Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Relational model wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Functional Database Model wikipedia , lookup
Serializability wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Database model wikipedia , lookup
Clusterpoint wikipedia , lookup
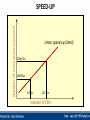
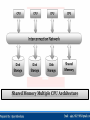
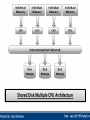
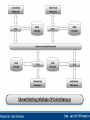
Unit - 4 Introduction to the Other Databases Introduction : Today single CPU based architecture is not capable enough for the modern database that are required to handle more demanding and complex requirements of the users, for example, high performance, increase availability, distributed access to data, analysis of distributed data and so on. To meet the complex requirement of users, the modern database system today operate with the architecture where multiple CPUs are working parallel to provide the complex database services. In some of the architectures, multiple CPUs are working in parallel and are physically located in closed environment, in the same building and communicating at very high speed. The databases operating in such a environment are called Parallel Databases. In parallel database system, multiple CPUs work in parallel to improve performance through parallel implementation of various operations such as loading data, building indexes and evaluating queries. Parallel processing divides a large task into many smaller task and execute the smaller tasks concurrently on several CPUs. As a result the larger task complete more quickly. Parallel database system improve the processing and I/O speed by using multiple CPUs and disks working in parallel. the parallel databases are essentially useful for applications that have to query large databases and process large number of transactions per second. In parallel processing many operations are performed simultaneously, as opposed to the centralized processing, in which serial computation is performed. The goal of Parallel Database System : To ensure that the database system can continue to perform at one acceptable speed, even as the size of database and the number of transactions increases. And this can be done by increasing the capacity of the system by increasing the parallelism provides a smoother path for growth for an enterprise then does replacing a centralized system by a faster machine. The parallel database systems are usually designed to provide a best cost-performance and they are quit uniform in site machine architecture. The cooperation between site machines is usually achieved at the level of the transaction module of the database system. Parallel database system represent an attempt to construct a faster centralized computer using several small CPUs. WHY DO WE NEED THEM? • More and More Data! We have databases that hold a high amount of data, in the order of 1012 bytes: 10,000,000,000,000 bytes! • Faster and Faster Access! We have data applications that need to process data at very high speeds: 10,000s transactions per second! SINGLE-PROCESSOR DBMS CANNOT DO THIS JOB.....! Advantages of Parallel Database System : Increase Throughput (Scale-Up). Increase Response time (Speed-Up) Useful to the application to query extremely large databases and to process an extremely large number of transactions rate (in order of thousands of transactions per second). Increase availability of the system. Grater flexibility. Possible to serve a large number of users. Disadvantages of Parallel Database System : More Start-Up Cost. Interface Problem. BENEFITS OF A PARALLEL DBMS Improves Response Time. INTERQUERY PARALLELISM It is possible to process a number of transactions in parallel with each other. Improves Throughput. INTRAQUERY PARALLELISM It is possible to process ‘sub-tasks’ of a transaction in parallel with each other. HOW TO MEASURE THE BENEFITS Speed-Up. As you multiply resources by a certain factor, the time taken to execute a transaction should be reduced by the same factor: 10 seconds to scan a DB of 10,000 records using 1 CPU 1 second to scan a DB of 10,000 records using 10 CPUs Scale-up. As you multiply resources the size of a task that can be executed in a given time should be increased by the same factor. 1 second to scan a DB of 1,000 records using 1 CPU 1 second to scan a DB of 10,000 records using 10 CPUs Number of transactions/second SPEED-UP Linear speed-up (ideal) 2000/Sec 1000/Sec 5 CPUs 10 CPUs Number of CPUs Number of transactions/second SCALE-UP 1000/Sec 5 CPUs 1 GB Database Linear scale-up (ideal) 10 CPUs 2 GB Database Number of CPUs, Database size 1.) Shared-Memory Multiple CPU :2.) Shared-Disk Multiple CPU :3.) Shared-Nothing Multiple CPU :- Shared-Memory Multiple CPU : In this system a computer has multiple simultaneously active CPUs that are attached to an interconnected network and can share a single MAIN MEMORY. Thus in this architecture a single copy of a multithreaded Operating System and multithreaded DBMS can support multiple CPUs. This architecture of Parallel Database System is closest to the traditional single CPU processer of centralized database system, but much faster in performance as compare to the single CPU of the same power. Shared Memory Multiple CPU Architecture Benefits of Shared-Memory : Communication between CPUs is extremely efficient. Data can be access by any CPU without being moved with software. A CPU can send a message to the other CPU much faster by using memory writes, which usually takes less then a microsecond, then by sending a message through a communication mechanism. The communication overhead are low, because of main memory can be used for this purpose and operating services can be used to utilize the additional CPUs. Limitations of Shared-Memory : Memory access uses a very high speed mechanism that is difficult to partition without losing efficiency. Thus the design must take the special type of different CPUs have equal access to a common memory. Since the communication bus or interconnection network is shared by all CPUs, this architecture is not capable beyond 80 or 100 CPUs in parallel. The bus and interconnection network become a bottleneck as the number CPUs increase. The addition of more CPUs causes CPUs to spend time waiting for their turn on the bus to access memory. Shared-Disk Multiple CPU : In this system multiple CPUs are attached to an interconnection network and each CPU ha its own memory but all of them have access to the same disk storage or more commonly to the shared array of disk. The scalability of the system is largely determine by the capacity and the throughput of the interconnection network. Since the main memory is not shared among the CPU, each machine has its own OS and its own DBMS. It is possible that with the same data accessible, two or more nodes want to read or write the same data at the same time. Therefore the global locking scheme is require to preservation of the data integrity. Shared Disk Multiple CPU Architecture Benefits of Shared Disk Architecture : Easy to load balance, because data does not have to be permanently divided among available CPUs. Since each CPU has its own memory, the memory bus is not a bottleneck. It offers a low cost solution to provide a degree of fault tolerance. In this case of a CPU or memory failure, the other CPUs take over its task; since the database is resident on disk that are accessible from all CPUs. It has found acceptance in wide applications. Limitations of Shared Disk : It is also facing the problems of interface and memory contention bottleneck as the number of CPUs increase. As more CPUs are added, the existing CPUs are slow down because of the increased contention for memory accesses and network bandwidth. It is also having the problem of scalability. The interconnection to the disk subsystem become bottleneck, particularly when the database makes the large number of access to the disk. Shared Nothing Multiple CPU :In this system multiple CPUs are attached with interconnecting network and each CPU has a local memory and a local disk storage, but no two CPU can access the same storage area. All communication between CPUs is through a high-speed interconnection network. Thus the shared nothing environments involve no sharing on memory or disk. Each CPU has its own copy of OS and its own copy of DBMS and its own copy of a portion of a data managed by DBMS. In this type of architecture CPUs sharing responsibilities for database services usually split up the data among themselves. CPUs then perform the transactions and queries by dividing up the work and communicating by messages over the high speed network. Shared Nothing Multiple CPU Architecture Benefits of Shared Nothing Architecture :This architecture minimized the connection of CPUs by not sharing resources and therefore offer a high degree of scalability. Since local disk references are serviced by local disk ay each CPU, this architecture overcomes the limitations of requiring all I/O to go through a single interconnection network. Only queries accesses to non-local disk and result relation pass through the network. The interconnection network for this architecture are usually designed to be scalable. Thus adding more CPUs and more disks enables the system grow in a manner that is divided the power and the capacity of the newly added component. In other words the shared-nothing architecture provides linear Speed-Up and linear Scale-Up. Linear Speed-Up and Scale-Up properties increase the transmission capacity of sharednothing architecture as more nodes are added and therefore, it can easily support the large number of CPUs. Limitations of Shared Nothing Architecture : Shared nothing architecture are difficult to load-balance. In many multi CPU environments, it necessary to split the system work load in some way so that all system resources are being used efficiently. Proper splitting or balancing workload across the shared nothing system requires an administrator to properly partition or divide the data across the various disks. In practice this is difficult to achieve. Adding a new CPU and disk to Shared-Nothing Architecture means the data may needed to be redistributed in order to make advantage of the new resources and thus require more extensive reorganization of DBMS. The cost of communication and non-local disk access are higher then in Shared-Disk or SharedMemory architecture because of sending data involves software interaction at both the ends. The high speed network are limited in size, because of speed-of –light consideration. This leads to the requirement that a parallel architecture has CPUs that are physically closed together. It requires an OS that is capable of accommodating the heavy amount of messaging that are require to support the inter processor communication. 1.) Speed-Up :2.) Scale-Up :3.) Synchronization :4.) Locking :- 1.) Speed-Up : Speed-Up is the property in which the time taken for performing the task decreases in case of increasing the number of CPUs. In other word Speed-Up is the property of running a given task in less time by increasing the degree of parallelism (more number of hardware). With additional hardware, Speed-Up holds the task constant and measure the time saved. Thus, Speed-Up enables user to improve the system response time for their queries, assuming the size of their database remain the same. To = Execution time of a task on the original or smaller machine (or original processing time) Tp = execution time of the same task on parallel or larger machine (or parallel processing time). Here the original processing time To is the time spent by a centralized system or small system on the given task. And the parallel processing time Tp is the time spent by large system or Parallel System on the same task. Consider a database application running on a parallel system with a certain number of CPUs and disks. Now suppose the size of system is increase by increasing the number of CPUs, disks and other hardware components. The goal is to process the task in time inversely proportional to the number of CPUs and disk allocated. For example, if original system takes 60 seconds to perform the task and the parallel system (with double capacity) takes 30 seconds to complete the same task then the value of Speed-Up = 60/30 = 2. the Speed-Up value 2 in indicate the Linear Speed-Up. If the Speed-Up is N when the larger system has N times the resources of the smaller system. If the Speed-Up value is less then N then the system is said to demonstrate Sub Linear Speed-Up. Number of transactions/second SPEED-UP Linear speed-up (ideal) 2000/Sec Sub Linear speed-up 1000/Sec 5 CPUs 10 CPUs Number of CPUs 2.) Scale-Up : Scale-Up is the property in which the performance of the parallel database is sustained if the number of CPU and disk are increased in proportional to the amount of data. In other word, Scale-Up is the ability of handling the large task by increasing the degree of parallelism, in the same time period as the original system. With added hardware the formula for Scale-Up holds the time constant and measure the increase size of task. Thus the Scale-Up enable users to increase the size of their database while maintaining the same response time. Vp = Parallel or Large Processing Volume. Vo =Original or Small Processing Volume. Here the Original Processing Volume is the transaction volume process in the given amount of time on a smaller system. Parallel Processing Volume is the transaction volume process in the given amount of time on a larger system. For Example, if the original system can process 3000 transactions in given amount of time and if the parallel system can process 6000 transactions in the same amount of time then the Scale-Up = 6000/3000 = 2. The Scale-Up value 2 is an indication of the Linear Scale-Up, which means that the twice as much of hardware can process twice the data volume in same amount of time. If the Scale-Up value is less then 2 then it is called Sub Linear Scale-Up. That means as much of times we increase the resources of the parallel system, the value of Linear Scale-Up will also be increase that much of times. Number of transactions/second SCALE-UP 1000/Sec Linear scale-up (ideal) Sub Linear scale-up 5 CPUs 1 GB Database 10 CPUs 2 GB Database Number of CPUs, Database size 3.) Synchronization : Synchronization is the coordination of the current task. For a successful operation of the parallel database system , the task should be divided such that the synchronization requirement is less. It is necessary for the correctness. With less synchronization requirement better speed-up and scale-up can be achieved. The amount of synchronization depends on the amount of resources and the number of users and the task working on the resources. More synchronization is require to coordinate large number of concurrent tasks. 4.) Locking : Locking is a method of synchronizing current task., Both internal as well as external locking mechanisms are used for synchronization of tasks that are required by the parallel database system. For external locking, a distributed lock manager (DLM) is used, which is apart of the OS. DLM coordinate the resources sharing between communication nodes running a parallel server. The instances of parallel server use the DLM to communicate with each other and coordinate modification of database resources. The DLM allows application to synchronize access to resources such as data, software and devices, so that current requests for the same resource are coordinate between applications running on different nodes. 1.) Intra-Query Parallelism :2.) Inter-Query Parallelism :3.) Intra-Operation Parallelism :4.) Inter-Operation Parallelism :5.) Input / Output Parallelism :- 1.) Intra-Query Parallelism : Intra-Query Parallelism refers to the execution of single query in parallel on multiple CPUs using Shared-Nothing Architecture Technique. It is some times called Parallel Query Processing. For example, suppose a table has been partitioned across multiple disks by range partitioning on some attribute and now user want to perform SORT on the partitioning attribute. The SORT operation can be implemented by sorting each portion in parallel, then concatenating the sorted portions to get the final sorted relation. Thus a query can be parallelized by parallelizing individual operations. CPU 1 CPU 2 CPU 3 CPU ‘N’ Interconnection Network Query 1 Advantages : Intra-Query Parallelism Speeds Up long running queries. They are beneficial for decision support applications that issues complex, read-only queries, including queries involving multiple JOINs. 2.) Inter-Query Parallelism : In Inter-Query Parallelism multiple transactions are executed in parallel, One by each CPU. It sometimes also called as Parallel Transaction Processing. The primary use of Inter-Query Parallelism is to Scale-Up a Transaction Processing system to support a large number of transaction per second. To support a Inter-Query Parallelism DBMS generally uses a task or transaction dispatching. Efficient lock management is another method to used by DBMS to support Inter-Query Parallelism, particularly in Shared-Disk Architecture. Since in Inter-Query Parallelism each query is run sequentially, it does not help in speeding up in long running query. In such a case DBMS must understand the locks held by different transactions executing on different CPUs in order to preserve data integrity. Inter-Query Parallelism on Shared-Disk architecture perform best when transactions that execute in parallel do not access the same disk. Transaction 1 Transaction 1 Transaction 1 Transaction N CPU 1 CPU 2 CPU 3 CPU N Interconnection Network Advantages : Easiest form of parallelism to support in a database system, particularly in Shared-Disk Parallel System. It Scale-Up a transaction processing system to support a large number of transactions per second. Disadvantages : Response time of individual transaction are no faster then they would be if the transaction were run in isolation. It is more complicated in Shared-Memory and Shared-Nothing Architectures. 3.) Intra-Operation Parallelism : In Intra-Query Parallelism of each individual operation of a task, such as sorting, projection, join and so on. Since the number of operations in a typical query small, compared to the number of tuples processed by each operation, Intra-Operation Parallelism scales better with increasing parallelism. Advantages : Inter-Operation Parallelism is natural in a Database. Degree of Parallelism is potentially enormous. 4.) Inter-Operation Parallelism : In Inter-Operation Parallelism, the different operations in a query expression are executed in parallel. Following two types of Inter-Operation Parallelism are used : Pipelined Parallelism : Independent Parallelism :1. Pipelined Parallelism : In this parallelism output tuples of one operation A are consumed by second operation B, even before the first operation has produced the entire set of tuples in its output. Thus it is possible to run operation A and B simultaneously in different processors, so that the operation B consumes tuples in parallel with operation A producing them. Advantages : Pipelined parallelism useful with smaller number of CPUs. Also pipelined execution avoid writing intermediate result to disk. Disadvantages : It does not Scale-Up well. Pipelined chain do not attain sufficient length to provide a high degree of parallelism. It is not possible to pipeline relational operators that do not produce output until all inputs have been accessed. Only marginal Speed-Up is obtained for the frequent case in which one operation’s cost is much higher then the others. 2. Independent Parallelism : In an independent parallelism the operations in query expression that do not depend on one other can be ececute in parallel. Advantages : It is useful with a lower degree of parallelism. Disadvantages :- Like pipelined parallelism, independent parallelism does not provide a high degree of parallelism so it is less useful in highly parallel system.