Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
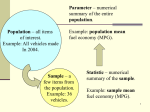
Linearization Introduction Given three models: 1. 𝑦 = 𝑎𝑒 𝑏𝑥 - wide application in engineering and science to characterize quantity that changes proportionally to its own magnitude (eg. population growth). 2. 𝑦 = 𝑎𝑥 𝑏 - wide application in engineering and science fit experimental data when underlying model is not known. 𝑎𝑥 3. 𝑦 = 𝑏+𝑥 – saturation-growth-rate equation, characterizes population growth when under limiting condition. 1. Transform them into linear form. Knowing linear regression coefficients give a recipe how to compute a and b coeff. 2. Generate a vector of 20 data points from models 1-3. 3. Can you tell a method of simulating “real” experimental data of experiments described by models 1-3 using MATLAB? 4. Apply your method to generate a vector of “real” data points from model 1-3 (if you do not know how ask your teacher). 5. Using polyfit function estimate a and b coeff. How much of original variance was explained by the model? 6. Inspect residuals of the fit (stem). Plot its histogram. Are residuals normally distributed? Is the distribution symmetric? Do you see a pattern in the residuals? What does it mean? Real case example Enzymes act as catalysts to speed up the rate of chemical reactions in living cells. In most cases, they convert one chemical, the substrate, into another, the product. The Michaelis-Menten equation is commonly used to describe such reactions: 𝑣 [𝑆] 𝑣 = 𝑘 𝑚+[𝑆] (1) 𝑠 Where v – the initial reaction rate, 𝑣𝑚 – the maximum initial rate, [S] – substrate concentration and 𝑘𝑠 – half-saturation constant. Although the Michaelis-Menten model provides a nice starting point, it has been refined and extended to incorporate additional features of enzyme kinetics. One simple extension involves socalled allosteric enzymes, where the binding of a substrate molecule at one site leads to enhanced binding of subsequent molecules at other sites. For cases with two interacting bonding sites, the following second-order version often results in a better fit: 𝑣 [𝑆]2 𝑣 = 𝑘 2𝑚+[𝑆]2 (2) 𝑠 Having experimental data [S] 1.3 1.8 3 4.5 6 8 9 v 0.07 0.13 0.22 0.275 0.335 0.35 0.36 1. Plot both models in one plot. What are the qualitative differences between two models? 2. Transform both equation into linear form. 3. Using polyfit function estimate 𝑣𝑚 and 𝑘𝑠 using first order M-M model (eq. 1). How much of original variance was explained by the model? Are your values reasonable? 4. Inspect residuals of the fit. Plot its histogram. Are residuals normally distributed? Remember that in the case of only 7 data points this analysis is VERY qualitative. Is the distribution symmetric? Do you see a pattern in the residuals? What does it mean? 5. Plot your model together with a scatter plot of your data points. Calculate residuals of untransformed model (eq. 1). Again inspect its distribution. 6. Using polyfit function estimate 𝑣𝑚 and 𝑘𝑠 using second order M-M model (eq. 2). How much of original variance was explained by the model? Are your values reasonable? What has changed? 7. Inspect residuals of the fit. Plot its histogram. Are residuals normally distributed? Do you see a pattern in the residuals? What does it mean? Plot your model together with a scatter plot of your data points. Calculate residuals of untransformed model (eq. 2). Again inspect its distribution. 8. Can you tell which data point is an outlier and why? Can you give any statistical reason to confirm you thesis?