Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Sufficient statistic wikipedia , lookup
Foundations of statistics wikipedia , lookup
Psychometrics wikipedia , lookup
History of statistics wikipedia , lookup
Degrees of freedom (statistics) wikipedia , lookup
Bootstrapping (statistics) wikipedia , lookup
Taylor's law wikipedia , lookup
Misuse of statistics wikipedia , lookup
Statistical inference wikipedia , lookup
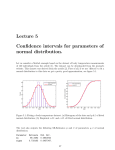
6.1 Inference for the Mean of a Population Note. Some assumptions for inference about a mean are: • Our data are a simple random sample (SRS) of size n from the population. • Observations from the population have a normal distribution with mean µ and standard deviation σ. Both µ and σ are unknown parameters. Definition. When the standard deviation of a statistic is estimated from the data, the result is called the standard error of the statistic. √ The standard error of the sample mean x is s/ n. The t Distribution Definition. Draw an SRS of size n from a population that has the normal distribution with mean µ and standard deviation σ. The onesample t statistic x−µ √ s/ n has the t distribution with n − 1 degrees of freedom. t= Note. There is a different t distribution for each sample size. We specify a particular t distribution by giving its degrees of freedom. The degrees of freedom for the one-sample t statistic come from the sample 1 standard deviation s in the denominator of t. We will write the t distribution with k degrees of freedom as t(k) for short. Note. Figure 6.1 (and TM-97) compares the density curves of the standard normal distribution and the t distributions with 2 and 9 degrees of freedom. The figure illustrates these facts about the t distribution: • The density curves of the t distributions are similar in shape to the standard normal curve. They are symmetric about zero and are bell-shaped. • The spread of the t distributions is a bit greater than that of the standard normal distribution. The t distributions in Figure 6.1 (TM-101) have more probability in the tails and less in the center than does the standard normal. This is true because substituting the estimate s for the fixed parameter σ introduces more variation into the statistic. • As the degrees of freedom k increase, the t(k) density curve approaches the N (0, 1) curve ever more closely. This happens because s estimates σ more accurately as the sample size increases. So using s in place of σ causes little extra variation when the sample is large. 2 The t Confidence Intervals and Tests Note. The one-sample t procedure is as follows: Draw an SRS of size n from a population having unkown mean µ. A level of confidence interval for µ is s x ± t∗ √ n where t∗ is the upper (1−C)/2 critical value for the t(n−1) distribution. This interval is exact when the population distribution is normal and is approximately correct for large n in other cases. To test the hypothesis H0 : µ = µ0 based on an SRS of size n, compute the one-sample t statistic t= x − µ0 √ . s/ n In terms of a variable T having the t(n − 1) distribution, the P −value for a test of H0 against Ha : µ > µ0 is P (T ≥ t) Ha : µ < µ0 is P (T ≤ t) Ha : µ = µ0 is P (T ≥ |t|). These P −values are exact if the population distribution is normal and are approximately correct for large n in other cases. Example 6.1. To study the metabolism of insects, researchers fed cockroaches measured amounts of sugar solution. After 2, 5, and 10 hours, they dissected some of the cockroaches and measured the amount of sugar in various tissues. Five roaches fed the sugar D-glucose and 3 dissected after 10 hours had the following amounts (in micrograms) of D-glucose in their hindguts: 55.95 68.24 52.73 21.50 23.78. The researchers gave a 95% confidence interval for the mean amount of D-glucose in cockroach hindguts under these conditions. First calculate that x = 44.44 and s = 20.741. The degrees of freedom are n − 1 = 4. From Table C (and TM-142) we find that for 95% confidence t∗ = 2.776. The confidence interval is s 20.741 x ± t∗ √ = 44.44 ± 2.776 √ n 5 = 44.44 ± 25.75 = (18.69, 70, 19). Comparing this estimate with those for other body tissues and diferent times before dissection led to new insight into cockroach metabolism and to new ways of eliminating roaches from homes and restaurants. The large margin of error is due to the small sample size and the rather large variation among the cockroaches, reflected in the large value of s. Matched Pairs t Procedures Note. One common design to compare two treatments makes use of one-sample procedures. In a matched pairs design, subjects are matched in pairs and each treatment is given to one subject in each pair. Note. To compare the responses to the two treatments in a matched pairs design, apply the one-sample t procedures to the observed differences. 4 Example 6.3. The National Endowment for the Humanities sponsors summer institutes to improve the skills of high school language teachers. One institute hosted 20 French teachers for four weeks. At the beginning of the period, the teachers took the Modern Language Association’s listening test of understanding of spoken French. After four weeks of immersion in French in and out of class, they took the listening test again. (The actual spoken French in the two tests was different, so that simply taking the first test should not improve the score on the second test.) Table 6.1 (and TM-101) gives the pretest and posttest scores. The maximum possible score on the test is 36. To analyze these data, subtract the pretest score from the posttest score to obtain the improvement for each teacher. These 20 differences form a single sample. They appear in the “Gain” column in Table 6.1 (TM101). The first teacher, for example, improved from 32 to 34, so the gain is 34 − 32 = 2. Step 1: Hypothesis. To assess whether the institute significantly improved the teacher’s comprehension of spoken French, we test H0 : µ = 0 Ha : µ > 0. Here µ is the mean improvement that would be achieved if the entire population of French teachers attended a summer institute. The null hypothesis says that no improvement occurs, and Ha says that posttest scores are higher on the average. Step 2: Test Statistic. The 20 differences have x = 2.5 and s = 5 2.893. The one-sample t statistic is therefore t= x−0 2.5 − 0 √ = 3.86. √ = s/ n 2.893/ 20 Step 3: P −Value. Find the P −value from the t(19) distribution. Table C (TM-142) shows that 3.86 lies between the upper 0.001 and 0.0005 critical values of the t(10) distribution. The P −value therefore lies between these values. A computer statistical package gives the value P = .00053. The improvement in listening scores is very likely to be due to chance alone. We have strong evidence that the institute was effective in raising scores. In scholarly publications, the details of routine statistical procedures are usually omitted. This test would be reported in the form “The improvement in scores was significant (t = 3.86, df = 19, P = .00053).” A 90% confidence interval for the mean improvement in the entire population requires the critical value t∗ = 1.729 from Table C (TM-142). The confidence interval is s 2.8393 x ± t∗ √ = 2.5 ± 1.729 √ n 20 = 2.5 ± 1.12 = (1.38, 3.62) The estimated average improvement is 2.5 points, with margin of error 1.12 for 90% confidence. Though statistically significant, the effect of attending the institute was rather small. Robustness of t Procedures Definition. A confidence interval or significance test is called robust if 6 the confidence level or P −value does not change very much when the assumptions of the procedure are violated. Note. Use the t procedures when: • Except in the case of small samples, the assumption that the data are an SRS from the population of interest is more important than the assumption that the population distribution is normal. • Sample size less than 15. Use t procedures if the data are close to normal. If the data are clearly nonnormal or if outliers are present, do not use t. • Sample size at least 15. The t procedures can be used except in the presence of outliers or strong skewness. • Large Samples. The t procedures can be used even for clearly skewed distributions when the sample is large, roughly n ≥ 40. Example 6.4. Consider several of the data sets we graphed in Chapter 1. Figure 6.6 (and TM-103) shows the histograms. • Figure 6.6(a) is a histogram of the percent of each state’s residents who are over 65 years of age. We have data on the entire population of 50 states, so formal inference makes no sense. • Figure 6.6(b) shows the time of the first lightning strike each day in a mountain region in Colorado. The data contain more than 70 observations that have a symmetric distribution. You can use the t procedures to draw conclusions about the mean time of a day’s 7 first lightning strike with high confidence. • Figure 6.6(c) shows that the distribution of word lengths in Shakespeare’s plays is skewed to the right. We aren’t told how large the sample is. You can use the t procedures for a distribution like this if the sample size is roughly 40 or larger. 8