Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Perceptual control theory wikipedia , lookup
Collaborative information seeking wikipedia , lookup
Visual servoing wikipedia , lookup
Catastrophic interference wikipedia , lookup
Machine learning wikipedia , lookup
Embodied cognitive science wikipedia , lookup
Concept learning wikipedia , lookup
Higher Coordination with Less Control
– A Result of Information Maximization
in the Sensorimotor Loop
Keyan Zahedi, Nihat Ay, Ralf Der
(Published on: May 19, 2012)
Artificial Neural Network
Biointelligence Lab
School of Computer Science and Engineering
Seoul National University
Presenter:
Sangam Uprety
Student ID: 2012-82153
October 09, 2012
Contents
1.
2.
3.
4.
5.
6.
7.
Abstract
Introduction
Learning Rule
Experiment
Results
Questions
Discussion and Conclusion
1. Abstract
• A novel learning method in the context of embodied artificial
intelligence and self-organization
• Less assumptions and restrictions within the world and the
underlying model
• Uses the principle of maximizing the predictive information in
the sensorimotor loop
• Evaluated on robot chains of varying length with individually
controlled, non-communicating segments
• Maximizing the predictive information per wheel leads to a
higher coordinated behavior
• Longer chains with less capable controllers outperform those
of shorter length and more complex controllers
2. Introduction
• Embodied artificial intelligence or cognitive systems use
learning and adaption rules
• Most are based on an underlying model – so they are limited
to the model
• They use intrinsically generated reinforcement signals
[prediction errors] as an input to a learning algorithm
• Need of a learning rule independent of model structure,
requires less assumptions about the environment
• Self-organized learning
• Our way out: Directly calculate the gradient of the policy as a
result of the current locally available approximation of the
predictive information
• A learning rules based on Shannon’s information theory
• A neural network in which earlier layers maximize the
information passed to the next layer
3. Learning Rule
3.1 Basic Sensori-motor loop
W0,1,…,t world state
S0,1,…,t sensor state
M0,1,…t memory state
A0,1,…,t Actions
3. Learning Rule (Contd.)
• The sensor state St depends only on the current world state
Wt.
• The memory state Mt+1 depends on the last memory state
Mt, the previous action At, and the current sensor state St+1.
• The world state Wt+1 depends on the previous state Wt and
on the action At.
• No connection between the action At and the memory state
Mt+1, because we clearly distinguish between inputs and
outputs of the memory Mt (which is equivalent to the
controller).
• Any input is given by a sensor state St, and any output is given
in form of the action state At.
• The system may not monitor its outputs At directly, but
through a sensor, hence the sensor state St+1.
3.2 Reduced sensori-motor loop
•
•
•
•
Progression from step t to t+1
A, W, S present states given by distribution µ
α(a|s) defines the policy
β(w’|w,a) evolution of world given present world w and
action a
• ϒ(s’|w’) effect of the world on the sensor state
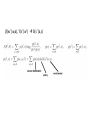
3.3 Derivation of Learning Rule
The Entropy H(X) of a random variable X, measuring the
uncertainty, is:
The mutual information of two random variables X and Y is:
This gives how much knowledge of Y reduces the uncertainly of
X.
The maximal entropy is the entropy of a uniform distribution:
H(X) <= log2|X|.
β(w’|w,a), ϒ(s’|w’) δ(s’|a,s)
• p(s), α(a|s) and δ(s’|a,s) are represented as matrices
Update Rule for sensor distribution p(s)
Update Rule for world model δ(s’|a,s)
Update rule for policy α(a|s)
4. Experiment
4.1 Simulators
YARS (Zahedi et al, 2008) has been used for the simulator
4.2 Robots
Two wheeled differential drive robots with circular body – the
Khepera I robot (Mondada et al., 1993)
• Input-output desired wheel velocity (At) and current actual
velocity (St)
• At and St mapped linearly to the interval [-1,1]
• -1 maximum negative speed (backwards motion)
• +1 maximal positive speed (forward motion)
• Robots are connected by a limited hinge joint with a maximal
deviation of ±0.9 rad (approx. 100 degree) avoiding
intersection of neighboring robots
• Experiments with single robot, three-, and five-segment
chaings
4.3 Controller
•
•
•
•
Each robot controlled locally
Two control paradigms: combined and split
No communication between controllers
Interaction occurs through world state Wt through sensor St
current actual wheel velocity
• r-c notation
• r {1,3,5}
• c {r,2r}
4.4 Environment
• 8x8 meters, bounded, featureless environment
• Large enough for the chains to learn a coordinated behavior
5. Results
• If pi increased over time for all six configurations?
• If the maximization of the pi leads to qualitative changes on
the behavior?
• Videos
5.1 Maximizing the predictive information
Fig. Average-PI plots for each of the six experiments: 1-1, 3-3, 55, 1-2, 3-6, 5-10
Comparison of intrinsically calculated PI (left) and PI calculated
on recorded data per robot
5.2 Comparing Behaviors
Fig. Trajectories of the six systems for the first 10 minutes (gray)
and the last 100 minutes (black)
1. All configurations explore the entire area
2. Longer consecutive trails relate to higher average sliding
window coverage entropy
3. The configurations which show longer consecutive trails are
those, which reach higher coverage entropy sooner
Movements only occur for chains with length larger than
one if the majority of the segments moves in one direction
Cooperation of the segments
Higher cooperation among the segments of the split
configuration
Higher pi relates to higher coverage entropy and higher
sliding window coverage entropy, for the split controller
paradigm
4.3 Behavior Analysis
Chosen bins: -3/4, -1/2, 1/2, 3/4
With Configuration 1-2
Transient plot wheel velocities oscillates between -1/2 and 3/4
S=-1/2 A {-1/2, 1/2, 3/4} S=-1/2
A=-3/4 chosen with probability 0.95
With probability 0.05, change of direction of velocity occurs,
leading to either rotation of the system, or inversion of the
translational behavior
Sensor entropy H(S) is high, conditional entropy H(S’|S) is low,
hence high PI
With configuration 3-6
• Wheel velocity of one wheel is no longer only influenced by
its controller, but also by the actions of the other controllers
• Current direction of the wheel rotation is maintained with the
probability 0.6
• For the entire system to progress, at least two robots [i.e four
related controllers] must move in the same direction
probability 0.4 4
4.4 Incremental Optimization
• The derived learning rule is able to maximize the predictive
information for systems in the sensorimotor loop
• Increase of the PI relate to changes in the behavior and here
to a higher coverage entropy – and indirect measure for
coordination among the coupled robots
6. Questions
Q.1 Explain the concept of the perception-action-cycle in fig. 1. What
are the essential characteristics of this concept? How is this concept
distinguished from traditional symboloc AI approach?
Q.2 Explain the simplified version of the perception-action-cycle in fig.
2. What are their differences from the full version of figg. 1? How
reasonable is this simplification? When it will work and when it
does not?
Q.3 Define mutual information. Define the predictive information. Give
a learning rule that maximizes the predictive information. Derive
the learning rules.
Q.4 Explain the experimental tasks that are designed by the authors to
evaluate the learning rule for predictive information maximization.
What’s the setup? What is the task? What has been measured in
simulation experiments? Summarize the results. What’s the
conclusion of the experiments?
7. Discussion & Conclusion
• A novel approach to self-organized learning in the
sensorimotor loop, which is free of assumptions on the world
and restrictions on the model
• Learning algorithm derived from the principle of maximizing
the predictive information
• The average approximated predictive information increased
over time in each of the settings in the experiment [Goal #1
achieved]
• There is a higher coverage entropy, a measure for coordinated
behavior, for chain configurations with more robots (and well
with split controllers) [counterintutive!]
Thank you!