Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
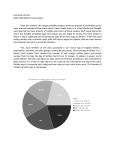
Angela Morrow Professor Sanborn Skittles Term Project Introduction: The goal of our project was to apply statistics into your daily life. Each member of our class (27) was to obtain a bag of skittles (2.07 oz) then you must sort them according to the color of the candies (red, orange, yellow, green, and purple). Each person is to count and record the number of each candy and then give the results to the teacher. Our teacher than compiled a spreadsheet of individual and combined data. This data allows each student to learn about different statistical methods that we have learned throughout this semester. I initially thought that thought that there would be little difference from bags to bag, but to my surprise my hypothesis was incorrect. There is actually quite a bit of differences between bag to bag, but when the data is complied together. The differences seemed less significant. Categorical Data: Colors Skittles Porportions by Color 18% 23% Red Purple Yellow 19% 20% 20% Orange Green Skittles Porportions by Color 400 350 300 Red 250 Purple 200 376 329 150 Yellow 328 315 291 100 Orange Green 50 0 RED PURPLE YELLOW ORANGE GREEN I have created a Pie Chart and Pareto Chart to show the proportions of candies of each color for the whole class (27). The data shown above reflects very similar results. Therefore, you can determine that many of the students got similar results. Although the bag states they all weigh exactly the same, there are some bags with more or less. This could cause some statistical errors, also known as outliers. Show below are tables showing my individual data and the data the class got as a group from our skittles bags. Red 10 0.163 Orange 12 0.196 Red 376 0.229 Orange 315 0.192 Individual Data Yellow Green 14 8 0.229 0.131 Group Data Yellow 328 0.200 Green 291 0.177 Purple 17 0.278 Total 61 Purple 329 0.200 Summary statistics Column n Candies per Bag 27 Mean Variance Std. dev. Median Range Min Max Q1 Q3 60.73 2.28 1.51 61 6 58 64 59 62 Total 1639 Figure 1 Candies Per Bag Figure 2 Candies Per Bag Twenty-seven bags of data were collected. After analyzing this data and compiling them into various charts. I determined that the results showing were normally distributed. This is what I expected to see because of the data collected you can assume with the weight that there will be almost the same amount in each bag, with a few outliers. Total # of Bags in Sample Skittles Candies in my Bag 27 Bags 61 Candies Reflection: There are two types of data, quantitative (numerical) and categorical (qualitative). Quantitative data is data that can be measured or counted. An example of quantitative data would be the numbers of candies per color of Skittle. Categorical data is values or observations. An example would be the colors of Skittles in each bag. The Pareto and Pie Charts are used categorical data. Scatterplot, and dot-plot are good examples for us of quantitative data. The types are not useful for quantitative data are Pie and Pareto charts because they do not use numbers to graph the data. The types that are not ideal for categorical data are box plots, or a histogram, because these graphs only use numbers. Confidence Interval Estimates: The purpose of Confidence Intervals is to estimate the true value of a population proportion by using a sample proportion. We use a confidence interval, rather than a single value to estimate more accurate results. 99% Confidence Interval for the true proportion of green candies at 99% confidence. n=1639 x=291 p= 178 0.153 < u < 0.202 Based on the calculations from our data, we are 99% confidence that the interval between 0.153 and 0.202 actually does contain the true value of the population proportion p. This means that if we were to select many different samples of size 1639 and construct the corresponding confidence intervals, 99% of them would actually contain the value of the population proportion p. True mean # of candies per bag at 95% confidence. n= 27 x=60.73 s=1.5 95% Cl t=2.056 df= 26 60.137 < μ < 61.323 Based on the calculations from our data, we are 95% confident that the interval from actually does contain the true value of μ. This means that if we were to select many different samples of the same size and construct the corresponding confidence intervals, in the long run 95% of them would actually contain the value of μ. Standard Deviation of # of candies per bag at 98% confidence 98%Cl n=27 s=1.5 DF=26 ²R = 45.642 ²L = 12.198 σ = (1.132< 2.190) Based on this result, we have 98% confidence that the limits of 1.132 and 2.190 contain the true value of σ. Hypothesis Tests A hypothesis test is a test whether a claim of a value of a population proportion, a population mean, or a population standard deviation and whether or not the claim is true. The purpose of a hypothesis test is to make a conclusion about a claim. N=1639 X=329 Hₒ : p = .20 H₁: p ≠ .20 Fail to reject the Hₒ There is not sufficient evidence to warrant rejection of the claim that 20% of all Skittles candies are purple. Claim: The mean number of Skittles in a 2.17 oz bag is 62. (p=62) Hₒ : p = 62 H₁: p ≠ 62 two tail test 𝞪 = 0.01 n = 27 x = 60.73 There is not sufficient evidence to warrant the rejection of the claim that the mean number of candies in 2.17oz bag of Skittles is 62. The conditions needed for interval estimates include that the sample is a random sample and that the population is normally distributed. Our samples did meet these requirements as our data came from a subset of samples that was part of a larger set, or population. The collection of all date allows for our sample to be normally distributed, with our total n being 1639. Possible errors could include counting errors, within each color of Skittle, and total number of candies per bag. The sampling method could be improved by increasing the sample size and/or encouraging full participation. We could also improve the sampling method by acquiring bags from different parts of the country and/or world, rather than the local/surrounding area. I have drawn the conclusion that the true mean number of candies in each bag of Skittles is close to the actual mean we found by compiling our data. I have also drawn the conclusion that each color of Skittle is some what evenly proportioned from one bag to the next. Reflection on Term Skittles Project I still remember looking at the instructions for this project and thinking that I was reading something in another language. I had a hard time working on it because of how difficult it seemed at first. I was amazed at how much work this was actually going to require. We needed to create a random sample of data, have that data organized, create graphs, charts and interpret what the information means. Throughout the semester we were thought a great variety of statistical concepts that gave us the necessary tools to be able to complete this project. Little by little I realized that I was not only capable of gradually understanding the instructions, but I was also able to perform the correct sequence of steps for each one of the exercises that were part of this project. As in any other discipline and class, after learning the theory, practice makes the whole difference. This project allowed us to put into practice key principles studied throughout the term, from using a sampling method to performing hypothesis testing. The most challenging aspects of the project were really understanding each concept, and how it applied to the population of Skittles not just our sample. This project and the class in general have gave me the tools to differentiate between valid professional papers from those that end up being questionable sources of information when analyzing things like graphs, and confidence levels and intervals that can make the whole difference when trying to see if the study is well done. To be able to understand the language behind the statistical analysis of studies with simple, but important terms such as media, range, mean, and mode that are so frequently use in so many instances. I have always struggled with math but found that this course allowed me to see how math does apply to real life, and was refreshing to take a course outside of the classroom and math book. I have always gritted my teeth at story problems but his course gave a whole new approach and meaning to the information provided. I never thought I would say this, but math can be fun at times, especially when you can understand how it applies to the real life situations helping us to better understand the world around us.