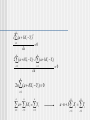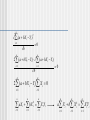Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Introduction to Linear and Logistic Regression Basic Ideas Linear Transformation Finding the Regression Line Minimize sum of the quadratic residuals Curve Fitting Logistic Regression Odds and Probability Basic Ideas Jargon IV = X = Predictor (pl. predictors) DV = Y = Criterion (pl. criteria) Regression of Y on X Linear Model = relations between IV and DV represented by straight line. Y X (population values) i i i A score on Y has 2 parts – (1) linear function of X and (2) error. Basic Ideas (2) Yi a bX i ei Sample value: Intercept – place where X=0 Slope – change in Y if X changes 1 unit If error is removed, we have a predicted value for each person at X (the line): Y a bX Suppose on average houses are worth about 50.00 Euro a square meter. Then the equation relating price to size would be Y’=0+50X. The predicted price for a 2000 square meter house would be 250,000 Euro Linear Transformation 1 to 1 mapping of variables via line Y a bX Permissible operations are addition and multiplication (interval data) 4 0 3 5 3 0 2 5 Y 2 = 0 1 5 1 0 h a 1 Y = n 5 Y 1 C in g Y Y C = 3 0 2 0 + 0 1 5 2 Y + 0 hg X= 2 Y + a 2 5 X = Y X nt gh + 5 = 2 + 5 1 0 5 0 0 0 2 4 6 X Add a constant 8 1 0 0 2 4 6 8 X Multiply by a constant Linear Transformation (2) Centigrade to Fahrenheit 240 Note 1 to 1 map 200 160 Intercept? 120 Slope? Degrees F Y a bX 212 degrees F, 100 degrees C 80 40 32 degrees F, 0 degrees C 0 0 30 60 90 120 Degrees C Intercept is 32. When X (Cent) is 0, Y (Fahr) is 32. Slope is 1.8. When Cent goes from 0 to 100 (run), Fahr goes from 32 to 212 (rise), and 212-32 = 180. Then 180/100 =1.8 is rise over run is the slope. Y = 32+1.8X. F=32+1.8C. Standard Deviation and Variance Square root of the variance, which is the sum of squared distances between each value and the mean divided by population size (finite population) N 1 xi x N i1 Example • 1,2,15 Mean=6 1 6 2 • (2 6) (15 6) 2 40.66 3 2 =6.37 2 Correlation Analysis Correlation coefficient (also called Pearson’s product moment coefficient) rXY x i x y i y (n 1) X Y If rX,Y > 0, X and Y are positively correlated (X’s values increase as Y’s). The higher, the stronger correlation. rX,Y = 0: independent; rX,Y < 0: negatively correlated ig Regression of Weight on Height X 61 105 62 120 63 120 65 160 65 120 68 145 69 175 70 160 72 185 75 210 N=10 N=10 mean=67 mean=150 =4.57 = 33.99 R R ee gg rr e Wt 2 2 4 0 1 0 Y a bX Y = - 1 8 0 1 5 0 R R W Ht 1 2 9 0 6 0 6 6 u 0 6 0 6 2 H 6 4 7 6 e 87 7 0 ig Correlation (r) = .94. Regression equation: Y’=-316.86+6.97X Predicted Values & Residuals Y a bX •Y’ is called the predicted value •Y-Y’ the residual (RS) •The residual is the error •Mean of Y’ and Y is the same •Variance of Y is equal to the variance Y’ + RS Numbers for linear part and error. N Ht Wt Y' RS 1 61 105 108.19 -3.19 2 62 120 115.16 4.84 3 63 120 122.13 -2.13 4 65 160 136.06 23.94 5 65 120 136.06 -16.06 6 68 145 156.97 -11.97 7 69 175 163.94 11.06 8 70 160 170.91 -10.91 9 72 185 184.84 0.16 10 75 210 205.75 4.25 mean 67 150 150.00 0.00 4.57 33.99 31.85 11.89 V 20.89 1155.56 1014.37 141.32 Finding the Regression Line Need to know the correlation, standard deviation and means of X and Y Y b rXY To find the intercept, use: X a Y bX Suppose rXY = .50, X = .5, meanX = 10, Y = 2, meanY = 5. Slope Intercept 2 b .5 2 .5 a 5 2(10) 15 Y ' 15 2 X Line of Least Squares Assume linear relations is reasonable, so the 2 variables can be represented by a line. Where should the line go? Place the line so errors (residuals) are small The line we calculate has a sum of errors = 0 It has a sum of squared errors that are as small as possible; the line provides the smallest sum of squared errors or least squares Minimize sum of the quadratic residuals n SRS min (RS) 2 i1 RSi a bXi Yi n SRS min (a bX i Yi ) 2 i1 • Derivation equal 0 n (a bX i Yi ) 2 i1 a n 0 (a bX i Yi ) 2 i1 b 0 n (a bX i Yi ) 2 i1 a 0 n n i1 i1 2 (a bX i Yi ) (a bX i Yi ) a 0 n 2n (a bX i Yi ) 0 i1 n n n a bX Y i i1 i1 i i1 n n i1 i1 a n b X i Yi n (a bX i Yi ) 2 i1 b 0 n n i1 i1 2 (a bX i Yi ) (a bX i Yi ) b n n i1 i1 0 2 (a bX i Yi ) X i 0 n n n i1 i1 i1 2 a X bX i i X iYi n n n i1 i1 i1 a X i b X i2 X iYi The coefficients a and b are found by solving the following system of linear equations n n X i i1 n X i a Yi i1 i1 n n b 2 X i X iYi i1 i1 n Curve Fitting Linear Regression Y a bX Exponential Curve Y ae bX Logarithmic Curve a0 Y a bln( x) Power Curve Y aX b a0 The coefficients a and b are found by solving the following system of linear equations n n ˆ X i i1 n ˆ ˆ X Y i aˆ i i1 i1 n n b ˆ ˆ 2 ˆ X i X iYi i1 i1 n with Linear Regression aˆ : a Xˆ i : X i Exponential Curve aˆ : ln( a) Xˆ i : X i Yˆi : Yi Yˆi : ln(Y)i Logarithmic Curve aˆ : a Xˆ i : ln( Xi ) Yˆi : Yi Power Curve aˆ : ln( a) Xˆ i : ln( X i ) Yˆi : ln(Yi ) Multiple Linear Regression Ti a bXi cYi The coefficients a, b and c are found by solving the following system of linear equations n n X i i1n Y i i1 n X i i1 n X 2 i i1 n X Y i i i1 n Yi Ti i1 a i1 n n X iYi b X iTi i1 i1 c n n Yi2 YiTi i1 i1 n Polynomial Regression Yi a bX i cX i2 The coefficients a, b and c are found by solving the following system of linear equations n n X i i1 n X 2 i i1 n X i i1 n X 2 i i1 n X i1 n X Yi i1 a i1 n n 3 X i b X iYi i1 i1 c n n X i4 X i2Yi i1 i1 n 3 i 2 i Logistic Regression Variable is binary (a categorical variable that has two values such as "yes" and "no") rather than continuous binary DV (Y) either 0 or 1 For example, we might code a successfully kicked field goal as 1 and a missed field goal as 0 or we might code yes as 1 and no as 0 or admitted as 1 and rejected as 0 or Cherry Garcia flavor ice cream as 1 and all other flavors as zero. If we code like this, then the mean of the distribution is equal to the proportion of 1s in the distribution. For example if there are 100 people in the distribution and 30 of them are coded 1, then the mean of the distribution is .30, which is the proportion of 1s The mean of a binary distribution so coded is denoted as P, the proportion of 1s The proportion of zeros is (1-P), which is sometimes denoted as Q The variance of such a distribution is PQ, and the standard deviation is Sqrt(PQ) Suppose we want to predict whether someone is male or female (DV, M=1, F=0) using height in inches (IV) We could plot the relations between the two variables as we customarily do in regression. The plot might look something like this Zur Anzeige wird der QuickTime™ Dekompressor „TIFF (Unkomprimiert)“ benötigt. None of the observations (data points) fall on the regression line They are all zero or one Predicted values (DV=Y)correspond to probabilities If linear regression is used, the predicted values will become greater than one and less than zero if one moves far enough on the Xaxis Such values are theoretically inadmissible a bX e 1 P : Y a bX 1 e 1 e(a bX ) Linear vs. Logistic regression Zur Anzeige wird der QuickTime™ Dekompressor „TIFF (Unkomprimiert)“ benötigt. Zur Anzeige wird der QuickTime™ Dekompressor „TIFF (Unkomprimiert)“ benötigt. Odds and Probability P odds 1 P P log( odds) log it(P) ln 1 P log it(P) a bX P e a bX 1 P a bX e P 1 e a bX Linear regression! Zur Anzeige wird der QuickTime™ Dekompressor „TIFF (Unkomprimiert)“ benötigt. Zur Anzeige wird der QuickTime™ Dekompressor „TIFF (Unkomprimiert)“ benötigt. Basic Ideas Linear Transformation Finding the Regression Line Minimize sum of the quadratic residuals Curve Fitting Logistic Regression Odds and Probability