Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
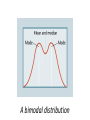
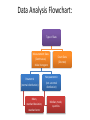
Quantitative Skills: Data Analysis and Graphing. Data analysis is one of the first steps toward determining whether an observed pattern has validity. Data analysis also helps distinguish among multiple working hypotheses. Most of the data you will collect will fit into two categories: measurements or counts. Measurement data Count data Most measurements are continuous, meaning there is an infinite number of potential measurements over a given range. Count data are recordings of qualitative, or discrete, data. Number of leaf stomata Number of white eyed individuals When an investigation involves measurement data, one of the first steps is to construct a histogram, or frequency diagram, to represent the data’s distribution If the data show an approximate normal distribution on a histogram, then they are parametric data (normal). If the data do not show an approximate normal distribution on a histogram, then they are nonparametric data. Different descriptive statistics and tests need to be applied to those data. Sometimes, due to sampling bias, data might not fit a normal distribution even when the actual population could be normally distributed. In this case, a larger sample size might be needed. For parametric data (a normal distribution), the appropriate descriptive statistics include : • • • • • the mean (average) sample size variance standard deviation standard error The mean (x)of the sample is the average. The mean summarizes the entire sample and might provide an estimate of the entire population’s true mean. The sample size (n) refers to how many members of the population are included in the study. Sample size is important when estimating how well the sample set represents the entire population. Variance (s2) and standard deviation (s) measure how far a data set is spread out. A variance of zero indicates that all the values in a data set are identical. Variance Distance from the mean Because the differences from the mean are squared to calculate variance, the units of variance are not the same units as in the original data set. The standard deviation is the square root of the variance. The standard deviation is expressed in the same units as the original data set, which makes it generally more useful than the variance. A small standard deviation indicates that the data tend to be very close to the mean. A large standard deviation indicates that the data are very spread out away from the mean. A little more than two-thirds of the data points will fall between +1 standard deviation and −1 standard deviation from the sample mean. More than 95% of the data falls between ±2 standard deviations from the sample mean. 68–95–99.7 Rule In a normal distribution, 68.27% of all values lie within one standard deviation of the mean. 95.45% of the values lie within two standard deviations of the mean. 99.73% of the values lie within three standard deviations of the mean. Sample standard error (SE) is a statistic used to make an inference about how well the sample mean matches up to the true population mean. Standard error should be represented by including error bars on graphs when appropriate. Error bars are used on graphs to indicate the uncertainty of a reported measurement. Different statistical tools are used in the case of data that does not resemble a normal distribution (nonparametric data, or data that is skewed or includes large outliers). • • • • median mode quartiles box-and-whisker plots The median is the value separating the higher half of a data sample from the lower half. To find the median of a data set, first arrange the data in order from lowest to highest value and then select the value in the middle. 5, 1, 3, 7, 2 1, 2, 3, 5, 7 median If there are two values in the middle of an ordered data set, the median is found by averaging those two values. 5, 1, 3, 7, 4, 2 1, 2, 3, 4, 5, 7 3.5 median The mode is the value that appears most frequently in a data set. 3, 5, 1, 3, 7, 2 3 is the mode in this example because it appears more frequently than any other number. A bimodal distribution Data Analysis Flowchart: Type of Data Measurement Data Count Data (Continuous) (Discrete) · Make histogram Parametric (normal distribution) Mean, standard deviation, standard error Nonparametric (not a normal distribution) Median, mode, quartiles Example of Data Analysis: Do shady English ivy leaves have a larger surface area than sunny English ivy leaves? Since the data collected is in centimeters, it is measurement data, not count data. So the first step is to make a: HISTOGRAM Does the data resemble a normal curve? (Close enough, with possible differences due to sampling error) Next, the appropriate statistical tools are applied: A bar graph can then be produced to compare the means: Do the error bars for the shady leaf mean overlap with the error bars for the sunny leaf mean? (No.) A more rigorous statistical test will need to be performed, but because the error bars do not overlap there is a high probability that the two populations are indeed different from each other. Example of Data Analysis: Is 98.6°F actually the average body temperature for humans? Since the data collected is in Farenheit, it is measurement data, not count data. So the first step is to make a: HISTOGRAM Does the data resemble a normal curve? (Close Enough) Next, the appropriate statistical tools are applied: *Note that by convention, descriptive statistics rounds the calculated results to the same number of decimal places as the number of data points plus 1. According to the 68–95–99.7 Rule, 68% of all samples lie within one standard deviation from the mean. This means that around 68% of the temperatures should be between 97.51 and 98.99. Including the standard error, we can say with a 68% confidence that the mean human body temperature of our sample is 98.25 ± 0.06°F. Categories of data: • Qualitative data is not numerical and is usually subjective. • Quantitative data is numerical and lends itself to statistical analysis. 1.75 mL Quantitative data can be either discrete or continuous. • Discrete data has finite values, such as integers, or bucket categories such as “red” or “tall”. • Continuous data has an infinite number of values and forms a continuum. Which graph shows continuous data and which graph shows discrete data? Graph A Graph B One of the first steps in data analysis is to create graphical displays of the data. Visual displays can make it easy to see patterns and can clarify how two variables affect each other. Line Graphs • Used when data on both scales of the graph (the x and y axes) are continuous. • The dots indicate measurements that were actually made. Basic Traits of A Good Graph 1. A Good Title • A good title is one that tells exactly what information the author is trying to present with the graph. Relation Between Study Time and Score on a Biology Exam in 2011 -orStudy Time vs. Score on a Biology Exam in 2011 Basic Traits of A Good Graph 2. Axes should be consistently numbered. 3. Axes should contain labels, including units. Basic Traits of A Good Graph 6. The independent variable is always shown on the x axis. 7. The dependent variable is always shown on the y axis. Dependent Variable Independent Variable Extrapolation is a prediction of what the chart might look like beyond the measured set of data. A broken line is used, indicating this a prediction and not data actually collected. The slope of a line indicates the rate at which the variables being graphed are changing. y m= x = y2 – y1 x 2 – x1 Rise Slope = Run Positive Slope Negative Slope Zero Slope Rate Increasing Rate Decreasing Constant Rate Indicates some values were skipped Line charts can be plotted with multiple data sets, allowing for better comparison. Makes use of a legend Effective graphs use statistics as an essential part of the display. Statistics is the study of the collection, organization, analysis, interpretation and presentation of data. Population vs. Sample • Often, researchers want to know things about a population (N), but it may not be feasible to obtain data for every member of an entire population. • A sample (n) is a smaller group of members of a population selected to represent the population. The sample must be random. Descriptive statistics and graphical displays allow us to estimate how well sample data represent the true population. If a sample is not collected randomly, it may not closely reflect the original population. This is called sampling bias. A normal distribution, also known as a “bell curve” or “normal curve”, can be formed with continuous data. The type of data being collected during an investigation should be determined before performing the actual experiment. The type of data will determine the statistical analyses that can be used. Three Types of Data: • Parametric data: data that fit a normal curve • Nonparametric data: data that do not fit a normal curve • Frequency or count data: generated by counting Normal or parametric data • Measurement data that fit a normal curve or distribution. • Data is continuous, generally in decimal form. Nonparametric data • Do not fit a normal distribution, may include large outliers, or may be count data that can be ordered. • Can be qualitative data. Frequency or count data • Generated by counting how many of an item fit into a category. • Can be data that are collected as percentages. Two Types of Descriptive Statistics: • Comparative statistics: compare variables • Association statistics: look for correlations between variables Comparative statistics compare phenomena, events, or populations (Is A different from B?). Bar Graph Box-and-Whisker Plot Parametric Data (normal data) Nonparametric Data Bar Graph or Pie Chart Frequency Data (counts) Association statistics look for associations between variables (How are A and B correlated?). Scatterplot Parametric Data and Nonparametric Data Types of graphs commonly used with the three data types and suggested statistical tests: Bar Graphs • Used to visually compare two samples of categorical or count data. • Are also used to visually compare the calculated means with error bars of normal data . Sample standard error bars (also known as the sample error of the sample mean) are the notations at the top of each shaded bar that shows the sample standard error (SE). Scatterplots • Used when comparing one measured variable against another. • Used when looking for trends. If the relationship is thought to be linear, a linear regression line or best fit line can be plotted to help define the pattern. Box-and-Whisker Plots • Allow graphical comparison of two samples of nonparametric data (data that do not fit a normal distribution). In a box-and-whisker graph, the ticks at the tops and bottoms of the vertical lines show the highest and lowest values in the dataset, respectively. The top of each box shows the upper quartile, the bottom of each box shows the lower quartile, and the horizontal line represents the median. Histograms (Frequency Diagrams) • Used to display the distribution of data, providing a representation of the central tendencies and the spread of data. Creating a histogram requires setting up bins — uniform range intervals that cover the entire range of the data. Then the number of measurements that fit in each bin are counted and graphed. If the data on a histogram show an approximate normal distribution, then these are parametric data. If the data do not approximate a normal distribution then they are nonparametric data. References: AP® Biology Investigative Labs: An Inquiry-Based Approach and AP® Biology Quantitative Skills: A Guide for Teachers