Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
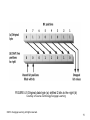
Chapter 4 Processor Technology and Architecture CSCI 311 Dr. Frank Li ©2016. Cengage Learning. All rights reserved. FIGURE 4.1 Topics covered in this chapter Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 2 CPU Components & Functions • The central processing unit (CPU) is the computer system “brain”: – Executes program instructions including computation, comparison, and branching – Directs all computer system actions including processing, storage, input/output, and data movement • CPU components include: – Control unit – directs flow of data to/from memory, registers, and the arithmetic logic unit – Arithmetic logic unit (ALU) – executes computation and comparison instructions – Registers – storage locations within the CPU that hold ALU inputs, ALU outputs, and other data for fast access ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition CPU and Other Computer System Components Figure 4.2 CPU components Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Instruction and Execution Cycles • The CPU constantly alternates between two stages (or cycles): – Instruction cycle: • Also called the fetch cycle • The control unit reads an instruction from primary storage • The control unit increments the instruction pointer (address of the next instruction to be read) • The control unit stores the instruction is stored in the instruction register • If there are data inputs embedded in the instruction they’re loaded into registers as inputs for the ALU • If the instruction includes memory addresses of data inputs they’re copied from memory and loaded into registers as inputs for the ALU – Execution cycle: • Data movement instructions are executed by the control unit itself • Computation and comparison instructions are executed by the ALU in response to a signal from the control unit. Data inputs flow from registers through processing circuitry and the output(s) flows to one or more registers ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Instruction and Execution Cycles - Continued Figure 4.3 Control and data flow during the fetch and execution cycles Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Instruction Format • An instruction is a command to the CPU to perform a single processing function on specific data inputs • As stored in memory or a register, an instruction is a sequence of bits that must be decoded to extract the processing function and data inputs (or the location of the data inputs • Instruction components: – Op code - a unique binary number representing the processing function and a template for extracting the operands – Operands – one or more groups of bits after the op code that contain data to be processed or identify the location of that data (a register or memory address) ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Instruction Format - Continued • Different kinds of operands have different lengths depending on the type of data or address stored therein • The same processing function may correspond to many different op-codes with different operand formats (e.g., an ADD instruction for integers stored as operands, another for integers stored in registers, and another for integers stored in memory) FIGURE 4.4 An instruction containing one op code and two operands Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Instruction Summary • MOVE – Copy data from: – A memory address to a register (a load operation) – A register to memory address (a store operation) – A register to another register • Boolean logic – convert individual bits within a bit string (bitwise operations) or treat entire bit strings as true or false and manipulate/combine them (logic operations) – NOT – flip every bit, or change true to false and vice versa – AND – two 1 bits yields a 1 but, all other combinations are 0, or two trues are true, all other combinations are false – OR – two 0 bits yields a 0, all other combinations are 1, or two falses are false, all other combinations are true – Exclusive OR (XOR) – 0 and 1 are 1, all other combinations are 0, or true and false is true, all other combinations are false ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Instruction Summary - Continued • ADD – Produce the arithmetic sum of two bit strings – Need multiple ADD instructions, one per data type/format • SHIFT – Move all bits left or right and fill in zeros – Can be used to extract single bit values (logical shift) – Can be used for binary multiplication and division (arithmetic shift) ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition FIGURE 4.5 Original data byte (a) shifted 2 bits to the right (b) Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 11 FIGURE 4.6 Extracting a single bit with logical SHIFT instructions Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 12 FIGURE 4.7 Multiplying and dividing unsigned binary values with SHIFT instructions Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 13 Instruction Summary - Continued • BRANCH – Also called JUMP – Alters next instruction fetched/executed – Unconditional branch – always changes sequence (e.g., a GOTO statement) – Conditional branch – changes only if the value true is stored in a register (value was stored as a result of a previous comparison instruction) • HALT – self-explanatory ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Simple and Complex Instructions • The instructions on the previous slides comprise the minimal set of instructions needed to implement a full-fledged CPU, for example: • More complex operations such as exponentiation and operations on non-integer data types can be implemented by complex combinations of the simple instructions – For example, subtraction can be implemented as: 710−310 = ADD(ADD(XOR(0011,1111),0001),0111) = ADD(ADD(1100,0001),0111) = ADD(1101,0111) = 10100 – Pros of providing only a minimal instruction set • Processor is simple to build and construct • Simple = cheaper CPUs with very fast clock rates – Cons of providing only a minimal instruction set • Programs that need complex processing/data are complex • Complex = expensive, slow, and error-prone program development ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Simple and Complex Instructions - Continued • Modern CPUs provide a far richer set of instructions than the minimal set: – Duplicate instructions for multiple data types (e.g., signed/unsigned, integer/real, and single/doubleprecision) – Higher-order computational functions (e.g., subtraction. Multiplication/division, exponentiation, trig functions) – Higher-order logical functions (e.g., greater than or equal to) – Instructions that combine data movement to/from memory with processing • Complex silicon CPU circuits are cheaper than programmers! ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition RISC versus CISC • Reduced Instruction Set Computing (RISC) – Avoid “unnecessary” complex instructions – keep instruction count to several dozen to a few hundred – Minimize number/complexity of instruction formats – Minimize maximum instruction length – Avoid combining data movement with transformation (sometimes called load-store architecture) – “Less is more” – For example, IBM POWER CPUs • Complex Instruction Set Computing (CISC) – Opposite of RISC – For example, Intel Core and Xeon CPUs ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition RISC versus CISC - Continued • CPU Complexity/Speed – RISC simplifies the job of the control unit by simplifying the instruction set – Simpler fetch = faster fetch = higher clock rate? • Program execution speed – Higher clock rate = faster program execution? – BUT: • No complex instructions • Thus, more instructions must be fetched/executed to do “complex” operations • Bottom line – it’s a trade-off among: – Clock rate – Number of complex operations in “typical” programs – Relative penalty/benefit of providing or not providing single CPU instructions for those complex operations • Also: – The contrast isn’t a stark as the manufacturer’s white papers might lead you to believe – Both “camps” borrow heavily from the others’ best ideas ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Clock Rate • The CPU has an internal clock that generates “ticks” at regular intervals: – The CPU clock rate is the frequency of those ticks – Typically stated in gigahertz (GHz) – billions of cycles (ticks) per second – Fetch/execute cycles are fractions of the clock rate – Clock rate is assumed to be the time needed to fetch (with no wait states) and execute the simplest instruction (e.g., NOT) – Modern CPUs are much too complex for that simplistic assumption to work (more on these topics later)! • • • • Memory caches Multiple core processors Multiple ALUs per core Pipelining ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition MIPS and MFLOPS • Instruction-oriented performance measures include: – MIPS – millions of (fetched/executed) instructions per second – presumed to be integer instructions or a “typical” mix – MFLOPS – millions of (fetched/executed) floating point operations per second • Both terms are outdated as modern CPUs get faster (e.g., GFLOPS, TFLOPS, and PFLOPS) • Both terms can apply to performance of: – Processor in isolation – Entire computer system ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition MIPS and MFLOPS - Continued • MIPS/MFLOPS may be lower than implied by clock rate – WHY? – Programs do more than execute NOT statements! – More complex operations require more execution time (multiple clock cycles) – Wait states for: • Access to memory • Access to system bus • Access to storage and I/O devices ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Benchmarks • A benchmark is a performance measure for a computer system or one of its components when performing a specific and realistic type of software task, for example: – – – – – Responding to an HTTP request Processing a complex database transaction Reading/writing a disk Redrawing the screen in an animation Combinations of the above • Benchmarks can roughly divided into 2 classes: – Artificial – a “made-up” workload that is supposed to be representative of a class of real workloads – Live-Load – a workload based on “real” tasks such as playing an online game, encoding a DVD, or responding to web server requests • Benchmarks have their limitations, but even the artificial ones are generally more realistic and reliable indicators of computer system performance than MIPS and MFLOPS. ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Sample Benchmarks • Standard Performance Evaluation Corporation (SPEC) provides a suite a benchmarks including: – SPEC CPU: computational performance with integers and floating point numbers – SPEC MPI: computational performance of problems distributed across a cluster – SPECviewperf: workstation graphics performance – SPECmail: email server performance – http://www.spec.org • TPC – Server-oriented performance for processing business or database transactions – http://www.tpc.org • PassMark – Test suite for microcomputers – http://www.passmark.com ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Registers • Registers can be roughly divided into two classes: – General-purpose • Used as high-performance scratchpad memory by the ALU(s) • More are better up to a point (law of diminishing returns) • Modern CPUs typically provide a few dozen per ALU – Special-purpose registers • Used primarily by the control unit in CPU management tasks • Examples include: – Instruction pointer – memory address for next instruction fetch, a.k.a. program counter – Instruction register – copy of most recently fetched instruction – Program status word (PSW) – Goes by many different names - Set of bit flags containing error and other codes related to processing results, for example: » Result of comparison operations » Divide by zero » Overflow and underflow ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Word Size • A word is: – A fixed number of bits/bytes – The basic “unit” of data transformation in a CPU – The size of a data item that the CPU manipulates when executing a “normal” instruction – The size of a memory address? • The term has fallen into disuse as ever more complex CPU designs employ multiple word sizes – For example, a 64-bit Intel Core CPU has word sizes ranging from 16 to 128 bits ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Word Size and Performance • • • ALU circuitry manipulates all bits of a word in parallel while executing a single instruction Larger word size implies larger and more complex ALU and other circuitry thus increasing CPU expense and slowing clock rate (all other things being equal) Mismatches between CPU word size and the size of data items manipulated by a program include: – CPU word size > program data size • • • – CPU word size = program data size • – • • • Performance and cost are both optimal – best case scenario CPU word size < program data size • • • Lots of zeros are carried through fetches, registers, and ALU circuitry Performance is suboptimal – CPU is more complex than the program requires – more complex = slower Cost is higher than needed since “extra” word size is unused Avoids cost of extra bits Incurs substantial performance penalty due to breaking data items into word-sized chunks and performing piece-wise operations on the words Performance penalty varies with the size mismatch and the complexity of the processing function(s) Cost of CPU is lower since small word size = simpler CPU = less expensive CPU Take the cost statements in the slide with half a shaker of salt – modern CPUs are so cheap that word size must be VERY large to significantly increase cost Bottom line – for best cost/performance ratio, match CPU word size to the size of data that will be processed (assuming that’s feasible) ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Word Size and Performance - Continued • Typical “normal data sizes” – “Business” applications – 32 or 64 bits – “Scientific” applications – 64 or 128 bits – Database and multimedia applications – highly variable, but more is generally better! • Early CPUs had small word size (e.g., 8 or 16 bits) due to technology limitations and thus had suboptimal performance for all but the simplest applications • The gap between needed and actual CPU word size continued until the early/mid 2000s • Most modern CPUs have 64-bit word size • Will 128-bit CPUs appear? When? Why? ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Performance Enhancement Techniques • Thus far we’ve described a relatively simplistic view of CPU operation that matches CPUs of the 1960s-1980s • As fabrication technology has improved, CPU designers have been able to employ ever more complex performance improvement techniques individually and in combination, including: – – – – Memory caching (Chapter 5) Pipelining Branch prediction and speculative execution Multiprocessing ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Pipelining • Pipelining is a Henry Ford era technique (i.e., the sequential assembly line) applied to executing program instructions • Execution stages: 1. 2. 3. 4. 5. 6. Fetch from memory Increment and store instruction pointer (IP) Decode instruction and store operands and instruction pointer Access ALU inputs Execute instruction within the ALU Store ALU output • Pipelining attempts to overlap instruction execution by performing each stage on a different instruction at the same time ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition FIGURE 4.10 Overlapped instruction execution via pipelining Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 30 Pipelining - Continued • Sounds great in theory, but there are some complexities with which to deal: – – – – – Is one instruction pointer enough? Is one instruction register enough? Is one set of general purpose registers enough? Is one ALU enough? What happens if a branch is encountered? • Pipelining can be “finer-grained” than we’ve shown thus far – For example, execution (usually the longest stage) could be (and often is) further subdivided into additional stages) ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Multiprocessing • Pipelining goes hand-in-hand with at least some duplication of processor circuitry • Multiprocessing carries the duplication to higher levels, such as: – Multiple ALUs (with parallel execution of instructions) per CPU (common by late 1990s) – Multiple CPUs on a single motherboard (common by early 2000s) – Multiple CPUs on a single chip (common by late 2000s) • Operating systems are more complex because they now manage more processing resources and more complex application software • Application software that takes advantage of multiprocessing is more complex because it must be designed for parallel execution (a.k.a. multithreading as discussed in a later chapter) ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Branch Prediction and Speculative Execution • Branches cause problems with pipelining because they invalidate the partially executed instructions that follow them: – The wrong instructions (after the branch) were fetched and partially executed – Special- and general-purpose register contents are incorrect • The pipeline must be flushed and filling it with the proper set of instructions (the branch target) must being anew • Real programs have lots of branches – Thus, pipelining will often “fail” unless preventive measures are employed ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Branch Prediction and Speculative Execution - Continued • Preventive Measures: – Look-ahead – “watch” incoming instructions for branches and alter standard behavior accordingly – Branch prediction – if a conditional branch is fetched attempt to guess the condition result and load/execute the corresponding instructions (this is called speculative execution) – Speculatively execute both paths beyond a conditional branch • Requires multiple execution units • Half the results will be thrown away (half the effort is wasted) • Modern CPUs employ all three techniques to improve pipelining performance ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition The Physical CPU • Complex system of interconnected electrical switches • Contains millions of switches, which perform basic processing functions • Physical implementation of switches and circuits ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 35 Switches and Gates • Switches and gates are building blocks of CPU and memory circuitry: – Switch – a device that can be open or closed to allow or block passage of electricity – implemented as a transistor – Gate – multiple switches wired together to perform a processing function on one bit: a) b) c) d) e) NOT AND OR XOR NAND ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition FIGURE 4.12 Electrical component symbols for a signal inverter or NOT gate (a), an AND gate (b), an OR gate (c), an XOR gate (d), and a NAND gate (e) Courtesy of Course Technology/Cengage Learning Circuits • Gates are wired into circuits to perform more complex processing (e.g., half and full adder below) FIGURE 4.13 Circuit diagrams for half adder (a) and full adder (b) Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Electricity • Since circuits are electrical devices they benefit and suffer from electricity advantages/limitations: – Speed – electrons move through circuitry at approximately 70% of light speed – Speed of processing is thus directly proportional to circuit length – Conductivity – circuits must be constructed of highly conductive material – e.g., copper or gold – Resistance – even good conductors turn some electrical energy into heat • Circuit length is limited because energy loss accumulates • Heat must be dissipated to prevent higher resistance or physical damage to conductors ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Electrical Properties Conductivity Capability of an element to enable electron flow Resistance Loss of electrical power that occurs within a conductor Heat Negative effects of heat: • Physical damage to conductor • Changes to inherent resistance of conductor Dissipate heat with a heat sink Speed and circuit length Time required to perform a processing operation is a function of length of circuit and speed of light ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 39 FIGURE 4.14 A heat sink attached to a surface-mounted microprocessor Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 40 Processor Fabrication • Modern CPUs are fabricated as microprocessors – silicon chips containing billions of transistors and their wiring implementing multiple CPUs, memory caches, and memory/bus interface circuitry • Speed has been improved over time by shrinking the physical size of the wires and transistors – currently 22 nanometers ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition FIGURE 4.15 The Intel 4004 microprocessor containing 2300 transistors Courtesy of Intel Corporation ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 42 Processor Fabrication - Continued FIGURE 4.17 A wafer of processors with 410 million transistors each Courtesy of Intel Corporation ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Processor Fabrication - Continued ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Copyright © 2009 IBM Corporation Processor Fabrication – Looming Problems • Moore’s Law – transistor count on a chip doubles every 18-24 months at no cost increase – Implies greater power and/or speed IF the additional transistors are used as effectively as the previous ones • Rock’s Law – cost of a processor fabrication facility doubles every four years – Currently >10 billion dollars • Process shrinkage has limits that we’ll soon hit: – Etching process requires higher and higher wavelength beams (currently using X-Rays) – Fabrication errors accumulate (e.g., material impurities) – Molecular width of conductors is a theoretical lower bound (single-digit nanometers) ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition FIGURE 4.18 Increases in transistor count for Intel microprocessors Courtesy of Course Technology/Cengage Learning ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 46 Processor Fabrication – Where to From Here? • ± 10 years of improvements left to current silicon-based fabrication processes • Optical interconnects – – – – Reduces or eliminates wiring Logical extension of current technology Unknown price/performance characteristics Many manufacturing issues yet to be worked out • Optical CPUs – none yet demonstrated in lab • Quantum processors – we don’t fully understand the physics let alone the physical implementation! ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition Summary • • • • • • • CPU operation Instruction set and format Clock rate Registers Word size Physical implementation Future trends ©2016. Cengage Learning. All rights reserved. Systems Architecture, Seventh Edition 48