Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Turn Waste into Wealth:
On Simultaneous Clustering and
Cleaning over Dirty Data
Shaoxu Song, Chunping Li, Xiaoquan Zhang
Tsinghua University
Motivation
• Dirty data commonly exist
– Often a (very) large portion
– E.g., GPS readings
• Density-based clustering
– Such as DBSCAN
– Successfully identify noises
– Grouping non-noise points
in clusters
– Discarding noise points
KDD 2015
2
Mining
Cleaning
Useless
Guide
Make
Valuable
KDD 2015
Find
3
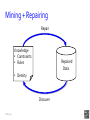
Mining + Repairing
Repair
Knowledge
• Constraints
• Rules
Repaired
(Dirty)
Data
• Density
Discover
KDD 2015
4
Discarding vs. Repairing
• Simply discarding a large number of dirty points (as noises)
could greatly affect clustering results
(a) Clusters in ground truth
C1
C2
(b) Clusters in dirty data without repairing
C1
C2
C3
Noise
(c) Clusters in dirty data with repairing
C1
C2
• Propose to repair and utilize noises to support clustering
• Basic idea: simultaneously repairing noise points w.r.t. the
density of data during the clustering process
KDD 2015
5
Density-based Cleaning
• Both the clustering and repairing tasks benefit
– Clustering: with more supports from repaired noise points
– Repairing: under the guide of density information
• Already embedded in the data
• Rather than manually specified knowledge
KDD 2015
6
Basics
• DBSCAN: density-based identification of noise points
– Distance threshold 𝞮
– Density threshold 𝞰
• 𝞮-neighbor:
– if two points have distance less than 𝞮
• Noise point
– With the number of 𝞮-neighbors less than 𝞰
– Not in 𝞮-neighbor of some other points
that have 𝞮-neighbors no less than 𝞰 (core points)
KDD 2015
7
Modification Repair [SIGMOD’05] [ICDT’09]
• A repair over a set of points is a mapping λ : P → P
• We denote λ(pi) the location of point pi after repairing
• The ε-neighbors of λ(pi) after repairing is
Cλ(pi) = { pj ∈ P | δ( λ(pi) , λ(pj) ) ≤ ε }
KDD 2015
8
Repair Cost
• Following the minimum change principle in data cleaning
– Intuition: systems or humans always try to minimize
mistakes in practice
– prefer a repair close to the input
• The repair cost ∆(λ) is defined as
∆(λ) = ∑i w( pi , λ(pi) )
– w( pi , λ(pi) ) is the cost of repairing a point pi to the new
location λ(pi)
– E.g., by counting modified data points
KDD 2015
9
Problem Statement
• Given a set of data points P, a distance threshold ε and a
density threshold η
• Density-based Optimal Repairing and Clustering (DORC)
problem is to find a repair λ (a mapping λ : P → P ) such that
(1) the repairing cost ∆(λ) is minimized, and
(2) each repaired λ(pi) is either a core point or a board point
– for each repaired λ(pi), either |Cλ(pi)| ≥ η (core points),
– or |Cλ(pj)| ≥ η for some pj with δ(λ(pi),λ(pj)) ≤ ε
All the points are utilized, no noise remains
KDD 2015
10
Technique Concern
• Simply repairing only the noise points to the closest clusters
is not sufficient
– e.g., repairing all the noise points to C1 does not help in
identifying the second cluster C2
• Indeed, it should be considered that dirty points may possibly
form clusters with repairing (i.e., C2)
KDD 2015
11
Problem Solving
• No additional parameters are introduced for DORC
– besides the density and distance requirements η and ε for
clustering
• ILP formulation
– Efficient solvers can be applied
• Quadratic time approximation
– via LP relaxation
• Trade-off between Effectiveness and Efficiency
– By grouping locally data points into several partitions
KDD 2015
12
Experimental Results
• Answers the following questions
– By utilizing dirty data, can it form more accurate clusters?
– By simultaneous repairing and clustering, in practice is the
repairing accuracy improved compared with the existing data
repairing approaches?
dirty
– How do the approaches scale?
• Criteria
truth
RMS
repair
– Clustering Accuracy: purity and NMI
– Repairing Accuracy: root-mean-square error (RMS) between
truth and repair results
KDD 2015
13
Artificial Data Set
• Compared to existing methods without repairing
– DBSCAN and OPTICS
• Proposed DORC (ILP/Quadratic-time-approximation) shows
1
0.98
0.96
0.94
0.92
0.9
0.88
0.86
0.84
0.82
0.8
(a) e=15, h=6
DBSCAN
ILP
QDORC
LDORC(t/e=1/5)
LDORC(t/e=1/10)
OPTICS
0.03 0.06 0.09 0.12 0.15 0.18 0.21
Dirty rate
KDD 2015
Repairing error
Clustering purity
– Higher clustering purity
5.5
5
4.5
4
3.5
3
2.5
2
1.5
1
0.5
(b) e=15, h=6
ILP
QDORC
LDORC(t/e=1/5)
LDORC(t/e=1/10)
0.03 0.06 0.09 0.12 0.15 0.18 0.21
Dirty rate
14
Real GPS Data
• With errors naturally embedded, and manually labelled
• Compared to Median Filter (MF)
– A filtering technique for cleaning the noisy data in timespace correlated time-series
• DORC is better than MF+DBSCAN
0.014
0.92
0.88
0.84
(a) e=8E-5, h=8
0.012
0.96
0.8
0.02
KDD 2015
(a) e=8E-5, h=8
Repairing error
Clustering purity
1
DBSCAN
MF+DBSCAN
QDORC
MF+QDORC
OPTICS
0.06
0.1
Dirty rate
0.01
0.008
0.006
MF
QDORC
MF+QDORC
0.004
0.14
0.18
0.002
0.02
0.06
0.1
Dirty rate
0.14
0.18
15
Restaurant Data
• Tabular data, with artificially injected noises
– Widely considered in conventional data cleaning
• Compared to FD
(a) e=0.22, h=16
DBSCAN
FD+DBSCAN
QDORC
FD+QDORC
Clustering purity
0.95
0.9
0.85
0.8
0.75
0.7
0.1
KDD 2015
0.14
0.18
0.22
Dirty rate
0.26
0.3
Repairing error
– A repairing approach under integrity constraints
(Functional Dependencies), [name,address → city]
0.3
0.29
0.28
0.27
0.26
0.25
0.24
0.23
0.22
0.21
0.2
0.1
(a) e=0.22, h=16
FD
QDORC
FD+QDORC
0.14
0.18
0.22
Dirty rate
0.26
0.3
16
More results
• Two labeled publicly available benchmark data,
– Iris and Ecoli, from UCI
• Normalized mutual information (NMI) clustering accuracy
– Similar results are observed
– DORC shows higher accuracy than DBSCAN and OPTICS
(a) GPS
0.9
0.8
0.8
0.6
0.7
0.6
0.5
0.02
KDD 2015
DBSCAN
MF+DBSCAN
QDORC
MF+QDORC
OPTICS
0.06
0.1
Dirty rate
(b) UCI
1
NMI
NMI
1
DBSCAN
OPTICS
QDORC
0.4
0.2
0
0.14
0.18
Iris
Ecoli
Dataset
17
Summary
• Preliminary density-based clustering can successfully identify noisy
data but
– without cleaning them
• Existing constraint-based repairing relies on external constraint
knowledge
– without utilizing density information embedded inside the data
• With the happy marriage of clustering and repairing advantages
– both the clustering and repairing accuracies are significantly
improved
KDD 2015
18
References (data repairing)
• [SIGMOD’05] P. Bohannon, M. Flaster, W. Fan, and R. Rastogi. A
cost-based model and effective heuristic for repairing constraints
by value modification. In SIGMOD Conference, pages 143–154,
2005.
• [TODS’05] J. Wijsen. Database repairing using updates. ACM Trans.
Database Syst., TODS, 30(3):722–768, 2005.
• [PODS’08] W. Fan. Dependencies revisited for improving data
quality. In PODS, pages 159–170, 2008.
• [ICDT’09] S. Kolahi and L. V. S. Lakshmanan. On approximating
optimum repairs for functional dependency violations. In ICDT,
pages 53–62, 2009.
KDD 2015
19
Thanks