Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
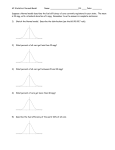
How good are our predictions using the regression line? or How well does the line summarize the relationship between the variables? Finding the answer. We compute the answer to these questions by finding r and squaring it. So, if the correlation coefficient between the two variables is 0.80, then the answer to these questions is 0.802 = 0.64 . Sometimes this is reported as 64%. Interpreting the answer. There are two different equivalent (and correct) ways to interpret this. They mean the same thing. 1. Our regression predictions of the response variable are 64% better than the predictions we would get if we didn't use regression on the explanatory variable. 2. 64% of the variation in the response variable is explained by the variation in the explanatory variable. Understanding why this is a good answer. Consider a data set where the explanatory variable is the weight of a car (in lbs.) and the response variable is gas mileage (mpg.) Regression Plot Y = 47.3069 - 7.47E-03X R-Sq = 92.3 % 40 mpg 30 20 10 2000 3000 4000 5000 weight Now, if we have an additional car that weighs 4500 lbs, what do we predict the gas mileage would be? (Answer: From the graph -- about 14 mpg. From the regression equation: 13.692 mpg) What if we didn't have any regression predictions -- like if we didn't have any of the x values at all? Then, when we want to predict the mpg for another car, what would we choose? • Would we choose 50 mpg? (No -- no car in whole study has mileage that good. So it would be silly to predict that another car would unless we had some additional information.) • Would we choose 4 mpg? (No -- no car in the whole study has mileage that bad. So it would be silly to predict that another car would unless we had some additional information.) • Would we choose a "typical" value for mpg? (Yes, like maybe the mean of the values. The average is often considered a "typical" value. For these data, the mean is 24 mpg.) So, our prediction of mpg if we didn't have regression is the mean of mpg, which is 24 mpg. Our prediction of the mpg if we use regression is 13.7 mpg. Which do you think is better? How could we measure how much better the regression predictions are than the predictions using the mean? Think about the prediction errors (also called residuals.) In the figure on page 108, these are indicated by dotted lines. There's an error like this for each observed data point. The formula for these prediction errors is also on page 108. Some are positive numbers and some are negative numbers. In the following figures, sketch all the prediction errors in each. Which figure has smaller prediction errors? And how much smaller are they? We want to look at the overall prediction errors in each case, but we can't just add them up because the positive and negative ones would cancel each other out. So, instead, we square the prediction errors before we add them up. Which of these pictures will have the smaller sum of the squared prediction errors? What we are measuring is how much smaller the sum of the squared prediction errors on the left is than the sum of the squared prediction errors on the right. Below is the actual formula for this. And then algebraically, it turns out that this is equivalent to taking the square of the correlation coefficient. (In an advanced course, we might prove that. Not in this course.) ∑ (Y − Y ) − ∑ (Y − Yˆ ) ∑ (Y − Y ) 2 2 2 = r2 For the car data, r=-0.96, so this value is 0.92 or 92%. Our regression predictions of mpg are 92% better than our predictions without using regression. That's a lot better! Regression is very useful for predictions in this example. Go back to the top page for link the data. With this you can use MINITAB to do actual computations of the sums of the squared prediction errors and the computation of the ratio above and of r-squared. And they turn out to be the same (except for round-off error.) I tried to do it myself and just make the entire project available to you, but I'm having trouble figuring out how to post it so that you can download the project file and have it work. I'm going to work on that more. The second interpretation discusses "explained variation." The idea here is that there is a lot of variation in the y values as such. Look along the vertical axis. The values go from about 10 to 40. So it looks like mpg is very variable. But, if we take into account the weight of the car, we see that light cars have high mpg and heavy cars have low mpg. In a quite predictable manner. So the fact that the weights vary from about 1800 to about 5000 goes a long way toward explaining why there is so much variation in the mpg. In fact, it explains 92% of that variation in mpg. Last updated September 20, 2001. Mary Parker