Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Immunity-aware programming wikipedia , lookup
Current source wikipedia , lookup
Sound level meter wikipedia , lookup
Alternating current wikipedia , lookup
Resistive opto-isolator wikipedia , lookup
Opto-isolator wikipedia , lookup
Stray voltage wikipedia , lookup
Switched-mode power supply wikipedia , lookup
Buck converter wikipedia , lookup
Voltage optimisation wikipedia , lookup
Rectiverter wikipedia , lookup
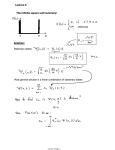
Examples of Stationary Processes
1) Strong Sense White Noise: A process ǫt
is strong sense white noise if ǫt is iid with mean
0 and finite variance σ 2.
2) Weak Sense (or second order or wide
sense) White Noise: ǫt is second order stationary with
E(ǫt) = 0
and
Cov(ǫt , ǫs) =
σ 2
0
s=t
s 6= t
In this course: ǫt denotes white noise; σ 2 denotes variance of ǫt. Use subscripts for variances of other things.
16
Example Graphics:
White noise: iid N (0, 1) data
IID N(0,1)
0
200
400
600
800
1000
White noise: Xt = ǫt · · · ǫt+9
Wide Sense White Noise
0
200
400
600
800
1000
17
2) Moving Averages: if ǫt is white noise then
Xt = (ǫt + ǫt−1)/2 is stationary. (If you use
second order white noise you get second order
stationary. If the white noise is iid you get
strict stationarity.)
Example proof: E(Xt) = E(ǫt) + E(ǫt−1) /2 =
0 which is constant as required. Moreover:
Cov(Xt , Xs) is
Var(ǫt )+Var(ǫt−1 )
4
1
4 Cov(ǫt + ǫt−1, ǫt+1 + ǫt)
1 Cov(ǫ + ǫ
t
t−1, ǫt+2 + ǫt+1)
4
.
s=t
s=t+1
s=t+2
.
Most of these covariances are 0. For instance
Cov(ǫt + ǫt−1, ǫt+2 + ǫt+1) =
Cov(ǫt, ǫt+2) + Cov(ǫt , ǫt+1)
+ Cov(ǫt−1, ǫt+2) + Cov(ǫt−1, ǫt+1) = 0
because the ǫs are uncorrelated by assumption.
18
The only non-zero covariances occur for s = t
and s = t ± 1. Since Cov(ǫt , ǫt) = σ 2 we get
2
σ
2
2
Cov(Xt , Xs) = σ
4
0
s=t
|s − t| = 1
otherwise
Notice that this depends only on |s − t| so that
the process is stationary.
The proof that X is strictly stationary when
the ǫs are iid is in your homework; it is quite
different.
19
Example Graphics:
Xt = (ǫt + ǫt−1)/2
MA(1)Process
0
200
400
600
800
1000
Xt = ǫt + 6ǫt−1 + 15ǫt−2 + 20ǫt−3
+15ǫt−4 + 6ǫt−5 + ǫt−6
MA(6) Process
0
200
400
600
800
1000
20
The trajectory of X can be made quite smooth
(compared to that of white noise) by averaging
over many ǫs.
3) Autoregressive Processes:
AR(1) process X: process satisfying equations:
Xt = µ + ρ(Xt−1 − µ) + ǫt
(1)
where ǫ is white noise. If Xt is second order
stationary with E(Xt ) = θ, say, then take expected values of (1) to get
θ = µ + ρ(θ − µ)
which we solve to get
θ(1 − ρ) = µ(1 − ρ) .
Thus either ρ = 1 (later – X not stationary)
or θ = µ. Calculate variances:
Var(Xt ) = Var(µ + ρ(Xt−1 − µ) + ǫt)
= Var(ǫt) + 2ρCov(Xt−1, ǫt)
+ ρ2Var(Xt−1)
21
Now assume that the meaning of (1) is that
ǫt is uncorrelated with Xt−1, Xt−2, · · · .
Strictly stationary case: imagining somehow
Xt−1 is built up out of past values of ǫs which
are independent of ǫt.
Weakly stationary case: imagining that Xt−1 is
actually a linear function of these past values.
Either case: Cov(Xt−1, ǫt) = 0.
2
If X is stationary: Var(Xt ) = Var(Xt−1) ≡ σX
so
2
2
= σ 2 + ρ2σX
σX
whose solution is
2
σ
2 =
σX
1 − ρ2
22
Notice that this variance is negative or undefined unless |ρ| < 1. There is no stationary
process satisfying (1) for |ρ| ≥ 1.
Now for |ρ| < 1 how is Xt determined from the
ǫs? (We want to solve the equations (1) to get
an explicit formula for Xt .) The case µ = 0 is
notationally simpler. We get
Xt = ǫt + ρXt−1
= ǫt + ρ(ǫt−1 + ρXt−2)
..
= ǫt + ρǫt−1 + · · · + ρk−1ǫt−k+1
+ ρk Xt−k
Since |ρ| < 1 it seems reasonable to suppose
that ρk Xt−k → 0 and for a stationary series
X this is true in the appropriate mathematical
sense. This leads to taking the limit as k → ∞
to get
Xt =
∞
X
ρj ǫt−j .
j=0
23
Claim: if ǫ is a weakly stationary series then
P∞
Xt = j=0 ρj ǫt−j converges (technically it converges in mean square) and is a second order
stationary solution to the equation (1).
If ǫ is a strictly stationary process then under
some weak assumptions about how heavy the
P
jǫ
ρ
tails of ǫ are Xt = ∞
t−j converges almost
j=0
surely and is a strongly stationary solution of
(1).
In fact; if . . . , a−1, a0, a1, a2, . . . are constants
P 2
such that
aj < ∞ and ǫ is weak sense white
noise (respectively strong sense white noise with
finite variance) then
Xt =
∞
X
aj ǫt−j
j=−∞
is weakly stationary (respectively strongly stationary with finite variance). In this case we
call X a linear filter of ǫ.
24
Example Graphics:
AR(1)Process: Rho=0.99
0
200
400
600
800
1000
AR(1) Process: Rho=0.5
0
200
400
600
800
1000
25
Motivation of the jargon “filter” comes from
physics.
Consider an electric circuit with a resistance R
in series with a capacitance C.
Apply “input” voltage U (t) across the two elements.
Measure voltage drop across capacitor.
Call this voltage drop “output” voltage; denote
output voltage by Xt.
26
The relevant physical rules are these:
1. The total voltage drop around the circuit is
0. This drop is −U (t) plus the voltage drop
across the resistor plus X(t). (The negative sign is a convention; the input voltage
is not a “drop”.)
2. Voltage drop across resistor is Ri(t) where
i is current flowing in circuit.
3. If the capacitor starts off with no charge
on its plates then the voltage drop across
its plates at time t is
Rt
i(s) ds
X(t) = 0
C
These rules give
Rt
i(s) ds
0
U (t) = Ri(t) +
C
27
Differentiate the definition of X to get
X ′(t) = i(t)/C
so that
U (t) = RCX ′(t) + X(t) .
Multiply by et/RC /RC to see that
′
et/RC U (t)
t/RC
= e
X(t)
RC
whose solution, remembering X(0) = 0, is obtained by integrating from 0 to s to get
s
1
s/RC
et/RC U (t) dt
e
X(s) =
RC 0
leading to
Z
s
1
X(s) =
e(t−s)/RC U (t) dt
RC Z0
s
1
e−u/RC U (s − u) du
=
RC 0
This formula is the integral equivalent of our
definition of filter and shows X = filter(U ).
Z
28
Defn: If {ǫt} is a white noise series and µ and
b0, . . . , bp are constants then
Xt = µ + b0ǫt + b1ǫt−1 + · · · + bpǫt−p
is a moving average of order p; write M A(p).
Defn: A process X is an autoregression of
order p (written AR(p)) if
Xt =
p
X
aj Xt−j + ǫt.
1
Defn: Process X is an ARM A(p, q) (mixed
autoregressive of order p and moving average
of order q) if for some white noise ǫ:
φ(B)X = ψ(B)ǫ
φ(B) = I −
p
X
aj B j
p
X
bj B j
1
and
ψ(B) = I −
1
Problems: existence, stationarity, estimation,
etc.
29
Other Stationary Processes:
Periodic processes: Suppose Z1 and Z2 are independent N (0, σ 2) random variables and that
ω is a constant. Then
Xt = Z1 cos(ωt) + Z2 sin(ωt)
has mean 0 and
Cov(Xt , Xt+h) = σ 2 [cos(ωt) cos(ω(t + h))
+ sin(ωt) sin(ω(t + h))]
= σ 2 cos(ωh)
Since X is Gaussian we find that X is second
order and strictly stationary. In fact (see your
homework) You can write
Xt = R sin(ωt + Φ)
where R and Φ are suitable random variables
so that the trajectory of X is just a sine wave.
30
Poisson shot noise processes:
Poisson process is a process N (A) indexed by
subsets A of R such that each N (A) has a Poisson distribution with parameter λlength(A) and
if A1, . . . Ap are any non-overlapping subsets of
R then N (A1), . . . , N (Ap) are independent. We
often use N (t) for N ([0, t]).
Shot noise process: X(t) = 1 at those t where
there is a jump in N and 0 elsewhere; X is
stationary.
If g a function defined on [0, ∞) and decreasing
sufficiently quickly to 0 (like say g(x) = e−x)
then the process
Y (t) =
X
g(t − τ )1(X(τ ) = 1)1(τ ≤ t)
is stationary.
Y jumps every time t passes a jump in Poisson
process; otherwise follows trajectory of sum of
several copies of g (shifted around in time).
We commonly write
Y (t) =
Z ∞
0
g(t − τ )dN (τ )
31
ARCH Processes: (Autoregressive Conditional
Heteroscedastic)
Defn: Mean 0 process X is ARCH(p) if
Var(Xt+1 |Xt, Xt−1, · · · ) ∼ N (0, Ht)
where
Ht = α0 +
p
X
1
2
αiXt+1−i
GARCH Processes: (Generalized Autoregressive Conditional Heteroscedastic)
Defn: The process X is GARCH(p, q) if X has
mean 0 and
Var(Xt+1 |Xt, Xt−1, · · · ) ∼ N (0, Ht)
where
Ht = α0 +
p
X
1
2
αiXt+1−i
+
q
X
βj Ht−j
1
Used to model series with patches of high and
low variability.
32
Markov Chains
Defn: A transition kernel is a function P (A, x)
which is, for each x in a set X (the state space),
a probability on X .
Defn: A sequence Xt is Markov (with stationary transitions P ) if
P (Xt+1 ∈ A|Xt, Xt−1, · · · ) = P (A, Xt)
That is, the conditional distribution of Xt+1
given all history to time t depends only on value
of Xt .
Fact: under some conditions as t → ∞ Xt, Xt+1, . . .
becomes stationary.
Fact: under similar conditions can give X0 a
distribution (called stationary initial distribution) so that X is a strictly stationary process.
33