Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
High Performance Networks in
multicore/manycore Era
Atul Bodas
HPC Technologies Group
C-DAC, Pune
A brief talk about “State Of HPC networks” in current
multicore/manycore computing Era
(heavily influenced by perspective of a hardware designer)
About HPC-Technology Development Group
• Our group works in the area of high performance network
design: From conceptualization to product: covering multiple
aspects of hardware, software development, integration and
deployment aspects
• Last several years, the group has been developing high speed
networks used as a building block for Indigenous PARAM
supercomputers . This network component is called PARAMNet
• Over last 15+ years, three generations of PARAMNet have been
developed and deployed in PARAM systems in India and
Abroad
• Currently developing the next generation of network in the
series “Trinetra” under NSM project
History of PARAMNet
Network
Data Speed
Co-Processor
Switch
Software Stack
Primary
Deployment
PARAMNet-I
(beta)
100 Mbits/sec
CCP-I
8-port, 100
MBits/sec, Copper
(DS Link)
CDAC
Proprietary
PARAM
PARAMNet-I
400 Mbits/sec
CCP-II
8-port
400 Mbits/sec
Copper (DS Link)
CDAC
Proprietary
Fast Sockets
PARAM 10000
PARAMNet-II
2.5 Gbits/sec
CCP-III “Neo”
16-port
2.5 Gbps, full
duplex, Fiber
VIPL compliant
PARAM Padma
PARAMNet-3
10 Gbits/sec
Gemini
48-port
10 Gbps/sec, full
duplex
Copper (CX-4)
DAPL
SDP
TCP/IP
compliant
PARAM
Work initiated on next generation network: Trinetra
9000
Yuva
HPC Systems today
• Race to Exascale machines is on
– Millions of compute cores rather than thousands
• Transition to Multi/Manycore Era
– Requires new programming paradigms
• (Low) Power is now new Mantra (power/performance)
– Contributions from Silicon (circuit design) to systems (eg Liquid
cooling)
• Exascale applications: few potential candidates identified
– Need of few applications goes well beyond Exascale!
• Data no longer can be ignored
– (Exa) Flops require (Exa) Bytes!
• HPC influenced system architectures are finally emerging
– Eg Intel Xeon Phi
• Principles of HPC are now enjoying wider support
– { Distributed, Deep learning, Data center centric } apps
New Challenges
• How to extract performance?
– Ever increasing gap between theoretical and useful performance
– Fragmented community and conflicting vendors interests
– No clear directives or framework for end users (application
developers)
• From Open systems to Closed Systems?
– Commercial interests prevent emergence of a mutually acceptable
framework
– More so for programming (processor) framework
– Hardware + HPC software stack + Guidelines
• Guidelines: Generic supported by everyone, performance driven:
Custom!!
• Heterogeneous system architectures as demanded by
application classes complicates matters further
– {classical HPC, GPGPU, Data intensive, Memory intensive}
Network as a HPC building block
• Key components towards performance and scalability of
systems using distributed computing principles ie clusters
• Principles of operation
– Latency and bandwidth (raw)
– Intelligence (transport offload, collectives, atomics,..)
• Standard consumers : MPI, and (storage)
– Industry standard interfaces such as VPA, DAPL, OFA
• Infiniband is (was?) a de-facto network
– IBTA consortium driven
• Transition from Open components to Closed components?
–
–
–
–
IB: Single vendor (mellanox) => proprietary(?)
Intel (Qlogic, Cray) => OPA (proprietary)
Custom networks (Many eg Cray,IBM,Fujitsu,China)..
Hardware + HPC software stack + Guidelines
Generic interfaces: supported by all, performance driven:
Custom!!
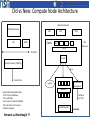
Old vs New: Compute Node Architecture
Memory Channels
100 MHz processor
NB
Ch0
MEM
Cores
Ch1
Ch(n)
MC
Processor
3GHz
L2/L3
32-bit PCI
Pci root
Comm Processor (33 MHz)
pci-e
True Fat Tree
NP(800 MHz)
Hardwired
Legacy
System Imbalances/Bottlenecks
- CPU: L2/L3 and Memory
- PCI-e and DMA
- Acc Processor: Shared L2/GDDR
- NP arch inferior to Processor
- Multitier network
Network as Afterthought ??
Shared L2
Blocking
Fat Tree
G-DDR (few GB)
Accelerator
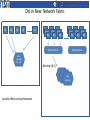
Old vs New: Network Fabric
N1
N2
N3
N4
Nn
N1
N2
N3
N1
N2
N3
N1
N2
N3
N1
N2
N3
N1
N2
N3
N1
N2
N3
Edge Switches
Edge Switches
Nonblocking
Fat Tree
Blocking (N:1)
Core
Switches
Locality affects end performance
Experiences with application developers
• Have no idea of network fabric and underlying
architecture
• Have a magical expectations from network fabric
• Are not at all sensitive or aware of network centric
programming
• Too much stress on raw performance figures: A lot of
(mis) marketing involved
• May spend a considerable time optimizing code
while the problem is in network
“Need to change for large scale systems of tomorrow”
Design Drivers for new networks
• Scalability of design
– Support for accelerator based paradigms
– Large cluster deployments
• Latest Technologies at hardware level
– Host interface
– Physical link interfaces: Roadmaps upto 400 Gbps feasible in
next 2-3 years
– Multiple multi-giga link SERDES in hardware
– Silicon photonics for cheaper and robust fiber interfaces
• Raw vs Real Life (application) performance
– Handholding with users to extract useable performance
• Topology
– {Fat tree} scaling issues: fully nonblocking blocking
– Cost
– Torus or derivatives ?
Design Drivers for new networks
• Intelligence
– MPI collectives, atomics in hardware
– Onload or Offload?
• Hybrid?
• Make use of “free” cores in multicore architecture
• Robustness/ Reliability
– Fault tolerance
– Forward Error Correction / other techniques to minimize end-end
retries
• Power
– Power budget (20%): significant!
• Experimental platforms for Exascale
– Enough design hooks for new ideas experimentation
• Help from middleware
– Topology aware schedulers,..
– Power aware? : power saving hints to network hardware
Some of design issues
• I/O far from processor cores
– I/O bus too far from processor, not really optimized for latency
sensitive traffic
– I/O bus bridge component is an afterthought (HT was better)
– Licensed interfaces (QPI, NV-Link)
– PCI-e as a component is becoming fragmented
• CAPI (IBM)
• CCIX (consortium)
– Memory subsystem of processor is OS centric, DRAM centric
• Endpoint problem: exponential increase in resources
– Hardware has limited resources: exceeding these results in
inefficiencies. Not clear in performance figures
• Locality unawareness
– More so for Torus, also true for blocking Fat Trees
Some of design issues
• Known and unknown bottlenecks in the system
– Lot of buck passing: compute/network/software:
confusion at application level
• Congestion: local, global, deadlocks, livelocks, jitter
in performance
– Deterministic performance essential
• P-states in network: Programming model is towards
“always on” network (unlike p-states in processor)
– Power saving tricky
• QoS: Mixed traffic (eg appln/storage)
– Increased resources (buffer memories) at chip level
Application development
• Awareness of resource crunch at hardware level
• Locality principles to be extended to network
– Topology aware programming
• Pipelined or overlapping communication and
compute
– Burst of heavy traffic
• Power saving
– Hints to hardware thru middleware?
• Swarms of clusters model
Summary
• No clear directions or architecture capable of driving
exascale platform: need of experimentations
• New challenges for designers, middleware and end
consumers for Exascale
• Network architecture, hardware capabilities and
resources need to be used optimally
• Need of closely working together instead of isolated
communities
– Network aware programming need of hour?
• Power will continue to drive future architecture:
power/performance to be kept in mind at each layer in
design
Thank You
Questions/Comments?
[email protected]