Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Clustering
What is Cluster Analysis
k-Means
Adaptive Initialization
EM
Learning Mixture Gaussians
E-step
M-step
k-Means vs Mixture of Gaussians
k-Means Clustering
Zur Anzeige wird der QuickTime™
Dekompressor „TIFF (LZW)“
benötigt.
Feature space
Sample
x
(1)
(2)
, x ,.., x ,.., x
x1
x
2
d
x
..
..
x d
(k)
xy
(n )
d
2
(x
y
)
i i
i1
Norm
||x|| ≥ 0 equality only if x=0
|| x||=|| ||x||
||x1+x2||≤ ||x1||+||x2||
1
p
lp
norm
x
p
d p
x i
i1
Metric
d(x,y) ≥ 0 equality holds only if x=y
d(x,y) = d(y,x)
d(x,y) ≤ d(x,z)+d(z,y)
d
2
d2 (x,z )
x
z
i
i
i1
1
2
k-means Clustering
d
2
d2 (x,z )
x
z
i
i
i1
1
2
Cluster centers c1,c2,.,ck with clusters C1,C2,.,Ck
Error
k
E
d (x,c
2
j
)
2
j1 x C j
The error function has a local minima if,
k-means Example
(K=2)
Pick seeds
Reassign clusters
Compute centroids
Reasssign clusters
x
x
x
x
Compute centroids
Reassign clusters
Converged!
Algorithm
Random initialization of k cluster centers
do
{
-assign to each xi in the dataset the nearest
cluster center (centroid) cj according to d2
-compute all new cluster centers
}
until ( |Enew - Eold| < or
number of iterations max_iterations)
Adaptive k-means learning (batch modus)
for large datasets
Random initialization of cluster centers
do
{
chose xi from the dataset
cj* nearest cluster center (centroid) cj according to d2
c
*new
j
c
*old
j
1
C
old
j*
x c
1
*old
j
}
until ( |Enew - Eold| < or
number of iterations max_iterations)
How to chose k?
You have to know your data!
Repeated runs of k-means clustering on
the same data can lead to quite different
partition results
Why? Because we use random initialization
Zur Anzeige wird der QuickTime™
Dekompressor „TIFF (LZW)“
benötigt.
Adaptive Initialization
Choose a maximum radius within every data
point should have a cluster seed after
completion of the initialization phase
In a single sweep go through the data and
assigns the cluster seeds according to the
chosen radius
A data point becomes a new cluster seed, if it is not
covered by the spheres with the chosen radius of the
other already assigned seeds
K-MAI clustering (Wichert et al. 2003)
EM
Expectation Maximization Clustering
Feature space
Sample
x
(1)
(2)
(k)
, x ,.., x ,.., x
x1
x
2
d
x
..
..
xy
x d
(n )
(x ) (x )
T
m
Mahalanobis distance
1
Bayes’s rule
After the evidence is obtained; posterior probability
P(a|b)
The probability of a given that all we know is b
P(a | b)P(b)
P(b | a)
P(a)
(Reverent Thomas Bayes 1702-1761)
Covariance
Measuring the tendency two features xi and xj
varying in the same direction
The covariance between features xi and xj is
estimated for n patterns
n
c ij
k1
x i mi x j
(k )
n 1
(k )
mj
c11 c12
c
c
21
22
..
..
c d1 c d 2
.. c1d
.. c 2d
.. ..
.. c dd
Learning Mixture Gaussians
What kind of probability distribution might
have generated the data
Clustering presumes that the data are
generated from mixture distributions, P
The Normal Density
Univariate density
Density which is analytically tractable
Continuous density
A lot of processes are asymptotically Gaussian
P( x )
2
1
1 x
exp
,
2
2
Where:
= mean (or expected value) of x
2 = expected squared deviation or variance
Example: Mixture of 2
Gaussians
Zur Anzeige wird der QuickTime™
Dekompressor „TIFF (LZW)“
benötigt.
Multivariate density
Multivariate normal density in d dimensions is:
P( x )
1
( 2 )
d/2
1/ 2
1
t
1
exp ( x ) ( x )
2
where:
x = (x1, x2, …, xd)t (t stands for the transpose vector form)
= (1, 2, …, d)t mean vector
= d*d covariance matrix
|| and -1 are determinant and inverse respectively
Zur Anzeige wird der QuickTime™
Dekompressor „TIFF (LZW)“
benötigt.
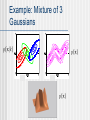
Example: Mixture of 3
Gaussians
A mixture distribution has k components,
each of which is a distribution in its own
A data point is generated by first choosing
a component and than generating a
sample from that component
Let C denote the component with values 1,…,k
Mixture distribution is given by
k
P(x) P(C i)P(x | C i)
i1
k
1 P(C i)
I 1
x refers to the data point
wi=P(C=i) the weight of each component
µi the mean (vector) of each component ∑i (matrix)
the covariance of each component
P( x )
1
( 2 )d / 2
1/ 2
1
exp ( x )t 1 ( x )
2
If we knew which component generated
each data point, then it would be easy to
recover the component Gaussians
We could fit the parameters of a Gaussian
to a data set
P( x )
1
( 2 )d / 2
1/ 2
1
exp ( x )t 1 ( x )
2
Basic EM idea
Pretend that we know the parameters of the
model
Infer the probability that each data point
belongs to each component
Refit the component to the data, where each
component is fitted to the entire data set
Each point is weighted by the probability that it
belongs to that component
Algorithm
We initialize the mixture parameters arbitrarily
E- step (expectation):
Compute the probabilities pij=P(C=i|xj), the
probability that xj was generated by the component I
By Bayes’ rule pij=P(xj|C=i)P(C=i)
• P(xj|C=i) is just the probability at xj of the ith Gaussian
• P(C=i) is just the weight parameter of the ith Gaussian
n
pi pij
j1
M-step (maximization):
n
pij x j
i
j1 pi
n
j1
i
wi pi
wi=P(C=i)
pij x j x j
pi
T
Zur Anzeige wird der QuickTime™
Dekompressor „TIFF (LZW)“
benötigt.
Problems
Gaussians component shrinks so that it covers just a
single point
Variance goes to zero, and likelihood will go to infinity
Two components can “merge”, acquiring identical
means and variances and sharing their data points
Serious problems, especially in high dimensions
It helps to initialize the parameters with reasonable
values
k-Means vs
Mixture of Gaussians
Both are iterative algorithms to assign points to clusters
k
K-Means: minimize E
2
d
(x,c
)
2 j
j1 x C j
MixGaussian: maximize P(x|C=i)
P( x )
1
( 2 )d / 2
1/ 2
1
exp ( x )t 1 ( x )
2
Mixture of Gaussian is the more general formulation
Equivalent to k-Means when ∑i =I
,
1
P(C i) k
0
Ci
else
What is Cluster Analysis
k-Means
Adaptive Initialization
EM
Learning Mixture Gaussians
E-step
M-step
k-Means vs Mixture of Gaussians
Tree Clustering
COBWEB