Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
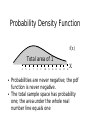
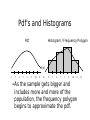
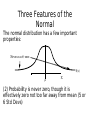
ECO 72 - INTRODUCTION TO ECONOMIC STATISTICS Topic 6 The Normal Distribution These slides are copyright © 2003 by Tavis Barr. This material may be distributed only subject to the terms and conditions set forth in the Open Publication License, v1.0 or later (the latest version is presently available at http://www.opencontent.org/openpub/). The Normal Distribution ● Introduction to Continuous Random Variables ● The Normal Distribution ● The Standard Normal Distribution ● Using the Normal to approximate the Binomial Continuous Random Variables ● ● Random variables map events (results of experiments) to the number line Discrete random variables: we divide events into categories, and assign a number to each category – Example: We ship out five cars. What is the probability that one is defective? Two? Three? Fuzzy vague sample space: Product qualities 1 2 3 4 5 Random Variable: Number defective 6 Continuous Random Variables ● Discrete random variables: we divide events into categories, and assign a number to each category – ● Example: We ship out five cars. What is the probability that one is defective? Two? Three? Sometimes we want to map events straight to numbers rather than categories. – Fuzzy vague sample space: Jobs For example: Height, Sales, Wages. 1 2 3 4 5 Random Variable: Wages 6 Continuous Random Variables ● ● A continuous random variable maps events to ranges of numbers Fuzzy vague sample space: Jobs The way it takes on probabilities is different. – – If a person walks into the room right now, what is the probability that that person will be exactly 6 feet tall, down to the subatomic particle? What is the probability that that person will be between 5'11” and 6'1” tall? 1 2 3 4 5 Random Variable: Wages 6 Continuous Random Variables ● The way it takes on probabilities is different. – If a person walks into the room right now, what is the probability that that person will be exactly 6 feet tall, down to the subatomic particle? ZERO. – What is the probability that that person will be between 5'11” and 6'1” tall? SMALL, BUT NOT ZERO. Fuzzy vague sample space: Jobs 1 2 3 4 5 Random Variable: Wages 6 Describing Probabilities – Discrete vs. Continuous ● A discrete random variable takes on specific values with positive probabilities. So we can tabulate the probabilities: Passengers Probability 0 1 2 3 4 .30 .35 .15 .10 .10 Describing Probabilities – Discrete vs. Continuous ● ● With a continuous random variable, no outcome happens with a positive probability. So we can't tabulate them this way: Exact Height Probability 5'2” 5'3” 5'4” 5'5” 5'6” ... .00 .00 .00 .00 .00 ... We need a different way of describing outcomes Probability Density Function f(x) P(11<X<16) P(5<X<9) 4 5 6 7 8 9 10 11 12 13 14 15 X 16 A probability density function (pdf) is a function where the area under the curve between any two numbers shows the probability that the variable will take on a value between the two numbers. Probability Density Function f(x) Total area of 1 4 ● ● 5 6 7 8 9 10 11 12 13 14 15 16 X Probabilities are never negative; the pdf function is never negative. The total sample space has probability one; the area under the whole real number line equals one Pdf's and Historgrams A histogram is a graph of a sample where the heights of each column reflects the fraction of the sample in that interval on the number line Histogram 0.4 Fraction of Observations ● 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 0-1.99 2-3.99 4-5.99 Number interval 6-7.99 Pdf's and Histograms ● A histogram is a graph of a sample where the heights of each column reflects the fraction of the sample in that interval on the number line A frequency polygon is a line connecting the tops of the columns, anchored to zero at the edges. 0.4 Fraction of Observations ● Histogram 0.35 0.3 0.25 0.2 0.15 0.1 0.05 0 0-1.99 2-3.99 4-5.99 6-7.99 Number interval Pdf's and Histograms Pdf Histogram / Frequency Polygon f(x) 4 5 ● 6 7 8 9 10 11 12 4 5 6 7 8 9 10 11 As the sample gets bigger and includes more and more of the population, the frequency polygon begins to approximate the pdf. 12 Cumulative Distribution Function F(t) P(X≤16) P(X≤9) 4 5 6 7 8 9 10 11 12 13 14 15 16 t The cumulative distribution function , usually written F(t), shows the probability that a random variable will be less than some number X, i.e., P(X≤t). Cumulative Distribution Function F(t) P(X≤16) P(X≤9) 4 5 6 7 8 9 10 11 12 13 14 15 16 t The cdf is never less than 0 or greater than 1 ● The cdf never gets smaller as t gets bigger ● Cumulative Distribution Function ● ● This means that for any two numbers a and b P(a≤X≤b) = F(b) – F(a). We can prove this using the laws of probability: – – (X<a) and (a≤X≤b) are mutually exclusive P(X<a)P(a≤X≤b) Same P(X≤b) a X<a b a≤X≤b X X>b So P[(X<a) or (a≤X≤b)] = P(X<a) +P(a≤X≤b) Mutually exclusive Cumulative Distribution Function ● Want to prove: P(a≤X≤b) = F(b) – F(a). – – P[(X<a) or (a≤X≤b)] = P(X<a) +P(a≤X≤b) P(X<a) F(a) P(a≤X≤b) Same P(X≤b) F(b) From def'n of cdf: P(X<a) = F(a) ● P(X≤b) = F(b) a ● X<a b a≤X≤b X X>b Mutually exclusive Cumulative Distribution Function ● Want to prove: P(a≤X≤b) = F(b) – F(a). – – P[(X<a) or (a≤X≤b)] = P(X<a) +P(a≤X≤b) P(X<a) F(a) Same P(X≤b) F(b) From def'n of cdf: P(X<a) = F(a) ● P(X≤b) = F(b) So: F(a) +P(a≤X≤b) = F(b) a ● ● ● P(a≤X≤b) Subtr. F(a) from both sides X<a b a≤X≤b X X>b Mutually exclusive Cumulative Distribution Function F(x) .8 ↕P(5≤X≤9) .4 P(x≤9) ↕P(X<5) 4 5 6 7 8 9 10 11 12 13 14 15 16 X A graphical illustration: P(a≤X≤b) = F(b)–F(a) ● Example: If F(9) = 0.8 and F(5) = 0.4, then P(5≤X≤9) = 0.8 – 0.4 = 0.4 The Normal Distribution ● Tends to be useful in describing quantities that result from the average or combined effect of a whole lot of small, independent events. – Test scores – Height – Product quality Three Features of the Normal The normal distribution has a few important properties: 50% less 50% more than than f(x) X (1) Its density (pdf) is symmetric; the mean, median, and mode are all the same Three Features of the Normal The normal distribution has a few important properties: Never exactly zero f(x) X (2) Probability is never zero, though it is effectively zero not too far away from mean (5 or 6 Std Devs) Three Features of the Normal The normal distribution has a few important properties: f(x) X (3) There are many Normal distributions; they are uniquely specified by a mean and a standard deviation. The Standard Normal =1 =1 2 ● 1 =0 1 (z) z 2 The standard Normal distribution is the Normal distribution with mean zero and standard deviation one The Standard Normal =1 =1 2 ● ● 1 =0 1 (z) z 2 Its cdf is denoted by (z) and its pdf by (z) (z) is well-known and easily available; this is not true of other normal distributions The Standard Normal =1 =1 2 ● 1 =0 1 (z) z 2 However, the standard normal can be used to calculate the cdf of any normally distributed variable, whether it is standard normal or not Standard Normal Example ● Before using the standard normal to approximate other distibutions, let's practice using it alone – Suppose we play at a slot machine whose winnings are normally distributed with mean $0 and standard deviation $1 – What is the probability of winning between 50 cents and $1.50? Calculating P(a≤X≤b) ● ● ● ● On the web site, there is a table that tells us P(X≤a) From this table, F(1.5) =.9332 Also, F(0.5) = .6915 So P(0.5≤z≤1.5) = .9332 - .6915 = .2417 P(X<1.5) 2 1 Z 0 (z) z 2 1 Probability .00 .01 .02 0.0 .5000 .5040 .5080 ... 0.5 .6915 .6950 .6985 ... 1.0 .8413 .8438 .8461 ... 1.5 .9332 .9345 .9357 ... .03 .5120 .7019 .8485 .9370 Standard Normal Table (cont'd) CALCULATING P(-1<z<1): ● P(z<1) = .8413 P(z<1) = .8413 2 1 Z 0 1 Probability .00 .01 .02 0.0 .5000 .5040 .5080 ... 0.5 .6915 .6950 .6985 ... 1.0 .8413 .8438 .8461 ... 1.5 .9332 .9345 .9357 ... (z) z 2 .03 .5120 .7019 .8485 .9370 Standard Normal Table (cont'd) CALCULATING P(-1<z<1): ● P(z<1) = .8413 ● P(z≤-1) = .1587 ● P(-1≤z≤1) = .8413 - .1587 = .6826 .1587. 2 1 Z P(z<1) = .8413 0 1 Probability .00 .01 .02 0.0 .5000 .5040 .5080 ... 0.5 .6915 .6950 .6985 ... 1.0 .8413 .8438 .8461 ... 1.5 .9332 .9345 .9357 ... (z) z 2 .03 .5120 .7019 .8485 .9370 Standard Normal Table Z Probability .00 .01 0.0 .0000 .0040 ... 0.5 .1915 .1950 ... 1.0 .3413 .3438 ... 1.5 .4332 .4345 ... .02 .03 .0080 .0120 .1985 .2019 P(0<z<1.5) =.4332 .3461 .3485 .4357 .4370 2 1 0 1 (z) z 2 OUR TABLE IS NON-STANDARD Most statistics textbooks have a table that tells us not the cdf of a standard normal variable, but the probability that the variable is between 0 and the number we're interested in Standard Normal Table (cont'd) Z Probability .00 .01 0.0 .0000 .0040 ... 0.5 .1915 .1950 ... 1.0 .3413 .3438 ... 1.5 .4332 .4345 ... .02 .03 .0080 .0120 .1985 .2019 .3461 .3485 .4357 .4370 0.5 prob. 2 1 P(0<z<1.5) = .4332 0 1 (z) z 2 OUR TABLE IS NON-STANDARD ● Because 0 is the median of a standard normal, the probability it is less than zero is 0.5 ● So we can add 0.5 to the number in the table to get the value of the cdf at that number The Normal, In General ● ● If X is normally distributed with mean and standard deviation , then (X - )/ is standard normally distributed This means that if we want to figure out P(X<t) for some number t, all we have to figure out is P(z< [t - ]/) Normal Distribution – Example 1 ● In the Czech Republic in 2002, the average region had an unemployment rate of 9.94%, with a standard deviation of 4.15%. Source: http://www.cazv.cz/2003/ZE%2012_03/4-Dufek.pdf ● ● Assume that regional unemployment rates are Normally distributed What fraction of regions would you expect to have an unemployment rate of 5 to 15 percent? Normal Distribution – Example 1 ● In the Czech Republic in 2002, the average region had an unemployment rate of 9.94%, with a standard deviation of 4.15%. Source: http://www.cazv.cz/2003/ZE%2012_03/4-Dufek.pdf ● What fraction of regions would you expect to have an unemployment rate of 5 to 15 percent? – Here, we want to know P(5<X<15) = F(15) – F(5) – So one “t” is 5 and the other is 5 – Want to know ([15-9.94]/4.15) - ([5-9.94]/4.15) Normal Distribution – Example 1 ● In the Czech Republic in 2002, the average region had an unemployment rate of 9.94%, with a standard deviation of 4.15%. Source: http://www.cazv.cz/2003/ZE%2012_03/4-Dufek.pdf ● What fraction of regions would you expect to have an unemployment rate of 5 to 15 percent? – Here, we want to know P(5<X<15) = F(15) – F(5) – So one “t” is 5 and the other is 5 – Want to know ([15-9.94]/4.15) - ([5-9.94]/4.15) i.e., (1.22) - (-1.19) Normal Distribution – Example 1 ● In the Czech Republic in 2002, the average region had an unemployment rate of 9.94%, with a standard deviation of 4.15%. Source: http://www.cazv.cz/2003/ZE%2012_03/4-Dufek.pdf ● What fraction of regions would you expect to have an unemployment rate of 5 to 15 percent? – Want to know ([15-9.94]/4.15) - ([5-9.94]/4.15) i.e., (1.22) - (-1.19) – From the chart: (1.22)= 0.8888 and (-1.19) = 0.1170 – So, the answer is 0.8888 – 0.1170, i.e., 0.7718. Normal Distribution – Example 2 ● Average taxi time at Logan airport is 19.3 minutes, with a standard deviation of 7.3 minutes. Source: http://dspace.mit.edu/bitstream/1721.1/37322/1/TaxiOutModel.pdf ● ● Suppose that taxi time is Normally distributed. What percentage of flights are on the runway for at least 30 mins? Normal Distribution – Example 2 ● ● Average taxi time at Logan airport is 19.3 minutes, with a standard deviation of 7.3 minutes. What percentage of flights are on the runway for at least 30 mins? – Here, we want to know P(X > 30), i.e., our “t” is 30. – So we want to look at P(z > [30-]/), i.e., P(z > [30 – 19.3]/7.3), i.e., P(z > 1.47). Normal Distribution – Example 2 ● ● Average taxi time at Logan airport is 19.3 minutes, with a standard deviation of 7.3 minutes. What percentage of flights are on the runway for at least 30 mins? – Here, we want to know P(X > 30), i.e., t = 30. – So we want to look at P(z > [30-]/), i.e., P(z > [30 – 19.3]/7.3), i.e., P(z > 1.47). – From Table, P(z < 1.47) = 0.9292 Normal Distribution – Example 2 ● ● Average taxi time at Logan airport is 19.3 minutes, with a standard deviation of 7.3 minutes. What percentage of flights are on the runway for at least 30 mins? – Here, we want to know P(X > 30), i.e., t = 30. – So we want to look at P(z > [30-]/), i.e., P(z > [30 – 19.3]/7.3), i.e., P(z > 1.47). – From Table, P(z < 1.47) = 0.9292 – So, P(z>1.47) = 1-P(z<1.47) = 1-.9292 =.0708 Normal Approx. to Binomial ● ● ● ● Remember, when k is large enough, k! is impossible to calculate Most calculators go up to about 50!, my computer goes up to 170! but is inaccurate This makes Binomial probabilities impossible to calculate for many practical problems It turns out many Binomial probabilities can be approximated by the Normal distribution. Normal Approximation to Binomial ● ● ● This only works when both np and n(1-p) are at least five If so, then we just plug in the mean and the standard deviation of the Binomial. Remember, if X is Binomial with n and p: np 1−p – Its mean is np – Its standard deviation is Approx. to Binomial – Example ● ● Suppose probability of an employee stealing from a company is 0.2. If there are 100 employees, what is the probability that at least 25 steal? Approx. to Binomial – Example ● ● Suppose probability of employee stealing from company is 0.2. If there are 100 employees, what is the probability that at least 25 steal? – This is a Binomial with n = 100 and p = 0.2 Approx. to Binomial – Example ● ● Suppose probability of employee stealing from company is 0.2. If there are 100 employees, what is the probability that at least 25 steal? – This is a Binomial with n = 100 and p = np 1−p= 16=4 0.2 – So we can approximate by a normal with mean np = 100(.2) = 20 and std. dev. Approx. to Binomial – Example ● ● Suppose probability of employee stealing from company is 0.2. If there are 100 employees, what is the probability that at least 25 steal? – This is a Binomial with n = 100 and p = 0.2 – So we can approximate by a normal with mean np = 100(.2) = 20 and std. dev. np 1−p= 16=4 – So we want to know the probability that a Normal variable with mean 20 and std. dev. 4 is at least 25 Approx. to Binomial – Example ● ● Suppose probability of employee stealing from company is 0.2. If there are 100 employees, what is the probability that at least 25 steal? – This is a Binomial with n = 100 and p = 0.2 – So we want to know the probability that a Normal variable with mean 20 and std. dev. 4 is at least 25 – We have to round up to 25.5 Approx. to Binomial – Example ● ● Suppose probability of employee stealing from company is 0.2. If there are 100 employees, what is the probability that at least 25 steal? – So we want to know the probability that a Normal variable with mean 20 and std. dev. 4 is at least 25.5 – This is the same as 1-([25.5-20]/4) = 1- (1.375) = 1-0.9154 = .0846 Approximation to Binomial Another Example ● ● The probability of someone being a vegetarian is 6 percent. In a group of 300 people, what is the probability that there are less than 10 vegetarians? Approximation to Binomial Another Example ● ● The probability of someone being a vegetarian is 6 percent. In a group of 300 people, what is the probability that there are less than 10 vegetarians? – Approximate using a normal with mean np and standard deviation np 1−p Approximation to Binomial Another Example ● ● The probability of someone being a vegetarian is 6 percent. In a group of 300 people, what is the probability that there are less than 10 vegetarians? – Approximate using a normal with mean np and standard deviation np 1−p – n = 300, p = .06 so np = 18 and np1−p=4.11 – So we want to know Prob. that N(18,4.11) < 10 (- 0.5) Approximation to Binomial Another Example ● ● The probability of someone being a vegetarian is 6 percent. In a group of 300 people, what is the probability that there are less than 10 vegetarians? – Approximate using a normal with mean np and standard deviation np 1−p – n = 300, p = .06 so np = 18 and – So we want to know Prob. that N(18,4.11) < 9.5 – This is the same as ([10.5-18]/4.11)= (-2.06) = .0197 np1−p=4.11