Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Fast Algorithms For Mining
Association Rules
By Rakesh Agrawal and R. Srikant
Presented By: Chirayu Modi
What is Data mining ?
Data mining is a set of techniques used in an automated
approach to exhaustively explore and bring to the surface
complex relationships in very large datasets.“
“…is the process of discovering interesting knowledge...from
large amounts of data stored in databases, data warehouses,
and other information repositories.“
Some method includes:
Classification and Clustering
Association
Sequencing
Association Rules
Association rules are (local) patterns, which model dependencies
between attributes.
Finding frequent patterns, associations, correlations, or causal
structures among sets of items or objects in transaction databases,
relational databases, and other information repositories.
Applications:
Basket data analysis, cross-marketing, catalog design, lossleader analysis, clustering, classification, etc
Rule form: “Body Head [support, confidence]”.
Examples:
buys(x, “beers”) buys(x, “chips”) [0.5%, 60%]
major(x, “CS”) and takes(x, “DB”) grade(x, “A”) [1%, 75%]
Association Rule: Basic Concepts
Given: (1) database of transactions, (2) each transaction is a list of
items (purchased by a customer in a visit)
Find: all rules that correlate the presence of one set of items with
that of another set of items
E.g., 98% of people who purchase tires and auto accessories
also get automotive services done
Applications
* Maintenance Agreement (What the store should do to boost
Maintenance Agreement sales)
Home Electronics * (What other products should the store
stocks up?)
Attached mailing in direct marketing
Mining Association Rules—An Example
Transaction ID
2000
1000
4000
5000
Items Bought
A,B,C
A,C
A,D
B,E,F
Min. support 50%
Min. confidence 50%
Frequent Itemset Support
{A}
75%
{B}
50%
{C}
50%
{A,C}
50%
For rule A C:
support = support({A C}) = 50%
confidence = support({A C})/support({A}) = 66.6%
The Apriori principle:
Any subset of a frequent itemset must be frequent
Mining Frequent Itemsets: the Key Step
Find the frequent itemsets: the sets of items that have minimum
support
A subset of a frequent itemset must also be a frequent itemset
i.e., if {AB} is a frequent itemset, both {A} and {B} should be a
frequent itemset
Iteratively find frequent itemsets with cardinality from 1 to k (kitemset)
Use the frequent itemsets to generate association rules.
Mining algorithm
IDEA: It relies on the ”a priori” or downward closure property: if an
itemset has minimum support (frequent itemset) then every subset
of itemset also has minimum support.
In the first pass the support for each item is counted and the large
itemsets are obtained.
In the second pass the large itemsets obtained from the first pass
are extended to generate new itemsets called candidate itemsets.
The support of the candidate itemsets is measured and large
itemsets are obtained.
This is repeated till no large itemsets can be formed.
AIS algorithm
Two concepts are
Extension of an itemset.
Determining what should be in the candidate itemset.
In case of the AIS, candidate sets are generated on the fly. New
candidate item sets are generated by extending the large item sets
that were generated in the previous pass with other items in the
transaction.
SETM
The implementation is based on expressing the algorithm in the form
of SQL queries.
The 2 steps are:
Generating the candidate itemsets using join operations.
Generating the support counts and determining the large
itemsets.
In case of the SETM too, the candidate sets are generated on the
fly. New candidate item sets are generated by extending the large
item sets that were generated in the previous pass with other items
in the transaction.
Drawbacks of AIS and SETM
They were very slow.
Generated large number of itemsets with the support/confidence
lower than the user specified minimum support/confidence.
Makes a number of passes over the database.
All aspects of data mining cannot be represented using SETM
algorithm.
Apriori algorithm
Candidate itemsets were generated from large itemsets of previous
pass without considering the database.
The large itemsets of the previous pass were extended to get the
new candidate itemsets.
Pruning was done using the fact that any subset of a frequent
itemset should be frequent.
Step 1 - discover all frequent items that have support above the
minimum support required.
Step 2 - Use the set of frequent items to generate the association
rules that have high enough confidence
Apriori Candidate Generation
Monotonicity Property: All subset of a frequent set are frequent
Given Lk-1, Ck can be generated in two steps:
Join: Join Lk-1 with Lk-1, with the join condition that the first k-1
items should be the same
Prune: delete all candidates whose support is lower than the
minimum support specified
The Apriori Algorithm
Pseudo-code:
Ck: Candidate itemset of size k
Lk : frequent itemset of size k
L1 = {frequent items};
for (k = 1; Lk !=; k++) do begin
Ck+1 = candidates generated from Lk;
for each transaction t in database do
increment the count of all candidates in Ck+1
that are contained in t
Lk+1 = candidates in Ck+1 with min_support
end
return k Lk;
Apriori candidate generation (join step)
The Apriori-generation function takes as argument F(k-1), the set of
all frequent (k-1)-item sets. It returns a superset of the set of all
frequent k-item sets. The function works as follows: First, in the join
step, we join F(k-1) with F(k-1):
insert into C(k) select p.item(1), p.item(2),... p.item(k-1),
q.item(k-1) from F(k-1) as p, F(k-1) as qwhere p.item(1) =
q.item(1),...,p.item(k-2) = q.item(k-2), p.item(k-1) < q.item(k-1)
The prune step
We delete all the item sets c in C(k) such that some (k-1)-subset of c
is not in F(k-1):
for each item sets c in C(k) do
for each (k-1)-subsets s of c do
if (s not in F(k-1)) then
delete c from C(k);
Any subset of a frequent item set must be frequent
Lexicographic order of items is assumed!
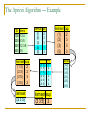
The Apriori Algorithm — Example
TID
100
200
300
400
Items
134
235
1235
25
itemset
{1 3}
{2 3}
{2 5}
{3 5}
sup
2
2
3
2
itemset
{2 3 5}
itemset sup.
{1}
2
{2}
3
{3}
3
{4}
1
{5}
3
itemset sup
{1 2}
1
{1 3}
2
{1 5}
1
{2 3}
2
{2 5}
3
{3 5}
2
itemset sup
{2 3 5} 2
itemset
{1}
{2}
{3}
{5}
sup.
2
3
3
3
itemset
{1 2}
{1 3}
{1 5}
{2 3}
{2 5}
{3 5}
Buffer Management
In the candidate generation phase of pass k , we need storage for
large itemsets Lk-1 and the candidate itemsets Ck. In the counting
phase, we need storage for Ck and at least one page to buffer the
database transactions. (Ct is a subset of Ck)
Lk fits in memory and Ck does not: generate as many Ck as
possible, scan database and count support and write Fk to disk.
Delete small itemsets. Repeat until all of Fk is generated for that
pass.
Lk-1 does not fit in memory: externally sort Lk-1. Bring into memory
Lk-1 items in which the first k-2 items are the same. Generate
Candidate itemsets. Scan data and generate Fk. Unfortunately,
pruning cannot be done.
CORRECTNESS
Ck is a superset of Fk.
Ck is a superset of Fk by the way Ck is generated.
Subset pruning is based on the monotonicity property and every
item pruned is guaranteed not be large.
Hence, Ck is always a superset of Fk.
AprioriTid Algorithm
It is similar to the Apriori Algorithm and uses Apriori-gen function to
determine the candidate sets.
But the basic difference is that for determining the support , the
database is not used after the first pass.
Rather a set C’k is used for this purpose
Each member of C’k is of the form <TID, {Xk} > where Xk is
Potentially large k itemset present in the transaction with the
identifier TID
C’1 corresponds to database D.
Algorithm AprioriTID
1)
2)
3)
4)
5)
6)
7)
8)
9)
10)
11)
12)
13)
14)
L1 = ( large 1-itemsets);
C1’= database D;
for (k=2; Lk-1 ; k++) do begin
Ck = apriori-gen(Lk-1); //New candidates
Ck’= ;
forall entries t Ck-1’ do begin
//determine candidate itemsets in Ck contained in the transaction with
identifier t.TID
Ct ={c Ck |(c-c[k]) t.set-of-itemsets (c-c[k-1]) t.set-ofitemsets };
forall candidates c Ct do
c.count++;
if (Ct ) then Ck’+= < t.TID, Ct>;
end;
Lk = {c Ck | c.count minsup}
End
Answer = Uk Lk;
Buffer management
In the kth pass, AprioriTid needs memory for Lk-1 and Ck-1 during
candidate generation.
During the counting phase, it needs memory for Ck-1 , Ck , and a
page for Ck-1 ‘ and Ck ‘. entries in C’k-1 are needed sequentially, but
C’k can be written out as generated.
Drawbacks of Apriori and AprioriTid
Apriori
Takes longer time for calculating support of candidate itemsets.
For determining the support of the candidate sets the algorithm
always looks into every transaction in the database. Hence it
takes a longer time (more passes on data)
AprioriTid
During the initial passes the candidate itemsets generated are
very large equivalent to the size of the database. Hence the time
taken will be equal to that of Apriori. And also it might incur an
additional cost if it cannot completely fit into the memory.
Experimental results
As the minimum support decreases, the execution times of all the
algorithms increase because of increases in the total number of
candidate and large itemsets.
Apriori beats SETM by more than an order of magnitude for large
datasets.
Apriori beats AIS for all problem sizes, by factors ranging from 2 for
high minimum support to more than an order of magnitude for low
levels of support.
For small problems, AprioriTid did about as well as Apriori, but
performance degraded to about twice as slow for large problems.
Apriori Hybrid
Initial pass: Apriori performs better
Later pass: AprioriTid performs better
Apriori Hybrid:
Uses Apriori in the initial passes and later shifts to AprioriTid.
Drawback:
An extra cost is incurred when shifting from Apriori to AprioriTid.
Suppose at the end of K th pass we decide to switch from Apriori
to AprioriTid. Then in the (k+1) pass, after having generated the
candidate sets we also have to add the Tids to C’k+1
Is Apriori Fast Enough? — Performance
Bottlenecks
The core of the Apriori algorithm:
Use frequent (k – 1)-itemsets to generate candidate frequent kitemsets
Use database scan and pattern matching to collect counts for the
candidate itemsets
The bottleneck of Apriori: candidate generation
Huge candidate sets:
104 frequent 1-itemset will generate 107 candidate 2-itemsets
To discover a frequent pattern of size 100, e.g., {a1, a2, …,
a100}, one needs to generate 2100 1030 candidates.
Multiple scans of database:
Needs (n +1 ) scans, n is the length of the longest pattern
Conclusions
Experimental results were shown to prove that the proposed
algorithms outperform AIS and SETM. The performance gap
increased with the problem size, and ranged from a factor of three
for small problems to more than an order of magnitude for large
problems.
Best features of the two proposed algorithms can be combined
into a hybrid algorithm which then becomes an algorithm of
choice. Experiments demonstrate the feasibility of using
AprioriHybrid in real applications involving very large databases.
Future Scope
In future authors plan to extend this work along the following dimensions:
Multiple taxonomies (is-a hierarchies) over items are often available. An
example of such a hierarchy is that a dish washer is a kitchen appliance is a
heavy electric appliance, etc. Authors are interested in discovering the
association rules that use such hierarchies. Authors did not consider the
quantities of the items bought in a transaction, which are useful for some
applications. Finding such rules needs further work.
Questions
&
Answers