Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
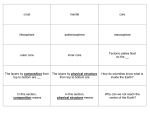
CSC532 Term Paper Software Development Architectures Ankur K. Rajopadhye ([email protected]) Louisiana Tech University Software Development Architectures Ankur K. Rajopadhye Abstract This paper intends to introduce different architectures used for software development starting with 1-tier architecture, 2 tier, 3 tier and finally N- tier architectures. Advantages and disadvantages of using these architectures are discussed. Critical factors for the architecture to be successful are described. Keywords: Client-Server, N-tier architecture, Presentation logic, Business logic, Data Access Logic 1. Introduction High-volume e-Business transactions are putting new pressures on the corporate computing environment. Functionality and stability are no longer sufficient to provide a competitive advantage. Businesses must be able to deploy and adapt applications quickly to address rising workloads and changing business requirements. Data and applications must be integrated across the enterprise to improve efficiency, and the highest levels of performance and availability must be maintained to support business-critical processes. Infrastructure analysts have outlined a strategy that can help IT organizations meet these demands. The strategy is built around the N-tier architecture, which partitions systems and software to enable a more flexible, building block approach to infrastructure design and growth. By taking advantage of off-the-shelf middleware and the N-tier architecture, businesses can design, deploy and integrate e-Business applications more quickly and cost-effectively. N-tier applications have become the norm for building enterprise software today. To most people, an N-tier application is anything that is divided into discrete logical parts. The most common choice is a three-part breakdown—presentation, business logic, and data—although other possibilities exist. N-tier applications first emerged as a way of solving some of the problems associated with traditional client/server applications, but with the arrival of the Web, this architecture has come to dominate new development. Rest of this paper is organized as follows. It starts with 1-tier architecture in section 2, 2-tier architecture in section 3, 3-tier architecture in section 4, and the discussion continues to N-tier architecture in section 5. Critical factors for the success of any architecture and best practices to be followed are described in Section 6. Section 7 is the comparative study of these architectures and the conclusion. 2. The 1-Tier Architecture A component in a 1-Tier structure contains all the code necessary to deal with the user interface, the data validation, and all communication with the physical database. Where several components access the same data objects (files, tables or entities whatever you want to call them) there can quite a bit of duplication. Apart from having to spend extra time in the first place to create components with similar code it also means that any subsequent changes to data objects or business rules would then require the same code changes to be replicated in what could turn out to be a large number of components. Presentation logic = User Interface, displaying data to the user, accepting input from the user. Business logic = Data Validation, ensuring the data is kosher before being added to the database. Data Access Logic = Database Communication, accessing tables and indices, packing and unpacking data. A component based on the 1-Tier structure can therefore be represented in shown in figure 2.1: Figure 2.1 - The 1-Tier Structure A good example of a 1-tier application is a Microsoft Access database. Figure 2.2 represents an Access solution. An Access solution consists of one file; in this particular example that file is named mydb.mdb. Notice how Access combines the data, business logic, and presentation all into one file. The main advantage of a 1-tier application is that it is usually easy and quick to develop. Most 1-tier solutions work well for small offices that don't need to track much data. The disadvantages of using these types of applications are that they are difficult to upgrade, they are not scalable, and they don't protect valuable "Business Logic" very well. For example, if you had an Access application you used to run your business, an employee could take the .mdb file and use it to start up a competing business. 3. The 2-Tier Architecture In a 2-Tier structure the logic is split into two tiers (or layers), usually done by splitting off the data access logic. This results in the structure shown in figure 2.1: Figure 3.1 - The 2-Tier Structure This removes all the complexities of communicating with the database to a separate layer. It should therefore be possible to switch to a different database system just by changing the contents of the data layer. Provided that the operations and signatures with the 1st layer remain consistent there should be no need to modify any component in the 1st layer. One reason why the 2-tier model is so widespread is because of the quality of the tools and middleware that have been most commonly used since the 90’s: RemoteSQL, ODBC, relatively inexpensive and well integrated PC-tools (like Visual Basic, Power-Builder, MS Access, 4-GL-Tools by the DBMS manufactures). In comparison the server side uses relatively expensive tools. In addition the PC-based tools show good Rapid-Application-Development (RAD) qualities i.e. those simpler applications can be produced in a comparatively short time. The 2-tier model is the logical consequence of the RAD-tools’ popularity: for many managers it was and is simpler to attempt to achieve efficiency in software development using tools, than to choose the steep and stony path of "brain ware". Unfortunately the 2-tier model shows striking weaknesses that make the development and maintenance of such applications much more expensive. The complete development accumulates on the PC. The PC processes and presents information which leads to monolithic applications that are expensive to maintain. That’s why it’s called a "fat client". In 2-tier architecture, business-logic is implemented on the PC. Even the businesslogic never makes direct use of the windowing-system; programmers have to be trained for the complex API under Windows. Windows 3.X and Mac-systems have tough resource restrictions. For these reason applications programmers also have to be well trained in systems technology, so that they can optimize scarce resources. Increased network load: since the actual processing of the data takes place on the remote client, the data has to be transported over the network. As a rule this leads to increased network stress. How to conduct transactions is controlled by the client. Advanced techniques like two-phase-committing can’t be run. PCs are considered to be "untrusted" in terms of security, i.e. they are relatively easy to crack. Nevertheless, sensitive data is transferred to the PC, for lack of an alternative. Data is only "offered" on the server, not processed. Stored-procedures are a form of assistance given by the database provider. But they have a limited application field and a proprietary nature. Application logic can’t be reused because it is bound to an individual PCprogram. The influences on change-management are drastic: due to changes in business politics or law (e.g. changes in VAT computation) processes have to be changed. Thus possibly dozens of PC-programs have to be adapted because the same logic has been implemented numerous times. It is then obvious that in turn each of these programs have to undergo quality control, because all programs are expected to generate the same results again. The 2-tier-model implies a complicated software-distribution-procedure: as all of the application logic is executed on the PC, all those machines (maybe thousands) have to be updated in case of a new release. This can be very expensive, complicated, prone to error and time consuming. Distribution procedures include the distribution over networks (perhaps of large files) or the production of an adequate media like floppies or CDs. Once it arrives at the user’s desk, the software first has to be installed and tested for correct execution. Due to the distributed character of such an update procedure, system management cannot guarantee that all clients work on the correct copy of the program. 3- and n-tier architectures endeavor to solve these problems. This goal is achieved primarily by moving the application logic from the client back to the server. 4. The 3-Tier Architecture This architecture splits each of the three logical areas into its own layer. For this structure to work effectively there should be clearly defined interfaces between each of the layers. This should then enable components in one layer to be modified without requiring changes any changes to components in other layers. Figure 4.1 shows the split in layers. The main advantage of this structure over the 2-Tier system is that all business logic is contained in its own layer and is shared by many components in the presentation layer. Any changes to business rules can therefore be made in one place and be instantly available throughout the whole application. Figure 4.1 - The 3-Tier Structure 3-tier architecture solves a number of problems that are inherent to 2-tier architectures. Naturally it also causes new problems, but these are outweighed by the advantages. Clear separation of user-interface-control and data presentation from applicationlogic. Through this separation more clients are able to have access to a wide variety of server applications. The two main advantages for client-applications are clear: quicker development through the reuse of pre-built business-logic components and a shorter test phase, because the server-components have already been tested. Re-definition of the storage strategy won’t influence the clients. RDBMS’ offer a certain independence from storage details for the clients. However, cases like changing table attributes make it necessary to adapt the client’s application. In the future, even radical changes, like let’s say switching form an RDBMS to an OODBS, won’t influence the client. In well designed systems, the client still accesses data over a stable and well designed interface which encapsulates all the storage details. Business-objects and data storage should be brought as close together as possible, ideally they should be together physically on the same server. This way especially with complex accesses - network load is eliminated. The client only receives the results of a calculation - through the business-object, of course. In contrast to the 2-tier model, where only data is accessible to the public, business-objects can place applications-logic or "services" on the net. As an example, an inventory number has a "test-digit", and the calculation of that digit can be made available on the server. As a rule servers are "trusted" systems. Their authorization is simpler than that of thousands of "untrusted" client-PCs. Data protection and security is simpler to obtain. Therefore it makes sense to run critical business processes that work with security sensitive data, on the server. Dynamic load balancing: if bottlenecks in terms of performance occur, the server process can be moved to other servers at runtime. Change management: of course it’s easy - and faster - to exchange a component on the server than to furnish numerous PCs with new program versions. To come back to our VAT example: it is quite easy to run the new version of a tax-object in such a way that the clients automatically work with the version from the exact date that it has to be run. It is, however, compulsory that interfaces remain stable and that old client versions are still compatible. In addition such components require a high standard of quality control. This is because low quality components can, at worst, endanger the functions of a whole set of client applications. At best, they will still irritate the systems operator. As shown on the diagram, it is relatively simple to use wrapping techniques in 3tier architecture. As implementation changes are transparent from the viewpoint of the object's client, a forward strategy can be developed to replace legacy system smoothly. 5. The N-Tier Architecture The name implies a structure which contains ‘N’ number of tiers where ‘N’ is a variable number. This is usually achieved by taking a component in one of the standard layers of the 3-Tier structure and breaking it down into subcomponents, each performing a specific low-level task. For example, the initial three layers into something which resembles the structure shown in figure 5.1.: Figure 5.1 - Splitting 3 layers into ‘N’ layers The function of each of these components is described in the following table: Form Interacts with the user. Uses the Decorator to read and write all data. Controller Controls the flow of a use case, navigating from one form to another in the correct sequence. Decorator Interface between the presentation layer and the business layer. Obtains data for a form and distributes data from a form when database updates are required. Presentation Object Presentation logic for a use case. Used for logic which is specific to a use case rather than a business object. Business Component Interface One per domain or logical group of entities. Business Object Business object for a logical entity. Contains all the business rules for that entity. Business Bridge Business component to business component interface. Service View An indexed list of keys for an object. Translator Translation between the logical data layer and the physical data layer. Cache Holds business data for a use case. Data Service Performs physical database IO. N-tier architecture offers following advantages. Easy to change: you can decide to switch from desktop applications to web based applications by just changing the UI layer (a small part of the application). The same thing with the database system. Easy to manage: if each layer has its own functionality, when something needs to be changed you will know what to change Easy to reuse: if another application is developed for the same domain, it can use a big part of the business layer Easy to develop: each layer can be developed by separate teams, and focus only on theirs specific problems (you don’t have to know HTML, ASP, OO design and SQL at the same time). Disadvantages of n-tier architecture are as below: In small applications, the benefits are usually not visible. Every data that goes in the system from the user to the database must pass through the components in the middle layers, and therefore the response time of the system will be slower. 6. Critical Success factors Success of architecture generally depends upon the following factors. 6.1 System interface In reality the boundaries between tiers are represented by object interfaces. Due to their importance they have to be very carefully designed, because their stability is crucial to the maintenance of the system, and for the reuse of components. Architecture can be defined as the sum of important long-term system interfaces. They include basic system services as well as object-meta-information. In distributed object systems, the architecture is of great importance. The architecture document is a reference guideline to which all the developers and users must adhere. If not, an expensive and time- consuming chaos results. 6.2 Security Here we are dealing with distributed systems, so data-protection and access control is the important thing. For the CORBA-standard, OMG completed the security-service in different versions in 1995. In the simplest form (level "0") authentication, authorization and encryption are guaranteed by Netscape’s secure-socket-layer protocol. Level 1 provides authentication control for security unaware applications. Level 2 is much more fine-grained. Each message invocation can be checked against an access control list, but programming by the ORB user is required. There are implementations for all levels available today. 6.3 Transactions For high availability, in spite of fast processing, transaction mechanisms have to be used. Standardized OMG interfaces are also present here, and many implementations have been done. The standard defines interfaces to two-phase-commit and offers new concepts like nested transactions. Best Practice Recommendations • Become proficient at designing and deploying N-tier architecture: Partitioning presentation logic, Business logic, and data management functionality will simplify upgrades and integration. During application development, push session management back to the database layer, to improve scalability at the front-end and middle tier. • Deploy High-Quality Application Server Software (middleware). Proper implementation will reduce application development costs and help to standardize your e-Business environment. • Scale Out at the Front-end. Redundant arrays of inexpensive servers (RAIS) can be scaled incrementally and affordably, and provide virtually unlimited levels of performance and availability. Take advantage of affordable Intel® Pentium® III processor-based servers for basic front-end services; and consider systems based on the Intel® Xeon™ processor family when higher levels of performance, availability and manageability are required. • Scale Out at the Middle Tier. With appropriate middleware, the advantages of scaling out can also be realized at the application layer. For best results, use middleware tools rather than the operating system to configure failover and clustering solutions. The advanced features of 4-way and 8-way Intel® Pentium® III Xeon™ processor-based servers are recommended to meet the heavier transaction demands of most middle tier applications. • Scale Up in the Back-end. Intel Pentium III Xeon processor-based servers configured with 8, 16, and 32 processors lead the industry in absolute performance, price/performance and compatibility for back-end applications. Larger configurations are available from specialized vendors. Servers based on the new 64-bit Intel® Itanium™ processor will soon extend Intel architecture solutions even further, to accommodate the most demanding of back-end applications—and to meet the extraordinary demands of next-generation e-Business. 7. Conclusion Comparative study of the discussed architectures leads to the following table. Each architecture has its own advantages and disadvantages. Size of the application will decide which architecture to use. References http://www.d-tec.ch/e/3tier.html http://www.prolifics.com/docs/panther/html/gt_html/panover.htm http://n-tier.com/ http://www.infusionsoft.com/Technology/index.jsp http://www.summithq.com/tech/ntier.htm http://www.marston-home.demon.co.uk/Tony/uniface/index.html Object Oriented Modeling And Design: A book by S. D. Joshi