Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Unsupervised Intrusion Detection
Using Clustering
Approach
Muhammet Kabukçu
Sefa Kılıç
Ferhat Kutlu
Teoman Toraman
1/29
Outline
Introduction
Using Clustering for Intrusion Detection
Methodology
Overall Summary
Conclusion
References
2/29
Introduction
• Intrusion detection is the process of monitoring the events
occurring in a computer system or network and analyzing
them for signs of possible incidents.
• Incidents are violations or
imminent threats of violation of:
* computer security policies,
* acceptable use policies,
* standard security practices.
3/29
Introduction
• An intrusion detection
system (IDS) is software
that automates the
intrusion detection
process.
• IDSs are primarily focuses on identifying possible
incidents and detecting when an attacker has
successfully compromised a system by exploiting
vulnerability in the system.
4 /29
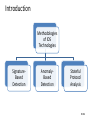
Introduction
Methodologies
of IDS
Technologies
SignatureBased
Detection
AnomalyBased
Detection
Stateful
Protocol
Analysis
5 /29
Signature-Based Detection
A signature is a pattern that corresponds to a known
threat (e.g. a telnet attempt with a username of "root",
which is a violation of an organization's security policy).
Signature-based detection is the process of comparing
signatures against observed events to identify possible
incidents.
Advantage: Very effective at detecting known threats.
Disadvantage: Ineffective at detecting previously
unknown threats.
6 /29
Anomaly-Based Detection
The process of comparing definitions of what activity is
considered normal against observed events to identify
significant deviations.
Capable of detecting previously unknown threats.
Uses host or network-specific profiles.
7 /29
Detection by Stateful Protocol Analysis
The process of comparing predetermined profiles of
generally accepted definitions of benign protocol activity
for each protocol state against observed events to
identify deviations.
Relies on vendor-developed universal profiles that
specify how particular protocols should and should not
be used.
8 /29
Using Clustering for Intrusion Detection
Methods other than Signature-Based Detection use data
mining and machine learning algorithms to train on
labeled network data.
For training data, there are two major paradigms:
Misuse Detection
Anomaly Detection.
Which one to use ???
9 /29
Using Clustering for Intrusion Detection
- Misuse Detection In misuse detection, machine learning algorithms
are used with labeled data.
By using the extracted features from labeled
network traffic, network data is classified.
By using new data which includes new type of
attacks, detection models are retrained.
10 /29
Using Clustering for Intrusion Detection
- Anomaly Detection In anomaly detection,
models are built by training on normal data,
deviations are searched over the normal model.
Generating purely normal data is
very difficult and costly in practice.
It is very hard to guarantee that
there are no attacks during the time
the traffic is collected from the
network.
11 /29
Using Clustering for Intrusion Detection
Misuse Detection
Anomaly Detection.
Use a mechanism to detect
intrusions by using unlabeled
data as a train model.
Find intrusions buried within that
data.
12/29
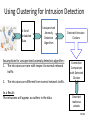
Using Clustering for Intrusion Detection
A Set of
Unlabeled
Data
Unsupervised
Anomaly
Detection
Algorithm
Assumptions for unsupervised anomaly detection algorithm:
1. The intrusions are rare with respect to normal network
traffic.
2.
Detected Intrusion
Clusters
Connection
Comparison
with Detected
Clusters
The intrusions are different from normal network traffic.
As a Result:
The intrusions will appear as outliers in the data.
Detected
malicious
attacks
13 /29
Using Clustering for Intrusion Detection
The unsupervised anomaly
detection algorithm clusters
the unlabeled data instances
together into clusters using a
simple distance-based metric.
14 /29
Using Clustering for Intrusion Detection
Once data is clustered, all of the
instances that appear in
small clusters are labeled as
Intrusion cluster
anomalies because;
The normal instances should
form large clusters compared to
the intrusions,
Malicious intrusions and normal
instances are qualitatively
different, so they do not fall into
the same cluster.
Normal cluster
15 /29
Methodology
1. Description of the dataset
2. Metric & Normalization
3. Clustering Algorithm
a) Portnoy et. al.
b) Y-means Algorithm
4. Labeling Clusters
5. Intrusion Detection
16 /29
Description of the dataset
• KDD Cup 1999 Data
• Main attack categories
– DOS: Denial of Service, (e.g. synood)
– R2L: Unauthorized access from a remote machine
(e.g. guessing password)
– U2R: Unauthorized access to local superuser
(root) privileges (e.g. various buffer overflow
attacks)
– Probing: Surveillance and other probing (e.g. port
scanning)
• In total, 24 attack types in training data; 14
17/29
additional ones in test data...
Metric & Normalization
• Euclidean Metric
(for distance computation)
• Feature Normalization
(to eliminate the difference in the scale of features)
18/29
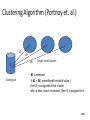
Clustering Algorithm (Portnoy et. al.)
.
d1
Xi
Training set
.
.
d2
d3
Empty set of clusters
- d1 is selected.
- if d1 < W ( predefined threshold value ),
then Xi is assigned to that cluster.
- else, a new cluster is created, then Xi is assigned to it.
19/29
Clustering Algorithm (Portnoy et. al.)
• Advantage: No need to know the initial no. of
clusters.
• Disadvantage: Need to know W, which may label
instances wrong in some cases.
• However…
20/29
Clustering Algorithm (Y-means Algorithm)
• 3 main parts:
1. assigning instances to k clusters
2. splitting clusters
3. merging clusters
21/29
Clustering Algorithm (Y-means Algorithm)
1. assigning instances to k clusters
...
...
...
...
...
...
...
...
...
...
redefine
cluster
centroid
...
...
k: no. of clusters
n: no. of instances
1<k<n
Dataset
22/29
Clustering Algorithm (Y-means Algorithm)
2. splitting clusters
t ( normal threshold) = 2.32 σ
σ = standard deviation
di
.
Xi ( instance )
.
t
Confident area
• if di > t , Xi is an outlier.
• New clusters are created firstly
with the farthest outliers.
23/29
Clustering Algorithm (Y-means Algorithm)
3. merging clusters
.
Xi
If Xi is in the confident area of two clusters, merge these
clusters back.
24/29
Labeling Clusters
• Our first assumption:
# of normal instances >> # of intrusions
• Label instances in large clusters: normal
• Label instances in small clusters: intrusion
• Start labeling as normal, until 99% of data is labeled
as normal, label rest of them as intrusion.
Normal cluster
Intrusion cluster
25/29
Intrusion Detection
For test instance x,
Measure the distance to each cluster.
Select the nearest cluster C.
If C is normal cluster, label x as normal,
Otherwise label x as intrusion.
26/29
Overall Summary
• IDS & IDS Technologies
• Using Clustering for Intrusion Detection
• Methodology
1. Description of the dataset
2. Metric & Normalization
3. Clustering Algorithm
4. Labeling Clusters
5. Intrusion Detection
Conclusion
• Unsupervised Clustering is choosen.
• KDD Cup 1999 Data
• Y-means Algorithm is used for creating ID System.
27/29
References
[1] KDD Cup 1999 data.
http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html.
[2] Y. Guan and A. A. Ghorbani. Y-means: A clustering method for
intrusion detection. In Proceedings of Canadian Conference
on Electrical and Computer Engineering, pages 1083{1086,
2003.
[3] L. Portnoy, E. Eskin, and S. Stolfo. Intrusion detection with
unlabeled data using clustering. In Proceedings of ACM CSS
Workshop on Data Mining Applied to Security (DMSA-2001),
2001.
[4] K. Scarfone and P. Mell. Guide to intrusion detection and
prevention systems (idps), 2007.
28/29
Questions?
29/29