Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
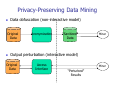
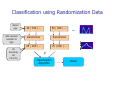
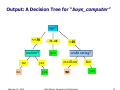
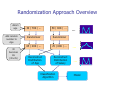
Introduction to Data Mining Privacy preserving data mining Li Xiong Slides credits: Chris Clifton Agrawal and Srikant 4/3/2011 1 Privacy Preserving Data Mining Privacy concerns about personal data AOL query log release Netflix challenge Data scraping A race to the bottom: privacy ranking of Internet service companies A study done by Privacy International into the privacy practices of key Internet based companies Amazon, AOL, Apple, BBC, eBay, Facebook, Friendster, Google, LinkedIn, LiveJournal, Microsoft, MySpace, Skype, Wikipedia, LiveSpace, Yahoo!, YouTube A Race to the Bottom: Methodologies Corporate administrative details Data collection and processing Data retention Openness and transparency Customer and user control Privacy enhancing innovations and privacy invasive innovations A race to the bottom: interim results revealed Why Google Retains a large quantity of information about users, often for an unstated or indefinite length of time, without clear limitation on subsequent use or disclosure Maintains records of all search strings with associated IP and time stamps for at least 18-24 months Additional personal information from user profiles in Orkut Use advanced profiling system for ads Remember, they are always watching … Some advice from privacy campaigners … Use cash when you can. Do not give your phone number, social-security number or address, unless you absolutely have to. Do not fill in questionnaires or respond to telemarketers. Demand that credit and data-marketing firms produce all information they have on you, correct errors and remove you from marketing lists. Check your medical records often. Block caller ID on your phone, and keep your number unlisted. Never leave your mobile phone on, your movements can be traced. Do not user store credit or discount cards If you must use the Internet, encrypt your e-mail, reject all “cookies” and never give your real name when registering at websites Better still, use somebody else’s computer Privacy-Preserving Data Mining Data obfuscation (non-interactive model) Original Data Anonymization “Sanitized” Data Miner Output perturbation (interactive model) Original Data Access Interface Miner “Perturbed” Results Classes of Solutions Methods Input obfuscation Perturbation Generalization Output perturbation Differential privacy Metrics Privacy vs. Utility Data Perturbation Data randomization Randomization (additive noise) Geometric perturbation and projection (multiplicative noise) Randomized response technique (categorical data) Randomization Based Decision Tree Learning (Agrawal and Srikant ’00) Basic idea: Perturb Data with Value Distortion User provides xi+r instead of xi r is a random value Uniform, uniform distribution between [-α, α] Gaussian, normal distribution with µ = 0, σ Hypothesis Miner doesn’t see the real data or can’t reconstruct real values Miner can reconstruct enough information to identify patterns Classification using Randomization Data Alice’s age Add random number to Age 30 becomes 65 (30+35) 30 | 70K | ... 50 | 40K | ... Randomizer Randomizer 65 | 20K | ... 25 | 60K | ... ... ... ? Classification Algorithm Model Output: A Decision Tree for “buys_computer” age? <=30 31..40 overcast student? no no February 12, 2008 yes >40 credit rating? excellent yes yes Data Mining: Concepts and Techniques fair yes 14 Attribute Selection Measure: Gini index (CART) If a data set D contains examples from n classes, gini index, gini(D) is defined as n gini ( D ) = 1 − ∑ p 2j j =1 where pj is the relative frequency of class j in D If a data set D is split on A into two subsets D1 and D2, the gini index gini(D) is defined as | D1 | |D2 | gini ( D 1) + gini ( D 2 ) gini A ( D ) = |D | |D | Reduction in Impurity: ∆gini( A) = gini( D) − giniA ( D) The attribute provides the smallest ginisplit(D) (or the largest reduction in impurity) is chosen to split the node February 12, 2008 Data Mining: Concepts and Techniques 15 Randomization Approach Overview Alice’s age Add random number to Age 30 becomes 65 (30+35) 30 | 70K | ... 50 | 40K | ... Randomizer Randomizer 65 | 20K | ... 25 | 60K | ... Reconstruct Distribution of Age Reconstruct Distribution of Salary Classification Algorithm ... ... ... Model Original Distribution Reconstruction x1, x2, …, xn are the n original data values Using value distortion, Drawn from n iid random variables with distribution X The given values are w1 = x1 + y1, w2 = x2 + y2, …, wn = xn + yn yi’s are from n iid random variables with distribution Y Reconstruction Problem: Given FY and wi’s, estimate FX Original Distribution Reconstruction: Method Bayes’ theorem for continuous distribution The estimated density function (minimum mean square error estimator): f (w − a ) f X (a ) 1 n f X′ (a ) = ∑ ∞ Y i n i =1 ∫ fY (wi − z ) f X ( z )dz −∞ Iterative estimation The initial estimate for fX at j=0: uniform distribution Iterative estimation f Y (wi − a ) f Xj (a ) 1 n j +1 f X (a ) = ∑ ∞ j n i =1 ( ) f w − z f X ( z )dz ∫ Y i −∞ Stopping Criterion: difference between successive iterations is small Reconstruction of Distribution Number of People 1200 1000 800 Original Randomized Reconstructed 600 400 200 0 20 60 Age Original Distribution Reconstruction Original Distribution Construction for Decision Tree When are the distributions reconstructed? Global ByClass Reconstruct for each attribute once at the beginning Build the decision tree using the reconstructed data First split the training data Reconstruct for each class separately Build the decision tree using the reconstructed data Local First split the training data Reconstruct for each class separately Reconstruct at each node while building the tree Accuracy vs. Randomization Level Fn 3 Accuracy 100 90 80 Original Randomized ByClass 70 60 50 40 10 20 40 60 80 100 Randomization Level 150 200 More Results Global performs worse than ByClass and Local ByClass and Local have accuracy within 5% to 15% (absolute error) of the Original accuracy Overall, all are much better than the Randomized accuracy Privacy metrics Privacy metrics of random additive data perturbation 4/3/2011 Data Mining: Principles and Algorithms 24 Unfortunately Random additive data perturbation are subject to data reconstruction attacks Original data can be estimated using spectral filtering techniques H. Kargupta , S. Datta. On the privacy preserving properties of random data perturbation techniques, in ICDM 2003 4/3/2011 Data Mining: Principles and Algorithms 25 Estimating distribution and data values 4/3/2011 Data Mining: Principles and Algorithms 26 Follow-up Work Multiplicative randomization Geometric randomization Also subjective to data reconstruction attacks! Known input-output Known samples 4/3/2011 Data Mining: Principles and Algorithms 27 Data Perturbation Data randomization Randomization (additive noise) Geometric perturbation and projection (multiplicative noise) Randomized response technique (categorical data) Data Collection Model Data cannot be shared directly because of privacy concern Background: Randomized Response The true answer is “Yes” Biased coin: P(Yes) = θ (θ ≠ 0.5) P ( Head ) = θ θ ≠ 0 .5 Do you smoke? Head Tail Yes No P'(Yes) = P(Yes) ⋅ θ + P(No) ⋅ (1− θ ) P'(No) = P(Yes) ⋅ (1− θ ) + P(No) ⋅ θ Decision Tree Mining using Randomized Response Multiple attributes encoded in bits Biased coin: P(Yes) = θ (θ ≠ 0.5) P ( Head ) = θ θ ≠ 0 .5 Head True answer E: 110 Tail False answer !E: 001 Column distribution can be estimated for learning a decision tree Using Randomized Response Techniques for Privacy-Preserving Data Mining, Du, 2003 Generalization for Multi-Valued Categorical Data q1 q2 q3 q4 True Value: Si Si Si+1 Si+2 Si+3 P'(s1) q1 q4 q3 q2 P(s1) P'(s2) = q2 q1 q4 q3 P(s2) P'(s3) q3 q2 q1 q4 P(s3) P'(s4) q4 q3 q2 q1 P(s4) M A Generalization RR Matrices [Warner 65], [R.Agrawal 05], [S. Agrawal 05] RR Matrix can a11 a21 M= a31 a41 be arbitrary a12 a13 a14 a22 a23 a24 a32 a33 a34 a42 a43 a44 Can we find optimal RR matrices? OptRR:Optimizing Randomized Response Schemes for Privacy-Preserving Data Mining, Huang, 2008 What is an optimal matrix? Which of the following is better? 1 0 0 M1 = 0 1 0 0 0 1 13 1 M2 = 3 13 1 3 1 3 1 3 1 3 1 3 1 3 Privacy: M2 is better Utility: M1 is better So, what is an optimal matrix? Optimal RR Matrix An RR matrix M is optimal if no other RR matrix’s privacy and utility are both better than M (i, e, no other matrix dominates M). Privacy Quantification Utility Quantification Privacy and utility metrics Privacy: how accurately one can estimate individual info. Utility: how accurately we can estimate aggregate info. Optimization algorithm Evolutionary Multi-Objective Optimization (EMOO) The algorithm Start with a set of initial RR matrices Repeat the following steps in each iteration Mating: selecting two RR matrices in the pool Crossover: exchanging several columns between the two RR matrices Mutation: change some values in a RR matrix Meet the privacy bound: filtering the resultant matrices Evaluate the fitness value for the new RR matrices. Note : the fitness values is defined in terms of privacy and utility metrics Output of Optimization The optimal set is often plotted in the objective space as Pareto front. Worse M6 M8 Utility M7 M5 M4 M 3 M1M2 Better Privacy Classes of Solutions Methods Input obfuscation Output perturbation Perturbation Generalization Differential privacy Metrics Privacy vs. Utility Data Re-identification Disease Birthdate Zip Sex Name k-anonymity & l-diversity 40 Privacy preserving data mining Generalization principles k-anonymity, l-diversity, … Methods Optimal Greedy Top-down vs. bottom-up 41 Mondrian: Greedy Partitioning Algorithm Problem Need an algorithm to find multi-dimensional partitions Optimal k-anonymous strict multi-dimensional partitioning is NP-hard Solution Use a greedy algorithm Based on k-d trees Complexity O(nlogn) Example k = 2; Quasi Identifiers: Age, Zipcode What should be the splitting criteria? Patient Data Multi-Dimensional Unfortunately Generalization based principles and methods are subjective to attacks Background knowledge sensitive Attack dependent 4/3/2011 Data Mining: Principles and Algorithms 44 Classes of Solutions Methods Input obfuscation Perturbation Generalization Output perturbation Differential privacy Metrics Privacy vs. Utility Differential Privacy Differential privacy requires the outcome to be formally indistinguishable when run with and without any particular record in the data set D1 Bob in D2 Bob out Q(D1) + Y1 Differentially Private Interface Q A(D1) User Q(D2) + Y2 A(D2) Differential Privacy Differential privacy Laplace mechanism Q(D) + Y where Y is drawn from Query sensitivity D1 Bob in D2 Bob out Q(D1) + Y1 Differentially Private Interface Q A(D1) User Q(D2) + Y2 A(D2) Coming up Data mining algorithms using differential privacy Decision tree learning (Data Mining with Differential Privacy, SIGKDD 10) Frequent itemsets mining (discovering frequent patterns in sensitive data, SIGKDD 10) 4/3/2011 Data Mining: Principles and Algorithms 48 Midterm Exam Adjusted mean: 85.3 Adjusted max: 101 Your favorite topics: Clustering, frequent itemsets mining, decision tree Your favorite assignments: Apriori Your least favorite: SOM, Weka analysis 4/3/2011 Data Mining: Principles and Algorithms 49