Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Data Extraction
Building a Web Crawler in Python
CSE, HKUST
Feb 20
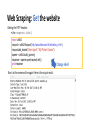
Web Scraping Workflow
ESSENTIAL PARTS OF WEB SCRAPING
Web Scraping follows this workflow:
• Get the website - using HTTP library
• Parse the html document - using any parsing library
• Store the results - either a db, csv, text file, etc
Web Scraping: Get the website
Suppose that we want to crawl this web page:
https://www.hkex.com.hk/eng/index.htm
Web Scraping: Get the website
How to view the source html code of this page?
Web Scraping: Get the website
In Chrome:
• Right-click, choose “View Page Source”
Web Scraping: Get the website
In Chrome:
• Or use the Developer’s Tools
• More Tools
• Developer’s Tools
Web Scraping: Get the website
We need to collect useful information from this page source HTML code:
Web Scraping: Get the website
• We use urllib2 library in Python
• urllib2 — extensible library for opening URLs
• http://docs.python.org/library/urllib2.html
• Almost the same as urllib, but has more stuff (easier to add headers, encode form data, etc.)
Web Scraping: Get the website
• Use the class urllib2.Request to get the web content:
• class urllib2.Request(url[, data][, headers][, origin_req_host][,
unverifiable])
• This class is an abstraction of a URL request.
• url should be a string containing a valid URL. This is the only compulsory parameter!
• data may be a string specifying additional data to send to the server, or None if no such data is
needed. Currently HTTP requests are the only ones that use data; the HTTP request will be a POST
instead of a GET when the data parameter is provided.
• headers should be a dictionary, and will be treated as if add_header() was called with each key and
value as arguments. This is often used to “spoof” the User-Agent header value, which is used by a
browser to identify itself – some HTTP servers only allow requests coming from common browsers as
opposed to scripts. For example, Mozilla Firefox may identify itself
as "Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11", while urllib2‘s default user
agent string is "Python-urllib/2.6" (on Python 2.6).
• The final two arguments are only of interest for correct handling of third-party HTTP cookies:
Web Scraping: Get the website
• The most simple example:
import urllib2
url = 'http://www.hkex.com.hk/chi/index_c.htm'
request = urllib2.Request(url)
response = urllib2.urlopen(request).read()
print response
Web Scraping: Get the website
• A more “polite” example:
Polite crawlers identify themselves with the User-Agent http header
import urllib2
request = urllib2.Request('http://www.hkex.com.hk/chi/index_c.htm')
request.add_header("User-Agent", "My Python Crawler")
opener = urllib2.build_opener()
response = opener.open(request).read()
print response
Save this code to example.py, and run “python example.py” in your command line. Have a try!
Web Scraping: Get the website
Here is the output in the command line
Web Scraping: Get the website
Getting the HTTP headers:
• Use response.info()
import urllib2
request = urllib2.Request('http://www.hkex.com.hk/chi/index_c.htm')
request.add_header("User-Agent", "My Python Crawler")
opener = urllib2.build_opener()
response = opener.open(request).info()
print response
Change
Run it at the command line again! Here is the output result:
Here!
Web Scraping: Get the website
Getting the Content-Type:
• Use response.info().get(‘Content-Type’)
• It’s helpful to know what type of content was returned
• Typically just search for links in html content
import urllib2
request = urllib2.Request('http://www.hkex.com.hk/chi/index_c.htm')
request.add_header("User-Agent", "My Python Crawler")
opener = urllib2.build_opener()
response = opener.open(request).info(). get(‘Content-Type’)
print response
Change Here!
Run it at the command line again to see the result!
Web Scraping: Escape from Blacklist
• Most of the servers of your target websites will check your request headers to
determine whether you are a robot or a real person.
• We need to disguise our codes as real persons
• Otherwise the target website may stop sending back response to us (or drag our IP into
their black list!)
• How to prevent getting blacklisted while scraping? Here are some useful and
interesting articles:
• https://www.scrapehero.com/how-to-prevent-getting-blacklisted-while-scraping/’
• https://www.import.io/post/why-isnt-my-crawler-working-webinar/
• Some basic methods:
• Disguise yourself as a browser by adding formal request headers
• Make the crawling slower, set some sleep period between every two requests
• Do not follow the same crawling pattern
• …
Web Scraping: Disguise yourself
• Change your IP
• A server can easily detects a bot by checking the requests from a single IP address, so if
you use different IP addresses for making requests to a server, the detection becomes
harder. Create a pool of IPs that you can use and use random ones for each request.
• User-agent Spoofing and Use a Formal Request Header
• What does a formal request header include?
• Accept
• Accept-Encoding
• Accept-Language
• User-Agent
• Referer
• Authorization
• Charge-To
• If-Modified-Since
• Pragma
• …
Web Scraping: Disguise yourself
• What does a formal request header include? You can check using your browser…
• Chrome Developer Tools Network Choose a file from the response (e.g. an
image, a html file, a css file…)Headers Look at the “Request Headers” part
Web Scraping: Disguise yourself
• Check your user agent here:
• http://www.whoishostingthis.com/tools/user-agent/
• In your code, you can directly use your browser’s user agent:
•
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/48.0.2564.116 Safari/537.36’
• Or create a list of user agents, and randomly picking a random one for each request
• Or use the fake-user-agent package from Python, to create a fake agent for each request
• https://pypi.python.org/pypi/fake-useragent
Web Scraping: Disguise yourself
Add a formal header:
import urllib2
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive'}
url = ‘http://www.hkex.com.hk/chi/index_c.htm’
request = urllib2.Request(url, None, headers)
opener = urllib2.build_opener()
Change Here!
response = opener.open(request).info(). get(‘Content-Type’)
print response
Run it at the command line again to see the result!
Web Scraping: Store the Result
Saving the Response to Disk
• Output html content to myfile.html
f = open('myfile.html', 'w')
f.write(html)
f.close()
Run it at the command line again to see the result!
Web Scraping: Parsing
Useful Parsing Libraries:
• re
• scrapy
• BeautifulSoup (bs4) The easiest one for beginners
• lxml
• Selenium
Web Scraping: BeautifulSoup Installation
How to install BeautifulSoup?
Follow the official documents here:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-beautiful-soup
Method 1: in the command line
• If you’re using a recent version of Debian or Ubuntu Linux, you can install Beautiful
Soup with the system package manager:
$ apt-get install python-bs4
• Beautiful Soup 4 is published through PyPi, so if you can’t install it with the system
packager, you can install it with easy_install or pip. The package name
is beautifulsoup4, and the same package works on Python 2 and Python 3.
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
If you do not have pip in your system, check here to install it: https://pip.pypa.io/en/stable/installing/
Web Scraping: BeautifulSoup Installation
If you don’t have easy_install or pip installed, you can download the Beautiful Soup 4
source tarball and install it with setup.py.
Resource link:
https://www.crummy.com/software/BeautifulSoup/bs4/download/4.0/
Command after download and unzip:
$ python setup.py install
Web Scraping: Parser Installation
• Beautiful Soup supports the HTML parser included in Python’s standard library, but it
also supports a number of third-party Python parsers. One is the lxml parser.
Depending on your setup, you might install lxml with one of these commands:
$ apt-get install python-lxml
$ easy_install lxml
$ pip install lxml
• Another alternative is the pure-Python html5lib parser, which parses HTML the way a
web browser does. Depending on your setup, you might install html5lib with one of
these commands:
$ apt-get install python-html5lib
$ easy_install html5lib
$ pip install html5lib
• We recommend you install and use lxml for speed
Web Scraping: Making the Soup
• To parse a document, pass it into the BeautifulSoup constructor. You can pass in a
string or an open filehandle:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html")) # an html file
soup = BeautifulSoup("<html>data</html>") # a string
Web Scraping: Making the Soup
• Use a string as example
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>"""
soup = BeautifulSoup(html)
Web Scraping: Making the Soup
• Print the content in the soup object in better format
• print soup.prettify()
• Here is the output:
Web Scraping: Making the Soup
• Beautiful Soup transforms a complex HTML document into a complex tree of
Python objects. But you’ll only ever have to deal with about four kinds of objects:
• Tag,
• NavigableString,
• BeautifulSoup
• Comment.
Web Scraping: Tag
• A Tag object corresponds to an XML or HTML tag in the original document:
• Example:
• <title>The Dormouse's story</title>
• <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
• Use BeautifulSoup to get the tags in a convenient way
• soup.(name of the tag) returns the first tag with this name
• Example :
•
•
•
•
•
•
print soup.title
#<title>The Dormouse's story</title>
print soup.head
#<head><title>The Dormouse's story</title></head>
print soup.a
#<a class="sister" href="http://example.com/elsie" id="link1"><!-Elsie --></a>
Web Scraping: Tag
• Every tag has a name, accessible as .name
• print soup.head.name
• #head
• A tag may have any number of attributes. The
tag <b class="boldest"> has an attribute “class” whose value is
“boldest”. You can access a tag’s attributes by treating the tag like a dictionary:
• print soup.p.attrs
• #{'class': ['title'], 'name': 'dromouse'}
• print soup.p['class']
• #['title']
• print soup.p.get('class')
• #['title']
• print type(soup.p)
• #<class 'bs4.element.Tag'>
Web Scraping: NavigableString
• A string corresponds to a bit of text within a tag. Beautiful Soup uses
the NavigableString class to contain these bits of text:
• print soup.p.string
• #The Dormouse's story
Web Scraping: BeautifulSoup
• The BeautifulSoup object itself represents the document as a whole. For most
purposes, you can treat it as a Tag object.
print type(soup.name)
#<type 'unicode'>
print soup.name
# [document]
print soup.attrs
#{} empty dictionary
Web Scraping: Comment
• Tag, NavigableString, and BeautifulSoup cover almost everything you’ll
see in an HTML or XML file, but there are a few leftover bits. The only
one you’ll probably ever need to worry about is the comment:
print soup.a
#<a class="sister" href="http://example.com/els
ie" id="link1"><!-- Elsie --></a>
print soup.a.string
#Elsie
Not correct, since “Elsie” is just a
comment in the html code…
print type(soup.a.string)
#<class 'bs4.element.Comment'>
We can see the type is a Comment!
Web Scraping: Comment
if type(soup.a.string)==bs4.element.Comment:
print soup.a.string
Use if statement to check whether it is a
comment first!
More about BeautifulSoup…
Official Document:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
(Get help here!)