Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Data center wikipedia , lookup
Predictive analytics wikipedia , lookup
Data analysis wikipedia , lookup
Information privacy law wikipedia , lookup
Business intelligence wikipedia , lookup
Forecasting wikipedia , lookup
Data vault modeling wikipedia , lookup
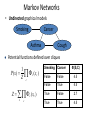
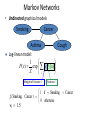
11/16: After Sanity Test Post-mortem Project presentations in the last 2-3 classes Start of Statistical Learning Sanity Test.. • Max: 52.5 Min: 6 Avg: 24.6 Stdev: 14.8 – Including those sitting-in: Avg: 24.42; Stdev: 13.8 » » » » » » » » 70+: 0 60-70: 0 50-60: 2 40-50: 0 30-40: 3 20-30: 4 10-20: 5 0-10: 2 • Students with low scores have to re-do the test at home (with access to notes, web etc.). An eventual score of less than 45 will be viewed as failing on the content P(hi ) is called the hypothesis prior Nothing special about “learning” – just vanilla probabilistic inference Where is the hypothesis prior? i.i.d. assumption How did this prediction come about? Which hypothesis did we use? The analogy with diagnosis Medical diagnosis Full Bayesian learning • • • • • • Given symptoms of a patient, predict whether she will have other symptoms (such as death…) Can try predicting directly from symptoms (is what we did before the advent of medicine) But we normally assume that diseases cause symptoms.. Thus we want to first figure out the disease and then predict other symptoms Diseases have prior probabilities (in fact, the “ignored prior” fallacy is the main reason for internet induced hypochondria) Given the symptoms, we compute the posterior on the diseases, and then use that to predict other symptoms • • • • Given training data, predict test data Can try predicting test data directly from training data (e.g. k-NN) But we normally assume that hypothesis explain data. Thus we want to first figure out the hypotheses causing the data and then using them predict test data Hypotheses have prior probabilities (as to how likely they are— independent of the data being seen right now). Given the data, we compute the posterior on the hypotheses, and then use that to predict test data How many Equivalently minimize - log P(d|hi) – log P(hi) Additional bits required to specify d Bits required to specify hi Why should P(hi ) be low for complex hypotheses? --connection to MDL principle --because “statisticians” distrust priors (and want the data to speak for itself) When will ML hit roadblock? Small data Should AI also distrust priors? Priors can encode background knowledge.. (There is even evidence that human brain uses priors) http://web.mit.edu/cocosci/Papers/significance.pdf A technical head ache with priors: What if the posterior keeps changing parametrically? Conjugate priors.. 11/18 Density Estimation • The general task of learning a probability model, given data that are assumed to be generated from that model • Given data D whose instances are made-up of attributes x that are distributed according to P*(x), we want to learn an estimate P’ to P* such that the distance between P* and P’ is minimized – Distance between distributions is typically measured using KL Divergence – D(P*||P’) = EP*[log P*(x)/P’(x)] • But alas, we don’t know P* = EP* log P*(x) - EP* log P’(x) • The first term is constant and can be ignored in comparing two estimates P’ and P’’ • But how do we get the second term? Since the data instances are drawn from P*, a P’ that maximizes their log likelihood is the best. • If data are drawn i.i.d, then their joint likelihood is a product and log terms over all data instances can be summed.. Bias-Variance Tradeoff (learning with bias vs. regularization) • So, we want to get the distribution P’ that maximizes EP* log P’(x) – Learning is just optimization! • But how do we select the candidate space of distributions (hypotheses)? • [Bias problem] If the class of distributions we consider is too small/inflexible (“highly biased”), then the best we get may still be too far from P* • [Variance problem] If the class of distributions considered is too large/expressive, then small random fluctuations in the choice of data can radically change the properties of the model, thus exhibiting high variance on the test data • Standard solutions: 1. 2. 3. Limit attention to a “reasonable class of distributions” (e.g. Naïve Bayes) Allow a large class of distributions, but “penalize” the more complex ones [Also called “regularization”]. Combination of both.. A class of distributions can be defined by restricting the class of graphical models (e.g. only naïve bayes models) or CPDs (only noisy-or or conditional Gaussians) allowed in the hypothesis space Generative vs. Discriminative Learning • Often, we are really more interested in predicting only a subset of the attributes given the rest. – E.g. we have data attributes split into subsets X and Y, and we are interested in predicting Y given the values of X • You can do this by either by – learning the joint distribution P(X, Y) [Generative learning] – or learning just the conditional distribution P(Y|X) [Discriminative learning] • Often a given classification problem can be handled either generatively or discriminatively – E.g. Naïve Bayes and Logistic Regression • Which is better? Generative vs. Discriminative P(y)P(x|y) = P(y,x) = P(x)P(y|x) Generative Learning Discriminative Learning • More general (after all if you have P(Y, X) you can predict Y given X as well as do other inferences • More to the point (if what you want is P(Y|X), why bother with P(Y,X) which is after all P(Y|X) *P(X) and thus models the dependencies between X’s also? • Since we don’t need to model dependencies among X, we don’t need to make any independence assumptions among them. So, we can merrily use highly correlated features.. – You can predict jokes as well as make them up (or predict spam mails as well as generate them) • In trying to learn P(Y,X), we are often forced to make many independence assumptions both in Y and X—and these may be wrong.. – Interestingly, this type of high bias can help generative techniques when there is too little data – Interestingly, this freedom can hurt discriminative learners when there is too little data (as over fitting is easy) Bayes networks are not well suited for discriminative learning; Markov Networks are --thus Conditional Random Fields are basically MNs doing discriminative learning --Logistic regression can be seen as a simple CRF Taxonomy of (statistical) Learning Tasks Model constraints Observability of data • Type of network being learned • Complete data – Bayes Network vs. Markov network • Topology given; CPTs to be learned • Only relevant attributes are given; need to learn topology as well as CPTs – Tricky part for MLE is that increasing the connectivity of a network cannot reduce likelihood • We don’t know what the relevant attributes are – Each data instance gives the values of each of the attributes • Incomplete data – Some of the data instances might be missing the values for some of the attributes • Hidden attributes (variables) – None of the data instances have values for some of the attributes (which often correspond to “intermediate” concepts which help improve the sparsity of network. E.g. “syndromes” which connect symptoms to diseases; or class variables in mixture models Sample complexity linearly varies with # parameters to be learned, and #parameters vary exponentially with # edges in the graphical model 11/23 Steps in ML based learning 1. Write down an expression for the likelihood of the data as a function of the parameter(s) Assume i.i.d. distribution 2. 3. Write down the derivative of the log likelihood with respect to each parameter Find the parameter values such that the derivatives are zero There are two ways this step can become complex Individual (partial) derivatives lead to non-linear functions (depends on the type of distribution the parameters are controlling; binomial is a very easy case) Individual (partial) derivatives will involve more than one parameter (thus leading to simultaneous equations) In general, we will need to use continuous function optimization techniques One idea is to use gradient descent to find the point where the derivative goes to zero. But for gradient descent to find global optimum, we need to know for sure that the function we are optimizing has a single optimum (this is why convex functions are important. If the likelihood is a convex function, then gradient descent will be guaranteed to find the global minimum). Note that for us, data are 2-attribute tuples [Flavor, Wrapper] No entanglement of parameters for complete data for Bayes nets with known topology and tabular CPTs Specifically, each partial derivative will involve only one parameter i.e., each partial derivative contains only one parameter so you are solving single variable equations rather than simultaneous equations. doesn’t hold for markov nets ; doesn’t also hold for Bayes nets where CPDs induce direct parameter dependencies Celebrating ease of learning for bayes nets with complete data! • So we just noted that if we know the topology of the Bayes net, and we have complete data then the parameters are un-entangled, and can be learned separately from just data counts. • Questions: How big a deal is this? – Can we have complete data? – Can we have known topology? Learning the parameters of a Gaussian Case Study: Learning Bayes Net models for Relational database tables • Consider a relational table in RDBMS with n attributes – • • • Say an employee table giving the age, position, salary etc of each employee Suppose we want to learn the generative model underlying it Suppose we were able to hypothesize the topology – • We might be able to do so if (a) we know the domain or (b) we know some of the causal dependencies in the data If the relational table is “complete” –i.e.., every tuple gives the value for every attribute, (which is the standard RDBMS model), then learning the parameters of this network is easy! Now, suppose the table is slightly “dirty”—in that there are tuples that have some missing values for some of the attributes – • If only a small percent of the tuples are incomplete, then we can – – • Say, some of the employee tuples are missing age information, others are missing salary information etc. 1. Learn the model using the complete tuples 2. predict the null values in the dirty tuples using the learned model But, if a non-trivial percent of the tuples are incomplete, then, we might want to continue for step 2 above by – 3. Now that we have “completed” all the incomplete tuples, we have fully complete data. Learn the model with this Completed data; and see if it is any better • • A model is better if it provides a higher likelihood for the observed data But why stop here? Continue and use the new model to re-predict the missing values, and iterate – This is the basic idea of EM (Expectation Maximization) algorithm What if the best generative model contains attribute that are not mentioned in the table? • • In the previous relational table scenario, we assumed that some of the tuples are missing some of the attribute values. What if all tuples are missing some attribute values? – • Can we still use EM? – – E.g. Educational level of the employee can be an attribute that is missing in the current table. This is like having an attribute column whose value is not known for any of the tuples – – • • But why would we do it? – Why would we do it? Can we still use EM? – – • Surprisingly, it turns out yes. In the earlier scenario, we used the complete tuples for setting up the initial model, but then used it to complete the data, and loop There is no reason why we should initialize using complete data. We can initialize the model (parameters) randomly, and still do the EM looping! Given a complete relational table, such as the employee one, why would we start hypothesizing hidden attributes? Because the right hypothesis on the hidden attribute can significantly reduce the number of parameters For example, the educational level of the employee might cluster employees into “PhD” folks (who presumably have high salaries, interesting positions, and mature ages), and “non-PhD” folks (who presumably have low salaries, green-behind-the-ears ages, and assembly programming kind of jobs), and in each cluster the distributions of the attribute values are different (as described above) So, – – Hypothesizing hidden attributes reduces the parameters to be estimated, but makes their estimation hard Not hypothesizing them allows us to deal with complete data, but might require exponentially many parameters to be learned (from the same data—making the parameters, while easy to estimate, pretty worthless in terms of accuracy. Missing data (but no hidden variables) Involves Bayes Net inference; can get by with approximate inference Which is a more representative Obama Picture? 11/25 Hidden Variable: Your party affiliation (liberal vs. conservative) Study by Eugene Caruso, To be published in PNAS Where P(Xj|Ci) can be any distribution… 0. Initialize the parameters randomly Loop Inference Candy Example Start with 1000 samples Initialize parameters as Why does EM Work? The “size of the step” is determined adaptively by where the max of the lowerbound is.. --In contrast, gradient descent requires a stepsize parameter --Newton Raphson requires second derivative.. Log of Sums don’t have easy closed form optima; use Jensen’s inequality and focus on Sum of logs which will be a lower bound Structure (Topology) Learning • Search over different network topologies • Question: How do we decide which topology is better? – Idea 1: Check if the independence relations posited by the topology actually hold – Idea 2: Consider which topology agrees with the data more (i.e., provides higher likelihood) • But need to be careful--increasing edges in a network cannot reduce likelihood – Idea 3: Need to penalize complexity of the network (either using prior on network topologies, or using syntactic complexity measures) 11/30 Problems with ML and Bayesian Learning.. • ML based learning is unable to take the size of the data into account (1/3 is the same as 1M/3M) • We however tend to start with a prior, and are less willing to change the prior unless shown enough evidence – Bayesian learning can handle this.. If a thumbtack came up heads once when you tossed it 3 times, what is the probability that it will come up heads the next time? Now, a coin came up heads once when you tossed it heads three times. What do you think is the probability that it will come up heads next time? How about if it came up heads 1million times in 3 million trials? Bayesian Learning (for coin toss..) • Let q be the probability that the coin comes heads – Each different value of q is a different hypothesis – So P(h) –the hypothesis prior– can be specified by specifying P(q) • Starting with prior on q, we just need to compute the posterior • Challenge: Find a distribution over continuous space that – can be represented compactly – and updated efficiently when we get new data • Example: Uniform; but what if we have a more information? • Beta distributions – Think of a and b as the number of heads and tails you have seen prior to the start of this experiment – Update: “Conjugate Prior” • A prior distribution family Pc is considered a conjugate prior for a likelihood function family Pl if starting with a hypothesis prior Pc1 from Pc and seeing data with likelihood Pl from Pl the posterior of the hypothesis prior will also be in Pc – Beta distributions are conjugate priors for bernouli (Binomial) likelihood distributions – Dirichlet distributions are conjugate priors for Multinomial likelihood distributions – Normal-Wishart distributions are conjugate priors for Gaussian likelihood distributions Bayesian Prediction • So suppose we started with Beta[a,b] as the prior – Probability of heads will be a/(a+b) • Need to integrate P(heads|q )P(q) dq over 0 to 1 • Now after seeing Dh heads and Dt tails, the posterior will be Beta[a+Dh, b+Dt ] – Probability of heads now will be • (a+Dh )/(a+Dh + b+Dt ) • So, to the ML estimate, you just add a + b virtual samples… – Is what you did with Laplace Smoothing… Laplace smoothing is a backdoor way of making ML predictions be in line with full Bayesian learning… Multi-parameter case (Assume Parameter Independence) Priors and Background Knowledge • Hypothesis priors can be seen as providing background knowledge • Background knowledge is also helpful in “logical learning” – Sao Paulo airport example Undirected Probabilistic Graphical Models (Markov Nets) (Slides from Sam Roweis Lecture) Connection to MCMC: MCMC requires sampling a node given its markov blanket Need to use P(x|MB(x)). For Bayes nets MB(x) contains more nodes than are mentioned in the local distribution CPT(x) For Markov nets, Because neighbor relation is symmetric nodes xi and xj are both neighbors of each other.. Markov Networks • Undirected graphical models Smoking Cancer Asthma Cough Potential functions defined over cliques 1 P( x) c ( xc ) Z c Z c ( xc ) x c Smoking Cancer Ф(S,C) False False 4.5 False True 4.5 True False 2.7 True True 4.5 Markov Networks • Undirected graphical models Smoking Cancer Asthma Cough Log-linear model: 1 P( x) exp wi f i ( x) Z i Weight of Feature i Feature i 1 if Smoking Cancer f1 (Smoking, Cancer ) 0 otherwise w1 1.5 Markov Nets vs. Bayes Nets Property Markov Nets Bayes Nets Form Prod. potentials Prod. potentials Potentials Arbitrary Cond. probabilities Cycles Allowed Forbidden Partition func. Z = ? global Indep. check Z = 1 local Graph separation D-separation Indep. props. Some Some Inference Convert to Markov MCMC, BP, etc. Inference in Markov Networks • Goal: Compute marginals & conditionals of P( X ) 1 exp wi f i ( X ) Z i Z exp wi f i ( X ) X i • Exact inference is #P-complete • Conditioning on Markov blanket is easy: w f ( x) P( x | MB( x )) exp w f ( x 0) exp w f ( x 1) exp i i i i • Gibbs sampling exploits this i i i i i Partition function cancels out MCMC: Gibbs Sampling state ← random truth assignment for i ← 1 to num-samples do for each variable x sample x according to P(x|neighbors(x)) state ← state with new value of x P(F) ← fraction of states in which F is true Other Inference Methods • • • • Many variations of MCMC Belief propagation (sum-product) Variational approximation Exact methods Learning Markov Networks • Learning parameters (weights) – Generatively – Discriminatively • Learning structure (features) • In this tutorial: Assume complete data (If not: EM versions of algorithms) Entanglement in log likelihood… a b c P( X ) 1 exp wi f i ( X ) Z i Z exp wi f i ( X ) X i Generative Weight Learning • Maximize likelihood or posterior probability • Numerical optimization (gradient or 2nd order) • No local maxima log Pw ( x) ni ( x) Ew ni ( x) wi No. of times feature i is true in data Expected no. times feature i is true according to model • Requires inference at each step (slow!) Discriminative Weight Learning • Maximize conditional likelihood of query (y) given evidence (x) log Pw ( y | x) ni ( x, y ) Ew ni ( x, y ) wi No. of true groundings of clause i in data Expected no. true groundings according to model • Approximate expected counts by counts in MAP state of y given x Structure Learning • How to learn the structure of a Markov network? – … not too different from learning structure for a Bayes network: discrete search through space of possible graphs, trying to maximize data probability….