Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Serializability wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Microsoft Access wikipedia , lookup
Oracle Database wikipedia , lookup
Team Foundation Server wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Concurrency control wikipedia , lookup
Ingres (database) wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Versant Object Database wikipedia , lookup
Relational model wikipedia , lookup
ContactPoint wikipedia , lookup
Database model wikipedia , lookup
PROFESSIONAL DBA SERIES
Christopher Kempster
SQL Server
A Practical Guide to
Backup, Recovery & Troubleshooting
SQL Server – Professional DBA Series
Dedicated to my dearest friend and wife Veronica
and my kids Carl and Cassidy.
Special thanks goes to Trevor Williams for editing the e-book.
Copyright © 2004, 2005 Christopher Kempster
Perth, Western Australia
Copying, selling, duplication or reproduction of this work is expressly forbidden without the copyright holder’s written consent.
All scripts and examples are used at your own risk.
The author does not assume any liability for errors or omissions anywhere in this ebook.
Always backup before performing system changes or attempting a system recovery.
Never test recovery procedures on a production server, be it on a separate database, instance or node in a cluster.
Microsoft Word 2000 is a registered trademark of the Microsoft Corporation.
SQL Server and SQL Server 2000 is a registered trademark of the Microsoft Corporation.
CutePDF v3.07 is a registered product of Acro Software Inc.
FOREWORD
Dear Readers,
I was delighted when Chris asked me to write a forward for his second book, which
covers the important topics of backup, recovery and high availability with Microsoft SQL
Server. This is an exciting release that will fill an important gap in the Database
Administration book market. Microsoft SQL Server is being increasingly used for large
mission critical enterprise systems, which require robust backup and recovery systems.
Providing high availability solutions requires careful planning and implementation and
Chris covers each topic in detail so that the reader is guided every step of the way.
Chris enjoyed good sales with his previous ebook, entitled "SQL Server 2000 for the
Oracle DBA", both in Australia and internationally and I look forward to him achieving
further success with this exciting new release.
ASG welcomes the opportunity to encourage and grow staff excellence wherever
possible. Chris has enjoyed an extensive working relationship with ASG. Chris is always
highly motivated and enthusiastic, and has impressed us all with his in depth knowledge
of both Microsoft SQL Server and Oracle, and importantly his ability to apply this
knowledge to the maximum benefit of our clients. We are delighted to see that Chris is
willing to share his knowledge and experiences with others in the IT Community
through the release of his second ebook. This is very much in line with one of ASG’s key
objectives of “contributing to the development of the IT community”.
Finally, I would like to thank Chris for the opportunity to provide some excellent
international coverage with respect to our world-class technical capabilities in the area
of Microsoft SQL Server administration.
Steve Tull
Chief Solutions Officer
ASG Group Limited.
ii
Table of Contents
PLANNING AND PREPARATION ..........................6
WHAT IS DISASTER RECOVERY PLANNING?..............6
Disaster Recovery Plans (DRP) ............................7
DRP for SQL Server Databases ............................9
Example - Disaster Recovery Planning...............11
FRAMEWORKS FOR IT SERVICE MANAGEMENT ......17
CoBIT (Control Objectives for Best IT Practices)
..............................................................................17
ITIL (Information Infrastructure Library)...........18
Microsoft Enterprise Services Framework (ESF)20
Balanced Scorecard .............................................21
SERVICE LEVEL METRICS ........................................21
The Scale of Nines................................................21
Other availability metrics ....................................22
What is achievable with SQL Server? .................23
RESPONSIBILITY VS. ACCOUNTABILITY ..................23
BUILDING STAFF CAPABILITY..................................24
Consider an Emergency Response Team (ERT)..24
DBA Taining and Skills (building ERT expertise)
..............................................................................25
CHANGE CONTROL...............................................28
MANAGING CHANGE CONTROL BY EXAMPLE .........28
Environment Overview ........................................28
Pre-change window resource meeting ................31
Visual Source Safe (VSS) .....................................32
Managing Servers ................................................33
Development Server .............................................33
Test Server............................................................35
Refreshing TEST from PRODUCTION..........36
Production Support..............................................37
Production............................................................37
Hot Fixes ..............................................................38
Smarten up your applications (Autonomic
Computing)...........................................................39
MRAC of IR/Task Completion .............................40
Summary...............................................................40
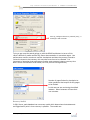
USING VSS BY EXAMPLE - PART 1 ..........................41
Terminology .........................................................41
Build Phase – Moving to the new change control
structure ...............................................................41
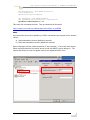
First Change Control...........................................43
Moving Code to TEST..........................................45
Overwriting existing code in TEST from DEV ....46
Taking a Change Control into Production ..........47
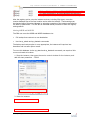
USING VSS BY EXAMPLE - PART 2 ..........................49
How do I move files to next weeks change control?
..............................................................................49
What does VSS look like after 2 iterations of
change? ................................................................51
I forgot to take a file into production for a
schedule change...................................................52
I have a special project that will span many weeks,
now what? ............................................................52
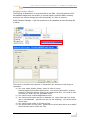
USING VSS BY EXAMPLE - PART 3 ..........................54
Re-iterating our chosen VSS structure ................54
What does my VSS look like to date?...................55
What do you do with /development after each
change control? ...................................................56
What do you branch into /development in terms
of VB6 COM code? .........................................56
VSS Issues ............................................................57
Share/Branching files from /test into /production
..........................................................................57
Building the new /production project ..............57
Adding/Removing Project Source Files ..........57
Error on Renaming Projects ............................58
Use Labels where appropriate .........................59
The "guest" user...............................................59
Security Issues in /production for Branching
files...................................................................59
Welcome to .Net ...................................................61
Initial Configuration of Visual Studio.Net ......61
VS.Net Solutions and Projects .............................62
Important Notes before we continue ...............62
Adding a new (simple) Solution to Source
Control - Example............................................63
VSS FOR THE DBA...................................................66
THEORY AND ESSENTIAL SCRIPTS.................67
UNDO & REDO MANAGEMENT ARCHITECTURE ......67
AUDIT THE SQL SERVER INSTANCE ........................73
META DATA FUNCTIONS ..........................................75
LISTING SQL SERVER INSTANCES ...........................76
INFORMATION SCHEMA VIEWS ................................76
DATABASE, FILE AND FILE GROUP INFORMATION ..77
Extracting Basic Database Information ..............77
Determining Database Status Programmatically77
USING O/ISQL .........................................................78
RETRIEVING LICENSING INFORMATION ...................79
Alter licensing mode after install?.......................79
ALLOWING WRITES TO SYSTEM TABLES ..................80
COUNT ROWS & OBJECT SPACE USAGE ..................81
Space and Memory Usage ...............................82
BLACK BOX TRACING ..............................................82
SCAN ERROR LOG FOR MESSAGES?.........................85
DATABASE LAST RESTORED AND FROM WHERE?.....85
WHAT STORED PROCEDURES WILL FIRE WHEN MY
INSTANCE STARTS?...................................................86
WHEN THE DATABASE WAS LAST ACCESSED? .........86
ESSENTIAL TRACE FLAGS FOR RECOVERY &
DEBUGGING ..............................................................86
Example of setting and verifying the trace flags .87
“TRACE OPTION(S) NOT ENABLED FOR THIS
CONNECTION” ? ........................................................89
BULK COPY OUT ALL TABLE DATA FROM DATABASE
..................................................................................89
SQLSERVR BINARY COMMAND LINE OPTIONS.....89
SQL SERVER LOG FILES ..........................................90
Read Agent Log Example................................91
How and When do I switch sql server logs?........91
DETECTING AND DEALING WITH DEADLOCKS .........91
Example Deadlock Trace.................................94
ORPHANED LOGINS ..................................................95
ORPHANED SESSIONS - PART 1 ................................96
ORPHANED SESSIONS - PART 2 ................................97
CHANGE DB OWNER ................................................97
TRANSFER DIAGRAMS BETWEEN DATABASES .........98
TRANSFER LOGINS BETWEEN SERVERS ...................99
KILLING SESSIONS ....................................................99
The ALTER Statement ........................................100
How do I trace the session before Killing it ? ...100
SETTING UP AND SENDING SQL ALERTS VIA SMTP
................................................................................101
The Stored Procedure ........................................103
Creating the Alert ..............................................103
Testing the Alert .................................................106
Recommended Backup and Restore Alerts ........106
HIGH AVAILABILITY..........................................107
PURCHASING THE HARDWARE ...............................107
So what hardware should I buy? .......................107
What is the HCL or the “Windows Catalog”....110
HIGH AVAILABILITY USING CLUSTERS ..................110
VMWARE SQL Cluster - by Example................111
Using VMWARE in Production? .......................112
Step 1. Software & Licensing............................112
Step 2. Create the virtual servers .....................113
Step 3. Build your domain controller ...............115
Step 4. Build member server 1 (node 1 of the
cluster)................................................................118
Adding SCSI Disks ........................................118
Adding another NIC for the Private Network120
Prepare your SCSI disks ................................121
Install Cluster Services on Server (node) 1 ...122
Validate Node 1 in the cluster via Cluster
Administrator .................................................124
Step 5. Build member server 2 ..........................125
Step 6. Install SQL Server 2k in the cluster
(Active/Passive)..................................................126
Test Connectivity ...........................................134
HIGH AVAILABILITY USING LOG SHIPPING............135
Manual Log Shipping - Basic Example .............136
Custom Logshipping – Enterprise Example ......140
Log Shipping Example 1 - Setup and Running
........................................................................143
Server 1 (source) ............................................143
Server 2 (destination).....................................144
Log Shipping Example 2 - Finalising Recovery /
Failover ..........................................................146
Concluding thoughts ......................................146
TROUBLESHOOTING SQL CLUSTERS...........147
TROUBLE SHOOTING AND MANAGING CLUSTERS .147
How many MSMQ’s can I have per cluster?.....147
I am having trouble starting the cluster (Win2k)
............................................................................147
Why can’t I backup to C Drive? ........................148
Move SQL Server cluster between SANs ...........148
Should I change the Service Dependencies in
Cluster Administrator? ......................................149
How can I stop Full Text indexing affecting the
whole cluster group? .........................................149
Diagnosing Issues, where to look? ....................149
Can I delete the BUILTIN\Administrators group in
SQL?...................................................................150
Correct way of stopping a clustered SQL instance
............................................................................151
How do I keep the Instance offline but start it
locally for maintenance? ...................................151
Can I automatically schedule a fail-over? ........152
Correct way to initiate a failure in Cluster
Administrator .....................................................152
Any Windows 2003 restrictions with clustering?
............................................................................153
Changing Service Account Logins/Passwords ..153
Event logs between cluster nodes – can I sync
them also? ..........................................................153
Nodes in a cluster via Query Analyser? ............153
Failed to obtain TransactionDispenserInterface:
Result Code = 0x8004d01b ...............................153
Altering Server Network Properties for the
Instance ..............................................................153
Add Disk E: to our list of disk resources for SQL
Server .................................................................154
Cluster Network Name resource 'SQL Network
Name(SQLCLUSTER1)' cannot be brought online
because the name could not be added to the
system. ................................................................155
I renamed my sql server virtual cluster name –
now I am getting errors and the instance will not
start? ..................................................................156
How to I alter the IP address of the virtual server?
............................................................................157
The Microsoft Clustering Service failed to restore
a registry key for resource SQL Server .............157
Reinstall SQL Server on a Cluster Node ...........157
How to remove a SQL Server Instance from the
cluster.................................................................158
Remove/add a single sqlserver node from the
clustered instance (not evicting a node from the
cluster service itself) ..........................................158
COMCLUST and Windows 2003 Server ...........158
Try to run service pack setup.bat and tells me
“Setup initialization error. Access Denied” .....158
Applying a service pack to the SQL Server
clustered instance ..............................................159
BACKUP...................................................................160
BACKUP FUNDAMENTALS ......................................160
Importance of Structure and Standards ............160
Directory Structures.......................................161
Naming Rules ................................................162
Database File Names .....................................163
Logical Filenames and File group Names .....163
Default properties ..........................................164
Recovery Interval ...............................................165
Recovery Models................................................166
What privileges do I need to backup databases?
............................................................................168
Backup and Restore between Editions of SQL 2k
............................................................................168
Backup Devices ..................................................168
Database Maintenance Plans ............................168
Data Dictionary Views.......................................171
Removing Backup History from MSDB .......172
Full (complete) Backups ....................................172
Differential Backups ..........................................174
Transaction Log Backups ..................................175
Log backups failing when scheduled via
Database Maintenance Plan ...........................176
Filegroup Backups .............................................176
OLAP Backups ...................................................177
Can I compress backups? ..................................177
Can I backup and restore over a UNC path?....177
Logon failure: unknown user name or bad
password.........................................................178
What is the VDI? ................................................178
WHAT, WHEN, WHERE, HOW TO BACKUP .............178
What is the DBA responsible for? .....................178
What do I backup? .............................................179
How do I backup? ..............................................179
When do I backup?.............................................180
Where do I backup? ...........................................180
HOW BIG WILL MY BACKUP FILE BE? .....................180
Full .....................................................................180
Differential .........................................................181
Transaction Log .................................................181
Using the MSDB to view historical growth .......181
HOW DO I BACKUP/COPY DTS PACKAGES? ..........182
SOME BACKUP (AND RECOVERY) BEST PRACTICE 183
BACKUP CLUSTERS - DBA.....................................185
BACKUP PERFORMANCE.........................................185
CUSTOM BACKUP ROUTINES – HOW TO ................186
RECOVERY & TROUBLESHOOTING..............187
IMPORTANT FIRST STEPS ........................................187
CONTACTING MS SUPPORT ....................................188
WHAT PRIVILEGES DO I NEED TO RESTORE A
DATABASE? ............................................................189
REVISITING THE RESTORE COMMAND .................190
AUTO-CLOSE OPTION & TIMEOUTS ON EM ..........192
CAN I RE-INDEX OR FIX SYSTEM TABLE INDEXES? 192
CONNECTIONREAD (WRAPPERREAD()). [SQLSTATE
01000] ....................................................................193
SPACE UTILISATION NOT CORRECTLY REPORTED? 194
GUEST LOGIN MISSING ON MSDB DATABASE .......194
TROUBLESHOOTING FULL TEXT INDEXES (FTI)....194
General FTI Tips................................................195
LOCKED OUT OF SQL SERVER? .............................195
INSTANCE STARTUP ISSUES....................................196
“Could not start the XXX service on Local
Computer” .........................................................196
SSPI Context Error – Example with Resolution 197
Account Delegation and SETSPN......................200
I’M GETTING A LOCK ON MODEL ERROR WHEN
CREATING A DB? ....................................................201
TRANSACTION LOG MANAGEMENT .......................202
Attempt backup but get “transaction log is full”
error ...................................................................202
Alter recovery model, backup and shrink log file
............................................................................203
Shrinking Transaction Log Files .......................203
Step 1. Get basic file information ..................203
Step 2. I don’t mind loosing transaction log
data (point in time recovery is not important to
me), just shrink the file ..................................204
Step 3. I need the transaction log file for
recovery..........................................................204
Step 4. Shrink the transaction log.................205
Rebuilding & Removing Log Files ....................206
Removing log files without detaching the
database..........................................................206
Re-attaching databases minus the log?..........207
Using DBCC REBUILD_LOG()...................209
CAN I LISTEN ON MULTIPLE TCP/IP PORTS?..........210
OPERATING SYSTEM ISSUES ..................................210
I see no SQL Server Counters in Perfmon?.......210
Server hostname has changed ...........................211
Use DFS for database files? ..............................214
Use EFS for database files? ..............................214
Use Compressed Drives for database files?......216
“previous program installation created pending
file operations” ..................................................216
DEBUGGING DISTRIBUTED TRANSACTION
COORDINATOR (MSDTC) PROBLEMS ....................216
Failed to obtain TransactionDispenserInterface:
Result Code = 0x8004d01b ...............................216
Essential Utilities ...............................................216
Check 1 - DTC Security Configuration .............217
Check 2 - Enable network DTC access installed?
............................................................................217
Check 3 - Firewall separates DB and Web Server?
............................................................................218
Check 4 - Win 2003 only - Regression to Win 2000
............................................................................218
Check 5 - Win 2003 only - COM+ Default
Component Security...........................................219
COMMON DEVELOPMENT/DEVELOPER ISSUES ......219
I’m getting a TCP bind error on my SQL Servers
Startup?..............................................................219
Error 7405 : Heterogeneous queries.................219
Linked server fails with enlist in transaction
error? .................................................................220
How to I list tables with Identity Column property
set? .....................................................................220
How do I reset Identity values? .........................220
How do I check that my foreign key constraints are
valid?..................................................................220
I encrypted my stored proc and I don’t have the
original code!.....................................................220
How do I list all my procs and their parameters?
............................................................................221
Query Analyser queries time out? .....................221
“There is insufficient system memory to run this
query” ................................................................221
My stored procedure has different execution
plans? .................................................................222
Using xp_enum_oledb_providers does not list all
of them?..............................................................223
The columns in my Views are out of
order/missing? ...................................................224
PRINT statement doesn’t show results until the
end?....................................................................225
PRINT can result in Error Number 3001 in
ADO ...............................................................225
Timeout Issues....................................................225
ADO ...............................................................225
COM+ ............................................................226
OLEDB Provider Pooling Timeouts .............227
IIS...................................................................227
SQL Server.....................................................229
Sample Error Messages .................................230
Is the timeout order Important? .....................231
DBCC COMMANDS ................................................231
What is – dbcc dbcontrol() ? .............................231
What is - dbcc rebuild_log() ? ...........................232
TROUBLESHOOTING DTS AND SQL AGENT ISSUES
................................................................................233
Naming Standards..............................................233
I’m getting a “deferred prepare error” ? .........233
Debugging SQLAgent Startup via Command Line
............................................................................233
Don’t forget your package history! ...................234
Where are my packages stored in SQL Server? 234
DTS Package runtime logging...........................235
I get an “invalid class string” or “parameter is
not correct”........................................................236
I lost the DTS package password.......................236
I lost a DTS package - can I recover it?............236
Access denied error on running scheduled job .237
Changing DTS package ownership ...................237
I have scheduled a package, if I alter it do I recreate the job?....................................................237
xpsql.cpp: Error 87 from GetProxyAccount on line
604......................................................................237
DTSRUN and Encrypted package call ..............238
TEMPDB IN RAM – INSTANCE FAILS TO START ...238
RESTORE A SINGLE TABLE FROM A FILE GROUP ....239
Pre-Recovery Steps ............................................239
Recovery Steps ...................................................240
Can I do a partial restore on another server and
still get the same result? ....................................243
Can I do a partial restore over the live database
instead? ..............................................................243
Restore over database in a loading status?.......244
MOVING YOUR SYSTEM DATABASES ......................244
Moving MASTER and Error Logs .....................244
Moving MSDB and MODEL..............................245
Moving TEMPDB...............................................246
Moving User Databases.....................................247
Some issues with MODEL and MSDB
databases ........................................................251
Fixed dbid for system databases ....................251
Scripting Database Objects ...............................252
Verifying Backups ..............................................254
RECOVERY ..............................................................255
A quick reminder about the order of recovery ..255
Killing User Connections and Stopping Further
Connects.............................................................256
Using the GUI for Recovery ..............................256
Options - Leave database in non-operational
state but able to restore additional logs .........257
Options – Using the Force restore over existing
database option...............................................258
Restoring a databases backup history from backup
files .....................................................................259
SQLServer Agent must be able to connect to
SQLServer as SysAdmin.....................................259
Restore cannot fit on disk...................................260
“Exclusive access could not be obtained..” ......260
Restore uses “logical” names ...........................260
UNABLE TO READ LOCAL EVENT LOG. THE EVENT
LOG IS CORRUPTED .................................................261
WHAT IS A “GHOST RECORD CLEANUP”?..............261
HOW DO I SHRINK TEMPDB? ...............................261
Shutdown and re-start........................................262
Use DBCC SHRINKDATABASE .......................262
Use DBCC SHRINKFILE ..................................263
HOW DO I MIGRATE TO A PREVIOUS SERVICE PACK?
................................................................................265
Full Rollback......................................................265
Service Pack install hangs when “checking
credentials”........................................................267
OLAP .....................................................................268
Recovery of OLAP cubes to another server ......268
Non-interface error: CoCreate of DSO for
MSOLAP ............................................................268
What TCP port does Analysis Services use? .....269
RESTORATION SCENARIOS .....................................269
Dealing with Database Corruption ...................269
How do I detect it?.........................................269
How do I recover from it? .............................270
“Database X cannot be opened, its in the middle
or a restore” ......................................................272
Installing MSDB from base install scripts.........272
Model and MSDB databases are de-attached
(moving db files)? ..............................................272
Restore Master Database ..................................275
Restore MSDB and Model Databases ...............277
No backups of MODEL ? ..............................277
No backups of MSDB ?................................277
Recovery of System Databases and
NORECOVERY option.......................................277
Collation Issues - Restores from other Instances or
v7 Upgrades .......................................................278
Suspect Database (part 1) .................................280
Suspect Database (part 2) and the 1105 or 9002
error ...................................................................281
Suspect Database (part 3) – restore makes
database suspect? ..............................................283
Suspect Database (part 4) – Cannot open FCB for
invalid file X in database XYZ ...........................284
Suspect Database (part 5) – drop index makes
database suspect? ..............................................285
How do I rename a database and its files? .......288
Database is in “Loading” Mode ? ....................290
Restore with file move........................................290
Restore to a network drive.................................290
Restore a specific File Group ............................291
Adding or Removing Data Files (affect on
recovery) ............................................................293
Emergency Mode ...............................................293
Restore Full Backup...........................................294
Partial (stop at time) PITR Restore on a User
Database ............................................................295
Corrupt Indexes (DBMS_REPAIR) ...................295
Worker Thread Limit of N has been reached? ..296
Reinstall NORTHWIND and PUBS...................296
Some of my replicated text/binary data is being
truncated? ..........................................................296
Other Recovery Scenarios .................................296
Scenario 1 - Lost TEMPDB Database..........296
Scenario 2 - Rebuildm.exe...........................297
Scenario 4 - Disks lost, must restore all system
and user databases from backup to new
drive/file locations .........................................301
INDEX.......................................................................302
APPENDIX A ...........................................................306
UNDERSTANDING THE DISK, TAPE AND STORAGE
MARKET .................................................................306
SAN (Storage Area Network).............................306
Example SAN Configuration.........................310
What is NAS (Network Attached Storage) ? ......310
What is iSCSI? ...................................................311
Anything else apart from iSCSI? .......................313
Using Serial ATA over SCSI ..............................314
SCSI, Fiber or iSCSI? ........................................315
Hard Disk Availability - Overview of RAID......316
Summary ........................................................316
Performance/Cost/Usage ...............................316
Disk Performance...........................................317
Database File Placement - General Rules......318
Example RAID Configurations .....................319
Virtualising Storage Management – the end game
............................................................................322
So as a DBA - what storage scheme do I pick?.323
TAPE Drives ......................................................326
Building a Backup Server..............................329
Who needs tapes when I can go to Disk? ..........331
IN THE DATA CENTRE ............................................332
Understanding server Racks..............................332
What are Blade Servers and Blade Centers? ....334
REFERENCES.........................................................337
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
1
Chapter
“..how you develop [it] is at least as important as the final result”
A.M.Schneiderman
Planning and Preparation
T
he role of DBA is undoubtedly an important one, but many DBAs tend to be
somewhat blasé about backup and recovery. This e-book attempts to bridge the
knowledge gap and provide working scenarios, policy/procedure and best practice
for database backup and recovery.
As with my previous e-book, I assume a reasonable knowledge of DBMS architecture and
in particular some general DBA experience with SQL Server.
This first chapter covers a range of planning and preparation strategies that will
ultimately define your system design, backups and recovery procedures. We will focus
on disaster recovery planning and frameworks for IT service management, then take this
further in chapter two and change management (by example) then chapter three with
alternatives for high availability.
What is Disaster Recovery Planning?
This is a complex question. It conjures thoughts of business continuity, data and
database recovery, network and server availability, staff expertise/training/availability
and policy and procedures. So the question is probably not so much “what is disaster
recovery?” (the title tends to be self explanatory), but “at what point do you draw the
line?”, and how much time and money are you prepared to spend curbing the multitude
of possibilities?
That said; let us define disaster recovery planning.
Planning for Disaster Recovery is synonymous with contingency planning; it is “a plan for
backup procedures, emergency response and post-disaster recovery”. This plan
encompasses the who/how/where/when of “emergency response, back operations and
post-disaster” procedures to “ensure the availability of critical resources and to facilitate
the continuity of” business “operations in an emergency situation” (2).
It is very interesting reading the variety of thoughts in this space (3), one particularly
interesting one was the division of the DR from that of business continuity planning:
Christopher Kempster
6
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
a) Disaster Recovery (DR) - the process of restoring systems [including manual and
automated business process] to an operational [state] after a catastrophic
systems failure leading to a complete loss of operational capability. (3a)
b) Business Continuity (BC) - is the forethought to prevent loss of operational
capability even though there may be a catastrophic failure in some parts of the
system. BC includes DR plans to restore failed system components. (3a)
Here the two key elements are forethought to prevention and the process of recovery/
resumption of business – both are essential components partners in building, maintaining
and sustaining capability at a technical and business services level (we understand the
risks, decrease the risks, and manage the risks). Only at this point can we, through a
fine balance of money and persistent capability, be confident in our ongoing DR planning
(DRP).
Disaster Recovery Plans (DRP)
Disaster recovery is divided into two distinct processes:
a) IT recovery planning or IT system recovery planning
b) business continuity planning – business and IT risk assessment, mitigation
planning, both manual, automated, physical and logical. This is a overarching
feeder to a) in terms of where a bulk of the focus will be for IT disaster plans,
based upon known business imperatives (ie. we only doing what is relevant to the
business and its overarching strategy).
For simplicity sake, we will use the acronym DRP to encompass a). Although important,
b) will not be covered any further in this ebook.
The focus of DRP is in the “recovery of the essential [IT] functions and [IT] systems of an
organization”, and “emphasizes recovery within the shortest possible time” (51). The
DRP provides the road-map that details the actions performed before, during and after a
disaster. The plan(s) are a comprehensive set of statements that address any IT disaster
that could damage the business and its [core business] services. (51)
The process of planning is an iterative one, base upon:
a) efficiency : doing the right thing at the right time, before, during and after a
disaster (speed, sustainability and thoroughness)
b) effectiveness : cost-effective resumption and business service recovery, effective
coordination of recovery (cost, coordination, end-game achieved)
c) [professional, legal] obligations, [formal] contractual commitments and
accountabilities
In order to effectively write and measure IT performance against SLA’s; or underpinning
contracts with external providers and operational level agreements (between your IT
sections, i.e. comms, prod support, in-house developers, help desk etc), the DRP is a
fundamental driver for defining the contracts and outlining areas of concern. The
commitment to high quality through legally (and financially) bound commitment ensures
efforts are made to honor them. (51)
Christopher Kempster
7
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The DRP documentation is context based, typically in one of three strategic views: (51)
1) Mitigation
What measures are in place to minimize the impact of identified disaster
scenarios.
2) Anticipation
What are the measures to respond to and recovery from a disaster.
3) Preventative
What measures are in place to prevent disasters from happening? This includes
problem and known error management.
Baselining your existing environment to secure and manage business and IT
dependencies in which to forge prevention strategies.
Our disaster plan “table of contents”, its ownership and iterative management is very
much based on the document’s strategic view. Be aware that DRP documents need to
be:
•
Prescriptive;
•
Simple to follow; and
•
Fact orientated.
to be an effective working document. This may require professional (third party)
assistance.
The process of DRP definition can be broken down as: (52)
Initiate
Maintain
Analysis
Test
Create
Initiate - form team, identify scope, resources required, timeline, stakeholders, budget
and management buy-in. Link the DRP’s statement of work to existing initiatives and
most importantly to the business continuity requirements. The identification of
overarching strategic view is required.
IMPORTANT – The DBAs may need to drive the process if nothing is currently in place
or is not actively persued by management. The process of drafting the first DRP
document may be the process initiator.
Analysis – requirements gathering, scope item drill through, build activity list, pass
through concerns and highlight issues, priorities and set deliverables.
Christopher Kempster
8
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Create – create plan, document all processes/procedures/steps required to meet stated
scope and activities from the analysis and initiation phases.
Test (iterative) – evaluate and walkthrough DRP, of key importance is the relevancy or
effectiveness for the stated objective. The planned should be appropriate for the reader,
simple to implement and care taken with the workflow of steps, identifying contact points
and highlighting weaknesses as early as possible. Test plans are retained for audit, and
to assist with managed re-iteration.
Maintain (iterative) – ongoing plan maintenance, review and active ownership; measures
should be applied at this stage to ensure the plan is persisted. Assign group
responsibility and accountability.
Avoid merging DRP documents into one or two overarching papers for the entire IT shop,
or for all databases. I highly recommend dividing them based on the context in which it
is written. The plans should be key part of the Intranet website (secured appropriately
of course), versioned and burnt to CD. There is little point in planning unless the results
are documented and made available.
DRP for SQL Server Databases
Depending on the site the DBA may be more or less prescriptive with the steps taken to
restore a service (i.e. list all steps for restoring the master db for example), this may be
based on in-house expertise, team size and site attendance.
Based on our discussion of strategy and the iterative approach to DRP definition, the DBA
needs to consider:
•
•
Impact on system users if the database is not available
o
The DBA needs to understand the user and business impacts of the
database not being available, both for read/write and read-only. You need
to be somewhat pragmatic with the choices made to keep the system
available, and be sure the business users are heavily involved; a 24x7
system with 1hr maximum downtime may consider a one day loss of data
as an acceptable compromise for example; a online shopping system may
not.
o
Communication plan – who is contacted and when? how? apart from
your technical staff does the communication plan encompass business
users?
Storage of installation disks, associated physical media and license keys
o
Physical access (lockdown and security procedures) and storage of SQL
Server installation media, especially license keys
o
Third party utilities must be considered
o
OS installation disks and license keys
o
How the change management process ensures media is updated (in the
right areas and in a timely fashine)
Christopher Kempster
9
S Q L
•
•
•
•
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Restoration
o
Can we restore in time to meet SLA’s? what can we do to achieve them?
The cost of trying to do so (even at the risk of human error due to
complexities involved) and do we need to revisit the SLA?
o
Recovery scenarios (server, full instance and binaries, databases, tables,
replication, full text indexes, OLAP cubes)
o
User account/login details (consider essential OS and domain level logins,
DBMS service accounts, dialup procedures and access rights and software
required etc)
o
Access to backup tapes, time to restore and responsibilities, re-call of tape
procedure (the cost and signatories to receive media)
o
Processes for dealing with corrupt backups, missing tapes (or overwritten
ones) and/or database files
o
Process for system database restoration
o
Checkpoints before recovery will begin
Staff capability and availability
o
Key staff contact and escalation list, phone numbers (and physical phones
- never use private phones for business work)
o
Microsoft Support contact numbers and keys/credit information
o
New training requirements based on proposed HW/SW selection or base
capability to date
o
External vendor support and underpinning contracts for DBA expertise
o
Reference books/manuals and how-to’s
o
Dialup/remote access procedures (includes after hours system access,
taxi/resource expense claims, minimum hardware required for remote
access, what staff “cant” do whilst on call).
Inter-system dependencies and distributed transactions or replicas
o
Dependencies to other business components, such as web servers, middle
tier, distributed systems, especially where transactions span time and
service.
o
Startup order, processing sequence of events (ie. data resend or
replication re-publishing steps etc). This is very important in sites using
replication where the time taken to restore such services and re-push or
pull replicas may be significant.
Backups
Christopher Kempster
10
S Q L
•
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
o
Backup file access and file retention periods, both tape and on-disk
o
Speed of accessing backups, simplicity of? Require others to intervene?
o
Full backup cycle, including regular system database backups
o
Verify backups. Test restore procedures and measure to ensure this is
occurring
o
Combinations of Full, Differential and Log backups
o
Log shipping – including the security and compression/encryption of log
shipped files and the complexity this may bring
o
System dependencies that will affect the backup, namely the Windows
registry, OS binaries (system state) etc.
Database hooks, associated modules and links
o
Installed extended stored procedures
o
Database links and their usage/security/properties
o
Full text catalogs
•
Hardware and Software Spares
•
Change Management Procedures
•
Audit of existing environment
•
Fail-safe tasks – I recommend the following at a minimum
o
Full db script monthly
o
Check for DB corruption daily (when possible – dbcc checkdb)
o
SQL Diagnostic (sqldiag.exe) dump daily to assist with debugging major
system crashes
o
Maintenance of global instance and database parameters (configuration
and initialization settings, trace flags, startup stored procedures, database
properties and file locations etc)
With these and others, the DBA is well on track to provide a solid framework in which to
base DRP; that being database and associated service recovery in a efficient and effective
manner.
Example - Disaster Recovery Planning
It will be rare that your existing company has no DR plans in some form that you can
leverage and build upon – so my advise is go and look for it. It is important that you
blend in with the initiatives of other team members and that of management to gain
Christopher Kempster
11
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
support in the time you will spend writing and maintaining them (which can be
significant).
The DR documentation may be similar to the organizational chart, where all management
and exective members are signatories to, and part of the communication of service based
recovery plans. I say service based in that the databases you manage from day to day
support core applications and delivery critical services to the business in which you are a
part of.
The diagram below provides an example of the DR documentation produced for an
organization, and its context in terms of the services it applies to:
Master Disaster
Recovery Plan
Corporate
App.System Plan
DBA – Database
Recovery Plan
AP – Application
Recovery Plan
a) “Crisis and Disaster Management” document contents
a. Provides general guidance for management of a disaster.
b. Defines the roles and responsibilities associated with the management of a
crisis. It is not unusual to have three core roles - crisis manager,
communications manager, recovery manager and the finance/purchasing
manager.
Christopher Kempster
12
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Crisis
Manager
Vendors
Purchasing
& Finance
Recovery
Manager
Recovery Teams
Operations
App Support
Vendors
etc
Comms
Manager
External
Firms /
Contractors
Help
Desk
Purchasing
& Finance
Company
Management
Disaster
Coordinator
Legal Reps
Board/
Directors
Media
Coordinator
Media
Public
Users
c. Communication initiation “sequence of events” and associated flow-charts,
including:
i. Initial Notification
ii. Ongoing Updates
iii. Communication Method(s)
iv. Logging of communications and time based events
v. Communication Milestones (dependencies) – this will include the
when, responsibility and action information.
d. Reference to the “Crisis and Disaster Contact Details” document and its
use and maintenance.
e. Crisis Management section that defines
i. When a crisis is declared (pre-conditions)
ii. Crisis Management coordination process(es) – includes the use of
a central communications center, crisis meetings, record keeping,
involvement of the business, crisis closure
iii. Disaster Management coordination process(es) – escalation to a
disaster (triggers), disaster management center (where?,
staffing?, point of contact?, notifications, record keeping, requests
for resources, public/media questions)
iv. Service Restoration Prioirity List – list of core services (ie. IT
applications/services)
v. Release of Funds
vi. Templates for
Christopher Kempster
13
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
1. Crisis and Disaster Review Meetings
2. Actions Lists (notifications/escalations)
3. Contact Lists
4. Sample email and SMS messages
5. Broadcast messages
6. Activity Logs
7. Crisis and Disaster Declaration Memo’s
b) “Crisis and Disaster Contact List” document contents
a. Simple tabular form divided into section, representative of the contacts
“role”, for example management, external partners, help desk/others
b. Includes confidentiality notices and reference to the above plan on its use
c) “Backup and Disaster Recovery Testing” document contents
a. This document is an overarching statement of work that spells out the
process of backup and disaster recovery testing. The document lays out
the ground rules and what is expected by all parties identified as
responsible and accountable for the application. The document will
include schedules for annual/monthly tests, including signoff forms and
registers.
b. Specifically, the document should include the following content items:
i. Definition of Application class levels and their frequency of disaster
recovery testing
ii. List of core applications and their business priority and the class of
application
iii. Description of the disaster recovery testing cycle (iterative cycle
consisting of walk-though, simulation testing, parallel testing and
full interpretation testing (running prod on DR machines).
iv. Detailed summary and flow charts of the implementation of a
disaster recovery test. Including references to template
documentation, staff contacts etc.
Christopher Kempster
14
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
v. Backup test procedures – basic summary of what a backup is,
what should be considered when testing a backup.
d) “[AppName] – Disaster Recovery Plan” document contents
a. This document is based upon a template from the master recovery plan
and is used for each and every core service. Typical content items
include:
i. Introduction, scope and audience
ii. Recovery strategy – including a summary of the availability times
(from SLA if you have one), invocation (who is authorized to),
guidance as to how to initiate and control the situation, system
dependencies (system, doc reference, contact), recovery team
(name, title, contact), how to request additional resources,
recovery team checklist (ie. confirmed invocation?, established
recovery team?, arranged for backup/SW media? etc..)
iii. Recovery procedure – Infrastrucure (locations, media), Data
Recovery (OS, file systems, databases), Application Recovery
(interfaces, user interface), Assumptions/Risks, Referring low level
documentation (see next).
e) “[AppName] - Setup and Configuration” document contents
a. This document provides step by step instructions for complete reinstallation of all components making up the service. The document
should NOT refer to lengthly installation sheets from vendors where
possible, but if so, it needs to be well clarified with environment specific
notes.
b. In writing the document, consider colour coding based on responsibility
(sys admin, DBA, help desk) and function (web server, database, middle
tier etc). The document should be executed serially where possible.
c. Based on the Master Recovery Plan, this document will include the
communication and escalation paths in a flow chart format. Contact
details are also included which are specific to the application being
delivered.
f)
“[AppName] - [DBA] - Disaster Recovery Plan” document contents
a. Your specific database backup plan may be part of a wider (enterprise)
based backup and restore strategy for all corporate databases. A classic
example is backups driven via centrally managed backup software, where
the process for restore is the same no matter the underling DBMS (to
some degree).
b. The experitise of DBA’s may dictate the prescriptive nature of this
document; for example, will you describe at length the process for
restoring the system databases? Consider this when developing the
contents, for example:
Christopher Kempster
15
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
i. Backup schedule
1. Types of backups taken and their retention periods, for
example, you may do a nightly full, but also mention a full
monthly that is retained for 6 months.
2. Backups start when and normally run for how long?
(include the reasoning behind the times chosen and if any
other job may impact the schedule)
3. special conditions apply? ie. is there any reason why the
schedule will differ for a specific part of the month or year?
4. Standard backup file retention period
5. How the backups are performed (written to disk first then
taken to tape?, log shipped? Etc)
ii. Backup Maintenance
1. Monitoring of backups
2. Archival of older backups
3. Backup testing
4. Assumptions and risks of testing
iii. Recovery process
1. Initiation and Communication Procedures (is a timely
reminder of the overarching process that must be followed)
2. Media and Passwords
3. Requesting File Restoration
4. Database and Instance Configuration
a. Server level properties (applicable to the DBMS)
b. Instance level properties
c. Database level properties
d. Replication Configuration
e. Full Text Indexing
f.
Logins and Users (including their database security
properties)
g. DTS Packages and their Job schedules
Christopher Kempster
16
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
5. Order of Recovery
6. System Interface Recovery Procedures
7. Database Recovery
a. Pre-Conditions (recovery of media etc)
b. Recovery Senarions (may include a wide variety of
senarions, from system databases, suspect
databases, lost DTS jobs, moving to the DR server
etc).
c. Post-Conditions (including steps to be taken if
partial recovery was only possible)
Frameworks for IT Service Management
What I discuss throughout this book is very much technical; covering the how and why of
backup and recovery at the DBMS. At a higher level, this should simply be part of a
Corporate and IT Governance framework that actively translates business objectives to IT
objectives through a common language, roles/responsibilities, accountabilities, and help
drive the same strategic goals for the business.
This section will provide a very short summary of frameworks in relation to IT service
management processes.
I cannot stress enough the importance of such frameworks within your organization.
Later in this book I discuss a customised version of change management for a small
applications development group, but many governance models take this much further in
terms of a complete solution for service management and delivery.
CoBIT (Control Objectives for Best IT Practices)
CoBIT is an open standard outlining good practice for the management of IT processes,
and most of which is free to download (www.isaca.org). The “ISACA and its affiliated IT
Governance Institute lead the information technology control community and serve its
practitioners by providing the elements needed by IT professionals in an ever-changing
worldwide environment.” (4)
The key items of focus in terms of DR are found under the Delivery and Support control
objective (aka Domain):
a) Manage Changes – outlines the process of change, requests for, SW release
policies, maintenance and documentation etc, all essential components that can
assist in further DR planning.
b) Ensure Continuous Service – the establishment of a continuity framework with
business process owners.
c) Manage third party services – providers of third party services are controlled,
documented and interfaces managed. This encompasses continuity of service
risks.
Christopher Kempster
17
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
d) Educate and train users
e) Manage problems and incidents
f)
Ensure system security
The reader should download and read the Framework documentation related to Delivery
and Support as we have only touched a small number of processes.
NOTE – Many (if not all) of the COBIT processes map 1:1 to the ITIL framework
discussed next.
ITIL (Information Infrastructure Library)
ITIL has developed into a defacto world standard for IT Service Management from its
beginnings in the late 1980’s by the British CCTA (Central Computer &
Telecommunications Agency – now called the Office of Government Commerce). From
its original library of some 32 books, the latest revision (2000/2001) sees a complete
restructure down to two core condensed volumes, concerning itself with the delivery and
support of IT services appropriate to the requirements of the business.
The framework itself provides proven methods for the planning of common processes,
roles and activities and their inter-relationships (communication lines). More importantly,
the framework (like others) is goal orientated around modules, so each process can be
used on its own or part of a larger model.
In terms of DR within the ITIL framework (www.itil.co.uk), both the service delivery and
service support sides provide complementary processes for the delivery of IT services to
the business:
Christopher Kempster
18
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
Operational Level
(Service Support)
&
T R O U B L E S H O O T I N G
Tactical Level
(Service Delivery)
Incident
Management
Service Level
Management
Problem
Management
Availability
Management
Configuration
Management
Change
Management
Release
Management
Capacity
Management
CMDB
Financial
Management
Continuity
Management
Service Desk
Some of these are:
a) Availability Management – deals with and guarantees the demands of systems
availability. It is focused on the reliability and flexibility of operational systems,
not only from internal staff with hard/soft problems, but includes contractual
stipulations by suppliers.
b) IT Service Continuity – also known as contingency planning manages all
information required to recover an IT service. It notes the importance of a
business and IT focuses to continuity management and that both part of the same
fabric. Through risk analysis, assessment and measurement, it will stipulate the
how and when of the recovery cycle in terms of real business need.
c) Configuration Management – register of configurable items and their relationships
(not just an IT asset register) within a database known as the CMDB. This
provides the fundamental basis for other processes, with the registration of not
only hardware and software, but SLA’s, known errors and incidents etc. The key
is relationship management to drive corporate repository of knowledge to assist
all key ITIL processes in some form.
d) Release Management – manages the planned and applied changes to components
in the IT infrastructure.
e) Problem Management – deals with the root causes of disruptions to IT services.
The process attempts to distinguish, recognize, research and rectify issues with
the aim to minimizing recurrence of such problems.
Christopher Kempster
19
S Q L
f)
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Incident Management – first line support processes/applications in place for
customers where they experience problems with IT services.
g) Change Management – is accountable for all service changes within the IT
environment. It is driven via a formal set of steps and management processes to
manage change and coordinate the deployment of change with release
management; updating the CMDB along the way. The change management
processes are driven via RFC’s (requests for change) and typically a CAB meeting
to track, accept and evaluate proposed changes. Forward schedules of change
clearly define the proposed release dates and keep all parties well informed.
All of the processes naturally encompass the daily working practices of any IT shop, no
matter the size, and ITIL can be effectively adapted from the guiding principles it
provides. Remember this is a service management system of core processes to assist in
aligning IT to the business, and it is far from being a technical or prescriptive how-to for
IT management.
Microsoft Enterprise Services Framework (ESF)
There are three components to the cyclic ESF framework:
1) Prepare – Microsoft Readiness Framework (MRF)
2) Plan and Build – Microsoft Solutions Framework (MSF)
3) Manage – Microsoft Operations Framework (MOF)
The MOF part of ESF can may be regarded as an extension to ITIL in terms of distributed
IT environments and the latest IT trends (web transactional based systems etc). In
practice, it is a Microsoft implementation around Microsoft technologies.
The MOF has two core elements:
a) Team Model – describes in detail how to structure operations teams, the key
activities, tasks and skills of each of the role functions, and what guiding
principles top uphold in running a Microsoft platform.
b) Process Model – Is based around four basic concepts
a. IT service management has a life cycle
b. The cycle has logical phases that run concurrently
c. Operational reviews are release and time based
d. IT service management touches all aspects of the enterprise
With that in mind, the process model has four integrated phases: changing,
operating, supporting, optimizing, and all forming a spiral life cycle. Each phase
follows with a review milestone tailored to measure the effectiveness of
proceeding phases.
The diagram below shows the high level roles and four process phases within MOF:
Christopher Kempster
20
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Illustration:MOF Process Model and Team Model, Roles and Process Phases,
http://www.serview.de/content/english/itsm/4mof/7abbildung/view
Balanced Scorecard
Although not a service delivery framework, the balanced scorecard
(www.balancedscorecard.org) is a measurement-based management approach that
works on the idea that “all business processes should be part of a measurement system
with feedback loops”. (12) The system takes into consideration both strategic and
technical plans that are deployed along with a measurement system; more importantly,
this is a continuous cycle that is “aimed at continuous improvement and continuous
adjustment of strategy to new business conditions” (12).
It should be noted that the balanced scorecard is a corporate “strategy into action” tool
rather than an IT Governance framework (please be aware that I have used “strategy
into action” very loosely, it is much more than simply this). Such a strategy is a key
element in which governance models can reside and is well worth understanding at a
high level.
Service Level Metrics
In order to improve you need to something to measure against. Simply we know, but
rarely done in many fields of business, including IT. This section covers the scale of nines
as one of the many forms of measurement, primarily used in service level agreements to
define a level of system availability in its most simplisitic form.
The Scale of Nines
Many service level availability measures talk in terms of the “nines”, as the table below
shows:
Percentage
Downtime/Year
100
99.9999
99.999
99.99
None.
<= 30 secs
<= 5.2m
<= 52.22m
Christopher Kempster
21
S Q L
99.9
99.0
90.0
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
<= 8hrs 46m
<= 87hrs 36m
<= 36days 12hrs
The five and six nines are a formidable and complex requirement for equipment vendors
to deliver (and therefore they ask a premium price), and even more so within your
organization. There are no hard and fast rules simply to say the higher the nines the
more costly the solution, both in raw capital and operationally. Generally speaking,
select the rating that represents the comfort level the organization (culturally,
economically, politically) – be reminded that it is a predictive measure and not a hard and
fast rule as its mathematical calculation in even the simplest environment is absurdly
complicated. (38)
For the SLA, the measurement is outside the scope of scheduled downtime or commonly
known as a change window. The window must be relatively flexible in terms of its size to
encompass large changes, but a fixed maximum period may be unavoidable. In order for
this to occur, management must revisit current change practices, underpinning contrafts
with external suppliers and operational (internal) contracts between business entities.
Other availability metrics
Who you are establishing a service level with will ultimately determine the technical
detail, or lack of, in terms of the availability measures we use.
For example, if we are establishing service levels between an IT shop and an external
data carrier for your privately connected data centers, then availability metrics based
upon packet loss, allocation errors, minimum transfer speeds, are effective measures. If
the IT shop is dealing with the application owners using the data center services, then
these metrics mean (and measure) nothing of any value and will not be able to be
related to the overall experience of service.
Generally speaking there is no one definitive measure that can be applied to any one
service, client or business. The choice of a metric depends upon the nature of the service
and the technical sophistication of the users. (39).
All said, there are some common formulas and definitions, the value of which is tough to
crack and more importantly, must be justified and documented if the final figures are
challenged. They are:
%Availability = (MTBF / (MTBF + MTTR)) * 100
- or %Availability = (Units_of_time – downtime) / total_units_of_time
- where MTBF = mean time between failures
MTTR = mean time to recover
Be aware that availability metrics are very different to latency / response time metrics, or
throughput or capacity metrics, let alone utilization metrics. Be warned that these types
of metrics require the utmost confidence in terms of measurement and how they pan out
for ALL users of the service.
Christopher Kempster
22
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Remember that availability is purely “how much time a system is available for normal
operation”, be that a fixed figure or one that varies throughout the SLA term. Where
possible, utilize past statistics, trial availability measures and orientate the SLA to whom
you are dealing with.
NOTE – Without effective IT service measures in place, never attempt a charge
back model.
What is achievable with SQL Server?
In order to achieve anything more than 99.99% uptime outside of a standard change
window for the DBMS, the DBA may should consider the following:
Percentage
Downtime/Year
Considerations
100
99.9999
None.
<= 30 secs
99.999
<= 5.2m
99.99
<= 52.22m
Impossible. Possible in a perfect world with no change.
Improbable. In a highly redundant environment using
Microsoft clustering or a third party product the system will
always fault for a short period of time (in the order of 30sec to
one minute). The key here is the services around the DBMS
and eliminating all single points of failure. Change
management and access to the servers is critically important.
Such a system cannot test “live failovers” unless it is part of
the change widow, but is extremely risky.
Possible. With multiple redundant services in play. There is
not time for inline hardware replacement during an
emergency.
Possible and easily sustained (at a price$). Hardware spares
must be easily available if we choose not to cover all single
points of failure. Reboots of hardware are not possible in most
cases.
Responsibility vs. Accountability
When establishing any plan it is of utmost importance to not only define a persons
“role(s)”, but clearly identify it in terms of responsibility and accountability.
A responsibility is a basic requirement when performing an activity, i.e. when there is
something we are required to do (13). For example, a DBA is responsible for making and
validating backups of the database to facilitate complete recovery to a point in time.
An accountability stems from actions we (or others we are managing as a Senior DBA) do
or don’t take, regardless of the whether they are our direct responsibility or not. Simply
put, we are answerable for actions and their results. (13) Clearly identifying them is
difficult, but extremely important as a measure of service delivery and professionalism.
One interesting flow on topic is that of authority; “if you make someone responsible but
do not give them authority, can they be held accountable”? (14). If you look at this
pragmatically the point of writing down, and agreeing upon tasks that are in effect
promises tends to require a level of authority for these tasks. Management need to
ensure this remains in focus and does not fragment into the realms of shared
accountability to a point where being accountable is no different from having
responsibility.
It is critically important for business continuity, disaster planning and systems recovery
that time is taken to identify responsibilities and those accountable for the actions taken.
Christopher Kempster
23
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The assignment of accountability and responsibility builds upon the fabric of process,
procedure and control as without it, no one will be answerable to actions taken (or not as
it seems in many cases) and can be a disasterous situation for the business.
NOTE – A classic case from ITIL with the terminology applied is that of change and
release management – the change manager is accountable for all changes within
the IT environment, the release manager is responsible for making and
communicating the change. At all points in times the final outcome of the change
in production rests with the change manager.
Having a shared, global understanding of these terms is an important step forward in the
allocation and measurement of work that forms the hygiene factors of any business. This
is especially the case when dealing with disaster and change management.
Building Staff Capability
Consider an Emergency Response Team (ERT)
An emergency response team (ER for IT or your dedicated production support team and
signatory body and owners of all disaster recovery plans) will:
a) verify (testing) backups and associated recovery procedure checklists
b) assist customers and management in recognising risks and steps (and costs) to
mitigate them
c) respond to, manage, and coordinate emergency recovery procedures
d) ensure staff capability training policies are in place to better facilitate systems
recovery, especially as services change over time, be they new technologies or
upgrades ones.
e) attend change management meetings and be well advised of new system
development initiatives or purchases/evaluations
f)
be actively involved in business continuity planning; to ensure staff have a solid
understanding of the procedures in place, and what manual procedures need to
be followed if system downtime is in the order or hours or days.
As a very basic example, I worked in a small development team (25 staff in total) for a
Government Department. The business unit was responsible for all business systems
development and subsequently included some core business applications. The ER-team
was formed based upon the following:
Christopher Kempster
24
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Overarching
plan
Lead
Developer C
Manager
(Accountable)
Team Help
Desk
Lead
Developer B
Lead
Developer A
Coordinate
customer
communications
and impact on
other services
Direct customer
communications via
Dev.Manager and
business continunity
procedure initiation
DR-documentation and Systems
Recovery Procedures
& Communication plans
Customers
Apps’
Coordinate
activities of
network and
server recovery
and problem
determination
Database
Administrator
(Responsible)
Service Desk
External
Vendor
Support
Server/Network
Administrators
DBMS
Business
Continunity
Procedures
This sort of model will differ based on the underling IT governance model your business is
pursuing, its culture and political boundaries, and of course budgetary constraints. That
said, the driver here is the coordination of team members via a strict set of recovery
processes, with the responsibilities defined and documentation in place to monitor,
measure and coordinate actions during an emergency.
DBA Taining and Skills (building ERT expertise)
In terms of database administration roles, I divide them into the following streams based
upon different skill sets and IT focuses that of course mean a different style of training
and self improvement (we do not cover mixed roles, namely Developer/DBA etc.):
DBA stream
Skill requirements
Training plan
Production
Support DBA
• Highly skilled pure DBA
with expert knowledge
of all facets of the
DBMS.
• Has little involvement
with developers apart
from tuning on
request.
• Provide expert advice
and skills for system
upgrades, replication,
advanced SQL and
DBMS features.
• Expert in maintaining
multiple, large and
small scale databases
systems in a
production
The production support DBA is a
specialist role. The DBA is typically
found in large data centers, ISP’s or
business with numerous mission
critical databases that rely on a
fulltime production presence.
Christopher Kempster
The DBA must focus on certification
and the key driver for ongoing skills
development, along with seminars
and short term training courses
relevant to the technologies planned
or being implemented.
The DBA must have a solid grasp of
recovery and high availability
scenarios; as such, time must be
given to sustain these skills.
25
Differentiating
yourself
This role requires the
DBA to cross skill in
Oracle or DB2 at an
absolute minimum
with certification.
Consider future roles
such as Chief DBA,
Operations Manager
and beyond.
S Q L
Application
Development DBA
Christopher Kempster
S E R V E R
B A C K U P , R E C O V E R Y
environment.
• Expert in database and
systems recovery
scenarios.
• Highly skilled at
“thinking outside the
box”
• Applying systems
recovery calming and
methodically.
• 24x7 support is often
required.
• Highly skilled in
writing, tuning and
passing on expert SQL
and DBMS design
knowledge to
developers.
• Highly skilled in logical
and physical database
modeling, including
classic patterns,
(de)normalization,
modeling tools
• Advanced DTS
• Good understanding of
the implications and
development
requirements or issues
of using replication,
clustering, XML in the
DB, blob data storage,
large database design
etc.
• OLAP management and
good MDX skills
• Average system
administration skills,
including the OS, IIS,
FTP, encryption, SSL
• Database performance
tuning.
• Skilled at
Backup/Recovery
(typically due to the
fact that developers
require numerous
copies of databases)
• Server performance
management,
marrying up figures to
the underlying DBMS
• Expert in profiler, user
and DB tracing,
especially blocking,
locking and deadlocks
• Has a good
understanding of the
SQL Server engine, but
is a little rough in
some areas due to the
wide range of skills
required
• Can tend to be a little
on the “cowboy” DBA
side and care must be
&
T R O U B L E S H O O T I N G
Consider jobs that encompass a wide
range of databases vendors and
numerous production instances or
where uptime is critical and achieved
through enterprise-class hardware
and software features.
To remain effective in this role the
DBA needs to thoroughly embrace
and cross skill in the languages and
development technologies in play
against the DBMS – but at the same
time not becoming part of the
development team and locking you in
as a “Developer/DBA” which is a very
different role. That said, back-end
development in T-SQL etc, is a core
requisite, include complex DTS builds
etc. These skills should be
continually developed; don’t alienate
yourself from the development team.
The DBA is asked frequently about
indexing, fragmentation
management, and
moving/exporting/importing/restoring
databases throughout the day. More
importantly, the DBA must keep on
top of any new DBMS feature and
determining the costs/benefits and
issues with its use and
implementation for the sake of the
team and its agility. Major decisions
will be made off the DBA’s
recommendations, research skills and
ability to sell and pursue ideas are
important.
The DBA should
really take a team
leadership role where
possible; bringing
the team together
and driving the
importance of
standards,
procedure, change
management, DBMS
design and SQL
improvements etc.
Consider running
Special Interest
Group sessions
during lunch times to
drive this goal.
Keep highly
informed, it is one
thing understanding
the technology, but
apply critique,
cost/benefit analysis
backed by the
wisdom of yourself,
others and research
is the magic value
add. Strive for this in
the role.
Consider IT
consulting courses
over certification.
26
S Q L
•
Applications DBA
•
•
•
•
Christopher Kempster
S E R V E R
B A C K U P , R E C O V E R Y
taken to pull them into
line to follow process
and procedures.
Regarded as a “Jack of
all trades”.
Good DBA skills, solid
daily administration,
SQL tuning, profiling
and tracing
Good understanding of
OLAP, DTS, MSDTC,
XML, TSQL etc
Good to Expert
knowledge of two or
more core vendor
applications (Microsoft,
SAP, Oracle etc),
especially for
application
customization and
extension
Advanced TSQL, DTS
skills. May include 3rd
party lanuage and
excellent report writing
skills.
&
T R O U B L E S H O O T I N G
The applications DBA is a skilled DBA
role with specialist knowledge of a
enterprise class application, such as
SAP over SQL Server for example.
Apart from a thorough understand of
the underling database structures,
the DBA has expert knowledge of
deployment, setup, and
administration of the application over
the chosen DBMS platform. Training
should be clearly orientated around
these skills and maintaining them. At
the same time, looking at vendor
hooks for adhoc reporting and
application extension should be
considered and make part of the
persons work plan.
27
Consider enterprise
class application
only, namely SAP,
CRM, Portal, BizTalk
and other Integration
technologies, Oracle
Applications etc.
Specialist skills in
such products are
highly sought after,
but watch the
market carefully;
especially your local
one and adapt
accordingly.
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
2
Chapter
Change Control
T
he need for a managed change control procedure is a fundamental requirement for
any IT department. In terms of disaster recovery, it allows the business to analyse
the risk a change will have on business as usual, and clealy spells out the pre and
post tasks to be performaned when applying a change.
The idea here is managed change to reduce human error and impact on the business.
This chapter will the policies and procedures of an example change management system,
and detail the use of Microsoft Visual Source safe for source code management.
Managing Change Control by Example
This section will discuss the processes I used from day to day for change management in
a relatively large development. We will cover:
1. formalizing the process
a. document
b. agree upon and prepare the environment
c. build and maintain list of definitive software and server install audit log
d. management support
2. database script management
3. developer security privileges in extreme programming environments
4. going live with change
5. managing ad-hoc (hot fix) changes
Environment Overview
Christopher Kempster
28
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
With any serious, mission critical applications development, we should always have three
to five core environments in which the team is operating. They include:
1. Development
a. rarely the environment (database) is rebuilt from production. Its servers
are generally busy and reflects any number of pending change controls,
some of which never get to test and others go all the way through to
production.
2. Test
a. refreshed from production of a regular basis and in sync with a “batch” of
change controls that are going to production within a defined change
control window.
b. ongoing user acceptance testing
c. database security privileges reflect what will (or is) in production
3. Production Support (optional, some regard as Test) / Maintenace
a. mirror of production at a point in time for user testing and the testing of
fixes or debugging of critical problems rather than working in production.
4. Pre-production or Compile Server (optional)
a. a copy of production as of “now”
b. used when “compiling code” into production and the final pre-testing of
production changes
c. locked down image to ensure maximum compatibility on go live
5. Production
The cycle of change is shown in the diagram below through some of these servers:
Christopher Kempster
29
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The whole change management system, be it in-house built or a third party product has
seen a distinct shift to the whole CRM (relationship management) experience, tying in a
variety of processes to form (where possible) this:
Christopher Kempster
30
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
This ties in a variety of policy and procedures to provide end-to-end service delivery for
the customer. The “IR (incident record) database” shown does not quite get meet all
requirements, but covers resource planning, IR and task management, and subsequent
change window planning. With good policy and practice, paper based documentation of
server configuration and application components will assist in other areas of the service
delivery and maintenance.
See ITIL framework for complete coverage of the underling concepts presented in the
diagram above.
Pre-change window resource meeting
Every fortnight the team leaders, DBAs and the development manager discuss planned
and continuing work over the next two weeks. The existing team of 20 contract
programmers works on a variety of tasks, from new development projects extending
current application functionality (long term projects and mini projects) to standard bug
(incident request) fixing and system enhancements. All of this is tracked in a small SQL
Server database with an Access front end, known as the “IR (incident reporting)”
system.
The system tracks all new developments (3 month max cycle), mini projects (5-10 days),
long term projects (measured and managed in 3 month blocks) and other enhancements
and system bugs. This forms the heart and soul of the team in terms of task
management and task tracking. As such, it also drives the change control windows and
what of the tasks will be rolled into production each week (we have a scheduled
downtime of 2 hours each Wednesday for change controls).
The resource meeting identifies and deals with issues within the environments, tasks to
be completed or nearing completion, and the work schedule over the next two weeks.
The Manager will not dictate the content of the change window but guide resource and
task allocation issues. The team leaders and the development staff will allocate their
tasks to a change control window with a simple incrementing number representing the
Christopher Kempster
31
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
next change window. This number and associated change information in the IR database
is linked to a single report that the DBA will use to on Tuesday afternoon to “lock” the
change control away and use it to prepare for a production rollout.
Visual Source Safe (VSS)
The key item underpinning any development project is source control software. There is
a variety on the market but most sites I have visited to date use Microsoft VSS.
Personally, I dislike the product; with its outdated interface, lack of functionality and
unintuitive design, it’s something most tend to put up with (its better than nothing!).
Even so, a well managed and secured VSS database is critical to ongoing source
management.
Consider these items when using VSS:
•
Spend time looking around for better change manage front-ends that lever off the
VSS API / automation object model, if possible. Web-based applications that
allow remote development would be handy.
•
Consider separate root project folders for each environment
o
$/
development
test (unit test)
production
•
Understand what labeling and pinning mean in detail, along with the process f
sharing files and repining. These fundamentals are often ignored and people
simply make complete separate copies for each working folder or worse still, have
a single working folder for dev, test and production source code (i.e. 1 copy of the
source).
•
All developers should check in files before leaving for the day to ensure backups
cover all project files.
•
Take time to review the VSS security features and allocation permissions
accordingly.
•
If pinning, labeling, branching etc is too complex, get back to basics with either
three separate VSS databases covering development, test and production source
code, or even three project folders. Either way the development staff needs to be
disciplined in their approach to source control management.
•
Apply latest service packs
We will discuss VSS in depth later in the chapter.
Christopher Kempster
32
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Managing Servers
There are few development teams that I have come across that have their own server
administrators. It is also rare that the servers fall under any SOE or contractual
agreement in terms of their ongoing administration on the LAN and responsibility of the
IT department. As such, the DBA should take the lead and be responsible for all server
activities where possible, covering:
•
server backups – including a basic 20 tape cycle (daily full backups) and
associated audit log. Insist that tapes are taken off site and keep security in
mind.
•
software installed – the DBA should log all installations and de-installations of
software on the server. The process should be documented and proactively
tracked. This is essential for the future rollout of application components in
production and for server rebuilds.
•
licensing and terminal server administration
•
any changes to active-directory (where applicable)
•
user management and password expiration
•
administrator account access
On the Development and Test servers I allow Administrator access to all developers to
simplify the whole process. Before going live, security is locked down on the application
and its OS access to mimic production as best we can. If need be, we will contact the
companys systems administrators to review work done and recommend changes.
In terms of server specifications, aim for these at a minimum:
•
RAID-1, 0+1 or RAID-5 for all disks – I had 4 disks fail on my development and
test servers over a one year period. These servers really take a beating at times
and contractor downtime is expensive. I recommend:
o
2+ Gb RAM minimum with expansion to 4+ Gb
o
Dual PIII 900Mhz CPU box
Allowing administrative access to any server usually raises concerns, but in a managed
environment with strict adherence of responsibilities and procedure, this sort of flexibility
with staff is appreciated and works well with the team.
Development Server
The DBA maintains a “database change control form”, separate from the IR management
system and any other change management documentation. The form includes the three
core server environments (dev, test and prod) and associated areas for developers to
sign in order for generated scripts from dev to make their way between server
environments. This form is shown below:
Christopher Kempster
33
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
In terms of security and database source management, the developers are fully aware
of:
•
naming conventions for all stored procedures and views
•
the DBA is the only person to make any database change
•
database roles to be used by the application database components
•
DBO owns all objects
•
Database roles will be verified and re-checked before code is promoted to test
•
Developers are responsible for utilizing visual source safe for stored procedure
and view management
•
the DBA manages and is responsible for all aspects of database auditing via
triggers and their associated audit tables
•
production server administrators must be contacted when concerned with file
security (either the DBA if they have the responsibility or system administrators)
and associated proxy user accounts setup to run COM+ components, ftp access,
and security shares and to remove virtual directory connections via IIS used by
the application.
Christopher Kempster
34
S Q L
•
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
strict NTFS security privileges
With this in mind, I am quite lenient with the server and database environment, giving
the following privileges. Be aware that I am a change control nut and refuse to move
any code into production unless the above is adhered to and standard practices are met
throughout the server change cycle. There are no exceptions.
1. Server
a. Administrator access is given to all developers via terminal services to
manage any portion of the application
b. DBA is responsible for server backups to tape (including OS, file system
objects applicable to the application and the databases)
2. Database
a. ddl_admin access – to add, delete or alter stored procedures, views, and
user defined functions.
b. db_securityadmin access – to deny/revoke security as need be to their
stored procedures and views.
No user has db_owner or sysadmin access; DBA’s should be aware that developers may
logon to the server as administrator and use the built-in/administrator account to attain
sysadmin access. I do not lock it down, but make people fully aware of the
consequences (i.e. changes don’t go to production and may be promptly removed).
Database changes are scripted and the scripts stored in visual source safe. The form is
updated with the script and its run order or associated pre-post manual tasks to be
performed. To generate the scripts, I am relatively lazy. I alter all structures via the
diagrammer, generate the script, and alter those that can be better scripted. This
method (with good naming conventions) is simple and relatively fail-safe, and may I say,
very quickly. All scripts are stored in VSS.
The database is refreshed during “quite” times from production. This may only be a data
refreshed but when possible (based on the status of changes between servers), a full
database replacement from a production database backup is done. The timeline varies,
but on average a data refresh occurs every 3-5 months and a complete replacement
every 8-12 months.
Test Server
The test server database configuration in relation to security, user accounts, OS
privileges, database settings are close to production as we can get them. Even so, it’s
difficult to mimic the environment in its entirety as many production systems include web
farms, clusters, disk arrays etc that are too expensive to replicate in test.
Here the DBA will apply scripts generated from completed change control forms that alter
database structure, namely tables, triggers, schema bound views, full-text indexing, user
defined data types and changes in security (and which have already run successfully in
Christopher Kempster
35
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
development). The developers will ask the DBA to move up stored procedures and views
from development into test as need be to complete UAT (user acceptance testing).
The DBA will “refresh” the test server database on a regular basis from production. This
tends to coincide with a production change control window rollout. On completion of the
refresh, the DBA might need to re-apply database change control forms still “in test”.
All scripts are sourced from VSS.
Refreshing TEST from PRODUCTION
We will only dot point one of many possibilities from a database perspective, the process
can be very complex with large numbers of application components and runtime libraries.
•
Notify developers of your intention – check that important user or change testing
is not underway. The DBA doesn’t really want to synchronise the table data as it
can be an overly complex task in large database schemas (100+ tables for
example – my last DB had 550!)
•
Check free space on the test server to restore the database backup from
prodiction (backup file) and accommodate the expanded storage after the restore.
o
If the production databases are huge and the only free space is in
production, then consider restoring a recent copy of production as
“test_<prodname>” within the production instance, deleting/purging
appropriate records and shrinking before taking a backup of this database
over to test.
•
Restore the database into the test database instance as “new_<db-name>” (for
example), allowing the developers to continue using the existing test database.
•
Fix the database users to the logins (sp_change_user_login) as required – retain
existing default database
•
Notify developers that no further changes to DBMS structure will be accepted.
•
Use a scripting tool (SQL Compare from RedGate software is very good) to
compare the existing database structures. You may not take over all existing
changes. Go back over your change control documentation and changes raise
and marked as “in test” as these will be the key changes the developers will
expect to see. This process can take a full day to complete and you may have to
restore again if you get it wrong (very easy to do).
•
Email development staff notifying them of the cutover
•
Switch the databases by renaming them.
•
Check user and logins carefully, change the default database as required.
•
Fix full text indexes as required.
•
Fix any internal system parameter or control tables that may be referring to
production. Copy the data from the old test database as required.
Christopher Kempster
36
S Q L
•
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Notify developers that the database is available.
Production Support
The production support server box is similar to that of test, but is controlled by the
person who is packaging up the next production release of scripts and other source code
ready for production. This server is used for:
•
production support – restoring the production database to it at a point in time and
debugging critical application errors, or pre-running end of month/quarter jobs.
•
pre-production testing – final test before going live with code, especially handy
when we have many DLL’s with interdependencies and binary compatibilities
issues.
All database privileges are locked down, as is the server itself.
Production
The big question here is, “who has access to the production servers and databases?”.
Depending on your SLAs, this can be wide and varied, from all access to the development
team via internally managed processes all the way to having no idea where the servers
are let alone getting access to it. I will take the latter approach with some mention of
stricter access management.
If the development team has access, it’s typically under the guise of a network/server
administration team that oversee all servers, their SOE configuration and network
connectivity, OS/server security and more importantly, OS backups and virus scanning.
From here, the environment is “handed over” to the apps team for application
configuration, set-up, final testing and “go live”.
In this scenario, a single person within the development team should manage change
control in this environment. This tends to be the application architect or the DBA.
When rolling out changes into production:
a. application messages are shown (users notified)
b. web server is shutdown
c. MSDTC is stopped
d. Crystal reports and other batch routines scheduled to run are closed and/or
disabled during the upgrade
e. prepare staging area “c:\appbuild” to store incoming CC window files
f.
backup all components being replaced, “c:\appatches\<system>\YYYYMMDD”
a. I tend to include entire virtual directories (even if only 2 files are being
altered)
Christopher Kempster
37
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b. COM+ DLL’s are exported and the DLL itself is also copied just in case the
export is corrupt
g. full backup of the database is done if any scripts are being run
h. consider a system state backup and registry backup, emergency disks are a must
and should always be kept up to date.
Take care with service packs of any software (never bundle a application change with a
service pack). The change (upgrade or downgrade) of MDAC, and the slight changes in
system stored procedures and system catalogs with each SQL Server update, can grind
parts (or all) of your application to a halt.
Here is an example of an apppatches directory on the server we are about to apply a
application change to. The directory is created, and all files to be replaced are copied:
The DBA may choose to copy these files to tape or copy to another server before running
the upgrade. If the change was a virtual directory, I would copy the entire directory
rather than selective files, it simplifies backup process and avoids human error.
Hot Fixes
Unless you are running a mission critical system, there will always be minor system bugs
that result in hot fixes in production. The procedure is relatively simple but far from ideal
in critical systems.
a. Warn all core users of the downtime. Pre-empt with a summary of the errors
being caused and how to differentiate the error from other system messages.
b. If possible, re-test the hot fix on the support server
c. Bring down the application in an orderly fashion (e.g. web-server, component
services, sql-agent, database etc).
d. Backup all core components being replaced/altered
Database hot fixes, namely statements rolling back the last change window, are tricky.
Do not plan to disconnect users if possible. But careful testing is critical to prevent
having to do point in time recovery if this gets worse.
Christopher Kempster
38
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Finally, any hot fix should end with a ½ page summary of the reasons why the change
was made in the monthly production system report. Accountability is of key importance
in any environment.
Smarten up your applications (Autonomic Computing)
Autonomic computing “is an approach to self-managed computing systems with a
minimum of human interference” (IBM). In other words, self repairing, reporting,
managing systems that looks after the whole of the computing environment. So what
has this got to do with change management? everything actually.
The whole change management process is about customers and the service we provide
them as IT professionals. To assist in problem detection and ideally, resolution, system
architects of any application should consider either:
a. API for monitoring software to plug in error trapping/correcting capability
b. Application consists of single entry point for all system messages (errors, warning,
information) related to daily activity
c. The logging system is relatively fault tolerant itself, i.e. if it can not write
messages to a database it will try a file system or event log.
d. Where possible, pre-allocate range of codes with a knowledge base description,
resolution and rollback scenario if appropriate. Take care that the numbers
allocated don’t impose on sysmessages (and its ADO errors) and other OS related
error codes as you don’t want to skew the actual errors being returned.
A simplistic approach we have taken is shown below; it’s far from self healing but meets
some of the basic criteria so we can expand in the future:
It is not unusual for commercial applications to use web-services to securely connect to
the vendors support site for automatic patch management, error logging and self
Christopher Kempster
39
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
correction. This adds a further complexity for the system administrators in terms of
firewall holes and their ability to control the application.
MRAC of IR/Task Completion
This is going off track a little in terms of change control but I felt its worth sharing with
you. The MRAC (Manage, Resource, Approve, Complete) principle is a micro guide to
task management for mini projects and incident requests spanning other teams/people
over a short period of time. The idea here is to get developers who own the task to
engage in basic project management procedures. This not only assists in documenting
their desired outcome, but communicating this to others involved and engaging the
resources required to see the entire task through to its completion.
The process is simple enough as shown in the table below. The development manager
may request this task breakdown at any time based on the IR’s complexity. The
developer is expected to meet with the appropriate resources and drive the task and its
processes accordingly. This is not used in larger projects in which a skilled project
manager will take control and responsibility of the process.
Task or deliverable
Planned
Completion
Date
Managed
by
Resourced
to
Approved
by
Completed
by
Requirements
Design
Build
Test
Implement
Audit (optional)
The tasks of course will vary, but rarely sway from the standard requirements, design,
build, test, implement life-cycle. Some of the key definitions related to the process are
as follows:
Managed
Resourced
Accepted
Approved
Authorized
Variation
Each task or deliverable is managed by the person who is given the responsibility of ensuring
that it is completed
The person or persons who are to undertake a task or prepare a deliverable
The recorded decision that a product or part of a product has satisfied the requirements and
may be delivered to the Client or used in the next part of the process.
The recorded decision that the product or part of the product has satisfied the quality
standards.
The recorded decision that the record or product has been cleared for use or action.
A formal process for identifying changes to the Support Release or its deliverables and
ensuring appropriate control over variations to the Support Release scope, budget and
schedule. It may be associated with one or more Service Requests.
This simple but effective process allows developers and associated management to better
track change and its interdependencies throughout its lifecycle.
Summary
No matter the procedures and policies in place, you still need the commitment from
management. Accountability and strict adherence to the defined processes is critical to
avoid the nightmare of any project, that being source code versions that we can never
re-created, or a production environment in which we do not have the source code.
Christopher Kempster
40
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Failure to lay down the law with development staff (including the DBA) is a task easily
put in the too hard basket. It is not easy, but you need to start somewhere.
This section has presented a variety of ideas on the topic that may prompt you to take
further action.
Using VSS by Example - Part 1
This section is divided in multiple parts to introduce you to a VSS (Microsoft Visual Souce
Safe) framework that I have successfully used for a large applications development team.
It provides a working framework for source code management in Microsoft Visual Source
Safe. The framework presented support a system currently under support and
maintenance, as well as other development initiatives (mini projects) that may be adding
new functionality.
For those working with multi-client software in which “production source code” is at
different patch levels (and may include custom code), you will need to rework VSS to
adopt the strategy – namely due to multiple side-by-side releases with different custom
changes to the same product.
The article is scenario driven, starting with a very basic scenario. We then move to more
complex changes.
Terminology
CCM
Project
Branch
Share
Merge
Change Control Manager.
Is similar to a folder in explorer. It contains configuration items (files),
VSS will automatically version projects and files with an internal value.
Is synonymous to a copy in explorer, but VSS maintain links between
versions of branches to facilitate merging at some later stage. VSS via its
internal version numbering will maintain the “logical branch history” in
order to facilitate merging with any other branch.
A shared file is a “link” to its master, or in other terms, a shortcut. The
shared file will be automatically pinned (cannot change this action by
VSS); to alter it you must unpin it. If the shared file is altered its master
will also be changed, along with any other “shortcut” (share).
Process of merging the changes from two branched files. The VSS GUI will
show the hierarchies of branches and associated links/paths, broken
branches that can not be merged too, or branches from incompatible
parents (can merge the branches from two different trees!).
Build Phase – Moving to the new change control structure
The project folder layout of VSS is as follows:
Christopher Kempster
41
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
This structure maps to your equivalent development, test and server environments.
Source code for development and test environments is built from VSS production code
project (projects are shown as Windows explorer folders in VSS) and the subsequent
development/test project code applied over top (roll forward) to form the environment.
The developers need to manage themselves when there are multiple “versions” of a DLL
or other file source moving into test over time. Either way, the VSS environment allows
the full “build” of development or test servers from a known image of production source
code (which is critical):
The /production project folder includes the names of other applications currently under
the change control process. To start the process of change management using this
structure, we will be introducing a new application call “MYAPP”. The CCM will:
a. create a new project in /production call “myapp”
b. create sub-projects to hold myapps’s source code
c. label the MYAPP project as “MYAPP Initial Release”
d. arrange a time with the developer(s) and check-in source code into the projects
created
This will give the structure:
Christopher Kempster
42
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The production folder is “read only” for all but the change control manager (CCM).
First Change Control
All application project changes in the /production project “folder”, follow a change control
window path, as such, in the development project folder the CCM will:
a. create a new project in the development folder representing the change control
window (if none exist)
b. notify developers of VSS development project status
For example:
The MYAPP developer needs to alter his single ASP and COM files for this change control
window. The developer will need to:
a. Create a “MYAPP” project under the CC001 project in development
Expand the production source code project, navigate to MYAPP and the COM
Libraries project, then with a right click and drag the project to
/development/cc001/myapp and from the menu displayed, select share and
branch
Christopher Kempster
43
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Check the “recursive” check box if any sub-project folders are also required.
b. Do the same for Web Sites. Important – If there are multiple websites and you
only want selected projects, then manually create the same structure in dev then
use VSS to share the projects from there.
c. REVISE WHAT YOU HAVE DONE – ONLY SHARE/BRANCH THE FILES REQUIRED
FOR THE CHANGE CONTROL. IF YOU FORGET FILES OR REQUIRE OTHERS, THEN
REPEAT THIS PROCESS FROM THE SAME PRODUCTION SOURCE PROJECT.
ALWAYS KEEP THE SAME PROJECT FOLDER STRUCTURE AS IN THE PRODUCTION
PROJECT
d. If you make a mistake, delete your project and start again.
The above steps will leave us with the following project structure:
Christopher Kempster
44
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
To review where the original source came from in the production folder:
a. select a file
b. right click properties
c. select the paths tab
d. click links if the GUI is hard to read
We can now check in/out code as need be in the development project folder. The DEV
(development) server environment is then built (i.e. refreshed) from this source code in
VSS.
Moving Code to TEST
The CCM will:
a. create a CC001 project in the /test project “folder”
The developer(s) will:
Christopher Kempster
45
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b. remove any reference to “myapp” in the /test/cc001 project (if applicable)
c. expand the cc001/myapp project, select myapp then right click and drag to the
/test/cc001 project, selecting the share and branch option
d. Select “recursive” check box (as all code for MYAPP is going up as a single unit of
testing).
This will give us:
This scenario will assume all code will transition from DEV and TEST and into PROD.
The TEST server environment is then built (refreshed) from this source in VSS.
Overwriting existing code in TEST from DEV
During testing we found a range of problems with our ASP page. We fixed the problem in
/development and now want to overwrite/replace the VSS /test copy for the CC001
change control.
The developer will:
a. Check-in code in the development folder for the change control
Christopher Kempster
46
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b. Navigate to the /test/cc001/myapp/Web Sites/ project
Delete from this point
IMPORTANT – You can do individual files if you need to, rather than a whole project
c. Goto the /development/cc001/myapp project folder, right click and drag the
websites project
Test now has the fixes made in dev. Use the files to build/update the test server
environment.
Taking a Change Control into Production
The developers will:
a. ensure all code in the /test/cc001 folder is OK to go live
Christopher Kempster
47
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b. remove any files that are not ready
The CCM will:
c. create a new project in the production project folder to represent the change
control going “live”
d. share and branch the myapp application (entire structure) into the new project
folder in production:
e. Navigate to the /test/cc001/myapp project, get a list of files to “go live”
f.
Navigate back to /production/cc001/myapp project and locate these files, for each
file:
a. Select the file, SourceSafe
b.
Merge Branches
Pick the appropriate branch to merge to
Press the merge button.
c. Check conflicts if need be.
The /production project structure is:
Christopher Kempster
48
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Once all files are merged into the new production project folder, the production server
environment can be built from these altered files.
The branching in VSS provides an effective solution to managing versions and the interrelationships between components (files) and physical projects. The above scenario for
example gave us this tree like structure to work from (versions in diagram are VSS
internal versioning numbers – use labels to assist with source identification if you are
having trouble with it):
Using VSS by Example - Part 2
In this section we expand on other source control scenarios and how our defined project
structure and VSS branching functionality accommodates it.
How do I move files to next weeks change control?
In the previous example, we only processed the single ASP file, for some reason, the
developers wanted to delay the DLL for the next round of change controls. Therefore we
need to get the COM file in /development/cc001 into the new project
/development/cc002 for it to be included in that change window.
The CCM will:
a. create /cc002 in /development folder
Christopher Kempster
49
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b. The developer will branch the DLL code from /production/cc001 into
/development/cc002
c. Select the file(s) to be merged in /development/cc002.
Christopher Kempster
50
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
d. Resolve the differences (we know what they are and are fine with all of them)
e. After the merge, double check your code before moving on with development.
What does VSS look like after 2 iterations of change?
After two complete iterations of changes, we end up with this structure in VSS:
We have a snapshot of production for all iterations:
a. initial snapshot
b. change control 1
c. change control 2
Christopher Kempster
51
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
We can also rebuild the test server from a production build and roll forward through
change controls. In the development project, we have a well managed source
environment for each change and its progression through the environments.
I forgot to take a file into production for a schedule change
The CCM needs to:
a. check files are in the equivalent /test project folder
b. if not, the developer should update this project folder by branching the missing
files from the equivalent development folder.
c. As the /production/ccxxx folder already exists (had to for other code to go into
prod), the CCM simply merges this missing file into the project and takes the files
from here to the production server environment.
I have a special project that will span many weeks, now what?
The scenario is this:
a. we do weekly change controls
b. a new special project will take 2 standard chance control iterations to move into
production
c. the standard change controls will be altering files the special project will be using
d. we need to ensure that the standard change controls are not affected and visa
versa for the special project until the special project is ready to do live.
To manage this we need to ensure these rules apply:
a. strict branching from a single point in time from the /production project folder
b. the special project files will merge with some future change control and go live
with this change control window to ensure VSS consistency.
At CC003, we start a new special MYAPP project that affects the single ASP file we have.
The CCM will:
a. create /development/CC003 project
b. create /development/MYAPP Mini Project
Christopher Kempster
52
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c. The developer branches in the files to be altered into both /development/cc003
and /myapp mini project
d. Now both project folders in dev are branched from the single “tree root” (for one
of a better word). Developers continue to work in DEV and branch to test as need
be to facilitate standard app testing.
Merging “MYAPP Mini Project” back into the standard change control.
Here we assume CC003 and CC004 changes over the last 2 weeks are in production, we
need to get MYAPP Mini Project live, this will be done in CC005. The VSS structure is:
a. CCM creates /development/CC005
b. CCM branches code used in “MYAPP Mini Project” from /production/cc004 (current
production source)
c. CCM then, working with the developers, merges into /development/MYAPP Mini
Project with the /development/CC005 project files.
d) Merging is not straight forward in VSS. Take care, and where possible
attempt do this “offline” from the product (using 3rd party source compare tools
for example).
Christopher Kempster
53
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
d. On completion of the merge, remove MYAPP Mini Project or renamed to “use
CC005 – MYAPP Mini Project”
e. Go through standard dev
document.
test
prod VSS practices as outlined through this
Using VSS by Example - Part 3
Re-iterating our chosen VSS structure
The structure we have chosen, i.e. /development, /test, /production VSS project folders,
is perhaps seen by many as just a file system with undelete and some labeling capability,
and that's fine. We have divided off the "environments" from one another and know that
source for production at some known point in time is at location XYZ in VSS and not part
of a single copy that is being used for ongoing development. This goes with the /test
project and was the main reason why we went down this path.
It takes some time to get developers used to the fact that we do have three
environments in VSS between which code is shared/branched (copied) between; for all
intended purposes, developers should see no real difference in the way they currently
develop and interact with VSS via their development software IDE.
The development staff, in liaison with a senior developer (the ultimate owner of code
branched from /dev to /test then /prod), can setup the local PC development
Christopher Kempster
54
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
environment, and hook in the /development folder to their IDE with little effort, and
continue working in this environment.
The developers need to use the VSS GUI to add code as required into /development
folders. The only real complaint here is the need to branch code into /test which some
complain as time consuming (but just darn lazy in my opinion).
The key in /test is the naming of our folders. The folders represent the change control
numbers, which means that your testing of component XYZ is planned to be released into
production as change control number 20041201. If it isn’t, then we branch/move it to
another change control. All said and done, we are not overly strict in /test within VSS,
we do allow other folders to be created to suit the needs of the team, but nothing rolls
into /production that isn’t inside of a /test/cc folder.
Finally the /production folder. The fundamental concept here is the full duplication of all
source that makes up the production server before the change control was rolled into
production. We copy this source to a new project folder and the change manager then
merges code from our /test/cc folder into this copy, thus forming the new production
source code image.
This method is simplistic and easy to use. As the change manager of VSS becomes more
adept with the product, one may use labeling as the core identifier of source at a single
point in time; be warned that it is not simple and a mistake can be very costly.
What does my VSS look like to date?
Here is the screen shot of my VSS project after seven iterations of scheduled change
controls:
Christopher Kempster
55
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
I will discuss /development next. As we see, /production has a "as of now" project folder
for each application, and then the copies of the same folder "as at YYYYMMDD". So for
the STARS application we see:
/production/stars
/production/stars20030917
(developers branch into /development from here for any changes to prod code)
(the STARS system and all its source code as at 17/09/2003)
I will archive off the projects in production as soon as the size of VSS gets too large. It
grows quickly with such a scheme. Even so, it doesn’t slow VSS and disk space is
plentiful (200Gb free so I am not stressed over it).
As we can see in the /test project folder, we have projects representative of the change
control. It is important to remember that this folder is used to build the test server
before formal testing of your changes to go up for that change control. It takes some
discipline for developers to do this and not copy files from the development server to the
test server without going via VSS. The developers are responsible at the end of the day,
and I have solid backing from the development manager.
On a change control go live, I email the team notifying them of the lock down of the /test
change control folder. I then check for checked-pout files in this project then use VSS
security to lock the project. I then do a “get latest version” to my pre-production server,
compile all DLL's, developers test once I have emailed a "please test pre-prod" request,
and wait for final approvals from the developers before 5.30pm that night.
Generally, all working well to date.
What do you do with /development after each change control?
The general thinking here is the removal of all /development code that was taken into
production for a change control and is not being worked on further. I let the senior
developers take responsibility here and they manage this well. I have yet to see any
issues caused by poor management of the /development project folder and its contents.
The developers use the compare and merge facilities of VSS extensively between /test,
/dev and at times /production.
What do you branch into /development in terms of VB6 COM code?
You basically have two options here will branch all your COM project code into
development, or branch only selected class files for the COM project. The development
team opts for selected classes only, and does a get latest version on the production
source to their local computer for compilation. This allows team member to more
effectively track what classes are being altered in development without relying on the
versioning of VSS, file dates or leaving files checked out. This tends to be senior
developer specific on what approach is taken in the /development projects for each
application.
As shown above, the /development/cms application folder holding our COM (cms.dll), we
find only 4 of the 16 class files for this component.
Christopher Kempster
56
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
VSS Issues
Share/Branching files from /test into /production
You cannot overwrite files with share/branch. If I attempt to share/branch the file
myfile.txt from one project to another and the file exists at the destination, you are told
this but the branch will give you no option to overwrite the file.
To get around this, delete the files at the destination project first, then share/branch from
your source file. An alternatively method is via merging, but can be very time consuming
and error prone.
Building the new /production project
When a change control is complete and all code is now in production from our
/test/CCYYYYMMDD project, we need to re-establish our production source environment
again. For example, for the STARS application we would see this:
/test/CC20031204/STARS/<other projects and altered source taken into prod>
/production
/STARS
/STARS20031204
(copy all source from /STARS20031204 and merge /test/CC20031204/STARS/ here)
(before the change control)
So the /STARS project under production is a image of all source currently on the
production server.
To do the copy of /STARS20031204 and paste as /STARS, one would think they could
simply share/branch this folder the /production and be prompted to rename? Well, it
doesn't work. You need to manually create the /STARS project, then for each subproject folder under /STARS20041204 share/branch it to /STARS. This is extremely
inconvienant and does not follow standard GUI interactivity as per other MS products.
Adding/Removing Project Source Files
If you remove files from a project folder in VSS, you will find that VSS tracks this removal
for subsequent recovery, all fine and good. When you add files back into this project
folder, you will get something like this:
Christopher Kempster
57
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
In this case I am adding 45 files that are part of a single large DLL. There is no "yes all"
option, so I need to click on NO forty-five times.
When deleting files, you are prompted with the list, and a small dialog, check the
"destroy permanently" option:
This will prevent the previous message from popping up forty five times but there is no
rollback.
IMPORTANT - If you delete a range of source files from a project, then check new
files in over the top, you may find all history is lost of previous actions against these
files. Consequently, always branch from /test back into /production to retain this
history. Developer rely on this history and may get very upset if it’s lost.
Error on Renaming Projects
Removing large project from VSS is an issue. When I rename, say, /production/stars to
/product/stars20031204, it sits there for 20+sec then I repeated get this message:
then this:
Christopher Kempster
58
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
This will carry on for all sub-project folders. If I kill the process via task manager and
return to VSS, the project has been successfully renamed and I have no further issues
with the project.
Use Labels where appropriate
This is not a gripe on VSS, but a feature I encourage. Anytime code is checked-in, VSS
will assign it an internal version number. The developers can complement this with labels
that can act as textual version numbers to provide better clarity on what a specific
version encompasses. It is not unusual to label a single project and all its files, once
done, we can get latest version based on this label to retrieve all marked source files
with this label. This is done by right clicking on the VSS project - show history - check
the labels only check box in the project history dialog shown. A list of labels is shown,
click on the label to be retrieved and click get; this will do a get latest version to the
projects marked working directory.
The "guest" user
A very quick one - the guest account cannot be granted check-in/out, add/rename/delete
or destroy privileges on VSS project folders. As such, when bulk changing user access
unselect the guest account to allow you to bulk change the remainder of the users.
Security Issues in /production for Branching files
In the /production project folder, a developer cannot branch files into the /development
folder unless they have the check-in/out security option enabled for the /production
project. This is a real problem for me. Why? Developers can not check in/out over
production source and may also branch incorrectly (i.e. share rather than branch). As
Christopher Kempster
59
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
shown below, the developer requires read and check in/out for the branch option to be
available.
Here are some possible options to get around the issues:
a) Ask developers to email me what files are required for branching into development
(far from ideal)
b) Pre-branch from /production back into /development and the developers can sort out
what to remove or keep for their next phase of development
c) Give developers the check-in/out access in production and trust that all will be fine
and source will be branched corrected and never checked in/out of the production folder
directly.
d) Change the way to name /production folders so we always have a "copy" of current
production (locked down) and another for developers to branch from.
e) Microsoft upgrades VSS (not likely - come on guys, all other software has seen major
change except VSS). That said, the change has been in the VS.Net GUI space as we will
see later.
Me? I have opted for c) for the time being to remain flexible.
NOTE - Do not forget that, if using option c), developers incorrectly share rather
than branch code, or check in/out of the /production folder rather than
/development you have all the VSS features to resolve the issue, namely the inbuilt
versioning of source (i.e. we can rollback), the viewing of this version history, and
the fact that in /production we have denied the "destroy" (delete) option.
Christopher Kempster
60
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Welcome to .Net
Initial Configuration of Visual Studio.Net
You require Visual Source Safe SP6d or greater for Visual Studio .Net 2003 to complete
the following steps. I have found that, under some circumstances VSS 6c will not work,
the source control options are shown but are all grayed out (disabled), very strange
indeed.
Start VS.Net and select Tools then Options to open the IDE options dialog below. From
here we are interested in two key areas in relation to VSS, the source control options:
Click on SCC Provider to connect to your source safe database, for example:
From here we configure the VSS database connection string, some core check in/out
options and login details. These are automatically populated based on my existing VSS
client setup.
Christopher Kempster
61
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Equally important is the projects and solution settings under environment. All developers
should map to the same physical location on their development machines, in this
example it is c:\AppProjects, I do not like to prefix the company’s name or division/team
name as, like all things, they tend to change often. The directory will be automatically
created.
IMPORTANT - If you repair your VS.Net installation you may need to re-install
VSS 6d as the source safe option may "disappear" from your File menu.
VS.Net Solutions and Projects
Important Notes before we continue
Here are some general rules before we continue on with examples:
a) Use VS.Net source control options where possible - don’t run the VSS GUI,
checkout code, then go about opening the source. Use the VS.Net options
and the open from source control menu option.
b) Developers need to standardize a local PC directory structure for the
checkout of code from source safe, it is not difficult, but means everyone
gets together than sorts out the base working directory structure for
checked out code. You may find VSS and VS.Net hard coding specific
directories that will make life very difficult for you later in the development
phase.
c) Keep your project and solutions simple. Avoid multiple solutions for
multiple sub-components of an application, keep the structure flat and
simple. Only “play” when you (and your team) are sufficiently
experienced comfortable with it.
Christopher Kempster
62
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Adding a new (simple) Solution to Source Control - Example
Here is a very simple (default) solution called cktest1. No rocket science here by any
means.
From the file menu, select Source Control and Add to source, you are presented with this
warning in relation to Front-Page, if all fine, press continue.
You are prompted for the root location of this solution within VSS. You can name your
VSS project folder different to that of the solution, but I do not recommend it. Here we
select our /development folder:
Christopher Kempster
63
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The /cktest1 VSS project is then created and the lock icons within VS.Net represent the
source control activation against this solution and its project(s).
The VSS structure is a little messy though - we get this by default:
/cktest1 is the solution, and /cktest1_1 is the project, so lesson learnt - name your
solution and projects before hand. Either a prefix or postfix standard is recommend here,
for example:
cktest1Solution and cktest1Project
but does get a little more complicated with many projects.
If you want to change your solution and project names you will get this message:
Christopher Kempster
64
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Cancel this change. If you don’t like the VSS standard structure, and prefer a more
logical hierarchy like this:
/development/cktest1 (aka. the system name!)
/cktest1Solution
/cktest1Project
It gets a little tricky.
To do this, check-in all code into VSS and close your solution. Open the VSS GUI, and
navigate to your newly created project.
Now share & branch your code from:
/cktest1/cktest1 == to ==> /cktest1/cktest1Solution
and
/cktest1/cktest1_1 == to ==> /cktest1/cktest1Solution/cktest1Project
Do not remove the old project folders.
Go back to VS.Net and open the solution once again (do not checkout code!).
Select the solution, then select File, Source Control, and pick the Change Source Control
option.
Under the server bindings area, we select the new project folders as create previously.
The solution will be automatically checked-out to complete the new VSS bindings.
Open the VSS GUI and remove the old /cktest1 and /cktest1_1 projects. I would
recommend a get latest version on the root project just in case.
Whether you remain with a flat structure, or re-bind as we have done above, is an issue
for the change manager more than anything in terms of best practice.
Christopher Kempster
65
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
VSS for the DBA
The examples have presented a complete solution for change control management using
VSS.
For the DBA may choose to store scripts in VSS created from development, test and
those applied to production. The examples apply in all cases, as scripts are simply files
they need to be managed between environments; and VSS is the tool for the job.
The DBA should also consider VSS as a backup utility. The DBA should script all
production databases on a monthly basis, and store the scripts within VSS. Using VSS
and its merge functionality can be handy in this respect to locate differences between
months for example, or retrieve the definitions of lost database objects, constraints,
views etc rather than recoverying full databases from tape.
The DBA should not forget objects outside of the user database, namely:
•
Full text index definitions
•
Logins
•
Important passwords
•
Scripted DTS jobs
•
DTS Packages saved as VB files
•
Linked Server Defintions
•
Publication and Subscription scripts
Christopher Kempster
66
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
3
Chapter
Theory and Essential Scripts
T
he DBA must have a solid understanding of the instance and the databases. The
DBA can then better plan system backup and recovery procedures. This chapter
provides the knowledge to better understand your SQL environment.
As a reminder, this ebook is not a beginners guide to SQL databases. This chapter
provides value added knowledge to those already familiar with installation, setup and
configuration of SQL Server 2000.
Undo & Redo Management Architecture
The key component for rollback and redo in SQL Server is the transaction log that is
present in each database within the instance. The transaction log is a serial record of all
transactions (DML and DDL) executed against the database. It is used to store:
•
•
•
•
•
start of each transaction
before and after changes made by the transaction
allocation and de-allocation of pages and extents
commit and rollback of transactions
all DDL and DML
The transaction log itself consists of one or more physical database files. The size of the
first must be greater than or equal to 512Kb in size. SQL Server breaks down the
physical file into two or more virtual transaction logs. The size of the file and its autogrowth settings will influence the number of virtual logs and their size. The DBA cannot
control the number of, or sizing of, virtual logs.
Physical transaction log file (min size 512Kb with 2 virtual logs)
Virtual Log File
(min 256Kb)
The log-writer thread manages the writing of records to the transaction log and the
underlying data/index pages. As pages are requested and read into the buffer cache,
changes are sent to the log-cache as a write-ahead operation which log-writer must
complete with a write to the transaction log before the committed change is written to
Christopher Kempster
67
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
the data files as part of a check-point. In terms of an update, the before and after
images are written to the log; a delete the before image is written; an insert tracks only
the new records (not including many other record entries as mentioned previously as part
of the transaction). The log-writer (or log manager) allocates a unique LSN (log
sequence number – a 32bit#) to each DML/DDL statement including the transaction ID
that links like log entries together.
NOTE – The log manager (writer) alone does not do all of the writing; the
logwriter thread will write pages that the worker threads don’t handle.
Log Cache
Log flushed, LSN allocated and
transaction id stamped with before/after
images of the records updated.
Physical transaction log file
Write-ahead log cache, must
complete before buffer cache
pages written back to
physical data files.
Buffer Cache / Log Manager
Dirty buffer pages,
log-write requested
Select and update of database record
Database Data Files
Checkpoint completes - writes back to
buffer cache entries to data files only
after log write is compete.
The transaction entries (committed and uncommitted) in the transaction log are doubly
linked lists and each linked entry may contain a range of different (sequential) LSN’s.
The buffer manager guarantees the log entries are written before database changes are
written, this is known as write-ahead logging; this is facilitated via the LSN and its
mapping to a virtual log. The buffer manager also guarantees the order of log page
writes.
NOTE – every database page has a LSN in its header; this is compared to the log
entry LSN to determine if the log entry is a redo entry.
The transaction itself remains in the active portion of the transaction log until it is either
committed or rolled back and the checkpoint process successfully completes.
Christopher Kempster
68
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Physical transaction log file
Doubly linked list log-entries for the transaction.
Free space
in virtual
logs
Active Portion of
Log
NOTE – The checkpoint process keeps around 100 pending I/O operations
outstanding before it will yield to the User Mode Scheduler (UMS). The
performance monitor counter checkpoint pages/sec is an effective measure of the
duration of checkpoints.
Although not shown above, space is also allocated for each log entry record for rollback
purposes; therefore actual space utilisation can be significantly more than expected.
Microsoft defines the active part of the log to be the portion of the log file from the
MinLSN to the last written log record (end of logical log).
The MinLSN is the first of possibly many yet uncommitted (or roll backed) transactions.
Cyclic and serial
transaction log
Free virtual log
space
End/start of next virtual log file
BEGIN
TRAN
T1
UPD
TRAN
T1
BEGIN
TRAN
T2
COMIT
TRAN
T1
CHECK
POINT
DEL
TRAN
T2
LSN
112
LSN
113
LSN
114
LSN
115
LSN
116
LSN
117
- active portion Min LSN
Last Log
record
The log records for transaction are written to disk before a commit acknowledgement is
sent to the client. Even so, the physical write to the data files may have not occurred.
Writes to the log are synchronous but the writes to data pages are asynchronous. The
log contains all the necessary information for redo in the event of failure and we don’t
have to wait for every I/O request to complete. (33)
When the database is using a full or bulk-logged recovery model, the non-active portion
of the log will only become “free” (can be overwritten) when a full backup or transaction
log backup is executed. This ensures that recovery is possible if need be via the backup
and the DBMS can happily continue and overwrite the now free log space. If the
database is using the simple recovery model at a database checkpoint, any committed
(and check pointed) or rollback (and checkpointed) transaction’s log space will become
immediately free for other transactions to use. Therefore, point in time recovery is
impossible.
Christopher Kempster
69
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The checkpoint process is key to completing the committed transactions and writing the
dirty buffers back to disk. In relation to the transaction log, a checkpoint will:
a) write a log entry for the start of the checkpoint
b) write the start LSN for the checkpoint chain to the database for subsequent
recovery on instance failure
c) write a list of active (outstanding) transactions to the log
d) write all dirty log and data pages to disk for all transactions
e) writes a log file record marking the end of the checkpoint
The checkpoint will occur:
a)
b)
c)
d)
On issue of the CHECKPOINT or ALTER DATABASE statement
On instance shutdown (SHUTDOWN statement)
On SQL service shutdown
Automatic checkpointing
a. DBMS calculate timing based on the recovery interval setting
b. “Fullness” of the transaction log and number of transactions
c. Based on timing set with recovery internal parameter
d. Database using simple recovery mode?
i. If becomes 70% full
ii. Based on recovery interval parameter
NOTE – dirty page flushing is performed by the lazywriter thread. A commit does not
trigger an immediate checkpoint.
You can see the checkpoint operation in action via the ::fn_virtualfilestats (SQL 2k)
system function. The function has two parameters, the database ID and the file ID. The
statistics returned are cumulative. The test is simple enough, here we run insert and
update DML, we call :fn_virtualfilestats between each operation and at the end force a
checkpoint, here is what we see:
DbId FileId
---- -----7
2
7
3
7
2
7
3
7
2
7
3
7
2
7
3
7
2
7
3
7
2
TimeStamp
----------1996132578
1996132578
1996132578
1996132578
1996132578
1996132578
1996132593
1996132593
1996132593
1996132593
1996132625
NumberReads
-------------------317
30
317
30
317
30
317
30
317
30
317
NumberWrites
-------------------154
42
156
42
158
42
160
42
162
42
165
BytesRead
-------------------17096704
819200
17096704
819200
17096704
819200
17096704
819200
17096704
819200
17096704
BytesWritten
-------------------2127360
540672
2128384 [1024 diff]
540672 [0 diff]
2129408 [1024 diff]
540672 [0 diff]
2130432 [1024 diff]
540672 [0 diff]
2131456 [1024 diff]
540672 [0 diff]
2140672 [9216 checkpt]
7
1996132625
30
43
819200
548864
3
[8192 written]
File ID 2 = Log File
File ID 3 = Data File
Each colour band represents new DML operations being performed. The last operation
we perform is the CHECKPOINT. Here we see the BytesWritten increase as the logs are
forced to flush to disk (file ID 3).
Running the LOG command you will see the checkpoint operations:
DBCC LOG(3, TYPE=-1)
where 3 is the database ID (select name, dbid from master..sysdatabases order by 1)
Christopher Kempster
70
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Apart from the recovery interval and recovery mode parameters, the DBA has little
control of checkpointing. It can be forced via the CHECKPOINT statement if need be and
I recommend this before each backup log statement is issued.
To drill into the virtual logs and the position, status, size, MinLSN within the
transaction log files, use the commands:
dbcc loginfo
dbcc log(<db#>, TYPE=-1)
The 3rd party tool “SQL File Explorer” includes a simple but effective GUI view of your
transaction log file and its virtual logs. This can be very handy when resolving log file
shrink issues.
..and a textual view..
Christopher Kempster
71
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
NOTE – To get even more details about log entries, consider the command:
select * from ::fn_dblog(null, null)
The process of recovery involves both:
d) Redo (rolling forward or repeating history to time of the crash); and
e) Undo (rolling back or undoing un-committed transactions) operations.
NOTE – In SQL Server 2k, the database is only available after undo complete (not
including when the STANDBY restore clause is used). In SQL Server Yukon, the
database is available when undo begins! Providing faster restore times.
The redo operation is a check, we are asking “for each redo log entry, check the physical
files and see if they change has already been applied”, if not, the change is applied via
this log entry. The undo operation requires the removal of changes. The running of
these tasks is based upon the last checkpoint record in the transaction log. (33)
The management of transactions is a complex tasks, and is dealt with not but the buffer
manager, but via the transaction manager within the SQL engine. Its task includes:
a) isolation level lock coordination with the lock manager, namely when locks
can be released to protect the isolation level requested; and
b) management of nested and distributed transactions and their boundaries
in which they span; this includes the coordination with the MSDTC service
using RPC calls. The manager also persists user defined savepoints within
transactions.
Christopher Kempster
72
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
REMINDER – The transaction log is a write-ahead log. Log writes are synchronous
and single threaded Actual DB writes are asynchronous, multi-threaded and as
shown in the diagrams, optimistic. Also note that compressed drives and their
associated algorithms disable the write-ahead logging (WAL) protocol, and can
effectively stall checkpoints and the timing of calls.
Audit the SQL Server Instance
Walking into a new server environment is never easy, and quickly understanding the
database running on your instances at a high level is a basic task that needs to be
completed quickly and accurately. The DBA should the following – all are important in
some way to systems recovery (DR) and system troubleshooting in general:
a) Instance version and clustered node information (if applicable)
b) Base instance properties covering switches, memory, security settings etc.
c) Service startup accounts, including the SQL instance service, SQL Agent and the
SQL Agent proxy account (if used)
d) Select snapshot of configuration settings
e) The existing of performance counters and statistics from a select few
f)
List of sysadmin and dbowner users/logins
g) List of databases, options set, total size and current transaction log properties, if
database has no users other that DBO:
a. Files used and their drive mappings
b. Count of non-system tables with no indexes
c. Count of non-system tables with no statistics
d. List of Duplicate indexes
e. Count of non-system tables with no clustered index
f.
Tables with instead-of triggers
g. List of schema bound views
h. Count of procedures, views, functions that are encrypted
i.
List of any user defined data types
j.
List of PINNED tables
k. For each user, a count of objects owned by them rather than DBO
h) Last database full backup times – see section on backups.
Christopher Kempster
73
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
i)
Publications currently in existence
j)
Subscriptions currently in existence
&
T R O U B L E S H O O T I N G
k) Startup stored procedures in effect
l)
Currently running traces and flags set on startup
m) List of linked servers and their properties
n) If the database is currently experiencing blocking
o) Login accounts with no password, and those with sysadmin access
p) Non standard users in the master and msdb databases (consider model as well to
determine if any special “generic” user exists when other databases are created),
those users with xp_cmdshell access
q) Current free space on local disks
r) Full text index statistics/summary
This e-book provides many of these answers based on the problem at hand. The internet
is a huge source of scripts, I have no single script but use many crafted by fellow DBA’s.
Rather than deal with the issues of copyright, I charge you with the task of accumulating
and adapting suitable scripts. Feel free to email me if you require assistance.
As a general guide for systems recovery, collect the following:
DBCC MEMORYSTATUS
SELECT @@VERSION
exec master..xp_msver
exec sp_configure
select * from master..syslogins
select * from master..sysaltfiles
select * from master..sysdatabases
select * from master..sysdevices
select * from master..sysconfigures
select * from master..sysservers
select * from master..sysremotelogins
select * from master..sysfilegroups
select * from master..sysfiles
select * from master..sysfiles1
sp_MSforeachtable and sp_MSforeachdb stored procedures
execute master..sp_helpsort
execute master..sp_helpdb -- for every database within the instance.
To determine the actual “edition” of the SQL instance, search the internet for a site listing
the major and minor releases. A very good one can be found at:
http://www.krell-software.com/mssql-builds.htm
The SERVERPROPERTY command is a handy one, giving you the ability to ping small but
important information from the instance. For example:
SELECT SERVERPROPERTY('ISClustered')
SELECT SERVERPROPERTY('COLLATION')
Christopher Kempster
74
S Q L
SELECT
SELECT
SELECT
SELECT
SELECT
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
SERVERPROPERTY('EDITION')
SERVERPROPERTY('ISFullTextInstalled')
SERVERPROPERTY('ISIntegratedSecurityOnly')
SERVERPROPERTY('ISSingleUser')
SERVERPROPERTY('NumLicenses')
The database level equivalent is DATABASEPROPERTY and is covered well in the BOL.
To locate the install path (undocumented command):
DECLARE @sql SYSNAME
DECLARE @data SYSNAME
EXEC master..sp_msget_setup_paths @sql OUTPUT, @data OUTPUT
SELECT @sql, @data
Do not forget the SQLDIAG.EXE command to dump to into a single ASCII file core system
and SQL coinfiguration information. I highly recommend that you run this daily to assist
with systems recovery:
cd "C:\Microsoft SQL Server\MSSQL$CORPSYS\binn"
sqldiag -icorpsys -oc:\sqldiag_corpsys.txt
-- corpsys is the named instance
Goto the binn dir for the instance and run sqldiag. Remove the –i<myinstancename> as
necessary. I always run named instances of sql server (a personal preference more than
anything – especially if you want to run an older DBMS version of SQL on the box), so
the default instance will be:
C:\Program Files\Microsoft SQL Server\MSSQL\Binn>sqldiag -oc:\sqldiag.txt
Meta Data Functions
It is easy to forget about the SQL Server meta data functions, all of which are essential to
making life a damn site easier with more complex scripts. I recommend you spend some
time exploring the following at a minimum:
Function Name
DB_NAME
DB_ID
FILE_NAME
FILEGROUP_NAME
FILEGROUPPROPERTY
FILEPROPERTY
Christopher Kempster
Purpose
Given the database ID from the master..sysdatabases table, returns the
name of the database.
As above but you pass the name and the ID is returned.
Given the fileid number from sysfiles for the current database, returns
the logical name of the file. The value is equivalent to the name column
in sysfiles. Be aware that databases in the instance can share the same
ID number, so file_name(1) can work equally well in any database, this
ID value is not unique for the entire instance.
Pass in the groupid value as represented in sysfilegroups for each
database and returns the groupname column. Remember that we can
have primary and user defined filegroups, transaction logs do not have
a group with a maximum of 256 filegroups per database.
We can use the previous command as the first input into this routine,
the next parameter includes three basic options, IsReadOnly,
IsUserDefinedFG, IsDefault, this undoubtedly change with future
releases on SQL Server.
Will return file specific property information, we can use the FILE_NAME
function as the first input, the next parameter can be one of the
following: IsReadOnly, IsPrimaryFile, IsLogFile, SpaceUsed. The space
is in pages.
75
S Q L
FULLTEXTSERVICEPROPERTY
OBJECT_NAME
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Returns the MSSEARCH (Microsoft Search Service) service properties
specific to SQL Server full text engine integration.
Based on the current database of the connection
Listing SQL Server Instances
To get a list of SQL Instances on the network, consider this command:
isql –L
-orosql –L
There are a range of third party alternatives available on the internet, such as
sqlping.exe from www.sqlsecurity.com. Also check my website under hints/tips for a
bunch of SQL tools from a variety of authors.
Information Schema Views
It is not uncommon for system tables to change between releases; so significant can be
the change that impacts on existing scripts can result in complete re-writes. To ease the
pain a little, a range of what I call Metadata++ views are available that tend to be more
consistent and additive, rather than taken away.
The metadata views are referred to as the information_schema.
Information Schema
information_schema.tables
Column Summary
Catalog (database), Owner, Object name, Object type
(includes views)
Catalog (database), Owner, Object name, View Source
(if not encrypted), Check Option?, Is Updatable?
Catalog (database), Owner, Table name, Col Name, Col
Position, Col Default, Is Nullable, Data Type, Char Min
Len, Char Octal Len, Numeric Prec <etc>
Database Name, Schema Name, Schema Owner, Def
Char Set Catalog, Def Char Set Schema, Def Char Set
Name
Catalog (database), Owner, Constraint Name, Unique
Constraint Database, Unique Constraint Owner, Unique
Constraint Name, Update Rule, Delete Rule
information_schema.views
information_schema.columns
information_schema.schema
information_schema.referential_constraints
Note that the views return data for the currently active (set) database. To query another
database use the db-name(dot) prefix:
select * from mydb.information_schema.tables
There are no special security restrictions for the views and they are accessible through
the public role. Be aware though that the schema views will only return data to which
the user has access to. This is determined within the views themselves via the
permissions() function.
To view the code of any of the views:
use master
exec sp_helptext 'information_schema.Referential_Constraints'
Christopher Kempster
76
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
As you have probably noticed, the views are very much DDL orientated and lack items
such as databases or linked servers for example; these would prove very handy rather
than having to query system tables. (34)
Database, File and File Group Information
Extracting Basic Database Information
Use the system stored procedure found in the master database:
exec sp_helpdb mydatabase
Determining Database Status Programmatically
The sysdatabases table in the master database includes the status column of type
int(eger). This is an essential column for many scripts to use to determine the state of
instance databases before continuing on with a specific recovery scenario etc. Here is an
example:
alter database pubs set read_only
go
select name, ‘DB is Read Only’
from master..sysdatabases
where status & 0x400 = 1024
go
where 0x400 is equivalent to 10000000000 binary, (BOL tells us that bit position 11 (or
1024 decimal) tells us the database is in read-only mode). Including more than one
option is a simple matter of addition; the DBA should recognize that 0x (zero x) is the
prefix for a hexadecimal value.
Status
32
64
128
256
512
1024
2048
4096
32768
Binary & Hex
Codes
0x20
100000
0x40
1000000
0x80
10000000
0x100
100000000
0x200
1000000000
0x400
10000000000
0x800
100000000000
0x1000
1000000000000
0x8000
1000000000000000
Meaning
Loading
Pre-Recovery
Recovering
Not Recovered
Offline
Read Only
DBO use only
Single User
Emergancy Mode
Common Status Code Bits.
An alternate method is a call to the DATASEPROPERTY function and is much more
understandable:
Christopher Kempster
77
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
select name, ‘DB is Read Only’
from master..sysdatabases
where DATABASEPROPERTY(name, N’IsReadOnly’) = 1
go
The DATABASEPROPERTYEX function is a drill-through function, providing more specific
property information about the database itself. These functions are called meta-data
functions.
Remember – multiple bits can be set at any one time. The list above is not the
definitive set of values, but are the most important to recognize in terms of Backup
and Recovery.
Using O/ISQL
The osql or isql command line routines are very handy and are well worth exploring. For
a majority of DBA work though, the command can go unused, but occasionally they
prove essential, especially for complex scripts where dumping data to flat files is
required. For example:
osql -E -h-1 -w 158 -o test.txt -Q "SET NOCOUNT ON SELECT name FROM
master..sysdatabases WHERE name <> 'model'"
or run an external SQL file:
exec master..xp_cmdshell 'osql -S MySQLServer -U sa -P ic:\dbscripts\myscript.sql'
Rather than embedding the username/password, especially within stored procedures via
xp_cmdshell, consider –E for integrated login via the service user account. The SQL
script may contain multiple statements, be they in a global transaction or not.
NOTE – to represent a TAB deliminator for output files, use –s “ “, the space
represents a TAB character.
Taking this further, a Mike Labosh at www.devdex.com shows how to process many .sql
scripts in a directory using a single batch file:
RunScripts.bat
@ECHO OFF
IF "%1"=="" GOTO Syntax
FOR %f IN (%1\*.sql) DO osql -i %f <--- also add other switches for osql.exe
GOTO End
:Syntax
ECHO Please specify a folder like this:
ECHO RunScripts c:\scripts
ECHO to run all the SQL scripts in that folder
:End
ECHO.
Christopher Kempster
78
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Retrieving Licensing Information
To locate information about the existing licensing scheme, run the following within Query
Analyzer:
select SERVERPROPERTY('LicenseType')
select SERVERPROPERTY('NumLicenses')
where 'NumLicenses' is not applicable for the per CPU scheme. If you are running the
Developer Edition, 'LicenseType' returns “disabled” and 'NumLicenses' is NULL.
The License Manager program (control-panel -> administrative tools) cannot display
information related to per-processor licensing for SQL Server (Q306247). To get around
this issue the installation will create a new administrative tool program to track such
information as shown in the screen shots below.
SQL Server 2k licence applet, this
is very different under v7.
Version 2000
Version 7
The Settings
Control panel
Licensing
shows only server licensing for SQL Server
2000 installations (unlike v7). The applet above is used instead. Notice that you cannot
switch to a per-processor license; you must re-install the instance to do this.
NOTE – Unless specified in your license contract or SQL Server version on
installation, the installed instance will not automatically expire or end.
Alter licensing mode after install?
Once the licensing mode is set on instance installation, that’s it. You cannot change it
back. In control panel we have the icon:
Christopher Kempster
79
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
This will allow you administer your licenses, but you will see one of the options is grayed
out, such as:
To get around this go to the following registry key entry:
Change the mode to 1 (default is zero) and you get both options:
Microsoft may not support you if this method is used.
Allowing writes to system tables
Use the following code whilst logged in as SA or with sysadmin privileges:
exec sp_configure "allow updates", 1 -- 0 (zero) to disable
go
reconfigure with override -- force immediate change in config item
Updating system tables directly is not supported by Microsoft, but there are some
occasions where it is required. In terms of DR, it is important to understand the process
if you need to apply changes.
Christopher Kempster
80
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Count Rows & Object Space Usage
The DBA has a number of methods here to return a table rowcount and space utilization
details. Ensure your scripts return table objects and not schema bound views or views
themselves:
OBJECTPROPERTY(<object-id>, 'IsUserTable') = 1
If you want to run a SQL command for each table in the database, consider the
command master..sp_MSforeachtable, for example:
exec sp_MSforeachtable @command1=”select count(*) from ?”
The only other MS options are master..sp_MSforeachdb or
master..sp_MSforeach_worker. It is a pity we have no others for views, functions, stored
procedures etc. Search Google and you will find many examples:
http://www.sqlservercentral.com/columnists/bknight/sp_msforeachworker.asp
Do note that the MS_ @command1 parameter itself can accept multiple physical
commands. For example this is valid:
@command1=”declare @eg int print ‘?’ select count(*) from ?”
- or @command1=”declare @name varchar(50) set @name=parsename(‘?’, 1) dbcc
updateusage(0, @name) with no_infomsgs select count(*) from ?”
Here are some methods of row counting and returning object space usage:
Method
select
count(*)
from
mytable
SELECT
FROM
WHERE
AND
General Notes
Will not return total number of bytes used by the table.
IO intensive operation in terms of table and/or index
scanning.
Patch or version changes in DBMS can break script.
Returns row count and bytes/space used. Does not
factor in multiple indexes.
May not be 100% accurate (based on last statistics
update).
Consider DBCC UPDATEUSAGE before-hand.
The indid column value may be zero (no clustered
indexes) or one (clustered); note that 0 and 1 will not
exist together.
object_name(id) ,rowcnt ,dpages * 8
mydb..sysindexes
indid IN (1,0)
OBJECTPROPERTY(id, 'IsUserTable') = 1
- OR SELECT o.name, i.[rows], i.dpages * 8
FROM
sysobjects o
INNER JOIN sysindexes i
ON
o.id = i.id
WHERE (o.type = 'u') AND (i.indid = 1)
and o.name not like ‘dt%’
ORDER BY o.name
exec sp_spaceused ‘mytable’
Returns data and index space usage.
Will auto-update the sysindexes table.
Will scan each data block, therefore can be slow on
larger tables – use the @updateusage parameter set to
‘false’ to skip this scan.
Prefix with master.., and the routine will search this DB
for the object name passed in.
Performs a physical data integrity check on tables or
indexed views; CHECKALLOC is more thorough in terms
of all allocation structure validation.
Slow and DBMS engine intensive.
Will return structural error information with the table (if
dbcc checktable(‘mytable’)
Christopher Kempster
81
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
any), along with a row and pages used count.
Can repair errors (see BOL for options).
Will validate all indexes unless specified.
Another example using the msforeachtable routine
(undocumented system routine).
exec sp_msforeachtable
@command1=@command1=”declare @name
varchar(50) set @name=parsename(‘?’, 1) dbcc
updateusage(0, @name) select count(*)
from ?”
Space and Memory Usage
To get the current database size along with data/index/reserved space:
use mydb
exec sp_spaceused
- or just the basic file information select fileid, size from sysfiles
- or via FILEPROPERTY USE master
go
SELECT FILEPROPERTY('master', 'SpaceUsed')
To retrieve fixed disk space usage:
exec xp_fixeddrives
To get the space used on a table:
exec sp_spaceused largerow, @updateusage = true
To retrieve transaction log space usage:
dbcc sqlperf (logspace)
To determine amount of free space for a database, consider the following SQL:
select name, sum(size), sum(maxsize) from mydb..sysfiles where status & 64 = 0 group
by name -- size is in 8Kb pages
select sum(reserved) from mydb..sysindexes where indid in (0,1,255)
NOTE – The DBCC UPDATEUSAGE command should be run before sp_spaceused
command it run to avoid inconsistencies with the reported figures.
Black Box Tracing
Microsoft Support recommends the black box trace when dealing with instance lockups
and other strange DBMS errors that are difficult to trace. The trace itself will create the
Christopher Kempster
82
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
files blackbox.trc, blackbox_0n.trc (switches every 5Mb). These return critical system
error messages. The trace is activated via:
declare @traceID int
exec sp_trace_create @traceID OUTPUT, 8
exec sp_trace_setstatus @traceID, 1
-- Create the trace
-- Start the trace
and produces this file:
If you want to start the trace every time SQL Server starts, then place the code into a
stored procedure within the master database and set the option:
exec sp_procoption ‘mystoredprocnamehere’, ‘startup’, true
As a general rule, do not unless you have a specific need. To verify the trace:
USE master
GO
SELECT * FROM ::fn_trace_getinfo(1)
GO
Do not run the trace as a regular enabled trace as it may degrade system performance.
Here is a more complete script to startup the blackbox trace. It includes logging
messages to the error log.
use master
go
CREATE PROC dbo.sp_blackbox
AS
declare @traceID int
declare @errid int
declare @logmessage varchar(255)
exec @errid = sp_trace_create @traceID OUTPUT, 8 -- Create the TRACE_PRODUCE_BLACKBOX
exec sp_trace_setstatus @traceID, 1
-- Start the trace
if @errid <> 0 begin
set @logmessage
as varchar)
exec xp_logevent
end
else begin
set @logmessage
varchar)
exec xp_logevent
end
GO
Christopher Kempster
= 'Startup of Black box trace failed - sp_blackbox - error code - ' + cast(@errid
60000, @logmessage, ERROR
= 'Startup of Black box trace success - trace id# - ' + cast(@traceID as
60000, @logmessage, INFORMATIONAL
83
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
exec sp_procoption N'sp_blackbox', N'startup', N'true'
GO
To stop the trace:
declare @traceID int
set @traceID = 1
exec sp_trace_setstatus @traceID, 0
If you are really keen, run Process Explorer from sysinternals.com and look through the
handles for the sqlserver process. It will list the black box trace file.
To read a trace file, the easiest approach is to run the Profiler GUI. Here is our example
file showing commands running at the time of the crash:
Be very careful with re-starting your instance after a crash. The instance will overwrite
the file if you leave the default filename. In your stored procedure, write some smarter
code to better control the filename, for example:
set @v_filename = ‘BlackTrace_’ + convert(varchar(20),getdate(), 112) + '_' +
convert(varchar(20), getdate(), 108)
giving you files like:
BlackTrace_20030512_150000.trc
If you want to create a table from the trace file, rather than opening it via profiler, the
use the command ::fn_trace_gettable():
SELECT *
INTO myTraceResults
FROM ::fn_trace_gettable('c:\sqltrace\mytrace_20040101.trc', default)
Christopher Kempster
84
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If the single trace created many files (split by size), and this if the first then the default
parameter will ensure ALL files are loaded into the table (very handy feature).
Scan Error Log for Messages?
Our friends at Microsoft released a great support document 115519, “INF: How to Scan
SQL Errorlog or DBCC Output for Errors”, namely with the findstr DOS command.
Database last restored and from where?
When you select properties of a database within an instance, it pops up a window with a
range of tabs. The General tab provides a high level summary of the database, including
the last fullback and transaction log backup. But for development/test servers, the
question is often posed, “where and when was this database restored from?”.
From a backup perspective, the table msdb..backupset stores the dates used within EM,
namely the column backup_finished_date where type =’D’ for full backups and ‘L’ for
transaction logs.
To retrieve restoration history, query the table msdb..restorehistory:
select
destination_database_name as DBName,
user_name as ByWhom,
max(restore_date) as DateRestored
from
msdb..restorehistory
where
destination_database_name = 'mydb'
and
restore_type = 'D' -- full
group by
destination_database_name, user_name
Join this query to msdb..restorefile over the restore_history_id column to retrieve the
physical file name for each database file restored.
If you want to get the backup files dump location and name from where the restore
occurred, then look at the msdb..backup* tables. The restorehistory table column
backup_set_id joins to msdb..backupset and is the key for locating the necessary
information. This table is an important one as it stores all the essential information
related to the database restored, namely its initial create date, last LSN’s etc. This
restored history is the main reason why many prefer EM for restoration to graphically
view this meta data.
Also consider the command:
restore headeronly from disk='c:\mydb.bak'
to view backup file header information.
Christopher Kempster
85
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
What stored procedures will fire when my instance starts?
The DBA can specify custom stored procedures kept in the master database to run on
service startup via the command:
exec sp_procoption 'mystoredproc', 'startup', 'on'
It can also be set within Enterprise Manager when editing your stored procedures (see
checkbox at the bottom of the edit stored proc window).
The DBA can “skip” the procedures on instance startup via the trace flag:
-T4022
You can check if the option is enabled for a stored procedure using OBJECT_PROPERTY
statement:
SELECT OBJECTPROPERTY(OBJECT_ID('mystoredproc'), 'ExecIsStartup')
Alternatively run this command to get a listing. Care is required when using the system
tables between SQL Server version changes:
select name
from sysobjects
where category & 16 = 16
order by name
When the database was last accessed?
The best command I have seen to date is this:
EXEC master..xp_getfiledetails 'C:\work\ss2kdata\MSSQL$CKTEST1\Data\pubs_log.ldf'
Essential Trace Flags for Recovery & Debugging
The following trace flags are essential for a variety of recovery scenarios. These flags are
referred to throughout this handbook. The use of trace flags allow the DBA to gain a
finer granularity of control on the DBMS not normally given.
260
1200
1204
1205
1206
1704
3502
3607
3608
3609
Show version information on extended stored procedures
Prints lock information (process ID and lock requested)
Lock types participating in deadlocking
Detailed information on commands being run at time of deadlock
Complements 1204.
Show information about the creation/deletion of temporary tables
Prints information about start/end of a checkpoint
Skip auto-recovery for all instance databases
As above, except master database
Skip creation of the tempdb database
Christopher Kempster
86
S Q L
4022
7300
7502
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Bypass master database stored procedure that run on instance startup
Get extended error information on running a distributed query
Disable cursor plan caching for extended stored procedures
Remember that each flag has its own –T<trace#>. Do not try and use spaces or
commas for multiple flags and a single –T command. Always review trace output in the
SQL Server error log to ensure startup flags have taken effect.
Example of setting and verifying the trace flags
The trace flag can be enabled via EM as shown below:
This particular trace will force the logging of checkpoints:
checkpoint
-- force the checkpoint
Important – Trace flags set with the –T startup option affect all connections.
The DBA can also enable trace flags on the command line via the sqlservr.exe
binary:
Christopher Kempster
87
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Rather than at the command line, we can also enable traces via the services applet:
To view the current enabled session and database wide traces, use these commands:
DBCC TRACEON(3604)
DBCC TRACESTATUS(-1)
Or rather than using –1, enter the specific trace event#.
For the current connection we can use the DBCC TRACEON and DBCC TRACEOFF
commands. You can set multiple flags on and off via DBCC TRACEON(8722,
8602[,etc]). Use -1 as the last parameter to affect all connections:
Christopher Kempster
88
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
DBCC TRACEON (xxxxx, -1)
Use profiler to trace existing connections. Remember that these trace flags are not the
same as trace events as used by profiler (sp_trace_setevent).
IMPORTANT – To check startup parameters without connecting to the instance,
run regedit, navigate to HKLM/Software/Microsoft/Microsoft SQL
Server/<instance>/MSSQLServer/Parameters, and review the SQLArgX list of
string values.
“Trace option(s) not enabled for this connection” ?
You may get this message with attempting to view trace flag status via the command:
DBCC TRACESTATUS(-1)
You may know that XYZ flags are enabled, but this routine returns the above message,
leaving you in the dark. You could go back over your SQL Server logs and hope to catch
the DBCC TRACEON output for the flags used. Otherwise run this first (before
tracestatus):
DBCC TRACEON(3604)
Bulk copy out all table data from database
Basically I am not going to reinvent the wheel here. There is a MS support document
176818 titled “INF: How to bulk copy out all the tables in a database”. Do note that it
simply does a select * from tables and uses BCP via xp_cmdshell to dump the files to
disk. This may be problematic with TEXT fields. If so, consider the textcopy.exe utility
that came with SQL Server 6.5 and 7.0. An excellent coverage of this routine can be
found on Alexander Chigrik’s website at – “Copy text or image into or out of SQL Server”,
http://www.mssqlcity.com/Articles/KnowHow/Textcopy.htm
SQLSERVR Binary Command Line Options
Starting the SQL Server instance (default or named) manually via the command line is an
essential skill for the DBA to master. When I say master, I generally mean that you
should be familiar with the options and have experienced first hand the outcome of the
option.
The options as of SQL Server 2000 are:
Option
-I<IO affinity mask>
Summary / Use
Introduced in SP1 of SS2k.
-c
-d<path\filename>
-l<path\filename>
-e<path\filename>
-m
Do not run as a service
Fully qualified path to the master database primary data file
Fully qualified path to the master database log file
Fully qualified path to the error log files
Start SQL Server in single user (admin) mode; fundamental for master
database recovery from backup files.
Minimum configuration mode. Tempdb will be of size 1Mb for its data file and
-f
Christopher Kempster
89
S Q L
-Ttrace-number
-yerror-number
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
the log will be 0.5Mb; this will only occur if you have not altered tempdb as it
only works over the tempdev and templog logical files.
Startup the instance with specified trace flag. Use multiple –T commands for
each trace number used.
If error-number is encountered, SQL will write a stack trace out to the SQL
Server error log file.
NOTE – Although not mandatory, the –c and –f parameters are typically used
together when starting an instance in minimum configuration mode.
SQL Server Log Files
In SQL Server the error log and its destination is defined by the –e startup
parameter. This is also stored within the registry during instance start-up:
From within EM, we can right click the instance for global properties and view the startup parameters rather then searching the registry:
The management folder in EM allows the DBA to view the contents of the log files. I say
files because SQL Server will cycle through six different log files (default setting). The
cycling of the files will occur on each re-start of the SQL Server instance, or via exec
sp_cycle_errorlog.
The DBA can control the number of cycled logs via a registry change. This change
can be done within Query analyser if you like or via EM by right click for properties in
the SQL Server Logs item under the Management folder.
Exec xp_instance_regwrite
N'HKEY_LOCAL_MACHINE',
N'SOFTWARE\Microsoft\MSSQLServer\MSSQLServer',
Christopher Kempster
90
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
N'NumErrorlogs', REG_DWORD, 6
The DBA can view error logs within query analyser using:
exec master.dbo.xp_readerrorlog [number of log file, values 0 to 6]
The valid list can be retrieved via:
exec sp_enumerrorlogs
Archive#
0
1
2
3
4
5
6
Date
06/15/2002
06/14/2002
06/03/2002
06/03/2002
05/26/2002
05/12/2002
05/11/2002
23:59
21:25
21:36
10:29
14:25
16:27
15:54
Log File Size (Byte)
3646
21214
3063
49852
31441
5414
2600
The error log for SQL*Agent is best managed with EM. With SQL*Agent shutdown, select
its properties and you can control a range of log settings:
Location & filename of the error log.
Include full error trace with log entries
Use non-unicode file format
Read Agent Log Example
The website “SQLDev.Net” (http://sqldev.net/sqlagent.htm) has a fantastic stored
procedure that really simplifies the reading of the SQL Agent logs. Well worth a look.
How and When do I switch sql server logs?
I switch them manually at the end of each day (around midnight). The files can get huge
and makes life overly difficult when looking for errors, especially with deadlock tracing
enabled. To switch them I created a small SQL Agent Job which can be invoked with the
following SQL command:
exec sp_cycle_errorlog
You may feel the need to retain 10 or more logs, rather than the standard 6 (see
previous section item). I find the default is more than enough when cycled daily.
Detecting and dealing with Deadlocks
Christopher Kempster
91
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The NT performance monitor is a good place to start to determine the extent of a
problem. We use the counter:
SQLServer:Locks \ Number of Deadlocks\sec
Ideally its value is zero and/or a rare event. There are situations where this is difficult especially third party applications or your OLTP database that is also being used for
reporting and other batch type events out of your control. The DBA should follow up
with SQL Profiler to better trace the deadlocks occurring.
Profiler is a powerful tracing tool, but it does have some problems when tracing
deadlocks as we will see later. On starting a new trace, the DBA should include the
events:
Errors and Warnings
Exception
Locks
Lock: Deadlock
Lock: Deadlock Chain
If you stayed with this, and waited for your expectant deadlock to occur, you will get very
little information of the objects affected or statements executed unless you select the
data column Object Id. From here you need to manually use OBJECT_NAME to
determine the object affected.
Why is this a problem? To get more information you typically include the event T-SQL:
SQL: Batch Completed. If you run the trace with this option then you will be tracing ALL
completed batches and in a busy system, this can mean thousands of entries within
minutes; This makes tracing a difficult and time consuming task. Even so, if you can
deal with this, you will get a thorough list of statements related to the deadlock; stop the
trace after the deadlock occurred and use the find dialog to search the columns for
deadlock event, then search backwards from the SPIDS involved in the trace to get a
summary of the commands before the deadlock.
NOTE – Running profiler whilst locking is already underway and a problem, will do
you no good. You may only get a small amount of relevant information about the
issue (i.e. profiler doesn’t magically trace already running processes before
continuing on its way with current events).
The client application involved in a deadlock will receive the error# 1205, as shown
below:
Server: Msg 1205, Level 13, State 50, Line 1
Transaction (Process ID 54) was deadlocked on {lock} resources with another process
and has been chosen as the deadlock victim. Rerun the transaction.
To assist in this circumstance, utilise EM or run the following commands:
exec sp_who2
dbcc inputbuffer (52)
exec sp_MSget_current_activity 56,4,@spid=52
information
Christopher Kempster
92
-- view all sessions
-- get SQL buffer for 52
-- get extended locking
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Finally, the DBA can utilise trace flags. This is an effective method for debugging
deadlocks and provides some excellent error log data. The flags are:
1204 Get lock type and current command affected by deadlock
1205 Get extended information about the command being executed (e.g.
graph)
1206 Complements 1204, get other locks also participating in the deadlock
3605 Send trace output to the error log (optional, will go there anyhow).
The screen shots below illustrate the output from a deadlock with the traces enabled. I
have no statistics on the adverse effect to DBMS performance, but this is a very effective
method for debugging problem systems that are deadlocking frequently but you can
never get a comprehensive set of data to debug it.
The actual deadlock is around the customer and employer tables. Two processes have
updated one of the two separately and have yet to commit the transaction; they
attempted to select each others locked resources resulting in the deadlock. This is not
reflected in the log dump.
Christopher Kempster
93
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The ECID is the execution context ID of a thread for the SPID. The value of zero
represents the parent thread and other ECID values are sub-threads.
Check with http://support.microsoft.com for some excellent scripts to monitor blocking in
SQL Server.
Example Deadlock Trace
We have a large COM+ based application that was experiencing deadlocking issues. The
key issue here is that COM+ transactions use an isolation level of serialisable. As such,
locks of any sort can be a real problem in terms of concurrency. To start resolving the
problem we:
a) Worked with the developers in determining out how to replicate the error
a. this allowed us to identify the code segments possible causing the error
and assisted of course with testing.
b) Set instance startup parameters -T1204 -T1205 -T1206, re-started the instance
c) Ran Profiler
a. Filter the database we are concerned with
b. Include event classes
i. Lock:Deadlock
ii. Lock:Deadlock Chain
iii. SQL:StmtCompleted
iv. RPC:Completed
c. Included standard columns, namely TextData and SPID
d) Ran the code to cause the deadlock.
Search the profiler trace:
Lock:Deadlock identifies that SPID 67 was killed. Go back through the trace to locate the
commands executed in sequence for the two SPIDS in the chain. Take some time with
this, you need to go back through the chain of transaction begins (in this case they are
COM+ transactions) to clearly determine what has happened for each SPID’s transaction
block.
Christopher Kempster
94
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
To assist with further debugging, goto your instance error log and locate the deadlock
dump chain:
IX lock wanting to
be taken out
Last command from
buffer. (stored proc or
DML statement
select object_name(918450496) will give
you the table name to help identity the
possible problem statement to start looking
for in the batch of SQL being executed.
Current lock being
held
Orphaned Logins
At times, the DBA will restore a database from one instance to another. In doing so,
even though the login exists for the instance, the SID (varbinary security ID) for the
login is different to that in the other instance. This effectively “orphans” the
database user from the database login due to this relationship between
master..syslogins and mydb..sysusers.
master database
user database
syslogins
sysusers
SELECT SUSER_SID('user1')
0x65B613CE2A01B04FB5E2C5310427D5D5 -- SID of user1 login, instance A
0x680298C78C5ABC47B0216F035B3ED9CC -- SID of user1 login, instance B
Christopher Kempster
95
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
In most cases, simply running the command below will fix the relationship and allow the
login to access the user database (must run against every database in which the login is
valid).
exec sp_change_users_login <see books online>
This will only work for SQL logins and not fully integrated logins (which is a down right
pain). Write your own script to resolve this problem.
If you are still getting errors, consider removing the user from the sysusers table in the
restored database, and re-add the user.
The DBA can validate NT login accounts via the command:
EXEC sp_validatelogins
NOTE – Do not use ALIASES; this allowed the DBA to map a single login to many
database user. This is a dated feature that may disappear in newer versions.
Microsoft released a great support document related to the scripting of logins, which
includes the original password. The script is not complete in terms of all possible options,
but is very handy:
Example: (http://support.microsoft.com/default.aspx?scid=kb;[LN];Q246133)
/* sp_help_revlogin script
** Generated Nov 17 2002 12:14PM on SECA\MY2NDINSTANCE */
DECLARE @pwd sysname
-- Login: BUILTIN\Administrators
EXEC master..sp_grantlogin 'BUILTIN\Administrators'
-- Login: user1
SET @pwd = CONVERT (varbinary(256),
0x0100420A7B5781CB9B7808100781ECAC953CB1F115839B9248C3D489AC69FA8D5C4BE3B11B1ED1A3
0154D955B8DB)
EXEC master..sp_addlogin 'user1', @pwd, @sid = 0x680298C78C5ABC47B0216F035B3ED9CC,
@encryptopt = 'skip_encryption'
-- Login: user2
SET @pwd = CONVERT (varbinary(256),
0x01006411A2058599E4BE5A57528F64B63A2D50991BC14CC59DB0D429A9E9A24CA5606353B317F4D4C
A10D19A2E82)
EXEC master..sp_addlogin 'user2', @pwd, @sid = 0xF1C954D9C9524C41A9ED3EA6E4EA82F4,
@encryptopt = 'skip_encryption'
Orphaned Sessions - Part 1
I rarely have to deal with orphaned sessions and worry little about them unless of course
it’s resulting in system degradation or chewing server CALs. The trick here is the
identification of the database session. This can be confusing, especially with connection
sharing via COM+ components - database process that you believe is related to a COM+
connection could be different when you next refresh the screen.
Christopher Kempster
96
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
We can assume the session is orphaned or killable by:
a) Processes Status = ‘awaiting command’
b) Proccesses Last Batch date – Getdate() is longer than what we typically expect
c)
We know the XYZ application and its logins/db connect properties crashed, but
processes remain.
d) If the SPID is -2 then assume the session is orphaned
The process information can be gleamed from sp_who or sp_who2 or querying
sysprocesses; and the utmost care must be taken. As such, I highly recommend you:
a) Run – DBCC INPUTBUFFER against the spid to determine its last statement of
work
b) Run – sp_lock to determine if the SPID is locking objects
To kill the SPID, use the KILL command.
The System Administrator may consider altering the TCP/IP keep alive timeout setting in
the registry:
HKLM\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\KeepAliveTime
The default is 2hrs and is measured in milliseconds. As a general guide, consider a lower
value in the order of one hour.
Orphaned Sessions - Part 2
An orphaned session has a SPID of –2. Orphaning may be caused by a variety of things
(though are rare) and is typically linked to the distributed transaction coordinator (DTC).
A DTC related problem will show up in the SQL Server log files with an error such as “SQL
Server detected a DTC in-doubt transaction for UOW <value>”. If the transaction issue
can not be resolved, then a kill statement can be issued over the UOW code. For
example:
Kill 'FD499C76-F345-11DA-CD7E-DD8F16748CE'
The table syslockinfo has the UOW column.
NOTE – Use Component Services when appropriate to drill into COM+ classes and
their instantiations to locate UOW to assist with killing the correct SPID at the
database.
Change DB Owner
You can change the database owner with the command:
Christopher Kempster
97
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
USE MyDatabase
EXEC sp_changedbowner 'MyUser'
GO
This requires the sysadmin instance privilege, and the user will logically replace the dbo
user (dbo can never be revoked/removed altogether). You cannot run this command
against the system databases. There is seldom any need to use this command.
Transfer Diagrams between databases
To transfer a database diagram from one database to another:
a) Determine the Object Id (or diagram) to be copied from database A to B.
The id column for dtproperties is an identity column. I have two
diagrams, one called “CKTEST” and the other called “Another Diagram”.
select objectid, value from dtproperties
b) To transfer the diagram, we need to ensure the objectid column is unique.
If not, we can set the value manually to whatever value we like.
INSERT INTO B.dbo.dtproperties
(objectid, property, value, lvalue, version)
SELECT objectid, property, value, lvalue, version
FROM A.dbo.dtproperties
The databases should be identical of course. If not, opening diagrams will result in the
loss of objects within the diagram OR you will simply see no diagrams listed at the
destination.
IMPORTANT – No diagrams in the destination database? The dtproperties table
will not exist and will, of course require changes to the steps above.
Christopher Kempster
98
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Transfer Logins between Servers
To transfer logins between servers and retain the logins’ passwords (SQL Logins),
consider utilizing the DTS task to transfer logins between servers, or use the following
SQL statement:
select 'sp_addlogin @loginame = ' + name + ', @passwd = "' + password
+ '", @encryptopt = skip_encryption, @deflanguage = "' + language + '"'
+ char(13) + 'go' from syslogins
where name in ('user1', 'user2')
The key to this script is the skip encryption option. Note that we still need to:
a) setup the login
database user relationship (sp_adduser)
b) assign database user privileges
Killing Sessions
Within SQL Server, each connection (physical login) is allocated a spid (system
server process identifier and worker thread). To identify them we can execute the
system stored procedures:
exec sp_who
or
exec sp_who2
The DBA can also use the current activity option under the Management Group folder
and select Process Info.
NOTE - Be warned. I have experienced major performance problems when
forcing the refresh of current activity via Enterprise Manager to a point where the
CPU’s hit a solid 50% for 5 minutes before returning back to me. This is not
acceptable when running against a hard working production system.
Once the SPID has been identified, we use the KILL command to remove the session.
For example:
select @@spid
exec sp_who2
Kill 55
Kill 55 with statusonly
-----
get my sessions SPID, in this case its 51
from output, determine SPID to be killed
issue kill request to DBMS
get status of the request
SPID 55: transaction rollback in progress. Estimated rollback completion: 100%.
Estimated time remaining: 0 seconds.
The DBA should reissue sp_who2 to monitor the SPID after the kill to ensure
success. Also consider looking at and joining over the tables:
• sysprocesses
• syslock
• syslockinfo
Christopher Kempster
99
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
You cannot kill your own processes. Be very careful you do not kill system
processes. The processadmin fixed system role will allow a user to kill SQL Server
sessions.
NOTE - Killing SPIDs running extended stored procedures or which did a call-out
to a user created DLL may take some time to kill and, in some cases, seem to have
stopped but remain as a running process.
The ALTER Statement
An alternative method to the KILL command is the alter database statement. The only
issue here is the alter database statement requires the database status to be altered, you
cannot simply kill user connections without making the database read only, for DBO use
only for example. Therefore, it may not suite your specific requirements.
Here is a practical example of its use:
alter database northwind set restricted_user with rollback immediate
The termination clause will perform the session removal and rollback of transactions. If
the termination clause is omitted, the command will wait until all current transactions
have been committed/rolled back.
See BOL for more information about the command. Try and use this command over KILL
when you need to disconnect all databases sessions AND change the database status.
How do I trace the session before Killing it ?
To get further information about a session, consider the command:
DBCC PSS (suid, spid, print-option)
For example:
--Trace flag 3604 must be on
DBCC TRACEON (3604)
--Show all SPIDs
DBCC PSS
DBCC TRACEOFF (3604)
GO
Another option apart from utilizing profiler is:
exec sp_who2
dbcc inputbuffer (52)
exec sp_MSget_current_activity 56,4,@spid=52
-- view all sessions
-- get SQL buffer for 52
-- get extended locking information
Taking this a step further, adapt the code fragment below to iterate through SPIDs
and capture their event data returned from INPUTBUFFER for further checking.
DECLARE @ExecStr varchar(255)
CREATE TABLE #inputbuffer
Christopher Kempster
100
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
(
EventType nvarchar(30),
Parameters int,
EventInfo nvarchar(255)
)
SET @ExecStr = 'DBCC INPUTBUFFER(' + STR(@@SPID) + ')'
INSERT INTO #inputbuffer
EXEC (@ExecStr)
SELECT EventInfo
FROM #inputbuffer
NOTE – DBCC INPUTBUFFER only shows a maximum of 255 characters and the
first statement only if the process is executing a batch. Consider ::fn_get_sql()
instead.
As of SQL Server 2000 SP3 (or 3a), the DBA can use the system function
::fn_get_sql() in association with the master..sysprocesses table and its three
new columns:
• sql_handle – handle to the currently running query, batch or stored proc,
a value of 0x0 means there is no handle
• stmt_start – starting offset within the handle
• stmt_end – end of the statement within the handle (-1 = end handle)
For a single script to save your time try this site:
http://vyaskn.tripod.com/fn_get_sql.htm
Setting up and Sending SQL Alerts via SMTP
This section will show you, through code, how to enable SQL Agent alerts and using a
simple stored procedure and DLL, send emails via an SMTP server rather than using SQL
Mail. We will cover these items:
•
SQL Agent Event Alerts
•
SQL Agent Tokens
•
Calling DLL's via sp_OA methods
•
Using RAISEERROR
•
The SMTP DLL
Here is the code for our simplecdo DLL (some items have been cut to make the code
easier to read). The routine is coded in VB and makes use of the standard CDO library:
Public Function SendMessage(ByVal ToAddress As String, _
ByVal FromAddress As String, _
ByVal SubjectText As String, _
ByVal BodyText As String, _
ByVal Server As String, _
ByRef ErrorDescription As String) As Long
'This is the original function (no attachments).
'
Christopher Kempster
101
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Dim lngResult As Long
lngResult = Send(ToAddress, FromAddress, SubjectText, BodyText, Server, "", ErrorDescription)
SendMessage = lngResult
End Function
Private Function Send(ByVal ToAddress As String, _
ByVal FromAddress As String, _
ByVal SubjectText As String, _
ByVal BodyText As String, _
ByVal Server As String, _
ByVal AttachmentFileName As String, _
ByRef ErrorDescription As String)
'Simple function for sending email from an SQL Server stored procedure.
'Returns 0 if OK and 1 if FAILED.
'
Dim Result As Long
Dim Configuration As CDO.Configuration
Dim Fields As ADODB.Fields
Dim Message As CDO.Message
On Error GoTo ERR_HANDLER
'Initialise variables.
Result = 0
ErrorDescription = ""
'Set the configuration.
Set Configuration = New CDO.Configuration
Set Fields = Configuration.Fields
With Fields
.Item(CDO.CdoConfiguration.cdoSMTPServer) = Server
.Item(CDO.CdoConfiguration.cdoSMTPServerPort) = 25
.Item(CDO.CdoConfiguration.cdoSendUsingMethod) = CdoSendUsing.cdoSendUsingPort
.Item(CDO.CdoConfiguration.cdoSMTPAuthenticate) = CdoProtocolsAuthentication.cdoAnonymous
.Update
End With
'Create the message.
Set Message = New CDO.Message
With Message
.To = ToAddress
.From = FromAddress
.Subject = SubjectText
.TextBody = BodyText
Set .Configuration = Configuration
'Send the message.
.Send
End With
EXIT_FUNCTION:
'Clean up objects.
Set Configuration = Nothing
Set Fields = Nothing
Set Message = Nothing
Send = Result
Exit Function
ERR_HANDLER:
Result = Err.Number
Christopher Kempster
102
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
ErrorDescription = "Number [" & Err.Number & "] Source [" & Err.Source & "] Description
[" & Err.Description & "]"
Me.LastErrorDescription = ErrorDescription
GoTo EXIT_FUNCTION
End Function
Copy the compiled DLL to your DB server and run the command below to install:
regsvr32 simplecdo.dll
The Stored Procedure
The routine below makes the simple call to the SMTP email DLL. We have hard coded
the IP (consider making it a parameter). I was also sloppy with the subject heading for
the email. Again this should be a parameter or better still a SQL Agent Token (see later).
CREATE PROCEDURE usp_sendmail (@recipients varchar(200), @message varchar(2000)) AS
declare @object int, @hr int, @v_returnval varchar(1000), @serveraddress varchar(1000)
set @serveraddress = '163.232.xxx.xxx'
exec @hr = sp_OACreate 'SimpleCDO.Message', @object OUT
exec @hr = sp_OAMethod @object, 'SendMessage', @v_returnval OUT, @recipients, @recipients, 'test',
@message, @serveraddress, @v_returnval
exec @hr = sp_OADestroy @object
GO
Creating the Alert
Run Enterprise Manager, under the Management folder expand SQL Agent and right click
Alerts - New Alert.
Christopher Kempster
103
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
In this case our alert is called CKTEST. We are going to send the DBA an email whenever
a logged severity 16 message occurs for any databases (not really practical, but this is
just an example).
Click on the Response tab next.
Uncheck the email, pager and net send options (where applicable for your system).
Check the execute job checkbox, drop down the list box and scroll to the top, and select
<New Job>.
Enter the Name of the new SQL Agent Job, then press the Steps button to create a step
that will call our stored procedure.
Christopher Kempster
104
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Here we enter the step name, it is a t-sql script of course, and the command which is:
exec master.dbo.usp_sendmail @recipients = '[email protected]',
@message = '
Error: [A-ERR]
Severity: [A-SEV]
Date: [STRTDT]
Time: [STRTTM]
Database: [A-DBN]
Message: [A-MSG]
Check the [SRVR] SQL Server ErrorLog and the Application event log on the
server for additional details'
This is where the power of Agent Tokens comes into play. The tokens will be
automatically filled in. There are numerous tokens you can leverage; here are some
examples:
[A-DBN]
[A-SVR]
[DATE]
[TIME]
[MACH]
[SQLDIR]
[STRTDT]
[STRTTM]
[LOGIN]
[OSCMD]
[INST]
Alert Database name
Alert Server name
Current Date
Current Time
Machine name
SQL Server root directory
Job start time
Job end time
SQL login ID
Command line prefix
Instance name (blank if default instance)
Click OK twice. The Job and its single step are now created. In the Response windows
press Apply, then press OK to exit the Alert creation window and return back to
enterprise manager.
Christopher Kempster
105
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Goto Jobs under SQL Server agent to confirm the new Job and its step we have just
created.
Testing the Alert
Run Query Analyser and run the following:
RAISERROR ('Job id 1 expects the default level of 10.', 16, 1) with log
The with log clause is important. The alert will not fire without it.
Shortly I receive the following email:
Recommended Backup and Restore Alerts
The following alerts are highly recommend for monitoring SQL Server backups and
recovery (59):
a) Error – 18264, Severity – 10, Database successfully backed up
b) Error – 18204 and 18210, Severity – 16, Backup device failed
c) Error – 3009, Severity – 16, Cannot insert backup/restore history in MSDB
d) Error – 3201, Severity – 16, Cannot open backup device
e) Error – 18267, Severity – 10, Database restore successfully
f)
Error – 18268, Severity – 10, Database log restored successfully
g) Error – 3443, Severity – 21, Database marked as standby or readonly but has
been modified, restore log cannot be performed.
The DBA can alter the text, and include the alert tokens as necessary.
Christopher Kempster
106
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
4
Chapter
High Availability
O
ne of the most important issues for many organisations revolves around disaster
recovery (DR), which goes hand-in-hand with the topic of high availability.
When we talk about high availability, we are primarily focused on almost
seamless failover of our servers hosting the applications they are running; and the
technologies to support the continuation of service with as little interruption to the
business as possible. The solution you come up with will be dictated by the realization of
its:
a) value-add to the business and customer expectations (latent and blatant)
b) cost of system downtime and manual cutover
c) issues of business continuity and system reliance
The problem you tend to have is that systems typically grow into this realization rather
than being born with it. As such, the DBA and system architects must carefully consider
the overarching issues with application state, server configuration, OS and DBMS editions
purchased, technologies being used (clusterable?) and to some degree, “brail the future
environment” in which the application will live and breath.
Throughout this chapter, we will compare and contrast the high availability options to
support your DR plan and identify issues in advance. We also cover clustering with
VMWARE so you can repeat the same tests using your home PC.
Purchasing the Hardware
So what hardware should I buy?
The selection of hardware, be it for a cluster or not is a tough job. The DBA relies on past
performance indicators, systems growth, wisdom of yourself and fellow IT professionals
and of course, restrictions outlined by enterprise architecture initiatives (and how much
of the budget you have). These and other factors can turn a great system into one that
has mediocre performance with great disaster-recovery, visa versa or none of these.
This section discusses some of many issues related to hardware selection.
Here are some general “rules”:
Christopher Kempster
107
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
a) Enterprise quality applications require hardware from enterprise hardware
vendors (HP/COMPAQ, IBM, DELL etc) - but shop around
b) Try and picture your future production environment and the business applications
hosted within it. Attempt to marry it with your enterprise architecture and its
possible visions for systems consolidation, this may also asssit in building your
dev/test environment. Looking forward is an essential planning skill that takes
some time to master, especially with IT.
c) Consider cheaper “components”, i.e. RAM, prices can be hugely inflated from the
larger hardware vendors. An absolute minimum for RAM is 2Gb ECC. Be very
careful with desupport dates on hardware, and again, looking into the future
through research may save you thousands of dollars.
d) Check OS compatibility lists carefully; you may find Windows 2003 is not on the
supported OS list for example – never take the risk.
e) Plan to use RAID in your DEV/TEST servers - but watch out for the number of free
drive bays, size your disks carefully!
f)
Be pragmatic with your RAID configuration, instances with multiple databases will
not mean a single RAID-1 set for each transaction log. Be concerned with
logical/physical read/writes and the tuning of SQL to reduce overall system load.
Be aware that RAID-5, with suitable HBA backup cache, and read/write cache will
meet most expectations.
g) Go SCSI-320 for internal disks. Read the next section on RAID and Storage for a
further insight. In production we should try a leverage enterprise class shared
mass storage devices (SAN’s) over direct attached storage solutions or very large
internal system storage.
h) Plan to hook into your enterprise backup software rather than buying the
hardware and tapes – networking issues? size of backups? impact on the
business? time to backup and restore? responsibilities and accountabilities? agent
OS compatibility? Tape drive per server is a very costly solution in the longer
term.
i)
When you make a decision on the hardware specs take time research the choice –
any issues? compatibility problems? potential install nightmares?
j)
Always pay for longer terms parts/labour warranties – but read the conditions and
turn around times very carefully.
k) Consider 64bit computing as the end-game for future hardware infrastructure.
Taking this a little further, here is a simple list to review and add to when selecting
hardware:
Server Check List
Operating systems supported by the hardware have been checked? (and you know the
OS requirements of the services to be run?)
Existing order will cover the services to be provisioned?
Enterprise backup agents/software supported on the chosen HW and OS?
Christopher Kempster
108
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
SAN connection required? Dual HBA’s? and is there a standard HBA to suit existing
switch technology?
Existing RACK’s can house proposed servers (in terms of free space and existing rack
dimensions)
Warranty and support has been factored in? restrictions based on distance, public
holidays, where parts are located etc
CPU, RAM (including stick configurations and free slots), HBA’s, NIC’s, Power
(swappable?)
BTU and power draw?
Installation and shipping included? Insurance covered?
Monitor/CD-ROM/USB/Mouse required?
SAN bootable? (any specific restrictions?)
Additional RAID card to achieve RAID-5?
Power slots required?
Management network interface?
Specific cluster support/restrictions ie. ex-public holidays, parts are stored on the other
side of the country?
Can the OS you plan to load onto the hardware support the features you plan to
purchase? ie. all the RAM/CPU’s, multi-clustered nodes etc.
What is the desupport date for the hardware? Is it old technology?
Do you plan to use virtualization technology? and if so, will the vendor support it?
What are the limits of a virtual machine that will adversely effect the services delivered
on them?
Is vertical scalability important? what criteria does this impose?
Can the power requirements of the server or rack be met in terms of its placement?
Can the equipment be moved to the location? (physical restrictions)
UPS required?
Dual Ethernet and HBA cards required? Communications team have standardized on
specific models?
So you are ordering a 4 cpu machine – what are the database licensing implications?
Will you purchase software assurance?
Hardware listed in the Windows HCL? (discussed in the next section)
I often see the consolidation of servers (incl. storage) and their hosted applications onto
one of the following architectures:
1) Medium to large scale co-located servers in clusters within a data center;
this typically represents the same set of servers for each application but
with their co-location to a single managed environment.
2) SAN (fiber or iSCSI) mass storage, leveraged by racked 1U and 2U blade
servers . The blade servers are of course co-located servers into a data
center; this is similar to 1) but sees the introduction of storage
consolidation and commodity blade servers.
3) SAN (fiber or iSCSI) mass storage, leveraged by consolidated large scale
servers hosting numerous virtual servers using virtual server software/or
alternatively virtualized at the BIOS/OS level where supported (typically
Unix implementations). This is taking 1) a step further with the reduction
in the total number of servers into clustered large-scale enterprise servers
that virtually host a reduced number of environments where possible.
4) SAN with VMWARE or other server virtualization technology (such as
LPAR) on highly scalable server infrastructure.
Christopher Kempster
109
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
See Appendix A for further information on SAN, NAS, iSCSI, RAID and TAPE
issues. We also cover the basics of data center based hardware such as racks and
blade servers.
No matter the project’s budget or the timeframe for production rollout, make every
attempt to align with your enterprise vision for hosted production systems and seek
active buy-in and support from executive management.
What is the HCL or the “Windows Catalog”
The Quality Online Service offered by Microsoft is a quality endorsement policy and
procedure that allows hardware and software vendors to use the “designed for windows”,
“certified for windows” and “.net connected” logos. The vendor must pass a range of
tests, typically managed by a third party company which at last view was managed by
VeriTest (www.veritest.com). Apart from the fact that software and hardware is retested independently, the certification typically means you will (potentially) have fewer
issues when purchasing the goods and will be better supported by Microsoft. This is
particularly important in clustered server implementations.
As a general recommendation, read before you buy! Do not purchase hardware without
some prior understanding of HCL (hardware compatibility list) and the Microsoft Windows
Catalog support; especially in large scale enterprise solutions and associated operating
systems (like data centre server). I personally do not believe Microsoft would provide
any different support to that given to HCL hardware/software buyers, but will certainly
make your life harder if you do have serious problems.
A classic case in note was iSCSI (discussed later) support within Windows 2003 and MS
Exchange. Although fully supported, the HCL was very sparse in terms of vendors
compliance as at March 2004.
Read more at: https://winqual.microsoft.com/download/default.asp
High Availability using Clusters
In my previous e-book, “SQL Server 2k for the Oracle DBA”, I discussed SQL Clustering
in some depth but not much a lot about recovery in this environment. This chapter will
cover a large number of day-to-day issues you may experience using this technology,
and provide a walkthrough using VMWARE.
Please download the free chapter on High Availability from my website for more
information on SQL Clusters.
Let us clarify first the following availability terminology:
a) Hot Standby (passive SQL Cluster) – immediate restoration of IT services
following an irrecoverable incident. The delay will be less than 2-4hrs.
b) Warm Standby (bring online passive DR servers) – re-establishment of a
service within 24 to 72hrs, be it local or remote in nature. The full service
is typically restored.
Christopher Kempster
110
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) Cold Standby (establishment of new servers/environment) – longer than
72hr restoration of full IT services.
Identification of SPOF (single points of failure) and their risk/mitigation and contingencies
strategies is of key importance. The design for high availability needs to consider the
elimination of single points of failure or provision alternate components to minimize
business impact. The ITIL framework suggests these definitions:
a) High Availability – mask or minimizes the effect of IT component failure.
b) Continuous Operation – mask or minimize the effect of planned downtime.
c) Continuous Availability - mask or minimize the effect of ALL failures.
From a SQL perspective, the DBA can utilize a number of strategies to mitigate the risks:
a) Windows Clustering and SQL Server cluster technology;
b) Log Shipping;
c) Replication - can be complex to configure and manage. Also remember
that changes are not automatically provisioned into the published
replica(s), requiring ongoing administrative effort and careful change
control practices. Due to this, I do not regard it as a overly effective form
of high availability; and
d) Federated Databases - primarily for performance over availability.
This chapter will cover a) and b) only. There are many third party high availability
solutions not covered in this ebook, including:
a) Legato Costandby Server
b) PolyServe Matrix HA
c) SteelEye LifeKeeper
d) Veritas Clustering Service (VCS) and ClusterX products
Using VMWARE we will cover SQL Server Clustering and troubleshooting techniques.
VMWARE SQL Cluster - by Example
The VMWARE software from VMWARE the company (www.vmware.com) allows us to run
virtual machines (VM) over an existing operating system, creating an interface layer
between physical devices and allowing the user to define virtual hardware from it. The
software goes further though, allowing us to build new devices that physically do not
exist, such as new disk drives, network cards etc.
The version we will be using is called VMWARE Workstation v4.0, check the vendors
website for new editions. The direct competitor to VMWARE in the Microsoft space is
Microsoft Virtual PC (and server when it is released). Although a good product, I found it
slow and did not support SQL clustering during the writing of this particular chapter.
Christopher Kempster
111
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
IMPORTANT – Installing VMWARE virtual machines will NOT replace your existing
host operating system in any way. The VMWARE itself depends on the host OS
itself to run.
The aim here is to:
a) allow the DBA to replicate SQL Cluster testing with a relatively low spec PC – the
machine used for this example is a AMD 2.6Ghz, 1Gb RAM, single 80Gb drive;
b) catalyst to discuss cluster design issues; and
c) allow DBA’s to realize the benefits of virtual server environments as another form
of high-availability and server consolidation.
Using VMWARE in Production?
To be right up front, I am a BIG advocate for VMWARE, not only in your
development/test environments, but also in production. As an example, I worked with a
customer that ran mission critical applications in high-scalable IBM x445 servers (16
CPU’s) over VMWARE ESX.
Four servers were provisioned within a in a geographically dispersed environment
connected to large SAN’s via fiber interconnects. The servers ran a mix of Linux and
Windows 2003 operating systems, all provisioned from golden templates (discussed
later) running as SQL clusters and a variety of other smaller applications.
The essential value added extras with the virtualized server environment were:
a) speed in which new virtual servers (and application services) can be provisioned;
b) virtual servers could be moved in near realtime (whilst running) between physical
hardware through VMOTION technology;
c) test environments could be establish as mirrors of production within a matter of
minutes;
d) VMWARE Virtual Center provides a single unified management interface to all
systems, no matter their underlying OS; and
e) large capacity (and relatively cheap x86 architecture) hardware can be better
utilized.
Step 1. Software & Licensing
In the following steps we are using VMWare Workstation 4.0.5; you can download a trial
from www.vmware.com. Install the software as per installation guide. As a general idea I
run Windows XP Pro with 1Gb RAM on a 2.6Ghz AMD chip; reserve approximately 1.8Gb
of HDD space per server then add around 500Mb per SCSI disk in the fake disk array
thereafter (we install 3 non-raid disks in the array).
At the same time, think about the server operating system you plan to install. We require
three nodes in a virtual network, being:
1) Domain Controller
Christopher Kempster
112
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
2) Cluster Node 1
3) Cluster Node 2
Take care with this step. The OS must support the cluster service (of course). The
following example is using Microsoft Windows 2000 Advanced Server edition. Check
carefully with your local Microsoft vendor/re-seller regarding personal use licensing
issues, as we are installing three servers.
The DBA should be aware of the following limits:
Windows 2000 Advanced Server
Windows 2000 Data Center Server
Max 2 Nodes, 8 CPU’s, 8Gb RAM
Max 4 Nodes, 32 CPU’s, 64 Gb RAM
Windows 2003 Enterprise Ed
Windows 2003 Data Center Ed
Max 8 Nodes, 8 CPU’s, 32Gb RAM
Max 8 Nodes, 32 CPU’s, 64Gb RAM
Paul Thurrott has a great website for feature comparisons and Windows in general http://www.winsupersite.com/showcase/winserver2003_editions.asp
http://www.winsupersite.com/reviews/win2k_datacenter.asp
IMPORTANT – “Microsoft does not support issues that occur in Microsoft
operating systems or programs that run in a virtual machine until it is determined
that the same issue can be reproduced outside the virtual machine environment.”,
See MS Support #273508 for the full support note. Do note that many corporate
resellors of VMWARE will provide this level support.
Step 2. Create the virtual servers
Run VMWARE, select File
New Virtual Machine, select typical machine configuration
and from the drop down list we pick Windows 2000 Advanced Server. Enter the name of
the virtual server (it makes no difference to the host name of the server itself) and the
location of you server on disk. I have placed all virtual servers at:
C:\work\virtualservers\
VMWare will pick up all current PC hardware and provide a summary, along with RAM
(memory) it plans to use on the virtual machines startup. Generally no changes are
required. Do not alter the network unless you are very comfortable with vmware
network bridging.
Below is a screen shot of the server before startup:
Christopher Kempster
113
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
You can create all of your virtual servers now if you like to save you repeating the
process, but we only start off with the domain controller. The three servers I have
created are:
a) winas2kdc – domain controller
b) winas2kcn1 – cluster node 1
c) winas2kcn2 – cluster node 2
NOTE – We do not use VMWARE server templates (also known as golden
templates) as it requires extensive coverage by system administrators (not me!).
The golden template is a “known image” (or copy) of a virtual server at some point
in time. The image includes the base software any of your normally provisioned
servers would include and is carefully crafted to remove networking issues when
new servers are created from the template and put online.
Click on edit virtual machine settings, and reduce the Guest Size (MB): value down to
around 150 to 220Mb of RAM. No other change is required.
The “end game” is this configuration:
Christopher Kempster
114
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
MYDOMAIN.COM
MSCS Service
“MYCLUSTER”
192.168.1.75
winas2kdc
192.168.0.132
DNS
C:
“SQLCLUSTER1”
192.168.0.78
winas2kcn1
192.168.0.134
AD
DHCP
NIC1
NIC1
NIC1
C:
winas2kcn1
192.168.0.136
C:
NIC2
NIC2
10.1.1.3
Q:
10.1.1.2
E:
F:
NOTE – My naming conventions for the servers - please do not take them to
heart; they are only examples and care must be taken using the OS installed as
part of the hostname for obvious reasons.
Step 3. Build your domain controller
Place the Windows server disk in the cd-rom and start the virtual machine. From here
complete a standard installation of the operating system. The VMWare software will not
affect your current PC operating system, so don’t concern yourself about the steps
related to formatting disks. Ensure NTFS is selected for the file system.
•
When asked, you have no domain or work group to join. If prompted to enter a
new one, enter the word: MYDOMAIN
•
Leave all network options standard (typical). Do not alter them yet.
•
When the install is complete, login to the server as administrator.
By default, the Windows 2000 Configure Your Server dialog is shown with a range of
options. First step is to install active directory. Select this option and follow the prompts.
When asked for the domain name, enter MYDOMAIN.COM and carry on with the defaults
from there.
Run the DNS management tool. We need to configure a zone for mydomain.com.
Expand the tree in the left hand pane and right click properties on Forward Lookup Zones
and select new. I have selected active directory integrated. Once created, select the
zone, right click for properties and click add host. We are going to add the a host entry
representative of the virtual IP of the cluster itself. This host/server will be called
Christopher Kempster
115
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
mycluster (or mycluster.mydomain.com). One of the member servers that are active at
the time in the cluster will take on this IP as we will see later. The IP is 192.168.1.75
Exit from the DNS management utility.
Before we continue, minimize all windows, and on the desktop, select properties of the
My Network Places, I have only one NIC defined for this virtual server so I see:
Select properties of the LAN connection, my TCP/IP properties are as follows:
Christopher Kempster
116
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The default gateway was actually picked up from my local PC settings, and this is the
gateway properties used for my internet connection sharing with another PC on the
network. Note the IP address and the DNS entries, as expected for the role of the
server.
Under the networking option in Windows 2000 Configure Your Server installs DHCP in
order for the domain controller to allocate IPs to the two member servers when they
come online. The IPs will be reflected in the DNS as the servers are built and come
online into the domain, as one would expect of the DNS.
Create a new scope within DHCP, I called it mynetwork. I have allocated a DHCP address
pool with a range between 192.168.0.133 to 192.168.0.140 (any server member server
will get a IP from this range).
Clicking next will ask for any exclusions (or reservations). Ignore this, and retain the
default lease period of 8 days to complete the DHCP configuration.
Close the DHCP management utility. Go back to Windows 2000 Configure Your Server
and select Active Directory and Manage. We need to create another user with
administrative rights. This is our cluster admin user:
Christopher Kempster
117
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The username is cluster (for want of a better word), and is a member of the
administrators group. Exit once this is done.
NOTE – Using DHCP for your cluster nodes is NOT recommended and is far from
best practice. I have used it as a demonstration; revert to fixed IPs and remember
to update the DHCP IP range as need be.
Step 4. Build member server 1 (node 1 of the cluster)
Leave the domain controller up and available. We now configure a member server. This
will be node 1 of our cluster. Before we start this virtual server and carry on with the
installation, we need to setup a number of fake SCSI disks (to simulate a disk array in
which the cluster will add as disk resources) and another NIC for the clusters private
network (remember I only have 1 physical NIC in my server, so I need to add a virtual
one in VMWARE).
IMPORTANT – try and keep installation directories and servers identical in the cluster node
installation to avoid any later issues.
Adding SCSI Disks
To simulate a disk array/SAN, or a “bunch of disks” for the cluster, VMWARE allows us to
create virtual disks (simply files in a directory) and add them to both servers in the
cluster via a disk.locking=false clause in the .VMX file for each node.
Before we continue, the solution presented here does not use VMWARE edit server
options to add a hard disk:
Christopher Kempster
118
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
After some effort, I found the VMWARE SCSI drivers did not load on the node, and could
not re-install them. To get around this, visit Rob Bastiaansen’s website to download plain
disks:
http://www.robbastiaansen.nl/tools/tools.html#plaindisks
And extract the disks into a folder called:
C:\work\virtualservers\disks
Edit the .PLN file for the disk and change the path to the disk (.DAT) file; do not alter any
other setting in the .PLN file. I copied the file twice, giving me three 500Mb plain disks.
For each .VMX file on our virtual server cluster nodes (not our DC):
a) shutdown the node
b) locate and edit with notepad the .VMX file for the node
c) Add the following:
<after the memsize option add..>>
disk.locking = "FALSE"
Christopher Kempster
119
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
<<add these near the bottom of the file>>
scsi1.present="true"
scsi1:0.present= "true"
scsi1:0.deviceType= "plainDisk"
scsi1:0.fileName = "C:\work\virtualservers\disks\plainscsi1500mb.pln"
scsi1:1.present= "true"
scsi1:1.deviceType= "plainDisk"
scsi1:1.fileName = "C:\work\virtualservers\disks\plainscsi2500mb.pln"
scsi1:2.present= "true"
scsi1:2.deviceType= "plainDisk"
scsi1:2.fileName = "C:\work\virtualservers\disks\plainscsi3500mb.pln"
Before we start the first server of our cluster, we need to add another NIC.
Adding another NIC for the Private Network
For each server that will be a node in the cluster, we require two NIC’s:
1) For the private network between cluster nodes
2) For the public facing communication to the node
I assume that most people have at least one NIC, if not, use VMWARE and the edit
hardware option to add the two NIC’s. Leave options as default.
For each node when booted, set up IP properties as such:
Node 1
Node 2
For each node, disable netbios over TCPIP for DHCP:
Christopher Kempster
120
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The actual networking and connection of the server’s NICs can be varied, and I suggest
that the Network Administrators / Communications Specialists be approached well before
the purchase of any hardware. At a high level, we tend to this sort of configuration:
Server
/Node
NIC
Teamed network cards via
SW/HW and trunking
Switch
“Private” network via
switch is configured as
a VLAN
Switch
Multi-switch redundency
Switch
Also, be aware the of the following:
“By agreement with the Internet Assigned Numbers Authority (IANA), several IP networks are always left
available for private use within an enterprise. These reserved numbers are:
•
10.0.0.0 through 10.255.255.255 (Class A)
•
172.16.0.0 through 172.31.255.255 (Class B)
•
192.168.0.0 through 192.168.255.255 (Class C)
You can use any of these networks or one of their subnets to configure a private interconnect for a cluster.
For example, address 10.0.0.1 can be assigned to the first node with a subnet mask of 255.0.0.0. Address
10.0.0.2 can be assigned to a second node, and so on. No default gateway or WINS servers should be
specified for this network.”
Prepare your SCSI disks
With the disks and NICs added, we need to partition and format the disks.
a) Start your DC server first
Christopher Kempster
121
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b) Start server 1 (winas2kcn1), leave the other server down for the time being.
c) When booting the server, notice in the bottom right hand corner the list of
resources for this server (ignore floppy disk drive messages):
d) Login to the server using the domain administrator account
e) When you login, the server will detect new hardware and install the VMWARE
SCSI drivers for you.
f)
My computer
g) Storage
Manage
Disk Management
h) For each of the three disks listed, DO NOT MAKE THEM DYNAMIC DISKS (also
known as disk signing). Simply create a partition, and format using NTFS,
extended partitions.
a. My disks are mapped to Q:\ (disk1, will be Quorum disk), E:\ and F:\
i)
Repeat this for the other cluster node - winas2kcn2
j)
Once done, shutdown server 2 - winas2kcn2.
Install Cluster Services on Server (node) 1
Now the disks have been added and prepared, and we have two NIC’s defined for our
server nodes:
a) Start your DC server first – already started from previous step
b) Start server 1 (winas2kcn1) – already started from previous step
Christopher Kempster
122
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) Leave server 2 (winas2kcn2) down
d) Login with your domain administrator account
e) Navigate to control panel, add/remove programs, add/remove windows
components. The cluster services option will be shown. Run this option
f)
This will be the first node in the cluster:
g) Enter the name of your cluster: MYCLUSTER (the virtual host entry we made in
DNS)
h) Enter the username and password of our cluster administrator user. We called it
“cluster”, and the domain name MYDOMAIN.
i)
Your SCSI disks are shown. We will retain all three disks for this managed cluster
resource.
j)
Pick our Q:\ as the quorum drive (holds all cluster checkpoint and log files
essential to the cluster resource group).
k) Next we are asked about our network configuration. At the first prompt pick your
private network card and select the radio button option “internal cluster
communications only” (private network).
l)
Then we are asked about our public network. Select “all communications (mixed
network)” in the radio button. Addressing is self explanatory.
m) Click through and the cluster service should be up and running:
Christopher Kempster
123
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
NOTE – The following examples are using Windows 2000. Do note that in
Windows 2003, if no shared disks are detected, then a local quorum will be
automatically created; you can also create a local quorum resource after cluster
installation. The local quorum information will be stored in
%systemroot%\cluster\MSCS. Of course, being local it will remain a single node
cluster installation.
To create the quorum with a local resource, use the /fixquorum switch. The
creation is also covered in MS Support article #283715.
Validate Node 1 in the cluster via Cluster Administrator
Open the cluster administrator program:
And we see this. Notice our node 1 (winas2kcn1) is the owner of the resources? Click
through options to familiarize yourself with the cluster.
Run IP config (ipconfig command via the DOS prompt), notice that this server has the IP
address of mycluster (as defined in DNS).
Christopher Kempster
124
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Step 5. Build member server 2
With the DC (domain controller) and node 1 online, we have added both disks to both
servers and configured their private networks. Now we complete installation by installing
cluster services on node 2.
Boot node 2. Using the control panel wizard continue with cluster service installation by
selecting the second or next node in the cluster:
You will be asked the name of the cluster to join. DO NOT USE “mycluster”. Use the
name of server 1 (winas2kcn1) that currently owns the cluster. Use our cluster user
account to authenticate.
Run cluster administrator to verify your node:
Christopher Kempster
125
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Step 6. Install SQL Server 2k in the cluster (Active/Passive)
Our VMWARE cluster is now up and running. We will install SQL Server 2k in
active/passive mode in the cluster (i.e. a single named instance on the cluster, not
multiple instances running on both nodes). Remember than only one server (node) in
the cluster can open and read/write to/from the database files at any one time, no
matter how many nodes you have in the cluster. An active/active cluster simply means
two separate instances with their OWN disks and database files are running on both
nodes of a two server cluster (for failover reasons, DON’T install two default instances on
each node – simple but common mistake).
IMPORTANT – SQL Server 2000 SP3 or higher is only supported under a
Windows 2003 cluster.
I will not discuss the wide and varying issues with clusters and sql server 2k installation.
Please visit Microsoft Support and MSDN for detailed articles covering a majority of them.
Also take the time to visit www.sql-server-performance.com and
www.sqlservercentral.com for their feature (and free) articles on clustering sql server.
REMEMBER – You can only install SQL Server Enterprise Edition on a cluster.
You will require:
a) SQL Server 2k Enterprise Edition
b) Latest service pack
IMPORTANT – The setup of COM+ on Windows 2003 is completely different to
running comclust.exe on Windows 2000. The administrator must manually create
the MSDTC group, including IP, Network Name and the DTC resource via the
Cluster Administrator.
Follow these steps to install the DBMS (assumes all servers are up and
installed/configured as described earlier).
Christopher Kempster
126
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
1) On each cluster node, run comclust.exe:
2) From the primary node in the cluster, run cluster administrator
3) Verify MSDTC is clustered correctly by navigating to the resources folder. Check
each node to ensure the distributed transaction coordinator service is running.
Nodes with a DTC issue are shown in the administrator tool:
My node 2 locked up with the CLB setup. A CTRL-C did the trick and a manual
bring resource online via cluster administrator worked without failure. This ebook does not cover such issues.
4) It is generally recommended you turn off all services except the following before
installation (confirm between OS releases):
Alerter
Cluster Service
Computer Browser
Distributed File System
Distributed Link Tracking Client
Distributed Link Tracking Server
DNS Client
Event Log
IPSEC Policy Agent
License Logging Service
Logical Disk Manager
Messenger
Net Logon
Plug and Play
Process Control
Remote Procedure Call (RPC) Locator
Remote Procedure Call (RPC) Service
Remote Registry Service
Removable Storage
Security Accounts Manager
Server
Christopher Kempster
127
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Spooler
TCP/IP NetBIOS Helper
Windows Management Instrumentation Driver Extensions
Windows NT LM Security Support Provider
Windows Time Service
Workstation
5) Before we install SQL Server 2k – use cluster administrator to offline DTC, right
click for resource properties:
6) Place your SQL Server disk in the CD-ROM, and begin installation on node 1
(win2kascn1)
7) You are prompted, by default for the virtual server name, we will call this
sqlcluster1:
8) We are prompted for the virtual IP of our sql server instance within the cluster.
The resource will be failed over as required in the cluster. Before I enter the IP
here, goto to your domain controller server, run DNS, and add a new Host record
for this server. Double check your DHCP settings also to ensure the integrity of
the allocated IP:
Christopher Kempster
128
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
9) Pick our default data file disk, don’t use your Q:\ (quorum drive); we will use F:\
10) Our two nodes will be shown. We want all servers to be used; no changes
required.
11) Go back to your domain controller. Create a new domain user called
“SQLServerAdmin” and add it to the administrators group. This is the service
account that will run our SQL Server clustered instance.
Christopher Kempster
129
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
for each node, add this user in the administrators group:
and continue on with the SQL Server installation with this domain account:
Christopher Kempster
130
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
12) Enter the instance name, we will use a named instance:
13) You are shown the standard summary screen:
Christopher Kempster
131
T R O U B L E S H O O T I N G
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
We do not install the binaries on the clustered disks. They remain local to the
node. Check Custom and continue.
14) Select your components. Note that Full Text Indexing is not on the list. This will
be installed by default as a cluster resource.
15) Select you service startup account:
16) Then run through your authentication mode, collation, and network library
properties. I leave all default but choose mixed mode.
IMPORTANT – For each instance, ensure you fix the PORT properties over TCPIP.
Do not let SQL Server automatically assign the port as it can change between nodes in
the cluster.
17) Setup begins, node 1 then automatically on node 2:
Christopher Kempster
132
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
18) Complete
19) Reboot Node 1, then Node 2
20) Run Cluster Administrator on either node to verify the cluster:
Note that all resources are under disk group 2. Move them with caution as all are
dependent on one another for a successful failover.
For the active node (node 1), check its IP configuration:
SQL Server virtual IP
Cluster virtual IP
Node 1’s DHCP IP
You should be able to PING the:
a) server cluster IP address - 192.168.1.75
b) server cluster name (network name of the cluster) – 192.168.0.78
Christopher Kempster
133
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
IMPORTANT – In an active/active cluster, remember that the total memory usage
of all instances should be less than the total memory of a single node. If all
instances fail to one node then it must be able to support, in terms of memory, all
databases. If not you will experience severe paging and very poor performance.
Also be reminded that a maximum of 8 instances can run on a single node, and
only one default instance may exist within the entire cluster.
Test Connectivity
Our SQL Server Named instance is referred to as : SQLCLUSTER1\SS2KTESTC1
The port and this instance name can be verified by running the server network utility on
either node in the cluster.
From my PC (that is running VMWARE), install the client tools (client network utility,
query analyzer), and create an alias via the client network utility as such:
If you cannot connect, double check the server name, the port, the enabled protocols,
attempt to ping the sql server virtual IP and the cluster IP.
Christopher Kempster
134
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
High Availability using Log Shipping
The process in SQL Server works at a database level, not at a global instance level as you
will see later. The aim here is the create a warm standby server in which one or more
databases are permanently in recovery mode. The source database ships transaction log
backup files to the destination server and we restore (with no recovery option) the logs
sequentially (in order). If there is a failure on the source server we attempt to recover
the last of the transaction logs, ship it to the destination server and complete the
database recovery. Once done, we send client connects to the new server and they
continue to work with little or no data loss.
Windows Domain
Server B
(standby)
Server A
(primary)
DatabaseA
DatabaseA
Client
Connections
Backup
Transaction
Log to network
share
Restore
Log with
norecovery on
destination
server
NOTE - we have not diagrammed the full database backups that must also be logshipped to start the process.
The DBA can use a custom written script or the SQL Server Wizard to do the shipping.
The shipping in most cases will be to a server on the same Windows 2k network domain,
but there is no reason why VPN tunnels over large distances or other remote scenarios
are not utilized.
IMPORTANT – You do not require enterprise edition of SQL Server for log
shipping.
If you further help over what has been provided in this ebook for custom shipping,
then get hold of the SQL Server 2000 Resource Kit from Microsoft.
Christopher Kempster
135
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The supplied wizard provides all necessary steps to setup log shipping for selected
databases. Before doing so remember the following:
document the process before running the wizard
how will the client application components detect the failover?
databases must be in full or bulk-logged recovery mode
ensure instance names are the same on source and destination servers
pre-determine the log backup schedule for the source database
pre-setup the transaction log backup directory via a network UNC path (referred
to by both source and destination DTS jobs)
create DTS packages on both servers and use the transfer logins job to facilitate
the transferring of login information between shipped servers.
Must run the wizard using a login that has sysadmin system privileges
Once the log shipping DTS (maintenance plan) has been created, go to the Management
Folder in EM and select properties of the log-shipping job to view the process/steps.
See reference (56) for a documented “How-To” for log shipping in a SQL Server 2k
environment using the Wizard.
Manual Log Shipping - Basic Example
Here we will discuss a working example that was coded using two stored procedures,
a linked server, two DTS packages and (optionally) pre-defined backup devices.
This example revolves around a single server with two named instances:
Christopher Kempster
136
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Primary Database Instance - SECA\MY2NDINSTANCE
Standby Database Instance - SECA\MY3RDINSTANCE
i.
Setup disk locations for primary and destination backups and test with SQL
Server service account.
Backups on primary server are dumped to \primary and
are then “shipped” via a simple xcopy to the \standby
directory from which they are restored.
ii. Pre-determine what account will be used for doing the backups, establish the
linked server and restore backups on the primary and standby databases. I
recommend that you create a new account with sysadmin rights on both
servers to facilitate this.
iii.
Setup Linked Server on primary server to destination server
We will link from the primary server
over to the standby server via the
account specified in step 2. Data
source is the server/instance name we
are connecting too.
In this case we are using the SA
account which is not best practice, but
will suffice for this example.
Apart from the SA account mapping
above, no other mapping will be valid.
Christopher Kempster
137
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Ensure remote procedure call options are
set to facilitate the calling of t-sql stored
procedures on the standby server from the
primary server.
* If you are using EM, and have registered the server under an account not mapped in the linked
server, then the linked server will not work for you. Check your EM registration before attempting
to view tables/view under the linked server within EM.
iv.
Setup database backup devices on primary server
This is completely optional and really depends on the backup model you are
using. SQL Server allows you to pre-create backup devices, once created, we
can use the logical name for the backup device (which maps to a physical file)
rather than the using the physical path and filename for the backup. This
makes scripting much friendlier and easier to read/change.
Here we create two devices, one for full backups and the other for logs. See
management folder within Enterprise Manager and the backup folder item item
to create these:
v.
Check primary server database recovery model. Select properties of the
database via EM. Ensure the model is in line with the backups you will be logshipping.
vi.
Write two stored procedures that will reside in the master database on the
standby server for recovery of the FULL and LOG backups. The standby restore
option is what tells SQL Server that the database is in warm standby mode.
CREATE PROCEDURE dbo.StandbyServer_restore_full_database_backup AS SET NOCOUNT ON
RESTORE DATABASE logshiptest
FROM DISK = 'e:\backups\standby\logship_primaryserver_full_backup.BAK'
WITH
RESTRICTED_USER, -- leave db in DBO only use
REPLACE, -- ensure overwite of existing
STANDBY = 'e:\backups\standby\undo_logshiptest.ldf', -- holds uncommitted trans
MOVE 'logshiptest_data' TO 'e:\standbydb.mdf',
MOVE 'logshiptest_log' TO 'e:\standbydb.ldf'
GO
CREATE PROCEDURE dbo.StandbyServer_restore_log_database_backup AS SET NOCOUNT ON
RESTORE LOG logshiptest
FROM DISK = 'e:\backups\standby\logship_primaryserver_log_backup.BAK'
WITH
RESTRICTED_USER,
STANDBY = 'e:\backups\standby\undo_logshiptest.ldf' -- holds uncommitted trans
GO
Christopher Kempster
138
S Q L
vii.
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Write two DTS packages on the primary server, one to do a full backup and the
other a log backup.
Package 1 – Primary Server, Full Database Backup
exec
standbyserver.master.dbo.StandbyServer_restore_full_database_backup
BACKUP LOG logshiptest
WITH TRUNCATE_ONLY
WAITFOR DELAY '00:00:05'
BACKUP DATABASE logshiptest TO
logship_primaryserver_full_backup
WITH INIT
WAITFOR DELAY '00:00:05'
Package 2 – Primary Server, Log Database Backup
BACKUP LOG logshiptest TO
logship_primaryserver_log_backup
WITH INIT, NO_TRUNCATE
exec
standbyserver.master.dbo.StandbyServer_restore_log_database_backup
WAITFOR DELAY '00:00:05'
Christopher Kempster
139
S Q L
viii.
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Test Full then Log DTS routines and debug as required
ix.
Schedule DTS packages
x.
Monitor
xi.
On failure of the primary, do the following
-- Login to primary server (depends on failure), and attempt to backup last database
log file
BACKUP LOG logshiptest TO logship_primaryserver_log_backup WITH INIT,
NO_TRUNCATE
-- Login into standby server
restore database logshiptest with recovery
Deleting database file 'e:\backups\standby\undo_logshiptest.ldf'.
RESTORE DATABASE successfully processed 0 pages in 4.498 seconds (0.000 MB/sec).
-- Ensure client connections are connection to the now live “standby” server.
Some thoughts about this setup:
a) The full and log backups are being appended to the same file, consider writing
better backup routine on the primary server than produces separate files for
each backup with a date/time stamp. Do this in a T-SQL stored procedure on
the primary database and consider replacing the DTS copy command with a
call to xp_cmdshell within the stored procedure.
b) If using a), parameterize the two recovery procedures on the standby server
to accept the file path/filename of the file to be recovered. The routine in a)
will have all this information and can pass it to the standby server without
any problems.
c) Consider email on failure DTS tasks.
d) Consider how you will remove backups N days old?
e) Will the standby ever become the primary and effectively swap serve roles?
Custom Logshipping – Enterprise Example
The Enterprise Edition of SQL Server 2k includes the ability to configure and run log
shipping; I find the process overly complex and a little restrictive in terms of control (i.e.
I want to zip files, or FTP them to remote sources – we have no such options in the
supplied method).
The scenarios I have implemented the custom log ship routines on are:
a) Heavily used OLTP database hosted on our “source server”
b) We currently backup to two destinations (called duplexing) on disk
Christopher Kempster
140
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) We have a reporting requirement as well (destination server), and have chosen to
log ship the database to this server.
The architecture is summarized below:
We take full and transaction log backups via a custom written stored procedure. The
routine will dump the files to a disk array on the source server and optionally gzip
(compress) them. The stored procedure will then copy the file to the remote server over
a network share with appropriate service user privileges for the instance. Any failures
are reported to the DBA via email. Also note that the copy to the remote server can be
easily changed to an FTP and servers must be time-synchronized otherwise you will get
the error "There is a time difference between the client and the server".
At the destination server, we manually run the Initialize stored procedure. This routine
will search the dump directory for specific pre and post fixed files specified by the
procedures incoming parameters. Using xp_cmdshell and the dir command, we build up
a list of files in the directory, locate the last FULL (unzip) then restore. We then search
for a differential backup, apply this, and carry on applying the subsequent transaction log
files. All restore commands used for the database are logged into a user defined master
database table.
Finally, we call a simple monitoring stored procedure that looks for errors in the log table
every N minutes (as defined by the DBA); emailing errors via CDO-SYS and your local
SMTP server.
Advantages
•
No requirement for linked servers
Christopher Kempster
141
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
•
Simply scripts with no complex lookups over the MSDB database, very easy
the change and enhance
•
Easy to setup and configure
•
Will not, by default, force the overwriting of existing database files used by
other databases
•
Will search for full, differentials and logs and apply in correct order, so long as
files copy OK
Disadvantages/Issues
•
Requires a network share to copy files (can be a security issue)
•
Cant pre-detect missed or missing files (as you could if you utilized the
MSDB)
•
Cant pre-detect invalid file sizes
•
Does not do a quick header and file check and compare DBA's passed in
parameters with
•
Relies on the DBA to supply move commands for the restore as a parameter
(see later), does not dynamically pick up database files/filegroups from the
backup files themselves.
•
User sessions must be killed on the log shipped database before attempting
the restore command
o
The only way I can see around this is via a physical log reader/parser
program and the DBA runs SQL scripts rather than applying the log
itself.
Configuration & Installation
All scripts are custom written and are typically stored in the master database of the
instance.
Source Server (server-1)
The source server utilizes the following database objects:
•
DBBackup_sp - master database - dumps full, log or differential backups to
specified directory on source server, optionally zips files, emails on error,
copies (duplexes) backups to destination server via UNC path, delete files
older the N days.
•
SendMail_sp - master database - utilises simplecdo.dll (custom written VB
COM that uses CDOSYS to send emails, can use JMail instead) to email the
administrator on backup errors.
Christopher Kempster
142
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
•
dtdelete.exe - c:\scripts\ - command line executable that will remove files
from a directory (and recursively if so desired) that are N days old from the
backup destination directory
•
gzip.exe - c:\scripts\ - command line file compression utility for backup files
Destination Server (server-2)
The destination server utilises the following database objects:
•
usp_LogShipping_Init - master database - run manually (1st time only or
on serious error). Searches the incoming backup directory, applies most
recent FULL backup, then last differential (if any) and applies subsequent
transaction log files. Leaves database in norecovery or standby mode. Logs all
recoveries to its audit table.
•
usp_LogShipping_Continue - master database - as above, but searches for
differentials and transaction logs only. If a full is found then Init is recalled to
reapply the full backup again. Logs all recoveries to its audit table.
•
usp_LogShipping_Finish - master database - manually called by the DBA,
will finalise the recovery of a database and make it available for read/write.
IMPORTANT - DBA must turn off log shipping jobs on the destination server
before attempting this command.
•
usp_LogShipping_Monitor - master database - reads the audit table below
and emails the errors found to the DBA.
•
LogShipping_Audit - master database - table that to which all recovery
attempts are logged.
•
SendMail_sp - master database - utilises simplecdo.dll to email the
administrator on backup errors.
•
gzip.exe - c:\scripts\ - command line file de-compression utility for backup
files
•
usp_KillUsers - master database - kills all users connected to a database for
the instance
IMPORTANT - Consider using the command alter database xxx set resticted_user
rollback immediate rather than utilizing the usp_KillUsers stored procedure. The
routines themselves use alter database command as required.
Log Shipping Example 1 - Setup and Running
Server 1 (source)
Here we assume the server has been configured, instances and databases all running
nicely and the DBA is now ready to sort out the backup recovery path for the database
MYDB. This database has four file groups (1 data file per group) and a single log file.
The database itself is approx 3.6Gb in size, full recovery mode and requires point in time
recovery in 10min cycles.
Christopher Kempster
143
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The DBA creates the following directory on the source server to hold backups:
d:\dbbackup\mydb\
There is ample space for 4 days worth of backups. Litespeed or other 3rd party backup
products are not being used. The DBA wants the full backup files zipped, and files older
than 4 days automatically removed.
On the remote server, the DBA creates the duplex directory: e:\dbbackup\mydb\
A share is created on the dbbackup directory called standbydest for one of a better word
and NT security configured accordingly.
The DBA configures the following stored procedure to run 2 x daily for FULL backups via a
DTS job:
exec DBBackup_sp 'full', 'mydb', 'c:\scripts', 4, 'c:\scripts', 1,
'd:\dbbackup\mydb\','\\server2\standbydest\mydb\', '[email protected]', 'Y'
We are running full backups at 6am and 8pm to cover ourselves nicely in terms of
recovery (not shown here, in DTS). We chose not to run differentials and are happy with
recovery times in general. The script above and its parameters tells the backup where
our gzip and dtdelete.exe files are (c:\scripts), the backup destination, and the duplex
destination on server-2. We are retaining files less than 4 days old and the value one (1)
tells the routine to zip the file created.
Next we schedule the transaction log file backups:
exec DBBackup_sp 'log', 'mydb', 'c:\scripts', 4, 'c:\scripts', 0,
'd:\dbbackup\mydb\','\\server2\standbydest\mydb\', '[email protected]', 'N'
The script above and its parameters tells the backup where our gzip and dtdelete.exe
files are (c:\scripts), the backup destination, the duplex destination on server-2. We are
retaining files less than 4 days old and the value one (1) tells the routine to zip the file
created. The value zero (0) represents the email, when zero the DBA is only notified on
backup failure, not success.
The DBA should actively monitor the backups for a good two or three days, ensuring full
and log backups are copied successfully, the backups can be manually restored on
server-2, and the deletion of files older than N days is working fine.
Server 2 (destination)
As mentioned in server 1 (source) setup, the DBA has already created the duplex
directory e:\dbbackup\mydb\ and configured a share on the \dbbackup directory called
standbydest using NT security. For server-2, we schedule three jobs that execute stored
procedure routines to initialise, continue and monitor log-shipping.
Initialise
The main stored procedure is log shipping initialize. We supply the routine a number of
parameters, being the name of the database to be restored, the location of the backups
(remember - files were copied from server-1), the standby redo file, the pre and post-fix
file extensions so the routine can build a list of files from disk to restore from, and finally,
the MOVE command for each database filegroup.
Christopher Kempster
144
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Here is an example:
exec usp_LogShipping_Init
'mydb'
,'e:\dbbackup\mydb\'
,'e:\dbbackup\mydb_standby.rdo'
,'mydb_'
,'.bak*'
,'_full.bak'
,'_dif.bak'
,'_trn.bak'
,'
MOVE ''MYDB_SYSTEM'' TO ''c:\dbdata\mydb\mydbstandby_system01.mdf'',
MOVE ''MYDB_DATA'' TO ''c:\dbdata\mydb\mydbstandby_data01.mdf'',
MOVE ''MYDB_INDEX'' TO ''c:\dbdata\mydb\mydbstandby_index01.mdf'',
MOVE ''MYDB_AUDIT'' TO ''c:\dbdata\mydb\mydbstandby_audit01.mdf'',
MOVE ''MYDB_LOG'' TO ''c:\dbdata\mydb\mydbstandby_log01.mdf''
'
,'c:\scripts'
The DBA may consider further customization of this script, namely the building of the
MOVE statement by reading the backup file header. You can, but I work on the KISS
principle and in this scenario we can’t go wrong.
The initialise routine is NOT SCHEDULED and is only run manually if we need to force the
re-initialization of log shipping from the last full backup.
The master..LogShipping_Audit is updated accordingly with the files applied by the
routine or any failure/error information.
NOTE - This routine will locate the last full backup and apply it, then the last
differential (if any) and all subsequent transaction logs.
Continue
This is the crux of the log shipping routines and is scheduled to run every two hours from
7am to 10pm. The routine has identical parameters to that of the initialise procedure.
When run, the routine will determine if Initialise must be called (missing standby
database), or a new full backup file has been found and we need to start from scratch
with the full and differentials. This routine is basically the driver for log shipping, in both
its initializing and continuing to apply transaction logs as they arrive in the backup
directory from server-1.
exec usp_LogShipping_Continue
'mydb'
,'e:\dbbackup\mydb\'
,'e:\dbbackup\mydb_standby.rdo'
,'mydb_'
,'.bak*'
,'_full.bak'
,'_dif.bak'
,'_trn.bak'
,'
MOVE ''MYDB_SYSTEM'' TO ''c:\dbdata\mydb\mydbstandby_system01.mdf'',
MOVE ''MYDB_DATA'' TO ''c:\dbdata\mydb\mydbstandby_data01.mdf'',
MOVE ''MYDB_INDEX'' TO ''c:\dbdata\mydb\mydbstandby_index01.mdf'',
MOVE ''MYDB_AUDIT'' TO ''c:\dbdata\mydb\mydbstandby_audit01.mdf'',
MOVE ''MYDB_LOG'' TO ''c:\dbdata\mydb\mydbstandby_log01.mdf''
Christopher Kempster
145
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
'
,'c:\scripts'
Monitor
Using a simple-cdo custom DLL, this scheduled job running at the same schedule as
continue log shipping calls this:
exec usp_LogShipping_Monitor '[email protected]', 'LOGSHIP', 15
The DBA is emailed error rows from the master..LogShipping_Audit table. Here is an
example of its contents:
Log Shipping Example 2 - Finalising Recovery / Failover
The DBA will attempt the following in order, I say "attempt" as the first steps may fail
and must be carefully monitored.
1) Re-evaluate the need to cutover and double check that the situation is such
that cut over is required
2) Attempt to run a backup on server-1 using your scheduled DBBackup_sp
command or via Query Analyser
3) Verify backup and file copy, manually copy if required
4) Run usp_LogShipping_Continue (or its scheduled job) on server-2
5) Disable above job
6) Manually run exec..usp_LogShipping_Finish 'db-name-here'
Concluding thoughts
The method presented is simple, easy to implement and does not rely on linked servers
or numerous system table lookups. One of the big disadvantages with log shipping is
more to do with the recovery process (albeit short – consider this when testing), that
being "user sessions must be killed before attempting to recover the database". If users
need to be kicked from the standby database to apply further logs, then its tough setting
a specific recover time if the database is also used for corporate reporting.
Christopher Kempster
146
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
5
Chapter
Troubleshooting SQL Clusters
F
ollowing on from the previous chapter on High Availability, we will cover some of
hints and tips for SQL Server Cluster administration and troubleshooting.
Where possible, leverage the VMWARE environment to test all scenarios before
attempting any maintenance work in production. It is important to note that this
chapter is not designed as a start to finish read; many of the solutions are scenario based
and do not expand on terminology used (such as the definition and usage of “MSMQ” for
example).
Trouble Shooting and Managing Clusters
How many MSMQ’s can I have per cluster?
Only one instance per cluster.
I am having trouble starting the cluster (Win2k)
Cluster start problems tend to reside with the service account that is running the cluster
service. Before doing anything further, check this account by logging into any of the
cluster nodes with the service account user; the event logs may highlight authentication
issues as well.
If this is not the problem, then consider these steps:
a) Ping each node in the cluster. Verify/check all networking properties on all nodes,
and ping each node.
b) Node has a valid cluster database? Check the file clusdb in %systemroot%\cluster
exists. If the file does not exist, then refer to this MS support document for
detailed recovery - http://support.microsoft.com/default.aspx?scid=kb;ENUS;224999
c) Check the registry key HKLM\Cluster exists.
d) The cluster.log file must not be read-only; verify the service account has full
access to this file.
e) Can the node see the quorum disk?
Christopher Kempster
147
S Q L
f)
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Check the system event log and cluster.log file carefully; the quorum disk may be
corrupted. If this is suspected, or you get an error related to the cluster logs,
then review this MS Support document carefully:
http://support.microsoft.com/default.aspx?scid=kb;EN-US;245762
Why can’t I backup to C Drive?
The SQL Server cluster may only see drives that are in its cluster group, and local disks
are not here and would never be as all nodes cannot access it. Choose another resource.
Move SQL Server cluster between SANs
This tip is provided by Loay Shbeilat from Microsoft; the tip can be found on the MS SQL
groups. As it is very handy, and with permission, I have included it here:
Assumptions:
1) The machines will not change
2) The storage will be changed
3) The 2 SANs will be accessible to the cluster for the migration purpose.
4) Assume the Old disk drive is O: and the New disk Drive is N:
Steps I followed:
1) Backup the disks
2) Backup the disk signatures/geometry. You can use "confdisk.exe" to do that.
3) On the new SAN create a new partition that you will use for the SQL. Name the
disk N:\
4) Create a Disk Resource for the new disk and include it with the SQL group.
5) Offline the SQL cluster resource (so that no one would be writing to the disk
anymore)
6) Keep the disk resources online.
7) Using a copy utility replicate the data from the old drive to the new drive make
sure to copy the correct ACL's/attributes/etc. The " /o " switch with xcopy does
copy the ACL's. You can also ntbackup then restore the data.
8) Now add the new disk as a dependency for the SQL resource. The SQL
resource at this point of time will have 2 disk dependencies: Disk O: and Disk N:
9) Go to disk management. Rename the Old disk drive from O: to X:
10) Rename the New disk drive from N: to O:
11) Back to cluster administrator, rename the resource from "Disk O:" to "Disk
X:"
Christopher Kempster
148
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
12) Rename the resource from "Disk N:" to "Disk O:"
13) Remove the "Disk X:" dependency from the SQL resource. Now it should only
have one disk dependency "disk O:"
14) I would go to the advanced properties of the SQL resource, and set it to "Do
not restart" (just in case things dont go well, you dont want the resource failing
back and forth between the nodes)
15) Try to online the SQL resource
Does it work?
Then go back to Advanced tab in properties and set it to "Restart"
Does it fail?
Go the event viewer and check the system and the application events. Does it
shed any light on the problem?
Should I change the Service Dependencies in Cluster Administrator?
Generally NO. Microsoft support states that the only time would be to add an additional
disk resource or when configuring Analysis Services (OLAP) for clustering. The default
SQL Server 2k dependency tree is:
See MS Support document - http://support.microsoft.com/default.aspx?kbid=835185
How can I stop Full Text indexing affecting the whole cluster group?
Uncheck the “affect the group” option for the properties of the full text resource via the
cluster administration GUI (third TAB).
Diagnosing Issues, where to look?
The first and most obvious place to look is the event log, particularly the application
event log section. Refer to these log files:
a) cluster.log - %systemroot%\cluster\ - cluster service log
b) sqlclstr.log - %systemroot%\ - when clustered instance starts log
c) sqlspN.log - %systemroot%\ - SQL service pack and setup logs
The logs above are standard ASCII files. Always check Microsoft support and search
Google Groups before calling MS support. Many issues are covered in service packs.
You can view the destination of the main log via:
Christopher Kempster
149
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Other variables include:
a) ClusterLogLevel=2
(0=none, 1=errors, 2=errors and warnings, 3=all events)
b) ClusterLogSize=20
(size in megabytes)
c) ClusterLogOverwrite=0
(1 = overwrite each time cluster service starts)
Refer to KB#168801 on the Microsoft Support website.
Can I delete the BUILTIN\Administrators group in SQL?
No. This account is used for the isalive ping between nodes in the cluster.
On deleting the account, I get these errors (it may differ between installs):
[sqsrvres] checkODBCConnectError: sqlstate = 28000; native error = 4818; message =
[Microsoft][ODBC SQL Server Driver][SQL Server]Login failed for user 'MYDOMAIN\cluster'.
[sqsrvres] ODBC sqldriverconnect failed
It is only when I attempt to restart that I get the stream of messages.
If you run Cluster Administrator and attempt a refresh you may find the screen locks up;
no need to reboot, the control will eventually be returned to you; this can happen with
the SQL Service Control Manager (SCM).
From your active node, goto the services applet and check the instance is up. If not, look
over the SQL Server logs if not to further clarify the issue. Run EM. You may need to
alter your registration properties to the SA account. Once in, re-create the
BUILTIN\Administrators login and attempt to re-start via the cluster administrator utility.
You may notice that the instance comes back online within the cluster administrator as
soon as the user is created.
If the error above persists and this solution doesn’t resolve your issue:
a) Check the event log and its application log area is not full
b) Ensure all nodes are rebooted
c) Ensure cluster administrator and SQL Server Instance administrator users have
administrator privileges
d) You may find there is a SQL instance dependency to the Quorum drive, if your
cluster resource groups are split into cluster group or your SQL Server group, you
may find the SQL Server instance fails to come online (status pending). If you
failover the cluster group then you should see the SQL Server instance come
Christopher Kempster
150
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
online as well. You can not create dependencies between groups, only between
resources within groups; also note the groups themselves have a server owner.
I regard this as a major problem, and have experienced ongoing systems errors; as such,
I would do a complete re-install of your instance.
Correct way of stopping a clustered SQL instance
It is important to remember that a single instance in a clustered environment is running
on one and only one node at any time (share nothing cluster); as such, we need to first
of all use the cluster administrator to determine the active node.
In SQL Server 2k use the Service Control Manager (SCM) which is cluster aware unlike
SQL Server v7. As an example, using SCM to shutdown the instance on my active node I
see it cleanly takes the instance offline:
The startup via SCM is also fine, taking the group items back online.
IMPORTANT – Taking the SQL Server virtual instance offline via the Cluster
Administrator will shutdown the instance. If you want to keep it offline, but start
the instance on the active node then don’t use Enterprise Manager (EM) - it is
cluster aware and will start the instance within the cluster !
How do I keep the Instance offline but start it locally for maintenance?
Taking the SQL Server virtual instance offline via the Cluster Administrator will shutdown
the instance. If you want to keep it offline, but start the instance on the active node then
do not use Enterprise Manager (EM.
If I offline the instance via Cluster Administrator on the active node, I see the service
completely shutdown. Run net start:
Christopher Kempster
151
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
When I run Enterprise Manager, it tells me the instance is down. But this is the virtual
instance, and therefore a little confusing at first. As I know the instance IS up, I drill
through via EM:
..and in Cluster administrator we confirm its offline:
If I right click properties of on the EM instance registration, and START, then instance will
come online within Cluster Administrator.
Can I automatically schedule a fail-over?
Use the cluster command via DOS command line. It can be schedule via AT on the
current active node. This is an effective way to fail the SQL Server over:
cluster MySQLGroup group “SQLCLUSTER1” /MOVETO:Server2
Correct way to initiate a failure in Cluster Administrator
Open the cluster administrator, navigate to your SQL Server group and initiate failure of
the “SQL IP…” address resource item three times.
Avoid stopping the SQL Server service outside the cluster administrator as a way of
initiating failover. There is a possibility of corrupting or shutting completely down the
SQL cluster or the cluster service(s) itself.
Christopher Kempster
152
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Any Windows 2003 restrictions with clustering?
Be aware that the maximum number of nodes is 8 and the maximum number of SQL
instances within the cluster is 16 (8 per node in an active/active two node cluster). Read
the Microsoft documentation carefully between releases.
Changing Service Account Logins/Passwords
Use Enterprise Manager at the Active node in all cases to avoid problems at other nodes.
Event logs between cluster nodes – can I sync them also?
Primarily for Windows 2000 installations you can enable/disable event log replication
between nodes via:
cluster [name of node] /prop EnableEventLogReplication={0,1}
Nodes in a cluster via Query Analyser?
Use the following command:
SELECT * FROM ::FN_VIRTUALSERVERNODES()
Failed to obtain TransactionDispenserInterface: Result Code = 0x8004d01b
This is not necessarily a sql cluster only issue. You may get this error when:
a) MSDTC has been forcible stopped or restarted (or crashed and re-started)
b) The SQL Server service started before MSDTC
Altering Server Network Properties for the Instance
First of all, locate the active node and run the server network utility; do not offline the
virtual instance at this point in time via cluster administrator as the server network utility
requires it up to determine the instance’s currently supported protocols and their
properties.
You will notice that named pipes cannot be removed. Make the changes as required and
you will be given the standard warning about having to restart the instance.
The Server Network Utility is supposedly cluster aware, but I had trouble with this under
my SQL Server 2k SP3 instance. The port changes I made for the TCPIP protocol were
not reflected between nodes. Consequently, node 1 was under 1456 and node 2 was
using 2433.
To sort this out, I edited the registry of Node 1 and altered the tcpport key under the
supersocketsnetlib folder:
Christopher Kempster
153
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Take time to check your nodes after any change, and do allow a few minutes (5+mins)
for the replication to occur between nodes.
IMPORTANT – If you are using the force protocol encryption option, make sure
you have a certificate for each node for the virtual instance.
Add Disk E: to our list of disk resources for SQL Server
On installation, we selected F:\ for the default data directory. As such all system and
example databases in the instance refer to F:\
To add E:\ to the list of valid drives for our clustered SQL Server instance:
1) Open cluster administrator
2) Under the groups folder, look through each group and locate “Disk E:”
3) Move this resource to the same group as your SQL Server instance
resource are
4) Rename this group to make it more readable. Here is what I see:
5) Take “SQL Server (<name>)” offline:
Christopher Kempster
154
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
6) Select properties of “SQLServer (<name>)” and the dependencies tab,
add Disk E: as a dependency.
7) Apply and bring the resource back online.
8) From enterprise manager or query analyzer, you should be able to select
E:\ along with our original F:\ drive.
This was also covered by Microsoft support in article 295732.
Cluster Network Name resource 'SQL Network Name(SQLCLUSTER1)' cannot be
brought online because the name could not be added to the system.
This is a minor problem typically caused by incorrect DNS settings for forward and
reverse (PTR) lookups.
Goto your domain controller and run the DNS manager utility.
We have a single forward lookup zone defined called “mydomain”, under which lists the
DHCP hosts allocated IPs and the virtual entries for:
a) mycluster (MSCS service virtual IP) – 192.168.1.75
b) sqlcluster1 (SQL Server virtual cluster IP) – 192.168.0.78
For correct names resolution, we also require reverse lookup zones for these subnets.
The reverse zone lookup asks for the first three parts of the IP (aka the subnet). Once
created, right click on the reverse lookup zone and select new pointer. Browse the
forward zone and select the appropriate entry for the subnet created.
Christopher Kempster
155
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
In my configuration I have this:
Reboot your nodes and the effect should take with the names resolving.
I renamed my sql server virtual cluster name – now I am getting errors and the
instance will not start?
This is a nasty problem. Basically – don’t change it!
The issue is described in a MS support article:
http://support.microsoft.com/?id=307336
With errors such as (typically in the cluster administrator GUI):
MSSQLSERVER Error (3) 17052 N/A BOPDEV1 [sqsrvres]
checkODBCConnectError: sqlstate = 08001; native error = 11; message =
[Microsoft][ODBC SQL Server Driver][DBNETLIB]SQL Server does not exist or
access denied.
MSSQLSERVER Error (3) 17052 N/A BOPDEV1 [sqsrvres] ODBC sqldriverconnect
failed
and event log messages such as:
Cluster resource 'SQL Server (SS2KTESTC1)' failed.
You can repeat this error by selecting properties of the “SQL Network Name (<name>)”
resource and in the parameters tab changing the virtual name here. This resource will
come up fine, but will error on the next resource, that being the instance itself. If you
cant remember the old virtual name, even from DNS, then you are in trouble (revisit
Windows Event logs and SQL Server logs).
I have found no way of renaming this virtual name and believe the only safe way is
reinstallation.
Christopher Kempster
156
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
How to I alter the IP address of the virtual server?
This is documented in Microsoft Support KB#Q244980. I have validated their approach
and the steps taken are fine. In our VMWARE example, we have created a DNS entry for
sqlcluster1 (192.168.0.78). If we want to move IPs:
•
Run the setup disk on the active node for the instance
•
Click advanced options
•
Click maintain virtual servers, enter the virtual server name to manage
•
In the screen below, we see our existing IP. Add the new IP and remove the
existing
•
Continue on from here to complete the operation.
The Microsoft Clustering Service failed to restore a registry key for resource SQL
Server
This is a nasty problem, I simulated this same error a few times by rebooting the node
within a few seconds (around 50) of completing the installation of my SQL instance. Each
time node 2 reported this error when attempting to start the instance.
The error is indicative of a registry corruption and/or mismatch.
Reinstall SQL Server on a Cluster Node
The full procedure can be found in the BOL. The general tasks are:
a) Ensure the node is not active for the SQL Server instance
b) Run SQL Server setup
c) Remove the node from the configuration
d) Do whatever is required to the server (node)
Christopher Kempster
157
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
e) Run SQL Server setup once again
f)
Add the node back into the virtual instance
g) Reboot the node after installation
h) Reinstall service packs as required.
Read on for more specific information/scenarios.
How to remove a SQL Server Instance from the cluster
Pick the active node. Run your SQL Server setup, enter the name of the virtual sql
server to be removed, then pick the instance under this virtual server. Supply the
login/password for the cluster administrator user, not your SQL Server instance startup
user. The instance will take time to remove and will clean up effectively. You will be
asked to reboot all nodes in the cluster.
NOTE – When running Setup, the “upgrade, remove, or add components to an
existing instance of SQL Server” will be unavailable if all nodes are not available,
only the advanced options radio button will be available.
Remove/add a single sqlserver node from the clustered instance (not evicting a
node from the cluster service itself)
Run the setup disk, install database server, select advanced options (if not shown
recheck the virtual server name you entered), maintain the cluster, skip past the IP
configuration (should already be there), and select the host to remove / add. Enter the
cluster administrator user account credentials. Goto to the node in question after a
removal, you will find the binaries/reg entries for this instance are completely removed.
Reboot as required.
When adding a node remember to reapply the current service pack/patch level before
attempting a failover.
COMCLUST and Windows 2003 Server
There is no need to run comclust under Windows 2003. This will be done during the
Cluster installation. You may need to add the DTC to the SQL Server group as a
dependency to ensure the instance starts without ongoing client connectivity issues.
Try to run service pack setup.bat and tells me “Setup initialization error. Access
Denied”
For some very strange reason I had this error on one node but not the other. The
problem for me was the node that didn’t have the error wasn’t the current active node in
the cluster. Now I could have failed the instance over, but I wanted to sort out this
problem.
When running setup.bat, I was shown a dialog with the message:
***
Setup initialization error.
Access denied.
Source: 'C:\sql2ksp3\x86\setup\sqlspre.ini'
Christopher Kempster
158
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Target: 'C:\DOCUME~\ADMINI~1.000\LOCALS~1\Temp\setupsql.ini'
***
To get around this problem:
a) Ensure you login to the node as the domain or local administrator
b) Create a new folder, called c:\temp (if does exist)
c) Ensure Everyone group has full control
d) Alter the TMP and TEMP environment variables to use this directory, ensure there
are no embedded spaces or special characters.
e) Re-try the setup.
Applying a service pack to the SQL Server clustered instance
Apart from the pre-planning and backup stages before applying any patch or service
pack, follow these steps:
a) Ensure all nodes in the cluster are up and available that host your instance
b) From the current primary node, run the service pack setup.exe from this server
a. You will be told to reboot your node if you have not done so from a recent
sql server instance installation. You can bypass this via the next button
(may not be present on all service pack releases!).
c) Enter the name of the virtual sql cluster
d) You may be presented with other options related to the service pack or if multiple
instances for the virtual SQL cluster are being hosted
e) Enter the sa account or use windows authentication
f)
Enter the cluster administrator login details
g) OK to complete
h) SQL Server will upgrade all nodes
i)
Verify via cluster administrator (group up?) event log, sql server log and upgrade
log file
j)
Reboot one node at time to maintain maximum uptime.
IMPORTANT – For replicated instances, install service pack at the distributor first,
then the publisher and finally the subscribers.
Christopher Kempster
159
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
6
Chapter
Backup
T
he database backup is a simple operation but funnily enough, it is what we take
for granted most that comes back to haunt us sooner rather than later.
Throughout this chapter we reiterate the fundamentals of SQL Server backups,
then look at more advanced options to customize your backup regime.
Backup Fundamentals
Importance of Structure and Standards
From a backup and recovery perspective, it is important the DBA clearly defines and
documents:
a) the sql server binaries directory structure (for single or multiple instances)
b) database file locations
c) instance and database naming standards
d) base instance and database properties that are regarded as “default”
values for any installation, including
i. including server, instance and database collation settings
ii. security properties – integrated or mixed mode, service user
runtime account, domain (and its trusts to other domains as
required to facilitate logins)
iii. SA account passwords and its security, use of the sysadmin
system role
iv. instance memory – will you fix min/max memory?
e) the most basic system backups to be performed and a how-to and whereto summary
f)
location of other external files, such as full-text index catalogs, instance
error files.
Christopher Kempster
160
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
So why is this important? well, it is all about the consistency of management, no matter
the underlying hardware or database services running within it. Consistency in this form
means no surprises, ease of DBMS navigation and problem determination, simplify
systems recovery, and to quickly establish some rudimentary but important knowledge of
any new service support requirement.
At its most basic level, the DBA should prepare a single document that clearly defines the
above elements. The document should be readily available on the technical intranet for
the support team, and most importantly, be adapted over time to include new features
and simple changes as the team determines what fits within their business.
We will discuss some of these elements in more detail.
Directory Structures
Having a standard directory structure for your SQL installations is very important. If you
are attempting to recover specific database files from tape onto a server you know little
about, there is nothing more frustrating than wasting time restoring them to temporary
locations only to be moved later (as you discover more of the system), or having to
search for files, or removing the wrong files that happened to be for another instance
that was down at the time (it can happen).
Taking a page from Oracle’s book of best practice, we have the importance of a “flexible
architecture” for directory and file creation. The OFA, or Optimal Flexible Architecture
basically describes:
Establish a documented and orderly directory structure for installation binaries
and database files that is compatible with any disk resource
eg. c:\SQLServer2kBin\<instance-name>\bin\{binaries}
c:\SQLServer2kData\<instance-name>\<db-name>\{data files}
c:\SQLServer2kLog\<instance-name>\<db-name>\{log files}
c:\SQLServer2kErr\<instance-name>\{error log files}
Separate segments of different behavior into different file-groups:
Consider separation based on usage, creating for user’s databases a
separate file-group for DATA, INDEXES, AUDITING, and not using the
PRIMARY group for user objects.
Consider file-group separation based on disk resource contention
Consider file-group separation based on their historical data content
Consider separation based on file management – size of files, write
intensity etc.
Separate database components across different disk resources for reliability and
performance
Christopher Kempster
161
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
NOTE – Be aware of SQL Server data striping (not to mention RAID striping). If
you have two or more database files for a single file-group, SQL Server will
automatically stripe data across these based on the percentage of free space with
each data file. Allow this if you are also planning disk striping “by hand” during
installation/restore.
The example above (i.e. c:\SQLServer2kData) is probably not optimal if you plan to
upgrade the instance and the files stay exactly where they are – no DBA likes to create
additional work for themselves. So here are two examples I have used that attempt to
define a working OFA style structure for DBMS directories:
Naming conventions
for instances
(i<name>) assist in
grouping DB files
and identifying
services
Contextual naming
of the directory
clear states its DB
purpose
Although not shown above, we can add in the database binaries (dbbin), separate the
error log files (dberrlog) and others with relative ease.
NOTE – On installation you are prompted for the system directory data and log file
destination (for all system databases). We can adapt the above structure to include
a \mssql\system directory outside of the dbdata\master etc for easier file
identification at this point.
Naming Rules
Here are some example naming suggestions:
•
Use 01 to 99 to ID the file-number in the group.
•
Try and stay within the 256 character boundary for directory depth, just in case
some restore scenario or internally documented/undocumented SQL command
has this restriction (you never know). Besides, long names are very inconvenient
when performing command line restores.
•
Do not use spaces and avoid under-scores (_), but use capitalization to your
advantage. If you do use underscores, then use them consistently.
Christopher Kempster
162
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
•
Apply restrictions to the size of names, but leave it flexible. For example, impose
a 10 character limit on your instance and user database names, but allow a 4 or 5
letter names as well.
•
Names should be context or service driven for example, migration databases
copied from production onto your development server may be named MIGMyApp;
where possible. Avoid the temptation to call a database oldcopyprd or dbatestdb.
•
Avoid the prefix of “dev”, “test”, “prod” for instance
Database File Names
For a new database (includes a single data file for the primary file group and single
transaction log), SQL Server will name them:
<db-name>_Data
<db-name>_Log
e.g. mydb_Data, file extension is .MDF to default data dir
e.g. mydb_Log, file extension is .LDF to default log dir
I name them as following during DB creation:
<instance-name>_<db-name>_SYSTEM
<instance-name>_<db-name>_LOG01
If it’s the default instance then leave <instance-name> blank. If you used the directory
conventions described earlier then you may choose to omit the instance name from the
files.
The DBA should retain the file-extension standards from Microsoft for overall consistency:
.mdf
.ndf
.ldf
master data file
next data file (for any other files created for the database)
transaction log file
Logical Filenames and File group Names
The logical database filename is a unique name that will identify the file within the filegroup. I like to use it to identify the general contents of the file within the file-group to
simplify recovery, for example MYDB_DATA or MYDB_AUDIT. This can be said for file
group names as well. Here is an example:
Try and be practical with the number of files, and the file groups. I only do the above
file-group split when the disk capacity and volumes provide a clear advantage for me to
do so.
Christopher Kempster
163
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
It is important to remember that a file-group with two or more database files causes SQL
Server to stripe writes over the files based on the percentage of free space available
within each. Depending on your application this may provide a performance
enhancement as SQL Server creates a new IO thread for each file. This is not the case
though with transaction log files which are written sequentually. Best practice states that
where have one and only one database file per file-group.
Default properties
The DBA should, where possible, clearly document the basic instance and database
settings to avoid potential show stoppers at a later stage, especially with collation
settings. They are simply things, but easily missed.
Some of the items to cover in a checklist:
•
•
Instance Level
o
Instance runs as a known SQLServerAdmin (or similar) domain account
user
o
Use named instances are used, default instance should be avoided
o
Consider fixing named instances to specific ports
o
Min/Max memory settings for the instance
o
Server and Instance installation collation
o
Directory structures (as above)
o
Sysadmin role security
o
Security settings (Mixed/Integrated)
o
Licensing mode and validation of
o
Naming convention
o
Auto-start services (Instance, SQL Agent, MSDTC)
o
Disable NT fiber usage, disable boost SQL Server priority
o
Recovery Interval (eg. 2+ minutes) – requirement dependent
o
Default user language
o
Document the SQL Server log file destination, consider moving it to a
more appropriate location than the default
o
Access-to/documentation-of SA account
Database Level
Christopher Kempster
164
S Q L
•
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
o
Database collation (use <server default> where possible)
o
Cross ownership chaining OFF (SP3)
o
Auto close database is OFF
o
Auto-update statistics is ON
o
Auto-shrink database is OFF
o
Simple recovery model – alter as the business requires
o
At an absolute minimum do full backups of all database via maintenance
plans and retain last 2-3 days if possible.
o
No business defined user account has been given db_owner privilege
o
Move to a fixed size file growth over % (the percentage growth and
exponentially grow files)
SQL Agent
o
Set service account
o
Set/alter the SQL agent og file destination
o
Auto-restart enabled
o
Set proxy account as required
o
Alter SQL Server authentication connection account as required
NOTE – The DBA should consider moving the default filegroup away from the
primary if you are creating other file-groups – the primary filegroup should store
system related tables only in this case. For example:
alter database mydb MODIFY FILEGROUP mydb_data DEFAULT
Recovery Interval
The recovery interval is set at an instance level and affects the checkpoint timeout period
for all databases in the SQL Server instance (it will not accurately dictate how long a
recovery will take in terms of applying files, roll-back or roll-forward). This of course has
flow on effects for instance recovery in terms of the number of possible transactions SQL
Server must rollback (uncommitted transactions) and roll forward (committed but not
written to the physical database data files) during its recovery cycle on instance startup.
The default value is zero (SQL Server managed). Any value greater than zero sets the
recoivery interval in minutes and when altered, its value takes effect immediately. (In a
majority of circumstances leave the setting at the default).
The value can be set via Enterprise Manager, or via a SQL statement:
Christopher Kempster
165
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
exec sp_configure N'recovery interval (min)', 2
reconfigure with override
Trying to pre-empt the actual goings-on with the DBMS architecture in terms of this
value is difficult to predict and the SQL Server documentation is somewhat vague. Use
performance monitor counters to monitor checkpoints and alter the recovery interval to
review the impact to the instance, this may take some time to be reflected. It is
important to remember that performance monitor wont measure instance recovery time.
Noe in some circumstances it can effect your SLA (service level agreement).
Number of pages flushed by checkpoint or
other operations that require all dirty pages
to be flushed.
In this case we are monitoring the default
instance. Other instances will have their
own counters.
Recovery Models
In SQL Server, each database has a recovery model which determines what statements
are logged and if point in time recovery is possible. The models are:
Christopher Kempster
166
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
a) Simple – transaction log (redo log) entries are truncated on completion of a
checkpoint. Point in time recovery is not possible.
b) Full – transaction log entries are retained and the log file will grow until the
DBA back’s up the transaction log and the committed log data to disk
(archived log mode in Oracle).
c) Bulk Logged – as per full but selected commands are not fully logged
(therefore the commands are not recoverable). These commands include
select into, bcp and bulk insert, create index and indexed view creation, text
and image operations (write and update text).
Mapping these models back to the SQL Server 7 days:
Select Into Bulk Copy
Off
On
Off
On
Truncate Log on Chkpt
Off
Off
On
On
SS2k Recovery Model
Full
Bulk Logged
Simple
Simple
The default system database recovery models are:
MASTER
MSDB
MODEL
TEMPDB
Simple (only full backups can be performance on master)
Simple
Simple
Simple (recovery properties cannot be set for this DB)
Normally, do not alter recovery model properties for any system database. The DBA of
course can alter the recovery model properties for user databases via Enterprise Manager
or a SQL statement:
ALTER DATABASE [BUYSMART]
SET RECOVERY [SIMPLE, FULL,
BULK_LOGGED]
For backward compatibility the
sp_dboption command is also
available.
Christopher Kempster
167
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The alteration will take immediate affect. The DBA should issue a full backup and if using
full or bulk-logged options, continue with planned transaction log backups as necessary.
What privileges do I need to backup databases?
In order to backup a database the DBA requires the db_owner privilege. If this is not
suitable from a security perspective then db_backupoperator also grants the permission.
The fixed server role for all databases is sysadmin and will of course grant the
permission.
Backup and Restore between Editions of SQL 2k
The DBA can backup/restore without any problem between standard and enterprise
editions of SQL Server 2k. So long as the service packs are identical, or, the destination
database is a higher service pack to that of the source instance.
Backup Devices
A “backup device” is simply a logical name (alias) for a physical file that may be a disk
location (physical or UNC) or tape device. The device is visible to all databases within
the instance.
The device is not necessarily required, but is there for convenience and does allow
backup scripts to separate themselves from the physical location of data files. Altering a
script to backup elsewhere can be done by changing the destination of the backup
device.
exec sp_addumpdevice N'disk',
N'mydevice',
N'e:\dbbackups\mydevice.BAK'
The above dialog will run exec xp_fileexist "e:\dbbackups\mydevice.BAK" to verify the
location and warn the DBA accordingly.
The device has some flow on affects within the Enterprise Manager in terms of viewing
their content and selecting the device as a drop down item when backing up databases
via the EM.
IMPORTANT – The Database Maintenance Plan wizards do not utilise these
backup devices for some strange reason.
Database Maintenance Plans
Christopher Kempster
168
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If you are just starting out with SQL Server and want to get backups up and running
quickly, along with some integrity checking, then consider database maintenance plans.
NOTE – Maintenance Plans are found under the Management folder within
Enterprise Manager.
The maintenance plan is simply a wizard that generates a series of MSDB jobs that are
scheduled and run by SQL*Agent. These jobs may include the following against one or
more databases:
Database backups (full and log backups only)
a) Can specify auto-removal of media sets that are N
days/weeks/months/seconds /minutes old
a) Can specify destination directory and the option to auto-create sub-directories
for each database to be backed-up
b) Database re-organisation
c) Update database statistics
d) Shrink databases (remove un-used space)
e) Database integrity checks
For backups, SQL Server will create one media set per backup set. This means one
physical disk file (media set) backup and inside it, a single log or full backup (backup
set). It will NOT append backup sets to existing media.
NOTE – Many of these items can be scheduled individually, away from the backup
job times. Note that SQL Server will not warn you of overlapping jobs or the fact
that another maintenance job already exists of that type.
With respect to backups, the maintenance plan can be a little restrictive though, consider
some of these:
no support for differential backups
many of the backup options are not available, such as the password parameter
can not duplex backup files (copy to another disk or server as part of the backup)
does not support appended backups to an existing backup device (media set)
NOTE – Natively, SQL Server has no built in mechanism for compressing or
zipping backup files. Consider writing your own backup t-sql stored procedure and
using the xp_cmdshell extended stored procedure.
The maintenance plan backup screens are shown below. Remember that at this point we
have already selected the databases to be included in this overall maintenance plan (first
screen of the wizard).
Christopher Kempster
169
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
This screen is for FULL backups of
the selected databases. We can
optionally verify the backup.
Disk or pre-defined tape backups
Full backup schedule
Always use a different directory to
that recommended. The SQL
Server path is too deep in the
directory structure.
Nice feature, will remove media sets
that are N days (and other periods)
old and auto-create sub-directories
for each database.
The next screen is related to transaction log backups. Be warned here that not all
databases you have selected in the first screen may be privy to log backups and can
result in failure of the scheduled maintenance plan.
NOTE - Check the job carefully, it may try and backup the logs for all databases.
Christopher Kempster
170
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
This screen and those
following it are very
similar to the FULL backup
screens. The default file
extension is TRN rather
than BAK.
The DBA can review and alter the maintenance plan at any time by simply selecting
properties for the generated plan and editing it as necessary within Enterprise Manager.
Data Dictionary Views
It is important to understand the difference between a media set and a backup set.
These concepts are used throughout the following sections and within the online help
for SQL Server.
A physical backup device is the media set. Within the media we can store one or
more logical backup sets of one or more databases (typically its all the same
database). This is shown below with their properties:
MEDIA SET (NAME, DESCRIPTION, PASSWORD, MEDIA-SEQUENCE)
BACKUP SET (NAME, SERVER, DATABASE, BACKUP TYPE, DATE, EXPIRES, SIZE, DESC)
BACKUP SET (NAME, SERVER, DATABASE, BACKUP TYPE, DATE, EXPIRES, SIZE, DESC)
Backup set
Media set
BACKUP DATABASE [mydb]
TO DISK = ‘e:\dbbackups\mydb\mydb_20040624_full.bak’
WITH INIT,
NAME = ‘Full Backup of MYDB on 24/06/2002’
Christopher Kempster
171
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The backup information is recorded in the MSDB database, here is a snapshot of the
physical data model:
Backup
media set
media_
set_id
backup
_set_id
Backup set
Restore
history
Backup file
Backup
media
family
Restore file
Restore_
history_id
backup
_set_id
media_
set_id
Restore_
history_id
Log mark
history
Restore file
group
NOTE – rather than using msdb.. (which tells SQL Server that it will find the stored
procedure in the msdb system database and use the dbo owner), we could have
entered use [msdb] before we ran the procedure.
If you append backups to a media set then refer to each appended backup via the
FILE option (backup and restore commands) as you will see in the examples
presented throughout the chapter.
Removing Backup History from MSDB
The DBA should purge this information on a regular basis. I have personally found that
recovering a database via the GUI with a large number of backup records can result in a
huge delay (4+ minutes at times) as you wait for the GUI to return control back to you.
set dateformat dmy
exec msdb..sp_delete_backuphistory ‘15/06/2002’
-- remove records older than date specified
Full (complete) Backups
A full backup in SQL Server is a hot backup. The database does not come offline or
becomes unavailable to the end-user during a full backup. In terms of the entire SQL
Server instance though, full backups should encompass all system backups in order to
successfully recovery the entire instance. There is no single backup or recovery
statement that will cover all databases within the instance.
At a bare minimum the DBA should consider:
MASTER
MSDB
MODEL
<User DB>
Full backups, nightly
Full backups, nightly
Full backups, nightly
Full backups, nightly
The tempdb system database is rebuilt automatically to the destination defined in the
sysdatabases system table in the master database on instance start-up.
Christopher Kempster
172
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The GUI is very simple to understand. In most cases the DBA will create a Database
Maintenance Plan to schedule and manage the full database backup.
An example full backup statement is:
BACKUP DATABASE [mydb]
TO DISK = ‘e:\dbbackups\mydb\mydb_20020624_full.bak’
WITH INIT,
PASSWORD = ‘my db password’,
NAME = ‘Full Backup of MYDB on 24/06/2002’
Processed 112 pages for database 'mydb', file 'mydb_Data' on file 1.
Processed 1 pages for database 'mydb', file 'mydb_Log' on file 1.
BACKUP DATABASE successfully processed 113 pages in 0.534 seconds (1.720 MB/sec).
BACKUP DATABASE [ANOTHERDB]
TO DISK = 'e:\anotherdb_20020603_full.bak'
WITH INIT,
NAME = 'Full Backup of ANOTHERDB on 03/06/2002',
EXPIREDATE = '03/06/2002'
If we tried to run the above command again we get the error below due to the expiration
date we have set. To get over this and still use the INIT option then we need to use the
SKIP option as well.
Server: Msg 4030, Level 16, State 1, Line 1
The medium on device 'e:\aa_20020624_full.bak' expires on Jun 3 2002 12:00:00:000AM and
cannot be overwritten.
Server: Msg 3013, Level 16, State 1, Line 1
BACKUP DATABASE is terminating abnormally.
NOTE – take a close look at the WITH clause syntax. The books online cover this
command very well and should be reviewed thoroughly.
The DBA should have a good understanding of all backup and recovery options, but
some of the key items are:
•
•
•
•
•
•
TO [DISK, TAPE] = ‘<backup device name or physical location>’
o Logical of physical location for the database backup to be placed
WITH INIT
o Force overwrite of the backup file if exists
WITH NOINIT
o Will “append” the backup to the existing backup set within the media.
MEDIA[name, password, description]
o These options set the name, description and password for the entire
media. A backup media (disk or tape) can contain one or more backup
sets
FORMAT, NOFORMAT
o Format renders the entire media set un-usable and ready for new
backup sets. Does NOT preserve the media header.
o No-format tells SQL Server to retain the existing media header. It will
not overwrite the media device unless INIT is also used.
EXPIREDATE = <dd/mm/yyyy>, RETAINDAYS = <number of days>
Christopher Kempster
173
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Prevents the overwriting of a backup based on the expire date and
retain days parameters.
BLOCKSIZE = <bytes>
o If media requires backups to be of a specific block size in order for a
restore from that media to be successfully read.
o
•
The Enterprise Manager GUI is a little restrictive when it comes to restoring database
backups when the PASSWORD option has been used. It does not give you the option to
specify it and displays the error:
NOTE – Use passwords on backups only as a deterant, not a security feature.
Differential Backups
The differential backup will backup any 64Kb extent within the database that contains an
altered page. Remember this when viewing the backup size of the media set as you may
be surprised. The tracking is managed by the SQL Server storage engine using the DCM
(differential change map) page present in each non-log data file.
A differential backup is not supported in Database Maintenance Plans (should change in
the next version of SQL Server). Therefore DBAs need to resort to writing their own
scripts that can be a right pain. In many cases full and log backups will suffice but this
may slow the recovery process when applying large numbers of archived log files.
Differentials are used to speed the recovery process. The DBA will need to do their own
performance tuning and measurements to determine if differentials are required to meet
the recovery SLA.
Here is an example differential backup:
BACKUP DATABASE [mydb]
TO DISK = ‘e:\dbbackups\mydb\mydb_20020624_full.bak’
WITH DIFFERENTIAL,
INIT,
NAME = 'Differential Backup of MYDB on 24/06/2002'
The differential backup will backup all extents modified since the last full backup, and
NOT since the last differential. This is very important to understand, especially during
recovery. The last differential backup done must be used on recovery; they are
cumulative unlike log backups.
To get these backups up and running quickly, write a T-SQL stored procedure and use a
DTS to call it with an email notification for error tracking. Simply schedule the package
to run as required.
Christopher Kempster
174
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Important – You cannot use differential backups to do point-in-time recovery (i.e.
the STOP AT clause is not valid to recover to a point in time for the period the
differential backup covers).
Transaction Log Backups
Transaction log backups are a fundamental requirement for “point in time recovery”
(PITR) of a database.
Remember that a transaction log exists for each database within the SQL Server instance
and is a mandatory requirement for the database to exist. The log backup is supported
via Maintenance Plans, making it very simple for the DBA to quickly set up full backups
with scheduled log backups.
The database must be in full or bulk-logged recovery modes before attempting a
transaction log backup. If not you will receive the error:
Server: Msg 4208, Level 16, State 1, Line 1
The statement BACKUP LOG is not allowed while the recovery model is SIMPLE. Use BACKUP
DATABASE or change the recovery model using ALTER DATABASE.
Server: Msg 3013, Level 16, State 1, Line 1
BACKUP LOG is terminating abnormally.
Attempting to backup the log file for the master database will result in the error:
Server: Msg 4212, Level 16, State 1, Line 1
Cannot back up the log of the master database. Use BACKUP DATABASE instead.
Server: Msg 3013, Level 16, State 1, Line 1
BACKUP LOG is terminating abnormally.
You can alter the recovery mode of the MSDB database if you like and do transaction log
backups, but it is not recommended unless there is an important requirement to do so.
Attempting to backup the log file for the tempdb database will result in the error:
Server: Msg 3147, Level 16, State 1, Line 1
Backup and restore operations are not allowed on database tempdb.
Server: Msg 3013, Level 16, State 1, Line 1
BACKUP LOG is terminating abnormally.
Microsoft documentation states that concurrent full and log backups are compatible.
After some testing I concur and after many months have yet to experience any backup or
recovery issues.
IMPORTANT – Before you attempt to restore an individual file or filegroup, you
must backup the transaction log.
There are several important parameters the DBA should understand when using log
backups. Note that many of these parameters are NOT available when creating
maintenance plans. Therefore, for the advanced DBA this may be too restrictive.
BACKUP LOG [mydb]
TO DISK = 'c:\master.bak'
WITH <see books online for comprehensive list of parameters>
Christopher Kempster
175
S Q L
Parameter
NO_TRUNCATE
NO_LOG
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Notes
Special parameter used when database is in a damaged state,
allows us to attempt a log backup without truncating the virtual log
files. This is important if we are still trying to recover the instance
whilst we attempt to build another (i.e. standby database).
Is synonymous to no_truncate and is available for backward
compatibility only.
NOTE – Remember that the databases transaction log will continue to fill as
committed and non-committed transactions execute against the database. The
backup transaction log will write all committed transactions to your selected
transaction log backup file (an archived log).
The DBA can truncate the transaction log via the WITH NO_LOG or WITH
TRUNCATE_ONLY option. This is used in a variety of situations, the classic being when
you accidentally used the full or bulk-logged recovery model when you didn’t want
transactions permanently logged for point in time recovery. The log then grows and
typically results in full transaction log errors. This command will remove all non-active
transactions from the log, from there, the DBA can think shrink the log files and change
the recovery model as need be.
BACKUP LOG [mydb] WITH TRUNCATE_ONLY
Remember - you cannot selectively truncate transactions in the log file, it’s all or
nothing. The DBA must do a full backup immediately as you cannot recovery
through a truncate (as you would except).
Log backups failing when scheduled via Database Maintenance Plan
Take care with the integrity check before backup option with transaction log backups
done via maintenance plans. The job may simply fail and the log backup not start. This
can be related to permissions because the database must be in single user mode whilst
the integrity check runs. Uncheck and re-test, run integrity checks outside of, or
separate to your backup schedule.
Filegroup Backups
The DBA can also do tablespace (file-group) backups, although fine I rarely use them as
it typically complicates recovery. For very large databases this may be the only option
though. Here is an example:
BACKUP DATABASE [mydb]
FILE = N'myprimarydatafile',
TO DISK = N'C:\mydb_fg_myprimarydatafile.bak'
WITH
INIT ,
NOUNLOAD ,
NOSKIP ,
STATS = 10,
NOFORMAT
-- logical filename of physical file
-- backup destination
NOTE – Your database must be using the full or bulk-logged recovery model
Christopher Kempster
176
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
OLAP Backups
To backup Analysis Services, the DBA must:
a) Backup the Registry (\Microsoft\OLAP Server)
b) Backup the repository data files. Even if you migrate the repository to SQL
Server you should backup the bin directory to ensure maximum
recoverability. This includes the msmdrep.mdb database (unless you have
migrated the repository to SQL Server).
c) Backup the OLAP data-files
The ROLAP storage model for OLAP cubes, can complicate your backup as the
aggregations will be stored in the data-source in which your cube is utilizing to source its
fact data. This may be problematic with very large cubes.
Within Analysis Service manager you can export your cube database, this is the primary
method for backup that is probably the most reliable. This will export the aggregations,
security privileges, not the actual processed cubes with their data. On restoring the OLAP
database you will need to do a complete re-process of the OLAP database (repository).
Use the command line executable msmdarch.exe to archive a specific database into a
single .cab file. The DBA should extend this backup to include the items discussed above.
Can I compress backups?
You cannot (natively) compress SQL backups via Maintenance Plans or through the
native BACKUP command. To get around this, consider a custom stored procedure that
shells out to the command line (xp_cmdshell) and calls a third party zip/compression
program. Most of the popular vendors like WinZip and RAR have command line options.
For example:
SELECT @cmdline = @p_zippath + '\gzip.exe ' + @v_filename
EXEC @v_error = master..xp_cmdshell @cmdline, NO_OUTPUT
See a full script at: http://www.chriskempster.com/scripts/dbbackup_ss2k.sql
Can I backup and restore over a UNC path?
Yes you can, but the service account user must have the NTFS permission to do so;
check this carefully when debugging. Here is a working example I did some time back to
prove that it is possible:
restore database northwind_unc
from disk = '\\pc-124405\unctest\northwind.bak'
WITH MOVE 'Northwind' TO 'c:\testdb.mdf',
MOVE 'Northwind_log' TO 'c:\testdb.ldf'
Processed 320 pages for database 'northwind_unc', file 'Northwind' on file 1.
Processed 1 pages for database 'northwind_unc', file 'Northwind_log' on file 1.
RESTORE DATABASE successfully processed 321 pages in 0.247 seconds (10.621 MB/sec
Christopher Kempster
177
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Logon failure: unknown user name or bad password
You may find developers getting this error when attempting commands like:
exec xp_cmdshell ‘dir \\myserver\sharename’
The service account must have the NTFS permission to successfully complete this
command.
What is the VDI?
From version 7 of SQL Server the VDI (virtual device interface or specification) was
introduced to backup and restore database instances. It is essential that any 3rd party
backup software leverages VDI as its core API for SQL backups (unless explicitly
underwritten by Microsoft).
On backup via VDI, the files are read remotely via the API and data is passed to the 3rd
party application. The VDI also supports split-mirror and copy-on-write technologies.
The VDI is free-threaded.
Note that VDI has not been especially adapted or optimized for Windows 2003 volume
shadow copy function.
What, When, Where, How to Backup
What is the DBA responsible for?
The DBA is responsible for in terms of backups:
•
Ensuring the instance and its databases are fully recoverable to a known point in
time. At a minimum this point should be daily.
•
Notifying system/backup administrators as to what directories should be backed
up
•
Verifying daily backups are valid (recoverable).
•
Ensuring appropriate log backups occur if point in time recovery is required
•
Ensuring full text indexes, OLAP cubes and DTS packages/jobs are backed up and
recoverable
•
Working with system/backup administrators in testing recovery scenarios
•
Checking and correcting database corruption (database integrity)
•
Determinining the need to log ship or copy backup files to other servers, and if so,
configuring, testing and managing this environment
•
Ensuring recovery documentation is kept up to date
Christopher Kempster
178
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
What do I backup?
The DBA should backup at the most primitive level:
a) all databases – full backup each night
b) sql server binaries – in other words the installation directory
c) system registry – via a system state backup using NTBackup or equivalent
The DBA needs to liaise with the system administrators regarding further OS and system
backups, especially if physical database files are being read and how these may/may-not
affect the DBMS itself. If you have complete responsibility over the servers (typically in
DEV and TEST) then stay simple where possible. Use NTBACKUP to take files off to tape
or duplex (copy) backups between DEV and TEST servers. In all cases, you source safe
environment is the critical component here and should be managed by server
administration professionals.
NOTE - Software and software agents like Tivoli Storage Manager and its TDP
agents (for SQL backups) will typically replace SQL Server backup routines and do
the work for you. As a DBA, you will be responsible for what and when this is
backed up. Ensure you document it well and communicate this back to the Backup
Administrator.
If point in time recovery (requires FULL or BULK-LOGGED recovery models) is expected
on a database, then FULL backups once per day, LOG backups once per hour or whatever
time span is acceptable in terms of recovery to the last backup. Backups are not CPU
intensive, but take care in terms of IO performance.
If you don’t require point in time recovery, and do not mind loosing all work between the
last FULL backup and the last differential (if applicable), then do a FULL backup each day.
Test a database recovery at least once every month.
Ensure your recovery model is set correctly for each user database. Finally as a general
rule backup your system databases daily no matter if you are experiencing little change.
How do I backup?
Often I simply use a Database Maintenance Plan – its is simple and effective for a
majority of instances. Very large instance databases, or the more experienced DBA, one
may choose to customize with their own routines (typically stored procedures run via SQL
Agent scheduled jobs). Custom routines may do a mixture of differentials and log
backups with specific filegroups. Compress, copy (to another server), email the
administrator and possibly encrypt the backup.
The business may leverage 3rd party software, this is fine but simply requires testing,
especially between service packs. Very large databases may require specialist backup
software such as that from Lightspeed Systems; this software creates very small backup
files, encrypted and at double (or more) the speed (half the time) of a standard SQL
Server backup.
Christopher Kempster
179
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
When do I backup?
Most instances require daily full backups. Ensure that daily backup gets copied to tape in
a timely matter and not be a day behind in terms of the physical tapes date stamp (test
your recovery!).
The backup in SQL Server is hot meaning you will not experience locking issues during a
full, log or differential backup. As such, synchronize your timings with the system
administrators and avoid peak disk IO periods around. Typically we see full backups
running very early in the morning or later in the evening. Always monitor the average
time taken for backups and factor in your batch jobs.
Where do I backup?
Where possible, to disk then to tape. Be aware of:
a) disk capacity for FULL backups, can you store multiple full backups on disk? If you
can, try and store a number of backup days on disk.
b) additional IO resulting from full, log or differential backups – use perfmon.exe and
other IO monitoring tools to carefully check Disk queue lengths, and contention
around the backup destination disks.
c) security – who has access and why?
Tapes should be taken offsite where possible with a SLA monitored tape recall process in
place with solid vendor commitment. The responsibilities and accountabilities of not
inserting the correct tapes into drives for backup should be in place and well understood.
How big will my backup file be?
SQL Server (natively) will not compress or encrypt your backups. Consequently you may
find them overly large at times. The size of a backup is in direct relation to:
a) the databases recovery model (and the supported backup methods)
b) the type of backup being performed
c) the amount of change incurred between the last backup
d) the ALU format size (see format MSDOS command) and disk partition strategy
Full
A full backup will write out all database file data to the backup, including the transaction
logs virtual log files not currently free.
Although the total size of the backup does not measure one to one with the total used
space of the databases files, the restore of the backup file will ensure the physical
database file size within it are returned to the size at the time of the backup.
Christopher Kempster
180
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If my log file was 4Gb at the time of the full backup, and the resulting backup file is 1Gb,
then a restore will create the log file of size 4gb; it will never shrink/data-compress the
files for you based on the data physically backed-up at the time.
To give you a broad idea of full backup size:
a) Total DB size (all files) = 3Gb, Backup size = 1.9Gb
b) Total DB size (all files) = 9.5Gb, Backup size = 5.4Gb
c) Total DB size (all files) = 34Gb, Backup size = 22Gb
To view the space required (in bytes) to perform a restore from a full backup:
RESTORE FILELISTONLY FROM DISK=’myfull.bak’
GO
This can be applied to all backup file types.
Differential
A differential backup will include all extents altered from the last FULL or DIFFERENTIAL
backup. As an extent is 64k, even a small 1 byte change in a single page will result in
the extent in which the page resides being backed-up. The differential is of course
significantly larger that transaction log backups, but can speed recovery time as it will be
a replacement for all previous transaction log backups (and differentials) taken between
the last FULL to the point when the differential was run.
Transaction Log
Some of the smallest log files will be around 56k, covering basic header information to
facilitate effective recovery using this file even though no change may have occurred
within the database (files are always created for a log backup regardless of data
changes). Changes are typically page level with another as need be for rollback/forward
information.
Using the MSDB to view historical growth
A good method of tracking backup files sizes is via the MSDB database backup tables,
namely msdb..backupset and msdb..backupfile. A great script was written by “Lila”, a
member of www.sqlservercentral.com that is well worth trying:
/***********************************************************
Check growth of .LDF and .MDF from backuphistory.
Lines returned depends on the frequency of full backups
Parameters: database name
fromdate (date from which info is required in smalldatetime)
Results best viewed in grid
***********************************************************/
--- Change these vars for your database
declare @dbname varchar(128)
declare @fromdate smalldatetime
select @dbname = 'mydatabase'
select @fromdate = getdate()-30 ---filegrowth last 30 days
Christopher Kempster
181
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
create table #sizeinfo
(
filedate datetime null,
dbname nvarchar(128) null,
Dsize numeric (20,0) null,
Lsize numeric (20,0) null,
backup_set_id int null,
backup_size numeric (20,0) null
)
--- tmp pivot table to get mdf en ldf info in one line
insert #sizeinfo
select
filedate=bs.backup_finish_date,
dbname=bs.database_name,
SUM(CASE file_type WHEN 'D' THEN file_size ELSE 0 END) as Dsize,
SUM(CASE file_type WHEN 'L' THEN file_size ELSE 0 END) as Lsize,
bs.backup_set_id,
bs.backup_size
from
msdb..backupset bs, msdb..backupfile bf
where
bf.backup_set_id = bs.backup_set_id
and
rtrim(bs.database_name) = rtrim(@dbname)
and
bs.type = 'D' -- database
and
bs.backup_finish_date >= @fromdate
group by
bs.backup_finish_date, bs.backup_set_id, bs.backup_size, bs.database_name
order by
bs.backup_finish_date, bs.backup_set_id, bs.backup_size, bs.database_name
select
Date=filedate,
Dbname=dbname,
MDFSizeInMB=(Dsize/1024)/1024,
LDFSizeInMB=(Lsize/1024)/1024,
TotalFIleSizeInMB=((Dsize+Lsize)/1024)/1024,
BackupSizeInMB=(backup_size/1024)/1024
from
#sizeinfo
order by
filedate
drop table #sizeinfo
We can export this easily to Microsoft Excel and graph for regular monthly meetings and
ongoing capacity planning. Third party tools like Diagnostic Manager from NetIQ have
this sort of functionality built in.
How do I Backup/Copy DTS packages?
When you create and save a DTS package, you have these options:
a) save as a local package (also known as saving to SQL Server) – in the
sysdtspackages table of the MSDB system database
Christopher Kempster
182
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b) save to Meta Data Services – RTbl prefixed tables that use the r_iRTbl prefixed
stored procedures in the MSDB system database. Does have some security
implications.
c) save as a Structure Storage File – file name required, stored on disk
d) save as a Visual Basic File – file name required, stored on disk
NOTE – Unless there is a need for capturing lineage information on package
execution, do not use meta data services for storage. It’s slow and there are some
security issues.
For a) and b) the DBA needs to:
a) backup MSDB database on a regular basis
a. for not just the package, but also the schedules which can be just as
important for some applications.
b) consider exporting (bcp) out the msdb..sysdtspackages table for non-meta data
services stored packages for added protection.
For c) and d) make sure your file system backup encompasses the file.
To move packages between servers, consider the above routine or the 3rd party products
below. Another option is to simply save-as the packages to the other server.
A large number of 3rd party backup products include “DTS” specific operations, but test
carefully. My concerns in this space are primarily with:
a) recovery of all packages and their history
b) persistence of the package owner properties from a security perspective
c) persistence of scheduled packages (jobs)
d) persistence of job tasks
Here are some 3rd party DTS specific export products to evaluate:
a) RobotiQ.com - http://robotiq.com/index.asp?category=sqldtscreator
b) SQLDTS.com - http://www.sqldts.com/default.aspx?272
Some Backup (and Recovery) Best Practice
The following should be carefully considered when establishing the DR plan for your SQL
Server databases. You will probably find that some are more security driven than
anything, and that is appropriate; DR is not simply backup and restore, but establishes a
range of scenarios and contingency plans that will undoubtedly cover many other aspects
of DBMS management.
Christopher Kempster
183
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
a) Do not use the DBO (db_owner) privilege for any non-dba user; no user should
be granted sysadmin or db_owner privileges that may result in “accidental”
damage to your instance or its databases over normal change management
procedures.
b) Do not make it a habit of connecting to production as sa to view data on a adhoc
basis or even to check on the system. The DBA must be very careful as a simple
mistake can prove fatal to the business.
c) Use the native SQL Server backup commands / maintenance plan rather than
using 3rd party products where possible. If you do use 3rd party products to
enhance speed, security or functionality, then run it on your test server for a few
months and test recovery scenarios carefully before moving forward into
production. Understand the implications of version changes (can still read your
old backup tapes?) and even expired registration keys (what will happen if your
key expires on Friday night and the system fails on Sunday? support available?
can you recover?)
d) Avoid streaming directly to tape
e) “Duplex” (copy) backups to another server. Do this as the last operation in the
backup and add in a step to email the DBA on failure. The system administrators
should ensure server times are synchronized to avoid “time out of sync” errors on
copy/xcopy.
f)
Try and store at least 2 days worth of backups on disk, consider compressing
backups via winzip/gzip commands. This will assist in faster recovery cycles and
avoid requesting backup tapes.
g) Monitor disk queue lengths carefully if you are sharing your backups and database
files, especially during peak loads when transaction log backups are being
dumped.
h) Run DBCC CHECKDB, CHECKCATALOG on a regular basis; take care with very
large databases and test carefully. This is essential in locating database
corruption that may go unnoticed for days, especially in lightly used or rarely hit
tables/databases. Run at off-peak times
i)
Who has access to your backup destination? How do backups get to your
development/test servers? Do not forget about the security implications.
j)
Are backups encrypted? Is the process fully documented in terms of restoration
and de-encryption? Where are the private and public keys stored?
k) Where are the system passwords stored? Do you have an emergency contact
list? What is your change policy?
l)
Ensure custom backup scripts are well tested, and flexible, ensuring that changes
in database structure do not affect the recoverability of your backup regime.
m) Choose your recovery model carefully to match business expectations. Re-affirm
the commitment made and test thoroughly, especially during bulk inserts etc.
Christopher Kempster
184
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
n) Manually script (or automate if possible) your entire database on a regular basis,
include all objects, users, database create statement etc.
o) Run SQLDIAG weekly
p) Monitor log file growth carefully and match it with an appropriate recovery model
and associated backups. Plan to shrink as required. Take care with disk space.
Keep a careful eye on transaction log sizes for example after a DBREINDEX etc.
q) Use mirror RAID arrays where possible. If write cache is enabled, cover yourself
with a UPS.
Backup Clusters - DBA
Backing up a cluster is no different from backing up a non-clustered installation. In order
to backup to disk, the disk resource must be added as a resource in the cluster group.
The rest is routine in terms of SQL*Agent jobs scheduling the write etc and the command
itself.
Microsoft have released a support document detailing NTBACKUPs over Windows 2003
within a cluster - http://support.microsoft.com/default.aspx?scid=kb;en-us;286422. In
summary, the system administrator should backup:
a) OS on each node
b) Registry on each node (system state)
c) Cluster configuration database
d) Quorum drive
e) Local drive data/SQL binaries.
If copying files between nodes, consider the /o option to retain ACL’s.
Backup Performance
To check backup and performance speed, consider the following performance monitor
(perfmon.exe) counters:
a) SQL Server Backup Device: Device Throughput Bytes/sec
To give you an idea of the raw bytes transferred over the period and
length of time taken if perfmon was monitoring for the entire period.
b) Physical Disk: % Disk Time
Generally speaking, the value should be <= 55%; anything in the order of
90% for a sustained period (5+sec) will be a problem. Drill into c) to
clarify the findings.
Christopher Kempster
185
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) Physical Disk Object: Avg. Disk [Write] Queue Length
Any value of 2 or higher sustained over a continuous period (5+ seconds
etc) tends to highlight an IO bottleneck. You must divide the figure by the
number of spindles in the array.
To accurately measure and understand what the figures mean, you must have an
intimate understanding of the underlying disk subsystem.
Custom Backup Routines – How to
There comes the time where the mainstream maintenance plan backup doesn’t give you
the freedom to achieve your backup requirements, be they compressed or encrypted
files, or even the need to move to a custom log shipping scenario. As the DBA works
through the multitude of recovery senarions, and becomes familiar with the backup and
restore commands, the ability to streamline the process also grows.
With appropriate sysadmin privilege, the stored procedure code is relatively simple. To
view a sample (working) routine, go here on my website:
http://www.chriskempster.com/scripts/dbbackup_ss2k.sql
The logic is:
a)
Check parameter validity
b) Check dump destination paths, estimate free space required from current
database and log size (full backups)
c) Check database status before attempting the backup
d) Determine if the backup operation requested is valid against the database
in question (ie. log backup against master will not work)
e) Create backup device
f)
Set backup parameters as per requested backup type
g) Run the backup
h) Determine if request has been made to zip/compress the file generated to
another location, and attempt the zip
i)
Determine if request has been made to copy the file generated to another
location, and attempt the copy
j)
Check for files older than N days, and remove them
The second routine will do a dir (directory listing) of a database backup file dump location
and based on the filters supplied generate the restore commands (in order). To make
this routine a lot more complex, consider RESTORE with FILEHEADERONLY etc for each
Christopher Kempster
186
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
file, then based on the result set build the appropriate restore commands without the
need for file filters to determine file types etc.
http://www.chriskempster.com/scripts/restoredbfromfiles.sql
Recovery & Troubleshooting
T
hroughout this chapter we will cover recovery scenarios. This hands-on approach
will provide detailed information about the steps taken, areas to watch out for
and how previously discussed backup plans and procedures are put to use.
The chapter is not designed for start to finish reading, it is very much a hands on
reference in which the DBA, meeting a problem, can use this chapter as a key reference
to determine the next steps and ideally an immediate solution.
Important first steps
The first thing that will strike you about this chapter is the multitude of problems the DBA
can face from day to day. Keeping yourself abreast of standard recovery scenarios
through staged scenario repetition is an essential task for all DBA’s, but no matter how
comfortable you feel about recovery, it is of utmost importance that you take the time to:
a)
Evaluate the situation
The DBA needs to determine what is in error, and more importantly why.
This involves a simple note taking of the sequence of events and times
before and after the issues was detected, and to the best of our ability the
internal and external factors surrounding the events. From here, pull
together key staff and mind map around this; do not talk recovery paths
or strategies as yet or fall into the trap of initiating a known immediate
recovery scenario.
b) Research and review possible recovery scenarios
With a solid picture of the situation, we begin to brain storm the recovery
process. If this is a relatively simple recovery or a known problem, the
review may be as quick as revisiting the processes as its applicable to the
Christopher Kempster
187
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
situation. The steps should be bullet pointed and tentatively agreed by
those present. The services SLA may dictate a specific route to be taken
or if further information is required.
c) Pull in existing DRP plans and determine their relevancy and map the
action plan. Depending on the thoroughness of the plan, it will tend to be
the key driver for recovery and communication.
d) Plan, review and communicate the strategy
Team leaders/management will be ultimately responsible for the actions
taken. This process will commit the resources required to initiate the plan.
If not already done, detailed steps and communication points are added to
the plan (paper or electronic based) and controlled via the technical
services manager.
e) Define the backup and rollback strategy
This is done in parallel to c). The DBAs and other support staff will define
the initial backups to be done before the recovery is started (very
important) and the rollback strategy on failure. Some recovery scenarios
will consist of multiple checkpoint steps with different rollback strategies.
f)
Audit your environment
The environment should be quickly audited. From a DBA perspective, the
DBA should record and validate basic server properties (for example OS
patch level, DBA collation/versions, file locations etc). This “yard-stick”
information can prove very handy throughout the recovery.
g) Take action - execute the plan.
h) Review and repeat cycle
IMPORTANT – As a manager, do not take the “we have a cluster, we can simply
fail over now and be up and running within minutes” as the immediate solution. It
is of utmost importance that we talk through the impact with technical staff. For
whatever the reason, failover may be the biggest mistake you can make. Deal
with the issue after the fact and try and work the problem through a no-blame
culture.
The first chapter highlighted some of the important management elements to build upon
within your IT shop. A structured approach to systems recovery is of utmost importance
as the pressure builds to return services back in working order. Here, effective mitigation
of human error is the key.
Contacting MS Support
Microsoft support services is highly recommend, primarily in clustered or replicated
database scenarios, or when you feel uncomfortable with the recovery scenario (never
Christopher Kempster
188
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
hesitate and take a gamble in production ). The website for support numbers can be
found at:
http://support.microsoft.com/default.aspx?scid=fh;EN-US;CNTACTMS
A more effective costing structure for most would be the “SQL Database Support
Package” at around $1900 US (shop around, many gold partners of Microsoft offer
equivalent services and special rates). This will cover 12 non-defect support incidents
with a variety of other features.
Before you ring Microsoft, collect the following information:
a) Have a quick scan through the fix list of SQL Server service packs (depending on
the version you are running) http://support.microsoft.com/default.aspx?kbid=290211
b) Did you try a Google search over your specific problem/error? –there may well be
a very simple solution.
c) SQL Product version and current build
d) Collect server information and dump to a standard text file
e) Run SQLDIAG where possible and dump to a file
f)
Run DBCC CHECKDB and dump results to a file
Include diagrams of your architecture, and information about applications running against
the instance etc.
The Microsoft support team may also direct you to the utility, PSSDIAG. It is covered
well on MS Support:
http://support.microsoft.com/default.aspx?kbid=830232
What privileges do I need to Restore a Database?
The instance wide (server) roles that allow backup and restore privileges are sysadmin
and dbcreator only. The db_owner database privilege allows backup privileges only. You
cannot restore databases with only this privilege, even if you are the “owner” of the
database within the instance.
The DBA can work around the restore problem for db_owner users (and other logins) via
the xp_cmdshell extended stored procedure running a simple isql command via a trusted
login. For example, the stored procedure may include this statement:
set @sqlstring = 'RESTORE DATABASE mydb
' + 'FROM DISK=''' + @p_path + ''' ' +
'WITH MOVE ''corpsys_raptavetmiss_Data'' TO
''d:\dbdata\mydb\mydb_data01.mdf'',
MOVE ''corpsys_raptavetmiss_Log'' TO
''d:\dbdata\mydb\mydb_log01.mdf'', RECOVERY'
Christopher Kempster
189
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
set @isqlstring = 'isql -S' + @@SERVERNAME + ' -E -Q "' + @sqlstring + '"'
exec master..xp_cmdshell @isqlstring
Of course you may need to setup the sql*agent proxy account to leverage xp_cmdshell
(see later), and secure this routine appropriately. The isql command which connects to
the instance uses the service account user that is running the instance. This user has
sysadmin privileges.
Revisiting the RESTORE command
To be honest the BOL covers the RESTORE command very well and its hardly worth the
effort re-interating the syntax. That said, we will cover the more common syntax
statements used throughout the ebook.
The restore command has two core functions:
a) Restoration and/or re-application of database backup files against the
instance to restore to a known point in time
b) Verification-of and meta-data dumps of backup file information
For a), the command is simple RESTORE [DATABASE, LOG] <options>, where-as with b)
we have:
1) restore filelistonly
2) restore headeronly
3) restore labelonly
4) restore verifyonly
These commands can prove very usefull when determing the contents of backup files to
facilitate more effective and timely recovery. Perhaps the most helpful is the headeronly
option and its databaseversion column returned. See the BOL for a comprehensive
summary.
The restore command is broken down into:
a) restoration of full and differential backup files only via the restore database
<options> command; or
b) restoration of log backup files via the restore log <options> command.
I believe most DBA’s will utilize a small number of options with the command. The most
essential is the FROM clause (where the backup is), and the MOVE clause (where the files
are restored to on the file system), for example:
restore database mydb from disk = ‘c:\mydb_full.bak’ with recovery
- or -
Christopher Kempster
190
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
exec sp_addumpdevice 'disk', 'mydb_fullbackup', 'c:\mydb_full.bak'
restore database mydb from mydb_fullbackup with recovery
The MOVE command is essential to restore files to another location (note the MOVE
option is repeated for each file with a single WITH option):
RESTORE DATABASE mydb FROM DISK = 'c:\mydb_full.bak'
WITH MOVE 'mydb' TO 'c:\mydb_test.mdf',
MOVE 'mydb_log' TO 'c:\mydb_test.ldf'
Be it the LOG or DATABASE option the options are basically the same.
The final part of restoration is the state in which the command leave us when its run,
namely:
a) WITH STANDBY = <filename>
The STANDBY clause is essential for log-shipping, but also allows the DBA
to recover a database file backup AND open the database in read only
mode; this is very handy when trying to determine the point in which to
end recovery or when corruption began etc. The filename specified will
include undo information to “continue the recovery where it was stopped”.
restore database mydb from disk = ‘c:\mydb_full.bak’ with
standby=’c:\mydb_undo.bak’
b) WITH NORECOVERY
Leaves the database in a state in which further backup files can be
applied, in other words, the restore will NOT rollback any uncommitted
transactions. The command is classically used when rolling forward from
a full backup, and subsequently applied one more differential or log
backups. For example:
restore database mydb from disk = ‘c:\mydb_full.bak’ with norecovery
restore log mydb from disk = ‘c:\mydb_log1.bak’ with norecovery
restore log mydb from disk = ‘c:\mydb_log2.bak’ with recovery
go
c) WITH RECOVERY
Completes the recovery process and marks the database as open and
available for user connections. The command completes recovery with the
rollback of uncommitted transaction. This option is the default option in
this list.
restore database mydb with recovery
d) WITH STOPAT[mark]
The STOPAT clause can only be specified with differential and log backup
files. This option will roll forward to a specific date/time only within the
backup file, if the time specified is outside of or not encompassed by the
Christopher Kempster
191
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
file, then you will be told. You cannot use this option to skip
time/transactions or backup files. Once specified its basically the end point
of recovery, and thus it tends to be used hand-in-hand with the WITH
RECOVERY option.
restore database mydb from disk = ‘c:\mydb_full.bak’ with norecovery
restore log mydb from disk = ‘c:\mydb_log1.bak’ with norecovery
restore log mydb from disk = ‘c:\mydb_log2.bak’ with recovery, stopat
= ‘May 20, 2004 1:01 PM’
From this quick overview, we will, in no particular order, tackle the multitude of recovery
scenarios. At the end of the day, practice makes perfect (so they say).
Auto-Close Option & Timeouts on EM
Enabling this database option is bad practice and should be avoided (hopefully the option
will be removed completely in the future). Basically the option opens (mounts) and
closes (dismounts) the database (and its files) on a regular basis (which is typically
connection based, or in other words how busy the database is at a point in time).
An adverse effect from having this option on for larger databases (or numerous
databases within an instance) is a very slow enterprise manager and slow OLEDB
connections. Expanding the databases folder can take an agonizing amount of time.
This can also happen if ODBC tracing options are enabled.
Can I re-index or fix system table indexes?
Generally speaking, system object problems should be treated with utmost caution, and
dbcc checkdb should be run over other databases to determine the extent of the problem
at hand. Personally, I would restore from backup or call Microsoft support to ensure I am
covering all bases.
If you experience errors with a system object and its index, the undocumented command
sp_fixindex may assist you. The routine exists in the master database and you can view
the code. Do note (as per the code), that the database must be in single user mode for
the command to run. The command itself will run a:
a. dbcc dbrepair – with repairindex option; or
b. dbcc dbreindex
This command will not repair the clustered index on sysindexes or sysobjects.
NOTE – The instance can be started in Single User Mode via the –m startup
parameter.
The steps may be:
Christopher Kempster
192
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
--- Backup mydb database first!, the mydb database and its sysfilegroups table is corrupt
-use master
go
exec sp_dboption mydb, single, true
go
use mydb
go
checkpoint
go
exec sp_fixindex mydb, sysfilegroups, 2
go
exec checkdb
go
exec checkalloc
go
exec sp_dboption mydb, single, false
go
--- Backup again!
--
If the command refuses to run, for whatever reason, then consider running the DBCC
equivalents yourself.
ConnectionRead (WrapperRead()). [SQLSTATE 01000]
This is a strange error that I have seen in two distinct cases:
a) Windows 2000/2003 – Confirmed bug as per 827452
b) Windows NT 4.0
If you have multiple SQL Server listener protocols enabled, such as tcpip and named
pipes, the error may result due to a malformed or overfilled TCPIP packets for the
instance. The user will experience the error and an immediate disconnection from the
instance. The error will persist for further connections to the instance but not every
operation.
We have found that a simple reboot under Windows NT 4.0 resolves the error. I found
no support documents related to known problems. Another option:
a) for the code segment – try and split over two distinct transactions or
blocks of code (between BEGIN END statements)
b) add SET ONCOUNT ON
c) force TCP over named pipes (especially) or other protocols
d) did you change the network packet size option? reset if you can back to
4096 (default). The error may also be related to the default being too
small, but I would highly recommend that you do not alter it without
thorough testing.
Christopher Kempster
193
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Space utilisation not correctly reported?
A DBA comes to you puzzled about the size of the database. He had run sp_spaceused to
determine how much space the database was using and it had returned an unexpected
result. The space was substantially incorrect. The most likely approach to fix this problem
is to run:
DBCC UPDATEUSAGE (0)
Guest Login missing on MSDB database
If the guest user is removed from MSDB you may experience a variety of symptoms,
such as:
a) List of packages under Data Transformation Services in EM are
blank/missing
b) Cannot create package error – “server user ‘mylogin’ is not a valid user in
database ‘msdb’”
The guest user has public role permissions only to MSDB. The guest user is not mapped
to a specific login as such (virtual login user), and has these base properties as defined in
msdb..ssyusers:
a) uid = 2
b) status = 2
c)
name = guest
d) gid = 0
e)
hasdbaccess = 1, islogin = 1, issqluser = 1 (other is columns are zero)
If you logged in as some user, we could add this user to the MSDB database, grant public
role access and the errors disappear. Otherwise, we need to re-create the guest user in
MSDB database.
Troubleshooting Full Text Indexes (FTI)
There is a very good Microsoft Support document on this. The article number is
240867, titled “INF: How to Move, Copy, and Backup Full-Text Catalog Folders and
Files”.
Although fine and well, the document is lengthy and involves numerous registry changes
– all are high risk changes; consider a rebuild of the catalog if its not overly large and you
can deal with the wait (and added CPU load). My general approach to FTI is to code two
alternatives in your application logic:
a) you can actively “turn off” FTI via a single parameter (row in a table); or
Christopher Kempster
194
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b) some other variable embedded in each stored procedure that uses FTI and will
execute an equivalent non-FTI SQL (typically using like %__%). This requires
more maintenance/coding (two sets of SQL), but it can really save your bacon.
If you do copy a database to another server, FTI is solid enough to rebuild its catalogs in
its default FTI destination folder without too many complaints and reconfiguration from
your side. I have a classic case in production where my catalogs are on e:\. This path
doesn’t exist on my DEV and TEST servers. I simply select the catalog and ask it to
rebuild, and it will move to d:\ (its default path). If this does not work, then run the
rebuild at the table level instead, and repeat for each table using FTI.
General FTI Tips
Here are some general tips:
•
"Language database/cache file could not be found" – can be caused by missing
cache files (wdbase.*), that can be copied from the SQL CD; there should be 8
files
•
Check the value for ‘default full-text language’ option returned by sp_configure;
check this language code file exists, US_English = 1033, UK_English = 2057 for
example.
•
If the catalog is not building, check your language breaker and try NEUTRAL – run
a full populate after the change. Check all columns carefully.
•
Ensure the MSSEARCH service is starting correctly. Review services applet and
event logs.
•
Use a completely different catalog to the existing (working) FTI'ed table columns.
On build via EM, at the table level force a full refresh, then check the indexes
population and current row counts.
•
Try very simple full text queries first. The indexing may be working but your
query isn’t.
•
The incremental update of the catalog can only work if the table has a timestamp
column; depending on your server and how busy the system is, the catalog can
take between 20sec to a minute to update. Take care with large updates, the
catalog can take some time to catch up.
•
If you want to be accent insensitive, then set the language settings appropriately
on the table columns being indexed. I have had problems with this. It simply did
not work under SQL Server 2k and I believe it to be a bug.
Locked out of SQL Server?
This problem is typically related to your authentication mode for SQL Server (32), that
being:
a) SQL & Windows (also know as mixed mode)
b) Windows – which effectively disables the sa account
Christopher Kempster
195
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
DBAs may find themselves locked out after removing the BUILTIN/Administrators login.
This login allows all NT users with administrator privilege to connect to the instance with
sysadmin privileges. As such, its not uncommon to remove this account and possible reassign it. In the process, the unsuspecting DBAs may find themselves locked out.
If you cannot login via Windows security but know the SA account, then first check the
LoginMode entry in the registry:
SQL Server 7.0:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft \MSSQLServer\MSSQLServer\LoginMode
SQL Server 2000:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MicrosoftSQLServer\<instance_name>\MSSQLServer\LoginMode
NOTE – Also check the administrator account and/or the service running your SQL
Server instance service has access to this key via regedt32.exe
A value of 1 (one) is Windows authentication only, and 2 (two) for SQL & Windows
(mixed mode). If this value is 1, then alter it to 2 and restart the instance. IF you know
the SA password, you should be able to login (remember – the default install PW is
typically blank).
If you cannot remember your SA account, then leverage from the
BUILTIN\Administrators account to login to the instance and alter it. This of course
assumes you have not removed it, or have an alternative Windows or SQL login to get in.
Another idea (and more drastic solution) is to restore the master database, either from a
previous backup or using rebuildm.exe
If you still have issues, consider a password cracking organization such as Password
Crackers Inc found at www.pwcrack.com, or try Microsoft Support Services.
Instance Startup Issues
“Could not start the XXX service on Local Computer”
This is a classic problem in which the SQL Server service is failing to start. Unless
reported otherwise in the SQL Server logs or the SQL Server Agent logs, the service itself
is an issue and not the underlying DBMS and its data files/binaries. Here is a check list of
points to consider when debugging the problem:
a) check service account user – is the:
a. password expired / account locked?
i. If the user is a domain account, this may be the case, and you
need to check carefully with the systems administrators but
account/group policies being applied
b. is the user account part of the BUILTIN/Administrator group in SQL
Server, in which access to the instance is being granted?
i. If not
Christopher Kempster
196
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
1. does the user has a instance login account with the
sysadmin (sa) privilege?
2. is the default database for the login valid?
c. If the service account user is anything by the system account, login locally
to the server, did it work? Get your administrator to verify your
underlying OS privileges if you have customized the account to and not
given it administrator access.
d. Try and use the built in SYSTEM account and re-start the instance, same
error? or no problems?
e. Has the domain name changed? is the login account for the user (if not
using builtin/administrators) still valid?
f.
Instance name has special characters in it? (typically picked from the
name of the host). Even “-“ may affect the connection.
g. Has the 1434 UDP port been blocked?
If you are desperate, create a new local administrator account and start the service with
it. Debug flow on issues regarding SQL Server Agent and possibly replication problems
thereafter.
SSPI Context Error – Example with Resolution
In this example, I have created a domain user called “SQLServerAdmin” that will run the
SQL Server Service including SQL Agent for a named instance. The software was
installed as this user, we did not select the named pipes provider though on installation,
only opting for TCP/IP over port 2433.
The instance started OK, but when attempting to connect via EM (enterprise manager)
using pure windows authentication whilst logged in as SQLServerAdmin domain user, we
had the following message:
Christopher Kempster
197
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The SQL Agent service was also failing to start with the following message:
SQL Agent Error:
[165] ODBC Error: 0, Cannot generate SSPI context [SQLSTATE HY000]
If we changed the services startup user to local system then we had no issues. Also, if
we re-enabled named-pipes and kept SQLServerAdmin user, again we had no issues with
SSPI context. Even so, I didn’t like it and took action.
First of all we needed to check the SPN via the setspn command downloadable from this
site: http://www.petri.co.il/download_free_reskit_tools.htm
Get the hostname of the server, run hostname.exe from the DOS command line, and
pass it through to setspn as follows:
C:\Program Files\Resource Kit>setspn -L royntsq02
Registered ServicePrincipalNames for
CN=ROYNTSQ02,CN=Computers,DC=corpsys,DC=training,DC=wa,DC=gov,DC=au:
MSSQLSvc/royntsq02.corpsys.training.wa.gov.au:2433
HOST/ROYNTSQ02
HOST/royntsq02.corpsys.training.wa.gov.au
The key item is:
MSSQLSvc/royntsq02.corpsys.training.wa.gov.au:2433
Christopher Kempster
198
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
All seems fine here. As we are using TCP/IP, we need to ensure the nslookup command
is successful:
C:\Program Files\Resource Kit>nslookup
DNS request timed out.
timeout was 2 seconds.
*** Can't find server name for address 163.232.6.19: Timed out
DNS request timed out.
timeout was 2 seconds.
*** Can't find server name for address 163.232.6.22: Timed out
*** Default servers are not available
Default Server: UnKnown
Address: 163.232.6.19
Again, if we enabled named pipes we don’t have an issue. Therefore the error must be
related to the nslookup results. These were resolved by the systems administrator,
giving us:
C:\Documents and Settings\SQLServerAdmin>nslookup
Default Server: roy2kds1.corpsys.training.wa.gov.au
Address: 163.232.6.19
Finally, we shutdown the instance, and set it back to the SQLServerAdmin user account
once more, only to give us this message:
Christopher Kempster
199
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The server administrators were contacted, the time resynced and the server rebooted.
On startup the service account started without any further issues and access via EM was
successful using windows authentication.
NOTE - using the SQL Server option to register the instance in AD (active
directory) was also unsuccessful.
Account Delegation and SETSPN
If you work in a multi-server environment, namely a separate web server and database
server, you "may" experience a problem when relying on integrated security to connect
through to the underlying DBMS. The error is similar to this:
Server: Msg 18456, Level 14, State 1, Line 1
Login failed for user 'NT AUTHORITY\ANONYMOUS LOGON'
This error message may also pop up when connecting between databases on different
servers.
To get around this issue, try to activate account delegation. This allows the retention of
authentication credentials from the original client. For this to work, all servers must be
running Windows 2000 with Kerberos support enabled, and of course using Active
Directory Services.
To activate delegation, shutdown your SQL Server instance, and for the service user
(don’t use the system account), select properties of the account and check the box
"account is trusted for delegation". This is found with other options such as reset
Christopher Kempster
200
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
password, account locked etc. The user requesting the delegation must not have this
option set.
Once done, the SQL Server requires a SPN (service principal name) assigned by the
administrator domain account. This must be assigned to the SQL Server service account.
This is done via the setspn utility found in the Windows 2k resource kit, for example:
setspn -a MSSQLService/myserver.chriskempster.com sqlserveradmin
You must be using tcpip as setspn can only target TCPIP sockets. Multiple ports? create
an SPN for each.
setspn -a MSSQLService/myserver.chriskempster.com:2433 sqlserveradmin
I’m getting a lock on MODEL error when creating a DB?
The DBA may experience this error:
You may get this error when another SPID has a open session against the model
database:
Close or kill the session and try again.
If two create database commands attempt to run simultaneously, you will also receive
the error.
Christopher Kempster
201
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Transaction Log Management
Attempt backup but get “transaction log is full” error
The backup command itself will attempt a checkpoint which may fail if the transaction log
is full and cannot extend/grow to accommodate the operation. Use the command DBCC
SQLPERF(LOGSPACE) against the database to view current usage properties. The DBA
should check for any open transactions via the command DBCC OPENTRAN or
::fn_get_sql(), determining the SPID via the master..sp_who2 command.
The DBA needs to:
a) Check free disk space
Determine if more disk space can be allocate for the database file extension and
its auto-grow value at a absolute minimum.
This is a simple operation and requires no explanation. Be aware though of the
database transaction log files growth properties which may been to be altered, if
you attempt this you may get the same error again when all you you need to do
is make more free space on disk.
b) Check database recovery model (full, simple or bulk logged?)
Was the database in a bulk-logged or full recovery model by mistake? But do not
change it for the sake of simply resolving your immediate problem.
a. I only do full backups at night. I’m using full / bulk logged recovery, but
it’s mid-day and my transaction logs are huge and now full ! I don’t want
to loose any transactions, now what?
i. You have no choice but to backup the transaction log file, or
attempt a full backup. If disk space is an issue but the standard
SQL Server backup is too large, then consider a third party backup
routine like Litespeed. Once backed up, we will cover transaction
log shrinking later in the section.
b. Whoops, I wanted a simple recovery model not a full or bulk-logged !
i. Discussed in the next section.
c) Simply hit the files grow limit?
Alter as required via enterprise manager with a right click and properties on the
database and altering the max-file-size properties.
d)
Can another database log file be added against another disk?
IMPORTANT - Before selecting an option above, consider a quick re-test backing
up the transaction log via the command:
backup log MyDb to disk = ‘c:\mydb.bak’ with init
Christopher Kempster
202
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The error itself will be something like:
The log file for database ‘mydb' is full. Back up the transaction log for the database to free up some log space.
Alter recovery model, backup and shrink log file
If you believe b) is the best option then:
a) Run enterprise manager
b) Alter recovery model of the database of the database to simple. You may get this
error message:
c) Ignore this message. Double check via Enterprise Manager by checking the
recovery model once again, you will find it is set to simple.
d) Backup the log file with truncate only option
backup log mydb with truncate_only
e) Check the file size, its large size will remain, to shrink this file select properties of
the database, navigate to the transaction log tab, and remember the filename
(logical), this is used in the command below to shrink this now truncated file.
Once done re-check the size via Enterprise Manager. If no change close the
properties window of the database and take another look.
dbcc shrinkfile (mydb_log, truncateonly)
IMPORTANT – You will lose all ability to perform a point in time recovery after
step d) is performed. I recommend that you do a full backup of the database if
necessary after e).
Shrinking Transaction Log Files
Step 1. Get basic file information
Before we attempt any shrink command, we need to collect some basic information on
the transaction log file:
exec sp_helpdb
select name, size from mydb..sysfiles
DBCC LOGINFO(‘mydb’)
The DBCC command will return the virtual logs within the physical log. Be warned that it
may be large:
Christopher Kempster
203
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The transaction log of course expands itself in units of the virtual log file (VLF) size, and
may only compress itself to a VLF boundary. A VLF itself can be in a state of:
a) active – starts from the minimum LSN (log sequence number) of an active
or uncommitted transaction. The last VLF ends at the last written LSN.
b) recoverable – portion of the log that precedes the oldest active transaction
c) reusable
The key here is based on the recovery model of the database, SQL will maintain the LSN
sequence for log backup consistence within the VLF’s, ensuring the minimum LSN cannot
be overwritten until we backup or truncate the log records.
The key here is the STATUS and position of the most active log (status = 2). Also check
for uncommitted or open transactions and note their SPIDS.
use mydb
go
dbcc opentran
select
spid, blocked, open_tran, hostname, program_name, cmd, loginame,
sql_handle
from
master..sysprocesses
where
open_tran > 0
or
blocked <> 0
Step 2. I don’t mind loosing transaction log data (point in time recovery is not important to
me), just shrink the file
Run the following command to free the full virtual logs in preparation for shrinking:
BACKUP LOG mydb WITH TRUNCATE_ONLY
- or BACKUP DATABASE mydb TO DISK = 'NUL'
Once done, alter the recovery model of the database as need be.
Skip to step 4.
Step 3. I need the transaction log file for recovery
Then simply backup the transaction log file, free disk/tape space may be your problem
here. Also, be conscious of your log shipping database and its recovery if you are using a
standby database.
Christopher Kempster
204
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Step 4. Shrink the transaction log
The DBCC SHRINKFILE command is the command we will use. Be aware that in SQL
Server v7 the DBA would need to generate dummy transactions to move the active
virtual log to the start of the file (see results of the DBCC command in step 1). This is
not required in 2000.
DBCC shrinkfile (mydb_log, 10)
.. and revisit file sizing.
If you expect log growth, then pre-empt the growth to some degree by pre-allocating the
appropriate storage rather than letting SQL do the work for you.
Consider a fixed growth rate in Mb over a percentage of the current total. The files can
“run-away” in terms of used space. Always be aware that auto-growth options should be
used as a contingency for unexpected growth.
Be aware that shrinking data files will result in a large number of transaction log entries
being generated as pages are moved. Keep a close eye on this when running the
command for these files.
Here is another example:
backup log corpsys_raptavetmiss with truncate_only
dbcc shrinkfile (corpsys_raptavetmiss_log, truncateonly)
DbId FileId CurrentSize MinimumSize UsedPages EstimatedPages
------ ------ ----------- ----------- ----------- -------------10
2
128
128
128
128
(1 row(s) affected)
Christopher Kempster
205
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Rebuilding & Removing Log Files
Removing log files without detaching the database
To remove (or consolidate) transaction log files from many to a single file, without deattaching the database from the instance then follow these steps. The scenario is based
on a test database with three log files.
a) Backup or truncate the transaction log file(s) – all files, though physically
separate, are treated as a single logical file written to serially.
b) Check the position of the active portion of the log file using the DBCC
LOGINFO(‘cktest’) command, and look at cktest..sysfiles to marry up the
file_id to the physical filename:
dbcc loginfo('cktest')
select fileid, name, filename from cktest..sysfiles
c) Be warned that active transaction will impact the success of the following
commands. We will use DBCC shrinkfile and its emptyfile option to tell
SQL not to write to log files two and three:
DBCC SHRINKFILE ('cktest_log2', EMPTYFILE )
DBCC SHRINKFILE ('cktest_log3', EMPTYFILE )
Christopher Kempster
206
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
d) Remove the files:
ALTER DATABASE cktest REMOVE FILE cktest_log2
ALTER DATABASE cktest REMOVE FILE cktest_log3
e) Check via dbcc loginfo:
The physical files are also deleted.
Re-attaching databases minus the log?
Do not action this method. It is more of an informational process, or warning if you may,
to demonstrate that it is not possible:
a. Backup the database transaction log before detaching
b. Via EM or the command line, detach the database (remove sessions of
course):
c. Copy or rename the log files to be removed
d. Use the command line, or EM to attach the database:
Christopher Kempster
207
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Note that OK is greyed out. Also note that the command line alternative
will give you this error:
Server: Msg 1813, Level 16, State 2, Line 1
Could not open new database 'cktest'. CREATE DATABASE is aborted.
Device activation error. The physical file name 'c:\cktest_log2_Log.LDF'
may be incorrect.
Device activation error. The physical file name 'c:\cktest_log3_Log.LDF'
may be incorrect.
So what next?
e. The sp_attach_single_file_db command shown below will not work, as this
simple command relies on a LDF file only, which is not our situation:
EXEC sp_attach_single_file_db @dbname = 'cktest', @physname =
'C:\cktest_data.mdf'
Server: Msg 1813, Level 16, State 2, Line 1
Could not open new database 'cktest'. CREATE DATABASE is aborted.
Device activation error. The physical file name 'c:\cktest_Log.LDF' may be
incorrect.
Device activation error. The physical file name 'c:\cktest_log2_Log.LDF'
may be incorrect.
Device activation error. The physical file name 'c:\cktest_log3_Log.LDF'
may be incorrect.
You can only work around this with sp_attach_db; the
sp_attach_single_file_db is not intended for multi-log file databases.
As you can see here, we can use the detach and attach method only for moving files, and
not to consolidate them.
Christopher Kempster
208
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Using DBCC REBUILD_LOG()
The DBCC REBUILD_LOG command can be used to re-create the databases transaction
log file (or consolidate from many log files down to one), dropping all extents and writing
a new log of a single new page. Do note that this is an undocumented command.
In order for this command to work, you need to:
a)
Kill (or ask people to logoff) user sessions from DB
b) Have the master database active - use master – otherwise you will get the
error “User must be in the master database.”
c) Database must be must be put in bypass recovery (emergency) mode to
rebuild the log.
d) Stop/Start SQL Server – may cause you to look at an alternate method?
e) Run the DBCC command now
No specific trace flag is required for this command to run.
WARNING – Do not take this command lightly. Before any rebuild ask yourself
the question “do I need to backup the transactions I am possibly about to remove
in rebuilding the log file?”. Especially if the DB is part of replication and the
transactions have yet to be pushed/pulled. Consider another solution if all you are
trying to do is shrink the log file.
Here is an example:
-- do a full backup, and ideally backup the physical database files as well
use master
go
-- so we can set the DB in bypass recovery mode (or emergency mode)
exec sp_configure 'allow updates', 1
reconfigure with override
go
select * from sysdatabases where name = '<db_name>'
-- remember the STATUS and DBID column values
begin tran
-- set DB into emergency mode
update sysdatabases
set status = 32768
where name = '<db_name>'
-- only 1 row is updated? If so, commit, query again if need be
commit tran
-- STOP the SQL Server instance now.
-- Delete or rename the log file
-- START the SQL Server instance.
-- Run the DBCC command
DBCC REBUILD_LOG (trackman,'c:\work\ss2kdata\MSSQL$CKTEST1\data\testapp_log.ldf' )
Warning: The log for database 'trackman' has been rebuilt. Transactional consistency has been lost.
DBCC CHECKDB should be run to validate physical consistency. Database options will have to be reset,
and extra log files may need to be deleted.
Christopher Kempster
209
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
-- optional - run Check DB as mentioned to validate the database, check SQL Server logs as well.
exec sp_configure 'allow updates', 0
reconfigure with override
go
Do note that if the database was, say, in DBO use only mode before the rebuild, it will be
returned to this mode after a successful DBCC REBUILD_LOG. The DBA should re-check
the STATUS of the database carefully, and update the sysdatabases tables accordingly if
the status has not return to its original value. If the old log file was renamed, remove it.
The file size will be the default 512Kb. Check growth properties, and resize as you see
fit. Revisit your backup strategy for this database as well to be on the safe side.
Can I listen on multiple TCP/IP ports?
Run the server network utility GUI, select the appropriate instance. Highlight the enabled
protocol (TCP/IP) and click the properties button; for the default port enter your port
numbers separated by commas, for example: 1433,2433,2432. Restart the instance for
the changes to take effect and check your sql server logs.
You will see something like:
SQL server listening on 163.232.12.3:1433, 163.232.12.3:2433, 163.232.12.3:2432, 127.0.0.1:1433,
127.0.0.1:2433, 127.0.0.1:2432.
SQL Server is ready for client connections
Remember not to use 1434, which is a reserved UDP port for SQL Server instance "ping".
Operating System Issues
I see no SQL Server Counters in Perfmon?
This problem is a real pain and I have yet to determine why this issue occurs. The
problem “seems” to manifest itself on installation but this of course may vary per site.
Follow the steps below to assist in recovering them.
The SQL Server counters are automatically installed with the instance. If they are
not, then try to re-register sqlctr80.dll and run the file sqlctr.ini, both located in the binn
directory for the instance. The DBA should also try the command lodctr.exe sqlctr.ini,
and the unlodctr command. Always issue the unlodctr command before lodctr, eg:
C:\>unlodctr MSSQL$MY2NDINSTANCE
Removing counter names and explain text for MSSQL$MY2NDINSTANCE
Updating text for language 009
C:\Chris Kempster>
C:\Program Files\Microsoft SQL Server\MSSQL$MY2NDINSTANCE\Binn>
lodctr MSSQL$MY2NDINSTANCE sqlctr.ini
Re-start your server.
Christopher Kempster
210
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Some important items to remember though with the counters:
a) each database instance has its own set of counters as per the \binn directory
for each instance, (C:\<my ss2k install
path>\<instance>\BINN\SQLCTR80.DLL)
b) the system table master..sysperfinfo includes many of the database
performance counters. Many of these values are cumulative. See this
Microsoft article for example views over this table:
http://support.microsoft.com/search/preview.aspx?scid=kb;en-us;Q283886
c) you can monitor a server remotely, if you are having problems, map a drive
or authenticate to the remote domain first then try again, try the server IP
then the host-name (\\163.222.12.11 for example). You may need to restart performance monitor after authenticating as you can continue to have
authentication problems.
If you still have problems review the following registry keys via regedit or regedt32
(allows altering of key permissions) and ensure that:
a) they exist
b) service account running the instance has permission to create/manage the key
/HKEY_LOCAL_MACHINE/SYSTEM/ControlSet001/Services/MSSQLSERVER
/HKEY_LOCAL_MACHINE/SYSTEM/CurrentControlSet/Services/MSSQLSERVER
/HKEY_LOCAL_MACHINE/SYSTEM/CurrentControlSet/Services/MSSQL$<instance-name>/performance
Server hostname has changed
My old PC name was SECA, and was altered via xxxx to OLDCOMP. This is confirmed
(after rebooting) with the hostname DOS command:
When I run query analyser I get this:
Christopher Kempster
211
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The hostname change is fine and has filtered through service manager (services
themselves are not affected, named instances don’t pre or postfix hostnames or depend
upon them), but the list of instances in Query Analyser is a problem.
The DBA should be aware that is not only this utility that if affected. Run Query Analyser,
connect to your instances, then run this command:
SELECT @@SERVERNAME
I get the output SECA\MY2NDINSTANCE, and not OLDCOMP\MY2NDINSTANCE as one
would expect.
For v7.0 instances:
a) After rebooting the server you may find that instances will not start or you fail to
connect. If so, re-run your SQL Server setup disk (remember your edition? – look
at past log files in notepad if not). Don’t worry about service packs etc.
b) The setup runs as per normal and upgrade your instance.
c) Start your instances, run query analyser and type in the commands:
a. SELECT @@SERVERNAME -- note the old name
b. exec sp_dropserver 'SECA\MY2NDINSTANCE' -- old name
c. exec sp_addserver 'OLDCOMP\MY2NDINSTANCE','local' -- new name
d. re-start instance
e. SELECT @@SERVERNAME -- new name?
For v2000 instances simply run step c) to e) above.
Christopher Kempster
212
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
NOTE – If you run Enterprise Manager, take note of the registered instance
names, you will need to re-register the instances before you can successfully
connect.
If you run exec sp_dropserver and get the message:
Server: Msg 15190, Level 16, State 1, Procedure sp_dropserver, Line 44
There are still remote logins for the server 'SECA\MY2NDINSTANCE'.
If replication is enabled, then disable replication in EM by connecting to the instance and
selecting properties of the replication folder:
This can be a real drama for some DBAs as this option states:
Therefore, consider the Generate SQL Script option beforehand over this EM group.
On dropping, you may get this error:
In my case this didn’t seem to matter. Tracing the output of the drop actually does a
majority of the work related to the remote users, therefore exec sp_dropserver
'SECA\MY2NDINSTANCE' and exec sp_addserver 'OLDCOMP\MY2NDINSTANCE','local'
worked fine. As for the jobs, the problem is related to the originating_server column of
msdb..sysjobs table. Consider a manual update to this column where appropriate:
Christopher Kempster
213
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
DECLARE @server sysname
SET @server = CAST(SERVERPROPERTY('ServerName') AS sysname)
UPDATE msdb..sysjobs
SET originating_server = @server
WHERE originating_server = 'seca\my2ndinstance'
Use DFS for database files?
Using DFS (distributed file system – Windows 2000 and 2003), is not recommended as
generally it is not overly different to storing your database files over standard network
shares. The issue here is more to do with the DFS replication and overall reliability of
replication end-points within the DFS; this is especially the case if you plan to use DFS as
a form of high availability.
I have not been able to find any official MS document that states that you cannot use
DFS. For best practice sake though, do it at your own peril.
MS Support document 304261 discusses the support of network database files with SQL
7 and 2000. The recommendation is SAN or NAS attached storage over any network file
shares (which require –T1807 trace flag to enable access). This is again interesting as I
have been numerous NAS implementations managed at a higher level through DFS,
albeit SQL Server was not involved.
Use EFS for database files?
The DBA may consider the Windows 2000 or above Encrypted File Systems (EFS) for
database files on NTFS volumes. To use this option:
Backup all instance databases
shutdown your database instance – if you don’t the cipher command will
report the file is currently in use.
login with the service account the SQL Server instance is using
select properties of the folder(s) in which the database files reside via
Windows explorer
select advanced option button and follow prompts to encrypt files/folders
re-start the SQL Server service
verify the successful start-up of instance and databases affected via the
encryption (or create databases after the fact over the encrypted directories).
Verify encryption of the database files via cipher.exe
IMPORTANT – Always test this process BEFORE apply it to your production
instance. Don’t laugh, I have seen it happen. Take nothing for granted. Also, do
not treat EFS as a “data encryption” scheme for your DBMS. It’s purely at a file
system level.
Christopher Kempster
214
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
For an internals overview of EFS read “Inside Encrypting File System, Part 1 and 2” from
www.winntmag.com.
To check if EFS is enabled via the command line, use the cipher command:
E:\dbdata\efs>cipher
Listing E:\dbdata\efs\
New files added to this directory will be encrypted.
E
E
EFSTEST_Data.MDF
EFSTEST_Log.LDF
Depending on the version of your OS and its Window Explorer options, the files and/or
folders may appear a different colour when encrypted.
As EFS is based on public/private keys, we can look at the certificate and export as
required:
On encrypting, the DBA should export the certificate and store it for emergency recovery
procedures if the need arises:
The importing/exporting of key information is a fundamental requirement when using
EFS – do not forget it.
If you attempt to start the service as any user other than the user that encrypted the
database data files, the instance will not start and/or your database will be marked
suspect. Here is an example SQL Server error log entry:
udopen: Operating system error 5(error not found) during the creation/opening of physical device
E:\cktemp\efs\efs_Data.MDF.
FCB::Open failed: Could not open device E:\cktemp\efs\efs_Data.MDF for virtual device number
(VDN) 1.
udopen: Operating system error 5(error not found) during the creation/opening of physical device
E:\cktemp\efs\efs_Log.LDF.
FCB::Open failed: Could not open device E:\cktemp\efs\efs_Log.LDF for virtual device number
(VDN) 2.
If the service cannot be started and, subsequently, no error is reported in the logs, check
if encryption is (one of) the issues via the cipher command.
Christopher Kempster
215
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
IMPORTANT – Install service pack two or greater of SQL Server 2000 to avoid
errors such as “there are no EFS keys in sqlstp.log for error 6006”. See support
document 299494.
Also be aware that, depending on your Windows operating system, you may experience
the problem quoted in support document 322346 (“You cannot access protected data
after you changed your password”). Specifically, EFS uses your domain password to
create a hash value for the encryption algorithm; each time a file is saved (or written to)
the system encrypts it using this hash key value. When the password is altered Windows
will not re-encrypt EFS files/folders, only when they are accessed (20). Simply be aware
of this potential problem.
Use Compressed Drives for database files?
Sure, but Microsoft may not support you; SQL Server does not support writable,
database file storage on a compressed drive. The compression algorithms disable the
Write-Ahead Logging (WAL) protocol and can affect the timing of the WriteFile calls. As
such, this can also lead to stalling conditions during checkpoint.
“previous program installation created pending file operations”
Check to see if the following key exists, if so delete it and re-try. I have successfully
done this numerous times over a Windows 2000 server with no further issues.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\PendingFileRenameOperations
Debugging Distributed Transaction Coordinator (MSDTC)
problems
Failed to obtain TransactionDispenserInterface: Result Code = 0x8004d01b
The DBA may receive this error when:
a) MSDTC is forcibly stopped and re-started whilst the instance is running or starting
b) The SQL Server service has started before the MSDTC service has
The error can be common in clustered environments where services can lag behind one
another during startup.
Essential Utilities
Microsoft support tends to use three core utilities for debugging MSDTC transactions and
associated errors:
1) DTCPing - download from and documented at
http://support.microsoft.com/default.aspx?scid=kb;en-us;306843
2) DTCTester - download from and documented at
http://support.microsoft.com/default.aspx?scid=kb;en-us;293799
3) NetMon - found on Windows setup disks or resource kit
Christopher Kempster
216
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Check 1 - DTC Security Configuration
This is a mandatory check Windows 2003 boxes (all of them if you run separate web and
database servers) if MSDTC service is intended to be used.
In administrative tools, navigate down through Component Services -> Computers, and
right-click on My Computer to get properties. There should be an MSDTC tab, with a
"Security Configuration" button. Click on that, and make sure network transactions are
enabled.
Check 2 - Enable network DTC access installed?
Navigate via the Control Panel and Add/Remove Programs, Add/Remove Windows
Components, select Application Server and click details. Ensure the Enable network DTC
access is checked. Verify whether you also require COM+ access.
Christopher Kempster
217
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Check 3 - Firewall separates DB and Web Server?
The transaction coordinator uses random RPC (remote procedure call) ports. By default
the RPC service randomly selects the port numbers around 1024 (note that port 135 is
fixed and is the RPC endpoint port).
To alter the registry entries, see MS Support document:
http://support.microsoft.com/default.aspx?scid=kb;EN-US;250367
The keys are located at:
HKEY_LOCAL_MACHINE\Software\Microsoft\Rpc
and include key items:
a. Ports
b. PortsInternetAvailable
c. UseInternetPorts
The document states that ports 5000 to 5020 are recommended, but can range from
1024 to 65535.
This is required on the DB server and Web server. Reboot is required.
Check 4 - Win 2003 only - Regression to Win 2000
Ensure checks 1 and 2 are complete before reviewing this scenario. Once done, run
through the following items as discussed on this support document:
http://support.microsoft.com/?kbid=555017
If you have success, add in/alter the following registry key, where 1 is ON:
HKLM\Software\Microsoft\MSDTC\FallbackToUnsecureRpcIfNecessary, DWORD, 0/1
Apply to all of the servers involved in the DTC conversation. You need to restart the
MSDTC service.
Christopher Kempster
218
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Check 5 - Win 2003 only - COM+ Default Component Security
New COM+ containers created in COM 1.5 (Windows 2003) will have the "enforce access
checks for this application" enabled.
Uncheck this option if you are experiencing component access errors, or cannot
instantiate object errors on previously running DLLs. Upgraded operation systems and
their containers will not have this option checked.
Also refer to MS support article http://support.microsoft.com/?id=810153
Common Development/Developer Issues
I’m getting a TCP bind error on my SQL Servers Startup?
For developers using personal edition of SQL Server, they may experience this error:
2004-06-14 16:01:02.12 server SuperSocket Info: Bind failed on TCP port 1433.
Basically port 1433 is already in use and another must be selected or use dynamic port
selection. We can try and identifying the process using the port with port query
command line utility available from Microsoft (or change your SQL listener port):
http://support.microsoft.com/default.aspx?scid=kb;EN-US;310099
Error 7405 : Heterogeneous queries
Here is a classic error scenario - I have added a SQL 2000 linked server on one of the
servers. When I try to write a SP that inserts data into the local server from the linked
server table it doesn’t allow me to compile the SP and gives the error below.
"Error 7405 : Heterogeneous queries require the ANSI_NULLS and
ANSI_WARNINGS options to be set for the connection. This ensures consistent
query symantics.Enable these options and then reissue your query."
To get around the problem you need to set those ansi settings outside the text of the
procedure.
set ANSI_NULLS ON
set ANSI_WARNINGS ON
create procedure <my proc name here> as
<etc>
go
Christopher Kempster
219
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Linked server fails with enlist in transaction error?
When attempting a transaction over a linked server, namely between databases on
disparate domains, you may receive this:
Server: Msg 7391, Level 16, State 1, Line 1
The operation could not be performed because the OLE DB provider 'SQLOLEDB' was unable to begin a
distributed transaction.
[OLE/DB provider returned message: New transaction cannot enlist in the specified transaction
coordinator. ]
OLE DB error trace [OLE/DB Provider 'SQLOLEDB' ITransactionJoin::JoinTransaction returned
0x8004d00a].
The DBA should review the DTC trouble shooting section in this book (namely DTCPing).
If you are operating between disparate domains in which a trust or an indirect transitive
trust does not exist you may also experience this error; SQL queries will run fine over db
links.
For COM+ developers, you may find that moving to supported rather than required for
the transaction model resolves the problem, namely for COM+ components on a
Windows 2003 domain server which are accessing a Windows 2000 SQL Server instance.
Again, the DTC trouble shooting tips will assist. Also check the firewall careful, and
consider the following registry entry:
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Rpc\Internet]
"PortsInternetAvailable"="Y"
"UseInternetPorts"="Y"
"Ports"=hex(7):35,00,30,00,35,00,30,00,2d,00,35,00,31,00,30,00,30,00,00,00,00,\00
Update the hosts file and include the HOST/IP combination if netbios and/or DNS
resolution is a problem.
How to I list tables with Identity Column property set?
Consider the following query:
select TABLE NAME, COLUMN NAME from INFORMATION SCHEMA.COLUMNS where
COLUMNPROPERTY (object id(TABLE NAME), COLUMN NAME, 'IsIdentity') = 1
How do I reset Identity values?
Use the command: DBCC CHECKINDENT, to view current seeded values. This command
is also used to re-seed (see BOL), but it will NOT fill in partially missing values. For
example, it will not add 5 to this list 1,2,3,4,6,7… but will carry on from 8. Do note that
truncation of a table (TRUNCATE command) will reset the seed.
How do I check that my foreign key constraints are valid?
Use the command: DBCC CHECKCONSTRAINTS
I encrypted my stored proc and I don’t have the original code!
I have seen this happen a few times and it’s a nasty problem to solve. I have used the
script written by SecurityFocus and Jamie Gama. The idea developed though by Josepth
Gama. Search on www.planet-source-code.com for “Decrypt SQL Server 2000 Stored
Procedures, Views and Triggers (with examples)”, or locate it at:
Christopher Kempster
220
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
http://www.planet-source-code.com/vb/scripts/ShowCode.asp?txtCodeId=505&lngWId=5
This original set of code has some size SP restrictions, so consider this instead:
http://www.planet-source-code.com/URLSEO/vb/scripts/ShowCode!asp/txtCodeId!728/lngWid!5/anyname.htm
How do I list all my procs and their parameters?
Use the command:
exec sp_sproc_columns.
To get a row set listing for a specific procedure consider this command:
exec sp_procedure_params_rowset dt_addtosourcecontrol
Or query the information schema: INFORMATION_SCHEMA.ROUTINE
Query Analyser queries time out?
Run query analyzer, select tools and options from the menu. Change query time-out via
the connections tab to zero.
“There is insufficient system memory to run this query”
This particular error can happen for a variety of reasons; one of which was fixed with
service pack 3 of SQL Server 2000. Refer to bug# 361298. This error was caused when
a query used multiple full outer joins followed by a possible 701 error in the SQL Server
log.
The other time I have experienced this problem is on machines with relatively little RAM
but a large number of running queries, or queries that are pulling large record sets from
numerous tables.
The problem with this error is that it may render the instance complete useless, not
accepting any further connections to the instance in a timely manner.
If you experience this problem:
a)
Recheck your SQL Server memory allocation, namely the max server
memory value. I generally recommend that all DBA’s physical set the
maximum allowable RAM. Be aware though that this value only limits the
size of the SQL Server buffer pool, it does not limit remaining unreserved
(private) memory (i.e. COMs, extended stored procs, MAPI etc).
Christopher Kempster
221
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b) Check carefully what tables you are PINNING; alter as required, especially
when in a development environment vs production.
c) Consider trapping large SQL statements via profiler and working with your
developers to reduce IO.
d) Consider freeing the procedure and buffer caches every few days in
development – It can cause some adverse performance issue, but at the
same time have found it to resolve the issues.
e) Buy more RAM ! ☺ (to decrease buffer pool thrashing)
f)
If you do have a lot of memory, did you forget the /3GB and /PAE settings
in your boot INI?
As a general reminder for your boot.ini:
4GB RAM
/3GB (AWE support is not used)
8GB RAM
/3GB /PAE
16GB RAM
/3GB /PAE
16GB + RAM
/PAE
Memory greater than 4Gb - use the AWE enabled database option:
sp_configure 'show advanced options', 1
RECONFIGURE
GO
sp_configure 'awe enabled', 1
RECONFIGURE
Note that unless max server memory is specified with this option in SQL Server, the
instance will take all but 128Mb of RAM for itself.
My stored procedure has different execution plans?
There is a nasty “feature” with SQL Server related to parameter sniffing by the SQL
Server engine.
When you have a stored procedure with one or more parameters, the SQL engine will
generate a plan based on the incoming values and how they influence the execution
path; if the parameter value is a date for example, the optimizer may experience some
difficulty generating a optimal plan that will suffice well for ALL the possible values passed
into this parameter. This can result in very poor performance, even when table statistics
are up to date.
To get around this:
a) Assign incoming parameters to local variables and use them, rather than
the parameters.
b) Use sp_executesql to run the actual SQL statements
c) Consider with recompile in the procedure definition (does not always help
through).
Christopher Kempster
222
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
A classic example I had was an infrequently run stored procedure. The stored proc took
30 seconds to run, but take the embedded SQL out and run separately in query analyzer
saw the performance go down to 2 seconds. What was worse, the 30sec version was
doing 8 million logical reads verses 1000 for the raw SQL. Using a) resolved the
problem.
Using xp_enum_oledb_providers does not list all of them?
To get a list of OLE-DB providers on the server, run the following command:
You can search on the parse name in the registry to locate the underlying DLL.
The list will not show providers that:
a. may not be able to partake in Linked Server
b. versions of drivers where a later version has been installed.
To get a definitive list, consider the VB Script below:
'The script writes all installed OLEDB providers.
Option Explicit
Dim OutText, S, Key
'Create a server object
Set S = CreateObject("RegEdit.Server")
'
'Optionally connect to another computer
S.Connect "muj"
OutText = OutText & "OLEDB providers installed on " & _
s.Name & ":" & vbCrLf
OutText = OutText & "************************************" & vbCrLf
For Each Key In S.GetKey("HKCR\CLSID").SubKeys
Christopher Kempster
223
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If Key.ExistsValue("OLEDB_SERVICES") Then
OutText = OutText & Key.Values("").Value & vbtab & _
" : " &
Key.SubKeys("OLE DB Provider").Values("") & vbCrLf
End If
Next
Wscript.Echo OutText
This script was developed by Antonin Foller, © 1996 to 2004, fine this at:
http://www.pstruh.cz/help/RegEdit/sa117.htm
There is also a bug in MDAC 2.7, “FIX: MSOLAP Providers Not Displayed is SQL Server
Enterprise Manager After You Upgrade Data Access Components 2.7”, Q317059.
The columns in my Views are out of order/missing?
A problem with SQL Server is the updating of view metadata in relation to the underlying
schema. Only on the creation of the view (or subsequent alter view) command or
sp_refreshview will the view meta-data be altered.
If your view includes select * statements (which it should never as best practice!), this
can be a real problem when the underlying tables are altered. The problem shows its
ugly head as new columns are missing from your views and worse still, columns suddenly
inherit another’s data (columns seem to have shifted), crashing your applications or
populating fields with incorrect values.
To get around this issue – always run sp_refreshviews for all views (or selected ones if
you are confident with the impact of the change) when a new table column and/or other
view column (if embedding calls to other views) has been created or its name altered.
The routine is very quick so I would not trouble yourself with analyzing the dependencies
and trying for formulate some fancy query logic to filter out specific views.
Here is a great example script from Dan Guzman MVP that I have adapted slightly.
DECLARE @RefreshViewStatement nvarchar(4000)
DECLARE RefreshViewStatements
CURSOR LOCAL FAST_FORWARD READ_ONLY FOR
SELECT
'EXEC sp_refreshview N''' +
QUOTENAME(TABLE_SCHEMA) +
N'.' +
QUOTENAME(TABLE_NAME) +
''''
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'VIEW' AND
OBJECTPROPERTY(
OBJECT_ID(QUOTENAME(TABLE_SCHEMA) +
N'.' +
QUOTENAME(TABLE_NAME)),
'IsMsShipped') = 0
OPEN RefreshViewStatements
FETCH NEXT FROM RefreshViewStatements INTO @RefreshViewStatement
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC(@RefreshViewStatement)
Christopher Kempster
224
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
FETCH NEXT FROM RefreshViewStatements INTO @RefreshViewStatement
END
CLOSE RefreshViewStatements
DEALLOCATE RefreshViewStatements
GO
The refresh view procedure will stop when a view is invalid (i.e. columns are missing in
the underlying tables and/or other views have been removed causing it to become
invalid).
PRINT statement doesn’t show results until the end?
The PRINT statement works at the TDS level. Within a stored procedure via query
analyzer, if its buffer fills, you may see the results of your statements, otherwise you will
not see the flush until the completion of the statement.
As an alternative, use RAISEERROR. The results will show up in the output screen of
query analyser immediately, rather than waiting for the buffer to fill or dumping the
output to you on error or at the end of the routine.
RAISERROR('A debug or timing message here', 10, 1) WITH NOWAIT
This does not affect @@ERROR.
PRINT can result in Error Number 3001 in ADO
If you are executing T-SQL stored procedures then double check that you have removed
all PRINT statements (typically used when debugging your code).
Timeout Issues
The application development DBA needs a good understanding of the overarching
application architecture and subsequent technologies (ADO/OLE-DB, COM+, MSMQ, IIS,
and ASP etc) to more proactively debug and track down database performance problems.
A good place to start is common timeout error. This section will provide a brief overview
of where to look and how to set the values.
ADO
Within ADO, the developer can set:
a) connection timeout (default 15 seconds)
a. if the connection cannot be established within the timeframe specified
b) command timeout (default 30 seconds)
a. cancellation of the executing command for the connection if it does not
respond within the specified time.
These properties also support a value of zero, representing an indefinite wait.
Here is some example code:
Dim MyConnection as ADODB.Connection
Set MyConnection = New ADODB.Connection
MyConnection.ConnectionTimeout = 30
MyConnection.Open
- and -
Christopher Kempster
225
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Set MyConnection = New ADODB.Connection
<<set strMyConn>>
MyConnection.Open strMyConn
Set myCommand = New ADODB.Command
Set myCommand.ActiveConnection = MyConnection
myCommand.CommandTimeout = 15
Take care with command timeouts. They are described by Microsoft:
http://support.microsoft.com/default.aspx?scid=KB;en-us;q188858
COM+
Any component service DLLs partaking in COM+ transactions are exposed to two timeout
values:
a) global transaction timeout (default 60 seconds)
b) class level transaction timeout (default 60 seconds)
Open component services, select properties of “My Computer”. The screen shots shown
below may differ based on the server and of course the MSDTC version being run. The
options tab allows us to set this global value for all registered COM+ DLLs:
Christopher Kempster
226
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The next layer down is not at the individual COM component, but at the class level within
each component. This cannot be programmatically altered. Once installed, drill through
to the specific COM and select properties for the class:
Again this option is only available for those classes partaking in COM+ transactions. The
GUI also allows transaction support properties to be altered, but this can be fully
controlled (and should be) by the developer.
OLEDB Provider Pooling Timeouts
This is somewhat off track for the ebook, but the DBA should know that control over the
pooling of unused open sessions can be controlled at the OLEDB provider level. This is
applicable from MDAC v2.1 onwards. Examples of this can be found at:
http://support.microsoft.com/default.aspx?scid=kb;en-us;237977
IIS
Within IIS we can set session timeout values:
a)
b)
c)
d)
globally for the website
for each virtual directory for a website
in a virtual directory global.asa
at the individual ASP page
For the website, open IIS, right click for properties and select the home directory tab.
From here click the configuration button. This is very similar for each individual virtual
directory:
Christopher Kempster
227
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Where session state is applicable the default value is 60 minutes, and ASP script timeout
default is 90 seconds. The values represent:
a) session timeout
a. user sessions - the IIS server can create per user session objects and can
be used to maintain basic state information for the “session” via user
defined session variables. The session object is created on storing or
accessing a session object in ASP code, which will fire the session_onstart
event
i. timeout controlled programmatically via
Session.Timeout = [n-minutes]
ii. User page refresh will reset the timeout period
iii. Get the unique session ID via Session.SessionID
iv. Control locality that affects date displays etc via
Session.LCID
= [value]
v. Create a session variable and show contents:
Session(“myData”) = “some value here”
response.write Session(“myData”)
b. application sessions – similar to user sessions but are accessible to all user
sessions for the virtual directory. They cannot timeout as such but will
reset on IIS being re-started. Its values are typically initialised via the
global.asa
i. initialised on first page served by IIS
ii. use: Application(“myData”) = “some value here”
b) script timeout
a. limit for page execution time
b. default of 90 seconds
c. also set via the following for a specific ASP page
Christopher Kempster
228
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
i. <%@ LANGUAGE=”VBSCRIPT”%>
<% Server.ScriptTimeout = 1800 %>
Be aware that IIS has a restricted maximum value for session timeout, that being 24hrs
(1440 minutes). In most cases, developers will proactively use a single point of
reference for application wide variables, session and script timeouts.
SQL Server
For SQL Server we have:
a) LOCK_TIMEOUT
a. Will timeout the executing command after N milliseconds if it is waiting for
locks.
b. Typically called at the top of stored procedures (along with set nocount)
c. Is not Pandora’s box for solving deadlock issues
d. Check value via select @@LOCK_TIMEOUT
e. Over linked servers, test carefully. You may find that a 4-part naming
convention does not work. Worse still setting the value before using
OPENQUERY may also not work. If you experience this problem, try this
syntax:
select *
from openquery([myremoteserver],
‘set lock_timeout 1000 select col1 from myremotetable’)
b) ‘remote login timeout’
a. linked server login timeout.
b. OLE-DB providers, default is 20 seconds
c. exec sp_configure N' remote login timeout (s)', 1000
c) ‘remote query timeout’
a. linked server query timeout.
b. default 600 seconds (ten minutes)
c. exec sp_configure N'remote query timeout (s)', 1000
d) ‘query wait’
a. default 25 times cost estimated (-1), value in seconds
b. wait time occurs when resources are not available and process has to be
queued
c. if used incorrectly, can hide other errors related to deadlocking
d. will not stop/cancel blocking issues
e. set at instance level only
f. don’t use in an attempt to stop a query after N seconds, its resource
related only.
g. exec sp_configure 'query wait', 5
e) ‘query governor cost limit’
a. default zero, value is in seconds, upper time for DML to run
b. execute/runtime, not parse time
c. is an estimated figure by the optimizer
d. globally for the instance
i. sp_configure ‘query governor cost limit’, 1
e. manually set per connection
i. SET QUERY_GOVERNOR_COST_LIMIT 1
Remember that deadlocks are not the same as LOCK_TIMEOUT issues. The DBA should
Christopher Kempster
229
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
have a careful look at the DTS timeout options; select properties at a variety of levels
and active-x objects to determine where values can be set.
Sample Error Messages
Here is a table of sample error messages propagated from a basic web based application
to the end user. Be careful, as the actual error message can depend on many factors
such as the network providers being used and much more.
ASP Script Timeout
(website or the
virtual directory,
check both carefully
when debugging)
COM+ Transaction
Timeout
or
ADO Connection
Timeout
Christopher Kempster
230
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
ADO Command
Timeout
Runtime error -214721781 (80040e31)
SQL – Query
Governor cost limit
reached
Server: Msg 8649, Level 17, State 1, Line 1
SQL - Lock Timeout
Server: Msg 1222, Level 16, State 54, Line 2
[Microsoft][ODBC SQL Server Driver]Timeout expired
The query has been cancelled because the estimated cost of
this query (7) exceeds the configured threshold of 1. Contact
the system administrator.
Lock request time out period exceeded.
SQL – Query Wait
Server: Msg 1204, Level 19, State 1, Line 1
The SQL Server cannot obtain a LOCK resource at this time.
Rerun your statement when there are fewer active users or ask
the system administrator to check the SQL Server lock and
memory configuration.
Is the timeout order Important?
The order really depends on the developer and their specific requirements. Even so, the
DBA and developer should have a good understanding of the settings being used to
better assist in tracking and resolving timeout issues.
In most cases, the developer is inclined to start debugging from the DBMS and work up
(not necessarily for session timeouts though). Doing so allows the developer to better
understand errors related to DBMS connectivity and command execution verses higher
level problems in the business and interface layer tiers.
Care must be taken with long running batch jobs or complex SQL. It is not unusual for
developers to fix class level transaction timeouts in COM+ and associated IIS level
timeout values. Unless you have done a lot of testing, command timeouts are difficult to
manage due to spikes in user activity.
DBCC Commands
What is – dbcc dbcontrol() ?
This DBCC option is the same as sp_dboption, and takes two parameters setting the
database online or offline:
USE master
GO
DBCC DBCONTROL (pubs,offline)
GO
--View status of database
SELECT CASE DATABASEPROPERTY('pubs','IsOffline')
WHEN 1 THEN 'Offline'
Christopher Kempster
231
S Q L
ELSE
END
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
'Online'
AS 'Status'
This command does not work under service pack three (a) of SQL Server 2000.
What is - dbcc rebuild_log() ?
This is an undocumented DBCC command. It will basically drop all virtual log extents and
create a new log file. The command requires the database to be in bypass recovery
mode before it can be run:
server: Msg 5023, Level 16, State 2, Line 1
Database must be put in bypass recovery mode to rebuild the log.
Another name for bypass recovery mode is Emergancy Mode, therefore:
use master
go
sp_configure 'allow updates', 1
reconfigure with override
go
update sysdatabases set status = 32768 where name = '<db-name-here>'
We now stop SQL Server instance delete the database log file before re-starting the
instance, otherwise you get this error:
Server: Msg 5025, Level 16, State 1, Line 1
The file 'F:\Program Files\Microsoft SQL
Server\MSSQL$SS2KTESTC1\data\cktest_Log.LDF' already exists. It should be
renamed or deleted so that a new log file can be created.
With the instance restarted. Run the command:
dbcc rebuild_log(cktest)
-- cktest is the name of the database
Warning: The log for database 'cktest' has been rebuilt. Transactional consistency
has been lost. DBCC CHECKDB should be run to validate physical consistency.
Database options will have to be reset, and extra log files may need to be
deleted.
If you need to specify a different filename use:
dbcc traceon (3604)
dbcc rebuild_log(cktest, ‘c:\dblog\cktest_log.ldf’)
If successful, the db status is dbo use only. The file will be created in the default data
directory; if the previous database had multiple log files, they will be lost (but not
physically deleted from the file-system, do this manually). Only a single log file is
created 1Mb in size.
Use EM or the alter database command to restore its status. Use sp_deattach and
sp_attach commands (or via EM) if you need to move the database log file to another
location.
Christopher Kempster
232
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Troubleshooting DTS and SQL Agent Issues
Naming Standards
A quick note. The DBA should follow a strict naming standard for DTS packages and stick
with it. The convention used should make the purpose and context of the package easy
to identify. For example:
<application/module> - <function or task> [ - <part N or app versioning, sub-task>]
eg:
EIS – Load HR Data – v1.223.1
DBA – Log Shipping - Init
I’m getting a “deferred prepare error” ?
A SQL comment embedded in a stored procedure/SQL edited within DTS designer then
run can cause this error. I experienced this error on SQL Server 2000 SP2.
Debugging SQLAgent Startup via Command Line
On http://www.sqlservercentral.com, Andy Warren discussed a problem with SQL Agent
and his success with Microsoft support in resolving the startup issues with the agent. In
the article, he mentions some command line options well worth knowing to assist you in
debugging the agent.
For example:
cd c:\Program Files\Microsoft SQL Server\MSSQL$CKDB\Binn>
sqlagent.exe -i ckdb -c -v > c:\logfile.txt
where:
-i [instancename], my named instance. If there is a problem here you will be told
about it
2003-07-09 15:45:28 - ! [246] Startup error: Unable to read SQLServerAgent
registry settings (from SOFTWARE\Microsoft\Microsoft SQL
Server\SQLAGENT$CKDB\SQLServerAgent)
in the error above, I used sqlagent$ckdb, rather than the straight CKDB.
-c, command line startup
-v, verbose error mode
> c:\filename.txt, send errors to this file
So on startup I get this:
Microsoft (R) SQLServerAgent 8.00.760
Copyright (C) Microsoft Corporation, 1995 - 1999.
2003-07-09 15:45:59 - ? [094] SQLServerAgent started from command line
2003-07-09 15:46:02 - ? [100] Microsoft SQLServerAgent version 8.00.760 (x86 unicode retail build) :
Process ID
2003-07-09 15:46:02 - ? [100] Microsoft SQLServerAgent version 8.00.760 (x86 unicode retail build) :
Process ID 840
Christopher Kempster
233
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
2003-07-09 15:46:02 - ? [101] SQL Server PC-124405\CKDB version 8.00.760 (0 connection limit)
2003-07-09 15:46:02 - ? [102] SQL Server ODBC driver version 3.81.9031
2003-07-09 15:46:02 - ? [103] NetLib being used by driver is DBMSLPCN.DLL; Local host server is PC124405\CKDB
2003-07-09 15:46:02 - ? [310] 1 processor(s) and 256 MB RAM detected
2003-07-09 15:46:02 - ? [339] Local computer is PC-124405 running Windows NT 5.0 (2195) Service
Pack 3
2003-07-09 15:46:02 - + [260] Unable to start mail session (reason: No mail profile defined)
2003-07-09 15:46:02 - + [396] An idle CPU condition has not been defined - OnIdle job schedules will
have no effect
CTRL-C to stop, Y response shuts down immediately, no enter required.
Don’t forget your package history!
Everytime you save a DTS package to SQL Server, a version or copy is created in the
msdb..packagedata system table (or msdb..sysdtspackages) in the MSDB database:
Deleting the only version of a package will of course remove the entire package and
subsequent scheduled jobs will not run. To remove a version use the command below
(or EM):
exec msdb..sp_drop_dtspackage NULL, NULL, "CA49CFB3-60D1-4084-ABCF-32BD7F93E766"
where the GUID string is from the versionid column in msdb..packagedata. Packages
saved to disk or file will not carry with it the SQL Server versioning.
Where are my packages stored in SQL Server?
A SQL Server saved package will be stored in the sysdtspackages table within the MSDB
database. The key here is the packagedata column which is a binary (image) blob of the
package itself:
The DBA can use the textcopy.exe utility to dump the contents of a package (note that
the table holds multiple versions of a single package) into a .DTS file. Once there you
can open the file via Enterprise Manager (right click properties of data transformation
services) and attempt to open the file.
Here is an example of textcopy.exe:
Christopher Kempster
234
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
textcopy /S MYSERVER\CKTEST /U sa /P /D msdb /T sysdtspackages /C
packagedata /W "where name='TEST'" /F c:\dtsfile.dts /O
DTS Package runtime logging
To enable logging within your package, right click on any white space within the design
screen for the package, and select package properties:
Under the logging tab, we can log runtime data of the package to:
a) SQL Server – to your current or another SQL Server instance
b) file on disk (at the server)
Option a) will call two MSDB stored procedures:
exec msdb..sp_log_dtspackage_begin
and
exec msdb..sp_log_dtspackage_end
which write to the table sysdtspackagelog. If you are suspicious of MSDB growth, check
this table first before moving onto the sysdtspackages table and reviewing the history of
packages.
Option b) will generate something like:
The execution of the following DTS Package succeeded:
Package Name: (null)
Package Description: (null)
Package ID: {1F84517D-1D5C-4AB0-AE0C-D7EC364F5052}
Package Version: {1F84517D-1D5C-4AB0-AE0C-D7EC364F5052}
Package Execution Lineage: {FA5B1E8F-A786-4C24-9B91-232D1D155D7A}
Executed On: NEWCOMP
Executed By: admin
Execution Started: 7/03/2004 9:29:01 AM
Execution Completed: 7/03/2004 9:29:01 AM
Total Execution Time: 0 seconds
Christopher Kempster
235
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Package Steps execution information:
There is no API call exposed (or option within the DTS designer) to overwrite the file, so it
will grow and grow with each execution of the package. One possible solution is to
leverage the filesystemobject (fso) API calls and use a small active-x script as the first
step in your package to clear this file (31).
I get an “invalid class string” or “parameter is not correct”
With each release of SQL Server comes new DTS controls, such as transfer-database or
logins for example. If you attempt to open a package that utilizes these objects and the
corresponding DLL (active-x) is not part of your clients (or servers) EM, then you may get
this error. Be very careful in this case when custom objects are used within DTS
packages.
So what can you do?
First of all, its technically not a SQL Server problem, its yours, so don’t plan on ringing up
Microsoft support and asking for a free call (not that I would of course). A classic case in
which this error can occur is if you have old SQL Server 7 packages that used the OLAP
Manager add-in to process OLAP cubes, found at:
http://www.microsoft.com/sql/downloads/dtskit.asp?SD=GN&LN=EN-AU&gssnb=1
As a fix, download the package and install on the server and your client, the package will
then open without error as it would fine the class-id (pointing to the underlying DLL).
I lost the DTS package password
If the package has been scheduled, and the DTSRUN command will use either an
encrypted or unencrypted runtime string. This may be the user password of the
package, not the owner password (can view the package definition). Be aware that once
a user password is set, the owner password must also be specified.
The password is also stored in msdb..sysdtspackages. For meta-data-services packages
the password is stored in msdb..rtbldmbprops (col11120).
I believe that a de-encryption program is available, consider MS support.
I lost a DTS package - can I recover it?
Consider the following in order:
Christopher Kempster
236
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
a) Can you retrieve an older version – assuming you made an edit error and need to
rollback
b) Consider restoring your MSDB database from a recent backup
Access denied error on running scheduled job
Check the following:
a) If the package is accessing UNC paths, specific files or directories, ensure the SQL
Agent service account user has the correct privileges.
b) With trial and error, and the inherent versioning of DTS packages, break down the
package to determine the failing task
c) Ensure the service account running SQL Agent has the appropriate privilege
d) An alternative for b), consider running the SQL Agent service account under
localsystem; did you remove builtin/administrator account from SQL?
Changing DTS package ownership
For non sysadmin users, it is not unusual for end users to receive the message “only the
owner of DTS Package ‘MyDTSPackage’ or a member of the sysadmin role may create
new versions of it’. This comes from the call to msdb..sp_add_dtspackage.
If multiple people need to work on the package, and most are not sysadmin users (we
hope not), then we have a problem of package ownership.
To resolve this we can use the undocumented command:
exec sp_reassign_dtspackageowner ‘package-name’, ‘package-id’, ‘newloginname’
A nice wrapper script can be found at : http://www.sqldts.com/default.aspx?271
I have scheduled a package, if I alter it do I re-create the job?
No. The scheduled job is a 1:1 map to the package and the most recently saved version
of the package. You can alter the package, save it, and the job will run this version
without the need to re-create the job.
xpsql.cpp: Error 87 from GetProxyAccount on line 604
Only system administrators (sysadmin users) can run xp_cmdshell commands. Even
though you have granted a non-sysadmin user to execute privilege, you will still receive
this error. To resolve, we need to set the proxy account in which xp_cmdshell will run
under on the database server.
To set, right click and select properties for SQL Agent. Under the Job System tab, the
bottom group allows us to specify/reset the proxy account:
Christopher Kempster
237
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Uncheck the box, and click the reset proxy account button:
Alter the account to a domain user with the appropriately restricted privileges to the
server, press OK. This GUI is equivalent to the command xp_sqlagent_proxy_account.
Stop and start SQL Agent for the proxy user to take effect.
DTSRUN and Encrypted package call
When you schedule a package to run via Enterprise Manager, the step properties will
show you something like this:
DTSRun
/~Z0x6D75AA27E747EB79AC882A470A386ACEB675DF1E7CB370A93244AA80916653FC9F13B50CA6F
6743BB5D6C31862B66195B63F4EBEE17F6D4E824F6C4AD4EADD8C323C89F3D976BC15152730A8AF
5DB536B84A75D03613D6E9AF2DD5BC309EB9621F56AF
This is equivalent to this:
DTSRun /S MySQLServer /E /N "MyDTSPackage"
Review the parameter set carefully to determine if further runtime items are required.
Generally, this makes for a much more readable job to package relationship.
IMPORTANT – If you do alter it, any subsequent save of the package will not
prevent the job from using this latest change.
TEMPDB in RAM – Instance fails to start
This option is not supported in SQL Server 7 and 2000. If you do experience the error in
past versions attempt the following:
a) Stop all SQL Server services, exit from Enterprise Manager and Query Analyser.
b) Go to the \binn directory for your instance and at the command line type in:
sqlservr –c -f
Christopher Kempster
238
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) The above command will start the Instance in single user mode with minimal
configuration. You will see the SQL Server error log output to this command
window, wait until SQL Server completes recovery and the instance has started.
d) Run Query Analyser (isql) and connect with sysadmin privileges (aka the SA
account)
e) Run:
f)
sp_configure tempdb,0
go
reconfigure
go
Go back to the command line, type shutdown OR CTRL-D, you will be asked to
shutdown the instance.
g) Re-start the instance as per normal.
h) Check TEMPDB status and more importantly, validate that its size is adequate for
your particular instance.
Restore a single table from a File Group
A table was dropped. You know the filegroup it comes from. Application can still run
albeit with some errors.
This scenario can be easily adapted to include any DBMS object.
Pre-Recovery Steps
The DR plan is initiated. The team meets to determine:
a) cause of the problem (if possible at this early stage)
b) impact of the tables removal/corruption/missing data
c) time to repair vs full database restore to a point in time, or, is it a
reporting/generated table that will simply be recreated later or can be rebuilt
overnight?
d) Amount of DML activity occurring within the DBMS – hot tables?
e) time the error was noticed or occurred at (to facilitate accurate point in time
recovery)
f)
a copy of the database resides elsewhere? (to assist with scripting if required)
Time is of the essence with this recovery scenario. The longer you delay in making a
decision the more work application users may need to repeat if you decide on a complete
point in time recovery before the error occurred.
Christopher Kempster
239
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
To ensure maximum availability a decision is made to restore this single table and its
associated indexes, constraints, triggers.
Recovery Steps
We have the following backups:
FULL
LOG
LOG
LOG
6am
9am
10am
11am
fgtest_full.bak
fgtest_log1.bak
fgtest_log2.bak
fgtest_log3.bak
missing table detected around this point
All files have been checked, uncompressed and are on disk ready for use. The database
structure is:
You can also do this:
restore filelistonly from disk='c:\fgtest_full.bak' with nounload
Logical F.Name
fgtest_primary
fgtest_data01
fgtest_data02
fgtest_Log
Physical Filename/Path
C:\Program Files\Microsoft SQL Server\MSSQL$CKDB\data\fgtest_primary_Data.MDF
C:\Program Files\Microsoft SQL Server\MSSQL$CKDB\data\fgtest_data01_Data.NDF
C:\Program Files\Microsoft SQL Server\MSSQL$CKDB\data\fgtest_data02_Data.NDF
C:\Program Files\Microsoft SQL Server\MSSQL$CKDB\data\fgtest_Log.LDF
Type
D
D
D
L
FileGrp
PRIMARY
DATA01
DATA02
NULL
We will restore the database to the same instance but of course, with a different
database name. Later we will discuss the issues of recovery on the “live” database. The
partial clause is required to start the recovery, I have had limited success via EM so I
would highly recommend doing this via query analyser.
RESTORE DATABASE [fgtest_temp]
FILE = N'fgtest_data02'
FROM DISK = N'C:\fgtest_full.bak'
WITH PARTIAL, RESTRICTED_USER, REPLACE,
MOVE 'fgtest_primary' TO 'c:\temp1.ndf',
MOVE 'fgtest_data02' TO 'c:\temp2.ndf',
MOVE 'fgtest_log' TO 'c:\temp3.ndf',
STANDBY = 'c:\undo.ldf'
-- norecovery option is not applicable
To complete partial the recovery of the database and fg_data02 filegroup via the creation
of a new database, you of course must include:
a) primary file group – system tables/meta-data for the database
b) log files – to facilitate the recovery process
The primary file group files are also recovered with our specific file group. This is
mandatory as the dictionary information for the database and its objects only exist due to
the sys tables in the primary file group. Take this into consideration if the primary file
group is large.
Christopher Kempster
240
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
To confirm the restore and recovery of fgtest_data02 and primary filegroups, run the
command:
select * from fgtest_temp..sysfiles
File refers to the existing database, notice the zero size, growth and a status
If you attempt to query an object that resides in fgtest_data01 you will get this message:
Server: Msg 8653, Level 16, State 1, Line 1
Warning: The query processor is unable to produce a plan because the table 'aa' is
marked OFFLINE.
The STANDBY clause allows us to inspect the database after each restore, providing us
with the opportunity to check the status of our missing table. The standby clause of
course is used for log shipping scenarios, creating a warm standby database for high
availability.
RESTORE LOG fgtest_temp
FROM DISK='c:\fgtest_log1.bak'
WITH STANDBY = 'c:\undo.ldf', RESTRICTED_USER
select * from fgtest_temp..bb
-- exists.
RESTORE LOG fgtest_temp
FROM DISK='c:\fgtest_log2.bak'
WITH STANDBY = 'c:\undo.ldf', RESTRICTED_USER
select * from fgtest_temp..bb
-- exists.
RESTORE LOG fgtest_temp
FROM DISK='c:\fgtest_log3.bak'
WITH STANDBY = 'c:\undo.ldf', RESTRICTED_USER
select * from fgtest_temp..bb
-- doesnt exist!
Get end time of this log file and between this time and the log2, try the stop at clause to
determine how close you can get to the drop being issues, OR, use a 3rd party log reader
application to assist you in locating the STOPAT time.
-- run this first:
RESTORE LOG fgtest_temp
FROM DISK='c:\fgtest_log3.bak'
WITH STANDBY = 'c:\undo.ldf', RESTRICTED_USER,
STOPAT = 'May 30, 2003 02:05:12 PM'
select * from fgtest_temp..bb
-- doesnt exist!
-- then run:
RESTORE LOG fgtest_temp
FROM DISK='c:\fgtest_log3.bak'
WITH STANDBY = 'c:\undo.ldf', RESTRICTED_USER,
STOPAT = 'May 30, 2003 02:05:05 PM'
Christopher Kempster
241
S Q L
S E R V E R
select * from fgtest_temp..bb
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
-- exists!
The current live database is in a state where a range of constraints (foreign key),
triggers, views and stored procedure may be invalid due to the missing table. This
operation is somewhat tricky and the DBA needs to be confident with the underlying
relationship the object has to other objects, let alone its own properties such as triggers
etc (object dependent of course). There are few sites where the database does not exist
already in some known state, such as a test or development database server, therefore,
you will have a good idea as to the additional restore steps to take.
In this particular example, to restore the table, its constraints, table and column
descriptions we need do the following. Remember that, as we use the standby file, we
can utilise EM to open the database during each recovery step and script out the
necessary code ready to run on the “live” production database.
REMEMBER – You cannot create diagrams on a read only database, which is the
mode our standby database is in during the recovery process.
a) Goto EM and script the table, all options are selected:
b) From the script
a. run the create table statement on the live database
b. copy the contents of the fgtest_temp..bb (standby database) to fgtest..bb
(live database). The data is now restored
c. Re-create triggers
d. for all views on the live production database run sp_refreshview. No need
to take action on stored procedures unless some were manually altered to
cater for the temporary loss of the table.
e. Re-create table constraints (primary and foreign keys) on fgtest..bb from
the script, include defaults and check constraints.
f.
Re-create other non-keyed indexes from the script
c) Although fine, we might be missing foreign keys from other objects to the newly
restored table. Remember that SQL Server will not allow you to drop a table if it’s
Christopher Kempster
242
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
referenced by foreign keys (with referring data). Even so, you need to double
check and re-create any missing keys.
This command runs the master..sp_MSdependencies stored procedure, or use
query analyser:
exec sp_MSdependencies ‘?’
For all tables shown, select them in the standby database, script them with only
the foreign/primary key option selected only. Before running the script, re-check
the production database. Don’t run with the drop statements in the script.
Always run the drop statements without them otherwise you will end up having a
very bad day with your recovery.
On completion, drop your partially recovered database and notify all users via the ER
Team.
Can I do a partial restore on another server and still get the same result?
Its important to remember that all meta-data related to the database is restored with the
primary file-group. SQL Server EM will allow you to script any portion of the database
but you will not be able to view table data for those file groups not physically restored via
the partial restore option.
Can I do a partial restore over the live database instead?
Of course - but typically as a last resort. The key issues here are:
a) restore without standby - is restricted to recovery commands only
b) restore with standby – database will be in read-only mode between restores
c) primary file group is part of the recovery
So in general, the database will be unavailable to end-users throughout the restore. This
tends to defeat the objective of ensuring as little downtime to the end-user whilst we
recover single objects.
If you decide to continue with this option, remember what is happening with the partial
restore. In this example, only the fgtest_data02 filegroup is being partially restored, the
primary and other user defined file-groups remain at the current LSN. If we issue the
Christopher Kempster
243
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
recover command over fgtest_data02 then the whole database goes into recovery mode
and its objects (tables, views etc) are inaccessible. Therefore, we use the standby
option after killing existing database user sessions:
IMPORTANT – Do a full backup before attempting this operation.
RESTORE DATABASE [fgtest]
FILE = N'fgtest_data02'
FROM DISK = N'C:\fgtest_full.bak'
WITH PARTIAL, RESTRICTED_USER,
STANDBY = 'c:\undo.ldf'
-- over the live prod database !
This example doesn’t show it but the database objects we need to restore were not part
of the initial full backup. The above command resulted in an empty database with no
user objects, if it was not included then the objects would have been there. Either way,
this is what we would expect to ensure consistency with the data dictionary in the
partially recovered file-group.
Even though fgtest_data01 is not part of the partial recovery, its tables (eg. [aa]) are still
not accessible, giving us the error:
Server: Msg 8653, Level 16, State 1, Line 1
Warning: The query processor is unable to produce a plan because the table 'fgtest..aa' is
marked OFFLINE.
To complete the recovery, the DBA needs to restore all database files for the database to
a single known point in time. The DBA must decide when this point will be. As
mentioned earlier, this scenario is a bad one and should not be attempted unless you
have very good reason to do so.
Restore over database in a loading status?
Recently I came across an interesting issue with restoring over a database in a state of
"loading". Any attempt to restore over the file resulted in strange IO errors. It should be
noted that removing a loading database within EM will not remove the physical data files.
If you get this issue and it’s applicable, simply remove the files completely and the
restore will succeed, unless of course you really do have a physical disk problem.
Moving your system databases
Moving MASTER and Error Logs
The instance start-up parameters in the registry can be altered, effectively allowing you
to move the master database files to another location.
Christopher Kempster
244
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Alter the registry entries, stop the instance services, including SQL Agent, move the
master database files to the new location and re-start the instance. These settings can
be changed within Enterprise Manager by selecting properties of the instance and altering
the start-up parameters. This will call an extended stored procedure to alter the registry
settings above.
Moving MSDB and MODEL
The DBA can move the MSDB and MODEL databases via:
Full backup then restore to a new destination
Use the sp_attach and sp_deattach commands
The backup and restore option is more appropriate, the instance will require a less
downtime and is a safer option overall.
To move this database via the sp_attach and sp_deattach commands, we require a little
more work needs to be done.
1. Stop the instance, then open the service control window for the instance, and
add the start parameter -T3608
2. Start the instance
Christopher Kempster
245
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
3. Run query analyser, login in with sysadmin privileges
4. Run the following command, writing down the name, fileid and filename
displayed
go
use msdb
go
sp_helpfile
5. De-attach the database from the instance with the command
use master
go
sp_detach_db 'msdb'
go
6. Refresh enterprise manager, you will notice that MSDB has now disappeared.
7. Copy or Move the database files listed in 4 to their new destination
8. Run a command similar to the following to re-attach the MSDB database files
use master
go
sp_attach_db 'msdb','C:\msdbdata.mdf','c:\msdblog.ldf'
go
9. Go back to the service control window. Shutdown services, clear the trace flag
and re-start the service.
10. Refresh or re-start Enterprise Manager.
11. Re-run step 4 to verify the new file location
Repeat the process above for the MODEL database.
WARNING - if doing both databases at the same time attach the MODEL
database before MSDB. If not you can come across a situation where MSDB takes
on the role of MODEL which is far from ideal (57).
Moving TEMPDB
The TEMPDB database is the same as the temporary tablespace option within Oracle.
This database is used for sorting and temporary tables. It is common practice,
where possible, to move this database to its own RAID 1 or RAID 10 set. This needs
to be carefully evaluated to determine if the use of the database and the set of disks
it is residing on is a bottleneck. To move the database files for this system
database:
Christopher Kempster
246
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
1. Run query analyzer. Check existing location of the tempdb database files
use tempdb
go
sp_helpfile
go
2. Get the destination directory ready and document the results above. Recheck the locations.
3.
Issue the alter statement to logically move the files
alter database tempdb
modify file (name=tempdev, filename=c:\dbdata\sys\tempdb.dbf)
alter database tempdb
modify file (name=templog, filename=d:\dblog\sys\templog.ldf)
Restart the instance for the files to be re-created at the new location.
Consider trace flag 3608 or 3609 (skips tempdb creation) if you have issues with the
new destination or with the model database (from which it’s created).
You can also resize the tempdb database via the SIZE option in the alter database
statement.
Moving User Databases
The DBA can move or copy databases via the sp_attach and sp_deattach commands.
This works on all database files, not selected file-groups. We have a variety of options:
a)
b)
c)
d)
Shutdown instance, copy database files, and re-attach at destination server
Offline the database, copy files, and re-attach at destination server.
De-attach the database, copy files, and re-attach at destination server.
Run a split mirror, offline or read-only the database, break the mirror and use
the files from the mirrored disk.
Some of these methods are described below.
Remember - copying a database will not take the logins with it, as this
information is stored in the master database.
Remember – If you do not have database backups, but still have all the database
files, the re-attaching the database will be your last remaining hope of recovering
your database.
Shutdown instance method
Simply shutdown the SQL Server instance, taking care when running multiple instances
on the same server. When down, copy the database files to the other server (or
copy/rename/move if it will be attached to the same server). As the database was cleanly
shutdown there will be no issues with re-attaching so long as the copy did not fail
unexpectedly. If the instance did fail unexpectedly and you have no backups, reattaching may still be possible (with the added risk of data corruption).
Christopher Kempster
247
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
When using this method, the database will of course remain on the source server with no
change what-so-ever to the source database.
To shutdown the instance use one of the following:
a) use NET STOP service command from the operating system
b) use Enterprise Manager and their GUI option
c) issue the SHUTDOWN transact-SQL command
Offline a Database method
Once the database is “offline”, you can copy its database files to a new server and
re-attach. Use this method when shutting down the SQL Server instance is not
desirable and you want to retain the database on the source server.
Reminder – User sessions will not be disconnected; this is applicable for
sp_dboption and the ALTER database command.
To take the instance offline:
exec sp_dboption N'mydb', N'offline', N'true'
or
alter database [mydb] set offline with rollback after 60 seconds
or
alter database [mydb] set offline with rollback immediate
or
DBCC DBCONTROL (mydb,offline)
Using the alter database statement (SQL Server 2k and beyond) is the preferred method.
The rollback after statement will force currently executing statements to rollback after N
seconds. The default is to wait for all currently running transactions to complete and for
the sessions to be terminated. Use the rollback immediate clause to rollback transactions
immediately.
When running the command with users connected you will get something like:
sp_dboption (does not wait like the alter database command, see below)
Server: Msg 5070, Level 16, State 2, Line 1
Database state cannot be changed while other users are using the database 'mydb'
Server: Msg 5069, Level 16, State 1, Line 1
ALTER DATABASE statement failed.
sp_dboption command failed.
alter database [aa] set offline [any parameter combination]
This command will run forever, waiting for sessions to disconnect. When it completes you will get
something like:
Nonqualified transactions are being rolled back. Estimated rollback completion: 100%.
See the script http://www.sqlservercentral.com/scripts/scriptdetails.asp?scriptid=271 to
kill off all connections for a database.
To confirm the offline status:
SELECT DATABASEPROPERTY('pubs','IsOffline')
or
SELECT DATABASEPROPERTYEX('mydb', 'Status')
Christopher Kempster
248
-- 1 if yes
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Attempting to connect to the database will give you:
Server: Msg 942, Level 14, State 4, Line 1
Database 'mydb' cannot be opened because it is offline.
De-Attaching the database
If you want to completely remove the database from the master database and the
SQL Server instance, use the detach command rather than offlining the database.
When attempting to de-attach with Enterprise manager it will warn you when:
a) there are users connected to the database
b) replication is active
All user sessions must be disconnected and replication disabled before attempting the deattachment.
The command is:
exec sp_detach_db N'mydb', N'false'
The second parameter denotes whether to include a statistics collection before deattaching the database. You must be a member of the sysadmin system role to issue this
command. Also note the error:
Server: Msg 7940, Level 16, State 1, Line 1
System databases master, model, msdb, and tempdb cannot be detached.
Funny enough, statistics are still updated before receiving this error.
The de-attachment will remove the database from the sysdatabases table in the master
database. The sysxlogins table will retain references to the de-attached database,
therefore, you will need to either remove the login(s) or alter their default database
connections:
exec sp_defaultdb N'myuser', N'master'
-- change default db from myuser to the master database.
exec sp_droplogin N'mytest'
Dropping logins is not straight forward. You need to either orphan the login from its
associated database user or drop the user, otherwise you will get this message:
Server: Msg 15175, Level 16, State 1, Procedure sp_droplogin, Line 93
Login 'myuser' is aliased or mapped to a user in one or more database(s). Drop the
user or alias before dropping the login.
You cannot remove users that own database objects. The standard drop user command
is:
use [mydb]
exec sp_dropuser N’myuser’
Checking Files before Attaching
Christopher Kempster
249
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
You should note that you cannot attach more than 16 files for a single database. Before
attaching the database, issue the following commands over the primary file-group data
file to get a listing of files that make up the database structure:
--Is the file a primary file-group MDF file?
dbcc checkprimaryfile (N'E:\SQLServerData\MSSQL\Data\mydb_Data.MDF', 0)
--Get me the database name, version and collation
dbcc checkprimaryfile (N'E:\SQLServerData\MSSQL\Data\mydb_Data.MDF', 2)
--Get a list of all files associated with the database. (original name)
dbcc checkprimaryfile (N'E:\SQLServerData\MSSQL\Data\mydb_Data.MDF', 3)
Attaching the database
The sp_attach_db command allows you to re-attach your database onto the SQL Server
instance. For example:
exec sp_attach_db
N'mydb' ,
N'E:\SQLServerData\MSSQL\Data\new_aa_Data.MDF',
N'E:\SQLServerData\MSSQL\Data\new_aa_Log.LDF'
The syntax is simple enough, the first being the name of the database to attach and its
associated database files. The database being attached must not already exist. You can
also attach databases not previously de-attached so long as the database was closed and
files where copied successfully.
Server: Msg 1801, Level 16, State 3, Line 1
Database 'mydb' already exists.
After re-attaching, especially if it’s on different server, you will need to fix orphaned
logins via the command:
exec sp_change_users_login <see SQL Server BOL for parameter list>
Attaching a single file
The sp_attach_single_file_db command is quite powerful. It allows you to re-attach a
database by specifying only its initial master data file. If your database had other data
files (even in the primary file-group) they will be automatically re-attached (only to their
previous destination though) for you by reading sysfiles within the primary MDF. This is
all fine if you want the data files restored to the same location from which the database
once existed along with the physical file name; apart from that you have no control and
will need to opt for sp_attach.
When re-attaching with this command, you have the ability for SQL Server to
automatically recreate your log file so long as it’s not available for SQL Server to
automatically re-attach when it looks up sysfiles. This method is handy when you have a
large log file and want to shrink it back to a manageable size. For example:
exec sp_attach_single_file_db N'MyxxDb' ,
N'E:\SQLServerData\MSSQL\Data\xx_Data.MDF'
Christopher Kempster
250
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
<..shows the message below, replace XX with the required name..>
Device activation error. The physical file name
'e:\sqlserverdata\MSSQL\data\xx_Log.LDF' may be incorrect.
New log file 'E:\SQLServerData\MSSQL\Data\xxxx_log.LDF' was created.
The new file size E:\SQLServerData\MSSQL\Data\xxxx_log.LDF will be 512k.
This command will not work if you have multiple log files:
Server: Msg 1813, Level 16, State 2, Line 1
Could not open new database 'mytest'. CREATE DATABASE is aborted.
Device activation error. The physical file name 'e:\sqlserverdata\MSSQL\data\mt_Log.LDF'
may be
incorrect.
Device activation error. The physical file name 'e:\sqlserverdata\MSSQL\data\mt_2_Log.LDF' may be
incorrect.
Some issues with MODEL and MSDB databases
To detach the model or msdb system databases, you need to set the trace flag –T3608
on instance startup. In all cases you must attach the model before the msdb database,
remembering that SQL*Agent for the instance must be stopped. As a side note, the
attach command executes something like the following:
CREATE DATABASE [mydb] ON
(FILENAME = ‘C:\dbdata\mydb\mydb_data.mdf’,
FILENAME = ‘C:\dbdata\mydb\mydb_log.ldf’)
FOR ATTACH
The create database command has dependencies on the model database, therefore
affecting its re-attachment.
Fixed dbid for system databases
The DBA should also be aware of the master..sysdatabases system table and its dbid
value for dbid for system databases. In some very rare occasions, it is possible that a
restore results in a corruption, or “mixup” in the dbid for the database, this may occur
when restoring databases in the wrong order. The flow on effect is some very strange
errors and confusion all round. See reference (57) for a great example of this.
The dbid for system databases are:
1
Master
2
Tempdb
3
Model
4
Msdb
Christopher Kempster
251
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Scripting Database Objects
The scripting of databases is an important task for the DBA. Using the features of EM,
the database diagrammer and profiler (to a lesser degree) assist the DBA in building
scripts for new system changes and most importantly, is a form of recovery.
Using Enterprise Manager - right click properties on any database and the following GUI
is shown:
The screen is simplistic and requires no explanation but there are a few things to
remember:
a) You must select objects (tables, views) in order to script
indexes/triggers/constraints/permissions. You cannot “generically” script all
indexes for example without selecting all tables/views first. You need to filter
out what you need from the generated script.
b) You cannot script multiple databases at once
c) You cannot script logins specific to database (i.e. logins that map to a single
user in one database – typically the one you are scripting). You cannot script
the sa login.
d) You cannot script linked or remote servers.
e) The options tab is the key here. Remember to select permissions as probably
the most basic option under this TAB.
Christopher Kempster
252
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Use the preview option to view the generated script in mini-dialog windows (which
you can cut into the clipboard from).
The diagrammer is also another handy place to generate scripts. For example - if you
need to make a variety of database changes and need a script to run then:
a) create a new (or use an existing) diagram and save it
b) make the changes within the diagrammer
c) press the script button (see below).
d) Copy the script generated to notepad or equivalent.
e) Don’t SAVE the diagram (we don’t want to apply the changes as yet – the script
will do it for us) and exit the diagrammer.
You can then use the saved script to apply on other identical databases (i.e. test /
support / prod databases) to mimic the changes and/or new objects.
You can cut the
scripted text from
here into notepad.
One of the key problems with the diagrammer is that you cannot allocate object
permissions whilst editing tables. This can adversely complicate your script generation
ideas.
NOTE – Be careful with generated scripts from the diagrammer. Always review
the generated script before running. In my experience EM has never generated a
script with errors.
Christopher Kempster
253
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If you select the “design table” option and alter the table, the same script option is
available to the DBA. Note that this is not the case for “design view” although the SQL
statement is selectable.
Another method for scripting is via EM and its listing of tables and views, for
example:
Select objects in
Enterprise Manager,
CTRL-C to copy.
Run Query Analyser, open a new
connection, and paste, a script is
generated for the selected objects.
Verifying Backups
To verify a backup, use the command:
restore verifyonly from ‘c:\myfullbackup.bak’
The DBA can also load the backup history in the backup file into the MSDB database.
This can be handy when analyzing the backup before attempting a recovery. Apart
from this SQL Server has no method as such for validating the backup until recovery.
Christopher Kempster
254
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Recovery
In SQL Server the DBA has a range of methods to facilitate recovery:
a) rebuildm.exe (from setup CD for rebuilding the system databases)
b) Enterprise Manager and its GUI wizards
c) Query Analyser (GUI or command line version)
d) SQL Server Service Control Manager, Windows Services applet itself or the
command line options for the sqlservr.exe
Many of the scenarios in this section refer to trace flags to control system database
recovery and lookup.
Recovery is potentially more complex than other DBMS systems due to the fact that
we are not dealing with one or more user databases, but with many system
databases as well as many user databases with depend on them for the single
instance. This section provides a summary by example in which the DBA can then
base further tests to drill down into this very important topic.
NOTE – Many of the examples use the GUI tools and at times reference the
equivalent T-SQL command.
A quick reminder about the order of recovery
It is critical that you remember what backup files to be applied when recovering a
database from SQL backups. It is simple enough but often forgotten. The diagrams
show which backup files must be used to recover to the point of failure.
Full backup
Differential
Time
T.Log backup
Restore Order
(left to right)
Failure Point
If you are running in transaction log mode, and you want to recover a specific database
file only:
Do a log file backup immediately
after the failure and before the
recovery begins for the file. This
file should be applied to complete
the database files recovery.
Christopher Kempster
255
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Killing User Connections and Stopping Further Connects
Killing off user connections is simple enough and there are many scripts on the internet
to do the job. An example script by [email protected] is shown below:
CREATE PROC Kill_Connections (@dbName varchar(128))
as
DECLARE @ProcessId varchar(4)
DECLARE CurrentProcesses SCROLL CURSOR FOR
select spid from sysprocesses where dbid =
(select dbid from sysdatabases where name = @dbName )
order by spid FOR READ ONLY
OPEN CurrentProcesses
FETCH NEXT FROM CurrentProcesses INTO @ProcessId
WHILE @@FETCH_STATUS <> -1
BEGIN
--print 'Kill ' + @processid
Exec ('KILL ' + @ProcessId)
--Kill @ProcessId
FETCH NEXT FROM CurrentProcesses INTO @ProcessId
END
CLOSE CurrentProcesses
DeAllocate CurrentProcesses
GO
Also consider the command to more elegantly terminate users and close off the
connection:
ALTER DATABASE mydb
SET SINGLE_USER WITH [<termination clause>]
eg:
ALTER DATABASE mydb
SET SINGLE_USER WITH ROLLBACK IMMEDIATE
To stop further connections, alter the database to dbo access only, or disable the
database logins via sp_denylogin (NT logins only).
Remember – you cannot recover a database whilst users are connected.
Using the GUI for Recovery
Unless you have major system database problems (which require additional steps before
running EM), the DBA will find that using EM for recovery is the simplist approach. The
best thing about the GUI when it comes to recovery is its reading of the MSDB sys
backup tables and correctly listing out the backup files to be used in a recovery. Later,
we will discuss a script I wrote that does a similar thing.
IMPORTANT – This section will use restore and recovery [of databases] to mean
the same thing. Always check the context in which it is being used.
Christopher Kempster
256
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Name of the database. We can enter a
new name if required. If you do, click on
the options tab if you do to double check
the name of the database files and the
destination
For the selected database in the drop
down above, is listed the date of all full
backups.
From the full backup selected above, the
MSDB is searched and lists, in hierarchical
order its proposed restore list to do a
complete recovery. We can select the
option to restore to a point in time. If
available.
The DBA can uncheck the appropriate
backup files as need be. Note that we
cannot alter the source of the backups
listed which can be very restrictive.
HINT – When using EM for recovery, run profiler at the same time to trace the TSQL recovery routines being executed. This is the best way to learn the recovery
commands and the context in which they are being used.
WARNING – If you restore a database, say, Northwind, and restore it as a
different name (database), then be careful when removing the new database. It
will ask if you want to remove all backup history. If you say yes then kiss good-bye
to the Northwind database’s MSDB backup entries.
We will cover some of the GUI options in brief. Remember that virtually ALL restore
operations require that no users to be connected to the database.
Options - Leave database in non-operational state but able to restore additional logs
This option allows us to restore the instance to any specific point, but leave it in a state
where we can apply further backups as need be.
Selecting properties of the restored instance in loading state gives us the error:
Christopher Kempster
257
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If you realize that you have no further backups and want to complete the recovery of the
instance, then (note that exec sp_helpdb will not show the database):
SELECT DATABASEPROPERTY('aa', N'IsInRecovery')
SELECT DATABASEPROPERTYEX('aa', 'status')
restore database aa with recovery
RESTORE DATABASE successfully processed 0 pages in 1.178 seconds (0.000 MB/sec).
An instance re-start will also issue the recovery statement. The non-operational
state simply executes the with norecovery option on restore of the last specified
backup file.
Options – Using the Force restore over existing database option
Using EM can be a tad strange when restoring databases. If you attempt to restore the
currently selected database, it will never prompt you that you are trying to overwrite
existing databases data files, even though (technically speaking here) you are! If we
attempted to restore say the northwind database as the pubs database, we will be
prompted with the following dialog:
It seems be to something related to the MSDB backup and restore tables which
determines whether or not this dialog is shown. Anyhow, to get around this, we click on
the options tab and select the Force restore over existing database option.
The command is not different to a standard restore. There is no magical restore option
related to the prevention of file overrides.
RESTORE DATABASE [bb]
FROM DISK = N'c:\northwind_full.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, RECOVERY ,
MOVE N'Northwind_log' TO N'C:\dblog\bb_log.ldf',
MOVE N'Northwind' TO N'C:\dbdata\bb_data.mdf'
Be very careful with this option in EM. Personally, I never use it unless I am 100%
sure that the files I am writing over are fine and I have already backed them up.
Christopher Kempster
258
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Restoring a databases backup history from backup files
In this example we have the following database, with associated backups:
Database: mydb
Data and Log files: c:\mydb.mdb, c:\mydb.ldf
Backups:
Full
Diff
Log
Log
c:\mydb_full.bak
c:\mydb_diff.bak
c:\mydb_log1.bak
c:\mydb_log2.bak
On selecting the restore in EM for the database, it magically lists all backups for a
successful restoration of my database up to the point of mydb_log2.bak from MSDB.
If we lost this information, then suddenly our nice GUI dialog is not so helpful
anymore.
To re-populate the MSDB database tables with the backup history I recommend that
you do not use the GUI. It is overly time consuming for such a simple task:
RESTORE
RESTORE
RESTORE
RESTORE
VERIFYONLY
VERIFYONLY
VERIFYONLY
VERIFYONLY
FROM
FROM
FROM
FROM
DISK
DISK
DISK
DISK
=
=
=
=
N'C:\mydb_full.bak' WITH NOUNLOAD , LOADHISTORY
N'C:\mydb_diff.bak' WITH NOUNLOAD , LOADHISTORY
N'C:\mydb_log1.bak' WITH NOUNLOAD , LOADHISTORY
N'C:\mydb_log2.bak' WITH NOUNLOAD , LOADHISTORY
NOTE - if you backup media had multiple, appended backups, then you may also
need to use the WITH FILE = option.
Once done, using the EM restore option, we select the database and work off the
restore history to pick the best path for restoration.
Remember, before restoring always double check the database name and the options,
ensuring paths and names are correct.
SQLServer Agent must be able to connect to SQLServer as SysAdmin
It is important to remember that the SQL Server service, along with the SQL Server
Agent service, can be started under a NT user account other than the default system
account. This tends to be best practice for security reasons and the ability to define strict
NTFS privileges to the user account.
Christopher Kempster
259
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The DBA needs to be careful with the privileges this user account has within the SQL
Server instance. The base system role privilege must be sysadmin. This must be
allocated for the SQL or Agent service accounts (typically the same account).
If you don’t, you may receive this error:
SQLServerAgent could not be started (reason: SQLServerAgent must be able to connect to SQLServer
as SysAdmin, but '(Unknown)' is not a member of theSysAdmin role). "
The DBA should check the SQL Server and SQL Agent log files at a minimum in any case.
If the error persists with the Agent, then:
“did you remove the BUILTIN/ADMINISTRATORS” group login?
This is often the case if you have reverted your service agent account back to run under
the system account but the group has been removed. If so, you need to add the
BuiltIn/Administrators group back in to use the system account for SQL Agent startup.
Restore cannot fit on disk
This is a classic problem. Basically, your attempt to restore a backup results in an
out of space error and asks you to free more space before re-attempting the restore.
In this particular scenario, SQL Server wants to restore the database files to the
same size as at the time when they were backed up. There is no option to alter the
physical file size (i.e. shrink) during the restore.
The general recommendation here is the shrink the database before any full backup
to reduce the possibility of this error. If that doesn’t work, try and restore and move
files as best you can to distribute the space amongst many disks, then shrink after
the restore. Backup and try to restore again with a more appropriate placement of
database files.
“Exclusive access could not be obtained..”
As a general reminder - you cannot restore the database whilst users or SPID are
connected; this message is related to this fact. Check master..sysprocesses or sp_who2
carefully, as system SPID attempting to cleanup from a large operation or completing an
internal SQL task should not be forcibly killed without a thorough investigation as to what
is happening.
Restore uses “logical” names
In the examples presented below, the restore operations work over the logical name
for each database file being restored (where this is appropriate of course). If you do
not know the logical name of the physical files or the name of the file-group, then
you will have some problems successfully restoring. Apart from using the GUI, we
can execute the command:
restore filelistonly from disk='c:\mydb.bak'
Also review the commands:
restore headeronly from disk='c:\mydb.bak'
restore labelonly from disk='c:\mydb.bak'
Christopher Kempster
260
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Unable to read local event log. The event log is corrupted
I have only had this error once, as shown below:
Why? The hard disk was full, simple as that. There were no errors in the SQL Server
logs, but I did notice my custom backup scripts were no longer running; these returned
no errors and their run time was virtual instantaneous:
Freeing space on the drive was enough to kick start the DTS jobs once again.
What is a “Ghost Record Cleanup”?
Running profiler, or querying sysprocesses, you may see “error:602, severity:21,
state:13” (16), this is related to a background process running a ghost record cleanup.
Depending on the statement being run (typically a bulk delete), SQL Server will mark the
objects as ghosts which is the same as marking them for pending deletion. A
background process (seen as “TASK MANAGER” in sysprocesses) removes the records
asynchronously (17).
How do I Shrink TEMPDB?
There are numerous ways to shrink TEMPDB. In each case we have a named instance
called CKTEST1, and the TEMPDB data file is 80Mb in size. Our target size in all cases if
1Mb for our single data and log file.
The following solutions are fully tested scenarios as per MS Support doc 307487.
Christopher Kempster
261
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Shutdown and re-start
The draw back here of course is the shutdown of the instance, far from ideal in many
production systems. That said, Microsoft do warn that the two alternatives (discussed
next) may result in physical corruption of the database if in use at the time.
a) Shutdown the named instance
b) Restart the service via the command line using –c and -f:
C:\Program Files\Microsoft SQL Server\MSSQL$CKTEST1\Binn>
sqlservr.exe -c -f –scktest1
c) Connect to the instance via query analyzer or other and run:
ALTER DATABASE tempdb MODIFY FILE (NAME = 'tempdev', SIZE = 1)
ALTER DATABASE tempdb MODIFY FILE (NAME = 'templog', SIZE = 1)
d) Check the physical file size. You may notice the file size is not immediately
reflected.
e) CTRL-C to stop the service.
f)
Re-start the service as per normal
g) Check file size via EM and on disk.
Use DBCC SHRINKDATABASE
This command is a good one to quickly shrink the tempdb data and log files. The shrink
is % used space based (as you will see) and not a physical value. This can be somewhat
frustrating. Also be aware that if ALTER DATABASE MODIFY FILE was used against
tempdb to set the minimum size of the data and log files, this command will set it to the
value specified at an absolute minimum. Use sp_helpfile against TEMPDB beforehand
and review the size column to confirm this.
a) Check Existing file size via sp_spaceusage
b) Determine shrink percentage of free space to be left after the shrink. The
dependency here is the target percentage specified in c) is based on the current
space used only.
Christopher Kempster
262
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) Run the shrink with percentage from b)
d) Check file size via EM and on disk, or use sp_spaceusage again
During a large tempdb operation along with shrinking the database, we may experience
the following locks:
Use DBCC SHRINKFILE
Here we repeat the operations as per shrinkdatabase, namely:
a)
Check Existing file size via sp_spaceusage
b) Determine the large files for shrinking via tempdb..sysfiles
Christopher Kempster
263
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) Attempt to shrink:
The command has three parameters, they being:
1) the file name or file id as per sysfiles
2) a integer value, representing target size in Mb
3) one of three option options, they being EMPTYFILE (),
NOTRUNCATE (realloc pages below specified size, empty pages not
released), TRUNCATEONLY (release unused to last allocated
extent)
dbcc shrinkfile (tempdev, 10)
The command will not shrink a file less than the data currently allocated
within the file.
d) Check file size via EM and on disk, or use sp_spaceusage again:
The shrinkfile command takes out the following locks:
The EMPTYFILE option is typically used for multifile file-groups, where the DBA wants to
migrate data and heap structures from one file in a filegroup to another, and prevent
further writes to the file (as writes are typically dispersed evenly amongst files in the
filegroup based on free space). There was a problem (Q279511) in SQL Server 7 that
was resolved in SP3 and SQL Server 2k.
IMPORTANT – Shrinkfile cannot make the database smaller than the size of the
model database.
The DBA may experience this error if the database is in use:
Server: Msg 2501, Level 16, State 1, Line 1 Could not find table named '1525580473'. Check
sysobjects.
-orServer: Msg 8909, Level 16, State 1, Line 0 Table Corrupt: Object ID 1, index ID 0, page ID %S_PGID.
The PageId in the page header = %S_PGID.
Christopher Kempster
264
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Under SP3 of SQL Server 2k, I could not replicate the error. The target size was
restricted to the last extent currently in use.
How do I migrate to a previous service pack?
The applying of SQL service packs may result in a two fold change:
a)
they may alter the physical binaries of the SQL Instance and system wide
DLLs (aka MDAC)
b) they alter your system and possibly all user databases for the instance
being upgraded
Before you attempt to apply a service pack follow these general rules:
1) Retrieve the current version of your SQL Instance being migrated back
and check other instances and their current versions as well.
2) Run MDAC checker to get the current MDAC version
3) Run SQLDiag.exe against your instance to collect other global information
about your instance (for recover reference)
4) Full backup your instances system databases (master, msdb, model)
5) Full backup all user databases
IMPORTANT – Always double check the instance you are connecting to, and
ensure that utilities (sqldiag/query-analyser) are run against the correct instance.
Never skip backups, no matter how confident you are.
When making a decision to rollback, have a good look over the SQL Server installation
logs. Pass the errors through www.google.com (Google groups). If possible, call MS
support, but take care as immediate resolution may not be possible and may be very
costly in terms of downtime.
Full Rollback
A complete rollback from a service pack is time consuming and at times risky (more in
terms of forgetting something, either by mistake or through poor documentation). The
rollback complexity is exponentially increased when dealing with clusters, replicated
instances, or where multiple applications share the same server.
To return back to the previous services pack I have successfully used the following
process (we assume the system databases were backed up before the service pack was
applied):
a) Check and record the SQL Server version
b) Check and record the MDAC version (MDAC checker from Microsoft)
Christopher Kempster
265
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
c) Stop all SQL Server services and physically backup all database files.
Alternatively, complete a full backup of all database files for the instance,
including the binaries directory.
d) Re-start the instance
e) Disable replication if it’s currently in use (publications, and the distribution)
f)
Restore the backed-up master, msdb and model databases that was taken
before you applied the service pack
g) Re-apply the service pack prior to the new service pack that you are rolling back
from (of course).
h) Re-build fulltext catalogs (if necessary, I have had no issues in the past)
i)
Re-start replication as required
j)
Check MDAC again. Determine the need to reapply as required.
k) Check and record the SQL Server version
l)
Start/Stop the instance and check Windows event log and SQL Server logs;
debug as required.
Be aware the service packs vary considerably in terms of system change. The rollback
will not remove new DLL’s, and DLL’s that are not overwritten by the service pack you
are re-applying.
If you are not happy with this, the only path you can take is a complete un-install,
reboot, registry check and cleanup, then re-install of SQL Server. This can be tough work
as we need to return the instance back to proper collation, re-create replication, DTS jobs
and packages, users and logins, along the restoration of past system databases (covers
off DTS, logins etc). This is tough work and is summaried below as per the MS Support
document 314823:
NOTE – DLLs added to the %system root% directory are not guaranteed to be
removed
a) Check and record the SQL Server version
b) Check and record the MDAC version (MDAC checker from Microsoft)
c) Script all database logins, script replication setup where possible
d) Record collation/language of instance and databases
e) De-attach all user databases – it may be rare for changes to be made in user
databases, but they do host system tables and as such, are fair game during
upgrades.
Christopher Kempster
266
S Q L
f)
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Stop all SQL Server services, and physically backup all database files.
Alternatively, complete a full backup of all database files for the instance,
including the binaries directory and full text indexes and log files.
g) Uninstall SQL Server via Add/Remove programs
h) Reboot the server
i)
Check MDAC level, and re-install SQL Server
j)
Reboot the server
k) Apply service pack as required
l)
Reboot the server if asked to do so. Check MDAC level
m) Restore master, msdb, model system database from a recent backup in this order
(users databases will be automatically re-attached)
n) Check logins, user databases, DTS packages and jobs
o) Restore and or resynchronize full text indexes
p) Reapply replication
NOTE – The DBA may consider a complete restore from tape backup, including
system state, Windows and SQL binaries and of course the database files. Be
warned that a small mistake in this process will be disasterous.
The readme.txt files from service packs are a good reference point in terms of what’s
changed and may provide some guidance on cleaning your server without a complete
rebuild. Also, refer to the chapter on High Availability regarding clusters.
You may be asked to reboot after applying the service pack. Do so before continuing to
reduce the possibility of further error.
Finally, as a general rule, always read the documentation accompanying service packs no
matter how simple the upgrade seems.
Service Pack install hangs when “checking credentials”
To fix this issue change the "DSQuery" value under:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQLServer\Client\ConnectTo\DSQuery
to "DBNETLIB". The installation should complete successfully.
Christopher Kempster
267
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
OLAP
Recovery of OLAP cubes to another server
For very large OLAP cubes and associated repository, it is one thing restoring cubes or its
meta-data, but its another reprocessing cubes and meeting your SLA. The cubes are
broken down into:
\%analysis-path%\<db-name>\<dimension-name>.*
..and..
\%analysis-path%\<db-name>\<cube-name>.*
For dimensions the extensions are:
.dim
.dimcr
.dimprop
.dimtree
Dimension meta-data
Custom rollups
Properties
Member data
For cubes the extensions are:
#.agg.flex.map
#.agg.rigid.map
#.fact.map
.agg.flex.data
.agg.rigid.data
.pdr
.prt
.fact.data
changing dimension aggregation data
aggregation data
aggregation data
changing dimension aggregation data (partitions)
aggregation data (partitions)
partition meta-data
partition meta-data
cube data
The need to re-process is based on how much of the above you have backed-up and
what period you are refreshing from. The files can be restored “inline” without the need
to stop the service.
Non-interface error: CoCreate of DSO for MSOLAP
If you create a linked server to OLAP services (using the OLEDB provider for OLAP
Services X.X), and get the above error then set the “allowinprocess” option for the
provider:
Christopher Kempster
268
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
As the dialog states, all linked services using the provider will be affected. Click on the
provider option for the above settings when creating or editing a linked server:
What TCP port does Analysis Services use?
It uses port 2725. It also uses 2393 and 2394 if you are connecting via a OLAP Services
(v7) client. If you are using HTTP via IIS then it will be port 80 or 443 for SSL based
connections.
Restoration Scenarios
Dealing with Database Corruption
How do I detect it?
It is of utmost importance that data corruption be detected as soon as possible. The
longer it goes undetected (and it can be a long time) the harder your time will be for
recovery. In the worst case, your backups become unusable and may span many hours
or days of lost work.
As a general best practice rule, I highly recommend you run DBCC CHECKDB once per
day. Ideally, write the results of the command to disk and store the output for a week.
The command can be a handy reference point for yourself and MS Support Services. The
command can take its toll on the tempdb. For large databases, we can estimate tempdb
usage:
DBCC CHECKDB with ESTIMATEONLY
NOTE – I had a classic database corruption where very selective queries would
simply timeout for no apparent reason; via query analyzer you would get a
disconnection if you queried between rows 120,000 and 128,000 only on a single
table. This sort of database corruption can do undetected for some time if the DBA
is not actively checking system integrity.
A fellow DBA, Rrodrigo Acosta, wrote a great script to do just this. It can be downloaded
from my website. The command calls isql via xp_cmdshell to connect back to the
instance and run CHECKDB with a redirect of the output to a text file:
set @osql='EXEC master.dbo.xp_cmdshell '+''''+'isql -E -S' + @@servername + ' -Q"DBCC Checkdb
("'+@dbname+'")" -oC:\CheckDB\'+@date+'\'+@dbname+'_'+@date+'.log'+''''
Christopher Kempster
269
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
EXEC (@osql)
To avoid the detailed analysis, use no_infomsgs. This may reduce tempdb required work
for large schemas.
dbcc checkdb with no_infomsgs
If you suspect HW related errors, consider the PHYSICAL_ONLY option:
dbcc checkdb with physical_only
Use the NO_INDEX option to gain overall execution speed, but I tend to find indexes to
be more of an issue that heap structures.
Taking the command further, we can add a check for allocation and consistency errors.
If found, the DBA is emailed with the file attached:
set @osql='EXEC master.dbo.xp_cmdshell ' + ''' echo "Line_Text" > C:\CheckDB\tem.txt'''
exec (@osql)
set @osql='EXEC master.dbo.xp_cmdshell ' + ''' more ' + @pattachmentfilename + ' >> C:\CheckDB\tem.txt'''
exec (@osql)
set @status = -1
select @status = 1 from OpenRowset('MSDASQL', 'Driver={Microsoft Text Driver (*.txt; *.csv)};
DefaultDir=C:\CheckDB;','select Line_Text from "tem.txt"') where Line_Text like 'CHECKDB found 0
allocation errors and 0 consistency errors%'
Note that SQL 2k will apply a schema lock only against the object. If you experience an
access violation when run, review MS support article 293292.
The DBA may also review other integrity checking commands:
•
DBCC TEXTALL
•
DBCC CHECKTABLE
•
DBCC CHECKCATALOG
•
DBCC CHECKALLOC
The DBA will find that CHECKTABLE does not verify the consistency of all the allocation
structures in the object; consider using CHECKALLOC as well.
If you suspect that the statistic objects (text blobs) are corrupt (_wa objects), attempt to
script them before using DROP STATISTICS table-name.statistic-name. As a guide use
the DBCC SHOW_STATISTICS (table-name, index-name) command, or query
sysindexes.
These are covered extensively in the BOL.
How do I recover from it?
The “potentially” corrupt database can be a pain to deal with. A big problem here is
“fake” corruption, that’s right, I have experienced it a few times, for no apparent reason,
where checkdb would return different results on each execution but generally settle on a
Christopher Kempster
270
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
set of objects; only to find a simple reboot of the server saw the instance and database
mount and was clear of all errors. Very strange.
Before you run any repair command, or attempt to restore or detach the database,
always attempt to backup the database, either logically (via SQL backup command) or
physically copy the file. Do not delete files, no matter how right you think you are in the
path you’re about to execute.
Generally speaking messages related to corruption will provide information about the
object affected, and the index identifier:
Object ID 13451531, index ID 0: Page (1:21112) could not be processed. See other errors for details.
Where the index ID:
Indid
Indid
Indid
Indid
0 is a data page with no clustered index.
1 is a data page with a clustered index.
2 to 254 is a non-clustered index page.
255 is a text page.
The DBA can use OBJECT_NAME(id) to get the name of the table, or DBCC PAGE(dbid,
pagenum). Set trace flag DBCC TRACEON(3604) before running the command.
The DBA should place the database in single user mode and reconfirm the database
integrity:
Disconnect/kill all user sessions or wait till they disconnect
exec sp_dboption 'northwind', 'SINGLE_USER', 'on'
use northwind
DBCC CHECKDB
After a complete database backup, attempt to recover:
DBCC CHECKDB('northwind', REPAIR_REBUILD)
Then check system integrity again. The repair_allow_data_loss option, as per the BOL
should be used sparingly. If the issues persist, move to standard backup file recovery
procedures.
If you suspect major hardware issues, stop the instance, copy the database files to
another SQL Server and attempt to attach the database files (sp_attach_db). The event
or SQL Server logs “should” include some valuable information related to physical IO
problems.
NOTE – A suspect database may be a function of corrupt pages. Check the events
logs and SQL Server logs carefully.
If worst comes to worst, also consider third party tools; for example:
http://www.mssqlrecovery.com/mssql/index.htm
Christopher Kempster
271
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
“Database X cannot be opened, its in the middle or a restore”
This may occur when the last backup applied during a restore option used the WITH
NORECOVERY command. If so, we can complete recovery at this point and open the
database via:
restore database mydb with recovery
See the BOL for the RESTART command if the restores were directed via tape media at
the time.
Installing MSDB from base install scripts
If you have no backups of MSDB, one may consider the instmsdb.sql script to re-create
the MSDB database; this of course will completely remove any packages, jobs, alters etc
you defined previously. The MSDB re-create script is found at:
..also note the northwind and pubs database scripts.
Shutdown the instance and use trace flag –T3608 to only recover the master database on
startup:
You will see this is a common step for many database restore scenarios.
Deattach the database and run the script (see next regarding MSDB detachment).
As a side note, you can also copy the MSDB database files off the installation CD and reattach using these files; simple and effective.
Model and MSDB databases are de-attached (moving db files)?
You cannot de-attach system databases:
Christopher Kempster
272
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Server: Msg 7940, Level 16, State 1, Line 1
System databases master, model, msdb, and tempdb cannot be detached.
To get around this, start SQL Server with the trace flag –T3608 then re-run the deattach
command again:
The commands below run without error:
If you still have issues with MSDB, then stop SQL Agent.
On starting the instance (minus the trace flag) we get this error:
2004-01-19 23:07:42.04
spid5
Could not find database ID 3.
Database may not be activated yet or may be in transition.
The default ID’s for the system databases are as follows:
MASTER
MODEL
Christopher Kempster
1
3
273
S Q L
MSDB
TEMPDB
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
4
2
The DBA should at all times, re-attach in order of these identifiers to avoid possible issues
after restoration. In our case, the instance is now down. We can use the services applet
or run SQL Server via the command like with trace ID#3608. I also start the instance
with –m:
sqlservr –m –sCKTEST1 -f –T3608
where cktest1 is the instance name.
The instance starts successfully. Run Enterprise Manager. Notice that the lists of
databases are blank:
Go back to your command line. Notice that sqlservr has exited and shutdown the
instance:
Once when starting the instance using trace flag 3609 (skip creation of tempdb) and then
invoking EM, I had a process dump which ended with:
2004-02-18 22:47:46.07 spid51 Error: 3313, Severity: 21, State: 2
2004-02-18 22:47:46.07 spid51 Error while redoing logged operation in
database 'tempdb'. Error at log record ID (5:19:22)..
Therefore is probably best we stick with using Query Analyser to complete the reattachment (note that –m or –f will have no affect also). Re-start via the command line
and connect via Query Analyser:
sqlservr –sCKTEST1 -f –T3608
Quering the master..sysdatabases table, we see this:
master
Northwind
Christopher Kempster
1
6
274
S Q L
pubs
tempdb
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
5
2
Re-attach MODEL then MSDB:
use master
go
sp_attach_db 'model',
'c:\work\ss2kdata\MSSQL$CKTEST1\data\model.mdf',
'c:\work\ss2kdata\MSSQL$CKTEST1\data\modellog.ldf'
go
sp_attach_db 'msdb',
'c:\work\ss2kdata\MSSQL$CKTEST1\data\msdbdata.mdf',
'c:\work\ss2kdata\MSSQL$CKTEST1\data\msdblog.ldf'
go
Shutdown SQL Server via a CTRL-C at the command prompt. Use Service Control to
start the instance and re-check the log. The instance should start without error.
Remove the trace flag before you re-start the instance once you are satisfied all is well.
Restore Master Database
Restoring the master database is not fun but it is necessary in rare circumstances. In
this scenario we need to restore back to the last full backup of the master database as a
variety of logins have disappeared and some configuration changes have been made, so
we are sure that the restore will assist in resolving the problem.
1. Backup the existing master database and verify the backup
i. Copy the back to another server and also to tape where
possible
2. Attempting to restore from EM will give you this:
3. Kick off all users, and shutdown the instance.
4. Alter the service properties to force instance startup in single user
mode by entering –m in the startup options for the service.
Christopher Kempster
275
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
5. Leave the service window open
6. Run EM. Connect to the instance and open the restore database dialog
for the master database. Here, we have selected the backup to be
restored and ensured beforehand that the file is ready and available.
7. On successful restore, the following dialog is shown. Go back to the
service control window and remove the –m single user mode option
and re-start the service.
Christopher Kempster
276
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
8. Close and reopen EM, connecting to the instance. Check the SQL
Server error logs on failure to start the instance.
This example is simplistic and there are scenarios where this operation can create further
problems. The key issue here is that the master database includes a variety of system
tables, with the file paths for the model and msdb and tempdb system databases. If you
restore the master (which stops your instance immediately), and attempt to re-start,
unless those paths are still valid, the instance will not start.
Consider the rebuildm.exe command (rebuild master) to assist in restoring back to a
state where at least the instance starts and then you can recover each system database
thereafter.
Restore MSDB and Model Databases
For a system database, this is simple and painless. The DBA must shutdown SQL*Agent
before attempting a restore. Once done, double check via exec sp_who2 and
connections to the MSDB database. They must be disconnected before attempting the
restore.
Restoring the MODEL database is like any other user database.
The DBA should restore MODEL before MSDB (if it requires restoration of course).
No backups of MODEL ?
Another option the DBA has is to copy the model.mdf and modellog.ldf files from the SQL
Server Installation CD. Read the next section for more information on collation issues
and how this can be done.
No backups of MSDB ?
For MSDB, consider the instmsdb.sql script.
Recovery of System Databases and NORECOVERY option
Microsoft support released a support note that explains how the restoration of a system
database, in which the NORECOVERY restore option was used, can result in instance
startup problems. In the case of the model database being left in this mode on instance
re-start the database has been left in a non-operational state, on startup the database
cannot be opened and tempdb cannot be created.
To get around the issue:
a) Start SQL Server with the following command line options:
-c, -m, -T3608, -T4022
b) Attempt to end recovery of the database:
restore database model with recovery
c) Otherwise, update the sysdatabases table and the status column to 16 for the model
database only.
d) Restart the instance minus the parameters in a)
Christopher Kempster
277
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Collation Issues - Restores from other Instances or v7 Upgrades
The system databases, namely master, msdb, tempdb and model, do not necessarily
require the same collation for the instance to start. Here is an example. We have
installed a new named instance with a Greek collation as shown below, the default was
Latin1_General with Accent sensitivity.
On confirming the installation with a simple connect, we shutdown the instance and
delete the model database files.
On starting the instance we get the following error:
2004-01-19 13:36:59.70 spid5
FCB::Open failed: Could not open device C:\Program
Files\Microsoft SQL Server\MSSQL$CKTEST1\data\model.mdf for virtual device number (VDN)
1.
2004-01-19 13:36:59.75 server
SQL server listening on TCP, Shared Memory, Named Pipes.
2004-01-19 13:36:59.75 server
SQL Server is ready for client connections
2004-01-19 13:36:59.75 spid5
Device activation error. The physical file name
'C:\Program Files\Microsoft SQL Server\MSSQL$CKTEST1\data\model.mdf' may be incorrect.
2004-01-19 13:36:59.81 spid5
Device activation error. The physical file name
'C:\Program Files\Microsoft SQL Server\MSSQL$CKTEST1\data\modellog.ldf' may be incorrect.
2004-01-19 13:36:59.84 spid5
Database 'model' cannot be opened due to inaccessible
files or insufficient memory or disk space. See the SQL Server errorlog for details.
We copy the model database files back from CD (see previous scenario), alter the files’
read-only property, and re-start the instance. The instance will start fine.
Christopher Kempster
278
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Checking the system database collations we see this:
master – Greek_CS_AS_KS
model – SQL_Latin1_General_CP1_CI_AS
msdb - Greek_CS_AS_KS
tempdb - SQL_Latin1_General_CP1_CI_AS
NOTE - Select properties of the database in EM, or run exec sp_helpdb via query
analyzer to get the database collation.
So now we can alter the model database (and therefore the tempdb collation on instance
re-start) and its collation right? Wrong:
alter database model collate greek_CS_AS_KS
Server: Msg 3708, Level 16, State 5, Line 1
Cannot alter the database 'model' because it is a system database.
This is actually a SS2k feature. Previous SQL Server versions prevented system
database restores of a different character set / sort order. This has been brought on by
the ability to set collation at install time, for each user database, and at the column/t-sql
variable & SQL statement level. At the same time though, you cannot alter the collation
of any system database via the simple alter command, even though a restore from a
backup may change it from the installed default for the instance.
The flow on effect can be this error within your database applications:
'cannot resolve collation conflict for equal to operation'
If you utilize temporary tables (# / ##), or tempdb is used to complete a large sort
operation, having tempdb (built from your model database on startup) with say
SQL_Latin1 and your user databases in say Greek_CS may result in this error, preventing
the operation from running until you explicitly state the conversion via the COLLATE
command in the DML operation. This is far from ideal and can render applications close
the useless (are you going to re-write the app code? I don’t think so).
Therefore, be very wary when restoring database files from other instances to complete
your recovery; especially where collation is concerned.
To get around the collation issue, take the following into consideration:
a) Use rebuildm.exe (rebuild master) and restore with the appropriate collation.
From here retain the model database and re-apply your “typical user database”
settings to model for future databases, along with the specific initial properties for
tempdb. If MSDB is still an issue for you, export DTS packages, jobs, and reapply these on the new MSDB database.
b) ALTER DATABASE mydb COLLATE – this command will alter the user database
collation, but will not alter any existing string column collations for existing
database tables. Consider looking at information_schema.columns to determine
what tables are affected and altering the column collation. Always test carefully
to ensure the change has taken affect. The worst case is having to import/export
the altered table data to take up the new collation.
Christopher Kempster
279
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
IMPORTANT – Get the MODEL database collation correct and TEMPDB will follow.
Suspect Database (part 1)
A database may become suspect for a variety of reasons such as device errors,
missing files etc, or another process (like a 3rd party backup program) has a lock on
the database files during instance startup etc.
Within EM you will see this:
NOTE – You can confirm the database status via the command:
select databasepropertyex(‘northwind’, ‘status’)
First of all, check the error logs to better gauge the extent of the problem. In this
particular case the error is:
Starting up database 'Northwind'.
udopen: Operating system error 32(error not found) during the creation/opening of physical
device C:\Program Files\Microsoft SQL Server\MSSQL$MY2NDINSTANCE\data\northwnd.mdf.
FCB::Open failed: Could not open device C:\Program Files\Microsoft SQL
Server\MSSQL$MY2NDINSTANCE\data\northwnd.mdf for virtual device number (VDN) 1.
If the physical device is missing or a simple restore is required with the move option.
This is assuming we cannot quickly resolve the error otherwise. The DBA may need
to use a third party utility to determine if another process has the file open. There
are many available on the internet (for example www.sysinternals.com).
If the file is “open” but the process is orphaned for whatever reason, we can
attempt:
a) If the instance is UP, attempt to backup the database (may fail, but is well
worth the try). Also, check disk space available for all drives used by system
databases.
b) If the instance is down, physically backup all system database files to another
disk
c) Attempt to kill off the rogue operating system processes holding the files open
and stop/start the instance with the –m parameter
d) Attempt to run:
a. exec sp_resetstatus ‘northwind’
Database 'northwind' status reset!
Christopher Kempster
280
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
WARNING: You must reboot SQL Server prior to accessing this database!
e) Run DBCC CHECKDB or DCC CHECKCATALOG if possible and copy the results
to a ascii file (for reference).
f) If all fine – shutdown the instance and re-start without –m
a. Full backup the database
g) Reboot the server (or restart the instance) or attempt to run DBCC
DBRECOVER (northwind)
h) If you decide to place the database in emergency mode, then do so as a last
resort. You will have the ability to BCP out data (even corrupt data), but is
far from ideal.
SP_CONFIGURE 'allow updates', 1
RECONFIGURE WITH OVERRIDE
GO
UPDATE master..sysdatabases set status = -32768 WHERE name = 'mydb'
GO
SP_CONFIGURE 'allow updates', 0
RECONFIGURE WITH OVERRIDE
WARNING – Before attempting any recovery or change of database status,
always shutdown the instance and backup the database files.
On any change of DB status related to recovery, the DBA should run the following on
the database and use the CHECKDB parameters accordingly to recover corruption.
dbcc checkdb
dbcc newalloc
dbcc textall
Be aware that using REPAIR_ALLOW_DATA_LOSS option for CHECKDB should be a
last resort.
IMPORTANT - I should iterate that suspect databases must be carefully analysed,
in some cases I have found that, for some unexplained reason (i.e. no error log
entries) the instance starts and a user database is in suspect mode. If you have
verified the existence of all database files, then attempt to re-attach the database
via the sp_deattach and sp_attach commands. Always backup the database files
before attempting any sort of recovery. See Part 2 for further some insight.
The DBA may also consider detaching the suspect database (via EM is fine). Go to
your file system, move the missing files, then return to EM and run the attach
database wizard. In the wizard window, you will see red crosses where the file
name/path is invalid. Alter the path/filenames, set the “attach as” and set the owner
to “sa” and the database should be successfully re-attached and operational.
Suspect Database (part 2) and the 1105 or 9002 error
From the vaults of MSDN, Microsoft mention that under rare circumstances (I personally
have never had the error) the automatic recovery of a database on instance startup may
fail, typically due to insufficient disk space. Message 1105 and/or 9002 will be
generated.
The database will be:
Christopher Kempster
281
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
a) Marked as suspect
b) Database is taken offline
The resolution to both the 1005 and 9002 errors are detailed on MSDN as:
NOTE - The DBA should check free disk space carefully, and check the log file to
determine if it is size restricted (auto-growth disabled). Where possible we want to
avoid adding more log files to the database but, if it suspected to be corrupt or in
error, we can also add log files via the ALTER DATABASE command with the ADD
FILE option or enlarge the existing file via the MODIFY FILE option.
..and..
If you reset the status via sp_resetstatus, it will ask you to complete recovery before
accessing the database, if you don’t you will get something like this:
Christopher Kempster
282
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Prior to updating sysdatabases entry for database 'northwind', mode = 0 and status = 256 (status
suspect_bit = 256).For row in sysdatabases for database 'northwind', the status bit 256 was forced off
and mode was forced to 0.Warning: You must recover this database prior to access.
As the documentation above states, we can use DBCC DBRECOVER. If you attempt to
use the command restore database XXX with recovery you will get the same message
above.
Ensure you visit the website for more/updated information before you attempt these
steps. As a general rule, if the database is down, then backup the database files before
you attempt any form of recovery.
Suspect Database (part 3) – restore makes database suspect?
I have not experienced this error myself, but was discussed on the www.lazydba.com
news group and a solution offered by Bajal Mohammed. The people involved attempted
the following without success:
a) after making sure that all the files are physically there, we tried to reset the status
and restart the SQL Server service, but the server was not able to recover the database.
Hence it was marked suspect again. The error that we were getting was "Failed
Assertion"
b) we created a new dummy database with same file structure and file groups and gave
the filenames as *_new.mdf, *_new.ndf, *_new.ndf & *_new.ldf (in the same locations
as the original database. Files were 1 GB each (log file 10 MB). Then we took the new
database offline, renamed the files of the Original production database to the new file
names (after renaming them to old) and tried to restart SQL Service, but when it tried to
restore the database, gave a strange error that MS was not able to explain either. It gave
the filename (with path) of the *.NDF files, saying that this is not a primary file... etc.
c) finally we decided to restore from backup. Since EMC took a backup (scheduled)
around 1am, of the corrupt Databases, we had to restore from Tape. The tape restore
finished, but the database is still suspect. When we reset the status using sp_resetstatus,
it came up with the same error in b) above.
The presented solution was as follows:
1) create one database with name of "mytestdb". The database file should reside in the
same directory as the user database. For example,
F:\Program Files\Microsoft SQL Server\MSSQL$xyz\Data
2) Offline SQL server.
3) rename mytestdb.mdf to mytestdb.mdf.bak. Rename your userdatabase.mdf to
mytestdb.mdf. userdatabase.mdf is the name of the user database MDF file.
4) Online SQL server. Now mytestdb may be in suspect mode.
5) run the below script to put mytestdb to emergency mode:
use master
go
Christopher Kempster
283
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
sp_configure 'allow updates', 1
reconfigure with override
go
update sysdatabases set status = 32768 where name = 'mytestdb'
6) offline and online SQL server again.
7) rebuild the log for mytestdb:
DBCC TRACEON (3604)
DBCC REBUILD_LOG('mytestdb','mytestlog1.ldf')
8) Set the database in single-user mode and run DBCC CHECKDB to validate physical
consistency:
sp_dboption 'mytestdb', 'single user', 'true'
DBCC CHECKDB('<db_name>')
go
9) Check the database is no longer suspect.
Suspect Database (part 4) – Cannot open FCB for invalid file X in database XYZ
This is nasty error; I have experienced the error when system indexes in the primary file
group data file are corrupt. The error shown may be something like:
The database may still be accessible, but this seems to be for a finite time and is directly
related to any further IO against the database.
On running DBCC CHECKDB it reports no allocation or consistency errors. If you profile
the database and SQL against it, you may see random errors such as:
ie:
Christopher Kempster
284
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
I have also noted that, on re-start of the instance the DB may come up correctly with no
error but there will come a time when you will receive this error:
And marks the database as suspect:
Using trace flags to override recovery is not effective. Following the standard approach to
dealing with suspect database (see contents page) also failed. I also tried copying the
database files and re-attaching as a new name, but again we receive the error:
EXEC sp_attach_db @dbname = N'recovertest',
@filename1 = N'c:\temp\yyyy.mdf',
@filename2 = N'c:\temp\xxxx.ldf'
Server: Msg 5180, Level 22, State 1, Line 1
Could not open FCB for invalid file ID 0 in database 'recovertest'.
Connection Broken
A deattach DB again the now suspect database tells us the database does not exist;
along with a drop database command. Even so, dropping the database via Enterprise
Manager was fine.
In the end, a simple database restore from the last full backup was fine. Rolling forward
on the logs requires careful analysis of the SQL Server log files to determine at what
point to stop the recovery before the problem occurred. Take the time to check for
physical device corruption.
Suspect Database (part 5) – drop index makes database suspect?
A good friend of mine running developer edition of SQL Server, found his database in
Christopher Kempster
285
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
suspect mode after dropping an index from a very large database table (DB was over
40Gb on this low spec’ed PC). Unfortunately he had no record of the sql server error log
entries, and there was nothing within the Windows event log. He also set the database
to emergency mode.
To effectively resolve suspect databases, you really do need to error entries around the
time of the suspected problem, without it can make live difficult when determining the
path we need to take. In this case, the database files were not deleted, but the dropping
of the index may have resulting in corruption with the data or log files (only two files for
this database) OR the classic 9002 errors due to out of space errors.
Attempting to run CHECKDB over the 40gb database was taking a huge amount of time,
in the order of 8hrs plus from our estimates. Due to the urgency of fix, this was deemed
not an option. The final solution was a restore from a previous backup, in the mean
time; we attempt to get the database back online.
Let us sidetrack for a moment. Before we attempt any action, the DBA must:
d) full backup the master database, or better still the master data and log
files
e) backup/copy the suspect databases data and log files
The DBA can attempt to set the database mode from suspect to emergency via:
update sysdatabases
set status = status | -32768
where name = 'northwind'
-- Status now = -32740
and set it back to “normal” by setting the STATUS column to a value of 24. There is no
guarantee of course that playing with status fields will achieve the database property you
desire (i.e. from suspect to open and normal!). Note that bit 256 in the status column
represents a suspect database (not recovered); to see a list of all possible bit values look
up the BOL or query:
select * from master..spt_values
so setting the status to a raw 256 only, forces the database into suspect mode.
If the database is truly suspect then any SQL will leave it as suspect. Attempt to
checkpoint the database and re-check the database. If no change/still-suspect, attempt
to run dbcc checkdb or restart the sql instance and check the error log. Classically
suspect databases in which the database files are available and named correctly indicates
either:
a) free disk space problem preventing effective transaction logging
b) corrupt virtual transaction log(s)
Christopher Kempster
286
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
An effective way to test transaction log validity is to:
a) sp_resetstatus
b) dbcc dbrecover (see part 3)
Back to our example now ☺
The database is in emergency mode, and we suspect either a data or log file corruption.
The above steps are recommended over what we are going to do below as an example.
In an attempt to fix the problem, we will sp_detach_db the database. On doing this we
found the database currently in use:
To get an idea of SQL 2k wait types, consider http://sqldev.net/misc/waittypes.htm , this
latch type is a shared latch typically taken whilst allocating a new page, perhaps due to
space issue OR high contention for the resource. The resource column, holding the value
2:1:24 that can be decoded to DBID, File and Page ID. The issue here is not so much
SPID 55, but SPID 53, note its wait-type, referencing DBID 7 which is our suspect
database.
NOTE – look at the sysprocesses table carefully, especially for blocking process that
may relate to the underlying reason for the suspect. This MS support document
contains queries for viewing blocking data:
http://support.microsoft.com/default.aspx?scid=kb;EN-US;283725
In this case we killed the SPID 55 process and attempted the command once again:
The message is not overly encouraging, and turned out to be a HUGE mistake as we will
see.
When we attempted to attach the database the following Windows event messages in the
application log (note that we are attaching the database with a new name):
Christopher Kempster
287
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
From the messages we believed the transaction log was corrupt. We attempted to use
the command sp_attach_single_file_db but with no luck:
With no way to re-attach the database without error, we have no other choice but to:
a) shutdown the instance
b) copy back the database files from backup (master and our problem database)
c) re-start the instance
Once in emergency mode, we can BCP out the data etc. We did not try it, but as we
knew the log file is corrupt, we could have tried the command
sp_add_log_file_recover_db; and attempt to remove the old log file (covered in this ebook).
How do I rename a database and its files?
Here is an example where we have changed the name of our prototype application from
“testapp” to “trackman”. We also want to:
Christopher Kempster
288
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
a) rename its database
b) rename the databases logical and physical filenames
c) fix/check logins and their default database property
NOTE – I do not cover it, but linked servers, publications, cross database chains
etc may be invalidated with the change. Replication should be addressed before
you rename the database.
To rename the database:
-- Remove users before attempting the rename, to avoid the error:
-- The database could not be exclusively locked to perform the operation.
alter database testapp set restricted_user with rollback immediate
exec sp_renamedb 'testapp', 'trackman'
The good thing about this command is that the rename will take the default database
property for selected logins with it. So steps a) and c) are now complete.
Next we will attempt to modify the file, filegroup and logical names of the database files.
Be aware that the alter database command is the key, but for some strange reason the
filename clause in the rename only works for tempdb files and no other, so this
command:
alter database trackman
modify file
(name = 'testapp_system',
newname='trackman_system',
filename='c:\work\trackman_system.mdb')
Gives you this error:
Server: Msg 5037, Level 16, State 1, Line 1
MODIFY FILE failed. Do not specify physical name.
So rename each logical file name for each file:
alter database trackman
modify file
(name = 'testapp_system',
newname='trackman_system')
The file name 'trackman_system' has been set.
Repeat this for each logical file.
To rename the filegroups we run:
alter database trackman modify filegroup DATA name = trackman_data
Repeat for each filegroup. Remember the transaction log does not have one.
To rename the database files:
Christopher Kempster
289
S Q L
a.
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
De-attach the database using Enterprise Manager (right click
properties of the database, all tasks, deattach database), or use
sp_detach_db
b. Rename the physical files via Windows Explorer or command line
c. Re-attach the database using EM (right click properties of the
databases folder) or use sp_attach_db
Alter the database to MULTI_USER mode as required.
Database is in “Loading” Mode ?
The DBA may see something like this:
This typically occurs when the database has been restored to an inconsistent state in
which it is still pending full recovery. Attempting complete recovery may give you
something like:
restore database nonefs with recovery
Server: Msg 4331, Level 16, State 1, Line 1
The database cannot be recovered because the files have been restored to
inconsistent points in time.
Verify your order of restore carefully before attempting the restoration again, and use the
NORECOVERY and RECOVERY commands appropriately.
Restore with file move
Here is a simple example:
RESTORE DATABASE [nonefs] FROM DISK = N'C:\aa.bak'
WITH
FILE = 2,
NOUNLOAD ,
STATS = 10,
RECOVERY , MOVE N'nonefs_Log' TO N'f:\nonefs_Log.LDF'
Restore to a network drive
To use database files over a network device, start the instance with trace flag 1807.
Otherwise you will receive the error:
"File mydb.mdf is on a network device not supported for database files."
Christopher Kempster
290
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Restore a specific File Group
Database: mydb
File-group name
mydb_primary
mydb_data
mydb_index
N/A
Backups:
C:\mydb_full.bak
C:\mydb_log1.bak
C:\mydb_diff1.bak
C:\mydb_log2.bak
C:\mydb_log3.bak
{failure occured}
Physical file-name
c:\mydb_system.bak
c:\mydb_data.bak
c:\mydb_index.bak
c:\mydb_log.ldf
Full
Log
Differential
Log
Log
IMPORTANT – You cannot do file/file-group backups for databases using a simple
recovery model
If mydb_data file-group failed/is-corrupt (the logical name of the filegroup and the
logical name of the file are the same in this case), we need to restore:
If you attempt a restore, and there is not current transaction log backup, you will get
this error:
Therefore, begin by running a transaction log backup against the database. So our
backup list changes to this:
Backups:
C:\mydb_full.bak
C:\mydb_log1.bak
C:\mydb_diff1.bak
C:\mydb_log2.bak
C:\mydb_log3.bak
{failure occured}
C:\mydb_log4.bak
Full
Log
Differential
Log
Log
Log
Before attempting the restore (and possibly getting the same message again, you should
alter the database and place it in restricted mode, so users cannot connect whilst the
database recovery is completed.
Christopher Kempster
291
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If we attempt to restore, say up to mydb_log3.bak, you will get something like this:
Why? Basically all other filegroups are further forward in time (LSN) relative to that of the
filegroup we are attempting to restore. As such, the DBA must select the option:
or in other words, NORECOVERY. Alternatively use the STANDBY clause. The entire
database is effectively read only at this point due to the incomplete recovery of this single
file-group.
To complete the recovery, the restore list is:
a)
b)
c)
d)
e)
mydb_full (mydb_data filegroup only)
mydb_log1
mydb_log2
mydb_log3
mydb_log4 (with RECOVERY)
IMPORTANT – Note that we don’t use the differential backup to complete the
recovery in this scenario.
-- File Group from FULL backup
RESTORE DATABASE [mydb]
FILE = N'mydb_data',
-- logical name of the file in the FG
FILEGROUP = N'mydb_data'
-- this is optional if only 1 file in the FG
FROM DISK = N'C:\mydb_full.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, NORECOVERY
-- Log backup @ time 1, restore logs as normal
RESTORE LOG [mydb]
FROM DISK = N'C:\mydb_log1.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, NORECOVERY
-- Log backup @ time 2
RESTORE LOG [mydb]
FROM DISK = N'C:\mydb_log2.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, NORECOVERY
-- Log backup @ time 3
RESTORE LOG [mydb]
FROM DISK = N'C:\mydb_log3.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, NORECOVERY
Christopher Kempster
292
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
-- Log backup @ time 4
RESTORE LOG [mydb]
FROM DISK = N'C:\mydb_log4.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, RECOVERY
Once complete, do a final LOG or FULL backup.
Adding or Removing Data Files (affect on recovery)
Consider the situation where a database file has been added to the database between
transaction logs. Therefore we have this scenario:
Backups:
C:\mydb_full.bak
C:\mydb_log1.bak
Full backup
Log backup
-- new file added to database
ALTER DATABASE mydb
ADD FILE
(
NAME = mydb_newfile,
FILENAME ='c:\mydb_newfile.mdf',
SIZE = 1MB,
FILEGROWTH = 10%
)
GO
C:\mydb_log2.bak
{failure occured}
Log backup
To restore we need to:
RESTORE DATABASE [mydb]
FROM DISK = N'C:\mydb_full.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, NORECOVERY
RESTORE LOG [mydb]
FROM DISK = N'C:\mydb_log1.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, NORECOVERY
RESTORE LOG [mydb]
FROM DISK = N'C:\mydb_log2.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, RECOVERY
The completed restore will show the newly added file with no further issues. Be aware
though, Microsoft Support document Q286280 states otherwise, and there may be a
scenario where the above does not work. Revisit this support document for assistance.
Emergency Mode
This mode is undocumented and is technically unsupported, but is required on very
rare occasions. This mode allows the DBA to access a database without the log file
being present.
-- Allow updates to sys tables
exec sp_configure N'allow updates', 1
reconfigure with override
Christopher Kempster
293
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
-- If possible, attempt to set db in DBO only access mode (for safety sake)
exec sp_dboption N'Northwind', N'dbo use', N'true'
-- Record the existing record entry for the database
SELECT * FROM master..sysdatabases WHERE NAME='northwind'
-- Set DB into emergency mode
UPDATE master..SYSDATABASES SET STATUS=32768 WHERE NAME='northwind'
Stop and Re-start MSDTC.
-- Refresh Enterprise Manager
Attempting a backup or any other operation that uses transactions will result in the error:
To export out the data and associated objects, create a blank database in the same or
another database instance. Once done, run the Export wizard, select the database in
emergency mode and follow the prompts. A DTS will be created and will happily export
the database, typically without error so long as there are no underlying permission
issues.
Drop the source database as need be.
This is a very simplistic example but provides some direction towards dealing with the
problem.
NOTE – Setting a database to emergency mode is very handy when suspect
databases wont allow you to investigate the problem via DBCC commands etc.
Altering the status to emergency mode and then running, say, DBCC CHECKDB will
allow you access to the database and execute a variety of commands to resolve the
problem.
Restore Full Backup
For user databases, I tend to opt for EM as it’s simple and quick. Before restoring by
any method always check:
Christopher Kempster
294
S Q L
a)
b)
c)
d)
e)
f)
g)
h)
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
can I backup the database before the restore? (i.e. yes)
notification of end-users and killing sessions
database name
location and name of the files
remembering to fix orphaned logins if restoring to another server
re-checking the database recovery model and associated options
verifying subsequent backups will still operate as per normal
always write down in a log what you did, why and the files used.
No example is required for this scenario.
Partial (stop at time) PITR Restore on a User Database
To restore to a point in time, ending at a specific transaction log backup in your backup
sequence, we use the STOPAT command, for example:
RESTORE LOG [mydb]
FROM DISK = N'C:\mydb_log2.bak'
WITH FILE = 1, NOUNLOAD , STATS = 10, RECOVERY ,
STOPAT = N'8/08/2002 9:42:02 PM'
Use the GUI, or the commands:
restore headeronly from disk = 'C:\mydb_log1.bak'
restore headeronly from disk = 'C:\mydb_log2.bak'
and the backupfinishdate column to determine the most appropriate log files to be
used.
Corrupt Indexes (DBMS_REPAIR)
The DBA should be regularly running the following against all databases:
DBCC CHECKDB
DBCC TEXTALL
DBCC CHECKCATALOG
DBCC CHECKALLOC
These routines will report on allocation inconsistencies with tables and indexes that
typically point at data corruption. Even so, don’t be too quick to react. Before doing
anything always full backup the existing databases and try the following:
DBCC CHECKDB(‘mydatabase’, REPAIR_REBUILD)
a.
b.
c.
d.
Kill off all users or wait till they disconnect
exec sp_dboption 'northwind', 'SINGLE_USER', 'on'
DBCC CHECKDB('northwind', REPAIR_REBUILD)
exec sp_dboption 'northwind', 'SINGLE_USER', 'off'
Also try DBCC CHECKALLOC.
Christopher Kempster
295
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
IMPORTANT – Do not use dbcc dbrepair
If you are getting desperate, Microsoft has an undocumented command (typically
suggested by Microsoft support) called sp_fixindex. Restart the instance in single user
mode, checkpoint, run sp_fixindex, checkpoint again and backup once more. Re-start
the instance and re-run the DBCC routines.
See Microsoft support document Q106122 for more information.
Worker Thread Limit of N has been reached?
The DBA can configure the number of worker threads available to core SQL processes
such as handling checkpoints, user connections etc. The threads are pooled and released
quickly, therefore the system default of 255 is rarely changed. If the value is exceeded,
you will receive the limit message in the SQL Server log.
To resolve the issue:
a) review why so many threads are being used and be convinced it is not simply an
application in error.
b) use the sp_configure command to change the value
exec sp_configure
-- check the current value
exec sp_configure ‘max worker threads’, 300
reconfigure
-- force the change
-- set the new value
Reinstall NORTHWIND and PUBS
Run the scripts found in the /install directory for the instance:
Instnwnd.sql
Instpubs.sql
Some of my replicated text/binary data is being truncated?
The Max Text Repl Size option allows you to specify the size (in bytes) of text and image
data that can be replicated to subscription servers. The DBA can change the default
value via the Max Text Repl Size option:
a) Run Query Analyser
b) Connect to the SQL Server.
c) Run the following
exec sp_configure 'max text repl size', 6000000
go
reconfigure
go
Other Recovery Scenarios
Scenario 1 - Lost TEMPDB Database
Christopher Kempster
296
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
If you delete the tempdb and templog databases files, they are simply re-created on
instance startup. Assuming of course the model database is available and the disk
sub-system has sufficient free space:
It is created based on the entry in master..sysdatabases
use tempdb
go
sp_helpfile
go
The DBA can move this location via the commands below and re-starting the
instance.
use master
go
alter database tempdb modify file (name = tempdev, filename = 'c:\tempdb.mdf')
go
alter database tempdb modify file (name = templog, filename = 'c:\templog.ldf')
Go
File 'tempdev' modified in sysaltfiles. Delete old file after restarting SQL Server.
File 'templog' modified in sysaltfiles. Delete old file after restarting SQL Server.
Note that after the alter statement the entries in master..sysaltfiles,
master..sysdatabases and master..sysdevices remain unchanged. On restart, the
tempdb files have now moved to their new location but the entry in master..sysdevices
remains unchanged. Only sysaltfiles and sysdatabases has been altered.
If the device in which the tempdb datafiles are created is no longer available, the
instance will not start, as there is no other default value SQL Server will magically use.
To resolve this problem we need to use the rebuildm.exe (see Scenario 2.)
Scenario 2 - Rebuildm.exe
There comes a time in every DBA’s life where the rebuildm.exe (rebuild master) utility is
used, either to change the instances global collation or due to a disaster in which one or
more system databases need to be restored and we don’t have a valid or any full backup
(this should never happen for any reason).
The rebuildm.exe is found on the installation CD, cd-rom:\x86\binn. In the following
example we will run the command and highlight the subsequent steps to complete the
recovery.
NOTE – If copying the CD to disk, make sure the files in ?:\x86\data\ are not
read-only or have their archive bit set.
Christopher Kempster
297
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
A digression - when using disk two and running rebuildm.exe, I received the
following error:
To get around this unforeseen problem I copied it to disk and renamed the directory
c:\x86\binn\res\1033 to c:\x86\binn\Resources\3081. The utility then ran without a
problem.
REMEMBER – DON’T restore your master database after running rebuildm.exe if
the objective was to alter the server collation. Always backup as much as possible,
and consider scripting logins before attempting this process.
The steps involved are:
1. Shutdown the instance we plan to rebuild.
Christopher Kempster
298
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
2. Run the rebuildm.exe from the CD-ROM or do the above and copy to disk (not a
bad idea generally during emergency recovery scenarios). The following dialog
is shown:
The instance whose system
databases will be restored
over.
Source of the CDROM default
database files.
The DBA can also set the new
collation.
Default data directory for the
installation, this can not be
altered.
3. Press the rebuild button and respond yes to the prompt
4. The database files are copied to the new destination and the “server
configuration progress” dialog is shown, this takes around 1-2mins maximum.
Try This – Run FileMonitor from www.sysinternals.com to view the file IO and
thread calls during this process.
5. Don’t be fooled. This process affects ALL system databases not just the master
database.
Christopher Kempster
299
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
6. Check data file properties before re-starting to ensure they are not read-only.
7. Start your instance
8. Review the previous and current error log. The previous log has some good
information about the tasks undertaken with the system databases rebuild.
9. Optionally re-apply service packs
10. Optionally restore your master, model, msdb databases as need be
Before your re-start the instance with the files copied by rebuildm.exe, double check
they are not read-only. This is a common problem when the files are copied off the
CD-ROM. If this problem affects the use of rebuildm.exe then copy the files to disk
and refer to point two above.
Be careful when only restoring one or two of the system databases. All system
databases should be current with a single service pack, I have never been in a
position where a subsequent restore of the master database that had SP2 applied
existed with the MSDB database with no service packs. The DBA should think very
carefully about this and apply the service pack as required to ensure minimal amount
of error.
Scenario 3 – Lost all (or have no) backups, only have database files
To recover from this scenario:
1. Backup all database files (if available) to another server and/or to tape.
2. Check the registry for the MASTER database, and alter and/or ensure the
files are in the correct registry entry
HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Microsoft SQL
Server/<instance name>/MSSQLServer/Parameters/{SQLArg0 and 1}
3. Attempt to re-start the instance
4. If there are still errors with system databases, namely MSDB, MASTER or
MODEL, check error log carefully and attempt to place database files at
these locations.
5. If you have no luck, run rebuildm.exe (see previous scenario)
6. The instance should successfully start
7. For MSDB database
8. Shutdown SQL*Agent service
9. Drop MSDB database
10. Reattach from your original database files
Christopher Kempster
300
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
11. For each user database re-attach database files
12. Fix orphaned logins as need be (if any)
13. Run DBCC checkdb and checkalloc against all databases
14. Check database recovery models
15. Backup databases
The DBA should revise trace flags on instance startup to assist in the task.
Scenario 4 - Disks lost, must restore all system and user databases from backup to new
drive/file locations
This is a difficult scenario. In order to start the instance, we require a valid master
database; this database also defines the subsequent location of the MSDB, MODEL
and TEMPDB database data files. If we restore the master database from our full
backup (with the move option to another disk), the sysdatabases, sysaltfiles and
sysaltdevices system tables will still contain invalid paths for the other system and
user databases as we lost those particular disks. This is made even worse, as any
time you restore the master database the instance shuts down immediately,
therefore, an instance re-start will result in numerous file-missing errors and fail to
start.
This may bring mixed comments from DBA’s, but consider the following:
1.
2.
3.
4.
5.
6.
7.
8.
9.
Run rebuildm.exe to restore system databases onto new disk(s)
Recover MSDB database from last full backup
Recover MODEL database (if very different from the original)
Restore master database from full backup and master_old
Alter system to allow changes to system tables
Transfer contents of syslogins from master_old to the master database
Re-start instance
Check system error log
Recover user databases from full backups
Christopher Kempster
301
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
INDEX
crisis manager · 12
:
D
::fn_get_sql() · 203
DAS · 325
Database
Database ID's · 253
Diagrammer · 255
Scripting · 254
database administration roles · 25
database diagram
transfer · 98
Database Maintenance Plans
differential backups · 174
database recovery models · 167
DATABASEPROPERTYEX · 78, 250
DBCC DBCONTROL · 233
dbcc inputbuffer · 100
DBCC INPUTBUFFER · 97
DBCC LOG · 70
dbcc loginfo · 71
DBCC OPENTRAN · 203
dbcc rebuild_log · 234
DBCC REBUILD_LOG · 210
DBCC SHRINKFILE · 265
dbcc sqlperf · 82
DBCC TRACEON · 88
DBCC TRACESTATUS · 88
DBCC UPDATEUSAGE · 194
DBCONTROL · 250
dbrepair · 298
Deadlocking · 92
deattach · 250
dettach system databases · 275
DFS · 215
diagrammer
scripting · 255
differential backup · 174, 181
directory structure
standards · 161
Disaster recovery · 7
disaster recovery planning · 6
distributed file system
for database files · 215
DR documentation · 12
DTS
dtsrun · 239
troubleshooting · 234
DTS package
backup · 182
A
accountability · 23
active/passive mode · 126
air conditioning · 330
authority · 23
Autonomic computing · 38
availability measures · 21
B
Backing Up with Tape Drives · 328
backup
verify · 256
Backup
history of · 261
no more space · 262
BACKUP DATABASE · 173
BACKUP LOG · 175
Backup schedule · 15
backup set · 171
blade center · 335
blade server · 335
Business Continunity · 7
business priority · 14
C
cable management · 335
change control form · 32
change management system · 29
CHECKALLOC · 298
CHECKDB · 273, 298
checkpoint · 87
CoBIT · 17
comclust · 158
communications manager · 12
compressed drive
database support · 217
Corrupt
indexes · 297
Counters
performance monitor · 211
Crisis and Disaster Contact Details · 13
Christopher Kempster
302
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
T R O U B L E S H O O T I N G
enlist error · 221
locked out
sql server · 196
log writer · 67
logical database filename · 163
LSN · 68
LUN configuration · 310
E
ECID · 94
EFS · 215
emergency response team · 23
EMPTYFILE · 266
Encrypted File Systems
for database files · 215
error log · 90
M
maintenance plan
backups · 169
maintenance plan backup · 169
Master Recovery Plan · 15
media set · 171
meta data functions · 75
Microsoft support services · 189
MOF · 19
Moving
master database · 246
MSDB and MODEL databases · 246
TEMPDB database · 248
User Databases · 249
MRAC · 39
MSDB
install script · 274
MSDTC · 217
F
FCB · 286
filegroup
recovery · 240
FILELISTONLY · 181
full backup · 173, 180
Full Text Indexing
cluster · 132
G
ghost record cleanup · 263
H
HBA · 307
HCL · 110
High Availability · 110
host bus adapter · 307
hostname change · 213
hot backup · 172
hot fixes · 37
N
naming standards · 234
NAS · 311, 312, 326
Network Attached Storage · 311, 312
Northwind
re-install · 298
I
O
iFC · 309
isalive ping · 150
iSCSI · 309, 312
isql · 78
ITIL · 18
OBJECTPROPERTY · 81
olap
backup · 177
OLAP cubes · 270
OLE-DB providers · 224
orphaned session · 97
orphaned sessions · 96
osql · 78
K
KILL command · 99
Killing users · 258
KVM switch · 334
P
parallel testing · 14
parameter sniffing · 223
personal edition · 220
physical backup device · 171
power distribution units (PDU’s) · 334
PRINT · 226
L
License Manager · 79
licensing mode · 79
linked server
Christopher Kempster
&
303
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
T R O U B L E S H O O T I N G
service level
metrics · 21
service pack
hangs · 269
service packs
rollback · 267
setspn · 202
shrink
log files · 204
Shrink Database · 264
shrink TEMPDB · 263
Shutdown instance · 249
simulation testing · 14
sp_attach_db · 251
sp_attach_single_file_db · 252
sp_change_users_login · 96
sp_configure · 80
sp_cycle_errorlog · 91
sp_delete_backuphistory · 172
sp_dropserver · 214
sp_enumerrorlogs · 91
sp_MSdependencies · 244
sp_MSforeachtable · 81
sp_procoption · 83
sp_refreshviews · 225
sp_spaceused · 82
spt_values · 288
SQL Server Named instance
cluster · 134
SQL Server Wizard · 135
storage virtualization · 323
streaming directly to tape · 184
Striping · 162
support services · 189
Suspect Database · 282
sysdtspackage · 236
production server · 36
Profiler · 92
Q
Quality Online Service · 110
R
rack heights · 334
racks · 333
racks side rails · 334
RAID · 108
RAID configurations · 320
RAISERROR · 226
re-attach · 251
reconfigure · 80
Recovery · 257
recovery interval · 165
recovery manager · 12
recovery scenarios · 188
Recovery strategy · 14
REMOVE FILE · 208
rename a database · 291
REPAIR_REBUILD · 298
responsibility · 23
restoration history · 85
Restore
emergancy mode · 296
file added · 295
file group · 293
filelistonly · 262
full backup · 297
loading mode · 292
logical names · 262
master database · 277
MSDB and MODEL databases · 279
point in time · 297
rebuildm.exe · 300
Senarios · 271
suspect database · 282
tempdb · 299
with file move · 292
RETAINDAYS · 173
robotic tape racks · 329
rollback and redo · 67
T
tablespace backup · 176
Tape drive · 327
tempdb
in RAM · 240
TEMPDB
shrinking · 263
test server · 34
time difference · 141
timeout
ado · 226
com+ · 227
IIS · 229
oledb · 229
SQL Server · 230
TOE · 331
trace flags · 86
Tracing
black box · 82
transaction coordinator · 219
S
SAN · 109, 307, 325
SATA · 315
Scripting · 254
serial advanced technology attachment ·
315
SERVERPROPERTY · 79
Service Control Manager · 151
Christopher Kempster
&
304
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
VeriTest · 110
virtual device interface · 178
virtual IP · 128
VSAN’s · 323
VSS · 31, 40
.Net · 60
branching · 48
transaction log
consolidate files · 207
shrink · 205
transaction manager · 72
transfer logins · 99
truncate
transaction log · 176
TRUNCATE_ONLY · 176
W
U
walk-though · 14
warm standby · 135
write log entry · 70
User
database ownership · 97
orphaned · 95, 96
X
V
xp_fileexist · 168
xp_fixeddrives · 82
xp_readerrorlog · 91
VDI · 178
VERIFYONLY · 261
Christopher Kempster
305
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Appendix A
Understanding the Disk, Tape and Storage Market
Throughout this section we will cover some theory of SAN and NAS based storage
solutions and revisit RAID. Why? well clustering and high availability in general are
based around these fundamentals and it is important for the DBA to be aware of the
technologies in play, and how large scale systems architectures may effective the way
you build, manage and performance tune your database servers.
SAN (Storage Area Network)
A SAN is a high-speed sub-network (separate from your existing network infrastructure
or direct fiber) of shared storage devices. The peripherals (drives) are interconnected by
Fiber (FC) or SCSI.
The storage devices themselves are cabinets with a large number of interconnected drive
bays, RAID levels supported, power, IO controllers, network adapters or host bus adapter
cards (SCSI or Fiber), management software and operating system with a variety of
interfaces, be it web based, terminal serviced or other API call over TCP.
The SAN device is connected to front-facing switches in which servers connect via host
bus adapter (HBA) cards. For example:
A servers dual HBA’s
(for multi-path IO)
8-port
2Gb/sec switches
(SAN Fabric)
Fibre cable
Network
SAN
Diagram sourced from - http://www.bellmicro.com/product/asm/spotlights/sanplicity/
The HBA and operating system drivers provide the host/server with access to the SAN
and offloads block-level storage I/O processing from the hosts CPU(s). The devices are
highly intelligent, high throughput IO processors. The HBA’s exist at both the SAN
storage array and the server:
Christopher Kempster
306
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Chapter 13 – Architecture Overview, Storage Networks: The Complete Reference, R.Spalding, 2003, Figure 13-3.
Chapter 13 – Architecture Overview, Storage Networks: The Complete Reference, R.Spalding, 2003.
Christopher Kempster
307
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The HBAs connect the server to the SAN. Two or more interconnected switches create a
SAN Fabric. The fabric is designed for redundancy, performance and scalability. The
switches themselves include intelligent operating systems for management, monitoring
and security.
New switch technology allows for iFC and iSCSI connectivity (discussed later) from the
clients standard ethernet adapters over IP rather than fiber or SCSI specific HBA’s, this
offers greater flexibility to terms of connectivity and cost, which is a major issue in the
fiber networking.
The SAN itself is managed by highly-intelligent software coupled with large internal cache
that tends to marry up with the growth in SAN capacity. The SAN typically requires
specialist training for administration and performance. Be aware that vendors may not
bundle all core administrative software with the SAN and can be a costly addition at a
later date.
The following diagram provides a good logical overview of the SAN internals:
Vendors may restrict
physical loops to a
specific number of
drives, such as max
of 7 disks in a RAID5. RAID restrictions
may apply!
Otherwise
known as
LUN’s
Eg. 8Gb
Read,
300Mb
write
Server Clusters: Storage Area Networks – For Windows 2000 and Windows Server 2003,
figure 10
The virtualization of storage is the key through LUNs (logical units) that are typically seen
as basic disks under the Windows OS disk management applet.
Christopher Kempster
308
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Server Clusters: Storage Area Networks – For Windows 2000 and Windows Server 2003,
figure 15
The administrator should take the time to evaluate vendors in terms of:
•
Licensing and maintenance model
•
Cache size and upgrade paths
o
Be very careful here as upgrades can result in new per terabyte or other
licensing model that can be very costly.
o
Maximum disk and cache capacity
o
Disk costs and vendor buy restrictions
•
SCSI and Fiber Channel support, along with switch compatibility
•
LUN configuration
o
Internal limits on size? minimum and maximum sizes?
o
Channel and/or loop restrictions in terms of physical disk connectivity
Christopher Kempster
309
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
•
Ability to inter-connect SAN’s for added resilience and storage
•
Technologies like PPRC and Flashcopy to replicate, in near real time, block level
storage from one SAN to another.
•
RAID types
o
RAID types supported? many support RAID-0 or 5 only.
NOTE – Microsoft supports booting from SANs but do note the restrictions in KB
305547.
Generally speaking, I tend to lean heavily on the senior systems administrators in terms
of actual configuration. Even so, the DBA should be confident in understanding the
performance issues of RAID arrays, how your database files will be created over the
array, striping size issues, LUN configuration and HCL issues (especially in MSCS
clusters), and most importantly the effect of large SAN disk cache on performance.
Example SAN Configuration
The following is an example of a SAN configuration for high availability. This is based on
a dual data center in which the primary SAN is duplicated to the standby SAN via PPRC
(point to point remote copy).
Gigabit ethernet
Switch
Switch
Backup
agents via
SNMP etc.
Server A
Dual SCSI or fibre
HBAs for multi-path
I/O + Teamed NIC’s
FC Switch
FC Switch
FC Switch
FC Switch
Shortwave fibre
Conv.
SAN 1
Block level
storage Tx
Single mode
duplex fibre
(9 micron)
Conv.
SAN 2
Enterp.
Backup
Software
PPRC
Real-time
Replica of
stored files
(for Dev/Test)
Flash
Copy
SCSI
DLT\LTO
TAPE
Library
What is NAS (Network Attached Storage) ?
A Network Attached Storage device (NAS) is a dedicated server with a very large [SCSI,
SATA] hard disk capacity, cutdown OS and management tools via a web-interface,
Christopher Kempster
310
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
teamed network adapters to facilitate direct connection to your existing Ethernet network
infrastructure and supporting numerous protocols including iSCSI, NFS, SMB and others.
The client may be able to:
a) map drives directly to the NAS
b) overlay additional storage virtualization technology over the NAS devices
such as Windows DFS or hardware based virtualization. Therefore the
clients know nothing of the physical NAS.
c) talk iSCSI directly or via a SCSI/iSCSI gateway
d) Mixture of the above.
The NAS device has been a god-send for many businesses that do not have the money to
deploy large scale SANs, but still want the advantages of a consolidated and scalable
storage infrastructure. The NAS is typically a plug and play solution from most vendors,
with a variety of pre-packaged or purchased add-ons for backup, fault tolerance, different
RAID configurations and expandability. But NAS performance is clearly far below that of
SAN solutions, every passing month it changes of course, so if you are performance
conscious. You do require expertise to assist in the NAS device selection and its
associated impact on the network infrastructure.
Another item worth considering is that of expandability and management of the NAS.
Multiple NAS may require individual administration, and may also result in vendor lock-in
when purchasing more capacity or clustering the NAS.
The NAS is not recommended for heavy IO database solutions, but is a very cost effective
mass storage solution for many small to mid-sized companies. The real value add comes
with its relatively “plug-and-play” setup and configuration, ease of extensibility and its
ability to leverage off your existing network investment without issues of DAS (direct
attached storage) becoming in-accessible because your server its connected or investing
it expensive switch technology or HBAs.
With virtualization of disk resource and management, the NAS will have a well earned life
within the organization for many years to come.
What is iSCSI?
The iSCSI (internet small computer system interface) protocol (ratified by IETF ) is all
about the (un)packing of SCSI commands in IP packets. The packets hold data block
level commands, are decoded by the appropriate end-point driver, and are interpreted as
if the SCSI interface was directly connected. This technology is a key driver for NAS
(Network Attached Storage) devices.
Benefits of iSCSI:
•
No need to invest in another cable network (aka Fiber)
•
No investment required in dedicated switches and protocol specific switches, we
can use standard Enternet based network cards with iSCSI drivers.
Christopher Kempster
311
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
•
Does not have the distance issues as experienced with Fiber channel (10km
reach).
•
Can be scaled in terms of speed of IP network (100Mps
•
Stable and familiar standards.
•
High degree of interoperability
1Gbps
10+Gbps)
NOTE - The iSCSI device, like DAS and SAN attached storage, knows nothing
about the "files," but only about "raw I/O" or blocks. The iSCSI appliances are well
suited to general purpose storage applications, including file I/O applications.
Some issues to be aware of:
•
Current iSCSI SAN and NAS support is questionable, check vendors carefully.
o
Particularly iSCSI Host Adapters, Disk Arrays and tape aware libraries.
•
Network management staff will start to take on many of the storage QoS
functions in terms of packet loss, latency, bandwidth and performance etc; role
shift for storage professionals?
•
Impact on CPU performance at the server/NAS device
o
TOE (TCP offload engines) cards may be used.
•
Impact on your existing network infrastructure and switch capacity. Such
implementations typically share your existing core IP infrastructure and are not
running separate physical cabling.
•
Latency may occur over your IP network; a 2 or 3% error/latency will significantly
impact your iSCSI implementation and the underlying drivers and Network OS’s
must be able to manage the data loss.
Like fiber and iSCSI connects, the storage can be virtualized (logical rather than physical)
for redundancy. The Windows 2003 family of servers is iSCSI aware.
NOTE – The only real requirement for database file creation over iSCSI storage is
the server’s ability to “see” the storage via the underlying OS.
Christopher Kempster
312
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Anything else apart from iSCSI?
In terms of IP storage network transport protocols, we have three core models that work
over block level storage:
a) iSCSI (iSCSI/IP end device, IP fabric)
SCSI commands in TCP packets over an IP network; interconnected via
gateway (switch); be they local or remote connections to fiber SANS or
other NAS devices, even replacing the SCSI connect in DAS disk array
devices to the gateway, and the HBA’s within the server.
DAS
Array
iSCSI
Device
SCSI
iSCSI
Gateway
IP
Direct to any other IP
enabled server or
storage device.
IP (WAN/Internet/LAN/MAN)
Fibre
Device
iSCSI
Gateway
Fibre
The iSCSI interface is limited by the Ethernet connection speed; many of
which are 1Gb channels, while fiber can run at 2Gbps to 4Gbps (10Gbps
is on the horizon – along with 10Gbps ethernet).
b) FCIP (Fiber end device, Fiber fabric)
Tunnels fiber channels over IP network but can push the boundaries of
the fibers existing distance restrictions (terms of raw speed), actively
relying upon the networks packet congestion management, resend and in
order delivery.
c) iFCP (Fiber end device, IP fabric)
Fiber channel layer 4 FCP over a TCP/IP network via a gateway-togateway protocol. Lower layer FC transport is replaced with TCP/IP via
gigabit ethernet.
FC
Device
FC “Session”
iFCP
Gateway
iFCP over TCP/IP
(replaces the fibre SAN
fabric components)
device to device
device to SAN
SAN to SAN
communications.
”… Cisco FCIP only works with Cisco FCIP, Brocade FCIP only works with
Brocade FCIP, CNT FCIP only works with CNT FCIP, and McDATA iFCP only
works with McDATA iFCP.”
Christopher Kempster
313
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
There are numerous gateway (switch) vendors where you can expect to pay anything
from $17k to over $75k. The devices typically include virtualization technology
(discussed later) along with the FC-to-FC, FC-to-iSCSI, FC-Gb-Ethernet etc bridging.
NOTE - A variety of researchers are looking at alternatives to block level storage
protocols, namely something at a higher level of abstraction, perhaps at the
“object” level. (45)
Using Serial ATA over SCSI
A “new kid” on the block that evolved from the parallel ATA (or IDE) storage interface
comes serial advanced technology attachment (SATA) storage. The
interface is a single, thin cable with a minimum of four wires in differential
pairs in a point to point connection. The key here is its small form-factor,
reduced voltage requirement, thin cabling (see comparative picture on
right) up to a one meter span, 1.5Ghz clock rate giving around 150Mb/sec
with a comparative cost to that of ATA drives (in your home PC).
NOTE - Serial ATA 300 has a 3Gb/s signaling speed, with a theoretical maximum
speed of 300Mb/s.
Many storage vendors are jumping onto the SATA band-wagon, offering NAS based SATA
storage solutions, typically with a mix of SCSI for added resilience. The key here is more
drives for your dollar, driving down the possible concerns with drive resilience and
increasing your spindle per RAID array for even greater performance.
It is difficult to sum up the differences, but this table can be a guide:
Comparison
Cost per megabyte
MTBF
Exposure/Market
Penetration (2003)
Emerging or
Complementing
Technologies
Tagged command
queuing
Example pricing
3 – 5c
1.2 million hrs
80%
Serial
ATA
1 – 2c
500k to 600k hrs
20%
SAS
Serial ATA II, III
Since 1990’s
Serial ATA II, specific vendors
SCSI
$876 ($219 x 4 Raptors) + $159
$1356 ($339 x 4 Cheetahs) +
(FastTrak TX4200) = $1035 (4$379 (AcceleRaid 170) =
drive SATA RAID Array)
$1735 (4-drive SCSI RAID
Array)
Good
Poor to Moderate
CPU Usage
For full review based on pricing and performance of SCSI vs SATA, see the article “TCQ, RAID, SCSI,
SATA”, www.storagereview.com
NOTE – SATA is a CPU hog. Consider a TCP offload engine (TOE) NIC with
appropriate storage protocol drivers (like iSCSI) to offload CPU time. The SATA
controllers can be a major performance bottleneck.
At www.computerworld.com, L.Mearian provides this general performance summary. It
Christopher Kempster
314
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
is somewhat broad at 150Mb/sec for SATA v1.0, you may find actual raw performance
somewhat less; this figure tends to state multi-channel sustained performance over a
number of drives.
Serial ATA Takes on SCSI, L.Mearian, www.computerworld.com
NOTE – SCSI has used TCQ (tagged command queuing) since the 1990’s; the
feature intelligently reorders requests to minimize HDD actuator movement.
Without TCQ a drive can only accept a single command at a time (first come first
serve). The host adapter adds commands in which the controller and disk work in
unison to optimize, this is transparent to the OS. With SATA II standard includes
the provisioning of native TCQ also known as NCQ (native). Please remember that
the drive AND controller must support TCQ.
There are a large number of vendors on the market, some of which are:
•
EMC Symmetrix, EMC Centera storage appliance (uses parallel ATA drives that
require a dedicated ATA backplane and controller)
•
Hitachi Ltd Lightning arrays
•
Clarian with ATA
•
Adaptec
•
Sun StorEdge 3511 FC Array with SATA
•
NetApp (NearStore, gFiler)
Look over the article from Meta Group titled “SAN/NAS Vendor Landscape”, 7 June 2004,
P.Goodwin. This report takes a “midterm” look at the various vendors in the context of
new technologies and current strategies.
SCSI, Fiber or iSCSI?
Well, it really depends on your specific requirements and underlying infrastructure,
budget, and service requirements. There is a very good article on the internet that is
well worth reading:
“iSCSI Total Cost of Ownership” found at:
http://www.adaptec.com/worldwide/product/markeditorial.html?prodkey=ips_tco
_whitepaper&type=Common&cat=%2FCommon%2FIP+Storage
Christopher Kempster
315
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Hard Disk Availability - Overview of RAID
Understanding RAID is basic high availability requirement. The DBA should be savvy with
the RAID levels, and understand what they mean in terms of performance and
recoverability. In this section we cover the core RAID levels, and drill into some example
RAID configurations over SAN based implementations.
Summary
RAID
Level
0
Technique Used
Summary
Capacity
Striping (no parity)
File is broken down into stripes (of a
user defined size) and sent to each
disk in the array.
Each disk has a copy or replica of
itself. Can incorporate the duplexing
of the RAID controller card as well for
each drive for added protection.
Data is stripped over data disks at the
bit level and also on redundancy disks.
Redundancy bits are calculated via
hamming codes (ECC) that are written
and read as data disks are
written/read to/from. Bit errors can
be effectively corrected on the fly via
the ECC.
Data is striped at the byte level across
disks, typically 1024 bytes per stripe.
Parity data is send to a dedicated
parity disk, any other disk can fail and
the parity disk will manage the failure.
This parity disk can be a bottleneck.
As per 3 but at a block level instead of
bytes.
Size of Smallest
Disk * No Drives
1
Mirroring/Duplex
2
Bit level striping with
hamming code ECC
(error checking and
control) disks
3
Byte level striping with
dedicated parity
4
Block level striping with
dedicated parity.
5
Block level striping with
distributed parity
6
Block level striping with
2x distributed parity
7
Asynchronous cached
striping with dedicated
parity
Mirrored stripes (or
RAID 10)
0+1
As per 4 but no dedicated parity disk,
parity is also striped across the disks
and removing the dedicated disk
bottleneck.
As per RAID-5 but two sets of parity
information is generated for each
parcel of data.
Not an open standard.
Mixture of RAID 1 and RAID 0;
RAID0+1 is a mirrored config of 2x
striped sets, RAID1+0 is a stripe
across a number of mirrored disks.
Minimum
Disks
2
Size of Smaller
Drive
2
Varies
e.g. 10 data
disks + 4 ECC
disks
(vendor
specific)
Size of Smallest
Disk * (No
Drives – 1)
3
Size of Smallest
Disk * (No
Drives – 1)
Size of Smallest
Disk * (No
Drives – 1)
3
Size of Smallest
Disk * (No
Drives – 2)
Varies
4
(Size of
Smallest Disk) *
(No Drives) / 2
4
3
Varies
Performance/Cost/Usage
RAID
Level
0
Random
Read
V.Good
Random
Write
V.Good
Seq Read
Fault
Tolerance
None
Cost
V.Good
Seq
Write
V.Good
1
Good
Good
Fair
Good
V.Good
High
2
Fair
Poor
V.Good
Fair/Avg
Fair
V.High
3
Good
Poor
V.Good
Fair/Avg
Good
Moderate
Christopher Kempster
316
Lowest
Example
Usage
TEMPDB
database
SYSTEM
databases, LOG
file groups.
Not
recommended
Not
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
4
5
V.Good
V.Good
Poor/Fair
Fair
Good/V.Good
Good/V.Good
6
V.Good
Poor
Good/V.Good
Fair/Avg
Poor
(avg to
good
with
caching)
Fair
7
V.Good
V.Good
V.Good
V.Good
V.Good/
Excellent
Good/
V.Good
V.Good/
Excellent
Good/
V.Good
0+1
(10)
&
T R O U B L E S H O O T I N G
Good
Ok - Good
Moderate
Moderate
V.Good/
Excellent
V.Good
High
V.Good
(RAID0+1),
Excellent
(RAID1+0)
High/
V.High
High/
V.High
recommended
Rarely used
DATA or INDEX
filegroups, take
care with heavy
writes. Most
economical
Rarely used
Specialized high
end only
Any, high
performance
READ/WRITE
For more information consider - www.pcguide.com/ref/hdd/perf/raid/levels as at 26 Nov 2003
Disk Performance
Is typically measure by:
a) Interface type (SCSI, Fiber) and their theoretical and physical limitations
b) Disk speed in RPM (10k, 15k)
c) Read and Write IO Queue lengths (how “busy” the drive can be in terms of
raw IO)
d) Random vs Serial disk read/write performance
e) Sustained vs Burst data transfer in Mb/sec
f)
Array type and the working spindles as a divisor or multiplier to some of
the performance figures returned
NOTE - Measuring the raw speed of your disk sub-system is an important task. I
recommend IOMETER from Intel. The key measure here is IOs per second, this
measure can be extrapolated to the measurement of Gb/hr when reviewing the
speed of backups to disk, for example:
XX IO’s/sec * #-disks * stripe-size = XXX,XXXX Kb/sec = XXX.X Gb/sec
Different raid configurations and stripe sizes may see some staggering differences
in raw speed. Take care when measuring read vs write between raid sets.
You should also take into consideration:
•
External Issues
o
Interface type, mode and speed of (theoretical maximums, sustained
transfer raid, burst speed)
o
System Bus
o
Network Interface
Christopher Kempster
317
S Q L
o
•
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Specific RAID level support
Internal Issues
o
Controller Cache Size and Type
o
Write cache – configuration, setup and control over
o
Thermal properties of the device(s)
o
Integrated vs additional card controllers
o
Channel distribution against the RAID set
Where possible, opt for open systems for vendor independence to lower (potential) costs.
Take care not to rush your disk installation; make sure you spend sufficient time with
SCSI channel to array configuration, read/write cache settings, specific bus jumper
settings, stripe (format) size, RAID selection etc.
Database File Placement - General Rules
Consider the following:
•
Try to separate your transaction logs from data filegroups where possible.
Reduce the erratic random access behaviour exhibited of database files over the
serial transaction logs.
•
Don’t fall into the trap of creating multiple transaction log files in an attempt to
stripe writes, log files do not work this way.
•
Mirror your transaction log file disks (aka RAID-1, RAID-10) for maximum
performance and recovery purposes.
•
Retain a set of internal disks in which to store backups. Consider the impact of
large backup file writes for OLTP systems against disks also shared by database
files
•
The system databases are typically small and rarely read/write intensive so
consider using a single disk mirrored RAID-1 or RAID-5 array. For maximum
space per $, RAID-5 with read/write cache enabled will suffice a majority of
systems. Generally speaking, RAID-5 is inappropriate for heavy log file writes
(sequential in nature) and should be avoided.
•
Large/heavily used TEMPDB – the ideal configuration is RAID-0.
•
For larger databases where division of IO is important, use the file-groups to
break down the database into logical disk units, namely “data”, “index”, “audit”,
for example, so like database objects can be easily moved to appropriately
configured arrays.
Christopher Kempster
318
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Example RAID Configurations
So let us talk about some real world RAID configurations. The DBA needs to be fully
aware of the read/write characteristics of the services you plan to run on the DBMS.
That said, take care with raw statistical figures, or even worse, the so called perfect RAID
configurations many DBA’s banter around on newsgroups and articles – many are based
on specific scenarios or the nirvana configuration for a single database within a single
instance on a server and disk pack all on their lonesome – very rare in the real world!
Over anything disk related, the DBA needs to focus primarily on system performance
gains by enhancing buffer cache utilization on reads, and enhancing writes through
effective use of indexing (not overindexing), batching commits, and completing
transactions as quickly as possible to minimize writers blocking readers. Through
ongoing performance tuning of SQL, Stored Procedures, Statistics/Histograms, View
management and Indexing, will you achive maximum gain over the shuffelling of disks,
file groups and RAID arrays.
For RAID and database files, do not be overly concerned about the transaction log files
being on their own RAID array or many database log files sharing the same array. The
log files are written serially as we know, but the key here is a RAID configuration that
does not suffer the added penalies of additional writes to maintain availability (aka RAID5 parity bits); we generally want the writes to complete as fast as possible – as such
RAID-1 or RAID-10 is highly recommended where possible. Many database logs sharing
the same array is not a problem. The key here is little or no disk fragmentation and not
sharing the array with data files that may be experiencing a multitude of writes in many
pages, from many users, all many parts of the disk. Seperating the logs from the rest of
the database files reduces this potential disk latency.
For the rest of the database, simply remember that RAID-5 is not as bad as many make
out – BUT – it will be the first to experience performance issues under heavy writes. The
examples below utilize RAID-5 extensively for a majority of database files. The systems
get away with this through:
a) enabling read/write cache for the RAID-5 array at the risks of database corruption
(very small risk that is mitigated through effective backup/recovery).
b) keep transactions as small as possible (in terms of records and objects affected
and the time to run)
c) splitting where possible indexes away from data to increase the spindle count on
reads and writes - in parallel.
d) not dumping backups to the same array or using the disks for other non-database
related activities.
e) effective SQL tuning and RAM
f)
ongoing monitoring of disk queue lengths and batch jobs
g) understanding that read performance is excellent and will, in a majority of cases,
be the higher percentage over writes that is enhanced through performance
tuning.
Christopher Kempster
319
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Example System
System:
Hardware:
Disks:
2120 users, 40-90 concurrent, 80 trans/sec avg, 8 databases, 1 instance
Dual XEON 2.8Ghz with hyper-threading, 4Gb RAM
8x15k SCSI 320 Disks 36Gb (external disk array)
2x36Gb SCSI 320 Disks 36Gb (local disk)
Dual Channel SCSI 320 RAID Controller, 128Mb, battery backup cache
Read/write enabled cache
Battery cache backup +
128Mb cache with RAID-5
Raid-1
Raid-1
Raid-1
Raid-5
eg. 100Gb\sec\channel
over 4 channels
MASTER DATA/LOG
MSDB DATA/LOG
MODEL DATA/LOG
TEMPDB
MYDB DATA (audit tables)
MYDB DATA (indexes)
MYDB DATA (tables)
MYDB LOG
Christopher Kempster
320
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Example System
System:
Hardware:
Disks:
3892 users, OLTP, 5 user databases, 1 instance
using a SQL Cluster (therefore the quorum disks below)
Quad XEON 1.9Ghz with hyper-threading, 8Gb RAM
IBM Shark SAN connected, PPRC’ed to remote backup SAN
LUNS or Logical Disks (may span many
physical RAID arrays)
Each SAN vendor can have wide and varying physical disk configuration limitations, such
as no-raid, or RAID-5 only, or a minimum set of 5 disks per array; either way, ongoing
license costs is a concern as storage grows. Be careful that you are not locked into
vendor only drives with little avenue for long term negotiation.
To distribute IO amongst the SAN, one may adapt the scenario above such as:
Be aware that the physical array may be used by other logical LUN’s, adding to the
complexity of drive and IO utilization. In any case, work with the vendor closely to
Christopher Kempster
321
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
monitor and managing system configuration and performance; consider under-pinning
contracts with the vendor to persist ongoing support with suitable response.
Virtualising Storage Management – the end game
One of the many buzz words in the storage market is that of “storage virtualization”.
This falls into the market space of vendors like Cicso, Brocade and Sun Microsystems just
to name a few. The solutions tend to be a specialized switch that supports a variety of
protocols and connection types (Fiber, Gigabit Ethernet, SCSI, iSCSI, iFUD etc). The
switch includes a complex API set and associated management software that allows
storage vendors to “plug in” their existing devices and translate their specific storage API
set with that of the virtualization switch; effectively creating a single virtualization
platform for a multiplicity of storage devices.
A classic example is that of the Cisco MDS 9509 (right) with 112
ports of 2Gbps fiber channel it delivers a single management
interface and QoS (quality of service) provisioning within its
embedded software for SAN routing. The devices themselves
include hot swappable power, are typically clusterable and include
redundant fabric controller cards.
Where this gets interesting is using VLANS for your SAN, also known as VSAN’s:
VSANs separate groups of ports into discrete “virtual fabrics”, up to 1000 per
switch. This isolates each VSAN group from the disruptive effects of fabric reconvergence that may occur in another VSAN. And, as with VLANs, routing is used
to forward frames between initiator and target (SAN source and destination) pairs
in different VSANs. Cisco has integrated VLANs and VSANs effectively: The IP
Storage Services Module, which extends the SAN fabric into an IP network, can
map 802.11q VLAN tags to VSAN identifiers. (42)
The main point here is the simplicity of storage management and depending on the
vendor, even more separation from the physical storage for a multitude of services. But
it is more than that. Consolidation through a storage integration engine brings reduced
TCO via:
a) single point monitoring and global storage management
b) active (de)provisioning
c) security
d) multi-protocol support
e) focused staff capability and management
Christopher Kempster
322
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Here is a visualization of what we have discussed:
Any server with compatible HBA
1st tier storage
2nd tier storage
Virtualised access to
legacy DAS resources
Storage Virtualisation Gateway
Direct
Fibre
Direct
SCSI
iSCSI
iSCSI
NAS
SAN
DAS
NAS
DAS
Data life cycle management – offloading corporate data
(in real time) via the virtualised VSAN interface layer.
The end-game here is not so much SAN vs NAS, or fiber over iSCSI etc. These are all
decisions made from your specific performance, environment and budgetary
requirements. The key is the ease with which mass storage that can be provisioned
effectively using a variety of protocols and underlying storage technologies (the
enterprise and even the smaller business should avoid DAS). The CISCO solution, along
with VSAN’s is an important setup forward for the large enterprise.
So as a DBA - what storage scheme do I pick?
One of the mistakes DBAs make early in the piece when determining the server and
storage requirements is being overly concerned with the need to use a specific type of
RAID array for a transaction log file, and that all data files need to be striped this way
and that over yet another RAID which has 128Mb cache and is dual channeled etc. Who
really cares to be honest! What we do need to be concerned with is - what is the
availability, security, capacity, and growth estimations for the services (applications and
their databases) I am trying to deliver to the business?
From here we make decisions based on the cost effectiveness and efficiency of solutions
we propose to meet the business need. Reminding ourselves that:
a) Effectiveness = doing the right thing
b) Efficiency = cost based utilization
The DBA needs to engage the enterprise and technical architects, or system
administrators to determine if, through server and storage consolidation, we can meet
this need to the betterment of making IT work well for the business.
If you lock in the need for specific RAID types and huge storage too early, along with all
your perceived ideas about backups, tapes and procedures, you will always come out
Christopher Kempster
323
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
with “I need my own dedicated server and storage because of…” argument, which, funny
enough holds up in business cases because the systems owners simply want closure and
their service running (and HW can be relatively cheap).
This all comes to the simple answer – where possible, engage technical staff with the
business requirements and follow enterprise initiatives of server consolidation, shared or
virtual computing environments typically over clusters using large shared disk resources.
Some general considerations:
•
•
DAS (Direct Attached Storage) – be it a server with large disk capacity or a
directly connected disk array using a SCSI or Fiber HBA
o
Business ownership is unclear or segmented (un-sharable resources)
o
No existing (consolidated) infrastructure to work with, will plan to host a
variety of databases from the server and storage selected with space to
grow
o
Segregated application hosting domain, storage is not a shared resource
o
SCSI 160 or 320 only
o
Very specific HDD disk layout requirements to meet a high performance
need
o
Do not mind if storage becomes unavailable when attached server is
down, not a sharable/clusterable resource (some storage arrays are multihomed/self powered and can remain available).
o
Limited, where limited scalable storage is fine
o
Per server storage administration and maintenance model
o
Good system administrator skills required
SAN (storage area network)
o
Fiber connects, or virtualized through iSCSI or iFCP gateways to broaden
access to the SAN.
o
Very large scale (4+TB) consolidated shared disk storage for numerous
services
o
May require specialist administration knowledge
o
Ability to replicate entire storage in real time to remote SAN
o
Server boot from SAN disks, shared disk resource through virtualization
o
Dynamic storage provisioning on an as needs basis and highly scalable
o
Single point of global storage administration and monitoring
Christopher Kempster
324
S Q L
•
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
o
Typically fiber HBA and switch based (FC-AL or switch fabric)
o
Performance sensitive with low latency (over NAS)
o
Large IO’s or data transfers (over NAS)
o
Expertise required
o
Limited by distance (<=10km)
NAS (network attached storage)
o
Relatively cheap and easy to install, but can be single points of
administration for higher staff overheads.
o
Need for storage consolidation
o
iSCSI or similar access, no fiber
o
Reduced overall performance at the expense of simplicity and low
maintenance
o
File and print sharing
o
Cluster ready
o
Simple interface (Ethernet, FDDI, ATM etc)
o
No distance limitations
o
Regarded as 2nd tier mass storage
o
Typically SATA based, but watch performance carefully, consider TOE
cards.
Do note that many in the storage world believe NAS and SAN will eventually converge as
technologies through virtualization to get the benefits of both worlds.
From raw experience to date, the DAS and SAN are the only real alternatives for
database driven OLTP or DSS based applications. The NAS is perfect for what I call
second tier storage such as file and print services; test performance very careful if using
NAS for database files. The choice of SAN is typically an enterprise one and should be
taken as so in terms of responsibility to provide a storage solution for your database
service (aka performance, availability, scalability and capacity).
From a disk array configuration perspective, be pragmatic about the decisions made.
The DBA should spend a fair amount of time tuning applications with developers, or
trying to catch major vendor based application bottlenecks as early as possible. The key
here is to reduce overall physical IO through optimized query, maximizing buffer cache
usage and minimizing large reads causing large cache flushes. The purchase of suitable
RAM (2+Gb at a minimum) is very important (from a performance perspective more than
DR).
Christopher Kempster
325
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The big issue here with RAID is raw storage. We used to deal in 9Gb drives, and would
purchase a lot of them with a multitude of raid-arrays to fit our individual database files.
With cheap 145Gb disk drives that are priced the same if not less that the 72’s or 36’s,
then filling valuable disk bays to increase spindle counts can be a hard ask. Do not be
afraid of using RAID-5 (3+ disks) with a large (128Mb+) write-enabled caching and
battery backup on the controller – but where possible avoid large log files on raid-5
arrays (minus SAN’s that have huge write cache and generally null-in-void effect for a
majority of applications).
Try as you may, the creation of a perfect file to array layout can be quickly unstuck as
more databases come on line, or the expected IO distribution is different to what you
originally estimated. With effective tuning, large RAID-5 or 10 arrays will be the best bet
for many solutions. The guide to RAID in this chapter has provided some examples.
In terms of backup, try to:
b) utilize enterprise wide backups. Watch out for SW locking database files or
skipping open files. Monitor times carefully to ensure backups are not streaming
during peak periods if a private backup network is not in use.
c) avoid direct attached tapes where possible
d) backup to disk and store as many days as you can. Avoid peak times for daily full
backups. Avoid sharing backups with database files over the same RAID
array/disk spindles; log backups are very quick (typically if regular) and you will
see little impact on a shared raid-5 array for a majority of cases
a) copy backup files to remove servers where possible, compress and encrypt files if
you can.
TAPE Drives
Tape drive technology is wide and varying with more convoluted acronyms and
associated technologies you can throw a stick at. It is therefore not unusual for system
engineers/architects to take a half hearted look at tape selection (be it a consolidated
solution or a tape drive per server). Either way this section attempts to cover out some
of the key tape technologies and what questions to ask on selection and implementation.
Some of the many tape technologies are listed below. Although not listed, interface
technology and tape library architecture is equally important (i.e. SCSI 160/320 etc):
Notes
Capacity Range
Sustained
(varies with
Transfer
Compression)
(GB/Hr)
DAT
1 to 4
20 to 40Gb
e.g. HP DAT 12/24Gb
SLR
1 to 3
20 to 100Gb
e.g. Tandberg 100
DLT
10 to 15
up to 300Gb
8000, VS80, VS160, Super DLT
LTO*
5 to 12
100 to 200Gb
* Ultrium LTO 1
SDLT
129 to 250
300 to 600Gb
SDLT600
SAIT
108 to 280
500Gb to 1.3Tb
Sony SAIT-1 - Ultra160 SCSI
LTO**
Up to 245
Up to 400Gb
** HP 2nd Generation LTO, LTO-2
“Due in 2003, Tandberg's first-generation O-Mass offering will have an uncompressed
storage capacity of 600GB, with succeeding releases rising up to an amazing 10 terabytes
(TB) on a single cartridge. Transfer rates on O-Mass' first generation cartridge is expected
to be 64MBps, accessing data in less than 3.5 seconds.” (1x)
Technology
Christopher Kempster
326
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
NOTE – The above figures are sourced from vendor documentation and may not
reflect real world results. I highly recommend testing on your chosen hardware
platform or researching as best you can. The maximum capacity is based on a
compression ratio that is typically 2:1, but again varies per vendor.
Be aware of the underlying interface and the raw throughput in which it can support
- namely SCSI (160, 320 etc) or Fiber Channel (measured in Gb). Price will
typically be measured in $ per Gb.
Speed can vary significantly based on the number of files being backed up, file
fragmentation, size of files (numerous small vs small number of large files), type
and number of network cards, other processes running at the time etc.
Here is another example from DELL in a year 2000 article:
Backup and Restore Strategies with SQL Server 2000,
http://www1.us.dell.com/content/topics/global.aspx/power/en/ps4q00_martin?c=us&cs=555&l=en&s=biz
I highly recommend the Toms Hardware Guide website for recent tape performance tests
and recommendations http://www6.tomshardware.com/storage/20030225/index.html,
refer to “Backing Up with Tape Drives: Security is what counts” for a starter.
Apart from raw transfer rate (be aware that the server, interface and connectors also
play a part in the stated figures), other metrics include:
a) Meters/second
b) Load time to beginning of tape (BOT)
c) Unload from BOT and average file access time from BOT.
d) We also have the connected interface, being SCSI or fiber and its respective
throughput (Mb/s) and source disk performance (to a lesser degree).
Take into careful consideration the procurement of tapes as the cost of these can vary
markedly; and be aware of supported operating systems and hardware, as market
penetration can be significantly different between the larger vendors (that tend to sell
their own tape technologies). At the other end of the scale, the evaluator needs to
consider MTBF (mean time before failure) which is typically measured as a percentage of
duty cycles and represented in hours.
Christopher Kempster
327
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
Taking the above a little further, we should consider the following questions when
purchasing tape solutions:
a) What is the overarching systems architecture for tape backups within your
organization? Will you serve all server backups via a single tape array? Or have a
single drive per server, or perhaps group tape backup units per domain or
application requirement?
a. Be aware that global enterprise backup solutions can be tiered, namely a
1st teir solution for your SAN, and 2nd tier solutions for NAS, DAS or simply
internal disks storage. The second tier is typically managed by cheaper
software solutions and their agents, pulling files over the IP network rather
than SCSI or fiber connections.
b) Will you consider highly redundant tape solutions? If your enterprise class
solution goes down, what is your mitigation strategy to continue processing the
following nights backups, identifying the backup tapes or reading existing tapes?
c) Do you have an accurate history of space usage? Can you see over the horizon
and how confident do you feel with the figures? This brings with it questions of
system extensibility and long term maintenance.
d) Do you have overarching documentation that records what/why/where data is
stored to tape? are there restrictions in terms of times backups can be made? If
you don’t, do you really understand a) and b)?
e) How is your [IP] network infrastructure impacted by large data volumes? Do you
collect definitive figures of network bandwidth usage during key backup times and
know what areas are experiencing lag? And are server NICS bottlenecks? Do
your business applications suffer in performance at these times and do you know
what is being affected?
f)
Are you being locked into vendor specific tapes? What is the TCO in terms of the
drives supported infrastructure and tapes required meet your medium to long
term needs? Where are they sourced from and can you wrap SLA’s around this?
(do you need to?)
g) Have you considered off-site tape storage? If you do, ensure tapes are available
locally where possible, visit 3rd party vendors and make enquires with their
clients, ensure costs are well defined in terms of tape retrieval, loss of tapes and
insurance to cover such issues. Take care with TCO measures here.
h) Do you require robotic tape racks/library for large-scale backup tape
management?
•
This typically requires enterprise class storage software such as Tivoli
Storage Manager from IBM. This software supports a wide gamut of
remote agents, operating systems and interfaces. The software resides on
a central backup server in which CPU and network connectivity will be
your greatest concern.
Christopher Kempster
328
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
•
Take to time to check the software licensing options (typically per CPU
based), and how the tape library can cross support different tape types
(i.e. LTO and LTO 2 for example).
•
Finally, check the backup schedule very carefully, and how tapes are
chosen from the rack. As data is streamed into the library you may find a
single applications content could span multiple tapes. The dispersed data
may result in skewed restore times and difficulty in recalling tapes from
offsite storage.
i)
Does your backup software support the tapes and their lengths/formats?
j)
Calculate air conditioning requirements to ensure optimal run-time environment
for your drives, Issues with tape writes where the temperature is outside of the
drives (and tapes) limit poses a major risk.
From a DBA perspective we would consider the following:
a) What is your backup strategy? When will you run full backups? Will you do
differentials each day and a single full once per week? What is the impact on your
recovery plans and SLA’s (especially with tape recovery and restore time). Think
carefully about multiple concurrent backups and how the business strategy for
backups will effect the use of a native SQL backup.
b) What are you [really] backing up? The all drives approach is typically an overkill
and will cost you down-stream with large storage requirements, backup server
bottlenecks and the need for more network throughput and overall time. The
DBA should consider “open file” database backups and include the SQL binaries,
full text catalogs, OLAP cubes, error logs etc at a minimum.
c) How will the backup meta-data be stored and checked? It is not uncommon for
DBA’s to schedule daily native SQL backups with are email to ping the DBA on
failure.
Building a Backup Server
Many organizations invest large sums of money in building and maintaining a single
backup server, and rightly so; supporting 40+ computers each night with individual tape
requirements represents a significant TCO for the business. Here we will present some
strategies for system design rather than physical solutions for enterprise backups:
1) Revisit and audit your server application backup requirements. Application
vendors and/or your development team should be approached in all cases, and
recovery specialist in your firm made part of this team – don’t take the backup
everything approach.
a. Review not only the size of the backup, but the break down of the files.
Are we talking thousands of small files? If so we really need to test the
backup software agents. Small files have tendency (in mass) to increase
CPU and IO resource usage and bottleneck the software itself. Consider
more RAM and review IO and network card utilization carefully during your
tests.
Christopher Kempster
329
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
b. If CPU usage is an issue and identifiable during backup, consider a TOE
(TCP offline engine) card. Such cards offload TCPIP processing from the
host CPU(s).
2) How will the data be transferred from the source to the destination server?
a. The hardware and network infrastructure is critical here with attention
paid to routers/switches, cabling and current bandwidth and lag issues,
the agents and their service packs/updates, network cards, crossing
network domain boundaries and SLA’s in terms of availability and
responsibility.
b. Consider the connectivity between servers carefully. Using the shared IP
network means possible conjestion and significant performance loss with
the services running on the machine. Also be aware of the performance
impact backup agents have on the server.
3) The Backup Server (destination)
a. Streaming data from numerous servers, serially and more often
asynchronously significantly impacts the performance of the hosts CPU,
HBA cards and connected tape drives and internal hard drives. Managing
the bottleneck is the real challenge here. As discussed, we can install TOE
cards (OS supported?) to reduce CPU throttling due to streamed traffic,
but two more frequently used solutions to maximize throughput and
enhance growth are:
i. Build a SAN or consider a NAS – the SAN is typically used to buffer
and/or queue incoming backup streams before going off to tape
(and subsequently offsite). A SAN based mass storage device is
an expensive solution for pre-hosting backups before offlining to
tape, so it must be compared with similar NAS devices or even
large scale internal disk capacity (which can easily stretch to 3+Tb
at as little as $400 for a 146Gb 10k SCSI-320 drive.
1. There are a range of re-packaged “disk to disk” (as they
are called) SAN backup solutions, such systems are
packaged as custom appliances, a 500Gb system costing
around $11,200 US from NexSAN Technologies Ltd for
example. Such systems utilize the ATA interface (common
in desktop PCs) internally, but present SCSI, Fiber or
Gigabyte interfaces externally.
a. Such systems should not be used to replace data
archiving or high availability requirements of very
large data centers.
ii. Consider direct SCSI of Fiber data streaming direct to tape rather
than over IP (via the agents) – appropriate configured switches
and routers can assist in conjection management and bottlenecks.
iii. Check CPU utilization performance and load test
Christopher Kempster
330
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
4) Test the market, the vendor and product availability and support, audit other sites
and their experiences
a. Be very careful with licencing. For example, you may find the backup
software require a cpu licence for the server, then another per cpu licence
for the agent, and yet another if the server is talking to a SAN, and
another again if it also manages database backups! Ouch!
b.
Site references are very important and must be timely and relevant.
5) Make a decision, build SLAs around business imperatives
6) Install, refine your source/destination server connections, document the process
and procedures, test recovery scenarios frequently (its not backed up until its
been restored!)
7) Build a series of metrics to measure performance, capacity and utilization. The
administrator should report against these on a monthly basis.
8) Train your staff and define the boundaries for responsibility and accountability
The backup software is really the end-game here. A product like IBM Tivoli Storage
Manager is a large scale, enterprise solution that virtualizes and wrappers a solid
foundation around corporate backup via server agents, the backup server (disk buffer)
and tape infrastructure or library.
Who needs tapes when I can go to Disk?
There is no doubt that backing up to disk is faster and more convenient. Large enterprise
backup solutions do just that. With the installation of backup agents and over a separate
backup or management network infrastructure (if you’re lucky), the backup management
server directs the agents to stream (typically in parallel) data from the servers to the
“backup server”. This tends to be a NAS or SCSI based disk storage solution, with TCP
offload cards and large internal disk capacity (in the order of 500Gb+); dual P4’s and
4+Gb RAM is nothing unusual as the job is system resource intensive.
Generally speaking, it is not unusual to see a range of disk-backup approaches taken:
a) Ntbackup, xcopy or other software over a file share, typically a physically remote
server on the same domain or 2nd-tier storage device (NAS, Serial ATA disk farm)
b) Backup to a SAN or other storage system that is not part of the source application
– can be relatively expensive in terms of $/Mb and restrictive in distance from
SAN for Fiber based HBA’s.
c) FTP file remotely – as the standard Windows (IIS) FTP service does not
encompass encryption third party software that does (128bit SSL) is used.
d) Streaming backups over HTTPS – rarely used
e) Log shipping to remote servers with a combination of the above
f)
Split-mirrors and removable disks
Christopher Kempster
331
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
g) Enterprise backups via agents to a shared robotic tape array
Here are some interesting points to consider:
2) 1xterrabyte of data – 10xAIT-3 tapes or 10xIDE 120Gb drives - we must compare
hardware infrastructure in each case and the cost of potential growth
3) MTBF for a tape vs disk, consider the numerous additional electronic components
for a drive, you will be surprised at the MTBF figures of hard drives vs tapes.
4) Disk storage is very adaptable and can be easily moved between servers
(generally), tape drive failure can result in longer downtime and costly
replacement
5) A mix of drive sizes can be utilized with ease
6) SCSI sub-systems typically have a 5+yr warranty, consider this when looking at
other interfaces.
I recommend that you should budget for large internal disk capacity no matter if you are
hooked to a SAN or are leveraging from your enterprise backup solution, should be
budgeted for to dump local backups to disk via the native solution(s) provided by the
DBMS. The DBA has the flexibility to quickly reapply stored backups on disk in
emergency scenarios, and as the free space to backup databases without pulling
resources in from the enterprise backup team to assist you with a recovery.
In the Data Centre
Understanding server Racks
The use of racks (server cabinets) for hosting a large number of “rack savvy” servers has
been around for years. As a DBA, its worth while understanding the basic “system admin
speak” of rack components.
The rack itself is simply a large steel cabinet (enclosed or simple framed).
The cabinet may include cable conduits, front and rear lockable doors
(degree of swing, locks etc), ventilated side panels, cut-safe steel, floor or
wall bolt and bracket provisioning, anti-tilt floor tray, wheels, rack dividers
etc, with a standard (usually) width and depth (600mm, 800mm, 900mm,
1m).
Many vendors sell-on fully equipped racks, but they
are typically component based over the rack frame.
Panels may include ventilation fans, doors of a
variety of types etc. The buyer may include racked ventilation fans
(to the left) for example.
IMPORTANT – Standardization to existing and proposed server hardware, Security
and Accessibility are key considerations in determining the best rack for your needs.
Christopher Kempster
332
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The racks side rails are evenly drilled into what are called RUs (rack units) or simply Us,
compatible vendor servers are measured by the RU’s taken within the rack housing (1RU
or 1U = 1.75 inches) and are typically numbered bottom up. You may fine that the cage
nuts or screws, are priced separately. The rack heights (24U, 30U, 38U, 45U) can vary
of course to suite a wide range of requirements.
NOTE - many hardware vendors include rack mount kits for existing tower cased
machines.
The servers in the rack share a common keyboard, video and mouse via a device called a
KVM switch. The size and port configuration of the KVM will vary but is very similar in
function. Here is an example (only one server can be managed at any one time from the
console):
The KVM will come with a rack mounting kit, but may be sold with a special extending
keyboard and tray, along with a monitor and its rack trays/dividers to hold it in place.
The switch is a smart device taking a double-ctrl key click and showing you a character
based menu to pick the server in which to connect . Note that the KVM itself may have a
max screen resolution and may include added security features. If you are running low
on ports then most KVMs can be connected together.
To get power to the rack servers, one or more power distribution units (PDUs) are
installed. The PDU are installed on the sides of the rack (within the space provided) or
horizontally racked (see diagram). A large server
may include a number of redundant power
supplies, and you may find a single PDU cannot
serve its full compliment of outlets, so it’s not
unusual to see four or five PDUs within a rack.
The PDUs may be distributed in nature, i.e. half
of the PDU’s are serviced by one power source, and the other half by another for
redundancy. Take care in determining the power (AMP) draw required by racks PDUs.
Be aware of your mains power connectors:
To connect servers to the network, we may run dual or quad ethernet cables from the
individual servers out to a switch/router. Another alternative is the install the switch
within the rack itself. Multiple redundant switches may be used.
Christopher Kempster
333
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
The same can be said for the racked servers host bus adapters (HBAs). The HBA cards
facilitate connectivity to separate/detached storage, such as a SAN or direct attached
storage device (DAS). The HBA’s may connect to one or more racked switches off to
external disk storage.
Finally, cable management is a right pain within racks. No matter the vendor you will
always experience cable management problems. To ease your pain, consider
a labeling and documentation strategy early; color coding is effective but can
be difficult with numerous 1U servers for example. To pull cables together,
heat shrink tubing for example may be used to pull and tighten like cables.
The racks themselves may include additional cable management kits, but take
the time to position KVM, PDU, switches etc beforehand. This is especially
important when you need to move or replace servers, especially in production
racks. Also note that cable management trays or cable conduits can be purchased
separately in most cases.
The rack servers themselves should include rack
rails or rack mounting kit. This may not include
screws. The modern rack mounted server offers
state of the art technology and high performance,
from 1 to 16 or even more CPUs, terabytes of
internal disk storage and multiple redundant
power supplies.
Be very careful of server depth. Some servers require 1m deep racks, moving away
from the 800 and 900mm racks (the 1m servers fit minus the racks back door or panel).
What are Blade Servers and Blade Centers?
The blade server is a thin, hot-swappable server, independent of others in terms of CPU,
storage (typically a maximum of two disks), OS, network controllers (via extension cards
typically), but does share (with other like blades) power, fans, floppy disks, core ethernet
and HBA switches, KVM ports etc – this is managed via a backplane. This function is
served by the blade center. Let’s break down the components.
The blade center or chassis is the key component, housing the blades within the rack and
providing the essential services of power, serial/parallel/scsi ports, ethernet switching,
SAN switching, KVM connectors etc.
Power supply modules
Gigabit Ethernet and
fibre channel switch
modules (ESM’s)
Christopher Kempster
Fan/blower modules
334
Management Module for fault
detection, remote depoloyment
software etc.
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
An example configuration may be:
Active and Standby Links via NIC teaming
The chassis houses a range of blades, with a backplane that determines the connectors,
its supporting modules, and the types of server it supports.
The servers themselves can be a range of sizes, from 1 to 4U typically. The servers are
densely packed with minimal internal storage. Even so, many vendor blades are
enterprise class in terms of raw performance, with dual or quad CPU’s and large RAM
capacity.
Dual CPU’s, Quad CPU’s are less common but available. Their
footprint increases from 1U to 2 or even 3U though.
Backplane connectors
Dual internal disks, 1 can be supplemented for
SAN/NAS HBA
8Gb ECC RAM
Dual integrated Ethernet
Enternet connections can be Teamed for
added reduncency, but tends to require
additional software/drivers.
The true value of blades comes in the form of service virtualization within the blade
center. What do I mean by this? The blade takes utility or dense computing that step
further in terms of little space for high performance gain, all without the need to buy
single, large CPU (clustered) servers with fortune-500 price tags. In order to take
advantage of blades, the software that runs business services needs to be aware of this
virtual environment. The move to grid computing by a variety of vendors is a classic
example.
The Oracle 10g suite of products is a good example of this in play, where any number of
blades can be provisioned to serve a single Oracle Application Server (or database)
hosted business application, maintaining state and of course stability and scalability.
In the Microsoft space, using MSCS (Microsoft Cluster Service), component load
balancing, or network load-balancing coupled with .Net state server or database for
session management is an excellent equivalent/competing technology. All said, the
blades are more frequently used for Web and Applications servers over databases at
present – this I believe is more of a stigma of the technology in play rather than any
specific reason why you wouldn’t take the infrastructure seriously for large production
Christopher Kempster
335
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
systems. If this is the case, I would highly recommend two blade chasis and dividing
your SQL Cluster amongst blades within them to reduce the single point of failure (that
can take out 14+- servers in one hit).
Images above are from IBM corporate website and their blade server product range – June 2004.
Christopher Kempster
336
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
References
1. How to consolidate physical files and rename the logical file name of a database in
sql server 2000. Microsoft Support Services,
http://support.microsoft.com/?kbid=814576
2. Definition of “Contingency Plan”,
http://www.atis.org/tg2k/_contingency_plan.html
3. Comments from members on the article “From the soapbox – Does anyone know
what disaster recovery is?”. James Luetkehoelter, 2004.
www.SQLServerCentral.com
4. CoBIT framework overview, as at 12 Febuary 2004,
http://www.isaca.org/Content/NavigationMenu/About_ISACA/Overview_and_Hist
ory/Overview_and_History.htm
5. Orphaned Sessions, Rahul Sharma, printed from www.dbazine.com as at
6/3/2003.
6. Help! My Database is Marked Suspect, Brian Knight, 31/3/2004 @
www.sqlservercentral.com
7. Step-by-step guide to clustering Windows 2000 and SQL Server 2000, Brian
Knight, 12/7/2002 @ www.sqlservercentral.com
8. Clustering SQL Server 2000 from 500 feet, Brian Knight, 2/7/2001 @
www.sqlservercentral.com
9. Quantum SDLT-600, ZDNet Australia, product review,
http://www.zdnet.com.au/reviews/hardware/peripherals/0,39023417,391159274,00.htm
10. Beware of mixing collation with SQL Server 2000 – Part 1, Gregory Larsen,
19/2/2003,
http://www.databasejournal.com/features/mssql/article.phpr/1587631
11. “LTO 2 verses SDLT 600”, www.openstore.com, printed @ 6/4/2004
12. Background and History of Measurement-Based Management, Paul Arveson,
1998, http://www.balancedscorecard.org/bkgd/bkgd.html
13. Child Support Issues – Accountability vs Responsibility, 29 Dec 2003,
http://www.childcustody.org/childsupport/_disc84/00003786.htm
14. Responsibility vs Accountability, Formum Posts,
http://world.std.com/~lo/95.09/0304.html
Christopher Kempster
337
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
15. Tape vs Disk: Another View…, Computer Technology News, Feb 2002,
http://www.filetek.com/press/media/tapevrsdisk2.htm
16. Ghost Record Cleanup and Error 602, SQL Server Magazine, 6 August 2003,
http://www.microsoft.com/sql/techinfo/tips/administration/ghostrecords.asp
17. BUG – A failed assertion is generated during a bulk insert statement, Microsoft
Support, http://support.microsoft.com/default.aspx?scid=kb;en-us;815594
18. Brian Cryers Glossary of IT Terms with Links,
http://www.cryer.co.uk/glossary/D.htm
19. C.Russel, S.Crawford, J.Gerend, MS Press 2003, Chapter 19, Microsoft Windows
Server 2003 Administrators Companion.
20. P.Sharick, SQL Server SP2 Problems, Slow Open/Save Operations, EFS and
Password Changes, www.winntmag.com
21. B.Hollinshead, Reader to Reader - Shrinking Active Log Files Revisited,
www.winntmag.com
22. Experts Exchange, Shrink and move transaction log – easy, http://www.expertsexchange.com/Databases/Microsoft_SQL_Server/Q_20823435.html
23. Backing Up Disk to Disk – Computer World, Robert Mitchell, 3 June 2002
24. How to: Shrink the tempdb database in SQL Server, Microsoft Support Services,
http://support.microsoft.com/default.aspx?scid=kb;EN-US;Q307487
25. INF: Creating Database or Changing Disk File Locations on a Shared Cluster
Drive on Which SQL Server 2000 was not Originally Installed,
http://support.microsoft.com/default.aspx?scid=kb;en-us;295732
26. How to: Remove a SQL Server Service Pack, Microsoft Support Services,
http://support.microsoft.com/?kbid=314823
27. How to install SQL Server 2000 Clustering: Preparing for SQL Server 2000
clustering, B.McGehee, www.sql-server-performance.com
28. How can I fix a corruption in a system table?, N.Pike, 5/3/1999,
http://www.winnetmag.com/Article/ArticleID/14051/14051.html
29. Why you want to be restrictive with shrink of database files, T.Karaszi,
http://www.karaszi.com/SQLServer/info_dont_shrink.asp
30. My DTS package is stored inside SQL Server. Now I cannot open it.,
http://www.mssqlcity.com/FAQ/Trouble/OpenDTSPack.htm
31. How to overwrite DTS package log everytime the package executes,
N.V.Kondreddi, http://vyaskn.tripod.com/sql_server_dts_error_file.htm
32. Locked out of SQL Server, Microsoft,
http://www.microsoft.com/sql/techinfo/tips/administration/May3.asp
Christopher Kempster
338
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
33. Inside Microsoft SQL Server 2000, K.Delaney, 2001, Microsoft Press 2001.
34. Automatically gathering server information part 2, S.Jones, 25/12/2003,
www.sqlservercentral.com
35. SQL Server Central, Questions of the Day, www.sqlservercentral.com
36. List Available DBCC Commands, www.extremeexperts.com
37. Technical Resources – DBCC commands, www.umachandar.com
38. Five Nines – but the book, K.Percy, 14/4/2003,
http://www.nwfusion.com/columnists/2003/0414testerschoice.html
39. Most wanted service metrics (answer), R.Sturm,
http://www.greenspun.com/bboard/q-and-a-fetch-msg.tcl?msg_id=009E21
40. Computer Performance Metrics, FrontRunner Computer Performance Consulting,
http://www.frontrunnercpc.com/info/metrics.htm
41. Team development with visual studio.net and visual sourcesafe, Microsoft
Corporation, Jan 2002,
http://msdn.microsoft.com/library/default.asp?url=/library/enus/dnbda/html/tdlg_ch6.asp
42. Cisco’s flawless director of traffic, R.Birdsall & E.Mier, 16/6/2004,
http://www.arnnet.com.au/index.php?id=981505022
43. First serial ATA drive: Expectations Exceed Results,
http://www.extremetech.com/article2/0,1558,1150388,00.asp
44. “TCQ, RAID, SCSI and SATA”,
http://www.storagereview.com/articles/200406/20040625TCQ_6.html
45. Future of storage: is disk dead?, J.Mehlman, July 2004,
www.technologyandbusiness.com.au
46. Storage – Hard and Tape Drive Market First Quarter 2004, Evans Research,
http://www.evansresearch.com/snapshots/hardtape.html
47. AIT Tape and SAIT Tape – Advanced Intelligent Tape,
http://www.aittape.com/roadmap.html
48. Sony’s S-AIT Tape Gets Jump on Competitors, L.Mearian, Dec 2002,
http://www.computerworld.com/hardwaretopics/storage/story/0,10801,77003,00
.html
49. Disaster Recovery Plan Template – version 2.7, http://www.ejanco.com/drp_template.htm
50. Learn about SQL Server Disaster Recovery from Greg Robidoux of Edgewood
Solutions – Interview, B.McGeHee, http://www.sql-serverperformance.com/greg_robidoux_interview.asp
Christopher Kempster
339
S Q L
S E R V E R
B A C K U P , R E C O V E R Y
&
T R O U B L E S H O O T I N G
51. Disaster Recovery Planning, Chapt 1. An Overview, R.J.Sandhu, Premier Press ©
2002
52. Disaster Recovery Planning, Chapt 1. Disaster Recovery Planning Strategies,
R.J.Sandhu, Premier Press © 2002
53. INF: sp_attach_single_file_db Does not work for databases with multiple log
files, Microsoft Support, http://support.microsoft.com/default.aspx?scid=kb;enus;271223
54. Finding SQL Servers running on a network, J.Deere, www.sqlteam.com
55. Collecting System Information in SQL Server 2000, R.Sharma, 30/11/2000,
www.databasejournal.com
56. Simple Log Shipping in SQL Server 2000 Standard Edition, R.Talmage, SQL
Server Magazine.
57. The features of the local quorum resource on Windows Server 2003 Cluster,
Microsoft Support.
58. How to troubleshoot cluster service startup issues, Microsoft Support,
http://support.microsoft.com/?kbid=266274
59. Alert! Alert! Alert! Backup and Restore – Baby!, J.Kadlec, 12/4/2004,
http://www.edgewoodsolutions.com/resources/BackupAndRestoreBaby.asp
Christopher Kempster
340