Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
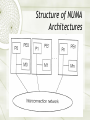
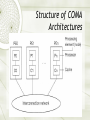
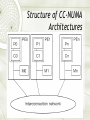
Computer Architecture Introduction to MIMD architectures Ola Flygt Växjö University http://w3.msi.vxu.se/users/ofl/ [email protected] +46 470 70 86 49 Outline {Multi-processor} {Multi-computer} 15.1 Architectural concepts 15.2 Problems of scalable computers 15.3 Main design issues of scalable MIMD computers CH01 Multi-computer: Structure of Distributed Memory MIMD Architectures Multi-computer (distributed memory system): Advantages and Disadvantages + Highly Scalable + Message passing solves memory access synchronization problem - Load balancing problem - Deadlock in message passing - Need to physically copying data between processes Multi-processor: Structure of Shared Memory MIMD Architectures Multi-processor (shared memory system): Advantages and Disadvantages + No need to partition data or program, uniprocessor programming techniques can be adapted + Communication between processor is efficient - Synchronized access to share data in memory needed. Synchronising constructs (semaphores, conditional critical regions, monitors) result in nondeterministc behaviour which can lead programming errors that are difficult to discover - Lack of scalability due to (memory) contention problem Best of Both Worlds: Multicomputer using virtual shared memory Also called distributed shared memory architecture The local memories of multi-computer are components of global address space: any processor can access the local memory of any other processor Three approaches: Non-uniform memory access (NUMA) machines Cache-only memory access (COMA) machines Cache-coherent non-uniform memory access (CC-NUMA) machines Structure of NUMA Architectures NUMA Logically shared memory is physically distributed Different access of local and remote memory blocks. Remote access takes much more time – latency Sensitive to data and program distribution Close to distributed memory systems, yet the programming paradigm is different Example: Cray T3D NUMA: remote load Structure of COMA Architectures COMA Each block of the shared memory works as local cache of a processor Continuous, dynamic migration of data Hit-rate decreases the traffic on the Interconnection Network Solutions for data-consistency increase the same traffic (see cache coherency problem later) Examples: KSR-1, DDM Structure of CC-NUMA Architectures CC-NUMA A combination of NUMA and COMA Initially static data distribution, then dynamic data migration Cache coherency problem is to be solved COMA and CC-NUMA are used in newer generation of parallel computers Examples: Convex SPP1000, Stanford DASH, MIT Alewife Classification of MIMD computers Problems and solutions Problems of scalable computers 1. Tolerate and hide latency of remote loads 2. Tolerate and hide idling due to synchronization Solutions 1. Cache memory problem of cache coherence 2. Prefetching 3. Threads and fast context switching