Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
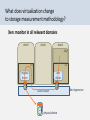
Storage benchmarking cookbook How to perform solid storage performance measurements Stijn Eeckhaut Stijn De Smet, Brecht Vermeulen, Piet Demeester The situation today: storage systems can be very complex Example: Clients (local file system + I/O stack) IP network Essence Files File system Cluster nodes FC network (SAN) I/O blocks Storage controllers FC-AL loops (disk connection network) Hard disks Logical segments Physical sectors Picture provided by Luc Andries, VRT Complexity can impede correct measurement of the storage system We need a storage measurement methodology … … to guarantee realistic storage measurements that predict production behavior of the storage system Storage benchmarking cookbook How to perform solid storage performance measurements Stijn Eeckhaut Stijn De Smet, Brecht Vermeulen, Piet Demeester In this cookbook … Description of a number of storage peculiarities What should a solid storage measurement look like? … … … Storage peculiarities: individual disk throughput depends on applied load best case worst case 1 partition on outer tracks of device 1 partition on outer tracks + 1 partition on inner tracks 1 sequential access pattern (small disk head movement) accessing both partitions (maximum disk head movement) Storage peculiarities: workarounds to speed up performance Individual disks are slow and not reliable – Typical 5 70 MB/s Workarounds to speed up storage performance – Combining disks into RAID arrays – Caching on different system levels Storage peculiarities: lower maximum performance when more load Example: performance of 1 storage box Test system : AMD Opteron CPU, Areca Raid controller (ARC1160), 12 SATA disks of 500 GB in RAID 6, xfs file system. Load Max READ [MB/s] Max WRITE [MB/s] 1 READ 311 - 1 WRITE - 246 100 READS 89 - 100 WRITES - 79 100 READS + 10 WRITES 50 20 100 READS + 100 WRITES 27 26 (all sequential) What would you consider as a solid storage measurement? We can reproduce the measurement The applied test load reflects the real load of the system We measure the right bottleneck – avoid measuring the cache unless we want to – avoid file copying – … What would you consider as a solid storage measurement? Other criteria – analysis phase between subsequent measurements – determine deviation by performing measurement more than once – Work bottom up in order to know the efficiency of each layer – … How to perform a reproducible measurement Clients (local file system + I/O stack) “What value did we use for that parameter?” IP network File system Cluster nodes “What if we did…” FC network (SAN) Storage controllers “I want to do an extra measurement” FC-AL loops (disk connection network) Hard disks How to perform a reproducible measurement Client hardware Operating System Application parameters Transport protocol parameters … Server hardware Operating System File System settings (caching, prefetching, redundancy,…) Transport protocol parameters … Network topology Network technology Network delay Network protocol parameters … Controller configuration Controller cache settings RAID settings LUN settings Number of disks Disk size Place on disk of partition Disk segment size Disk cache Clients (local file system + I/O stack) IP network File system Cluster nodes FC network (SAN) Storage controllers FC-AL loops (disk connection network) Hard disks How to perform a reproducible measurement • Take the time to describe the System Under Test • Describe the test – Or automate the test with a test script • Collect relevant system parameters – Take disk images – Keep config files – Save output of Linux monitoring tools • dmesg, sysctl, ifconfig, ethtool, lspci, netstat, /proc dir,… Clients (local file system + I/O stack) IP network File system Cluster nodes FC network (SAN) Storage controllers FC-AL loops (disk connection network) Hard disks Measurement iterations make reproducibility more difficult Observation: often multiple iterations needed difficult to know all test parameter values in advance keep data of all relevant iterations measurements Analysis/model simulation What would you consider as a solid storage measurement? We can reproduce the measurement The applied test load reflects the real load of the system We measure the right bottleneck – avoid measuring the cache unless we want to – avoid file copying – … How to choose your test load Do you want to – Test the storage performance of a specific application? – Run a standard storage benchmark? Test load that resembles a specific application – What are your application characteristics? Test load of a standard storage benchmark – E.g. to compare vendors without a specific application in mind – E.g.: SPC storage benchmark What are your application’s characteristics? What is its storage access pattern? – – – – Sequential or random access Read/Write ratio Temporal and spatial locality of storage access requests Number of simultaneous access requests What is its requested performance? – Needed throughput – Latency sensitivity Used together with other applications? – Real load consists of a mix of applications – Concurrent sharing of data Storage benchmarks like SPC-1 and SPC-2 try to standardize storage system evaluation Storage Performance Council (SPC) defines industry-standard storage workloads – “forces” vendors to publish a standardized performance of their storage systems SPC-1 and SPC-2 evaluate complete storage systems SPC-1C and SPC-2C evaluate storage subsystems – e.g. individual disk drives, HBAs, storage software (e.g. LVM, …) – In development SPC-1 defines random I/O workloads SPC-2 defines sequential I/O workloads SPC-1 SPC-2 Typical applications • database operations • mail servers • OLTP • large file processing • large database queries • video on demand Workload Random I/O 1 or more concurrent sequential I/Os Workload variations • address request distribution: uniform + sequential • R/W ratio • transfer size • R/W ratio • number of outstanding I/O requests Reported metrics • I/O rate (IOPS) • Total storage capacity • Price-performance • Data rate (MBPS) • Total storage capacity • Price-performance URL: www.storageperformance.org What would you consider as a solid storage measurement? We can reproduce the measurement The applied test load reflects the real load of the system We measure the right bottleneck – avoid measuring the cache unless we want to – avoid file copying – … Only measure the cache if you want to Caching exists on multiple system levels Hard disk cache : default set to write-back mode on SATA disks default set to write-through mode on SCSI disks (on the disks tested) 43 cache 45 Min. sequential write throughput [MB/s] 9 SATA disk without cache SATA with cache SCSI without cache Only measure the cache if you want to Caching exists on multiple system levels cache Disk controller cache : (RAID) controller Only measure the cache if you want to GPFS caching & prefetching GPFS tries to recognize access pattern : sequential, random, fuzzy sequential, strided requested GPFS cache GPFS tries to prefetch data into its cache : based on the detected access pattern requested prefetched GPFS also caches inodes of recently used files GPFS LUNs Only measure the cache if you want to NFS client side caching NFSv3 clients cache cache Close-to-open cache consistency no POSIX semantics Reads may or may not get last data written NFSv3 server If you don’t want to measure the cache Use a large data set Allocate buffer-cache before the measurement – e.g. with a small C program – disable swap Clear the cache between measurements – restart GPFS file system, NFS server,… – remount file system Only measure the cache if you want to Measure the link transfer speed, not the writing speed to the socket buffer 1 Gbps link Example: link measurement with iperf tool data first written to socket buffer, then sent on the link iperf reports write transfer speed to the buffer remedy: also check with link monitoring tools Measurement: “transfer speed > 1 Gbps”? Socket buffer size parameters: /proc/sys/net/core/rmem_max /proc/sys/net/core/rmem_max Measure your system bottom-up Facilitates efficiency assessment of each layer – better determine influence of parameter variations in each layer – comparison with subsystem performance Example: NFS protocol Example: FTP server NFS FTP app TCP/IP file system Ethernet RAID (NFS loopback) hard disk (file system) (RAM disk) Tools, benchmarks, appliances for different system layers Load generator/ Benchmark Monitor application layer • real application (FTP, NFS client,…) • SPC (seq/random R/W) • SPECsfs2008 (CIFS, NFS) • DVDstore (SQL) • TPC (transactions) • avalanche appliance (application layer network testing) • top network layer • iperf (TCP/UDP bandwidth) • smartbits appliance (network infrastructure testing) • dstat • wireshark/ethereal • optiview link analyzer filesystem layer • dd • iozone (file operations) • dstat device layer • dd (sequential R/W) • dstat (resource statistics) • iometer (random/sequential R/W) • iostat, vmstat • diskspeed32, hdtune, hdtach, zcav • Linux /proc directory • own tool (e.g. written in C) Example: monitoring the network layer with Optiview Optiview Tap Optiview Link Analyzer 256 MB buffer Optiview Protocol Expert Use memory-to-memory transfers to measure network protocol performance Example: measure TCP/UDP performance with iperf no disk access at both sides NFSv3 clients Example: measure NFS performance first use server with NFS-exported RAM disk then replace with real storage memory memory TCP/UDP (iperf) RAM disk memory memory NFSv3 server Avoid using file copy commands Use special Linux devices to avoid disk access dd if=/dev/zero of=outputfile bs=1M count=1048576 sequential write to storage with dd tool dd if=inputfile of=/dev/null bs=1M sequential read from storage with dd tool /dev/urandom creates random contents when you read from it may load the CPU however Monitor all CPUs/cores Not all cores may be equally loaded E.g. output from dstat tool for 4-core machine: total --cpu0-usage-- -------cpu1-usage------- --cpu2-usage-- --cpu3-usage-- -------cpu-usage------idl: 100: 100: 100: 100: 100: 100: 100: usr sys idl wai hiq siq: 100 0 0 0 0 0: 100 0 0 0 0 0: 100 0 0 0 0 0: 100 0 0 0 0 0: 100 0 0 0 0 0: 100 0 0 0 0 0: 100 0 0 0 0 0: 1 CPU 100% loaded idl: 100: 100: 100: 100: 100: 100: 100: idl: 100: 100: 100: 100: 100: 100: 100: usr sys idl wai hiq siq 25 0 75 0 0 0 25 0 75 0 0 0 25 0 75 0 0 0 25 0 75 0 0 0 25 0 75 0 0 0 25 0 75 0 0 0 25 0 75 0 0 0 CPUs only 25% loaded? CPU states: “iowait time is idle time” CPU iowait (“wai”) state: – amount of time the CPU has been waiting for I/O to complete A CPU is only bottleneck if “idl”= 0% and “wai”= 0% – if “wai” > 0%, extra calculations can be executed on the CPU Output from dstat tool: -------cpu-usage------- -disk/totalusr sys idl wai hiq siq|_read write 0 35 0 59 0 6| 0 159M 0 34 0 60 0 5|2458B 157M 0 33 0 62 0 5| 0 151M 0 32 0 63 0 5|4096B 142M 0 33 0 62 0 5| 0 150M CPU states : usr: user CPU time, sys: system CPU time, idl: idle CPU time, ni: nice CPU time, wai: iowait time, hiq: hardware IRQ servicing time, siq: software IRQ servicing time. What does virtualization change to storage measurement methodology? Xen: monitor in all relevant domains dom0 domU domU App OS OS original driver Xen driver event channel physical device Xen hypervisor Monitoring tools for Xen Monitor domains with Xentop & virt-top – CPU, memory, network What would you consider as a solid storage measurement? We can reproduce the measurement The applied test load reflects the real load of the system know your application’s storage access pattern We measure the right bottleneck avoid caching, file copying measure bottom-up resource monitoring Storage benchmarking cookbook With acknowledgement to the team members of the IBBT FIPA and GEISHA projects http://www.ibbt.be/en/project/fipa http://www.ibbt.be/en/project/geisha Stijn Eeckhaut Stijn De Smet, Brecht Vermeulen, Piet Demeester