Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Genome (book) wikipedia , lookup
Nutriepigenomics wikipedia , lookup
Microevolution wikipedia , lookup
Quantitative comparative linguistics wikipedia , lookup
Epigenetics of human development wikipedia , lookup
Metabolic network modelling wikipedia , lookup
Designer baby wikipedia , lookup
Gene expression programming wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
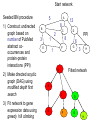
Pathway construction using integrative Bayesian Networks Group meeting 29th Sep 2009 Ståle Nygård Network of differentially expressed genes is constructed based on (1) co-occurrences in PubMed abstracts, (2) protein-protein interactions (3) co-regulations AA B C E F D D G H Start network Seeded BN procedure 1) Construct undirected graph based on number of PubMed abstract cooccurrences and protein-protein interactions (PPI) A 5 12 8 B C 2 3 8 1 E F 1 AA 2) Make directed acyclic graph (DAG) using modified depth first search B 3) Fit network to gene expression data using greedy hill climbing E D PPI 6 G 3 H Fitted network C F D D G H Extensions of seeded BN: Integrating ligand-receptor bindings The Database of Ligand–Receptor Partners (DLRP) includes 175 protein ligands, 131 protein receptors and 451 experimentally determined ligandreceptor pairings. I Receptor 12 7 Ligand D A 5 8 B 2 3 C 8 1 E 1 F PPI 6 G 3 H Receptor Integrating transcription factor binding data TRANSFAC® 7.0 Public 2005 and other databases contain data on transcription factors, their experimentelly-proven binding sites, and regulated genes. TF target gene TF target gene I A 12 8 B 10 1 3 E TF 5 2 1 C D 8 F PPI 6 G 3 H Using sequence homologies HOGENOM contains sequence data on homologous genes from fully sequenced organisms IA Include homologues of genes already in the network. Fitted network can be used to infer function of previously uncharacterized genes. I and A are sequence homologues AA B C E F D D G H Methodological problem (1): Going from PDAG to DAG - Adding ligand/receptors or TF binding data gives a start network which is a partially directed acyclic graph (PDAG). - BN needs a directed acyclic graph (DAG). - Dor & Tarsi (1992) provide a method for going from PDAG to DAG I Receptor 12 7 Ligand D A 5 8 B 2 3 C 8 1 E 1 F Receptor PPI 6 G 3 H Methodological problem (2): Quantification of local dependencies How to quantify P(child | parents), e.g P(E | B,C)? AA Suggestions by Friedman (2000): - Discretization of gene expressions and multinomial model: - Continous gene expressions and linear Gausian model Newer suggestions - Non-parametric models (e.g Ko et al, 2007) - Mixture models using latent variables (e.g. Grzegorczyk et al 2008) B C E F D D G H Methodological problem (3): Fitting DAG to expression data -In Seeded BN, greedy hill climbing is used to optimize network. Problem: global optimum is not guaranteed. - Another possibility: Markov Chain Monte Carlo (MCMC) (e.g. Grzegorczyk and Husmeier, 2008) AA B C E F D D G H Project plan Java source code (from Quackenbush) Modification of source code New method generates network of interactions based on: - PubMed Articles - PPI data bases - DLRP - TRANSFAC - HOGENOM Network is trained to fit expression data Apply improved method to KO data (with unknown molecular response) Does the new method improve the identifiacation of known pathways? Project participants Eivind Vegard Trevor Geir Christensen, Institute for Experimental Medical Research, OUS - Ullevål