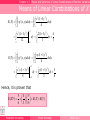Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Probability and Statistics
Lecture 5
Dr.-Ing. Erwin Sitompul
President University
http://zitompul.wordpress.com
2 0 1 3
President University
Erwin Sitompul
PBST 5/1
Chapter 4.2
Variance and Covariance
Variance and Covariance
The mean or expected value of a random variable X is important
because it describes the center of the probability distribution.
However, the mean does not give adequate description of the
shape and variability in the distribution.
Distribution with equal
means but different
dispersions (variability)
The most important measure of variability of a random variable X
is obtained by letting g(X) = (X– μ)2.
This variability measure is referred to as the variance of the
random variable X or the variance of the probability 2
distribution
of X. It is denoted by Var(X) or the symbol X , or
2
simply by .
President University
Erwin Sitompul
PBST 5/2
Chapter 4.2
Variance and Covariance
Variance and Covariance
Let X be a random variable with probability distribution f(x) and
mean μ. The variance of X is
2 E[( X )2 ] ( x )2 f ( x)
if X is discrete, and
2 E[( X )2 ]
if X is continuous.
x
2
(
x
)
f ( x)dx
The positive square root of the variance, σ, is called the standard
deviation of X.
President University
Erwin Sitompul
PBST 5/3
Chapter 4.2
Variance and Covariance
Variance and Covariance
Let the random variable X represent the
number of cars that are used for official
business purposes on any given
workday. The probability distribution for
company A and company B are
Company A
Company B
Show that the variance of the probability distribution for company B
is greater than that of company A.
E ( X ) (1)(0.3) (2)(0.4) (3)(0.3) 2
3
( x 2) 2 f ( x) (1 2)2 (0.3) (2 2)2 (0.4) (3 2)2 (0.3) 0.6
2
x 1
E ( X ) (0)(0.2) (1)(0.1) (2)(0.3) (3)(0.3) (4)(0.1) 2
3
( x 2) 2 f ( x) (0 2) 2 (0.3) (1 2) 2 (0.3) (2 2) 2 (0.4)
2
x 1
1.6
(3 2) 2 (0.3) (4 2) 2 (0.3)
Clearly, the variance of the number of cars that are used for official
business purposes is greater for company B than for company A.
President University
Erwin Sitompul
PBST 5/4
Chapter 4.2
Variance and Covariance
Variance and Covariance
The variance of a random variable X is also given by
2 E( X 2 ) 2
Let the random variable X represent the number of defective parts
for a machine when 3 parts are sampled from a production line and
tested. The following is the probability distribution of X
Calculate the variance σ2.
(0)(0.51) (1)(0.38) (2)(0.10) (3)(0.01) 0.61
3
E ( X ) x 2 f ( x) (0)2 (0.51) (1)2 (0.38) (2)2 (0.10) (3) 2 (0.01) 0.87
2
x 0
2 E ( X 2 ) 2 0.87 (0.61)2 0.4979
President University
Erwin Sitompul
PBST 5/5
Chapter 4.2
Variance and Covariance
Variance and Covariance
The weekly demand for a drinking-water product, in thousands liters,
from a local chain of efficiency stores, is a continuous random
variable X having the probability density
f ( x)
2( x 1), 1 x 2
0,
elsewhere
Find the mean and variance of X.
2
2
2
5
x 2( x 1)dx x3 x 2
3
3
1
1
2
2
2
2
17
E ( X 2 ) x 2 2( x 1)dx x 4 x3
6
4
3 1
1
2
17 5
1
2 E( X 2 ) 2
6 3
18
President University
Erwin Sitompul
PBST 5/6
Chapter 4.2
Variance and Covariance
Variance and Covariance
Let X be a random variable with probability distribution f(x). The
variance of the random variable g(X) is
g2( X ) E{[ g ( X ) g ( X ) ]2 } [ g ( X ) g ( X ) ]2 f ( x)
if X is discrete, and
x
g2( X ) E{[ g ( X ) g ( X ) ]2 } [ g ( X ) g ( X ) ]2 f ( x)dx
if X is continuous.
President University
Erwin Sitompul
PBST 5/7
Chapter 4.2
Variance and Covariance
Variance and Covariance
Calculate the variance of g(X) = 2X + 3, where X is a random
variable with probability distribution given as
1
3
1
1
1
g ( X ) 2 X 3 (2 x 3) f ( x) (3) (5) (7) (9) 6
4
8
2
8
x 0
g2( X ) E{[ g ( X ) g ( X ) ]2} E{[(2 X 3) 6]2}
3
E[4 X 12 X 9] (4 x 2 12 x 9) f ( x)
2
x 0
1
1
1
1
(9) (1) (1) (9) 4
4
8
2
8
President University
Erwin Sitompul
PBST 5/8
Chapter 4.2
Variance and Covariance
Variance and Covariance
Let X be a random variable with density function
x2
f ( x) 3 , 1 x 2
elsewhere
0,
Find the variance of the random variable g(X) = 4X + 3 if it is known
that the expected value of g(X) = 8.
42X 3 E{[(4 X 3) 8]2 } E[16 X 2 40 X 25]
x2
(16 x 40 x 25) f ( x)dx (16 x 40 x 25)
3
1
1
2
2
2
2
dx
2
1 16 5 40 4 25 3
1
4
3
2
x
x
16
x
40
x
25
x
dx
x
3 5
4
3 1
3 1
1 136 323 459 51
3 15 15 45
5
2
President University
Erwin Sitompul
PBST 5/9
Chapter 4.2
Variance and Covariance
Variance and Covariance
Let X and Y be a random variables with probability distribution
f(x, y). The covariance of the random variables X and Y is
XY E[( X X )(Y Y )] ( x X )( y Y ) f ( x, y )
x
if X and Y are discrete, and
XY E[( X X )(Y Y )]
if X and Y are continuous.
σXY >0,
Positive
correlation
President University
y
(x
X
)( y Y ) f ( x, y ) dxdy
σXY <0
Negative
correlation
Erwin Sitompul
PBST 5/10
Chapter 4.2
Variance and Covariance
Variance and Covariance
The covariance of two random variables X and Y with means μX
and μY, respectively, is given by
XY E ( XY ) X Y
President University
Erwin Sitompul
PBST 5/11
Chapter 4.2
Variance and Covariance
Variance and Covariance
Referring back again to the “ballpoint
pens” example, find the covariance of
X and Y.
2
2
2
5
15
3 3
(1)
(2)
14
28
28 4
X E ( X ) xf ( x, y) xg ( x) (0)
x 0 y 0
2
2
x 0
2
15
3
1 1
(1)
(2)
28
7
28 2
Y E (Y ) yf ( x, y) yh( y) (0)
x 0 y 0
XY E ( XY ) X Y
y 0
3 3 1
9
14 4 2
56
See again
Lecture 4
President University
Erwin Sitompul
PBST 5/12
Chapter 4.2
Variance and Covariance
Variance and Covariance
The fraction X of male runners and the fraction Y of female runners
who compete in marathon races is described by the joint density
function
8 xy, 0 y x 1
f ( x, y )
0,
elsewhere
Find the covariance of X and Y
4 x3 , 0 x 1
g ( x)
elsewhere
0,
1 1
E ( XY ) 8 x 2 y 2 dxdy
0 y
4 y (1 y 2 ), 0 y 1
h( y )
elsewhere
0,
XY E ( XY ) X Y
1
4
X E ( X ) 4 x dx
5
0
4
1
Y E (Y ) 4 y 2 (1 y 2 )dy
0
President University
4
9
4 4 8
4
9 5 15 225
8
15
Erwin Sitompul
PBST 5/13
Chapter 4.2
Variance and Covariance
Variance and Covariance
Although the covariance between two random variables does
provide information regarding the nature of the relationship, the
magnitude of σXY does not indicate anything regarding the
strength of the relationship, since σXY is not scale free.
This means, that its magnitude will depend on the units measured
for both X and Y.
There is a scale-free version of the covariance called the
correlation coefficient, that is used widely in statistics.
Let X and Y be random variables with covariance σXY and standard
deviation σX and σY, respectively. The correlation coefficient X
and Y is
XY
XY
XY
President University
Erwin Sitompul
PBST 5/14
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
If a and b are constant, then
E (aX b) aE ( X ) b
Applying theorem to the discrete random variable g(X) = 2X – 1,
rework the carwash example.
E (2 X 1) 2 E ( X ) 1
9
X E ( X ) xf ( x)
x4
1
1
1
1
1
1 41
(4) (5) (6) (7) (8) (9)
12
12
4
4
6
6 6
41
2 X 1 2 X 1 2 1 $12.67
6
President University
Erwin Sitompul
PBST 5/15
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
Let X be a random variable with density function
x2
f ( x) 3 , 1 x 2
elsewhere
0,
Find the expected value of g(X) = 4X + 3 by using the theorem
presented recently.
E (4 X 3) 4 E ( X ) 3
x2
x3
5
E ( X ) x dx dx
3
4
3
1
1
2
2
5
E (4 X 3) 4 3 8
4
President University
Erwin Sitompul
PBST 5/16
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
The expected value of the sum or difference of two or more
functions of a random variable X is the sum or difference of the
expected values of the functions. That is
E[ g ( X ) h( X )] E[ g ( X )] E[h( X )]
Let X be a random variable with probability
distribution as given next. Find the expected
value of Y = (X – 1)2.
E[( X 1)2 ] E[ X 2 2 X 1]
E ( X 2 ) 2E ( X ) E (1)
1
1
1
E ( X ) (0) (1) (2)(0) (3) 1
3
2
6
1
1
1
E ( X 2 ) (0) (1) 2 (2) 2 (0) (3) 2 2
3
2
6
E[( X 1)2 ] 2 (2)(1) 1 1
President University
Erwin Sitompul
PBST 5/17
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
The weekly demand for a certain drink, in thousands of liters, at a
chain of convenience stores is a continuous random variable g(X) =
X2 + X – 2, where X has the density function
f ( x)
2( x 1), 1 x 2
0,
elsewhere
Find the expected value for the weekly demand of the drink.
E ( X 2 X 2) E ( X 2 ) E ( X ) E (2)
2
2
E ( X ) 2 x( x 1)dx 2 ( x 2 x)dx
1
1
2
2
1
1
5
3
E ( X 2 ) 2 x 2 ( x 1)dx 2 ( x3 x 2 )dx
E ( X 2 X 2)
President University
17
3
17 5
5
2
6 3
2
Erwin Sitompul
PBST 5/18
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
The expected value of the sum or difference of two or more
functions of a random variables X and Y is the sum or difference of
the expected values of the functions. That is
E g ( X , Y ) h( X , Y ) E g ( X , Y ) E h( X , Y )
Let X and Y be two independent random variables. Then
E ( XY ) E ( X ) E (Y )
President University
Erwin Sitompul
PBST 5/19
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
In producing gallium-arsenide microchips, it is known that the ratio
between gallium and arsenide is independent of producing a high
percentage of workable wafers, which are the main components of
microchips.
Let X denote the ratio of gallium to arsenide and Y denote the
percentage of workable microwafers retrieved during a 1-hour
period. X and Y are independent random variables with the joint
density being known as
x(1 3 y 2 )
, 0 x 2, 0 y 1
f ( x, y)
4
elsewhere
0,
Illustrate that E(XY) = E(X)E(Y).
x 2 y(1 3 y 2 )
E ( XY ) xyf ( x, y)dxdy
dxdy
4
0 0
0 0
1 2
x 3 y (1 3 y 2 )
12
0
1
President University
1 2
x2
2 y(1 3 y 2 )
5
dy
dy
3
6
0
x 0
1
Erwin Sitompul
PBST 5/20
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
x 2 (1 3 y 2 )
dxdy
E ( X ) xf ( x, y)dxdy
4
0 0
0 0
1 2
1 2
x (1 3 y )
12
0
1
3
2
x2
2(1 3 y 2 )
4
dy
dy
3
3
0
x 0
1
xy(1 3 y 2 )
E (Y ) yf ( x, y)dxdy
dxdy
4
0 0
0 0
1 2
x 2 y (1 3 y 2 )
8
0
1
1 2
x2
y(1 3 y 2 )
5
dy
dy
2
8
0
x 0
1
Hence, it is proven that
E ( XY )
5 4 5
E ( X ) E (Y )
6 3 8
President University
Erwin Sitompul
PBST 5/21
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
If a and b are constant, then
2
2 2
2 2
aX
a
a
b
X
If X and Y are random variables with joint probability distribution
f(x, y), then
2
2 2
2 2
aX
bY a X b Y 2ab XY
President University
Erwin Sitompul
PBST 5/22
Chapter 4.3
Means and Variances of Linear Combinations of Random Variables
Means of Linear Combinations of X
If X and Y are random variables with variances X 2 , Y 4 , and
covariance σXY = –2, find the variance of the random variable
Z = 3X – 4Y + 8.
2
2
Z2 32X 4Y 8 32X 4Y 9 X2 16 Y2 24 XY (9)(2) (16)(4) (24)(2)
130
Let X and Y denote the amount of two different types of impurities in
a batch of a certain chemical product. Suppose that
X and Y
are
2
2
independent random variables with variances X 2 and Y 3. Find
the variance of the random variable Z = 3X – 2Y + 5.
Z2 32X 2Y 5 32X 2Y 9 X2 4 Y2 (9)(2) (4)(3)
30
President University
Erwin Sitompul
PBST 5/23
Chapter 4.4
Chebyshev’s Theorem
Chebyshev’s Theorem
As we already discussed, the variance of a random variable tells us
something about the variability of the observation about the mean.
If a variable has a small variance or standard deviation, we
would expect most of the values to be grouped around the mean.
The probability that a random variable assumes a value within a
certain interval about the main is greater in this case.
If we think of probability in terms of area, we would expect a
continuous distribution with a small standard deviation to have
most of its area close to μ.
Variability of continuous
observations about the mean
President University
Erwin Sitompul
PBST 5/24
Chapter 4.4
Chebyshev’s Theorem
Chebyshev’s Theorem
We can argue the same way for a discrete distribution. The spread
out of an area in the probability histogram indicates a more
variable distribution of measurements or outcomes.
Variability of discrete
observations about the mean
President University
Erwin Sitompul
PBST 5/25
Chapter 4.4
Chebyshev’s Theorem
Chebyshev’s Theorem
A Russian mathematician P. L. Chebyshev discovered that the
fraction of the area between any two values symmetric about the
mean is related to the standard deviation.
|Chebyshev’s Theorem| The probability that any random
variable X will assume a value within k standard deviations of the
mean is at least 1 – 1/k2.
That is
P( k X k ) 1
1
k2
Chebyshev’s Theorem holds for any distribution of observations
and, for this reason, the results are usually weak.
The value given by the theorem is a lower bound only. Exact
probabilities can only be determined when the probability
distribution is known.
The use of Chebyshev’s Theorem is relegated to situations where
the form of the distribution is unknown.
President University
Erwin Sitompul
PBST 5/26
Chapter 4.4
Chebyshev’s Theorem
Chebyshev’s Theorem and Normal Distribution
President University
Erwin Sitompul
PBST 5/27
Chapter 4.4
Chebyshev’s Theorem
Chebyshev’s Theorem
A random variable X has a mean μ = 8, a variance σ2 = 9, and an
unknown probability distribution. Find
(a) P(–4 < X < 20)
(b) P(|X – 8| ≥ 6)
(a)
P(4 X 20) P 8 (4)(3) X 8 (4)(3)
1 1 42
15 16
(b)
P( X 8 6) 1 P X 8 6
1 P 6 X 8 6
1 P 8 (2)(3) X 8 (2)(3)
1 1 1 4
1 4
President University
Erwin Sitompul
PBST 5/28
Probability and Statistics
Homework 5A
1. For the joint probability distribution of the two random variables X and Y
as given in the following figure, calculate the covariance of X and Y.
(Mo.E5.27 p.0172)
2. The photoresist thickness in semiconductor manufacturing has a mean of
10 micrometers and a standard deviation of 1 micrometer. Bound the
probability that the thickness is less than 6 or greater than 14
micrometers.
(Mo.S5.25 p05.15)
President University
Erwin Sitompul
PBST 5/29