Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
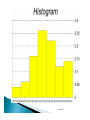
Assoc. Prof. Dr. M. Tevfik ÖZLÜDEMİR Lecture 2 Lecture 2 Due to errors, repeated measurements will often vary Precision is the degree to which measurements are consistent – measurements with a smaller variation are more precise Good precision generally requires much skill Precision is directly related to random error Lecture 2 Accuracy is the nearness to the true value Since the true value is unknown, true accuracy is unknown It is generally accepted practice to assess accuracy by comparison with measurements taken with superior equipment and procedures (the so-called test against a higher-accuracy standard) Lecture 2 Observation pacing taping EDM 1 571 567.17 567.133 2 563 567.08 567.124 3 566 567.12 567.129 4 588 567.38 567.165 5 557 567.01 567.144 average 569 567.15 567.133 Which is more precise? Which is more accurate? Lecture 2 (a) Accurate and precise (b) Accurate on average, but not precise (c) Precise but not accurate (d) Neither accurate nor precise Questions: Can one shot be precise? Can a group of shots be accurate? Lecture 2 Redundant measurements are those taken in excess of the minimum required A prudent professional always takes redundant measurements Mathematical conditions can be applied to redundant measurements Examples – sum of angles of a plane triangle = 200g, sum of latitudes and departures in a plane traverse equal zero, averaging measurements of the length of a line Lecture 2 Can apply least squares adjustment which is a mathematically superior method Often disclose mistakes Better results through averaging (adjustment) Allows one to assign a plus/minus tolerance to the answer Lecture 2 Most rigorous of all adjustment procedures Enables post-adjustment analysis Gives most probable values Can be used to perform survey design for a specified level of precision Can handle any network configuration (not limited to traverse, for example) Lecture 2 Lecture 2 Note that in this section, we are talking about multiple measurements of the same quantity. Numerical analysis – computation of statistical quantities (mean, variance, etc.) Graphical analysis – construction of bar charts, scatter diagrams, etc. Lecture 2 Most often, we collect a small data sample from a much larger population. For example, say we wanted to determine the ratio of ITU students speaking French. Theoretically we could visit every ITU student and collect this information – then compute the ratio. This would be an assessment of the population, which gives the actual ratio. Lecture 2 Visiting every ITU student would take a very long time, so we might collect a smaller sample. If we compute the ratio from this sample, we would get an estimate of the actual ratio. It is important to be unbiased. If we based our sample on students in this room, we would get a biased estimate. Lecture 2 The population size for measurements is infinite. Thus, we are always dealing with samples when analyzing measurements. Lecture 2 The range (sometimes called dispersion) is the difference between the largest and smallest values. Generally, a smaller range implies better precision. The median is the middle value of a sorted data set. When the number of data elements is even, take the mean of the two middle values. Lecture 2 20.1 21.9 22.5 22.8 23.1 23.5 23.8 24.2 24.8 25.4 20.5 22.0 22.6 22.9 23.2 23.6 23.9 24.3 25.0 25.5 21.2 22.2 22.6 22.9 23.2 23.7 24.0 24.4 25.2 25.9 21.7 22.3 22.7 23.0 23.3 23.8 24.1 24.6 25.3 25.9 21.8 22.3 22.8 23.1 23.4 23.8 24.1 24.7 25.3 26.1 Range = 26.1-20.1 = 6.0 Median is 23.45 (the average of 23.4 and 23.5) Note that the difference between the lowest value and the median is 3.35 and between the highest and the median is 2.65 Lecture 2 The frequency histogram (or simply histogram) is a graphical representation of data A histogram is a bar graph that illustrates the data distribution To produce a histogram, the data are divided into classes which are subranges that are usually equal in width The number of classes can vary depending on the number of values, but odd numbers like 7, 9, or 11 are often good choices Lecture 2 Say we want to construct a histogram of the previous data set using 7 classes spanning the range. The class width will be 6.0/7 = 0.857143 = 0.86 Therefore the first class subrange will be 20.10 – 20.96, the second subrange will be 20.96 – 21.81, the third will be 21.81 – 22.67, etc. We then count the number of values falling within those classes and compute the fraction of the total. Lecture 2 Class interval 20.10 20.96 21.81 22.67 23.53 24.39 25.24 - 20.96 21.81 22.67 23.53 24.39 25.24 26.1 Class frequency 2 3 8 13 11 6 7 Class relative frequency 2/50 = 0.04 3/50 = 0.06 8/50 = 0.16 13/50 = 0.26 11/50 = 0.22 6/50 = 0.12 7/50 = 0.14 Σ= 50/50 = 1 Lecture 2 Lecture 2 Symmetry Range Frequencies Steepness indicates precision, but only if the histograms have the same class intervals and scales. Lecture 2 Lecture 2 Measures of central tendency Measures of data variation Lecture 2 Arithmetic mean or average Median (mentioned previously) Mode Lecture 2 n y y i i 1 n y is the sample mean n is the number of values yi are the individual values Lecture 2 n y y i 1 n i 1175.0 23.500 50 Lecture 2 The median is the middle value. Half of the values are above and half are below. It is more effective as a measure of central tendency when there are outliers (blunders) in the data set. Lecture 2 The mode is the most frequently occurring value. It is seldom of use when dealing with measurements (real numbers). More useful with integers (e.g. most common age). Lecture 2 True value. A quantity’s theoretically correct or exact value. In theory, it is the population mean, μ, which is indeterminate for measurements Error (ε). The difference between a measurement and the true value i yi Lecture 2 Most probable value (y ). Derived from a sample, it is the average of equally weighted measurements Residual (v). The difference between the most probable value and an individual measurement. It is similar to an error, but definitely not the same thing vi y yi Lecture 2 Degrees of Freedom. The number of observations that are in excess of the minimum number necessary to solve for the unknowns – it equals the number of redundant observations Population variance (σ2). This quantifies the precision of the population of a set of data. It can also be called the mean squared error n 2 2 i i 1 n Lecture 2 Sample variance (S2). This is an unbiased estimate of the population variance. n 2 i S2 v i 1 n 1 Standard error (σ). Square root of population variance – 68.3% of all observations lie within ±σ of the true value Lecture 2 Standard deviation (S). This is the square root of the sample variance – it is an estimate of the standard error. (Do not expect 68.3% of sample observations to fall within ±S of the sample mean unless n is large.) Lecture 2 Standard deviation of the mean ( S y ) The mean value will have a lower standard deviation than any single measurement. As n →∞, S y →0. S Sy n Lecture 2 n 2 2 ( y y ) i i 1 S n 1 n 2 yi n 2 i 1 y n i n n 2 2 i 1 y n y i i 1 S2 n 1 n 1 Lecture 2 Week 2, February 14, 2012 20.1 21.9 22.5 22.8 23.1 23.5 23.8 24.2 24.8 25.4 20.5 22.0 22.6 22.9 23.2 23.6 23.9 24.3 25.0 25.5 21.2 22.2 22.6 22.9 23.2 23.7 24.0 24.4 25.2 25.9 21.7 22.3 22.7 23.0 23.3 23.8 24.1 24.6 25.3 25.9 21.8 22.3 22.8 23.1 23.4 23.8 24.1 24.7 25.3 26.1 y 23.50 Lecture 2 n 2 v i S 92.36 1.37 n 1 50 1 i 1 Lecture 2 By alternate form: 2 y i 27,704.86 27,704.86 50( 23.50) 2 S 50 1 27,704.86 27,612.50 92.36 S 1.37 50 1 49 Standard deviation of the mean 1.37 Sy 0.194 50 (Note the higher precision for the mean) Lecture 2 About 68% of the values should be between ±S of the mean. So: 23.50 ±1.37 22.13 to 24.87 34 out of the 50 values fall within that range, which is 68% Lecture 2 Quote of the lecture (*) “Experience is the name everyone gives to their mistakes.” Oscar Wilde (Lady Windermere's Fan, 1892) (*) http://en.wikiquote.org Have a nice week Lecture 2