Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
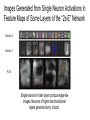
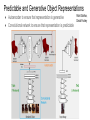
Learning to Generate Chairs, Tables and Cars with Convolutional Networks Alexey Dosovitskiy, Jost Tobias Springenberg, Maxim Tatarchenko, Thomas Brox Liu Jiang and Ian Tam Introduction and Related Work Overview (Part 1) ● Goal: Using a dataset of 3D models (chairs, tables, and cars), train generative ‘up-convolutional’ neural networks that can generate realistic 2D projections of objects from high-level descriptions ○ ○ ○ Object style Viewpoint Additional transformation parameters (e.g. color and brightness) Overview (Part 2) ● Networks do not merely memorize images but find a meaningful representation of 3D models, allowing them to: ○ Transfer knowledge within object class ○ ○ ○ Transfer knowledge between classes Interpolate between different objects within a class and between classes Invent new objects not present in the training set Related Work ● Train undirected graphical models, which treat encoding and generation as a joint inference problem ○ ○ Deep Boltzmann Machines (DBMs) Restricted Boltzmann Machines (RBMs) ● Train directed graphical models of the data distribution ○ ○ ○ Gaussian mixture models Autoregressive models Stochastic variations of neural networks Previous Work vs. This Paper ● Previous work ○ ○ ○ Unsupervised generative models that can be extended to incorporate label information, forming semi-supervised models Restricted to small models and images (maximum of 48 x 48 pixels) Require extensive inference procedure for both training and image generation ● This paper ○ ○ ○ Supervised learning and assumes high-level latent representation of the images Generate large high quality images of 128 x 128 images Complete control over which images to generate. Downside is the need for labels that fully describe the appearance of each image Network Architectures and Training Network Architecture ● Targets are the RGB output image x and the segmentation mask s. Generative network g(c, v, θ) is composed of three vectors: ○ ○ ○ c: model style v: horizontal angle and elevation of the camera position θ: parameters of additional transformations applied to the images ● Mostly generated 128 x 128 pixel images but also experimented with 64 x 64 and 256 x 256 ○ ○ Only difference in the architectures is one less or more up-convolution Adding a convolutional layer after each up-convolution increases quality of generated images 2-Stream Network Architecture FC - fully connected, unconv - unpooling+convolution Build a shared, high dimensional hidden representation Generate an image and object segmentation mask Network Training Network parameters W are trained by minimizing error of reconstructing the segmented-out chair image and the segmentation mask. Qualitative results with different networks trained on chairs “1s-S-deep” network is best both qualitatively and quantitatively Per-pixel mean squared error of generated images and # of parameters in expanding network parts Training Set Size and Data Augmentation ● Experimented with data augmentation: fixing the network architecture and varying the training set size ○ ○ Effect is qualitatively similar to increasing training set size Worse reconstruction of fine details but better generalization Qualitative results for different numbers of car models in the training set Interpolation between two car models Top: W/O data augmentation Bottom: W/ data augmentation Key Experiments / Results Modeling Transformations Viewpoint Interpolation Elevation Transfer / Extrapolation ● ● Network trained on both tables and chairs can transfer knowledge about elevations from table dataset to chair dataset and vice-versa Training on both object classes forces network to model general 3D geometry Style Interpolation ● Interpolation between feature/label input vectors Style Interpolation II ● Interpolation between multiple chairs Feature Space Arithmetic Correspondences ● ● Given two images from training set, generate style interpolations (of say, 64 images) between the two Use refined optical flow between interpolations to determine correspondences between objects in the two images Analysis of the Network Reminder: “2S-E” Network Architecture Images Generated from Single Unit Activations in Feature Maps of Different Fully Connected Layers Activating neurons of FC-1 and FC-2 feature maps of the class stream while fixing viewpoint and transformation inputs Activating neurons of FC-3 and FC-4 feature maps of the class stream with non-fixed viewpoints ‘Zoom Neuron’ Increasing the activation of a specialized neuron while keeping all other activations fixed results in these transformations Images Generated from Single Neuron Activations in Feature Maps of Some Layers of the “2s-E” Network Unconv-2 Unconv-1 FC-5 Single neurons in later layers produce edge-like images. Neurons of higher deconvolutional layers generate blurry ‘clouds’. Network Can Generate Fine Details Through a Combination of Spatially Neighboring Neurons Smooth interpolation between a single activation and the whole chair: Neurons are activated in the center and the size of the center region is increased from 2 x 2 to 8 x 8. Interaction of neighboring neurons is important. In the center, where many neurons are active, the image is sharp, while in the periphery, it is blurry. Conclusion and Recap ● Supervised training of CNNs can be used to generate images given high-level information ● Network does not simply learn to generate training samples but instead learns an implicit 3D shape and geometry representation ● When trained stochastically, the network can even invent new chair styles Other Approaches to Generative Networks Generative Adversarial Networks Deep Convolutional Generative Adversarial Networks ● ● ● Radford, Metz and Chintala Generator Network A generates images Discriminator Network B distinguishes generated images from real images Backpropagate through both generator and discriminator : ○ ○ ● ● Discriminator learns to distinguish real images from generated images Generator learns to “fool” discriminator by generating images similar to real images Ideally, generator improves such that discriminator can’t distinguish images However, training the generator can be unstable - Oscillations or collapse of the generator solution can happen Generator-Discriminator Network Generator Architecture Bedrooms in Latent Space Face Rotations Face Arithmetic Generated Faces and Albums InfoGAN Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever , Pieter Abbeel ● ● Maximizes the mutual information between latent variables and observations Learns disentangled representations - Each latent variable corresponds to some meaningful variable in semantic space (e.g. viewing angle, lighting) Voxel-Based Approaches Predictable and Generative Object Representations ● ● Autoencoder to ensure that representation is generative Convolutional network to ensure that representation is predictable Rohit Girdhar, David Fouhey Results on IKEA Dataset Results on IKEA Dataset Thank You Variational Autoencoders ● ● ● Bayesian inference on probabilistic graphical model with latent variables. Jointly learn the recognition model (encoder) parameters and generative model (decoder) parameters θ. Recognition model q (z|x) approximates the intractable posterior pθ(z|x) Deep Recurrent Attentive Writer (DRAW) ● ● Variational Autoencoders + Recurrent Networks Network decides at each time step ○ ○ ○ Where to Read Where to Write What to Write DRAWings PixelRNN ● ● Model the conditional distribution of each individual pixel given previous pixels LSTM network approximates ideal context PixelRNN - Inpainting PixelRNN - Generated ImageNet 64x64