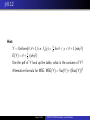Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
PSTAT 120B Probability and Statistics - Week 5
Fang-I Chu
University of California, Santa Barbara
May 2, 2013
Fang-I Chu
PSTAT 120B Probability and Statistics
Announcement
Office hour: Tuesday 11:00AM-12:00PM
Please make use of office hour or email if you have question
about hw problem.
Put a circle around your name on roster if you bring your two
blue books and hand them to me (after section).
If you haven’t received any group email from me, please put
your email down in the back of roster.
Fang-I Chu
PSTAT 120B Probability and Statistics
Topic for review
Exercise #8.15
Exercise #8.13
Exercise #9.26
Hint for homework problem 1(#7.58)
Hint for homework problem 4(#8.8)
Hint for homework problem 5(#8.12)
Hint for homework problem 8(#9.5)
Fang-I Chu
PSTAT 120B Probability and Statistics
Exercise 8.15
8.15
Let Y1 , Y2 , . . . , Yn denote a random sample of size n from a
population whose density is given by
3β 3 y −4
β≤y
f (y ) =
0
elsewhere
where β > 0 is unknown. (This is one of the Pareto distributions
introduced in Exercise 6.18.)
Consider the estimator β̂ = min(Y1 , Y2 , . . . , Yn )
(a)Derive the bias of the estimator β̂.
(b)Derive MSE(β̂)
Fang-I Chu
PSTAT 120B Probability and Statistics
#8.15
8.15(a)
(a)Derive the bias of the estimator β̂.
Solution:
Known:
Y has pdf as f (y ) = 3β 3 y −4 , β ≤ y
Definition: bias of estimator β̂ is written as E (β̂) − β
Denote β̂ = Y(1)
Goal: Derive the bias of the estimator β̂.
.
Fang-I Chu
PSTAT 120B Probability and Statistics
#8.15
8.15(a)
(a)Derive the bias of the estimator β̂.
Solution:
Way to approach:
Find cdf of y using given pdf
Use Theorem 6.5 on page 336, obtain
fy(1) (y ) = 3nβ 3n y −(3n+1) , y ≥ β
Using definition not expected value, obtain E (Y(1) ) =
3n
1
Bias(β̂) = E (Y(1) ) − β = 3n−1
β − β = ( 3n−1
)β
Fang-I Chu
PSTAT 120B Probability and Statistics
3n
3n−1
β
#8.15
8.15(b)
(b) Derive MSE(β̂)
Known:
Y has pdf as f (y ) = 3β 3 y −4 , β ≤ y
Definition: MSE of estimator β̂ is written as
MSE (β̂) = E (β̂ − β)2
Denote β̂ = Y(1)
Goal: Derive the MSE of the estimator β̂.
.
Fang-I Chu
PSTAT 120B Probability and Statistics
#8.15
8.15(b)
(b) Derive MSE(β̂)
Way to approach:
3n
)β and
By definition, use pdf, we find E (Y(1) ) = ( 3n−1
3n
2
2
E (Y(1) ) = 3n−2 β
MSE(β̂) = E (β̂ − β)2
2
= E (Y(1)
) − 2βE (Y(1) ) + β 2
3n
3n
β 2 − 2β · (
)β + β 2
3n − 2
3n − 1
2
=
β2
(3n − 1)(3n − 2)
=
Fang-I Chu
PSTAT 120B Probability and Statistics
Exercise 8.13
8.13
We have seen that if Y has a binomial distribution with
parameters n and p, then Yn is an unbiased estimator of p. To
estimate the variance of Y, we generally use n( Yn )(1 − Yn ).
(a) Show that the suggested estimator is a biased estimator of
V (Y )
(b) Modify n( Yn )(1 − Yn ) slightly to form an unbiased estimator of
V (Y ).
Fang-I Chu
PSTAT 120B Probability and Statistics
#8.13
#8.13(a)
(a) Show that the suggested estimator is a biased estimator of
V (Y )
Solution:
1. Information:
Y has a binomial distribution with parameters n and p
Y
n is an unbiased estimator of p.
2. Goal:
Show that n( Yn )(1 −
Y
n
) is a biased estimator of V (Y )
Fang-I Chu
PSTAT 120B Probability and Statistics
#8.13
Solution:
Way to approach:
E (Y ) = np and V (Y ) = npq so E (Y 2 ) = npq + (np)2
E {n(
Y
1
Y ) 1−
} = E (Y ) − E (Y 2 )
n
n
n
= np − pq − np 2
= (n − 1)pq
#8.13(b)
(b) Modify n( Yn )(1 −
V (Y ).
the estimator
V (Y )
Y
n
) slightly to form an unbiased estimator of
n2 Y
n−1 ( n
)(1 −
Fang-I Chu
Y
n
) is an unbiased estimator of
PSTAT 120B Probability and Statistics
Exercise 9.26
#9.26
It is sometimes relatively easy to establish consistency or lack of
consistency by appealing directly to Definition 9.2, evaluating
P(|θ̂n − θ| ≤ ) directly, and then showing that
limn→∞ P(|θ̂n − θ| ≤ ) = 1. Let Y1 , Y2 . . . , Yn denote a random
sample of size n from a uniform distribution on the interval (0, θ).
If Y(n) = max(Y1 , Y2 , . . . , Yn ), we showed in Exercise 6.74 that the
probability distribution function of Y(n) is given by
0
( y )n
F(n) (y ) =
θ
1
Fang-I Chu
y <0
0≤y ≤θ
y >θ
PSTAT 120B Probability and Statistics
Exercise 9.26
#9.26
(a)For each n ≥ 1 and every > 0, it follows that
P(|Y(n) − θ| ≤ ) = P(θ − ≤ Y(n) ≤ θ + ). If > θ verify that
P(θ − ≤ Y(n) ≤ θ + ) = 1 and that, for every positive , we
n
.
obtain P(θ − ≤ Y(n) ≤ θ + ) = 1 − (θ−)
θ
1. Information:
F(n) (y ) = ( yθ )n for 0 ≤ y ≤ θ
P(|Y(n) − θ| ≤ ) = P(θ − ≤ Y(n) ≤ θ + )
2. Goal:
show when > θ, we have P(θ − ≤ Y(n) ≤ θ + ) = 1 and,
n
for > 0, we obtain P(θ − ≤ Y(n) ≤ θ + ) = 1 − (θ−)
θ
Fang-I Chu
PSTAT 120B Probability and Statistics
Exercise 9.26
#9.26
(a)For each n ≥ 1 and every > 0, it follows that
P(|Y(n) − θ| ≤ ) = P(θ − ≤ Y(n) ≤ θ + ). If > θ verify that
P(θ − ≤ Y(n) ≤ θ + ) = 1 and that, for every positive , we
n
.
obtain P(θ − ≤ Y(n) ≤ θ + ) = 1 − (θ−)
θ
3. Bridge:
when > θ ,F(n) (θ + ) = 1 and F(n) (θ − ) = 0 (why?)
n
when < θ ,F(n) (θ + ) = 1 and F(n) (θ − ) = ( θ−
θ ) (why?)
4. Fine tune:
Therefore, for > θ, P(θ − ≤ Y(n) ≤ θ + ) = 1
n
For < θ, P(θ − ≤ Y(n) ≤ θ + ) = 1 − ( θ−
θ )
Fang-I Chu
PSTAT 120B Probability and Statistics
Exercise 9.26
#9.26
(b)Using the result from part (a), show that Y(n) is a consistent
estimator for θ by showing that, for every > 0,
limn→∞ P(|Y(n) − θ| ≤ ) = 1.
1. Information: From (a), > 0,
n
P(θ − ≤ Y(n) ≤ θ + ) = 1 − ( θ−
θ )
2. Goal: Y(n) is a consistent estimator for θ i.e. or every > 0,
limn→∞ P(|Y(n) − θ| ≤ ) = 1
3. Bridge:
limn→∞ P(θ − ≤ Y(n) ≤ θ + ) = limn→∞ 1 −
θ− n
θ
4. Fine tune: we have got our proof!
Fang-I Chu
PSTAT 120B Probability and Statistics
=1
Exercise 7.58
7.58
Suppose that X1 , X2 , . . . , Xn and Y1 , Y2 , . . . , Yn are independent
random samples from populations with means µ1 and µ2 and
variances σ12 and σ22 , respectively. Show that the random variable
Un =
(X̄ − Ȳ ) − (µ1 − µ2 )
q
(σ12 +σ22 )
n
satisfies the conditions of Theorem 7.4 and thus that the
distribution function of Un converges to a standard normal
distribution function as n → ∞. (Hint: Consider Wi = Xi − Yi ,
for i = 1, 2 . . . , n.)
Fang-I Chu
PSTAT 120B Probability and Statistics
#7.58
Hint:
Our goal is to show Un ∼ Z =
W̄ −µW̄
Var(W̄ )
when n → ∞.
Find E (W̄ ) and Var(W̄ )
Use the given facts that Xi ’s and Yi ’s are independent when
deriving Var(W̄ )
Fang-I Chu
PSTAT 120B Probability and Statistics
Exercise 8.8
#8.8
Suppose that Y1 , Y2 , Y3 denote a random sample from an
exponential distribution with density function
1 −y
(θe θ
y >0
f (y ) =
0
elsewhere
Consider the following five estimators of θ: θ̂1 = Y1 ,
θ̂2 = Y1 + Y2 , θ̂3 = Y1 + 2Y2 , θ̂4 = min(Y1 , Y2 , Y3 ), θ̂5 = Ȳ
(a) Which of these estimators are unbiased?
(b) Among the unbiased estimators, which has the smallest
variance?
Fang-I Chu
PSTAT 120B Probability and Statistics
# 8.8
Hint:
Use linear combination property in expected value to find
E (θ̂1 ), E (θ̂2 ), and E (θ̂3 ).
Use the result from exercise 6.81 to find E (θ̂4 ) and Var(θ̂4 )
Use the given fact that Y1 , Y2 and Y3 are random sample. i.e.
they are independent to each other.
Fang-I Chu
PSTAT 120B Probability and Statistics
Exercise 8.12
#8.12
The reading on a voltage meter connected to a test circuit is
uniformly distributed over the interval (θ, θ + 1), where θ is the
true but unknown voltage of the circuit. Suppose that
Y1 , Y2 , . . . , Yn denote a random sample of such readings.
(a) Show that Y is a biased estimator of θ and compute the bias.
(b) Find a function of Y that is an unbiased estimator of θ.
(c) Find MSE(Y ) when Y is used as an estimator of θ.
Fang-I Chu
PSTAT 120B Probability and Statistics
#8.12
Hint:
Y ∼ Uniform(θ, θ + 1) i.e. fy (y ) =
E (Y ) = θ +
1
2
1
2
for θ < y < θ + 1 (why?)
(why?)
Use the pdf of Y look up the table, what is the variance of Y ?
Alternative formula for MSE: MSE(Y ) = Var(Y ) + (Bias(Y ))2
Fang-I Chu
PSTAT 120B Probability and Statistics
Exercise 9.5
#9.5
Suppose that Y1 , Y2 , . . . , Yn is a random sample from a normal
distribution with mean µ and variance σ 2 .Two unbiased estimators
of σ 2 are
n
σˆ12 = S 2 =
1
1 X
(Yi − Ȳ )2 and σ̂22 = (Y1 − Y2 )
n−1
2
i=1
Find the efficiency of σ̂12 relative to σ̂22
Fang-I Chu
PSTAT 120B Probability and Statistics
#9.5
Hint:
Using Theorem 7.3, we have
(n−1)S 2
σ2
∼ χ2n−1
2
E ( (n−1)S
) = n − 1 (why?)
σ2
2
) = 2(n − 1) (why?)
V ( (n−1)S
σ2
Use definition of relative efficiency in section 9.2.
Fang-I Chu
PSTAT 120B Probability and Statistics