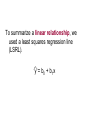Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
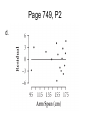
Chapter 11 Inference for Regression Section 11.1 Variation in the Slope from Sample to Sample Using Samples Anytime we take a sample from the population, our result is some type of an _________. Using Samples Anytime we take a sample from the population, our result is some type of an estimate. Using Samples Anytime we take a sample from the population, our result is some type of an estimate. To obtain exact answers, we would have to take a _______ of the entire population. Using Samples Anytime we take a sample from the population, our result is some type of an estimate. To obtain exact answers, we would have to take a census of the entire population. Consider the scatterplots below. In which scatterplots is it reasonable to model the relationship between y and x with a line? Consider the scatterplots below. In which scatterplots is it reasonable to model the relationship between y and x with a line? I, III, IV, V (must be linear pattern) Consider the scatterplots below. If you fit a line through each scatterplot by the method of least squares, which plot will give a line with slope closest to 0? Consider the scatterplots below. If you fit a line through each scatterplot by the method of least squares, which plot will give a line with slope closest to 0? IV (points most scattered) Consider the scatterplots below. In which scatterplots is it meaningful to use correlation to describe the relationship between y and x? Consider the scatterplots below. In which scatterplots is it meaningful to use correlation to describe the relationship between y and x? I, III, IV, V (must be linear pattern) Consider the scatterplots below. Which plot shows a correlation coefficient closest to 1? Consider the scatterplots below. Which plot shows a correlation coefficient closest to 1? V (points packed tightest to LSRL) To summarize a linear relationship, we used a least squares regression line (LSRL). y = b0 + b1x To summarize a linear relationship, we used a least squares regression line (LSRL). y = b0 + b1x For this model to be complete, what do you have to have? To summarize a linear relationship, we used a least squares regression line (LSRL). y = b0 + b1x For this model to be complete, what do you have to have? The complete population To summarize a linear relationship, we used a least squares regression line (LSRL). y = b0 + b1x If you only have a random sample, the values of b0 and b1 are estimates of true population parameters. “True” linear relationship is: response = prediction from true regression line + random deviation “True” linear relationship is: response = prediction from true regression line + random deviation Need random deviation because the point may not fall exactly on the true regression line - some will be above, some below, and some on the line “True” linear relationship is: response = prediction from true regression line + random deviation y = ( 0 1x) “True” linear relationship is: response = prediction from true regression line + random deviation y = ( 0 1x) where 0 and 1 refer to the intercept and slope of the true regression line if you had data for the entire population. “True” linear relationship is: response = prediction from true regression line + random deviation y = ( 0 1x) where 0 and 1 refer to the intercept and slope of the true regression line if you had data for the entire population. is size of random deviation – how far point falls above or below true regression line True regression line aka line of means aka line of averages is written: True regression line aka line of means aka line of averages is written: y = ( 0 1x) Suppose we wanted to study the relationship of children’s heights vs their ages in years. Suppose we wanted to study the relationship of children’s heights vs their ages in years. Which variable goes on which axis? Horizontal axis: Vertical axis: Suppose we wanted to study the relationship of children’s heights vs their ages in years. Which variable goes on which axis? Horizontal axis: ages in years Vertical axis: children’s heights Suppose we wanted to study the relationship of children’s heights vs their ages in years. On average, kids from ages 8 to 13 grow taller at the rate of 2 inches per year. Heights of 8-year-olds average about 51 inches. At each age, the heights are approximately normal, with a standard deviation of roughly 2.1 inches. On average, kids from ages 8 to 13 grow taller at the rate of 2 inches per year. Heights of 8-year-olds average about 51 inches. At each age, the heights are approximately normal, with a standard deviation of roughly 2.1 inches. Average Height Age, x from Model, µy 8 ? 9 10 11 12 On average, kids from ages 8 to 13 grow taller at the rate of 2 inches per year. Heights of 8-year-olds average about 51 inches. At each age, the heights are approximately normal, with a standard deviation of roughly 2.1 inches. Average Height Age, x from Model, µy 8 51 9 10 11 12 On average, kids from ages 8 to 13 grow taller at the rate of 2 inches per year. Heights of 8-year-olds average about 51 inches. At each age, the heights are approximately normal, with a standard deviation of roughly 2.1 inches. Average Height Age, x from Model, µy 8 51 9 53 10 11 12 On average, kids from ages 8 to 13 grow taller at the rate of 2 inches per year. Heights of 8-year-olds average about 51 inches. At each age, the heights are approximately normal, with a standard deviation of roughly 2.1 inches. Average Height Age, x from Model, µy 8 51 9 53 10 55 11 57 12 59 If we collected a random sample of the heights of children, we would have different heights for each year of age. Conditional distribution of y given x refers to all the values of y for a fixed value of x Conditional distribution of y given x refers to all the values of y for a fixed value of x Each conditional distribution of height for a given age has: Mean: y for a population and y for sample Each conditional distribution of height for a given age has: Mean: y for a population and y for sample Measure of variability: for a population and s for sample Linear model is appropriate for set of data if: Linear model is appropriate for set of data if: 1) Conditional means fall near a line Linear model is appropriate for set of data if: 1) Conditional means fall near a line Linear model is appropriate for set of data if: 1) Conditional means fall near a line 2) Variability is about the same for each conditional distribution Linear model is appropriate for set of data if: 1) Conditional means fall near a line 2) Variability is about the same for each conditional distribution Linear model is appropriate for set of data if: 1) Conditional means fall near a line 2) Variability is about the same for each conditional distribution Page 744, D4 Linear model is appropriate for set of data if: 1) Conditional means fall near a line 2) Variability is about the same for each conditional distribution Page 744, D4 Two potential problems here. First, the data appear to have curvature. The centers of the conditional distributions of y do not lie on a straight line, which is one of the conditions for a linear fit. Page 744, D4 Second, the conditional distribution of responses at x = 2 has far greater variation than either of the other two conditional distributions. The assumption of equal variances of responses across all values of x is violated. Common variability of y at each x is called . Common variability of y at each x is called . It is estimated by s, which can be thought of as the standard deviation of the residuals. Common variability of y at each x is called . It is estimated by s, which can be thought of as the standard deviation of the residuals. Spread in values of x is measured by: Recall, most of the time the theoretical slope, β1, is _________. Recall, most of the time the theoretical slope, β1, is unknown. Recall, most of the time the theoretical slope, β1, is unknown. So, we use ___ to estimate β1. Recall, most of the time the theoretical slope, β1, is unknown. So, we use b1 to estimate β1. The slope b1 _____ from sample to sample. The slope b1 varies from sample to sample. Is this variation a good thing or not so good? The slope b1 varies from sample to sample. Is this variation a good thing or not so good? Not so good as the variation affects our predictions. The slope b1 varies from sample to sample. Bold line is true regression line for the population. Page 741, D2 Page 741, D2 The parameter, 1 , is the slope of the theoretical model and generally will not be known. Page 741, D2 The statistic, b1, is an estimate of 1 that is calculated from observed data. The value of b1 will vary from sample to sample. Page 741, D2 Further, the theoretical model takes into account that not every point is expected to lie on the line. An error term is built in. Epsilon, , is the deviation of a given point from the true regression line. Page 741, D2 Further, the theoretical model takes into account that not every point is expected to lie on the line. An error term is built in. Epsilon, , is the deviation of a given point from the true regression line. Whereas is the residual from the regression line calculated from the sample data. Page 749, P1 Page 749, P1 Fat contains 9 calories per gram. The theoretical slope, β1, would be 9 calories per gram of fat. Page 749, P1 What is the slope, b1, of the regression line? Page 749, P1 What is the slope, b1, of the regression line? b1 ≈ 14.9 calories per gram of fat. Page 749, P1 b. Intercept of line tells us the number of calories associated with a serving containing no grams of fat. What is the intercept, b0, of the regression line? Page 749, P1 b. Intercept of line tells us the number of calories associated with a serving containing no grams of fat. What is the intercept, b0, of the regression line? b0 ≈ 111.6 Page 749, P1 c. Pizza has calories from carbohydrates and protein as well as fat. There may be other sources of variation in the measurement process. Page 749, P2 Page 749, P2 mean heightarm span = arm span Page 749, P2 b. LSRL: Height = 7.915 + 0.952 Arm Span Page 749, P2 b. LSRL: Height = 7.915 + 0.952 Arm Span The interpretation of the estimated slope is that height tends to increase by about 0.952 cm for each 1-cm increase in arm span. Page 749, P2 b. LSRL: Height = 7.915 + 0.952 Arm Span The estimated slope, b1, of 0.952 is very close to Leonardo’s theoretical slope, β1 of 1. Page 749, P2 b. LSRL: Height = 7.915 + 0.952 Arm Span The estimated slope of 0.952 is very close to Leonardo’s theoretical slope of 1. The estimated intercept, b0, is 7.915 cm, which is quite far from Leonardo’s theoretical intercept, β0, of 0. Page 749, P2 (c) Mean height arm span = 0 + arm span + Page 749, P2 (c) Mean height arm span = 0 + arm span + So, = mean height arm span – arm span Page 749, P2 (c) Mean height = 0 + arm span + So, = mean height – arm span Use L3 = L2 – L1 How do you plot the random deviations? STAT PLOTS 1: Plot 1 ….On Type: select scatterplot Xlist: L1 Ylist: L3 Mark: Page 749, P2 (c) Page 749, P2 (c) This plot shows the random deviations from the theoretical line y = x plotted against the x-values. The plot shows a pattern: All of the negative deviations are for larger arm spans, and the plot shows a downward trend. Page 749, P2 (d) How do you calculate the residuals? Page 749, P2 (d) How do you calculate the residuals? 8: LinReg(a + bx) L1, L2 Page 749, P2 (d) How do you plot the residuals? STAT PLOTS 1: Plot 1 ….On Type: select scatterplot Xlist: L1 Ylist: RESID Mark: Page 749, P2 (d) How do you plot the residuals? STAT PLOTS 1: Plot 1 ….On Type: scatterplot Xlist: L1 Ylist: RESID [2nd, LIST, NAMES, 7:RESID] Mark: Page 749, P2 d. Page 749, P2 Page 749, P3 Page 749, P3 Page 749, P3 Page 749, P3 Page 749, P3 Questions?