akses hasil penelitian pada 2679 nama bahasa yang terdokumentasi di dunia berikut dengan daftar publikasi berkenaan dengan bahasa-bahasa yang ada pada daftar. Contoh lain, Ethnologue juga menyediakan informasi mengenai 7105 bahasa di dunia. Lalu, sebagai peneliti Indonesia, apa yang dapat kita petik dari ulasan rangkaian kesatuan metodologi kontemporer ini? Beaugrande menganjurkan peneliti untuk “mengkaji ulang prioritas penelitian” (hlm. 293) Kita telah biasa menghadapi permasalahan bagaimana mengaitkan unsur teori dan empiris. Kita juga telah terbiasa merumuskan kategori berdasarkan data yang kita terima dari lapangan. Akan tetapi, justru pada persimpangan milenium ini kita perlu mempertanyakan diri kembali: apakah metodologi yang digunakan telah menyentuh segala aspek yang diperlukan dan menggunakan sebanyak mungkin perangkat penelitian yang tersedia sehingga data dapat muncul sebagai ”potret” yang mampu menceritakan keunikan dan potensi kontribusi ilmiah bagi ilmu linguistik. Pada akhirnya, penggalian ilmiah mengenai bahasa merupakan suatu proses yang mendewasakan kemampuan bermetodologi peneliti dan memajukan keilmuan ke arah yang lebih beranekaragam dan interdisipliner. Sebagai peneliti kita merupakan bagian dari kontinum besar keilmuan ini, yaitu pemegang peranan penting bagi penemuan linguistik (linguistic discovery), advokat pelestarian bahasa, dan duta keberlanjutan ilmu bahasa sebagai bagian dari kemajuan peradaban manusia. Penelitian linguistik tetap akan terus berevolusi dan menemukan kembali aspek-aspek bahasa yang belum terkuak. Sama pentingnya, penelitian linguistik mesti tetap meninjau konsep-konsep linguistik sebagai hipotesis yang masih harus terus dibuktikan melalui data bahasa sebagaimana dipakai dalam tindak komunikasi dan kerangka teoritis yang komprehensif. DAFTAR PUSTAKA Beaugrande, Robert de. 2011. Text Linguistics. Dalam Östman, Jan-Ola, Zienkowski, Jan, dan Verschueren, Jef (ed.). 2011. Discursive Pragmatics. Amsterdam: John Benjamins. 97 Jelajah Linguistik Cysouw, Michael. 2013. Inclusive/Exclusive Distinction in Independent Pronouns. Dalam Dryer, Matthew S. dan Haspelmath, Martin (Ed.). The World Atlas of Language Structures Online. Leipzig: Max Planck Institute for Evolutionary Anthropology. (Available online at http://wals.info/chapter/39, Accessed on 2014-03-09.) Dryer, Matthew S. & Haspelmath, Martin (Ed.). 2013. The World Atlas of Language Structures Online. Diakses pada 23 Februari 2014 dari http://wals.info Ethnologue. Diakses pada 23 Februari 2014 dari http://www.ethnologue.com Idayu, Yayasan. 1988. Bibliografi Bahasa & Kesusastraan Indonesia dan Daerah 1945-1988. Ed. 1. Jakarta: CV Haji Masagung. Salverda, Reinier. 1985. Leading Conceptions in Linguistic Theory: Formalist Tendencies in Structural Linguistics. Amsterdam: Vrije Universiteit te Amsterdam. 98 Linguistik Indonesia, Februari 2014, 99-102 Copyright©2014, Masyarakat Linguistik Indonesia, ISSN: 0215-4846 Volume ke-32, No. 1 BINCANG ANTARA KITA DARI DUNIA MAYA SUSUNAN PENGURUS MLI DAN DEWAN EDITOR LINGUISTIK INDONESIA PERIODE 2014-2016; DEKLARASI DAN IKRAR ANGGOTA MLI Pada Rabu, 5 Maret 2014 18:09, MLI <[email protected]> menulis: Yth. Bapak/Ibu Anggota MLI, Dalam Musyawarah Nasional Masyarakat Linguistik Indonesia yang diselenggarakan di Hotel Sheraton Lampung, tanggal 20 Februari 2014 yang lalu, diadakan pemilihan Ketua MLI periode 2014-2016. Sebagai Ketua MLI terpilih untuk periode 2014-2016, melalui milis ini saya ingin mengumumkan susunan Pengurus MLI periode 2014-2016, sebagai berikut: Ketua Wakil Ketua Sekretaris Bendahara : : : : Dr. Katharina Endriati Sukamto (Unika Atma Jaya) Dr. Fairul Zabadi (Badan Pengembangan dan Pembinaan Bahasa) Dr. Ifan Iskandar (Universitas Negeri Jakarta) Dr. Yanti (Unika Atma Jaya) Untuk pengelolaan jurnal Linguistik Indonesia, Dewan Editor periode 2014-2016 adalah: Editor Utama : Prof. Dr. Bambang Kaswanti Purwo (Unika Atma Jaya) Editor Pendamping : Dr. Lanny Hidayat (Unika Atma Jaya) Anggota : akan ditentukan kemudian Selain kedua hal di atas, kami juga ingin menyampaikan Deklarasi KIMLI 2014 dan Ikrar Anggota MLI yang dibacakan pada saat penutupan acara KIMLI tanggal 22 Februari 2014 (mohon lihat lekapan). Kiranya Bapak/Ibu berkenan menyebarluaskan Deklarasi dan Ikrar ini kepada rekan kerja dan bahasawan yang Bapak/Ibu kenal dan tidak hadir pada KIMLI 2014 di Lampung. Rencana kegiatan Pengurus MLI periode 2014-2016 akan kami sampaikan pada kesempatan berikutnya. Demikian informasi ini kami sampaikan. Mari kita majukan MLI, dengan berperan serta secara aktif dalam kegiatan-kegiatan yang dipelopori oleh MLI. Para Ketua Cabang MLI di mana pun di seluruh Indonesia, kami mengimbau untuk menggerakkan peran serta dan motivasi para anggota di tempat masing-masing. Terima kasih dan salam MLI, Katharina Endriati Sukamto Ketua MLI Bincang antara Kita dari Dunia Maya REKOMENDASI KIMLI 2014 KIMLI 2014, yang bertemakan “Peran Bahasa Ibu dan Bahasa Nasional dalam Pengembangan Potensi Penutur Bahasa”, dalam empat hari kongresnya di Bandar Lampung (19-22 Februari 2014) sebagai bentuk kerja sama antara MLI Pusat dan MLI Cabang Universitas Lampung, menghasilkan rekomendasi berikut. Dalam beberapa puluh tahun terakhir ini pewarisan bahasa ibu ke generasi muda mengalami “putus mata rantai”; banyak di antara generasi muda yang tidak lagi menguasai bahasa ibunya. Padahal bahasa ibu -- bagi anak yang berkembang melalui bahasa ini -- merupakan pintu pertama untuk mengembangkan potensi akademik serta potensi penguasaan bahasa kedua, ketiga, dan seterusnya. Untuk itu marilah kita, seluruh anggota Masyarakat Linguistik Indonesia, mengucapkan ikrar sebagai berikut: IKRAR ANGGOTA MASYARAKAT LINGUISTIK INDONESIA Pada hari ini, Sabtu, 22 Februari 2014, kami anggota MLI berikrar untuk memberi perhatian kepada bahasa ibu di daerah kita masing-masing, mendorong penggunaannya, membantu proses pewarisan ke generasi penerus melalui kegiatan pendidikan, penelitian, dan pengabdian kepada masyarakat. Bandar Lampung, 22 Februari 2014 Tertanda Seluruh anggota MLI 100 Linguistik Indonesia, Volume ke-32, No. 1, Februari 2014 IURAN KEANGGOTAAN MLI DAN SUMBANGAN PENERBITAN ARTIKEL LI Pada Kamis, 24 April 2014 14:32, MLI <[email protected]> menulis: 101 Bincang antara Kita dari Dunia Maya 102 FORMAT PENULISAN NASKAH Naskah diketik dengan menggunakan MS Word dikirimkan ke Redaksi melalui e-mail [email protected] atau dalam bentuk disket dan satu printout. Panjang naskah, termasuk daftar pustaka, adalah minimal 15 halaman dan maksimal 30 halaman, dengan spasi tunggal dan jenis huruf Times New Roman 11 point. Naskah disertai dengan abstrak sekitar 150 kata dan kata kunci (key words) maksimal tiga kata. Abstrak dan kata kunci ditulis dalam dua bahasa: bahasa Indonesia dan bahasa Inggris, diletakkan setelah judul naskah dan afiliasi penulis. Kutipan hendaknya dipadukan dalam kalimat penulis, kecuali bila panjangnya lebih dari tiga baris. Dalam hal ini, kutipan diketik dengan spasi tunggal, menjorok ke dalam (indented) sepuluh karakter, letak tengah (centered), dan tanpa tanda petik. Nama penulis yang dirujuk hendaknya ditulis dengan urutan berikut: nama akhir penulis, tahun penerbitan, dan nomor halaman (bila diperlukan); misalnya, (Radford 1997), (Radford 1997:215). Catatan ditulis pada akhir naskah (endnote), tidak pada bagian bawah halaman (footnote). Setiap rujukan baik artikel maupun buku tanpa dipilah-pilah jenisnya, diurutkan menurut abjad berdasarkan nama akhir, tanpa diberi nomor urut. Untuk buku: (1) nama akhir, (2) koma, (3) nama pertama, (4) titik, (5) tahun penerbitan, (6) titik, (7) judul buku cetak miring, (8) titik, (9) kota penerbitan, (10) titik dua (colon), (11) nama penerbit, dan (12) titik, seperti pada contoh berikut: Gass, Susan M. dan J. Schachter. 1990. Linguistic Perspectives on Second Language Acquisition. Cambridge: Cambridge University Press. Thornbury, Scott. 2005. Beyond the Sentence: Introducing Discourse Analysis. Oxford: Macmillan. Untuk artikel dalam jurnal: (1) nama akhir, (2) koma, (3) nama pertama, (4) titik, (5) tahun penerbitan, (6) titik, (7) tanda petik buka, (8) judul artikel, (9) titik, (10) tanda petik tutup, (11) nama jurnal cetak miring, (12) volume, (13) titik, (14) nomor (kalau ada), (15) koma, (16) spasi, (17) halaman, (18) titik, seperti pada contoh berikut: Chung, Sandra. 1976. “An Object-Creating Rule in Bahasa Indonesia.” Linguistic Inquiry 7.1, 41-87. Steinhauer, Hein. 1985.“Number in Biak. Counterevidence to Two Alleged Language Universals.” Bijdragen Tot De Taal-, Land- En Volkenkunde 141.4, 462-485. Untuk artikel dalam buku: (1) nama akhir, (2) koma, (3) nama pertama, (4) titik, (5) tahun penerbitan, (6) titik, (7) tanda petik buka, (8) judul artikel, (9) titik, (10) tanda petik tutup, (11) berilah kata "Dalam", (12) titik dua, (13) nama editor disusul (ed.), (14) koma, (15) halaman, (16) titik. Buku ini harus pula dirujuk secara lengkap dalam lema tersendiri, seperti pada contoh berikut: Dardjowidjojo, Soenjono. 2007. “Derajat Keuniversalan dalam Pemerolehan Bahasa.” Dalam: Nasanius (ed.), 233-261. Nasanius, Yassir. (ed.). 2007. PELBBA 18. Jakarta: Yayasan Obor Indonesia. Jika ada lebih dari satu artikel oleh pengarang yang sama, nama pengarangnya ditulis ulang secara lengkap, dimulai dengan tahun terbitan yang lebih dulu, mengikuti contoh ini: Shibatani, Masayoshi. 1977. “Grammatical Relations and Surface Cases.” Language 53, 789- 809. Shibatani, Masayoshi. 1985. “Passives and Related Constructions: A Prototype Analysis.” Language 61, 821-848.