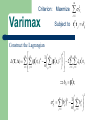Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Feature Extraction 主講人:虞台文 Content Principal Component Analysis (PCA) Factor Analysis Fisher’s Linear Discriminant Analysis Multiple Discriminant Analysis Feature Extraction Principal Component Analysis (PCA) Principle Component Analysis It is a linear procedure to find the direction in input space where most of the energy of the input lies. – – Feature Extraction Dimension Reduction It is also called the (discrete) KarhunenLoève transform, or the Hotelling transform. The Basis Concept x w Assume data x (random vector) has zero mean. PCA finds a unit vector w to reflect the largest amount of variance of the data. That is, w* argmax E[( w x) ] T Demo ||w||1 2 Remark: C is symmetric and semipositive definite. The Method E[( w x) ] w Cw T 2 T E[(wT x) 2 ] E[wT xxT w] E[wT (xxT )w] wT E[xxT ]w 1 E[xx ] N T N T x x i i C Covariance Matrix i 1 w* argmax E[( w x) ] T ||w||1 2 E[( w x) ] w Cw T 2 The Method maximize subject to f (w) w Cw T g (w) w w 1 0 T The method of Lagrange multiplier: Define L(w ) f (w ) g (w ) The extreme point, say, w* satisfies w L(w*) w f (w*) w g (w*) 0 T E[( w x) ] w Cw T 2 T The Method maximize subject to f (w) w Cw T g (w) w w 1 0 T L(w ) f (w ) g (w ) wT Cw (wT w 1) L(w ) 2Cw 2w Setting L(w ) 0 Cw w E[( w x) ] w Cw T 2 T Discussion At extreme points w Cw w w T T Let w1, w2, …, wd be the eigenvectors of C whose corresponding eigenvalues are 1≧ 2 ≧ … ≧ d. They are called the principal components of C. Their significance can be ordered according to their eigenvalues. w is a eigenvector of C, and is its corresponding eigenvalue. Cw w E[( w x) ] w Cw T 2 T Discussion At extreme points w Cw w w T T Let w1, w2, …, wd be the eigenvectors of C whose corresponding eigenvalues are 1≧ 2 ≧ … ≧ d. They are called the principal components of C. Their significance can be ordered according to their eigenvalues. If C is symmetric and semipositive definite, all their eigenvectors are orthogonal. They, hence, form a basis of the feature space. For dimensionality reduction, only choose few of them. Applications Image Processing Signal Processing Compression Feature Extraction Pattern Recognition Example Projecting the data onto the most significant axis will facilitate classification. This also achieves dimensionality reduction. Issues PCA is effective for identifying the multivariate signal distribution. Hence, it is good for signal reconstruction. But, it may be inappropriate for pattern classification. The most significant component obtained using PCA. The most significant component for classification Whitening Whitening is a process that transforms the random vector, say, x = (x1, x2 , …, xn )T (assumed it is zero mean) to, say, z = (z1, z2 , …, zn )T with zero mean and unit variance. E[zz ] I T z is said to be white or sphered. This implies that all of its elements are uncorrelated. However, this doesn’t implies its elements are independent. Clearly, D is a diagonal matrix and E is an orthonormal matrix. Whitening Transform Let V be a whitening transform, then z Vx E[zz ] VE[xx ]V VC x V T T T Decompose Cx as Cx EDE Set V D 1 / 2 E T T E[zz ] I T T Cx EDE VD T 1 / 2 Whitening Transform If V is a whitening transform, and U is any orthonormal matrix, show that UV, i.e., rotation, is also a whitening transform. Proof) E[zz ] UVE[xx ]V U T T T UVC x V U UIU I T T T T E T Why Whitening? With PCA, we usually choose several major eigenvectors as the basis for representation. This basis is efficient for reconstruction, but may be inappropriate for other applications, e.g., classification. By whitening, we can rotate the basis to get more interesting features. Feature Extraction Factor Analysis What is a Factor? If several variables correlate highly, they might measure aspects of a common underlying dimension. – These dimensions are called factors. Factors are classification axis along which the measures can be plotted. – The greater the loading of variables on a factor, the more that factor can explain intercorrelations between those variables. Graph Representation +1 1 Verbal Skill (F2) +1 1 Quantitative Skill (F1) What is Factor Analysis? A method for investigating whether a number of variables of interest Y1, Y2, …, Yn, are linearly related to a smaller number of unobservable factors F1, F2, …, Fm. For data reduction and summarization. Statistical approach to analyze interrelationships among the large number of variables & to explain these variables in term of their common underlying dimensions (factors). What factors influence students’ grades? Quantitative skill? Example Observable Data Verbal skill? unobservable The Model Y1 11F1 12 F2 1m Fm e1 Y2 21F1 22 F2 2 m Fm e2 Yn n1 F1 n 2 F2 nm Fm en y Bf ε y: Observation Vector E[ y ] 0 B: Factor-Loading Matrix f: Factor Vector E[f ] 0, E[f T f ] I : Gaussian-Noise Matrix E[ε] 0, E[εT ε] diag [ 12 , n2 ] The Model E[yy ] Cy E[(Bf ε)(Bf ε) ] BB Q T T y Bf ε T y: Observation Vector E[ y ] 0 B: Factor-Loading Matrix f: Factor Vector E[f ] 0, E[f T f ] I : Gaussian-Noise Matrix E[ε] 0, E[εT ε] diag [ 12 , n2 ] y Bf ε The Model E[yy ] Cy E[(Bf ε)(Bf ε) ] BB Q T T Can be obtained from the model Can be estimated from data s sY Y Cy 2 1 sYnY1 2 Y1 sY1Y2 2 Y2 s sYnY2 sY1Yn sY2Yn sY2n m 2 1 j m j 1 2 j j1 BBT j 1 m j 1 nj j1 T m j 1 m 1j j 1 j2 2 2j m j 1 nj j2 m 1j jn 2 j jn j 1 m 2 nj j 1 j 1 m 12 0 2 0 2 Q 0 0 0 0 n2 y Bf ε The Model E[yy ] Cy E[(Bf ε)(Bf ε) ] BB Q T T T Var[Yi ] s 2 Yi s sY Y Cy 2 1 sYnY1 2 Y1 sY1Y2 2 Y2 s sYnY2 sY1Yn sY2Yn sY2n 2 i1 m 2 1 j m j 1 2 j j1 BBT j 1 m j 1 nj j1 2 i2 2 im 2 i Commuality Specific Variance Explained Unexplained m j 1 m 1j j 1 j2 2 2j m j 1 nj j2 m 1j jn 2 j jn j 1 m 2 nj j 1 j 1 m 12 0 0 12 Q 0 0 0 0 n2 Example E[yy ] Cy E[(Bf ε)(Bf ε) ] BB Q T Cy BBT + Q = T T Goal E[yy ] Cy E[(Bf ε)(Bf ε) ] BB Q T T T Our goal is to minimize trace[Cy B B] trace[Q] T Hence, B* arg min trace[C y B B] T B Uniqueness E[yy ] Cy E[(Bf ε)(Bf ε) ] BB Q T T T Is the solution unique? There are infinite number of solutions. Since if B* is a solution and T is an orthonormal transformation (rotation), then BT is also a solution. Cy = Example Which one is better? 0.5 0.5 B1 0.3 0.3 0.5 0.5 0 0.707 B 2 0.231 0 0 0.707 Left: each factor have nonzero loading for all variables. Example i2 i2 i1 0.5 0.5 B1 0.3 0.3 0.5 0.5 Right: each factor controls different variables. i1 0 0.707 B 2 0.231 0 0 0.707 The Method Determine the first set of loadings using principal component method. Cy EE T [e1 ,, e m ,, e n ]diag [1 ,, m ,, n ][e1 ,, e m ,, e n ]T B [e1 , , e m ]diag [ ,, ] 1/ 2 1 Q Cy BB T 1/ 2 m Example Cy 3.136773 0.023799 B 0.132190 2.237858 0.127697 1.731884 Factor Rotation 11 21 B n1 12 1m 22 2 m n2 nm t11 t12 t 21 t 22 T t m1 t m 2 Factor-Loading Matrix Factor Rotation: B BT t1m t2m t mm Rotation Matrix Factor Rotation 11 21 B n1 12 1m 22 2 m n2 nm Factor-Loading Matrix Factor Rotation: B BT Criteria: Varimax Quartimax Equimax Orthomax Oblimin m Criterion: Maxmize 2 F i i 1 Varimax Subject to tTi t j ij Let B β1 , β2 ,, βn T T t1 , t 2 ,, t m β1T t1 β1T t 2 T β 2 t1 βT2 t 2 BT βT t βT t n 2 n 1 β1T t m T β mt m [bij ]nm βTn t m b 2 Fi ... 2 F1 2 F2 bij βTj t i 2 Fm n j 1 2 2 ij 1 2 bij n j 1 n 2 m Criterion: Maxmize 2 F i i 1 Varimax Subject to tTi t j ij Construct the Lagrangian 2 n n m m 1 L(T, Λ) (βTj t i ) 4 (βTj t i ) 2 2 ij t Ti t j n j 1 i 1 j 1 i 1 j 1 m bij βTj t i b n 2 Fi j 1 2 2 ij 1 2 bij n j 1 n 2 2 n n m m 1 L(T, Λ) (βTj t i ) 4 (βTj t i ) 2 2 ij t Ti t j n j 1 i 1 j 1 i 1 j 1 m Varimax n n n m L(T, Λ) 4 4 (βTj t k )3 β j (βTj t k ) 2 (βTj t k )β j 4 ik t i t k n j 1 j 1 i 1 j 1 cjk dk m 1 4 c jk d k b jk β j 4 ik t i n j 1 i 1 n bjk n m L(T, Λ) 1 4 c jk d k b jk β j 4 ik t i t k n j 1 i 1 Varimax B β1 , β2 ,, βn T T t1 , t 2 ,, t m Define C [b3jk ]nm n BT [b jk ]nm D diag[d1 ,, d m ] d k b 2jk b jk β t j A [ij ]mm T k is the kth column of L(T, Λ ) T T 1 t k 4[B C n B BTD TA ] j 1 n m L(T, Λ) 1 4 c jk d k b jk β j 4 ik t i t k n j 1 i 1 Varimax L(T, Λ ) 4[M TA ] T M BT [C 1n BTD] is the kth column of L(T, Λ ) T T 1 t k 4[B C n B BTD TA ] M B [C 1n BTD] T Varimax Goal: TA M L(T, Λ ) 4[M TA ] T L (T, Λ ) reaches maximum once TA M M B [C 1n BTD] T Varimax Goal: TA M Initially, • obtain B0 by whatever method, e.g., PCA. • set T0 as the approximation rotation matrix, e.g., T0=I. Iteratively execute the following procedure: B1 B 0T0 evaluate C1 , D1 and M1 You need information of B1. Next slide find T1 and A1 such that T1A1 M1 if T1 T0 stop T0 T1 Repeat M B [C 1n BTD] T Varimax Goal: TA M Pre-multiplying each side by its transpose. Initially, T e.g., PCA. T • obtain method, 0 by U U A12B Mwhatever M 1 1 • set T0 as the approximation rotation matrix, e.g., T0=I. 1/ 2 T A U 1 execute U Iteratively the following procedure: B1 T 1 B0T M0 1A11 evaluate C1 , D1 and M1 You need information of B1. Next slide find T1 and A1 such that T1A1 M1 if T1 T0 stop T0 T1 Repeat Varimax 11 21 B BT n1 12 1m 2 m 22 n 2 nm Criterion: Maximize m J (T) i 1 ... F2 F2 1 2 F2 F2 Var[.i 2 ] i m 2 Fi m Varimax Maximize J (T) i 1 2 Fi Let B β1 , β2 ,, βm T 11 21 B BT n1 12 1m 2 m 22 n 2 nm T t1 , t 2 ,, t m ij βTi t j 1 2 ( ) ij n j 1 j 1 n 2 Fi n 2 2 ij 2 n n 1 J (T) (βTi t j ) 4 (βTi t j ) 2 n j 1 i 1 j 1 m 2 Feature Extraction Fisher’s Linear Discriminant Analysis Main Concept PCA seeks directions that are efficient for representation. Discriminant analysis seeks directions that are efficient for discrimination. Classification Efficiencies on Projections Criterion Two-Category ||w|| = 1 m1 w ~ m 1 m2 ~ m 2 1 mi ni xDi 1 ~ mi ni 1 w x w xD i ni x wT mi T T x xD i Between-Class Scatter Matrix S B (m1 m 2 )(m1 m 2 )T Scatter ||w|| = 1 1 mi ni m1 w ~ m 1 xDi ~ wT m m i i Between-Class Scatter m2 ~ m 2 x ~ m ~ ) 2 (w T m w T m ) 2 (m 1 2 1 2 wT (m1 m 2 )(m1 m 2 )T w wT S B w The larger the better Between-Class Scatter Matrix S B (m1 m 2 )(m1 m 2 )T Scatter ||w|| = 1 2 SW (x m i )( x m i ) i 1 xD i Si m1 w Within-Class Scatter Matrix ~ m 1 ~ si 2 m2 ~ m 2 (x m )(x m ) xD i i T i T ~ ) 2 wT S w ( w x m i i xDi Within-Class Scatter T ~ s2 ~ s12 ~ s22 w (S1 S 2 )w w T SW w The smaller the better T Between-Class Scatter Matrix S B (m1 m 2 )(m1 m 2 )T Within-Class Scatter Matrix Goal 2 SW (x m i )( x m i ) i 1 xD i T ||w|| = 1 w SBw Define J (w ) T w SW w m1 w Generalized Rayleigh quotient ~ m 1 m2 ~ m 2 w* arg max J (w ) w The length of w is immaterial. T S B (m1 m 2 )(m1 m 2 )T S B w c(m1 m2 ) Generalized Eigenvector To maximize J(w), w is the generalized eigenvector associated with largest generalized eigenvalue. That is, S B w SW w or S S B w w 1 W wT S B w Define J (w ) T w SW w Generalized Rayleigh quotient w* arg max J (w ) w 1 W w S (m1 m 2 ) The length of w is immaterial. S B (m1 m 2 )(m1 m 2 )T S B w c(m1 m2 ) Proof To maximize J(w), w is the generalized eigenvector associated with largest generalized eigenvalue. That is, S B w SW w or S S B w w 1 W 1 W w S (m1 m 2 ) wT S B w J (w ) T w SW w 2SW w w T S B w dJ (w ) 2S B w T T dw w SW w w SW w w T SW w dJ (w ) Set 0 dw 2SW w w T S B w 2S B w T T w SW w w SW w w T SW w wT S B w SW w SW w S B w T w SW w Example 1 W w S (m1 m 2 ) w w w Feature Extraction Multiple Discriminant Analysis Generalization of Fisher’s Linear Discriminant For the c-class problem, we seek a (c1)-dimension projection for efficient discrimination. Scatter Matrices Feature Space Total Scatter Matrix ST (x m)( x m)T x m2 m1 + m Within-Class Scatter Matrix c SW (x m i )( x m i )T m3 i 1 xD i Between-Class Scatter Matrix c S B ni (m i m)(m i m)T i 1 ST S B SW The (c1)-Dim Projection The projection space will be described using a d(c1) matrix W. W [w1 w 2 w c 1 ] m2 m1 + m m3 Scatter Matrices Projection Space Total Scatter Matrix ~ ST W T S T W Within-Class Scatter Matrix ~ SW WT SW W m2 m1 ~ m 1 Between-Class Scatter Matrix ~ S B WT S B W ~ m 2 ~ +m ~ m 3 + m m3 W Criterion Total Scatter Matrix ~ ST W T S T W Within-Class Scatter Matrix ~ SW WT SW W ~ T SB W SBW J ( W) ~ T W SW W SW W* arg max J ( W ) Between-Class Scatter Matrix ~ S B WT S B W W