Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
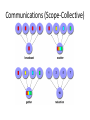
Designing Parallel Programs David Rodriguez-Velazquez CS-6260 Spring-2009 Dr. Elise de Doncker Manual vs. Automatic Parallelization • Designing and developing parallel programs has been a very MANUAL process. • The programmer is responsible for both: – Identifying & Implementing parallelism • Manually developing parallel codes is a – Time consuming – Complex – Error-prone – Iterative process Outline • • • • • • • • • Parallelization Partitioning Communication Efficiency Synchronization Data Dependency Load Balancing Granularity I/O • • • • • • Amdhal’s Law Complexity Portability Resource Requirements Scalability MPI demo – – – – Matrix Share Memory Matrix multiplication Alltoall Heat Equation Parallelizing Compiler (Pre-Processor) • Most common type of tool used to automatically parallelize a serial program into parallel programs • Parallelizing Compiler works in 2 different ways: – Fully Automatic – Programmer Directed Parallelizing Compiler (Fully Automatic) • The compiler analyzes the source code and identifies opportunities for parallelism • The analysis includes: – Identifying inhibitors to parallelism – Possibly a cost weighting on whether or not the parallelism would actually improve performance – Loops (do, for) loops are the most frequent target for automatic parallelization Parallelizing Compiler (Programmer Directed) • Using “compiler directives” or possibly compiler flags, the programmer explicitly tell the compiler how to parallelize the code • May be able to be used in conjunction with some degree of automatic parallelization also Automatic Parallelization(Caveats) • • • • • Wrong results may be produced Performance may actually degrade Much less flexible than manual parallelization Limited to a subset (mostly loops) of code May actually not parallelize code if the analysis suggest there are inhibitors or the code is too complex Understand the Problem & the Program • First step in developing parallel software is to: – Understand the problem that you wish to solve in parallel (from serial program you need to understand the existing code) – Before spending time : determine whether or not the problem is one that can actually be parallelized – Identify the program’s hotspots (Know where of the real work is being done. Performance analysis tools can help here) – Identify bottlenecks ( I/O is usually something that slows a program down. Change algorithms to reduce or eliminate unnecessary slow areas) – Investigate other algorithms – Investigate inhibitors to parallelism . One common class of inhibitor is data dependence Examples (Parallelizable?) – Example of Parallelizable Problem • Calculate the potential energy for each of several thousand independent conformations of a molecule. When done, find the minimum energy conformation • Each of the molecular conformation is independently determinable. The calculation of the minimum energy conformation is also a parallelizable problem – Example of Non-parallelizable Problem • Calculation of the Fibonacci series (1,1,2,3,5,8,13,21) • F(K + 2) = F(K + 1) + F(K) • The calculation of the Fibonacci sequences as shown would entail dependent calculations rather than independents ones. The calculation of the k + 2 values uses those of both k + 1 and k. These three terms cannot be calculated independently and therefore, not in parallel PARTITIONING • PARTITIONING – Break the problem into discrete “chunks” of work that can be distributed to multiple tasks – Domain decomposition & Functional decomposition Partition • Domain Decomposition: the data associated with a problem is decomposed. Each parallel task then works on a portion of of the data. Partition • Functional Decomposition: In this approach, the focus is on the computation that is to be performed rather than on the data manipulated by the computation. The problem is decomposed according to the work that must be done. Each task then performs a portion of the overall work. Partition (Functional Decomposition) Communications • Who needs Communications : – You don’t need : • Some types of problems can be decomposed and execute in parallel. Embarrassingly parallel. • Very little inter-task communication is required • Eg. Image processing operation, every pixel in a black and white image needs to have its color reversed – You do need • Most parallel applications do require to share data with each other. (Eg. Ecosystem) COMMUNICATIONS (Factors to consider) • There are a number of important factors to consider when designing program’s inter-task communications: – Cost of communications – Latency vs. Bandwidth – Visibility of communications – Synchronous vs. Asynchronous communication – Scope of communications – Efficiency of communications Communications (Cost) • Inter-task communication virtually always implies overhead • Machine cycles and resources that could be used for computation are instead used to package and transmit data. • Communications frequently require some type of synchronization between tasks, which can result in tasks spending time "waiting" instead of doing work. • Competing communication traffic can saturate the available network bandwidth, further aggravating performance problems Communications (Latency vs. Bandwidth) • latency is the time it takes to send a minimal (0 byte) message from point A to point B. Commonly expressed as microseconds. • bandwidth is the amount of data that can be communicated per unit of time. Commonly expressed as megabytes/sec or gigabytes/sec. • Sending many small messages can cause latency to dominate communication overheads. Often it is more efficient to package small messages into a larger message, thus increasing the effective communications bandwidth. Communications (Visibility) • Message passing Model: communications are explicit (under control of the programmer) • Data Parallel Model: communications occur transparently to the programmer, usually on distributed memory architectures. Communications (Synchronous vs. Asynchronous) • Synchronous requires some type of “handshaking” between task that are sharing data. • Synchronous : Blocking communications • Asynchronous allow tasks to transfer data independently from one another. • Asynchronous: Non-Blocking communications • Interleaving computation with communication is the greatest benefit. Communications (Scope) • Knowing which tasks must communicate with each other is critical during design stage of a parallel code. • Two scoping can be implementing sync. Or async. – Point to Point: 2 task (sender/producer of data and receiver/consumer) – Collective: data sharing between more than two tasks Communications (Scope-Collective) Efficiency of communications • Very often, the programmer will have a choice with regard to factors that can affect communications performance. • Which implementation for a given model should be used? (Eg.MPI implementation may be faster on a given hardware platform than another) • What type of communication operations should be used? (Eg. asynchronous communication operations can improve overall program performance) • Network media - some platforms may offer more than one network for communications. Which one is best? SYNCHRONIZATION (Types) • Barrier – All tasks are involved – Each task perform its work. When the last task reaches the barrier, all task are synchronized • Lock / semaphore – Typically used to serialize access to global data or section of code. Task must wait to use the code • Synchronous communication operations – Involves only those tasks executing a communication operations (handshaking) Data Dependencies • A dependence exists between program statements when the order of statements execution affects the results of the program • A data dependence results from multiple use of the same location(s) in storage by different tasks. • Dependencies are important to parallel programming because they are one of the primary inhibitors to parallelism Data Dependencies • Loop carried data dependence (most important) DO J = MYSTART,MYEND A(J) = A(J-1) * 2.0 CONTINUE • The value of A(J-1) must be computed before the value of A(J), therefore A(J) exhibits a data dependency on A(J-1). Parallelism is inhibited. • If Task 2 has A(J) and task 1 has A(J-1), computing the correct value of A(J) necessitates: 1 Calculate, 2 get value • Loop independent data dependence – task 1 X=2 Y = X**2 task 2 X=4 Y = X**3 • As with the previous example, parallelism is inhibited. The value of Y is dependent on: Data Dependencies • How to Handle Data Dependencies: – Distributed memory architectures - communicate required data at synchronization points. – Shared memory architectures -synchronize read/write operations between tasks. Load Balancing • Refers to the practice of distributing work among tasks so that all task are kept busy all of the time. • It can be considered a Minimization of task idle time • Important for performance reasons Load Balancing • How to achieve – Equally partition the work each task receives – Use dynamic work assignment How to Achieve (Load Balancing) • Equally partition the work each task receives – For array/matrix operations where each task performs similar work, evenly distribute the data set among the tasks. – For loop iterations where the work done in each iteration is similar, evenly distribute the iterations across the tasks. How to Achieve (Load Balancing) • Use dynamic work assignment – When the amount of work each task will perform is intentionally variable, or is unable to be predicted, it may be helpful to use a scheduler - task pool approach. As each task finishes its work, it queues to get a new piece of work. – It may become necessary to design an algorithm which detects and handles load imbalances as they occur dynamically within the code. • Sparse arrays:some task with zeros • Adaptive grid methods: some task need to refine their mesh How to Achieve (Load Balancing) Granularity (Computation / Communication Ratio) • Granularity is a qualitative measure of the ratio of computation to communication • Periods of computation are typically separated from periods of communication by synchronization events • Two types – Fine-grain Parallelism – Coarse-grain Parallelism Granularity (Fine-grain Parallelism) • Relatively small amounts of computational work are done between communication events • Low computation to communication ratio • Implies high communication overhead • If granularity is too fine it is possible that the overhead required for communications and synchronization between tasks takes longer than the computation Granularity (Coarse-grain Parallelism) • Relatively large amounts of computational work are done between communication/synchronization events • High computation to comunication rate • Implies more opportunity for performance increase • Harder to load balance efficiently Granularity (What is Best?) • The most efficient granularity depend on the algorithm and the hardware environment in which it runs • In most cases the overhead associated with communication and synchronization is high relative to execution speed so it is advantageous to have coarse granularity • Fine-grain parallelism can help reduce overheads due to load imbalance. Facilitates load balancing I/O • I/O operations are inhibitors to parallelism • Parallel I/O systems may be inmature or not available for all platforms • If all of the tasks see the same file space, WRITE operations can result in file overwriting • Read operations can be affected by the file server’s ability to handle multiple read requests at the same time • I/O over networks can cause bottlenecks/crash file servers Amdahl’s Law • States that: “Potential program speedup is defined by the fraction of code (P) that can be parallelized” Speedup = 1 / (1 – P) • • • If P = 0 then speedup = 1 (no code parallelized) If P = 1 then speedup is infinite (all code parallelized) If P = .5 then speedup is 2 (50% of the code parallelized) meaning the code will run twice as fast. Amdahl’s Law • Introducing the number of processors performing the parallel fraction of work Speedup = 1 / ((P / N) + S) P = parallel fraction, N = number of processors S = serial fraction Complexity • Parallel applications are much more complex than corresponding serial applications. • Cost of complexity is measured in programmer time in every aspect of the software development cycle – Design, Coding, Debugging, Tuning, Maintenance Portability • There are standardization in some API’s s.t. MPI – Implementations will differ in a number of details, requiring code modifications – Hw architectures can affect portability – Operating systems can play a key role in code portability issues – All of the portability issues associated with serial programs apply to parallel programs Resource Requirements • Goal of Parallel programming is decrease execution wall clock time, more CPU time is required. Eg. 1 parallel code that runs 1 hour on 8 processors actually use 8 hours of CPU time • Amount of memory can be greather in parallel • Short parallel code it is possible a decrease in performance. (setting up the parallel environment, task creation/termination, communication) Scalability • Result of a numer of interrelated factors • Adding more machines is rarely the answer • At some point, adding more resources causes performance to decrease • Hardware factors play a significant role in scalability. – Communications network bandwidth – Amount of memory available on any machine • Parallel support libraries and subsystems (limit) References • Author: Blaise Barney, Livermore Computing. • A search on the WWW for "parallel programming" or "parallel computing" will yield a wide variety of information. • "Designing and Building Parallel Programs". Ian Foster. http://www-unix.mcs.anl.gov/dbpp/ • "Introduction to Parallel Computing". Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar. http://www-users.cs.umn.edu/~karypis/parbook/ Question • Mention 5 Communication factors to be consider when you are designing a Parallel Program – Cost of Communication – Latency , Bandwidth – Visibility – Synchronous , Asynchronous – Scope