Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
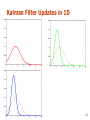
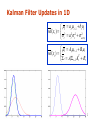
Probabilistic Robotics Bayes Filter Implementations Bayes Filter Reminder •Prediction bel ( xt ) p( xt | ut , xt 1 ) bel ( xt 1 ) dxt 1 •Correction bel ( xt ) p( zt | xt ) bel ( xt ) Gaussians p ( x) ~ N ( , 2 ) : p ( x) 1 2 2 e 1 ( x )2 2 2 Univariate - p(x) ~ Ν (μ,Σ) : p ( x) 1 (2 ) d /2 Σ 1/ 2 e Multivariate 1 ( x μ ) t Σ 1 ( x μ ) 2 Properties of Gaussians X ~ N ( , 2 ) 2 2 Y ~ N ( a b , a ) Y aX b 2 2 22 X 1 ~ N ( 1 , 1 ) 1 1 p ( X ) p ( X ) ~ N , 1 2 1 2 2 2 2 2 2 2 2 1 2 1 2 X 2 ~ N ( 2 , 2 ) 1 2 Multivariate Gaussians X ~ N ( , ) T Y ~ N ( A B , A A ) Y AX B X 1 ~ N ( 1 , 1 ) 2 1 1 1 2 , p( X 1 ) p( X 2 ) ~ N 1 1 X 2 ~ N ( 2 , 2 ) 1 2 1 2 1 2 • We stay in the “Gaussian world” as long as we start with Gaussians and perform only linear transformations. Discrete Kalman Filter Estimates the state x of a discrete-time controlled process that is governed by the linear stochastic difference equation xt At xt 1 Bt ut t with a measurement zt Ct xt t 6 Components of a Kalman Filter At Matrix (nxn) that describes how the state evolves from t to t-1 without controls or noise. Bt Matrix (nxm) that describes how the control ut changes the state from t to t-1. Ct Matrix (kxn) that describes how to map the state xt to an observation zt. t t Random variables representing the process and measurement noise that are assumed to be independent and normally distributed with covariance Rt and Qt respectively. 7 Bayes Filter Reminder •Prediction bel ( xt ) p( xt | ut , xt 1 ) bel ( xt 1 ) dxt 1 •Correction bel ( xt ) p( zt | xt ) bel ( xt ) 8 Kalman Filter Algorithm 1. Algorithm Kalman_filter( t-1, t-1, ut, zt): 2. 3. 4. Prediction: t At t 1 Bt ut 5. 6. 7. 8. Correction: 9. Return t, t t At t 1 AtT Rt Kt t CtT (Ct t CtT Qt )1 t t Kt ( zt Ct t ) t ( I Kt Ct )t 9 Linear Gaussian Systems: Dynamics • Dynamics are linear function of state and control plus additive noise: xt At xt 1 Bt ut t p( xt | ut , xt 1 ) N xt ; At xt 1 Bt ut , Rt bel ( xt ) p( xt | ut , xt 1 ) bel ( xt 1 ) dxt 1 ~ N xt ; At xt 1 Bt ut , Rt ~ N xt 1 ; t 1 , t 1 10 Linear Gaussian Systems: Observations • Observations are linear function of state plus additive noise: zt Ct xt t p( zt | xt ) N zt ; Ct xt , Qt bel ( xt ) p( zt | xt ) bel ( xt ) ~ N zt ; Ct xt , Qt ~ N xt ; t , t 11 Linear Gaussian Systems: Initialization • Initial belief is normally distributed: bel ( x0 ) N x0 ; 0 , 0 12 Kalman Filter Updates in 1D 13 Kalman Filter Updates 14 Kalman Filter Updates in 1D t at t 1 bt ut bel ( xt ) 2 2 2 2 a t t act ,t t t At t 1 Bt ut bel ( xt ) T A A t t 1 t Rt t 15 Kalman Filter Updates in 1D t t K t ( zt t ) bel ( xt ) 2 2 ( 1 K ) t t t t t Kt ( zt Ct t ) bel ( xt ) t ( I Kt Ct )t with with t2 Kt 2 2 t obs ,t Kt t CtT (Ct t CtT Qt ) 1 16 Linear Gaussian Systems: Dynamics bel ( xt ) p ( xt | ut , xt 1 ) bel ( xt 1 ) dxt 1 ~ N xt ; At xt 1 Bt ut , Rt ~ N xt 1 ; t 1 , t 1 1 bel ( xt ) exp ( xt At xt 1 Bt ut )T Rt1 ( xt At xt 1 Bt ut ) 2 1 T 1 exp ( xt 1 t 1 ) t 1 ( xt 1 t 1 ) dxt 1 2 t At t 1 Bt ut bel ( xt ) T A A t t t 1 t Rt 17 Linear Gaussian Systems: Observations bel ( xt ) p( zt | xt ) bel ( xt ) ~ N zt ; Ct xt , Qt ~ N xt ; t , t 1 1 bel ( xt ) exp ( zt Ct xt )T Qt1 ( zt Ct xt ) exp ( xt t )T t1 ( xt t ) 2 2 t t K t ( zt Ct t ) bel ( xt ) t ( I K t Ct ) t with K t t CtT (Ct t CtT Qt ) 1 18 The Prediction-Correction-Cycle Prediction t at t 1 bt ut bel ( xt ) 2 2 2 2 t at t act ,t At t 1 Bt ut bel ( xt ) t T t At t 1 At Rt 19 The Prediction-Correction-Cycle K t ( zt t ) t2 bel ( xt ) t 2 t , K t 2 2 t2 obs t (1 K t ) t ,t t K t ( zt Ct t ) bel ( xt ) t , K t t CtT (Ct t CtT Qt ) 1 ( I K C ) t t t t Correction 20 The Prediction-Correction-Cycle Prediction K t ( zt t ) t2 bel ( xt ) t 2 t , K t 2 2 t2 obs t (1 K t ) t ,t t at t 1 bt ut bel ( xt ) 2 2 2 2 t at t act ,t t K t ( zt Ct t ) bel ( xt ) t , K t t CtT (Ct t CtT Qt ) 1 ( I K C ) t t t t At t 1 Bt ut bel ( xt ) t T t At t 1 At Rt Correction 21 Kalman Filter Summary • Highly efficient: Polynomial in measurement dimensionality k and state dimensionality n: O(k2.376 + n2) • Optimal for linear Gaussian systems! • Most robotics systems are nonlinear! 22 Nonlinear Dynamic Systems • Most realistic robotic problems involve nonlinear functions xt g (ut , xt 1 ) zt h( xt ) 23 Linearity Assumption Revisited 24 Non-linear Function 25 EKF Linearization (1) 26 EKF Linearization (2) 27 EKF Linearization (3) 28 EKF Linearization: First Order Taylor Series Expansion • Prediction: g (ut , t 1 ) g (ut , xt 1 ) g (ut , t 1 ) ( xt 1 t 1 ) xt 1 g (ut , xt 1 ) g (ut , t 1 ) Gt ( xt 1 t 1 ) • Correction: h( t ) h( xt ) h( t ) ( xt t ) xt h( xt ) h( t ) H t ( xt t ) 29 EKF Algorithm 1. Extended_Kalman_filter( t-1, t-1, ut, zt): 2. 3. 4. Prediction: t g (ut , t 1 ) t At t 1 Bt ut t Gt t 1GtT Rt t At t 1 AtT Rt 5. 6. 7. 8. Correction: Kt t HtT ( Ht t HtT Qt )1 t t Kt ( zt h(t )) 9. Return t, t t ( I Kt H t )t h( t ) Ht xt Kt t CtT (Ct t CtT Qt )1 t t Kt ( zt Ct t ) t ( I Kt Ct )t g (ut , t 1 ) Gt xt 1 30 EKF Summary • Highly efficient: Polynomial in measurement dimensionality k and state dimensionality n: O(k2.376 + n2) • Not optimal! • Can diverge if nonlinearities are large! • Works surprisingly well even when all assumptions are violated! 31 Unscented Transform Sigma points Weights w 0 i 0 m ( n ) i n wmi wci w 0 c 1 2(n ) n (1 2 ) for i 1,...,2n Pass sigma points through nonlinear function i g ( i ) Recover mean and covariance 2n ' wmi i i 0 2n ' wci ( i )( i )T i 0 32 Linearization via Unscented Transform EKF UKF 33 UKF Sigma-Point Estimate (2) EKF UKF 34 UKF Sigma-Point Estimate (3) EKF UKF 35 UKF Algorithm 36 UKF Summary • Highly efficient: Same complexity as EKF, with a constant factor slower in typical practical applications • Better linearization than EKF: Accurate in first two terms of Taylor expansion (EKF only first term) • Derivative-free: No Jacobians needed • Still not optimal! 37 Particle Filters Represent belief by random samples Monte Carlo filter, Survival of the fittest, Condensation, Bootstrap filter, Particle filter Filtering: [Rubin, 88], [Gordon et al., 93], [Kitagawa 96] Estimation of non-Gaussian, nonlinear processes Computer vision: [Isard and Blake 96, 98] Dynamic Bayesian Networks: [Kanazawa et al., 95]d 38 Particle Filters 39 Particle Filter Algorithm 40 Resampling • Given: Set S=(w1, w2, …, wM ) of weight samples. • Wanted : Random sample, where the probability of drawing xi is given by wi. • Typically done M times with replacement to generate new sample set Xt. 41 Resampling Algorithm 42 Resampling wn Wn-1 wn w1 w2 Wn-1 w3 • Roulette wheel • Binary search, n log n w1 w2 w3 • Stochastic universal sampling • Systematic resampling • Linear time complexity • Easy to implement, low variance 43 Summary • Particle filters are an implementation of • • • • recursive Bayesian filtering They represent the posterior by a set of weighted samples. In the context of localization, the particles are propagated according to the motion model. They are then weighted according to the likelihood of the observations. In a re-sampling step, new particles are drawn with a probability proportional to the likelihood of the observation. 44