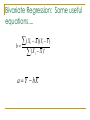Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Instrumental variables estimation wikipedia , lookup
Time series wikipedia , lookup
German tank problem wikipedia , lookup
Confidence interval wikipedia , lookup
Choice modelling wikipedia , lookup
Resampling (statistics) wikipedia , lookup
Linear regression wikipedia , lookup
Quantitative Methods Review—Bivariate Regression What is the criterion that OLS uses to “fit” a line to your data? What is a parameter? A parameter estimate? What are independent variables—or rhs (right-hand-side) variables? Dependent variables? What is the slope? The intercept? The error term (in the population) or the residual (in the sample)? Review—Bivariate Regression Review of notation—slope, intercept, error (estimated or sample VS. true or population) Two possible consequences of violating an OLS assumption—”bias” (what does that mean?) and inflated / deflated standard errors (what does that mean?) Review—Bivariate Regression Assumptions: No measurement error Specification—include all relevant rhs variables, no irrelevant rhs variables, linear relationship Is this likely what our data look like? Homeskedastic error terms (no heteroskedasticity) No autocorrelation Bivariate Regression: Robustness A discussion about standard errors, p-values, ad statistical significance Confidence intervals. What are they? Confidence intervals are a range in which you would expect the true parameter to fall a pre-specified percentage of the time. Bivariate Regression: Robustness The wider the confidence interval, the less certain you are of the estimate. (A relatively wide confidence interval means that you could gather another sample, and would not be confident that your new slope estimate would be relatively close to the one you have from this sample). The wider the confidence interval.... The higher the p-value (farther away from .05 or .01)... The less statistically significant the results.... The less confident you are that there is a non-zero effect of the independent variable on the dependent variable Bivariate Regression: Robustness The narrower the confidence interval, the more “robust”, “efficient”, “stable” the results are. If you were to gather an infinite number of samples from your population, and calculate an infinite number of slope estimates (one from each sample), you dno’t expect that the slope estimate will change much from sample to sample... Bivariate Regression: Robustness The standard error and variance of the slope estimate.... is a closely related concept. The larger the standard error, the less confident you are in your results (and the wider your confidence interval). Recall the image of the seesaw. Bivariate Regression: Robustness Let’s start with the variance of the residual. The formula for the variance of the residual (or the estimated variance of the error term): e e 2 i ˆ n2 2 Bivariate Regression: Robustness Note two elements of that equation-First, what (by assumption) is the average residual? And second, why are we subtracting 2 from our sample size? Bivariate Regression: Robustness What is the variance of the slope estimate? ˆ 2 2 Xi x 2 Bivariate Regression: Robustness Note the numerator of the variance of the slope estimate b: it taps into the variance of the residuals (or, how well the data “fit” your estimated line) Note the denominator of the variance of the slope estimate b: it taps into the range or variance of X. Bivariate Regression: Robustness So, if the data fit your line well.... The numerator of that equation is reduced The variance of the slope estimate b is reduced; your results are more stable The confidence interval for β is narrower Your results are more statistically significant; your p-value is relatively low. You are more likely to reject the null hypothesis that β=0 Bivariate Regression: Robustness And, if you have relatively good variance in X... The denominator of that equation is increased The variance of the slope estimate b is reduced; your results are more stable The confidence interval for β is narrower Your results are more statistically significant; your p-value is relatively low. You are more likely to reject the null hypothesis that β=0 Bivariate Regression: Robustness The equation above is for the variance of your estimated slope b. Your computer printouts will generally give you the standard error of b. How do we calculate a standard error based on a variance? Bivariate Regression: Robustness The confidence interval for b is analogous to the variance and standard error, as noted above... ˆ n 2 ˆ t * 2 ˆ , ˆ t n 2 * ˆ ˆ 2 Bivariate Regression: Robustness So, the slope estimate plus / minus The t-value * the standard error of the slope estimate What is α? (It is 100-CL. Our CL is predetermined). Why are we dividing α by 2? Where can we find the t-value? How do we interpret a confidence interval? Bivariate Regression: T values Recall the central limit theorem, which said that for any population with known mean μ and known variance σ2, random samples can be drawn, and the means of these samples will be 2 x N ( , ) n Bivariate Regression: T values We use the t distribution in probability testing. Suppose X is some Random Variable with a true mean of μ and a true variance of σ2. Of course, in “real life”, we never know these ‘true” values. We estimate μ with x And we don’t know σ2, so we estimate it with s2. So instead of saying that we approximate a normal distribution, we say.... Bivariate Regression: T values And we don’t know σ2, so we estimate it with s2. So instead of saying that we approximate a normal distribution, we say.... x s/ n ~ Tn-1 Bivariate Regression: T values As n gets larger, T distribution is closer to N(0,1) distribution; the mean of the t distribution is always 0, and as n increases, the variance of the t-distribution shrinks to 1. x s/ n ~ Tn-1 Bivariate Regression: T values Our t value is calculated by setting μ to a hypothesized value (usually 0), and then taking our sample estimate, and dividing it by the standard error. Note that this corresponds to the formula below (although note that instead of the mean of X, we will be using “b” as our sample / estimated slope) x s/ n ~ Tn-1 Bivariate Regression: Hypothesis Testing If our 1- α confidence interval includes zero, then we do not reject (we “fail to reject” our null hypothesis H0: β=0 at the 1- α level (2 tailed test). Of course, if our 1- α CI does not include zero, then we accept H1: β ≠ 0 (we do reject H0: β=0) at the 1- α Confidence Level. Bivariate Regression: Prob-Values Prob values for slope coefficient are analogous to confidence intervals. Most computer packages will report these p-values for each slope coefficient. The universal decision rule indicates that we Reject H0: β=0 with (1-α) confidence if p-value < α Bivariate Regression: Prob-Values Pre-Determined CI 1-α α reported p-value Is p-value < α? Conclusion 90% 1-.10 .10 .0374 Yes Reject Ho 95% 1-.05 .05 .0374 Yes Reject Ho 98% 1-.02 .02 .0374 No Fail to Reject Ho 99% 1-.01 .01 .0374 No Fail to Reject Ho Bivariate Regression: One-tailed versus two-tailed tests. We use one-tailed tests when we have a directional hypothesis. One tailed tests make parameter estimates more significant, because you are restricting H1 to a narrower set of possibilities. In confidence intervals, the α remains the same, because you’ve picked a pre-determined confidence level—but you can think of the p-value (the area under the curve that represents greater than t) as being halved. Bivariate Regression: Summary We are estimating slopes and intercepts—and so we talk about the degree of confidence we have, based on our sample slopes and intercepts. That concept of “confidence”, “robustness”, “efficiency”, “stability” is part of inferential statistics. And, in general, a better fit of the data to the model— and more variance in the explanatory / independent variables – tends to make the findings more robust. Bivariate Regression: Summary This makes sense—if you only ask a couple of people who they are voting for in the Democratic / Republican primaries, you will not have much variance—and you would not be confident if you tried to generalize to a larger population. And research problems where there isn’t much variance in the independent variables (or dependent variable), and where the dependent variable is a “rare event” are just inherently difficult to predict (although there are ways to weight the observations so that one can address those issues). Bivariate Regression: Summary Likewise, we are always going to be thinking about two possible problems—we can have deflated or inflated standard errors if we are violating OLS assumptions (so, our results are more or less significant than they would otherwise be). Or our results are biased, which means that the estimated slope would not average out to the true slope, even if one collected an infinite number of samples, and an infinite number of estimate slopes. Bivariate Regression: Summary These concepts—of confidence and bias—also carry over to all inferential methods. And, keep in mind that there is a difference between statistical significance (as signaled by p-values or tvalues or confidence intervals) and the magnitude of b. You may have a very small effect, but it is “statistically significant” because it is very robust (remember what goes into the t-- Bivariate Regression: Summary You may have a very small effect, but it is “statistically significant” because it is very robust (remember what goes into the t—the value of b, divded by the standard error of b). Or, you may have a very large effect, but cannot conclude that it is different from 0, because it is not very robust— you’re not that sure it would be large if you collected a different sample. These concepts, too, carry over across methods. It is very important to interpret both statistical significance and magnitude, and to recognize they are not the same. Bivariate Regression: Residuals True Model: yi = σ + βxi + εi Which is estimated with: Yi = a + bXi + ei εi is the true error term for observation i. “e” is the estimated error (residual) for observation i. Bivariate Regression: Residuals So, ei = yi – (a + bxi) Or ei = observed Y – predicted Y Think of the error term in the population as not an error, but as a disturbance or a stochastic shock, whose deviation from the “true” population line is due to randomness. Bivariate Regression: R2 Notice that observed Y – Mean Y = total deviation of Yi from mean Y. Notice that predicted Y – mean of Y is the deviation of Yi from the mean of Y explained by OLS regression line And notice that observed Y – predicted Y is the remaining unexplained deviation of Yi from mean Y (error) Bivariate Regression: R2 Case (i) Ordering 1 P<O<M 2 O<P<M 3 P<M<O 4 O<M<P 5 M<P<O 6 M<O<P Total (observed-mean) Explained (predicted - mean) Unexplained (Error) (observed-predicted) Bivariate Regression: R2 Of course, in any sample we have n data points— so we’ll have n total deviations And n explained deviations And n unexplained deviations Bivariate Regression: R2 Suppose we square each individual total, explained, and unexplained deviation. And then we sum up all of the squared total deviations, do the same for all the squared explained deviations, and the same for all the squared unexplained deviations. We would see that Sum of the Squared Total Deviations = Sum of the Squared Explained Deviations + Sum of the Squared Unexplained Deviations Bivariate Regression: R2 OR, TSS = Total Sum of Squares = RSS (Regression Sum of Squares / Explained Sum of Squares) + ESS (Error Sum of Squares / Residual Sum of Squares) Bivariate Regression: R2 And R2 = RSS / TSS (Note that this is the same as 1 – proportion of total deviation (TSS) of Y from the mean that is “unexplained” by OLS) So, if R2 = .34, we can say that 34% of the total variation in Y has been accounted for by the OLS regression of Y and X Bivariate Regression: R2 Why is R2 useful? What are the limits of R2? It is not really a measure of magnitude of the effect. It is a measure of correlation, and so it depends in part on the standard deviation of X and Y—and cannot be compared across samples. Models with high R2 are not necessarily “good”—and models with low R2 are not necessarily “bad”. Bivariate Regression: R2 It is not really a measure of magnitude of the effect. It is a measure of correlation, and so it depends in part on the standard deviation of X and Y—and cannot be compared across samples. Models with high R2 are not necessarily “good”—and models with low R2 are not necessarily “bad”. R2 can be biased, particularly in small samples. And it can be a reflection of the number of variables on the left hand sides (although there are ways to account for this—adjusted R2) Bivariate Regression: R2 The bottom line? – R2 is a measure of goodness of fit, and as such can be useful. It is not a measure of how good your results are. And, when you think about it, what the R2 is doing is telling you how well the data fit the line—how good your prediction is compared to just using the mean. The mean isn’t a great predictor of Y, so the utility of the R2 is limited. Bivariate Regression: Standard Error of Estimate ˆ 2 ei n2 Bivariate Regression: Some useful equations.... ( X X )(Y Y ) b ( X X ) i i 2 i a Y bX