Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Big Data Challenge
Peta 10^15
Tera 10^12
Pig Latin
Giga 10^9
Mega 10^6
Applications
Support Scientific Simulations (Data Mining and Data Analysis)
Kernels, Genomics, Proteomics, Information Retrieval, Polar Science,
Scientific Simulation Data Analysis and Management, Dissimilarity
Computation, Clustering, Multidimensional Scaling, Generative Topological
Mapping
Security, Provenance, Portal
Services and Workflow
Programming
Model
Runtime
Storage
Infrastructure
Hardware
High Level Language
Cross Platform Iterative MapReduce (Collectives, Fault Tolerance, Scheduling)
Distributed File Systems
Object Store
Windows Server
Linux HPC Amazon Cloud
HPC
Bare-system
Bare-system
Virtualization
CPU Nodes
Data Parallel File System
Azure Cloud
Virtualization
GPU Nodes
Grid
Appliance
Judy Qiu
Bingjing Zhang
School of Informatics and Computing
Indiana University
Contents
Data mining and Data analysis Applications
Twister: Runtime for Iterative MapReduce
Twister Tutorial Examples
K-means Clustering
Multidimensional Scaling
Matrix Multiplication
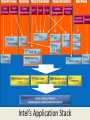
Intel’s Application Stack
SALSA
Motivation
• Iterative algorithms are commonly used in many domains
• Traditional MapReduce and classical parallel runtimes
cannot solve iterative algorithms efficiently
– Hadoop: Repeated data access to HDFS, no
optimization to data caching and data transfers
– MPI: no nature support of fault tolerance and
programming interface is complicated
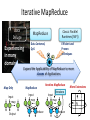
What is Iterative MapReduce
• Iterative MapReduce
– Mapreduce is a Programming Model instantiating the paradigm of
bringing computation to data
– Iterative Mapreduce extends Mapreduce programming model and
support iterative algorithms for Data Mining and Data Analysis
• Interoperability
– Is it possible to use the same computational tools on HPC and Cloud?
– Enabling scientists to focus on science not programming distributed
systems
• Reproducibility
– Is it possible to use Cloud Computing for Scalable, Reproducible
Experimentation?
– Sharing results, data, and software
Distinction on static and variable data
Configurable long running (cacheable)
map/reduce tasks
Pub/sub messaging based
communication/data transfers
Broker Network for facilitating
communication
Version 0.9 (hands-on)
Version beta
Iterative MapReduce Frameworks
•
Twister[1]
– Map->Reduce->Combine->Broadcast
– Long running map tasks (data in memory)
– Centralized driver based, statically scheduled.
•
Daytona[2]
– Microsoft Iterative MapReduce on Azure using cloud services
– Architecture similar to Twister
•
Twister4Azure[3]
– A decentralized Map/reduce input caching, reduce output caching
•
Haloop[4]
– On disk caching, Map/reduce input caching, reduce output caching
•
Spark[5]
– Iterative Mapreduce Using Resilient Distributed Dataset to ensure the fault tolerance
•
Pregel[6]
– Graph processing from Google
•
Mahout[7]
– Apache project for supporting data mining algorithms
Others
• Network Levitated Merge[8]
– RDMA/infiniband based shuffle & merge
• Mate-EC2[9]
– Local reduction object
• Asynchronous Algorithms in MapReduce[10]
– Local & global reduce
• MapReduce online[11]
– online aggregation, and continuous queries
– Push data from Map to Reduce
• Orchestra[12]
– Data transfer improvements for MR
• iMapReduce[13]
– Async iterations, One to one map & reduce mapping, automatically
joins loop-variant and invariant data
• CloudMapReduce[14] & Google AppEngine MapReduce[15]
– MapReduce frameworks utilizing cloud infrastructure services
Applications & Different Interconnection Patterns
Map Only
Input
map
Classic
MapReduce
Input
map
Iterative MapReduce
Twister
Input
map
Loosely
Synchronous
iterations
Pij
Output
reduce
reduce
CAP3 Analysis
Document conversion
(PDF -> HTML)
Brute force searches in
cryptography
Parametric sweeps
High Energy Physics
(HEP) Histograms
SWG gene alignment
Distributed search
Distributed sorting
Information retrieval
Expectation
maximization algorithms
Clustering
Linear Algebra
Many MPI scientific
applications utilizing
wide variety of
communication
constructs including
local interactions
- CAP3 Gene Assembly
- PolarGrid Matlab data
analysis
- Information Retrieval HEP Data Analysis
- Calculation of Pairwise
Distances for ALU
Sequences
- Kmeans
- Deterministic
Annealing Clustering
- Multidimensional
Scaling MDS
- Solving Differential
Equations and
- particle dynamics
with short range forces
Domain of MapReduce and Iterative Extensions
MPI
Parallel Data Analysis using Twister
•
•
•
•
•
MDS (Multi Dimensional Scaling)
Clustering (Kmeans)
SVM (Scalable Vector Machine)
Indexing
…
Application #1
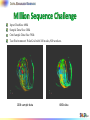
Twister MDS Output
MDS projection of 100,000 protein sequences showing a few experimentally
identified clusters in preliminary work with Seattle Children’s Research Institute
Application #2
Data Intensive Kmeans Clustering
─ Image Classification: 1.5 TB; 500 features per image;10k clusters
1000 Map tasks; 1GB data transfer per Map task node
Iterative MapReduce
Data
Deluge
Classic Parallel
Runtimes (MPI)
MapReduce
Experiencing
in many
domains
Data Centered,
QoS
Efficient and
Proven
techniques
Expand the Applicability of MapReduce to more
classes of Applications
Map-Only
Input
map
Output
MapReduce
Iterative MapReduce
iterations
Input
map
Input
map
reduce
More Extensions
Pij
reduce
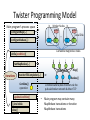
Twister Programming Model
Worker Nodes
Main program’s process space
configureMaps(..)
Local Disk
configureReduce(..)
Cacheable map/reduce tasks
while(condition){
runMapReduce(..)
Map()
Iterations
monitorTillCompletion(..)
Reduce()
Combine()
operation
updateCondition()
} //end while
close()
Communications/data transfers via the
pub-sub broker network & direct TCP
•
Main program may contain many
MapReduce invocations or iterative
MapReduce invocations
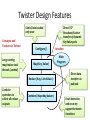
Twister Design Features
Static Data Loaded
only once
Concepts and
Features in Twister
Long running
map/reduce task
threads (cached)
Configure()
Map(Key, Value)
Reduce (Key, List<Value>)
Combine
operation to
collect all reduce
outputs
Combine ( Map<Key,Value>)
Direct TCP
Broadcast/Scatter
transfer of dynamic
KeyValue pairs
Iteration
Main
Program
Direct data
transfer via
pub/sub
Fault detection
and recovery
support between
iterations
Twister APIs
1.
2.
3.
4.
configureMaps()
configureMaps(String partitionFile)
configureMaps(List<Value> values)
configureReduce(List<Value> values)
5. addToMemCache(Value value)
6. addToMemCache(List<Value> values)
7. cleanMemCache()
8. runMapReduce()
9. runMapReduce(List<KeyValuePair> pairs)
10. runMapReduceBCast(Value value)
11. map(MapOutputCollector collector, Key key, Value val)
12. reduce(ReduceOutputCollector collector, Key key,
List<Value> values)
13. combine(Map<Key, Value> keyValues)
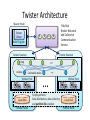
Twister Architecture
Master Node
Twister
Driver
B
B
B
Pub/Sub
Broker Network
and Collective
Communication
Service
B
Main Program
Twister Daemon
Twister Daemon
map
reduce
Cacheable tasks
Worker Pool
Local Disk
Worker Node
Worker Pool
Scripts perform:
Data distribution, data collection,
and partition file creation
Local Disk
Worker Node
Data Storage and Caching
•
•
•
•
•
Use local disk to store static data files
Use Data Manipulation Tool to manage data
Use partition file to locate data
Data on disk can be cached into local memory
Support using NFS (version 0.9)
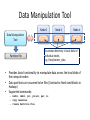
Data Manipulation Tool
Node 0
Node 1
Node n
Data Manipulation
Tool
Partition File
A common directory in local disks of
individual nodes
e.g. /tmp/twister_data
• Provides basic functionality to manipulate data across the local disks of
the compute nodes
• Data partitions are assumed to be files (Contrast to fixed sized blocks in
Hadoop)
• Supported commands:
–
–
–
mkdir, rmdir, put, putall, get, ls
Copy resources
Create Partition File
Partition File
File No
Node IP
Daemon No
File Partition Path
0
149.165.229.10
0
/tmp/zhangbj/data/kmeans/km_142.bin
8
149.165.229.34
24
/tmp/zhangbj/data/kmeans/km_382.bin
16
149.165.229.147
78
/tmp/zhangbj/data/kmeans/km_370.bin
24
149.165.229.12
2
/tmp/zhangbj/data/kmeans/km_57.bin
• Partition file allows duplicates to show replica availability
• One data file and its replicas may reside in multiple nodes
• Provide information required for caching
Pub/Sub Messaging
• For small control messages only
• Currently support
– NaradaBrokering: single broker and manual
configuration
– ActiveMQ: multiple brokers and auto
configuration
Broadcast
• Use addToMemCache operation to broadcast
dynamic data required by all tasks in each iteration
MemCacheAddress memCacheKey
= driver.addToMemCache(centroids);
TwisterMonitor monitor
= driver.runMapReduceBCast(memCacheKey);
• Replace original broker-based methods to direct TCP
data transfers
• Algorithm auto selection
• Topology-aware broadcasting
Broadcast
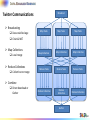
Twister Communications
Broadcasting
Data could be large
Chain & MST
Map Collectives
Local merge
Reduce Collectives
Collect but no merge
Map Tasks
Map Tasks
Map Tasks
Map Collective
Map Collective
Map Collective
Reduce Tasks
Reduce Tasks
Reduce Tasks
Reduce Collective
Reduce
Collective
Reduce Collective
Combine
Direct download or
Gather
Gather
Twister Broadcast Comparison
Sequential vs. Parallel implementations
Time (Unit: Seconds)
500
400
300
200
100
0
Per Iteration Cost (Before)
Combine
Shuffle & Reduce
Per Iteration Cost (After)
Map
Broadcast
Twister Broadcast Comparison:
Ethernet vs. InfiniBand
InfiniBand Speed Up Chart – 1GB bcast
35
30
Second
25
20
15
10
5
0
Ethernet
InfiniBand
Failure Recovery
• Recover at iteration boundaries
• Does not handle individual task failures
• Any Failure (hardware/daemons) result the following
failure handling sequence
– Terminate currently running tasks (remove from memory)
– Poll for currently available worker nodes (& daemons)
– Configure map/reduce using static data (re-assign data
partitions to tasks depending on the data locality)
– Re-execute the failed iteration
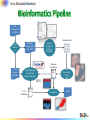
Twister MDS demo
Gene
Sequences (N
= 1 Million)
Select
Referenc
e
N-M
Sequence
Set (900K)
Pairwise
Alignment
& Distance
Calculation
Reference
Sequence Set
(M = 100K)
Reference
Coordinates
Interpolative MDS
with Pairwise
Distance Calculation
x, y, z
O(N2)
N-M
x, y, z
Coordinates
Visualization
Distance Matrix
MultiDimensional
Scaling
(MDS)
3D Plot
Input DataSize: 680k
Sample Data Size: 100k
Out-Sample Data Size: 580k
Test Environment: PolarGrid with 100 nodes, 800 workers.
100k sample data
680k data
Dimension
Reduction
Algorithms
• Multidimensional Scaling (MDS) [1]
• Generative Topographic Mapping
o Given the proximity information among
points.
o Optimization problem to find mapping in
target dimension of the given data based on
pairwise proximity information while
minimize the objective function.
o Objective functions: STRESS (1) or SSTRESS (2)
(GTM) [2]
o Find optimal K-representations for the given
data (in 3D), known as
K-cluster problem (NP-hard)
o Original algorithm use EM method for
optimization
o Deterministic Annealing algorithm can be used
for finding a global solution
o Objective functions is to maximize loglikelihood:
o Only needs pairwise distances ij between
original points (typically not Euclidean)
o dij(X) is Euclidean distance between mapped
(3D) points
[1] I. Borg and P. J. Groenen. Modern Multidimensional Scaling: Theory and Applications. Springer, New York, NY, U.S.A., 2005.
[2] C. Bishop, M. Svens´en, and C. Williams. GTM: The generative topographic mapping. Neural computation, 10(1):215–234, 1998.
High Performance Data Visualization..
• Developed parallel MDS and GTM algorithm to visualize large and high-dimensional data
• Processed 0.1 million PubChem data having 166 dimensions
• Parallel interpolation can process up to 2M PubChem points
MDS for 100k PubChem data
100k PubChem data having 166
dimensions are visualized in 3D
space. Colors represent 2 clusters
separated by their structural
proximity.
GTM for 930k genes and diseases
Genes (green color) and diseases
(others) are plotted in 3D space,
aiming at finding cause-and-effect
relationships.
[3] PubChem project, http://pubchem.ncbi.nlm.nih.gov/
GTM with interpolation for
2M PubChem data
2M PubChem data is plotted in 3D
with GTM interpolation approach.
Red points are 100k sampled data
and blue points are 4M interpolated
points.
Twister-MDS Demo
II. Send intermediate
results
Master Node
Twister
Driver
ActiveMQ
Broker
MDS Monitor
Twister-MDS
PlotViz
I. Send message to
start the job
Client Node
Input: 30k metagenomics data
MDS reads pairwise distance matrix of all sequences
Output: 3D coordinates visualized in PlotViz
Twister-MDS Demo Movie
http://www.youtube.com/watch?v=jTUD_yLrW1s&feature=share
Questions?
Twister Hands-on Session
How it works?
wikipedia
39
SALSA
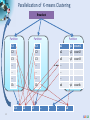
Parallelization of K-means Clustering
Broadcast
Partition
Partition
C1
C1
x1
y1
C1 count1
C2
C2
x2
y2
C2 count2
C3
C3
x3
y3
C3 count3
…
…
…
…
…
…
…
…
…
…
…
…
…
Ck
Ck
xk
C1
40
Partition
C2
C3
…
…
…
yk
Ck countk
Ck
SALSA
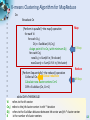
K-means Clustering Algorithm for MapReduce
*
Do
*
Broadcast Cn
*
Map
*
[Perform in parallel] –the map() operation
*
for each Vi
*
for each Cn,j
*
Dij <= Euclidian (Vi,Cn,j)
E-Step
*
Assign point Vi to Cn,j with minimum Dij
*
for each Cn,j
*
newCn,j <=Sum(Vi in j'th cluster)
*
newCountj <= Sum(1 if Vi in j'th cluster)
*
Reduce
*
[Perform Sequentially] –the reduce() operation
Global reduction
*
Collect all Cn
M-Step
*
Calculate new cluster centers Cn+1
*
Diff<= Euclidian (Cn, Cn+1)
*
*
while (Diff <THRESHOLD)
Vi
refers to the ith vector
Cn,j refers to the jth cluster center in nth * iteration
Dij refers to the Euclidian distance between ith vector and jth * cluster center
41
K
is the number of cluster centers
SALSA
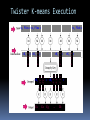
Twister K-means Execution
<c, File1 > <c, File2 >
<K,
C1
C2
C3
…
Ck
> <K,
C1
C2
C3
…
Ck
<K,
C1
<c, Filek >
>
C1
C2
C3
…
Ck
C1
C2
C3
…
Ck
C2
> <K,
C3
<K,
C1
C2
C3
…
Ck
C1
C2
C3
…
Ck
C1
C2
C3
…
Ck
C1
C2
C3
…
Ck
…
Ck
>
>
<K,
C1
C2
C3
…
Ck
>
K-means Clustering
Code Walk-through
• Main Program
– Job Configuration
– Execution iterations
• KMeansMapTask
– Configuration
– Map
• KMeansReduceTask
– Reduce
• KMeansCombiner
– Combine
Code Walkthrough – Main Program
Code Walkthrough – Map
Code Walkthrough – Reduce/Combine
File Structure
/root/software/
twister/
• bin/
• start_twister.sh
• twister.sh
• create_partition_file.sh
• samples/kmeans/bin/
• run_kmeans.sh
• twisterKmeans_init_clusters.txt
• data/ (input data directory)
• data/ (Twister common data directory)
apache-activemq-5.4.2/bin/
• activemq
Download Resources
• Download Virtual Box and Appliance
Step 1
Download Virtual Box
https://www.virtualbox.org/wiki/Downloads
Step 2
Download Appliance
http://salsahpc.indiana.edu/ScienceCloud/apps/salsaDPI/virtu
albox/chef_ubuntu.ova
Step 3
Import Appliance
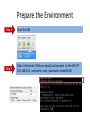
Prepare the Environment
Step 4
Start the VM
Step 5
Open 3 terminals (Putty or equal) and connect to the VM (IP:
192.168.56.1, username: root, password: school2012)
Start ActiveMQ in Terminal 1
Step 6
cd $ACTIVEMQ_HOME/bin
./activemq console
Start Twister in Terminal 2
Step 7
cd $TWISTER_HOME/bin
./start_twister.sh
Data Contents
• Data Files
• Contents
Distribute Data in Terminal 2
• Create a directory to hold the data
Step 8
cd $TWISTER_HOME/bin
./twister.sh mkdir kmeans
• Distribute data
Step 9
./twister.sh put ~/software/twister0.9/samples/kmeans/bin/data/ kmeans km 1 1
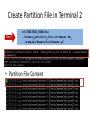
Create Partition File in Terminal 2
Step 9
cd $TWISTER_HOME/bin
./create_partition_file.sh kmeans km_
../samples/kmeans/bin/kmeans.pf
• Partition File Content
Run K-means Clustering in Terminal 3
Step 10
cd $TWISTER_HOME/samples/kmeans/bin
./run_kmeans.sh
twisterKmeans_init_clusters.txt 80 kmeans.pf
Matrix Multiplication
• For two big Matrices A and B, do Matrix
Multiplication 𝐴 × 𝐵
• Split Matrix A and B
• Distribute Matrix B
• Send Matrix A rows by rows in iterations
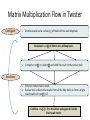
Matrix Multiplication Flow in Twister
Configure
1.
Distribute and cache 𝑐𝑜𝑙𝑢𝑚𝑛 𝑗 of Matrix B into each Map task
Broadcast 𝑟𝑜𝑤 𝑖 of Matrix A to all Map tasks
1.
Compute 𝑟𝑜𝑤 𝑖 × 𝑐𝑜𝑙𝑢𝑚𝑛 𝑗 and send the result to the reduce task
Iterations
1. Only one reduce task is used.
2. Reduce task collects the results from all the Map tasks to form a single
result matrix of 𝑟𝑜𝑤 𝑖 × 𝐵
Combine 𝑟𝑜𝑤 𝑖 × 𝐵 to the driver and append it to the
final result matrix
SALSA HPC Group
http://salsahpc.indiana.edu
School of Informatics and Computing
Indiana University