Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
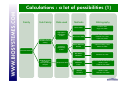
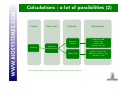
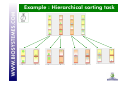
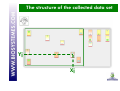
Sorting, Napping® &co Let’s practice! Holistic / global approaches Analytical Traditional descriptive analyses Free Choice profiling Flash profiling Main reasons to try Sorting, Napping® Spontaneous Less cost Reduce time Criteria important to the individual Are you sure the goal is reached? A lot of comments about the methods (various comments heard among users): POSITIVE ASPECTS “It's easy to perform and easy for panelists to understand” “useful as initial screening of prototypes or category samples.” ‘very intuitive... ’ “practical to screen sensory properties of a large set of products” … Sorting NEGATIVE ASPECTS “needs a certain amount of products to make it work, but this is not always possible” “not a diagnostic tool” “request simultaneous presentation of products and not suitable for cosmetic products” “Sorting is a technique to discover what is salient to consumers/judges not a substitute for DA” … Are you sure the goal is reached? A lot of comments about the methods (various comments heard among users): POSITIVE ASPECTS “rapid, inexpensive, easy-to-use” “compact, easy to visualize” “highly flexible and easy to understand for consumer” “practical to screen sensory properties of a large set of product” Napping® … NEGATIVE ASPECTS “hard to understand” “challenge to analyse” “hard to interprete, time consuming” “difficult for consumers to position the products” “Very difficult task for consumers + data analysis” … Application of the methods in real life The idea of this tutorial is to have a look at the main difficulties of the two methods and to see the way they have been used, modified, transformed, adapted by the different users to suit their needs facing the different difficulties. We will just propose some solutions that we have seen working for some users, we won’t discuss them. They may be suitable for you, your products, your working area… or not. It’s just a panel where you may pick ideas for your own work. Calculation seems to be a key point: difficult for some, easy for others… We will see this with the specialist Sebastien who will explain what you can do with all this. The example used in this presentation The objects are 16 cards. Each card contains a geometric shape combining 7 criteria (shape, color, size...). Those cards have been presented several times by AgroCampus Ouest in different publications. The sorting Task The simple sorting task The subject is invited to group the different products according to their resemblances. For example, you can ask: Please group the different products according to their resemblances. You must put two products in the same group if they are similar. You must assess the resemblances or the differences between these products according to your own criteria. The structure of the collected data set Each subject gives his own partition of the 16 cards. Group 1 Group 2 Group 1 Group 1 Group 1 … Group 2 Group 3 … Group 3 Group 2 … Group 2 Group 3 … How to code data N subjects are sorting P products. For a particular subject, K groups are built. You can consider this as: • N Partitions of P products • N Individual dissimilarity matrix (distance matrix) • Aggregated dissimilarity matrix • N Individual disjunctive table • Aggregated disjunctive table Depending on the calculation method you will apply, the data will be coded differently. Example for Subject (1) 0 0 1 1 1 0 0 1 1 1 1 1 0 1 0 1 1 1 0 1 1 1 0 1 0 and in group 1 so distance()=0 and in different group so distance()=1 Dissimilarity Matrix for Subject Example for Subject Group 1 Group 2 Group 3 1 0 0 1 0 0 0 1 0 0 0 1 0 1 0 Disjunctive table for Subject (2) Calculations : a lot of possibilities (1) Family Sub Family Data used Aggregated dissimilarity matrix Methods Metric MDS Kruskal, 1964 Gygi et al, 2007 Non metric MDS Schiffman, 1981; Lawless, 1989 Falahee et al, 1997 Faye et al, 2004 Metric INDSCAL Distatis Caroll et Chang, 1970 Abdi et al, 2007 Non Metric INDSCAL Takane et al, 1977 Methods closed to Multidimensional scaling Individual dissimilarity matrix Factorial Methods Methods closed to multiple correspondence analysis Disjunctive table Bibliography ACM MDSORT FAST IDSORT CCSORT Van der Kloot et Van Herk, 1991 Takane, 1981 Cadoret et al, 2009 Takane, 1982 Qannari et al, 2009 Calculations : a lot of possibilities (2) Family Clustering Data used Methods Bibliography Hierachical clustering Lebart et al, 2006 Coxon, 1999 Lawless, 1989 Giboreau et al, 2001 Additive trees Sattah et Tversky, 1977 Barthélémy in Dubois, 1991 Poitevineau, 2002 Aggregated dissimilarity matrix Extract : MODULAD, 2011, Num43, P.Faye, P.Courcoux, E.M.Qannari, A.Giboreau Calculations : a lot of possibilities (3) You will see an example of what can be done easily with R later with Sebastien. Several topics of the conference will also cover this. Used, modified, transformed, adapted… Used with trained panel, consumers, specialists (panel not formally trained but highly experienced) depending on the objective Verbalization task: the subjects are asked to describe the groups • Free comments • Comments with a predefined list of terms Hierarchical sorting task • Descending: first the judges have to divide the set of products into groups and he can subdivide these groups into finer groups, etc., until the final groups of products are homogeneous (Cadoret &Al, 2010) • Ascending: make bigger groups of the groups previously made (Qannari &Al, 2010) Used to understand the process of a sorting task. Example : Hierarchical sorting task Napping® Napping® Projective mapping was first introduced by Risvik & al. 1994. Napping® (The name derives from the French word ‘nappe’, meaning ‘tablecloth' ) has been elaborated by Pages & al. 2003. Each subject is given all the samples and a large table or sheet of paper. They arrange their samples on the table, using the distance between them to indicate how similar (closely spaced) or different (more widely spaced) they perceive them to be. For example, you can ask: Please position the different products on the rectangular map. The closer two products are, the more similar they seem to be. Conversely, two products are distant if you perceive much difference between them. You must assess the resemblances or the differences between these products according to your own criteria. Napping® Closed products Very different products The structure of the collected data set Yj Xj The structure of the collected data set Each subject gives 2 coordinates for the 16 cards. X Y Xj Yj X Y X Y Calculations : a lot of possibilities The final data frame is composed of P individual and 2*N variables. Several statistical methods have been developed to analyze this kind of structure. The most known (used?) are MFA (Multiple Factorial Analyses), PMFA (Procustean Multiple Factor Analyses), INDSCAL model, DISTATIS… The aim of those algorithms is to find a common configuration that will represent the product space (MFA, INDSCAL, DISTATIS) and to compare the structure given by each subject to the common configuration (PMFA). Used, modified, transformed, adapted… Used with trained panel, consumers, specialists (panel not formally trained but highly experienced) depending on the objective Verbalization task: the subjects are asked to describe the products to explain the dimensions of the resulting perceptual map • Free comments • Comments with a predefined list of terms (it can be a very long list of terms near 200-300 items) Spontaneity vs Easier and faster interpretation… and as time is money… Structure & size of the ‘tablecloth’ Sometimes you may need axes to be more structured or the subject may need to materialize them. Cr. P. Deneulin Structure & size of the ‘tablecloth’ The subject may be able to directly explain the axis he chose. On a square map, the subject may be able to define the graduation of the axes and modify them. For example here, the subject could want to precise that the origin of the X axis is not null as a shape exists on the card. Napping® by modality Idea first suggested by Pagès (2003), tested and presented by Gilbert (2008) as a “happy medium” between the complete holistic approach and the analytical approach of a profiling by attribute. It consists in conducting a Napping® exercise separately for each relevant sensory modality for example appearance, odor, flavor, texture... MFA can be used for each modality (to get a consensus map by modality). HMFA (Hierarchical Multiple Factor Analysis) can be used to get a global consensus map. More time needed by subject May be easier for the subject to have a more analytical approach May be closer to the profiling results Depends on you product category! The sorted Napping® The subjects are asked to provide a map but they have the possibility to group them according to their similarity. They are asked to describe the group. Another happy medium between time and information gathered. The structure of the collected data set Each subject gives 2 coordinates and the group allocation by product. Sorting Task Napping X Y Gr Xj Yj Gj X Y Gr X Y Gr Time to practice! Practice You will have to do two tests: A Sorted Napping with categorization on 11 Gingerbreads A Sorting with categorization on 10 Apple Juices Practice: Sorted Napping You will have to position and sort 11 samples. Please position the different products on the rectangular map. The closer two products are, the more similar they seem to be. Conversely, two products are distant if you perceive much difference between them. You must assess the resemblances or the differences between these products according to your own criteria. In order to position the products, please click on the product code which is displayed in the right part and drag it towards its position on the map. You can move it later by clicking on it and dragging it towards a new position. To allocate a sample into a group: - If you drop the sample on a free area, a new group is created, except if the maximum number of groups has been reached. In this case the sample is allocated to the closest group. - If you drop the sample on another one, it will be allocated to the same group. You may also click on a sample with the right button of the mouse in order to make appear the contextual menu and define the group allocation. To cancel the group allocation of a sample: you may click on the sample and drag it back to the start right area, or allocate it to another group. You may also click with the right button and select Reset group in the contextual menu. To comment a group: please click on '>>' button. Practice: Sorting You will have to sort 10 samples. Please group the different products according to their resemblances. You must put two products in the same group if they are similar. You must assess the resemblances or the differences between these products according to your own criteria. To allocate a sample into a group, please click on the product code which is displayed in the right part and drag it towards its position on the map. - If you drop the sample on a free area, a new group is created, except if the maximum number of groups has been reached. In this case the sample is allocated to the closest group. - If you drop the sample on another one, it will be allocated to the same group. You may also click on a sample with the right button of the mouse in order to make appear the contextual menu and define the group allocation. To cancel the group allocation of a sample: you may click on the sample and drag it back to the start right area, or allocate it to another group. You may also click with the right button and select Reset group in the contextual menu. To change the group allocation of a product: you may click on the sample and move it on a sample of the desired group. The sample will be then allocated to this group. You may also click on the sample with the right button of the mouse to make appear the contextual menu and change the group allocation. To comment a group: when you are happy with the groups presented, click on the >> button to comment the different groups. Questions Did you find the task easy? Did you remember the products’ characteristics easily? Were you happy with your work? Did you find easily when to stop separating the products? Any comment about the number of products? Any comment about the tasks? Statistics break What you have tested (Napping) 729 803 056 519 161 982 340 Craft biscuit factory 087 445 266 Organic 624 Use of the text file in R (example) Example with the function fasnt (extract) (do not forget to load the SensoMineR library first!) Script to be used: What you have tested (Sorting) 109 076 863 453 158 535 Local Handwork 994 240 Organic 699 371 Use of the text file in R (example) Example with the function fast (extract) (do not forget to load the SensoMineR library first!) Script to be used: Data used in this presentation Fizz Users The tested sessions will be downloadable from our Web Site. All participants To use the results in R, the exported text files from Fizz will also be accessible on our Web site (in the Sensometrics News). Contact us for any question! Thank you!