Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Minitab 16
Excel 2010
Reference Guide
Prepared for MATH201/MATH202
Bryan Crissinger
University of Delaware
Department of Mathematical Sciences
Contents
Introduction ................................................................................................................................................ 5
Troubleshooting (Minitab) .......................................................................................................................... 6
Troubleshooting (Excel)............................................................................................................................. 7
Getting More Help ..................................................................................................................................... 8
Descriptive Statistics
Frequency Table (Minitab) ........................................................................................................................ 9
Bar Chart (Minitab) .................................................................................................................................. 11
Bar Chart (Excel) ..................................................................................................................................... 13
Pie Chart (Minitab) ................................................................................................................................... 14
Pie Chart (Excel) ..................................................................................................................................... 16
Creating New Variables (Minitab) ............................................................................................................ 17
Creating New Variables (Excel) .............................................................................................................. 20
Descriptive Statistics (Minitab) ................................................................................................................ 21
Descriptive Statistics (Excel) ................................................................................................................... 24
Dotplot (Minitab) ...................................................................................................................................... 26
Histogram (Minitab) ................................................................................................................................. 28
Histogram (Excel) .................................................................................................................................... 33
Boxplot (Minitab) ...................................................................................................................................... 35
Stem-and-Leaf Plot (Minitab) .................................................................................................................. 37
Normal Probability Plot (Minitab) ............................................................................................................. 39
Graphical Summary (Minitab) .................................................................................................................. 41
Scatterplot (Minitab) ................................................................................................................................ 43
Scatterplot (Excel) ................................................................................................................................... 46
Probability Distributions
Binomial Distribution (Minitab) ................................................................................................................. 47
Binomial Distribution (Excel) ................................................................................................................... 50
Poisson Distribution (Minitab) .................................................................................................................. 52
Poisson Distribution (Excel) .................................................................................................................... 55
Normal Distribution (Minitab) ................................................................................................................... 57
Normal Distribution (Excel) ...................................................................................................................... 62
t Distribution (Minitab).............................................................................................................................. 64
t Distribution (Excel) ................................................................................................................................ 68
Chi-Square Distribution (Minitab) ............................................................................................................ 71
Chi-Square Distribution (Excel) ............................................................................................................... 74
2
F Distribution (Minitab) ............................................................................................................................ 77
F Distribution (Excel) ............................................................................................................................... 80
One-Sample Inference
z-interval and z-test for 𝝁 (Minitab).......................................................................................................... 82
t-test and t-interval for 𝝁 (Minitab) ........................................................................................................... 84
t-interval for 𝝁 (Excel) .............................................................................................................................. 86
Interval and Test for 𝒑 (Minitab) .............................................................................................................. 88
Interval and Test for 𝝈𝟐 (Minitab)............................................................................................................. 90
Two-Sample Inference
t-Interval and t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Minitab) ................................................. 92
t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Excel) .......................................................................... 95
t-Interval and t-Test for 𝝁𝟏 − 𝝁𝟐 Using Paired Samples (Minitab) ........................................................... 98
t-Test for 𝝁𝟏 − 𝝁𝟐 Using Paired Samples (Excel) .................................................................................. 100
z-Interval and z-Test for 𝒑𝟏 − 𝒑𝟐 Using Independent Samples (Minitab) .............................................. 102
Test and Interval for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Minitab) ...................................................... 105
F-Test for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Excel) .......................................................................... 108
ANOVA
One-Way ANOVA (Minitab) ................................................................................................................... 111
One-Way ANOVA (Excel)...................................................................................................................... 115
Two-Way ANOVA (Minitab) ................................................................................................................... 117
Two-Way ANOVA (Excel)...................................................................................................................... 121
Interaction Plot (Minitab)........................................................................................................................ 125
Contingency Tables
Chi-Square Test for One-Way Table (Minitab) ...................................................................................... 126
Chi-Square Test for Two-Way Table (Minitab) ...................................................................................... 129
Regression
Regression (Minitab) ............................................................................................................................. 132
Regression (Excel) ................................................................................................................................ 137
Control Charts
̅ Chart (Minitab) .................................................................................................................................... 140
𝒙
R Chart (Minitab) ................................................................................................................................... 143
P Chart (Minitab) ................................................................................................................................... 146
3
Time Series
Time Series Plot (Minitab) ..................................................................................................................... 148
Moving Averages (Minitab) .................................................................................................................... 149
Single Exponential Smoothing (Minitab) ............................................................................................... 151
Trend Analysis (Minitab) ........................................................................................................................ 153
Trend Analysis (Excel)........................................................................................................................... 156
Seasonal Regression Models ................................................................................................................ 158
4
Introduction
Minitab
Modern statistical practice always involves the use of software to do data analysis. We will use Minitab
(version 16) or Excel (2010 or 2013) to do many statistical analyses and it will be beneficial for you to use
such a package to do homework problems that require the use of software, especially where hand
computations are burdensome. 101 Ewing is not open to students other than during lab times, so if you
need to use Minitab, there are two options:
Computer labs on campus where Minitab software is installed: 305 Pearson Hall, 111 and 113
MacDowell Hall, Smith Hall Computing Site, B&E Lab in Purnell
Download Minitab at www.onthehub.com/minitab. This site allows you try Minitab free for 30 days,
rent Minitab for 6 months ($30), or buy a copy ($100). Minitab is currently available for Windows only.
Excel
While Excel is designed as spreadsheet software, it can perform basic data analysis functions as well.
Since Excel is used extensively in business, it’s worthwhile to learn about its statistical capabilities (and
limitations).
To enable the data analysis features in Excel, you must make sure two add-ins are activated.
Excel 2007: Click on the Office Button in the upper left corner of the window
Excel 2010 or 2013: Choose File > Options
and then select Excel Options. Choose Add-Ins from the menu at the left. You should see the following
active application add-ins:
Analysis ToolPak
Analysis ToolPak – VBA
If not, make sure Excel Add-ins are selected to manage at the bottom of the window and click Go.
Check the two Analysis ToolPak add-ins and click Ok. You may have to restart Excel for the change to
take effect.
These two features activate the Data Analysis option under the Data tab at the top of your Excel window.
Textbook Datasets
You can directly input to Minitab and Excel most of the datasets referenced in your textbook, rather than
entering the data by hand. The files are located on the CD that comes with your textbook.
5
Troubleshooting (Minitab)
In Minitab Express, when I try to copy and
paste a data set into the worksheet,
everything ends up in one column.
Minitab Express may recognize the
columns for data copied from Excel better
than from other sources.
Try copying/pasting into an Excel
spreadsheet first. If the same thing
happens in Excel, check out the
Troubleshooting (Excel) section below to
separate the data into columns in Excel.
Once you do that, copy from Excel and
paste into your Minitab Express
worksheet.
I'm using File > Open Project… to open a
data file but the data file doesn't show up
in the dialog box.
If the data file is a Minitab worksheet, you
must use File > Open Worksheet…
instead of File > Open Project….
Minitab shows a column contains text
data, e.g. C3-T, but I only have numbers
in the column.
It's possible you may have typed or
copied a non-numeric character in one of
the cells. Try using Data > Change Data
Type > Text to Numeric… and store the
numeric columns in a new column.
In a dialog box, a column I need to use is
not shown in the list of available columns
on the left.
Try clicking in the box where you want to
use the column first. If that doesn't work,
it could be that Minitab is expecting a
numeric data column and the column
you're trying to use contains text data.
Text data columns are indicated with a T
suffix in the column heading, e.g. C3-T.
Paired t-test or regression: I get an error
message that my two columns must be of
the same length.
Both columns must have the same
number of values (can include missing
values).
2-Sample t-test: I get an error that there
must be exactly two distinct subgroups.
You may be using stacked data format
where there are more than 2 distinct
values in the grouping variable column
(subscripts).
6
Troubleshooting (Excel)
When I try to copy and paste a data set
into the worksheet, everything ends up in
one column.
Copy the data as usual. Select the cell in
the top left corner of the space where you
want to paste the data. Right-click on this
cell, select Paste Special…, and choose
Text as the source.
If that doesn't work, highlight the column
you pasted, choose Data > Text to
Columns, and choose Delimited as the
file type. Select delimiters from the list
until the columns are shown separated
properly.
If that fails, try importing the data to
Minitab first, copy the Minitab worksheet,
and paste into Excel.
There are no statistics displayed when I
request descriptive statistics.
You must check the Summary statistics
box in the dialog box.
A histogram is not displayed when I
request a histogram.
You must check the Chart Output box in
the dialog box.
I get this error message: "Input range
contains non-numeric data."
If an input range contains a column label,
check the Labels or Labels in First Row
box in the dialog box. Otherwise, there
may be non-numeric characters in the
column (usually indicated by left-justified
numbers).
Paired t-test or regression: I get an error
message that my two columns must have
the same number of rows.
Excel doesn't handle missing data for
either a paired analysis of means or
regression. All columns used must
contain only non-missing values and be of
the same length.
7
Getting More Help
This guide is designed to be a quick-reference tool, not an exhaustive reference.
Minitab
Excel
Help Buttons
You can access documentation for specific
dialog boxes by clicking on the Help button
in the dialog box.
? Button
Click on the ? in the upper right of the
window to access Microsoft's help for
Excel.
Help > Help
Access help by topic as well as use the
index and search features.
Note: The Excel/DDXL or Excel/XLSTAT
parts of the Using Technology sections at
the ends of the chapters will not apply
unless you install the DDXL add-in (on the
CD accompanying the textbook). We do
not use this add-in as it is not generally
available with Excel.
Help > Methods and Formulas
This feature shows the methods and
formulas used in the procedures you
specify.
Textbook: Using Technology Sections
You'll find documentation on using many of
the tools listed in this guide and others in
the Using Technology sections at the end
of each chapter.
8
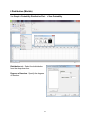
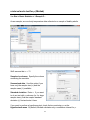
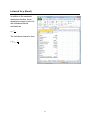
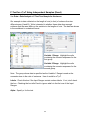
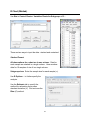
Frequency Table (Minitab)
The data should be entered in the Minitab worksheet with one row per observation. In
this example we have data on several students in a class. The variables are Student ID
and Class.
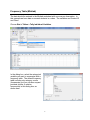
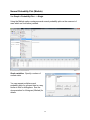
Choose Stat > Tables > Tally Individual Variables.
In the dialog box, select the categorical
variable you want to summarize with a
frequency table. The default frequency
table includes only category counts
(frequencies) but you can also request
percents (similar to relative
frequencies) in this dialog box, as
shown here.
9
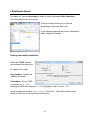
Frequency Table (Minitab)
The frequency table will be displayed in the Session window. Note that misspelled
words are considered a different category.
10
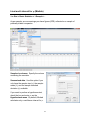
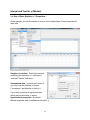
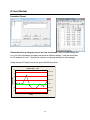
Bar Chart (Minitab)
The data should be entered in the Minitab worksheet with one row per observation. In
this example we have data on several students in a class. The variables are Student ID
and Class.
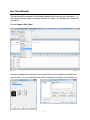
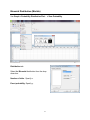
Choose Graph > Bar Chart.
Choose the Simple bar chart option and specify Class as the categorical variable you
want to chart. You can customize the chart by using the six buttons in the dialog box.
11
Bar Chart (Minitab)
The chart will display in a separate graph window.
Chart of Class
6
5
Count
4
3
2
1
0
Frehsman
Freshman
Junior
Class
Senior
Sophomore
12
Bar Chart (Excel)
Enter the frequency table in the worksheet; Excel won’t do this automatically for you.
Highlight the cells containing the frequency table and choose Insert > Column for a
vertical bar chart or Insert > Bar for a horizontal bar chart.
13
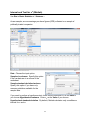
Pie Chart (Minitab)
The data should be entered in the Minitab worksheet with one row per observation. In
this example we have data on several students in a class. The variables are Student ID
and Class.
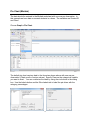
Choose Graph > Pie Chart.
The default pie chart requires data in the format as shown above with one row per
observation (Chart counts of unique values). Specify Class as the categorical variable
you want to chart. You can customize the chart by using the six buttons in the dialog
box. Use the Labels button and the Slice Labels tab to label the pie slices with the
category percentages.
14
Pie Chart (Minitab)
The pie chart will be shown in a separate graph window.
Pie Chart of Class
7.1%
14.3%
C ategory
Frehsman
Freshman
Junior
Senior
Sophomore
42.9%
21.4%
14.3%
15
Pie Chart (Excel)
Enter the frequency table in the worksheet; Excel won’t do this automatically for you.
Highlight the cells containing the frequency table and choose Insert > Pie.
An easy way to add the percentages to the chart is to select the first Chart Layout after
you've created the pie chart. Click on the chart title to edit it.
Class Rank
2
16%
4
36%
4
19%
6
29%
16
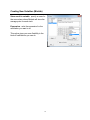
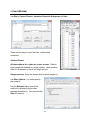
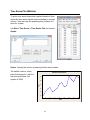
Creating New Variables (Minitab)
You can create new columns using the data in existing columns quickly and easily.
Option 1: Calc > Row Statistics…
Here we want to compute an average price for each
of the stocks in the worksheet using the four existing
prices.
Input variables: select the four columns of prices
Store result in: specify a name for the new column
where Minitab will store the average price for each
stock
17
Creating New Variables (Minitab)
Minitab computes the average prices and stores them in the worksheet in the next
available column.
Option 2: Calc > Calculator…
18
Creating New Variables (Minitab)
Store result in variable: specify a name for
the new column where Minitab will store the
average price for each stock
Expression: write the expression for the
calculation you want to do
This option gives you more flexibility in the
kinds of calculations you can do.
19
Creating New Variables (Excel)
In Excel, you create new columns by writing formulas in the cells. Begin the formula
with an equal sign.
Then copy the cell containing the formula and paste it to all the cells below it. An easy
way to do that is to drag the lower right corner of the cell straight down. The cursor will
change from a white cross to a black cross.
Since we did not use any absolute cell references (e.g. $B$2), the references
automatically change to the appropriate rows.
20
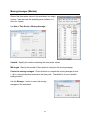
Descriptive Statistics (Minitab)
Option 1: Use Stat > Basic Statistics > Display Descriptive Statistics… to obtain
many numeric descriptive statistics for columns of numeric data.
Here we have data on the number of soft drinks consumed per week for a sample of
males and a sample of females. The data are shown in the worksheet in two different
formats:
Unstacked Format (C1 and C2): Each sample of data has its own column.
Stacked Format (C3 and C4): Both samples are stacked in C3 with a column of
gender indicators in C4.
In practice, we typically have grouped data in only one format.
21
Descriptive Statistics (Minitab)
Variables: Specify the column(s) containing the data you want to summarize.
If you want to summarize data separately for different groups, specify the analysis as
shown below depending on whether you have unstacked or stacked data.
Unstacked
Stacked
The output will display in the
session window. Note the
slight differences in the output
for the two data formats. Many
tools in Minitab can
accommodate data in either
format.
22
Descriptive Statistics (Minitab)
Option 2: Use Calc > Column Statistics… to obtain a single statistic for a numeric
data column.
Specify the Statistic you want.
Input variable: Specify the column
containing the data you want to summarize.
By default, the output will display in the
Session window unless you specify an
optional storage column.
23
Descriptive Statistics (Excel)
Use Data > Data Analysis > Descriptive Statistics.
Here we have data in unstacked format.
Input Range: Highlight the cells containing
the data.
Grouped By: Columns
This tells Excel we have unstacked data.
Labels in First Row: Check this box if the
Input Range contains column labels. If not,
don't check the box. Checking the box tells
Excel to ignore what's in the first row of the
Input Range.
Summary Statistics: You must check this
box for the output to display.
24
Descriptive Statistics (Excel)
The output will be displayed in a separate worksheet. Make the columns containing the
labels (here A and C) wider so that the entire labels are displayed.
25
Dotplot (Minitab)
Use Graph > Dotplot…
The dialog box gives you several input options depending on the format of the data.
One Y, Simple: Use this for one-sample
analysis, i.e. a single column of numeric data.
One Y, With Groups: Use for stacked data.
Multiple Y's, Simple: Use for unstacked data.
Multiple Y's, With Groups: Use for stacked
data having multiple response/comparison
variables.
While you have the option to stack the dots in the two dotplots with grouped data, this is
not recommended as it makes determining features such as shape difficult to
determine.
26
Dotplot (Minitab)
One Y, Simple: Displays the distribution of number of soft drinks combined for males
and females.
Dotplot of Number
2
4
6
Number
8
10
12
Multiple Y's, Simple: Uses the unstacked data to display the distribution of number of
soft drinks separately for males and females.
Dotplot of NumMales, NumFemales
NumMales
NumFemales
2
4
6
Data
8
10
12
One Y, With Groups: Same comparison analysis using the stacked data.
Gender
Dotplot of Number
Female
Male
27
2
4
6
Number
8
10
12
Histogram (Minitab)
Use Graph > Histogram…
The dialog box gives you several input options depending on the format of the data.
Simple: Use this for one-sample analysis, i.e. a
single column of numeric data.
With Outline and Groups: Use for stacked data.
You also have the option of having Minitab draw the
best fitting normal distribution either on the
histogram.
28
Histogram (Minitab)
Simple: Displays the distribution of number of soft drinks combined for males and
females.
Histogram of Number
16
14
Frequency
12
10
8
6
4
2
0
1.5
3.0
4.5
6.0
7.5
Number
9.0
10.5
12.0
Group Comparisons
An alternative to using the With Outline and Groups option to create multiple histograms
for grouped data (as the picture can get messy with all the outlines overlaid) is to use
the Simple option and the Multiple Graphs… button.
Stacked Data
Graph Variables: Specify the single
column of numeric data, i.e. the
response/comparison variable.
29
Histogram (Minitab)
Click on Multiple Graphs… and request that
the multiple histograms be shown In
separate panels of the same graph.
Also check the box so that the X axis scales
and bins will be the same for the histograms.
By Variable tab: Specify Gender as the "by
variable", i.e. the grouping variable.
Histogram of Number
It is important that the x-axis
scales be identical to allow for
an accurate comparison of the
features of the distributions.
1.5
Female
12
Frequency
8
6
4
2
1.5
3.0
4.5
6.0
7.5
9.0 10.5 12.0
Number
Panel variable: Gender
30
4.5
6.0
7.5
Male
10
0
3.0
9.0 10.5 12.0
Histogram (Minitab)
Unstacked Data
Graph Variables: Specify both numeric
data columns.
Click on Multiple Graphs… and request that
the multiple histograms be shown In
separate panels of the same graph.
Also check the box so that the X axis scales
and bins will be the same for the histograms.
Note that the scales of the
frequency axes are different;
these could be made identical
by checking the Same Y in
the Multiple Graphs… dialog.
Histogram of NumMales, NumFemales
1.5
NumMales
12
5
Frequency
4
8
3
6
2
4
1
2
1.5
3.0
4.5
31
6.0
7.5
4.5
6.0
7.5
9.0
NumFemales
10
0
3.0
9.0
10.5 12.0
0
10.5 12.0
Histogram (Minitab)
You can change the default interval (bin) definitions by right-clicking on the bars of the
histogram once it's created and selecting Edit Bars…
Under the Binning tab change Interval Type
to Cutpoint.
Define the Cutpoint positions with a list of the
endpoints of the intervals. You can do this
long-hand: 0 1 2 3 4 5 6 7 8 9 10 11 12
or by using Minitab short-hand as shown
here.
0:12/1 requests intervals starting at 0 and
ending at 12 each with width of 1.
Histogram of Number
10
Frequency
8
6
4
2
0
0
2
4
6
Number
8
10
12
Note: Minitab's interval/bin definitions use the [ , ) convention. For example, in the
above histogram, the interval [1, 2) includes the 4 subjects who drink 1 soft drink per
week.
Note: You can also use the Midpoint Interval Type and change the Number of
intervals to the desired number without having to specify the individual endpoints.
32
Histogram (Excel)
In addition to having the data entered in the worksheet, you must enter a list of the
endpoints of the intervals (bins) for the histogram somewhere in the worksheet.
Use Data > Data Analysis > Histogram.
Input Range: Highlight the column of
cells containing the data.
Bin Range: Highlight the column of
cells containing the interval endpoints.
Labels: Check this box if both the Input
Range and Bin Range contain column
labels. If not, don't check the box.
Checking the box tells Excel to ignore
what's in the first row of these ranges.
Chart Output: You must check this box for the histogram to display.
33
Histogram (Excel)
Once the histogram is created, select the bars portion
of the graph and right-click. Choose Format Data
Series… and change the Gap Width to 0% (No Gap).
Excel outputs both the histogram and a frequency
table showing the counts in each interval (bin). The
Bin Endpoints in the frequency table are the upper
endpoints of each interval. For example, there are 5
observations in the interval (6, 8], 3 observations in the
interval (8, 10], etc.
In order to construct multiple histograms, you must do a separate analysis for each
group. Be sure to use the same Bin Range for each.
Note: Excel's interval/bin definitions use the ( , ] convention. For example, in the above
histogram, the interval (4, 6] includes the 7 subjects who drink either 5 or 6 soft drinks
per week.
34
Boxplot (Minitab)
Use Graph > Boxplot…
For this example we'll use data on length of time in practice (years) for a sample of
physicians.
The dialog box gives you several input options depending on the format of the data.
One Y, Simple: Use this for one-sample
analysis, i.e. a single column of numeric data.
One Y, With Groups: Use for stacked data.
Multiple Y's, Simple: Use for unstacked data.
Multiple Y's, With Groups: Use for stacked
data having multiple response/comparison
variables.
35
Boxplot (Minitab)
Here we show an analysis of length of time in practice (YRSPRAC) by specialty
(SPEC). Since these data are stacked (single numeric column of times and a
categorical column of specialty indicators), we'll use the One Y, With Groups input
option.
Graph variables: Specify the single
column of numeric data, i.e. the
response/comparison variable.
Categorical variables for grouping:
Specify the categorical grouping variable.
You can display the boxplot horizontally instead of
vertically (the default) by using the Scale… button
and checking the box to Transpose value and
category scales.
Boxplot of YRSPRAC
MED
SPEC
The output shows an outlier at 40 years in
practice in the Surgery specialty sample.
Minitab classifies any observations outside
the inner fences as outliers and shows them
as asterisks in the boxplot.
SURG
The whiskers extend to the most extreme
observations just inside the inner fences.
0
10
20
YRSPRAC
30
Hover the mouse pointer over the boxplot to see some descriptive statistics and
numeric features of the boxplot.
36
40
Stem-and-Leaf Plot (Minitab)
Use Graph > Stem-and-Leaf…
Graph variables: Specify a column of
numeric data.
By variable: Specify the categorical grouping
variable.
Note: The by variable needs to be coded with
numbers in the worksheet for you to be able to
use it here. In our data example, we'd first
have to create a new column with numeric
codes first: for example 1 = SURG 2 = MED.
You can do this automatically using Data > Code > Text to Numeric…
37
Stem-and-Leaf Plot (Minitab)
This particular graph is displayed to the Session Window.
The leftmost column in the stem-and-leaf plot shown is called the depths. The numbers
are cumulative counts of numbers of leaves in each row staring from each extreme and
increasing up to the row containing the median. The depth for the row containing the
median is a simple count of the number of leaves in that row and is indicated in
parentheses.
In this example, there are 16 leaves in the first row, 21 in the second row for a total of
37, 2 leaves in the last row, 1 in the next to last row for a total of 3, etc. The median is
in the third row. There are 23 leaves in that row.
38
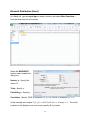
Normal Probability Plot (Minitab)
Use Graph > Probability Plot… > Single
Using the Multiple option overlays several normal probability plots on the same set of
axes which can look rather jumbled.
Graph variables: Specify a column of
numeric data.
You can request multiple normal
probability plots for grouped data in a way
similar to that for histograms. See the
documentation for Histogram (Minitab) for
details.
39
Normal Probability Plot (Minitab)
Probability Plot of YRSPRAC
Normal - 95% CI
99.9
Mean
StDev
N
AD
P-Value
99
95
90
Percent
The extent to which the pattern of
points deviates from a straight line is
an indication as to the lack of fit of a
normal model for the data. Minitab
also provides confidence bands and
the Anderson-Darling test for normality:
80
70
60
50
40
30
20
10
H0: data come from a normal model
Ha: data do not come from a normal
model
5
1
0.1
40
-20
-10
0
10
20
YRSPRAC
30
40
50
14.60
9.161
112
0.954
0.015
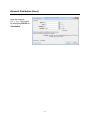
Graphical Summary (Minitab)
This tool displays many important numeric statistics alongside several graphical
summaries for numeric variables.
Use Stat > Basic Statistics > Graphical Summary…
The data shown are eruption data for several eruptions of the Old Faithful geyser in
Yellowstone National Park, Wyoming. Here we summarize the actual time until the next
eruption in minutes (ATM).
Graph variables: Specify a column of numeric
data.
By variables (optional): Specify an optional
categorical variable for grouping if you want
separate analyses for different groups.
Confidence level: Specify a confidence level for
confidence intervals for the population mean,
median, and standard deviation.
41
Graphical Summary (Minitab)
In addition to many basic descriptive statistics, Minitab shows the results of a formal test
for normality (see Normal Probability Plot) and several confidence intervals.
The histogram is editable, just like the output of Graph > Histogram so that, for example,
you can change the interval/bin definitions by right-clicking on one of the bars (see
Histogram).
Summary for ATM
A nderson-D arling N ormality Test
50
60
70
80
90
A -S quared
P -V alue <
1.65
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
76.352
16.494
272.044
-0.07322
-1.40627
54
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
100
49.000
60.000
82.000
91.000
107.000
95% C onfidence Interv al for M ean
71.850
80.854
95% C onfidence Interv al for M edian
65.000
85.643
95% C onfidence Interv al for S tD ev
9 5 % C onfidence Inter vals
13.865
Mean
Median
65
70
75
80
85
42
20.362
Scatterplot (Minitab)
There are several ways to obtain a scatterplot of
(x,y) pairs of numeric data. The data must be
entered in the worksheet with two columns for the
numeric data and where the rows represent each
observation.
Here we have 24 orange juice samples, 6 from
each of 4 brands, the pectin content, and measure
of sweetness for each.
Basic scatterplots: Use Graph > Scatterplot…
You can also add regression lines and use
different plotting symbols for different groups.
We show two examples here.
Simple: Specify the columns containing the y-axis and x-axis coordinates.
Scatterplot of SweetIndex vs Pectin
6.0
5.9
SweetIndex
5.8
5.7
5.6
5.5
5.4
5.3
5.2
5.1
200
43
250
300
Pectin
350
400
Scatterplot (Minitab)
With Regression and Groups: Specify the columns containing the y-axis and x-axis
coordinates.
Categorical variables for grouping: Specify the column containing the group
indicators.
Scatterplot of SweetIndex vs Pectin
Brand
A
B
C
D
6.0
5.9
SweetIndex
5.8
5.7
5.6
5.5
5.4
5.3
5.2
5.1
200
250
300
Pectin
350
400
Scatterplot with some regression output: Use Stat > Regression > Fitted Line
Plot…
Response (Y): Specify the column
containing the y-axis coordinates.
Predictor (X): Specify the column
containing the x-axis coordinates.
Type of Regression Model: Specify
the relationship between x and y; the
default is Linear; you may also specify a Quadratic or Cubic model.
44
Scatterplot (Minitab)
The graph output shows the regression line overlaid on the scatterplot as well as the
estimated regresstion equation and some basic regression statistics. The session
window shows these statistics as well as the regression ANOVA table.
Regression Analysis: SweetIndex versus Pectin
Fitted Line Plot
SweetIndex = 6.252 - 0.002311 Pectin
The regression equation is
SweetIndex = 6.252 - 0.002311 Pectin
S
R-Sq
R-Sq(adj)
6.0
5.9
S = 0.214998
R-Sq = 22.9%
R-Sq(adj) = 19.4%
Analysis of Variance
SweetIndex
5.8
5.7
5.6
5.5
5.4
5.3
Source
Regression
Error
Total
DF
1
22
23
SS
0.30140
1.01693
1.31833
MS
0.301402
0.046224
F
6.52
P
0.018
5.2
5.1
200
45
250
300
Pectin
350
400
0.214998
22.9%
19.4%
Scatterplot (Excel)
The data must be entered in the worksheet with two columns
for the numeric data and where the rows represent each
observation. The column containing the x-axis coordinates
must be first.
Here we have 24 orange juice samples, the pectin content,
and measure of sweetness for each.
Highlight both columns of data and then choose Insert >
Scatter.
Axis labels should be added: with the graph window active,
choose Layout > Axis Titles and select a format for the
Horizontal and Vertical axes.
You can also delete the legend and delete or change the
chart title.
SweetIndex
A regression line can be overlaid on the scatterplot by rightclicking on one of the points and selecting Add Trendline…
6.1
6
5.9
5.8
5.7
5.6
5.5
5.4
5.3
5.2
5.1
0
100
200
300
400
Pectin
46
500
Binomial Distribution (Minitab)
Use Graph > Probability Distribution Plot… > View Probability.
Distribution tab:
Select the Binomial distribution from the dropdown box.
Number of trials: Specify 𝑛.
Event probability: Specify 𝑝.
47
Binomial Distribution (Minitab)
Shaded Area tab: The following dialogs show how to specify several kinds of
probability calculations.
To input values of 𝑥 and compute probabilities, specify that you want to Define Shaded
Area By X Value.
Below are several examples where the random variable 𝑋 has a Binomial distribution
with 𝑛 = 10 and 𝑝 = .3.
𝑃(𝑋 ≥ 4) = .3504
Distribution Plot
Binomial, n=10, p=0.3
0.30
0.25
Probability
0.20
0.15
0.10
0.05
0.00
0.3504
0
4
X
𝑃(𝑋 ≤ 4) = .8497
Distribution Plot
Binomial, n=10, p=0.3
0.30
0.25
0.8497
Probability
0.20
0.15
0.10
0.05
0.00
48
4
X
8
Binomial Distribution (Minitab)
𝑃(4 ≤ 𝑋 ≤ 6) = .3398
Distribution Plot
Binomial, n=10, p=0.3
0.30
0.25
Probability
0.20
0.15
0.3398
0.10
0.05
0.00
0
4
X
6
8
Note: To get individual probabilities of the form 𝑃(𝑋 = 𝑘), use the Middle option and
specify the same values for x1 and x2.
𝑃(𝑋 = 4) = .2001
Distribution Plot
Binomial, n=10, p=0.3
0.30
0.25
0.2001
Probability
0.20
0.15
0.10
0.05
0.00
49
0
4
X
8
Binomial Distribution (Excel)
In a blank cell, type an equal sign to insert a function and select More Functions…
from the drop-down list of functions.
Select the BINOMDIST
function and complete the
dialog box.
Number_s: Specify the
value of 𝑘.
Trials: Specify 𝑛.
Probability_s: Specify 𝑝.
Cumulative: Specify TRUE to compute 𝑃(𝑋 ≤ 𝑘) or FALSE to compute 𝑃(𝑋 = 𝑘).
In this example we compute 𝑃(𝑋 ≤ 4) = .849731667 for 𝑛 = 10 and 𝑝 = .3. The result
is shown in the dialog box as soon as you specify all four inputs.
50
Binomial Distribution (Excel)
Here we compute
𝑃(𝑋 = 4) = .200120949
by specifying FALSE for
Cumulative.
51
Poisson Distribution (Minitab)
Use Graph > Probability Distribution Plot… > View Probability.
Distribution tab:
Select the Poisson distribution from the dropdown box.
Mean: Specify 𝜆.
52
Poisson Distribution (Minitab)
Shaded Area tab: The following dialogs show how to specify several kinds of
probability calculations.
To input values of 𝑥 and compute probabilities, specify that you want to Define Shaded
Area By X Value.
Below are several examples where the random variable 𝑋 has a Poisson distribution
with 𝜆 = 3.8.
𝑃(𝑋 ≥ 6) = .1844
Distribution Plot
Poisson, Mean=3.8
0.20
Probability
0.15
0.10
0.05
0.1844
0.00
0
X
6
𝑃(𝑋 ≤ 3) = .4735
Distribution Plot
Poisson, Mean=3.8
0.20
0.4735
Probability
0.15
0.10
0.05
0.00
53
3
X
11
Poisson Distribution (Minitab)
𝑃(2 ≤ 𝑋 ≤ 7) = .8525
Distribution Plot
Poisson, Mean=3.8
0.20
0.8525
Probability
0.15
0.10
0.05
0.00
0
2
X
7
11
Note: To get individual probabilities of the form 𝑃(𝑋 = 𝑘), use the Middle option and
specify the same values for x1 and x2.
𝑃(𝑋 = 4) = .1944
Distribution Plot
Poisson, Mean=3.8
0.1944
0.20
Probability
0.15
0.10
0.05
0.00
54
0
4
X
11
Poisson Distribution (Excel)
In a blank cell, type an equal sign to insert a function and select More Functions…
from the drop-down list of functions.
Select the POISSON function
and complete the dialog box.
X: Specify the value of 𝑘.
Mean: Specify 𝜆.
Cumulative: Specify TRUE to
compute 𝑃(𝑋 ≤ 𝑘) or FALSE
to compute 𝑃(𝑋 = 𝑘).
In this example we compute 𝑃(𝑋 ≤ 4) = .667843601 for 𝜆 = 3.8. The result is shown in
the dialog box as soon as you specify all three inputs.
55
Poisson Distribution (Excel)
Here we compute
𝑃(𝑋 = 4) = .194358757
by specifying FALSE for
Cumulative.
56
Normal Distribution (Minitab)
Use Graph > Probability Distribution Plot… > View Probability.
Distribution tab:
Select the Normal distribution from the
drop-down box.
Mean: Specify 𝜇.
Standard deviation: Specify 𝜎.
Note: The default normal distribution is
the standard normal.
57
Normal Distribution (Minitab)
Shaded Area tab: The following dialogs show how to specify several kinds of
probability calculations.
To input values of 𝑥 and compute probabilities, specify that you want to Define Shaded
Area By X Value.
Below are several examples where the random variable 𝑋 has a standard normal
distribution.
𝑃(𝑋 ≥ 1.28) = .1003
Distribution Plot
Normal, Mean=0, StDev=1
0.4
Density
0.3
0.2
0.1
0.1003
0.0
0
X
1.28
𝑃(𝑋 ≤ 1.28) = .8997
Distribution Plot
Normal, Mean=0, StDev=1
0.4
Density
0.3
0.8997
0.2
0.1
0.0
58
0
X
1.28
Normal Distribution (Minitab)
𝑃(|𝑋| > 1.96) = 𝑃(𝑋 < −1.96) + 𝑃(𝑋 > 1.96) = .0250 + .0250 = .0500
Distribution Plot
Normal, Mean=0, StDev=1
0.4
Density
0.3
0.2
0.1
0.02500
0.0
0.02500
-1.96
0
X
1.96
𝑃(−2 < 𝑋 < 1) = .8186
Distribution Plot
Normal, Mean=0, StDev=1
0.4
0.8186
Density
0.3
0.2
0.1
0.0
59
-2
0
X
1
Normal Distribution (Minitab)
Note: For continuous distributions, 𝑃(𝑋 = 𝑘) = 0 since there is no area under the curve
at a point.
𝑃(𝑋 = 1.55) = 0
Distribution Plot
Normal, Mean=0, StDev=1
0.4
Density
0.3
0.2
0
0.1
0.0
0
X
1.55
To input probability values and compute 𝑥 values, specify that you want to Define
Shaded Area By Probability.
Find 𝑥0 such that 𝑃(𝑋 > 𝑥0 ) = .90.
𝑥0 = −1.282
Distribution Plot
Normal, Mean=0, StDev=1
0.4
Density
0.3
0.9
0.2
0.1
0.0
60
-1.282
0
X
Normal Distribution (Minitab)
Find 𝑥0 such that 𝑃(𝑋 < 𝑥0 ) = .75.
𝑥0 = .6745
Distribution Plot
Normal, Mean=0, StDev=1
0.4
Density
0.3
0.75
0.2
0.1
0.0
Find 𝑥0 such that 𝑃(|𝑋| > 𝑥0 ) = .01.
0
X
0.6745
𝑥0 = 2.576
Distribution Plot
Normal, Mean=0, StDev=1
0.4
Density
0.3
0.2
0.1
0.0
61
0.005
0.005
-2.576
0
X
2.576
Normal Distribution (Excel)
In a blank cell, type an equal sign to insert a function and select More Functions…
from the drop-down list of functions.
Select the NORMDIST
function and complete the
dialog box.
X: Specify the value of 𝑘.
Mean: Specify 𝜇.
Standard_dev: Specify 𝜎.
Cumulative: Specify
TRUE to compute 𝑃(𝑋 ≤
𝑘). Specifying FALSE will compute 𝑓(𝑘), the height of the normal curve at 𝑋 = 𝑘.
In this example we compute 𝑃(𝑋 ≤ −.55) = .291159687 for the standard normal
distribution. The result is shown in the dialog box as soon as you specify all four inputs.
62
Normal Distribution (Excel)
To input probability values and compute 𝑥 values, use the NORMINV function.
Find 𝑥0 such that 𝑃(𝑋 ≤ 𝑥0 ) = .95.
𝑥0 = 1.644853627
Probability: Specify the
cumulative probability, i.e.
the area under the curve
to the left of 𝑥0 .
Mean: Specify 𝜇.
Standard_dev: Specify 𝜎.
63
t Distribution (Minitab)
Use Graph > Probability Distribution Plot… > View Probability.
Distribution tab: Select the t distribution
from the drop-down box.
Degrees of freedom: Specify the degrees
of freedom.
64
t Distribution (Minitab)
Shaded Area tab: The following dialogs show how to specify several kinds of
probability calculations.
To input values of 𝑥 (𝑡 values) and compute probabilities, specify that you want to
Define Shaded Area By X Value.
Below are several examples where the random variable 𝑋 has a t distribution with 12
degrees of freedom.
𝑃(𝑡 > 2.179) = .02499
Distribution Plot
T, df=12
0.4
Density
0.3
0.2
0.1
0.02499
0.0
0
X
2.179
𝑃(𝑡 ≤ 3.055) = .9950
Distribution Plot
T, df=12
0.4
0.9950
Density
0.3
0.2
0.1
0.0
65
0
X
3.055
t Distribution (Minitab)
𝑃(|𝑡| > 1.356) = .1000
Distribution Plot
T, df=12
0.4
Density
0.3
0.2
0.1
0.1000
0.0
0.1000
-1.356
0
X
1.356
𝑃(1.5 ≤ 𝑡 ≤ 2.5) = .06577
Distribution Plot
T, df=12
0.4
Density
0.3
0.2
0.1
0.06577
0.0
66
0
X
1.5
2.5
t Distribution (Minitab)
To input probability values and compute 𝑥 values, specify that you want to Define
Shaded Area By Probability.
Find 𝑡0 such that 𝑃(𝑡 ≥ 𝑡0 ) = .05.
𝑡0 = 1.782
Distribution Plot
T, df=12
0.4
Density
0.3
0.2
0.1
0.05
0.0
Find 𝑡0 such that 𝑃(|𝑡| > 𝑡0 ) = .01.
0
X
1.782
𝑡0 = 3.055
Distribution Plot
T, df=12
0.4
Density
0.3
0.2
0.1
0.0
67
0.005
-3.055
0.005
0
X
3.055
t Distribution (Excel)
In a blank cell, type an equal sign to insert a function and select More Functions…
from the drop-down list of functions.
There are several functions you can use
depending on what you want to do.
In the following examples we'll use a t-distribution
with 6 degrees of freedom.
Finding lower-tailed probabilities:
Select the T.DIST function
and complete the dialog box.
X: Specify the 𝑡 value.
Deg_freedom: Specify the
degrees of freedom.
Cumulative: Specify TRUE
to compute 𝑃(𝑡 ≤ −1.76).
Specifying FALSE will compute 𝑓(−1.76), the height of the t curve at −1.76.
In this example we compute 𝑃(𝑡 ≤ −1.76) = .064447607. The result is shown in the
dialog box as soon as you specify all three inputs.
68
t Distribution (Excel)
Finding upper-tailed probabilities:
Select the T.DIST.RT
function and complete the
dialog box.
X: Specify the 𝑡 value.
Deg_freedom: Specify the
degrees of freedom.
In this example we compute 𝑃(𝑡 > 2.73) = .017093009. The result is shown in the
dialog box as soon as you specify both inputs.
Finding two-tailed probabilities:
Select the T.DIST.2T
function and complete the
dialog box.
X: Specify the 𝑡 value. This
must be a positive value.
Deg_freedom: Specify the
degrees of freedom.
In this example we compute 𝑃(|𝑡| > 1.56) = .169778183. The result is shown in the
dialog box as soon as you specify both inputs.
69
t Distribution (Excel)
To input probability values and compute 𝑡 values, use these functions:
Find 𝑡0 such that 𝑃(𝑡 ≤ 𝑡0 ) = .95.
𝑡0 = 1.943180281
Select the T.INV function
and complete the dialog
box.
Probability: Specify the
cumulative probability, i.e.
the area under the curve to
the left of 𝑡0 .
Deg_freedom: Specify the
degrees of freedom.
Find 𝑡0 such that 𝑃(|𝑡| > 𝑡0 ) = .05.
𝑡0 = 2.446911851
Probability: Specify the
total tail probability, i.e. the
area under the curve to the
left of −𝑡0 plus the area to
the right of 𝑡0 .
Deg_freedom: Specify the
degrees of freedom.
70
Chi-Square Distribution (Minitab)
Use Graph > Probability Distribution Plot… > View Probability.
Distribution tab: Select the Chi-Square
distribution from the drop-down box.
Degrees of freedom: Specify the degrees
of freedom.
71
Chi-Square Distribution (Minitab)
Shaded Area tab: The following dialogs show how to specify several kinds of
probability calculations.
To input values of 𝑥 2 and compute probabilities, specify that you want to Define
Shaded Area By X Value.
Below are several examples where the random variable 𝑋 2 has a Chi-Square
distribution with 9 degrees of freedom.
𝑃(𝑋 2 > 1.735) = .995
Distribution Plot
Chi-Square, df=9
0.10
Density
0.08
0.06
0.9950
0.04
0.02
0.00
0 1.735
X
𝑃(𝑋 2 ≤ 1.735) = .005
Distribution Plot
Chi-Square, df=9
0.10
Density
0.08
0.06
0.04
0.02
0.005001
0.00
0 1.735
72
X
Chi-Square Distribution (Minitab)
To input probability values and compute 𝑥 2 values, specify that you want to Define
Shaded Area By Probability.
Find 𝑥02 such that 𝑃(𝑋 2 > 𝑥02 ) = .05.
𝑥02 = 16.92
Distribution Plot
Chi-Square, df=9
0.10
Density
0.08
0.06
0.04
0.02
0.05
0.00
0
X
Find 𝑥12 and 𝑥22 such that 𝑃(𝑋 2 < 𝑥12 𝑜𝑟 𝑋 2 > 𝑥22 ) = .05.
16.92
𝑥12 = 2.700 𝑥22 = 19.02
Distribution Plot
Chi-Square, df=9
0.10
Density
0.08
0.06
0.04
0.02
0.00
73
0.025
0.025
0
2.700
X
19.02
Chi-Square Distribution (Excel)
In a blank cell, type an equal sign to insert a function and select More Functions…
from the drop-down list of functions.
There are several functions you can use
depending on what you want to do.
In the following examples we'll use a Chi-Square
distribution with 9 degrees of freedom.
Finding lower-tailed probabilities:
Select the CHISQ.DIST
function and complete the
dialog box.
X: Specify the 𝑥 2 value.
Deg_freedom: Specify the
degrees of freedom.
Cumulative: Specify TRUE to
compute 𝑃(𝑋 2 ≤ 1.6837). Specifying FALSE will compute 𝑓(14.6837), the height of the
chi-square curve at 14.6837.
In this example we compute 𝑃(𝑋 2 ≤ 14.6837) = .900001297. The result is shown in the
dialog box as soon as you specify all three inputs.
74
Chi-Square Distribution (Excel)
Finding upper-tailed probabilities:
Select the CHISQ.DIST.RT
function and complete the
dialog box.
X: Specify the 𝑥 2 value.
Deg_freedom: Specify the
degrees of freedom.
In this example we compute 𝑃(𝑋 2 > 3.325) = .950005451. The result is shown in the
dialog box as soon as you specify both inputs.
To input probability values and compute 𝑥 2 values, use these functions:
Find 𝑥02 such that 𝑃(𝑋 2 ≤ 𝑥02 ) = .90.
𝑥02 = 14.68365657
Select the CHISQ.INV
function and complete the
dialog box.
Probability: Specify the
cumulative probability, i.e.
the area under the curve to
the left of 𝑥02 .
Deg_freedom: Specify the
degrees of freedom.
75
Chi-Square Distribution (Excel)
Find 𝑥02 such that 𝑃(𝑋 2 > 𝑥02 ) = .05.
𝑥02 = 16.9189776
Select the CHISQ.INV.RT
function and complete the
dialog box.
Probability: Specify the
upper-tailed probability, i.e.
the area under the curve to
the right of 𝑥02 .
Deg_freedom: Specify the
degrees of freedom.
76
F Distribution (Minitab)
Use Graph > Probability Distribution Plot… > View Probability.
Distribution tab: Select the F distribution
from the drop-down box.
Numerator df: Specify the numerator
degrees of freedom.
Denominator df: Specify the denominator
degrees of freedom.
77
F Distribution (Minitab)
Shaded Area tab: The following dialogs show how to specify several kinds of
probability calculations.
To input values of 𝑓 and compute probabilities, specify that you want to Define Shaded
Area By X Value.
Below are several examples where the random variable 𝐹 has an F distribution with 4
numerator degrees of freedom and 10 denominator degrees of freedom.
𝑃(𝐹 > 3.48) = .04993
Distribution Plot
F, df1=4, df2=10
0.7
0.6
Density
0.5
0.4
0.3
0.2
0.1
0.0
78
0.04993
0
X
3.48
F Distribution (Minitab)
To input probability values and compute 𝑓 values, specify that you want to Define
Shaded Area By Probability.
Find 𝑓0 such that 𝑃(𝐹 > 𝑓0 ) = .025.
𝑓0 = 4.468
Distribution Plot
F, df1=4, df2=10
0.7
0.6
Density
0.5
0.4
0.3
0.2
0.1
0.0
79
0.025
0
X
4.468
F Distribution (Excel)
In a blank cell, type an equal sign to insert a function and select More Functions…
from the drop-down list of functions.
There are several functions you can use
depending on what you want to do.
In the following examples we'll use an F
distribution with 4 numerator degrees of
freedom and 10 denominator degrees of
freedom.
Finding upper-tailed probabilities:
Select the F.DIST.RT
function and complete the
dialog box.
X: Specify the 𝑓 value.
Deg_freedom1: Specify the
numerator degrees of
freedom.
Deg_freedom2: Specify the denominator degrees of freedom.
In this example we compute 𝑃(𝐹 > 5.99) = .010023913. The result is shown in the
dialog box as soon as you specify all three inputs.
80
F Distribution (Excel)
To input probability values and compute 𝑓 values, use these functions:
Find 𝑓0 such that 𝑃(𝐹 > 𝑓0 ) = .10.
𝑓0 = 2.605336431
Select the F.INV.RT function
and complete the dialog box.
Probability: Specify the
upper-tailed probability, i.e. the
area under the curve to the
right of 𝑓0 .
Deg_freedom1: Specify the
numerator degrees of
freedom.
Deg_freedom2: Specify the denominator degrees of freedom.
81
z-interval and z-test for 𝝁 (Minitab)
Use Stat > Basic Statistics > 1-Sample Z…
As an example, we use body temperature data collected on a sample of healthy adults.
We'll assume that 𝜎 = .75.
Samples in columns: Specify the column
containing the raw data.
Summarized data: Use this option if you
have only the sample size (𝑛) and the
sample mean (𝑥̅ ) available.
Standard deviation: Enter 𝜎. If you want
to do a z-test with 𝜎 unknown (i.e. for large
sample sizes), find the sample standard
deviation (𝑠) first and enter it here.
If you want to perform a hypotheses test, check the box and enter 𝜇0 as the
Hypothesized mean. By default, Minitab calculates only a confidence interval for 𝜇.
82
z-interval and z-test for 𝝁 (Minitab)
To change the interval/test defaults, use Options…
Confidence level: Specify a different confidence level
for the interval. The default is 95%.
Alternative: Specify a different direction for 𝐻𝑎 . The
default is not equal (≠) for a two-tailed test. Leave this
as not equal to obtain the usual "two-tailed" confidence interval. Changing this option
will provide one-sided confidence intervals.
The output shows the
hypotheses,
𝐻0 : 𝜇 = 98.6
𝐻𝑎 : 𝜇 ≠ 98.6
indicates that the z-test
statistic and confidence
interval are computed
using 𝜎 = .75,
and displays the
endpoints of the
confidence interval and
the hypothesis test results
(z-test statistic and pvalue), in addition to
some descriptive
statistics.
83
t-test and t-interval for 𝝁 (Minitab)
Use Stat > Basic Statistics > 1-Sample t…
As an example, we use earnings per share figures (EPS) collected on a sample of
publically-traded companies.
Samples in columns: Specify the column
containing the raw data.
Summarized data: Use this option if you
only have the sample size (𝑛), the sample
mean (𝑥̅ ), and the sample standard
deviation (𝑠) available.
If you want to perform a hypotheses test,
check the box and enter 𝜇0 as the
Hypothesized mean. By default, Minitab
calculates only a confidence interval for 𝜇.
84
t-test and t-interval for 𝝁 (Minitab)
To change the interval/test defaults, use Options…
Confidence level: Specify a different confidence level
for the interval. The default is 95%.
Alternative: Specify a different direction for 𝐻𝑎 . The
default is not equal (≠) for a two-tailed test. Leave this
as not equal to obtain the usual "two-tailed" confidence
interval. Changing this option will provide one-sided
confidence intervals.
The output shows the
hypotheses,
𝐻0 : 𝜇 = 4
𝐻𝑎 : 𝜇 < 4
displays the
hypothesis test results
(t-test statistic and pvalue), and the upper
bound of a one-sided
confidence interval
(since the alternative
hypothesis is specified
as one-tailed), in
addition to some
descriptive statistics.
85
t-interval for 𝝁 (Excel)
Excel does not output results of a hypothesis test for 𝜇 but you can use it to construct a
confidence interval using the t procedure.
Enter the raw data in a column of the worksheet.
Use Data > Data Analysis > Descriptive Statistics.
Input Range: Highlight the cells containing the
data.
Grouped By: Columns
If the Input Range contains more than 1 column of
data, Excel does a separate analysis for each
one.
Labels in First Row: Check this box if the Input
Range contains column labels. If not, don't check
the box. Checking the box tells Excel to ignore
what's in the first row of the Input Range.
Summary Statistics: Check this box for the descriptive statistics to display.
Confidence Level for Mean: Check this box and specify the desired confidence level
(95% is the default).
86
t-interval for 𝝁 (Excel)
In addition to the univariate
descriptive statistics, Excel
displays the margin of error for
the confidence interval
calculated as
𝑡𝛼⁄2
𝑠
√𝑛
.
The confidence interval is then
𝑥̅ ± 𝑡𝛼⁄2
𝑠
.
√𝑛
87
Interval and Test for 𝒑 (Minitab)
Use Stat > Basic Statistics > 1 Proportion…
As an example, we use the results of a set of coin tosses where 9 were heads and 21
were tails.
Samples in columns: Specify the column
containing the raw data, i.e. a column of
"success"/"failure" indicators.
Summarized data: Use this input option if
you only know the Number of events
("successes") and Number of trials (𝑛).
If you want to perform a hypotheses test,
check the box and enter 𝑝0 as the
Hypothesized proportion. By default,
Minitab calculates only a confidence interval for 𝑝.
88
Interval and Test for 𝒑 (Minitab)
To change the interval/test defaults, use Options…
Confidence level: Specify a different confidence level
for the interval. The default is 95%.
Alternative: Specify a different direction for 𝐻𝑎 . The
default is not equal (≠) for a two-tailed test. Leave this
as not equal to obtain the usual "two-tailed" confidence
interval. Changing this option will provide one-sided confidence intervals.
Use test and interval based on normal distribution: Check this box to use the zinterval and z-test procedures if the sample size requirements are met. If not, leave the
box unchecked to use more robust procedures based on the binomial distribution.
The output shows the
hypotheses,
𝐻0 : 𝑝 = .5
𝐻𝑎 : 𝑝 ≠ .5
displays the endpoints
of the confidence
interval and the
hypothesis test results
(z-test statistic and pvalue), in addition to
the sample counts and
sample proportion of
successes.
89
Interval and Test for 𝝈𝟐 (Minitab)
Use Stat > Basic Statistics > 1 Variance…
As an example, we use earnings per share figures (EPS) collected on a sample of
publically-traded companies.
Data: Choose the input option.
Samples in columns: Specify this option
if the raw data are in a column of the
worksheet.
Sample standard deviation/variance:
Specify this option if you have only
summary statistics available for the
sample data.
If you want to perform a hypotheses test, check the box and enter 𝜎02 as the Value if
you choose Hypothesized variance. Enter 𝜎0 as the Value if you choose
Hypothesized standard deviation. By default, Minitab calculates only a confidence
interval for 𝜎 and 𝜎 2
90
Interval and Test for 𝝈𝟐 (Minitab)
To change the interval/test defaults, use Options…
Confidence level: Specify a different
confidence level for the interval. The default is
95%.
Alternative: Specify a different direction for 𝐻𝑎 .
The default is not equal (≠) for a two-tailed test.
Leave this as not equal to obtain the usual "twotailed" confidence interval. Changing this option will provide one-sided confidence
intervals.
Test and CI for One Variance: EPS
The output shows the
hypotheses,
𝐻0 : 𝜎 2 = 9
𝐻𝑎 : 𝜎 2 ≠ 9
displays the endpoints of the
confidence intervals for both 𝜎
and 𝜎 2 , and the hypothesis test
results, in addition to summary
statistics of the sample data.
Note that two different methods
are used depending on the
assumption you want to make
about the shape of the
population distribution from
which the data are sampled.
Method
Null hypothesis
Alternative hypothesis
Sigma-squared = 9
Sigma-squared not = 9
The chi-square method is only for the normal
distribution.
The Bonett method is for any continuous distribution.
Statistics
Variable
EPS
N
5
StDev
1.41
Variance
1.99
95% Confidence Intervals
Variable
EPS
Method
Chi-Square
Bonett
CI for
StDev
(0.85, 4.06)
(0.86, 3.80)
Method
Chi-Square
Bonett
Test
Statistic
0.89
—
CI for
Variance
(0.72, 16.46)
(0.75, 14.42)
Tests
Variable
EPS
DF
4
—
P-Value
0.147
0.103
Since the Chi-square procedures are sensitive to the normal distribution assumption, it's
a good idea to verify the data are closely normally distributed (e.g. with a normal
probability plot) before using them.
91
t-Interval and t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Minitab)
Use Stat > Basic Statistics > 2-Sample t…
Our example is data collected on the length of cuts (in feet) of columns from two
different saws (A and B). We're interested in whether these data show enough
evidence that one saw is cutting the columns shorter, on average, than the other saw.
The data are shown in the worksheet in both unstacked format (C1 and C2) and
stacked format (C3 and C4-T).
Samples in one column: Use this
option for stacked data. Specify the
column containing the numeric
response/comparison variable (Samples)
and the column containing the grouping
variable (Subscripts).
Note: When you use this option, Minitab
uses the group which comes first
alphanumerically in the Subscripts
column as the first term in the difference
in means. Here it would be 𝜇𝐴 − 𝜇𝐵 .
92
t-Interval and t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Minitab)
Samples in different columns: Use this option for unstacked data. Specify the both
columns of numeric values.
Note: When you use this option, the group whose data is specified as the First column
is used as the first term in the difference in means. Here it would be 𝜇𝐵 − 𝜇𝐴 .
Summarized data: Use this option if you have only the sample sizes and descriptive
statistics available for each sample.
Assume equal variances: Check this box if you want to assume equal population
variances, i.e. 𝜎12 = 𝜎22 . The default is to not assume equal variances. The differences
in the tests are shown below.
Assumption
𝜎12 = 𝜎22
𝜎12 ≠ 𝜎22
Test Statistic
𝑡=
(𝑥̅ 1 −𝑥̅ 2 )−𝐷0
𝑡=
(𝑥̅ 1 −𝑥̅2 )−𝐷0
2( 1 + 1 )
√𝑠𝑝
𝑛1 𝑛2
2
Degrees of Freedom
where 𝑠𝑝2 =
(𝑛1 −1 )𝑠12 +(𝑛2 −1 )𝑠22
𝑛1 +𝑛2 −2
𝑛1 + 𝑛2 − 2
2
2 2
𝑠
𝑠
( 1+ 2)
2
𝑠
𝑠
√ 1+ 2
𝑛1 𝑛2
⌊
𝑛1 𝑛2
2
2
2
𝑠2
𝑠
( 1)
( 2)
𝑛1
𝑛2
+
𝑛1 −1 𝑛2 −1
⌋
To change the interval/test defaults, use Options…
Confidence level: Specify a different confidence level
for the interval. The default is 95%.
Test difference: Specify the value of 𝐷0 . The default is
0.
Alternative: Specify a different direction for 𝐻𝑎 . The default is not equal (≠) for a twotailed test. Leave this as not equal to obtain the usual "two-tailed" confidence interval.
Changing this option will provide one-sided confidence intervals.
93
t-Interval and t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Minitab)
The output shows descriptive statistics for both groups.
In addition, the difference in means on which we're making inference is shown (𝜇𝐴 − 𝜇𝐵 )
as well as the point estimate for the difference (𝑥̅1 − 𝑥̅2 ) based on the data. The two last
lines display the results of the inference procedures: the endpoints of the confidence
interval for 𝜇𝐴 − 𝜇𝐵 and the results of the test of
𝐻0 : 𝜇𝐴 − 𝜇𝐵 = 0
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 ≠ 0 .
Two-Sample T-Test and CI: Length, Saw
Two-sample T for Length
Saw
A
B
N
9
9
Mean
8.0489
8.0700
StDev
0.0372
0.0224
SE Mean
0.012
0.0075
Difference = mu (A) - mu (B)
Estimate for difference: -0.0211
95% CI for difference: (-0.0524, 0.0102)
T-Test of difference = 0 (vs not =): T-Value = -1.46
94
P-Value = 0.168
DF = 13
t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Excel)
Use Data > Data Analysis > t-Test: Two-Sample Assuming Equal Variances
or Data > Data Analysis > t-Test: Two-Sample Assuming Unequal Variances
depending on whether you want to assume equal population variances (𝜎12 = 𝜎22 ) or not.
The differences in the tests are shown below.
Assumption
𝜎12 = 𝜎22
𝜎12 ≠ 𝜎22
Test Statistic
𝑡=
𝑡=
(𝑥̅ 1 −𝑥̅ 2 )−𝐷0
2( 1 + 1 )
√𝑠𝑝
𝑛1 𝑛2
Degrees of Freedom
where 𝑠𝑝2 =
(𝑛1 −1 )𝑠12 +(𝑛2 −1 )𝑠22
𝑛1 +𝑛2 −2
𝑛1 + 𝑛2 − 2
2
2 2
𝑠
𝑠
( 1+ 2)
(𝑥̅ 1 −𝑥̅2 )−𝐷0
𝑠2 𝑠2
√ 1+ 2
𝑛1 𝑛2
⌊
𝑛1 𝑛2
2
2
2
𝑠2
𝑠
( 1)
( 2)
𝑛1
𝑛2
+
𝑛1 −1 𝑛2 −1
⌋
Our example is data collected on the length of cuts (in feet) of columns from two
different saws (A and B). We're interested in whether these data show enough
evidence that one saw is cutting the columns shorter, on average, than the other saw.
The data are shown in the worksheet in unstacked format.
95
t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Excel)
Variable 1 Range: Highlight the cells
containing the numeric responses for the first
group.
Variable 2 Range: Highlight the cells
containing the numeric responses for the
second group.
Note: The group whose data is specified as
the Variable 1 Range is used as the first term
in the difference in means. Here it would be 𝜇𝐴 − 𝜇𝐵 .
Hypothesized Mean Difference: Specify 𝐷0 .
Labels: Check this box if the Input Ranges contain column labels. If not, don't check
the box. Checking the box tells Excel to ignore what's in the first row of the Input
Ranges.
Alpha: Specify 𝛼 for the test.
The output contains descriptive
statistics for both groups and results
of the hypothesis test of
𝐻0 : 𝜇𝐴 − 𝜇𝐵 = 0 .
Both one-tail and two-tail p-values
and critical values are reported.
t-Test: Two-Sample Assuming Unequal Variances
Mean
Variance
Observations
Hypothesized Mean Difference
df
t Stat
P(T<=t) one-tail
t Critical one-tail
P(T<=t) two-tail
t Critical two-tail
96
A
B
8.048889
8.07
0.001386 0.0005
9
9
0
13
-1.45831
0.084245
1.770933
0.16849
2.160369
t-Test for 𝝁𝟏 − 𝝁𝟐 Using Independent Samples (Excel)
IMPORTANT NOTE: Excel does not report one-tailed p-values and critical values
correctly, in general. The one-tailed “p-value” reported is actually the area under the tcurve in the upper or lower tail, depending on whether the value of the test statistic “t
Stat” is positive or negative, respectively. Excel mistakenly assumes that “t Stat” will be
positive if you have an upper-tailed test and negative if you have a lower-tailed test,
which usually happens, but not always. It is poor statistical practice to base the
direction of the hypotheses on the data. Also, the one-tailed “t Critical” reported is
actually the absolute value of the critical value, so it could have the wrong sign
depending on what the alternative hypothesis is.
Two-tailed p-values are reported correctly but there is a second critical value in the
lower tail having the same absolute value with a negative sign.
The following chart shows the correct rejection regions and p-values for the
corresponding tests. The highlighted values are the correct values.
Alternative Hypothesis
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 < 0
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 > 0
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 ≠ 0
Rejection Region
𝑡 < −1.770933
𝑡 > 1.770933
|𝑡| > 2.160369
p-value
𝑃(𝑇 < −1.45831) = .084245
𝑃(𝑇 > −1.45831) = 1 − .084245 = .915755
𝑃(|𝑇| > |−1.45831|) = .16849
97
t-Interval and t-Test for 𝝁𝟏 − 𝝁𝟐 Using Paired Samples (Minitab)
Use Stat > Basic Statistics > Paired t…
The example data are distances (yards) a golf ball was driven off a tee for a sample of
golfers. Each golfer hit two balls, one of brand A and one of brand B. The data are
shown in unstacked format.
Samples in columns: Use this option for
unstacked data. Specify the both columns of
numeric values.
Note: When you use this option, the group whose
data is specified as the First sample is used as the
first term in the difference in means. Here it would
be 𝜇𝐴 − 𝜇𝐵 .
Summarized data (differences): Use this option
if you have only the sample sizes and descriptive
statistics available for the paired differences.
98
t-Interval and t-Test for 𝝁𝟏 − 𝝁𝟐 Using Paired Samples (Minitab)
To change the interval/test defaults, use Options…
Confidence level: Specify a different confidence level
for the interval. The default is 95%.
Test difference: Specify the value of 𝐷0 . The default
is 0.
Alternative: Specify a different direction for 𝐻𝑎 . The default is not equal (≠) for a twotailed test. Leave this as not equal to obtain the usual "two-tailed" confidence interval.
Changing this option will provide one-sided confidence intervals.
The output shows descriptive statistics for both groups and the paired differences.
The two last lines display the results of the inference procedures: the endpoints of the
confidence interval for 𝜇𝐴 − 𝜇𝐵 and the results of the test of
𝐻0 : 𝜇𝐴 − 𝜇𝐵 = 0
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 ≠ 0 .
Paired T-Test and CI: A, B
Paired T for A - B
A
B
Difference
N
17
17
17
Mean
256.18
251.41
4.76
StDev
18.70
14.93
9.09
SE Mean
4.54
3.62
2.20
95% CI for mean difference: (0.09, 9.44)
T-Test of mean difference = 0 (vs not = 0): T-Value = 2.16
P-Value = 0.046
Note: An alternative is to use Stat > Basic Statistics > 1-Sample Z… or Stat > Basic
Statistics > 1-Sample t… and use the paired differences as the input data.
99
t-Test for 𝝁𝟏 − 𝝁𝟐 Using Paired Samples (Excel)
Use Data > Data Analysis > t-test: Paired Two-Sample for Means.
The example data are distances (yards) a golf ball was driven off a tee for a sample of
golfers. Each golfer hit two balls, one of brand A and one of brand B. The data are
shown in unstacked format.
Variable 1 Range: Highlight the cells containing the numeric responses for the first
group.
Variable 2 Range: Highlight the cells containing the numeric responses for the second
group.
Note: The group whose data is specified as the Variable 1 Range is used as the first
term in the difference in means. Here it would be 𝜇𝐴 − 𝜇𝐵 .
Hypothesized Mean Difference: Specify 𝐷0 .
Labels: Check this box if the Input Ranges contain column labels. If not, don't check
the box. Checking the box tells Excel to ignore what's in the first row of the Input
Ranges.
Alpha: Specify 𝛼 for the test.
100
t-Test for 𝝁𝟏 − 𝝁𝟐 Using Paired Samples (Excel)
The output contains descriptive
statistics for both groups and the
Pearson correlation coefficient (𝑟)
between the two samples. Also
shown are the results of the
hypothesis test of
𝐻0 : 𝜇𝐴 − 𝜇𝐵 = 0 .
Both one-tail and two-tail p-values
and critical values are reported.
t-Test: Paired Two Sample for Means
Mean
Variance
Observations
Pearson Correlation
Hypothesized Mean Difference
df
t Stat
P(T<=t) one-tail
t Critical one-tail
P(T<=t) two-tail
t Critical two-tail
A
B
256.1765 251.4118
349.7794 223.0074
17
17
0.877617
0
16
2.162019
0.023056
1.745884
0.046112
2.119905
IMPORTANT NOTE: Excel does
not report one-tailed p-values and
critical values correctly, in general. The one-tailed “p-value” reported is actually the
area under the t-curve in the upper or lower tail, depending on whether the value of the
test statistic “t Stat” is positive or negative, respectively. Excel mistakenly assumes that
“t Stat” will be positive if you have an upper-tailed test and negative if you have a lowertailed test, which usually happens, but not always. It is poor statistical practice to base
the direction of the hypotheses on the data. Also, the one-tailed “t Critical” reported is
actually the absolute value of the critical value, so it could have the wrong sign
depending on what the alternative hypothesis is.
Two-tailed p-values are reported correctly but there is a second critical value in the
lower tail having the same absolute value with a negative sign.
The following chart shows the correct rejection regions and p-values for the
corresponding tests. The highlighted values are the correct values.
Alternative Hypothesis
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 < 0
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 > 0
𝐻𝑎 : 𝜇𝐴 − 𝜇𝐵 ≠ 0
Rejection Region
𝑡 < −1.745884
𝑡 > 1.745884
|𝑡| > 2.119905
p-value
𝑃(𝑇 < 2.162019) = 1 − .023056 = .976944
𝑃(𝑇 > 2.162019) = .023056
𝑃(|𝑇| > |2.162019|) = .046112
Note: An alternative is to use Data > Data Analysis > Descriptive Statistics and use
the paired differences as the input data. This approach will only output the margin of
error for a paired t-interval for 𝜇1 − 𝜇2 .
101
z-Interval and z-Test for 𝒑𝟏 − 𝒑𝟐 Using Independent Samples (Minitab)
Use Stat > Basic Statistics > 2 Proportions…
The example data are indicators of whether or not a washing machine needed repairs in
the first five years of operation for a sample of the company's machines and a sample of
a competitor's machines. The data are shown in both unstacked format (C1-T and C2T) and stacked format (C3-T and C4-T). 13 of the 100 company's machines and 26 of
the 100 competitor's machines needed repairs.
Samples in one column: Use this option for
stacked data. Specify the column containing
the categorical response/comparison variable
(Samples) and the column containing the
grouping variable (Subscripts).
Note: When you use this option, Minitab uses
the group which comes first alphanumerically
in the Subscripts column as the first term in
the difference in proportions. Here it would be
𝑝𝐶𝑜𝑚𝑝𝑎𝑛𝑦 − 𝑝𝐶𝑜𝑚𝑝𝑒𝑡𝑖𝑡𝑜𝑟 .
102
z-Interval and z-Test for 𝒑𝟏 − 𝒑𝟐 Using Independent Samples (Minitab)
Samples in different columns: Use this option for unstacked data. Specify the both
columns of categorical responses.
Note: When you use this option, the group whose data is specified as the First column
is used as the first term in the difference in proportions. Here it would be 𝑝𝐶𝑜𝑚𝑝𝑎𝑛𝑦 −
𝑝𝐶𝑜𝑚𝑝𝑒𝑡𝑖𝑡𝑜𝑟 .
Summarized data: Use this option if you have only the sample sizes (Trials) and
numbers of "successes" (Events) for each sample.
To change the interval/test defaults, use Options…
Confidence level: Specify a different confidence level
for the interval. The default is 95%.
Test difference: Specify the value of 𝐷0 . The default
is 0.
Alternative: Specify a different direction for 𝐻𝑎 . The default is not equal (≠) for a twotailed test. Leave this as not equal to obtain the usual "two-tailed" confidence interval.
Changing this option will provide one-sided confidence intervals.
Use pooled estimate of p for test: Check this box if you want Minitab to compute the
z-test statistic as
𝑧=
(𝑝̂1 −𝑝̂2 )−0
1
1
√𝑝̂(1−𝑝̂)(𝑛 +𝑛 )
1
2
𝑥 +𝑥
where 𝑝̂ = 𝑛1+𝑛2 is the pooled estimate of 𝑝 and 𝑥1 and 𝑥2 are the
1
2
numbers of "successes" (Events) in each group. This is only appropriate under the
assumption that 𝑝1 = 𝑝2 = 𝑝, i.e. 𝑝1 − 𝑝2 = 0, so only check this box if you specify 𝐷0 =
0.
If you do not check the box, Minitab computes the z-test statistic as
𝑧=
(𝑝̂1 −𝑝̂2 )−𝐷0
̂ (1−𝑝
̂1) 𝑝
̂ (1−𝑝
̂2)
𝑝
√ 1
+ 2
𝑛1
𝑛2
.
Checking or not checking the box has no effect on the confidence interval for 𝑝1 − 𝑝2 .
103
z-Interval and z-Test for 𝒑𝟏 − 𝒑𝟐 Using Independent Samples (Minitab)
The output shows the numbers of events (X), the sample sizes (N), and sample
proportions (Sample p) for both samples.
In addition, the difference in proportions on which we're making inference is shown
(𝑝1 − 𝑝2) as well as the point estimate for the difference (𝑝̂1 − 𝑝̂2) based on the data.
The next two lines display the results of the z-procedures: the endpoints of the
confidence interval for 𝑝1 − 𝑝2 and the results of the test of
𝐻0 : 𝑝1 − 𝑝2 = 0
𝐻𝑎 : 𝑝1 − 𝑝2 ≠ 0 .
The last line shows the p-value for Fisher's exact test of hypotheses. Use this test when
the large samples condition (required for the validity of the z-procedures) fails.
Test and CI for Two Proportions
Sample
1
2
X
13
26
N
100
100
Sample p
0.130000
0.260000
Difference = p (1) - p (2)
Estimate for difference: -0.13
95% CI for difference: (-0.238331, -0.0216688)
Test for difference = 0 (vs not = 0): Z = -2.32
Fisher's exact test: P-Value = 0.031
104
P-Value = 0.020
Test and Interval for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Minitab)
Use Stat > Basic Statistics > 2 Variances…
Our example is data collected on the length of cuts (in feet) of columns from two
different saws (A and B). We're interested in whether these data show enough
evidence that the saws differ on the variation in the lengths of cuts. The data are shown
in the worksheet in both unstacked format (C1 and C2) and stacked format (C3 and C4T).
Data: Specify the input option.
Samples in one column: Use this
option for stacked data format.
Specify the numeric
response/comparison variable
(Samples) and the categorical
grouping variable (Subscripts).
Note: When you use this option, Minitab uses the group which comes first
alphanumerically in the Subscripts column as the numerator term in the ratio of
variances. Here it would be 𝜎𝐴2 /𝜎𝐵2 .
105
Test and Interval for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Minitab)
Samples in different columns: Use
this option for unstacked data.
Specify both columns of numeric
responses.
Note: When you use this option, the
group whose data is specified as the
First column is used as the numerator
term in the ratio of variances. Here it
would be 𝜎𝐴2 /𝜎𝐵2 .
Sample standard deviations/variances: Use these options if you have only
descriptive statistics available for both groups. The group whose summaries are
specified as the First sample is used as the numerator term in the ratio of variances.
To change the interval/test defaults, use
Options…
Confidence level: Specify a different
confidence level for the interval. The
default is 95%.
Hypothesized ratio: Specify the Value of
the null hypothesized ratio of standard deviations (default) or variances. The default
Value is 1, i.e. 𝐻0 :
𝜎1
𝜎2
= 1 or 𝐻0 :
𝜎12
𝜎22
= 1.
Alternative: Specify a different direction for 𝐻𝑎 . The default is not equal (≠) for a twotailed test. Leave this as not equal to obtain the usual "two-tailed" confidence interval.
Changing this option will provide one-sided confidence intervals.
106
Test and Interval for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Minitab)
The output shows the hypotheses,
𝐻0 :
2
𝜎𝐴
=1
2
𝜎𝐵
𝐻𝑎 :
2
𝜎𝐴
2
𝜎𝐵
≠1
displays descriptive statistics for each group, and point estimates of the population
ratios of standard deviations and variances:
point estimate of
𝜎12
𝜎22
𝜎12
𝜎22
𝑠1
𝑠2
𝜎
𝑠2
as the point estimate of 𝜎1 and 𝑠12 as the
2
2
. Next are the endpoints of the confidence intervals for both
𝜎1
𝜎2
and
, and the hypothesis test results.
Note that two different methods are used depending on the assumption you want to
make about the shapes of the two population distributions from which the data are
sampled. Since the F procedures are sensitive to the normal distribution assumption,
it's a good idea to verify that both samples of data are closely normally distributed (e.g.
with a normal probability plot) before using them.
Test and CI for Two Variances: Length vs Saw
Method
Null hypothesis
Alternative hypothesis
Significance level
Variance(A) / Variance(B) = 1
Variance(A) / Variance(B) not = 1
Alpha = 0.05
Statistics
Saw
A
B
N
9
9
StDev
0.037
0.022
Variance
0.001
0.001
Ratio of standard deviations = 1.665
Ratio of variances = 2.772
95% Confidence Intervals
Distribution
of Data
Normal
Continuous
CI for StDev
Ratio
(0.791, 3.506)
(0.446, 3.441)
CI for
Variance
Ratio
(0.625, 12.290)
(0.199, 11.844)
Tests
Method
F Test (normal)
Levene's Test (any continuous)
DF1
8
1
DF2
8
16
Test
Statistic
2.77
0.87
107
P-Value
0.171
0.365
F-Test for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Excel)
Use Data > Data Analysis > F-Test Two-Sample for Variances.
Our example is data collected on the length of cuts (in feet) of columns from two
different saws (A and B). We're interested in whether these data show enough
evidence that the saws differ on the variation in the lengths of cuts. The data are shown
in the worksheet in unstacked format.
Variable 1 Range: Highlight the cells
containing the numeric responses for the
first group.
Variable 2 Range: Highlight the cells
containing the numeric responses for the
second group.
Note: The group whose data is specified as the Variable 1 Range is used as the
numerator term in the ratio of variances. Here it would be 𝜎𝐴2 /𝜎𝐵2 .
Labels: Check this box if the Input Ranges contain column labels. If not, don't check
the box. Checking the box tells Excel to ignore what's in the first row of the Input
Ranges.
Alpha: Specify 𝛼 for the test.
108
F-Test for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Excel)
The output contains descriptive
statistics for both groups and the
results of the hypothesis test of
𝐻0 :
2
𝜎𝐴
2
𝜎𝐵
=1
Only "one-tail p-values" and "one-tail
critical values" are reported.
F-Test Two-Sample for Variances
Mean
Variance
Observations
df
F
P(F<=f) one-tail
F Critical one-tail
A
8.048889
0.001386
9
8
2.772222
0.085334
3.438101
B
8.07
0.0005
9
8
IMPORTANT NOTE: Excel does
not report one-tailed p-values and critical values correctly, in general. The one-tailed “pvalue” reported is actually the area under the F-curve in the upper or lower tail,
depending on the value of the test statistic “F.” Excel mistakenly assumes that “F” will
be relatively large if you have an upper-tailed test and relatively small if you have a
lower-tailed test, which usually happens, but not always. The one-tailed “F Critical”
reported also corresponds to the direction Excel chooses for the alternative. It is poor
statistical practice to base the direction of the hypotheses on the data.
To conduct a two-tailed test,
𝐻0 :
𝐻𝑎 :
2
𝜎𝐴
2
𝜎𝐵
2
𝜎𝐴
2
𝜎𝐵
=1
≠1
use the Excel function F.TEST.
In a blank cell, type an equal sign to
insert a function and select More
Functions… from the drop-down list of
functions.
109
F-Test for 𝝈𝟐𝟏 /𝝈𝟐𝟐 Using Independent Samples (Excel)
Select the F.TEST function and complete the dialog box.
Array 1: Highlight the cells
containing the numeric
responses for the first
group. You may highlight
the column labels if you
choose; Excel will ignore
any non-numeric data.
Array 2: Highlight the cells
containing the numeric
responses for the second
group. You may highlight the column labels if you choose; Excel will ignore any nonnumeric data.
Note: The group whose data is specified as the Array 1 range is used as the numerator
term in the ratio of variances. Here it would be 𝜎𝐴2 /𝜎𝐵2 .
The two-tailed p-value (.170667608 here) is shown in the dialog box as soon as you
specify both arrays.
110
One-Way ANOVA (Minitab)
Stacked Data
Use Stat > ANOVA > One-Way…
All response data must be in a single column with a
second column indicating the levels of the factor. In the
worksheet at the right, we have random samples of 10
scores from each of 3 different training programs.
Response: Specify the response variable.
Factor: Specify the column containing the factor levels.
Use the Comparisons… button to specify a
multiple comparisons analysis.
Here we request Tukey's adjustment for multiple
comparisons so that the family (experimentwise)
error rate remains at .05 (5%).
111
One-Way ANOVA (Minitab)
The output shows the ANOVA table, individual confidence intervals for the population
means (NOT adjusted for multiple comparisons), and the multiple comparisons analysis
(if requested).
One-way ANOVA: Score versus Program
Source
Program
Error
Total
DF
2
27
29
S = 9.823
Level
1
2
3
N
10
10
10
SS
62.1
2605.3
2667.4
MS
31.0
96.5
R-Sq = 2.33%
Mean
71.200
70.300
67.800
StDev
10.261
9.627
9.566
F
0.32
P
0.728
R-Sq(adj) = 0.00%
Individual 95% CIs For Mean Based on
Pooled StDev
-------+---------+---------+---------+-(-----------*------------)
(------------*-----------)
(------------*-----------)
-------+---------+---------+---------+-65.0
70.0
75.0
80.0
Pooled StDev = 9.823
Grouping Information Using Tukey Method
Program
1
2
3
N
10
10
10
Mean
71.200
70.300
67.800
Grouping
A
A
A
Means that do not share a letter are significantly different.
Tukey 95% Simultaneous Confidence Intervals
All Pairwise Comparisons among Levels of Program
Individual confidence level = 98.04%
Program = 1 subtracted from:
Program
2
3
Lower
-11.803
-14.303
Center
-0.900
-3.400
Upper
10.003
7.503
+---------+---------+---------+--------(---------------*--------------)
(--------------*---------------)
+---------+---------+---------+---------14.0
-7.0
0.0
7.0
Program = 2 subtracted from:
Program
3
Lower
-13.403
Center
-2.500
Upper
8.403
+---------+---------+---------+--------(--------------*---------------)
+---------+---------+---------+---------14.0
-7.0
0.0
7.0
112
One-Way ANOVA (Minitab)
Unstacked Data
Use Stat > ANOVA > One-Way(Unstacked)…
Response data must be in separate columns, one for
each sample. In the worksheet at the right, we have
random samples of 10 scores from each of 3 different
training programs.
Responses (in separate columns): Specify the columns containing the response
data.
Use the Comparisons… button to specify a multiple comparisons analysis.
Here we request Tukey's adjustment for multiple
comparisons so that the family (experimentwise)
error rate remains at .05 (5%).
113
One-Way ANOVA (Minitab)
The output shows the ANOVA table, individual confidence intervals for the population
means (NOT adjusted for multiple comparisons), and the multiple comparisons analysis
(if requested).
One-way ANOVA: Score_1, Score_2, Score_3
Source
Factor
Error
Total
DF
2
27
29
S = 9.823
Level
Score_1
Score_2
Score_3
N
10
10
10
SS
62.1
2605.3
2667.4
MS
31.0
96.5
R-Sq = 2.33%
Mean
71.200
70.300
67.800
F
0.32
P
0.728
R-Sq(adj) = 0.00%
StDev
10.261
9.627
9.566
Individual 95% CIs For Mean Based on
Pooled StDev
-------+---------+---------+---------+-(-----------*------------)
(------------*-----------)
(------------*-----------)
-------+---------+---------+---------+-65.0
70.0
75.0
80.0
Pooled StDev = 9.823
Grouping Information Using Tukey Method
Score_1
Score_2
Score_3
N
10
10
10
Mean
71.200
70.300
67.800
Grouping
A
A
A
Means that do not share a letter are significantly different.
Tukey 95% Simultaneous Confidence Intervals
All Pairwise Comparisons
Individual confidence level = 98.04%
Score_1 subtracted from:
Score_2
Score_3
Lower
-11.803
-14.303
Center
-0.900
-3.400
Upper
10.003
7.503
+---------+---------+---------+--------(---------------*--------------)
(--------------*---------------)
+---------+---------+---------+---------14.0
-7.0
0.0
7.0
Score_2 subtracted from:
Score_3
Lower
-13.403
Center
-2.500
Upper
8.403
+---------+---------+---------+--------(--------------*---------------)
+---------+---------+---------+---------14.0
-7.0
0.0
7.0
114
One-Way ANOVA (Excel)
Enter the data in the worksheet in unstacked format, i.e. the
responses in separate columns, one for each sample. In
the worksheet at the right, we have random samples of 10
scores from each of 3 different training programs.
Use Data > Data Analysis > ANOVA: Single Factor.
Input Range: Specify the input data as the range of cells
containing response columns.
Grouped By: Select columns. (You can also input the response data in separate rows,
one for each sample, but this is not typically done. In that case, select Rows here.)
Labels in First Row: Check this box if the Input Ranges contain column labels. If not,
don't check the box. Checking the box tells Excel to ignore what's in the first row of the
Input Range.
Alpha: The level of significance for critical values. The default is .05.
Note: Excel does not do multiple comparisons.
115
One-Way ANOVA (Excel)
The output shows summary statistics for each sample and the ANOVA table which
includes the critical value for the F-test statistic.
Anova: Single Factor
SUMMARY
Groups
Score_1
Score_2
Score_3
Count
Sum
10 712
10 703
10 678
Average Variance
71.2 105.2889
70.3 92.67778
67.8 91.51111
ANOVA
Source of
Variation
Between Groups
Within Groups
SS
62.06667
2605.3
df
MS
F
P-value
F crit
2 31.03333 0.321614 0.727717 3.354131
27 96.49259
Total
2667.367
29
116
Two-Way ANOVA (Minitab)
Data must be entered in stacked format with one column
for the numeric responses and one column for each
factor. In this example, we have factor A at 3 levels and
factor B at 2 levels.
There are two ways to do the analysis in Minitab. One
way is to use Stat > ANOVA > Two-Way…
Response: Specify the column containing the responses.
Row factor / Column factor: Specify columns containing the levels of each factor.
The output will be the ANOVA table.
Two-way ANOVA: Score versus FactorA, FactorB
Source
FactorA
FactorB
Interaction
Error
Total
S = 6.285
DF
2
1
2
6
11
SS
118.5
108.0
46.5
237.0
510.0
MS
59.25
108.00
23.25
39.50
R-Sq = 53.53%
F
1.50
2.73
0.59
P
0.296
0.149
0.584
R-Sq(adj) = 14.80%
Note that this tool does not allow for multiple comparisons. To do multiple comparisons
in a two-way ANOVA, use the General Linear Model tool:
Stat > ANOVA > General Linear Model
117
Two-Way ANOVA (Minitab)
Responses: Specify the column
containing the responses.
Model: Specify the sources of variation
you want to account for. Enter both
columns containing the factor levels. To
account for an interaction between two
factors, specify an interaction term using
an asterisk, as shown. You should only
specify an interaction term when there are
multiple observations per treatment.
The output will show the ANOVA table as well as a list of the factors and levels.
General Linear Model: Score versus FactorA, FactorB
Factor
FactorA
FactorB
Type
fixed
fixed
Levels
3
2
Values
1, 2, 3
1, 2
Analysis of Variance for Score, using Adjusted SS for Tests
Source
FactorA
FactorB
FactorA*FactorB
Error
Total
S = 6.28490
DF
2
1
2
6
11
Seq SS
118.50
108.00
46.50
237.00
510.00
R-Sq = 53.53%
Adj SS
118.50
108.00
46.50
237.00
Adj MS
59.25
108.00
23.25
39.50
F
1.50
2.73
0.59
P
0.296
0.149
0.584
R-Sq(adj) = 14.80%
Use the Comparisons… button to request a multiple comparisons analysis.
Row or Column Means Comparisons
Terms: Specify the column containing the
levels of the row or column factor, as
shown here.
Method: Select a multiple comparisons
method.
Check the Confidence interval approach
for displaying the results.
118
Two-Way ANOVA (Minitab)
The output shows a confidence interval (adjusted for multiple comparisons) for the
difference, 𝜇𝑖 − 𝜇𝑗 , between each pair of row means (𝜇1 , 𝜇2 , … , 𝜇𝑎 ) or column means
(𝜇1 , 𝜇2 , … , 𝜇𝑏 ). Here there are 3 levels of Factor A giving 3 row means (𝜇1 , 𝜇2 , 𝜇3 ) and
(32) = 3 pairs.
Tukey 95.0% Simultaneous Confidence Intervals
Response Variable Score
All Pairwise Comparisons among Levels of FactorA
FactorA = 1 subtracted from:
FactorA
2
3
Lower
-18.89
-11.39
FactorA = 2
FactorA
3
Center
-5.250
2.250
Upper
8.388
15.888
------+---------+---------+---------+
(-----------*----------)
(----------*----------)
------+---------+---------+---------+
-12
0
12
24
subtracted from:
Lower
-6.138
Center
7.500
Upper
21.14
------+---------+---------+---------+
(----------*-----------)
------+---------+---------+---------+
-12
0
12
24
Example: A 95% confidence interval for 𝜇2 − 𝜇1 is (−18.89 , 8.388).
Treatment/Cell Means Comparisons
Terms: Specify the interaction term using
an asterisk, as shown here.
Method: Select a multiple comparisons
method.
Check the Confidence interval approach
for displaying the results.
119
Two-Way ANOVA (Minitab)
The output shows a confidence interval (adjusted for multiple comparisons) for the
difference, 𝜇𝑖𝑗 − 𝜇𝑘𝑙 , between each pair of treatment means (𝜇11 , 𝜇12 , … , 𝜇𝑎𝑏 ). Here
there are 6 treatment means (𝜇11 , 𝜇12 , 𝜇21 , 𝜇22 , 𝜇31 , 𝜇32 ) and (62) = 15 pairs.
Tukey 95.0% Simultaneous Confidence Intervals
Response Variable Score
All Pairwise Comparisons among Levels of FactorA*FactorB
FactorA = 1
FactorB = 1 subtracted from:
FactorA
1
2
2
3
3
FactorB
2
1
2
1
2
FactorA = 1
FactorB = 2
FactorA
2
2
3
3
FactorA
2
3
3
FactorA
3
3
FactorA
3
------+---------+---------+---------+
(---------*---------)
(---------*---------)
(---------*---------)
(---------*---------)
(---------*---------)
------+---------+---------+---------+
-25
0
25
50
Lower
-39.02
-29.52
-27.02
-26.52
Center
-14.00
-4.50
-2.00
-1.50
Upper
11.02
20.52
23.02
23.52
------+---------+---------+---------+
(---------*---------)
(---------*---------)
(---------*---------)
(---------*---------)
------+---------+---------+---------+
-25
0
25
50
Lower
-15.52
-13.02
-12.52
Center
9.500
12.000
12.500
Upper
34.52
37.02
37.52
------+---------+---------+---------+
(---------*---------)
(---------*---------)
(---------*---------)
------+---------+---------+---------+
-25
0
25
50
Upper
27.52
28.02
------+---------+---------+---------+
(---------*---------)
(---------*---------)
------+---------+---------+---------+
-25
0
25
50
Upper
25.52
------+---------+---------+---------+
(---------*---------)
------+---------+---------+---------+
-25
0
25
50
subtracted from:
FactorB
1
2
FactorA = 3
FactorB = 1
Upper
33.02
19.02
28.52
31.02
31.52
subtracted from:
FactorB
2
1
2
FactorA = 2
FactorB = 2
Center
8.000
-6.000
3.500
6.000
6.500
subtracted from:
FactorB
1
2
1
2
FactorA = 2
FactorB = 1
Lower
-17.02
-31.02
-21.52
-19.02
-18.52
Lower
-22.52
-22.02
Center
2.500
3.000
subtracted from:
FactorB
2
Lower
-24.52
Center
0.5000
Example: A 95% confidence interval for 𝜇32 − 𝜇12 is (−26.52 , 23.52).
120
Two-Way ANOVA (Excel)
Enter the data in the worksheet in a format that resembles
the design (rows for factor A and columns for factor B). In
this example, we have factor A at 3 levels and factor B at
2 levels. There are 2 observations in each treatment.
If there is more than one observation per treatment, use
Data > Data Analysis > ANOVA: Two-Factor With
Replication.
Input Range: Specify the input data as the range of cells containing data table.
Include the labels in the range.
Rows per sample: Indicate how many observations were made in each treatment.
Alpha: The level of significance for critical values. The default is .05.
Note: Excel does not do multiple comparisons.
121
Two-Way ANOVA (Excel)
The output gives a table of descriptive statistics (count, sum, average, variance) of the
responses in each treatment as well as across each row and column. The ANOVA
table is displayed at the bottom.
Anova: Two-Factor With Replication
SUMMARY
1
2 Total
1
Count
Sum
Average
Variance
2
140
70
2
2
156
78
72
4
296
74
46
2
128
64
2
2
4
147
275
73.5 68.75
40.5 44.25
2
Count
Sum
Average
Variance
3
Count
Sum
Average
Variance
2
2
4
152
153
305
76 76.5 76.25
8 112.5 40.25
Total
Count
Sum
Average
Variance
ANOVA
Source of Variation
Sample
Columns
Interaction
Within
Total
6
420
70
31.2
6
456
76
49.2
SS
118.5
108
46.5
237
df
510
2
1
2
6
MS
F
P-value
F crit
59.25
1.5 0.296296 5.143253
108 2.734177 0.149307 5.987378
23.25 0.588608 0.584233 5.143253
39.5
11
122
Two-Way ANOVA (Excel)
If there is only one observation per cell (as in a
block design), use Data > Data Analysis >
ANOVA: Two-Factor Without Replication.
In this example of a block design, we have a factor
at 3 levels and a blocking variable at 5 levels.
Input Range: Specify the input data as the range of cells containing data table.
Labels: Check this box if you highlighted the row/column labels in the input range.
Alpha: The level of significance for critical values. The default is .05.
Note: Excel does not do multiple comparisons.
123
Two-Way ANOVA (Excel)
The output shows descriptive statistics of the responses across each row and column.
The ANOVA table is displayed at the bottom.
Anova: Two-Factor Without Replication
SUMMARY
Count
Sum
164.0231
86.89977
167.0332
101.9388
218.3436
Average
54.67437
28.96659
55.67772
33.9796
72.78119
Variance
139.9776
133.6837
1312.929
1603.765
158.9724
1
2
3
4
5
3
3
3
3
3
1
2
3
5 285.2015 57.04029 383.9797
5 235.5977 47.11954 778.1437
5 217.4393 43.48785 1341.297
ANOVA
Source of
Variation
Rows
Columns
Error
SS
3807.157
492.1318
6206.523
Total
10505.81
df
MS
F
P-value
F crit
4 951.7892 1.226824 0.372009 3.837853
2 246.0659 0.317171 0.736959 4.45897
8 775.8153
14
124
Interaction Plot (Minitab)
Data must be entered in stacked format with one column
for the numeric responses and one column for each
factor. In this example, we have factor A at 3 levels and
factor B at 2 levels.
Use Stat > ANOVA > Interactions Plot…
Responses: Specify the column containing the responses.
Factors: Specify the columns containing the levels of the two factors.
Display full interaction plot matrix: Check this box to construct the interaction plot
two ways: Factor A levels as x-axis and Factor B levels as different plotting symbols;
Factor B levels as x-axis and Factor A levels as different plotting symbols.
Interaction Plot for Score
Data Means
1
2
80
75
FactorA
FactorA
1
2
3
70
65
80
FactorB
1
2
75
FactorB
70
65
1
2
3
125
Chi-Square Test for One-Way Table (Minitab)
Use Stat > Tables > Chi-Square Goodness-of-Fit Test (One Variable)…
If the data are summarized as frequencies of the categories, use the first input option:
Observed counts: Specify the column containing the frequencies.
Category names (optional): Specify the column containing the category names.
If you have raw categorical data in a single column with one row per observation, use
the second input option:
Categorical data: Specify the column containing the
categorical data.
126
Chi-Square Test for One-Way Table (Minitab)
Under Test, specify what the null hypothesis of the test looks like:
Equal proportions: Use this option if the null hypothesis specifies equal proportions:
1
𝐻0 : 𝑝1 = 𝑝2 = ⋯ = 𝑝𝑘 = 𝑘
Specific proportions: Use this option if the null hypothesis specifies different
proportions. Specify a column in the worksheet that contains the proportions specified
in the null hypothesis. Here we use 𝐻0 : 𝑝𝐵𝑙𝑢𝑒 = .3, 𝑝𝑅𝑒𝑑 = .4, 𝑝𝑌𝑒𝑙𝑙𝑜𝑤 = .3.
Important Note: If you use the Observed counts input option, the specific proportions
must be in the same order as the order the categories appear in the frequency table. If
you use the Categorical data input option, the specific proportions must be correspond
to the alphabetical order of the categories in the data.
Here, since we're using the Categorical data input option, the null hypothesized
proportion for Blue comes first.
127
Chi-Square Test for One-Way Table (Minitab)
The output shows the frequency table with the observed counts, null hypothesized
proportions, expected counts, and chi-square contributions,
square test statistic value and p-value.
Chi-Square Goodness-of-Fit Test for Categorical Variable: Color
Category
Blue
Red
Yellow
N
44
N*
0
Observed
13
11
20
DF
2
Chi-Sq
5.98106
Test
Proportion
0.3
0.4
0.3
Expected
13.2
17.6
13.2
Contribution
to Chi-Sq
0.00303
2.47500
3.50303
P-Value
0.050
128
(𝑛𝑖 −𝐸𝑖 )2
𝐸𝑖
, as well as the chi-
Chi-Square Test for Two-Way Table (Minitab)
There are two menu options, depending on how the data are shown in the worksheet.
Raw/stacked data format: two columns holding the category
values of each variable
Here we have 3 random samples of 50 Plain, Peanut, and Dark
Chocolate M&Ms and observe the color of each.
Use Stat > Tables > Cross Tabulation and Chi-Square.
For rows: Specify the column containing the categories you'd like to use as the rows of
the 2-way contingency table.
For columns: Specify the column containing the categories you'd like to use as the
columns of the 2-way contingency table.
Use the Chi-Square… button to specify the ChiSquare analysis. You can also display the
expected counts.
129
Chi-Square Test for Two-Way Table (Minitab)
The output shows the contingency table and two versions of the chi-square test. Our
textbook uses the Pearson Chi-Square test.
Tabulated statistics: Type, Color
Rows: Type
Dark
Peanut
Plain
All
Columns: Color
Blue
Brown
Green
Orange
Red
Yellow
All
9
9
11
29
4
5
8
17
5
6
7
18
7
8
10
25
14
13
9
36
11
9
5
25
50
50
50
150
Cell Contents:
Count
Pearson Chi-Square = 6.105, DF = 10, P-Value = 0.806
Likelihood Ratio Chi-Square = 6.241, DF = 10, P-Value = 0.795
Summarized count data: worksheet holds
the contingency table counts
Here we have the results of 500 father/son
pairs classified by both the father's and the
son's occupation. The father's occupation is
shown on the rows and the son's on the
columns.
Use Stat > Tables > Chi-Square Test
(Two-Way Table in Worksheet)…
Columns containing the table: Specify the
columns of the worksheet containing the cell counts.
130
Chi-Square Test for Two-Way Table (Minitab)
The output shows the contingency table with expected counts and the individual
contributions to the chi-square statistic, along with the results of the chi-square test.
Chi-Square Test: Prof/Bus, Skilled, Unskilled, Farmer
Expected counts are printed below observed counts
Chi-Square contributions are printed below expected counts
Prof/Bus
55
34.20
12.650
Skilled
38
41.40
0.279
Unskilled
7
16.00
5.063
Farmer
0
8.40
8.400
Total
100
2
79
59.85
6.127
71
72.45
0.029
25
28.00
0.321
0
14.70
14.700
175
3
22
49.59
15.350
75
60.03
3.733
38
23.20
9.441
10
12.18
0.390
145
4
15
27.36
5.584
23
33.12
3.092
10
12.80
0.613
32
6.72
95.101
80
Total
171
207
80
42
500
1
Chi-Sq = 180.874, DF = 9, P-Value = 0.000
131
Regression (Minitab)
To perform regression analysis,
data must be entered in the
worksheet with one row per
observation and one column for
each variable term in the
regression model.
Here we have 24 orange juice
samples, 6 from each of 4
brands, the pectin content, and
measure of sweetness for each.
We use 3 dummy/indicator
variables to indicate the 4 levels
of brand.
Use Stat > Regression > Regression…
Response: Specify the column containing
the y-variable data.
Predictors: Specify the column(s) containing
the data corresponding to each term in the
model. Here we fit a simple linear model of
the form
𝑦 = 𝛽0 + 𝛽1 𝑃𝑒𝑐𝑡𝑖𝑛 + 𝜖
132
Regression (Minitab)
Use the Graphs… button to request residual
plots.
Residuals for Plots: Specify the type of
residuals.
Regular
Standardized
Deleted
𝑦𝑖 − 𝑦̂𝑖
𝑦𝑖 −𝑦̂𝑖
𝑠
𝑦𝑖 −𝑦̂𝑖∗
𝑠∗
where 𝑦̂𝑖∗ and 𝑠 ∗ are calculated based on the
model fit to the data where observation 𝑖 is omitted.
Residual Plots: Request plots individually or a Four-in-one display.
Residuals versus the variables: Request residuals (on the y-axis) plotted against any
variable in the worksheet.
Use the Options… button to request
additional analyses such as Variance
inflation factors (VIF) for each term in the
model and the Durbin-Watson statistic to
test for first-order autocorrelation.
Predication intervals for new
observations: Use this option to request
confidence intervals and prediction
intervals for a particular set of x's. Specify
the values of the x variables in the same
order as their terms appear in the model, i.e. in the same order as you entered the
terms in the Predictors box. Here we predict Sweetness for 250 ppm of Pectin.
133
Regression (Minitab)
The output of this analysis is displayed in both the session window and several graph
windows.
Regression Analysis: SweetIndex versus Pectin
The regression equation is
SweetIndex = 6.25 - 0.00231 Pectin
Predictor
Constant
Pectin
Coef
6.2521
-0.0023106
S = 0.214998
SE Coef
0.2366
0.0009049
R-Sq = 22.9%
T
26.42
-2.55
P
0.000
0.018
R-Sq(adj) = 19.4%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
1
22
23
SS
0.30140
1.01693
1.31833
MS
0.30140
0.04622
F
6.52
P
0.018
Unusual Observations
Obs
1
11
16
Pectin
220
410
383
SweetIndex
5.2000
5.4000
5.3000
Fit
5.7437
5.3047
5.3671
SE Fit
0.0552
0.1453
0.1222
Residual
-0.5437
0.0953
-0.0671
St Resid
-2.62R
0.60 X
-0.38 X
R denotes an observation with a large standardized residual.
X denotes an observation whose X value gives it large leverage.
Predicted Values for New Observations
New Obs
1
Fit
5.6744
SE Fit
0.0443
95% CI
(5.5825, 5.7664)
95% PI
(5.2192, 6.1297)
Values of Predictors for New Observations
New Obs
1
Pectin
250
Residual Plots for SweetIndex
Residuals Versus Pectin
Normal Probability Plot
(response is SweetIndex)
Percent
0.3
0.4
90
0.2
50
0.1
10
0.0
1
0.0
-0.2
-0.4
-0.50
-0.25
-0.1
0.00
Residual
0.25
0.50
5.3
5.4
Histogram
-0.2
-0.5
200
250
300
Pectin
350
400
0.2
6
4
2
0
134
5.7
Versus Order
Residual
-0.4
5.5
5.6
Fitted Value
0.4
8
-0.3
Frequency
Residual
0.2
Versus Fits
99
Residual
0.4
0.0
-0.2
-0.4
-0.4
-0.2
0.0
Residual
0.2
2
4
6
8 10 12 14 16 18 20 22 24
Observation Order
Regression (Minitab)
To fit separate, parallel lines to the data, one for each brand, we fit the multiple
regression model
𝑦 = 𝛽0 + 𝛽1 𝑃𝑒𝑐𝑡𝑖𝑛 + 𝛽2 𝐵𝑟𝑎𝑛𝑑𝐴 + 𝛽3 𝐵𝑟𝑎𝑛𝑑𝐵 + 𝛽4 𝐵𝑟𝑎𝑛𝑑𝐶 + 𝜖
Use Stat > Regression > Regression… and specify 4 predictor terms. We use the
Options… button to request a confidence interval and prediction interval for a pectin
content of 250 ppm from Brand B.
135
Regression (Minitab)
Regression Analysis: SweetIndex versus Pectin, Brand_A, Brand_B, Brand_C
The regression equation is
SweetIndex = 6.19 - 0.00193 Pectin - 0.024 Brand_A - 0.023 Brand_B
- 0.108 Brand_C
Predictor
Constant
Pectin
Brand_A
Brand_B
Brand_C
Coef
6.1924
-0.001927
-0.0238
-0.0233
-0.1081
S = 0.227640
SE Coef
0.2894
0.001151
0.1322
0.1362
0.1465
R-Sq = 25.3%
T
21.40
-1.68
-0.18
-0.17
-0.74
P
0.000
0.110
0.859
0.866
0.470
R-Sq(adj) = 9.6%
Analysis of Variance
Source
Regression
Residual Error
Total
Source
Pectin
Brand_A
Brand_B
Brand_C
DF
1
1
1
1
DF
4
19
23
SS
0.33375
0.98458
1.31833
MS
0.08344
0.05182
F
1.61
P
0.213
Seq SS
0.30140
0.00009
0.00407
0.02819
Unusual Observations
Obs
1
11
Pectin
220
410
SweetIndex
5.2000
5.4000
Fit
5.7446
5.3789
SE Fit
0.0932
0.1866
Residual
-0.5446
0.0211
St Resid
-2.62R
0.16 X
R denotes an observation with a large standardized residual.
X denotes an observation whose X value gives it large leverage.
Predicted Values for New Observations
New Obs
1
Fit
5.6873
SE Fit
0.0956
95% CI
(5.4873, 5.8873)
95% PI
(5.1705, 6.2040)
Values of Predictors for New Observations
New Obs
1
Pectin
250
Brand_A
0.000000
Brand_B
1.00
Brand_C
0.000000
136
Regression (Excel)
To perform regression analysis, data
must be entered in the worksheet
with one row per observation and
one column for each variable term in
the regression model.
All columns containing data for the
predictor terms in the model must be
in one contiguous block of columns.
Here we have 24 orange juice
samples, 6 from each of 4 brands,
the pectin content, and measure of
sweetness for each.
We use 3 dummy/indicator variables
to indicate the 4 levels of brand.
Use Data > Data Analysis > Regression.
Input Y Range: Specify the column
containing the y-variable data.
Input X Range: Specify the column or block
of columns containing the data corresponding
to each term in the model. Here we fit a
multiple regression model of the form
𝑦 = 𝛽0 + 𝛽1 𝑃𝑒𝑐𝑡𝑖𝑛 + 𝛽2 𝐵𝑟𝑎𝑛𝑑𝐴 + 𝛽3 𝐵𝑟𝑎𝑛𝑑𝐵 +
𝛽4 𝐵𝑟𝑎𝑛𝑑𝐶 + 𝜖 .
137
Regression (Excel)
Labels: Check this box if the input ranges include the column names.
Residual Plots: Request a residual plot of residuals vs. each predictor variable.
Normal Probability Plots: Request a normal probability plot of the response (y) data.
This is not really the plot we want to look at; we'd like a normal probability plot of the
residuals (see Minitab).
The output shows some regression summary statistics, the ANOVA table, and table of
parameter estimates. The interval estimates are confidence intervals for the 𝛽
parameters.
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.503153
R Square
0.253163
Adjusted R Square
0.095935
Standard Error
0.22764
Observations
24
ANOVA
df
Regression
SS
MS
4
0.333754
0.083438
Residual
19
0.98458
0.05182
Total
23
1.318333
Coefficients
Standard Error
Intercept
6.19237
Pectin
Brand_A
F
1.61016
Significance F
0.2127
Lower
95.0%
Upper
95.0%
6.797988
5.586752
6.797988
-0.00434
0.000481
-0.00434
0.000481
-0.30045
0.25291
-0.30045
0.25291
0.866215
-0.3084
0.261873
-0.3084
0.261873
0.469758
-0.4148
0.198622
-0.4148
0.198622
t Stat
P-value
0.289351
21.4009
9.27E-15
5.586752
-0.00193
0.001151
-1.67519
0.110277
-0.02377
0.132192
-0.17982
0.859196
Brand_B
-0.02326
0.136232
-0.17076
Brand_C
-0.10809
0.146541
-0.73762
138
Lower 95%
Upper
95%
Regression (Excel)
Pectin Residual Plot
Brand_A Residual
Plot
0.4
0.3
0.4
0.2
0.2
0
-0.1 0
200
400
Residuals
Residuals
0.1
600
-0.2
-0.3
-0.4
0
0
0.5
1
1.5
-0.2
-0.4
-0.5
-0.6
-0.6
Pectin
Brand_B Residual Plot
Brand_C Residual
Plot
0.4
0.4
0.2
0
0
0.5
1
Residuals
Residuals
0.2
1.5
-0.2
-0.4
0
-0.2
0
0.5
-0.4
-0.6
-0.6
Brand_B
Normal Probability Plot
6.5
SweetIndex
Brand_A
6
5.5
5
0
20
40
60
80
100
Sample Percentile
139
120
Brand_C
1
1.5
̅ Chart (Minitab)
𝒙
Use Stat > Control Charts > Variables Charts for Subgroups > X-bar…
There are two ways to input the data: stacked and
unstacked.
Stacked Format
All observations for a chart are in one column: Data for
each sample are stacked in a single column. Here we show
data for 10 samples of size 4 in a single column.
Subgroup sizes: Enter the sample size for each sample (𝑛).
Use Xbar Options… to further specify
the analysis:
Use the Estimate tab to specify the
method for estimating the process
standard deviation (𝜎). Our text uses the
Rbar (𝑅̅ ) method.
140
̅ Chart (Minitab)
𝒙
Use the S Limits tab to request control
limits and zone boundaries at 1-, 2-, and
3-standard deviations from the centerline.
Enter the multiples separated by spaces.
Note: "Standard deviation" here refers to
𝜎
𝜎𝑥̅ = 𝑛. If the Rbar method of estimating
√
𝜎 is used, 𝜎𝑥̅ ≈
̅
𝑅
𝑑2
√𝑛
.
Use the Tests tab to request all relevant
tests for special causes.
Note: The default settings of K
correspond to the tests in our text.
Xbar Chart of X
13
+3SL=12.658
12
Sample Mean
The output is an 𝑥̅ chart. If any of
the tests for special causes reveal
unusual patterns/points, they will
be noted in the session window
and flagged on the chart. Here,
none of the 8 tests reveal unusual
patterns.
+2SL=11.732
11
+1SL=10.806
_
_
X=9.880
10
9
-1SL=8.954
8
-2SL=8.028
7
-3SL=7.102
1
141
2
3
4
5
6
Sample
7
8
9
10
̅ Chart (Minitab)
𝒙
Unstacked Format
Observations for a subgroup are in one row of
columns: Data for each sample are in a row of the
worksheet and each row shows a different sample. Here we show data for 10 samples
of size 3. Specify the columns containing the data for each sample.
Using the same Xbar options as above gives the following chart.
Xbar Chart of X1, ..., X3
130
+3SL=125.21
Sample Mean
120
+2SL=117.82
+1SL=110.43
110
_
_
X=103.04
100
-1SL=95.65
90
-2SL=88.26
-3SL=80.86
80
1
2
3
4
5
6
Sample
7
8
9
10
142
R Chart (Minitab)
Use Stat > Control Charts > Variables Charts for Subgroups > R…
There are two ways to input the data: stacked and unstacked.
Stacked Format
All observations for a chart are in one column: Data for
each sample are stacked in a single column. Here we show
data for 10 samples of size 4 in a single column.
Subgroup sizes: Enter the sample size for each sample (𝑛).
Use R Options… to further specify the
analysis:
Use the Estimate tab to specify the
method for estimating the process
standard deviation (𝜎). Our text uses the
Rbar (𝑅̅ ) method.
143
R Chart (Minitab)
Use the S Limits tab to request control
limits and zone boundaries at 1-, 2-, and 3standard deviations from the centerline.
Enter the multiples separated by spaces.
Note: "Standard deviation" here refers to
the standard deviation of the sample
range, 𝜎𝑅 .
Use the Tests tab to request all relevant
tests for special causes.
Note: The default settings of K correspond
to the tests in our text.
R Chart of X
9
+3SL=8.699
8
+2SL=7.070
7
Sample Range
The output is an R chart. If any of
the tests for special causes reveal
unusual patterns/points, they will be
noted in the session window and
flagged on the chart. Here, none of
the 4 tests reveal unusual patterns.
6
+1SL=5.442
5
_
R=3.813
4
3
-1SL=2.185
2
1
-2SL=0.556
-3SL=0
0
1
144
2
3
4
5
6
Sample
7
8
9
10
R Chart (Minitab)
Unstacked Format
Observations for a subgroup are in one row of columns: Data for each sample are
in a row of the worksheet and each row shows a different sample. Here we show data
for 10 samples of size 3. Specify the columns containing the data for each sample.
Using the same R options as above gives the following chart.
R Chart of X1, ..., X3
60
+3SL=55.79
50
Sample Range
+2SL=44.42
40
+1SL=33.04
30
_
R=21.67
20
-1SL=10.30
10
0
-3SL=0
-2SL=0
1
2
3
4
5
6
Sample
7
8
9
10
145
P Chart (Minitab)
The data must be arranged in the worksheet with a column
containing the number of "successes" for each sample.
Here we have 15 samples of 20 items, each of which we
classify as defective or not. The number defective for each
sample is shown.
Use Stat > Control Charts > Attributes Chart > P…
Variables: Specify the column containing the number of successes for each sample.
Subgroup sizes: Enter the sample size for each sample (𝑛).
Use P Chart Options… to further spec ify
the analysis:
Use the S Limits tab to request control
limits and zone boundaries at 1-, 2-, and 3standard deviations from the centerline.
Enter the multiples separated by spaces.
Note: "Standard deviation" here refers to
𝑝(1−𝑝)
𝜎𝑝̂ = √
𝑛
. 𝑝 is estimated by 𝑝̅ , the
overall proportion of successes.
146
P Chart (Minitab)
Use the Tests tab to request all relevant
tests for special causes.
Note: The default settings of K correspond
to the tests in our text.
The output is a P chart. If any of the tests for special causes reveal unusual
patterns/points, they will be noted in the session window and flagged on the chart.
Here, none of the 4 tests reveal unusual patterns.
P Chart of Num Defective
0.30
+3SL=0.2754
0.25
+2SL=0.2125
Proportion
0.20
0.15
+1SL=0.1496
0.10
_
P=0.0867
0.05
-1SL=0.0238
0.00
-3SL=0
-2SL=0
1
2
3
4
5
6
7
8
9
Sample
10 11 12 13 14 15
147
Time Series Plot (Minitab)
To plot a time series obtained at regular intervals of time,
record the time series values in the worksheet in a single
column. Here we have the quarterly price (dollars) of a
stock for 4 years.
Use Stat > Time Series > Time Series Plot and choose
Simple.
Series: Specify the column containing the time series values.
The default x-axis is a time
index that begins at 1 with the
first time point (here, first
quarter of 2009).
Time Series Plot of Price
90
Price
80
70
60
50
40
2
148
4
6
8
Index
10
12
14
16
Moving Averages (Minitab)
Record the time series values in the worksheet in a single
column. Here we have the quarterly price (dollars) of a
stock for 4 years.
Use Stat > Time Series > Moving Average…
Variable: Specify the column containing the time series values.
MA length: Specify the number of time points to include in the moving average.
Center the moving averages: Check this box to compute the moving average at time
𝑖, (𝑀𝐴𝑖 ), using the window centered at the time point. The default is to use a window
ending at time 𝑖.
Use the Storage… button to store the moving
averages in the worksheet.
149
Moving Averages (Minitab)
Use the Graphs… button to plot the
smoothed vs. the actual values. The default
is to plot the predicted (previous smoothed
value) vs. the actual values.
The output shows the original time series (actual values), the smoothed series using
moving averages, and three accuracy measures.
Moving Average Plot for Price
Variable
A ctual
Smoothed
90
Mov ing A v erage
Length 3
Price
80
A ccuracy Measures
MA PE
8.5700
MA D
6.1674
MSD
53.6898
70
60
50
40
2
4
6
8
10
Index
12
14
16
150
Single Exponential Smoothing (Minitab)
Record the time series values in the worksheet in a single
column. Here we have the quarterly price (dollars) of a
stock for 4 years.
Use Stat > Time Series > Single Exp Smoothing…
Variable: Specify the column containing the time series values.
Weight to Use in Smoothing: Select the Use radio button and specify the weight, 𝑤.
The default is to use an optimizing algorithm to determine the weight.
Under Options… set the initial smoothed value as
the the first actual value (K = 1). This matches the
technique our text uses.
Use the Storage… button to store the smoothed
values in the worksheet.
151
Single Exponential Smoothing (Minitab)
Use the Graphs… button to plot the smoothed
vs. the actual values. The default is to plot the
predicted (previous smoothed value) vs. the
actual values.
The output shows the original time series (actual values), the smoothed series using
single exponential smoothing, and three accuracy measures.
Note: Minitab refers to the smoothing weight, 𝑤, as "Alpha."
Smoothing Plot for Price
Single Exponential Method
Variable
A ctual
Smoothed
Price
90
80
Smoothing Constant
A lpha 0.7
70
A ccuracy Measures
MA PE
10.8279
MA D
7.5114
MSD
94.7440
60
50
40
2
4
6
8
10
Index
12
14
16
152
Trend Analysis (Minitab)
Record the time series values in the worksheet in a single
column. Here we have the quarterly price (dollars) of a
stock for 4 years.
Use Stat > Time Series > Trend Analysis…
Variable: Specify the column containing the time series values.
Model Type: Select the type of trend model you want to fit. Here we select a linear
trend model (linear regression model) of the form 𝑌𝑡 = 𝛽0 + 𝛽1 𝑡 + 𝜖 where 𝑡 =
1, 2, 3, … , 𝑛. Minitab creates this column for you so that you don't need to specify a
predictor column.
Use Generate forecasts to compute predicted values of the time series for a specified
number of time periods past the end of the observed series. Here we request a
forecasted price for first quarter 2013.
153
Trend Analysis (Minitab)
The graph shows the estimated trend model, the original time series (actual values), the
predicted values using the estimated trend model (fits), and the forecasted values,
along with three accuracy measures. These summaries are also shown in the session
window where the values of the forecasts are also displayed.
Trend Analysis for Price
Data
Length
NMissing
Trend Analysis Plot for Price
Linear Trend Model
Yt = 43.53 + 2.93*t
Price
16
0
100
90
A ccuracy Measures
MA PE
8.8131
MA D
5.7672
MSD
42.1620
80
Price
Fitted Trend Equation
Yt = 43.53 + 2.93*t
Variable
A ctual
Fits
Forecasts
70
60
Accuracy Measures
50
MAPE
MAD
MSD
40
8.8131
5.7672
42.1620
2
Forecasts
Period
17
Forecast
93.3646
Note: You can also use Stat > Regression >
Regression… to obtain the same estimated trend
model. You must first add a time index column
having the values 1, 2, 3, … , 𝑛 to the worksheet and
then specify that column as the Predictor column.
154
4
6
8
10
Index
12
14
16
Trend Analysis (Minitab)
Use the Options… button to request
forecasts by specifying the value of 𝑡 for the
desired time period.
The output will be formatted differently but
will show the same estimated model and
forecasts.
Note: Be careful when using p-values and
confidence intervals in a time series context
as the assumption of independent errors
may be violated.
Regression Analysis: Price versus t
The regression equation is
Price = 43.5 + 2.93 t
Predictor
Constant
t
Coef
43.532
2.9313
S = 6.94155
SE Coef
3.640
0.3765
R-Sq = 81.2%
T
11.96
7.79
P
0.000
0.000
R-Sq(adj) = 79.9%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
1
14
15
SS
2921.5
674.6
3596.1
MS
2921.5
48.2
F
60.63
P
0.000
Unusual Observations
Obs
12
t
12.0
Price
91.96
Fit
78.71
SE Fit
2.18
Residual
13.26
St Resid
2.01R
R denotes an observation with a large standardized residual.
Predicted Values for New Observations
New Obs
1
Fit
93.36
SE Fit
3.64
95% CI
(85.56, 101.17)
95% PI
(76.55, 110.18)
Values of Predictors for New Observations
New Obs
1
t
17.0
155
Trend Analysis (Excel)
Record the time series values in the worksheet in
a single column. Here we have the quarterly price
(dollars) of a stock for 4 years.
Add a time index column having the values
1, 2, 3, … , 𝑛 to the worksheet.
Use Data > Data Analysis > Regression to fit
the trend model to the data. Here we fit the linear
trend model (linear regression model) of the form
𝑌𝑡 = 𝛽0 + 𝛽1 𝑡 + 𝜖
Input Y Range: Specify the column containing the time series values.
Input X Range: Specify the column containing the time index column.
Labels: Check this box if the input ranges contain the column labels.
156
Trend Analysis (Excel)
From the regression output, you can obtain the estimated trend model and use it to
generate forecasts.
Note: Be careful when using p-values and confidence intervals in a time series context
as the assumption of independent errors may be violated.
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.901338
R Square
0.81241
Adjusted R Square
0.799011
Standard Error
6.941553
Observations
16
ANOVA
df
Regression
SS
MS
F
60.63097
1
2921.513
2921.513
Residual
14
674.5922
48.18516
Total
15
3596.105
Coefficients
Standard Error
43.532
2.931328
Intercept
t
Significance F
1.87E-06
t Stat
P-value
3.640181
11.95875
9.78E-09
35.72459
0.376459
7.786589
1.87E-06
2.123905
157
Lower 95%
Upper
95%
Lower
95.0%
Upper
95.0%
51.33942
35.72459
51.33942
3.738751
2.123905
3.738751
Seasonal Regression Models
Record the time series values
in the worksheet in a single
column. Here we have the
quarterly price (dollars) of a
stock for 4 years.
Include columns for 𝑙 − 1
dummy/indicator variables to
represent 𝑙 seasons. Here we
use 3 dummy variables to
represent the 4 quarters.
If you want to incorporate a
trend component in the model,
add a time index column to the
worksheet.
Refer to Regression (Minitab) or Regression (Excel) in this guide to fit the desired
model to the data:
Components
Seasonal only
Seasonal + Trend
Model
𝑌𝑡 = 𝛽0 + 𝛽1 𝑥1 + 𝛽2 𝑥2 + 𝛽3 𝑥3 + 𝜖
𝑌𝑡 = 𝛽0 + 𝛽1 𝑥1 + 𝛽2 𝑥2 + 𝛽3 𝑥3 + 𝛽4 𝑡 + 𝜖
158