Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
CSE 5331/7331
Fall 2010
DATA MINING
Introductory and Related Topics
Margaret H. Dunham
Department of Computer Science and Engineering
Southern Methodist University
Slides extracted from Data Mining, Introductory and Advanced Topics, Prentice Hall, 2002.
CSE 5331/7331 F'2010
1
Data Mining Outline
PART I
– Introduction
– Techniques
PART II – Core Topics
PART III – Related Topics
CSE 5331/7331 F'2010
2
Introduction Outline
Goal: Provide an overview of data mining.
Define data mining
Data mining vs. databases
Basic data mining tasks
Data mining development
Data mining issues
CSE 5331/7331 F'2010
3
Introduction
Data is growing at a phenomenal rate
Users expect more sophisticated
information
How?
UNCOVER HIDDEN INFORMATION
DATA MINING
CSE 5331/7331 F'2010
4
Data Mining Definition
Finding hidden information in a
database
Fit data to a model
Similar terms
– Exploratory data analysis
– Data driven discovery
– Deductive learning
CSE 5331/7331 F'2010
5
Data Mining Algorithm
Objective: Fit Data to a Model
– Descriptive
– Predictive
Preference – Technique to choose the
best model
Search – Technique to search the data
– “Query”
CSE 5331/7331 F'2010
6
Database Processing vs. Data
Mining Processing
Query
– Well defined
– SQL
Data
– Poorly defined
– No precise query language
– Operational data
Output
– Precise
– Subset of database
CSE 5331/7331 F'2010
Query
Data
– Not operational data
Output
– Fuzzy
– Not a subset of database
7
Query Examples
Database
– Find all credit applicants with last name of Smith.
– Identify customers who have purchased more
than $10,000 in the last month.
– Find all customers who have purchased milk
Data Mining
– Find all credit applicants who are poor credit
risks. (classification)
– Identify customers with similar buying habits.
(Clustering)
– Find all items which are frequently purchased
with milk. (association rules)
CSE 5331/7331 F'2010
8
Data Mining Models and Tasks
CSE 5331/7331 F'2010
9
Basic Data Mining Tasks
Classification maps data into predefined
groups or classes
– Supervised learning
– Pattern recognition
– Prediction
Regression is used to map a data item to a
real valued prediction variable.
Clustering groups similar data together into
clusters.
– Unsupervised learning
– Segmentation
– Partitioning
CSE 5331/7331 F'2010
10
Basic Data Mining Tasks
(cont’d)
Summarization maps data into subsets with
associated simple descriptions.
– Characterization
– Generalization
Link Analysis uncovers relationships among
data.
– Affinity Analysis
– Association Rules
– Sequential Analysis determines sequential
patterns.
CSE 5331/7331 F'2010
11
Ex: Time Series Analysis
Example: Stock Market
Predict future values
Determine similar patterns over time
Classify behavior
CSE 5331/7331 F'2010
12
Data Mining vs. KDD
Knowledge Discovery in Databases
(KDD): process of finding useful
information and patterns in data.
Data Mining: Use of algorithms to
extract the information and patterns
derived by the KDD process.
CSE 5331/7331 F'2010
13
KDD Process
Modified from [FPSS96C]
Selection: Obtain data from various sources.
Preprocessing: Cleanse data.
Transformation: Convert to common format.
Transform to new format.
Data Mining: Obtain desired results.
Interpretation/Evaluation: Present results
to user in meaningful manner.
CSE 5331/7331 F'2010
14
KDD Process Ex: Web Log
Selection:
– Select log data (dates and locations) to use
Preprocessing:
– Remove identifying URLs
– Remove error logs
Transformation:
– Sessionize (sort and group)
Data Mining:
– Identify and count patterns
– Construct data structure
Interpretation/Evaluation:
– Identify and display frequently accessed sequences.
Potential User Applications:
– Cache prediction
– Personalization
CSE 5331/7331 F'2010
15
Data Mining Development
•Relational Data Model
•SQL
•Association Rule Algorithms
•Data Warehousing
•Scalability Techniques
•Similarity Measures
•Hierarchical Clustering
•IR Systems
•Imprecise Queries
•Textual Data
•Web Search Engines
•Bayes Theorem
•Regression Analysis
•EM Algorithm
•K-Means Clustering
•Time Series Analysis
•Algorithm Design Techniques
•Algorithm Analysis
•Data Structures
CSE 5331/7331 F'2010
•Neural Networks
•Decision Tree Algorithms
16
KDD Issues
Human Interaction
Overfitting
Outliers
Interpretation
Visualization
Large Datasets
High Dimensionality
CSE 5331/7331 F'2010
17
KDD Issues (cont’d)
Multimedia Data
Missing Data
Irrelevant Data
Noisy Data
Changing Data
Integration
Application
CSE 5331/7331 F'2010
18
Social Implications of DM
Privacy
Profiling
Unauthorized use
CSE 5331/7331 F'2010
19
Data Mining Metrics
Usefulness
Return on Investment (ROI)
Accuracy
Space/Time
CSE 5331/7331 F'2010
20
Visualization Techniques
Graphical
Geometric
Icon-based
Pixel-based
Hierarchical
Hybrid
CSE 5331/7331 F'2010
21
Models Based on Summarization
Visualization: Frequency distribution, mean, variance,
median, mode, etc.
Box Plot:
CSE 5331/7331 F'2010
22
Scatter Diagram
CSE 5331/7331 F'2010
23
Data Mining Techniques Outline
Goal: Provide an overview of basic data
mining techniques
Statistical
–
–
–
–
–
Point Estimation
Models Based on Summarization
Bayes Theorem
Hypothesis Testing
Regression and Correlation
Similarity Measures
Decision Trees
Neural Networks
– Activation Functions
Genetic Algorithms
CSE 5331/7331 F'2010
24
Point Estimation
Point Estimate: estimate a population
parameter.
May be made by calculating the parameter for a
sample.
May be used to predict value for missing data.
Ex:
–
–
–
–
R contains 100 employees
99 have salary information
Mean salary of these is $50,000
Use $50,000 as value of remaining employee’s
salary.
Is this a good idea?
CSE 5331/7331 F'2010
25
Estimation Error
Bias: Difference between expected value and
actual value.
Mean Squared Error (MSE): expected value
of the squared difference between the
estimate and the actual value:
Why square?
Root Mean Square Error (RMSE)
CSE 5331/7331 F'2010
26
Jackknife Estimate
Jackknife Estimate: estimate of parameter
is obtained by omitting one value from the set
of observed values.
Ex: estimate of mean for X={x1, … , xn}
CSE 5331/7331 F'2010
27
Maximum Likelihood
Estimate (MLE)
Obtain parameter estimates that maximize
the probability that the sample data occurs for
the specific model.
Joint probability for observing the sample
data by multiplying the individual probabilities.
Likelihood function:
Maximize L.
CSE 5331/7331 F'2010
28
MLE Example
Coin toss five times: {H,H,H,H,T}
Assuming a perfect coin with H and T equally
likely, the likelihood of this sequence is:
However if the probability of a H is 0.8 then:
CSE 5331/7331 F'2010
29
MLE Example (cont’d)
General likelihood formula:
Estimate for p is then 4/5 = 0.8
CSE 5331/7331 F'2010
30
Expectation-Maximization
(EM)
Solves estimation with incomplete data.
Obtain initial estimates for parameters.
Iteratively use estimates for missing
data and continue until convergence.
CSE 5331/7331 F'2010
31
EM Example
CSE 5331/7331 F'2010
32
EM Algorithm
CSE 5331/7331 F'2010
33
Bayes Theorem
Posterior Probability: P(h1|xi)
Prior Probability: P(h1)
Bayes Theorem:
Assign probabilities of hypotheses given a
data value.
CSE 5331/7331 F'2010
34
Bayes Theorem Example
Credit authorizations (hypotheses):
h1=authorize purchase, h2 = authorize after
further identification, h3=do not authorize,
h4= do not authorize but contact police
Assign twelve data values for all
combinations of credit and income:
1
Excellent
Good
Bad
x1
x5
x9
2
3
4
x2
x6
x10
x3
x7
x11
x4
x8
x12
From training data: P(h1) = 60%; P(h2)=20%;
P(h3)=10%; P(h4)=10%.
CSE 5331/7331 F'2010
35
Bayes Example(cont’d)
Training Data:
ID
1
2
3
4
5
6
7
8
9
10
CSE 5331/7331 F'2010
Income
4
3
2
3
4
2
3
2
3
1
Credit
Excellent
Good
Excellent
Good
Good
Excellent
Bad
Bad
Bad
Bad
Class
h1
h1
h1
h1
h1
h1
h2
h2
h3
h4
xi
x4
x7
x2
x7
x8
x2
x11
x10
x11
x9
36
Bayes Example(cont’d)
Calculate P(xi|hj) and P(xi)
Ex: P(x7|h1)=2/6; P(x4|h1)=1/6; P(x2|h1)=2/6;
P(x8|h1)=1/6; P(xi|h1)=0 for all other xi.
Predict the class for x4:
– Calculate P(hj|x4) for all hj.
– Place x4 in class with largest value.
– Ex:
»P(h1|x4)=(P(x4|h1)(P(h1))/P(x4)
=(1/6)(0.6)/0.1=1.
»x4 in class h1.
CSE 5331/7331 F'2010
37
Hypothesis Testing
Find model to explain behavior by
creating and then testing a hypothesis
about the data.
Exact opposite of usual DM approach.
H0 – Null hypothesis; Hypothesis to be
tested.
H1 – Alternative hypothesis
CSE 5331/7331 F'2010
38
Chi Squared Statistic
O – observed value
E – Expected value based on hypothesis.
Ex:
– O={50,93,67,78,87}
– E=75
– c2=15.55 and therefore significant
CSE 5331/7331 F'2010
39
Regression
Predict future values based on past
values
Linear Regression assumes linear
relationship exists.
y = c 0 + c1 x 1 + … + c n x n
Find values to best fit the data
CSE 5331/7331 F'2010
40
Linear Regression
CSE 5331/7331 F'2010
41
Correlation
Examine the degree to which the values
for two variables behave similarly.
Correlation coefficient r:
• 1 = perfect correlation
• -1 = perfect but opposite correlation
• 0 = no correlation
CSE 5331/7331 F'2010
42
Similarity Measures
Determine similarity between two objects.
Similarity characteristics:
Alternatively, distance measure measure how
unlike or dissimilar objects are.
CSE 5331/7331 F'2010
43
Similarity Measures
CSE 5331/7331 F'2010
44
Distance Measures
Measure dissimilarity between objects
CSE 5331/7331 F'2010
45
Twenty Questions Game
CSE 5331/7331 F'2010
46
Decision Trees
Decision Tree (DT):
– Tree where the root and each internal node is
labeled with a question.
– The arcs represent each possible answer to
the associated question.
– Each leaf node represents a prediction of a
solution to the problem.
Popular technique for classification; Leaf
node indicates class to which the
corresponding tuple belongs.
CSE 5331/7331 F'2010
47
Decision Tree Example
CSE 5331/7331 F'2010
48
Decision Trees
A Decision Tree Model is a computational
model consisting of three parts:
– Decision Tree
– Algorithm to create the tree
– Algorithm that applies the tree to data
Creation of the tree is the most difficult part.
Processing is basically a search similar to
that in a binary search tree (although DT may
not be binary).
CSE 5331/7331 F'2010
49
Decision Tree Algorithm
CSE 5331/7331 F'2010
50
DT
Advantages/Disadvantages
Advantages:
– Easy to understand.
– Easy to generate rules
Disadvantages:
– May suffer from overfitting.
– Classifies by rectangular partitioning.
– Does not easily handle nonnumeric data.
– Can be quite large – pruning is necessary.
CSE 5331/7331 F'2010
51
Neural Networks
Based on observed functioning of human
brain.
(Artificial Neural Networks (ANN)
Our view of neural networks is very
simplistic.
We view a neural network (NN) from a
graphical viewpoint.
Alternatively, a NN may be viewed from
the perspective of matrices.
Used in pattern recognition, speech
recognition, computer vision, and
classification.
CSE 5331/7331 F'2010
52
Neural Networks
Neural Network (NN) is a directed graph
F=<V,A> with vertices V={1,2,…,n} and arcs
A={<i,j>|1<=i,j<=n}, with the following
restrictions:
– V is partitioned into a set of input nodes, VI,
hidden nodes, VH, and output nodes, VO.
– The vertices are also partitioned into layers
– Any arc <i,j> must have node i in layer h-1
and node j in layer h.
– Arc <i,j> is labeled with a numeric value wij.
– Node i is labeled with a function fi.
CSE 5331/7331 F'2010
53
Neural Network Example
CSE 5331/7331 F'2010
54
NN Node
CSE 5331/7331 F'2010
55
NN Activation Functions
Functions associated with nodes in
graph.
Output may be in range [-1,1] or [0,1]
CSE 5331/7331 F'2010
56
NN Activation Functions
CSE 5331/7331 F'2010
57
NN Learning
Propagate input values through graph.
Compare output to desired output.
Adjust weights in graph accordingly.
CSE 5331/7331 F'2010
58
Neural Networks
A Neural Network Model is a computational
model consisting of three parts:
– Neural Network graph
– Learning algorithm that indicates how
learning takes place.
– Recall techniques that determine hew
information is obtained from the network.
We will look at propagation as the recall
technique.
CSE 5331/7331 F'2010
59
NN Advantages
Learning
Can continue learning even after
training set has been applied.
Easy parallelization
Solves many problems
CSE 5331/7331 F'2010
60
NN Disadvantages
Difficult to understand
May suffer from overfitting
Structure of graph must be determined
a priori.
Input values must be numeric.
Verification difficult.
CSE 5331/7331 F'2010
61
Genetic Algorithms
Optimization search type algorithms.
Creates an initial feasible solution and
iteratively creates new “better” solutions.
Based on human evolution and survival of the
fittest.
Must represent a solution as an individual.
Individual: string I=I1,I2,…,In where Ij is in
given alphabet A.
Each character Ij is called a gene.
Population: set of individuals.
CSE 5331/7331 F'2010
62
Genetic Algorithms
A Genetic Algorithm (GA) is a
computational model consisting of five parts:
– A starting set of individuals, P.
– Crossover: technique to combine two
parents to create offspring.
– Mutation: randomly change an individual.
– Fitness: determine the best individuals.
– Algorithm which applies the crossover and
mutation techniques to P iteratively using
the fitness function to determine the best
individuals in P to keep.
CSE 5331/7331 F'2010
63
Crossover Examples
000 000
000 111
000 000 00
000 111 00
111 111
111 000
111 111 11
111 000 11
Parents
Children
Parents
Children
a) Single Crossover
CSE 5331/7331 F'2010
a) Multiple Crossover
64
Genetic Algorithm
CSE 5331/7331 F'2010
65
GA Advantages/Disadvantages
Advantages
– Easily parallelized
Disadvantages
– Difficult to understand and explain to end
users.
– Abstraction of the problem and method to
represent individuals is quite difficult.
– Determining fitness function is difficult.
– Determining how to perform crossover and
mutation is difficult.
CSE 5331/7331 F'2010
66
Data Mining Outline
PART I - Introduction
PART II – Core Topics
– Classification
– Clustering
– Association Rules
PART III – Related Topics
CSE 5331/7331 F'2010
67
Classification Outline
Goal: Provide an overview of the classification
problem and introduce some of the basic
algorithms
Classification Problem Overview
Classification Techniques
– Regression
– Distance
– Decision Trees
– Rules
– Neural Networks
CSE 5331/7331 F'2010
68
Classification Problem
Given a database D={t1,t2,…,tn} and a set
of classes C={C1,…,Cm}, the
Classification Problem is to define a
mapping f:DgC where each ti is assigned
to one class.
Actually divides D into equivalence
classes.
Prediction is similar, but may be viewed
as having infinite number of classes.
CSE 5331/7331 F'2010
69
Classification Examples
Teachers classify students’ grades as
A, B, C, D, or F.
Identify mushrooms as poisonous or
edible.
Predict when a river will flood.
Identify individuals with credit risks.
Speech recognition
Pattern recognition
CSE 5331/7331 F'2010
70
Classification Ex: Grading
If x >= 90 then grade
=A.
If 80<=x<90 then
grade =B.
If 70<=x<80 then
grade =C.
If 60<=x<70 then
grade =D.
If x<50 then grade =F.
CSE 5331/7331 F'2010
x
<90
>=90
x
<80
x
<70
x
<50
F
A
>=80
B
>=70
C
>=60
D
71
Classification Ex: Letter
Recognition
View letters as constructed from 5 components:
CSE 5331/7331 F'2010
Letter A
Letter B
Letter C
Letter D
Letter E
Letter F
72
Classification Techniques
Approach:
1. Create specific model by evaluating
training data (or using domain
experts’ knowledge).
2. Apply model developed to new data.
Classes must be predefined
Most common techniques use DTs,
NNs, or are based on distances or
statistical methods.
CSE 5331/7331 F'2010
73
Defining Classes
Distance Based
Partitioning Based
CSE 5331/7331 F'2010
74
Issues in Classification
Missing Data
– Ignore
– Replace with assumed value
Measuring Performance
– Classification accuracy on test data
– Confusion matrix
– OC Curve
CSE 5331/7331 F'2010
75
Height Example Data
Name
Kristina
Jim
Maggie
Martha
Stephanie
Bob
Kathy
Dave
Worth
Steven
Debbie
Todd
Kim
Amy
Wynette
CSE 5331/7331 F'2010
Gender
F
M
F
F
F
M
F
M
M
M
F
M
F
F
F
Height
1.6m
2m
1.9m
1.88m
1.7m
1.85m
1.6m
1.7m
2.2m
2.1m
1.8m
1.95m
1.9m
1.8m
1.75m
Output1
Short
Tall
Medium
Medium
Short
Medium
Short
Short
Tall
Tall
Medium
Medium
Medium
Medium
Medium
Output2
Medium
Medium
Tall
Tall
Medium
Medium
Medium
Medium
Tall
Tall
Medium
Medium
Tall
Medium
Medium
76
Classification Performance
True Positive
False Negative
False Positive
True Negative
CSE 5331/7331 F'2010
77
Confusion Matrix Example
Using height data example with Output1
correct and Output2 actual assignment
Actual
Membership
Short
Medium
Tall
CSE 5331/7331 F'2010
Assignment
Short
Medium
0
4
0
5
0
1
Tall
0
3
2
78
Operating Characteristic Curve
CSE 5331/7331 F'2010
79
RegressionTopics
Linear Regression
Nonlinear Regression
Logistic Regression
Metrics
CSE 5331/7331 F'2010
80
Remember High School?
Y= mx + b
You need two points to determine a
straight line.
You need two points to find values for m
and b.
THIS IS REGRESSION
CSE 5331/7331 F'2010
81
Regression
Assume data fits a predefined function
Determine best values for regression
coefficients c0,c1,…,cn.
Assume an error: y = c0+c1x1+…+cnxn+e
Estimate error using mean squared error for
training set:
CSE 5331/7331 F'2010
82
Linear Regression
Assume data fits a predefined function
Determine best values for regression
coefficients c0,c1,…,cn.
Assume an error: y = c0+c1x1+…+cnxn+e
Estimate error using mean squared error for
training set:
CSE 5331/7331 F'2010
83
Classification Using Linear
Regression
Division: Use regression function to
divide area into regions.
Prediction: Use regression function to
predict a class membership function.
Input includes desired class.
CSE 5331/7331 F'2010
84
Division
CSE 5331/7331 F'2010
85
Prediction
CSE 5331/7331 F'2010
86
Linear Regression Poor Fit
Why
use sum of least squares?
http://curvefit.com/sum_of_squares.htm
Linear
doesn’t always work well
CSE 5331/7331 F'2010
87
Nonlinear Regression
Data does not nicely fit a straight line
Fit data to a curve
Many possible functions
Not as easy and straightforward as
linear regression
How nonlinear regression works:
http://curvefit.com/how_nonlin_works.htm
CSE 5331/7331 F'2010
88
Logistic Regression
Generalized linear model
Predict discrete outcome
– Binomial (binary) logistic regression
– Multinomial logistic regression
One dependent variable
Logistic Regression by Gerard E. Dallal
http://www.jerrydallal.com/LHSP/logistic.htm
CSE 5331/7331 F'2010
89
Logistic Regression (cont’d)
p
log(
) 0 1 x
1 p
Log Odds Function:
P is probability that outcome is 1
Odds – The probability the event occurs
divided by the probability that it does not
occur
Log Odds function is strictly increasing as p
increases
CSE 5331/7331 F'2010
90
Why Log Odds?
Shape of curve is desirable
Relationship to probability
Range – to +
CSE 5331/7331 F'2010
91
P-value
The probability that a variable has a
value greater than the observed value
http://en.wikipedia.org/wiki/P-value
http://sportsci.org/resource/stats/pvalues.html
CSE 5331/7331 F'2010
92
Covariance
Degree to which two variables vary in the
same manner
Correlation is normalized and covariance
is not
http://www.ds.unifi.it/VL/VL_EN/expect/expect3.
html
CSE 5331/7331 F'2010
93
Residual
Error
Difference between desired output and
predicted output
May actually use sum of squares
CSE 5331/7331 F'2010
94
Classification Using Distance
Place items in class to which they are
“closest”.
Must determine distance between an
item and a class.
Classes represented by
– Centroid: Central value.
– Medoid: Representative point.
– Individual points
Algorithm:
CSE 5331/7331 F'2010
KNN
95
K Nearest Neighbor (KNN):
Training set includes classes.
Examine K items near item to be
classified.
New item placed in class with the most
number of close items.
O(q) for each tuple to be classified.
(Here q is the size of the training set.)
CSE 5331/7331 F'2010
96
KNN
CSE 5331/7331 F'2010
97
KNN Algorithm
CSE 5331/7331 F'2010
98
Classification Using Decision
Trees
Partitioning based: Divide search
space into rectangular regions.
Tuple placed into class based on the
region within which it falls.
DT approaches differ in how the tree is
built: DT Induction
Internal nodes associated with attribute
and arcs with values for that attribute.
Algorithms: ID3, C4.5, CART
CSE 5331/7331 F'2010
99
Decision Tree
Given:
– D = {t1, …, tn} where ti=<ti1, …, tih>
– Database schema contains {A1, A2, …, Ah}
– Classes C={C1, …., Cm}
Decision or Classification Tree is a tree
associated with D such that
– Each internal node is labeled with attribute, Ai
– Each arc is labeled with predicate which can
be applied to attribute at parent
– Each leaf node is labeled with a class, Cj
CSE 5331/7331 F'2010
100
DT Induction
CSE 5331/7331 F'2010
101
DT Splits Area
Gender
M
F
Height
CSE 5331/7331 F'2010
102
Comparing DTs
Balanced
Deep
CSE 5331/7331 F'2010
103
DT Issues
Choosing Splitting Attributes
Ordering of Splitting Attributes
Splits
Tree Structure
Stopping Criteria
Training Data
Pruning
CSE 5331/7331 F'2010
104
Decision Tree Induction is often based on
Information Theory
So
CSE 5331/7331 F'2010
105
Information
CSE 5331/7331 F'2010
106
DT Induction
When all the marbles in the bowl are
mixed up, little information is given.
When the marbles in the bowl are all
from one class and those in the other
two classes are on either side, more
information is given.
Use this approach with DT Induction !
CSE 5331/7331 F'2010
107
Information/Entropy
Given probabilitites p1, p2, .., ps whose sum is
1, Entropy is defined as:
Entropy measures the amount of randomness
or surprise or uncertainty.
Goal in classification
– no surprise
– entropy = 0
CSE 5331/7331 F'2010
108
Entropy
log (1/p)
CSE 5331/7331 F'2010
H(p,1-p)
109
ID3
Creates tree using information theory
concepts and tries to reduce expected
number of comparison..
ID3 chooses split attribute with the highest
information gain:
CSE 5331/7331 F'2010
110
ID3 Example (Output1)
Starting state entropy:
4/15 log(15/4) + 8/15 log(15/8) + 3/15 log(15/3) = 0.4384
Gain using gender:
– Female: 3/9 log(9/3)+6/9 log(9/6)=0.2764
– Male: 1/6 (log 6/1) + 2/6 log(6/2) + 3/6 log(6/3) =
0.4392
– Weighted sum: (9/15)(0.2764) + (6/15)(0.4392) =
0.34152
– Gain: 0.4384 – 0.34152 = 0.09688
Gain using height:
0.4384 – (2/15)(0.301) = 0.3983
Choose height as first splitting attribute
CSE 5331/7331 F'2010
111
C4.5
ID3 favors attributes with large number of
divisions
Improved version of ID3:
– Missing Data
– Continuous Data
– Pruning
– Rules
– GainRatio:
CSE 5331/7331 F'2010
112
CART
Create Binary Tree
Uses entropy
Formula to choose split point, s, for node t:
PL,PR probability that a tuple in the training
set will be on the left or right side of the tree.
CSE 5331/7331 F'2010
113
CART Example
At
the start, there are six choices for
split point (right branch on equality):
– P(Gender)=2(6/15)(9/15)(2/15 + 4/15 + 3/15)=0.224
– P(1.6) = 0
– P(1.7) = 2(2/15)(13/15)(0 + 8/15 + 3/15) = 0.169
– P(1.8) = 2(5/15)(10/15)(4/15 + 6/15 + 3/15) = 0.385
– P(1.9) = 2(9/15)(6/15)(4/15 + 2/15 + 3/15) = 0.256
– P(2.0) = 2(12/15)(3/15)(4/15 + 8/15 + 3/15) = 0.32
Split at 1.8
CSE 5331/7331 F'2010
114
Classification Using Neural
Networks
Typical NN structure for classification:
– One output node per class
– Output value is class membership function value
Supervised learning
For each tuple in training set, propagate it
through NN. Adjust weights on edges to
improve future classification.
Algorithms: Propagation, Backpropagation,
Gradient Descent
CSE 5331/7331 F'2010
115
NN Issues
Number of source nodes
Number of hidden layers
Training data
Number of sinks
Interconnections
Weights
Activation Functions
Learning Technique
When to stop learning
CSE 5331/7331 F'2010
116
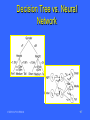
Decision Tree vs. Neural
Network
CSE 5331/7331 F'2010
117
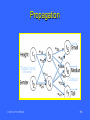
Propagation
Tuple Input
Output
CSE 5331/7331 F'2010
118
NN Propagation Algorithm
CSE 5331/7331 F'2010
119
Example Propagation
© Prentie Hall
CSE 5331/7331 F'2010
120
NN Learning
Adjust weights to perform better with the
associated test data.
Supervised: Use feedback from
knowledge of correct classification.
Unsupervised: No knowledge of
correct classification needed.
CSE 5331/7331 F'2010
121
NN Supervised Learning
CSE 5331/7331 F'2010
122
Supervised Learning
Possible error values assuming output from
node i is yi but should be di:
Change weights on arcs based on estimated
error
CSE 5331/7331 F'2010
123
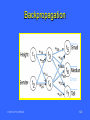
NN Backpropagation
Propagate changes to weights
backward from output layer to input
layer.
Delta Rule: r wij= c xij (dj – yj)
Gradient Descent: technique to modify
the weights in the graph.
CSE 5331/7331 F'2010
124
Backpropagation
Error
CSE 5331/7331 F'2010
125
Backpropagation Algorithm
CSE 5331/7331 F'2010
126
Gradient Descent
CSE 5331/7331 F'2010
127
Gradient Descent Algorithm
CSE 5331/7331 F'2010
128
Output Layer Learning
CSE 5331/7331 F'2010
129
Hidden Layer Learning
CSE 5331/7331 F'2010
130
Types of NNs
Different NN structures used for
different problems.
Perceptron
Self Organizing Feature Map
Radial Basis Function Network
CSE 5331/7331 F'2010
131
Perceptron
Perceptron is one of the simplest NNs.
No hidden layers.
CSE 5331/7331 F'2010
132
Perceptron Example
Suppose:
– Summation: S=3x1+2x2-6
– Activation: if S>0 then 1 else 0
CSE 5331/7331 F'2010
133
Self Organizing Feature Map
(SOFM)
Competitive Unsupervised Learning
Observe how neurons work in brain:
– Firing impacts firing of those near
– Neurons far apart inhibit each other
– Neurons have specific nonoverlapping
tasks
Ex: Kohonen Network
CSE 5331/7331 F'2010
134
Kohonen Network
CSE 5331/7331 F'2010
135
Kohonen Network
Competitive Layer – viewed as 2D grid
Similarity between competitive nodes and
input nodes:
– Input: X = <x1, …, xh>
– Weights: <w1i, … , whi>
– Similarity defined based on dot product
Competitive node most similar to input “wins”
Winning node weights (as well as
surrounding node weights) increased.
CSE 5331/7331 F'2010
136
Radial Basis Function Network
RBF function has Gaussian shape
RBF Networks
– Three Layers
– Hidden layer – Gaussian activation
function
– Output layer – Linear activation function
CSE 5331/7331 F'2010
137
Radial Basis Function Network
CSE 5331/7331 F'2010
138
Classification Using Rules
Perform classification using If-Then
rules
Classification Rule: r = <a,c>
Antecedent, Consequent
May generate from from other
techniques (DT, NN) or generate
directly.
Algorithms: Gen, RX, 1R, PRISM
CSE 5331/7331 F'2010
139
Generating Rules from DTs
CSE 5331/7331 F'2010
140
Generating Rules Example
CSE 5331/7331 F'2010
141
Generating Rules from NNs
CSE 5331/7331 F'2010
142
1R Algorithm
CSE 5331/7331 F'2010
143
1R Example
CSE 5331/7331 F'2010
144
PRISM Algorithm
CSE 5331/7331 F'2010
145
PRISM Example
CSE 5331/7331 F'2010
146
Decision Tree vs. Rules
Tree has implied
order in which
splitting is
performed.
Tree created based
on looking at all
classes.
CSE 5331/7331 F'2010
Rules have no
ordering of
predicates.
Only need to look at
one class to
generate its rules.
147
Clustering Outline
Goal: Provide an overview of the clustering
problem and introduce some of the basic
algorithms
Clustering Problem Overview
Clustering Techniques
– Hierarchical Algorithms
– Partitional Algorithms
– Genetic Algorithm
– Clustering Large Databases
CSE 5331/7331 F'2010
148
Clustering Examples
Segment customer database based on
similar buying patterns.
Group houses in a town into
neighborhoods based on similar
features.
Identify new plant species
Identify similar Web usage patterns
CSE 5331/7331 F'2010
149
Clustering Example
CSE 5331/7331 F'2010
150
Clustering Houses
Geographic
Size
Distance
Based Based
CSE 5331/7331 F'2010
151
Clustering vs. Classification
No prior knowledge
– Number of clusters
– Meaning of clusters
Unsupervised learning
CSE 5331/7331 F'2010
152
Clustering Issues
Outlier handling
Dynamic data
Interpreting results
Evaluating results
Number of clusters
Data to be used
Scalability
CSE 5331/7331 F'2010
153
Impact of Outliers on
Clustering
CSE 5331/7331 F'2010
154
Clustering Problem
Given a database D={t1,t2,…,tn} of
tuples and an integer value k, the
Clustering Problem is to define a
mapping f:Dg{1,..,k} where each ti is
assigned to one cluster Kj, 1<=j<=k.
A Cluster, Kj, contains precisely those
tuples mapped to it.
Unlike classification problem, clusters
are not known a priori.
CSE 5331/7331 F'2010
155
Types of Clustering
Hierarchical – Nested set of clusters
created.
Partitional – One set of clusters
created.
Incremental – Each element handled
one at a time.
Simultaneous – All elements handled
together.
Overlapping/Non-overlapping
CSE 5331/7331 F'2010
156
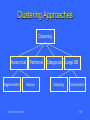
Clustering Approaches
Clustering
Hierarchical
Agglomerative
CSE 5331/7331 F'2010
Partitional
Divisive
Categorical
Sampling
Large DB
Compression
157
Cluster Parameters
CSE 5331/7331 F'2010
158
Distance Between Clusters
Single Link: smallest distance between
points
Complete Link: largest distance between
points
Average Link: average distance between
points
Centroid: distance between centroids
CSE 5331/7331 F'2010
159
Hierarchical Clustering
Clusters are created in levels actually
creating sets of clusters at each level.
Agglomerative
– Initially each item in its own cluster
– Iteratively clusters are merged together
– Bottom Up
Divisive
– Initially all items in one cluster
– Large clusters are successively divided
– Top Down
CSE 5331/7331 F'2010
160
Hierarchical Algorithms
Single Link
MST Single Link
Complete Link
Average Link
CSE 5331/7331 F'2010
161
Dendrogram
Dendrogram: a tree data
structure which illustrates
hierarchical clustering
techniques.
Each level shows clusters
for that level.
– Leaf – individual clusters
– Root – one cluster
A cluster at level i is the
union of its children clusters
at level i+1.
CSE 5331/7331 F'2010
162
Levels of Clustering
CSE 5331/7331 F'2010
163
Agglomerative Example
A B C D E
A
0
1
2
2
3
B
1
0
2
4
3
C
2
2
0
1
5
D
2
4
1
0
3
E
3
3
5
3
0
A
B
E
C
D
Threshold of
1 2 34 5
A B C D E
CSE 5331/7331 F'2010
164
MST Example
A
B
A B C D E
A
0
1
2
2
3
B
1
0
2
4
3
C
2
2
0
1
5
D
2
4
1
0
3
E
3
3
5
3
0
CSE 5331/7331 F'2010
E
C
D
165
Agglomerative Algorithm
CSE 5331/7331 F'2010
166
Single Link
View all items with links (distances)
between them.
Finds maximal connected components
in this graph.
Two clusters are merged if there is at
least one edge which connects them.
Uses threshold distances at each level.
Could be agglomerative or divisive.
CSE 5331/7331 F'2010
167
MST Single Link Algorithm
CSE 5331/7331 F'2010
168
Single Link Clustering
CSE 5331/7331 F'2010
169
Partitional Clustering
Nonhierarchical
Creates clusters in one step as opposed
to several steps.
Since only one set of clusters is output,
the user normally has to input the
desired number of clusters, k.
Usually deals with static sets.
CSE 5331/7331 F'2010
170
Partitional Algorithms
MST
Squared Error
K-Means
Nearest Neighbor
PAM
BEA
GA
CSE 5331/7331 F'2010
171
MST Algorithm
CSE 5331/7331 F'2010
172
Squared Error
Minimized squared error
CSE 5331/7331 F'2010
173
Squared Error Algorithm
CSE 5331/7331 F'2010
174
K-Means
Initial set of clusters randomly chosen.
Iteratively, items are moved among sets
of clusters until the desired set is
reached.
High degree of similarity among
elements in a cluster is obtained.
Given a cluster Ki={ti1,ti2,…,tim}, the
cluster mean is mi = (1/m)(ti1 + … + tim)
CSE 5331/7331 F'2010
175
K-Means Example
Given: {2,4,10,12,3,20,30,11,25}, k=2
Randomly assign means: m1=3,m2=4
K1={2,3}, K2={4,10,12,20,30,11,25},
m1=2.5,m2=16
K1={2,3,4},K2={10,12,20,30,11,25},
m1=3,m2=18
K1={2,3,4,10},K2={12,20,30,11,25},
m1=4.75,m2=19.6
K1={2,3,4,10,11,12},K2={20,30,25},
m1=7,m2=25
Stop as the clusters with these means
are the same.
CSE 5331/7331 F'2010
176
K-Means Algorithm
CSE 5331/7331 F'2010
177
Nearest Neighbor
Items are iteratively merged into the
existing clusters that are closest.
Incremental
Threshold, t, used to determine if items
are added to existing clusters or a new
cluster is created.
CSE 5331/7331 F'2010
178
Nearest Neighbor Algorithm
CSE 5331/7331 F'2010
179
PAM
Partitioning Around Medoids (PAM)
(K-Medoids)
Handles outliers well.
Ordering of input does not impact results.
Does not scale well.
Each cluster represented by one item,
called the medoid.
Initial set of k medoids randomly chosen.
CSE 5331/7331 F'2010
180
PAM
CSE 5331/7331 F'2010
181
PAM Cost Calculation
At each step in algorithm, medoids are
changed if the overall cost is improved.
Cjih – cost change for an item tj associated
with swapping medoid ti with non-medoid th.
CSE 5331/7331 F'2010
182
PAM Algorithm
CSE 5331/7331 F'2010
183
BEA
Bond Energy Algorithm
Database design (physical and logical)
Vertical fragmentation
Determine affinity (bond) between attributes
based on common usage.
Algorithm outline:
1. Create affinity matrix
2. Convert to BOND matrix
3. Create regions of close bonding
CSE 5331/7331 F'2010
184
BEA
Modified from [OV99]
CSE 5331/7331 F'2010
185
Genetic Algorithm Example
{A,B,C,D,E,F,G,H}
Randomly choose initial solution:
{A,C,E} {B,F} {D,G,H} or
10101000, 01000100, 00010011
Suppose crossover at point four and
choose 1st and 3rd individuals:
10100011, 01000100, 00011000
What should termination criteria be?
CSE 5331/7331 F'2010
186
GA Algorithm
CSE 5331/7331 F'2010
187
Clustering Large Databases
Most clustering algorithms assume a large
data structure which is memory resident.
Clustering may be performed first on a
sample of the database then applied to the
entire database.
Algorithms
– BIRCH
– DBSCAN
– CURE
CSE 5331/7331 F'2010
188
Desired Features for Large
Databases
One scan (or less) of DB
Online
Suspendable, stoppable, resumable
Incremental
Work with limited main memory
Different techniques to scan (e.g.
sampling)
Process each tuple once
CSE 5331/7331 F'2010
189
BIRCH
Balanced Iterative Reducing and
Clustering using Hierarchies
Incremental, hierarchical, one scan
Save clustering information in a tree
Each entry in the tree contains
information about one cluster
New nodes inserted in closest entry in
tree
CSE 5331/7331 F'2010
190
Clustering Feature
CT Triple: (N,LS,SS)
– N: Number of points in cluster
– LS: Sum of points in the cluster
– SS: Sum of squares of points in the cluster
CF Tree
– Balanced search tree
– Node has CF triple for each child
– Leaf node represents cluster and has CF value
for each subcluster in it.
– Subcluster has maximum diameter
CSE 5331/7331 F'2010
191
BIRCH Algorithm
CSE 5331/7331 F'2010
192
Improve Clusters
CSE 5331/7331 F'2010
193
DBSCAN
Density Based Spatial Clustering of
Applications with Noise
Outliers will not effect creation of cluster.
Input
– MinPts – minimum number of points in
cluster
– Eps – for each point in cluster there must
be another point in it less than this distance
away.
CSE 5331/7331 F'2010
194
DBSCAN Density Concepts
Eps-neighborhood: Points within Eps
distance of a point.
Core point: Eps-neighborhood dense enough
(MinPts)
Directly density-reachable: A point p is
directly density-reachable from a point q if the
distance is small (Eps) and q is a core point.
Density-reachable: A point si densityreachable form another point if there is a path
from one to the other consisting of only core
points.
CSE 5331/7331 F'2010
195
Density Concepts
CSE 5331/7331 F'2010
196
DBSCAN Algorithm
CSE 5331/7331 F'2010
197
CURE
Clustering Using Representatives
Use many points to represent a cluster
instead of only one
Points will be well scattered
CSE 5331/7331 F'2010
198
CURE Approach
CSE 5331/7331 F'2010
199
CURE Algorithm
CSE 5331/7331 F'2010
200
CURE for Large Databases
CSE 5331/7331 F'2010
201
Comparison of Clustering
Techniques
CSE 5331/7331 F'2010
202
Association Rules Outline
Goal: Provide an overview of basic
Association Rule mining techniques
Association Rules Problem Overview
– Large itemsets
Association Rules Algorithms
– Apriori
– Sampling
– Partitioning
– Parallel Algorithms
Comparing Techniques
Incremental Algorithms
Advanced AR Techniques
CSE 5331/7331 F'2010
203
Example: Market Basket Data
Items frequently purchased together:
Bread PeanutButter
Uses:
– Placement
– Advertising
– Sales
– Coupons
Objective: increase sales and reduce
costs
CSE 5331/7331 F'2010
204
Association Rule Definitions
Set of items: I={I1,I2,…,Im}
Transactions: D={t1,t2, …, tn}, tj I
Itemset: {Ii1,Ii2, …, Iik} I
Support of an itemset: Percentage of
transactions which contain that itemset.
Large (Frequent) itemset: Itemset
whose number of occurrences is above
a threshold.
CSE 5331/7331 F'2010
205
Association Rules Example
I = { Beer, Bread, Jelly, Milk, PeanutButter}
Support of {Bread,PeanutButter} is 60%
CSE 5331/7331 F'2010
206
Association Rule Definitions
Association Rule (AR): implication
X Y where X,Y I and X Y = ;
Support of AR (s) X Y:
Percentage of transactions that
contain X Y
Confidence of AR (a) X Y: Ratio
of number of transactions that contain
X Y to the number that contain X
CSE 5331/7331 F'2010
207
Association Rules Ex (cont’d)
CSE 5331/7331 F'2010
208
Association Rule Problem
Given a set of items I={I1,I2,…,Im} and a
database of transactions D={t1,t2, …, tn}
where ti={Ii1,Ii2, …, Iik} and Iij I, the
Association Rule Problem is to
identify all association rules X Y with
a minimum support and confidence.
Link Analysis
NOTE: Support of X Y is same as
support of X Y.
CSE 5331/7331 F'2010
209
Association Rule Techniques
1.
2.
Find Large Itemsets.
Generate rules from frequent itemsets.
CSE 5331/7331 F'2010
210
Algorithm to Generate ARs
CSE 5331/7331 F'2010
211
Apriori
Large Itemset Property:
Any subset of a large itemset is large.
Contrapositive:
If an itemset is not large,
none of its supersets are large.
CSE 5331/7331 F'2010
212
Large Itemset Property
CSE 5331/7331 F'2010
213
Apriori Ex (cont’d)
s=30%
CSE 5331/7331 F'2010
a = 50%
214
Apriori Algorithm
1.
2.
3.
4.
5.
6.
7.
8.
C1 = Itemsets of size one in I;
Determine all large itemsets of size 1, L1;
i = 1;
Repeat
i = i + 1;
Ci = Apriori-Gen(Li-1);
Count Ci to determine Li;
until no more large itemsets found;
CSE 5331/7331 F'2010
215
Apriori-Gen
Generate candidates of size i+1 from
large itemsets of size i.
Approach used: join large itemsets of
size i if they agree on i-1
May also prune candidates who have
subsets that are not large.
CSE 5331/7331 F'2010
216
Apriori-Gen Example
CSE 5331/7331 F'2010
217
Apriori-Gen Example (cont’d)
CSE 5331/7331 F'2010
218
Apriori Adv/Disadv
Advantages:
– Uses large itemset property.
– Easily parallelized
– Easy to implement.
Disadvantages:
– Assumes transaction database is memory
resident.
– Requires up to m database scans.
CSE 5331/7331 F'2010
219
Sampling
Large databases
Sample the database and apply Apriori to the
sample.
Potentially Large Itemsets (PL): Large
itemsets from sample
Negative Border (BD - ):
– Generalization of Apriori-Gen applied to
itemsets of varying sizes.
– Minimal set of itemsets which are not in PL,
but whose subsets are all in PL.
CSE 5331/7331 F'2010
220
Negative Border Example
PL
CSE 5331/7331 F'2010
PL BD-(PL)
221
Sampling Algorithm
1.
2.
3.
4.
5.
6.
7.
8.
Ds = sample of Database D;
PL = Large itemsets in Ds using smalls;
C = PL BD-(PL);
Count C in Database using s;
ML = large itemsets in BD-(PL);
If ML = then done
else C = repeated application of BD-;
Count C in Database;
CSE 5331/7331 F'2010
222
Sampling Example
Find AR assuming s = 20%
Ds = { t1,t2}
Smalls = 10%
PL = {{Bread}, {Jelly}, {PeanutButter},
{Bread,Jelly}, {Bread,PeanutButter}, {Jelly,
PeanutButter}, {Bread,Jelly,PeanutButter}}
BD-(PL)={{Beer},{Milk}}
ML = {{Beer}, {Milk}}
Repeated application of BD- generates all
remaining itemsets
CSE 5331/7331 F'2010
223
Sampling Adv/Disadv
Advantages:
– Reduces number of database scans to one
in the best case and two in worst.
– Scales better.
Disadvantages:
– Potentially large number of candidates in
second pass
CSE 5331/7331 F'2010
224
Partitioning
Divide database into partitions
D1,D2,…,Dp
Apply Apriori to each partition
Any large itemset must be large in at
least one partition.
CSE 5331/7331 F'2010
225
Partitioning Algorithm
1.
2.
3.
4.
5.
Divide D into partitions D1,D2,…,Dp;
For I = 1 to p do
Li = Apriori(Di);
C = L1 … Lp;
Count C on D to generate L;
CSE 5331/7331 F'2010
226
Partitioning Example
L1 ={{Bread}, {Jelly},
{PeanutButter},
{Bread,Jelly},
{Bread,PeanutButter},
{Jelly, PeanutButter},
{Bread,Jelly,PeanutButter}}
D1
D2
S=10%
CSE 5331/7331 F'2010
L2 ={{Bread}, {Milk},
{PeanutButter}, {Bread,Milk},
{Bread,PeanutButter}, {Milk,
PeanutButter},
{Bread,Milk,PeanutButter},
{Beer}, {Beer,Bread},
{Beer,Milk}}
227
Partitioning Adv/Disadv
Advantages:
– Adapts to available main memory
– Easily parallelized
– Maximum number of database scans is
two.
Disadvantages:
– May have many candidates during second
scan.
CSE 5331/7331 F'2010
228
Parallelizing AR Algorithms
Based on Apriori
Techniques differ:
– What is counted at each site
– How data (transactions) are distributed
Data Parallelism
– Data partitioned
– Count Distribution Algorithm
Task Parallelism
– Data and candidates partitioned
– Data Distribution Algorithm
CSE 5331/7331 F'2010
229
Count Distribution Algorithm(CDA)
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
Place data partition at each site.
In Parallel at each site do
C1 = Itemsets of size one in I;
Count C1;
Broadcast counts to all sites;
Determine global large itemsets of size 1, L1;
i = 1;
Repeat
i = i + 1;
Ci = Apriori-Gen(Li-1);
Count Ci;
Broadcast counts to all sites;
Determine global large itemsets of size i, Li;
until no more large itemsets found;
CSE 5331/7331 F'2010
230
CDA Example
CSE 5331/7331 F'2010
231
Data Distribution Algorithm(DDA)
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
Place data partition at each site.
In Parallel at each site do
Determine local candidates of size 1 to count;
Broadcast local transactions to other sites;
Count local candidates of size 1 on all data;
Determine large itemsets of size 1 for local
candidates;
Broadcast large itemsets to all sites;
Determine L1;
i = 1;
Repeat
i = i + 1;
Ci = Apriori-Gen(Li-1);
Determine local candidates of size i to count;
Count, broadcast, and find Li;
until no more large itemsets found;
CSE 5331/7331 F'2010
232
DDA Example
CSE 5331/7331 F'2010
233
Comparing AR Techniques
Target
Type
Data Type
Data Source
Technique
Itemset Strategy and Data Structure
Transaction Strategy and Data Structure
Optimization
Architecture
Parallelism Strategy
CSE 5331/7331 F'2010
234
Comparison of AR Techniques
CSE 5331/7331 F'2010
235
Hash Tree
CSE 5331/7331 F'2010
236
Incremental Association Rules
Generate ARs in a dynamic database.
Problem: algorithms assume static
database
Objective:
– Know large itemsets for D
– Find large itemsets for D {D D}
Must be large in either D or D D
Save Li and counts
CSE 5331/7331 F'2010
237
Note on ARs
Many applications outside market
basket data analysis
– Prediction (telecom switch failure)
– Web usage mining
Many different types of association rules
– Temporal
– Spatial
– Causal
CSE 5331/7331 F'2010
238
Advanced AR Techniques
Generalized Association Rules
Multiple-Level Association Rules
Quantitative Association Rules
Using multiple minimum supports
Correlation Rules
CSE 5331/7331 F'2010
239
Measuring Quality of Rules
Support
Confidence
Interest
Conviction
Chi Squared Test
CSE 5331/7331 F'2010
240
Data Mining Outline
PART I - Introduction
PART II – Core Topics
– Classification
– Clustering
– Association Rules
PART III – Related Topics
CSE 5331/7331 F'2010
241
Related Topics Outline
Goal: Examine some areas which are related to
data mining.
Database/OLTP Systems
Fuzzy Sets and Logic
Information Retrieval(Web Search Engines)
Dimensional Modeling
Data Warehousing
OLAP/DSS
Statistics
Machine Learning
Pattern Matching
CSE 5331/7331 F'2010
242
DB & OLTP Systems
Schema
– (ID,Name,Address,Salary,JobNo)
Data Model
– ER
– Relational
Transaction
Query:
SELECT Name
FROM T
WHERE Salary > 100000
DM: Only imprecise queries
CSE 5331/7331 F'2010
243
Fuzzy Sets Outline
Introduction/Overview
Material for these slides obtained from:
Data Mining Introductory and Advanced Topics by Margaret H. Dunham
http://www.engr.smu.edu/~mhd/book
Introduction to “Type-2 Fuzzy Logic” by Jenny Carter
http://www.cse.dmu.ac.uk/~jennyc/
CSE 5331/7331 F'2010
244
Fuzzy Sets and Logic
Fuzzy Set: Set membership function is a real valued
function with output in the range [0,1].
f(x): Probability x is in F.
1-f(x): Probability x is not in F.
EX:
– T = {x | x is a person and x is tall}
– Let f(x) be the probability that x is tall
– Here f is the membership function
DM: Prediction and classification are fuzzy.
CSE 5331/7331 F'2010
245
Fuzzy Sets and Logic
Fuzzy Set: Set membership function is a real
valued function with output in the range [0,1].
f(x): Probability x is in F.
1-f(x): Probability x is not in F.
EX:
– T = {x | x is a person and x is tall}
– Let f(x) be the probability that x is tall
– Here f is the membership function
CSE 5331/7331 F'2010
246
Fuzzy Sets
CSE 5331/7331 F'2010
247
IR is Fuzzy
Reject
Reject
Accept
Simple
CSE 5331/7331 F'2010
Accept
Fuzzy
248
Fuzzy Set Theory
A fuzzy subset A of U is characterized by a
membership function
(A,u) : U [0,1]
which associates with each element u of U
a number (u) in the interval [0,1]
Definition
– Let A and B be two fuzzy subsets of U. Also, let ¬A
be the complement of A. Then,
» (¬A,u) = 1 - (A,u)
» (AB,u) = max((A,u), (B,u))
» (AB,u) = min((A,u), (B,u))
CSE 5331/7331 F'2010
249
The world is imprecise.
Mathematical and Statistical techniques often
unsatisfactory.
– Experts make decisions with imprecise data in an
uncertain world.
– They work with knowledge that is rarely defined
mathematically or algorithmically but uses vague
terminology with words.
Fuzzy logic is able to use vagueness to
achieve a precise answer. By considering
shades of grey and all factors simultaneously,
you get a better answer, one that is more
suited to the situation.
250
CSE 5331/7331 F'2010
© Jenny Carter
Fuzzy Logic then . . .
is particularly good at handling uncertainty,
vagueness and imprecision.
especially useful where a problem can be
described linguistically (using words).
Applications include:
–
–
–
–
–
–
robotics
washing machine control
nuclear reactors
focusing a camcorder
information retrieval
train scheduling
CSE 5331/7331 F'2010
© Jenny Carter
251
Crisp Sets
Different heights have same ‘tallness’
CSE 5331/7331 F'2010
© Jenny Carter
252
Fuzzy Sets
The shape you see is known as the
membership function
CSE 5331/7331 F'2010
© Jenny Carter
253
Fuzzy Sets
Shows two membership functions: ‘tall’
and ‘short’
CSE 5331/7331 F'2010
© Jenny Carter
254
Notation
For the member, x, of a discrete set with membership µ we use the
notation µ/x . In other words, x is a member of the set to degree µ. Discrete
sets are written as:
A = µ1/x1 + µ2/x2 + .......... + µn/xn
Or
where x1, x2....xn are members of the set A and µ1, µ2, ...., µn are their
degrees of membership. A continuous fuzzy set A is written as:
CSE 5331/7331 F'2010
© Jenny Carter
255
Fuzzy Sets
The members of a fuzzy set are members to
some degree, known as a membership grade
or degree of membership.
The membership grade is the degree of
belonging to the fuzzy set. The larger the
number (in [0,1]) the more the degree of
belonging. (N.B. This is not a probability)
The translation from x to µA(x) is known as
fuzzification.
A fuzzy set is either continuous or discrete.
Graphical representation of membership
functions is very useful.
CSE 5331/7331 F'2010
© Jenny Carter
256
Fuzzy Sets - Example
Again, notice the overlapping of the sets reflecting the real world
more accurately than if we were using a traditional approach.
CSE 5331/7331 F'2010
© Jenny Carter
257
Rules
Rules often of the form:
IF x is A THEN y is B
where A and B are fuzzy sets defined on the
universes of discourse X and Y respectively.
– if pressure is high then volume is small;
– if a tomato is red then a tomato is ripe.
where high, small, red and ripe are fuzzy sets.
CSE 5331/7331 F'2010
© Jenny Carter
258
Example - Dinner for two
(p2-21 of FL toolbox user guide)
Dinner for two: this is a 2 input, 1 output, 3 rule system
Rule 1
Input 1
If service is poor or
food is rancid, then
tip is cheap
Service (0-10)
Rule 2
Output
If service is good,
then tip is average
Tip (5-25%)
Input 2
Food (0-10)
Rule 3
The inputs are crisp (nonfuzzy) numbers limited to a
specific range
CSE 5331/7331 F'2010
If service is excellent or
food is delicious, then tip
is generous
All rules are evaluated in
parallel using fuzzy
reasoning
© Jenny Carter
The results of the rules
are combined and
distilled (de-fuzzyfied)
The result is a crisp (nonfuzzy) number
259
Dinner for two
1.
Fuzzify the
input:
2.
Apply Fuzzy
operator
CSE 5331/7331 F'2010
© Jenny Carter
260
Dinner for two
3. Apply implication method
CSE 5331/7331 F'2010
© Jenny Carter
261
Dinner for two
4.
Aggregate
all outputs
CSE 5331/7331 F'2010
© Jenny Carter
262
Dinner for two
5. defuzzify
Various approaches
e.g.
centre of area
mean of max
CSE 5331/7331 F'2010
© Jenny Carter
263
Information Retrieval
Outline
Introduction/Overview
Material for these slides obtained from:
Modern Information Retrieval by Ricardo Baeza-Yates and Berthier Ribeiro-Neto
http://www.sims.berkeley.edu/~hearst/irbook/
Data Mining Introductory and Advanced Topics by Margaret H. Dunham
http://www.engr.smu.edu/~mhd/book
CSE 5331/7331 F'2010
264
Information Retrieval
Information Retrieval (IR): retrieving desired
information from textual data.
Library Science
Digital Libraries
Web Search Engines
Traditionally keyword based
Sample query:
Find all documents about “data mining”.
DM: Similarity measures;
Mine text/Web data.
CSE 5331/7331 F'2010
265
Information Retrieval
Information Retrieval (IR): retrieving desired
information from textual data.
Library Science
Digital Libraries
Web Search Engines
Traditionally keyword based
Sample query:
Find all documents about “data mining”.
CSE 5331/7331 F'2010
266
DB vs IR
Records (tuples) vs. documents
Well defined results vs. fuzzy results
DB grew out of files and traditional
business systesm
IR grew out of library science and need
to categorize/group/access
books/articles
CSE 5331/7331 F'2010
267
DB vs IR (cont’d)
Data retrieval
which docs contain a set of keywords?
Well defined semantics
a single erroneous object implies failure!
Information retrieval
information about a subject or topic
semantics is frequently loose
small errors are tolerated
IR system:
interpret contents of information items
generate a ranking which reflects relevance
notion of relevance is most important
CSE 5331/7331 F'2010
268
Motivation
IR in the last 20 years:
classification and categorization
systems and languages
user interfaces and visualization
Still, area was seen as of narrow interest
Advent of the Web changed this perception
once and for all
universal repository of knowledge
free (low cost) universal access
no central editorial board
many problems though: IR seen as key to finding the
solutions!
CSE 5331/7331 F'2010
269
Basic Concepts
Logical view of the documents
Accents
spacing
Docs
stopwords
Noun
groups
stemming
Manual
indexing
structure
structure
Full text
Index terms
Document representation viewed as a continuum:
logical view of docs might shift
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
270
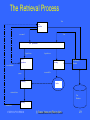
The Retrieval Process
Text
User
Interface
user need
Text
Text Operations
logical view
logical view
Query
Operations
Indexing
user feedback
query
Searching
DB Manager
Module
inverted file
Index
retrieved docs
Text
Database
Ranking
ranked docs
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
271
Information Retrieval
Similarity: measure of how close a query is
to a document.
Documents which are “close enough” are
retrieved.
Metrics:
– Precision = |Relevant and Retrieved|
|Retrieved|
– Recall = |Relevant and Retrieved|
|Relevant|
CSE 5331/7331 F'2010
272
Indexing
IR systems usually adopt index terms to
process queries
Index term:
– a keyword or group of selected words
– any word (more general)
Stemming might be used:
– connect: connecting, connection, connections
An inverted file is built for the chosen index
terms
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
273
Indexing
Docs
Index Terms
doc
match
Ranking
Information Need
query
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
274
Inverted Files
There are two main elements:
– vocabulary – set of unique terms
– Occurrences – where those terms appear
The occurrences can be recorded as
terms or byte offsets
Using term offset is good to retrieve
concepts such as proximity, whereas
byte offsets allow direct access
Vocabulary
…
CSE 5331/7331 F'2010
Occurrences (byte offset)
…
© Baeza-Yates and Ribeiro-Neto
275
Inverted Files
The number of indexed terms is often several
orders of magnitude smaller when compared
to the documents size (Mbs vs Gbs)
The space consumed by the occurrence list is
not trivial. Each time the term appears it must
be added to a list in the inverted file
That may lead to a quite considerable index
overhead
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
276
Example
1
Text:
6
12 16 18
25
29
36
40
45
54 58
66 70
That house has a garden. The garden has many flowers. The flowers are beautiful
Inverted file
Vocabulary
Occurrences
beautiful
70
flowers
45, 58
garden
18, 29
house
6
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
277
Ranking
A ranking is an ordering of the documents
retrieved that (hopefully) reflects the
relevance of the documents to the query
A ranking is based on fundamental
premisses regarding the notion of relevance,
such as:
– common sets of index terms
– sharing of weighted terms
– likelihood of relevance
Each set of premisses leads to a distinct IR model
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
278
Classic IR Models - Basic Concepts
Each document represented by a set of
representative keywords or index terms
An index term is a document word useful for
remembering the document main themes
Usually, index terms are nouns because
nouns have meaning by themselves
However, search engines assume that all
words are index terms (full text
representation)
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
279
Classic IR Models - Basic Concepts
The importance of the index terms is
represented by weights associated to
them
ki- an index term
dj - a document
wij - a weight associated with (ki,dj)
The weight wij quantifies the importance of
the index term for describing the document
contents
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
280
Classic IR Models - Basic Concepts
– t is the total number of index terms
– K = {k1, k2, …, kt} is the set of all index
terms
– wij >= 0 is a weight associated with (ki,dj)
– wij = 0 indicates that term does not belong
to doc
– dj= (w1j, w2j, …, wtj) is a weighted vector
associated with the document dj
– gi(dj) = wij is a function which returns the
weight associated with pair (ki,dj)
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
281
The Boolean Model
Simple model based on set theory
Queries specified as boolean expressions
– precise semantics and neat formalism
Terms are either present or absent. Thus,
wij e {0,1}
Consider
– q = ka (kb kc)
– qdnf = (1,1,1) (1,1,0) (1,0,0)
– qcc= (1,1,0) is a conjunctive component
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
282
The Vector Model
Use of binary weights is too limiting
Non-binary weights provide consideration for
partial matches
These term weights are used to compute a
degree of similarity between a query and
each document
Ranked set of documents provides for better
matching
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
283
The Vector Model
wij > 0 whenever ki appears in dj
wiq >= 0 associated with the pair (ki,q)
dj = (w1j, w2j, ..., wtj)
q = (w1q, w2q, ..., wtq)
To each term ki is associated a unitary vector i
The unitary vectors i and j are assumed to be
orthonormal (i.e., index terms are assumed to
occur independently within the documents)
The t unitary vectors i form an orthonormal basis
for a t-dimensional space where queries and
documents are represented as weighted vectors
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
284
Query Languages
Keyword Based
Boolean
Weighted Boolean
Context Based (Phrasal & Proximity)
Pattern Matching
Structural Queries
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
285
Keyword Based Queries
Basic Queries
– Single word
– Multiple words
Context Queries
– Phrase
– Proximity
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
286
Boolean Queries
Keywords combined with Boolean operators:
– OR: (e1 OR e2)
– AND: (e1 AND e2)
– BUT: (e1 BUT e2) Satisfy e1 but not e2
Negation only allowed using BUT to allow
efficient use of inverted index by filtering
another efficiently retrievable set.
Naïve users have trouble with Boolean logic.
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
287
Boolean Retrieval with Inverted Indices
Primitive keyword: Retrieve containing
documents using the inverted index.
OR: Recursively retrieve e1 and e2 and
take union of results.
AND: Recursively retrieve e1 and e2 and
take intersection of results.
BUT: Recursively retrieve e1 and e2 and
take set difference of results.
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
288
Phrasal Queries
Retrieve documents with a specific phrase
(ordered list of contiguous words)
– “information theory”
May allow intervening stop words and/or
stemming.
– “buy camera” matches:
“buy a camera”
“buying the cameras”
etc.
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
289
Phrasal Retrieval with Inverted Indices
Must have an inverted index that also stores
positions of each keyword in a document.
Retrieve documents and positions for each
individual word, intersect documents, and
then finally check for ordered contiguity of
keyword positions.
Best to start contiguity check with the least
common word in the phrase.
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
290
Proximity Queries
List of words with specific maximal
distance constraints between terms.
Example: “dogs” and “race” within 4
words
match “…dogs will begin
the race…”
May also perform stemming and/or not
count stop words.
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
291
Pattern Matching
Allow queries that match strings rather
than word tokens.
Requires more sophisticated data
structures and algorithms than inverted
indices to retrieve efficiently.
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
292
Simple Patterns
Prefixes: Pattern that matches start of word.
– “anti” matches “antiquity”, “antibody”, etc.
Suffixes: Pattern that matches end of word:
– “ix” matches “fix”, “matrix”, etc.
Substrings: Pattern that matches arbitrary
subsequence of characters.
– “rapt” matches “enrapture”, “velociraptor” etc.
Ranges: Pair of strings that matches any
word lexicographically (alphabetically)
between them.
– “tin” to “tix” matches “tip”, “tire”, “title”, etc.
CSE 5331/7331 F'2010
© Baeza-Yates and Ribeiro-Neto
293
IR Query Result Measures
and Classification
IR
CSE 5331/7331 F'2010
Classification
294
Dimensional Modeling
View data in a hierarchical manner more as
business executives might
Useful in decision support systems and mining
Dimension: collection of logically related
attributes; axis for modeling data.
Facts: data stored
Ex: Dimensions – products, locations, date
Facts – quantity, unit price
DM: May view data as dimensional.
CSE 5331/7331 F'2010
295
Dimensional Modeling
View data in a hierarchical manner more as
business executives might
Useful in decision support systems and mining
Dimension: collection of logically related
attributes; axis for modeling data.
Facts: data stored
Ex: Dimensions – products, locations, date
Facts – quantity, unit price
CSE 5331/7331 F'2010
296
Aggregation Hierarchies
CSE 5331/7331 F'2010
297
Multidimensional Schemas
Star Schema shows facts and dimensions
– Center of the star has facts shown in fact tables
– Outside of the facts, each diemnsion is shown
separately in dimension tables
– Access to fact table from dimension table via join
SELECT Quantity, Price
FROM Facts, Location
Where (Facts.LocationID = Location.LocationID) and
(Location.City = ‘Dallas’)
– View as relations, problem volume of data and
indexing
CSE 5331/7331 F'2010
298
Star Schema
CSE 5331/7331 F'2010
299
Flattened Star
CSE 5331/7331 F'2010
300
Normalized Star
CSE 5331/7331 F'2010
301
Snowflake Schema
CSE 5331/7331 F'2010
302
OLAP
Online Analytic Processing (OLAP): provides more
complex queries than OLTP.
OnLine Transaction Processing (OLTP): traditional
database/transaction processing.
Dimensional data; cube view
Visualization of operations:
– Slice: examine sub-cube.
– Dice: rotate cube to look at another dimension.
– Roll Up/Drill Down
DM: May use OLAP queries.
CSE 5331/7331 F'2010
303
OLAP Introduction
OLAP by Example
http://perso.orange.fr/bernard.lupin/englis
h/index.htm
What is OLAP?
http://www.olapreport.com/fasmi.htm
CSE 5331/7331 F'2010
304
OLAP
Online Analytic Processing (OLAP): provides more
complex queries than OLTP.
OnLine Transaction Processing (OLTP): traditional
database/transaction processing.
Dimensional data; cube view
Support ad hoc querying
Require analysis of data
Can be thought of as an extension of some of the basic
aggregation functions available in SQL
OLAP tools may be used in DSS systems
Multidimentional view is fundamental
CSE 5331/7331 F'2010
305
OLAP Implementations
MOLAP (Multidimensional OLAP)
– Multidimential Database (MDD)
– Specialized DBMS and software system capable of
supporting the multidimensional data directly
– Data stored as an n-dimensional array (cube)
– Indexes used to speed up processing
ROLAP (Relational OLAP)
– Data stored in a relational database
– ROLAP server (middleware) creates the
multidimensional view for the user
– Less Complex; Less efficient
HOLAP (Hybrid OLAP)
– Not updated frequently – MDD
– Updated frequently - RDB
CSE 5331/7331 F'2010
306
OLAP Operations
Roll Up
Drill Down
Single Cell
CSE 5331/7331 F'2010
Multiple Cells
Slice
Dice
307
OLAP Operations
Simple query – single cell in the cube
Slice – Look at a subcube to get more
specific information
Dice – Rotate cube to look at another
dimension
Roll Up – Dimension Reduction; Aggregation
Drill Down
Visualization: These operations allow the
OLAP users to actually “see” results of an
operation.
CSE 5331/7331 F'2010
308
Relationship Between Topcs
CSE 5331/7331 F'2010
309
Decision Support Systems
Tools and computer systems that assist
management in decision making
What if types of questions
High level decisions
Data warehouse – data which supports
DSS
CSE 5331/7331 F'2010
310
Unified Dimensional Model
Microsoft Cube View
SQL Server 2005
http://msdn2.microsoft.com/enus/library/ms345143.aspx
http://cwebbbi.spaces.live.com/Blog/cns!1pi7ET
ChsJ1un_2s41jm9Iyg!325.entry
MDX AS2005
http://msdn2.microsoft.com/enus/library/aa216767(SQL.80).aspx
CSE 5331/7331 F'2010
311
Data Warehousing
“Subject-oriented, integrated, time-variant, nonvolatile”
William Inmon
Operational Data: Data used in day to day needs of
company.
Informational Data: Supports other functions such as
planning and forecasting.
Data mining tools often access data warehouses rather
than operational data.
DM: May access data in warehouse.
CSE 5331/7331 F'2010
312
Operational vs. Informational
Application
Use
Temporal
Modification
Orientation
Data
Size
Level
Access
Response
Data Schema
CSE 5331/7331 F'2010
Operational Data
Data Warehouse
OLTP
Precise Queries
Snapshot
Dynamic
Application
Operational Values
Gigabits
Detailed
Often
Few Seconds
Relational
OLAP
Ad Hoc
Historical
Static
Business
Integrated
Terabits
Summarized
Less Often
Minutes
Star/Snowflake
313
Statistics
Simple descriptive models
Statistical inference: generalizing a model
created from a sample of the data to the entire
dataset.
Exploratory Data Analysis:
– Data can actually drive the creation of the
model
– Opposite of traditional statistical view.
Data mining targeted to business user
DM: Many data mining methods come
from statistical techniques.
CSE 5331/7331 F'2010
314
Machine Learning Outline
Introduction (Chuck Anderson)
CS545: Machine Learning
By Chuck Anderson
Department of Computer Science
Colorado State University
Fall 2006
CSE 5331/7331 F'2010
315
Machine Learning
Machine Learning: area of AI that examines how to
write programs that can learn.
Often used in classification and prediction
Supervised Learning: learns by example.
Unsupervised Learning: learns without knowledge of
correct answers.
Machine learning often deals with small static datasets.
DM: Uses many machine learning
techniques.
CSE 5331/7331 F'2010
316
What is Machine Learning?
Statistics ≈ the science of inference from data
Machine learning ≈ multivariate statistics +
computational statistics
Multivariate statistics ≈ prediction of values of
a function assumed to underlie a multivariate
dataset
Computational statistics ≈ computational
methods for statistical problems (aka
statistical computation) + statistical methods
which happen to be computationally intensive
Data Mining ≈ exploratory data analysis,
particularly with massive/complex datasets
CSE 5331/7331 F'2010
© Chuck Anderson
317
Kinds of Learning
Learning algorithms are often categorized
according to the amount of information
provided:
Least Information:
– Unsupervised learning is more exploratory.
– Requires samples of inputs. Must find regularities.
More Information:
– Reinforcement learning most recent.
– Requires samples of inputs, actions, and rewards
or punishments.
Most Information:
– Supervised learning is most common.
– Requires samples of inputs and desired outputs.
CSE 5331/7331 F'2010
© Chuck Anderson
318
Examples of Algorithms
Supervised learning
– Regression
» multivariate regression
» neural networks and kernel methods
– Classification
» linear and quadratic discrimination analysis
» k-nearest neighbors
» neural networks and kernel methods
Reinforcement learning
– multivariate regression
– neural networks
Unsupervised learning
– principal components analysis
– k-means clustering
– self-organizing networks
CSE 5331/7331 F'2010
© Chuck Anderson
319
CSE 5331/7331 F'2010
© Chuck Anderson
320
CSE 5331/7331 F'2010
© Chuck Anderson
321
CSE 5331/7331 F'2010
© Chuck Anderson
322
CSE 5331/7331 F'2010
© Chuck Anderson
323
Pattern Matching
(Recognition)
Pattern Matching: finds occurrences of
a predefined pattern in the data.
Applications include speech recognition,
information retrieval, time series
analysis.
DM: Type of classification.
CSE 5331/7331 F'2010
324
Image Mining Outline
Image Mining – What is it?
Feature Extraction
Shape Detection
Color Techniques
Video Mining
Facial Recognition
Bioinformatics
CSE 5331/7331 F'2010
325
The 2000 ozone hole over the antarctic seen by EPTOMS
CSE 5331/7331 F'2010 http://jwocky.gsfc.nasa.gov/multi/multi.html#hole
326
Image Mining – What is it?
Image Retrieval
Image Classification
Image Clustering
Video Mining
Applications
– Bioinformatics
– Geology/Earth Science
– Security
–…
CSE 5331/7331 F'2010
327
Feature Extraction
Identify major components of image
Color
Texture
Shape
Spatial relationships
Feature Extraction & Image Processing
http://users.ecs.soton.ac.uk/msn/book/
Feature Extraction Tutorial
http://facweb.cs.depaul.edu/research/vc/VC_Worksh
op/presentations/pdf/daniela_tutorial2.pdf
CSE 5331/7331 F'2010
328
Shape Detection
Boundary/Edge Detection
Time Series – Eamonn Keogh
http://www.engr.smu.edu/~mhd/8337sp07/sh
apes.ppt
CSE 5331/7331 F'2010
329
Color Techniques
Color Representations
RGB:
http://en.wikipedia.org/wiki/Rgb
HSV:
http://en.wikipedia.org/wiki/HSV_color_space
Color Histogram
Color Anglogram
http://www.cs.sunysb.edu/~rzhao/publications/Video
DB.pdf
CSE 5331/7331 F'2010
330
What is Similarity?
CSE 5331/7331 F'2010
(c) Eamonn Keogh, [email protected]
331
Video Mining
Boundaries between shots
Movement between frames
ANSES:
http://mmir.doc.ic.ac.uk/demos/anses.html
CSE 5331/7331 F'2010
332
Facial Recognition
Based upon features in face
Convert face to a feature vector
Less invasive than other biometric
techniques
http://www.face-rec.org
http://computer.howstuffworks.com/facialrecognition.htm
SIMS:
http://www.casinoincidentreporting.com/Products.
aspx
CSE 5331/7331 F'2010
333
Microarray Data Analysis
Each probe location associated with gene
Measure the amount of mRNA
Color indicates degree of gene expression
Compare different samples (normal/disease)
Track same sample over time
Questions
– Which genes are related to this disease?
– Which genes behave in a similar manner?
– What is the function of a gene?
Clustering
– Hierarchical
– K-means
CSE 5331/7331 F'2010
334
®
GeneChip
Affymetrix
Array
http://www.affymetrix.com/corporate/outreach/lesson_plan/educator_resources.affx
CSE 5331/7331 F'2010
335
Microarray Data Clustering
"Gene expression
profiling identifies
clinically relevant
subtypes of prostate
cancer"
Proc. Natl. Acad.
Sci. USA, Vol. 101,
Issue 3, 811-816,
January 20, 2004
CSE 5331/7331 F'2010
336
CSE 5331/7331 F'2010
337