Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Table of Contents
Overview
Introduction to Azure Data Factory
Concepts
Pipelines and activities
Datasets
Scheduling and execution
Get Started
Tutorial: Create a pipeline to copy data
Copy Wizard
Azure portal
Visual Studio
PowerShell
Azure Resource Manager template
REST API
.NET API
Tutorial: Create a pipeline to transform data
Azure portal
Visual Studio
PowerShell
Azure Resource Manager template
REST API
Tutorial: Move data between on-premises and cloud
FAQ
How To
Move Data
Copy Activity Overview
Data Factory Copy Wizard
Performance and tuning guide
Security considerations
Connectors
Data Management Gateway
Transform Data
HDInsight Hive Activity
HDInsight Pig Activity
HDInsight MapReduce Activity
HDInsight Streaming Activity
HDInsight Spark Activity
Machine Learning Batch Execution Activity
Machine Learning Update Resource Activity
Stored Procedure Activity
Data Lake Analytics U-SQL Activity
.NET custom activity
Invoke R scripts
Reprocess models in Azure Analysis Services
Compute Linked Services
Develop
Azure Resource Manager template
Samples
Functions and system variables
Naming rules
.NET API change log
Monitor and Manage
Monitoring and Management app
Azure Data Factory pipelines
Using .NET SDK
Troubleshoot Data Factory issues
Troubleshoot issues with using Data Management Gateway
Reference
PowerShell
.NET
REST
JSON
Resources
Release notes for Data Management Gateway
Learning path
Case Studies
Product Recommendations
Customer Profiling
Process large-scale datasets using Data Factory and Batch
Service updates
Pricing
MSDN Forum
Stack Overflow
Videos
Request a feature
Introduction to Azure Data Factory
5/3/2017 • 10 min to read • Edit Online
What is Azure Data Factory?
In the world of big data, how is existing data leveraged in business? Is it possible to enrich data generated in the
cloud by using reference data from on-premises data sources or other disparate data sources? For example, a
gaming company collects many logs produced by games in the cloud. It wants to analyze these logs to gain
insights in to customer preferences, demographics, usage behavior etc. to identify up-sell and cross-sell
opportunities, develop new compelling features to drive business growth, and provide a better experience to
customers.
To analyze these logs, the company needs to use the reference data such as customer information, game
information, marketing campaign information that is in an on-premises data store. Therefore, the company wants
to ingest log data from the cloud data store and reference data from the on-premises data store. Then, process
the data by using Hadoop in the cloud (Azure HDInsight) and publish the result data into a cloud data warehouse
such as Azure SQL Data Warehouse or an on-premises data store such as SQL Server. It wants this workflow to
run weekly once.
What is needed is a platform that allows the company to create a workflow that can ingest data from both onpremises and cloud data stores, and transform or process data by using existing compute services such as
Hadoop, and publish the results to an on-premises or cloud data store for BI applications to consume.
Azure Data Factory is the platform for this kind of scenarios. It is a cloud-based data integration service that
allows you to create data-driven workflows in the cloud for orchestrating and automating data
movement and data transformation. Using Azure Data Factory, you can create and schedule data-driven
workflows (called pipelines) that can ingest data from disparate data stores, process/transform the data by using
compute services such as Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics, and Azure Machine
Learning, and publish output data to data stores such as Azure SQL Data Warehouse for business intelligence (BI)
applications to consume.
It's more of an Extract-and-Load (EL) and then Transform-and-Load (TL) platform rather than a traditional ExtractTransform-and-Load (ETL) platform. The transformations that are performed are to transform/process data by
using compute services rather than to perform transformations like the ones for adding derived columns,
counting number of rows, sorting data, etc.
Currently, in Azure Data Factory, the data that is consumed and produced by workflows is time-sliced data
(hourly, daily, weekly, etc.). For example, a pipeline may read input data, process data, and produce output data
once a day. You can also run a workflow just one time.
How does it work?
The pipelines (data-driven workflows) in Azure Data Factory typically perform the following three steps:
Connect and collect
Enterprises have data of various types located in disparate sources. The first step in building an information
production system is to connect to all the required sources of data and processing, such as SaaS services, file
shares, FTP, web services, and move the data as-needed to a centralized location for subsequent processing.
Without Data Factory, enterprises must build custom data movement components or write custom services to
integrate these data sources and processing. It is expensive and hard to integrate and maintain such systems, and
it often lacks the enterprise grade monitoring and alerting, and the controls that a fully managed service can
offer.
With Data Factory, you can use the Copy Activity in a data pipeline to move data from both on-premises and
cloud source data stores to a centralization data store in the cloud for further analysis. For example, you can
collect data in an Azure Data Lake Store and transform the data later by using an Azure Data Lake Analytics
compute service. Or, collect data in an Azure Blob Storage and transform data later by using an Azure HDInsight
Hadoop cluster.
Transform and enrich
Once data is present in a centralized data store in the cloud, you want the collected data to be processed or
transformed by using compute services such as HDInsight Hadoop, Spark, Data Lake Analytics, and Machine
Learning. You want to reliably produce transformed data on a maintainable and controlled schedule to feed
production environments with trusted data.
Publish
Deliver transformed data from the cloud to on-premises sources like SQL Server, or keep it in your cloud storage
sources for consumption by business intelligence (BI) and analytics tools and other applications
Key components
An Azure subscription may have one or more Azure Data Factory instances (or data factories). Azure Data Factory
is composed of four key components that work together to provide the platform on which you can compose
data-driven workflows with steps to move and transform data.
Pipeline
A data factory may have one or more pipelines. A pipeline is a group of activities. Together, the activities in a
pipeline perform a task. For example, a pipeline could contain a group of activities that ingests data from an Azure
blob, and then run a Hive query on an HDInsight cluster to partition the data. The benefit of this is that the
pipeline allows you to manage the activities as a set instead of each one individually. For example, you can deploy
and schedule the pipeline, instead of the activities independently.
Activity
A pipeline may have one or more activities. Activities define the actions to perform on your data. For example,
you may use a Copy activity to copy data from one data store to another data store. Similarly, you may use a Hive
activity, which runs a Hive query on an Azure HDInsight cluster to transform or analyze your data. Data Factory
supports two types of activities: data movement activities and data transformation activities.
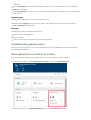
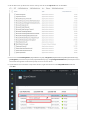
Data movement activities
Copy Activity in Data Factory copies data from a source data store to a sink data store. Data Factory supports the
following data stores. Data from any source can be written to any sink. Click a data store to learn how to copy
data to and from that store.
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data Warehouse
✓
✓
✓
Azure Search Index
Databases
NoSQL
File
Others
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
✓
✓
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
For more information, see Data Movement Activities article.
Data transformation activities
Azure Data Factory supports the following transformation activities that can be added to pipelines either
individually or chained with another activity.
DATA TRANSFORMATION ACTIVITY
COMPUTE ENVIRONMENT
Hive
HDInsight [Hadoop]
Pig
HDInsight [Hadoop]
MapReduce
HDInsight [Hadoop]
Hadoop Streaming
HDInsight [Hadoop]
Spark
HDInsight [Hadoop]
Machine Learning activities: Batch Execution and Update
Resource
Azure VM
Stored Procedure
Azure SQL, Azure SQL Data Warehouse, or SQL Server
Data Lake Analytics U-SQL
Azure Data Lake Analytics
DotNet
HDInsight [Hadoop] or Azure Batch
NOTE
You can use MapReduce activity to run Spark programs on your HDInsight Spark cluster. See Invoke Spark programs from
Azure Data Factory for details. You can create a custom activity to run R scripts on your HDInsight cluster with R installed.
See Run R Script using Azure Data Factory.
For more information, see Data Transformation Activities article.
Custom .NET activities
If you need to move data to/from a data store that Copy Activity doesn't support, or transform data using your
own logic, create a custom .NET activity. For details on creating and using a custom activity, see Use custom
activities in an Azure Data Factory pipeline.
Datasets
An activity takes zero or more datasets as inputs and one or more datasets as outputs. Datasets represent data
structures within the data stores, which simply point or reference the data you want to use in your activities as
inputs or outputs. For example, an Azure Blob dataset specifies the blob container and folder in the Azure Blob
Storage from which the pipeline should read the data. Or, an Azure SQL Table dataset specifies the table to which
the output data is written by the activity.
Linked services
Linked services are much like connection strings, which define the connection information needed for Data
Factory to connect to external resources. Think of it this way - a linked service defines the connection to the data
source and a dataset represents the structure of the data. For example, an Azure Storage linked service specifies
connection string to connect to the Azure Storage account. And, an Azure Blob dataset specifies the blob
container and the folder that contains the data.
Linked services are used for two purposes in Data Factory:
To represent a data store including, but not limited to, an on-premises SQL Server, Oracle database, file share,
or an Azure Blob Storage account. See the Data movement activities section for a list of supported data stores.
To represent a compute resource that can host the execution of an activity. For example, the HDInsightHive
activity runs on an HDInsight Hadoop cluster. See Data transformation activities section for a list of supported
compute environments.
Relationship between Data Factory entities
Figure 2. Relationships between Dataset, Activity, Pipeline, and Linked service
Supported regions
Currently, you can create data factories in the West US, East US, and North Europe regions. However, a data
factory can access data stores and compute services in other Azure regions to move data between data stores or
process data using compute services.
Azure Data Factory itself does not store any data. It lets you create data-driven workflows to orchestrate
movement of data between supported data stores and processing of data using compute services in other
regions or in an on-premises environment. It also allows you to monitor and manage workflows using both
programmatic and UI mechanisms.
Even though Data Factory is available in only West US, East US, and North Europe regions, the service
powering the data movement in Data Factory is available globally in several regions. If a data store is behind a
firewall, then a Data Management Gateway installed in your on-premises environment moves the data instead.
For an example, let us assume that your compute environments such as Azure HDInsight cluster and Azure
Machine Learning are running out of West Europe region. You can create and use an Azure Data Factory instance
in North Europe and use it to schedule jobs on your compute environments in West Europe. It takes a few
milliseconds for Data Factory to trigger the job on your compute environment but the time for running the job on
your computing environment does not change.
Get started with creating a pipeline
You can use one of these tools or APIs to create data pipelines in Azure Data Factory:
Azure portal
Visual Studio
PowerShell
.NET API
REST API
Azure Resource Manager template.
To learn how to build data factories with data pipelines, follow step-by-step instructions in the following tutorials:
TUTORIAL
DESCRIPTION
Move data between two cloud data stores
In this tutorial, you create a data factory with a pipeline that
moves data from Blob storage to SQL database.
Transform data using Hadoop cluster
In this tutorial, you build your first Azure data factory with a
data pipeline that processes data by running Hive script on
an Azure HDInsight (Hadoop) cluster.
Move data between an on-premises data store and a cloud
data store using Data Management Gateway
In this tutorial, you build a data factory with a pipeline that
moves data from an on-premises SQL Server database to
an Azure blob. As part of the walkthrough, you install and
configure the Data Management Gateway on your machine.
Pipelines and Activities in Azure Data Factory
6/13/2017 • 16 min to read • Edit Online
This article helps you understand pipelines and activities in Azure Data Factory and use them to
construct end-to-end data-driven workflows for your data movement and data processing scenarios.
NOTE
This article assumes that you have gone through Introduction to Azure Data Factory. If you do not have
hands-on-experience with creating data factories, going through data transformation tutorial and/or data
movement tutorial would help you understand this article better.
Overview
A data factory can have one or more pipelines. A pipeline is a logical grouping of activities that
together perform a task. The activities in a pipeline define actions to perform on your data. For
example, you may use a copy activity to copy data from an on-premises SQL Server to an Azure Blob
Storage. Then, use a Hive activity that runs a Hive script on an Azure HDInsight cluster to
process/transform data from the blob storage to produce output data. Finally, use a second copy
activity to copy the output data to an Azure SQL Data Warehouse on top of which business intelligence
(BI) reporting solutions are built.
An activity can take zero or more input datasets and produce one or more output datasets. The
following diagram shows the relationship between pipeline, activity, and dataset in Data Factory:
A pipeline allows you to manage activities as a set instead of each one individually. For example, you
can deploy, schedule, suspend, and resume a pipeline, instead of dealing with activities in the pipeline
independently.
Data Factory supports two types of activities: data movement activities and data transformation
activities. Each activity can have zero or more input datasets and produce one or more output datasets.
An input dataset represents the input for an activity in the pipeline and an output dataset represents
the output for the activity. Datasets identify data within different data stores, such as tables, files,
folders, and documents. After you create a dataset, you can use it with activities in a pipeline. For
example, a dataset can be an input/output dataset of a Copy Activity or an HDInsightHive Activity. For
more information about datasets, see Datasets in Azure Data Factory article.
Data movement activities
Copy Activity in Data Factory copies data from a source data store to a sink data store. Data Factory
supports the following data stores. Data from any source can be written to any sink. Click a data store
to learn how to copy data to and from that store.
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data
Warehouse
✓
✓
✓
Azure Search Index
Databases
NoSQL
File
Others
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business
Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
✓
✓
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
NOTE
Data stores with * can be on-premises or on Azure IaaS, and require you to install Data Management Gateway
on an on-premises/Azure IaaS machine.
For more information, see Data Movement Activities article.
Data transformation activities
Azure Data Factory supports the following transformation activities that can be added to pipelines
either individually or chained with another activity.
DATA TRANSFORMATION ACTIVITY
COMPUTE ENVIRONMENT
Hive
HDInsight [Hadoop]
Pig
HDInsight [Hadoop]
MapReduce
HDInsight [Hadoop]
Hadoop Streaming
HDInsight [Hadoop]
Spark
HDInsight [Hadoop]
Machine Learning activities: Batch Execution and
Update Resource
Azure VM
Stored Procedure
Azure SQL, Azure SQL Data Warehouse, or SQL Server
Data Lake Analytics U-SQL
Azure Data Lake Analytics
DotNet
HDInsight [Hadoop] or Azure Batch
NOTE
You can use MapReduce activity to run Spark programs on your HDInsight Spark cluster. See Invoke Spark
programs from Azure Data Factory for details. You can create a custom activity to run R scripts on your
HDInsight cluster with R installed. See Run R Script using Azure Data Factory.
For more information, see Data Transformation Activities article.
Custom .NET activities
If you need to move data to/from a data store that the Copy Activity doesn't support, or transform data
using your own logic, create a custom .NET activity. For details on creating and using a custom
activity, see Use custom activities in an Azure Data Factory pipeline.
Schedule pipelines
A pipeline is active only between its start time and end time. It is not executed before the start time or
after the end time. If the pipeline is paused, it does not get executed irrespective of its start and end
time. For a pipeline to run, it should not be paused. See Scheduling and Execution to understand how
scheduling and execution works in Azure Data Factory.
Pipeline JSON
Let us take a closer look on how a pipeline is defined in JSON format. The generic structure for a
pipeline looks as follows:
{
"name": "PipelineName",
"properties":
{
"description" : "pipeline description",
"activities":
[
],
"start": "<start date-time>",
"end": "<end date-time>",
"isPaused": true/false,
"pipelineMode": "scheduled/onetime",
"expirationTime": "15.00:00:00",
"datasets":
[
]
}
}
TAG
DESCRIPTION
REQUIRED
name
Name of the pipeline. Specify a
name that represents the action
that the pipeline performs.
Maximum number of
characters: 260
Must start with a letter
number, or an underscore
(_)
Following characters are not
allowed: “.”, “+”, “?”, “/”,
“<”,”>”,”*”,”%”,”&”,”:”,”\”
Yes
description
Specify the text describing what the
pipeline is used for.
Yes
TAG
DESCRIPTION
REQUIRED
activities
The activities section can have one
or more activities defined within it.
See the next section for details
about the activities JSON element.
Yes
start
Start date-time for the pipeline.
Must be in ISO format. For
example: 2016-10-14T16:32:41Z .
No
It is possible to specify a local time,
for example an EST time. Here is an
example:
2016-02-27T06:00:00-05:00 ",
which is 6 AM EST.
The start and end properties
together specify active period for
the pipeline. Output slices are only
produced with in this active period.
end
End date-time for the pipeline. If
specified must be in ISO format.
For example:
2016-10-14T17:32:41Z
It is possible to specify a local time,
for example an EST time. Here is an
example:
2016-02-27T06:00:00-05:00 ,
which is 6 AM EST.
If you specify a value for the end
property, you must specify value
for the start property.
The start and end times can both
be empty to create a pipeline. You
must specify both values to set an
active period for the pipeline to
run. If you do not specify start and
end times when creating a pipeline,
you can set them using the SetAzureRmDataFactoryPipelineActive
Period cmdlet later.
No
If you specify a value for the start
property, you must specify value
for the end property.
See notes for the start property.
To run the pipeline indefinitely,
specify 9999-09-09 as the value
for the end property.
A pipeline is active only between its
start time and end time. It is not
executed before the start time or
after the end time. If the pipeline is
paused, it does not get executed
irrespective of its start and end
time. For a pipeline to run, it should
not be paused. See Scheduling and
Execution to understand how
scheduling and execution works in
Azure Data Factory.
isPaused
If set to true, the pipeline does not
run. It's in the paused state. Default
value = false. You can use this
property to enable or disable a
pipeline.
No
TAG
DESCRIPTION
REQUIRED
pipelineMode
The method for scheduling runs for
the pipeline. Allowed values are:
scheduled (default), onetime.
No
‘Scheduled’ indicates that the
pipeline runs at a specified time
interval according to its active
period (start and end time).
‘Onetime’ indicates that the
pipeline runs only once. Onetime
pipelines once created cannot be
modified/updated currently. See
Onetime pipeline for details about
onetime setting.
expirationTime
Duration of time after creation for
which the one-time pipeline is valid
and should remain provisioned. If it
does not have any active, failed, or
pending runs, the pipeline is
automatically deleted once it
reaches the expiration time. The
default value:
No
"expirationTime":
"3.00:00:00"
datasets
List of datasets to be used by
activities defined in the pipeline.
This property can be used to define
datasets that are specific to this
pipeline and not defined within the
data factory. Datasets defined
within this pipeline can only be
used by this pipeline and cannot be
shared. See Scoped datasets for
details.
No
Activity JSON
The activities section can have one or more activities defined within it. Each activity has the following
top-level structure:
{
"name": "ActivityName",
"description": "description",
"type": "<ActivityType>",
"inputs": "[]",
"outputs": "[]",
"linkedServiceName": "MyLinkedService",
"typeProperties":
{
},
"policy":
{
},
"scheduler":
{
}
}
Following table describes properties in the activity JSON definition:
TAG
DESCRIPTION
REQUIRED
name
Name of the activity. Specify a
name that represents the action
that the activity performs.
Maximum number of
characters: 260
Must start with a letter
number, or an underscore
(_)
Following characters are not
allowed: “.”, “+”, “?”, “/”,
“<”,”>”,”*”,”%”,”&”,”:”,”\”
Yes
description
Text describing what the activity or
is used for
Yes
type
Type of the activity. See the Data
Movement Activities and Data
Transformation Activities sections
for different types of activities.
Yes
inputs
Input tables used by the activity
Yes
// one input table
"inputs": [ { "name":
"inputtable1" } ],
// two input tables
"inputs": [ { "name":
"inputtable1" }, { "name":
"inputtable2" } ],
TAG
DESCRIPTION
REQUIRED
outputs
Output tables used by the activity.
Yes
// one output table
"outputs": [ { "name":
"outputtable1" } ],
//two output tables
"outputs": [ { "name":
"outputtable1" }, { "name":
"outputtable2" } ],
linkedServiceName
Name of the linked service used by
the activity.
An activity may require that you
specify the linked service that links
to the required compute
environment.
Yes for HDInsight Activity and
Azure Machine Learning Batch
Scoring Activity
No for all others
typeProperties
Properties in the typeProperties
section depend on type of the
activity. To see type properties for
an activity, click links to the activity
in the previous section.
No
policy
Policies that affect the run-time
behavior of the activity. If it is not
specified, default policies are used.
No
scheduler
“scheduler” property is used to
define desired scheduling for the
activity. Its subproperties are the
same as the ones in the availability
property in a dataset.
No
Policies
Policies affect the run-time behavior of an activity, specifically when the slice of a table is processed.
The following table provides the details.
PROPERTY
PERMITTED VALUES
DEFAULT VALUE
DESCRIPTION
concurrency
Integer
1
Number of concurrent
executions of the activity.
Max value: 10
It determines the number
of parallel activity
executions that can
happen on different
slices. For example, if an
activity needs to go
through a large set of
available data, having a
larger concurrency value
speeds up the data
processing.
PROPERTY
PERMITTED VALUES
DEFAULT VALUE
DESCRIPTION
executionPriorityOrder
NewestFirst
OldestFirst
Determines the ordering
of data slices that are
being processed.
OldestFirst
For example, if you have
2 slices (one happening
at 4pm, and another one
at 5pm), and both are
pending execution. If you
set the
executionPriorityOrder to
be NewestFirst, the slice
at 5 PM is processed first.
Similarly if you set the
executionPriorityORder
to be OldestFIrst, then
the slice at 4 PM is
processed.
retry
Integer
0
Number of retries before
the data processing for
the slice is marked as
Failure. Activity execution
for a data slice is retried
up to the specified retry
count. The retry is done
as soon as possible after
the failure.
00:00:00
Timeout for the activity.
Example: 00:10:00
(implies timeout 10 mins)
Max value can be 10
timeout
TimeSpan
If a value is not specified
or is 0, the timeout is
infinite.
If the data processing
time on a slice exceeds
the timeout value, it is
canceled, and the system
attempts to retry the
processing. The number
of retries depends on the
retry property. When
timeout occurs, the
status is set to TimedOut.
delay
TimeSpan
00:00:00
Specify the delay before
data processing of the
slice starts.
The execution of activity
for a data slice is started
after the Delay is past the
expected execution time.
Example: 00:10:00
(implies delay of 10 mins)
longRetry
Integer
1
longRetry
Integer
1
PROPERTY
PERMITTED VALUES
DEFAULT VALUE
Max value: 10
The number of long retry
DESCRIPTION
attempts before the slice
execution is failed.
longRetry attempts are
spaced by
longRetryInterval. So if
you need to specify a
time between retry
attempts, use longRetry.
If both Retry and
longRetry are specified,
each longRetry attempt
includes Retry attempts
and the max number of
attempts is Retry *
longRetry.
For example, if we have
the following settings in
the activity policy:
Retry: 3
longRetry: 2
longRetryInterval:
01:00:00
Assume there is only one
slice to execute (status is
Waiting) and the activity
execution fails every time.
Initially there would be 3
consecutive execution
attempts. After each
attempt, the slice status
would be Retry. After first
3 attempts are over, the
slice status would be
LongRetry.
After an hour (that is,
longRetryInteval’s value),
there would be another
set of 3 consecutive
execution attempts. After
that, the slice status
would be Failed and no
more retries would be
attempted. Hence overall
6 attempts were made.
If any execution succeeds,
the slice status would be
Ready and no more
retries are attempted.
longRetry may be used in
situations where
dependent data arrives at
non-deterministic times
or the overall
environment is flaky
under which data
processing occurs. In
such cases, doing retries
one after another may
PROPERTY
longRetryInterval
PERMITTED VALUES
TimeSpan
DEFAULT VALUE
00:00:00
not help and doing so
DESCRIPTION
after an interval of time
results in the desired
output.
Word of caution: do not
set high values for
longRetry or
longRetryInterval.
Typically, higher values
imply other systemic
issues.
The delay between long
retry attempts
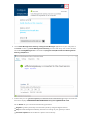
Sample copy pipeline
In the following sample pipeline, there is one activity of type Copy in the activities section. In this
sample, the copy activity copies data from an Azure Blob storage to an Azure SQL database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
],
"start": "2016-07-12T00:00:00Z",
"end": "2016-07-13T00:00:00Z"
}
}
Note the following points:
In the activities section, there is only one activity whose type is set to Copy.
Input for the activity is set to InputDataset and output for the activity is set to OutputDataset. See
Datasets article for defining datasets in JSON.
In the typeProperties section, BlobSource is specified as the source type and SqlSink is specified
as the sink type. In the Data movement activities section, click the data store that you want to use as
a source or a sink to learn more about moving data to/from that data store.
For a complete walkthrough of creating this pipeline, see Tutorial: Copy data from Blob Storage to SQL
Database.
Sample transformation pipeline
In the following sample pipeline, there is one activity of type HDInsightHive in the activities section.
In this sample, the HDInsight Hive activity transforms data from an Azure Blob storage by running a
Hive script file on an Azure HDInsight Hadoop cluster.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
],
"start": "2016-04-01T00:00:00Z",
"end": "2016-04-02T00:00:00Z",
"isPaused": false
}
}
Note the following points:
In the activities section, there is only one activity whose type is set to HDInsightHive.
The Hive script file, partitionweblogs.hql, is stored in the Azure storage account (specified by the
scriptLinkedService, called AzureStorageLinkedService), and in script folder in the container
adfgetstarted.
The defines section is used to specify the runtime settings that are passed to the hive script as Hive
configuration values (e.g ${hiveconf:inputtable} , ${hiveconf:partitionedtable} ).
The typeProperties section is different for each transformation activity. To learn about type properties
supported for a transformation activity, click the transformation activity in the Data transformation
activities table.
For a complete walkthrough of creating this pipeline, see Tutorial: Build your first pipeline to process
data using Hadoop cluster.
Multiple activities in a pipeline
The previous two sample pipelines have only one activity in them. You can have more than one activity
in a pipeline.
If you have multiple activities in a pipeline and output of an activity is not an input of another activity,
the activities may run in parallel if input data slices for the activities are ready.
You can chain two activities by having the output dataset of one activity as the input dataset of the
other activity. The second activity executes only when the first one completes successfully.
In this sample, the pipeline has two activities: Activity1 and Activity2. The Activity1 takes Dataset1 as an
input and produces an output Dataset2. The Activity takes Dataset2 as an input and produces an output
Dataset3. Since the output of Activity1 (Dataset2) is the input of Activity2, the Activity2 runs only after
the Activity completes successfully and produces the Dataset2 slice. If the Activity1 fails for some
reason and does not produce the Dataset2 slice, the Activity 2 does not run for that slice (for example: 9
AM to 10 AM).
You can also chain activities that are in different pipelines.
In this sample, Pipeline1 has only one activity that takes Dataset1 as an input and produces Dataset2 as
an output. The Pipeline2 also has only one activity that takes Dataset2 as an input and Dataset3 as an
output.
For more information, see scheduling and execution.
Create and monitor pipelines
You can create pipelines by using one of these tools or SDKs.
Copy Wizard.
Azure portal
Visual Studio
Azure PowerShell
Azure Resource Manager template
REST API
.NET API
See the following tutorials for step-by-step instructions for creating pipelines by using one of these
tools or SDKs.
Build a pipeline with a data transformation activity
Build a pipeline with a data movement activity
Once a pipeline is created/deployed, you can manage and monitor your pipelines by using the Azure
portal blades or Monitor and Manage App. See the following topics for step-by-step instructions.
Monitor and manage pipelines by using Azure portal blades.
Monitor and manage pipelines by using Monitor and Manage App
Onetime pipeline
You can create and schedule a pipeline to run periodically (for example: hourly or daily) within the start
and end times you specify in the pipeline definition. See Scheduling activities for details. You can also
create a pipeline that runs only once. To do so, you set the pipelineMode property in the pipeline
definition to onetime as shown in the following JSON sample. The default value for this property is
scheduled.
{
"name": "CopyPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": false
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
]
"name": "CopyActivity-0"
}
]
"pipelineMode": "OneTime"
}
}
Note the following:
Start and end times for the pipeline are not specified.
Availability of input and output datasets is specified (frequency and interval), even though Data
Factory does not use the values.
Diagram view does not show one-time pipelines. This behavior is by design.
One-time pipelines cannot be updated. You can clone a one-time pipeline, rename it, update
properties, and deploy it to create another one.
Next Steps
For more information about datasets, see Create datasets article.
For more information about how pipelines are scheduled and executed, see Scheduling and
execution in Azure Data Factory article.
Datasets in Azure Data Factory
5/1/2017 • 15 min to read • Edit Online
This article describes what datasets are, how they are defined in JSON format, and how they are
used in Azure Data Factory pipelines. It provides details about each section (for example, structure,
availability, and policy) in the dataset JSON definition. The article also provides examples for using
the offset, anchorDateTime, and style properties in a dataset JSON definition.
NOTE
If you are new to Data Factory, see Introduction to Azure Data Factory for an overview. If you do not have
hands-on experience with creating data factories, you can gain a better understanding by reading the data
transformation tutorial and the data movement tutorial.
Overview
A data factory can have one or more pipelines. A pipeline is a logical grouping of activities that
together perform a task. The activities in a pipeline define actions to perform on your data. For
example, you might use a copy activity to copy data from an on-premises SQL Server to Azure Blob
storage. Then, you might use a Hive activity that runs a Hive script on an Azure HDInsight cluster to
process data from Blob storage to produce output data. Finally, you might use a second copy
activity to copy the output data to Azure SQL Data Warehouse, on top of which business
intelligence (BI) reporting solutions are built. For more information about pipelines and activities,
see Pipelines and activities in Azure Data Factory.
An activity can take zero or more input datasets, and produce one or more output datasets. An
input dataset represents the input for an activity in the pipeline, and an output dataset represents
the output for the activity. Datasets identify data within different data stores, such as tables, files,
folders, and documents. For example, an Azure Blob dataset specifies the blob container and folder
in Blob storage from which the pipeline should read the data.
Before you create a dataset, create a linked service to link your data store to the data factory.
Linked services are much like connection strings, which define the connection information needed
for Data Factory to connect to external resources. Datasets identify data within the linked data
stores, such as SQL tables, files, folders, and documents. For example, an Azure Storage linked
service links a storage account to the data factory. An Azure Blob dataset represents the blob
container and the folder that contains the input blobs to be processed.
Here is a sample scenario. To copy data from Blob storage to a SQL database, you create two linked
services: Azure Storage and Azure SQL Database. Then, create two datasets: Azure Blob dataset
(which refers to the Azure Storage linked service) and Azure SQL Table dataset (which refers to the
Azure SQL Database linked service). The Azure Storage and Azure SQL Database linked services
contain connection strings that Data Factory uses at runtime to connect to your Azure Storage and
Azure SQL Database, respectively. The Azure Blob dataset specifies the blob container and blob
folder that contains the input blobs in your Blob storage. The Azure SQL Table dataset specifies the
SQL table in your SQL database to which the data is to be copied.
The following diagram shows the relationships among pipeline, activity, dataset, and linked service
in Data Factory:
Dataset JSON
A dataset in Data Factory is defined in JSON format as follows:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: AzureBlob, AzureSql etc...>",
"external": <boolean flag to indicate external data. only for input datasets>,
"linkedServiceName": "<Name of the linked service that refers to a data store.>",
"structure": [
{
"name": "<Name of the column>",
"type": "<Name of the type>"
}
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
},
"availability": {
"frequency": "<Specifies the time unit for data slice production. Supported
frequency: Minute, Hour, Day, Week, Month>",
"interval": "<Specifies the interval within the defined frequency. For example,
frequency set to 'Hour' and interval set to 1 indicates that new data slices should be produced
hourly>"
},
"policy":
{
}
}
}
The following table describes properties in the above JSON:
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
name
Name of the dataset.
See Azure Data Factory
- Naming rules for
naming rules.
Yes
NA
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
type
Type of the dataset.
Specify one of the types
supported by Data
Factory (for example:
AzureBlob,
AzureSqlTable).
Yes
NA
No
NA
For details, see Dataset
type.
structure
Schema of the dataset.
For details, see Dataset
structure.
typeProperties
The type properties are
different for each type
(for example: Azure
Blob, Azure SQL table).
For details on the
supported types and
their properties, see
Dataset type.
Yes
NA
external
Boolean flag to specify
whether a dataset is
explicitly produced by a
data factory pipeline or
not. If the input dataset
for an activity is not
produced by the current
pipeline, set this flag to
true. Set this flag to true
for the input dataset of
the first activity in the
pipeline.
No
false
availability
Defines the processing
window (for example,
hourly or daily) or the
slicing model for the
dataset production.
Each unit of data
consumed and
produced by an activity
run is called a data slice.
If the availability of an
output dataset is set to
daily (frequency - Day,
interval - 1), a slice is
produced daily.
Yes
NA
For details, see Dataset
availability.
For details on the
dataset slicing model,
see the Scheduling and
execution article.
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
policy
Defines the criteria or
the condition that the
dataset slices must
fulfill.
No
NA
For details, see the
Dataset policy section.
Dataset example
In the following example, the dataset represents a table named MyTable in a SQL database.
{
"name": "DatasetSample",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties":
{
"tableName": "MyTable"
},
"availability":
{
"frequency": "Day",
"interval": 1
}
}
}
Note the following points:
type is set to AzureSqlTable.
tableName type property (specific to AzureSqlTable type) is set to MyTable.
linkedServiceName refers to a linked service of type AzureSqlDatabase, which is defined in
the next JSON snippet.
availability frequency is set to Day, and interval is set to 1. This means that the dataset slice
is produced daily.
AzureSqlLinkedService is defined as follows:
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"description": "",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial
Catalog=<databasename>;User ID=<username>@<servername>;Password=<password>;Integrated
Security=False;Encrypt=True;Connect Timeout=30"
}
}
}
In the preceding JSON snippet:
type is set to AzureSqlDatabase.
connectionString type property specifies information to connect to a SQL database.
As you can see, the linked service defines how to connect to a SQL database. The dataset defines
what table is used as an input and output for the activity in a pipeline.
IMPORTANT
Unless a dataset is being produced by the pipeline, it should be marked as external. This setting generally
applies to inputs of first activity in a pipeline.
Dataset type
The type of the dataset depends on the data store you use. See the following table for a list of data
stores supported by Data Factory. Click a data store to learn how to create a linked service and a
dataset for that data store.
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data
Warehouse
✓
✓
✓
Azure Search Index
Databases
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business
Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
✓
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
NoSQL
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
File
Others
SUPPORTED AS A SINK
✓
NOTE
Data stores with * can be on-premises or on Azure infrastructure as a service (IaaS). These data stores
require you to install Data Management Gateway.
In the example in the previous section, the type of the dataset is set to AzureSqlTable. Similarly,
for an Azure Blob dataset, the type of the dataset is set to AzureBlob, as shown in the following
JSON:
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "input.log",
"folderPath": "adfgetstarted/inputdata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true,
"policy": {}
}
}
Dataset structure
The structure section is optional. It defines the schema of the dataset by containing a collection of
names and data types of columns. You use the structure section to provide type information that is
used to convert types and map columns from the source to the destination. In the following
example, the dataset has three columns: slicetimestamp , projectname , and pageviews . They are of
type String, String, and Decimal, respectively.
structure:
[
{ "name": "slicetimestamp", "type": "String"},
{ "name": "projectname", "type": "String"},
{ "name": "pageviews", "type": "Decimal"}
]
Each column in the structure contains the following properties:
PROPERTY
DESCRIPTION
REQUIRED
name
Name of the column.
Yes
type
Data type of the column.
No
culture
.NET-based culture to be used
when the type is a .NET type:
Datetime or Datetimeoffset .
The default is en-us .
No
format
Format string to be used when
the type is a .NET type:
Datetime or Datetimeoffset .
No
The following guidelines help you determine when to include structure information, and what to
include in the structure section.
For structured data sources, specify the structure section only if you want map source
columns to sink columns, and their names are not the same. This kind of structured data
source stores data schema and type information along with the data itself. Examples of
structured data sources include SQL Server, Oracle, and Azure table.
As type information is already available for structured data sources, you should not include
type information when you do include the structure section.
For schema on read data sources (specifically Blob storage), you can choose to store
data without storing any schema or type information with the data. For these types of data
sources, include structure when you want to map source columns to sink columns. Also
include structure when the dataset is an input for a copy activity, and data types of source
dataset should be converted to native types for the sink.
Data Factory supports the following values for providing type information in structure:
Int16, Int32, Int64, Single, Double, Decimal, Byte[], Bool, String, Guid, Datetime,
Datetimeoffset, and Timespan. These values are Common Language Specification (CLS)compliant, .NET-based type values.
Data Factory automatically performs type conversions when moving data from a source data store
to a sink data store.
Dataset availability
The availability section in a dataset defines the processing window (for example, hourly, daily, or
weekly) for the dataset. For more information about activity windows, see Scheduling and
execution.
The following availability section specifies that the output dataset is either produced hourly, or the
input dataset is available hourly:
"availability":
{
"frequency": "Hour",
"interval": 1
}
If the pipeline has the following start and end times:
"start": "2016-08-25T00:00:00Z",
"end": "2016-08-25T05:00:00Z",
The output dataset is produced hourly within the pipeline start and end times. Therefore, there are
five dataset slices produced by this pipeline, one for each activity window (12 AM - 1 AM, 1 AM - 2
AM, 2 AM - 3 AM, 3 AM - 4 AM, 4 AM - 5 AM).
The following table describes properties you can use in the availability section:
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
frequency
Specifies the time unit
for dataset slice
production.
Yes
NA
Supported frequency:
Minute, Hour, Day,
Week, Month
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
interval
Specifies a multiplier for
frequency.
Yes
NA
No
EndOfInterval
"Frequency x interval"
determines how often
the slice is produced.
For example, if you need
the dataset to be sliced
on an hourly basis, you
set frequency to Hour,
and interval to 1.
Note that if you specify
frequency as Minute,
you should set the
interval to no less than
15.
style
Specifies whether the
slice should be
produced at the start or
end of the interval.
StartOfInterval
EndOfInterval
If frequency is set to
Month, and style is set
to EndOfInterval, the
slice is produced on the
last day of month. If
style is set to
StartOfInterval, the
slice is produced on the
first day of month.
If frequency is set to
Day, and style is set to
EndOfInterval, the slice
is produced in the last
hour of the day.
If frequency is set to
Hour, and style is set
to EndOfInterval, the
slice is produced at the
end of the hour. For
example, for a slice for
the 1 PM - 2 PM
period, the slice is
produced at 2 PM.
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
anchorDateTime
Defines the absolute
position in time used by
the scheduler to
compute dataset slice
boundaries.
No
01/01/0001
No
NA
Note that if this
propoerty has date
parts that are more
granular than the
specified frequency, the
more granular parts are
ignored. For example, if
the interval is hourly
(frequency: hour and
interval: 1), and the
anchorDateTime
contains minutes and
seconds, then the
minutes and seconds
parts of
anchorDateTime are
ignored.
offset
Timespan by which the
start and end of all
dataset slices are
shifted.
Note that if both
anchorDateTime and
offset are specified, the
result is the combined
shift.
offset example
By default, daily ( "frequency": "Day", "interval": 1 ) slices start at 12 AM (midnight) Coordinated
Universal Time (UTC). If you want the start time to be 6 AM UTC time instead, set the offset as
shown in the following snippet:
"availability":
{
"frequency": "Day",
"interval": 1,
"offset": "06:00:00"
}
anchorDateTime example
In the following example, the dataset is produced once every 23 hours. The first slice starts at the
time specified by anchorDateTime, which is set to 2017-04-19T08:00:00 (UTC).
"availability":
{
"frequency": "Hour",
"interval": 23,
"anchorDateTime":"2017-04-19T08:00:00"
}
offset/style example
The following dataset is monthly, and is produced on the 3rd of every month at 8:00 AM (
3.08:00:00 ):
"availability": {
"frequency": "Month",
"interval": 1,
"offset": "3.08:00:00",
"style": "StartOfInterval"
}
Dataset policy
The policy section in the dataset definition defines the criteria or the condition that the dataset
slices must fulfill.
Validation policies
POLICY NAME
DESCRIPTION
APPLIED TO
REQUIRED
DEFAULT
minimumSizeMB
Validates that the
data in Azure
Blob storage
meets the
minimum size
requirements (in
megabytes).
Azure Blob
storage
No
NA
minimumRows
Validates that the
data in an Azure
SQL database or
an Azure table
contains the
minimum number
of rows.
No
NA
Examples
minimumSizeMB:
"policy":
{
"validation":
{
"minimumSizeMB": 10.0
}
}
minimumRows:
Azure SQL
database
Azure table
"policy":
{
"validation":
{
"minimumRows": 100
}
}
External datasets
External datasets are the ones that are not produced by a running pipeline in the data factory. If the
dataset is marked as external, the ExternalData policy may be defined to influence the behavior
of the dataset slice availability.
Unless a dataset is being produced by Data Factory, it should be marked as external. This setting
generally applies to the inputs of first activity in a pipeline, unless activity or pipeline chaining is
being used.
NAME
DESCRIPTION
REQUIRED
DEFAULT VALUE
dataDelay
The time to delay the
check on the availability
of the external data for
the given slice. For
example, you can delay
an hourly check by
using this setting.
No
0
The setting only applies
to the present time. For
example, if it is 1:00 PM
right now and this value
is 10 minutes, the
validation starts at 1:10
PM.
Note that this setting
does not affect slices in
the past. Slices with
Slice End Time +
dataDelay < Now are
processed without any
delay.
Times greater than
23:59 hours should be
specified by using the
day.hours:minutes:seconds
format. For example, to
specify 24 hours, don't
use 24:00:00. Instead,
use 1.00:00:00. If you
use 24:00:00, it is
treated as 24 days
(24.00:00:00). For 1 day
and 4 hours, specify
1:04:00:00.
NAME
DESCRIPTION
REQUIRED
DEFAULT VALUE
retryInterval
The wait time between a
failure and the next
attempt. This setting
applies to present time.
If the previous try failed,
the next try is after the
retryInterval period.
No
00:01:00 (1 minute)
No
00:10:00 (10 minutes)
No
3
If it is 1:00 PM right
now, we begin the first
try. If the duration to
complete the first
validation check is 1
minute and the
operation failed, the
next retry is at 1:00 +
1min (duration) + 1min
(retry interval) = 1:02
PM.
For slices in the past,
there is no delay. The
retry happens
immediately.
retryTimeout
The timeout for each
retry attempt.
If this property is set to
10 minutes, the
validation should be
completed within 10
minutes. If it takes
longer than 10 minutes
to perform the
validation, the retry
times out.
If all attempts for the
validation time out, the
slice is marked as
TimedOut.
maximumRetry
The number of times to
check for the availability
of the external data. The
maximum allowed value
is 10.
Create datasets
You can create datasets by using one of these tools or SDKs:
Copy Wizard
Azure portal
Visual Studio
PowerShell
Azure Resource Manager template
REST API
.NET API
See the following tutorials for step-by-step instructions for creating pipelines and datasets by using
one of these tools or SDKs:
Build a pipeline with a data transformation activity
Build a pipeline with a data movement activity
After a pipeline is created and deployed, you can manage and monitor your pipelines by using the
Azure portal blades, or the Monitoring and Management app. See the following topics for step-bystep instructions:
Monitor and manage pipelines by using Azure portal blades
Monitor and manage pipelines by using the Monitoring and Management app
Scoped datasets
You can create datasets that are scoped to a pipeline by using the datasets property. These
datasets can only be used by activities within this pipeline, not by activities in other pipelines. The
following example defines a pipeline with two datasets (InputDataset-rdc and OutputDataset-rdc)
to be used within the pipeline.
IMPORTANT
Scoped datasets are supported only with one-time pipelines (where pipelineMode is set to OneTime).
See Onetime pipeline for details.
{
"name": "CopyPipeline-rdc",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": false
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "InputDataset-rdc"
}
],
"outputs": [
{
"name": "OutputDataset-rdc"
}
],
"scheduler": {
"frequency": "Day",
"interval": 1,
"style": "StartOfInterval"
},
"name": "CopyActivity-0"
"name": "CopyActivity-0"
}
],
"start": "2016-02-28T00:00:00Z",
"end": "2016-02-28T00:00:00Z",
"isPaused": false,
"pipelineMode": "OneTime",
"expirationTime": "15.00:00:00",
"datasets": [
{
"name": "InputDataset-rdc",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "InputLinkedService-rdc",
"typeProperties": {
"fileName": "emp.txt",
"folderPath": "adftutorial/input",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": true,
"policy": {}
}
},
{
"name": "OutputDataset-rdc",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "OutputLinkedService-rdc",
"typeProperties": {
"fileName": "emp.txt",
"folderPath": "adftutorial/output",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": false,
"policy": {}
}
}
]
}
}
Next steps
For more information about pipelines, see Create pipelines.
For more information about how pipelines are scheduled and executed, see Scheduling and
execution in Azure Data Factory.
Data Factory scheduling and execution
5/22/2017 • 22 min to read • Edit Online
This article explains the scheduling and execution aspects of the Azure Data Factory application model. This
article assumes that you understand basics of Data Factory application model concepts, including activity,
pipelines, linked services, and datasets. For basic concepts of Azure Data Factory, see the following articles:
Introduction to Data Factory
Pipelines
Datasets
Start and end times of pipeline
A pipeline is active only between its start time and end time. It is not executed before the start time or after the
end time. If the pipeline is paused, it is not executed irrespective of its start and end time. For a pipeline to run,
it should not be paused. You find these settings (start, end, paused) in the pipeline definition:
"start": "2017-04-01T08:00:00Z",
"end": "2017-04-01T11:00:00Z"
"isPaused": false
For more information these properties, see create pipelines article.
Specify schedule for an activity
It is not the pipeline that is executed. It is the activities in the pipeline that are executed in the overall context of
the pipeline. You can specify a recurring schedule for an activity by using the scheduler section of activity
JSON. For example, you can schedule an activity to run hourly as follows:
"scheduler": {
"frequency": "Hour",
"interval": 1
},
As shown in the following diagram, specifying a schedule for an activity creates a series of tumbling windows
with in the pipeline start and end times. Tumbling windows are a series of fixed-size non-overlapping,
contiguous time intervals. These logical tumbling windows for an activity are called activity windows.
The scheduler property for an activity is optional. If you do specify this property, it must match the cadence
you specify in the definition of output dataset for the activity. Currently, output dataset is what drives the
schedule. Therefore, you must create an output dataset even if the activity does not produce any output.
Specify schedule for a dataset
An activity in a Data Factory pipeline can take zero or more input datasets and produce one or more output
datasets. For an activity, you can specify the cadence at which the input data is available or the output data is
produced by using the availability section in the dataset definitions.
Frequency in the availability section specifies the time unit. The allowed values for frequency are: Minute,
Hour, Day, Week, and Month. The interval property in the availability section specifies a multiplier for
frequency. For example: if the frequency is set to Day and interval is set to 1 for an output dataset, the output
data is produced daily. If you specify the frequency as minute, we recommend that you set the interval to no
less than 15.
In the following example, the input data is available hourly and the output data is produced hourly (
"frequency": "Hour", "interval": 1 ).
Input dataset:
{
"name": "AzureSqlInput",
"properties": {
"published": false,
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {}
}
}
Output dataset
{
"name": "AzureBlobOutput",
"properties": {
"published": false,
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mypath/{Year}/{Month}/{Day}/{Hour}",
"format": {
"type": "TextFormat"
},
"partitionedBy": [
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" }
},
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "HH" }}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Currently, output dataset drives the schedule. In other words, the schedule specified for the output dataset
is used to run an activity at runtime. Therefore, you must create an output dataset even if the activity does not
produce any output. If the activity doesn't take any input, you can skip creating the input dataset.
In the following pipeline definition, the scheduler property is used to specify schedule for the activity. This
property is optional. Currently, the schedule for the activity must match the schedule specified for the output
dataset.
{
"name": "SamplePipeline",
"properties": {
"description": "copy activity",
"activities": [
{
"type": "Copy",
"name": "AzureSQLtoBlob",
"description": "copy activity",
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >=
\\'{0:yyyy-MM-dd HH:mm}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 100000,
"writeBatchTimeout": "00:05:00"
}
},
"inputs": [
{
"name": "AzureSQLInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"scheduler": {
"frequency": "Hour",
"interval": 1
}
}
],
"start": "2017-04-01T08:00:00Z",
"end": "2017-04-01T11:00:00Z"
}
}
In this example, the activity runs hourly between the start and end times of the pipeline. The output data is
produced hourly for three-hour windows (8 AM - 9 AM, 9 AM - 10 AM, and 10 AM - 11 AM).
Each unit of data consumed or produced by an activity run is called a data slice. The following diagram shows
an example of an activity with one input dataset and one output dataset:
The diagram shows the hourly data slices for the input and output dataset. The diagram shows three input
slices that are ready for processing. The 10-11 AM activity is in progress, producing the 10-11 AM output slice.
You can access the time interval associated with the current slice in the dataset JSON by using variables:
SliceStart and SliceEnd. Similarly, you can access the time interval associated with an activity window by using
the WindowStart and WindowEnd. The schedule of an activity must match the schedule of the output dataset
for the activity. Therefore, the SliceStart and SliceEnd values are the same as WindowStart and WindowEnd
values respectively. For more information on these variables, see Data Factory functions and system variables
articles.
You can use these variables for different purposes in your activity JSON. For example, you can use them to
select data from input and output datasets representing time series data (for example: 8 AM to 9 AM). This
example also uses WindowStart and WindowEnd to select relevant data for an activity run and copy it to a
blob with the appropriate folderPath. The folderPath is parameterized to have a separate folder for every
hour.
In the preceding example, the schedule specified for input and output datasets is the same (hourly). If the input
dataset for the activity is available at a different frequency, say every 15 minutes, the activity that produces this
output dataset still runs once an hour as the output dataset is what drives the activity schedule. For more
information, see Model datasets with different frequencies.
Dataset availability and policies
You have seen the usage of frequency and interval properties in the availability section of dataset definition.
There are a few other properties that affect the scheduling and execution of an activity.
Dataset availability
The following table describes properties you can use in the availability section:
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
frequency
Specifies the time unit for
dataset slice production.
Yes
NA
Supported frequency:
Minute, Hour, Day, Week,
Month
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
interval
Specifies a multiplier for
frequency
Yes
NA
No
EndOfInterval
”Frequency x interval”
determines how often the
slice is produced.
If you need the dataset to
be sliced on an hourly
basis, you set Frequency
to Hour, and interval to 1.
Note: If you specify
Frequency as Minute, we
recommend that you set
the interval to no less than
15
style
Specifies whether the slice
should be produced at the
start/end of the interval.
StartOfInterval
EndOfInterval
If Frequency is set to
Month and style is set to
EndOfInterval, the slice is
produced on the last day of
month. If the style is set to
StartOfInterval, the slice is
produced on the first day
of month.
If Frequency is set to Day
and style is set to
EndOfInterval, the slice is
produced in the last hour
of the day.
If Frequency is set to Hour
and style is set to
EndOfInterval, the slice is
produced at the end of the
hour. For example, for a
slice for 1 PM – 2 PM
period, the slice is produced
at 2 PM.
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
anchorDateTime
Defines the absolute
position in time used by
scheduler to compute
dataset slice boundaries.
No
01/01/0001
No
NA
Note: If the
AnchorDateTime has date
parts that are more
granular than the
frequency then the more
granular parts are ignored.
For example, if the interval
is hourly (frequency: hour
and interval: 1) and the
AnchorDateTime contains
minutes and seconds,
then the minutes and
seconds parts of the
AnchorDateTime are
ignored.
offset
Timespan by which the
start and end of all dataset
slices are shifted.
Note: If both
anchorDateTime and offset
are specified, the result is
the combined shift.
offset example
By default, daily ( "frequency": "Day", "interval": 1 ) slices start at 12 AM UTC time (midnight). If you want the
start time to be 6 AM UTC time instead, set the offset as shown in the following snippet:
"availability":
{
"frequency": "Day",
"interval": 1,
"offset": "06:00:00"
}
anchorDateTime example
In the following example, the dataset is produced once every 23 hours. The first slice starts at the time specified
by the anchorDateTime, which is set to 2017-04-19T08:00:00 (UTC time).
"availability":
{
"frequency": "Hour",
"interval": 23,
"anchorDateTime":"2017-04-19T08:00:00"
}
offset/style Example
The following dataset is a monthly dataset and is produced on 3rd of every month at 8:00 AM ( 3.08:00:00 ):
"availability": {
"frequency": "Month",
"interval": 1,
"offset": "3.08:00:00",
"style": "StartOfInterval"
}
Dataset policy
A dataset can have a validation policy defined that specifies how the data generated by a slice execution can be
validated before it is ready for consumption. In such cases, after the slice has finished execution, the output slice
status is changed to Waiting with a substatus of Validation. After the slices are validated, the slice status
changes to Ready. If a data slice has been produced but did not pass the validation, activity runs for
downstream slices that depend on this slice are not processed. Monitor and manage pipelines covers the
various states of data slices in Data Factory.
The policy section in dataset definition defines the criteria or the condition that the dataset slices must fulfill.
The following table describes properties you can use in the policy section:
POLICY NAME
DESCRIPTION
APPLIED TO
REQUIRED
DEFAULT
minimumSizeMB
Validates that the
data in an Azure
blob meets the
minimum size
requirements (in
megabytes).
Azure Blob
No
NA
minimumRows
Validates that the
data in an Azure
SQL database or an
Azure table
contains the
minimum number of
rows.
No
NA
Examples
minimumSizeMB:
"policy":
{
"validation":
{
"minimumSizeMB": 10.0
}
}
minimumRows
"policy":
{
"validation":
{
"minimumRows": 100
}
}
Azure SQL
Database
Azure Table
For more information about these properties and examples, see Create datasets article.
Activity policies
Policies affect the run-time behavior of an activity, specifically when the slice of a table is processed. The
following table provides the details.
PROPERTY
PERMITTED VALUES
DEFAULT VALUE
DESCRIPTION
concurrency
Integer
1
Number of concurrent
executions of the activity.
Max value: 10
It determines the number
of parallel activity
executions that can happen
on different slices. For
example, if an activity needs
to go through a large set of
available data, having a
larger concurrency value
speeds up the data
processing.
executionPriorityOrder
NewestFirst
OldestFirst
OldestFirst
Determines the ordering of
data slices that are being
processed.
For example, if you have 2
slices (one happening at
4pm, and another one at
5pm), and both are
pending execution. If you
set the
executionPriorityOrder to
be NewestFirst, the slice at
5 PM is processed first.
Similarly if you set the
executionPriorityORder to
be OldestFIrst, then the
slice at 4 PM is processed.
retry
Integer
Max value can be 10
0
Number of retries before
the data processing for the
slice is marked as Failure.
Activity execution for a data
slice is retried up to the
specified retry count. The
retry is done as soon as
possible after the failure.
PROPERTY
PERMITTED VALUES
DEFAULT VALUE
DESCRIPTION
timeout
TimeSpan
00:00:00
Timeout for the activity.
Example: 00:10:00 (implies
timeout 10 mins)
If a value is not specified or
is 0, the timeout is infinite.
If the data processing time
on a slice exceeds the
timeout value, it is canceled,
and the system attempts to
retry the processing. The
number of retries depends
on the retry property.
When timeout occurs, the
status is set to TimedOut.
delay
TimeSpan
00:00:00
Specify the delay before
data processing of the slice
starts.
The execution of activity for
a data slice is started after
the Delay is past the
expected execution time.
Example: 00:10:00 (implies
delay of 10 mins)
longRetry
Integer
Max value: 10
1
The number of long retry
attempts before the slice
execution is failed.
longRetry attempts are
spaced by
longRetryInterval. So if you
need to specify a time
between retry attempts,
use longRetry. If both Retry
and longRetry are specified,
each longRetry attempt
includes Retry attempts and
the max number of
attempts is Retry *
longRetry.
For example, if we have the
following settings in the
activity policy:
Retry: 3
longRetry: 2
longRetryInterval: 01:00:00
Assume there is only one
slice to execute (status is
Waiting) and the activity
execution fails every time.
Initially there would be 3
consecutive execution
attempts. After each
attempt, the slice status
PROPERTY
PERMITTED VALUES
DEFAULT VALUE
would be Retry. After first 3
DESCRIPTION
attempts are over, the slice
status would be LongRetry.
After an hour (that is,
longRetryInteval’s value),
there would be another set
of 3 consecutive execution
attempts. After that, the
slice status would be Failed
and no more retries would
be attempted. Hence
overall 6 attempts were
made.
If any execution succeeds,
the slice status would be
Ready and no more retries
are attempted.
longRetry may be used in
situations where dependent
data arrives at nondeterministic times or the
overall environment is flaky
under which data
processing occurs. In such
cases, doing retries one
after another may not help
and doing so after an
interval of time results in
the desired output.
Word of caution: do not set
high values for longRetry or
longRetryInterval. Typically,
higher values imply other
systemic issues.
longRetryInterval
TimeSpan
00:00:00
The delay between long
retry attempts
For more information, see Pipelines article.
Parallel processing of data slices
You can set the start date for the pipeline in the past. When you do so, Data Factory automatically calculates
(back fills) all data slices in the past and begins processing them. For example: if you create a pipeline with start
date 2017-04-01 and the current date is 2017-04-10. If the cadence of the output dataset is daily, then Data
Factory starts processing all the slices from 2017-04-01 to 2017-04-09 immediately because the start date is in
the past. The slice from 2017-04-10 is not processed yet because the value of style property in the availability
section is EndOfInterval by default. The oldest slice is processed first as the default value of
executionPriorityOrder is OldestFirst. For a description of the style property, see dataset availability section. For
a description of the executionPriorityOrder section, see the activity policies section.
You can configure back-filled data slices to be processed in parallel by setting the concurrency property in the
policy section of the activity JSON. This property determines the number of parallel activity executions that can
happen on different slices. The default value for the concurrency property is 1. Therefore, one slice is processed
at a time by default. The maximum value is 10. When a pipeline needs to go through a large set of available
data, having a larger concurrency value speeds up the data processing.
Rerun a failed data slice
When an error occurs while processing a data slice, you can find out why the processing of a slice failed by
using Azure portal blades or Monitor and Manage App. See Monitoring and managing pipelines using Azure
portal blades or Monitoring and Management app for details.
Consider the following example, which shows two activities. Activity1 and Activity 2. Activity1 consumes a slice
of Dataset1 and produces a slice of Dataset2, which is consumed as an input by Activity2 to produce a slice of
the Final Dataset.
The diagram shows that out of three recent slices, there was a failure producing the 9-10 AM slice for Dataset2.
Data Factory automatically tracks dependency for the time series dataset. As a result, it does not start the
activity run for the 9-10 AM downstream slice.
Data Factory monitoring and management tools allow you to drill into the diagnostic logs for the failed slice to
easily find the root cause for the issue and fix it. After you have fixed the issue, you can easily start the activity
run to produce the failed slice. For more information on how to rerun and understand state transitions for data
slices, see Monitoring and managing pipelines using Azure portal blades or Monitoring and Management app.
After you rerun the 9-10 AM slice for Dataset2, Data Factory starts the run for the 9-10 AM dependent slice on
the final dataset.
Multiple activities in a pipeline
You can have more than one activity in a pipeline. If you have multiple activities in a pipeline and the output of
an activity is not an input of another activity, the activities may run in parallel if input data slices for the
activities are ready.
You can chain two activities (run one activity after another) by setting the output dataset of one activity as the
input dataset of the other activity. The activities can be in the same pipeline or in different pipelines. The second
activity executes only when the first one finishes successfully.
For example, consider the following case where a pipeline has two activities:
1. Activity A1 that requires external input dataset D1, and produces output dataset D2.
2. Activity A2 that requires input from dataset D2, and produces output dataset D3.
In this scenario, activities A1 and A2 are in the same pipeline. The activity A1 runs when the external data is
available and the scheduled availability frequency is reached. The activity A2 runs when the scheduled slices
from D2 become available and the scheduled availability frequency is reached. If there is an error in one of the
slices in dataset D2, A2 does not run for that slice until it becomes available.
The Diagram view with both activities in the same pipeline would look like the following diagram:
As mentioned earlier, the activities could be in different pipelines. In such a scenario, the diagram view would
look like the following diagram:
See the copy sequentially section in the appendix for an example.
Model datasets with different frequencies
In the samples, the frequencies for input and output datasets and the activity schedule window were the same.
Some scenarios require the ability to produce output at a frequency different than the frequencies of one or
more inputs. Data Factory supports modeling these scenarios.
Sample 1: Produce a daily output report for input data that is available every hour
Consider a scenario in which you have input measurement data from sensors available every hour in Azure
Blob storage. You want to produce a daily aggregate report with statistics such as mean, maximum, and
minimum for the day with Data Factory hive activity.
Here is how you can model this scenario with Data Factory:
Input dataset
The hourly input files are dropped in the folder for the given day. Availability for input is set at Hour
(frequency: Hour, interval: 1).
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/{Year}/{Month}/{Day}/",
"partitionedBy": [
{ "name": "Year", "value": {"type": "DateTime","date": "SliceStart","format": "yyyy"}},
{ "name": "Month","value": {"type": "DateTime","date": "SliceStart","format": "MM"}},
{ "name": "Day","value": {"type": "DateTime","date": "SliceStart","format": "dd"}}
],
"format": {
"type": "TextFormat"
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Output dataset
One output file is created every day in the day's folder. Availability of output is set at Day (frequency: Day and
interval: 1).
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/{Year}/{Month}/{Day}/",
"partitionedBy": [
{ "name": "Year", "value": {"type": "DateTime","date": "SliceStart","format": "yyyy"}},
{ "name": "Month","value": {"type": "DateTime","date": "SliceStart","format": "MM"}},
{ "name": "Day","value": {"type": "DateTime","date": "SliceStart","format": "dd"}}
],
"format": {
"type": "TextFormat"
}
},
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
Activity: hive activity in a pipeline
The hive script receives the appropriate DateTime information as parameters that use the WindowStart
variable as shown in the following snippet. The hive script uses this variable to load the data from the correct
folder for the day and run the aggregation to generate the output.
{
"name":"SamplePipeline",
"properties":{
"start":"2015-01-01T08:00:00",
"end":"2015-01-01T11:00:00",
"description":"hive activity",
"activities": [
{
"name": "SampleHiveActivity",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"linkedServiceName": "HDInsightLinkedService",
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adftutorial\\hivequery.hql",
"scriptLinkedService": "StorageLinkedService",
"defines": {
"Year": "$$Text.Format('{0:yyyy}',WindowStart)",
"Month": "$$Text.Format('{0:MM}',WindowStart)",
"Day": "$$Text.Format('{0:dd}',WindowStart)"
}
},
"scheduler": {
"frequency": "Day",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
The following diagram shows the scenario from a data-dependency point of view.
The output slice for every day depends on 24 hourly slices from an input dataset. Data Factory computes these
dependencies automatically by figuring out the input data slices that fall in the same time period as the output
slice to be produced. If any of the 24 input slices is not available, Data Factory waits for the input slice to be
ready before starting the daily activity run.
Sample 2: Specify dependency with expressions and Data Factory functions
Let’s consider another scenario. Suppose you have a hive activity that processes two input datasets. One of
them has new data daily, but one of them gets new data every week. Suppose you wanted to do a join across
the two inputs and produce an output every day.
The simple approach in which Data Factory automatically figures out the right input slices to process by
aligning to the output data slice’s time period does not work.
You must specify that for every activity run, the Data Factory should use last week’s data slice for the weekly
input dataset. You use Azure Data Factory functions as shown in the following snippet to implement this
behavior.
Input1: Azure blob
The first input is the Azure blob being updated daily.
{
"name": "AzureBlobInputDaily",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/{Year}/{Month}/{Day}/",
"partitionedBy": [
{ "name": "Year", "value": {"type": "DateTime","date": "SliceStart","format": "yyyy"}},
{ "name": "Month","value": {"type": "DateTime","date": "SliceStart","format": "MM"}},
{ "name": "Day","value": {"type": "DateTime","date": "SliceStart","format": "dd"}}
],
"format": {
"type": "TextFormat"
}
},
"external": true,
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
Input2: Azure blob
Input2 is the Azure blob being updated weekly.
{
"name": "AzureBlobInputWeekly",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/{Year}/{Month}/{Day}/",
"partitionedBy": [
{ "name": "Year", "value": {"type": "DateTime","date": "SliceStart","format": "yyyy"}},
{ "name": "Month","value": {"type": "DateTime","date": "SliceStart","format": "MM"}},
{ "name": "Day","value": {"type": "DateTime","date": "SliceStart","format": "dd"}}
],
"format": {
"type": "TextFormat"
}
},
"external": true,
"availability": {
"frequency": "Day",
"interval": 7
}
}
}
Output: Azure blob
One output file is created every day in the folder for the day. Availability of output is set to day (frequency: Day,
interval: 1).
{
"name": "AzureBlobOutputDaily",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/{Year}/{Month}/{Day}/",
"partitionedBy": [
{ "name": "Year", "value": {"type": "DateTime","date": "SliceStart","format": "yyyy"}},
{ "name": "Month","value": {"type": "DateTime","date": "SliceStart","format": "MM"}},
{ "name": "Day","value": {"type": "DateTime","date": "SliceStart","format": "dd"}}
],
"format": {
"type": "TextFormat"
}
},
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
Activity: hive activity in a pipeline
The hive activity takes the two inputs and produces an output slice every day. You can specify every day’s
output slice to depend on the previous week’s input slice for weekly input as follows.
{
"name":"SamplePipeline",
"properties":{
"start":"2015-01-01T08:00:00",
"end":"2015-01-01T11:00:00",
"description":"hive activity",
"activities": [
{
"name": "SampleHiveActivity",
"inputs": [
{
"name": "AzureBlobInputDaily"
},
{
"name": "AzureBlobInputWeekly",
"startTime": "Date.AddDays(SliceStart, - Date.DayOfWeek(SliceStart))",
"endTime": "Date.AddDays(SliceEnd, -Date.DayOfWeek(SliceEnd))"
}
],
"outputs": [
{
"name": "AzureBlobOutputDaily"
}
],
"linkedServiceName": "HDInsightLinkedService",
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adftutorial\\hivequery.hql",
"scriptLinkedService": "StorageLinkedService",
"defines": {
"Year": "$$Text.Format('{0:yyyy}',WindowStart)",
"Month": "$$Text.Format('{0:MM}',WindowStart)",
"Day": "$$Text.Format('{0:dd}',WindowStart)"
}
},
"scheduler": {
"frequency": "Day",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
See Data Factory functions and system variables for a list of functions and system variables that Data Factory
supports.
Appendix
Example: copy sequentially
It is possible to run multiple copy operations one after another in a sequential/ordered manner. For example,
you might have two copy activities in a pipeline (CopyActivity1 and CopyActivity2) with the following input
data output datasets:
CopyActivity1
Input: Dataset. Output: Dataset2.
CopyActivity2
Input: Dataset2. Output: Dataset3.
CopyActivity2 would run only if the CopyActivity1 has run successfully and Dataset2 is available.
Here is the sample pipeline JSON:
{
"name": "ChainActivities",
"properties": {
"description": "Run activities in sequence",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "Dataset1"
}
],
"outputs": [
{
"name": "Dataset2"
}
],
"policy": {
"timeout": "01:00:00"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "CopyFromBlob1ToBlob2",
"description": "Copy data from a blob to another"
},
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "Dataset2"
}
],
"outputs": [
{
"name": "Dataset3"
}
],
],
"policy": {
"timeout": "01:00:00"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "CopyFromBlob2ToBlob3",
"description": "Copy data from a blob to another"
}
],
"start": "2016-08-25T01:00:00Z",
"end": "2016-08-25T01:00:00Z",
"isPaused": false
}
}
Notice that in the example, the output dataset of the first copy activity (Dataset2) is specified as input for the
second activity. Therefore, the second activity runs only when the output dataset from the first activity is ready.
In the example, CopyActivity2 can have a different input, such as Dataset3, but you specify Dataset2 as an input
to CopyActivity2, so the activity does not run until CopyActivity1 finishes. For example:
CopyActivity1
Input: Dataset1. Output: Dataset2.
CopyActivity2
Inputs: Dataset3, Dataset2. Output: Dataset4.
{
"name": "ChainActivities",
"properties": {
"description": "Run activities in sequence",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "Dataset1"
}
],
"outputs": [
{
"name": "Dataset2"
}
],
"policy": {
"timeout": "01:00:00"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
},
"name": "CopyFromBlobToBlob",
"description": "Copy data from a blob to another"
},
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "Dataset3"
},
{
"name": "Dataset2"
}
],
"outputs": [
{
"name": "Dataset4"
}
],
"policy": {
"timeout": "01:00:00"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "CopyFromBlob3ToBlob4",
"description": "Copy data from a blob to another"
}
],
"start": "2017-04-25T01:00:00Z",
"end": "2017-04-25T01:00:00Z",
"isPaused": false
}
}
Notice that in the example, two input datasets are specified for the second copy activity. When multiple inputs
are specified, only the first input dataset is used for copying data, but other datasets are used as dependencies.
CopyActivity2 would start only after the following conditions are met:
CopyActivity1 has successfully completed and Dataset2 is available. This dataset is not used when copying
data to Dataset4. It only acts as a scheduling dependency for CopyActivity2.
Dataset3 is available. This dataset represents the data that is copied to the destination.
Tutorial: Copy data from Blob Storage to SQL
Database using Data Factory
4/28/2017 • 4 min to read • Edit Online
In this tutorial, you create a data factory with a pipeline to copy data from Blob storage to SQL
database.
The Copy Activity performs the data movement in Azure Data Factory. It is powered by a globally
available service that can copy data between various data stores in a secure, reliable, and scalable way.
See Data Movement Activities article for details about the Copy Activity.
NOTE
For a detailed overview of the Data Factory service, see the Introduction to Azure Data Factory article.
Prerequisites for the tutorial
Before you begin this tutorial, you must have the following prerequisites:
Azure subscription. If you don't have a subscription, you can create a free trial account in just a
couple of minutes. See the Free Trial article for details.
Azure Storage Account. You use the blob storage as a source data store in this tutorial. if you
don't have an Azure storage account, see the Create a storage account article for steps to create
one.
Azure SQL Database. You use an Azure SQL database as a destination data store in this tutorial.
If you don't have an Azure SQL database that you can use in the tutorial, See How to create and
configure an Azure SQL Database to create one.
SQL Server 2012/2014 or Visual Studio 2013. You use SQL Server Management Studio or Visual
Studio to create a sample database and to view the result data in the database.
Collect blob storage account name and key
You need the account name and account key of your Azure storage account to do this tutorial. Note
down account name and account key for your Azure storage account.
1. Log in to the Azure portal.
2. Click More services on the left menu and select Storage Accounts.
3. In the Storage Accounts blade, select the Azure storage account that you want to use in this
tutorial.
4. Select Access keys link under SETTINGS.
5. Click copy (image) button next to Storage account name text box and save/paste it somewhere
(for example: in a text file).
6. Repeat the previous step to copy or note down the key1.
7. Close all the blades by clicking X.
Collect SQL server, database, user names
You need the names of Azure SQL server, database, and user to do this tutorial. Note down names of
server, database, and user for your Azure SQL database.
1. In the Azure portal, click More services on the left and select SQL databases.
2. In the SQL databases blade, select the database that you want to use in this tutorial. Note down
the database name.
3. In the SQL database blade, click Properties under SETTINGS.
4. Note down the values for SERVER NAME and SERVER ADMIN LOGIN.
5. Close all the blades by clicking X.
Allow Azure services to access SQL server
Ensure that Allow access to Azure services setting turned ON for your Azure SQL server so that the
Data Factory service can access your Azure SQL server. To verify and turn on this setting, do the
following steps:
1.
2.
3.
4.
Click More services hub on the left and click SQL servers.
Select your server, and click Firewall under SETTINGS.
In the Firewall settings blade, click ON for Allow access to Azure services.
Close all the blades by clicking X.
Prepare Blob Storage and SQL Database
Now, prepare your Azure blob storage and Azure SQL database for the tutorial by performing the
following steps:
1. Launch Notepad. Copy the following text and save it as emp.txt to C:\ADFGetStarted folder
on your hard drive.
John, Doe
Jane, Doe
2. Use tools such as Azure Storage Explorer to create the adftutorial container and to upload the
emp.txt file to the container.
3. Use the following SQL script to create the emp table in your Azure SQL Database.
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50),
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
If you have SQL Server 2012/2014 installed on your computer: follow instructions from
Managing Azure SQL Database using SQL Server Management Studio to connect to your Azure
SQL server and run the SQL script. This article uses the classic Azure portal, not the new Azure
portal, to configure firewall for an Azure SQL server.
If your client is not allowed to access the Azure SQL server, you need to configure firewall for
your Azure SQL server to allow access from your machine (IP Address). See this article for steps
to configure the firewall for your Azure SQL server.
Create a data factory
You have completed the prerequisites. You can create a data factory using one of the following ways.
Click one of the options in the drop-down list at the top or the following links to perform the tutorial.
Copy Wizard
Azure portal
Visual Studio
PowerShell
Azure Resource Manager template
REST API
.NET API
NOTE
The data pipeline in this tutorial copies data from a source data store to a destination data store. It does not
transform input data to produce output data. For a tutorial on how to transform data using Azure Data
Factory, see Tutorial: Build your first pipeline to transform data using Hadoop cluster.
You can chain two activities (run one activity after another) by setting the output dataset of one activity as the
input dataset of the other activity. See Scheduling and execution in Data Factory for detailed information.
Tutorial: Create a pipeline with Copy Activity using
Data Factory Copy Wizard
5/16/2017 • 6 min to read • Edit Online
This tutorial shows you how to use the Copy Wizard to copy data from an Azure blob storage to an Azure
SQL database.
The Azure Data Factory Copy Wizard allows you to quickly create a data pipeline that copies data from a
supported source data store to a supported destination data store. Therefore, we recommend that you use the
wizard as a first step to create a sample pipeline for your data movement scenario. For a list of data stores
supported as sources and as destinations, see supported data stores.
This tutorial shows you how to create an Azure data factory, launch the Copy Wizard, go through a series of
steps to provide details about your data ingestion/movement scenario. When you finish steps in the wizard,
the wizard automatically creates a pipeline with a Copy Activity to copy data from an Azure blob storage to an
Azure SQL database. For more information about Copy Activity, see data movement activities.
Prerequisites
Complete prerequisites listed in the Tutorial Overview article before performing this tutorial.
Create data factory
In this step, you use the Azure portal to create an Azure data factory named ADFTutorialDataFactory.
1. Log in to Azure portal.
2. Click + NEW from the top-left corner, click Data + analytics, and click Data Factory.
3. In the New data factory blade:
a. Enter ADFTutorialDataFactory for the name. The name of the Azure data factory must be
globally unique. If you receive the error:
Data factory name “ADFTutorialDataFactory” is not available , change the name of the data
factory (for example, yournameADFTutorialDataFactoryYYYYMMDD) and try creating again. See
Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
b. Select your Azure subscription.
c. For Resource Group, do one of the following steps:
Select Use existing to select an existing resource group.
Select Create new to enter a name for a resource group.
Some of the steps in this tutorial assume that you use the name:
ADFTutorialResourceGroup for the resource group. To learn about resource groups,
see Using resource groups to manage your Azure resources.
d. Select a location for the data factory.
e. Select Pin to dashboard check box at the bottom of the blade.
f. Click Create.
4. After the creation is complete, you see the Data Factory blade as shown in the following image:
Launch Copy Wizard
1. On the Data Factory blade, click Copy data [PREVIEW] to launch the Copy Wizard.
NOTE
If you see that the web browser is stuck at "Authorizing...", disable/uncheck Block third-party cookies and
site data setting in the browser settings (or) keep it enabled and create an exception for
login.microsoftonline.com and then try launching the wizard again.
2. In the Properties page:
a. Enter CopyFromBlobToAzureSql for Task name
b. Enter description (optional).
c. Change the Start date time and the End date time so that the end date is set to today and start
date to five days earlier.
d. Click Next.
3. On the Source data store page, click Azure Blob Storage tile. You use this page to specify the source
data store for the copy task.
4. On the Specify the Azure Blob storage account page:
a.
b.
c.
d.
Enter AzureStorageLinkedService for Linked service name.
Confirm that From Azure subscriptions option is selected for Account selection method.
Select your Azure subscription.
Select an Azure storage account from the list of Azure storage accounts available in the
selected subscription. You can also choose to enter storage account settings manually by
selecting Enter manually option for the Account selection method, and then click Next.
5. On Choose the input file or folder page:
a. Double-click adftutorial (folder).
b. Select emp.txt, and click Choose
6. On the Choose the input file or folder page, click Next. Do not select Binary copy.
7. On the File format settings page, you see the delimiters and the schema that is auto-detected by the
wizard by parsing the file. You can also enter the delimiters manually for the copy wizard to stop autodetecting or to override. Click Next after you review the delimiters and preview data.
8. On the Destination data store page, select Azure SQL Database, and click Next.
9. On Specify the Azure SQL database page:
a. Enter AzureSqlLinkedService for the Connection name field.
b. Confirm that From Azure subscriptions option is selected for Server / database selection
c.
d.
e.
f.
method.
Select your Azure subscription.
Select Server name and Database.
Enter User name and Password.
Click Next.
10. On the Table mapping page, select emp for the Destination field from the drop-down list, click
down arrow (optional) to see the schema and to preview the data.
11. On the Schema mapping page, click Next.
12. On the Performance settings page, click Next.
13. Review information in the Summary page, and click Finish. The wizard creates two linked services, two
datasets (input and output), and one pipeline in the data factory (from where you launched the Copy
Wizard).
Launch Monitor and Manage application
1. On the Deployment page, click the link:
Click here to monitor copy pipeline
.
2. The monitoring application is launched in a separate tab in your web browser.
3. To see the latest status of hourly slices, click Refresh button in the ACTIVITY WINDOWS list at the
bottom. You see five activity windows for five days between start and end times for the pipeline. The list is
not automatically refreshed, so you may need to click Refresh a couple of times before you see all the
activity windows in the Ready state.
4. Select an activity window in the list. See the details about it in the Activity Window Explorer on the
right.
Notice that the dates 11, 12, 13, 14, and 15 are in green color, which means that the daily output slices
for these dates have already been produced. You also see this color coding on the pipeline and the
output dataset in the diagram view. In the previous step, notice that two slices have already been
produced, one slice is currently being processed, and the other two are waiting to be processed (based
on the color coding).
For more information on using this application, see Monitor and manage pipeline using Monitoring
App article.
Next steps
In this tutorial, you used Azure blob storage as a source data store and an Azure SQL database as a
destination data store in a copy operation. The following table provides a list of data stores supported as
sources and destinations by the copy activity:
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data
Warehouse
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
✓
Azure Search Index
Databases
NoSQL
File
Others
SUPPORTED AS A SINK
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
✓
✓
✓
✓
For details about fields/properties that you see in the copy wizard for a data store, click the link for the data
store in the table.
Tutorial: Use Azure portal to create a Data Factory
pipeline to copy data
6/13/2017 • 18 min to read • Edit Online
In this article, you learn how to use Azure portal to create a data factory with a pipeline that copies data from
an Azure blob storage to an Azure SQL database. If you are new to Azure Data Factory, read through the
Introduction to Azure Data Factory article before doing this tutorial.
In this tutorial, you create a pipeline with one activity in it: Copy Activity. The copy activity copies data from a
supported data store to a supported sink data store. For a list of data stores supported as sources and sinks,
see supported data stores. The activity is powered by a globally available service that can copy data between
various data stores in a secure, reliable, and scalable way. For more information about the Copy Activity, see
Data Movement Activities.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by
setting the output dataset of one activity as the input dataset of the other activity. For more information, see
multiple activities in a pipeline.
NOTE
The data pipeline in this tutorial copies data from a source data store to a destination data store. For a tutorial on how
to transform data using Azure Data Factory, see Tutorial: Build a pipeline to transform data using Hadoop cluster.
Prerequisites
Complete prerequisites listed in the tutorial prerequisites article before performing this tutorial.
Steps
Here are the steps you perform as part of this tutorial:
1. Create an Azure data factory. In this step, you create a data factory named ADFTutorialDataFactory.
2. Create linked services in the data factory. In this step, you create two linked services of types: Azure
Storage and Azure SQL Database.
The AzureStorageLinkedService links your Azure storage account to the data factory. You created a
container and uploaded data to this storage account as part of prerequisites.
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from
the blob storage is stored in this database. You created a SQL table in this database as part of
prerequisites.
3. Create input and output datasets in the data factory.
The Azure storage linked service specifies the connection string that Data Factory service uses at run
time to connect to your Azure storage account. And, the input blob dataset specifies the container and
the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory
service uses at run time to connect to your Azure SQL database. And, the output SQL table dataset
specifies the table in the database to which the data from the blob storage is copied.
4. Create a pipeline in the data factory. In this step, you create a pipeline with a copy activity.
The copy activity copies data from a blob in the Azure blob storage to a table in the Azure SQL
database. You can use a copy activity in a pipeline to copy data from any supported source to any
supported destination. For a list of supported data stores, see data movement activities article.
5. Monitor the pipeline. In this step, you monitor the slices of input and output datasets by using Azure
portal.
Create data factory
IMPORTANT
Complete prerequisites for the tutorial if you haven't already done so.
A data factory can have one or more pipelines. A pipeline can have one or more activities in it. For example, a
Copy Activity to copy data from a source to a destination data store and a HDInsight Hive activity to run a Hive
script to transform input data to product output data. Let's start with creating the data factory in this step.
1. After logging in to the Azure portal, click New on the left menu, click Data + Analytics, and click Data
Factory.
2. In the New data factory blade:
a. Enter ADFTutorialDataFactory for the name.
The name of the Azure data factory must be globally unique. If you receive the following error,
change the name of the data factory (for example, yournameADFTutorialDataFactory) and try
creating again. See Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
Data factory name “ADFTutorialDataFactory” is not available
b. Select your Azure subscription in which you want to create the data factory.
c. For the Resource Group, do one of the following steps:
Select Use existing, and select an existing resource group from the drop-down list.
Select Create new, and enter the name of a resource group.
Some of the steps in this tutorial assume that you use the name:
ADFTutorialResourceGroup for the resource group. To learn about resource groups, see
Using resource groups to manage your Azure resources.
d. Select the location for the data factory. Only regions supported by the Data Factory service are
shown in the drop-down list.
e. Select Pin to dashboard.
f. Click Create.
IMPORTANT
To create Data Factory instances, you must be a member of the Data Factory Contributor role at the
subscription/resource group level.
The name of the data factory may be registered as a DNS name in the future and hence become
publically visible.
3. On the dashboard, you see the following tile with status: Deploying data factory.
4. After the creation is complete, you see the Data Factory blade as shown in the image.
Create linked services
You create linked services in a data factory to link your data stores and compute services to the data factory. In
this tutorial, you don't use any compute service such as Azure HDInsight or Azure Data Lake Analytics. You use
two data stores of type Azure Storage (source) and Azure SQL Database (destination).
Therefore, you create two linked services named AzureStorageLinkedService and AzureSqlLinkedService of
types: AzureStorage and AzureSqlDatabase.
The AzureStorageLinkedService links your Azure storage account to the data factory. This storage account is
the one in which you created a container and uploaded the data as part of prerequisites.
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from the
blob storage is stored in this database. You created the emp table in this database as part of prerequisites.
Create Azure Storage linked service
In this step, you link your Azure storage account to your data factory. You specify the name and key of your
Azure storage account in this section.
1. In the Data Factory blade, click Author and deploy tile.
2. You see the Data Factory Editor as shown in the following image:
3. In the editor, click New data store button on the toolbar and select Azure storage from the dropdown menu. You should see the JSON template for creating an Azure storage linked service in the right
pane.
4. Replace
<accountname>
and
<accountkey>
with the account name and account key values for your
Azure storage account.
5. Click Deploy on the toolbar. You should see the deployed AzureStorageLinkedService in the tree
view now.
For more information about JSON properties in the linked service definition, see Azure Blob Storage
connector article.
Create a linked service for the Azure SQL Database
In this step, you link your Azure SQL database to your data factory. You specify the Azure SQL server name,
database name, user name, and user password in this section.
1. In the Data Factory Editor, click New data store button on the toolbar and select Azure SQL Database
from the drop-down menu. You should see the JSON template for creating the Azure SQL linked service in
the right pane.
2. Replace <servername> , <databasename> , <username>@<servername> , and <password> with names of your
Azure SQL server, database, user account, and password.
3. Click Deploy on the toolbar to create and deploy the AzureSqlLinkedService.
4. Confirm that you see AzureSqlLinkedService in the tree view under Linked services.
For more information about these JSON properties, see Azure SQL Database connector.
Create datasets
In the previous step, you created linked services to link your Azure Storage account and Azure SQL database to
your data factory. In this step, you define two datasets named InputDataset and OutputDataset that represent
input and output data that is stored in the data stores referred by AzureStorageLinkedService and
AzureSqlLinkedService respectively.
The Azure storage linked service specifies the connection string that Data Factory service uses at run time to
connect to your Azure storage account. And, the input blob dataset (InputDataset) specifies the container and
the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory service uses
at run time to connect to your Azure SQL database. And, the output SQL table dataset (OututDataset) specifies
the table in the database to which the data from the blob storage is copied.
Create input dataset
In this step, you create a dataset named InputDataset that points to a blob file (emp.txt) in the root folder of a
blob container (adftutorial) in the Azure Storage represented by the AzureStorageLinkedService linked service.
If you don't specify a value for the fileName (or skip it), data from all blobs in the input folder are copied to the
destination. In this tutorial, you specify a value for the fileName.
1. In the Editor for the Data Factory, click ... More, click New dataset, and click Azure Blob storage from
the drop-down menu.
2. Replace JSON in the right pane with the following JSON snippet:
{
"name": "InputDataset",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "adftutorial/",
"fileName": "emp.txt",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data
resides in an Azure blob storage.
linkedServiceName
Refers to the AzureStorageLinkedService that you
created earlier.
folderPath
Specifies the blob container and the folder that
contains input blobs. In this tutorial, adftutorial is the
blob container and folder is the root folder.
fileName
This property is optional. If you omit this property, all
files from the folderPath are picked. In this tutorial,
emp.txt is specified for the fileName, so only that file is
picked up for processing.
format -> type
The input file is in the text format, so we use
TextFormat.
columnDelimiter
The columns in the input file are delimited by comma
character ( , ).
PROPERTY
DESCRIPTION
frequency/interval
The frequency is set to Hour and interval is set to 1,
which means that the input slices are available hourly.
In other words, the Data Factory service looks for input
data every hour in the root folder of blob container
(adftutorial) you specified. It looks for the data within
the pipeline start and end times, not before or after
these times.
external
This property is set to true if the data is not generated
by this pipeline. The input data in this tutorial is in the
emp.txt file, which is not generated by this pipeline, so
we set this property to true.
For more information about these JSON properties, see Azure Blob connector article.
3. Click Deploy on the toolbar to create and deploy the InputDataset dataset. Confirm that you see the
InputDataset in the tree view.
Create output dataset
The Azure SQL Database linked service specifies the connection string that Data Factory service uses at run
time to connect to your Azure SQL database. The output SQL table dataset (OututDataset) you create in this
step specifies the table in the database to which the data from the blob storage is copied.
1. In the Editor for the Data Factory, click ... More, click New dataset, and click Azure SQL from the dropdown menu.
2. Replace JSON in the right pane with the following JSON snippet:
{
"name": "OutputDataset",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "emp"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
PROPERTY
DESCRIPTION
type
The type property is set to AzureSqlTable because
data is copied to a table in an Azure SQL database.
linkedServiceName
Refers to the AzureSqlLinkedService that you created
earlier.
tableName
Specified the table to which the data is copied.
frequency/interval
The frequency is set to Hour and interval is 1, which
means that the output slices are produced hourly
between the pipeline start and end times, not before or
after these times.
There are three columns – ID, FirstName, and LastName – in the emp table in the database. ID is an
identity column, so you need to specify only FirstName and LastName here.
For more information about these JSON properties, see Azure SQL connector article.
3. Click Deploy on the toolbar to create and deploy the OutputDataset dataset. Confirm that you see the
OutputDataset in the tree view under Datasets.
Create pipeline
In this step, you create a pipeline with a copy activity that uses InputDataset as an input and
OutputDataset as an output.
Currently, output dataset is what drives the schedule. In this tutorial, output dataset is configured to produce a
slice once an hour. The pipeline has a start time and end time that are one day apart, which is 24 hours.
Therefore, 24 slices of output dataset are produced by the pipeline.
1. In the Editor for the Data Factory, click ... More, and click New pipeline. Alternatively, you can right-click
Pipelines in the tree view and click New pipeline.
2. Replace JSON in the right pane with the following JSON snippet:
{
"name": "ADFTutorialPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
],
"start": "2017-05-11T00:00:00Z",
"end": "2017-05-12T00:00:00Z"
}
}
Note the following points:
In the activities section, there is only one activity whose type is set to Copy. For more information
about the copy activity, see data movement activities. In Data Factory solutions, you can also use
data transformation activities.
Input for the activity is set to InputDataset and output for the activity is set to OutputDataset.
In the typeProperties section, BlobSource is specified as the source type and SqlSink is specified
as the sink type. For a complete list of data stores supported by the copy activity as sources and
sinks, see supported data stores. To learn how to use a specific supported data store as a
source/sink, click the link in the table.
Both start and end datetimes must be in ISO format. For example: 2016-10-14T16:32:41Z. The
end time is optional, but we use it in this tutorial. If you do not specify value for the end
property, it is calculated as "start + 48 hours". To run the pipeline indefinitely, specify 9999-0909 as the value for the end property.
In the preceding example, there are 24 data slices as each data slice is produced hourly.
For descriptions of JSON properties in a pipeline definition, see create pipelines article. For
descriptions of JSON properties in a copy activity definition, see data movement activities. For
descriptions of JSON properties supported by BlobSource, see Azure Blob connector article. For
descriptions of JSON properties supported by SqlSink, see Azure SQL Database connector article.
3. Click Deploy on the toolbar to create and deploy the ADFTutorialPipeline. Confirm that you see the
pipeline in the tree view.
4. Now, close the Editor blade by clicking X. Click X again to see the Data Factory home page for the
ADFTutorialDataFactory.
Congratulations! You have successfully created an Azure data factory with a pipeline to copy data from an
Azure blob storage to an Azure SQL database.
Monitor pipeline
In this step, you use the Azure portal to monitor what’s going on in an Azure data factory.
Monitor pipeline using Monitor & Manage App
The following steps show you how to monitor pipelines in your data factory by using the Monitor & Manage
application:
1. Click Monitor & Manage tile on the home page for your data factory.
2. You should see Monitor & Manage application in a separate tab.
NOTE
If you see that the web browser is stuck at "Authorizing...", do one of the following: clear the Block third-party
cookies and site data check box (or) create an exception for login.microsoftonline.com, and then try to
open the app again.
3. Change the Start time and End time to include start (2017-05-11) and end times (2017-05-12) of your
pipeline, and click Apply.
4. You see the activity windows associated with each hour between pipeline start and end times in the list in
the middle pane.
5. To see details about an activity window, select the activity window in the Activity Windows list.
In Activity Window Explorer on the right, you see that the slices up to the current UTC time (8:12 PM)
are all processed (in green color). The 8-9 PM, 9 - 10 PM, 10 - 11 PM, 11 PM - 12 AM slices are not
processed yet.
The Attempts section in the right pane provides information about the activity run for the data slice. If
there was an error, it provides details about the error. For example, if the input folder or container does
not exist and the slice processing fails, you see an error message stating that the container or folder
does not exist.
6. Launch SQL Server Management Studio, connect to the Azure SQL Database, and verify that the rows
are inserted in to the emp table in the database.
For detailed information about using this application, see Monitor and manage Azure Data Factory pipelines
using Monitoring and Management App.
Monitor pipeline using Diagram View
You can also monitor data pipelines by using the diagram view.
1. In the Data Factory blade, click Diagram.
2. You should see the diagram similar to the following image:
3. In the diagram view, double-click InputDataset to see slices for the dataset.
4. Click See more link to see all the data slices. You see 24 hourly slices between pipeline start and end
times.
Notice that all the data slices up to the current UTC time are Ready because the emp.txt file exists all
the time in the blob container: adftutorial\input. The slices for the future times are not in ready state
yet. Confirm that no slices show up in the Recently failed slices section at the bottom.
5. Close the blades until you see the diagram view (or) scroll left to see the diagram view. Then, double-click
OutputDataset.
6. Click See more link on the Table blade for OutputDataset to see all the slices.
7. Notice that all the slices up to the current UTC time move from pending execution state => In progress
==> Ready state. The slices from the past (before current time) are processed from latest to oldest by
default. For example, if the current time is 8:12 PM UTC, the slice for 7 PM - 8 PM is processed ahead of the
6 PM - 7 PM slice. The 8 PM - 9 PM slice is processed at the end of the time interval by default, that is after
9 PM.
8. Click any data slice from the list and you should see the Data slice blade. A piece of data associated
with an activity window is called a slice. A slice can be one file or multiple files.
If the slice is not in the Ready state, you can see the upstream slices that are not Ready and are
blocking the current slice from executing in the Upstream slices that are not ready list.
9. In the DATA SLICE blade, you should see all activity runs in the list at the bottom. Click an activity run
to see the Activity run details blade.
In this blade, you see how long the copy operation took, what throughput is, how many bytes of data
were read and written, run start time, run end time etc.
10. Click X to close all the blades until you get back to the home blade for the ADFTutorialDataFactory.
11. (optional) click the Datasets tile or Pipelines tile to get the blades you have seen the preceding steps.
12. Launch SQL Server Management Studio, connect to the Azure SQL Database, and verify that the rows
are inserted in to the emp table in the database.
Summary
In this tutorial, you created an Azure data factory to copy data from an Azure blob to an Azure SQL database.
You used the Azure portal to create the data factory, linked services, datasets, and a pipeline. Here are the
high-level steps you performed in this tutorial:
1. Created an Azure data factory.
2. Created linked services:
a. An Azure Storage linked service to link your Azure Storage account that holds input data.
b. An Azure SQL linked service to link your Azure SQL database that holds the output data.
3. Created datasets that describe input data and output data for pipelines.
4. Created a pipeline with a Copy Activity with BlobSource as source and SqlSink as sink.
Next steps
In this tutorial, you used Azure blob storage as a source data store and an Azure SQL database as a destination
data store in a copy operation. The following table provides a list of data stores supported as sources and
destinations by the copy activity:
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data
Warehouse
✓
✓
Azure Search Index
✓
CATEGORY
Databases
NoSQL
File
Others
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure Table storage
✓
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
✓
✓
✓
To learn about how to copy data to/from a data store, click the link for the data store in the table.
Tutorial: Create a pipeline with Copy Activity using
Visual Studio
5/22/2017 • 19 min to read • Edit Online
In this article, you learn how to use the Microsoft Visual Studio to create a data factory with a pipeline that
copies data from an Azure blob storage to an Azure SQL database. If you are new to Azure Data Factory, read
through the Introduction to Azure Data Factory article before doing this tutorial.
In this tutorial, you create a pipeline with one activity in it: Copy Activity. The copy activity copies data from a
supported data store to a supported sink data store. For a list of data stores supported as sources and sinks,
see supported data stores. The activity is powered by a globally available service that can copy data between
various data stores in a secure, reliable, and scalable way. For more information about the Copy Activity, see
Data Movement Activities.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by
setting the output dataset of one activity as the input dataset of the other activity. For more information, see
multiple activities in a pipeline.
NOTE
The data pipeline in this tutorial copies data from a source data store to a destination data store. For a tutorial on how
to transform data using Azure Data Factory, see Tutorial: Build a pipeline to transform data using Hadoop cluster.
Prerequisites
1. Read through Tutorial Overview article and complete the prerequisite steps.
2. To create Data Factory instances, you must be a member of the Data Factory Contributor role at the
subscription/resource group level.
3. You must have the following installed on your computer:
Visual Studio 2013 or Visual Studio 2015
Download Azure SDK for Visual Studio 2013 or Visual Studio 2015. Navigate to Azure Download
Page and click VS 2013 or VS 2015 in the .NET section.
Download the latest Azure Data Factory plugin for Visual Studio: VS 2013 or VS 2015. You can also
update the plugin by doing the following steps: On the menu, click Tools -> Extensions and
Updates -> Online -> Visual Studio Gallery -> Microsoft Azure Data Factory Tools for Visual
Studio -> Update.
Steps
Here are the steps you perform as part of this tutorial:
1. Create linked services in the data factory. In this step, you create two linked services of types: Azure
Storage and Azure SQL Database.
The AzureStorageLinkedService links your Azure storage account to the data factory. You created a
container and uploaded data to this storage account as part of prerequisites.
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from
the blob storage is stored in this database. You created a SQL table in this database as part of
prerequisites.
2. Create input and output datasets in the data factory.
The Azure storage linked service specifies the connection string that Data Factory service uses at run
time to connect to your Azure storage account. And, the input blob dataset specifies the container and
the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory
service uses at run time to connect to your Azure SQL database. And, the output SQL table dataset
specifies the table in the database to which the data from the blob storage is copied.
3. Create a pipeline in the data factory. In this step, you create a pipeline with a copy activity.
The copy activity copies data from a blob in the Azure blob storage to a table in the Azure SQL
database. You can use a copy activity in a pipeline to copy data from any supported source to any
supported destination. For a list of supported data stores, see data movement activities article.
4. Create an Azure data factory when deploying Data Factory entities (linked services, datasets/tables, and
pipelines).
Create Visual Studio project
1. Launch Visual Studio 2015. Click File, point to New, and click Project. You should see the New Project
dialog box.
2. In the New Project dialog, select the DataFactory template, and click Empty Data Factory Project.
3. Specify the name of the project, location for the solution, and name of the solution, and then click OK.
Create linked services
You create linked services in a data factory to link your data stores and compute services to the data factory. In
this tutorial, you don't use any compute service such as Azure HDInsight or Azure Data Lake Analytics. You use
two data stores of type Azure Storage (source) and Azure SQL Database (destination).
Therefore, you create two linked services of types: AzureStorage and AzureSqlDatabase.
The Azure Storage linked service links your Azure storage account to the data factory. This storage account is
the one in which you created a container and uploaded the data as part of prerequisites.
Azure SQL linked service links your Azure SQL database to the data factory. The data that is copied from the
blob storage is stored in this database. You created the emp table in this database as part of prerequisites.
Linked services link data stores or compute services to an Azure data factory. See supported data stores for all
the sources and sinks supported by the Copy Activity. See compute linked services for the list of compute
services supported by Data Factory. In this tutorial, you do not use any compute service.
Create the Azure Storage linked service
1. In Solution Explorer, right-click Linked Services, point to Add, and click New Item.
2. In the Add New Item dialog box, select Azure Storage Linked Service from the list, and click Add.
3. Replace
<accountname>
and
<accountkey>
* with the name of your Azure storage account and its key.
4. Save the AzureStorageLinkedService1.json file.
For more information about JSON properties in the linked service definition, see Azure Blob Storage
connector article.
Create the Azure SQL linked service
1. Right-click on Linked Services node in the Solution Explorer again, point to Add, and click New Item.
2. This time, select Azure SQL Linked Service, and click Add.
3. In the AzureSqlLinkedService1.json file, replace <servername> , <databasename> , <username@servername> ,
and <password> with names of your Azure SQL server, database, user account, and password.
4. Save the AzureSqlLinkedService1.json file.
For more information about these JSON properties, see Azure SQL Database connector.
Create datasets
In the previous step, you created linked services to link your Azure Storage account and Azure SQL database
to your data factory. In this step, you define two datasets named InputDataset and OutputDataset that
represent input and output data that is stored in the data stores referred by AzureStorageLinkedService1 and
AzureSqlLinkedService1 respectively.
The Azure storage linked service specifies the connection string that Data Factory service uses at run time to
connect to your Azure storage account. And, the input blob dataset (InputDataset) specifies the container and
the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory service uses
at run time to connect to your Azure SQL database. And, the output SQL table dataset (OututDataset) specifies
the table in the database to which the data from the blob storage is copied.
Create input dataset
In this step, you create a dataset named InputDataset that points to a blob file (emp.txt) in the root folder of a
blob container (adftutorial) in the Azure Storage represented by the AzureStorageLinkedService1 linked
service. If you don't specify a value for the fileName (or skip it), data from all blobs in the input folder are
copied to the destination. In this tutorial, you specify a value for the fileName.
Here, you use the term "tables" rather than "datasets". A table is a rectangular dataset and is the only type of
dataset supported right now.
1. Right-click Tables in the Solution Explorer, point to Add, and click New Item.
2. In the Add New Item dialog box, select Azure Blob, and click Add.
3. Replace the JSON text with the following text and save the AzureBlobLocation1.json file.
{
"name": "InputDataset",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService1",
"typeProperties": {
"folderPath": "adftutorial/",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data
resides in an Azure blob storage.
linkedServiceName
Refers to the AzureStorageLinkedService that you
created earlier.
folderPath
Specifies the blob container and the folder that
contains input blobs. In this tutorial, adftutorial is the
blob container and folder is the root folder.
fileName
This property is optional. If you omit this property, all
files from the folderPath are picked. In this tutorial,
emp.txt is specified for the fileName, so only that file is
picked up for processing.
format -> type
The input file is in the text format, so we use
TextFormat.
columnDelimiter
The columns in the input file are delimited by comma
character ( , ).
PROPERTY
DESCRIPTION
frequency/interval
The frequency is set to Hour and interval is set to 1,
which means that the input slices are available hourly.
In other words, the Data Factory service looks for input
data every hour in the root folder of blob container
(adftutorial) you specified. It looks for the data within
the pipeline start and end times, not before or after
these times.
external
This property is set to true if the data is not generated
by this pipeline. The input data in this tutorial is in the
emp.txt file, which is not generated by this pipeline, so
we set this property to true.
For more information about these JSON properties, see Azure Blob connector article.
Create output dataset
In this step, you create an output dataset named OutputDataset. This dataset points to a SQL table in the
Azure SQL database represented by AzureSqlLinkedService1.
1. Right-click Tables in the Solution Explorer again, point to Add, and click New Item.
2. In the Add New Item dialog box, select Azure SQL, and click Add.
3. Replace the JSON text with the following JSON and save the AzureSqlTableLocation1.json file.
{
"name": "OutputDataset",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService1",
"typeProperties": {
"tableName": "emp"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureSqlTable because
data is copied to a table in an Azure SQL database.
linkedServiceName
Refers to the AzureSqlLinkedService that you created
earlier.
PROPERTY
DESCRIPTION
tableName
Specified the table to which the data is copied.
frequency/interval
The frequency is set to Hour and interval is 1, which
means that the output slices are produced hourly
between the pipeline start and end times, not before or
after these times.
There are three columns – ID, FirstName, and LastName – in the emp table in the database. ID is an
identity column, so you need to specify only FirstName and LastName here.
For more information about these JSON properties, see Azure SQL connector article.
Create pipeline
In this step, you create a pipeline with a copy activity that uses InputDataset as an input and
OutputDataset as an output.
Currently, output dataset is what drives the schedule. In this tutorial, output dataset is configured to produce a
slice once an hour. The pipeline has a start time and end time that are one day apart, which is 24 hours.
Therefore, 24 slices of output dataset are produced by the pipeline.
1. Right-click Pipelines in the Solution Explorer, point to Add, and click New Item.
2. Select Copy Data Pipeline in the Add New Item dialog box and click Add.
3. Replace the JSON with the following JSON and save the CopyActivity1.json file.
{
"name": "ADFTutorialPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"style": "StartOfInterval",
"retry": 0,
"timeout": "01:00:00"
}
}
],
"start": "2017-05-11T00:00:00Z",
"end": "2017-05-12T00:00:00Z",
"isPaused": false
}
}
In the activities section, there is only one activity whose type is set to Copy. For more information
about the copy activity, see data movement activities. In Data Factory solutions, you can also use
data transformation activities.
Input for the activity is set to InputDataset and output for the activity is set to OutputDataset.
In the typeProperties section, BlobSource is specified as the source type and SqlSink is
specified as the sink type. For a complete list of data stores supported by the copy activity as
sources and sinks, see supported data stores. To learn how to use a specific supported data store
as a source/sink, click the link in the table.
Replace the value of the start property with the current day and end value with the next day.
You can specify only the date part and skip the time part of the date time. For example, "201602-03", which is equivalent to "2016-02-03T00:00:00Z"
Both start and end datetimes must be in ISO format. For example: 2016-10-14T16:32:41Z. The
end time is optional, but we use it in this tutorial.
If you do not specify value for the end property, it is calculated as "start + 48 hours". To run the
pipeline indefinitely, specify 9999-09-09 as the value for the end property.
In the preceding example, there are 24 data slices as each data slice is produced hourly.
For descriptions of JSON properties in a pipeline definition, see create pipelines article. For
descriptions of JSON properties in a copy activity definition, see data movement activities. For
descriptions of JSON properties supported by BlobSource, see Azure Blob connector article. For
descriptions of JSON properties supported by SqlSink, see Azure SQL Database connector
article.
Publish/deploy Data Factory entities
In this step, you publish Data Factory entities (linked services, datasets, and pipeline) you created earlier. You
also specify the name of the new data factory to be created to hold these entities.
1. Right-click project in the Solution Explorer, and click Publish.
2. If you see Sign in to your Microsoft account dialog box, enter your credentials for the account that has
Azure subscription, and click sign in.
3. You should see the following dialog box:
4. In the Configure data factory page, do the following steps:
a. select Create New Data Factory option.
b. Enter VSTutorialFactory for Name.
IMPORTANT
The name of the Azure data factory must be globally unique. If you receive an error about the name of
data factory when publishing, change the name of the data factory (for example,
yournameVSTutorialFactory) and try publishing again. See Data Factory - Naming Rules topic for naming
rules for Data Factory artifacts.
c. Select your Azure subscription for the Subscription field.
IMPORTANT
If you do not see any subscription, ensure that you logged in using an account that is an admin or coadmin of the subscription.
d. Select the resource group for the data factory to be created.
e. Select the region for the data factory. Only regions supported by the Data Factory service are
shown in the drop-down list.
f. Click Next to switch to the Publish Items page.
5. In the Publish Items page, ensure that all the Data Factories entities are selected, and click Next to
switch to the Summary page.
6. Review the summary and click Next to start the deployment process and view the Deployment
Status.
7. In the Deployment Status page, you should see the status of the deployment process. Click Finish
after the deployment is done.
Note the following points:
If you receive the error: "This subscription is not registered to use namespace Microsoft.DataFactory",
do one of the following and try publishing again:
In Azure PowerShell, run the following command to register the Data Factory provider.
Register-AzureRmResourceProvider -ProviderNamespace Microsoft.DataFactory
You can run the following command to confirm that the Data Factory provider is registered.
Get-AzureRmResourceProvider
Login using the Azure subscription into the Azure portal and navigate to a Data Factory blade (or)
create a data factory in the Azure portal. This action automatically registers the provider for you.
The name of the data factory may be registered as a DNS name in the future and hence become publically
visible.
IMPORTANT
To create Data Factory instances, you need to be a admin/co-admin of the Azure subscription
Monitor pipeline
Navigate to the home page for your data factory:
1. Log in to Azure portal.
2. Click More services on the left menu, and click Data factories.
3. Start typing the name of your data factory.
4. Click your data factory in the results list to see the home page for your data factory.
5. Follow instructions from Monitor datasets and pipeline to monitor the pipeline and datasets you have
created in this tutorial. Currently, Visual Studio does not support monitoring Data Factory pipelines.
Summary
In this tutorial, you created an Azure data factory to copy data from an Azure blob to an Azure SQL database.
You used Visual Studio to create the data factory, linked services, datasets, and a pipeline. Here are the highlevel steps you performed in this tutorial:
1. Created an Azure data factory.
2. Created linked services:
a. An Azure Storage linked service to link your Azure Storage account that holds input data.
b. An Azure SQL linked service to link your Azure SQL database that holds the output data.
3. Created datasets, which describe input data and output data for pipelines.
4. Created a pipeline with a Copy Activity with BlobSource as source and SqlSink as sink.
To see how to use a HDInsight Hive Activity to transform data by using Azure HDInsight cluster, see Tutorial:
Build your first pipeline to transform data using Hadoop cluster.
You can chain two activities (run one activity after another) by setting the output dataset of one activity as the
input dataset of the other activity. See Scheduling and execution in Data Factory for detailed information.
View all data factories in Server Explorer
This section describes how to use the Server Explorer in Visual Studio to view all the data factories in your
Azure subscription and create a Visual Studio project based on an existing data factory.
1. In Visual Studio, click View on the menu, and click Server Explorer.
2. In the Server Explorer window, expand Azure and expand Data Factory. If you see Sign in to Visual
Studio, enter the account associated with your Azure subscription and click Continue. Enter
password, and click Sign in. Visual Studio tries to get information about all Azure data factories in
your subscription. You see the status of this operation in the Data Factory Task List window.
Create a Visual Studio project for an existing data factory
Right-click a data factory in Server Explorer, and select Export Data Factory to New Project to create
a Visual Studio project based on an existing data factory.
Update Data Factory tools for Visual Studio
To update Azure Data Factory tools for Visual Studio, do the following steps:
1. Click Tools on the menu and select Extensions and Updates.
2. Select Updates in the left pane and then select Visual Studio Gallery.
3. Select Azure Data Factory tools for Visual Studio and click Update. If you do not see this entry, you
already have the latest version of the tools.
Use configuration files
You can use configuration files in Visual Studio to configure properties for linked services/tables/pipelines
differently for each environment.
Consider the following JSON definition for an Azure Storage linked service. To specify connectionString with
different values for accountname and accountkey based on the environment (Dev/Test/Production) to which
you are deploying Data Factory entities. You can achieve this behavior by using separate configuration file for
each environment.
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"description": "",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Add a configuration file
Add a configuration file for each environment by performing the following steps:
1. Right-click the Data Factory project in your Visual Studio solution, point to Add, and click New item.
2. Select Config from the list of installed templates on the left, select Configuration File, enter a name
for the configuration file, and click Add.
3. Add configuration parameters and their values in the following format:
{
"$schema":
"http://datafactories.schema.management.azure.com/vsschemas/V1/Microsoft.DataFactory.Config.json",
"AzureStorageLinkedService1": [
{
"name": "$.properties.typeProperties.connectionString",
"value": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
],
"AzureSqlLinkedService1": [
{
"name": "$.properties.typeProperties.connectionString",
"value": "Server=tcp:spsqlserver.database.windows.net,1433;Database=spsqldb;User
ID=spelluru;Password=Sowmya123;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
}
]
}
This example configures connectionString property of an Azure Storage linked service and an Azure
SQL linked service. Notice that the syntax for specifying name is JsonPath.
If JSON has a property that has an array of values as shown in the following code:
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
Configure properties as shown in the following configuration file (use zero-based indexing):
{
"name": "$.properties.structure[0].name",
"value": "FirstName"
}
{
"name": "$.properties.structure[0].type",
"value": "String"
}
{
"name": "$.properties.structure[1].name",
"value": "LastName"
}
{
"name": "$.properties.structure[1].type",
"value": "String"
}
Property names with spaces
If a property name has spaces in it, use square brackets as shown in the following example (Database server
name):
{
"name": "$.properties.activities[1].typeProperties.webServiceParameters.['Database server name']",
"value": "MyAsqlServer.database.windows.net"
}
Deploy solution using a configuration
When you are publishing Azure Data Factory entities in VS, you can specify the configuration that you want to
use for that publishing operation.
To publish entities in an Azure Data Factory project using configuration file:
1. Right-click Data Factory project and click Publish to see the Publish Items dialog box.
2. Select an existing data factory or specify values for creating a data factory on the Configure data factory
page, and click Next.
3. On the Publish Items page: you see a drop-down list with available configurations for the Select
Deployment Config field.
4. Select the configuration file that you would like to use and click Next.
5. Confirm that you see the name of JSON file in the Summary page and click Next.
6. Click Finish after the deployment operation is finished.
When you deploy, the values from the configuration file are used to set values for properties in the JSON files
before the entities are deployed to Azure Data Factory service.
Use Azure Key Vault
It is not advisable and often against security policy to commit sensitive data such as connection strings to the
code repository. See ADF Secure Publish sample on GitHub to learn about storing sensitive information in
Azure Key Vault and using it while publishing Data Factory entities. The Secure Publish extension for Visual
Studio allows the secrets to be stored in Key Vault and only references to them are specified in linked services/
deployment configurations. These references are resolved when you publish Data Factory entities to Azure.
These files can then be committed to source repository without exposing any secrets.
Next steps
In this tutorial, you used Azure blob storage as a source data store and an Azure SQL database as a destination
data store in a copy operation. The following table provides a list of data stores supported as sources and
destinations by the copy activity:
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data
Warehouse
✓
✓
✓
Azure Search Index
Databases
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
✓
✓
✓
CATEGORY
NoSQL
File
Others
DATA STORE
SUPPORTED AS A SOURCE
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
✓
To learn about how to copy data to/from a data store, click the link for the data store in the table.
Tutorial: Create a Data Factory pipeline that moves
data by using Azure PowerShell
6/13/2017 • 17 min to read • Edit Online
In this article, you learn how to use PowerShell to create a data factory with a pipeline that copies data from an
Azure blob storage to an Azure SQL database. If you are new to Azure Data Factory, read through the
Introduction to Azure Data Factory article before doing this tutorial.
In this tutorial, you create a pipeline with one activity in it: Copy Activity. The copy activity copies data from a
supported data store to a supported sink data store. For a list of data stores supported as sources and sinks,
see supported data stores. The activity is powered by a globally available service that can copy data between
various data stores in a secure, reliable, and scalable way. For more information about the Copy Activity, see
Data Movement Activities.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by
setting the output dataset of one activity as the input dataset of the other activity. For more information, see
multiple activities in a pipeline.
NOTE
This article does not cover all the Data Factory cmdlets. See Data Factory Cmdlet Reference for comprehensive
documentation on these cmdlets.
The data pipeline in this tutorial copies data from a source data store to a destination data store. For a tutorial on how
to transform data using Azure Data Factory, see Tutorial: Build a pipeline to transform data using Hadoop cluster.
Prerequisites
Complete prerequisites listed in the tutorial prerequisites article.
Install Azure PowerShell. Follow the instructions in How to install and configure Azure PowerShell.
Steps
Here are the steps you perform as part of this tutorial:
1. Create an Azure data factory. In this step, you create a data factory named ADFTutorialDataFactoryPSH.
2. Create linked services in the data factory. In this step, you create two linked services of types: Azure
Storage and Azure SQL Database.
The AzureStorageLinkedService links your Azure storage account to the data factory. You created a
container and uploaded data to this storage account as part of prerequisites.
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from
the blob storage is stored in this database. You created a SQL table in this database as part of
prerequisites.
3. Create input and output datasets in the data factory.
The Azure storage linked service specifies the connection string that Data Factory service uses at run
time to connect to your Azure storage account. And, the input blob dataset specifies the container and
the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory
service uses at run time to connect to your Azure SQL database. And, the output SQL table dataset
specifies the table in the database to which the data from the blob storage is copied.
4. Create a pipeline in the data factory. In this step, you create a pipeline with a copy activity.
The copy activity copies data from a blob in the Azure blob storage to a table in the Azure SQL
database. You can use a copy activity in a pipeline to copy data from any supported source to any
supported destination. For a list of supported data stores, see data movement activities article.
5. Monitor the pipeline. In this step, you monitor the slices of input and output datasets by using PowerShell.
Create a data factory
IMPORTANT
Complete prerequisites for the tutorial if you haven't already done so.
A data factory can have one or more pipelines. A pipeline can have one or more activities in it. For example, a
Copy Activity to copy data from a source to a destination data store and a HDInsight Hive activity to run a Hive
script to transform input data to product output data. Let's start with creating the data factory in this step.
1. Launch PowerShell. Keep Azure PowerShell open until the end of this tutorial. If you close and reopen,
you need to run the commands again.
Run the following command, and enter the user name and password that you use to sign in to the
Azure portal:
Login-AzureRmAccount
Run the following command to view all the subscriptions for this account:
Get-AzureRmSubscription
Run the following command to select the subscription that you want to work with. Replace
<NameOfAzureSubscription> with the name of your Azure subscription:
Get-AzureRmSubscription -SubscriptionName <NameOfAzureSubscription> | Set-AzureRmContext
2. Create an Azure resource group named ADFTutorialResourceGroup by running the following
command:
New-AzureRmResourceGroup -Name ADFTutorialResourceGroup -Location "West US"
Some of the steps in this tutorial assume that you use the resource group named
ADFTutorialResourceGroup. If you use a different resource group, you need to use it in place of
ADFTutorialResourceGroup in this tutorial.
3. Run the New-AzureRmDataFactory cmdlet to create a data factory named
ADFTutorialDataFactoryPSH:
$df=New-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name
ADFTutorialDataFactoryPSH –Location "West US"
This name may already have been taken. Therefore, make the name of the data factory unique by
adding a prefix or suffix (for example: ADFTutorialDataFactoryPSH05152017) and run the command
again.
Note the following points:
The name of the Azure data factory must be globally unique. If you receive the following error, change
the name (for example, yournameADFTutorialDataFactoryPSH). Use this name in place of
ADFTutorialFactoryPSH while performing steps in this tutorial. See Data Factory - Naming Rules for
Data Factory artifacts.
Data factory name “ADFTutorialDataFactoryPSH” is not available
To create Data Factory instances, you must be a contributor or administrator of the Azure subscription.
The name of the data factory may be registered as a DNS name in the future, and hence become publicly
visible.
You may receive the following error: "This subscription is not registered to use namespace
Microsoft.DataFactory." Do one of the following, and try publishing again:
In Azure PowerShell, run the following command to register the Data Factory provider:
Register-AzureRmResourceProvider -ProviderNamespace Microsoft.DataFactory
Run the following command to confirm that the Data Factory provider is registered:
Get-AzureRmResourceProvider
Sign in by using the Azure subscription to the Azure portal. Go to a Data Factory blade, or create a
data factory in the Azure portal. This action automatically registers the provider for you.
Create linked services
You create linked services in a data factory to link your data stores and compute services to the data factory. In
this tutorial, you don't use any compute service such as Azure HDInsight or Azure Data Lake Analytics. You use
two data stores of type Azure Storage (source) and Azure SQL Database (destination).
Therefore, you create two linked services named AzureStorageLinkedService and AzureSqlLinkedService of
types: AzureStorage and AzureSqlDatabase.
The AzureStorageLinkedService links your Azure storage account to the data factory. This storage account is
the one in which you created a container and uploaded the data as part of prerequisites.
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from the
blob storage is stored in this database. You created the emp table in this database as part of prerequisites.
Create a linked service for an Azure storage account
In this step, you link your Azure storage account to your data factory.
1. Create a JSON file named AzureStorageLinkedService.json in C:\ADFGetStartedPSH folder with
the following content: (Create the folder ADFGetStartedPSH if it does not already exist.)
IMPORTANT
Replace <accountname> and <accountkey> with name and key of your Azure storage account before saving
the file.
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=
<accountname>;AccountKey=<accountkey>"
}
}
}
2. In Azure PowerShell, switch to the ADFGetStartedPSH folder.
3. Run the New-AzureRmDataFactoryLinkedService cmdlet to create the linked service:
AzureStorageLinkedService. This cmdlet, and other Data Factory cmdlets you use in this tutorial
requires you to pass values for the ResourceGroupName and DataFactoryName parameters.
Alternatively, you can pass the DataFactory object returned by the New-AzureRmDataFactory cmdlet
without typing ResourceGroupName and DataFactoryName each time you run a cmdlet.
New-AzureRmDataFactoryLinkedService $df -File .\AzureStorageLinkedService.json
Here is the sample output:
LinkedServiceName
ResourceGroupName
DataFactoryName
Properties
ProvisioningState
:
:
:
:
:
AzureStorageLinkedService
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
Microsoft.Azure.Management.DataFactories.Models.LinkedServiceProperties
Succeeded
Other way of creating this linked service is to specify resource group name and data factory name
instead of specifying the DataFactory object.
New-AzureRmDataFactoryLinkedService -ResourceGroupName ADFTutorialResourceGroup -DataFactoryName
<Name of your data factory> -File .\AzureStorageLinkedService.json
Create a linked service for an Azure SQL database
In this step, you link your Azure SQL database to your data factory.
1. Create a JSON file named AzureSqlLinkedService.json in C:\ADFGetStartedPSH folder with the
following content:
IMPORTANT
Replace <servername>, <databasename>, <username@servername>, and <password> with names of
your Azure SQL server, database, user account, and password.
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Server=tcp:<server>.database.windows.net,1433;Database=
<databasename>;User ID=<user>@<server>;Password=
<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
}
}
}
2. Run the following command to create a linked service:
New-AzureRmDataFactoryLinkedService $df -File .\AzureSqlLinkedService.json
Here is the sample output:
LinkedServiceName
ResourceGroupName
DataFactoryName
Properties
ProvisioningState
:
:
:
:
:
AzureSqlLinkedService
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
Microsoft.Azure.Management.DataFactories.Models.LinkedServiceProperties
Succeeded
Confirm that Allow access to Azure services setting is turned on for your SQL database server. To
verify and turn it on, do the following steps:
a.
b.
c.
d.
e.
f.
Log in to the Azure portal
Click More services > on the left, and click SQL servers in the DATABASES category.
Select your server in the list of SQL servers.
On the SQL server blade, click Show firewall settings link.
In the Firewall settings blade, click ON for Allow access to Azure services.
Click Save on the toolbar.
Create datasets
In the previous step, you created linked services to link your Azure Storage account and Azure SQL database
to your data factory. In this step, you define two datasets named InputDataset and OutputDataset that
represent input and output data that is stored in the data stores referred by AzureStorageLinkedService and
AzureSqlLinkedService respectively.
The Azure storage linked service specifies the connection string that Data Factory service uses at run time to
connect to your Azure storage account. And, the input blob dataset (InputDataset) specifies the container and
the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory service uses
at run time to connect to your Azure SQL database. And, the output SQL table dataset (OututDataset) specifies
the table in the database to which the data from the blob storage is copied.
Create an input dataset
In this step, you create a dataset named InputDataset that points to a blob file (emp.txt) in the root folder of a
blob container (adftutorial) in the Azure Storage represented by the AzureStorageLinkedService linked service.
If you don't specify a value for the fileName (or skip it), data from all blobs in the input folder are copied to the
destination. In this tutorial, you specify a value for the fileName.
1. Create a JSON file named InputDataset.json in the C:\ADFGetStartedPSH folder, with the following
content:
{
"name": "InputDataset",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "emp.txt",
"folderPath": "adftutorial/",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data
resides in an Azure blob storage.
linkedServiceName
Refers to the AzureStorageLinkedService that you
created earlier.
folderPath
Specifies the blob container and the folder that
contains input blobs. In this tutorial, adftutorial is the
blob container and folder is the root folder.
fileName
This property is optional. If you omit this property, all
files from the folderPath are picked. In this tutorial,
emp.txt is specified for the fileName, so only that file is
picked up for processing.
format -> type
The input file is in the text format, so we use
TextFormat.
columnDelimiter
The columns in the input file are delimited by comma
character ( , ).
PROPERTY
DESCRIPTION
frequency/interval
The frequency is set to Hour and interval is set to 1,
which means that the input slices are available hourly.
In other words, the Data Factory service looks for input
data every hour in the root folder of blob container
(adftutorial) you specified. It looks for the data within
the pipeline start and end times, not before or after
these times.
external
This property is set to true if the data is not generated
by this pipeline. The input data in this tutorial is in the
emp.txt file, which is not generated by this pipeline, so
we set this property to true.
For more information about these JSON properties, see Azure Blob connector article.
2. Run the following command to create the Data Factory dataset.
New-AzureRmDataFactoryDataset $df -File .\InputDataset.json
Here is the sample output:
DatasetName
ResourceGroupName
DataFactoryName
Availability
Location
Policy
Structure
Properties
ProvisioningState
:
:
:
:
:
:
:
:
:
InputDataset
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
Microsoft.Azure.Management.DataFactories.Common.Models.Availability
Microsoft.Azure.Management.DataFactories.Models.AzureBlobDataset
Microsoft.Azure.Management.DataFactories.Common.Models.Policy
{FirstName, LastName}
Microsoft.Azure.Management.DataFactories.Models.DatasetProperties
Succeeded
Create an output dataset
In this part of the step, you create an output dataset named OutputDataset. This dataset points to a SQL table
in the Azure SQL database represented by AzureSqlLinkedService.
1. Create a JSON file named OutputDataset.json in the C:\ADFGetStartedPSH folder with the following
content:
{
"name": "OutputDataset",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "emp"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureSqlTable because
data is copied to a table in an Azure SQL database.
linkedServiceName
Refers to the AzureSqlLinkedService that you created
earlier.
tableName
Specified the table to which the data is copied.
frequency/interval
The frequency is set to Hour and interval is 1, which
means that the output slices are produced hourly
between the pipeline start and end times, not before or
after these times.
There are three columns – ID, FirstName, and LastName – in the emp table in the database. ID is an
identity column, so you need to specify only FirstName and LastName here.
For more information about these JSON properties, see Azure SQL connector article.
2. Run the following command to create the data factory dataset.
New-AzureRmDataFactoryDataset $df -File .\OutputDataset.json
Here is the sample output:
DatasetName
ResourceGroupName
DataFactoryName
Availability
Location
Policy
Structure
Properties
ProvisioningState
:
:
:
:
:
:
:
:
:
OutputDataset
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
Microsoft.Azure.Management.DataFactories.Common.Models.Availability
Microsoft.Azure.Management.DataFactories.Models.AzureSqlTableDataset
{FirstName, LastName}
Microsoft.Azure.Management.DataFactories.Models.DatasetProperties
Succeeded
Create a pipeline
In this step, you create a pipeline with a copy activity that uses InputDataset as an input and
OutputDataset as an output.
Currently, output dataset is what drives the schedule. In this tutorial, output dataset is configured to produce a
slice once an hour. The pipeline has a start time and end time that are one day apart, which is 24 hours.
Therefore, 24 slices of output dataset are produced by the pipeline.
1. Create a JSON file named ADFTutorialPipeline.json in the C:\ADFGetStartedPSH folder, with the
following content:
{
"name": "ADFTutorialPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
],
"start": "2017-05-11T00:00:00Z",
"end": "2017-05-12T00:00:00Z"
}
}
Note the following points:
In the activities section, there is only one activity whose type is set to Copy. For more information
about the copy activity, see data movement activities. In Data Factory solutions, you can also use
data transformation activities.
Input for the activity is set to InputDataset and output for the activity is set to OutputDataset.
In the typeProperties section, BlobSource is specified as the source type and SqlSink is
specified as the sink type. For a complete list of data stores supported by the copy activity as
sources and sinks, see supported data stores. To learn how to use a specific supported data store
as a source/sink, click the link in the table.
Replace the value of the start property with the current day and end value with the next day.
You can specify only the date part and skip the time part of the date time. For example, "201602-03", which is equivalent to "2016-02-03T00:00:00Z"
Both start and end datetimes must be in ISO format. For example: 2016-10-14T16:32:41Z. The
end time is optional, but we use it in this tutorial.
If you do not specify value for the end property, it is calculated as "start + 48 hours". To run the
pipeline indefinitely, specify 9999-09-09 as the value for the end property.
In the preceding example, there are 24 data slices as each data slice is produced hourly.
For descriptions of JSON properties in a pipeline definition, see create pipelines article. For
descriptions of JSON properties in a copy activity definition, see data movement activities. For
descriptions of JSON properties supported by BlobSource, see Azure Blob connector article. For
descriptions of JSON properties supported by SqlSink, see Azure SQL Database connector
article.
2. Run the following command to create the data factory table.
New-AzureRmDataFactoryPipeline $df -File .\ADFTutorialPipeline.json
Here is the sample output:
PipelineName
ResourceGroupName
DataFactoryName
Properties
ProvisioningState
:
:
:
:
:
ADFTutorialPipeline
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
Microsoft.Azure.Management.DataFactories.Models.PipelinePropertie
Succeeded
Congratulations! You have successfully created an Azure data factory with a pipeline to copy data from an
Azure blob storage to an Azure SQL database.
Monitor the pipeline
In this step, you use Azure PowerShell to monitor what’s going on in an Azure data factory.
1. Replace <DataFactoryName> with the name of your data factory and run Get-AzureRmDataFactory,
and assign the output to a variable $df.
$df=Get-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name <DataFactoryName>
For example:
$df=Get-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name
ADFTutorialDataFactoryPSH0516
Then, run print the contents of $df to see the following output:
PS C:\ADFGetStartedPSH> $df
DataFactoryName
DataFactoryId
ResourceGroupName
Location
Tags
Properties
ProvisioningState
:
:
:
:
:
:
:
ADFTutorialDataFactoryPSH0516
6f194b34-03b3-49ab-8f03-9f8a7b9d3e30
ADFTutorialResourceGroup
West US
{}
Microsoft.Azure.Management.DataFactories.Models.DataFactoryProperties
Succeeded
2. Run Get-AzureRmDataFactorySlice to get details about all slices of the OutputDataset, which is the
output dataset of the pipeline.
Get-AzureRmDataFactorySlice $df -DatasetName OutputDataset -StartDateTime 2017-05-11T00:00:00Z
This setting should match the Start value in the pipeline JSON. You should see 24 slices, one for each
hour from 12 AM of the current day to 12 AM of the next day.
Here are three sample slices from the output:
ResourceGroupName
DataFactoryName
DatasetName
Start
End
RetryCount
State
SubState
LatencyStatus
LongRetryCount
:
:
:
:
:
:
:
:
:
:
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
OutputDataset
5/11/2017 11:00:00 PM
5/12/2017 12:00:00 AM
0
Ready
ResourceGroupName
DataFactoryName
DatasetName
Start
End
RetryCount
State
SubState
LatencyStatus
LongRetryCount
:
:
:
:
:
:
:
:
:
:
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
OutputDataset
5/11/2017 9:00:00 PM
5/11/2017 10:00:00 PM
0
InProgress
ResourceGroupName
DataFactoryName
DatasetName
Start
End
RetryCount
State
SubState
LatencyStatus
LongRetryCount
:
:
:
:
:
:
:
:
:
:
ADFTutorialResourceGroup
ADFTutorialDataFactoryPSH0516
OutputDataset
5/11/2017 8:00:00 PM
5/11/2017 9:00:00 PM
0
Waiting
ConcurrencyLimit
0
0
0
3. Run Get-AzureRmDataFactoryRun to get the details of activity runs for a specific slice. Copy the
date-time value from the output of the previous command to specify the value for the StartDateTime
parameter.
Get-AzureRmDataFactoryRun $df -DatasetName OutputDataset -StartDateTime "5/11/2017 09:00:00 PM"
Here is the sample output:
Id
: c0ddbd75-d0c7-4816-a775704bbd7c7eab_636301332000000000_636301368000000000_OutputDataset
ResourceGroupName : ADFTutorialResourceGroup
DataFactoryName
: ADFTutorialDataFactoryPSH0516
DatasetName
: OutputDataset
ProcessingStartTime : 5/16/2017 8:00:33 PM
ProcessingEndTime : 5/16/2017 8:01:36 PM
PercentComplete
: 100
DataSliceStart
: 5/11/2017 9:00:00 PM
DataSliceEnd
: 5/11/2017 10:00:00 PM
Status
: Succeeded
Timestamp
: 5/16/2017 8:00:33 PM
RetryAttempt
: 0
Properties
: {}
ErrorMessage
:
ActivityName
: CopyFromBlobToSQL
PipelineName
: ADFTutorialPipeline
Type
: Copy
For comprehensive documentation on Data Factory cmdlets, see Data Factory Cmdlet Reference.
Summary
In this tutorial, you created an Azure data factory to copy data from an Azure blob to an Azure SQL database.
You used PowerShell to create the data factory, linked services, datasets, and a pipeline. Here are the highlevel steps you performed in this tutorial:
1. Created an Azure data factory.
2. Created linked services:
a. An Azure Storage linked service to link your Azure storage account that holds input data.
b. An Azure SQL linked service to link your SQL database that holds the output data.
3. Created datasets that describe input data and output data for pipelines.
4. Created a pipeline with Copy Activity, with BlobSource as the source and SqlSink as the sink.
Next steps
In this tutorial, you used Azure blob storage as a source data store and an Azure SQL database as a destination
data store in a copy operation. The following table provides a list of data stores supported as sources and
destinations by the copy activity:
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure SQL Database
✓
✓
Azure SQL Data
Warehouse
✓
✓
✓
Azure Search Index
Databases
NoSQL
File
Others
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
✓
✓
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
To learn about how to copy data to/from a data store, click the link for the data store in the table.
Tutorial: Use Azure Resource Manager template to
create a Data Factory pipeline to copy data
5/18/2017 • 13 min to read • Edit Online
This tutorial shows you how to use an Azure Resource Manager template to create an Azure data factory. The
data pipeline in this tutorial copies data from a source data store to a destination data store. It does not transform
input data to produce output data. For a tutorial on how to transform data using Azure Data Factory, see Tutorial:
Build a pipeline to transform data using Hadoop cluster.
In this tutorial, you create a pipeline with one activity in it: Copy Activity. The copy activity copies data from a
supported data store to a supported sink data store. For a list of data stores supported as sources and sinks, see
supported data stores. The activity is powered by a globally available service that can copy data between various
data stores in a secure, reliable, and scalable way. For more information about the Copy Activity, see Data
Movement Activities.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by
setting the output dataset of one activity as the input dataset of the other activity. For more information, see
multiple activities in a pipeline.
NOTE
The data pipeline in this tutorial copies data from a source data store to a destination data store. For a tutorial on how to
transform data using Azure Data Factory, see Tutorial: Build a pipeline to transform data using Hadoop cluster.
Prerequisites
Go through Tutorial Overview and Prerequisites and complete the prerequisite steps.
Follow instructions in How to install and configure Azure PowerShell article to install latest version of Azure
PowerShell on your computer. In this tutorial, you use PowerShell to deploy Data Factory entities.
(optional) See Authoring Azure Resource Manager Templates to learn about Azure Resource Manager
templates.
In this tutorial
In this tutorial, you create a data factory with the following Data Factory entities:
ENTITY
DESCRIPTION
Azure Storage linked service
Links your Azure Storage account to the data factory. Azure
Storage is the source data store and Azure SQL database is
the sink data store for the copy activity in the tutorial. It
specifies the storage account that contains the input data for
the copy activity.
Azure SQL Database linked service
Links your Azure SQL database to the data factory. It
specifies the Azure SQL database that holds the output data
for the copy activity.
ENTITY
DESCRIPTION
Azure Blob input dataset
Refers to the Azure Storage linked service. The linked service
refers to an Azure Storage account and the Azure Blob
dataset specifies the container, folder, and file name in the
storage that holds the input data.
Azure SQL output dataset
Refers to the Azure SQL linked service. The Azure SQL linked
service refers to an Azure SQL server and the Azure SQL
dataset specifies the name of the table that holds the output
data.
Data pipeline
The pipeline has one activity of type Copy that takes the
Azure blob dataset as an input and the Azure SQL dataset as
an output. The copy activity copies data from an Azure blob
to a table in the Azure SQL database.
A data factory can have one or more pipelines. A pipeline can have one or more activities in it. There are two
types of activities: data movement activities and data transformation activities. In this tutorial, you create a
pipeline with one activity (copy activity).
The following section provides the complete Resource Manager template for defining Data Factory entities so
that you can quickly run through the tutorial and test the template. To understand how each Data Factory entity
is defined, see Data Factory entities in the template section.
Data Factory JSON template
The top-level Resource Manager template for defining a data factory is:
{
"$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": { ...
},
"variables": { ...
},
"resources": [
{
"name": "[parameters('dataFactoryName')]",
"apiVersion": "[variables('apiVersion')]",
"type": "Microsoft.DataFactory/datafactories",
"location": "westus",
"resources": [
{ ... },
{ ... },
{ ... },
{ ... }
]
}
]
}
Create a JSON file named ADFCopyTutorialARM.json in C:\ADFGetStarted folder with the following content:
{
"contentVersion": "1.0.0.0",
"$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"parameters": {
"storageAccountName": { "type": "string", "metadata": { "description": "Name of the Azure storage
account that contains the data to be copied." } },
"storageAccountKey": { "type": "securestring", "metadata": { "description": "Key for the Azure storage
account." } },
"sourceBlobContainer": { "type": "string", "metadata": { "description": "Name of the blob container in
the Azure Storage account." } },
"sourceBlobName": { "type": "string", "metadata": { "description": "Name of the blob in the container
that has the data to be copied to Azure SQL Database table" } },
"sqlServerName": { "type": "string", "metadata": { "description": "Name of the Azure SQL Server that
will hold the output/copied data." } },
"databaseName": { "type": "string", "metadata": { "description": "Name of the Azure SQL Database in
the Azure SQL server." } },
"sqlServerUserName": { "type": "string", "metadata": { "description": "Name of the user that has
access to the Azure SQL server." } },
"sqlServerPassword": { "type": "securestring", "metadata": { "description": "Password for the user." }
},
"targetSQLTable": { "type": "string", "metadata": { "description": "Table in the Azure SQL Database
that will hold the copied data." }
}
},
"variables": {
"dataFactoryName": "[concat('AzureBlobToAzureSQLDatabaseDF', uniqueString(resourceGroup().id))]",
"azureSqlLinkedServiceName": "AzureSqlLinkedService",
"azureStorageLinkedServiceName": "AzureStorageLinkedService",
"blobInputDatasetName": "BlobInputDataset",
"sqlOutputDatasetName": "SQLOutputDataset",
"pipelineName": "Blob2SQLPipeline"
},
"resources": [
{
"name": "[variables('dataFactoryName')]",
"apiVersion": "2015-10-01",
"type": "Microsoft.DataFactory/datafactories",
"location": "West US",
"resources": [
{
"type": "linkedservices",
"name": "[variables('azureStorageLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureStorage",
"description": "Azure Storage linked service",
"typeProperties": {
"connectionString": "
[concat('DefaultEndpointsProtocol=https;AccountName=',parameters('storageAccountName'),';AccountKey=',parame
ters('storageAccountKey'))]"
}
}
},
{
"type": "linkedservices",
"name": "[variables('azureSqlLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureSqlDatabase",
"description": "Azure SQL linked service",
"typeProperties": {
"connectionString": "
[concat('Server=tcp:',parameters('sqlServerName'),'.database.windows.net,1433;Database=',
parameters('databaseName'), ';User
ID=',parameters('sqlServerUserName'),';Password=',parameters('sqlServerPassword'),';Trusted_Connection=False
;Encrypt=True;Connection Timeout=30')]"
}
}
},
{
"type": "datasets",
"name": "[variables('blobInputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]",
"structure": [
{
"name": "Column0",
"type": "String"
},
{
"name": "Column1",
"type": "String"
}
],
"typeProperties": {
"folderPath": "[concat(parameters('sourceBlobContainer'), '/')]",
"fileName": "[parameters('sourceBlobName')]",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
},
{
"type": "datasets",
"name": "[variables('sqlOutputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureSqlLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "[variables('azureSqlLinkedServiceName')]",
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"typeProperties": {
"tableName": "[parameters('targetSQLTable')]"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
},
{
"type": "datapipelines",
"name": "[variables('pipelineName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]",
"[variables('azureSqlLinkedServiceName')]",
"[variables('blobInputDatasetName')]",
"[variables('sqlOutputDatasetName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"activities": [
{
"name": "CopyFromAzureBlobToAzureSQL",
"description": "Copy data frm Azure blob to Azure SQL",
"type": "Copy",
"inputs": [
{
"name": "[variables('blobInputDatasetName')]"
}
],
"outputs": [
{
"name": "[variables('sqlOutputDatasetName')]"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"sqlWriterCleanupScript": "$$Text.Format('DELETE FROM {0}', 'emp')"
},
"translator": {
"type": "TabularTranslator",
"columnMappings": "Column0:FirstName,Column1:LastName"
"columnMappings": "Column0:FirstName,Column1:LastName"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 3,
"timeout": "01:00:00"
}
}
],
"start": "2017-05-11T00:00:00Z",
"end": "2017-05-12T00:00:00Z"
}
}
]
}
]
}
Parameters JSON
Create a JSON file named ADFCopyTutorialARM-Parameters.json that contains parameters for the Azure
Resource Manager template.
IMPORTANT
Specify name and key of your Azure Storage account for storageAccountName and storageAccountKey parameters.
Specify Azure SQL server, database, user, and password for sqlServerName, databaseName, sqlServerUserName, and
sqlServerPassword parameters.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"storageAccountName": { "value": "<Name of the Azure storage account>"
},
"storageAccountKey": {
"value": "<Key for the Azure storage account>"
},
"sourceBlobContainer": { "value": "adftutorial" },
"sourceBlobName": { "value": "emp.txt" },
"sqlServerName": { "value": "<Name of the Azure SQL server>" },
"databaseName": { "value": "<Name of the Azure SQL database>" },
"sqlServerUserName": { "value": "<Name of the user who has access to the Azure SQL database>" },
"sqlServerPassword": { "value": "<password for the user>" },
"targetSQLTable": { "value": "emp" }
}
}
IMPORTANT
You may have separate parameter JSON files for development, testing, and production environments that you can use
with the same Data Factory JSON template. By using a Power Shell script, you can automate deploying Data Factory
entities in these environments.
Create data factory
1. Start Azure PowerShell and run the following command:
Run the following command and enter the user name and password that you use to sign in to the
Azure portal.
Login-AzureRmAccount
Run the following command to view all the subscriptions for this account.
Get-AzureRmSubscription
Run the following command to select the subscription that you want to work with.
Get-AzureRmSubscription -SubscriptionName <SUBSCRIPTION NAME> | Set-AzureRmContext
2. Run the following command to deploy Data Factory entities using the Resource Manager template you
created in Step 1.
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile C:\ADFGetStarted\ADFCopyTutorialARM.json -TemplateParameterFile
C:\ADFGetStarted\ADFCopyTutorialARM-Parameters.json
Monitor pipeline
1. Log in to the Azure portal using your Azure account.
2. Click Data factories on the left menu (or) click More services and click Data factories under
INTELLIGENCE + ANALYTICS category.
3. In the Data factories page, search for and find your data factory (AzureBlobToAzureSQLDatabaseDF).
4. Click your Azure data factory. You see the home page for the data factory.
5. Follow instructions from Monitor datasets and pipeline to monitor the pipeline and datasets you have created
in this tutorial. Currently, Visual Studio does not support monitoring Data Factory pipelines.
6. When a slice is in the Ready state, verify that the data is copied to the emp table in the Azure SQL database.
For more information on how to use Azure portal blades to monitor pipeline and datasets you have created in
this tutorial, see Monitor datasets and pipeline .
For more information on how to use the Monitor & Manage application to monitor your data pipelines, see
Monitor and manage Azure Data Factory pipelines using Monitoring App.
Data Factory entities in the template
Define data factory
You define a data factory in the Resource Manager template as shown in the following sample:
"resources": [
{
"name": "[variables('dataFactoryName')]",
"apiVersion": "2015-10-01",
"type": "Microsoft.DataFactory/datafactories",
"location": "West US"
}
The dataFactoryName is defined as:
"dataFactoryName": "[concat('AzureBlobToAzureSQLDatabaseDF', uniqueString(resourceGroup().id))]"
It is a unique string based on the resource group ID.
Defining Data Factory entities
The following Data Factory entities are defined in the JSON template:
1.
2.
3.
4.
5.
Azure Storage linked service
Azure SQL linked service
Azure blob dataset
Azure SQL dataset
Data pipeline with a copy activity
Azure Storage linked service
The AzureStorageLinkedService links your Azure storage account to the data factory. You created a container and
uploaded data to this storage account as part of prerequisites. You specify the name and key of your Azure
storage account in this section. See Azure Storage linked service for details about JSON properties used to define
an Azure Storage linked service.
{
"type": "linkedservices",
"name": "[variables('azureStorageLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureStorage",
"description": "Azure Storage linked service",
"typeProperties": {
"connectionString": "
[concat('DefaultEndpointsProtocol=https;AccountName=',parameters('storageAccountName'),';AccountKey=',parame
ters('storageAccountKey'))]"
}
}
}
The connectionString uses the storageAccountName and storageAccountKey parameters. The values for these
parameters passed by using a configuration file. The definition also uses variables: azureStroageLinkedService
and dataFactoryName defined in the template.
Azure SQL Database linked service
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from the blob
storage is stored in this database. You created the emp table in this database as part of prerequisites. You specify
the Azure SQL server name, database name, user name, and user password in this section. See Azure SQL linked
service for details about JSON properties used to define an Azure SQL linked service.
{
"type": "linkedservices",
"name": "[variables('azureSqlLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureSqlDatabase",
"description": "Azure SQL linked service",
"typeProperties": {
"connectionString": "
[concat('Server=tcp:',parameters('sqlServerName'),'.database.windows.net,1433;Database=',
parameters('databaseName'), ';User
ID=',parameters('sqlServerUserName'),';Password=',parameters('sqlServerPassword'),';Trusted_Connection=False
;Encrypt=True;Connection Timeout=30')]"
}
}
}
The connectionString uses sqlServerName, databaseName, sqlServerUserName, and sqlServerPassword
parameters whose values are passed by using a configuration file. The definition also uses the following variables
from the template: azureSqlLinkedServiceName, dataFactoryName.
Azure blob dataset
The Azure storage linked service specifies the connection string that Data Factory service uses at run time to
connect to your Azure storage account. In Azure blob dataset definition, you specify names of blob container,
folder, and file that contains the input data. See Azure Blob dataset properties for details about JSON properties
used to define an Azure Blob dataset.
{
"type": "datasets",
"name": "[variables('blobInputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]",
"structure": [
{
"name": "Column0",
"type": "String"
},
{
"name": "Column1",
"type": "String"
}
],
"typeProperties": {
"folderPath": "[concat(parameters('sourceBlobContainer'), '/')]",
"fileName": "[parameters('sourceBlobName')]",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Azure SQL dataset
You specify the name of the table in the Azure SQL database that holds the copied data from the Azure Blob
storage. See Azure SQL dataset properties for details about JSON properties used to define an Azure SQL
dataset.
{
"type": "datasets",
"name": "[variables('sqlOutputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureSqlLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "[variables('azureSqlLinkedServiceName')]",
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"typeProperties": {
"tableName": "[parameters('targetSQLTable')]"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Data pipeline
You define a pipeline that copies data from the Azure blob dataset to the Azure SQL dataset. See Pipeline JSON
for descriptions of JSON elements used to define a pipeline in this example.
{
"type": "datapipelines",
"name": "[variables('pipelineName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]",
"[variables('azureSqlLinkedServiceName')]",
"[variables('blobInputDatasetName')]",
"[variables('sqlOutputDatasetName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"activities": [
{
"name": "CopyFromAzureBlobToAzureSQL",
"description": "Copy data frm Azure blob to Azure SQL",
"type": "Copy",
"inputs": [
{
"name": "[variables('blobInputDatasetName')]"
}
],
"outputs": [
{
"name": "[variables('sqlOutputDatasetName')]"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"sqlWriterCleanupScript": "$$Text.Format('DELETE FROM {0}', 'emp')"
},
"translator": {
"type": "TabularTranslator",
"columnMappings": "Column0:FirstName,Column1:LastName"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 3,
"timeout": "01:00:00"
}
}
],
"start": "2017-05-11T00:00:00Z",
"end": "2017-05-12T00:00:00Z"
}
}
Reuse the template
In the tutorial, you created a template for defining Data Factory entities and a template for passing values for
parameters. The pipeline copies data from an Azure Storage account to an Azure SQL database specified via
parameters. To use the same template to deploy Data Factory entities to different environments, you create a
parameter file for each environment and use it when deploying to that environment.
Example:
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile ADFCopyTutorialARM.json -TemplateParameterFile ADFCopyTutorialARM-Parameters-Dev.json
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile ADFCopyTutorialARM.json -TemplateParameterFile ADFCopyTutorialARM-Parameters-Test.json
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile ADFCopyTutorialARM.json -TemplateParameterFile ADFCopyTutorialARM-Parameters-Production.json
Notice that the first command uses parameter file for the development environment, second one for the test
environment, and the third one for the production environment.
You can also reuse the template to perform repeated tasks. For example, you need to create many data factories
with one or more pipelines that implement the same logic but each data factory uses different Storage and SQL
Database accounts. In this scenario, you use the same template in the same environment (dev, test, or
production) with different parameter files to create data factories.
Next steps
In this tutorial, you used Azure blob storage as a source data store and an Azure SQL database as a destination
data store in a copy operation. The following table provides a list of data stores supported as sources and
destinations by the copy activity:
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data Warehouse
✓
✓
✓
Azure Search Index
Databases
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
✓
✓
CATEGORY
NoSQL
File
Others
DATA STORE
SUPPORTED AS A SOURCE
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
✓
✓
To learn about how to copy data to/from a data store, click the link for the data store in the table.
Tutorial: Use REST API to create an Azure Data
Factory pipeline to copy data
6/13/2017 • 17 min to read • Edit Online
In this article, you learn how to use REST API to create a data factory with a pipeline that copies data from an
Azure blob storage to an Azure SQL database. If you are new to Azure Data Factory, read through the
Introduction to Azure Data Factory article before doing this tutorial.
In this tutorial, you create a pipeline with one activity in it: Copy Activity. The copy activity copies data from a
supported data store to a supported sink data store. For a list of data stores supported as sources and sinks, see
supported data stores. The activity is powered by a globally available service that can copy data between various
data stores in a secure, reliable, and scalable way. For more information about the Copy Activity, see Data
Movement Activities.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by
setting the output dataset of one activity as the input dataset of the other activity. For more information, see
multiple activities in a pipeline.
NOTE
This article does not cover all the Data Factory REST API. See Data Factory REST API Reference for comprehensive
documentation on Data Factory cmdlets.
The data pipeline in this tutorial copies data from a source data store to a destination data store. For a tutorial on how to
transform data using Azure Data Factory, see Tutorial: Build a pipeline to transform data using Hadoop cluster.
Prerequisites
Go through Tutorial Overview and complete the prerequisite steps.
Install Curl on your machine. You use the Curl tool with REST commands to create a data factory.
Follow instructions from this article to:
1. Create a Web application named ADFCopyTutorialApp in Azure Active Directory.
2. Get client ID and secret key.
3. Get tenant ID.
4. Assign the ADFCopyTutorialApp application to the Data Factory Contributor role.
Install Azure PowerShell.
Launch PowerShell and do the following steps. Keep Azure PowerShell open until the end of this tutorial.
If you close and reopen, you need to run the commands again.
1. Run the following command and enter the user name and password that you use to sign in to the
Azure portal:
Login-AzureRmAccount
2. Run the following command to view all the subscriptions for this account:
Get-AzureRmSubscription
3. Run the following command to select the subscription that you want to work with. Replace
<NameOfAzureSubscription> with the name of your Azure subscription.
Get-AzureRmSubscription -SubscriptionName <NameOfAzureSubscription> | Set-AzureRmContext
4. Create an Azure resource group named ADFTutorialResourceGroup by running the following
command in the PowerShell:
New-AzureRmResourceGroup -Name ADFTutorialResourceGroup -Location "West US"
If the resource group already exists, you specify whether to update it (Y) or keep it as (N).
Some of the steps in this tutorial assume that you use the resource group named
ADFTutorialResourceGroup. If you use a different resource group, you need to use the name of
your resource group in place of ADFTutorialResourceGroup in this tutorial.
Create JSON definitions
Create following JSON files in the folder where curl.exe is located.
datafactory.json
IMPORTANT
Name must be globally unique, so you may want to prefix/suffix ADFCopyTutorialDF to make it a unique name.
{
"name": "ADFCopyTutorialDF",
"location": "WestUS"
}
azurestoragelinkedservice.json
IMPORTANT
Replace accountname and accountkey with name and key of your Azure storage account. To learn how to get your
storage access key, see View, copy and regenerate storage access keys.
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
For details about JSON properties, see Azure Storage linked service.
azuersqllinkedservice.json
IMPORTANT
Replace servername, databasename, username, and password with name of your Azure SQL server, name of SQL
database, user account, and password for the account.
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"description": "",
"typeProperties": {
"connectionString": "Data Source=tcp:<servername>.database.windows.net,1433;Initial Catalog=
<databasename>;User ID=<username>;Password=<password>;Integrated Security=False;Encrypt=True;Connect
Timeout=30"
}
}
}
For details about JSON properties, see Azure SQL linked service.
inputdataset.json
{
"name": "AzureBlobInput",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "adftutorial/",
"fileName": "emp.txt",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data resides
in an Azure blob storage.
PROPERTY
DESCRIPTION
linkedServiceName
Refers to the AzureStorageLinkedService that you created
earlier.
folderPath
Specifies the blob container and the folder that contains
input blobs. In this tutorial, adftutorial is the blob container
and folder is the root folder.
fileName
This property is optional. If you omit this property, all files
from the folderPath are picked. In this tutorial, emp.txt is
specified for the fileName, so only that file is picked up for
processing.
format -> type
The input file is in the text format, so we use TextFormat.
columnDelimiter
The columns in the input file are delimited by comma
character ( , ).
frequency/interval
The frequency is set to Hour and interval is set to 1, which
means that the input slices are available hourly. In other
words, the Data Factory service looks for input data every
hour in the root folder of blob container (adftutorial) you
specified. It looks for the data within the pipeline start and
end times, not before or after these times.
external
This property is set to true if the data is not generated by
this pipeline. The input data in this tutorial is in the emp.txt
file, which is not generated by this pipeline, so we set this
property to true.
For more information about these JSON properties, see Azure Blob connector article.
outputdataset.json
{
"name": "AzureSqlOutput",
"properties": {
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "emp"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureSqlTable because data is
copied to a table in an Azure SQL database.
linkedServiceName
Refers to the AzureSqlLinkedService that you created
earlier.
tableName
Specified the table to which the data is copied.
frequency/interval
The frequency is set to Hour and interval is 1, which means
that the output slices are produced hourly between the
pipeline start and end times, not before or after these times.
There are three columns – ID, FirstName, and LastName – in the emp table in the database. ID is an identity
column, so you need to specify only FirstName and LastName here.
For more information about these JSON properties, see Azure SQL connector article.
pipeline.json
{
"name": "ADFTutorialPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"description": "Push Regional Effectiveness Campaign data to Azure SQL database",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureSqlOutput"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
],
"start": "2017-05-11T00:00:00Z",
"end": "2017-05-12T00:00:00Z"
}
}
Note the following points:
In the activities section, there is only one activity whose type is set to Copy. For more information about the
copy activity, see data movement activities. In Data Factory solutions, you can also use data transformation
activities.
Input for the activity is set to AzureBlobInput and output for the activity is set to AzureSqlOutput.
In the typeProperties section, BlobSource is specified as the source type and SqlSink is specified as the sink
type. For a complete list of data stores supported by the copy activity as sources and sinks, see supported data
stores. To learn how to use a specific supported data store as a source/sink, click the link in the table.
Replace the value of the start property with the current day and end value with the next day. You can specify
only the date part and skip the time part of the date time. For example, "2017-02-03", which is equivalent to
"2017-02-03T00:00:00Z"
Both start and end datetimes must be in ISO format. For example: 2016-10-14T16:32:41Z. The end time is
optional, but we use it in this tutorial.
If you do not specify value for the end property, it is calculated as "start + 48 hours". To run the pipeline
indefinitely, specify 9999-09-09 as the value for the end property.
In the preceding example, there are 24 data slices as each data slice is produced hourly.
For descriptions of JSON properties in a pipeline definition, see create pipelines article. For descriptions of JSON
properties in a copy activity definition, see data movement activities. For descriptions of JSON properties
supported by BlobSource, see Azure Blob connector article. For descriptions of JSON properties supported by
SqlSink, see Azure SQL Database connector article.
Set global variables
In Azure PowerShell, execute the following commands after replacing the values with your own:
IMPORTANT
See Prerequisites section for instructions on getting client ID, client secret, tenant ID, and subscription ID.
$client_id = "<client ID of application in AAD>"
$client_secret = "<client key of application in AAD>"
$tenant = "<Azure tenant ID>";
$subscription_id="<Azure subscription ID>";
$rg = "ADFTutorialResourceGroup"
Run the following command after updating the name of the data factory you are using:
$adf = "ADFCopyTutorialDF"
Authenticate with AAD
Run the following command to authenticate with Azure Active Directory (AAD):
$cmd = { .\curl.exe -X POST https://login.microsoftonline.com/$tenant/oauth2/token -F
grant_type=client_credentials -F resource=https://management.core.windows.net/ -F client_id=$client_id -F
client_secret=$client_secret };
$responseToken = Invoke-Command -scriptblock $cmd;
$accessToken = (ConvertFrom-Json $responseToken).access_token;
(ConvertFrom-Json $responseToken)
Create data factory
In this step, you create an Azure Data Factory named ADFCopyTutorialDF. A data factory can have one or more
pipelines. A pipeline can have one or more activities in it. For example, a Copy Activity to copy data from a source
to a destination data store. A HDInsight Hive activity to run a Hive script to transform input data to product
output data. Run the following commands to create the data factory:
1. Assign the command to variable named cmd.
IMPORTANT
Confirm that the name of the data factory you specify here (ADFCopyTutorialDF) matches the name specified in the
datafactory.json.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data “@datafactory.json”
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/ADFCopyTutorialDF0411?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the data factory has been successfully created, you see the JSON for the data factory in
the results; otherwise, you see an error message.
Write-Host $results
Note the following points:
The name of the Azure Data Factory must be globally unique. If you see the error in results: Data factory
name “ADFCopyTutorialDF” is not available, do the following steps:
1. Change the name (for example, yournameADFCopyTutorialDF) in the datafactory.json file.
2. In the first command where the $cmd variable is assigned a value, replace ADFCopyTutorialDF with the
new name and run the command.
3. Run the next two commands to invoke the REST API to create the data factory and print the results
of the operation.
See Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
To create Data Factory instances, you need to be a contributor/administrator of the Azure subscription
The name of the data factory may be registered as a DNS name in the future and hence become publicly
visible.
If you receive the error: "This subscription is not registered to use namespace
Microsoft.DataFactory", do one of the following and try publishing again:
In Azure PowerShell, run the following command to register the Data Factory provider:
Register-AzureRmResourceProvider -ProviderNamespace Microsoft.DataFactory
You can run the following command to confirm that the Data Factory provider is registered.
Get-AzureRmResourceProvider
Login using the Azure subscription into the Azure portal and navigate to a Data Factory blade (or)
create a data factory in the Azure portal. This action automatically registers the provider for you.
Before creating a pipeline, you need to create a few Data Factory entities first. You first create linked services to
link source and destination data stores to your data store. Then, define input and output datasets to represent
data in linked data stores. Finally, create the pipeline with an activity that uses these datasets.
Create linked services
You create linked services in a data factory to link your data stores and compute services to the data factory. In
this tutorial, you don't use any compute service such as Azure HDInsight or Azure Data Lake Analytics. You use
two data stores of type Azure Storage (source) and Azure SQL Database (destination). Therefore, you create two
linked services named AzureStorageLinkedService and AzureSqlLinkedService of types: AzureStorage and
AzureSqlDatabase.
The AzureStorageLinkedService links your Azure storage account to the data factory. This storage account is the
one in which you created a container and uploaded the data as part of prerequisites.
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from the blob
storage is stored in this database. You created the emp table in this database as part of prerequisites.
Create Azure Storage linked service
In this step, you link your Azure storage account to your data factory. You specify the name and key of your Azure
storage account in this section. See Azure Storage linked service for details about JSON properties used to define
an Azure Storage linked service.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@azurestoragelinkedservice.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/linkedservices/AzureStorageLinkedService?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the linked service has been successfully created, you see the JSON for the linked service
in the results; otherwise, you see an error message.
Write-Host $results
Create Azure SQL linked service
In this step, you link your Azure SQL database to your data factory. You specify the Azure SQL server name,
database name, user name, and user password in this section. See Azure SQL linked service for details about
JSON properties used to define an Azure SQL linked service.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data “@azuresqllinkedservice.json”
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/linkedservices/AzureSqlLinkedService?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the linked service has been successfully created, you see the JSON for the linked service
in the results; otherwise, you see an error message.
Write-Host $results
Create datasets
In the previous step, you created linked services to link your Azure Storage account and Azure SQL database to
your data factory. In this step, you define two datasets named AzureBlobInput and AzureSqlOutput that represent
input and output data that is stored in the data stores referred by AzureStorageLinkedService and
AzureSqlLinkedService respectively.
The Azure storage linked service specifies the connection string that Data Factory service uses at run time to
connect to your Azure storage account. And, the input blob dataset (AzureBlobInput) specifies the container and
the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory service uses at
run time to connect to your Azure SQL database. And, the output SQL table dataset (OututDataset) specifies the
table in the database to which the data from the blob storage is copied.
Create input dataset
In this step, you create a dataset named AzureBlobInput that points to a blob file (emp.txt) in the root folder of a
blob container (adftutorial) in the Azure Storage represented by the AzureStorageLinkedService linked service. If
you don't specify a value for the fileName (or skip it), data from all blobs in the input folder are copied to the
destination. In this tutorial, you specify a value for the fileName.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@inputdataset.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/datasets/AzureBlobInput?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the dataset has been successfully created, you see the JSON for the dataset in the
results; otherwise, you see an error message.
Write-Host $results
Create output dataset
The Azure SQL Database linked service specifies the connection string that Data Factory service uses at run time
to connect to your Azure SQL database. The output SQL table dataset (OututDataset) you create in this step
specifies the table in the database to which the data from the blob storage is copied.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@outputdataset.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/datasets/AzureSqlOutput?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the dataset has been successfully created, you see the JSON for the dataset in the
results; otherwise, you see an error message.
Write-Host $results
Create pipeline
In this step, you create a pipeline with a copy activity that uses AzureBlobInput as an input and
AzureSqlOutput as an output.
Currently, output dataset is what drives the schedule. In this tutorial, output dataset is configured to produce a
slice once an hour. The pipeline has a start time and end time that are one day apart, which is 24 hours.
Therefore, 24 slices of output dataset are produced by the pipeline.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@pipeline.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/datapipelines/MyFirstPipeline?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the dataset has been successfully created, you see the JSON for the dataset in the
results; otherwise, you see an error message.
Write-Host $results
Congratulations! You have successfully created an Azure data factory, with a pipeline that copies data from
Azure Blob Storage to Azure SQL database.
Monitor pipeline
In this step, you use Data Factory REST API to monitor slices being produced by the pipeline.
$ds ="AzureSqlOutput"
IMPORTANT
Make sure that the start and end times specified in the following command match the start and end times of the pipeline.
$cmd = {.\curl.exe -X GET -H "Authorization: Bearer $accessToken"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.DataFactor
y/datafactories/$adf/datasets/$ds/slices?start=2017-05-11T00%3a00%3a00.0000000Z"&"end=2017-0512T00%3a00%3a00.0000000Z"&"api-version=2015-10-01};
$results2 = Invoke-Command -scriptblock $cmd;
IF ((ConvertFrom-Json $results2).value -ne $NULL) {
ConvertFrom-Json $results2 | Select-Object -Expand value | Format-Table
} else {
(convertFrom-Json $results2).RemoteException
}
Run the Invoke-Command and the next one until you see a slice in Ready state or Failed state. When the slice is
in Ready state, check the emp table in your Azure SQL database for the output data.
For each slice, two rows of data from the source file are copied to the emp table in the Azure SQL database.
Therefore, you see 24 new records in the emp table when all the slices are successfully processed (in Ready
state).
Summary
In this tutorial, you used REST API to create an Azure data factory to copy data from an Azure blob to an Azure
SQL database. Here are the high-level steps you performed in this tutorial:
1. Created an Azure data factory.
2. Created linked services:
a. An Azure Storage linked service to link your Azure Storage account that holds input data.
b. An Azure SQL linked service to link your Azure SQL database that holds the output data.
3. Created datasets, which describe input data and output data for pipelines.
4. Created a pipeline with a Copy Activity with BlobSource as source and SqlSink as sink.
Next steps
In this tutorial, you used Azure blob storage as a source data store and an Azure SQL database as a destination
data store in a copy operation. The following table provides a list of data stores supported as sources and
destinations by the copy activity:
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data Warehouse
✓
✓
✓
Azure Search Index
Databases
NoSQL
File
Others
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
✓
✓
✓
✓
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
To learn about how to copy data to/from a data store, click the link for the data store in the table.
Tutorial: Create a pipeline with Copy Activity using
.NET API
6/13/2017 • 14 min to read • Edit Online
In this article, you learn how to use .NET API to create a data factory with a pipeline that copies data from an
Azure blob storage to an Azure SQL database. If you are new to Azure Data Factory, read through the
Introduction to Azure Data Factory article before doing this tutorial.
In this tutorial, you create a pipeline with one activity in it: Copy Activity. The copy activity copies data from a
supported data store to a supported sink data store. For a list of data stores supported as sources and sinks, see
supported data stores. The activity is powered by a globally available service that can copy data between various
data stores in a secure, reliable, and scalable way. For more information about the Copy Activity, see Data
Movement Activities.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by
setting the output dataset of one activity as the input dataset of the other activity. For more information, see
multiple activities in a pipeline.
NOTE
For complete documentation on .NET API for Data Factory, see Data Factory .NET API Reference.
The data pipeline in this tutorial copies data from a source data store to a destination data store. For a tutorial on how to
transform data using Azure Data Factory, see Tutorial: Build a pipeline to transform data using Hadoop cluster.
Prerequisites
Go through Tutorial Overview and Pre-requisites to get an overview of the tutorial and complete the
prerequisite steps.
Visual Studio 2012 or 2013 or 2015
Download and install Azure .NET SDK
Azure PowerShell. Follow instructions in How to install and configure Azure PowerShell article to install Azure
PowerShell on your computer. You use Azure PowerShell to create an Azure Active Directory application.
Create an application in Azure Active Directory
Create an Azure Active Directory application, create a service principal for the application, and assign it to the
Data Factory Contributor role.
1. Launch PowerShell.
2. Run the following command and enter the user name and password that you use to sign in to the Azure
portal.
Login-AzureRmAccount
3. Run the following command to view all the subscriptions for this account.
Get-AzureRmSubscription
4. Run the following command to select the subscription that you want to work with. Replace
<NameOfAzureSubscription> with the name of your Azure subscription.
Get-AzureRmSubscription -SubscriptionName <NameOfAzureSubscription> | Set-AzureRmContext
IMPORTANT
Note down SubscriptionId and TenantId from the output of this command.
5. Create an Azure resource group named ADFTutorialResourceGroup by running the following command
in the PowerShell.
New-AzureRmResourceGroup -Name ADFTutorialResourceGroup -Location "West US"
If the resource group already exists, you specify whether to update it (Y) or keep it as (N).
If you use a different resource group, you need to use the name of your resource group in place of
ADFTutorialResourceGroup in this tutorial.
6. Create an Azure Active Directory application.
$azureAdApplication = New-AzureRmADApplication -DisplayName "ADFCopyTutotiralApp" -HomePage
"https://www.contoso.org" -IdentifierUris "https://www.adfcopytutorialapp.org/example" -Password
"Pass@word1"
If you get the following error, specify a different URL and run the command again.
Another object with the same value for property identifierUris already exists.
7. Create the AD service principal.
New-AzureRmADServicePrincipal -ApplicationId $azureAdApplication.ApplicationId
8. Add service principal to the Data Factory Contributor role.
New-AzureRmRoleAssignment -RoleDefinitionName "Data Factory Contributor" -ServicePrincipalName
$azureAdApplication.ApplicationId.Guid
9. Get the application ID.
$azureAdApplication
Note down the application ID (applicationID) from the output.
You should have following four values from these steps:
Tenant ID
Subscription ID
Application ID
Password (specified in the first command)
Walkthrough
1. Using Visual Studio 2012/2013/2015, create a C# .NET console application.
a. Launch Visual Studio 2012/2013/2015.
b. Click File, point to New, and click Project.
c. Expand Templates, and select Visual C#. In this walkthrough, you use C#, but you can use any .NET
language.
d. Select Console Application from the list of project types on the right.
e. Enter DataFactoryAPITestApp for the Name.
f. Select C:\ADFGetStarted for the Location.
g. Click OK to create the project.
2. Click Tools, point to NuGet Package Manager, and click Package Manager Console.
3. In the Package Manager Console, do the following steps:
a. Run the following command to install Data Factory package:
Install-Package Microsoft.Azure.Management.DataFactories
b. Run the following command to install Azure Active Directory package (you use Active Directory API in
the code): Install-Package Microsoft.IdentityModel.Clients.ActiveDirectory -Version 2.19.208020213
4. Add the following appSetttings section to the App.config file. These settings are used by the helper
method: GetAuthorizationHeader.
Replace values for <Application ID>, <Password>, <Subscription ID>, and <tenant ID> with your
own values.
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<appSettings>
<add key="ActiveDirectoryEndpoint" value="https://login.windows.net/" />
<add key="ResourceManagerEndpoint" value="https://management.azure.com/" />
<add key="WindowsManagementUri" value="https://management.core.windows.net/" />
<add key="ApplicationId" value="your application ID" />
<add key="Password" value="Password you used while creating the AAD application" />
<add key="SubscriptionId" value= "Subscription ID" />
<add key="ActiveDirectoryTenantId" value="Tenant ID" />
</appSettings>
</configuration>
5. Add the following using statements to the source file (Program.cs) in the project.
using
using
using
using
System.Configuration;
System.Collections.ObjectModel;
System.Threading;
System.Threading.Tasks;
using
using
using
using
Microsoft.Azure;
Microsoft.Azure.Management.DataFactories;
Microsoft.Azure.Management.DataFactories.Models;
Microsoft.Azure.Management.DataFactories.Common.Models;
using Microsoft.IdentityModel.Clients.ActiveDirectory;
6. Add the following code that creates an instance of DataPipelineManagementClient class to the Main
method. You use this object to create a data factory, a linked service, input and output datasets, and a
pipeline. You also use this object to monitor slices of a dataset at runtime.
// create data factory management client
string resourceGroupName = "ADFTutorialResourceGroup";
string dataFactoryName = "APITutorialFactory";
TokenCloudCredentials aadTokenCredentials = new TokenCloudCredentials(
ConfigurationManager.AppSettings["SubscriptionId"],
GetAuthorizationHeader().Result);
Uri resourceManagerUri = new Uri(ConfigurationManager.AppSettings["ResourceManagerEndpoint"]);
DataFactoryManagementClient client = new DataFactoryManagementClient(aadTokenCredentials,
resourceManagerUri);
IMPORTANT
Replace the value of resourceGroupName with the name of your Azure resource group.
Update name of the data factory (dataFactoryName) to be unique. Name of the data factory must be globally
unique. See Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
7. Add the following code that creates a data factory to the Main method.
// create a data factory
Console.WriteLine("Creating a data factory");
client.DataFactories.CreateOrUpdate(resourceGroupName,
new DataFactoryCreateOrUpdateParameters()
{
DataFactory = new DataFactory()
{
Name = dataFactoryName,
Location = "westus",
Properties = new DataFactoryProperties()
}
}
);
A data factory can have one or more pipelines. A pipeline can have one or more activities in it. For
example, a Copy Activity to copy data from a source to a destination data store and a HDInsight Hive
activity to run a Hive script to transform input data to product output data. Let's start with creating the
data factory in this step.
8. Add the following code that creates an Azure Storage linked service to the Main method.
IMPORTANT
Replace storageaccountname and accountkey with name and key of your Azure Storage account.
// create a linked service for input data store: Azure Storage
Console.WriteLine("Creating Azure Storage linked service");
client.LinkedServices.CreateOrUpdate(resourceGroupName, dataFactoryName,
new LinkedServiceCreateOrUpdateParameters()
{
LinkedService = new LinkedService()
{
Name = "AzureStorageLinkedService",
Properties = new LinkedServiceProperties
(
new AzureStorageLinkedService("DefaultEndpointsProtocol=https;AccountName=
<storageaccountname>;AccountKey=<accountkey>")
)
}
}
);
You create linked services in a data factory to link your data stores and compute services to the data
factory. In this tutorial, you don't use any compute service such as Azure HDInsight or Azure Data Lake
Analytics. You use two data stores of type Azure Storage (source) and Azure SQL Database (destination).
Therefore, you create two linked services named AzureStorageLinkedService and AzureSqlLinkedService
of types: AzureStorage and AzureSqlDatabase.
The AzureStorageLinkedService links your Azure storage account to the data factory. This storage account
is the one in which you created a container and uploaded the data as part of prerequisites.
9. Add the following code that creates an Azure SQL linked service to the Main method.
IMPORTANT
Replace servername, databasename, username, and password with names of your Azure SQL server, database,
user, and password.
// create a linked service for output data store: Azure SQL Database
Console.WriteLine("Creating Azure SQL Database linked service");
client.LinkedServices.CreateOrUpdate(resourceGroupName, dataFactoryName,
new LinkedServiceCreateOrUpdateParameters()
{
LinkedService = new LinkedService()
{
Name = "AzureSqlLinkedService",
Properties = new LinkedServiceProperties
(
new AzureSqlDatabaseLinkedService("Data Source=tcp:
<servername>.database.windows.net,1433;Initial Catalog=<databasename>;User ID=<username>;Password=
<password>;Integrated Security=False;Encrypt=True;Connect Timeout=30")
)
}
}
);
AzureSqlLinkedService links your Azure SQL database to the data factory. The data that is copied from the
blob storage is stored in this database. You created the emp table in this database as part of prerequisites.
10. Add the following code that creates input and output datasets to the Main method.
// create input and output datasets
Console.WriteLine("Creating input and output datasets");
string Dataset_Source = "InputDataset";
string Dataset_Destination = "OutputDataset";
string Dataset_Destination = "OutputDataset";
Console.WriteLine("Creating input dataset of type: Azure Blob");
client.Datasets.CreateOrUpdate(resourceGroupName, dataFactoryName,
new DatasetCreateOrUpdateParameters()
{
Dataset = new Dataset()
{
Name = Dataset_Source,
Properties = new DatasetProperties()
{
Structure = new List<DataElement>()
{
new DataElement() { Name = "FirstName", Type = "String" },
new DataElement() { Name = "LastName", Type = "String" }
},
LinkedServiceName = "AzureStorageLinkedService",
TypeProperties = new AzureBlobDataset()
{
FolderPath = "adftutorial/",
FileName = "emp.txt"
},
External = true,
Availability = new Availability()
{
Frequency = SchedulePeriod.Hour,
Interval = 1,
},
Policy = new Policy()
{
Validation = new ValidationPolicy()
{
MinimumRows = 1
}
}
}
}
});
Console.WriteLine("Creating output dataset of type: Azure SQL");
client.Datasets.CreateOrUpdate(resourceGroupName, dataFactoryName,
new DatasetCreateOrUpdateParameters()
{
Dataset = new Dataset()
{
Name = Dataset_Destination,
Properties = new DatasetProperties()
{
Structure = new List<DataElement>()
{
new DataElement() { Name = "FirstName", Type = "String" },
new DataElement() { Name = "LastName", Type = "String" }
},
LinkedServiceName = "AzureSqlLinkedService",
TypeProperties = new AzureSqlTableDataset()
{
TableName = "emp"
},
Availability = new Availability()
{
Frequency = SchedulePeriod.Hour,
Interval = 1,
},
}
}
});
In the previous step, you created linked services to link your Azure Storage account and Azure SQL
database to your data factory. In this step, you define two datasets named InputDataset and
OutputDataset that represent input and output data that is stored in the data stores referred by
AzureStorageLinkedService and AzureSqlLinkedService respectively.
The Azure storage linked service specifies the connection string that Data Factory service uses at run time
to connect to your Azure storage account. And, the input blob dataset (InputDataset) specifies the
container and the folder that contains the input data.
Similarly, the Azure SQL Database linked service specifies the connection string that Data Factory service
uses at run time to connect to your Azure SQL database. And, the output SQL table dataset (OututDataset)
specifies the table in the database to which the data from the blob storage is copied.
In this step, you create a dataset named InputDataset that points to a blob file (emp.txt) in the root folder
of a blob container (adftutorial) in the Azure Storage represented by the AzureStorageLinkedService
linked service. If you don't specify a value for the fileName (or skip it), data from all blobs in the input
folder are copied to the destination. In this tutorial, you specify a value for the fileName.
In this step, you create an output dataset named OutputDataset. This dataset points to a SQL table in the
Azure SQL database represented by AzureSqlLinkedService.
11. Add the following code that creates and activates a pipeline to the Main method. In this step, you
create a pipeline with a copy activity that uses InputDataset as an input and OutputDataset as an
output.
// create a pipeline
Console.WriteLine("Creating a pipeline");
DateTime PipelineActivePeriodStartTime = new DateTime(2017, 5, 11, 0, 0, 0, 0, DateTimeKind.Utc);
DateTime PipelineActivePeriodEndTime = new DateTime(2017, 5, 12, 0, 0, 0, 0, DateTimeKind.Utc);
string PipelineName = "ADFTutorialPipeline";
client.Pipelines.CreateOrUpdate(resourceGroupName, dataFactoryName,
new PipelineCreateOrUpdateParameters()
{
Pipeline = new Pipeline()
{
Name = PipelineName,
Properties = new PipelineProperties()
{
Description = "Demo Pipeline for data transfer between blobs",
// Initial value for pipeline's active period. With this, you won't need to set slice
status
Start = PipelineActivePeriodStartTime,
End = PipelineActivePeriodEndTime,
Activities = new List<Activity>()
{
new Activity()
{
Name = "BlobToAzureSql",
Inputs = new List<ActivityInput>()
{
new ActivityInput() {
Name = Dataset_Source
}
},
Outputs = new List<ActivityOutput>()
{
new ActivityOutput()
{
Name = Dataset_Destination
}
},
TypeProperties = new CopyActivity()
{
Source = new BlobSource(),
Sink = new BlobSink()
{
WriteBatchSize = 10000,
WriteBatchTimeout = TimeSpan.FromMinutes(10)
}
}
}
}
}
}
});
Note the following points:
In the activities section, there is only one activity whose type is set to Copy. For more information
about the copy activity, see data movement activities. In Data Factory solutions, you can also use data
transformation activities.
Input for the activity is set to InputDataset and output for the activity is set to OutputDataset.
In the typeProperties section, BlobSource is specified as the source type and SqlSink is specified as
the sink type. For a complete list of data stores supported by the copy activity as sources and sinks, see
supported data stores. To learn how to use a specific supported data store as a source/sink, click the
link in the table.
Currently, output dataset is what drives the schedule. In this tutorial, output dataset is configured to
produce a slice once an hour. The pipeline has a start time and end time that are one day apart, which is
24 hours. Therefore, 24 slices of output dataset are produced by the pipeline.
12. Add the following code to the Main method to get the status of a data slice of the output dataset. There is
only slice expected in this sample.
// Pulling status within a timeout threshold
DateTime start = DateTime.Now;
bool done = false;
while (DateTime.Now - start < TimeSpan.FromMinutes(5) && !done)
{
Console.WriteLine("Pulling the slice status");
// wait before the next status check
Thread.Sleep(1000 * 12);
var datalistResponse = client.DataSlices.List(resourceGroupName, dataFactoryName,
Dataset_Destination,
new DataSliceListParameters()
{
DataSliceRangeStartTime = PipelineActivePeriodStartTime.ConvertToISO8601DateTimeString(),
DataSliceRangeEndTime = PipelineActivePeriodEndTime.ConvertToISO8601DateTimeString()
});
foreach (DataSlice slice in datalistResponse.DataSlices)
{
if (slice.State == DataSliceState.Failed || slice.State == DataSliceState.Ready)
{
Console.WriteLine("Slice execution is done with status: {0}", slice.State);
done = true;
break;
}
else
{
Console.WriteLine("Slice status is: {0}", slice.State);
}
}
}
13. Add the following code to get run details for a data slice to the Main method.
Console.WriteLine("Getting run details of a data slice");
// give it a few minutes for the output slice to be ready
Console.WriteLine("\nGive it a few minutes for the output slice to be ready and press any key.");
Console.ReadKey();
var datasliceRunListResponse = client.DataSliceRuns.List(
resourceGroupName,
dataFactoryName,
Dataset_Destination,
new DataSliceRunListParameters()
{
DataSliceStartTime = PipelineActivePeriodStartTime.ConvertToISO8601DateTimeString()
}
);
foreach (DataSliceRun run in datasliceRunListResponse.DataSliceRuns)
{
Console.WriteLine("Status: \t\t{0}", run.Status);
Console.WriteLine("DataSliceStart: \t{0}", run.DataSliceStart);
Console.WriteLine("DataSliceEnd: \t\t{0}", run.DataSliceEnd);
Console.WriteLine("ActivityId: \t\t{0}", run.ActivityName);
Console.WriteLine("ProcessingStartTime: \t{0}", run.ProcessingStartTime);
Console.WriteLine("ProcessingEndTime: \t{0}", run.ProcessingEndTime);
Console.WriteLine("ErrorMessage: \t{0}", run.ErrorMessage);
}
Console.WriteLine("\nPress any key to exit.");
Console.ReadKey();
14. Add the following helper method used by the Main method to the Program class.
NOTE
When you copy and paste the following code, make sure that the copied code is at the same level as the Main
method.
public static async Task<string> GetAuthorizationHeader()
{
AuthenticationContext context = new
AuthenticationContext(ConfigurationManager.AppSettings["ActiveDirectoryEndpoint"] +
ConfigurationManager.AppSettings["ActiveDirectoryTenantId"]);
ClientCredential credential = new ClientCredential(
ConfigurationManager.AppSettings["ApplicationId"],
ConfigurationManager.AppSettings["Password"]);
AuthenticationResult result = await context.AcquireTokenAsync(
resource: ConfigurationManager.AppSettings["WindowsManagementUri"],
clientCredential: credential);
if (result != null)
return result.AccessToken;
throw new InvalidOperationException("Failed to acquire token");
}
15. In the Solution Explorer, expand the project (DataFactoryAPITestApp), right-click References, and click
Add Reference. Select check box for System.Configuration assembly. and click OK.
16. Build the console application. Click Build on the menu and click Build Solution.
17. Confirm that there is at least one file in the adftutorial container in your Azure blob storage. If not, create
Emp.txt file in Notepad with the following content and upload it to the adftutorial container.
John, Doe
Jane, Doe
18. Run the sample by clicking Debug -> Start Debugging on the menu. When you see the Getting run
details of a data slice, wait for a few minutes, and press ENTER.
19. Use the Azure portal to verify that the data factory APITutorialFactory is created with the following artifacts:
Linked service: LinkedService_AzureStorage
Dataset: InputDataset and OutputDataset.
Pipeline: PipelineBlobSample
20. Verify that the two employee records are created in the emp table in the specified Azure SQL database.
Next steps
For complete documentation on .NET API for Data Factory, see Data Factory .NET API Reference.
In this tutorial, you used Azure blob storage as a source data store and an Azure SQL database as a destination
data store in a copy operation. The following table provides a list of data stores supported as sources and
destinations by the copy activity:
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data Warehouse
✓
✓
✓
Azure Search Index
Databases
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
✓
✓
✓
CATEGORY
NoSQL
File
Others
DATA STORE
SUPPORTED AS A SOURCE
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
✓
To learn about how to copy data to/from a data store, click the link for the data store in the table.
Tutorial: Build your first pipeline to transform data
using Hadoop cluster
6/13/2017 • 4 min to read • Edit Online
In this tutorial, you build your first Azure data factory with a data pipeline. The pipeline transforms input data
by running Hive script on an Azure HDInsight (Hadoop) cluster to produce output data.
This article provides overview and prerequisites for the tutorial. After you complete the prerequisites, you
can do the tutorial using one of the following tools/SDKs: Azure portal, Visual Studio, PowerShell, Resource
Manager template, REST API. Select one of the options in the drop-down list at the beginning (or) links at the
end of this article to do the tutorial using one of these options.
Tutorial overview
In this tutorial, you perform the following steps:
1. Create a data factory. A data factory can contain one or more data pipelines that move and
transform data.
In this tutorial, you create one pipeline in the data factory.
2. Create a pipeline. A pipeline can have one or more activities (Examples: Copy Activity, HDInsight Hive
Activity). This sample uses the HDInsight Hive activity that runs a Hive script on a HDInsight Hadoop
cluster. The script first creates a table that references the raw web log data stored in Azure blob
storage and then partitions the raw data by year and month.
In this tutorial, the pipeline uses the Hive Activity to transform data by running a Hive query on an
Azure HDInsight Hadoop cluster.
3. Create linked services. You create a linked service to link a data store or a compute service to the
data factory. A data store such as Azure Storage holds input/output data of activities in the pipeline. A
compute service such as HDInsight Hadoop cluster processes/transforms data.
In this tutorial, you create two linked services: Azure Storage and Azure HDInsight. The Azure
Storage linked service links an Azure Storage Account that holds the input/output data to the data
factory. Azure HDInsight linked service links an Azure HDInsight cluster that is used to transform data
to the data factory.
4. Create input and output datasets. An input dataset represents the input for an activity in the pipeline
and an output dataset represents the output for the activity.
In this tutorial, the input and output datasets specify locations of input and output data in the Azure
Blob Storage. The Azure Storage linked service specifies what Azure Storage Account is used. An input
dataset specifies where the input files are located and an output dataset specifies where the output
files are placed.
See Introduction to Azure Data Factory article for a detailed overview of Azure Data Factory.
Here is the diagram view of the sample data factory you build in this tutorial. MyFirstPipeline has one
activity of type Hive that consumes AzureBlobInput dataset as an input and produces AzureBlobOutput
dataset as an output.
In this tutorial, inputdata folder of the adfgetstarted Azure blob container contains one file named
input.log. This log file has entries from three months: January, February, and March of 2016. Here are the
sample rows for each month in the input file.
2016-01-01,02:01:09,SAMPLEWEBSITE,GET,/blogposts/mvc4/step2.png,X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab837317ece6a1,80,-,1.54.23.196,Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+
(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36,,http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-andpost-scenarios.aspx,\N,200,0,0,53175,871
2016-02-01,02:01:10,SAMPLEWEBSITE,GET,/blogposts/mvc4/step7.png,X-ARR-LOG-ID=d7472a26-431a-4a4d-99ebc7b4fda2cf4c,80,-,1.54.23.196,Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+
(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36,,http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-andpost-scenarios.aspx,\N,200,0,0,30184,871
2016-03-01,02:01:10,SAMPLEWEBSITE,GET,/blogposts/mvc4/step7.png,X-ARR-LOG-ID=d7472a26-431a-4a4d-99ebc7b4fda2cf4c,80,-,1.54.23.196,Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+
(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36,,http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-andpost-scenarios.aspx,\N,200,0,0,30184,871
When the file is processed by the pipeline with HDInsight Hive Activity, the activity runs a Hive script on the
HDInsight cluster that partitions input data by year and month. The script creates three output folders that
contain a file with entries from each month.
adfgetstarted/partitioneddata/year=2016/month=1/000000_0
adfgetstarted/partitioneddata/year=2016/month=2/000000_0
adfgetstarted/partitioneddata/year=2016/month=3/000000_0
From the sample lines shown above, the first one (with 2016-01-01) is written to the 000000_0 file in the
month=1 folder. Similarly, the second one is written to the file in the month=2 folder and the third one is
written to the file in the month=3 folder.
Prerequisites
Before you begin this tutorial, you must have the following prerequisites:
1. Azure subscription - If you don't have an Azure subscription, you can create a free trial account in just a
couple of minutes. See the Free Trial article on how you can obtain a free trial account.
2. Azure Storage – You use an Azure storage account for storing the data in this tutorial. If you don't have
an Azure storage account, see the Create a storage account article. After you have created the storage
account, note down the account name and access key. See View, copy and regenerate storage access
keys.
3. Download and review the Hive query file (HQL) located at:
https://adftutorialfiles.blob.core.windows.net/hivetutorial/partitionweblogs.hql. This query transforms
input data to produce output data.
4. Download and review the sample input file (input.log) located at:
https://adftutorialfiles.blob.core.windows.net/hivetutorial/input.log
5. Create a blob container named adfgetstarted in your Azure Blob Storage.
6. Upload partitionweblogs.hql file to the script folder in the adfgetstarted container. Use tools such as
Microsoft Azure Storage Explorer.
7. Upload input.log file to the inputdata folder in the adfgetstarted container.
After you complete the prerequisites, select one of the following tools/SDKs to do the tutorial:
Azure portal
Visual Studio
PowerShell
Resource Manager template
REST API
Azure portal and Visual Studio provide GUI way of building your data factories. Whereas, PowerShell,
Resource Manager Template, and REST API options provides scripting/programming way of building your
data factories.
NOTE
The data pipeline in this tutorial transforms input data to produce output data. It does not copy data from a source
data store to a destination data store. For a tutorial on how to copy data using Azure Data Factory, see Tutorial: Copy
data from Blob Storage to SQL Database.
You can chain two activities (run one activity after another) by setting the output dataset of one activity as the input
dataset of the other activity. See Scheduling and execution in Data Factory for detailed information.
Tutorial: Build your first Azure data factory using
Azure portal
6/13/2017 • 14 min to read • Edit Online
In this article, you learn how to use Azure portal to create your first Azure data factory. To do the tutorial using
other tools/SDKs, select one of the options from the drop-down list.
The pipeline in this tutorial has one activity: HDInsight Hive activity. This activity runs a hive script on an Azure
HDInsight cluster that transforms input data to produce output data. The pipeline is scheduled to run once a
month between the specified start and end times.
NOTE
The data pipeline in this tutorial transforms input data to produce output data. For a tutorial on how to copy data using
Azure Data Factory, see Tutorial: Copy data from Blob Storage to SQL Database.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by setting the
output dataset of one activity as the input dataset of the other activity. For more information, see scheduling and execution
in Data Factory.
Prerequisites
1. Read through Tutorial Overview article and complete the prerequisite steps.
2. This article does not provide a conceptual overview of the Azure Data Factory service. We recommend that you
go through Introduction to Azure Data Factory article for a detailed overview of the service.
Create data factory
A data factory can have one or more pipelines. A pipeline can have one or more activities in it. For example, a
Copy Activity to copy data from a source to a destination data store and a HDInsight Hive activity to run a Hive
script to transform input data to product output data. Let's start with creating the data factory in this step.
1. Log in to the Azure portal.
2. Click NEW on the left menu, click Data + Analytics, and click Data Factory.
3. In the New data factory blade, enter GetStartedDF for the Name.
IMPORTANT
The name of the Azure data factory must be globally unique. If you receive the error: Data factory name
“GetStartedDF” is not available. Change the name of the data factory (for example, yournameGetStartedDF) and
try creating again. See Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
The name of the data factory may be registered as a DNS name in the future and hence become publically visible.
4. Select the Azure subscription where you want the data factory to be created.
5. Select existing resource group or create a resource group. For the tutorial, create a resource group named:
ADFGetStartedRG.
6. Select the location for the data factory. Only regions supported by the Data Factory service are shown in the
drop-down list.
7. Select Pin to dashboard.
8. Click Create on the New data factory blade.
IMPORTANT
To create Data Factory instances, you must be a member of the Data Factory Contributor role at the
subscription/resource group level.
9. On the dashboard, you see the following tile with status: Deploying data factory.
10. Congratulations! You have successfully created your first data factory. After the data factory has been
created successfully, you see the data factory page, which shows you the contents of the data factory.
Before creating a pipeline in the data factory, you need to create a few Data Factory entities first. You first create
linked services to link data stores/computes to your data store, define input and output datasets to represent
input/output data in linked data stores, and then create the pipeline with an activity that uses these datasets.
Create linked services
In this step, you link your Azure Storage account and an on-demand Azure HDInsight cluster to your data factory.
The Azure Storage account holds the input and output data for the pipeline in this sample. The HDInsight linked
service is used to run a Hive script specified in the activity of the pipeline in this sample. Identify what data
store/compute services are used in your scenario and link those services to the data factory by creating linked
services.
Create Azure Storage linked service
In this step, you link your Azure Storage account to your data factory. In this tutorial, you use the same Azure
Storage account to store input/output data and the HQL script file.
1. Click Author and deploy on the DATA FACTORY blade for GetStartedDF. You should see the Data
Factory Editor.
2. Click New data store and choose Azure storage.
3. You should see the JSON script for creating an Azure Storage linked service in the editor.
4. Replace account name with the name of your Azure storage account and account key with the access key of
the Azure storage account. To learn how to get your storage access key, see the information about how to
view, copy, and regenerate storage access keys in Manage your storage account.
5. Click Deploy on the command bar to deploy the linked service.
After the linked service is deployed successfully, the Draft-1 window should disappear and you see
AzureStorageLinkedService in the tree view on the left.
Create Azure HDInsight linked service
In this step, you link an on-demand HDInsight cluster to your data factory. The HDInsight cluster is automatically
created at runtime and deleted after it is done processing and idle for the specified amount of time.
1. In the Data Factory Editor, click ... More, click New compute, and select On-demand HDInsight
cluster.
2. Copy and paste the following snippet to the Draft-1 window. The JSON snippet describes the properties
that are used to create the HDInsight cluster on-demand.
{
"name": "HDInsightOnDemandLinkedService",
"properties": {
"type": "HDInsightOnDemand",
"typeProperties": {
"clusterSize": 1,
"timeToLive": "00:30:00",
"linkedServiceName": "AzureStorageLinkedService"
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
ClusterSize
Specifies the size of the HDInsight cluster.
TimeToLive
Specifies that the idle time for the HDInsight cluster,
before it is deleted.
linkedServiceName
Specifies the storage account that is used to store the
logs that are generated by HDInsight.
Note the following points:
The Data Factory creates a Windows-based HDInsight cluster for you with the JSON. You could also
have it create a Linux-based HDInsight cluster. See On-demand HDInsight Linked Service for details.
You could use your own HDInsight cluster instead of using an on-demand HDInsight cluster. See
HDInsight Linked Service for details.
The HDInsight cluster creates a default container in the blob storage you specified in the JSON
(linkedServiceName). HDInsight does not delete this container when the cluster is deleted. This
behavior is by design. With on-demand HDInsight linked service, a HDInsight cluster is created every
time a slice is processed unless there is an existing live cluster (timeToLive). The cluster is
automatically deleted when the processing is done.
As more slices are processed, you see many containers in your Azure blob storage. If you do not
need them for troubleshooting of the jobs, you may want to delete them to reduce the storage cost.
The names of these containers follow a pattern: "adfyourdatafactoryname-linkedservicenamedatetimestamp". Use tools such as Microsoft Storage Explorer to delete containers in your Azure
blob storage.
See On-demand HDInsight Linked Service for details.
3. Click Deploy on the command bar to deploy the linked service.
4. Confirm that you see both AzureStorageLinkedService and HDInsightOnDemandLinkedService in
the tree view on the left.
Create datasets
In this step, you create datasets to represent the input and output data for Hive processing. These datasets refer to
the AzureStorageLinkedService you have created earlier in this tutorial. The linked service points to an Azure
Storage account and datasets specify container, folder, file name in the storage that holds input and output data.
Create input dataset
1. In the Data Factory Editor, click ... More on the command bar, click New dataset, and select Azure Blob
storage.
2. Copy and paste the following snippet to the Draft-1 window. In the JSON snippet, you are creating a
dataset called AzureBlobInput that represents input data for an activity in the pipeline. In addition, you
specify that the input data is located in the blob container called adfgetstarted and the folder called
inputdata.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "input.log",
"folderPath": "adfgetstarted/inputdata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true,
"policy": {}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data
resides in an Azure blob storage.
linkedServiceName
Refers to the AzureStorageLinkedService you created
earlier.
folderPath
Specifies the blob container and the folder that contains
input blobs.
PROPERTY
DESCRIPTION
fileName
This property is optional. If you omit this property, all the
files from the folderPath are picked. In this tutorial, only
the input.log is processed.
type
The log files are in text format, so we use TextFormat.
columnDelimiter
columns in the log files are delimited by comma
character ( , )
frequency/interval
frequency set to Month and interval is 1, which means
that the input slices are available monthly.
external
This property is set to true if the input data is not
generated by this pipeline. In this tutorial, the input.log
file is not generated by this pipeline, so we set the
property to true.
For more information about these JSON properties, see Azure Blob connector article.
3. Click Deploy on the command bar to deploy the newly created dataset. You should see the dataset in the tree
view on the left.
Create output dataset
Now, you create the output dataset to represent the output data stored in the Azure Blob storage.
1. In the Data Factory Editor, click ... More on the command bar, click New dataset, and select Azure Blob
storage.
2. Copy and paste the following snippet to the Draft-1 window. In the JSON snippet, you are creating a
dataset called AzureBlobOutput, and specifying the structure of the data that is produced by the Hive
script. In addition, you specify that the results are stored in the blob container called adfgetstarted and the
folder called partitioneddata. The availability section specifies that the output dataset is produced on a
monthly basis.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "adfgetstarted/partitioneddata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
}
}
}
See Create the input dataset section for descriptions of these properties. You do not set the external
property on an output dataset as the dataset is produced by the Data Factory service.
3. Click Deploy on the command bar to deploy the newly created dataset.
4. Verify that the dataset is created successfully.
Create pipeline
In this step, you create your first pipeline with a HDInsightHive activity. Input slice is available monthly
(frequency: Month, interval: 1), output slice is produced monthly, and the scheduler property for the activity is also
set to monthly. The settings for the output dataset and the activity scheduler must match. Currently, output
dataset is what drives the schedule, so you must create an output dataset even if the activity does not produce any
output. If the activity doesn't take any input, you can skip creating the input dataset. The properties used in the
following JSON are explained at the end of this section.
1. In the Data Factory Editor, click Ellipsis (…) More commands and then click New pipeline.
2. Copy and paste the following snippet to the Draft-1 window.
IMPORTANT
Replace storageaccountname with the name of your storage account in the JSON.
{
"name": "MyFirstPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
],
"start": "2016-04-01T00:00:00Z",
"end": "2016-04-02T00:00:00Z",
"isPaused": false
}
}
In the JSON snippet, you are creating a pipeline that consists of a single activity that uses Hive to process
Data on an HDInsight cluster.
The Hive script file, partitionweblogs.hql, is stored in the Azure storage account (specified by the
scriptLinkedService, called AzureStorageLinkedService), and in script folder in the container
adfgetstarted.
The defines section is used to specify the runtime settings that are passed to the hive script as Hive
configuration values (e.g ${hiveconf:inputtable}, ${hiveconf:partitionedtable}).
The start and end properties of the pipeline specifies the active period of the pipeline.
In the activity JSON, you specify that the Hive script runs on the compute specified by the
linkedServiceName – HDInsightOnDemandLinkedService.
NOTE
See "Pipeline JSON" in Pipelines and activities in Azure Data Factory for details about JSON properties used in the
example.
3. Confirm the following:
a. input.log file exists in the inputdata folder of the adfgetstarted container in the Azure blob storage
b. partitionweblogs.hql file exists in the script folder of the adfgetstarted container in the Azure blob
storage. Complete the prerequisite steps in the Tutorial Overview if you don't see these files.
c. Confirm that you replaced storageaccountname with the name of your storage account in the
pipeline JSON.
4. Click Deploy on the command bar to deploy the pipeline. Since the start and end times are set in the past and
isPaused is set to false, the pipeline (activity in the pipeline) runs immediately after you deploy.
5. Confirm that you see the pipeline in the tree view.
6. Congratulations, you have successfully created your first pipeline!
Monitor pipeline
Monitor pipeline using Diagram View
1. Click X to close Data Factory Editor blades and to navigate back to the Data Factory blade, and click
Diagram.
2. In the Diagram View, you see an overview of the pipelines, and datasets used in this tutorial.
3. To view all activities in the pipeline, right-click pipeline in the diagram and click Open Pipeline.
4. Confirm that you see the HDInsightHive activity in the pipeline.
To navigate back to the previous view, click Data factory in the breadcrumb menu at the top.
5. In the Diagram View, double-click the dataset AzureBlobInput. Confirm that the slice is in Ready state. It
may take a couple of minutes for the slice to show up in Ready state. If it does not happen after you wait
for sometime, see if you have the input file (input.log) placed in the right container (adfgetstarted) and
folder (inputdata).
6. Click X to close AzureBlobInput blade.
7. In the Diagram View, double-click the dataset AzureBlobOutput. You see that the slice that is currently
being processed.
8. When processing is done, you see the slice in Ready state.
IMPORTANT
Creation of an on-demand HDInsight cluster usually takes sometime (approximately 20 minutes). Therefore, expect
the pipeline to take approximately 30 minutes to process the slice.
9. When the slice is in Ready state, check the partitioneddata folder in the adfgetstarted container in your
blob storage for the output data.
10. Click the slice to see details about it in a Data slice blade.
11. Click an activity run in the Activity runs list to see details about an activity run (Hive activity in our
scenario) in an Activity run details window.
From the log files, you can see the Hive query that was executed and status information. These logs are
useful for troubleshooting any issues. See Monitor and manage pipelines using Azure portal blades article
for more details.
IMPORTANT
The input file gets deleted when the slice is processed successfully. Therefore, if you want to rerun the slice or do the tutorial
again, upload the input file (input.log) to the inputdata folder of the adfgetstarted container.
Monitor pipeline using Monitor & Manage App
You can also use Monitor & Manage application to monitor your pipelines. For detailed information about using
this application, see Monitor and manage Azure Data Factory pipelines using Monitoring and Management App.
1. Click Monitor & Manage tile on the home page for your data factory.
2. You should see Monitor & Manage application. Change the Start time and End time to match start
(04-01-2016 12:00 AM) and end times (04-02-2016 12:00 AM) of your pipeline, and click Apply.
3. Select an activity window in the Activity Windows list to see details about it.
Summary
In this tutorial, you created an Azure data factory to process data by running Hive script on a HDInsight hadoop
cluster. You used the Data Factory Editor in the Azure portal to do the following steps:
1. Created an Azure data factory.
2. Created two linked services:
a. Azure Storage linked service to link your Azure blob storage that holds input/output files to the data
factory.
b. Azure HDInsight on-demand linked service to link an on-demand HDInsight Hadoop cluster to the
data factory. Azure Data Factory creates a HDInsight Hadoop cluster just-in-time to process input data
and produce output data.
3. Created two datasets, which describe input and output data for HDInsight Hive activity in the pipeline.
4. Created a pipeline with a HDInsight Hive activity.
Next Steps
In this article, you have created a pipeline with a transformation activity (HDInsight Activity) that runs a Hive script
on an on-demand HDInsight cluster. To see how to use a Copy Activity to copy data from an Azure Blob to Azure
SQL, see Tutorial: Copy data from an Azure blob to Azure SQL.
See Also
TOPIC
DESCRIPTION
Pipelines
This article helps you understand pipelines and activities in
Azure Data Factory and how to use them to construct endto-end data-driven workflows for your scenario or business.
Datasets
This article helps you understand datasets in Azure Data
Factory.
Scheduling and execution
This article explains the scheduling and execution aspects of
Azure Data Factory application model.
Monitor and manage pipelines using Monitoring App
This article describes how to monitor, manage, and debug
pipelines using the Monitoring & Management App.
Tutorial: Create a data factory by using Visual Studio
6/13/2017 • 22 min to read • Edit Online
This tutorial shows you how to create an Azure data factory by using Visual Studio. You create a Visual Studio
project using the Data Factory project template, define Data Factory entities (linked services, datasets, and
pipeline) in JSON format, and then publish/deploy these entities to the cloud.
The pipeline in this tutorial has one activity: HDInsight Hive activity. This activity runs a hive script on an Azure
HDInsight cluster that transforms input data to produce output data. The pipeline is scheduled to run once a
month between the specified start and end times.
NOTE
This tutorial does not show how copy data by using Azure Data Factory. For a tutorial on how to copy data using Azure
Data Factory, see Tutorial: Copy data from Blob Storage to SQL Database.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by setting the
output dataset of one activity as the input dataset of the other activity. For more information, see scheduling and execution
in Data Factory.
Walkthrough: Create and publish Data Factory entities
Here are the steps you perform as part of this walkthrough:
1. Create two linked services: AzureStorageLinkedService1 and HDInsightOnDemandLinkedService1.
In this tutorial, both input and output data for the hive activity are in the same Azure Blob Storage. You use
an on-demand HDInsight cluster to process existing input data to produce output data. The on-demand
HDInsight cluster is automatically created for you by Azure Data Factory at run time when the input data is
ready to be processed. You need to link your data stores or computes to your data factory so that the Data
Factory service can connect to them at runtime. Therefore, you link your Azure Storage Account to the data
factory by using the AzureStorageLinkedService1, and link an on-demand HDInsight cluster by using the
HDInsightOnDemandLinkedService1. When publishing, you specify the name for the data factory to be
created or an existing data factory.
2. Create two datasets: InputDataset and OutputDataset, which represent the input/output data that is
stored in the Azure blob storage.
These dataset definitions refer to the Azure Storage linked service you created in the previous step. For the
InputDataset, you specify the blob container (adfgetstarted) and the folder (inptutdata) that contains a blob
with the input data. For the OutputDataset, you specify the blob container (adfgetstarted) and the folder
(partitioneddata) that holds the output data. You also specify other properties such as structure, availability,
and policy.
3. Create a pipeline named MyFirstPipeline.
In this walkthrough, the pipeline has only one activity: HDInsight Hive Activity. This activity transform
input data to produce output data by running a hive script on an on-demand HDInsight cluster. To learn
more about hive activity, see Hive Activity
4. Create a data factory named DataFactoryUsingVS. Deploy the data factory and all Data Factory entities
(linked services, tables, and the pipeline).
5. After you publish, you use Azure portal blades and Monitoring & Management App to monitor the pipeline.
Prerequisites
1. Read through Tutorial Overview article and complete the prerequisite steps. You can also select the
Overview and prerequisites option in the drop-down list at the top to switch to the article. After you
complete the prerequisites, switch back to this article by selecting Visual Studio option in the drop-down list.
2. To create Data Factory instances, you must be a member of the Data Factory Contributor role at the
subscription/resource group level.
3. You must have the following installed on your computer:
Visual Studio 2013 or Visual Studio 2015
Download Azure SDK for Visual Studio 2013 or Visual Studio 2015. Navigate to Azure Download Page
and click VS 2013 or VS 2015 in the .NET section.
Download the latest Azure Data Factory plugin for Visual Studio: VS 2013 or VS 2015. You can also
update the plugin by doing the following steps: On the menu, click Tools -> Extensions and Updates
-> Online -> Visual Studio Gallery -> Microsoft Azure Data Factory Tools for Visual Studio ->
Update.
Now, let's use Visual Studio to create an Azure data factory.
Create Visual Studio project
1. Launch Visual Studio 2013 or Visual Studio 2015. Click File, point to New, and click Project. You should
see the New Project dialog box.
2. In the New Project dialog, select the DataFactory template, and click Empty Data Factory Project.
3. Enter a name for the project, location, and a name for the solution, and click OK.
Create linked services
In this step, you create two linked services: Azure Storage and HDInsight on-demand.
The Azure Storage linked service links your Azure Storage account to the data factory by providing the connection
information. Data Factory service uses the connection string from the linked service setting to connect to the
Azure storage at runtime. This storage holds input and output data for the pipeline, and the hive script file used by
the hive activity.
With on-demand HDInsight linked service, The HDInsight cluster is automatically created at runtime when the
input data is ready to processed. The cluster is deleted after it is done processing and idle for the specified
amount of time.
NOTE
You create a data factory by specifying its name and settings at the time of publishing your Data Factory solution.
Create Azure Storage linked service
1. Right-click Linked Services in the solution explorer, point to Add, and click New Item.
2. In the Add New Item dialog box, select Azure Storage Linked Service from the list, and click Add.
3. Replace <accountname> and <accountkey> with the name of your Azure storage account and its key. To learn
how to get your storage access key, see the information about how to view, copy, and regenerate storage
access keys in Manage your storage account.
4. Save the AzureStorageLinkedService1.json file.
Create Azure HDInsight linked service
1. In the Solution Explorer, right-click Linked Services, point to Add, and click New Item.
2. Select HDInsight On Demand Linked Service, and click Add.
3. Replace the JSON with the following JSON:
{
"name": "HDInsightOnDemandLinkedService",
"properties": {
"type": "HDInsightOnDemand",
"typeProperties": {
"clusterSize": 1,
"timeToLive": "00:30:00",
"linkedServiceName": "AzureStorageLinkedService1"
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
ClusterSize
Specifies the size of the HDInsight Hadoop cluster.
TimeToLive
Specifies that the idle time for the HDInsight cluster,
before it is deleted.
linkedServiceName
Specifies the storage account that is used to store the
logs that are generated by HDInsight Hadoop cluster.
IMPORTANT
The HDInsight cluster creates a default container in the blob storage you specified in the JSON
(linkedServiceName). HDInsight does not delete this container when the cluster is deleted. This behavior is by
design. With on-demand HDInsight linked service, a HDInsight cluster is created every time a slice is processed
unless there is an existing live cluster (timeToLive). The cluster is automatically deleted when the processing is done.
As more slices are processed, you see many containers in your Azure blob storage. If you do not need them for
troubleshooting of the jobs, you may want to delete them to reduce the storage cost. The names of these
containers follow a pattern: adf<yourdatafactoryname>-<linkedservicename>-datetimestamp . Use tools such as
Microsoft Storage Explorer to delete containers in your Azure blob storage.
For more information about JSON properties, see Compute linked services article.
4. Save the HDInsightOnDemandLinkedService1.json file.
Create datasets
In this step, you create datasets to represent the input and output data for Hive processing. These datasets refer to
the AzureStorageLinkedService1 you have created earlier in this tutorial. The linked service points to an Azure
Storage account and datasets specify container, folder, file name in the storage that holds input and output data.
Create input dataset
1. In the Solution Explorer, right-click Tables, point to Add, and click New Item.
2. Select Azure Blob from the list, change the name of the file to InputDataSet.json, and click Add.
3. Replace the JSON in the editor with the following JSON snippet:
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService1",
"typeProperties": {
"fileName": "input.log",
"folderPath": "adfgetstarted/inputdata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true,
"policy": {}
}
}
This JSON snippet defines a dataset called AzureBlobInput that represents input data for the hive activity
in the pipeline. You specify that the input data is located in the blob container called adfgetstarted and the
folder called inputdata .
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data
resides in Azure Blob Storage.
linkedServiceName
Refers to the AzureStorageLinkedService1 you created
earlier.
fileName
This property is optional. If you omit this property, all the
files from the folderPath are picked. In this case, only the
input.log is processed.
type
The log files are in text format, so we use TextFormat.
columnDelimiter
columns in the log files are delimited by the comma
character ( , )
frequency/interval
frequency set to Month and interval is 1, which means
that the input slices are available monthly.
external
This property is set to true if the input data for the
activity is not generated by the pipeline. This property is
only specified on input datasets. For the input dataset of
the first activity, always set it to true.
4. Save the InputDataset.json file.
Create output dataset
Now, you create the output dataset to represent output data stored in the Azure Blob storage.
1. In the Solution Explorer, right-click tables, point to Add, and click New Item.
2. Select Azure Blob from the list, change the name of the file to OutputDataset.json, and click Add.
3. Replace the JSON in the editor with the following JSON:
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService1",
"typeProperties": {
"folderPath": "adfgetstarted/partitioneddata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
}
}
}
The JSON snippet defines a dataset called AzureBlobOutput that represents output data produced by the
hive activity in the pipeline. You specify that the output data is produced by the hive activity is placed in the
blob container called adfgetstarted and the folder called partitioneddata .
The availability section specifies that the output dataset is produced on a monthly basis. The output
dataset drives the schedule of the pipeline. The pipeline runs monthly between its start and end times.
See Create the input dataset section for descriptions of these properties. You do not set the external
property on an output dataset as the dataset is produced by the pipeline.
4. Save the OutputDataset.json file.
Create pipeline
You have created the Azure Storage linked service, and input and output datasets so far. Now, you create a
pipeline with a HDInsightHive activity. The input for the hive activity is set to AzureBlobInput and output is
set to AzureBlobOutput. A slice of an input dataset is available monthly (frequency: Month, interval: 1), and the
output slice is produced monthly too.
1. In the Solution Explorer, right-click Pipelines, point to Add, and click New Item.
2. Select Hive Transformation Pipeline from the list, and click Add.
3. Replace the JSON with the following snippet:
IMPORTANT
Replace <storageaccountname> with the name of your storage account.
{
"name": "MyFirstPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService1",
"defines": {
"inputtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
],
"start": "2016-04-01T00:00:00Z",
"end": "2016-04-02T00:00:00Z",
"isPaused": false
}
}
IMPORTANT
Replace <storageaccountname> with the name of your storage account.
The JSON snippet defines a pipeline that consists of a single activity (Hive Activity). This activity runs a Hive
script to process input data on an on-demand HDInsight cluster to produce output data. In the activities
section of the pipeline JSON, you see only one activity in the array with type set to HDInsightHive.
In the type properties that are specific to HDInsight Hive activity, you specify what Azure Storage linked
service has the hive script file, the path to the script file, and parameters to the script file.
The Hive script file, partitionweblogs.hql, is stored in the Azure storage account (specified by the
scriptLinkedService), and in the script folder in the container adfgetstarted .
The defines section is used to specify the runtime settings that are passed to the hive script as Hive
configuration values (e.g ${hiveconf:inputtable} , ${hiveconf:partitionedtable}) .
The start and end properties of the pipeline specifies the active period of the pipeline. You configured the
dataset to be produced monthly, therefore, only once slice is produced by the pipeline (because the month
is same in start and end dates).
In the activity JSON, you specify that the Hive script runs on the compute specified by the
linkedServiceName – HDInsightOnDemandLinkedService.
4. Save the HiveActivity1.json file.
Add partitionweblogs.hql and input.log as a dependency
1. Right-click Dependencies in the Solution Explorer window, point to Add, and click Existing Item.
2. Navigate to the C:\ADFGettingStarted and select partitionweblogs.hql, input.log files, and click Add. You
created these two files as part of prerequisites from the Tutorial Overview.
When you publish the solution in the next step, the partitionweblogs.hql file is uploaded to the script folder in
the adfgetstarted blob container.
Publish/deploy Data Factory entities
In this step, you publish the Data Factory entities (linked services, datasets, and pipeline) in your project to the
Azure Data Factory service. In the process of publishing, you specify the name for your data factory.
1. Right-click project in the Solution Explorer, and click Publish.
2. If you see Sign in to your Microsoft account dialog box, enter your credentials for the account that has
Azure subscription, and click sign in.
3. You should see the following dialog box:
4. In the Configure data factory page, do the following steps:
a. select Create New Data Factory option.
b. Enter a unique name for the data factory. For example: DataFactoryUsingVS09152016. The name
must be globally unique.
c. Select the right subscription for the Subscription field. > [!IMPORTANT] > If you do not see any
subscription, ensure that you logged in using an account that is an admin or co-admin of the
subscription.
d. Select the resource group for the data factory to be created.
e. Select the region for the data factory.
f. Click Next to switch to the Publish Items page. (Press TAB to move out of the Name field to if the
Next button is disabled.)
IMPORTANT
If you receive the error Data factory name “DataFactoryUsingVS” is not available when publishing,
change the name (for example, yournameDataFactoryUsingVS). See Data Factory - Naming Rules topic for
naming rules for Data Factory artifacts.
5. In the Publish Items page, ensure that all the Data Factories entities are selected, and click Next to switch
to the Summary page.
6. Review the summary and click Next to start the deployment process and view the Deployment Status.
7. In the Deployment Status page, you should see the status of the deployment process. Click Finish after the
deployment is done.
Important points to note:
If you receive the error: This subscription is not registered to use namespace Microsoft.DataFactory,
do one of the following and try publishing again:
In Azure PowerShell, run the following command to register the Data Factory provider.
Register-AzureRmResourceProvider -ProviderNamespace Microsoft.DataFactory
You can run the following command to confirm that the Data Factory provider is registered.
Get-AzureRmResourceProvider
Login using the Azure subscription in to the Azure portal and navigate to a Data Factory blade (or)
create a data factory in the Azure portal. This action automatically registers the provider for you.
The name of the data factory may be registered as a DNS name in the future and hence become publically
visible.
To create Data Factory instances, you need to be an admin or co-admin of the Azure subscription
Monitor pipeline
In this step, you monitor the pipeline using Diagram View of the data factory.
Monitor pipeline using Diagram View
1. Log in to the Azure portal, do the following steps:
a. Click More services and click Data factories.
b. Select the name of your data factory (for example: DataFactoryUsingVS09152016) from the list of
data factories.
2. In the home page for your data factory, click Diagram.
3. In the Diagram View, you see an overview of the pipelines, and datasets used in this tutorial.
4. To view all activities in the pipeline, right-click pipeline in the diagram and click Open Pipeline.
5. Confirm that you see the HDInsightHive activity in the pipeline.
To navigate back to the previous view, click Data factory in the breadcrumb menu at the top.
6. In the Diagram View, double-click the dataset AzureBlobInput. Confirm that the slice is in Ready state. It
may take a couple of minutes for the slice to show up in Ready state. If it does not happen after you wait
for sometime, see if you have the input file (input.log) placed in the right container ( adfgetstarted ) and
folder ( inputdata ). And, make sure that the external property on the input dataset is set to true.
7. Click X to close AzureBlobInput blade.
8. In the Diagram View, double-click the dataset AzureBlobOutput. You see that the slice that is currently
being processed.
9. When processing is done, you see the slice in Ready state.
IMPORTANT
Creation of an on-demand HDInsight cluster usually takes sometime (approximately 20 minutes). Therefore, expect
the pipeline to take approximately 30 minutes to process the slice.
10. When the slice is in Ready state, check the
blob storage for the output data.
partitioneddata
11. Click the slice to see details about it in a Data slice blade.
folder in the
adfgetstarted
container in your
12. Click an activity run in the Activity runs list to see details about an activity run (Hive activity in our
scenario) in an Activity run details window.
From the log files, you can see the Hive query that was executed and status information. These logs are
useful for troubleshooting any issues.
See Monitor datasets and pipeline for instructions on how to use the Azure portal to monitor the pipeline and
datasets you have created in this tutorial.
Monitor pipeline using Monitor & Manage App
You can also use Monitor & Manage application to monitor your pipelines. For detailed information about using
this application, see Monitor and manage Azure Data Factory pipelines using Monitoring and Management App.
1. Click Monitor & Manage tile.
2. You should see Monitor & Manage application. Change the Start time and End time to match start (0401-2016 12:00 AM) and end times (04-02-2016 12:00 AM) of your pipeline, and click Apply.
3. To see details about an activity window, select it in the Activity Windows list to see details about it.
IMPORTANT
The input file gets deleted when the slice is processed successfully. Therefore, if you want to rerun the slice or do the
tutorial again, upload the input file (input.log) to the inputdata folder of the adfgetstarted container.
Additional notes
A data factory can have one or more pipelines. A pipeline can have one or more activities in it. For example, a
Copy Activity to copy data from a source to a destination data store and a HDInsight Hive activity to run a Hive
script to transform input data. See supported data stores for all the sources and sinks supported by the Copy
Activity. See compute linked services for the list of compute services supported by Data Factory.
Linked services link data stores or compute services to an Azure data factory. See supported data stores for all
the sources and sinks supported by the Copy Activity. See compute linked services for the list of compute
services supported by Data Factory and transformation activities that can run on them.
See Move data from/to Azure Blob for details about JSON properties used in the Azure Storage linked service
definition.
You could use your own HDInsight cluster instead of using an on-demand HDInsight cluster. See Compute
Linked Services for details.
The Data Factory creates a Windows-based HDInsight cluster for you with the preceding JSON. You could
also have it create a Linux-based HDInsight cluster. See On-demand HDInsight Linked Service for details.
The HDInsight cluster creates a default container in the blob storage you specified in the JSON
(linkedServiceName). HDInsight does not delete this container when the cluster is deleted. This behavior is
by design. With on-demand HDInsight linked service, a HDInsight cluster is created every time a slice is
processed unless there is an existing live cluster (timeToLive). The cluster is automatically deleted when the
processing is done.
As more slices are processed, you see many containers in your Azure blob storage. If you do not need
them for troubleshooting of the jobs, you may want to delete them to reduce the storage cost. The names
of these containers follow a pattern: adf**yourdatafactoryname**-**linkedservicename**-datetimestamp . Use
tools such as Microsoft Storage Explorer to delete containers in your Azure blob storage.
Currently, output dataset is what drives the schedule, so you must create an output dataset even if the activity
does not produce any output. If the activity doesn't take any input, you can skip creating the input dataset.
This tutorial does not show how copy data by using Azure Data Factory. For a tutorial on how to copy data
using Azure Data Factory, see Tutorial: Copy data from Blob Storage to SQL Database.
Use Server Explorer to view data factories
1. In Visual Studio, click View on the menu, and click Server Explorer.
2. In the Server Explorer window, expand Azure and expand Data Factory. If you see Sign in to Visual
Studio, enter the account associated with your Azure subscription and click Continue. Enter password,
and click Sign in. Visual Studio tries to get information about all Azure data factories in your subscription.
You see the status of this operation in the Data Factory Task List window.
3. You can right-click a data factory, and select Export Data Factory to New Project to create a Visual
Studio project based on an existing data factory.
Update Data Factory tools for Visual Studio
To update Azure Data Factory tools for Visual Studio, do the following steps:
1. Click Tools on the menu and select Extensions and Updates.
2. Select Updates in the left pane and then select Visual Studio Gallery.
3. Select Azure Data Factory tools for Visual Studio and click Update. If you do not see this entry, you
already have the latest version of the tools.
Use configuration files
You can use configuration files in Visual Studio to configure properties for linked services/tables/pipelines
differently for each environment.
Consider the following JSON definition for an Azure Storage linked service. To specify connectionString with
different values for accountname and accountkey based on the environment (Dev/Test/Production) to which you
are deploying Data Factory entities. You can achieve this behavior by using separate configuration file for each
environment.
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"description": "",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Add a configuration file
Add a configuration file for each environment by performing the following steps:
1. Right-click the Data Factory project in your Visual Studio solution, point to Add, and click New item.
2. Select Config from the list of installed templates on the left, select Configuration File, enter a name for
the configuration file, and click Add.
3. Add configuration parameters and their values in the following format:
{
"$schema":
"http://datafactories.schema.management.azure.com/vsschemas/V1/Microsoft.DataFactory.Config.json",
"AzureStorageLinkedService1": [
{
"name": "$.properties.typeProperties.connectionString",
"value": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
],
"AzureSqlLinkedService1": [
{
"name": "$.properties.typeProperties.connectionString",
"value": "Server=tcp:spsqlserver.database.windows.net,1433;Database=spsqldb;User
ID=spelluru;Password=Sowmya123;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
}
]
}
This example configures connectionString property of an Azure Storage linked service and an Azure SQL
linked service. Notice that the syntax for specifying name is JsonPath.
If JSON has a property that has an array of values as shown in the following code:
"structure": [
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
Configure properties as shown in the following configuration file (use zero-based indexing):
{
"name": "$.properties.structure[0].name",
"value": "FirstName"
}
{
"name": "$.properties.structure[0].type",
"value": "String"
}
{
"name": "$.properties.structure[1].name",
"value": "LastName"
}
{
"name": "$.properties.structure[1].type",
"value": "String"
}
Property names with spaces
If a property name has spaces in it, use square brackets as shown in the following example (Database server
name):
{
"name": "$.properties.activities[1].typeProperties.webServiceParameters.['Database server name']",
"value": "MyAsqlServer.database.windows.net"
}
Deploy solution using a configuration
When you are publishing Azure Data Factory entities in VS, you can specify the configuration that you want to use
for that publishing operation.
To publish entities in an Azure Data Factory project using configuration file:
1. Right-click Data Factory project and click Publish to see the Publish Items dialog box.
2. Select an existing data factory or specify values for creating a data factory on the Configure data factory
page, and click Next.
3. On the Publish Items page: you see a drop-down list with available configurations for the Select
Deployment Config field.
4. Select the configuration file that you would like to use and click Next.
5. Confirm that you see the name of JSON file in the Summary page and click Next.
6. Click Finish after the deployment operation is finished.
When you deploy, the values from the configuration file are used to set values for properties in the JSON files
before the entities are deployed to Azure Data Factory service.
Use Azure Key Vault
It is not advisable and often against security policy to commit sensitive data such as connection strings to the
code repository. See ADF Secure Publish sample on GitHub to learn about storing sensitive information in Azure
Key Vault and using it while publishing Data Factory entities. The Secure Publish extension for Visual Studio
allows the secrets to be stored in Key Vault and only references to them are specified in linked services/
deployment configurations. These references are resolved when you publish Data Factory entities to Azure. These
files can then be committed to source repository without exposing any secrets.
Summary
In this tutorial, you created an Azure data factory to process data by running Hive script on a HDInsight hadoop
cluster. You used the Data Factory Editor in the Azure portal to do the following steps:
1. Created an Azure data factory.
2. Created two linked services:
a. Azure Storage linked service to link your Azure blob storage that holds input/output files to the data
factory.
b. Azure HDInsight on-demand linked service to link an on-demand HDInsight Hadoop cluster to the
data factory. Azure Data Factory creates a HDInsight Hadoop cluster just-in-time to process input data
and produce output data.
3. Created two datasets, which describe input and output data for HDInsight Hive activity in the pipeline.
4. Created a pipeline with a HDInsight Hive activity.
Next Steps
In this article, you have created a pipeline with a transformation activity (HDInsight Activity) that runs a Hive script
on an on-demand HDInsight cluster. To see how to use a Copy Activity to copy data from an Azure Blob to Azure
SQL, see Tutorial: Copy data from an Azure blob to Azure SQL.
You can chain two activities (run one activity after another) by setting the output dataset of one activity as the
input dataset of the other activity. See Scheduling and execution in Data Factory for detailed information.
See Also
TOPIC
DESCRIPTION
Pipelines
This article helps you understand pipelines and activities in
Azure Data Factory and how to use them to construct datadriven workflows for your scenario or business.
Datasets
This article helps you understand datasets in Azure Data
Factory.
Data Transformation Activities
This article provides a list of data transformation activities
(such as HDInsight Hive transformation you used in this
tutorial) supported by Azure Data Factory.
TOPIC
DESCRIPTION
Scheduling and execution
This article explains the scheduling and execution aspects of
Azure Data Factory application model.
Monitor and manage pipelines using Monitoring App
This article describes how to monitor, manage, and debug
pipelines using the Monitoring & Management App.
Tutorial: Build your first Azure data factory using
Azure PowerShell
6/13/2017 • 14 min to read • Edit Online
In this article, you use Azure PowerShell to create your first Azure data factory. To do the tutorial using other
tools/SDKs, select one of the options from the drop-down list.
The pipeline in this tutorial has one activity: HDInsight Hive activity. This activity runs a hive script on an Azure
HDInsight cluster that transforms input data to produce output data. The pipeline is scheduled to run once a
month between the specified start and end times.
NOTE
The data pipeline in this tutorial transforms input data to produce output data. It does not copy data from a source data
store to a destination data store. For a tutorial on how to copy data using Azure Data Factory, see Tutorial: Copy data from
Blob Storage to SQL Database.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by setting the
output dataset of one activity as the input dataset of the other activity. For more information, see scheduling and execution
in Data Factory.
Prerequisites
Read through Tutorial Overview article and complete the prerequisite steps.
Follow instructions in How to install and configure Azure PowerShell article to install latest version of Azure
PowerShell on your computer.
(optional) This article does not cover all the Data Factory cmdlets. See Data Factory Cmdlet Reference for
comprehensive documentation on Data Factory cmdlets.
Create data factory
In this step, you use Azure PowerShell to create an Azure Data Factory named FirstDataFactoryPSH. A data
factory can have one or more pipelines. A pipeline can have one or more activities in it. For example, a Copy
Activity to copy data from a source to a destination data store and a HDInsight Hive activity to run a Hive script to
transform input data. Let's start with creating the data factory in this step.
1. Start Azure PowerShell and run the following command. Keep Azure PowerShell open until the end of this
tutorial. If you close and reopen, you need to run these commands again.
Run the following command and enter the user name and password that you use to sign in to the Azure
portal. PowerShell Login-AzureRmAccount
Run the following command to view all the subscriptions for this account.
PowerShell Get-AzureRmSubscription
Run the following command to select the subscription that you want to work with. This subscription
should be the same as the one you used in the Azure portal.
PowerShell Get-AzureRmSubscription -SubscriptionName <SUBSCRIPTION NAME> | Set-AzureRmContext
2. Create an Azure resource group named ADFTutorialResourceGroup by running the following command:
New-AzureRmResourceGroup -Name ADFTutorialResourceGroup -Location "West US"
Some of the steps in this tutorial assume that you use the resource group named
ADFTutorialResourceGroup. If you use a different resource group, you need to use it in place of
ADFTutorialResourceGroup in this tutorial.
3. Run the New-AzureRmDataFactory cmdlet that creates a data factory named FirstDataFactoryPSH.
New-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name FirstDataFactoryPSH –Location
"West US"
Note the following points:
The name of the Azure Data Factory must be globally unique. If you receive the error Data factory name
“FirstDataFactoryPSH” is not available, change the name (for example, yournameFirstDataFactoryPSH).
Use this name in place of ADFTutorialFactoryPSH while performing steps in this tutorial. See Data Factory Naming Rules topic for naming rules for Data Factory artifacts.
To create Data Factory instances, you need to be a contributor/administrator of the Azure subscription
The name of the data factory may be registered as a DNS name in the future and hence become publically
visible.
If you receive the error: "This subscription is not registered to use namespace
Microsoft.DataFactory", do one of the following and try publishing again:
In Azure PowerShell, run the following command to register the Data Factory provider:
Register-AzureRmResourceProvider -ProviderNamespace Microsoft.DataFactory
You can run the following command to confirm that the Data Factory provider is registered:
Get-AzureRmResourceProvider
Login using the Azure subscription into the Azure portal and navigate to a Data Factory blade (or) create
a data factory in the Azure portal. This action automatically registers the provider for you.
Before creating a pipeline, you need to create a few Data Factory entities first. You first create linked services to
link data stores/computes to your data store, define input and output datasets to represent input/output data in
linked data stores, and then create the pipeline with an activity that uses these datasets.
Create linked services
In this step, you link your Azure Storage account and an on-demand Azure HDInsight cluster to your data factory.
The Azure Storage account holds the input and output data for the pipeline in this sample. The HDInsight linked
service is used to run a Hive script specified in the activity of the pipeline in this sample. Identify what data
store/compute services are used in your scenario and link those services to the data factory by creating linked
services.
Create Azure Storage linked service
In this step, you link your Azure Storage account to your data factory. You use the same Azure Storage account to
store input/output data and the HQL script file.
1. Create a JSON file named StorageLinkedService.json in the C:\ADFGetStarted folder with the following
content. Create the folder ADFGetStarted if it does not already exist.
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"description": "",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Replace account name with the name of your Azure storage account and account key with the access
key of the Azure storage account. To learn how to get your storage access key, see the information about
how to view, copy, and regenerate storage access keys in Manage your storage account.
2. In Azure PowerShell, switch to the ADFGetStarted folder.
3. You can use the New-AzureRmDataFactoryLinkedService cmdlet that creates a linked service. This
cmdlet and other Data Factory cmdlets you use in this tutorial requires you to pass values for the
ResourceGroupName and DataFactoryName parameters. Alternatively, you can use GetAzureRmDataFactory to get a DataFactory object and pass the object without typing
ResourceGroupName and DataFactoryName each time you run a cmdlet. Run the following command to
assign the output of the Get-AzureRmDataFactory cmdlet to a $df variable.
$df=Get-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name FirstDataFactoryPSH
4. Now, run the New-AzureRmDataFactoryLinkedService cmdlet that creates the linked
StorageLinkedService service.
New-AzureRmDataFactoryLinkedService $df -File .\StorageLinkedService.json
If you hadn't run the Get-AzureRmDataFactory cmdlet and assigned the output to the $df variable, you
would have to specify values for the ResourceGroupName and DataFactoryName parameters as follows.
New-AzureRmDataFactoryLinkedService -ResourceGroupName ADFTutorialResourceGroup -DataFactoryName
FirstDataFactoryPSH -File .\StorageLinkedService.json
If you close Azure PowerShell in the middle of the tutorial, you have to run the Get-AzureRmDataFactory
cmdlet next time you start Azure PowerShell to complete the tutorial.
Create Azure HDInsight linked service
In this step, you link an on-demand HDInsight cluster to your data factory. The HDInsight cluster is automatically
created at runtime and deleted after it is done processing and idle for the specified amount of time. You could use
your own HDInsight cluster instead of using an on-demand HDInsight cluster. See Compute Linked Services for
details.
1. Create a JSON file named HDInsightOnDemandLinkedService.json in the C:\ADFGetStarted folder
with the following content.
{
"name": "HDInsightOnDemandLinkedService",
"properties": {
"type": "HDInsightOnDemand",
"typeProperties": {
"clusterSize": 1,
"timeToLive": "00:30:00",
"linkedServiceName": "StorageLinkedService"
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
ClusterSize
Specifies the size of the HDInsight cluster.
TimeToLive
Specifies that the idle time for the HDInsight cluster,
before it is deleted.
linkedServiceName
Specifies the storage account that is used to store the
logs that are generated by HDInsight
Note the following points:
The Data Factory creates a Windows-based HDInsight cluster for you with the JSON. You could also
have it create a Linux-based HDInsight cluster. See On-demand HDInsight Linked Service for details.
You could use your own HDInsight cluster instead of using an on-demand HDInsight cluster. See
HDInsight Linked Service for details.
The HDInsight cluster creates a default container in the blob storage you specified in the JSON
(linkedServiceName). HDInsight does not delete this container when the cluster is deleted. This
behavior is by design. With on-demand HDInsight linked service, a HDInsight cluster is created
every time a slice is processed unless there is an existing live cluster (timeToLive). The cluster is
automatically deleted when the processing is done.
As more slices are processed, you see many containers in your Azure blob storage. If you do not
need them for troubleshooting of the jobs, you may want to delete them to reduce the storage cost.
The names of these containers follow a pattern: "adfyourdatafactoryname-linkedservicenamedatetimestamp". Use tools such as Microsoft Storage Explorer to delete containers in your Azure
blob storage.
See On-demand HDInsight Linked Service for details.
2. Run the New-AzureRmDataFactoryLinkedService cmdlet that creates the linked service called
HDInsightOnDemandLinkedService.
New-AzureRmDataFactoryLinkedService $df -File .\HDInsightOnDemandLinkedService.json
Create datasets
In this step, you create datasets to represent the input and output data for Hive processing. These datasets refer to
the StorageLinkedService you have created earlier in this tutorial. The linked service points to an Azure Storage
account and datasets specify container, folder, file name in the storage that holds input and output data.
Create input dataset
1. Create a JSON file named InputTable.json in the C:\ADFGetStarted folder with the following content:
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"fileName": "input.log",
"folderPath": "adfgetstarted/inputdata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true,
"policy": {}
}
}
The JSON defines a dataset named AzureBlobInput, which represents input data for an activity in the
pipeline. In addition, it specifies that the input data is located in the blob container called adfgetstarted
and the folder called inputdata.
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data
resides in Azure blob storage.
linkedServiceName
refers to the StorageLinkedService you created earlier.
fileName
This property is optional. If you omit this property, all the
files from the folderPath are picked. In this case, only the
input.log is processed.
type
The log files are in text format, so we use TextFormat.
columnDelimiter
columns in the log files are delimited by the comma
character (,).
frequency/interval
frequency set to Month and interval is 1, which means
that the input slices are available monthly.
external
this property is set to true if the input data is not
generated by the Data Factory service.
2. Run the following command in Azure PowerShell to create the Data Factory dataset:
New-AzureRmDataFactoryDataset $df -File .\InputTable.json
Create output dataset
Now, you create the output dataset to represent the output data stored in the Azure Blob storage.
1. Create a JSON file named OutputTable.json in the C:\ADFGetStarted folder with the following content:
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "adfgetstarted/partitioneddata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
}
}
}
The JSON defines a dataset named AzureBlobOutput, which represents output data for an activity in the
pipeline. In addition, it specifies that the results are stored in the blob container called adfgetstarted and
the folder called partitioneddata. The availability section specifies that the output dataset is produced
on a monthly basis.
2. Run the following command in Azure PowerShell to create the Data Factory dataset:
New-AzureRmDataFactoryDataset $df -File .\OutputTable.json
Create pipeline
In this step, you create your first pipeline with a HDInsightHive activity. Input slice is available monthly
(frequency: Month, interval: 1), output slice is produced monthly, and the scheduler property for the activity is also
set to monthly. The settings for the output dataset and the activity scheduler must match. Currently, output
dataset is what drives the schedule, so you must create an output dataset even if the activity does not produce any
output. If the activity doesn't take any input, you can skip creating the input dataset. The properties used in the
following JSON are explained at the end of this section.
1. Create a JSON file named MyFirstPipelinePSH.json in the C:\ADFGetStarted folder with the following
content:
IMPORTANT
Replace storageaccountname with the name of your storage account in the JSON.
{
"name": "MyFirstPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "StorageLinkedService",
"defines": {
"inputtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable":
"wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
],
"start": "2016-04-01T00:00:00Z",
"end": "2016-04-02T00:00:00Z",
"isPaused": false
}
}
In the JSON snippet, you are creating a pipeline that consists of a single activity that uses Hive to process
Data on an HDInsight cluster.
The Hive script file, partitionweblogs.hql, is stored in the Azure storage account (specified by the
scriptLinkedService, called StorageLinkedService), and in script folder in the container adfgetstarted.
The defines section is used to specify the runtime settings that be passed to the hive script as Hive
configuration values (e.g ${hiveconf:inputtable}, ${hiveconf:partitionedtable}).
The start and end properties of the pipeline specifies the active period of the pipeline.
In the activity JSON, you specify that the Hive script runs on the compute specified by the
linkedServiceName – HDInsightOnDemandLinkedService.
NOTE
See "Pipeline JSON" in Pipelines and activities in Azure Data Factory for details about JSON properties that are used
in the example.
2. Confirm that you see the input.log file in the adfgetstarted/inputdata folder in the Azure blob storage,
and run the following command to deploy the pipeline. Since the start and end times are set in the past
and isPaused is set to false, the pipeline (activity in the pipeline) runs immediately after you deploy.
New-AzureRmDataFactoryPipeline $df -File .\MyFirstPipelinePSH.json
3. Congratulations, you have successfully created your first pipeline using Azure PowerShell!
Monitor pipeline
In this step, you use Azure PowerShell to monitor what’s going on in an Azure data factory.
1. Run Get-AzureRmDataFactory and assign the output to a $df variable.
$df=Get-AzureRmDataFactory -ResourceGroupName ADFTutorialResourceGroup -Name FirstDataFactoryPSH
2. Run Get-AzureRmDataFactorySlice to get details about all slices of the EmpSQLTable, which is the
output table of the pipeline.
Get-AzureRmDataFactorySlice $df -DatasetName AzureBlobOutput -StartDateTime 2016-04-01
Notice that the StartDateTime you specify here is the same start time specified in the pipeline JSON. Here is
the sample output:
ResourceGroupName
DataFactoryName
DatasetName
Start
End
RetryCount
State
SubState
LatencyStatus
LongRetryCount
:
:
:
:
:
:
:
:
:
:
ADFTutorialResourceGroup
FirstDataFactoryPSH
AzureBlobOutput
4/1/2016 12:00:00 AM
4/2/2016 12:00:00 AM
0
InProgress
0
3. Run Get-AzureRmDataFactoryRun to get the details of activity runs for a specific slice.
Get-AzureRmDataFactoryRun $df -DatasetName AzureBlobOutput -StartDateTime 2016-04-01
Here is the sample output:
Id
: 0f6334f2-d56c-4d48-b427d4f0fb4ef883_635268096000000000_635292288000000000_AzureBlobOutput
ResourceGroupName : ADFTutorialResourceGroup
DataFactoryName
: FirstDataFactoryPSH
DatasetName
: AzureBlobOutput
ProcessingStartTime : 12/18/2015 4:50:33 AM
ProcessingEndTime : 12/31/9999 11:59:59 PM
PercentComplete
: 0
DataSliceStart
: 4/1/2016 12:00:00 AM
DataSliceEnd
: 4/2/2016 12:00:00 AM
Status
: AllocatingResources
Timestamp
: 12/18/2015 4:50:33 AM
RetryAttempt
: 0
Properties
: {}
ErrorMessage
:
ActivityName
: RunSampleHiveActivity
PipelineName
: MyFirstPipeline
Type
: Script
You can keep running this cmdlet until you see the slice in Ready state or Failed state. When the slice is in
Ready state, check the partitioneddata folder in the adfgetstarted container in your blob storage for the
output data. Creation of an on-demand HDInsight cluster usually takes some time.
IMPORTANT
Creation of an on-demand HDInsight cluster usually takes sometime (approximately 20 minutes). Therefore, expect the
pipeline to take approximately 30 minutes to process the slice.
The input file gets deleted when the slice is processed successfully. Therefore, if you want to rerun the slice or do the tutorial
again, upload the input file (input.log) to the inputdata folder of the adfgetstarted container.
Summary
In this tutorial, you created an Azure data factory to process data by running Hive script on a HDInsight hadoop
cluster. You used the Data Factory Editor in the Azure portal to do the following steps:
1. Created an Azure data factory.
2. Created two linked services:
a. Azure Storage linked service to link your Azure blob storage that holds input/output files to the data
factory.
b. Azure HDInsight on-demand linked service to link an on-demand HDInsight Hadoop cluster to the
data factory. Azure Data Factory creates a HDInsight Hadoop cluster just-in-time to process input data
and produce output data.
3. Created two datasets, which describe input and output data for HDInsight Hive activity in the pipeline.
4. Created a pipeline with a HDInsight Hive activity.
Next steps
In this article, you have created a pipeline with a transformation activity (HDInsight Activity) that runs a Hive script
on an on-demand Azure HDInsight cluster. To see how to use a Copy Activity to copy data from an Azure Blob to
Azure SQL, see Tutorial: Copy data from an Azure Blob to Azure SQL.
See Also
TOPIC
DESCRIPTION
Data Factory Cmdlet Reference
See comprehensive documentation on Data Factory cmdlets
Pipelines
This article helps you understand pipelines and activities in
Azure Data Factory and how to use them to construct endto-end data-driven workflows for your scenario or business.
Datasets
This article helps you understand datasets in Azure Data
Factory.
Scheduling and Execution
This article explains the scheduling and execution aspects of
Azure Data Factory application model.
Monitor and manage pipelines using Monitoring App
This article describes how to monitor, manage, and debug
pipelines using the Monitoring & Management App.
Tutorial: Build your first Azure data factory using
Azure Resource Manager template
6/13/2017 • 12 min to read • Edit Online
In this article, you use an Azure Resource Manager template to create your first Azure data factory. To do the
tutorial using other tools/SDKs, select one of the options from the drop-down list.
The pipeline in this tutorial has one activity: HDInsight Hive activity. This activity runs a hive script on an Azure
HDInsight cluster that transforms input data to produce output data. The pipeline is scheduled to run once a
month between the specified start and end times.
NOTE
The data pipeline in this tutorial transforms input data to produce output data. For a tutorial on how to copy data using
Azure Data Factory, see Tutorial: Copy data from Blob Storage to SQL Database.
The pipeline in this tutorial has only one activity of type: HDInsightHive. A pipeline can have more than one activity. And,
you can chain two activities (run one activity after another) by setting the output dataset of one activity as the input
dataset of the other activity. For more information, see scheduling and execution in Data Factory.
Prerequisites
Read through Tutorial Overview article and complete the prerequisite steps.
Follow instructions in How to install and configure Azure PowerShell article to install latest version of Azure
PowerShell on your computer.
See Authoring Azure Resource Manager Templates to learn about Azure Resource Manager templates.
In this tutorial
ENTITY
DESCRIPTION
Azure Storage linked service
Links your Azure Storage account to the data factory. The
Azure Storage account holds the input and output data for
the pipeline in this sample.
HDInsight on-demand linked service
Links an on-demand HDInsight cluster to the data factory.
The cluster is automatically created for you to process data
and is deleted after the processing is done.
Azure Blob input dataset
Refers to the Azure Storage linked service. The linked service
refers to an Azure Storage account and the Azure Blob
dataset specifies the container, folder, and file name in the
storage that holds the input data.
Azure Blob output dataset
Refers to the Azure Storage linked service. The linked service
refers to an Azure Storage account and the Azure Blob
dataset specifies the container, folder, and file name in the
storage that holds the output data.
ENTITY
DESCRIPTION
Data pipeline
The pipeline has one activity of type HDInsightHive, which
consumes the input dataset and produces the output
dataset.
A data factory can have one or more pipelines. A pipeline can have one or more activities in it. There are two types
of activities: data movement activities and data transformation activities. In this tutorial, you create a pipeline with
one activity (Hive activity).
The following section provides the complete Resource Manager template for defining Data Factory entities so that
you can quickly run through the tutorial and test the template. To understand how each Data Factory entity is
defined, see Data Factory entities in the template section.
Data Factory JSON template
The top-level Resource Manager template for defining a data factory is:
{
"$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": { ...
},
"variables": { ...
},
"resources": [
{
"name": "[parameters('dataFactoryName')]",
"apiVersion": "[variables('apiVersion')]",
"type": "Microsoft.DataFactory/datafactories",
"location": "westus",
"resources": [
{ ... },
{ ... },
{ ... },
{ ... }
]
}
]
}
Create a JSON file named ADFTutorialARM.json in C:\ADFGetStarted folder with the following content:
{
"contentVersion": "1.0.0.0",
"$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"parameters": {
"storageAccountName": { "type": "string", "metadata": { "description": "Name of the Azure storage
account that contains the input/output data." } },
"storageAccountKey": { "type": "securestring", "metadata": { "description": "Key for the Azure
storage account." } },
"blobContainer": { "type": "string", "metadata": { "description": "Name of the blob container in
the Azure Storage account." } },
"inputBlobFolder": { "type": "string", "metadata": { "description": "The folder in the blob
container that has the input file." } },
"inputBlobName": { "type": "string", "metadata": { "description": "Name of the input file/blob." }
},
"outputBlobFolder": { "type": "string", "metadata": { "description": "The folder in the blob
container that will hold the transformed data." } },
"hiveScriptFolder": { "type": "string", "metadata": { "description": "The folder in the blob
container that contains the Hive query file." } },
"hiveScriptFile": { "type": "string", "metadata": { "description": "Name of the hive query (HQL)
file." } }
},
"variables": {
"dataFactoryName": "[concat('HiveTransformDF', uniqueString(resourceGroup().id))]",
"azureStorageLinkedServiceName": "AzureStorageLinkedService",
"hdInsightOnDemandLinkedServiceName": "HDInsightOnDemandLinkedService",
"blobInputDatasetName": "AzureBlobInput",
"blobOutputDatasetName": "AzureBlobOutput",
"pipelineName": "HiveTransformPipeline"
},
"resources": [
{
"name": "[variables('dataFactoryName')]",
"apiVersion": "2015-10-01",
"type": "Microsoft.DataFactory/datafactories",
"location": "West US",
"resources": [
{
"type": "linkedservices",
"name": "[variables('azureStorageLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureStorage",
"description": "Azure Storage linked service",
"typeProperties": {
"connectionString": "
[concat('DefaultEndpointsProtocol=https;AccountName=',parameters('storageAccountName'),';AccountKey=',paramet
ers('storageAccountKey'))]"
}
}
},
{
"type": "linkedservices",
"name": "[variables('hdInsightOnDemandLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "HDInsightOnDemand",
"typeProperties": {
"clusterSize": 1,
"timeToLive": "00:05:00",
"osType": "windows",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]"
}
}
},
{
"type": "datasets",
"name": "[variables('blobInputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]",
"typeProperties": {
"fileName": "[parameters('inputBlobName')]",
"folderPath": "[concat(parameters('blobContainer'), '/',
parameters('inputBlobFolder'))]",
"format": {
"type": "TextFormat",
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true
}
},
{
"type": "datasets",
"name": "[variables('blobOutputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]",
"typeProperties": {
"folderPath": "[concat(parameters('blobContainer'), '/',
parameters('outputBlobFolder'))]",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
}
}
},
{
"type": "datapipelines",
"name": "[variables('pipelineName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]",
"[variables('hdInsightOnDemandLinkedServiceName')]",
"[variables('blobInputDatasetName')]",
"[variables('blobOutputDatasetName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"description": "Pipeline that transforms data using Hive script.",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "[concat(parameters('blobContainer'), '/',
parameters('hiveScriptFolder'), '/', parameters('hiveScriptFile'))]",
"scriptLinkedService": "[variables('azureStorageLinkedServiceName')]",
"defines": {
"inputtable": "[concat('wasb://', parameters('blobContainer'), '@',
parameters('storageAccountName'), '.blob.core.windows.net/', parameters('inputBlobFolder'))]",
"partitionedtable": "[concat('wasb://', parameters('blobContainer'), '@',
parameters('storageAccountName'), '.blob.core.windows.net/', parameters('outputBlobFolder'))]"
}
},
"inputs": [
{
"name": "[variables('blobInputDatasetName')]"
}
],
"outputs": [
{
{
"name": "[variables('blobOutputDatasetName')]"
}
],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "[variables('hdInsightOnDemandLinkedServiceName')]"
}
],
"start": "2016-10-01T00:00:00Z",
"end": "2016-10-02T00:00:00Z",
"isPaused": false
}
}
]
}
]
}
NOTE
You can find another example of Resource Manager template for creating an Azure data factory on Tutorial: Create a
pipeline with Copy Activity using an Azure Resource Manager template.
Parameters JSON
Create a JSON file named ADFTutorialARM-Parameters.json that contains parameters for the Azure Resource
Manager template.
IMPORTANT
Specify the name and key of your Azure Storage account for the storageAccountName and storageAccountKey
parameters in this parameter file.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"storageAccountName": {
"value": "<Name of your Azure Storage account>"
},
"storageAccountKey": {
"value": "<Key of your Azure Storage account>"
},
"blobContainer": {
"value": "adfgetstarted"
},
"inputBlobFolder": {
"value": "inputdata"
},
"inputBlobName": {
"value": "input.log"
},
"outputBlobFolder": {
"value": "partitioneddata"
},
"hiveScriptFolder": {
"value": "script"
},
"hiveScriptFile": {
"value": "partitionweblogs.hql"
}
}
}
IMPORTANT
You may have separate parameter JSON files for development, testing, and production environments that you can use with
the same Data Factory JSON template. By using a Power Shell script, you can automate deploying Data Factory entities in
these environments.
Create data factory
1. Start Azure PowerShell and run the following command:
Run the following command and enter the user name and password that you use to sign in to the Azure
portal. PowerShell Login-AzureRmAccount
Run the following command to view all the subscriptions for this account.
PowerShell Get-AzureRmSubscription
Run the following command to select the subscription that you want to work with. This subscription
should be the same as the one you used in the Azure portal.
Get-AzureRmSubscription -SubscriptionName <SUBSCRIPTION NAME> | Set-AzureRmContext
2. Run the following command to deploy Data Factory entities using the Resource Manager template you
created in Step 1.
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile C:\ADFGetStarted\ADFTutorialARM.json -TemplateParameterFile
C:\ADFGetStarted\ADFTutorialARM-Parameters.json
Monitor pipeline
1. After logging in to the Azure portal, Click Browse and select Data factories.
2. In the Data Factories blade, click the data factory (TutorialFactoryARM) you created.
3. In the Data Factory blade for your data factory, click Diagram.
4. In the Diagram View, you see an overview of the pipelines, and datasets used in this tutorial.
5. In the Diagram View, double-click the dataset AzureBlobOutput. You see that the slice that is currently
being processed.
6. When processing is done, you see the slice in Ready state. Creation of an on-demand HDInsight cluster
usually takes sometime (approximately 20 minutes). Therefore, expect the pipeline to take approximately
30 minutes to process the slice.
7. When the slice is in Ready state, check the partitioneddata folder in the adfgetstarted container in your
blob storage for the output data.
See Monitor datasets and pipeline for instructions on how to use the Azure portal blades to monitor the pipeline
and datasets you have created in this tutorial.
You can also use Monitor and Manage App to monitor your data pipelines. See Monitor and manage Azure Data
Factory pipelines using Monitoring App for details about using the application.
IMPORTANT
The input file gets deleted when the slice is processed successfully. Therefore, if you want to rerun the slice or do the
tutorial again, upload the input file (input.log) to the inputdata folder of the adfgetstarted container.
Data Factory entities in the template
Define data factory
You define a data factory in the Resource Manager template as shown in the following sample:
"resources": [
{
"name": "[variables('dataFactoryName')]",
"apiVersion": "2015-10-01",
"type": "Microsoft.DataFactory/datafactories",
"location": "West US"
}
The dataFactoryName is defined as:
"dataFactoryName": "[concat('HiveTransformDF', uniqueString(resourceGroup().id))]",
It is a unique string based on the resource group ID.
Defining Data Factory entities
The following Data Factory entities are defined in the JSON template:
Azure Storage linked service
HDInsight on-demand linked service
Azure blob input dataset
Azure blob output dataset
Data pipeline with a copy activity
Azure Storage linked service
You specify the name and key of your Azure storage account in this section. See Azure Storage linked service for
details about JSON properties used to define an Azure Storage linked service.
{
"type": "linkedservices",
"name": "[variables('azureStorageLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureStorage",
"description": "Azure Storage linked service",
"typeProperties": {
"connectionString": "
[concat('DefaultEndpointsProtocol=https;AccountName=',parameters('storageAccountName'),';AccountKey=',paramet
ers('storageAccountKey'))]"
}
}
}
The connectionString uses the storageAccountName and storageAccountKey parameters. The values for these
parameters passed by using a configuration file. The definition also uses variables: azureStroageLinkedService
and dataFactoryName defined in the template.
HDInsight on-demand linked service
See Compute linked services article for details about JSON properties used to define an HDInsight on-demand
linked service.
{
"type": "linkedservices",
"name": "[variables('hdInsightOnDemandLinkedServiceName')]",
"dependsOn": [
"[variables('dataFactoryName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "HDInsightOnDemand",
"typeProperties": {
"clusterSize": 1,
"timeToLive": "00:05:00",
"osType": "windows",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]"
}
}
}
Note the following points:
The Data Factory creates a Windows-based HDInsight cluster for you with the above JSON. You could also
have it create a Linux-based HDInsight cluster. See On-demand HDInsight Linked Service for details.
You could use your own HDInsight cluster instead of using an on-demand HDInsight cluster. See HDInsight
Linked Service for details.
The HDInsight cluster creates a default container in the blob storage you specified in the JSON
(linkedServiceName). HDInsight does not delete this container when the cluster is deleted. This behavior
is by design. With on-demand HDInsight linked service, a HDInsight cluster is created every time a slice
needs to be processed unless there is an existing live cluster (timeToLive) and is deleted when the
processing is done.
As more slices are processed, you see many containers in your Azure blob storage. If you do not need
them for troubleshooting of the jobs, you may want to delete them to reduce the storage cost. The names
of these containers follow a pattern: "adfyourdatafactoryname-linkedservicename-datetimestamp".
Use tools such as Microsoft Storage Explorer to delete containers in your Azure blob storage.
See On-demand HDInsight Linked Service for details.
Azure blob input dataset
You specify the names of blob container, folder, and file that contains the input data. See Azure Blob dataset
properties for details about JSON properties used to define an Azure Blob dataset.
{
"type": "datasets",
"name": "[variables('blobInputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]",
"typeProperties": {
"fileName": "[parameters('inputBlobName')]",
"folderPath": "[concat(parameters('blobContainer'), '/', parameters('inputBlobFolder'))]",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true
}
}
This definition uses the following parameters defined in parameter template: blobContainer, inputBlobFolder, and
inputBlobName.
Azure Blob output dataset
You specify the names of blob container and folder that holds the output data. See Azure Blob dataset properties
for details about JSON properties used to define an Azure Blob dataset.
{
"type": "datasets",
"name": "[variables('blobOutputDatasetName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "[variables('azureStorageLinkedServiceName')]",
"typeProperties": {
"folderPath": "[concat(parameters('blobContainer'), '/', parameters('outputBlobFolder'))]",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
}
}
}
This definition uses the following parameters defined in the parameter template: blobContainer and
outputBlobFolder.
Data pipeline
You define a pipeline that transform data by running Hive script on an on-demand Azure HDInsight cluster. See
Pipeline JSON for descriptions of JSON elements used to define a pipeline in this example.
{
"type": "datapipelines",
"name": "[variables('pipelineName')]",
"dependsOn": [
"[variables('dataFactoryName')]",
"[variables('azureStorageLinkedServiceName')]",
"[variables('hdInsightOnDemandLinkedServiceName')]",
"[variables('blobInputDatasetName')]",
"[variables('blobOutputDatasetName')]"
],
"apiVersion": "2015-10-01",
"properties": {
"description": "Pipeline that transforms data using Hive script.",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "[concat(parameters('blobContainer'), '/', parameters('hiveScriptFolder'), '/',
parameters('hiveScriptFile'))]",
"scriptLinkedService": "[variables('azureStorageLinkedServiceName')]",
"defines": {
"inputtable": "[concat('wasb://', parameters('blobContainer'), '@',
parameters('storageAccountName'), '.blob.core.windows.net/', parameters('inputBlobFolder'))]",
"partitionedtable": "[concat('wasb://', parameters('blobContainer'), '@',
parameters('storageAccountName'), '.blob.core.windows.net/', parameters('outputBlobFolder'))]"
}
},
"inputs": [
{
"name": "[variables('blobInputDatasetName')]"
}
],
"outputs": [
{
"name": "[variables('blobOutputDatasetName')]"
}
],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "[variables('hdInsightOnDemandLinkedServiceName')]"
}
],
"start": "2016-10-01T00:00:00Z",
"end": "2016-10-02T00:00:00Z",
"isPaused": false
}
}
Reuse the template
In the tutorial, you created a template for defining Data Factory entities and a template for passing values for
parameters. To use the same template to deploy Data Factory entities to different environments, you create a
parameter file for each environment and use it when deploying to that environment.
Example:
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile ADFTutorialARM.json -TemplateParameterFile ADFTutorialARM-Parameters-Dev.json
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile ADFTutorialARM.json -TemplateParameterFile ADFTutorialARM-Parameters-Test.json
New-AzureRmResourceGroupDeployment -Name MyARMDeployment -ResourceGroupName ADFTutorialResourceGroup TemplateFile ADFTutorialARM.json -TemplateParameterFile ADFTutorialARM-Parameters-Production.json
Notice that the first command uses parameter file for the development environment, second one for the test
environment, and the third one for the production environment.
You can also reuse the template to perform repeated tasks. For example, you need to create many data factories
with one or more pipelines that implement the same logic but each data factory uses different Azure storage and
Azure SQL Database accounts. In this scenario, you use the same template in the same environment (dev, test, or
production) with different parameter files to create data factories.
Resource Manager template for creating a gateway
Here is a sample Resource Manager template for creating a logical gateway in the back. Install a gateway on your
on-premises computer or Azure IaaS VM and register the gateway with Data Factory service using a key. See
Move data between on-premises and cloud for details.
{
"contentVersion": "1.0.0.0",
"$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"parameters": {
},
"variables": {
"dataFactoryName": "GatewayUsingArmDF",
"apiVersion": "2015-10-01",
"singleQuote": "'"
},
"resources": [
{
"name": "[variables('dataFactoryName')]",
"apiVersion": "[variables('apiVersion')]",
"type": "Microsoft.DataFactory/datafactories",
"location": "eastus",
"resources": [
{
"dependsOn": [ "[concat('Microsoft.DataFactory/dataFactories/',
variables('dataFactoryName'))]" ],
"type": "gateways",
"apiVersion": "[variables('apiVersion')]",
"name": "GatewayUsingARM",
"properties": {
"description": "my gateway"
}
}
]
}
]
}
This template creates a data factory named GatewayUsingArmDF with a gateway named: GatewayUsingARM.
See Also
TOPIC
DESCRIPTION
Pipelines
This article helps you understand pipelines and activities in
Azure Data Factory and how to use them to construct endto-end data-driven workflows for your scenario or business.
Datasets
This article helps you understand datasets in Azure Data
Factory.
Scheduling and execution
This article explains the scheduling and execution aspects of
Azure Data Factory application model.
Monitor and manage pipelines using Monitoring App
This article describes how to monitor, manage, and debug
pipelines using the Monitoring & Management App.
Tutorial: Build your first Azure data factory using
Data Factory REST API
6/13/2017 • 14 min to read • Edit Online
In this article, you use Data Factory REST API to create your first Azure data factory. To do the tutorial using other
tools/SDKs, select one of the options from the drop-down list.
The pipeline in this tutorial has one activity: HDInsight Hive activity. This activity runs a hive script on an Azure
HDInsight cluster that transforms input data to produce output data. The pipeline is scheduled to run once a
month between the specified start and end times.
NOTE
This article does not cover all the REST API. For comprehensive documentation on REST API, see Data Factory REST API
Reference.
A pipeline can have more than one activity. And, you can chain two activities (run one activity after another) by setting the
output dataset of one activity as the input dataset of the other activity. For more information, see scheduling and execution
in Data Factory.
Prerequisites
Read through Tutorial Overview article and complete the prerequisite steps.
Install Curl on your machine. You use the CURL tool with REST commands to create a data factory.
Follow instructions from this article to:
1. Create a Web application named ADFGetStartedApp in Azure Active Directory.
2. Get client ID and secret key.
3. Get tenant ID.
4. Assign the ADFGetStartedApp application to the Data Factory Contributor role.
Install Azure PowerShell.
Launch PowerShell and run the following command. Keep Azure PowerShell open until the end of this
tutorial. If you close and reopen, you need to run the commands again.
1. Run Login-AzureRmAccount and enter the user name and password that you use to sign in to the
Azure portal.
2. Run Get-AzureRmSubscription to view all the subscriptions for this account.
3. Run Get-AzureRmSubscription -SubscriptionName NameOfAzureSubscription | SetAzureRmContext to select the subscription that you want to work with. Replace
NameOfAzureSubscription with the name of your Azure subscription.
Create an Azure resource group named ADFTutorialResourceGroup by running the following command
in the PowerShell:
New-AzureRmResourceGroup -Name ADFTutorialResourceGroup -Location "West US"
Some of the steps in this tutorial assume that you use the resource group named
ADFTutorialResourceGroup. If you use a different resource group, you need to use the name of your
resource group in place of ADFTutorialResourceGroup in this tutorial.
Create JSON definitions
Create following JSON files in the folder where curl.exe is located.
datafactory.json
IMPORTANT
Name must be globally unique, so you may want to prefix/suffix ADFCopyTutorialDF to make it a unique name.
{
"name": "FirstDataFactoryREST",
"location": "WestUS"
}
azurestoragelinkedservice.json
IMPORTANT
Replace accountname and accountkey with name and key of your Azure storage account. To learn how to get your
storage access key, see the information about how to view, copy, and regenerate storage access keys in Manage your
storage account.
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
hdinsightondemandlinkedservice.json
{
"name": "HDInsightOnDemandLinkedService",
"properties": {
"type": "HDInsightOnDemand",
"typeProperties": {
"clusterSize": 1,
"timeToLive": "00:30:00",
"linkedServiceName": "AzureStorageLinkedService"
}
}
}
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
ClusterSize
Size of the HDInsight cluster.
TimeToLive
Specifies that the idle time for the HDInsight cluster, before it
is deleted.
PROPERTY
DESCRIPTION
linkedServiceName
Specifies the storage account that is used to store the logs
that are generated by HDInsight
Note the following points:
The Data Factory creates a Windows-based HDInsight cluster for you with the above JSON. You could also
have it create a Linux-based HDInsight cluster. See On-demand HDInsight Linked Service for details.
You could use your own HDInsight cluster instead of using an on-demand HDInsight cluster. See HDInsight
Linked Service for details.
The HDInsight cluster creates a default container in the blob storage you specified in the JSON
(linkedServiceName). HDInsight does not delete this container when the cluster is deleted. This behavior
is by design. With on-demand HDInsight linked service, a HDInsight cluster is created every time a slice is
processed unless there is an existing live cluster (timeToLive) and is deleted when the processing is done.
As more slices are processed, you see many containers in your Azure blob storage. If you do not need
them for troubleshooting of the jobs, you may want to delete them to reduce the storage cost. The names
of these containers follow a pattern: "adfyourdatafactoryname-linkedservicename-datetimestamp".
Use tools such as Microsoft Storage Explorer to delete containers in your Azure blob storage.
See On-demand HDInsight Linked Service for details.
inputdataset.json
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "input.log",
"folderPath": "adfgetstarted/inputdata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
},
"external": true,
"policy": {}
}
}
The JSON defines a dataset named AzureBlobInput, which represents input data for an activity in the pipeline. In
addition, it specifies that the input data is located in the blob container called adfgetstarted and the folder called
inputdata.
The following table provides descriptions for the JSON properties used in the snippet:
PROPERTY
DESCRIPTION
type
The type property is set to AzureBlob because data resides in
Azure blob storage.
PROPERTY
DESCRIPTION
linkedServiceName
refers to the StorageLinkedService you created earlier.
fileName
This property is optional. If you omit this property, all the files
from the folderPath are picked. In this case, only the input.log
is processed.
type
The log files are in text format, so we use TextFormat.
columnDelimiter
columns in the log files are delimited by a comma character (,)
frequency/interval
frequency set to Month and interval is 1, which means that
the input slices are available monthly.
external
this property is set to true if the input data is not generated
by the Data Factory service.
outputdataset.json
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "adfgetstarted/partitioneddata",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Month",
"interval": 1
}
}
}
The JSON defines a dataset named AzureBlobOutput, which represents output data for an activity in the
pipeline. In addition, it specifies that the results are stored in the blob container called adfgetstarted and the
folder called partitioneddata. The availability section specifies that the output dataset is produced on a
monthly basis.
pipeline.json
IMPORTANT
Replace storageaccountname with name of your Azure storage account.
{
"name": "MyFirstPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable":
"wasb://adfgetstarted@<stroageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable":
"wasb://adfgetstarted@<stroageaccountname>t.blob.core.windows.net/partitioneddata"
}
},
"inputs": [{
"name": "AzureBlobInput"
}],
"outputs": [{
"name": "AzureBlobOutput"
}],
"policy": {
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Month",
"interval": 1
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}],
"start": "2016-07-10T00:00:00Z",
"end": "2016-07-11T00:00:00Z",
"isPaused": false
}
}
In the JSON snippet, you are creating a pipeline that consists of a single activity that uses Hive to process data on
a HDInsight cluster.
The Hive script file, partitionweblogs.hql, is stored in the Azure storage account (specified by the
scriptLinkedService, called StorageLinkedService), and in script folder in the container adfgetstarted.
The defines section specifies runtime settings that are passed to the hive script as Hive configuration values (e.g
${hiveconf:inputtable}, ${hiveconf:partitionedtable}).
The start and end properties of the pipeline specifies the active period of the pipeline.
In the activity JSON, you specify that the Hive script runs on the compute specified by the linkedServiceName –
HDInsightOnDemandLinkedService.
NOTE
See "Pipeline JSON" in Pipelines and activities in Azure Data Factory for details about JSON properties used in the preceding
example.
Set global variables
In Azure PowerShell, execute the following commands after replacing the values with your own:
IMPORTANT
See Prerequisites section for instructions on getting client ID, client secret, tenant ID, and subscription ID.
$client_id = "<client ID of application in AAD>"
$client_secret = "<client key of application in AAD>"
$tenant = "<Azure tenant ID>";
$subscription_id="<Azure subscription ID>";
$rg = "ADFTutorialResourceGroup"
$adf = "FirstDataFactoryREST"
Authenticate with AAD
$cmd = { .\curl.exe -X POST https://login.microsoftonline.com/$tenant/oauth2/token -F
grant_type=client_credentials -F resource=https://management.core.windows.net/ -F client_id=$client_id -F
client_secret=$client_secret };
$responseToken = Invoke-Command -scriptblock $cmd;
$accessToken = (ConvertFrom-Json $responseToken).access_token;
(ConvertFrom-Json $responseToken)
Create data factory
In this step, you create an Azure Data Factory named FirstDataFactoryREST. A data factory can have one or more
pipelines. A pipeline can have one or more activities in it. For example, a Copy Activity to copy data from a source
to a destination data store and a HDInsight Hive activity to run a Hive script to transform data. Run the following
commands to create the data factory:
1. Assign the command to variable named cmd.
Confirm that the name of the data factory you specify here (ADFCopyTutorialDF) matches the name
specified in the datafactory.json.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data “@datafactory.json”
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/FirstDataFactoryREST?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the data factory has been successfully created, you see the JSON for the data factory in
the results; otherwise, you see an error message.
Write-Host $results
Note the following points:
The name of the Azure Data Factory must be globally unique. If you see the error in results: Data factory
name “FirstDataFactoryREST” is not available, do the following steps:
1. Change the name (for example, yournameFirstDataFactoryREST) in the datafactory.json file. See Data
1. Change the name (for example, yournameFirstDataFactoryREST) in the datafactory.json file. See Data
Factory - Naming Rules topic for naming rules for Data Factory artifacts.
2. In the first command where the $cmd variable is assigned a value, replace FirstDataFactoryREST with
the new name and run the command.
3. Run the next two commands to invoke the REST API to create the data factory and print the results of
the operation.
To create Data Factory instances, you need to be a contributor/administrator of the Azure subscription
The name of the data factory may be registered as a DNS name in the future and hence become publicly
visible.
If you receive the error: "This subscription is not registered to use namespace
Microsoft.DataFactory", do one of the following and try publishing again:
In Azure PowerShell, run the following command to register the Data Factory provider:
Register-AzureRmResourceProvider -ProviderNamespace Microsoft.DataFactory
You can run the following command to confirm that the Data Factory provider is registered:
Get-AzureRmResourceProvider
Login using the Azure subscription into the Azure portal and navigate to a Data Factory blade (or)
create a data factory in the Azure portal. This action automatically registers the provider for you.
Before creating a pipeline, you need to create a few Data Factory entities first. You first create linked services to
link data stores/computes to your data store, define input and output datasets to represent data in linked data
stores.
Create linked services
In this step, you link your Azure Storage account and an on-demand Azure HDInsight cluster to your data factory.
The Azure Storage account holds the input and output data for the pipeline in this sample. The HDInsight linked
service is used to run a Hive script specified in the activity of the pipeline in this sample.
Create Azure Storage linked service
In this step, you link your Azure Storage account to your data factory. With this tutorial, you use the same Azure
Storage account to store input/output data and the HQL script file.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data “@azurestoragelinkedservice.json”
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/linkedservices/AzureStorageLinkedService?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the linked service has been successfully created, you see the JSON for the linked service
in the results; otherwise, you see an error message.
Write-Host $results
Create Azure HDInsight linked service
In this step, you link an on-demand HDInsight cluster to your data factory. The HDInsight cluster is automatically
created at runtime and deleted after it is done processing and idle for the specified amount of time. You could use
your own HDInsight cluster instead of using an on-demand HDInsight cluster. See Compute Linked Services for
details.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@hdinsightondemandlinkedservice.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/linkedservices/hdinsightondemandlinkedservice?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the linked service has been successfully created, you see the JSON for the linked service
in the results; otherwise, you see an error message.
Write-Host $results
Create datasets
In this step, you create datasets to represent the input and output data for Hive processing. These datasets refer to
the StorageLinkedService you have created earlier in this tutorial. The linked service points to an Azure Storage
account and datasets specify container, folder, file name in the storage that holds input and output data.
Create input dataset
In this step, you create the input dataset to represent input data stored in the Azure Blob storage.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@inputdataset.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/datasets/AzureBlobInput?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the dataset has been successfully created, you see the JSON for the dataset in the
results; otherwise, you see an error message.
Write-Host $results
Create output dataset
In this step, you create the output dataset to represent output data stored in the Azure Blob storage.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@outputdataset.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/datasets/AzureBlobOutput?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the dataset has been successfully created, you see the JSON for the dataset in the
results; otherwise, you see an error message.
Write-Host $results
Create pipeline
In this step, you create your first pipeline with a HDInsightHive activity. Input slice is available monthly
(frequency: Month, interval: 1), output slice is produced monthly, and the scheduler property for the activity is also
set to monthly. The settings for the output dataset and the activity scheduler must match. Currently, output
dataset is what drives the schedule, so you must create an output dataset even if the activity does not produce
any output. If the activity doesn't take any input, you can skip creating the input dataset.
Confirm that you see the input.log file in the adfgetstarted/inputdata folder in the Azure blob storage, and
run the following command to deploy the pipeline. Since the start and end times are set in the past and
isPaused is set to false, the pipeline (activity in the pipeline) runs immediately after you deploy.
1. Assign the command to variable named cmd.
$cmd = {.\curl.exe -X PUT -H "Authorization: Bearer $accessToken" -H "Content-Type: application/json"
--data "@pipeline.json"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.Dat
aFactory/datafactories/$adf/datapipelines/MyFirstPipeline?api-version=2015-10-01};
2. Run the command by using Invoke-Command.
$results = Invoke-Command -scriptblock $cmd;
3. View the results. If the dataset has been successfully created, you see the JSON for the dataset in the
results; otherwise, you see an error message.
Write-Host $results
4. Congratulations, you have successfully created your first pipeline using Azure PowerShell!
Monitor pipeline
In this step, you use Data Factory REST API to monitor slices being produced by the pipeline.
$ds ="AzureBlobOutput"
$cmd = {.\curl.exe -X GET -H "Authorization: Bearer $accessToken"
https://management.azure.com/subscriptions/$subscription_id/resourcegroups/$rg/providers/Microsoft.DataFactor
y/datafactories/$adf/datasets/$ds/slices?start=1970-01-01T00%3a00%3a00.0000000Z"&"end=2016-0812T00%3a00%3a00.0000000Z"&"api-version=2015-10-01};
$results2 = Invoke-Command -scriptblock $cmd;
IF ((ConvertFrom-Json $results2).value -ne $NULL) {
ConvertFrom-Json $results2 | Select-Object -Expand value | Format-Table
} else {
(convertFrom-Json $results2).RemoteException
}
IMPORTANT
Creation of an on-demand HDInsight cluster usually takes sometime (approximately 20 minutes). Therefore, expect the
pipeline to take approximately 30 minutes to process the slice.
Run the Invoke-Command and the next one until you see the slice in Ready state or Failed state. When the slice
is in Ready state, check the partitioneddata folder in the adfgetstarted container in your blob storage for the
output data. The creation of an on-demand HDInsight cluster usually takes some time.
IMPORTANT
The input file gets deleted when the slice is processed successfully. Therefore, if you want to rerun the slice or do the
tutorial again, upload the input file (input.log) to the inputdata folder of the adfgetstarted container.
You can also use Azure portal to monitor slices and troubleshoot any issues. See Monitor pipelines using Azure
portal details.
Summary
In this tutorial, you created an Azure data factory to process data by running Hive script on a HDInsight hadoop
cluster. You used the Data Factory Editor in the Azure portal to do the following steps:
1. Created an Azure data factory.
2. Created two linked services:
a. Azure Storage linked service to link your Azure blob storage that holds input/output files to the data
factory.
b. Azure HDInsight on-demand linked service to link an on-demand HDInsight Hadoop cluster to the
data factory. Azure Data Factory creates a HDInsight Hadoop cluster just-in-time to process input data
and produce output data.
3. Created two datasets, which describe input and output data for HDInsight Hive activity in the pipeline.
4. Created a pipeline with a HDInsight Hive activity.
Next steps
In this article, you have created a pipeline with a transformation activity (HDInsight Activity) that runs a Hive script
on an on-demand Azure HDInsight cluster. To see how to use a Copy Activity to copy data from an Azure Blob to
Azure SQL, see Tutorial: Copy data from an Azure Blob to Azure SQL.
See Also
TOPIC
DESCRIPTION
Data Factory REST API Reference
See comprehensive documentation on Data Factory cmdlets
Pipelines
This article helps you understand pipelines and activities in
Azure Data Factory and how to use them to construct endto-end data-driven workflows for your scenario or business.
Datasets
This article helps you understand datasets in Azure Data
Factory.
Scheduling and Execution
This article explains the scheduling and execution aspects of
Azure Data Factory application model.
Monitor and manage pipelines using Monitoring App
This article describes how to monitor, manage, and debug
pipelines using the Monitoring & Management App.
Move data between on-premises sources and the
cloud with Data Management Gateway
5/4/2017 • 14 min to read • Edit Online
This article provides an overview of data integration between on-premises data stores and cloud data stores
using Data Factory. It builds on the Data Movement Activities article and other data factory core concepts
articles: datasets and pipelines.
Data Management Gateway
You must install Data Management Gateway on your on-premises machine to enable moving data to/from
an on-premises data store. The gateway can be installed on the same machine as the data store or on a
different machine as long as the gateway can connect to the data store.
IMPORTANT
See Data Management Gateway article for details about Data Management Gateway.
The following walkthrough shows you how to create a data factory with a pipeline that moves data from an
on-premises SQL Server database to an Azure blob storage. As part of the walkthrough, you install and
configure the Data Management Gateway on your machine.
Walkthrough: copy on-premises data to cloud
Create data factory
In this step, you use the Azure portal to create an Azure Data Factory instance named
ADFTutorialOnPremDF.
1. Log in to the Azure portal.
2. Click + NEW, click Intelligence + analytics, and click Data Factory.
3. In the New data factory blade, enter ADFTutorialOnPremDF for the Name.
IMPORTANT
The name of the Azure data factory must be globally unique. If you receive the error: Data factory name
“ADFTutorialOnPremDF” is not available, change the name of the data factory (for example,
yournameADFTutorialOnPremDF) and try creating again. Use this name in place of ADFTutorialOnPremDF
while performing remaining steps in this tutorial.
The name of the data factory may be registered as a DNS name in the future and hence become publically
visible.
4. Select the Azure subscription where you want the data factory to be created.
5. Select existing resource group or create a resource group. For the tutorial, create a resource group
named: ADFTutorialResourceGroup.
6. Click Create on the New data factory blade.
IMPORTANT
To create Data Factory instances, you must be a member of the Data Factory Contributor role at the
subscription/resource group level.
7. After creation is complete, you see the Data Factory blade as shown in the following image:
Create gateway
1. In the Data Factory blade, click Author and deploy tile to launch the Editor for the data factory.
2. In the Data Factory Editor, click ... More on the toolbar and then click New data gateway.
Alternatively, you can right-click Data Gateways in the tree view, and click New data gateway.
3. In the Create blade, enter adftutorialgateway for the name, and click OK.
4. In the Configure blade, click Install directly on this computer. This action downloads the
installation package for the gateway, installs, configures, and registers the gateway on the computer.
NOTE
Use Internet Explorer or a Microsoft ClickOnce compatible web browser.
If you are using Chrome, go to the Chrome web store, search with "ClickOnce" keyword, choose one of the
ClickOnce extensions, and install it.
Do the same for Firefox (install add-in). Click Open Menu button on the toolbar (three horizontal lines in
the top-right corner), click Add-ons, search with "ClickOnce" keyword, choose one of the ClickOnce
extensions, and install it.
This way is the easiest way (one-click) to download, install, configure, and register the gateway in one
single step. You can see the Microsoft Data Management Gateway Configuration Manager
application is installed on your computer. You can also find the executable ConfigManager.exe in
the folder: C:\Program Files\Microsoft Data Management Gateway\2.0\Shared.
You can also download and install gateway manually by using the links in this blade and register it
using the key shown in the NEW KEY text box.
See Data Management Gateway article for all the details about the gateway.
NOTE
You must be an administrator on the local computer to install and configure the Data Management Gateway
successfully. You can add additional users to the Data Management Gateway Users local Windows group.
The members of this group can use the Data Management Gateway Configuration Manager tool to configure
the gateway.
5. Wait for a couple of minutes or wait until you see the following notification message:
6. Launch Data Management Gateway Configuration Manager application on your computer. In
the Search window, type Data Management Gateway to access this utility. You can also find the
executable ConfigManager.exe in the folder: C:\Program Files\Microsoft Data Management
Gateway\2.0\Shared
7. Confirm that you see adftutorialgateway is connected to the cloud service message. The status bar
the bottom displays Connected to the cloud service along with a green check mark.
On the Home tab, you can also do the following operations:
Register a gateway with a key from the Azure portal by using the Register button.
Stop the Data Management Gateway Host Service running on your gateway machine.
Schedule updates to be installed at a specific time of the day.
View when the gateway was last updated.
Specify time at which an update to the gateway can be installed.
8. Switch to the Settings tab. The certificate specified in the Certificate section is used to
encrypt/decrypt credentials for the on-premises data store that you specify on the portal. (optional)
Click Change to use your own certificate instead. By default, the gateway uses the certificate that is
auto-generated by the Data Factory service.
You can also do the following actions on the Settings tab:
View or export the certificate being used by the gateway.
Change the HTTPS endpoint used by the gateway.
Set an HTTP proxy to be used by the gateway.
9. (optional) Switch to the Diagnostics tab, check the Enable verbose logging option if you want to
enable verbose logging that you can use to troubleshoot any issues with the gateway. The logging
information can be found in Event Viewer under Applications and Services Logs -> Data
Management Gateway node.
You can also perform the following actions in the Diagnostics tab:
Use Test Connection section to an on-premises data source using the gateway.
Click View Logs to see the Data Management Gateway log in an Event Viewer window.
Click Send Logs to upload a zip file with logs of last seven days to Microsoft to facilitate
troubleshooting of your issues.
10. On the Diagnostics tab, in the Test Connection section, select SqlServer for the type of the data store,
enter the name of the database server, name of the database, specify authentication type, enter user
name, and password, and click Test to test whether the gateway can connect to the database.
11. Switch to the web browser, and in the Azure portal, click OK on the Configure blade and then on the
New data gateway blade.
12. You should see adftutorialgateway under Data Gateways in the tree view on the left. If you click it,
you should see the associated JSON.
Create linked services
In this step, you create two linked services: AzureStorageLinkedService and SqlServerLinkedService.
The SqlServerLinkedService links an on-premises SQL Server database and the
AzureStorageLinkedService linked service links an Azure blob store to the data factory. You create a
pipeline later in this walkthrough that copies data from the on-premises SQL Server database to the Azure
blob store.
Add a linked service to an on-premises SQL Server database
1. In the Data Factory Editor, click New data store on the toolbar and select SQL Server.
2. In the JSON editor on the right, do the following steps:
a. For the gatewayName, specify adftutorialgateway.
b. In the connectionString, do the following steps:
a. For servername, enter the name of the server that hosts the SQL Server database.
b. For databasename, enter the name of the database.
c. Click Encrypt button on the toolbar. This downloads and launches the Credentials
Manager application.
d. In the Setting Credentials dialog box, specify authentication type, user name, and
password, and click OK. If the connection is successful, the encrypted credentials are stored
in the JSON and the dialog box closes.
e. Close the empty browser tab that launched the dialog box if it is not automatically
closed and get back to the tab with the Azure portal.
On the gateway machine, these credentials are encrypted by using a certificate that the
Data Factory service owns. If you want to use the certificate that is associated with the
Data Management Gateway instead, see Set credentials securely.
c. Click Deploy on the command bar to deploy the SQL Server linked service. You should see
the linked service in the tree view.
Add a linked service for an Azure storage account
1.
2.
3.
4.
In the Data Factory Editor, click New data store on the command bar and click Azure storage.
Enter the name of your Azure storage account for the Account name.
Enter the key for your Azure storage account for the Account key.
Click Deploy to deploy the AzureStorageLinkedService.
Create datasets
In this step, you create input and output datasets that represent input and output data for the copy
operation (On-premises SQL Server database => Azure blob storage). Before creating datasets, do the
following steps (detailed steps follows the list):
Create a table named emp in the SQL Server Database you added as a linked service to the data factory
and insert a couple of sample entries into the table.
Create a blob container named adftutorial in the Azure blob storage account you added as a linked
service to the data factory.
Prepare On-premises SQL Server for the tutorial
1. In the database you specified for the on-premises SQL Server linked service
(SqlServerLinkedService), use the following SQL script to create the emp table in the database.
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50),
CONSTRAINT PK_emp PRIMARY KEY (ID)
)
GO
2. Insert some sample into the table:
INSERT INTO emp VALUES ('John', 'Doe')
INSERT INTO emp VALUES ('Jane', 'Doe')
Create input dataset
1. In the Data Factory Editor, click ... More, click New dataset on the command bar, and click SQL Server
table.
2. Replace the JSON in the right pane with the following text:
{
"name": "EmpOnPremSQLTable",
"properties": {
"type": "SqlServerTable",
"linkedServiceName": "SqlServerLinkedService",
"typeProperties": {
"tableName": "emp"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Note the following points:
type is set to SqlServerTable.
tableName is set to emp.
linkedServiceName is set to SqlServerLinkedService (you had created this linked service
earlier in this walkthrough.).
For an input dataset that is not generated by another pipeline in Azure Data Factory, you must set
external to true. It denotes the input data is produced external to the Azure Data Factory service.
You can optionally specify any external data policies using the externalData element in the
Policy section.
See Move data to/from SQL Server for details about JSON properties.
3. Click Deploy on the command bar to deploy the dataset.
Create output dataset
1. In the Data Factory Editor, click New dataset on the command bar, and click Azure Blob storage.
2. Replace the JSON in the right pane with the following text:
{
"name": "OutputBlobTable",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "adftutorial/outfromonpremdf",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Note the following points:
type is set to AzureBlob.
linkedServiceName is set to AzureStorageLinkedService (you had created this linked service
in Step 2).
folderPath is set to adftutorial/outfromonpremdf where outfromonpremdf is the folder in the
adftutorial container. Create the adftutorial container if it does not already exist.
The availability is set to hourly (frequency set to hour and interval set to 1). The Data Factory
service generates an output data slice every hour in the emp table in the Azure SQL Database.
If you do not specify a fileName for an output table, the generated files in the folderPath are
named in the following format: Data..txt (for example: : Data.0a405f8a-93ff-4c6f-b3bef69616f1df7a.txt.).
To set folderPath and fileName dynamically based on the SliceStart time, use the partitionedBy
property. In the following example, folderPath uses Year, Month, and Day from the SliceStart (start
time of the slice being processed) and fileName uses Hour from the SliceStart. For example, if a slice
is being produced for 2014-10-20T08:00:00, the folderName is set to
wikidatagateway/wikisampledataout/2014/10/20 and the fileName is set to 08.csv.
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}",
"fileName": "{Hour}.csv",
"partitionedBy":
[
{
{
{
{
"name":
"name":
"name":
"name":
"Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
"Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
"Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
"Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }
],
See Move data to/from Azure Blob Storage for details about JSON properties.
3. Click Deploy on the command bar to deploy the dataset. Confirm that you see both the datasets in the
tree view.
Create pipeline
In this step, you create a pipeline with one Copy Activity that uses EmpOnPremSQLTable as input and
OutputBlobTable as output.
1. In Data Factory Editor, click ... More, and click New pipeline.
2. Replace the JSON in the right pane with the following text:
{
"name": "ADFTutorialPipelineOnPrem",
"properties": {
"description": "This pipeline has one Copy activity that copies data from an on-prem SQL to
Azure blob",
"activities": [
{
"name": "CopyFromSQLtoBlob",
"description": "Copy data from on-prem SQL server to blob",
"type": "Copy",
"inputs": [
{
"name": "EmpOnPremSQLTable"
}
],
"outputs": [
{
"name": "OutputBlobTable"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "select * from emp"
},
"sink": {
"type": "BlobSink"
}
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"style": "StartOfInterval",
"retry": 0,
"timeout": "01:00:00"
}
}
],
"start": "2016-07-05T00:00:00Z",
"end": "2016-07-06T00:00:00Z",
"isPaused": false
}
}
IMPORTANT
Replace the value of the start property with the current day and end value with the next day.
Note the following points:
In the activities section, there is only activity whose type is set to Copy.
Input for the activity is set to EmpOnPremSQLTable and output for the activity is set to
OutputBlobTable.
In the typeProperties section, SqlSource is specified as the source type and BlobSink **is
specified as the **sink type.
SQL query select * from emp is specified for the sqlReaderQuery property of SqlSource.
Both start and end datetimes must be in ISO format. For example: 2014-10-14T16:32:41Z. The end
time is optional, but we use it in this tutorial.
If you do not specify value for the end property, it is calculated as "start + 48 hours". To run the
pipeline indefinitely, specify 9/9/9999 as the value for the end property.
You are defining the time duration in which the data slices are processed based on the Availability
properties that were defined for each Azure Data Factory dataset.
In the example, there are 24 data slices as each data slice is produced hourly.
3. Click Deploy on the command bar to deploy the dataset (table is a rectangular dataset). Confirm that the
pipeline shows up in the tree view under Pipelines node.
4. Now, click X twice to close the blades to get back to the Data Factory blade for the
ADFTutorialOnPremDF.
Congratulations! You have successfully created an Azure data factory, linked services, datasets, and a
pipeline and scheduled the pipeline.
View the data factory in a Diagram View
1. In the Azure portal, click Diagram tile on the home page for the ADFTutorialOnPremDF data
factory. :
2. You should see the diagram similar to the following image:
You can zoom in, zoom out, zoom to 100%, zoom to fit, automatically position pipelines and datasets,
and show lineage information (highlights upstream and downstream items of selected items). You
can double-click an object (input/output dataset or pipeline) to see properties for it.
Monitor pipeline
In this step, you use the Azure portal to monitor what’s going on in an Azure data factory. You can also use
PowerShell cmdlets to monitor datasets and pipelines. For details about monitoring, see Monitor and
Manage Pipelines.
1. In the diagram, double-click EmpOnPremSQLTable.
2. Notice that all the data slices up are in Ready state because the pipeline duration (start time to end time)
is in the past. It is also because you have inserted the data in the SQL Server database and it is there all
the time. Confirm that no slices show up in the Problem slices section at the bottom. To view all the
slices, click See More at the bottom of the list of slices.
3. Now, In the Datasets blade, click OutputBlobTable.
4. Click any data slice from the list and you should see the Data Slice blade. You see activity runs for
the slice. You see only one activity run usually.
If the slice is not in the Ready state, you can see the upstream slices that are not Ready and are
blocking the current slice from executing in the Upstream slices that are not ready list.
5. Click the activity run from the list at the bottom to see activity run details.
You would see information such as throughput, duration, and the gateway used to transfer the data.
6. Click X to close all the blades until you
7. get back to the home blade for the ADFTutorialOnPremDF.
8. (optional) Click Pipelines, click ADFTutorialOnPremDF, and drill through input tables (Consumed) or
output datasets (Produced).
9. Use tools such as Use tools such as Microsoft Storage Explorer to verify that a blob/file is created for
each hour.
Next Steps
See Data Management Gateway article for all the details about the Data Management Gateway.
See Copy data from Azure Blob to Azure SQL to learn about how to use Copy Activity to move data from
a source data store to a sink data store.
Azure Data Factory - Frequently Asked Questions
4/27/2017 • 22 min to read • Edit Online
General questions
What is Azure Data Factory?
Data Factory is a cloud-based data integration service that automates the movement and transformation of
data. Just like a factory that runs equipment to take raw materials and transform them into finished goods, Data
Factory orchestrates existing services that collect raw data and transform it into ready-to-use information.
Data Factory allows you to create data-driven workflows to move data between both on-premises and cloud data
stores as well as process/transform data using compute services such as Azure HDInsight and Azure Data Lake
Analytics. After you create a pipeline that performs the action that you need, you can schedule it to run periodically
(hourly, daily, weekly etc.).
For more information, see Overview & Key Concepts.
Where can I find pricing details for Azure Data Factory?
See Data Factory Pricing Details page for the pricing details for the Azure Data Factory.
How do I get started with Azure Data Factory?
For an overview of Azure Data Factory, see Introduction to Azure Data Factory.
For a tutorial on how to copy/move data using Copy Activity, see Copy data from Azure Blob Storage to Azure
SQL Database.
For a tutorial on how to transform data using HDInsight Hive Activity. See Process data by running Hive script
on Hadoop cluster
What is the Data Factory’s region availability?
Data Factory is available in US West and North Europe. The compute and storage services used by data factories
can be in other regions. See Supported regions.
What are the limits on number of data factories/pipelines/activities/datasets?
See Azure Data Factory Limits section of the Azure Subscription and Service Limits, Quotas, and Constraints
article.
What is the authoring/developer experience with Azure Data Factory service?
You can author/create data factories using one of the following tools/SDKs:
Azure portal The Data Factory blades in the Azure portal provide rich user interface for you to create data
factories ad linked services. The Data Factory Editor, which is also part of the portal, allows you to easily create
linked services, tables, data sets, and pipelines by specifying JSON definitions for these artifacts. See Build your
first data pipeline using Azure portal for an example of using the portal/editor to create and deploy a data
factory.
Visual Studio You can use Visual Studio to create an Azure data factory. See Build your first data pipeline using
Visual Studio for details.
Azure PowerShell See Create and monitor Azure Data Factory using Azure PowerShell for a
tutorial/walkthrough for creating a data factory using PowerShell. See Data Factory Cmdlet Reference content
on MSDN Library for a comprehensive documentation of Data Factory cmdlets.
.NET Class Library You can programmatically create data factories by using Data Factory .NET SDK. See Create,
monitor, and manage data factories using .NET SDK for a walkthrough of creating a data factory using .NET SDK.
See Data Factory Class Library Reference for a comprehensive documentation of Data Factory .NET SDK.
REST API You can also use the REST API exposed by the Azure Data Factory service to create and deploy data
factories. See Data Factory REST API Reference for a comprehensive documentation of Data Factory REST API.
Azure Resource Manager Template See Tutorial: Build your first Azure data factory using Azure Resource
Manager template fo details.
Can I rename a data factory?
No. Like other Azure resources, the name of an Azure data factory cannot be changed.
Can I move a data factory from one Azure subscription to another?
Yes. Use the Move button on your data factory blade as shown in the following diagram:
What are the compute environments supported by Data Factory?
The following table provides a list of compute environments supported by Data Factory and the activities that can
run on them.
COMPUTE ENVIRONMENT
ACTIVITIES
On-demand HDInsight cluster or your own HDInsight cluster
DotNet, Hive, Pig, MapReduce, Hadoop Streaming
Azure Batch
DotNet
Azure Machine Learning
Machine Learning activities: Batch Execution and Update
Resource
Azure Data Lake Analytics
Data Lake Analytics U-SQL
Azure SQL, Azure SQL Data Warehouse, SQL Server
Stored Procedure
How does Azure Data Factory compare with SQL Server Integration Services (SSIS )?
See the Azure Data Factory vs. SSIS presentation from one of our MVPs (Most Valued Professionals): Reza Rad.
Some of the recent changes in Data Factory may not be listed in the slide deck. We are continuously adding more
capabilities to Azure Data Factory. We are continuously adding more capabilities to Azure Data Factory. We will
incorporate these updates into the comparison of data integration technologies from Microsoft sometime later this
year.
Activities - FAQ
What are the different types of activities you can use in a Data Factory pipeline?
Data Movement Activities to move data.
Data Transformation Activities to process/transform data.
When does an activity run?
The availability configuration setting in the output data table determines when the activity is run. If input datasets
are specified, the activity checks whether all the input data dependencies are satisfied (that is, Ready state) before it
starts running.
Copy Activity - FAQ
Is it better to have a pipeline with multiple activities or a separate pipeline for each activity?
Pipelines are supposed to bundle related activities. If the datasets that connect them are not consumed by any other
activity outside the pipeline, you can keep the activities in one pipeline. This way, you would not need to chain
pipeline active periods so that they align with each other. Also, the data integrity in the tables internal to the
pipeline is better preserved when updating the pipeline. Pipeline update essentially stops all the activities within the
pipeline, removes them, and creates them again. From authoring perspective, it might also be easier to see the flow
of data within the related activities in one JSON file for the pipeline.
What are the supported data stores?
Copy Activity in Data Factory copies data from a source data store to a sink data store. Data Factory supports the
following data stores. Data from any source can be written to any sink. Click a data store to learn how to copy data
to and from that store.
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data Warehouse
✓
✓
✓
Azure Search Index
Databases
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
✓
CATEGORY
NoSQL
File
Others
DATA STORE
SUPPORTED AS A SOURCE
MySQL*
✓
Oracle*
✓
PostgreSQL*
✓
SAP Business Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
✓
✓
✓
NOTE
Data stores with * can be on-premises or on Azure IaaS, and require you to install Data Management Gateway on an onpremises/Azure IaaS machine.
What are the supported file formats?
Specifying formats
Azure Data Factory supports the following format types:
Text Format
JSON Format
Avro Format
ORC Format
Parquet Format
Specifying TextFormat
If you want to parse the text files or write the data in text format, set the format type property to TextFormat.
You can also specify the following optional properties in the format section. See TextFormat example section on
how to configure.
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
columnDelimiter
The character used to
separate columns in a file.
You can consider to use a
rare unprintable char which
not likely exists in your data:
e.g. specify "\u0001" which
represents Start of Heading
(SOH).
Only one character is
allowed. The default value is
comma (',').
No
rowDelimiter
The character used to
separate rows in a file.
Only one character is
allowed. The default value is
any of the following values
on read: ["\r\n", "\r", "\n"]
and "\r\n" on write.
No
escapeChar
The special character used to
escape a column delimiter in
the content of input file.
Only one character is
allowed. No default value.
No
You cannot specify both
escapeChar and quoteChar
for a table.
quoteChar
The character used to quote
a string value. The column
and row delimiters inside the
quote characters would be
treated as part of the string
value. This property is
applicable to both input and
output datasets.
You cannot specify both
escapeChar and quoteChar
for a table.
To use an Unicode character,
refer to Unicode Characters
to get the corresponding
code for it.
Example: if you have comma
(',') as the column delimiter
but you want to have the
comma character in the text
(example: "Hello, world"), you
can define ‘$’ as the escape
character and use string
"Hello$, world" in the source.
Only one character is
allowed. No default value.
For example, if you have
comma (',') as the column
delimiter but you want to
have comma character in the
text (example: ), you can
define " (double quote) as
the quote character and use
the string "Hello, world" in
the source.
No
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
nullValue
One or more characters
used to represent a null
value.
One or more characters. The
default values are "\N" and
"NULL" on read and "\N"
on write.
No
encodingName
Specify the encoding name.
A valid encoding name. see
Encoding.EncodingName
Property. Example: windows1250 or shift_jis. The default
value is UTF-8.
No
firstRowAsHeader
Specifies whether to consider
the first row as a header. For
an input dataset, Data
Factory reads first row as a
header. For an output
dataset, Data Factory writes
first row as a header.
True
False (default)
No
Integer
No
True (default)
False
No
See Scenarios for using
firstRowAsHeader and
skipLineCount for sample
scenarios.
skipLineCount
Indicates the number of
rows to skip when reading
data from input files. If both
skipLineCount and
firstRowAsHeader are
specified, the lines are
skipped first and then the
header information is read
from the input file.
See Scenarios for using
firstRowAsHeader and
skipLineCount for sample
scenarios.
treatEmptyAsNull
Specifies whether to treat
null or empty string as a null
value when reading data
from an input file.
TextFormat example
The following sample shows some of the format properties for TextFormat.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
To use an
escapeChar
instead of
quoteChar
, replace the line with
quoteChar
with the following escapeChar:
"escapeChar": "$",
Scenarios for using firstRowAsHeader and skipLineCount
You are copying from a non-file source to a text file and would like to add a header line containing the schema
metadata (for example: SQL schema). Specify firstRowAsHeader as true in the output dataset for this scenario.
You are copying from a text file containing a header line to a non-file sink and would like to drop that line.
Specify firstRowAsHeader as true in the input dataset.
You are copying from a text file and want to skip a few lines at the beginning that contain no data or header
information. Specify skipLineCount to indicate the number of lines to be skipped. If the rest of the file contains a
header line, you can also specify firstRowAsHeader . If both skipLineCount and firstRowAsHeader are specified,
the lines are skipped first and then the header information is read from the input file
Specifying JsonFormat
To import/export JSON files as-is into/from Azure Cosmos DB, see Import/export JSON documents section in
the Azure Cosmos DB connector with details.
If you want to parse the JSON files or write the data in JSON format, set the format type property to
JsonFormat. You can also specify the following optional properties in the format section. See JsonFormat
example section on how to configure.
PROPERTY
DESCRIPTION
REQUIRED
filePattern
Indicate the pattern of data stored in
each JSON file. Allowed values are:
setOfObjects and arrayOfObjects.
The default value is setOfObjects. See
JSON file patterns section for details
about these patterns.
No
jsonNodeReference
If you want to iterate and extract data
from the objects inside an array field
with the same pattern, specify the JSON
path of that array. This property is
supported only when copying data from
JSON files.
No
PROPERTY
DESCRIPTION
REQUIRED
jsonPathDefinition
Specify the JSON path expression for
each column mapping with a
customized column name (start with
lowercase). This property is supported
only when copying data from JSON files,
and you can extract data from object or
array.
No
For fields under root object, start with
root $; for fields inside the array chosen
by jsonNodeReference property, start
from the array element. See JsonFormat
example section on how to configure.
encodingName
Specify the encoding name. For the list
of valid encoding names, see:
Encoding.EncodingName Property. For
example: windows-1250 or shift_jis. The
default value is: UTF-8.
No
nestingSeparator
Character that is used to separate
nesting levels. The default value is '.'
(dot).
No
JSON file patterns
Copy activity can parse below patterns of JSON files:
Type I: setOfObjects
Each file contains single object, or line-delimited/concatenated multiple objects. When this option is chosen
in an output dataset, copy activity produces a single JSON file with each object per line (line-delimited).
single object JSON example
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
}
line-delimited JSON example
{"time":"2015-0429T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"56
7834760","switch1":"China","switch2":"Germany"}
{"time":"2015-0429T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"78
9037573","switch1":"US","switch2":"UK"}
{"time":"2015-0429T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"34
5626404","switch1":"Germany","switch2":"UK"}
concatenated JSON example
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
}
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
}
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
Type II: arrayOfObjects
Each file contains an array of objects.
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
JsonFormat example
Case 1: Copying data from JSON files
See below two types of samples when copying data from JSON files, and the generic points to note:
Sample 1: extract data from object and array
In this sample, you expect one root JSON object maps to single record in tabular result. If you have a JSON file with
the following content:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagmentProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
and you want to copy it into an Azure SQL table in the following format, by extracting data from both objects and
array:
ID
DEVICETYPE
TARGETRESOURCETYPE
RESOURCEMANAGMEN
TPROCESSRUNID
OCCURRENCETIME
ed0e4960-d9c511e6-85dcd7996816aad3
PC
Microsoft.Compute/vi
rtualMachines
827f8aaa-ab72-437cba48-d8917a7336a3
1/13/2017 11:24:37
AM
The input dataset with JsonFormat type is defined as follows: (partial definition with only the relevant parts). More
specifically:
section defines the customized column names and the corresponding data type while converting to
tabular data. This section is optional unless you need to do column mapping. See Specifying structure
definition for rectangular datasets section for more details.
jsonPathDefinition specifies the JSON path for each column indicating where to extract the data from. To copy
data from array, you can use array[x].property to extract value of the given property from the xth object, or
you can use array[*].property to find the value from any object containing such property.
structure
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagmentProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType":
"$.context.custom.dimensions[0].TargetResourceType", "resourceManagmentProcessRunId":
"$.context.custom.dimensions[1].ResourceManagmentProcessRunId", "occurrenceTime": "
$.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Sample 2: cross apply multiple objects with the same pattern from array
In this sample, you expect to transform one root JSON object into multiple records in tabular result. If you have a
JSON file with the following content:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
and you want to copy it into an Azure SQL table in the following format, by flattening the data inside the array and
cross join with the common root info:
ORDERNUMBER
ORDERDATE
ORDER_PD
ORDER_PRICE
CITY
01
20170122
P1
23
[{"sanmateo":"No 1"}]
01
20170122
P2
13
[{"sanmateo":"No 1"}]
01
20170122
P3
231
[{"sanmateo":"No 1"}]
The input dataset with JsonFormat type is defined as follows: (partial definition with only the relevant parts). More
specifically:
structure section defines the customized column names and the corresponding data type while converting to
tabular data. This section is optional unless you need to do column mapping. See Specifying structure
definition for rectangular datasets section for more details.
jsonNodeReference indicates to iterate and extract data from the objects with the same pattern under array
orderlines.
jsonPathDefinition specifies the JSON path for each column indicating where to extract the data from. In this
example, "ordernumber", "orderdate" and "city" are under root object with JSON path starting with "$.", while
"order_pd" and "order_price" are defined with path derived from the array element without "$.".
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd":
"prod", "order_price": "price", "city": " $.city"}
}
}
}
Note the following points:
If the structure and jsonPathDefinition are not defined in the Data Factory dataset, the Copy Activity detects
the schema from the first object and flatten the whole object.
If the JSON input has an array, by default the Copy Activity converts the entire array value into a string. You can
choose to extract data from it using jsonNodeReference and/or jsonPathDefinition , or skip it by not specifying it
in jsonPathDefinition .
If there are duplicate names at the same level, the Copy Activity picks the last one.
Property names are case-sensitive. Two properties with same name but different casings are treated as two
separate properties.
Case 2: Writing data to JSON file
If you have below table in SQL Database:
ID
ORDER_DATE
ORDER_PRICE
ORDER_BY
1
20170119
2000
David
2
20170120
3500
Patrick
3
20170121
4000
Jason
and for each record, you expect to write to a JSON object in below format:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
The output dataset with JsonFormat type is defined as follows: (partial definition with only the relevant parts).
More specifically, structure section defines the customized property names in destination file, nestingSeparator
(default is ".") will be used to identify the nest layer from the name. This section is optional unless you want to
change the property name comparing with source column name, or nest some of the properties.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Specifying AvroFormat
If you want to parse the Avro files or write the data in Avro format, set the format type property to AvroFormat.
You do not need to specify any properties in the Format section within the typeProperties section. Example:
"format":
{
"type": "AvroFormat",
}
To use Avro format in a Hive table, you can refer to Apache Hive’s tutorial.
Note the following points:
Complex data types are not supported (records, enums, arrays, maps, unions and fixed).
Specifying OrcFormat
If you want to parse the ORC files or write the data in ORC format, set the format type property to OrcFormat.
You do not need to specify any properties in the Format section within the typeProperties section. Example:
"format":
{
"type": "OrcFormat"
}
IMPORTANT
If you are not copying ORC files as-is between on-premises and cloud data stores, you need to install the JRE 8 (Java
Runtime Environment) on your gateway machine. A 64-bit gateway requires 64-bit JRE and 32-bit gateway requires 32-bit
JRE. You can find both versions from here. Choose the appropriate one.
Note the following points:
Complex data types are not supported (STRUCT, MAP, LIST, UNION)
ORC file has three compression-related options: NONE, ZLIB, SNAPPY. Data Factory supports reading data from
ORC file in any of these compressed formats. It uses the compression codec is in the metadata to read the data.
However, when writing to an ORC file, Data Factory chooses ZLIB, which is the default for ORC. Currently, there
is no option to override this behavior.
Specifying ParquetFormat
If you want to parse the Parquet files or write the data in Parquet format, set the format type property to
ParquetFormat. You do not need to specify any properties in the Format section within the typeProperties section.
Example:
"format":
{
"type": "ParquetFormat"
}
IMPORTANT
If you are not copying Parquet files as-is between on-premises and cloud data stores, you need to install the JRE 8 (Java
Runtime Environment) on your gateway machine. A 64-bit gateway requires 64-bit JRE and 32-bit gateway requires 32-bit
JRE. You can find both versions from here. Choose the appropriate one.
Note the following points:
Complex data types are not supported (MAP, LIST)
Parquet file has the following compression-related options: NONE, SNAPPY, GZIP, and LZO. Data Factory
supports reading data from ORC file in any of these compressed formats. It uses the compression codec in the
metadata to read the data. However, when writing to a Parquet file, Data Factory chooses SNAPPY, which is the
default for Parquet format. Currently, there is no option to override this behavior.
Where is the copy operation performed?
See Globally available data movement section for details. In short, when an on-premises data store is involved, the
copy operation is performed by the Data Management Gateway in your on-premises environment. And, when the
data movement is between two cloud stores, the copy operation is performed in the region closest to the sink
location in the same geography.
HDInsight Activity - FAQ
What regions are supported by HDInsight?
See the Geographic Availability section in the following article: or HDInsight Pricing Details.
What region is used by an on-demand HDInsight cluster?
The on-demand HDInsight cluster is created in the same region where the storage you specified to be used with the
cluster exists.
How to associate additional storage accounts to your HDInsight cluster?
If you are using your own HDInsight Cluster (BYOC - Bring Your Own Cluster), see the following topics:
Using an HDInsight Cluster with Alternate Storage Accounts and Metastores
Use Additional Storage Accounts with HDInsight Hive
If you are using an on-demand cluster that is created by the Data Factory service, specify additional storage
accounts for the HDInsight linked service so that the Data Factory service can register them on your behalf. In the
JSON definition for the on-demand linked service, use additionalLinkedServiceNames property to specify
alternate storage accounts as shown in the following JSON snippet:
{
"name": "MyHDInsightOnDemandLinkedService",
"properties":
{
"type": "HDInsightOnDemandLinkedService",
"typeProperties": {
"clusterSize": 1,
"timeToLive": "00:01:00",
"linkedServiceName": "LinkedService-SampleData",
"additionalLinkedServiceNames": [ "otherLinkedServiceName1", "otherLinkedServiceName2" ]
}
}
}
In the example above, otherLinkedServiceName1 and otherLinkedServiceName2 represent linked services whose
definitions contain credentials that the HDInsight cluster needs to access alternate storage accounts.
Slices - FAQ
Why are my input slices not in Ready state?
A common mistake is not setting external property to true on the input dataset when the input data is external to
the data factory (not produced by the data factory).
In the following example, you only need to set external to true on dataset1.
DataFactory1 Pipeline 1: dataset1 -> activity1 -> dataset2 -> activity2 -> dataset3 Pipeline 2: dataset3-> activity3
-> dataset4
If you have another data factory with a pipeline that takes dataset4 (produced by pipeline 2 in data factory 1), mark
dataset4 as an external dataset because the dataset is produced by a different data factory (DataFactory1, not
DataFactory2).
DataFactory2
Pipeline 1: dataset4->activity4->dataset5
If the external property is properly set, verify whether the input data exists in the location specified in the input
dataset definition.
How to run a slice at another time than midnight when the slice is being produced daily?
Use the offset property to specify the time at which you want the slice to be produced. See Dataset availability
section for details about this property. Here is a quick example:
"availability":
{
"frequency": "Day",
"interval": 1,
"offset": "06:00:00"
}
Daily slices start at 6 AM instead of the default midnight.
How can I rerun a slice?
You can rerun a slice in one of the following ways:
Use Monitor and Manage App to rerun an activity window or slice. See Rerun selected activity windows for
instructions.
Click Run in the command bar on the DATA SLICE blade for the slice in the Azure portal.
Run Set-AzureRmDataFactorySliceStatus cmdlet with Status set to Waiting for the slice.
Set-AzureRmDataFactorySliceStatus -Status Waiting -ResourceGroupName $ResourceGroup -DataFactoryName $df
-TableName $table -StartDateTime "02/26/2015 19:00:00" -EndDateTime "02/26/2015 20:00:00"
See Set-AzureRmDataFactorySliceStatus for details about the cmdlet.
How long did it take to process a slice?
Use Activity Window Explorer in Monitor & Manage App to know how long it took to process a data slice. See
Activity Window Explorer for details.
You can also do the following in the Azure portal:
1.
2.
3.
4.
5.
6.
Click Datasets tile on the DATA FACTORY blade for your data factory.
Click the specific dataset on the Datasets blade.
Select the slice that you are interested in from the Recent slices list on the TABLE blade.
Click the activity run from the Activity Runs list on the DATA SLICE blade.
Click Properties tile on the ACTIVITY RUN DETAILS blade.
You should see the DURATION field with a value. This value is the time taken to process the slice.
How to stop a running slice?
If you need to stop the pipeline from executing, you can use Suspend-AzureRmDataFactoryPipeline cmdlet.
Currently, suspending the pipeline does not stop the slice executions that are in progress. Once the in-progress
executions finish, no extra slice is picked up.
If you really want to stop all the executions immediately, the only way would be to delete the pipeline and create it
again. If you choose to delete the pipeline, you do NOT need to delete tables and linked services used by the
pipeline.
Move data by using Copy Activity
5/11/2017 • 9 min to read • Edit Online
Overview
In Azure Data Factory, you can use Copy Activity to copy data between on-premises and cloud data
stores. After the data is copied, it can be further transformed and analyzed. You can also use Copy
Activity to publish transformation and analysis results for business intelligence (BI) and application
consumption.
Copy Activity is powered by a secure, reliable, scalable, and globally available service. This article
provides details on data movement in Data Factory and Copy Activity.
First, let's see how data migration occurs between two cloud data stores, and between an onpremises data store and a cloud data store.
NOTE
To learn about activities in general, see Understanding pipelines and activities.
Copy data between two cloud data stores
When both source and sink data stores are in the cloud, Copy Activity goes through the following
stages to copy data from the source to the sink. The service that powers Copy Activity:
1. Reads data from the source data store.
2. Performs serialization/deserialization, compression/decompression, column mapping, and type
conversion. It does these operations based on the configurations of the input dataset, output
dataset, and Copy Activity.
3. Writes data to the destination data store.
The service automatically chooses the optimal region to perform the data movement. This region is
usually the one closest to the sink data store.
Copy data between an on-premises data store and a cloud data store
To securely move data between an on-premises data store and a cloud data store, install Data
Management Gateway on your on-premises machine. Data Management Gateway is an agent that
enables hybrid data movement and processing. You can install it on the same machine as the data
store itself, or on a separate machine that has access to the data store.
In this scenario, Data Management Gateway performs the serialization/deserialization,
compression/decompression, column mapping, and type conversion. Data does not flow through the
Azure Data Factory service. Instead, Data Management Gateway directly writes the data to the
destination store.
See Move data between on-premises and cloud data stores for an introduction and walkthrough. See
Data Management Gateway for detailed information about this agent.
You can also move data from/to supported data stores that are hosted on Azure IaaS virtual machines
(VMs) by using Data Management Gateway. In this case, you can install Data Management Gateway
on the same VM as the data store itself, or on a separate VM that has access to the data store.
Supported data stores and formats
Copy Activity in Data Factory copies data from a source data store to a sink data store. Data Factory
supports the following data stores. Data from any source can be written to any sink. Click a data store
to learn how to copy data to and from that store.
NOTE
If you need to move data to/from a data store that Copy Activity doesn't support, use a custom activity in
Data Factory with your own logic for copying/moving data. For details on creating and using a custom
activity, see Use custom activities in an Azure Data Factory pipeline.
CATEGORY
DATA STORE
SUPPORTED AS A SOURCE
SUPPORTED AS A SINK
Azure
Azure Blob storage
✓
✓
Azure Cosmos DB
(DocumentDB API)
✓
✓
Azure Data Lake Store
✓
✓
Azure SQL Database
✓
✓
Azure SQL Data
Warehouse
✓
✓
✓
Azure Search Index
Databases
Azure Table storage
✓
Amazon Redshift
✓
DB2*
✓
MySQL*
✓
Oracle*
✓
✓
✓
CATEGORY
NoSQL
File
Others
DATA STORE
SUPPORTED AS A SOURCE
PostgreSQL*
✓
SAP Business
Warehouse*
✓
SAP HANA*
✓
SQL Server*
✓
Sybase*
✓
Teradata*
✓
Cassandra*
✓
MongoDB*
✓
Amazon S3
✓
File System*
✓
FTP
✓
HDFS*
✓
SFTP
✓
Generic HTTP
✓
Generic OData
✓
Generic ODBC*
✓
Salesforce
✓
Web Table (table from
HTML)
✓
GE Historian*
✓
SUPPORTED AS A SINK
✓
✓
NOTE
Data stores with * can be on-premises or on Azure IaaS, and require you to install Data Management
Gateway on an on-premises/Azure IaaS machine.
Supported file formats
You can use Copy Activity to copy files as-is between two file-based data stores, you can skip the
format section in both the input and output dataset definitions. The data is copied efficiently without
any serialization/deserialization.
Copy Activity also reads from and writes to files in specified formats: Text, JSON, Avro, ORC, and
Parquet, and compression codec GZip, Deflate, BZip2, and ZipDeflate are supported. See
Supported file and compression formats with details.
For example, you can do the following copy activities:
Copy data in on-premises SQL Server and write to Azure Data Lake Store in ORC format.
Copy files in text (CSV) format from on-premises File System and write to Azure Blob in Avro
format.
Copy zipped files from on-premises File System and decompress then land to Azure Data Lake
Store.
Copy data in GZip compressed text (CSV) format from Azure Blob and write to Azure SQL
Database.
Globally available data movement
Azure Data Factory is available only in the West US, East US, and North Europe regions. However, the
service that powers Copy Activity is available globally in the following regions and geographies. The
globally available topology ensures efficient data movement that usually avoids cross-region hops.
See Services by region for availability of Data Factory and Data Movement in a region.
Copy data between cloud data stores
When both source and sink data stores are in the cloud, Data Factory uses a service deployment in
the region that is closest to the sink in the same geography to move the data. Refer to the following
table for mapping:
GEOGRAPHY OF THE DESTINATION
DATA STORES
REGION OF THE DESTINATION DATA
STORE
REGION USED FOR DATA MOVEMENT
United States
East US
East US
East US 2
East US 2
Central US
Central US
North Central US
North Central US
South Central US
South Central US
West Central US
West Central US
West US
West US
West US 2
West US
Canada East
Canada Central
Canada Central
Canada Central
Brazil
Brazil South
Brazil South
Europe
North Europe
North Europe
Canada
GEOGRAPHY OF THE DESTINATION
DATA STORES
United Kingdom
Asia Pacific
Australia
Japan
India
REGION OF THE DESTINATION DATA
STORE
REGION USED FOR DATA MOVEMENT
West Europe
West Europe
UK West
UK South
UK South
UK South
Southeast Asia
Southeast Asia
East Asia
Southeast Asia
Australia East
Australia East
Australia Southeast
Australia Southeast
Japan East
Japan East
Japan West
Japan East
Central India
Central India
West India
Central India
South India
Central India
Alternatively, you can explicitly indicate the region of Data Factory service to be used to perform the
copy by specifying executionLocation property under Copy Activity typeProperties . Supported
values for this property are listed in above Region used for data movement column. Note your
data goes through that region over the wire during copy. For example, to copy between Azure stores
in Korea, you can specify "executionLocation": "Japan East" to route through Japan region (see
sample JSON as reference).
NOTE
If the region of the destination data store is not in preceding list or undetectable, by default Copy Activity fails
instead of going through an alternative region, unless executionLocation is specified. The supported region
list will be expanded over time.
Copy data between an on-premises data store and a cloud data store
When data is being copied between on-premises (or Azure virtual machines/IaaS) and cloud stores,
Data Management Gateway performs data movement on an on-premises machine or virtual
machine. The data does not flow through the service in the cloud, unless you use the staged copy
capability. In this case, data flows through the staging Azure Blob storage before it is written into the
sink data store.
Create a pipeline with Copy Activity
You can create a pipeline with Copy Activity in a couple of ways:
By using the Copy Wizard
The Data Factory Copy Wizard helps you to create a pipeline with Copy Activity. This pipeline allows
you to copy data from supported sources to destinations without writing JSON definitions for linked
services, datasets, and pipelines. See Data Factory Copy Wizard for details about the wizard.
By using JSON scripts
You can use Data Factory Editor in the Azure portal, Visual Studio, or Azure PowerShell to create a
JSON definition for a pipeline (by using Copy Activity). Then, you can deploy it to create the pipeline
in Data Factory. See Tutorial: Use Copy Activity in an Azure Data Factory pipeline for a tutorial with
step-by-step instructions.
JSON properties (such as name, description, input and output tables, and policies) are available for all
types of activities. Properties that are available in the typeProperties section of the activity vary with
each activity type.
For Copy Activity, the typeProperties section varies depending on the types of sources and sinks.
Click a source/sink in the Supported sources and sinks section to learn about type properties that
Copy Activity supports for that data store.
Here's a sample JSON definition:
{
"name": "ADFTutorialPipeline",
"properties": {
"description": "Copy data from Azure blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputBlobTable"
}
],
"outputs": [
{
"name": "OutputSQLTable"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink"
},
"executionLocation": "Japan East"
},
"Policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
],
"start": "2016-07-12T00:00:00Z",
"end": "2016-07-13T00:00:00Z"
}
}
The schedule that is defined in the output dataset determines when the activity runs (for example:
daily, frequency as day, and interval as 1). The activity copies data from an input dataset (source) to
an output dataset (sink).
You can specify more than one input dataset to Copy Activity. They are used to verify the
dependencies before the activity is run. However, only the data from the first dataset is copied to the
destination dataset. For more information, see Scheduling and execution.
Performance and tuning
See the Copy Activity performance and tuning guide, which describes key factors that affect the
performance of data movement (Copy Activity) in Azure Data Factory. It also lists the observed
performance during internal testing and discusses various ways to optimize the performance of Copy
Activity.
Scheduling and sequential copy
See Scheduling and execution for detailed information about how scheduling and execution works in
Data Factory. It is possible to run multiple copy operations one after another in a sequential/ordered
manner. See the Copy sequentially section.
Type conversions
Different data stores have different native type systems. Copy Activity performs automatic type
conversions from source types to sink types with the following two-step approach:
1. Convert from native source types to a .NET type.
2. Convert from a .NET type to a native sink type.
The mapping from a native type system to a .NET type for a data store is in the respective data store
article. (Click the specific link in the Supported data stores table). You can use these mappings to
determine appropriate types while creating your tables, so that Copy Activity performs the right
conversions.
Next steps
To learn about the Copy Activity more, see Copy data from Azure Blob storage to Azure SQL
Database.
To learn about moving data from an on-premises data store to a cloud data store, see Move data
from on-premises to cloud data stores.
Azure Data Factory Copy Wizard
5/2/2017 • 4 min to read • Edit Online
The Azure Data Factory Copy Wizard eases the process of ingesting data, which is usually a first step in an end-toend data integration scenario. When going through the Azure Data Factory Copy Wizard, you do not need to
understand any JSON definitions for linked services, data sets, and pipelines. The wizard automatically creates a
pipeline to copy data from the selected data source to the selected destination. In addition, the Copy Wizard helps
you to validate the data being ingested at the time of authoring. This saves time, especially when you are ingesting
data for the first time from the data source. To start the Copy Wizard, click the Copy data tile on the home page of
your data factory.
Designed for big data
This wizard allows you to easily move data from a wide variety of sources to destinations in minutes. After you go
through the wizard, a pipeline with a copy activity is automatically created for you, along with dependent Data
Factory entities (linked services and data sets). No additional steps are required to create the pipeline.
NOTE
For step-by-step instructions to create a sample pipeline to copy data from an Azure blob to an Azure SQL Database table,
see the Copy Wizard tutorial.
The wizard is designed with big data in mind from the start, with support for diverse data and object types. You can
author Data Factory pipelines that move hundreds of folders, files, or tables. The wizard supports automatic data
preview, schema capture and mapping, and data filtering.
Automatic data preview
You can preview part of the data from the selected data source in order to validate whether the data is what you
want to copy. In addition, if the source data is in a text file, the Copy Wizard parses the text file to learn the row and
column delimiters and schema automatically.
Schema capture and mapping
The schema of input data may not match the schema of output data in some cases. In this scenario, you need to
map columns from the source schema to columns from the destination schema.
TIP
When copying data from SQL Server or Azure SQL Database into Azure SQL Data Warehouse, if the table does not exist in
the destination store, Data Factory support auto table creation using source's schema. Learn more from Move data to and
from Azure SQL Data Warehouse using Azure Data Factory.
Use a drop-down list to select a column from the source schema to map to a column in the destination schema. The
Copy Wizard tries to understand your pattern for column mapping. It applies the same pattern to the rest of the
columns, so that you do not need to select each of the columns individually to complete the schema mapping. If
you prefer, you can override these mappings by using the drop-down lists to map the columns one by one. The
pattern becomes more accurate as you map more columns. The Copy Wizard constantly updates the pattern, and
ultimately reaches the right pattern for the column mapping you want to achieve.
Filtering data
You can filter source data to select only the data that needs to be copied to the sink data store. Filtering reduces the
volume of the data to be copied to the sink data store and therefore enhances the throughput of the copy
operation. It provides a flexible way to filter data in a relational database by using the SQL query language, or files
in an Azure blob folder by using Data Factory functions and variables.
Filtering of data in a database
The following screenshot shows a SQL query using the
Filtering of data in an Azure blob folder
Text.Format
function and
WindowStart
variable.
You can use variables in the folder path to copy data from a folder that is determined at runtime based on system
variables. The supported variables are: {year}, {month}, {day}, {hour}, {minute}, and {custom}. For example:
inputfolder/{year}/{month}/{day}.
Suppose that you have input folders in the following format:
2016/03/01/01
2016/03/01/02
2016/03/01/03
...
Click the Browse button for File or folder, browse to one of these folders (for example, 2016->03->01->02), and
click Choose. You should see 2016/03/01/02 in the text box. Now, replace 2016 with {year}, 03 with {month}, 01
with {day}, and 02 with {hour}, and press the Tab key. You should see drop-down lists to select the format for
these four variables:
As shown in the following screenshot, you can also use a custom variable and any supported format strings. To
select a folder with that structure, use the Browse button first. Then replace a value with {custom}, and press the
Tab key to see the text box where you can type the format string.
Scheduling options
You can run the copy operation once or on a schedule (hourly, daily, and so on). Both of these options can be used
for the breadth of the connectors across environments, including on-premises, cloud, and local desktop copy.
A one-time copy operation enables data movement from a source to a destination only once. It applies to data of
any size and any supported format. The scheduled copy allows you to copy data on a prescribed recurrence. You
can use rich settings (like retry, timeout, and alerts) to configure the scheduled copy.
Next steps
For a quick walkthrough of using the Data Factory Copy Wizard to create a pipeline with Copy Activity, see Tutorial:
Create a pipeline using the Copy Wizard.
Load 1 TB into Azure SQL Data Warehouse under 15
minutes with Data Factory
6/6/2017 • 7 min to read • Edit Online
Azure SQL Data Warehouse is a cloud-based, scale-out database capable of processing massive volumes of data,
both relational and non-relational. Built on massively parallel processing (MPP) architecture, SQL Data Warehouse
is optimized for enterprise data warehouse workloads. It offers cloud elasticity with the flexibility to scale storage
and compute independently.
Getting started with Azure SQL Data Warehouse is now easier than ever using Azure Data Factory. Azure Data
Factory is a fully managed cloud-based data integration service, which can be used to populate a SQL Data
Warehouse with the data from your existing system, and saving you valuable time while evaluating SQL Data
Warehouse and building your analytics solutions. Here are the key benefits of loading data into Azure SQL Data
Warehouse using Azure Data Factory:
Easy to set up: 5-step intuitive wizard with no scripting required.
Rich data store support: built-in support for a rich set of on-premises and cloud-based data stores.
Secure and compliant: data is transferred over HTTPS or ExpressRoute, and global service presence ensures
your data never leaves the geographical boundary
Unparalleled performance by using PolyBase – Using Polybase is the most efficient way to move data into
Azure SQL Data Warehouse. Using the staging blob feature, you can achieve high load speeds from all types of
data stores besides Azure Blob storage, which the Polybase supports by default.
This article shows you how to use Data Factory Copy Wizard to load 1-TB data from Azure Blob Storage into Azure
SQL Data Warehouse in under 15 minutes, at over 1.2 GBps throughput.
This article provides step-by-step instructions for moving data into Azure SQL Data Warehouse by using the Copy
Wizard.
NOTE
For general information about capabilities of Data Factory in moving data to/from Azure SQL Data Warehouse, see Move
data to and from Azure SQL Data Warehouse using Azure Data Factory article.
You can also build pipelines using Azure portal, Visual Studio, PowerShell, etc. See Tutorial: Copy data from Azure Blob to
Azure SQL Database for a quick walkthrough with step-by-step instructions for using the Copy Activity in Azure Data
Factory.
Prerequisites
Azure Blob Storage: this experiment uses Azure Blob Storage (GRS) for storing TPC-H testing dataset. If you do
not have an Azure storage account, learn how to create a storage account.
TPC-H data: we are going to use TPC-H as the testing dataset. To do that, you need to use dbgen from TPCH toolkit, which helps you generate the dataset. You can either download source code for dbgen from TPC
Tools and compile it yourself, or download the compiled binary from GitHub. Run dbgen.exe with the
following commands to generate 1 TB flat file for lineitem table spread across 10 files:
Dbgen -s 1000 -S **1** -C 10 -T L -v
Dbgen -s 1000 -S **2** -C 10 -T L -v
…
Dbgen -s 1000 -S **10** -C 10 -T L -v
Now copy the generated files to Azure Blob. Refer to Move data to and from an on-premises file
system by using Azure Data Factory for how to do that using ADF Copy.
Azure SQL Data Warehouse: this experiment loads data into Azure SQL Data Warehouse created with 6,000
DWUs
Refer to Create an Azure SQL Data Warehouse for detailed instructions on how to create a SQL Data
Warehouse database. To get the best possible load performance into SQL Data Warehouse using Polybase,
we choose maximum number of Data Warehouse Units (DWUs) allowed in the Performance setting, which
is 6,000 DWUs.
NOTE
When loading from Azure Blob, the data loading performance is directly proportional to the number of DWUs you
configure on the SQL Data Warehouse:
Loading 1 TB into 1,000 DWU SQL Data Warehouse takes 87 minutes (~200 MBps throughput) Loading 1 TB into
2,000 DWU SQL Data Warehouse takes 46 minutes (~380 MBps throughput) Loading 1 TB into 6,000 DWU SQL
Data Warehouse takes 14 minutes (~1.2 GBps throughput)
To create a SQL Data Warehouse with 6,000 DWUs, move the Performance slider all the way to the right:
For an existing database that is not configured with 6,000 DWUs, you can scale it up using Azure portal.
Navigate to the database in Azure portal, and there is a Scale button in the Overview panel shown in the
following image:
Click the Scale button to open the following panel, move the slider to the maximum value, and click Save
button.
This experiment loads data into Azure SQL Data Warehouse using
xlargerc
resource class.
To achieve best possible throughput, copy needs to be performed using a SQL Data Warehouse user
belonging to xlargerc resource class. Learn how to do that by following Change a user resource class
example.
Create destination table schema in Azure SQL Data Warehouse database, by running the following DDL
statement:
CREATE TABLE [dbo].[lineitem]
(
[L_ORDERKEY] [bigint] NOT NULL,
[L_PARTKEY] [bigint] NOT NULL,
[L_SUPPKEY] [bigint] NOT NULL,
[L_LINENUMBER] [int] NOT NULL,
[L_QUANTITY] [decimal](15, 2) NULL,
[L_EXTENDEDPRICE] [decimal](15, 2) NULL,
[L_DISCOUNT] [decimal](15, 2) NULL,
[L_TAX] [decimal](15, 2) NULL,
[L_RETURNFLAG] [char](1) NULL,
[L_LINESTATUS] [char](1) NULL,
[L_SHIPDATE] [date] NULL,
[L_COMMITDATE] [date] NULL,
[L_RECEIPTDATE] [date] NULL,
[L_SHIPINSTRUCT] [char](25) NULL,
[L_SHIPMODE] [char](10) NULL,
[L_COMMENT] [varchar](44) NULL
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
With the prerequisite steps completed, we are now ready to configure the copy activity using the Copy
Wizard.
Launch Copy Wizard
1. Log in to the Azure portal.
2. Click + NEW from the top-left corner, click Intelligence + analytics, and click Data Factory.
3. In the New data factory blade:
a. Enter LoadIntoSQLDWDataFactory for the name. The name of the Azure data factory must be globally
unique. If you receive the error: Data factory name “LoadIntoSQLDWDataFactory” is not available,
change the name of the data factory (for example, yournameLoadIntoSQLDWDataFactory) and try
creating again. See Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
b. Select your Azure subscription.
c. For Resource Group, do one of the following steps:
a. Select Use existing to select an existing resource group.
b. Select Create new to enter a name for a resource group.
d. Select a location for the data factory.
e. Select Pin to dashboard check box at the bottom of the blade.
f. Click Create.
4. After the creation is complete, you see the Data Factory blade as shown in the following image:
5. On the Data Factory home page, click the Copy data tile to launch Copy Wizard.
NOTE
If you see that the web browser is stuck at "Authorizing...", disable/uncheck Block third party cookies and site
data setting (or) keep it enabled and create an exception for login.microsoftonline.com and then try launching the
wizard again.
Step 1: Configure data loading schedule
The first step is to configure the data loading schedule.
In the Properties page:
1. Enter CopyFromBlobToAzureSqlDataWarehouse for Task name
2. Select Run once now option.
3. Click Next.
Step 2: Configure source
This section shows you the steps to configure the source: Azure Blob containing the 1-TB TPC-H line item files.
1. Select the Azure Blob Storage as the data store and click Next.
2. Fill in the connection information for the Azure Blob storage account, and click Next.
3. Choose the folder containing the TPC-H line item files and click Next.
4. Upon clicking Next, the file format settings are detected automatically. Check to make sure that column
delimiter is ‘|’ instead of the default comma ‘,’. Click Next after you have previewed the data.
Step 3: Configure destination
This section shows you how to configure the destination:
database.
lineitem
table in the Azure SQL Data Warehouse
1. Choose Azure SQL Data Warehouse as the destination store and click Next.
2. Fill in the connection information for Azure SQL Data Warehouse. Make sure you specify the user that is a
member of the role xlargerc (see the prerequisites section for detailed instructions), and click Next.
3. Choose the destination table and click Next.
4. In Schema mapping page, leave "Apply column mapping" option unchecked and click Next.
Step 4: Performance settings
Allow polybase is checked by default. Click Next.
Step 5: Deploy and monitor load results
1. Click Finish button to deploy.
2. After the deployment is complete, click Click here to monitor copy pipeline to monitor the copy run
progress. Select the copy pipeline you created in the Activity Windows list.
You can view the copy run details in the Activity Window Explorer in the right panel, including the data
volume read from source and written into destination, duration, and the average throughput for the run.
As you can see from the following screen shot, copying 1 TB from Azure Blob Storage into SQL Data
Warehouse took 14 minutes, effectively achieving 1.22 GBps throughput!
Best practices
Here are a few best practices for running your Azure SQL Data Warehouse database:
Use a larger resource class when loading into a CLUSTERED COLUMNSTORE INDEX.
For more efficient joins, consider using hash distribution by a select column instead of default round robin
distribution.
For faster load speeds, consider using heap for transient data.
Create statistics after you finish loading Azure SQL Data Warehouse.
See Best practices for Azure SQL Data Warehouse for details.
Next steps
Data Factory Copy Wizard - This article provides details about the Copy Wizard.
Copy Activity performance and tuning guide - This article contains the reference performance measurements
and tuning guide.
Copy Activity performance and tuning guide
5/16/2017 • 28 min to read • Edit Online
Azure Data Factory Copy Activity delivers a first-class secure, reliable, and high-performance data loading
solution. It enables you to copy tens of terabytes of data every day across a rich variety of cloud and onpremises data stores. Blazing-fast data loading performance is key to ensure you can focus on the core “big
data” problem: building advanced analytics solutions and getting deep insights from all that data.
Azure provides a set of enterprise-grade data storage and data warehouse solutions, and Copy Activity offers a
highly optimized data loading experience that is easy to configure and set up. With just a single copy activity,
you can achieve:
Loading data into Azure SQL Data Warehouse at 1.2 GBps. For a walkthrough with a use case, see Load 1
TB into Azure SQL Data Warehouse under 15 minutes with Azure Data Factory.
Loading data into Azure Blob storage at 1.0 GBps
Loading data into Azure Data Lake Store at 1.0 GBps
This article describes:
Performance reference numbers for supported source and sink data stores to help you plan your project;
Features that can boost the copy throughput in different scenarios, including cloud data movement units,
parallel copy, and staged Copy;
Performance tuning guidance on how to tune the performance and the key factors that can impact copy
performance.
NOTE
If you are not familiar with Copy Activity in general, see Move data by using Copy Activity before reading this article.
Performance reference
NOTE
You can achieve higher throughput by leveraging more data movement units (DMUs) than the default maximum DMUs,
which is 32 for a cloud-to-cloud copy activity run. For example, with 100 DMUs, you can achieve copying data from
Azure Blob into Azure Data Lake Store at 1.0GBps. See the Cloud data movement units section for details about this
feature and the supported scenario. Contact Azure support to request more DMUs.
Points to note:
Throughput is calculated by using the following formula: [size of data read from source]/[Copy Activity run
duration].
The performance reference numbers in the table were measured using TPC-H data set in a single copy
activity run.
To copy between cloud data stores, set cloudDataMovementUnits to 1 and 4 (or 8) for comparison.
parallelCopies is not specified. See the Parallel copy section for details about these features.
In Azure data stores, the source and sink are in the same Azure region.
For hybrid (on-premises to cloud, or cloud to on-premises) data movement, a single instance of gateway
was running on a machine that was separate from the on-premises data store. The configuration is listed in
the next table. When a single activity was running on gateway, the copy operation consumed only a small
portion of the test machine's CPU, memory, or network bandwidth.
CPU
32 cores 2.20 GHz Intel Xeon E5-2660 v2
Memory
128 GB
Network
Internet interface: 10 Gbps; intranet interface: 40 Gbps
Parallel copy
You can read data from the source or write data to the destination in parallel within a Copy Activity run.
This feature enhances the throughput of a copy operation and reduces the time it takes to move data.
This setting is different from the concurrency property in the activity definition. The concurrency property
determines the number of concurrent Copy Activity runs to process data from different activity windows (1
AM to 2 AM, 2 AM to 3 AM, 3 AM to 4 AM, and so on). This capability is helpful when you perform a historical
load. The parallel copy capability applies to a single activity run.
Let's look at a sample scenario. In the following example, multiple slices from the past need to be processed.
Data Factory runs an instance of Copy Activity (an activity run) for each slice:
The data slice from the first activity window (1 AM to 2 AM) ==> Activity run 1
The data slice from the second activity window (2 AM to 3 AM) ==> Activity run 2
The data slice from the second activity window (3 AM to 4 AM) ==> Activity run 3
And so on.
In this example, when the concurrency value is set to 2, Activity run 1 and Activity run 2 copy data from two
activity windows concurrently to improve data movement performance. However, if multiple files are
associated with Activity run 1, the data movement service copies files from the source to the destination one
file at a time.
Cloud data movement units
A cloud data movement unit (DMU) is a measure that represents the power (a combination of CPU,
memory, and network resource allocation) of a single unit in Data Factory. A DMU might be used in a cloud-tocloud copy operation, but not in a hybrid copy.
By default, Data Factory uses a single cloud DMU to perform a single Copy Activity run. To override this default,
specify a value for the cloudDataMovementUnits property as follows. For information about the level of
performance gain you might get when you configure more units for a specific copy source and sink, see the
performance reference.
"activities":[
{
"name": "Sample copy activity",
"description": "",
"type": "Copy",
"inputs": [{ "name": "InputDataset" }],
"outputs": [{ "name": "OutputDataset" }],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"cloudDataMovementUnits": 32
}
}
]
The allowed values for the cloudDataMovementUnits property are 1 (default), 2, 4, 8, 16, 32. The actual
number of cloud DMUs that the copy operation uses at run time is equal to or less than the configured value,
depending on your data pattern.
NOTE
If you need more cloud DMUs for a higher throughput, contact Azure support. Setting of 8 and above currently works
only when you copy multiple files from Blob storage/Data Lake Store/Amazon S3/cloud FTP/cloud SFTP to
Blob storage/Data Lake Store/Azure SQL Database.
parallelCopies
You can use the parallelCopies property to indicate the parallelism that you want Copy Activity to use. You
can think of this property as the maximum number of threads within Copy Activity that can read from your
source or write to your sink data stores in parallel.
For each Copy Activity run, Data Factory determines the number of parallel copies to use to copy data from the
source data store and to the destination data store. The default number of parallel copies that it uses depends
on the type of source and sink that you are using.
SOURCE AND SINK
DEFAULT PARALLEL COPY COUNT DETERMINED BY SERVICE
Copy data between file-based stores (Blob storage; Data
Lake Store; Amazon S3; an on-premises file system; an onpremises HDFS)
Between 1 and 32. Depends on the size of the files and the
number of cloud data movement units (DMUs) used to
copy data between two cloud data stores, or the physical
configuration of the Gateway machine used for a hybrid
copy (to copy data to or from an on-premises data store).
Copy data from any source data store to Azure Table
storage
4
All other source and sink pairs
1
Usually, the default behavior should give you the best throughput. However, to control the load on machines
that host your data stores, or to tune copy performance, you may choose to override the default value and
specify a value for the parallelCopies property. The value must be between 1 and 32 (both inclusive). At run
time, for the best performance, Copy Activity uses a value that is less than or equal to the value that you set.
"activities":[
{
"name": "Sample copy activity",
"description": "",
"type": "Copy",
"inputs": [{ "name": "InputDataset" }],
"outputs": [{ "name": "OutputDataset" }],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 8
}
}
]
Points to note:
When you copy data between file-based stores, the parallelCopies determine the parallelism at the file
level. The chunking within a single file would happen underneath automatically and transparently, and it's
designed to use the best suitable chunk size for a given source data store type to load data in parallel and
orthogonal to parallelCopies. The actual number of parallel copies the data movement service uses for the
copy operation at run time is no more than the number of files you have. If the copy behavior is mergeFile,
Copy Activity cannot take advantage of file-level parallelism.
When you specify a value for the parallelCopies property, consider the load increase on your source and
sink data stores, and to gateway if it is a hybrid copy. This happens especially when you have multiple
activities or concurrent runs of the same activities that run against the same data store. If you notice that
either the data store or Gateway is overwhelmed with the load, decrease the parallelCopies value to relieve
the load.
When you copy data from stores that are not file-based to stores that are file-based, the data movement
service ignores the parallelCopies property. Even if parallelism is specified, it's not applied in this case.
NOTE
You must use Data Management Gateway version 1.11 or later to use the parallelCopies feature when you do a hybrid
copy.
To better use these two properties, and to enhance your data movement throughput, see the sample use cases.
You don't need to configure parallelCopies to take advantage of the default behavior. If you do configure and
parallelCopies is too small, multiple cloud DMUs might not be fully utilized.
Billing impact
It's important to remember that you are charged based on the total time of the copy operation. If a copy job
used to take one hour with one cloud unit and now it takes 15 minutes with four cloud units, the overall bill
remains almost the same. For example, you use four cloud units. The first cloud unit spends 10 minutes, the
second one, 10 minutes, the third one, 5 minutes, and the fourth one, 5 minutes, all in one Copy Activity run.
You are charged for the total copy (data movement) time, which is 10 + 10 + 5 + 5 = 30 minutes. Using
parallelCopies does not affect billing.
Staged copy
When you copy data from a source data store to a sink data store, you might choose to use Blob storage as an
interim staging store. Staging is especially useful in the following cases:
1. You want to ingest data from various data stores into SQL Data Warehouse via PolyBase. SQL Data
Warehouse uses PolyBase as a high-throughput mechanism to load a large amount of data into SQL Data
Warehouse. However, the source data must be in Blob storage, and it must meet additional criteria. When
you load data from a data store other than Blob storage, you can activate data copying via interim staging
Blob storage. In that case, Data Factory performs the required data transformations to ensure that it meets
the requirements of PolyBase. Then it uses PolyBase to load data into SQL Data Warehouse. For more
details, see Use PolyBase to load data into Azure SQL Data Warehouse. For a walkthrough with a use case,
see Load 1 TB into Azure SQL Data Warehouse under 15 minutes with Azure Data Factory.
2. Sometimes it takes a while to perform a hybrid data movement (that is, to copy between an onpremises data store and a cloud data store) over a slow network connection. To improve
performance, you can compress the data on-premises so that it takes less time to move data to the staging
data store in the cloud. Then you can decompress the data in the staging store before you load it into the
destination data store.
3. You don't want to open ports other than port 80 and port 443 in your firewall, because of
corporate IT policies. For example, when you copy data from an on-premises data store to an Azure SQL
Database sink or an Azure SQL Data Warehouse sink, you need to activate outbound TCP communication
on port 1433 for both the Windows firewall and your corporate firewall. In this scenario, take advantage of
the gateway to first copy data to a Blob storage staging instance over HTTP or HTTPS on port 443. Then,
load the data into SQL Database or SQL Data Warehouse from Blob storage staging. In this flow, you don't
need to enable port 1433.
How staged copy works
When you activate the staging feature, first the data is copied from the source data store to the staging data
store (bring your own). Next, the data is copied from the staging data store to the sink data store. Data Factory
automatically manages the two-stage flow for you. Data Factory also cleans up temporary data from the
staging storage after the data movement is complete.
In the cloud copy scenario (both source and sink data stores are in the cloud), gateway is not used. The Data
Factory service performs the copy operations.
In the hybrid copy scenario (source is on-premises and sink is in the cloud), the gateway moves data from the
source data store to a staging data store. Data Factory service moves data from the staging data store to the
sink data store. Copying data from a cloud data store to an on-premises data store via staging also is
supported with the reversed flow.
When you activate data movement by using a staging store, you can specify whether you want the data to be
compressed before moving data from the source data store to an interim or staging data store, and then
decompressed before moving data from an interim or staging data store to the sink data store.
Currently, you can't copy data between two on-premises data stores by using a staging store. We expect this
option to be available soon.
Configuration
Configure the enableStaging setting in Copy Activity to specify whether you want the data to be staged in
Blob storage before you load it into a destination data store. When you set enableStaging to TRUE, specify the
additional properties listed in the next table. If you don’t have one, you also need to create an Azure Storage or
Storage shared access signature-linked service for staging.
PROPERTY
DESCRIPTION
DEFAULT VALUE
REQUIRED
enableStaging
Specify whether you want
to copy data via an interim
staging store.
False
No
PROPERTY
DESCRIPTION
DEFAULT VALUE
REQUIRED
linkedServiceName
Specify the name of an
AzureStorage or
AzureStorageSas linked
service, which refers to the
instance of Storage that
you use as an interim
staging store.
N/A
Yes, when enableStaging
is set to TRUE
N/A
No
False
No
You cannot use Storage
with a shared access
signature to load data into
SQL Data Warehouse via
PolyBase. You can use it in
all other scenarios.
path
Specify the Blob storage
path that you want to
contain the staged data. If
you do not provide a path,
the service creates a
container to store
temporary data.
Specify a path only if you
use Storage with a shared
access signature, or you
require temporary data to
be in a specific location.
enableCompression
Specifies whether data
should be compressed
before it is copied to the
destination. This setting
reduces the volume of data
being transferred.
Here's a sample definition of Copy Activity with the properties that are described in the preceding table:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [{ "name": "OnpremisesSQLServerInput" }],
"outputs": [{ "name": "AzureSQLDBOutput" }],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "MyStagingBlob",
"path": "stagingcontainer/path",
"enableCompression": true
}
}
}
]
Billing impact
You are charged based on two steps: copy duration and copy type.
When you use staging during a cloud copy (copying data from a cloud data store to another cloud data
store), you are charged the [sum of copy duration for step 1 and step 2] x [cloud copy unit price].
When you use staging during a hybrid copy (copying data from an on-premises data store to a cloud data
store), you are charged for [hybrid copy duration] x [hybrid copy unit price] + [cloud copy duration] x [cloud
copy unit price].
Performance tuning steps
We suggest that you take these steps to tune the performance of your Data Factory service with Copy Activity:
1. Establish a baseline. During the development phase, test your pipeline by using Copy Activity against a
representative data sample. You can use the Data Factory slicing model to limit the amount of data you
work with.
Collect execution time and performance characteristics by using the Monitoring and Management
App. Choose Monitor & Manage on your Data Factory home page. In the tree view, choose the
output dataset. In the Activity Windows list, choose the Copy Activity run. Activity Windows lists
the Copy Activity duration and the size of the data that's copied. The throughput is listed in Activity
Window Explorer. To learn more about the app, see Monitor and manage Azure Data Factory pipelines
by using the Monitoring and Management App.
Later in the article, you can compare the performance and configuration of your scenario to Copy
Activity’s performance reference from our tests.
2. Diagnose and optimize performance. If the performance you observe doesn't meet your
expectations, you need to identify performance bottlenecks. Then, optimize performance to remove or
reduce the effect of bottlenecks. A full description of performance diagnosis is beyond the scope of this
article, but here are some common considerations:
Performance features:
Parallel copy
Cloud data movement units
Staged copy
Source
Sink
Serialization and deserialization
Compression
Column mapping
Data Management Gateway
Other considerations
3. Expand the configuration to your entire data set. When you're satisfied with the execution results and
performance, you can expand the definition and pipeline active period to cover your entire data set.
Considerations for the source
General
Be sure that the underlying data store is not overwhelmed by other workloads that are running on or against it.
For Microsoft data stores, see monitoring and tuning topics that are specific to data stores, and help you
understand data store performance characteristics, minimize response times, and maximize throughput.
If you copy data from Blob storage to SQL Data Warehouse, consider using PolyBase to boost performance.
See Use PolyBase to load data into Azure SQL Data Warehouse for details. For a walkthrough with a use case,
see Load 1 TB into Azure SQL Data Warehouse under 15 minutes with Azure Data Factory.
File -based data stores
(Includes Blob storage, Data Lake Store, Amazon S3, on-premises file systems, and on-premises HDFS)
Average file size and file count: Copy Activity transfers data one file at a time. With the same amount of
data to be moved, the overall throughput is lower if the data consists of many small files rather than a few
large files due to the bootstrap phase for each file. Therefore, if possible, combine small files into larger files
to gain higher throughput.
File format and compression: For more ways to improve performance, see the Considerations for
serialization and deserialization and Considerations for compression sections.
For the on-premises file system scenario, in which Data Management Gateway is required, see the
Considerations for Data Management Gateway section.
Relational data stores
(Includes SQL Database; SQL Data Warehouse; Amazon Redshift; SQL Server databases; and Oracle, MySQL,
DB2, Teradata, Sybase, and PostgreSQL databases, etc.)
Data pattern: Your table schema affects copy throughput. A large row size gives you a better performance
than small row size, to copy the same amount of data. The reason is that the database can more efficiently
retrieve fewer batches of data that contain fewer rows.
Query or stored procedure: Optimize the logic of the query or stored procedure you specify in the Copy
Activity source to fetch data more efficiently.
For on-premises relational databases, such as SQL Server and Oracle, which require the use of Data
Management Gateway, see the Considerations for Data Management Gateway section.
Considerations for the sink
General
Be sure that the underlying data store is not overwhelmed by other workloads that are running on or against it.
For Microsoft data stores, refer to monitoring and tuning topics that are specific to data stores. These topics can
help you understand data store performance characteristics and how to minimize response times and
maximize throughput.
If you are copying data from Blob storage to SQL Data Warehouse, consider using PolyBase to boost
performance. See Use PolyBase to load data into Azure SQL Data Warehouse for details. For a walkthrough
with a use case, see Load 1 TB into Azure SQL Data Warehouse under 15 minutes with Azure Data Factory.
File -based data stores
(Includes Blob storage, Data Lake Store, Amazon S3, on-premises file systems, and on-premises HDFS)
Copy behavior: If you copy data from a different file-based data store, Copy Activity has three options via
the copyBehavior property. It preserves hierarchy, flattens hierarchy, or merges files. Either preserving or
flattening hierarchy has little or no performance overhead, but merging files causes performance overhead
to increase.
File format and compression: See the Considerations for serialization and deserialization and
Considerations for compression sections for more ways to improve performance.
Blob storage: Currently, Blob storage supports only block blobs for optimized data transfer and
throughput.
For on-premises file systems scenarios that require the use of Data Management Gateway, see the
Considerations for Data Management Gateway section.
Relational data stores
(Includes SQL Database, SQL Data Warehouse, SQL Server databases, and Oracle databases)
Copy behavior: Depending on the properties you've set for sqlSink, Copy Activity writes data to the
destination database in different ways.
By default, the data movement service uses the Bulk Copy API to insert data in append mode, which
provides the best performance.
If you configure a stored procedure in the sink, the database applies the data one row at a time
instead of as a bulk load. Performance drops significantly. If your data set is large, when applicable,
consider switching to using the sqlWriterCleanupScript property.
If you configure the sqlWriterCleanupScript property for each Copy Activity run, the service
triggers the script, and then you use the Bulk Copy API to insert the data. For example, to overwrite
the entire table with the latest data, you can specify a script to first delete all records before bulkloading the new data from the source.
Data pattern and batch size:
Your table schema affects copy throughput. To copy the same amount of data, a large row size gives
you better performance than a small row size because the database can more efficiently commit
fewer batches of data.
Copy Activity inserts data in a series of batches. You can set the number of rows in a batch by using
the writeBatchSize property. If your data has small rows, you can set the writeBatchSize property
with a higher value to benefit from lower batch overhead and higher throughput. If the row size of
your data is large, be careful when you increase writeBatchSize. A high value might lead to a copy
failure caused by overloading the database.
For on-premises relational databases like SQL Server and Oracle, which require the use of Data
Management Gateway, see the Considerations for Data Management Gateway section.
NoSQL stores
(Includes Table storage and Azure Cosmos DB )
For Table storage:
Partition: Writing data to interleaved partitions dramatically degrades performance. Sort your
source data by partition key so that the data is inserted efficiently into one partition after another, or
adjust the logic to write the data to a single partition.
For Azure Cosmos DB:
Batch size: The writeBatchSize property sets the number of parallel requests to the Azure Cosmos
DB service to create documents. You can expect better performance when you increase
writeBatchSize because more parallel requests are sent to Azure Cosmos DB. However, watch for
throttling when you write to Azure Cosmos DB (the error message is "Request rate is large"). Various
factors can cause throttling, including document size, the number of terms in the documents, and the
target collection's indexing policy. To achieve higher copy throughput, consider using a better
collection, for example, S3.
Considerations for serialization and deserialization
Serialization and deserialization can occur when your input data set or output data set is a file. See Supported
file and compression formats with details on supported file formats by Copy Activity.
Copy behavior:
Copying files between file-based data stores:
When input and output data sets both have the same or no file format settings, the data movement
service executes a binary copy without any serialization or deserialization. You see a higher
throughput compared to the scenario, in which the source and sink file format settings are different
from each other.
When input and output data sets both are in text format and only the encoding type is different, the
data movement service only does encoding conversion. It doesn't do any serialization and
deserialization, which causes some performance overhead compared to a binary copy.
When input and output data sets both have different file formats or different configurations, like
delimiters, the data movement service deserializes source data to stream, transform, and then
serialize it into the output format you indicated. This operation results in a much more significant
performance overhead compared to other scenarios.
When you copy files to/from a data store that is not file-based (for example, from a file-based store to a
relational store), the serialization or deserialization step is required. This step results in significant
performance overhead.
File format: The file format you choose might affect copy performance. For example, Avro is a compact binary
format that stores metadata with data. It has broad support in the Hadoop ecosystem for processing and
querying. However, Avro is more expensive for serialization and deserialization, which results in lower copy
throughput compared to text format. Make your choice of file format throughout the processing flow
holistically. Start with what form the data is stored in, source data stores or to be extracted from external
systems; the best format for storage, analytical processing, and querying; and in what format the data should
be exported into data marts for reporting and visualization tools. Sometimes a file format that is suboptimal for
read and write performance might be a good choice when you consider the overall analytical process.
Considerations for compression
When your input or output data set is a file, you can set Copy Activity to perform compression or
decompression as it writes data to the destination. When you choose compression, you make a tradeoff
between input/output (I/O) and CPU. Compressing the data costs extra in compute resources. But in return, it
reduces network I/O and storage. Depending on your data, you may see a boost in overall copy throughput.
Codec: Copy Activity supports gzip, bzip2, and Deflate compression types. Azure HDInsight can consume all
three types for processing. Each compression codec has advantages. For example, bzip2 has the lowest copy
throughput, but you get the best Hive query performance with bzip2 because you can split it for processing.
Gzip is the most balanced option, and it is used the most often. Choose the codec that best suits your end-toend scenario.
Level: You can choose from two options for each compression codec: fastest compressed and optimally
compressed. The fastest compressed option compresses the data as quickly as possible, even if the resulting
file is not optimally compressed. The optimally compressed option spends more time on compression and
yields a minimal amount of data. You can test both options to see which provides better overall performance in
your case.
A consideration: To copy a large amount of data between an on-premises store and the cloud, consider using
interim blob storage with compression. Using interim storage is helpful when the bandwidth of your corporate
network and your Azure services is the limiting factor, and you want the input data set and output data set both
to be in uncompressed form. More specifically, you can break a single copy activity into two copy activities. The
first copy activity copies from the source to an interim or staging blob in compressed form. The second copy
activity copies the compressed data from staging, and then decompresses while it writes to the sink.
Considerations for column mapping
You can set the columnMappings property in Copy Activity to map all or a subset of the input columns to the
output columns. After the data movement service reads the data from the source, it needs to perform column
mapping on the data before it writes the data to the sink. This extra processing reduces copy throughput.
If your source data store is queryable, for example, if it's a relational store like SQL Database or SQL Server, or
if it's a NoSQL store like Table storage or Azure Cosmos DB, consider pushing the column filtering and
reordering logic to the query property instead of using column mapping. This way, the projection occurs while
the data movement service reads data from the source data store, where it is much more efficient.
Considerations for Data Management Gateway
For Gateway setup recommendations, see Considerations for using Data Management Gateway.
Gateway machine environment: We recommend that you use a dedicated machine to host Data
Management Gateway. Use tools like PerfMon to examine CPU, memory, and bandwidth use during a copy
operation on your Gateway machine. Switch to a more powerful machine if CPU, memory, or network
bandwidth becomes a bottleneck.
Concurrent Copy Activity runs: A single instance of Data Management Gateway can serve multiple Copy
Activity runs at the same time, or concurrently. The maximum number of concurrent jobs is calculated based on
the Gateway machine’s hardware configuration. Additional copy jobs are queued until they are picked up by
Gateway or until another job times out. To avoid resource contention on the Gateway machine, you can stage
your Copy Activity schedule to reduce the number of copy jobs in the queue at a time, or consider splitting the
load onto multiple Gateway machines.
Other considerations
If the size of data you want to copy is large, you can adjust your business logic to further partition the data
using the slicing mechanism in Data Factory. Then, schedule Copy Activity to run more frequently to reduce the
data size for each Copy Activity run.
Be cautious about the number of data sets and copy activities requiring Data Factory to connector to the same
data store at the same time. Many concurrent copy jobs might throttle a data store and lead to degraded
performance, copy job internal retries, and in some cases, execution failures.
Sample scenario: Copy from an on-premises SQL Server to Blob
storage
Scenario: A pipeline is built to copy data from an on-premises SQL Server to Blob storage in CSV format. To
make the copy job faster, the CSV files should be compressed into bzip2 format.
Test and analysis: The throughput of Copy Activity is less than 2 MBps, which is much slower than the
performance benchmark.
Performance analysis and tuning: To troubleshoot the performance issue, let’s look at how the data is
processed and moved.
1. Read data: Gateway opens a connection to SQL Server and sends the query. SQL Server responds by
sending the data stream to Gateway via the intranet.
2. Serialize and compress data: Gateway serializes the data stream to CSV format, and compresses the data
to a bzip2 stream.
3. Write data: Gateway uploads the bzip2 stream to Blob storage via the Internet.
As you can see, the data is being processed and moved in a streaming sequential manner: SQL Server > LAN >
Gateway > WAN > Blob storage. The overall performance is gated by the minimum throughput across
the pipeline.
One or more of the following factors might cause the performance bottleneck:
Source: SQL Server itself has low throughput because of heavy loads.
Data Management Gateway:
LAN: Gateway is located far from the SQL Server machine and has a low-bandwidth connection.
Gateway: Gateway has reached its load limitations to perform the following operations:
Serialization: Serializing the data stream to CSV format has slow throughput.
Compression: You chose a slow compression codec (for example, bzip2, which is 2.8 MBps
with Core i7).
WAN: The bandwidth between the corporate network and your Azure services is low (for example, T1
= 1,544 kbps; T2 = 6,312 kbps).
Sink: Blob storage has low throughput. (This scenario is unlikely because its SLA guarantees a minimum of
60 MBps.)
In this case, bzip2 data compression might be slowing down the entire pipeline. Switching to a gzip
compression codec might ease this bottleneck.
Sample scenarios: Use parallel copy
Scenario I: Copy 1,000 1-MB files from the on-premises file system to Blob storage.
Analysis and performance tuning: For an example, if you have installed gateway on a quad core machine,
Data Factory uses 16 parallel copies to move files from the file system to Blob storage concurrently. This
parallel execution should result in high throughput. You also can explicitly specify the parallel copies count.
When you copy many small files, parallel copies dramatically help throughput by using resources more
effectively.
Scenario II: Copy 20 blobs of 500 MB each from Blob storage to Data Lake Store Analytics, and then tune
performance.
Analysis and performance tuning: In this scenario, Data Factory copies the data from Blob storage to Data
Lake Store by using single-copy (parallelCopies set to 1) and single-cloud data movement units. The
throughput you observe will be close to that described in the performance reference section.
Scenario III: Individual file size is greater than dozens of MBs and total volume is large.
Analysis and performance turning: Increasing parallelCopies doesn't result in better copy performance
because of the resource limitations of a single-cloud DMU. Instead, you should specify more cloud DMUs to get
more resources to perform the data movement. Do not specify a value for the parallelCopies property. Data
Factory handles the parallelism for you. In this case, if you set cloudDataMovementUnits to 4, a throughput
of about four times occurs.
Reference
Here are performance monitoring and tuning references for some of the supported data stores:
Azure Storage (including Blob storage and Table storage): Azure Storage scalability targets and Azure
Storage performance and scalability checklist
Azure SQL Database: You can monitor the performance and check the database transaction unit (DTU)
percentage
Azure SQL Data Warehouse: Its capability is measured in data warehouse units (DWUs); see Manage
compute power in Azure SQL Data Warehouse (Overview)
Azure Cosmos DB: Performance levels in Azure Cosmos DB
On-premises SQL Server: Monitor and tune for performance
On-premises file server: Performance tuning for file servers
Azure Data Factory - Security considerations for data
movement
5/10/2017 • 10 min to read • Edit Online
Introduction
This article describes basic security infrastructure that data movement services in Azure Data Factory use to secure
your data. Azure Data Factory management resources are built on Azure security infrastructure and use all possible
security measures offered by Azure.
In a Data Factory solution, you create one or more data pipelines. A pipeline is a logical grouping of activities that
together perform a task. These pipelines reside in the region where the data factory was created.
Even though Data Factory is available in only West US, East US, and North Europe regions, the data movement
service is available globally in several regions. Data Factory service ensures that data does not leave a geographical
area/ region unless you explicitly instruct the service to use an alternate region if the data movement service is not
yet deployed to that region.
Azure Data Factory itself does not store any data except for linked service credentials for cloud data stores, which
are encrypted using certificates. It lets you create data-driven workflows to orchestrate movement of data between
supported data stores and processing of data using compute services in other regions or in an on-premises
environment. It also allows you to monitor and manage workflows using both programmatic and UI mechanisms.
Data movement using Azure Data Factory has been certified for:
HIPAA/HITECH
ISO/IEC 27001
ISO/IEC 27018
CSA STAR
If you are interested in Azure compliance and how Azure secures its own infrastructure, visit the Microsoft Trust
Center.
In this article, we review security considerations in the following two data movement scenarios:
Cloud scenario- In this scenario, both your source and destination are publicly accessible through internet.
These include managed cloud storage services like Azure Storage, Azure SQL Data Warehouse, Azure SQL
Database, Azure Data Lake Store, Amazon S3, Amazon Redshift, SaaS services such as Salesforce, and web
protocols such as FTP and OData. You can find a complete list of supported data sources here.
Hybrid scenario- In this scenario, either your source or destination is behind a firewall or inside an onpremises corporate network or the data store is in a private network/ virtual network (most often the source)
and is not publicly accessible. Database servers hosted on virtual machines also fall under this scenario.
Cloud scenarios
Securing data store credentials
Azure Data Factory protects your data store credentials by encrypting them by using certificates managed by
Microsoft. These certificates are rotated every two years (which includes renewal of certificate and migration of
credentials). These encrypted credentials are securely stored in an Azure Storage managed by Azure Data
Factory management services. For more information about Azure Storage security, refer Azure Storage Security
Overview.
Data encryption in transit
If the cloud data store supports HTTPS or TLS, all data transfers between data movement services in Data Factory
and a cloud data store are via secure channel HTTPS or TLS.
NOTE
All connections to Azure SQL Database and Azure SQL Data Warehouse always require encryption (SSL/TLS) while data is
in transit to and from the database. While authoring a pipeline using a JSON editor, add the encryption property and set it
to true in the connection string. When you use the Copy Wizard, the wizard sets this property by default. For Azure
Storage, you can use HTTPS in the connection string.
Data encryption at rest
Some data stores support encryption of data at rest. We suggest that you enable data encryption mechanism for
those data stores.
Azure SQL Data Warehouse
Transparent Data Encryption (TDE) in Azure SQL Data Warehouse helps with protecting against the threat of
malicious activity by performing real-time encryption and decryption of your data at rest. This behavior is
transparent to the client. For more information, see Secure a database in SQL Data Warehouse.
Azure SQL Database
Azure SQL Database also supports transparent data encryption (TDE), which helps with protecting against the
threat of malicious activity by performing real-time encryption and decryption of the data without requiring
changes to the application. This behavior is transparent to the client. For more information, see Transparent Data
Encryption with Azure SQL Database.
Azure Data Lake Store
Azure Data Lake store also provides encryption for data stored in the account. When enabled, Data Lake store
automatically encrypts data before persisting and decrypts before retrieval, making it transparent to the client
accessing the data. For more information, see Security in Azure Data Lake Store.
Azure Blob Storage and Azure Table Storage
Azure Blob Storage and Azure Table storage supports Storage Service Encryption (SSE), which automatically
encrypts your data before persisting to storage and decrypts before retrieval. For more information, see Azure
Storage Service Encryption for Data at Rest.
Amazon S3
Amazon S3 supports both client and server encryption of data at Rest. For more information, see Protecting Data
Using Encryption. Currently, Data Factory does not support Amazon S3 inside a virtual private cloud (VPC).
Amazon Redshift
Amazon Redshift supports cluster encryption for data at rest. For more information, see Amazon Redshift Database
Encryption. Currently, Data Factory does not support Amazon Redshift inside a VPC.
Salesforce
Salesforce supports Shield Platform Encryption that allows encryption of all files, attachments, custom fields. For
more information, see Understanding the Web Server OAuth Authentication Flow.
Hybrid Scenarios (using Data Management Gateway)
Hybrid scenarios require Data Management Gateway to be installed in an on-premises network or inside a virtual
network (Azure) or a virtual private cloud (Amazon). The gateway must be able to access the local data stores. For
more information about the gateway, see Data Management Gateway.
The command channel allows communication between data movement services in Data Factory and Data
Management Gateway. The communication contains information related to the activity. The data channel is used for
transferring data between on-premises data stores and cloud data stores.
On-premises data store credentials
The credentials for your on-premises data stores are stored locally (not in the cloud). They can be set in three
different ways.
Using plain-text (less secure) via HTTPS from Azure Portal/ Copy Wizard. The credentials are passed in plaintext to the on-premises gateway.
Using JavaScript Cryptography library from Copy Wizard.
Using click-once based credentials manager app. The click-once application executes on the on-premises
machine that has access to the gateway and sets credentials for the data store. This option and the next one are
the most secure options. The credential manager app, by default, uses the port 8050 on the machine with
gateway for secure communication.
Use New-AzureRmDataFactoryEncryptValue PowerShell cmdlet to encrypt credentials. The cmdlet uses the
certificate that gateway is configured to use to encrypt the credentials. You can use the encrypted credentials
returned by this cmdlet and add it to EncryptedCredential element of the connectionString in the JSON file
that you use with the New-AzureRmDataFactoryLinkedService cmdlet or in the JSON snippet in the Data Factory
Editor in the portal. This option and the click-once application are the most secure options.
JavaScript cryptography library-based encryption
You can encrypt data store credentials using JavaScript Cryptography library from the Copy Wizard. When you
select this option, the Copy Wizard retrieves the public key of gateway and uses it to encrypt the data store
credentials. The credentials are decrypted by the gateway machine and protected by Windows DPAPI.
Supported browsers: IE8, IE9, IE10, IE11, Microsoft Edge, and latest Firefox, Chrome, Opera, Safari browsers.
Click-once credentials manager app
You can launch the click-once based credential manager app from Azure portal/Copy Wizard when authoring
pipelines. This application ensures that credentials are not transferred in plain text over the wire. By default, it uses
the port 8050 on the machine with gateway for secure communication. If necessary, this port can be changed.
Currently, Data Management Gateway uses a single certificate. This certificate is created during the gateway
installation (applies to Data Management Gateway created after November 2016 and version 2.4.xxxx.x or later).
You can replace this certificate with your own SSL/TLS certificate. This certificate is used by the click-once credential
manager application to securely connect to the gateway machine for setting data store credentials. It stores data
store credentials securely on-premises by using the Windows DPAPI on the machine with gateway.
NOTE
Older gateways that were installed before November 2016 or of version 2.3.xxxx.x continue to use credentials encrypted and
stored on cloud. Even if you upgrade the gateway to the latest version, the credentials are not migrated to an on-premises
machine
GATEWAY VERSION (DURING CREATION)
CREDENTIALS STORED
CREDENTIAL ENCRYPTION/ SECURITY
< = 2.3.xxxx.x
On cloud
Encrypted using certificate (different
from the one used by Credential
manager app)
> = 2.4.xxxx.x
On premises
Secured via DPAPI
Encryption in transit
All data transfers are via secure channel HTTPS and TLS over TCP to prevent man-in-the-middle attacks during
communication with Azure services.
You can also use IPSec VPN or Express Route to further secure the communication channel between your onpremises network and Azure.
Virtual network is a logical representation of your network in the cloud. You can connect an on-premises network
to your Azure virtual network (VNet) by setting up IPSec VPN (site-to-site) or Express Route (Private Peering)
The following table summarizes the network and gateway configuration recommendations based on different
combinations of source and destination locations for hybrid data movement.
SOURCE
DESTINATION
NETWORK CONFIGURATION
GATEWAY SETUP
On-premises
Virtual machines and cloud
services deployed in virtual
networks
IPSec VPN (point-to-site or
site-to-site)
Gateway can be installed
either on-premises or on an
Azure virtual machine (VM)
in VNet
On-premises
Virtual machines and cloud
services deployed in virtual
networks
ExpressRoute (Private
Peering)
Gateway can be installed
either on-premises or on an
Azure VM in VNet
On-premises
Azure-based services that
have a public endpoint
ExpressRoute (Public
Peering)
Gateway must be installed
on-premises
The following images show the usage of Data Management Gateway for moving data between an on-premises
database and Azure services using Express route and IPSec VPN (with Virtual Network):
Express Route:
IPSec VPN:
Firewall configurations and whitelisting IP address of gateway
Firewall requirements for on-premise/private network
In an enterprise, a corporate firewall runs on the central router of the organization. And, Windows firewall runs
as a daemon on the local machine on which the gateway is installed.
The following table provides outbound port and domain requirements for the corporate firewall.
DOMAIN NAMES
OUTBOUND PORTS
DESCRIPTION
*.servicebus.windows.net
443, 80
Required by the gateway to connect to
data movement services in Data Factory
*.core.windows.net
443
Used by the gateway to connect to
Azure Storage Account when you use
the staged copy feature.
*.frontend.clouddatahub.net
443
Required by the gateway to connect to
the Azure Data Factory service.
*.database.windows.net
1433
(OPTIONAL) needed when your
destination is Azure SQL Database/
Azure SQL Data Warehouse. Use the
staged copy feature to copy data to
Azure SQL Database/Azure SQL Data
Warehouse without opening the port
1433.
*.azuredatalakestore.net
443
(OPTIONAL) needed when your
destination is Azure Data Lake store
NOTE
You may have to manage ports/ whitelisting domains at the corporate firewall level as required by respective data sources.
This table only uses Azure SQL Database, Azure SQL Data Warehouse, Azure Data Lake Store as examples.
The following table provides inbound port requirements for the windows firewall.
INBOUND PORTS
DESCRIPTION
8050 (TCP)
Required by the credential manager application to securely set
credentials for on-premises data stores on the gateway.
IP configurations/ whitelisting in data store
Some data stores in the cloud also require whitelisting of IP address of the machine accessing them. Ensure that the
IP address of the gateway machine is whitelisted/ configured in firewall appropriately.
The following cloud data stores require whitelisting of IP address of the gateway machine. Some of these data
stores, by default, may not require whitelisting of the IP address.
Azure SQL Database
Azure SQL Data Warehouse
Azure Data Lake Store
Azure Cosmos DB
Amazon Redshift
Frequently asked questions
Question: Can the Gateway be shared across different data factories? Answer: We do not support this feature yet.
We are actively working on it.
Question: What are the port requirements for the gateway to work? Answer: Gateway makes HTTP-based
connections to open internet. The outbound ports 443 and 80 must be opened for gateway to make this
connection. Open Inbound Port 8050 only at the machine level (not at corporate firewall level) for Credential
Manager application. If Azure SQL Database or Azure SQL Data Warehouse is used as source/ destination, then you
need to open 1433 port as well. For more information, see Firewall configurations and whitelisting IP addresses
section.
Question: What are certificate requirements for Gateway? Answer: Current gateway requires a certificate that is
used by the credential manager application for securely setting data store credentials. This certificate is a selfsigned certificate created and configured by the gateway setup. You can use your own TLS/ SSL certificate instead.
For more information, see click-once credential manager application section.
Next steps
For information about performance of copy activity, see Copy activity performance and tuning guide.
Move data From Amazon Redshift using Azure
Data Factory
6/6/2017 • 7 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from Amazon Redshift.
The article builds on the Data Movement Activities article, which presents a general overview of data movement
with the copy activity.
You can copy data from Amazon Redshift to any supported sink data store. For a list of data stores supported as
sinks by the copy activity, see supported data stores. Data factory currently supports moving data from Amazon
Redshift to other data stores, but not for moving data from other data stores to Amazon Redshift.
Prerequisites
If you are moving data to an on-premises data store, install Data Management Gateway on an on-premises
machine. Then, Grant Data Management Gateway (use IP address of the machine) the access to Amazon
Redshift cluster. See Authorize access to the cluster for instructions.
If you are moving data to an Azure data store, see Azure Data Center IP Ranges for the Compute IP address
and SQL ranges used by the Azure data centers.
Getting started
You can create a pipeline with a copy activity that moves data from an Amazon Redshift source by using
different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an Amazon Redshift data store, see JSON example: Copy data from Amazon Redshift to
Azure Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Amazon Redshift:
Linked service properties
The following table provides description for JSON elements specific to Amazon Redshift linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AmazonRedshift.
Yes
server
IP address or host name of the
Amazon Redshift server.
Yes
port
The number of the TCP port that the
Amazon Redshift server uses to listen
for client connections.
No, default value: 5439
database
Name of the Amazon Redshift
database.
Yes
username
Name of user who has access to the
database.
Yes
password
Password for the user account.
Yes
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy are similar for all dataset types (Azure SQL, Azure blob, Azure table,
etc.).
The typeProperties section is different for each type of dataset. It provides information about the location of
the data in the data store. The typeProperties section for dataset of type RelationalTable (which includes
Amazon Redshift dataset) has the following properties
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the Amazon
Redshift database that linked service
refers to.
No (if query of RelationalSource is
specified)
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policies are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
When source of copy activity is of type RelationalSource (which includes Amazon Redshift), the following
properties are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable.
No (if tableName of
dataset is specified)
JSON example: Copy data from Amazon Redshift to Azure Blob
This sample shows how to copy data from an Amazon Redshift database to an Azure Blob Storage. However,
data can be copied directly to any of the sinks stated here using the Copy Activity in Azure Data Factory.
The sample has the following data factory entities:
A linked service of type AmazonRedshift.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from a query result in Amazon Redshift to a blob every hour. The JSON properties used
in these samples are described in sections following the samples.
Amazon Redshift linked service:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "< The IP address or host name of the Amazon Redshift server >",
"port": <The number of the TCP port that the Amazon Redshift server uses to listen for client
connections.>,
"database": "<The database name of the Amazon Redshift database>",
"username": "<username>",
"password": "<password>"
}
}
}
Azure Storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Amazon Redshift input dataset:
Setting "external": true informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory. Set this property to true on an input dataset that is not produced
by an activity in the pipeline.
{
"name": "AmazonRedshiftInputDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": "AmazonRedshiftLinkedService",
"typeProperties": {
"tableName": "<Table name>"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutputDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/fromamazonredshift/yearno={Year}/monthno={Month}/dayno={Day}/hourno=
{Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with Azure Redshift source (RelationalSource) and Blob sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is set
to BlobSink. The SQL query specified for the query property selects the data in the past hour to copy.
{
"name": "CopyAmazonRedshiftToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "$$Text.Format('select * from MyTable where timestamp >= \\'{0:yyyy-MMddTHH:mm:ss}\\' AND timestamp < \\'{1:yyyy-MM-ddTHH:mm:ss}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "AmazonRedshiftInputDataset"
}
],
"outputs": [
{
"name": "AzureBlobOutputDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "AmazonRedshiftToBlob"
}
],
"start": "2014-06-01T18:00:00Z",
"end": "2014-06-01T19:00:00Z"
}
}
Type mapping for Amazon Redshift
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following two-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to Amazon Redshift, the following mappings are used from Amazon Redshift types to .NET
types.
AMAZON REDSHIFT TYPE
.NET BASED TYPE
SMALLINT
Int16
INTEGER
Int32
BIGINT
Int64
AMAZON REDSHIFT TYPE
.NET BASED TYPE
DECIMAL
Decimal
REAL
Single
DOUBLE PRECISION
Double
BOOLEAN
String
CHAR
String
VARCHAR
String
DATE
DateTime
TIMESTAMP
DateTime
TEXT
String
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Next Steps
See the following articles:
Copy Activity tutorial for step-by-step instructions for creating a pipeline with a Copy Activity.
Move data from Amazon Simple Storage Service
by using Azure Data Factory
4/19/2017 • 8 min to read • Edit Online
This article explains how to use the copy activity in Azure Data Factory to move data from Amazon Simple
Storage Service (S3). It builds on the Data movement activities article, which presents a general overview of
data movement with the copy activity.
You can copy data from Amazon S3 to any supported sink data store. For a list of data stores supported as sinks
by the copy activity, see the Supported data stores table. Data Factory currently supports only moving data
from Amazon S3 to other data stores, but not moving data from other data stores to Amazon S3.
Required permissions
To copy data from Amazon S3, make sure you have been granted the following permissions:
and s3:GetObjectVersion for Amazon S3 Object Operations.
s3:ListBucket for Amazon S3 Bucket Operations. If you are using the Data Factory Copy Wizard,
s3:ListAllMyBuckets is also required.
s3:GetObject
For details about the full list of Amazon S3 permissions, see Specifying Permissions in a Policy.
Getting started
You can create a pipeline with a copy activity that moves data from an Amazon S3 source by using different
tools or APIs.
The easiest way to create a pipeline is to use the Copy Wizard. For a quick walkthrough, see Tutorial: Create a
pipeline using Copy Wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. For step-by-step instructions to create a
pipeline with a copy activity, see the Copy activity tutorial.
Whether you use tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools or APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an Amazon S3 data store, see the JSON example: Copy data from Amazon S3 to Azure
Blob section of this article.
NOTE
For details about supported file and compression formats for a copy activity, see File and compression formats in Azure
Data Factory.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Amazon S3.
Linked service properties
A linked service links a data store to a data factory. You create a linked service of type AwsAccessKey to link
your Amazon S3 data store to your data factory. The following table provides description for JSON elements
specific to Amazon S3 (AwsAccessKey) linked service.
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
accessKeyID
ID of the secret access key.
string
Yes
secretAccessKey
The secret access key itself.
Encrypted secret string
Yes
Here is an example:
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AwsAccessKey",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": "<secret access key>"
}
}
}
Dataset properties
To specify a dataset to represent input data in Azure Blob storage, set the type property of the dataset to
AmazonS3. Set the linkedServiceName property of the dataset to the name of the Amazon S3 linked service.
For a full list of sections and properties available for defining datasets, see Creating datasets.
Sections such as structure, availability, and policy are similar for all dataset types (such as SQL database, Azure
blob, and Azure table). The typeProperties section is different for each type of dataset, and provides
information about the location of the data in the data store. The typeProperties section for a dataset of type
AmazonS3 (which includes the Amazon S3 dataset) has the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
bucketName
The S3 bucket name.
String
Yes
key
The S3 object key.
String
No
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
prefix
Prefix for the S3 object key.
Objects whose keys start
with this prefix are selected.
Applies only when key is
empty.
String
No
version
The version of the S3
object, if S3 versioning is
enabled.
String
No
format
The following format types
are supported:
TextFormat, JsonFormat,
AvroFormat, OrcFormat,
ParquetFormat. Set the
type property under
format to one of these
values. For more
information, see the Text
format, JSON format, Avro
format, Orc format, and
Parquet format sections.
No
If you want to copy files asis between file-based stores
(binary copy), skip the
format section in both
input and output dataset
definitions.
compression
Specify the type and level of
compression for the data.
The supported types are:
GZip, Deflate, BZip2, and
ZipDeflate. The supported
levels are: Optimal and
Fastest. For more
information, see File and
compression formats in
Azure Data Factory.
No
NOTE
bucketName + key specifies the location of the S3 object, where bucket is the root container for S3 objects, and key is
the full path to the S3 object.
Sample dataset with prefix
{
"name": "dataset-s3",
"properties": {
"type": "AmazonS3",
"linkedServiceName": "link- testS3",
"typeProperties": {
"prefix": "testFolder/test",
"bucketName": "testbucket",
"format": {
"type": "OrcFormat"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Sample dataset (with version)
{
"name": "dataset-s3",
"properties": {
"type": "AmazonS3",
"linkedServiceName": "link- testS3",
"typeProperties": {
"key": "testFolder/test.orc",
"bucketName": "testbucket",
"version": "XXXXXXXXXczm0CJajYkHf0_k6LhBmkcL",
"format": {
"type": "OrcFormat"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Dynamic paths for S3
The preceding sample uses fixed values for the key and bucketName properties in the Amazon S3 dataset.
"key": "testFolder/test.orc",
"bucketName": "testbucket",
You can have Data Factory calculate these properties dynamically at runtime, by using system variables such as
SliceStart.
"key": "$$Text.Format('{0:MM}/{0:dd}/test.orc', SliceStart)"
"bucketName": "$$Text.Format('{0:yyyy}', SliceStart)"
You can do the same for the prefix property of an Amazon S3 dataset. For a list of supported functions and
variables, see Data Factory functions and system variables.
Copy activity properties
For a full list of sections and properties available for defining activities, see Creating pipelines. Properties such
as name, description, input and output tables, and policies are available for all types of activities. Properties
available in the typeProperties section of the activity vary with each activity type. For the copy activity,
properties vary depending on the types of sources and sinks. When a source in the copy activity is of type
FileSystemSource (which includes Amazon S3), the following property is available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
recursive
Specifies whether to
recursively list S3 objects
under the directory.
true/false
No
JSON example: Copy data from Amazon S3 to Azure Blob storage
This sample shows how to copy data from Amazon S3 to an Azure Blob storage. However, data can be copied
directly to any of the sinks that are supported by using the copy activity in Data Factory.
The sample provides JSON definitions for the following Data Factory entities. You can use these definitions to
create a pipeline to copy data from Amazon S3 to Blob storage, by using the Azure portal, Visual Studio, or
PowerShell.
A linked service of type AwsAccessKey.
A linked service of type AzureStorage.
An input dataset of type AmazonS3.
An output dataset of type AzureBlob.
A pipeline with copy activity that uses FileSystemSource and BlobSink.
The sample copies data from Amazon S3 to an Azure blob every hour. The JSON properties used in these
samples are described in sections following the samples.
Amazon S3 linked service
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AwsAccessKey",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": "<secret access key>"
}
}
}
Azure Storage linked service
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Amazon S3 input dataset
Setting "external": true informs the Data Factory service that the dataset is external to the data factory. Set this
property to true on an input dataset that is not produced by an activity in the pipeline.
{
"name": "AmazonS3InputDataset",
"properties": {
"type": "AmazonS3",
"linkedServiceName": "AmazonS3LinkedService",
"typeProperties": {
"key": "testFolder/test.orc",
"bucketName": "testbucket",
"format": {
"type": "OrcFormat"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Azure Blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses the year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutputDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/fromamazons3/yearno={Year}/monthno={Month}/dayno={Day}/hourno=
{Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with an Amazon S3 source and a blob sink
The pipeline contains a copy activity that is configured to use the input and output datasets, and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to FileSystemSource, and sink type is
set to BlobSink.
{
"name": "CopyAmazonS3ToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "AmazonS3InputDataset"
}
],
"outputs": [
{
"name": "AzureBlobOutputDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "AmazonS3ToBlob"
}
],
"start": "2014-08-08T18:00:00Z",
"end": "2014-08-08T19:00:00Z"
}
}
NOTE
To map columns from a source dataset to columns from a sink dataset, see Mapping dataset columns in Azure Data
Factory.
Next steps
See the following articles:
To learn about key factors that impact performance of data movement (copy activity) in Data Factory,
and various ways to optimize it, see the Copy activity performance and tuning guide.
For step-by-step instructions for creating a pipeline with a copy activity, see the Copy activity tutorial.
Copy data to or from Azure Blob Storage using
Azure Data Factory
5/11/2017 • 31 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to copy data to and from Azure Blob
Storage. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
Overview
You can copy data from any supported source data store to Azure Blob Storage or from Azure Blob Storage
to any supported sink data store. The following table provides a list of data stores supported as sources or
sinks by the copy activity. For example, you can move data from a SQL Server database or an Azure SQL
database to an Azure blob storage. And, you can copy data from Azure blob storage to an Azure SQL Data
Warehouse or an Azure Cosmos DB collection.
Supported scenarios
You can copy data from Azure Blob Storage to the following data stores:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Data Lake Store
Azure Cosmos DB (DocumentDB API)
Azure SQL Database
Azure SQL Data Warehouse
Azure Search Index
Azure Table storage
Databases
SQL Server
Oracle
File
File system
You can copy data from the following data stores to Azure Blob Storage:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Cosmos DB (DocumentDB API)
Azure Data Lake Store
Azure SQL Database
Azure SQL Data Warehouse
Azure Table storage
CATEGORY
DATA STORE
Databases
Amazon Redshift
DB2
MySQL
Oracle
PostgreSQL
SAP Business Warehouse
SAP HANA
SQL Server
Sybase
Teradata
NoSQL
Cassandra
MongoDB
File
Amazon S3
File System
FTP
HDFS
SFTP
Others
Generic HTTP
Generic OData
Generic ODBC
Salesforce
Web Table (table from HTML)
GE Historian
IMPORTANT
Copy Activity supports copying data from/to both general-purpose Azure Storage accounts and Hot/Cool Blob
storage. The activity supports reading from block, append, or page blobs, but supports writing to only block
blobs. Azure Premium Storage is not supported as a sink because it is backed by page blobs.
Copy Activity does not delete data from the source after the data is successfully copied to the destination. If you need
to delete source data after a successful copy, create a custom activity to delete the data and use the activity in the
pipeline. For an example, see the Delete blob or folder sample on GitHub.
Get started
You can create a pipeline with a copy activity that moves data to/from an Azure Blob Storage by using
different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. This article has a walkthrough for creating a
pipeline to copy data from an Azure Blob Storage location to another Azure Blob Storage location. For a
tutorial on creating a pipeline to copy data from an Azure Blob Storage to Azure SQL Database, see Tutorial:
Create a pipeline using Copy Wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create a data factory. A data factory may contain one or more pipelines.
2. Create linked services to link input and output data stores to your data factory. For example, if you are
copying data from an Azure blob storage to an Azure SQL database, you create two linked services to link
your Azure storage account and Azure SQL database to your data factory. For linked service properties
that are specific to Azure Blob Storage, see linked service properties section.
3. Create datasets to represent input and output data for the copy operation. In the example mentioned in
the last step, you create a dataset to specify the blob container and folder that contains the input data.
And, you create another dataset to specify the SQL table in the Azure SQL database that holds the data
copied from the blob storage. For dataset properties that are specific to Azure Blob Storage, see dataset
properties section.
4. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output. In the
example mentioned earlier, you use BlobSource as a source and SqlSink as a sink for the copy activity.
Similarly, if you are copying from Azure SQL Database to Azure Blob Storage, you use SqlSource and
BlobSink in the copy activity. For copy activity properties that are specific to Azure Blob Storage, see copy
activity properties section. For details on how to use a data store as a source or a sink, click the link in the
previous section for your data store.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that
are used to copy data to/from an Azure Blob Storage, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Azure Blob Storage.
Linked service properties
There are two types of linked services you can use to link an Azure Storage to an Azure data factory. They are:
AzureStorage linked service and AzureStorageSas linked service. The Azure Storage linked service
provides the data factory with global access to the Azure Storage. Whereas, The Azure Storage SAS (Shared
Access Signature) linked service provides the data factory with restricted/time-bound access to the Azure
Storage. There are no other differences between these two linked services. Choose the linked service that
suits your needs. The following sections provide more details on these two linked services.
Azure Storage Linked Service
The Azure Storage linked service allows you to link an Azure storage account to an Azure data factory by
using the account key, which provides the data factory with global access to the Azure Storage. The
following table provides description for JSON elements specific to Azure Storage linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AzureStorage
Yes
connectionString
Specify information needed to
connect to Azure storage for the
connectionString property.
Yes
See the following article for steps to view/copy the account key for an Azure Storage: View, copy, and
regenerate storage access keys.
Example:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Storage Sas Linked Service
A shared access signature (SAS) provides delegated access to resources in your storage account. It allows
you to grant a client limited permissions to objects in your storage account for a specified period of time and
with a specified set of permissions, without having to share your account access keys. The SAS is a URI that
encompasses in its query parameters all the information necessary for authenticated access to a storage
resource. To access storage resources with the SAS, the client only needs to pass in the SAS to the
appropriate constructor or method. For detailed information about SAS, see Shared Access Signatures:
Understanding the SAS Model
The Azure Storage SAS linked service allows you to link an Azure Storage Account to an Azure data factory
by using a Shared Access Signature (SAS). It provides the data factory with restricted/time-bound access to
all/specific resources (blob/container) in the storage. The following table provides description for JSON
elements specific to Azure Storage SAS linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AzureStorageSas
Yes
sasUri
Specify Shared Access Signature URI
to the Azure Storage resources such
as blob, container, or table.
Yes
Example:
{
"name": "StorageSasLinkedService",
"properties": {
"type": "AzureStorageSas",
"typeProperties": {
"sasUri": "<storageUri>?<sasToken>"
}
}
}
When creating an SAS URI, considering the following:
Azure Data Factory supports only Service SAS, not Account SAS. See Types of Shared Access Signatures
for details about these two types.
Set appropriate read/write permissions on objects based on how the linked service (read, write,
read/write) is used in your data factory.
Set Expiry time appropriately. Make sure that the access to Azure Storage objects does not expire within
the active period of the pipeline.
Uri should be created at the right container/blob or Table level based on the need. A SAS Uri to an Azure
blob allows the Data Factory service to access that particular blob. A SAS Uri to an Azure blob container
allows the Data Factory service to iterate through blobs in that container. If you need to provide access
more/fewer objects later, or update the SAS URI, remember to update the linked service with the new URI.
Dataset properties
To specify a dataset to represent input or output data in an Azure Blob Storage, you set the type property of
the dataset to: AzureBlob. Set the linkedServiceName property of the dataset to the name of the Azure
Storage or Azure Storage SAS linked service. The type properties of the dataset specify the blob container
and the folder in the blob storage.
For a full list of JSON sections & properties available for defining datasets, see the Creating datasets article.
Sections such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure
SQL, Azure blob, Azure table, etc.).
Data factory supports the following CLS-compliant .NET based type values for providing type information in
“structure” for schema-on-read data sources like Azure blob: Int16, Int32, Int64, Single, Double, Decimal,
Byte[], Bool, String, Guid, Datetime, Datetimeoffset, Timespan. Data Factory automatically performs type
conversions when moving data from a source data store to a sink data store.
The typeProperties section is different for each type of dataset and provides information about the location,
format etc., of the data in the data store. The typeProperties section for dataset of type AzureBlob dataset
has the following properties:
PROPERTY
DESCRIPTION
REQUIRED
folderPath
Path to the container and folder in
the blob storage. Example:
myblobcontainer\myblobfolder\
Yes
fileName
Name of the blob. fileName is
optional and case-sensitive.
No
If you specify a filename, the activity
(including Copy) works on the specific
Blob.
When fileName is not specified, Copy
includes all Blobs in the folderPath for
input dataset.
When fileName is not specified for
an output dataset and
preserveHierarchy is not specified
in activity sink, the name of the
generated file would be in the
following this format: Data..txt (for
example: : Data.0a405f8a-93ff-4c6fb3be-f69616f1df7a.txt
partitionedBy
partitionedBy is an optional property.
You can use it to specify a dynamic
folderPath and filename for time
series data. For example, folderPath
can be parameterized for every hour
of data. See the Using partitionedBy
property section for details and
examples.
No
PROPERTY
DESCRIPTION
REQUIRED
format
The following format types are
supported: TextFormat,
JsonFormat, AvroFormat,
OrcFormat, ParquetFormat. Set the
type property under format to one
of these values. For more
information, see Text Format, Json
Format, Avro Format, Orc Format,
and Parquet Format sections.
No
If you want to copy files as-is
between file-based stores (binary
copy), skip the format section in both
input and output dataset definitions.
compression
Specify the type and level of
compression for the data. Supported
types are: GZip, Deflate, BZip2, and
ZipDeflate. Supported levels are:
Optimal and Fastest. For more
information, see File and compression
formats in Azure Data Factory.
No
Using partitionedBy property
As mentioned in the previous section, you can specify a dynamic folderPath and filename for time series data
with the partitionedBy property, Data Factory functions, and the system variables.
For more information on time series datasets, scheduling, and slices, see Creating Datasets and Scheduling &
Execution articles.
Sample 1
"folderPath": "wikidatagateway/wikisampledataout/{Slice}",
"partitionedBy":
[
{ "name": "Slice", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyyMMddHH" } },
],
In this example, {Slice} is replaced with the value of Data Factory system variable SliceStart in the format
(YYYYMMDDHH) specified. The SliceStart refers to start time of the slice. The folderPath is different for each
slice. For example: wikidatagateway/wikisampledataout/2014100103 or
wikidatagateway/wikisampledataout/2014100104
Sample 2
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}",
"fileName": "{Hour}.csv",
"partitionedBy":
[
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }
],
In this example, year, month, day, and time of SliceStart are extracted into separate variables that are used by
folderPath and fileName properties.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output datasets, and policies are available for all types of
activities. Whereas, properties available in the typeProperties section of the activity vary with each activity
type. For Copy activity, they vary depending on the types of sources and sinks. If you are moving data from
an Azure Blob Storage, you set the source type in the copy activity to BlobSource. Similarly, if you are
moving data to an Azure Blob Storage, you set the sink type in the copy activity to BlobSink. This section
provides a list of properties supported by BlobSource and BlobSink.
BlobSource supports the following properties in the typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
recursive
Indicates whether the data
is read recursively from the
sub folders or only from
the specified folder.
True (default value), False
No
BlobSink supports the following properties typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
copyBehavior
Defines the copy behavior
when the source is
BlobSource or FileSystem.
PreserveHierarchy:
preserves the file hierarchy
in the target folder. The
relative path of source file
to source folder is identical
to the relative path of
target file to target folder.
No
FlattenHierarchy: all files
from the source folder are
in the first level of target
folder. The target files have
auto generated name.
MergeFiles: merges all
files from the source folder
to one file. If the File/Blob
Name is specified, the
merged file name would be
the specified name;
otherwise, would be autogenerated file name.
BlobSource also supports these two properties for backward compatibility.
treatEmptyAsNull: Specifies whether to treat null or empty string as null value.
skipHeaderLineCount - Specifies how many lines need be skipped. It is applicable only when input
dataset is using TextFormat.
Similarly, BlobSink supports the following property for backward compatibility.
blobWriterAddHeader: Specifies whether to add a header of column definitions while writing to an
output dataset.
Datasets now support the following properties that implement the same functionality: treatEmptyAsNull,
skipLineCount, firstRowAsHeader.
The following table provides guidance on using the new dataset properties in place of these blob source/sink
properties.
COPY ACTIVITY PROPERTY
DATASET PROPERTY
skipHeaderLineCount on BlobSource
skipLineCount and firstRowAsHeader. Lines are skipped
first and then the first row is read as a header.
treatEmptyAsNull on BlobSource
treatEmptyAsNull on input dataset
blobWriterAddHeader on BlobSink
firstRowAsHeader on output dataset
See Specifying TextFormat section for detailed information on these properties.
recursive and copyBehavior examples
This section describes the resulting behavior of the Copy operation for different combinations of recursive
and copyBehavior values.
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
true
preserveHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the same structure as the source
Folder1
File1
File2
Subfolder1
File3
File4
File5.
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
true
flattenHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target Folder1 is created with the
following structure:
Folder1
auto-generated name for File1
auto-generated name for File2
auto-generated name for File3
auto-generated name for File4
auto-generated name for File5
true
mergeFiles
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target Folder1 is created with the
following structure:
Folder1
File1 + File2 + File3 + File4 + File 5
contents are merged into one file
with auto-generated file name
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
false
preserveHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure
Folder1
File1
File2
Subfolder1 with File3, File4, and File5
are not picked up.
false
flattenHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure
Folder1
auto-generated name for File1
auto-generated name for File2
Subfolder1 with File3, File4, and File5
are not picked up.
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
false
mergeFiles
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure
Folder1
File1 + File2 contents are merged
into one file with auto-generated file
name. auto-generated name for File1
Subfolder1 with File3, File4, and File5
are not picked up.
Walkthrough: Use Copy Wizard to copy data to/from Blob Storage
Let's look at how to quickly copy data to/from an Azure blob storage. In this walkthrough, both source and
destination data stores of type: Azure Blob Storage. The pipeline in this walkthrough copies data from a
folder to another folder in the same blob container. This walkthrough is intentionally simple to show you
settings or properties when using Blob Storage as a source or sink.
Prerequisites
1. Create a general-purpose Azure Storage Account if you don't have one already. You use the blob
storage as both source and destination data store in this walkthrough. if you don't have an Azure
storage account, see the Create a storage account article for steps to create one.
2. Create a blob container named adfblobconnector in the storage account.
3. Create a folder named input in the adfblobconnector container.
4. Create a file named emp.txt with the following content and upload it to the input folder by using tools
such as Azure Storage Explorer json John, Doe Jane, Doe ### Create the data factory
5. Sign in to the Azure portal.
6. Click + NEW from the top-left corner, click Intelligence + analytics, and click Data Factory.
7. In the New data factory blade:
a. Enter ADFBlobConnectorDF for the name. The name of the Azure data factory must be globally
unique. If you receive the error: *Data factory name “ADFBlobConnectorDF” is not available , change
the name of the data factory (for example, yournameADFBlobConnectorDF) and try creating again.
See Data Factory - Naming Rules topic for naming rules for Data Factory artifacts.
b. Select your Azure subscription.
c. For Resource Group, select Use existing to select an existing resource group (or) select Create
new to enter a name for a resource group.
d. Select a location for the data factory.
e. Select Pin to dashboard check box at the bottom of the blade.
f. Click Create.
8. After the creation is complete, you see the Data Factory blade as shown in the following image:
Copy Wizard
1. On the Data Factory home page, click the Copy data [PREVIEW] tile to launch Copy Data Wizard in
a separate tab.
NOTE
If you see that the web browser is stuck at "Authorizing...", disable/uncheck Block third party cookies and
site data setting (or) keep it enabled and create an exception for login.microsoftonline.com and then try
launching the wizard again.
2. In the Properties page:
a. Enter CopyPipeline for Task name. The task name is the name of the pipeline in your data
factory.
b. Enter a description for the task (optional).
c. For Task cadence or Task schedule, keep the Run regularly on schedule option. If you want to
run this task only once instead of run repeatedly on a schedule, select Run once now. If you select,
Run once now option, a one-time pipeline is created.
d. Keep the settings for Recurring pattern. This task runs daily between the start and end times you
specify in the next step.
e. Change the Start date time to 04/21/2017.
f. Change the End date time to 04/25/2017. You may want to type the date instead of browsing
through the calendar.
g. Click Next.
3. On the Source data store page, click Azure Blob Storage tile. You use this page to specify the source
data store for the copy task. You can use an existing data store linked service (or) specify a new data store.
To use an existing linked service, you would select FROM EXISTING LINKED SERVICES and select the
right linked service.
4. On the Specify the Azure Blob storage account page:
a. Keep the auto-generated name for Connection name. The connection name is the name of the
linked service of type: Azure Storage.
b. Confirm that From Azure subscriptions option is selected for Account selection method.
c. Select your Azure subscription or keep Select all for Azure subscription.
d. Select an Azure storage account from the list of Azure storage accounts available in the selected
subscription. You can also choose to enter storage account settings manually by selecting Enter
manually option for the Account selection method.
e. Click Next.
5. On Choose the input file or folder page:
a. Double-click adfblobcontainer.
b. Select input, and click Choose. In this walkthrough, you select the input folder. You could also
select the emp.txt file in the folder instead.
6. On the Choose the input file or folder page:
a. Confirm that the file or folder is set to adfblobconnector/input. If the files are in sub folders, for
example, 2017/04/01, 2017/04/02, and so on, enter adfblobconnector/input/{year}/{month}/{day}
for file or folder. When you press TAB out of the text box, you see three drop-down lists to select
formats for year (yyyy), month (MM), and day (dd).
b. Do not set Copy file recursively. Select this option to recursively traverse through folders for files
to be copied to the destination.
c. Do not the binary copy option. Select this option to perform a binary copy of source file to the
destination. Do not select for this walkthrough so that you can see more options in the next pages.
d. Confirm that the Compression type is set to None. Select a value for this option if your source
files are compressed in one of the supported formats.
e. Click Next.
7. On the File format settings page, you see the delimiters and the schema that is auto-detected by the
wizard by parsing the file.
a. Confirm that the file format is set to Text format. You can see all the supported formats in the
drop-down list. For example: JSON, Avro, ORC, Parquet.
b. Confirm that the column delimiter is set to Comma (,) . You can see the other column delimiters
supported by Data Factory in the drop-down list. You can also specify a custom delimiter.
c. Confirm that the row delimiter is set to Carriage Return + Line feed (\r\n) . You can see the
other row delimiters supported by Data Factory in the drop-down list. You can also specify a
custom delimiter.
d. Confirm that the skip line count is set to 0. If you want a few lines to be skipped at the top of the
file, enter the number here.
e. Confirm that the first data row contains column names is not set. If the source files contain
column names in the first row, select this option.
f. Confirm that the treat empty column value as null option is set.
g. Expand Advanced settings to see advanced option available.
h. At the bottom of the page, see the preview of data from the emp.txt file.
i. Click SCHEMA tab at the bottom to see the schema that the copy wizard inferred by looking at the
data in the source file.
j. Click Next after you review the delimiters and preview data.
8. On the Destination data store page, select Azure Blob Storage, and click Next. You are using the
Azure Blob Storage as both the source and destination data stores in this walkthrough.
9. On Specify the Azure Blob storage account page:
a. Enter AzureStorageLinkedService for the Connection name field.
b. Confirm that From Azure subscriptions option is selected for Account selection method.
c. Select your Azure subscription.
d. Select your Azure storage account.
e. Click Next.
10. On the Choose the output file or folder page:
a. specify Folder path as adfblobconnector/output/{year}/{month}/{day}. Enter TAB.
b. For the year, select yyyy.
c. For the month, confirm that it is set to MM.
d. For the day, confirm that it is set to dd.
e. Confirm that the compression type is set to None.
f. Confirm that the copy behavior is set to Merge files. If the output file with the same name
already exists, the new content is added to the same file at the end.
g. Click Next.
11. On the File format settings page, review the settings, and click Next. One of the additional options here
is to add a header to the output file. If you select that option, a header row is added with names of the
columns from the schema of the source. You can rename the default column names when viewing the
schema for the source. For example, you could change the first column to First Name and second column
to Last Name. Then, the output file is generated with a header with these names as column names.
12. On the Performance settings page, confirm that cloud units and parallel copies are set to Auto, and
click Next. For details about these settings, see Copy activity performance and tuning guide.
13. On the Summary page, review all settings (task properties, settings for source and destination, and copy
settings), and click Next.
14. Review information in the Summary page, and click Finish. The wizard creates two linked services, two
datasets (input and output), and one pipeline in the data factory (from where you launched the Copy
Wizard).
Monitor the pipeline (copy task)
1. Click the link Click here to monitor copy pipeline on the Deployment page.
2. You should see the Monitor and Manage application in a separate tab.
3. Change the start time at the top to 04/19/2017 and end time to 04/27/2017 , and then click Apply.
4. You should see five activity windows in the ACTIVITY WINDOWS list. The WindowStart times should
cover all days from pipeline start to pipeline end times.
5. Click Refresh button for the ACTIVITY WINDOWS list a few times until you see the status of all the
activity windows is set to Ready.
6. Now, verify that the output files are generated in the output folder of adfblobconnector container. You
should see the following folder structure in the output folder:
2017/04/21 2017/04/22 2017/04/23 2017/04/24 2017/04/25 For detailed information about monitoring and
managing data factories, see Monitor and manage Data Factory pipeline article.
Data Factory entities
Now, switch back to the tab with the Data Factory home page. Notice that there are two linked services, two
datasets, and one pipeline in your data factory now.
Click Author and deploy to launch Data Factory Editor.
You should see the following Data Factory entities in your data factory:
Two linked services. One for the source and the other one for the destination. Both the linked services
refer to the same Azure Storage account in this walkthrough.
Two datasets. An input dataset and an output dataset. In this walkthrough, both use the same blob
container but refer to different folders (input and output).
A pipeline. The pipeline contains a copy activity that uses a blob source and a blob sink to copy data from
an Azure blob location to another Azure blob location.
The following sections provide more information about these entities.
Linked services
You should see two linked services. One for the source and the other one for the destination. In this
walkthrough, both definitions look the same except for the names. The type of the linked service is set to
AzureStorage. Most important property of the linked service definition is the connectionString, which is
used by Data Factory to connect to your Azure Storage account at runtime. Ignore the hubName property in
the definition.
So u r c e b l o b st o r a g e l i n k e d se r v i c e
{
"name": "Source-BlobStorage-z4y",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString":
"DefaultEndpointsProtocol=https;AccountName=mystorageaccount;AccountKey=**********"
}
}
}
D e st i n a t i o n b l o b st o r a g e l i n k e d se r v i c e
{
"name": "Destination-BlobStorage-z4y",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString":
"DefaultEndpointsProtocol=https;AccountName=mystorageaccount;AccountKey=**********"
}
}
}
For more information about Azure Storage linked service, see Linked service properties section.
Datasets
There are two datasets: an input dataset and an output dataset. The type of the dataset is set to AzureBlob
for both.
The input dataset points to the input folder of the adfblobconnector blob container. The external property
is set to true for this dataset as the data is not produced by the pipeline with the copy activity that takes this
dataset as an input.
The output dataset points to the output folder of the same blob container. The output dataset also uses the
year, month, and day of the SliceStart system variable to dynamically evaluate the path for the output file.
For a list of functions and system variables supported by Data Factory, see Data Factory functions and system
variables. The external property is set to false (default value) because this dataset is produced by the
pipeline.
For more information about properties supported by Azure Blob dataset, see Dataset properties section.
I n p u t d a t a se t
{
"name": "InputDataset-z4y",
"properties": {
"structure": [
{ "name": "Prop_0", "type": "String" },
{ "name": "Prop_1", "type": "String" }
],
"type": "AzureBlob",
"linkedServiceName": "Source-BlobStorage-z4y",
"typeProperties": {
"folderPath": "adfblobconnector/input/",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
}
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": true,
"policy": {}
}
}
O u t p u t d a t a se t
{
"name": "OutputDataset-z4y",
"properties": {
"structure": [
{ "name": "Prop_0", "type": "String" },
{ "name": "Prop_1", "type": "String" }
],
"type": "AzureBlob",
"linkedServiceName": "Destination-BlobStorage-z4y",
"typeProperties": {
"folderPath": "adfblobconnector/output/{year}/{month}/{day}",
"format": {
"type": "TextFormat",
"columnDelimiter": ","
},
"partitionedBy": [
{ "name": "year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy"
} },
{ "name": "month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" }
},
{ "name": "day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } }
]
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": false,
"policy": {}
}
}
Pipeline
The pipeline has just one activity. The type of the activity is set to Copy. In the type properties for the activity,
there are two sections, one for source and the other one for sink. The source type is set to BlobSource as the
activity is copying data from a blob storage. The sink type is set to BlobSink as the activity copying data to a
blob storage. The copy activity takes InputDataset-z4y as the input and OutputDataset-z4y as the output.
For more information about properties supported by BlobSource and BlobSink, see Copy activity properties
section.
{
"name": "CopyPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": false
},
"sink": {
"type": "BlobSink",
"copyBehavior": "MergeFiles",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "InputDataset-z4y"
}
],
"outputs": [
{
"name": "OutputDataset-z4y"
}
],
"policy": {
"timeout": "1.00:00:00",
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"style": "StartOfInterval",
"retry": 3,
"longRetry": 0,
"longRetryInterval": "00:00:00"
},
"scheduler": {
"frequency": "Day",
"interval": 1
},
"name": "Activity-0-Blob path_ adfblobconnector_input_->OutputDataset-z4y"
}
],
"start": "2017-04-21T22:34:00Z",
"end": "2017-04-25T05:00:00Z",
"isPaused": false,
"pipelineMode": "Scheduled"
}
}
JSON examples for copying data to and from Blob Storage
The following examples provide sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data to and from Azure Blob Storage
and Azure SQL Database. However, data can be copied directly from any of sources to any of the sinks
stated here using the Copy Activity in Azure Data Factory.
JSON Example: Copy data from Blob Storage to SQL Database
The following sample shows:
1. A linked service of type AzureSqlDatabase.
2. A linked service of type AzureStorage.
3. An input dataset of type AzureBlob.
4. An output dataset of type AzureSqlTable.
5. A pipeline with a Copy activity that uses BlobSource and SqlSink.
The sample copies time-series data from an Azure blob to an Azure SQL table hourly. The JSON properties
used in these samples are described in sections following the samples.
Azure SQL linked service:
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=
<databasename>;User ID=<username>@<servername>;Password=
<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
}
}
}
Azure Storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Data Factory supports two types of Azure Storage linked services: AzureStorage and
AzureStorageSas. For the first one, you specify the connection string that includes the account key and for
the later one, you specify the Shared Access Signature (SAS) Uri. See Linked Services section for details.
Azure Blob input dataset:
Data is picked up from a new blob every hour (frequency: hour, interval: 1). The folder path and file name for
the blob are dynamically evaluated based on the start time of the slice that is being processed. The folder
path uses year, month, and day part of the start time and file name uses the hour part of the start time.
“external”: “true” setting informs Data Factory that the table is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/",
"fileName": "{Hour}.csv",
"partitionedBy": [
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "HH" } }
],
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure SQL output dataset:
The sample copies data to a table named “MyTable” in an Azure SQL database. Create the table in your Azure
SQL database with the same number of columns as you expect the Blob CSV file to contain. New rows are
added to the table every hour.
{
"name": "AzureSqlOutput",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "MyOutputTable"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
A copy activity in a pipeline with Blob source and SQL sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to BlobSource and sink type is set
to SqlSink.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "AzureBlobtoSQL",
"description": "Copy Activity",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureSqlOutput"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
JSON Example: Copy data from Azure SQL to Azure Blob
The following sample shows:
1.
2.
3.
4.
5.
A linked service of type AzureSqlDatabase.
A linked service of type AzureStorage.
An input dataset of type AzureSqlTable.
An output dataset of type AzureBlob.
A pipeline with Copy activity that uses SqlSource and BlobSink.
The sample copies time-series data from an Azure SQL table to an Azure blob hourly. The JSON properties
used in these samples are described in sections following the samples.
Azure SQL linked service:
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=
<databasename>;User ID=<username>@<servername>;Password=
<password>;Trusted_Connection=False;Encrypt=True;Connection Timeout=30"
}
}
}
Azure Storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Data Factory supports two types of Azure Storage linked services: AzureStorage and
AzureStorageSas. For the first one, you specify the connection string that includes the account key and for
the later one, you specify the Shared Access Signature (SAS) Uri. See Linked Services section for details.
Azure SQL input dataset:
The sample assumes you have created a table “MyTable” in Azure SQL and it contains a column called
“timestampcolumn” for time series data.
Setting “external”: ”true” informs Data Factory service that the table is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "AzureSqlInput",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}/",
"partitionedBy": [
{
"name": "Year",
"value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "HH" } }
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
A copy activity in a pipeline with SQL source and Blob sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to SqlSource and sink type is set to
BlobSink. The SQL query specified for the SqlReaderQuery property selects the data in the past hour to
copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "AzureSQLtoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": "AzureSQLInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"SqlReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >=
\\'{0:yyyy-MM-dd HH:mm}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data
Factory.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data to and from Azure Cosmos DB using
Azure Data Factory
5/11/2017 • 11 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data to/from Azure Cosmos
DB (DocumentDB API). It builds on the Data Movement Activities article, which presents a general overview of
data movement with the copy activity.
You can copy data from any supported source data store to Azure Cosmos DB or from Azure Cosmos DB to
any supported sink data store. For a list of data stores supported as sources or sinks by the copy activity, see
the Supported data stores table.
IMPORTANT
Azure Cosmos DB connector only support DocumentDB API.
To copy data as-is to/from JSON files or another Cosmos DB collection, see Import/Export JSON documents.
Getting started
You can create a pipeline with a copy activity that moves data to/from Azure Cosmos DB by using different
tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that are
used to copy data to/from Cosmos DB, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Cosmos DB:
Linked service properties
The following table provides description for JSON elements specific to Azure Cosmos DB linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
DocumentDb
Yes
connectionString
Specify information needed to connect
to Azure Cosmos DB database.
Yes
Dataset properties
For a full list of sections & properties available for defining datasets please refer to the Creating datasets
article. Sections like structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure
SQL, Azure blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for the dataset of type DocumentDbCollection has the
following properties.
PROPERTY
DESCRIPTION
REQUIRED
collectionName
Name of the Cosmos DB document
collection.
Yes
Example:
{
"name": "PersonCosmosDbTable",
"properties": {
"type": "DocumentDbCollection",
"linkedServiceName": "CosmosDbLinkedService",
"typeProperties": {
"collectionName": "Person"
},
"external": true,
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
Schema by Data Factory
For schema-free data stores such as Azure Cosmos DB, the Data Factory service infers the schema in one of
the following ways:
1. If you specify the structure of data by using the structure property in the dataset definition, the Data
Factory service honors this structure as the schema. In this case, if a row does not contain a value for a
column, a null value will be provided for it.
2. If you do not specify the structure of data by using the structure property in the dataset definition, the Data
Factory service infers the schema by using the first row in the data. In this case, if the first row does not
contain the full schema, some columns will be missing in the result of copy operation.
Therefore, for schema-free data sources, the best practice is to specify the structure of data using the structure
property.
Copy activity properties
For a full list of sections & properties available for defining activities please refer to the Creating Pipelines
article. Properties such as name, description, input and output tables, and policy are available for all types of
activities.
NOTE
The Copy Activity takes only one input and produces only one output.
Properties available in the typeProperties section of the activity on the other hand vary with each activity type
and in case of Copy activity they vary depending on the types of sources and sinks.
In case of Copy activity when source is of type DocumentDbCollectionSource the following properties are
available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Specify the query to read
data.
Query string supported by
Azure Cosmos DB.
No
Example:
SELECT
c.BusinessEntityID,
c.PersonType,
c.NameStyle, c.Title,
c.Name.First AS
FirstName, c.Name.Last
AS LastName, c.Suffix,
c.EmailPromotion FROM
c WHERE c.ModifiedDate
> \"2009-0101T00:00:00\"
nestingSeparator
Special character to indicate
that the document is
nested
Any character.
If not specified, the SQL
statement that is executed:
select <columns
defined in structure>
from mycollection
No
Azure Cosmos DB is a
NoSQL store for JSON
documents, where nested
structures are allowed.
Azure Data Factory enables
user to denote hierarchy
via nestingSeparator, which
is “.” in the above examples.
With the separator, the
copy activity will generate
the “Name” object with
three children elements
First, Middle and Last,
according to “Name.First”,
“Name.Middle” and
“Name.Last” in the table
definition.
DocumentDbCollectionSink supports the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
nestingSeparator
A special character in the
source column name to
indicate that nested
document is needed.
Character that is used to
separate nesting levels.
Character that is used to
separate nesting levels.
Default value is
Default value is
.
(dot).
.
(dot).
For example above:
Name.First in the output
table produces the
following JSON structure in
the Cosmos DB document:
"Name": {
"First": "John"
},
writeBatchSize
Number of parallel requests
to Azure Cosmos DB
service to create
documents.
Integer
No (default: 5)
timespan
No
You can fine-tune the
performance when copying
data to/from Cosmos DB
by using this property. You
can expect a better
performance when you
increase writeBatchSize
because more parallel
requests to Cosmos DB are
sent. However you’ll need
to avoid throttling that can
throw the error message:
"Request rate is large".
Throttling is decided by a
number of factors,
including size of
documents, number of
terms in documents,
indexing policy of target
collection, etc. For copy
operations, you can use a
better collection (e.g. S3) to
have the most throughput
available (2,500 request
units/second).
writeBatchTimeout
Wait time for the operation
to complete before it times
out.
Example: “00:30:00” (30
minutes).
Import/Export JSON documents
Using this Cosmos DB connector, you can easily
Import JSON documents from various sources into Cosmos DB, including Azure Blob, Azure Data Lake, onpremises File System or other file-based stores supported by Azure Data Factory.
Export JSON documents from Cosmos DB collecton into various file-based stores.
Migrate data between two Cosmos DB collections as-is.
To achieve such schema-agnostic copy,
When using copy wizard, check the "Export as-is to JSON files or Cosmos DB collection" option.
When using JSON editing, do not specify the "structure" section in Cosmos DB dataset(s) nor
"nestingSeparator" property on Cosmos DB source/sink in copy activity. To import from/export to JSON
files, in the file store dataset specify format type as "JsonFormat", config "filePattern" and skip the rest
format settings, see JSON format section on details.
JSON examples
The following examples provide sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data to and from Azure Cosmos DB and
Azure Blob Storage. However, data can be copied directly from any of the sources to any of the sinks stated
here using the Copy Activity in Azure Data Factory.
Example: Copy data from Azure Cosmos DB to Azure Blob
The sample below shows:
1.
2.
3.
4.
5.
A linked service of type DocumentDb.
A linked service of type AzureStorage.
An input dataset of type DocumentDbCollection.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses DocumentDbCollectionSource and BlobSink.
The sample copies data in Azure Cosmos DB to Azure Blob. The JSON properties used in these samples are
described in sections following the samples.
Azure Cosmos DB linked service:
{
"name": "CosmosDbLinkedService",
"properties": {
"type": "DocumentDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;AccountKey=<AccessKey>;Database=<Database>"
}
}
}
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Document DB input dataset:
The sample assumes you have a collection named Person in an Azure Cosmos DB database.
Setting “external”: ”true” and specifying externalData policy information the Azure Data Factory service that the
table is external to the data factory and not produced by an activity in the data factory.
{
"name": "PersonCosmosDbTable",
"properties": {
"type": "DocumentDbCollection",
"linkedServiceName": "CosmosDbLinkedService",
"typeProperties": {
"collectionName": "Person"
},
"external": true,
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
Azure Blob output dataset:
Data is copied to a new blob every hour with the path for the blob reflecting the specific datetime with hour
granularity.
{
"name": "PersonBlobTableOut",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "docdb",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"nullValue": "NULL"
}
},
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
Sample JSON document in the Person collection in a Cosmos DB database:
{
"PersonId": 2,
"Name": {
"First": "Jane",
"Middle": "",
"Last": "Doe"
}
}
Cosmos DB supports querying documents using a SQL like syntax over hierarchical JSON documents.
Example:
SELECT Person.PersonId, Person.Name.First AS FirstName, Person.Name.Middle as MiddleName, Person.Name.Last
AS LastName FROM Person
The following pipeline copies data from the Person collection in the Azure Cosmos DB database to an Azure
blob. As part of the copy activity the input and output datasets have been specified.
{
"name": "DocDbToBlobPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "DocumentDbCollectionSource",
"query": "SELECT Person.Id, Person.Name.First AS FirstName, Person.Name.Middle as MiddleName,
Person.Name.Last AS LastName FROM Person",
"nestingSeparator": "."
},
"sink": {
"type": "BlobSink",
"blobWriterAddHeader": true,
"writeBatchSize": 1000,
"writeBatchTimeout": "00:00:59"
}
},
"inputs": [
{
"name": "PersonCosmosDbTable"
}
],
"outputs": [
{
"name": "PersonBlobTableOut"
}
],
"policy": {
"concurrency": 1
},
"name": "CopyFromDocDbToBlob"
}
],
"start": "2015-04-01T00:00:00Z",
"end": "2015-04-02T00:00:00Z"
}
}
Example: Copy data from Azure Blob to Azure Cosmos DB
The sample below shows:
1.
2.
3.
4.
5.
A linked service of type DocumentDb.
A linked service of type AzureStorage.
An input dataset of type AzureBlob.
An output dataset of type DocumentDbCollection.
A pipeline with Copy Activity that uses BlobSource and DocumentDbCollectionSink.
The sample copies data from Azure blob to Azure Cosmos DB. The JSON properties used in these samples are
described in sections following the samples.
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Cosmos DB linked service:
{
"name": "CosmosDbLinkedService",
"properties": {
"type": "DocumentDb",
"typeProperties": {
"connectionString": "AccountEndpoint=<EndpointUrl>;AccountKey=<AccessKey>;Database=<Database>"
}
}
}
Azure Blob input dataset:
{
"name": "PersonBlobTableIn",
"properties": {
"structure": [
{
"name": "Id",
"type": "Int"
},
{
"name": "FirstName",
"type": "String"
},
{
"name": "MiddleName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
}
],
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"fileName": "input.csv",
"folderPath": "docdb",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"nullValue": "NULL"
}
},
"external": true,
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
Azure Cosmos DB output dataset:
The sample copies data to a collection named “Person”.
{
"name": "PersonCosmosDbTableOut",
"properties": {
"structure": [
{
"name": "Id",
"type": "Int"
},
{
"name": "Name.First",
"type": "String"
},
{
"name": "Name.Middle",
"type": "String"
},
{
"name": "Name.Last",
"type": "String"
}
],
"type": "DocumentDbCollection",
"linkedServiceName": "CosmosDbLinkedService",
"typeProperties": {
"collectionName": "Person"
},
"availability": {
"frequency": "Day",
"interval": 1
}
}
}
The following pipeline copies data from Azure Blob to the Person collection in the Cosmos DB. As part of the
copy activity the input and output datasets have been specified.
{
"name": "BlobToDocDbPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "DocumentDbCollectionSink",
"nestingSeparator": ".",
"writeBatchSize": 2,
"writeBatchTimeout": "00:00:00"
}
"translator": {
"type": "TabularTranslator",
"ColumnMappings": "FirstName: Name.First, MiddleName: Name.Middle, LastName: Name.Last,
BusinessEntityID: BusinessEntityID, PersonType: PersonType, NameStyle: NameStyle, Title: Title, Suffix:
Suffix, EmailPromotion: EmailPromotion, rowguid: rowguid, ModifiedDate: ModifiedDate"
}
},
"inputs": [
{
"name": "PersonBlobTableIn"
}
],
"outputs": [
{
"name": "PersonCosmosDbTableOut"
}
],
"policy": {
"concurrency": 1
},
"name": "CopyFromBlobToDocDb"
}
],
"start": "2015-04-14T00:00:00Z",
"end": "2015-04-15T00:00:00Z"
}
}
If the sample blob input is as
1,John,,Doe
Then the output JSON in Cosmos DB will be as:
{
"Id": 1,
"Name": {
"First": "John",
"Middle": null,
"Last": "Doe"
},
"id": "a5e8595c-62ec-4554-a118-3940f4ff70b6"
}
Azure Cosmos DB is a NoSQL store for JSON documents, where nested structures are allowed. Azure Data
Factory enables user to denote hierarchy via nestingSeparator, which is “.” in this example. With the
separator, the copy activity will generate the “Name” object with three children elements First, Middle and Last,
according to “Name.First”, “Name.Middle” and “Name.Last” in the table definition.
Appendix
1. Question: Does the Copy Activity support update of existing records?
Answer: No.
2. Question: How does a retry of a copy to Azure Cosmos DB deal with already copied records?
Answer: If records have an "ID" field and the copy operation tries to insert a record with the same ID,
the copy operation throws an error.
3. Question: Does Data Factory support range or hash-based data partitioning?
Answer: No.
4. Question: Can I specify more than one Azure Cosmos DB collection for a table?
Answer: No. Only one collection can be specified at this time.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Copy data to and from Data Lake Store by using
Data Factory
5/11/2017 • 18 min to read • Edit Online
This article explains how to use Copy Activity in Azure Data Factory to move data to and from Azure Data Lake
Store. It builds on the Data movement activities article, an overview of data movement with Copy Activity.
Supported scenarios
You can copy data from Azure Data Lake Store to the following data stores:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Data Lake Store
Azure Cosmos DB (DocumentDB API)
Azure SQL Database
Azure SQL Data Warehouse
Azure Search Index
Azure Table storage
Databases
SQL Server
Oracle
File
File system
You can copy data from the following data stores to Azure Data Lake Store:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Cosmos DB (DocumentDB API)
Azure Data Lake Store
Azure SQL Database
Azure SQL Data Warehouse
Azure Table storage
Databases
Amazon Redshift
DB2
MySQL
Oracle
PostgreSQL
SAP Business Warehouse
SAP HANA
SQL Server
Sybase
Teradata
NoSQL
Cassandra
MongoDB
CATEGORY
DATA STORE
File
Amazon S3
File System
FTP
HDFS
SFTP
Others
Generic HTTP
Generic OData
Generic ODBC
Salesforce
Web Table (table from HTML)
GE Historian
NOTE
Create a Data Lake Store account before creating a pipeline with Copy Activity. For more information, see Get started
with Azure Data Lake Store.
Supported authentication types
The Data Lake Store connector supports these authentication types:
Service principal authentication
User credential (OAuth) authentication
We recommend that you use service principal authentication, especially for a scheduled data copy. Token
expiration behavior can occur with user credential authentication. For configuration details, see the Linked
service properties section.
Get started
You can create a pipeline with a copy activity that moves data to/from an Azure Data Lake Store by using
different tools/APIs.
The easiest way to create a pipeline to copy data is to use the Copy Wizard. For a tutorial on creating a
pipeline by using the Copy Wizard, see Tutorial: Create a pipeline using Copy Wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create a data factory. A data factory may contain one or more pipelines.
2. Create linked services to link input and output data stores to your data factory. For example, if you are
copying data from an Azure blob storage to an Azure Data Lake Store, you create two linked services to
link your Azure storage account and Azure Data Lake store to your data factory. For linked service
properties that are specific to Azure Data Lake Store, see linked service properties section.
3. Create datasets to represent input and output data for the copy operation. In the example mentioned in
the last step, you create a dataset to specify the blob container and folder that contains the input data. And,
you create another dataset to specify the folder and file path in the Data Lake store that holds the data
copied from the blob storage. For dataset properties that are specific to Azure Data Lake Store, see dataset
properties section.
4. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output. In the
example mentioned earlier, you use BlobSource as a source and AzureDataLakeStoreSink as a sink for the
copy activity. Similarly, if you are copying from Azure Data Lake Store to Azure Blob Storage, you use
AzureDataLakeStoreSource and BlobSink in the copy activity. For copy activity properties that are specific
to Azure Data Lake Store, see copy activity properties section. For details on how to use a data store as a
source or a sink, click the link in the previous section for your data store.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that are
used to copy data to/from an Azure Data Lake Store, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Data Lake Store.
Linked service properties
A linked service links a data store to a data factory. You create a linked service of type AzureDataLakeStore
to link your Data Lake Store data to your data factory. The following table describes JSON elements specific to
Data Lake Store linked services. You can choose between service principal and user credential authentication.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to
AzureDataLakeStore.
Yes
dataLakeStoreUri
Information about the Azure Data
Lake Store account. This information
takes one of the following formats:
Yes
https://[accountname].azuredatalakestore.net/webhdfs/v1
or
adl://[accountname].azuredatalakestore.net/
.
subscriptionId
Azure subscription ID to which the
Data Lake Store account belongs.
Required for sink
resourceGroupName
Azure resource group name to which
the Data Lake Store account belongs.
Required for sink
Service principal authentication (recommended)
To use service principal authentication, register an application entity in Azure Active Directory (Azure AD) and
grant it the access to Data Lake Store. For detailed steps, see Service-to-service authentication. Make note of
the following values, which you use to define the linked service:
Application ID
Application key
Tenant ID
IMPORTANT
If you are using the Copy Wizard to author data pipelines, make sure that you grant the service principal at least a
Reader role in access control (identity and access management) for the Data Lake Store account. Also, grant the service
principal at least Read + Execute permission to your Data Lake Store root ("/") and its children. Otherwise you might
see the message "The credentials provided are invalid."
After you create or update a service principal in Azure AD, it can take a few minutes for the changes to take effect.
Check the service principal and Data Lake Store access control list (ACL) configurations. If you still see the message "The
credentials provided are invalid," wait a while and try again.
Use service principal authentication by specifying the following properties:
PROPERTY
DESCRIPTION
REQUIRED
servicePrincipalId
Specify the application's client ID.
Yes
servicePrincipalKey
Specify the application's key.
Yes
tenant
Specify the tenant information
(domain name or tenant ID) under
which your application resides. You
can retrieve it by hovering the mouse
in the upper-right corner of the Azure
portal.
Yes
Example: Service principal authentication
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": "<service principal key>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
}
}
}
User credential authentication
Alternatively, you can use user credential authentication to copy from or to Data Lake Store by specifying the
following properties:
PROPERTY
DESCRIPTION
REQUIRED
authorization
Click the Authorize button in the
Data Factory Editor and enter your
credential that assigns the
autogenerated authorization URL to
this property.
Yes
PROPERTY
DESCRIPTION
REQUIRED
sessionId
OAuth session ID from the OAuth
authorization session. Each session ID
is unique and can be used only once.
This setting is automatically generated
when you use the Data Factory Editor.
Yes
Example: User credential authentication
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"sessionId": "<session ID>",
"authorization": "<authorization URL>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
}
}
}
Token expiration
The authorization code that you generate by using the Authorize button expires after a certain amount of
time. The following message means that the authentication token has expired:
Credential operation error: invalid_grant - AADSTS70002: Error validating credentials. AADSTS70008: The
provided access grant is expired or revoked. Trace ID: d18629e8-af88-43c5-88e3-d8419eb1fca1 Correlation
ID: fac30a0c-6be6-4e02-8d69-a776d2ffefd7 Timestamp: 2015-12-15 21-09-31Z.
The following table shows the expiration times of different types of user accounts:
USER TYPE
EXPIRES AFTER
User accounts not managed by Azure Active Directory (for
example, @hotmail.com or @live.com)
12 hours
Users accounts managed by Azure Active Directory
14 days after the last slice run
90 days, if a slice based on an OAuth-based linked service
runs at least once every 14 days
If you change your password before the token expiration time, the token expires immediately. You will see the
message mentioned earlier in this section.
You can reauthorize the account by using the Authorize button when the token expires to redeploy the linked
service. You can also generate values for the sessionId and authorization properties programmatically by
using the following code:
if (linkedService.Properties.TypeProperties is AzureDataLakeStoreLinkedService ||
linkedService.Properties.TypeProperties is AzureDataLakeAnalyticsLinkedService)
{
AuthorizationSessionGetResponse authorizationSession = this.Client.OAuth.Get(this.ResourceGroupName,
this.DataFactoryName, linkedService.Properties.Type);
WindowsFormsWebAuthenticationDialog authenticationDialog = new
WindowsFormsWebAuthenticationDialog(null);
string authorization =
authenticationDialog.AuthenticateAAD(authorizationSession.AuthorizationSession.Endpoint, new
Uri("urn:ietf:wg:oauth:2.0:oob"));
AzureDataLakeStoreLinkedService azureDataLakeStoreProperties = linkedService.Properties.TypeProperties
as AzureDataLakeStoreLinkedService;
if (azureDataLakeStoreProperties != null)
{
azureDataLakeStoreProperties.SessionId = authorizationSession.AuthorizationSession.SessionId;
azureDataLakeStoreProperties.Authorization = authorization;
}
AzureDataLakeAnalyticsLinkedService azureDataLakeAnalyticsProperties =
linkedService.Properties.TypeProperties as AzureDataLakeAnalyticsLinkedService;
if (azureDataLakeAnalyticsProperties != null)
{
azureDataLakeAnalyticsProperties.SessionId = authorizationSession.AuthorizationSession.SessionId;
azureDataLakeAnalyticsProperties.Authorization = authorization;
}
}
For details about the Data Factory classes used in the code, see the AzureDataLakeStoreLinkedService Class,
AzureDataLakeAnalyticsLinkedService Class, and AuthorizationSessionGetResponse Class topics. Add a
reference to version 2.9.10826.1824 of Microsoft.IdentityModel.Clients.ActiveDirectory.WindowsForms.dll for
the WindowsFormsWebAuthenticationDialog class used in the code.
Dataset properties
To specify a dataset to represent input data in a Data Lake Store, you set the type property of the dataset to
AzureDataLakeStore. Set the linkedServiceName property of the dataset to the name of the Data Lake
Store linked service. For a full list of JSON sections and properties available for defining datasets, see the
Creating datasets article. Sections of a dataset in JSON, such as structure, availability, and policy, are
similar for all dataset types (Azure SQL database, Azure blob, and Azure table, for example). The
typeProperties section is different for each type of dataset and provides information such as location and
format of the data in the data store.
The typeProperties section for a dataset of type AzureDataLakeStore contains the following properties:
PROPERTY
DESCRIPTION
REQUIRED
folderPath
Path to the container and folder in
Data Lake Store.
Yes
PROPERTY
DESCRIPTION
REQUIRED
fileName
Name of the file in Azure Data Lake
Store. The fileName property is
optional and case-sensitive.
No
If you specify fileName, the activity
(including Copy) works on the specific
file.
When fileName is not specified, Copy
includes all files in folderPath in the
input dataset.
When fileName is not specified for
an output dataset and
preserveHierarchy is not specified in
activity sink, the name of the
generated file is in the format
Data.Guid.txt`. For example:
Data.0a405f8a-93ff-4c6f-b3bef69616f1df7a.txt.
partitionedBy
The partitionedBy property is
optional. You can use it to specify a
dynamic path and file name for timeseries data. For example, folderPath
can be parameterized for every hour
of data. For details and examples, see
The partitionedBy property.
No
format
The following format types are
supported: TextFormat, JsonFormat,
AvroFormat, OrcFormat, and
ParquetFormat. Set the type
property under format to one of
these values. For more information,
see the Text format, JSON format,
Avro format, ORC format, and
Parquet Format sections in the File
and compression formats supported
by Azure Data Factory article.
No
If you want to copy files "as-is"
between file-based stores (binary
copy), skip the format section in
both input and output dataset
definitions.
compression
Specify the type and level of
compression for the data. Supported
types are GZip, Deflate, BZip2, and
ZipDeflate. Supported levels are
Optimal and Fastest. For more
information, see File and compression
formats supported by Azure Data
Factory.
No
The partitionedBy property
You can specify dynamic folderPath and fileName properties for time-series data with the partitionedBy
property, Data Factory functions, and system variables. For details, see the Azure Data Factory - functions and
system variables article.
In the following example, {Slice} is replaced with the value of the Data Factory system variable SliceStart
in the format specified ( yyyyMMddHH ). The name SliceStart refers to the start time of the slice. The
folderPath property is different for each slice, as in wikidatagateway/wikisampledataout/2014100103 or
wikidatagateway/wikisampledataout/2014100104 .
"folderPath": "wikidatagateway/wikisampledataout/{Slice}",
"partitionedBy":
[
{ "name": "Slice", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyyMMddHH" } },
],
In the following example, the year, month, day, and time of
that are used by the folderPath and fileName properties:
SliceStart
are extracted into separate variables
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}",
"fileName": "{Hour}.csv",
"partitionedBy":
[
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }
],
For more details on time-series datasets, scheduling, and slices, see the Datasets in Azure Data Factory and
Data Factory scheduling and execution articles.
Copy activity properties
For a full list of sections and properties available for defining activities, see the Creating pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of activities.
The properties available in the typeProperties section of an activity vary with each activity type. For a copy
activity, they vary depending on the types of sources and sinks.
AzureDataLakeStoreSource supports the following property in the typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
recursive
Indicates whether the data
is read recursively from the
subfolders or only from the
specified folder.
True (default value), False
No
AzureDataLakeStoreSink supports the following properties in the typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
copyBehavior
Specifies the copy behavior.
PreserveHierarchy:
Preserves the file hierarchy
in the target folder. The
relative path of source file
to source folder is identical
to the relative path of
target file to target folder.
No
FlattenHierarchy: All files
from the source folder are
created in the first level of
the target folder. The
target files are created with
autogenerated names.
MergeFiles: Merges all
files from the source folder
to one file. If the file or blob
name is specified, the
merged file name is the
specified name. Otherwise,
the file name is
autogenerated.
recursive and copyBehavior examples
This section describes the resulting behavior of the Copy operation for different combinations of recursive and
copyBehavior values.
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
true
preserveHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the same structure as the source
Folder1
File1
File2
Subfolder1
File3
File4
File5.
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
true
flattenHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target Folder1 is created with the
following structure:
Folder1
auto-generated name for File1
auto-generated name for File2
auto-generated name for File3
auto-generated name for File4
auto-generated name for File5
true
mergeFiles
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target Folder1 is created with the
following structure:
Folder1
File1 + File2 + File3 + File4 + File 5
contents are merged into one file with
auto-generated file name
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
false
preserveHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure
Folder1
File1
File2
Subfolder1 with File3, File4, and File5
are not picked up.
false
flattenHierarchy
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure
Folder1
auto-generated name for File1
auto-generated name for File2
Subfolder1 with File3, File4, and File5
are not picked up.
RECURSIVE
COPYBEHAVIOR
RESULTING BEHAVIOR
false
mergeFiles
For a source folder Folder1 with the
following structure:
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure
Folder1
File1 + File2 contents are merged
into one file with auto-generated file
name. auto-generated name for File1
Subfolder1 with File3, File4, and File5
are not picked up.
Supported file and compression formats
For details, see the File and compression formats in Azure Data Factory article.
JSON examples for copying data to and from Data Lake Store
The following examples provide sample JSON definitions. You can use these sample definitions to create a
pipeline by using the Azure portal, Visual Studio, or Azure PowerShell. The examples show how to copy data
to and from Data Lake Store and Azure Blob storage. However, data can be copied directly from any of the
sources to any of the supported sinks. For more information, see the section "Supported data stores and
formats" in the Move data by using Copy Activity article.
Example: Copy data from Azure Blob Storage to Azure Data Lake Store
The example code in this section shows:
A linked service of type AzureStorage.
A linked service of type AzureDataLakeStore.
An input dataset of type AzureBlob.
An output dataset of type AzureDataLakeStore.
A pipeline with a copy activity that uses BlobSource and AzureDataLakeStoreSink.
The examples show how time-series data from Azure Blob Storage is copied to Data Lake Store every hour.
Azure Storage linked service
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Data Lake Store linked service
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": "<service principal key>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
}
}
}
NOTE
For configuration details, see the Linked service properties section.
Azure blob input dataset
In the following example, data is picked up from a new blob every hour ( "frequency": "Hour", "interval": 1 ).
The folder path and file name for the blob are dynamically evaluated based on the start time of the slice that is
being processed. The folder path uses the year, month, and day portion of the start time. The file name uses
the hour portion of the start time. The "external": true setting informs the Data Factory service that the table
is external to the data factory and is not produced by an activity in the data factory.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Data Lake Store output dataset
The following example copies data to Data Lake Store. New data is copied to Data Lake Store every hour.
{
"name": "AzureDataLakeStoreOutput",
"properties": {
"type": "AzureDataLakeStore",
"linkedServiceName": "AzureDataLakeStoreLinkedService",
"typeProperties": {
"folderPath": "datalake/output/"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with a blob source and a Data Lake Store sink
In the following example, the pipeline contains a copy activity that is configured to use the input and output
datasets. The copy activity is scheduled to run every hour. In the pipeline JSON definition, the source type is
set to BlobSource , and the sink type is set to AzureDataLakeStoreSink .
{
"name":"SamplePipeline",
"properties":
{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":
[
{
"name": "AzureBlobtoDataLake",
"description": "Copy Activity",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureDataLakeStoreOutput"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "AzureDataLakeStoreSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Example: Copy data from Azure Data Lake Store to an Azure blob
The example code in this section shows:
A linked service of type AzureDataLakeStore.
A linked service of type AzureStorage.
An input dataset of type AzureDataLakeStore.
An output dataset of type AzureBlob.
A pipeline with a copy activity that uses AzureDataLakeStoreSource and BlobSink.
The code copies time-series data from Data Lake Store to an Azure blob every hour.
Azure Data Lake Store linked service
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": "<service principal key>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
}
}
}
NOTE
For configuration details, see the Linked service properties section.
Azure Storage linked service
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Data Lake input dataset
In this example, setting "external" to true informs the Data Factory service that the table is external to the
data factory and is not produced by an activity in the data factory.
{
"name": "AzureDataLakeStoreInput",
"properties":
{
"type": "AzureDataLakeStore",
"linkedServiceName": "AzureDataLakeStoreLinkedService",
"typeProperties": {
"folderPath": "datalake/input/",
"fileName": "SearchLog.tsv",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure blob output dataset
In the following example, data is written to a new blob every hour ( "frequency": "Hour", "interval": 1 ). The
folder path for the blob is dynamically evaluated based on the start time of the slice that is being processed.
The folder path uses the year, month, day, and hours portion of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
A copy activity in a pipeline with an Azure Data Lake Store source and a blob sink
In the following example, the pipeline contains a copy activity that is configured to use the input and output
datasets. The copy activity is scheduled to run every hour. In the pipeline JSON definition, the source type is
set to AzureDataLakeStoreSource , and the sink type is set to BlobSink .
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "AzureDakeLaketoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": "AzureDataLakeStoreInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
In the copy activity definition, you can also map columns from the source dataset to columns in the sink
dataset. For details, see Mapping dataset columns in Azure Data Factory.
Performance and tuning
To learn about the factors that affect Copy Activity performance and how to optimize it, see the Copy Activity
performance and tuning guide article.
Push data to an Azure Search index by using Azure
Data Factory
6/5/2017 • 8 min to read • Edit Online
This article describes how to use the Copy Activity to push data from a supported source data store to Azure
Search index. Supported source data stores are listed in the Source column of the supported sources and sinks
table. This article builds on the data movement activities article, which presents a general overview of data
movement with Copy Activity and supported data store combinations.
Enabling connectivity
To allow Data Factory service connect to an on-premises data store, you install Data Management Gateway in
your on-premises environment. You can install gateway on the same machine that hosts the source data store
or on a separate machine to avoid competing for resources with the data store.
Data Management Gateway connects on-premises data sources to cloud services in a secure and managed way.
See Move data between on-premises and cloud article for details about Data Management Gateway.
Getting started
You can create a pipeline with a copy activity that pushes data from a source data store to Azure Search index
by using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data to Azure Search index, see JSON example: Copy data from on-premises SQL Server to Azure
Search index section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Azure Search Index:
Linked service properties
The following table provides descriptions for JSON elements that are specific to the Azure Search linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AzureSearch.
Yes
url
URL for the Azure Search service.
Yes
key
Admin key for the Azure Search
service.
Yes
Dataset properties
For a full list of sections and properties that are available for defining datasets, see the Creating datasets article.
Sections such as structure, availability, and policy of a dataset JSON are similar for all dataset types. The
typeProperties section is different for each type of dataset. The typeProperties section for a dataset of the type
AzureSearchIndex has the following properties:
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to
AzureSearchIndex.
Yes
indexName
Name of the Azure Search index. Data
Factory does not create the index. The
index must exist in Azure Search.
Yes
Copy activity properties
For a full list of sections and properties that are available for defining activities, see the Creating pipelines
article. Properties such as name, description, input and output tables, and various policies are available for all
types of activities. Whereas, properties available in the typeProperties section vary with each activity type. For
Copy Activity, they vary depending on the types of sources and sinks.
For Copy Activity, when the sink is of the type AzureSearchIndexSink, the following properties are available in
typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
WriteBehavior
Specifies whether to merge
or replace when a
document already exists in
the index. See the
WriteBehavior property.
Merge (default)
Upload
No
WriteBatchSize
Uploads data into the
Azure Search index when
the buffer size reaches
writeBatchSize. See the
WriteBatchSize property for
details.
1 to 1,000. Default value is
1000.
No
WriteBehavior property
AzureSearchSink upserts when writing data. In other words, when writing a document, if the document key
already exists in the Azure Search index, Azure Search updates the existing document rather than throwing a
conflict exception.
The AzureSearchSink provides the following two upsert behaviors (by using AzureSearch SDK):
Merge: combine all the columns in the new document with the existing one. For columns with null value in
the new document, the value in the existing one is preserved.
Upload: The new document replaces the existing one. For columns not specified in the new document, the
value is set to null whether there is a non-null value in the existing document or not.
The default behavior is Merge.
WriteBatchSize Property
Azure Search service supports writing documents as a batch. A batch can contain 1 to 1,000 Actions. An action
handles one document to perform the upload/merge operation.
Data type support
The following table specifies whether an Azure Search data type is supported or not.
AZURE SEARCH DATA TYPE
SUPPORTED IN AZURE SEARCH SINK
String
Y
Int32
Y
Int64
Y
Double
Y
Boolean
Y
DataTimeOffset
Y
String Array
N
GeographyPoint
N
JSON example: Copy data from on-premises SQL Server to Azure
Search index
The following sample shows:
1.
2.
3.
4.
5.
A linked service of type AzureSearch.
A linked service of type OnPremisesSqlServer.
An input dataset of type SqlServerTable.
An output dataset of type AzureSearchIndex.
A pipeline with a Copy activity that uses SqlSource and AzureSearchIndexSink.
The sample copies time-series data from an on-premises SQL Server database to an Azure Search index hourly.
The JSON properties used in this sample are described in sections following the samples.
As a first step, setup the data management gateway on your on-premises machine. The instructions are in the
moving data between on-premises locations and cloud article.
Azure Search linked service:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": "<AdminKey>"
}
}
}
SQL Server linked service
{
"Name": "SqlServerLinkedService",
"properties": {
"type": "OnPremisesSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>;Initial Catalog=<databasename>;Integrated
Security=False;User ID=<username>;Password=<password>;",
"gatewayName": "<gatewayname>"
}
}
}
SQL Server input dataset
The sample assumes you have created a table “MyTable” in SQL Server and it contains a column called
“timestampcolumn” for time series data. You can query over multiple tables within the same database using a
single dataset, but a single table must be used for the dataset's tableName typeProperty.
Setting “external”: ”true” informs Data Factory service that the dataset is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "SqlServerDataset",
"properties": {
"type": "SqlServerTable",
"linkedServiceName": "SqlServerLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Search output dataset:
The sample copies data to an Azure Search index named products. Data Factory does not create the index. To
test the sample, create an index with this name. Create the Azure Search index with the same number of
columns as in the input dataset. New entries are added to the Azure Search index every hour.
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"linkedServiceName": "AzureSearchLinkedService",
"typeProperties" : {
"indexName": "products",
},
"availability": {
"frequency": "Minute",
"interval": 15
}
}
}
Copy activity in a pipeline with SQL source and Azure Search Index sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to SqlSource and sink type is set to
AzureSearchIndexSink. The SQL query specified for the SqlReaderQuery property selects the data in the
past hour to copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "SqlServertoAzureSearchIndex",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": " SqlServerInput"
}
],
"outputs": [
{
"name": "AzureSearchIndexDataset"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"SqlReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >= \\'{0:yyyy-MMdd HH:mm}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "AzureSearchIndexSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
If you are copying data from a cloud data store into Azure Search, executionLocation property is required. The
following JSON snippet shows the change needed under Copy Activity typeProperties as an example. Check
Copy data between cloud data stores section for supported values and more details.
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "AzureSearchIndexSink"
},
"executionLocation": "West US"
}
Copy from a cloud source
If you are copying data from a cloud data store into Azure Search,
executionLocation
property is required. The
following JSON snippet shows the change needed under Copy Activity typeProperties as an example. Check
Copy data between cloud data stores section for supported values and more details.
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "AzureSearchIndexSink"
},
"executionLocation": "West US"
}
You can also map columns from source dataset to columns from sink dataset in the copy activity definition. For
details, see Mapping dataset columns in Azure Data Factory.
Performance and tuning
See the Copy Activity performance and tuning guide to learn about key factors that impact performance of data
movement (Copy Activity) and various ways to optimize it.
Next steps
See the following articles:
Copy Activity tutorial for step-by-step instructions for creating a pipeline with a Copy Activity.
Copy data to and from Azure SQL Database using
Azure Data Factory
6/9/2017 • 17 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data to and from Azure SQL
Database. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
Supported scenarios
You can copy data from Azure SQL Database to the following data stores:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Data Lake Store
Azure Cosmos DB (DocumentDB API)
Azure SQL Database
Azure SQL Data Warehouse
Azure Search Index
Azure Table storage
Databases
SQL Server
Oracle
File
File system
You can copy data from the following data stores to Azure SQL Database:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Cosmos DB (DocumentDB API)
Azure Data Lake Store
Azure SQL Database
Azure SQL Data Warehouse
Azure Table storage
Databases
Amazon Redshift
DB2
MySQL
Oracle
PostgreSQL
SAP Business Warehouse
SAP HANA
SQL Server
Sybase
Teradata
NoSQL
Cassandra
MongoDB
CATEGORY
DATA STORE
File
Amazon S3
File System
FTP
HDFS
SFTP
Others
Generic HTTP
Generic OData
Generic ODBC
Salesforce
Web Table (table from HTML)
GE Historian
Supported authentication type
Azure SQL Database connector supports basic authentication.
Getting started
You can create a pipeline with a copy activity that moves data to/from an Azure SQL Database by using
different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create a data factory. A data factory may contain one or more pipelines.
2. Create linked services to link input and output data stores to your data factory. For example, if you are
copying data from an Azure blob storage to an Azure SQL database, you create two linked services to link
your Azure storage account and Azure SQL database to your data factory. For linked service properties
that are specific to Azure SQL Database, see linked service properties section.
3. Create datasets to represent input and output data for the copy operation. In the example mentioned in
the last step, you create a dataset to specify the blob container and folder that contains the input data. And,
you create another dataset to specify the SQL table in the Azure SQL database that holds the data copied
from the blob storage. For dataset properties that are specific to Azure Data Lake Store, see dataset
properties section.
4. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output. In the
example mentioned earlier, you use BlobSource as a source and SqlSink as a sink for the copy activity.
Similarly, if you are copying from Azure SQL Database to Azure Blob Storage, you use SqlSource and
BlobSink in the copy activity. For copy activity properties that are specific to Azure SQL Database, see copy
activity properties section. For details on how to use a data store as a source or a sink, click the link in the
previous section for your data store.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that
are used to copy data to/from an Azure SQL Database, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Azure SQL Database:
Linked service properties
An Azure SQL linked service links an Azure SQL database to your data factory. The following table provides
description for JSON elements specific to Azure SQL linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AzureSqlDatabase
Yes
connectionString
Specify information needed to
connect to the Azure SQL Database
instance for the connectionString
property. Only basic authentication is
supported.
Yes
IMPORTANT
Configure Azure SQL Database Firewall the database server to allow Azure Services to access the server. Additionally, if
you are copying data to Azure SQL Database from outside Azure including from on-premises data sources with data
factory gateway, configure appropriate IP address range for the machine that is sending data to Azure SQL Database.
Dataset properties
To specify a dataset to represent input or output data in an Azure SQL database, you set the type property of
the dataset to: AzureSqlTable. Set the linkedServiceName property of the dataset to the name of the Azure
SQL linked service.
For a full list of sections & properties available for defining datasets, see the Creating datasets article.
Sections such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure
SQL, Azure blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for the dataset of type AzureSqlTable has the
following properties:
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table or view in the
Azure SQL Database instance that
linked service refers to.
Yes
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of
activities.
NOTE
The Copy Activity takes only one input and produces only one output.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
If you are moving data from an Azure SQL database, you set the source type in the copy activity to
SqlSource. Similarly, if you are moving data to an Azure SQL database, you set the sink type in the copy
activity to SqlSink. This section provides a list of properties supported by SqlSource and SqlSink.
SqlSource
In copy activity, when the source is of type SqlSource, the following properties are available in
typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
sqlReaderQuery
Use the custom query to
read data.
SQL query string. Example:
select * from MyTable .
No
sqlReaderStoredProcedure
Name
Name of the stored
procedure that reads data
from the source table.
Name of the stored
procedure. The last SQL
statement must be a
SELECT statement in the
stored procedure.
No
storedProcedureParameter
s
Parameters for the stored
procedure.
Name/value pairs. Names
and casing of parameters
must match the names
and casing of the stored
procedure parameters.
No
If the sqlReaderQuery is specified for the SqlSource, the Copy Activity runs this query against the Azure SQL
Database source to get the data. Alternatively, you can specify a stored procedure by specifying the
sqlReaderStoredProcedureName and storedProcedureParameters (if the stored procedure takes
parameters).
If you do not specify either sqlReaderQuery or sqlReaderStoredProcedureName, the columns defined in the
structure section of the dataset JSON are used to build a query ( select column1, column2 from mytable ) to run
against the Azure SQL Database. If the dataset definition does not have the structure, all columns are selected
from the table.
NOTE
When you use sqlReaderStoredProcedureName, you still need to specify a value for the tableName property in
the dataset JSON. There are no validations performed against this table though.
SqlSource example
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', SliceStart)", "type": "Int"}
}
}
The stored procedure definition:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SqlSink
SqlSink supports the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
writeBatchTimeout
Wait time for the batch
insert operation to
complete before it times
out.
timespan
No
writeBatchSize
Inserts data into the SQL
table when the buffer size
reaches writeBatchSize.
Integer (number of rows)
No (default: 10000)
sqlWriterCleanupScript
Specify a query for Copy
Activity to execute such
that data of a specific slice
is cleaned up. For more
information, see repeatable
copy.
A query statement.
No
sliceIdentifierColumnName
Specify a column name for
Copy Activity to fill with
auto generated slice
identifier, which is used to
clean up data of a specific
slice when rerun. For more
information, see repeatable
copy.
Column name of a column
with data type of
binary(32).
No
sqlWriterStoredProcedureN
ame
Name of the stored
procedure that upserts
(updates/inserts) data into
the target table.
Name of the stored
procedure.
No
storedProcedureParameter
s
Parameters for the stored
procedure.
Name/value pairs. Names
and casing of parameters
must match the names
and casing of the stored
procedure parameters.
No
Example: “00:30:00” (30
minutes).
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
sqlWriterTableType
Specify a table type name
to be used in the stored
procedure. Copy activity
makes the data being
moved available in a temp
table with this table type.
Stored procedure code can
then merge the data being
copied with existing data.
A table type name.
No
SqlSink example
"sink": {
"type": "SqlSink",
"writeBatchSize": 1000000,
"writeBatchTimeout": "00:05:00",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"sqlWriterTableType": "CopyTestTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" },
"decimalData": { "value": "1", "type": "Decimal" }
}
}
JSON examples for copying data to and from SQL Database
The following examples provide sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data to and from Azure SQL Database
and Azure Blob Storage. However, data can be copied directly from any of sources to any of the sinks stated
here using the Copy Activity in Azure Data Factory.
Example: Copy data from Azure SQL Database to Azure Blob
The same defines the following Data Factory entities:
1.
2.
3.
4.
5.
A linked service of type AzureSqlDatabase.
A linked service of type AzureStorage.
An input dataset of type AzureSqlTable.
An output dataset of type Azure Blob.
A pipeline with a Copy activity that uses SqlSource and BlobSink.
The sample copies time-series data (hourly, daily, etc.) from a table in Azure SQL database to a blob every
hour. The JSON properties used in these samples are described in sections following the samples.
Azure SQL Database linked service:
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User
ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection
Timeout=30"
}
}
}
See the Azure SQL Linked Service section for the list of properties supported by this linked service.
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
See the Azure Blob article for the list of properties supported by this linked service.
Azure SQL input dataset:
The sample assumes you have created a table “MyTable” in Azure SQL and it contains a column called
“timestampcolumn” for time series data.
Setting “external”: ”true” informs the Azure Data Factory service that the dataset is external to the data factory
and is not produced by an activity in the data factory.
{
"name": "AzureSqlInput",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
See the Azure SQL dataset type properties section for the list of properties supported by this dataset type.
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}/",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
See the Azure Blob dataset type properties section for the list of properties supported by this dataset type.
A copy activity in a pipeline with SQL source and Blob sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to SqlSource and sink type is set to
BlobSink. The SQL query specified for the SqlReaderQuery property selects the data in the past hour to
copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "AzureSQLtoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": "AzureSQLInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"SqlReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >= \\'{0:yyyyMM-dd HH:mm}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
In the example, sqlReaderQuery is specified for the SqlSource. The Copy Activity runs this query against the
Azure SQL Database source to get the data. Alternatively, you can specify a stored procedure by specifying
the sqlReaderStoredProcedureName and storedProcedureParameters (if the stored procedure takes
parameters).
If you do not specify either sqlReaderQuery or sqlReaderStoredProcedureName, the columns defined in the
structure section of the dataset JSON are used to build a query to run against the Azure SQL Database. For
example: select column1, column2 from mytable . If the dataset definition does not have the structure, all
columns are selected from the table.
See the Sql Source section and BlobSink for the list of properties supported by SqlSource and BlobSink.
Example: Copy data from Azure Blob to Azure SQL Database
The sample defines the following Data Factory entities:
1.
2.
3.
4.
5.
A linked service of type AzureSqlDatabase.
A linked service of type AzureStorage.
An input dataset of type AzureBlob.
An output dataset of type AzureSqlTable.
A pipeline with Copy activity that uses BlobSource and SqlSink.
The sample copies time-series data (hourly, daily, etc.) from Azure blob to a table in Azure SQL database
every hour. The JSON properties used in these samples are described in sections following the samples.
Azure SQL linked service:
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User
ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection
Timeout=30"
}
}
}
See the Azure SQL Linked Service section for the list of properties supported by this linked service.
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
See the Azure Blob article for the list of properties supported by this linked service.
Azure Blob input dataset:
Data is picked up from a new blob every hour (frequency: hour, interval: 1). The folder path and file name for
the blob are dynamically evaluated based on the start time of the slice that is being processed. The folder
path uses year, month, and day part of the start time and file name uses the hour part of the start time.
“external”: “true” setting informs the Data Factory service that this table is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/",
"fileName": "{Hour}.csv",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
See the Azure Blob dataset type properties section for the list of properties supported by this dataset type.
Azure SQL Database output dataset:
The sample copies data to a table named “MyTable” in Azure SQL. Create the table in Azure SQL with the
same number of columns as you expect the Blob CSV file to contain. New rows are added to the table every
hour.
{
"name": "AzureSqlOutput",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "MyOutputTable"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
See the Azure SQL dataset type properties section for the list of properties supported by this dataset type.
A copy activity in a pipeline with Blob source and SQL sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to BlobSource and sink type is set
to SqlSink.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "AzureBlobtoSQL",
"description": "Copy Activity",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureSqlOutput"
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"blobColumnSeparators": ","
},
"sink": {
"type": "SqlSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
See the Sql Sink section and BlobSource for the list of properties supported by SqlSink and BlobSource.
Identity columns in the target database
This section provides an example for copying data from a source table without an identity column to a
destination table with an identity column.
Source table:
create table dbo.SourceTbl
(
name varchar(100),
age int
)
Destination table:
create table dbo.TargetTbl
(
identifier int identity(1,1),
name varchar(100),
age int
)
Notice that the target table has an identity column.
Source dataset JSON definition
{
"name": "SampleSource",
"properties": {
"type": " SqlServerTable",
"linkedServiceName": "TestIdentitySQL",
"typeProperties": {
"tableName": "SourceTbl"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {}
}
}
Destination dataset JSON definition
{
"name": "SampleTarget",
"properties": {
"structure": [
{ "name": "name" },
{ "name": "age" }
],
"type": "AzureSqlTable",
"linkedServiceName": "TestIdentitySQLSource",
"typeProperties": {
"tableName": "TargetTbl"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": false,
"policy": {}
}
}
Notice that as your source and target table have different schema (target has an additional column with
identity). In this scenario, you need to specify structure property in the target dataset definition, which
doesn’t include the identity column.
Invoke stored procedure from SQL sink
For an example of invoking a stored procedure from SQL sink in a copy activity of a pipeline, see Invoke
stored procedure for SQL sink in copy activity article.
Type mapping for Azure SQL Database
As mentioned in the data movement activities article Copy activity performs automatic type conversions from
source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to and from Azure SQL Database, the following mappings are used from SQL type to .NET
type and vice versa. The mapping is same as the SQL Server Data Type Mapping for ADO.NET.
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
bigint
Int64
binary
Byte[]
bit
Boolean
char
String, Char[]
date
DateTime
Datetime
DateTime
datetime2
DateTime
Datetimeoffset
DateTimeOffset
Decimal
Decimal
FILESTREAM attribute (varbinary(max))
Byte[]
Float
Double
image
Byte[]
int
Int32
money
Decimal
nchar
String, Char[]
ntext
String, Char[]
numeric
Decimal
nvarchar
String, Char[]
real
Single
rowversion
Byte[]
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
smalldatetime
DateTime
smallint
Int16
smallmoney
Decimal
sql_variant
Object *
text
String, Char[]
time
TimeSpan
timestamp
Byte[]
tinyint
Byte
uniqueidentifier
Guid
varbinary
Byte[]
varchar
String, Char[]
xml
Xml
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns
in Azure Data Factory.
Repeatable copy
When copying data to SQL Server Database, the copy activity appends data to the sink table by default. To
perform an UPSERT instead, See Repeatable write to SqlSink article.
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Copy data to and from Azure SQL Data
Warehouse using Azure Data Factory
6/9/2017 • 25 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data to/from Azure SQL Data
Warehouse. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
TIP
To achieve best performance, use PolyBase to load data into Azure SQL Data Warehouse. The Use PolyBase to load
data into Azure SQL Data Warehouse section has details. For a walkthrough with a use case, see Load 1 TB into Azure
SQL Data Warehouse under 15 minutes with Azure Data Factory.
Supported scenarios
You can copy data from Azure SQL Data Warehouse to the following data stores:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Data Lake Store
Azure Cosmos DB (DocumentDB API)
Azure SQL Database
Azure SQL Data Warehouse
Azure Search Index
Azure Table storage
Databases
SQL Server
Oracle
File
File system
You can copy data from the following data stores to Azure SQL Data Warehouse:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Cosmos DB (DocumentDB API)
Azure Data Lake Store
Azure SQL Database
Azure SQL Data Warehouse
Azure Table storage
CATEGORY
DATA STORE
Databases
Amazon Redshift
DB2
MySQL
Oracle
PostgreSQL
SAP Business Warehouse
SAP HANA
SQL Server
Sybase
Teradata
NoSQL
Cassandra
MongoDB
File
Amazon S3
File System
FTP
HDFS
SFTP
Others
Generic HTTP
Generic OData
Generic ODBC
Salesforce
Web Table (table from HTML)
GE Historian
TIP
When copying data from SQL Server or Azure SQL Database to Azure SQL Data Warehouse, if the table does not exist
in the destination store, Data Factory can automatically create the table in SQL Data Warehouse by using the schema
of the table in the source data store. See Auto table creation for details.
Supported authentication type
Azure SQL Data Warehouse connector support basic authentication.
Getting started
You can create a pipeline with a copy activity that moves data to/from an Azure SQL Data Warehouse by
using different tools/APIs.
The easiest way to create a pipeline that copies data to/from Azure SQL Data Warehouse is to use the Copy
data wizard. See Tutorial: Load data into SQL Data Warehouse with Data Factory for a quick walkthrough on
creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create a data factory. A data factory may contain one or more pipelines.
2. Create linked services to link input and output data stores to your data factory. For example, if you are
copying data from an Azure blob storage to an Azure SQL data warehouse, you create two linked services
to link your Azure storage account and Azure SQL data warehouse to your data factory. For linked service
properties that are specific to Azure SQL Data Warehouse, see linked service properties section.
3. Create datasets to represent input and output data for the copy operation. In the example mentioned in
the last step, you create a dataset to specify the blob container and folder that contains the input data. And,
you create another dataset to specify the table in the Azure SQL data warehouse that holds the data copied
from the blob storage. For dataset properties that are specific to Azure SQL Data Warehouse, see dataset
properties section.
4. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output. In the
example mentioned earlier, you use BlobSource as a source and SqlDWSink as a sink for the copy activity.
Similarly, if you are copying from Azure SQL Data Warehouse to Azure Blob Storage, you use
SqlDWSource and BlobSink in the copy activity. For copy activity properties that are specific to Azure SQL
Data Warehouse, see copy activity properties section. For details on how to use a data store as a source or
a sink, click the link in the previous section for your data store.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that
are used to copy data to/from an Azure SQL Data Warehouse, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Azure SQL Data Warehouse:
Linked service properties
The following table provides description for JSON elements specific to Azure SQL Data Warehouse linked
service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AzureSqlDW
Yes
connectionString
Specify information needed to
connect to the Azure SQL Data
Warehouse instance for the
connectionString property. Only basic
authentication is supported.
Yes
IMPORTANT
Configure Azure SQL Database Firewall and the database server to allow Azure Services to access the server.
Additionally, if you are copying data to Azure SQL Data Warehouse from outside Azure including from on-premises
data sources with data factory gateway, configure appropriate IP address range for the machine that is sending data to
Azure SQL Data Warehouse.
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for the dataset of type AzureSqlDWTable has the
following properties:
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table or view in the
Azure SQL Data Warehouse database
that the linked service refers to.
Yes
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of
activities.
NOTE
The Copy Activity takes only one input and produces only one output.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
SqlDWSource
When source is of type SqlDWSource, the following properties are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
sqlReaderQuery
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable.
No
sqlReaderStoredProcedure
Name
Name of the stored
procedure that reads data
from the source table.
Name of the stored
procedure. The last SQL
statement must be a
SELECT statement in the
stored procedure.
No
storedProcedureParameter
s
Parameters for the stored
procedure.
Name/value pairs. Names
and casing of parameters
must match the names and
casing of the stored
procedure parameters.
No
If the sqlReaderQuery is specified for the SqlDWSource, the Copy Activity runs this query against the Azure
SQL Data Warehouse source to get the data.
Alternatively, you can specify a stored procedure by specifying the sqlReaderStoredProcedureName and
storedProcedureParameters (if the stored procedure takes parameters).
If you do not specify either sqlReaderQuery or sqlReaderStoredProcedureName, the columns defined in the
structure section of the dataset JSON are used to build a query to run against the Azure SQL Data Warehouse.
Example: select column1, column2 from mytable . If the dataset definition does not have the structure, all
columns are selected from the table.
SqlDWSource example
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', SliceStart)", "type": "Int"}
}
}
The stored procedure definition:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SqlDWSink
SqlDWSink supports the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
sqlWriterCleanupScript
Specify a query for Copy
Activity to execute such
that data of a specific slice
is cleaned up. For details,
see repeatability section.
A query statement.
No
allowPolyBase
Indicates whether to use
PolyBase (when applicable)
instead of BULKINSERT
mechanism.
True
False (default)
No
Using PolyBase is the
recommended way to
load data into SQL Data
Warehouse. See Use
PolyBase to load data into
Azure SQL Data
Warehouse section for
constraints and details.
polyBaseSettings
A group of properties that
can be specified when the
allowPolybase property is
set to true.
No
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
rejectValue
Specifies the number or
percentage of rows that
can be rejected before the
query fails.
0 (default), 1, 2, …
No
Learn more about the
PolyBase’s reject options in
the Arguments section of
CREATE EXTERNAL TABLE
(Transact-SQL) topic.
rejectType
Specifies whether the
rejectValue option is
specified as a literal value
or a percentage.
Value (default), Percentage
No
rejectSampleValue
Determines the number of
rows to retrieve before the
PolyBase recalculates the
percentage of rejected
rows.
1, 2, …
Yes, if rejectType is
percentage
useTypeDefault
Specifies how to handle
missing values in delimited
text files when PolyBase
retrieves data from the text
file.
True, False (default)
No
Learn more about this
property from the
Arguments section in
CREATE EXTERNAL FILE
FORMAT (Transact-SQL).
writeBatchSize
Inserts data into the SQL
table when the buffer size
reaches writeBatchSize
Integer (number of rows)
No (default: 10000)
writeBatchTimeout
Wait time for the batch
insert operation to
complete before it times
out.
timespan
No
Example: “00:30:00” (30
minutes).
SqlDWSink example
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
Use PolyBase to load data into Azure SQL Data Warehouse
Using PolyBase is an efficient way of loading large amount of data into Azure SQL Data Warehouse with
high throughput. You can see a large gain in the throughput by using PolyBase instead of the default
BULKINSERT mechanism. See copy performance reference number with detailed comparison. For a
walkthrough with a use case, see Load 1 TB into Azure SQL Data Warehouse under 15 minutes with Azure
Data Factory.
If your source data is in Azure Blob or Azure Data Lake Store, and the format is compatible with
PolyBase, you can directly copy to Azure SQL Data Warehouse using PolyBase. See Direct copy using
PolyBase with details.
If your source data store and format is not originally supported by PolyBase, you can use the Staged
Copy using PolyBase feature instead. It also provides you better throughput by automatically converting
the data into PolyBase-compatible format and storing the data in Azure Blob storage. It then loads data
into SQL Data Warehouse.
Set the allowPolyBase property to true as shown in the following example for Azure Data Factory to use
PolyBase to copy data into Azure SQL Data Warehouse. When you set allowPolyBase to true, you can specify
PolyBase specific properties using the polyBaseSettings property group. see the SqlDWSink section for
details about properties that you can use with polyBaseSettings.
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
Direct copy using PolyBase
SQL Data Warehouse PolyBase directly support Azure Blob and Azure Data Lake Store (using service
principal) as source and with specific file format requirements. If your source data meets the criteria described
in this section, you can directly copy from source data store to Azure SQL Data Warehouse using PolyBase.
Otherwise, you can use Staged Copy using PolyBase.
TIP
To copy data from Data Lake Store to SQL Data Warehouse efficiently, learn more from Azure Data Factory makes it
even easier and convenient to uncover insights from data when using Data Lake Store with SQL Data Warehouse.
If the requirements are not met, Azure Data Factory checks the settings and automatically falls back to the
BULKINSERT mechanism for the data movement.
1. Source linked service is of type: AzureStorage or AzureDataLakeStore with service principal
authentication.
2. The input dataset is of type: AzureBlob or AzureDataLakeStore, and the format type under type
properties is OrcFormat, or TextFormat with the following configurations:
a.
b.
c.
d.
e.
must be \n.
nullValue is set to empty string (""), or treatEmptyAsNull is set to true.
encodingName is set to utf-8, which is default value.
escapeChar , quoteChar , firstRowAsHeader , and skipLineCount are not specified.
compression can be no compression, GZip, or Deflate.
rowDelimiter
"typeProperties": {
"folderPath": "<blobpath>",
"format": {
"type": "TextFormat",
"columnDelimiter": "<any delimiter>",
"rowDelimiter": "\n",
"nullValue": "",
"encodingName": "utf-8"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
},
3. There is no skipHeaderLineCount setting under BlobSource or AzureDataLakeStore for the Copy
activity in the pipeline.
4. There is no sliceIdentifierColumnName setting under SqlDWSink for the Copy activity in the pipeline.
(PolyBase guarantees that all data is updated or nothing is updated in a single run. To achieve
repeatability, you could use sqlWriterCleanupScript ).
5. There is no columnMapping being used in the associated in Copy activity.
Staged Copy using PolyBase
When your source data doesn’t meet the criteria introduced in the previous section, you can enable copying
data via an interim staging Azure Blob Storage (cannot be Premium Storage). In this case, Azure Data Factory
automatically performs transformations on the data to meet data format requirements of PolyBase, then use
PolyBase to load data into SQL Data Warehouse, and at last clean-up your temp data from the Blob storage.
See Staged Copy for details on how copying data via a staging Azure Blob works in general.
NOTE
When copying data from an on-prem data store into Azure SQL Data Warehouse using PolyBase and staging, if your
Data Management Gateway version is below 2.4, JRE (Java Runtime Environment) is required on your gateway
machine that is used to transform your source data into proper format. Suggest you upgrade your gateway to the
latest to avoid such dependency.
To use this feature, create an Azure Storage linked service that refers to the Azure Storage Account that has
the interim blob storage, then specify the enableStaging and stagingSettings properties for the Copy
Activity as shown in the following code:
"activities":[
{
"name": "Sample copy activity from SQL Server to SQL Data Warehouse via PolyBase",
"type": "Copy",
"inputs": [{ "name": "OnpremisesSQLServerInput" }],
"outputs": [{ "name": "AzureSQLDWOutput" }],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDwSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "MyStagingBlob"
}
}
}
]
Best practices when using PolyBase
The following sections provide additional best practices to the ones that are mentioned in Best practices for
Azure SQL Data Warehouse.
Required database permission
To use PolyBase, it requires the user being used to load data into SQL Data Warehouse has the "CONTROL"
permission on the target database. One way to achieve that is to add that user as a member of "db_owner"
role. Learn how to do that by following this section.
Row size and data type limitation
Polybase loads are limited to loading rows both smaller than 1 MB and cannot load to VARCHR(MAX),
NVARCHAR(MAX) or VARBINARY(MAX). Refer to here.
If you have source data with rows of size greater than 1 MB, you may want to split the source tables vertically
into several small ones where the largest row size of each of them does not exceed the limit. The smaller
tables can then be loaded using PolyBase and merged together in Azure SQL Data Warehouse.
SQL Data Warehouse resource class
To achieve best possible throughput, consider to assign larger resource class to the user being used to load
data into SQL Data Warehouse via PolyBase. Learn how to do that by following Change a user resource class
example.
tableName in Azure SQL Data Warehouse
The following table provides examples on how to specify the tableName property in dataset JSON for
various combinations of schema and table name.
DB SCHEMA
TABLE NAME
TABLENAME JSON PROPERTY
dbo
MyTable
MyTable or dbo.MyTable or [dbo].
[MyTable]
dbo1
MyTable
dbo1.MyTable or [dbo1].[MyTable]
dbo
My.Table
[My.Table] or [dbo].[My.Table]
DB SCHEMA
TABLE NAME
TABLENAME JSON PROPERTY
dbo1
My.Table
[dbo1].[My.Table]
If you see the following error, it could be an issue with the value you specified for the tableName property.
See the table for the correct way to specify values for the tableName JSON property.
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net
SqlClient Data Provider
Columns with default values
Currently, PolyBase feature in Data Factory only accepts the same number of columns as in the target table.
Say, you have a table with four columns and one of them is defined with a default value. The input data
should still contain four columns. Providing a 3-column input dataset would yield an error similar to the
following message:
All columns of the table must be specified in the INSERT BULK statement.
NULL value is a special form of default value. If the column is nullable, the input data (in blob) for that column
could be empty (cannot be missing from the input dataset). PolyBase inserts NULL for them in the Azure SQL
Data Warehouse.
Auto table creation
If you are using Copy Wizard to copy data from SQL Server or Azure SQL Database to Azure SQL Data
Warehouse and the table that corresponds to the source table does not exist in the destination store, Data
Factory can automatically create the table in the data warehouse by using the source table schema.
Data Factory creates the table in the destination store with the same table name in the source data store. The
data types for columns are chosen based on the following type mapping. If needed, it performs type
conversions to fix any incompatibilities between source and destination stores. It also uses Round Robin table
distribution.
SOURCE SQL DATABASE COLUMN TYPE
DESTINATION SQL DW COLUMN TYPE (SIZE LIMITATION)
Int
Int
BigInt
BigInt
SmallInt
SmallInt
TinyInt
TinyInt
Bit
Bit
Decimal
Decimal
Numeric
Decimal
Float
Float
SOURCE SQL DATABASE COLUMN TYPE
DESTINATION SQL DW COLUMN TYPE (SIZE LIMITATION)
Money
Money
Real
Real
SmallMoney
SmallMoney
Binary
Binary
Varbinary
Varbinary (up to 8000)
Date
Date
DateTime
DateTime
DateTime2
DateTime2
Time
Time
DateTimeOffset
DateTimeOffset
SmallDateTime
SmallDateTime
Text
Varchar (up to 8000)
NText
NVarChar (up to 4000)
Image
VarBinary (up to 8000)
UniqueIdentifier
UniqueIdentifier
Char
Char
NChar
NChar
VarChar
VarChar (up to 8000)
NVarChar
NVarChar (up to 4000)
Xml
Varchar (up to 8000)
Repeatability during Copy
When copying data to Azure SQL/SQL Server from other data stores one needs to keep repeatability in mind
to avoid unintended outcomes.
When copying data to Azure SQL/SQL Server Database, copy activity will by default APPEND the data set to
the sink table by default. For example, when copying data from a CSV (comma separated values data) file
source containing two records to Azure SQL/SQL Server Database, this is what the table looks like:
ID
Product
...
...
6
Flat Washer
7
Down Tube
Quantity
...
3
2
ModifiedDate
...
2015-05-01 00:00:00
2015-05-01 00:00:00
Suppose you found errors in source file and updated the quantity of Down Tube from 2 to 4 in the source file.
If you re-run the data slice for that period, you’ll find two new records appended to Azure SQL/SQL Server
Database. The below assumes none of the columns in the table have the primary key constraint.
ID
Product
...
...
6
Flat Washer
7
Down Tube
6
Flat Washer
7
Down Tube
Quantity
...
3
2
3
4
ModifiedDate
...
2015-05-01 00:00:00
2015-05-01 00:00:00
2015-05-01 00:00:00
2015-05-01 00:00:00
To avoid this, you will need to specify UPSERT semantics by leveraging one of the below 2 mechanisms stated
below.
NOTE
A slice can be re-run automatically in Azure Data Factory as per the retry policy specified.
Mechanism 1
You can leverage sqlWriterCleanupScript property to first perform cleanup action when a slice is run.
"sink":
{
"type": "SqlSink",
"sqlWriterCleanupScript": "$$Text.Format('DELETE FROM table WHERE ModifiedDate >= \\'{0:yyyy-MM-dd
HH:mm}\\' AND ModifiedDate < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
}
The cleanup script would be executed first during copy for a given slice which would delete the data from the
SQL Table corresponding to that slice. The activity will subsequently insert the data into the SQL Table.
If the slice is now re-run, then you will find the quantity is updated as desired.
ID
Product
...
...
6
Flat Washer
7
Down Tube
Quantity
...
3
4
ModifiedDate
...
2015-05-01 00:00:00
2015-05-01 00:00:00
Suppose the Flat Washer record is removed from the original csv. Then re-running the slice would produce
the following result:
ID
...
7
Product
...
Down Tube
Quantity
...
4
ModifiedDate
...
2015-05-01 00:00:00
Nothing new had to be done. The copy activity ran the cleanup script to delete the corresponding data for that
slice. Then it read the input from the csv (which then contained only 1 record) and inserted it into the Table.
Mechanism 2
IMPORTANT
sliceIdentifierColumnName is not supported for Azure SQL Data Warehouse at this time.
Another mechanism to achieve repeatability is by having a dedicated column (sliceIdentifierColumnName)
in the target Table. This column would be used by Azure Data Factory to ensure the source and destination
stay synchronized. This approach works when there is flexibility in changing or defining the destination SQL
Table schema.
This column would be used by Azure Data Factory for repeatability purposes and in the process Azure Data
Factory will not make any schema changes to the Table. Way to use this approach:
1. Define a column of type binary (32) in the destination SQL Table. There should be no constraints on this
column. Let's name this column as ‘ColumnForADFuseOnly’ for this example.
2. Use it in the copy activity as follows:
"sink":
{
"type": "SqlSink",
"sliceIdentifierColumnName": "ColumnForADFuseOnly"
}
Azure Data Factory will populate this column as per its need to ensure the source and destination stay
synchronized. The values of this column should not be used outside of this context by the user.
Similar to mechanism 1, Copy Activity will automatically first clean up the data for the given slice from the
destination SQL Table and then run the copy activity normally to insert the data from source to destination
for that slice.
Type mapping for Azure SQL Data Warehouse
As mentioned in the data movement activities article, Copy activity performs automatic type conversions
from source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to & from Azure SQL Data Warehouse, the following mappings are used from SQL type
to .NET type and vice versa.
The mapping is same as the SQL Server Data Type Mapping for ADO.NET.
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
bigint
Int64
binary
Byte[]
bit
Boolean
char
String, Char[]
date
DateTime
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
Datetime
DateTime
datetime2
DateTime
Datetimeoffset
DateTimeOffset
Decimal
Decimal
FILESTREAM attribute (varbinary(max))
Byte[]
Float
Double
image
Byte[]
int
Int32
money
Decimal
nchar
String, Char[]
ntext
String, Char[]
numeric
Decimal
nvarchar
String, Char[]
real
Single
rowversion
Byte[]
smalldatetime
DateTime
smallint
Int16
smallmoney
Decimal
sql_variant
Object *
text
String, Char[]
time
TimeSpan
timestamp
Byte[]
tinyint
Byte
uniqueidentifier
Guid
varbinary
Byte[]
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
varchar
String, Char[]
xml
Xml
You can also map columns from source dataset to columns from sink dataset in the copy activity definition.
For details, see Mapping dataset columns in Azure Data Factory.
JSON examples for copying data to and from SQL Data Warehouse
The following examples provide sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data to and from Azure SQL Data
Warehouse and Azure Blob Storage. However, data can be copied directly from any of sources to any of the
sinks stated here using the Copy Activity in Azure Data Factory.
Example: Copy data from Azure SQL Data Warehouse to Azure Blob
The sample defines the following Data Factory entities:
1.
2.
3.
4.
5.
A linked service of type AzureSqlDW.
A linked service of type AzureStorage.
An input dataset of type AzureSqlDWTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses SqlDWSource and BlobSink.
The sample copies time-series (hourly, daily, etc.) data from a table in Azure SQL Data Warehouse database to
a blob every hour. The JSON properties used in these samples are described in sections following the
samples.
Azure SQL Data Warehouse linked service:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User
ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection
Timeout=30"
}
}
}
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure SQL Data Warehouse input dataset:
The sample assumes you have created a table “MyTable” in Azure SQL Data Warehouse and it contains a
column called “timestampcolumn” for time series data.
Setting “external”: ”true” informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "AzureSqlDWInput",
"properties": {
"type": "AzureSqlDWTable",
"linkedServiceName": "AzureSqlDWLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with SqlDWSource and BlobSink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to SqlDWSource and sink type is
set to BlobSink. The SQL query specified for the SqlReaderQuery property selects the data in the past hour
to copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "AzureSQLDWtoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": "AzureSqlDWInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >= \\'{0:yyyyMM-dd HH:mm}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
NOTE
In the example, sqlReaderQuery is specified for the SqlDWSource. The Copy Activity runs this query against the Azure
SQL Data Warehouse source to get the data.
Alternatively, you can specify a stored procedure by specifying the sqlReaderStoredProcedureName and
storedProcedureParameters (if the stored procedure takes parameters).
If you do not specify either sqlReaderQuery or sqlReaderStoredProcedureName, the columns defined in the structure
section of the dataset JSON are used to build a query (select column1, column2 from mytable) to run against the
Azure SQL Data Warehouse. If the dataset definition does not have the structure, all columns are selected from the
table.
Example: Copy data from Azure Blob to Azure SQL Data Warehouse
The sample defines the following Data Factory entities:
1. A linked service of type AzureSqlDW.
2.
3.
4.
5.
A linked service of type AzureStorage.
An input dataset of type AzureBlob.
An output dataset of type AzureSqlDWTable.
A pipeline with Copy activity that uses BlobSource and SqlDWSink.
The sample copies time-series data (hourly, daily, etc.) from Azure blob to a table in Azure SQL Data
Warehouse database every hour. The JSON properties used in these samples are described in sections
following the samples.
Azure SQL Data Warehouse linked service:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User
ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection
Timeout=30"
}
}
}
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Blob input dataset:
Data is picked up from a new blob every hour (frequency: hour, interval: 1). The folder path and file name for
the blob are dynamically evaluated based on the start time of the slice that is being processed. The folder path
uses year, month, and day part of the start time and file name uses the hour part of the start time. “external”:
“true” setting informs the Data Factory service that this table is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}",
"fileName": "{Hour}.csv",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure SQL Data Warehouse output dataset:
The sample copies data to a table named “MyTable” in Azure SQL Data Warehouse. Create the table in Azure
SQL Data Warehouse with the same number of columns as you expect the Blob CSV file to contain. New rows
are added to the table every hour.
{
"name": "AzureSqlDWOutput",
"properties": {
"type": "AzureSqlDWTable",
"linkedServiceName": "AzureSqlDWLinkedService",
"typeProperties": {
"tableName": "MyOutputTable"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with BlobSource and SqlDWSink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to BlobSource and sink type is set
to SqlDWSink.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "AzureBlobtoSQLDW",
"description": "Copy Activity",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureSqlDWOutput"
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"blobColumnSeparators": ","
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
For a walkthrough, see the see Load 1 TB into Azure SQL Data Warehouse under 15 minutes with Azure Data
Factory and Load data with Azure Data Factory article in the Azure SQL Data Warehouse documentation.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data to and from Azure Table using Azure
Data Factory
6/5/2017 • 16 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data to/from Azure Table
Storage. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
You can copy data from any supported source data store to Azure Table Storage or from Azure Table Storage
to any supported sink data store. For a list of data stores supported as sources or sinks by the copy activity,
see the Supported data stores table.
Getting started
You can create a pipeline with a copy activity that moves data to/from an Azure Table Storage by using
different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that are
used to copy data to/from an Azure Table Storage, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Azure Table Storage:
Linked service properties
There are two types of linked services you can use to link an Azure blob storage to an Azure data factory. They
are: AzureStorage linked service and AzureStorageSas linked service. The Azure Storage linked service
provides the data factory with global access to the Azure Storage. Whereas, The Azure Storage SAS (Shared
Access Signature) linked service provides the data factory with restricted/time-bound access to the Azure
Storage. There are no other differences between these two linked services. Choose the linked service that suits
your needs. The following sections provide more details on these two linked services.
Azure Storage Linked Service
The Azure Storage linked service allows you to link an Azure storage account to an Azure data factory by
using the account key, which provides the data factory with global access to the Azure Storage. The following
table provides description for JSON elements specific to Azure Storage linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AzureStorage
Yes
connectionString
Specify information needed to
connect to Azure storage for the
connectionString property.
Yes
See the following article for steps to view/copy the account key for an Azure Storage: View, copy, and
regenerate storage access keys.
Example:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Storage Sas Linked Service
A shared access signature (SAS) provides delegated access to resources in your storage account. It allows you
to grant a client limited permissions to objects in your storage account for a specified period of time and with
a specified set of permissions, without having to share your account access keys. The SAS is a URI that
encompasses in its query parameters all the information necessary for authenticated access to a storage
resource. To access storage resources with the SAS, the client only needs to pass in the SAS to the appropriate
constructor or method. For detailed information about SAS, see Shared Access Signatures: Understanding the
SAS Model
The Azure Storage SAS linked service allows you to link an Azure Storage Account to an Azure data factory by
using a Shared Access Signature (SAS). It provides the data factory with restricted/time-bound access to
all/specific resources (blob/container) in the storage. The following table provides description for JSON
elements specific to Azure Storage SAS linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
AzureStorageSas
Yes
sasUri
Specify Shared Access Signature URI
to the Azure Storage resources such
as blob, container, or table.
Yes
Example:
{
"name": "StorageSasLinkedService",
"properties": {
"type": "AzureStorageSas",
"typeProperties": {
"sasUri": "<storageUri>?<sasToken>"
}
}
}
When creating an SAS URI, considering the following:
Azure Data Factory supports only Service SAS, not Account SAS. See Types of Shared Access Signatures
for details about these two types.
Set appropriate read/write permissions on objects based on how the linked service (read, write,
read/write) is used in your data factory.
Set Expiry time appropriately. Make sure that the access to Azure Storage objects does not expire within
the active period of the pipeline.
Uri should be created at the right container/blob or Table level based on the need. A SAS Uri to an Azure
blob allows the Data Factory service to access that particular blob. A SAS Uri to an Azure blob container
allows the Data Factory service to iterate through blobs in that container. If you need to provide access
more/fewer objects later, or update the SAS URI, remember to update the linked service with the new URI.
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for the dataset of type AzureTable has the following
properties.
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the Azure Table
Database instance that linked service
refers to.
Yes. When a tableName is specified
without an azureTableSourceQuery, all
records from the table are copied to
the destination. If an
azureTableSourceQuery is also
specified, records from the table that
satisfies the query are copied to the
destination.
Schema by Data Factory
For schema-free data stores such as Azure Table, the Data Factory service infers the schema in one of the
following ways:
1. If you specify the structure of data by using the structure property in the dataset definition, the Data
Factory service honors this structure as the schema. In this case, if a row does not contain a value for a
column, a null value is provided for it.
2. If you don't specify the structure of data by using the structure property in the dataset definition, Data
Factory infers the schema by using the first row in the data. In this case, if the first row does not contain the
full schema, some columns are missed in the result of copy operation.
Therefore, for schema-free data sources, the best practice is to specify the structure of data using the
structure property.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output datasets, and policies are available for all types of
activities.
Properties available in the typeProperties section of the activity on the other hand vary with each activity type.
For Copy activity, they vary depending on the types of sources and sinks.
AzureTableSource supports the following properties in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
azureTableSourceQuery
Use the custom query to
read data.
Azure table query string.
See examples in the next
section.
No. When a tableName is
specified without an
azureTableSourceQuery, all
records from the table are
copied to the destination. If
an azureTableSourceQuery
is also specified, records
from the table that satisfies
the query are copied to the
destination.
azureTableSourceIgnoreTab
leNotFound
Indicate whether swallow
the exception of table not
exist.
TRUE
FALSE
No
azureTableSourceQuery examples
If Azure Table column is of string type:
azureTableSourceQuery": "$$Text.Format('PartitionKey ge \\'{0:yyyyMMddHH00_0000}\\' and PartitionKey le
\\'{0:yyyyMMddHH00_9999}\\'', SliceStart)"
If Azure Table column is of datetime type:
"azureTableSourceQuery": "$$Text.Format('DeploymentEndTime gt datetime\\'{0:yyyy-MM-ddTHH:mm:ssZ}\\' and
DeploymentEndTime le datetime\\'{1:yyyy-MM-ddTHH:mm:ssZ}\\'', SliceStart, SliceEnd)"
AzureTableSink supports the following properties in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
azureTableDefaultPartition
KeyValue
Default partition key value
that can be used by the
sink.
A string value.
No
azureTablePartitionKeyNam
e
Specify name of the
column whose values are
used as partition keys. If
not specified,
AzureTableDefaultPartition
KeyValue is used as the
partition key.
A column name.
No
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
azureTableRowKeyName
Specify name of the
column whose column
values are used as row key.
If not specified, use a GUID
for each row.
A column name.
No
azureTableInsertType
The mode to insert data
into Azure table.
merge (default)
replace
No
This property controls
whether existing rows in
the output table with
matching partition and row
keys have their values
replaced or merged.
To learn about how these
settings (merge and
replace) work, see Insert or
Merge Entity and Insert or
Replace Entity topics.
This setting applies at the
row level, not the table
level, and neither option
deletes rows in the output
table that do not exist in
the input.
writeBatchSize
Inserts data into the Azure
table when the
writeBatchSize or
writeBatchTimeout is hit.
Integer (number of rows)
No (default: 10000)
writeBatchTimeout
Inserts data into the Azure
table when the
writeBatchSize or
writeBatchTimeout is hit
timespan
No (Default to storage
client default timeout value
90 sec)
Example: “00:20:00” (20
minutes)
azureTablePartitionKeyName
Map a source column to a destination column using the translator JSON property before you can use the
destination column as the azureTablePartitionKeyName.
In the following example, source column DivisionID is mapped to the destination column: DivisionID.
"translator": {
"type": "TabularTranslator",
"columnMappings": "DivisionID: DivisionID, FirstName: FirstName, LastName: LastName"
}
The DivisionID is specified as the partition key.
"sink": {
"type": "AzureTableSink",
"azureTablePartitionKeyName": "DivisionID",
"writeBatchSize": 100,
"writeBatchTimeout": "01:00:00"
}
JSON examples
The following examples provide sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data to and from Azure Table Storage
and Azure Blob Database. However, data can be copied directly from any of the sources to any of the
supported sinks. For more information, see the section "Supported data stores and formats" in Move data by
using Copy Activity.
Example: Copy data from Azure Table to Azure Blob
The following sample shows:
1.
2.
3.
4.
A linked service of type AzureStorage (used for both table & blob).
An input dataset of type AzureTable.
An output dataset of type AzureBlob.
The pipeline with Copy activity that uses AzureTableSource and BlobSink.
The sample copies data belonging to the default partition in an Azure Table to a blob every hour. The JSON
properties used in these samples are described in sections following the samples.
Azure storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Data Factory supports two types of Azure Storage linked services: AzureStorage and
AzureStorageSas. For the first one, you specify the connection string that includes the account key and for
the later one, you specify the Shared Access Signature (SAS) Uri. See Linked Services section for details.
Azure Table input dataset:
The sample assumes you have created a table “MyTable” in Azure Table.
Setting “external”: ”true” informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "AzureTableInput",
"properties": {
"type": "AzureTable",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with AzureTableSource and BlobSink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to AzureTableSource and sink type
is set to BlobSink. The SQL query specified with AzureTableSourceQuery property selects the data from the
default partition every hour to copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "AzureTabletoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": "AzureTableInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "AzureTableSource",
"AzureTableSourceQuery": "PartitionKey eq 'DefaultPartitionKey'"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Example: Copy data from Azure Blob to Azure Table
The following sample shows:
1.
2.
3.
4.
A linked service of type AzureStorage (used for both table & blob)
An input dataset of type AzureBlob.
An output dataset of type AzureTable.
The pipeline with Copy activity that uses BlobSource and AzureTableSink.
The sample copies time-series data from an Azure blob to an Azure table hourly. The JSON properties used in
these samples are described in sections following the samples.
Azure storage (for both Azure Table & Blob) linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Data Factory supports two types of Azure Storage linked services: AzureStorage and
AzureStorageSas. For the first one, you specify the connection string that includes the account key and for
the later one, you specify the Shared Access Signature (SAS) Uri. See Linked Services section for details.
Azure Blob input dataset:
Data is picked up from a new blob every hour (frequency: hour, interval: 1). The folder path and file name for
the blob are dynamically evaluated based on the start time of the slice that is being processed. The folder path
uses year, month, and day part of the start time and file name uses the hour part of the start time. “external”:
“true” setting informs the Data Factory service that the dataset is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}",
"fileName": "{Hour}.csv",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Table output dataset:
The sample copies data to a table named “MyTable” in Azure Table. Create an Azure table with the same
number of columns as you expect the Blob CSV file to contain. New rows are added to the table every hour.
{
"name": "AzureTableOutput",
"properties": {
"type": "AzureTable",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"tableName": "MyOutputTable"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with BlobSource and AzureTableSink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to BlobSource and sink type is set to
AzureTableSink.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "AzureBlobtoTable",
"description": "Copy Activity",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureTableOutput"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "AzureTableSink",
"writeBatchSize": 100,
"writeBatchTimeout": "01:00:00"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Type Mapping for Azure Table
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following two-step approach.
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to & from Azure Table, the following mappings defined by Azure Table service are used
from Azure Table OData types to .NET type and vice versa.
ODATA DATA TYPE
.NET TYPE
DETAILS
Edm.Binary
byte[]
An array of bytes up to 64 KB.
Edm.Boolean
bool
A Boolean value.
ODATA DATA TYPE
.NET TYPE
DETAILS
Edm.DateTime
DateTime
A 64-bit value expressed as
Coordinated Universal Time (UTC).
The supported DateTime range begins
from 12:00 midnight, January 1, 1601
A.D. (C.E.), UTC. The range ends at
December 31, 9999.
Edm.Double
double
A 64-bit floating point value.
Edm.Guid
Guid
A 128-bit globally unique identifier.
Edm.Int32
Int32
A 32-bit integer.
Edm.Int64
Int64
A 64-bit integer.
Edm.String
String
A UTF-16-encoded value. String
values may be up to 64 KB.
Type Conversion Sample
The following sample is for copying data from an Azure Blob to Azure Table with type conversions.
Suppose the Blob dataset is in CSV format and contains three columns. One of them is a datetime column
with a custom datetime format using abbreviated French names for day of the week.
Define the Blob Source dataset as follows along with type definitions for the columns.
{
"name": " AzureBlobInput",
"properties":
{
"structure":
[
{ "name": "userid", "type": "Int64"},
{ "name": "name", "type": "String"},
{ "name": "lastlogindate", "type": "Datetime", "culture": "fr-fr", "format": "ddd-MMYYYY"}
],
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"fileName":"myfile.csv",
"format":
{
"type": "TextFormat",
"columnDelimiter": ","
}
},
"external": true,
"availability":
{
"frequency": "Hour",
"interval": 1,
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Given the type mapping from Azure Table OData type to .NET type, you would define the table in Azure Table
with the following schema.
Azure Table schema:
COLUMN NAME
TYPE
userid
Edm.Int64
name
Edm.String
lastlogindate
Edm.DateTime
Next, define the Azure Table dataset as follows. You do not need to specify “structure” section with the type
information since the type information is already specified in the underlying data store.
{
"name": "AzureTableOutput",
"properties": {
"type": "AzureTable",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"tableName": "MyOutputTable"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
In this case, Data Factory automatically does type conversions including the Datetime field with the custom
datetime format using the "fr-fr" culture when moving data from Blob to Azure Table.
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data
Factory.
Performance and Tuning
To learn about key factors that impact performance of data movement (Copy Activity) in Azure Data Factory
and various ways to optimize it, see Copy Activity Performance & Tuning Guide.
Move data from an on-premises Cassandra
database using Azure Data Factory
5/4/2017 • 10 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
Cassandra database. It builds on the Data Movement Activities article, which presents a general overview of
data movement with the copy activity.
You can copy data from an on-premises Cassandra data store to any supported sink data store. For a list of
data stores supported as sinks by the copy activity, see the Supported data stores table. Data factory currently
supports only moving data from a Cassandra data store to other data stores, but not for moving data from
other data stores to a Cassandra data store.
Supported versions
The Cassandra connector supports the following versions of Cassandra: 2.X.
Prerequisites
For the Azure Data Factory service to be able to connect to your on-premises Cassandra database, you must
install a Data Management Gateway on the same machine that hosts the database or on a separate machine to
avoid competing for resources with the database. Data Management Gateway is a component that connects
on-premises data sources to cloud services in a secure and managed way. See Data Management Gateway
article for details about Data Management Gateway. See Move data from on-premises to cloud article for stepby-step instructions on setting up the gateway a data pipeline to move data.
You must use the gateway to connect to a Cassandra database even if the database is hosted in the cloud, for
example, on an Azure IaaS VM. Y You can have the gateway on the same VM that hosts the database or on a
separate VM as long as the gateway can connect to the database.
When you install the gateway, it automatically installs a Microsoft Cassandra ODBC driver used to connect to
Cassandra database. Therefore, you don't need to manually install any driver on the gateway machine when
copying data from the Cassandra database.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises Cassandra data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises Cassandra data store, see JSON example: Copy data from Cassandra to
Azure Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to a Cassandra data store:
Linked service properties
The following table provides description for JSON elements specific to Cassandra linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesCassandra
Yes
host
One or more IP addresses or host
names of Cassandra servers.
Yes
Specify a comma-separated list of IP
addresses or host names to connect
to all servers concurrently.
port
The TCP port that the Cassandra
server uses to listen for client
connections.
No, default value: 9042
authenticationType
Basic, or Anonymous
Yes
username
Specify user name for the user
account.
Yes, if authenticationType is set to
Basic.
password
Specify password for the user account.
Yes, if authenticationType is set to
Basic.
gatewayName
The name of the gateway that is used
to connect to the on-premises
Cassandra database.
Yes
encryptedCredential
Credential encrypted by the gateway.
No
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type CassandraTable has the following
properties
PROPERTY
DESCRIPTION
REQUIRED
keyspace
Name of the keyspace or schema in
Cassandra database.
Yes (If query for CassandraSource is
not defined).
tableName
Name of the table in Cassandra
database.
Yes (If query for CassandraSource is
not defined).
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For Copy
activity, they vary depending on the types of sources and sinks.
When source is of type CassandraSource, the following properties are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL-92 query or CQL
query. See CQL reference.
No (if tableName and
keyspace on dataset are
defined).
When using SQL query,
specify keyspace
name.table name to
represent the table you
want to query.
consistencyLevel
The consistency level
specifies how many replicas
must respond to a read
request before returning
data to the client
application. Cassandra
checks the specified
number of replicas for data
to satisfy the read request.
ONE, TWO, THREE,
QUORUM, ALL,
LOCAL_QUORUM,
EACH_QUORUM,
LOCAL_ONE. See
Configuring data
consistency for details.
No. Default value is ONE.
JSON example: Copy data from Cassandra to Azure Blob
This example provides sample JSON definitions that you can use to create a pipeline by using Azure portal or
Visual Studio or Azure PowerShell. It shows how to copy data from an on-premises Cassandra database to an
Azure Blob Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in
Azure Data Factory.
IMPORTANT
This sample provides JSON snippets. It does not include step-by-step instructions for creating the data factory. See
moving data between on-premises locations and cloud article for step-by-step instructions.
The sample has the following data factory entities:
A linked service of type OnPremisesCassandra.
A linked service of type AzureStorage.
An input dataset of type CassandraTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses CassandraSource and BlobSink.
Cassandra linked service:
This example uses the Cassandra linked service. See Cassandra linked service section for the properties
supported by this linked service.
{
"name": "CassandraLinkedService",
"properties":
{
"type": "OnPremisesCassandra",
"typeProperties":
{
"authenticationType": "Basic",
"host": "mycassandraserver",
"port": 9042,
"username": "user",
"password": "password",
"gatewayName": "mygateway"
}
}
}
Azure Storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Cassandra input dataset:
{
"name": "CassandraInput",
"properties": {
"linkedServiceName": "CassandraLinkedService",
"type": "CassandraTable",
"typeProperties": {
"tableName": "mytable",
"keySpace": "mykeyspace"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Setting external to true informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1).
{
"name": "AzureBlobOutput",
"properties":
{
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties":
{
"folderPath": "adfgetstarted/fromcassandra"
},
"availability":
{
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with Cassandra source and Blob sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to CassandraSource and sink type is set
to BlobSink.
See RelationalSource type properties for the list of properties supported by the RelationalSource.
{
"name":"SamplePipeline",
"properties":{
"start":"2016-06-01T18:00:00",
"end":"2016-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "CassandraToAzureBlob",
"description": "Copy from Cassandra to an Azure blob",
"type": "Copy",
"inputs": [
{
"name": "CassandraInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Type mapping for Cassandra
CASSANDRA TYPE
.NET BASED TYPE
ASCII
String
BIGINT
Int64
BLOB
Byte[]
BOOLEAN
Boolean
DECIMAL
Decimal
DOUBLE
Double
CASSANDRA TYPE
.NET BASED TYPE
FLOAT
Single
INET
String
INT
Int32
TEXT
String
TIMESTAMP
DateTime
TIMEUUID
Guid
UUID
Guid
VARCHAR
String
VARINT
Decimal
NOTE
For collection types (map, set, list, etc.), refer to Work with Cassandra collection types using virtual table section.
User-defined types are not supported.
The length of Binary Column and String Column lengths cannot be greater than 4000.
Work with collections using virtual table
Azure Data Factory uses a built-in ODBC driver to connect to and copy data from your Cassandra database. For
collection types including map, set and list, the driver renormalizes the data into corresponding virtual tables.
Specifically, if a table contains any collection columns, the driver generates the following virtual tables:
A base table, which contains the same data as the real table except for the collection columns. The base
table uses the same name as the real table that it represents.
A virtual table for each collection column, which expands the nested data. The virtual tables that represent
collections are named using the name of the real table, a separator “vt” and the name of the column.
Virtual tables refer to the data in the real table, enabling the driver to access the denormalized data. See
Example section for details. You can access the content of Cassandra collections by querying and joining the
virtual tables.
You can use the Copy Wizard to intuitively view the list of tables in Cassandra database including the virtual
tables, and preview the data inside. You can also construct a query in the Copy Wizard and validate to see the
result.
Example
For example, the following “ExampleTable” is a Cassandra database table that contains an integer primary key
column named “pk_int”, a text column named value, a list column, a map column, and a set column (named
“StringSet”).
PK_INT
VALUE
LIST
MAP
STRINGSET
1
"sample value 1"
["1", "2", "3"]
{"S1": "a", "S2": "b"}
{"A", "B", "C"}
3
"sample value 3"
["100", "101", "102",
"105"]
{"S1": "t"}
{"A", "E"}
The driver would generate multiple virtual tables to represent this single table. The foreign key columns in the
virtual tables reference the primary key columns in the real table, and indicate which real table row the virtual
table row corresponds to.
The first virtual table is the base table named “ExampleTable” is shown in the following table. The base table
contains the same data as the original database table except for the collections, which are omitted from this
table and expanded in other virtual tables.
PK_INT
VALUE
1
"sample value 1"
3
"sample value 3"
The following tables show the virtual tables that renormalize the data from the List, Map, and StringSet
columns. The columns with names that end with “_index” or “_key” indicate the position of the data within the
original list or map. The columns with names that end with “_value” contain the expanded data from the
collection.
Table “ExampleTable_vt_List”:
PK_INT
LIST_INDEX
LIST_VALUE
1
0
1
1
1
2
1
2
3
3
0
100
3
1
101
3
2
102
3
3
103
PK_INT
MAP_KEY
MAP_VALUE
1
S1
A
1
S2
b
3
S1
t
Table “ExampleTable_vt_Map”:
Table “ExampleTable_vt_StringSet”:
PK_INT
STRINGSET_VALUE
1
A
1
B
1
C
3
A
3
E
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from DB2 using Azure Data Factory
4/12/2017 • 9 min to read • Edit Online
This article outlines how you can use the Copy Activity in an Azure data factory to copy data from an onpremises DB2 database to any data store listed under Sink column in the Supported Sources and Sinks section.
This article builds on the data movement activities article, which presents a general overview of data movement
with copy activity and supported data store combinations.
Data factory currently supports only moving data from a DB2 database to supported sink data stores, but not
moving data from other data stores to a DB2 database.
Prerequisites
Data Factory supports connecting to on-premises DB2 database using the Data Management Gateway. See
Data Management Gateway article to learn about Data Management Gateway and Move data from onpremises to cloud article for step-by-step instructions on setting up the gateway a data pipeline to move data.
Gateway is required even if the DB2 is hosted in an Azure IaaS VM. You can install the gateway on the same
IaaS VM as the data store or on a different VM as long as the gateway can connect to the database.
The Data Management Gateway provides a built-in DB2 driver, therefore you don't need to manually install any
driver when copying data from DB2.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Supported versions
This DB2 connector supports the following IBM DB2 platforms and versions with Distributed Relational
Database Architecture (DRDA) SQL Access Manager (SQLAM) version 9, 10 and 11:
IBM DB2 for z/OS 11.1
IBM DB2 for z/OS 10.1
IBM DB2 for i 7.2
IBM DB2 for i 7.1
IBM DB2 for LUW 11
IBM DB2 for LUW 10.5
IBM DB2 for LUW 10.1
TIP
If you hit error stating "The package corresponding to an SQL statement execution request was not found.
SQLSTATE=51002 SQLCODE=-805", user a high privilege account (power user or admin) to run the copy activity once,
then the needed package will be auto created during copy. Afterwards, you can switch back to normal user for your
subsequent copy runs.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises DB2 data store by using
different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises DB2 data store, see JSON example: Copy data from DB2 to Azure Blob
section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to a DB2 data store:
Linked service properties
The following table provides description for JSON elements specific to DB2 linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesDB2
Yes
server
Name of the DB2 server.
Yes
database
Name of the DB2 database.
Yes
schema
Name of the schema in the database.
The schema name is case-sensitive.
No
authenticationType
Type of authentication used to
connect to the DB2 database. Possible
values are: Anonymous, Basic, and
Windows.
Yes
username
Specify user name if you are using
Basic or Windows authentication.
No
password
Specify password for the user account
you specified for the username.
No
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the on-premises DB2 database.
Yes
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type RelationalTable (which includes DB2
dataset) has the following properties.
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the DB2
Database instance that linked service
refers to. The tableName is casesensitive.
No (if query of RelationalSource is
specified)
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policies are available for all types of
activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For Copy
activity, they vary depending on the types of sources and sinks.
For Copy Activity, when source is of type RelationalSource (which includes DB2) the following properties are
available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL query string. For
example:
No (if tableName of
dataset is specified)
"query": "select *
from
"MySchema"."MyTable""
.
NOTE
Schema and table names are case-sensitive. Enclose the names in "" (double quotes) in the query.
Example:
"query": "select * from "DB2ADMIN"."Customers""
JSON example: Copy data from DB2 to Azure Blob
This example provides sample JSON definitions that you can use to create a pipeline by using Azure portal or
Visual Studio or Azure PowerShell. It shows how to copy data from DB2 database and Azure Blob Storage.
However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data Factory.
The sample has the following data factory entities:
1. A linked service of type OnPremisesDb2.
2.
3.
4.
5.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from a query result in a DB2 database to an Azure blob hourly. The JSON properties
used in these samples are described in sections following the samples.
As a first step, install and configure a data management gateway. Instructions are in the moving data between
on-premises locations and cloud article.
DB2 linked service:
{
"name": "OnPremDb2LinkedService",
"properties": {
"type": "OnPremisesDb2",
"typeProperties": {
"server": "<server>",
"database": "<database>",
"schema": "<schema>",
"authenticationType": "<authentication type>",
"username": "<username>",
"password": "<password>",
"gatewayName": "<gatewayName>"
}
}
}
Azure Blob storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorageLinkedService",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<AccountName>;AccountKey=
<AccountKey>"
}
}
}
DB2 input dataset:
The sample assumes you have created a table “MyTable” in DB2 and it contains a column called “timestamp”
for time series data.
Setting “external”: true informs the Data Factory service that this dataset is external to the data factory and is
not produced by an activity in the data factory. Notice that the type is set to RelationalTable.
{
"name": "Db2DataSet",
"properties": {
"type": "RelationalTable",
"linkedServiceName": "OnPremDb2LinkedService",
"typeProperties": {},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobDb2DataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/db2/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is set
to BlobSink. The SQL query specified for the query property selects the data from the Orders table.
{
"name": "CopyDb2ToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "select * from \"Orders\""
},
"sink": {
"type": "BlobSink"
}
},
"inputs": [
{
"name": "Db2DataSet"
}
],
"outputs": [
{
"name": "AzureBlobDb2DataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "Db2ToBlob"
}
],
"start": "2014-06-01T18:00:00Z",
"end": "2014-06-01T19:00:00Z"
}
}
Type mapping for DB2
As mentioned in the data movement activities article, the Copy activity performs automatic type conversions
from source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to DB2, the following mappings are used from DB2 type to .NET type.
DB2 DATABASE TYPE
.NET FRAMEWORK TYPE
SmallInt
Int16
Integer
Int32
BigInt
Int64
Real
Single
DB2 DATABASE TYPE
.NET FRAMEWORK TYPE
Double
Double
Float
Double
Decimal
Decimal
DecimalFloat
Decimal
Numeric
Decimal
Date
Datetime
Time
TimeSpan
Timestamp
DateTime
Xml
Byte[]
Char
String
VarChar
String
LongVarChar
String
DB2DynArray
String
Binary
Byte[]
VarBinary
Byte[]
LongVarBinary
Byte[]
Graphic
String
VarGraphic
String
LongVarGraphic
String
Clob
String
Blob
Byte[]
DbClob
String
SmallInt
Int16
Integer
Int32
BigInt
Int64
DB2 DATABASE TYPE
.NET FRAMEWORK TYPE
Real
Single
Double
Double
Float
Double
Decimal
Decimal
DecimalFloat
Decimal
Numeric
Decimal
Date
Datetime
Time
TimeSpan
Timestamp
DateTime
Xml
Byte[]
Char
String
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Copy data to and from an on-premises file system
by using Azure Data Factory
6/9/2017 • 17 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to copy data to/from an on-premises
file system. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
Supported scenarios
You can copy data from an on-premises file system to the following data stores:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Data Lake Store
Azure Cosmos DB (DocumentDB API)
Azure SQL Database
Azure SQL Data Warehouse
Azure Search Index
Azure Table storage
Databases
SQL Server
Oracle
File
File system
You can copy data from the following data stores to an on-premises file system:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Cosmos DB (DocumentDB API)
Azure Data Lake Store
Azure SQL Database
Azure SQL Data Warehouse
Azure Table storage
Databases
Amazon Redshift
DB2
MySQL
Oracle
PostgreSQL
SAP Business Warehouse
SAP HANA
SQL Server
Sybase
Teradata
NoSQL
Cassandra
MongoDB
CATEGORY
DATA STORE
File
Amazon S3
File System
FTP
HDFS
SFTP
Others
Generic HTTP
Generic OData
Generic ODBC
Salesforce
Web Table (table from HTML)
GE Historian
NOTE
Copy Activity does not delete the source file after it is successfully copied to the destination. If you need to delete the
source file after a successful copy, create a custom activity to delete the file and use the activity in the pipeline.
Enabling connectivity
Data Factory supports connecting to and from an on-premises file system via Data Management Gateway.
You must install the Data Management Gateway in your on-premises environment for the Data Factory
service to connect to any supported on-premises data store including file system. To learn about Data
Management Gateway and for step-by-step instructions on setting up the gateway, see Move data between
on-premises sources and the cloud with Data Management Gateway. Apart from Data Management Gateway,
no other binary files need to be installed to communicate to and from an on-premises file system. You must
install and use the Data Management Gateway even if the file system is in Azure IaaS VM. For detailed
information about the gateway, see Data Management Gateway.
To use a Linux file share, install Samba on your Linux server, and install Data Management Gateway on a
Windows server. Installing Data Management Gateway on a Linux server is not supported.
Getting started
You can create a pipeline with a copy activity that moves data to/from a file system by using different
tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create a data factory. A data factory may contain one or more pipelines.
2. Create linked services to link input and output data stores to your data factory. For example, if you are
copying data from an Azure blob storage to an on-premises file system, you create two linked services to
link your on-premises file system and Azure storage account to your data factory. For linked service
properties that are specific to an on-premises file system, see linked service properties section.
3. Create datasets to represent input and output data for the copy operation. In the example mentioned in
the last step, you create a dataset to specify the blob container and folder that contains the input data. And,
you create another dataset to specify the folder and file name (optional) in your file system. For dataset
properties that are specific to on-premises file system, see dataset properties section.
4. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output. In the
example mentioned earlier, you use BlobSource as a source and FileSystemSink as a sink for the copy
activity. Similarly, if you are copying from on-premises file system to Azure Blob Storage, you use
FileSystemSource and BlobSink in the copy activity. For copy activity properties that are specific to onpremises file system, see copy activity properties section. For details on how to use a data store as a
source or a sink, click the link in the previous section for your data store.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that
are used to copy data to/from a file system, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to file system:
Linked service properties
You can link an on-premises file system to an Azure data factory with the On-Premises File Server linked
service. The following table provides descriptions for JSON elements that are specific to the On-Premises File
Server linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
Ensure that the type property is set
to OnPremisesFileServer.
Yes
host
Specifies the root path of the folder
that you want to copy. Use the
escape character ‘ \ ’ for special
characters in the string. See Sample
linked service and dataset definitions
for examples.
Yes
userid
Specify the ID of the user who has
access to the server.
No (if you choose
encryptedCredential)
password
Specify the password for the user
(userid).
No (if you choose
encryptedCredential
encryptedCredential
Specify the encrypted credentials that
you can get by running the NewAzureRmDataFactoryEncryptValue
cmdlet.
No (if you choose to specify userid
and password in plain text)
gatewayName
Specifies the name of the gateway
that Data Factory should use to
connect to the on-premises file
server.
Yes
Sample linked service and dataset definitions
SCENARIO
HOST IN LINKED SERVICE DEFINITION
FOLDERPATH IN DATASET DEFINITION
Local folder on Data Management
Gateway machine:
D:\\ (for Data Management Gateway
2.0 and later versions)
.\\ or folder\\subfolder (for Data
Management Gateway 2.0 and later
versions)
Examples: D:\* or
D:\folder\subfolder\*
localhost (for earlier versions than
Data Management Gateway 2.0)
Remote shared folder:
\\\\myserver\\share
D:\\ or D:\\folder\\subfolder (for
gateway version below 2.0)
.\\ or folder\\subfolder
Examples: \\myserver\share\* or
\\myserver\share\folder\subfolder\*
Example: Using username and password in plain text
{
"Name": "OnPremisesFileServerLinkedService",
"properties": {
"type": "OnPremisesFileServer",
"typeProperties": {
"host": "\\\\Contosogame-Asia",
"userid": "Admin",
"password": "123456",
"gatewayName": "mygateway"
}
}
}
Example: Using encryptedcredential
{
"Name": " OnPremisesFileServerLinkedService ",
"properties": {
"type": "OnPremisesFileServer",
"typeProperties": {
"host": "D:\\",
"encryptedCredential": "WFuIGlzIGRpc3Rpbmd1aXNoZWQsIG5vdCBvbmx5IGJ5xxxxxxxxxxxxxxxxx",
"gatewayName": "mygateway"
}
}
}
Dataset properties
For a full list of sections and properties that are available for defining datasets, see Creating datasets. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types.
The typeProperties section is different for each type of dataset. It provides information such as the location
and format of the data in the data store. The typeProperties section for the dataset of type FileShare has the
following properties:
PROPERTY
DESCRIPTION
REQUIRED
PROPERTY
DESCRIPTION
REQUIRED
folderPath
Specifies the subpath to the folder.
Use the escape character ‘\’ for special
characters in the string. See Sample
linked service and dataset definitions
for examples.
Yes
You can combine this property with
partitionBy to have folder paths
based on slice start/end date-times.
fileName
Specify the name of the file in the
folderPath if you want the table to
refer to a specific file in the folder. If
you do not specify any value for this
property, the table points to all files in
the folder.
No
When fileName is not specified for
an output dataset and
preserveHierarchy is not specified
in activity sink, the name of the
generated file is in the following
format:
Data.<Guid>.txt (Example:
Data.0a405f8a-93ff-4c6f-b3bef69616f1df7a.txt)
fileFilter
Specify a filter to be used to select a
subset of files in the folderPath rather
than all files.
No
Allowed values are: * (multiple
characters) and ? (single character).
Example 1: "fileFilter": "*.log"
Example 2: "fileFilter": 2014-1-?.txt"
Note that fileFilter is applicable for an
input FileShare dataset.
partitionedBy
You can use partitionedBy to specify a
dynamic folderPath/fileName for
time-series data. An example is
folderPath parameterized for every
hour of data.
No
PROPERTY
DESCRIPTION
REQUIRED
format
The following format types are
supported: TextFormat,
JsonFormat, AvroFormat,
OrcFormat, ParquetFormat. Set the
type property under format to one of
these values. For more information,
see Text Format, Json Format, Avro
Format, Orc Format, and Parquet
Format sections.
No
If you want to copy files as-is
between file-based stores (binary
copy), skip the format section in both
input and output dataset definitions.
compression
Specify the type and level of
compression for the data. Supported
types are: GZip, Deflate, BZip2, and
ZipDeflate. Supported levels are:
Optimal and Fastest. see File and
compression formats in Azure Data
Factory.
No
NOTE
You cannot use fileName and fileFilter simultaneously.
Using partitionedBy property
As mentioned in the previous section, you can specify a dynamic folderPath and filename for time series data
with the partitionedBy property, Data Factory functions, and the system variables.
To understand more details on time-series datasets, scheduling, and slices, see Creating datasets, Scheduling
and execution, and Creating pipelines.
Sample 1:
"folderPath": "wikidatagateway/wikisampledataout/{Slice}",
"partitionedBy":
[
{ "name": "Slice", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyyMMddHH" } },
],
In this example, {Slice} is replaced with the value of the Data Factory system variable SliceStart in the format
(YYYYMMDDHH). SliceStart refers to start time of the slice. The folderPath is different for each slice. For
example: wikidatagateway/wikisampledataout/2014100103 or
wikidatagateway/wikisampledataout/2014100104.
Sample 2:
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}",
"fileName": "{Hour}.csv",
"partitionedBy":
[
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }
],
In this example, year, month, day, and time of SliceStart are extracted into separate variables that the
folderPath and fileName properties use.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output datasets, and policies are available for all types of
activities. Whereas, properties available in the typeProperties section of the activity vary with each activity
type.
For Copy activity, they vary depending on the types of sources and sinks. If you are moving data from an onpremises file system, you set the source type in the copy activity to FileSystemSource. Similarly, if you are
moving data to an on-premises file system, you set the sink type in the copy activity to FileSystemSink. This
section provides a list of properties supported by FileSystemSource and FileSystemSink.
FileSystemSource supports the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
recursive
Indicates whether the data
is read recursively from the
subfolders or only from the
specified folder.
True, False (default)
No
ALLOWED VALUES
REQUIRED
FileSystemSink supports the following properties:
PROPERTY
DESCRIPTION
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
copyBehavior
Defines the copy behavior
when the source is
BlobSource or FileSystem.
PreserveHierarchy:
Preserves the file hierarchy
in the target folder. That is,
the relative path of the
source file to the source
folder is the same as the
relative path of the target
file to the target folder.
No
FlattenHierarchy: All files
from the source folder are
created in the first level of
target folder. The target
files are created with an
autogenerated name.
MergeFiles: Merges all
files from the source folder
to one file. If the file
name/blob name is
specified, the merged file
name is the specified name.
Otherwise, it is an autogenerated file name.
recursive and copyBehavior examples
This section describes the resulting behavior of the Copy operation for different combinations of values for
the recursive and copyBehavior properties.
RECURSIVE VALUE
COPYBEHAVIOR VALUE
RESULTING BEHAVIOR
true
preserveHierarchy
For a source folder Folder1 with the
following structure,
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the same structure as the source:
Folder1
File1
File2
Subfolder1
File3
File4
File5
RECURSIVE VALUE
COPYBEHAVIOR VALUE
RESULTING BEHAVIOR
true
flattenHierarchy
For a source folder Folder1 with the
following structure,
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target Folder1 is created with the
following structure:
Folder1
auto-generated name for File1
auto-generated name for File2
auto-generated name for File3
auto-generated name for File4
auto-generated name for File5
true
mergeFiles
For a source folder Folder1 with the
following structure,
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target Folder1 is created with the
following structure:
Folder1
File1 + File2 + File3 + File4 + File 5
contents are merged into one file with
an auto-generated file name.
false
preserveHierarchy
For a source folder Folder1 with the
following structure,
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure:
Folder1
File1
File2
Subfolder1 with File3, File4, and File5
is not picked up.
RECURSIVE VALUE
COPYBEHAVIOR VALUE
RESULTING BEHAVIOR
false
flattenHierarchy
For a source folder Folder1 with the
following structure,
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure:
Folder1
auto-generated name for File1
auto-generated name for File2
Subfolder1 with File3, File4, and File5
is not picked up.
false
mergeFiles
For a source folder Folder1 with the
following structure,
Folder1
File1
File2
Subfolder1
File3
File4
File5
the target folder Folder1 is created
with the following structure:
Folder1
File1 + File2 contents are merged
into one file with an auto-generated
file name.
Auto-generated name for File1
Subfolder1 with File3, File4, and File5
is not picked up.
Supported file and compression formats
See File and compression formats in Azure Data Factory article on details.
JSON examples for copying data to and from file system
The following examples provide sample JSON definitions that you can use to create a pipeline by using the
Azure portal, Visual Studio, or Azure PowerShell. They show how to copy data to and from an on-premises
file system and Azure Blob storage. However, you can copy data directly from any of the sources to any of the
sinks listed in Supported sources and sinks by using Copy Activity in Azure Data Factory.
Example: Copy data from an on-premises file system to Azure Blob storage
This sample shows how to copy data from an on-premises file system to Azure Blob storage. The sample has
the following Data Factory entities:
A linked service of type OnPremisesFileServer.
A linked service of type AzureStorage.
An input dataset of type FileShare.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses FileSystemSource and BlobSink.
The following sample copies time-series data from an on-premises file system to Azure Blob storage every
hour. The JSON properties that are used in these samples are described in the sections after the samples.
As a first step, set up Data Management Gateway as per the instructions in Move data between on-premises
sources and the cloud with Data Management Gateway.
On-Premises File Server linked service:
{
"Name": "OnPremisesFileServerLinkedService",
"properties": {
"type": "OnPremisesFileServer",
"typeProperties": {
"host": "\\\\Contosogame-Asia.<region>.corp.<company>.com",
"userid": "Admin",
"password": "123456",
"gatewayName": "mygateway"
}
}
}
We recommend using the encryptedCredential property instead the userid and password properties. See
File Server linked service for details about this linked service.
Azure Storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
On-premises file system input dataset:
Data is picked up from a new file every hour. The folderPath and fileName properties are determined based
on the start time of the slice.
Setting "external": "true" informs Data Factory that the dataset is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "OnpremisesFileSystemInput",
"properties": {
"type": " FileShare",
"linkedServiceName": " OnPremisesFileServerLinkedService ",
"typeProperties": {
"folderPath": "mysharedfolder/yearno={Year}/monthno={Month}/dayno={Day}",
"fileName": "{Hour}.csv",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob storage output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses the
year, month, day, and hour parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
A copy activity in a pipeline with File System source and Blob sink:
The pipeline contains a copy activity that is configured to use the input and output datasets, and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to FileSystemSource, and sink type
is set to BlobSink.
{
"name":"SamplePipeline",
"properties":{
"start":"2015-06-01T18:00:00",
"end":"2015-06-01T19:00:00",
"description":"Pipeline for copy activity",
"activities":[
{
"name": "OnpremisesFileSystemtoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": "OnpremisesFileSystemInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Example: Copy data from Azure SQL Database to an on-premises file system
The following sample shows:
A linked service of type AzureSqlDatabase.
A linked service of type OnPremisesFileServer.
An input dataset of type AzureSqlTable.
An output dataset of type FileShare.
A pipeline with a copy activity that uses SqlSource and FileSystemSink.
The sample copies time-series data from an Azure SQL table to an on-premises file system every hour. The
JSON properties that are used in these samples are described in sections after the samples.
Azure SQL Database linked service:
{
"name": "AzureSqlLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;User
ID=<username>@<servername>;Password=<password>;Trusted_Connection=False;Encrypt=True;Connection
Timeout=30"
}
}
}
On-Premises File Server linked service:
{
"Name": "OnPremisesFileServerLinkedService",
"properties": {
"type": "OnPremisesFileServer",
"typeProperties": {
"host": "\\\\Contosogame-Asia.<region>.corp.<company>.com",
"userid": "Admin",
"password": "123456",
"gatewayName": "mygateway"
}
}
}
We recommend using the encryptedCredential property instead of using the userid and password
properties. See File System linked service for details about this linked service.
Azure SQL input dataset:
The sample assumes that you've created a table “MyTable” in Azure SQL, and it contains a column called
“timestampcolumn” for time-series data.
Setting “external”: ”true” informs Data Factory that the dataset is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "AzureSqlInput",
"properties": {
"type": "AzureSqlTable",
"linkedServiceName": "AzureSqlLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
On-premises file system output dataset:
Data is copied to a new file every hour. The folderPath and fileName for the blob are determined based on the
start time of the slice.
{
"name": "OnpremisesFileSystemOutput",
"properties": {
"type": "FileShare",
"linkedServiceName": " OnPremisesFileServerLinkedService ",
"typeProperties": {
"folderPath": "mysharedfolder/yearno={Year}/monthno={Month}/dayno={Day}",
"fileName": "{Hour}.csv",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
A copy activity in a pipeline with SQL source and File System sink:
The pipeline contains a copy activity that is configured to use the input and output datasets, and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to SqlSource, and the sink type is
set to FileSystemSink. The SQL query that is specified for the SqlReaderQuery property selects the data in
the past hour to copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2015-06-01T18:00:00",
"end":"2015-06-01T20:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "AzureSQLtoOnPremisesFile",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": "AzureSQLInput"
}
],
"outputs": [
{
"name": "OnpremisesFileSystemOutput"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"SqlReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >= \\'{0:yyyyMM-dd}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "FileSystemSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 3,
"timeout": "01:00:00"
}
}
]
}
}
You can also map columns from source dataset to columns from sink dataset in the copy activity definition.
For details, see Mapping dataset columns in Azure Data Factory.
Performance and tuning
To learn about key factors that impact the performance of data movement (Copy Activity) in Azure Data
Factory and various ways to optimize it, see the Copy Activity performance and tuning guide.
Move data from an FTP server by using Azure Data
Factory
4/18/2017 • 11 min to read • Edit Online
This article explains how to use the copy activity in Azure Data Factory to move data from an FTP server. It
builds on the Data movement activities article, which presents a general overview of data movement with the
copy activity.
You can copy data from an FTP server to any supported sink data store. For a list of data stores supported as
sinks by the copy activity, see the supported data stores table. Data Factory currently supports only moving
data from an FTP server to other data stores, but not moving data from other data stores to an FTP server. It
supports both on-premises and cloud FTP servers.
NOTE
The copy activity does not delete the source file after it is successfully copied to the destination. If you need to delete the
source file after a successful copy, create a custom activity to delete the file, and use the activity in the pipeline.
Enable connectivity
If you are moving data from an on-premises FTP server to a cloud data store (for example, to Azure Blob
storage), install and use Data Management Gateway. The Data Management Gateway is a client agent that is
installed on your on-premises machine, and it allows cloud services to connect to an on-premises resource. For
details, see Data Management Gateway. For step-by-step instructions on setting up the gateway and using it,
see Moving data between on-premises locations and cloud. You use the gateway to connect to an FTP server,
even if the server is on an Azure infrastructure as a service (IaaS) virtual machine (VM).
It is possible to install the gateway on the same on-premises machine or IaaS VM as the FTP server. However,
we recommend that you install the gateway on a separate machine or IaaS VM to avoid resource contention,
and for better performance. When you install the gateway on a separate machine, the machine should be able
to access the FTP server.
Get started
You can create a pipeline with a copy activity that moves data from an FTP source by using different tools or
APIs.
The easiest way to create a pipeline is to use the Data Factory Copy Wizard. See Tutorial: Create a pipeline
using Copy Wizard for a quick walkthrough.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, PowerShell, Azure
Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools or APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an FTP data store, see the JSON example: Copy data from FTP server to Azure blob
section of this article.
NOTE
For details about supported file and compression formats to use, see File and compression formats in Azure Data
Factory.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to FTP.
Linked service properties
The following table describes JSON elements specific to an FTP linked service.
PROPERTY
DESCRIPTION
REQUIRED
DEFAULT
type
Set this to FtpServer.
Yes
host
Specify the name or IP
address of the FTP server.
Yes
authenticationType
Specify the authentication
type.
Yes
username
Specify the user who has
access to the FTP server.
No
password
Specify the password for
the user (username).
No
encryptedCredential
Specify the encrypted
credential to access the FTP
server.
No
gatewayName
Specify the name of the
gateway in Data
Management Gateway to
connect to an on-premises
FTP server.
No
port
Specify the port on which
the FTP server is listening.
No
21
enableSsl
Specify whether to use FTP
over an SSL/TLS channel.
No
true
enableServerCertificateValid
ation
Specify whether to enable
server SSL certificate
validation when you are
using FTP over SSL/TLS
channel.
No
true
Basic, Anonymous
Use Anonymous authentication
{
"name": "FTPLinkedService",
"properties": {
"type": "FtpServer",
"typeProperties": {
"authenticationType": "Anonymous",
"host": "myftpserver.com"
}
}
}
Use username and password in plain text for basic authentication
{
"name": "FTPLinkedService",
"properties": {
"type": "FtpServer",
"typeProperties": {
"host": "myftpserver.com",
"authenticationType": "Basic",
"username": "Admin",
"password": "123456"
}
}
}
Use port, enableSsl, enableServerCertificateValidation
{
"name": "FTPLinkedService",
"properties": {
"type": "FtpServer",
"typeProperties": {
"host": "myftpserver.com",
"authenticationType": "Basic",
"username": "Admin",
"password": "123456",
"port": "21",
"enableSsl": true,
"enableServerCertificateValidation": true
}
}
}
Use encryptedCredential for authentication and gateway
{
"name": "FTPLinkedService",
"properties": {
"type": "FtpServer",
"typeProperties": {
"host": "myftpserver.com",
"authenticationType": "Basic",
"encryptedCredential": "xxxxxxxxxxxxxxxxx",
"gatewayName": "mygateway"
}
}
}
Dataset properties
Dataset properties
For a full list of sections and properties available for defining datasets, see Creating datasets. Sections such as
structure, availability, and policy of a dataset JSON are similar for all dataset types.
The typeProperties section is different for each type of dataset. It provides information that is specific to the
dataset type. The typeProperties section for a dataset of type FileShare has the following properties:
PROPERTY
DESCRIPTION
REQUIRED
folderPath
Subpath to the folder. Use escape
character ‘ \ ’ for special characters in
the string. See Sample linked service
and dataset definitions for examples.
Yes
You can combine this property with
partitionBy to have folder paths
based on slice start and end datetimes.
fileName
Specify the name of the file in the
folderPath if you want the table to
refer to a specific file in the folder. If
you do not specify any value for this
property, the table points to all files in
the folder.
No
When fileName is not specified for an
output dataset, the name of the
generated file is in the following
format:
Data..txt (Example: Data.0a405f8a93ff-4c6f-b3be-f69616f1df7a.txt)
fileFilter
Specify a filter to be used to select a
subset of files in the folderPath,
rather than all files.
No
Allowed values are: * (multiple
characters) and ? (single character).
Example 1:
Example 2:
"fileFilter": "*.log"
"fileFilter": 2014-1-?.txt"
fileFilter is applicable for an input
FileShare dataset. This property is not
supported with Hadoop Distributed
File System (HDFS).
partitionedBy
Used to specify a dynamic folderPath
and fileName for time series data. For
example, you can specify a folderPath
that is parameterized for every hour of
data.
No
PROPERTY
DESCRIPTION
REQUIRED
format
The following format types are
supported: TextFormat, JsonFormat,
AvroFormat, OrcFormat,
ParquetFormat. Set the type
property under format to one of these
values. For more information, see the
Text Format, Json Format, Avro
Format, Orc Format, and Parquet
Format sections.
No
If you want to copy files as they are
between file-based stores (binary
copy), skip the format section in both
input and output dataset definitions.
compression
Specify the type and level of
compression for the data. Supported
types are GZip, Deflate, BZip2, and
ZipDeflate, and supported levels are
Optimal and Fastest. For more
information, see File and compression
formats in Azure Data Factory.
No
useBinaryTransfer
Specify whether to use the binary
transfer mode. The values are true for
binary mode (this is the default value),
and false for ASCII. This property can
only be used when the associated
linked service type is of type:
FtpServer.
No
NOTE
fileName and fileFilter cannot be used simultaneously.
Use the partionedBy property
As mentioned in the previous section, you can specify a dynamic folderPath and fileName for time series
data with the partitionedBy property.
To learn about time series datasets, scheduling, and slices, see Creating datasets, Scheduling and execution, and
Creating pipelines.
Sample 1
"folderPath": "wikidatagateway/wikisampledataout/{Slice}",
"partitionedBy":
[
{ "name": "Slice", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyyMMddHH" } },
],
In this example, {Slice} is replaced with the value of Data Factory system variable SliceStart, in the format
specified (YYYYMMDDHH). The SliceStart refers to start time of the slice. The folder path is different for each
slice. (For example, wikidatagateway/wikisampledataout/2014100103 or
wikidatagateway/wikisampledataout/2014100104.)
Sample 2
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}",
"fileName": "{Hour}.csv",
"partitionedBy":
[
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }
],
In this example, the year, month, day, and time of SliceStart are extracted into separate variables that are used
by the folderPath and fileName properties.
Copy activity properties
For a full list of sections and properties available for defining activities, see Creating pipelines. Properties such
as name, description, input and output tables, and policies are available for all types of activities.
Properties available in the typeProperties section of the activity, on the other hand, vary with each activity
type. For the copy activity, the type properties vary depending on the types of sources and sinks.
In copy activity, when the source is of type FileSystemSource, the following property is available in
typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
recursive
Indicates whether the data
is read recursively from the
subfolders, or only from the
specified folder.
True, False (default)
No
JSON example: Copy data from FTP server to Azure Blob storage
This sample shows how to copy data from an FTP server to Azure Blob storage. However, data can be copied
directly to any of the sinks stated in the supported data stores and formats, by using the copy activity in Data
Factory.
The following examples provide sample JSON definitions that you can use to create a pipeline by using Azure
portal, Visual Studio, or PowerShell:
A linked service of type FtpServer
A linked service of type AzureStorage
An input dataset of type FileShare
An output dataset of type AzureBlob
A pipeline with copy activity that uses FileSystemSource and BlobSink
The sample copies data from an FTP server to an Azure blob every hour. The JSON properties used in these
samples are described in sections following the samples.
FTP linked service
This example uses basic authentication, with the user name and password in plain text. You can also use one of
the following ways:
Anonymous authentication
Basic authentication with encrypted credentials
FTP over SSL/TLS (FTPS)
See the FTP linked service section for different types of authentication you can use.
{
"name": "FTPLinkedService",
"properties": {
"type": "FtpServer",
"typeProperties": {
"host": "myftpserver.com",
"authenticationType": "Basic",
"username": "Admin",
"password": "123456"
}
}
}
Azure Storage linked service
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
FTP input dataset
This dataset refers to the FTP folder
destination.
mysharedfolder
and file
test.csv
. The pipeline copies the file to the
Setting external to true informs the Data Factory service that the dataset is external to the data factory, and is
not produced by an activity in the data factory.
{
"name": "FTPFileInput",
"properties": {
"type": "FileShare",
"linkedServiceName": "FTPLinkedService",
"typeProperties": {
"folderPath": "mysharedfolder",
"fileName": "test.csv",
"useBinaryTransfer": true
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Azure Blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated, based on the start time of the slice that is being processed. The folder path uses the
year, month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/ftp/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
A copy activity in a pipeline with file system source and blob sink
The pipeline contains a copy activity that is configured to use the input and output datasets, and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to FileSystemSource, and the sink type
is set to BlobSink.
{
"name": "pipeline",
"properties": {
"activities": [{
"name": "FTPToBlobCopy",
"inputs": [{
"name": "FtpFileInput"
}],
"outputs": [{
"name": "AzureBlobOutput"
}],
"type": "Copy",
"typeProperties": {
"source": {
"type": "FileSystemSource"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 1,
"timeout": "00:05:00"
}
}],
"start": "2016-08-24T18:00:00Z",
"end": "2016-08-24T19:00:00Z"
}
}
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data Factory.
Next steps
See the following articles:
To learn about key factors that impact performance of data movement (copy activity) in Data Factory,
and various ways to optimize it, see the Copy activity performance and tuning guide.
For step-by-step instructions for creating a pipeline with a copy activity, see the Copy activity tutorial.
Move data from on-premises HDFS using Azure
Data Factory
5/22/2017 • 13 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
HDFS. It builds on the Data Movement Activities article, which presents a general overview of data movement
with the copy activity.
You can copy data from HDFS to any supported sink data store. For a list of data stores supported as sinks by
the copy activity, see the Supported data stores table. Data factory currently supports only moving data from
an on-premises HDFS to other data stores, but not for moving data from other data stores to an on-premises
HDFS.
NOTE
Copy Activity does not delete the source file after it is successfully copied to the destination. If you need to delete the
source file after a successful copy, create a custom activity to delete the file and use the activity in the pipeline.
Enabling connectivity
Data Factory service supports connecting to on-premises HDFS using the Data Management Gateway. See
moving data between on-premises locations and cloud article to learn about Data Management Gateway and
step-by-step instructions on setting up the gateway. Use the gateway to connect to HDFS even if it is hosted in
an Azure IaaS VM.
NOTE
Make sure the Data Management Gateway can access to ALL the [name node server]:[name node port] and [data node
servers]:[data node port] of the Hadoop cluster. Default [name node port] is 50070, and default [data node port] is
50075.
While you can install gateway on the same on-premises machine or the Azure VM as the HDFS, we
recommend that you install the gateway on a separate machine/Azure IaaS VM. Having gateway on a separate
machine reduces resource contention and improves performance. When you install the gateway on a separate
machine, the machine should be able to access the machine with the HDFS.
Getting started
You can create a pipeline with a copy activity that moves data from a HDFS source by using different
tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from a HDFS data store, see JSON example: Copy data from on-premises HDFS to Azure
Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to HDFS:
Linked service properties
A linked service links a data store to a data factory. You create a linked service of type Hdfs to link an onpremises HDFS to your data factory. The following table provides description for JSON elements specific to
HDFS linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
Hdfs
Yes
Url
URL to the HDFS
Yes
authenticationType
Anonymous, or Windows.
Yes
To use Kerberos authentication for
HDFS connector, refer to this section
to set up your on-premises
environment accordingly.
userName
Username for Windows
authentication.
Yes (for Windows Authentication)
password
Password for Windows authentication.
Yes (for Windows Authentication)
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the HDFS.
Yes
encryptedCredential
NewAzureRMDataFactoryEncryptValue
output of the access credential.
No
Using Anonymous authentication
{
"name": "hdfs",
"properties":
{
"type": "Hdfs",
"typeProperties":
{
"authenticationType": "Anonymous",
"userName": "hadoop",
"url" : "http://<machine>:50070/webhdfs/v1/",
"gatewayName": "mygateway"
}
}
}
Using Windows authentication
{
"name": "hdfs",
"properties":
{
"type": "Hdfs",
"typeProperties":
{
"authenticationType": "Windows",
"userName": "Administrator",
"password": "password",
"url" : "http://<machine>:50070/webhdfs/v1/",
"gatewayName": "mygateway"
}
}
}
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type FileShare (which includes HDFS
dataset) has the following properties
PROPERTY
DESCRIPTION
REQUIRED
folderPath
Path to the folder. Example:
Yes
myfolder
Use escape character ‘ \ ’ for special
characters in the string. For example:
for folder\subfolder, specify
folder\\subfolder and for
d:\samplefolder, specify
d:\\samplefolder.
You can combine this property with
partitionBy to have folder paths
based on slice start/end date-times.
PROPERTY
DESCRIPTION
REQUIRED
fileName
Specify the name of the file in the
folderPath if you want the table to
refer to a specific file in the folder. If
you do not specify any value for this
property, the table points to all files in
the folder.
No
When fileName is not specified for an
output dataset, the name of the
generated file would be in the
following this format:
Data..txt (for example: :
Data.0a405f8a-93ff-4c6f-b3bef69616f1df7a.txt
partitionedBy
partitionedBy can be used to specify a
dynamic folderPath, filename for time
series data. Example: folderPath
parameterized for every hour of data.
No
format
The following format types are
supported: TextFormat, JsonFormat,
AvroFormat, OrcFormat,
ParquetFormat. Set the type
property under format to one of these
values. For more information, see Text
Format, Json Format, Avro Format,
Orc Format, and Parquet Format
sections.
No
If you want to copy files as-is
between file-based stores (binary
copy), skip the format section in both
input and output dataset definitions.
compression
Specify the type and level of
compression for the data. Supported
types are: GZip, Deflate, BZip2, and
ZipDeflate. Supported levels are:
Optimal and Fastest. For more
information, see File and compression
formats in Azure Data Factory.
No
NOTE
filename and fileFilter cannot be used simultaneously.
Using partionedBy property
As mentioned in the previous section, you can specify a dynamic folderPath and filename for time series data
with the partitionedBy property, Data Factory functions, and the system variables.
To learn more about time series datasets, scheduling, and slices, see Creating Datasets, Scheduling & Execution,
and Creating Pipelines articles.
Sample 1:
"folderPath": "wikidatagateway/wikisampledataout/{Slice}",
"partitionedBy":
[
{ "name": "Slice", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyyMMddHH" } },
],
In this example {Slice} is replaced with the value of Data Factory system variable SliceStart in the format
(YYYYMMDDHH) specified. The SliceStart refers to start time of the slice. The folderPath is different for each
slice. For example: wikidatagateway/wikisampledataout/2014100103 or
wikidatagateway/wikisampledataout/2014100104.
Sample 2:
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}",
"fileName": "{Hour}.csv",
"partitionedBy":
[
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }
],
In this example, year, month, day, and time of SliceStart are extracted into separate variables that are used by
folderPath and fileName properties.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policies are available for all types of
activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For Copy
activity, they vary depending on the types of sources and sinks.
For Copy Activity, when source is of type FileSystemSource the following properties are available in
typeProperties section:
FileSystemSource supports the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
recursive
Indicates whether the data
is read recursively from the
sub folders or only from
the specified folder.
True, False (default)
No
Supported file and compression formats
See File and compression formats in Azure Data Factory article on details.
JSON example: Copy data from on-premises HDFS to Azure Blob
This sample shows how to copy data from an on-premises HDFS to Azure Blob Storage. However, data can be
copied directly to any of the sinks stated here using the Copy Activity in Azure Data Factory.
The sample provides JSON definitions for the following Data Factory entities. You can use these definitions to
create a pipeline to copy data from HDFS to Azure Blob Storage by using Azure portal or Visual Studio or Azure
PowerShell.
1.
2.
3.
4.
5.
A linked service of type OnPremisesHdfs.
A linked service of type AzureStorage.
An input dataset of type FileShare.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses FileSystemSource and BlobSink.
The sample copies data from an on-premises HDFS to an Azure blob every hour. The JSON properties used in
these samples are described in sections following the samples.
As a first step, set up the data management gateway. The instructions in the moving data between on-premises
locations and cloud article.
HDFS linked service: This example uses the Windows authentication. See HDFS linked service section for
different types of authentication you can use.
{
"name": "HDFSLinkedService",
"properties":
{
"type": "Hdfs",
"typeProperties":
{
"authenticationType": "Windows",
"userName": "Administrator",
"password": "password",
"url" : "http://<machine>:50070/webhdfs/v1/",
"gatewayName": "mygateway"
}
}
}
Azure Storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
HDFS input dataset: This dataset refers to the HDFS folder DataTransfer/UnitTest/. The pipeline copies all the
files in this folder to the destination.
Setting “external”: ”true” informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "InputDataset",
"properties": {
"type": "FileShare",
"linkedServiceName": "HDFSLinkedService",
"typeProperties": {
"folderPath": "DataTransfer/UnitTest/"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "OutputDataset",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/hdfs/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
A copy activity in a pipeline with File System source and Blob sink:
The pipeline contains a Copy Activity that is configured to use these input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to FileSystemSource and sink type is
set to BlobSink. The SQL query specified for the query property selects the data in the past hour to copy.
{
"name": "pipeline",
"properties":
{
"activities":
[
{
"name": "HdfsToBlobCopy",
"inputs": [ {"name": "InputDataset"} ],
"outputs": [ {"name": "OutputDataset"} ],
"type": "Copy",
"typeProperties":
{
"source":
{
"type": "FileSystemSource"
},
"sink":
{
"type": "BlobSink"
}
},
"policy":
{
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 1,
"timeout": "00:05:00"
}
}
],
"start": "2014-06-01T18:00:00Z",
"end": "2014-06-01T19:00:00Z"
}
}
Use Kerberos authentication for HDFS connector
There are two options to set up the on-premises environment so as to use Kerberos Authentication in HDFS
connector. You can choose the one better fits your case.
Option 1: Join gateway machine in Kerberos realm
Option 2: Enable mutual trust between Windows domain and Kerberos realm
Option 1: Join gateway machine in Kerberos realm
Requirement:
The gateway machine needs to join the Kerberos realm and can’t join any Windows domain.
How to configure:
On gateway machine:
1. Run the Ksetup utility to configure the Kerberos KDC server and realm.
The machine must be configured as a member of a workgroup since a Kerberos realm is different from
a Windows domain. This can be achieved by setting the Kerberos realm and adding a KDC server as
follows. Replace REALM.COM with your own respective realm as needed.
C:> Ksetup /setdomain REALM.COM
C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>
Restart the machine after executing these 2 commands.
2. Verify the configuration with Ksetup command. The output should be like:
C:> Ksetup
default realm = REALM.COM (external)
REALM.com:
kdc = <your_kdc_server_address>
In Azure Data Factory:
Configure the HDFS connector using Windows authentication together with your Kerberos principal
name and password to connect to the HDFS data source. Check HDFS Linked Service properties section on
configuration details.
Option 2: Enable mutual trust between Windows domain and Kerberos realm
Requirement:
The gateway machine must join a Windows domain.
You need permission to update the domain controller's settings.
How to configure:
NOTE
Replace REALM.COM and AD.COM in the following tutorial with your own respective realm and domain controller as
needed.
On KDC server:
1. Edit the KDC configuration in krb5.conf file to let KDC trust Windows Domain referring to the following
configuration template. By default, the configuration is located at /etc/krb5.conf.
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = REALM.COM
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
[realms]
REALM.COM = {
kdc = node.REALM.COM
admin_server = node.REALM.COM
}
AD.COM = {
kdc = windc.ad.com
admin_server = windc.ad.com
}
[domain_realm]
.REALM.COM = REALM.COM
REALM.COM = REALM.COM
.ad.com = AD.COM
ad.com = AD.COM
[capaths]
AD.COM = {
REALM.COM = .
}
Restart the KDC service after configuration.
2. Prepare a principal named krbtgt/[email protected] in KDC server with the following command:
Kadmin> addprinc krbtgt/[email protected]
3. In hadoop.security.auth_to_local HDFS service configuration file, add
RULE:[1:$1@$0](.*@AD.COM)s/@.*// .
On domain controller:
1. Run the following Ksetup commands to add a realm entry:
C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>
C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
2. Establish trust from Windows Domain to Kerberos Realm. [password] is the password for the principal
krbtgt/[email protected].
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /passwordt:[password]
3. Select encryption algorithm used in Kerberos.
a. Go to Server Manager > Group Policy Management > Domain > Group Policy Objects > Default
or Active Domain Policy, and Edit.
b. In the Group Policy Management Editor popup window, go to Computer Configuration >
Policies > Windows Settings > Security Settings > Local Policies > Security Options, and
configure Network security: Configure Encryption types allowed for Kerberos.
c. Select the encryption algorithm you want to use when connect to KDC. Commonly, you can
simply select all the options.
d. Use Ksetup command to specify the encryption algorithm to be used on the specific REALM.
C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTSHMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96
4. Create the mapping between the domain account and Kerberos principal, in order to use Kerberos
principal in Windows Domain.
a. Start the Administrative tools > Active Directory Users and Computers.
b. Configure advanced features by clicking View > Advanced Features.
c. Locate the account to which you want to create mappings, and right-click to view Name
Mappings > click Kerberos Names tab.
d. Add a principal from the realm.
On gateway machine:
Run the following Ksetup commands to add a realm entry.
C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>
C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
In Azure Data Factory:
Configure the HDFS connector using Windows authentication together with either your Domain Account
or Kerberos Principal to connect to the HDFS data source. Check HDFS Linked Service properties section on
configuration details.
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data
Factory.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from an HTTP source using Azure Data
Factory
4/10/2017 • 8 min to read • Edit Online
This article outlines how to use the Copy Activity in Azure Data Factory to move data from an onpremises/cloud HTTP endpoint to a supported sink data store. This article builds on the data movement
activities article that presents a general overview of data movement with copy activity and the list of data
stores supported as sources/sinks.
Data factory currently supports only moving data from an HTTP source to other data stores, but not moving
data from other data stores to an HTTP destination.
Supported scenarios and authentication types
You can use this HTTP connector to retrieve data from both cloud and on-premises HTTP/s endpoint by
using HTTP GET or POST method. The following authentication types are supported: Anonymous, Basic,
Digest, Windows, and ClientCertificate. Note the difference between this connector and the Web table
connector is: the latter is used to extract table content from web HTML page.
When copying data from an on-premises HTTP endpoint, you need install a Data Management Gateway in the
on-premises environment/Azure VM. See moving data between on-premises locations and cloud article to
learn about Data Management Gateway and step-by-step instructions on setting up the gateway.
Getting started
You can create a pipeline with a copy activity that moves data from an HTTP source by using different
tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using
Copy Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure
PowerShell, Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial
for step-by-step instructions to create a pipeline with a copy activity. For JSON samples to copy data
from HTTP source to Azure Blob Storage, see JSON examples section of this articles.
Linked service properties
The following table provides description for JSON elements specific to HTTP linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
Http .
Yes
url
Base URL to the Web Server
Yes
PROPERTY
DESCRIPTION
REQUIRED
authenticationType
Specifies the authentication type.
Allowed values are: Anonymous,
Basic, Digest, Windows,
ClientCertificate.
Yes
Refer to sections below this table on
more properties and JSON samples for
those authentication types
respectively.
enableServerCertificateValidation
Specify whether to enable server SSL
certificate validation if source is HTTPS
Web Server
No, default is true
gatewayName
Name of the Data Management
Gateway to connect to an onpremises HTTP source.
Yes if copying data from an onpremises HTTP source.
encryptedCredential
Encrypted credential to access the
HTTP endpoint. Auto-generated when
you configure the authentication
information in copy wizard or the
ClickOnce popup dialog.
No. Apply only when copying data
from an on-premises HTTP server.
See Move data between on-premises sources and the cloud with Data Management Gateway for details about
setting credentials for on-premises HTTP connector data source.
Using Basic, Digest, or Windows authentication
Set authenticationType as Basic , Digest , or Windows , and specify the following properties besides the HTTP
connector generic ones introduced above:
PROPERTY
DESCRIPTION
REQUIRED
username
Username to access the HTTP
endpoint.
Yes
password
Password for the user (username).
Yes
Example: using Basic, Digest, or Windows authentication
{
"name": "HttpLinkedService",
"properties":
{
"type": "Http",
"typeProperties":
{
"authenticationType": "basic",
"url" : "https://en.wikipedia.org/wiki/",
"userName": "user name",
"password": "password"
}
}
}
Using ClientCertificate authentication
To use basic authentication, set authenticationType as ClientCertificate , and specify the following properties
besides the HTTP connector generic ones introduced above:
PROPERTY
DESCRIPTION
REQUIRED
embeddedCertData
The Base64-encoded contents of
binary data of the Personal
Information Exchange (PFX) file.
Specify either the embeddedCertData
or certThumbprint .
certThumbprint
The thumbprint of the certificate that
was installed on your gateway
machine’s cert store. Apply only when
copying data from an on-premises
HTTP source.
Specify either the embeddedCertData
or certThumbprint .
password
Password associated with the
certificate.
No
If you use certThumbprint for authentication and the certificate is installed in the personal store of the local
computer, you need to grant the read permission to the gateway service:
1. Launch Microsoft Management Console (MMC). Add the Certificates snap-in that targets the Local
Computer.
2. Expand Certificates, Personal, and click Certificates.
3. Right-click the certificate from the personal store, and select All Tasks->Manage Private Keys...
4. On the Security tab, add the user account under which Data Management Gateway Host Service is running
with the read access to the certificate.
Example: using client certificate
This linked service links your data factory to an on-premises HTTP web server. It uses a client certificate that is
installed on the machine with Data Management Gateway installed.
{
"name": "HttpLinkedService",
"properties":
{
"type": "Http",
"typeProperties":
{
"authenticationType": "ClientCertificate",
"url": "https://en.wikipedia.org/wiki/",
"certThumbprint": "thumbprint of certificate",
"gatewayName": "gateway name"
}
}
}
Example: using client certificate in a file
This linked service links your data factory to an on-premises HTTP web server. It uses a client certificate file on
the machine with Data Management Gateway installed.
{
"name": "HttpLinkedService",
"properties":
{
"type": "Http",
"typeProperties":
{
"authenticationType": "ClientCertificate",
"url": "https://en.wikipedia.org/wiki/",
"embeddedCertData": "base64 encoded cert data",
"password": "password of cert"
}
}
}
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type Http has the following properties
PROPERTY
DESCRIPTION
REQUIRED
type
Specified the type of the dataset. must
be set to Http .
Yes
relativeUrl
A relative URL to the resource that
contains the data. When path is not
specified, only the URL specified in the
linked service definition is used.
No
To construct dynamic URL, you can
use Data Factory functions and
system variables, e.g. "relativeUrl":
"$$Text.Format('/my/report?month=
{0:yyyy}-{0:MM}&fmt=csv', SliceStart)".
requestMethod
Http method. Allowed values are GET
or POST.
No. Default is
additionalHeaders
Additional HTTP request headers.
No
requestBody
Body for HTTP request.
No
GET
.
PROPERTY
DESCRIPTION
REQUIRED
format
If you want to simply retrieve the
data from HTTP endpoint as-is
without parsing it, skip this format
settings.
No
If you want to parse the HTTP
response content during copy, the
following format types are supported:
TextFormat, JsonFormat,
AvroFormat, OrcFormat,
ParquetFormat. For more
information, see Text Format, Json
Format, Avro Format, Orc Format, and
Parquet Format sections.
compression
Specify the type and level of
compression for the data. Supported
types are: GZip, Deflate, BZip2, and
ZipDeflate. Supported levels are:
Optimal and Fastest. For more
information, see File and compression
formats in Azure Data Factory.
No
Example: using the GET (default) method
{
"name": "HttpSourceDataInput",
"properties": {
"type": "Http",
"linkedServiceName": "HttpLinkedService",
"typeProperties": {
"relativeUrl": "XXX/test.xml",
"additionalHeaders": "Connection: keep-alive\nUser-Agent: Mozilla/5.0\n"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Example: using the POST method
{
"name": "HttpSourceDataInput",
"properties": {
"type": "Http",
"linkedServiceName": "HttpLinkedService",
"typeProperties": {
"relativeUrl": "/XXX/test.xml",
"requestMethod": "Post",
"requestBody": "body for POST HTTP request"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of activities.
Properties available in the typeProperties section of the activity on the other hand vary with each activity type.
For Copy activity, they vary depending on the types of sources and sinks.
Currently, when the source in copy activity is of type HttpSource, the following properties are supported.
PROPERTY
DESCRIPTION
REQUIRED
httpRequestTimeout
The timeout (TimeSpan) for the HTTP
request to get a response. It is the
timeout to get a response, not the
timeout to read response data.
No. Default value: 00:01:40
Supported file and compression formats
See File and compression formats in Azure Data Factory article on details.
JSON examples
The following example provide sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data from HTTP source to Azure Blob
Storage. However, data can be copied directly from any of sources to any of the sinks stated here using the
Copy Activity in Azure Data Factory.
Example: Copy data from HTTP source to Azure Blob Storage
The Data Factory solution for this sample contains the following Data Factory entities:
1.
2.
3.
4.
5.
A linked service of type HTTP.
A linked service of type AzureStorage.
An input dataset of type Http.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses HttpSource and BlobSink.
The sample copies data from an HTTP source to an Azure blob every hour. The JSON properties used in these
samples are described in sections following the samples.
HTTP linked service
This example uses the HTTP linked service with anonymous authentication. See HTTP linked service section for
different types of authentication you can use.
{
"name": "HttpLinkedService",
"properties":
{
"type": "Http",
"typeProperties":
{
"authenticationType": "Anonymous",
"url" : "https://en.wikipedia.org/wiki/"
}
}
}
Azure Storage linked service
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
HTTP input dataset
Setting external to true informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "HttpSourceDataInput",
"properties": {
"type": "Http",
"linkedServiceName": "HttpLinkedService",
"typeProperties": {
"relativeUrl": "$$Text.Format('/my/report?month={0:yyyy}-{0:MM}&fmt=csv', SliceStart)",
"additionalHeaders": "Connection: keep-alive\nUser-Agent: Mozilla/5.0\n"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Azure Blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1).
{
"name": "AzureBlobOutput",
"properties":
{
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties":
{
"folderPath": "adfgetstarted/Movies"
},
"availability":
{
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to HttpSource and sink type is set to
BlobSink.
See HttpSource for the list of properties supported by the HttpSource.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "HttpSourceToAzureBlob",
"description": "Copy from an HTTP source to an Azure blob",
"type": "Copy",
"inputs": [
{
"name": "HttpSourceDataInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "HttpSource"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data
Factory.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data From MongoDB using Azure Data
Factory
5/22/2017 • 11 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
MongoDB database. It builds on the Data Movement Activities article, which presents a general overview of
data movement with the copy activity.
You can copy data from an on-premises MongoDB data store to any supported sink data store. For a list of data
stores supported as sinks by the copy activity, see the Supported data stores table. Data factory currently
supports only moving data from a MongoDB data store to other data stores, but not for moving data from
other data stores to an MongoDB datastore.
Prerequisites
For the Azure Data Factory service to be able to connect to your on-premises MongoDB database, you must
install the following components:
Supported MongoDB versions are: 2.4, 2.6, 3.0, and 3.2.
Data Management Gateway on the same machine that hosts the database or on a separate machine to
avoid competing for resources with the database. Data Management Gateway is a software that
connects on-premises data sources to cloud services in a secure and managed way. See Data
Management Gateway article for details about Data Management Gateway. See Move data from onpremises to cloud article for step-by-step instructions on setting up the gateway a data pipeline to move
data.
When you install the gateway, it automatically installs a Microsoft MongoDB ODBC driver used to
connect to MongoDB.
NOTE
You need to use the gateway to connect to MongoDB even if it is hosted in Azure IaaS VMs. If you are trying to
connect to an instance of MongoDB hosted in cloud, you can also install the gateway instance in the IaaS VM.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises MongoDB data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises MongoDB data store, see JSON example: Copy data from MongoDB to
Azure Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to MongoDB source:
Linked service properties
The following table provides description for JSON elements specific to OnPremisesMongoDB linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesMongoDb
Yes
server
IP address or host name of the
MongoDB server.
Yes
port
TCP port that the MongoDB server
uses to listen for client connections.
Optional, default value: 27017
authenticationType
Basic, or Anonymous.
Yes
username
User account to access MongoDB.
Yes (if basic authentication is used).
password
Password for the user.
Yes (if basic authentication is used).
authSource
Name of the MongoDB database that
you want to use to check your
credentials for authentication.
Optional (if basic authentication is
used). default: uses the admin account
and the database specified using
databaseName property.
databaseName
Name of the MongoDB database that
you want to access.
Yes
gatewayName
Name of the gateway that accesses
the data store.
Yes
encryptedCredential
Credential encrypted by gateway.
Optional
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type MongoDbCollection has the
following properties:
PROPERTY
DESCRIPTION
REQUIRED
collectionName
Name of the collection in MongoDB
database.
Yes
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of activities.
Properties available in the typeProperties section of the activity on the other hand vary with each activity type.
For Copy activity, they vary depending on the types of sources and sinks.
When the source is of type MongoDbSource the following properties are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL-92 query string. For
example: select * from
MyTable.
No (if collectionName of
dataset is specified)
JSON example: Copy data from MongoDB to Azure Blob
This example provides sample JSON definitions that you can use to create a pipeline by using Azure portal or
Visual Studio or Azure PowerShell. It shows how to copy data from an on-premises MongoDB to an Azure Blob
Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data
Factory.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesMongoDb.
A linked service of type AzureStorage.
An input dataset of type MongoDbCollection.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses MongoDbSource and BlobSink.
The sample copies data from a query result in MongoDB database to a blob every hour. The JSON properties
used in these samples are described in sections following the samples.
As a first step, setup the data management gateway as per the instructions in the Data Management Gateway
article.
MongoDB linked service:
{
"name": "OnPremisesMongoDbLinkedService",
"properties":
{
"type": "OnPremisesMongoDb",
"typeProperties":
{
"authenticationType": "<Basic or Anonymous>",
"server": "< The IP address or host name of the MongoDB server >",
"port": "<The number of the TCP port that the MongoDB server uses to listen for client
connections.>",
"username": "<username>",
"password": "<password>",
"authSource": "< The database that you want to use to check your credentials for authentication.
>",
"databaseName": "<database name>",
"gatewayName": "<mygateway>"
}
}
}
Azure Storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
MongoDB input dataset: Setting “external”: ”true” informs the Data Factory service that the table is external
to the data factory and is not produced by an activity in the data factory.
{
"name": "MongoDbInputDataset",
"properties": {
"type": "MongoDbCollection",
"linkedServiceName": "OnPremisesMongoDbLinkedService",
"typeProperties": {
"collectionName": "<Collection name>"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutputDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/frommongodb/yearno={Year}/monthno={Month}/dayno={Day}/hourno=
{Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with MongoDB source and Blob sink:
The pipeline contains a Copy Activity that is configured to use the above input and output datasets and is
scheduled to run every hour. In the pipeline JSON definition, the source type is set to MongoDbSource and
sink type is set to BlobSink. The SQL query specified for the query property selects the data in the past hour
to copy.
{
"name": "CopyMongoDBToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbSource",
"query": "$$Text.Format('select * from MyTable where LastModifiedDate >=
{{ts\'{0:yyyy-MM-dd HH:mm:ss}\'}} AND LastModifiedDate < {{ts\'{1:yyyy-MM-dd HH:mm:ss}\'}}', WindowStart,
WindowEnd)"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "MongoDbInputDataset"
}
],
"outputs": [
{
"name": "AzureBlobOutputDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "MongoDBToAzureBlob"
}
],
"start": "2016-06-01T18:00:00Z",
"end": "2016-06-01T19:00:00Z"
}
}
Schema by Data Factory
Azure Data Factory service infers schema from a MongoDB collection by using the latest 100 documents in the
collection. If these 100 documents do not contain full schema, some columns may be ignored during the copy
operation.
Type mapping for MongoDB
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to MongoDB the following mappings are used from MongoDB types to .NET types.
MONGODB TYPE
.NET FRAMEWORK TYPE
Binary
Byte[]
Boolean
Boolean
Date
DateTime
NumberDouble
Double
NumberInt
Int32
NumberLong
Int64
ObjectID
String
String
String
UUID
Guid
Object
Renormalized into flatten columns with “_” as nested
separator
NOTE
To learn about support for arrays using virtual tables, refer to Support for complex types using virtual tables section
below.
Currently, the following MongoDB data types are not supported: DBPointer, JavaScript, Max/Min key, Regular
Expression, Symbol, Timestamp, Undefined
Support for complex types using virtual tables
Azure Data Factory uses a built-in ODBC driver to connect to and copy data from your MongoDB database. For
complex types such as arrays or objects with different types across the documents, the driver re-normalizes
data into corresponding virtual tables. Specifically, if a table contains such columns, the driver generates the
following virtual tables:
A base table, which contains the same data as the real table except for the complex type columns. The base
table uses the same name as the real table that it represents.
A virtual table for each complex type column, which expands the nested data. The virtual tables are named
using the name of the real table, a separator “_” and the name of the array or object.
Virtual tables refer to the data in the real table, enabling the driver to access the denormalized data. See
Example section below details. You can access the content of MongoDB arrays by querying and joining the
virtual tables.
You can use the Copy Wizard to intuitively view the list of tables in MongoDB database including the virtual
tables, and preview the data inside. You can also construct a query in the Copy Wizard and validate to see the
result.
Example
For example, “ExampleTable” below is a MongoDB table that has one column with an array of Objects in each
cell – Invoices, and one column with an array of Scalar types – Ratings.
_ID
CUSTOMER NAME
INVOICES
SERVICE LEVEL
RATINGS
1111
ABC
[{invoice_id:”123”,
item:”toaster”,
price:”456”,
discount:”0.2”},
{invoice_id:”124”,
item:”oven”, price:
”1235”, discount:
”0.2”}]
Silver
[5,6]
2222
XYZ
[{invoice_id:”135”,
item:”fridge”, price:
”12543”, discount:
”0.0”}]
Gold
[1,2]
The driver would generate multiple virtual tables to represent this single table. The first virtual table is the base
table named “ExampleTable”, shown below. The base table contains all the data of the original table, but the
data from the arrays has been omitted and is expanded in the virtual tables.
_ID
CUSTOMER NAME
SERVICE LEVEL
1111
ABC
Silver
2222
XYZ
Gold
The following tables show the virtual tables that represent the original arrays in the example. These tables
contain the following:
A reference back to the original primary key column corresponding to the row of the original array (via the
_id column)
An indication of the position of the data within the original array
The expanded data for each element within the array
Table “ExampleTable_Invoices”:
_ID
EXAMPLETABLE_I
NVOICES_DIM1_ID
X
INVOICE_ID
ITEM
PRICE
DISCOUNT
1111
0
123
toaster
456
0.2
1111
1
124
oven
1235
0.2
2222
0
135
fridge
12543
0.0
Table “ExampleTable_Ratings”:
_ID
EXAMPLETABLE_RATINGS_DIM1_IDX
EXAMPLETABLE_RATINGS
1111
0
5
1111
1
6
_ID
EXAMPLETABLE_RATINGS_DIM1_IDX
EXAMPLETABLE_RATINGS
2222
0
1
2222
1
2
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Next Steps
See Move data between on-premises and cloud article for step-by-step instructions for creating a data pipeline
that moves data from an on-premises data store to an Azure data store.
Move data From MySQL using Azure Data Factory
5/15/2017 • 8 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
MySQL database. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
You can copy data from an on-premises MySQL data store to any supported sink data store. For a list of data
stores supported as sinks by the copy activity, see the Supported data stores table. Data factory currently
supports only moving data from a MySQL data store to other data stores, but not for moving data from other
data stores to an MySQL data store.
Prerequisites
Data Factory service supports connecting to on-premises MySQL sources using the Data Management
Gateway. See moving data between on-premises locations and cloud article to learn about Data Management
Gateway and step-by-step instructions on setting up the gateway.
Gateway is required even if the MySQL database is hosted in an Azure IaaS virtual machine (VM). You can
install the gateway on the same VM as the data store or on a different VM as long as the gateway can connect
to the database.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Supported versions and installation
For Data Management Gateway to connect to the MySQL Database, you need to install the MySQL
Connector/Net for Microsoft Windows (version 6.6.5 or above) on the same system as the Data Management
Gateway. MySQL version 5.1 and above is supported.
TIP
If you hit error on "Authentication failed because the remote party has closed the transport stream.", consider to
upgrade the MySQL Connector/Net to higher version.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises Cassandra data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises MySQL data store, see JSON example: Copy data from MySQL to Azure
Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to a MySQL data store:
Linked service properties
The following table provides description for JSON elements specific to MySQL linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesMySql
Yes
server
Name of the MySQL server.
Yes
database
Name of the MySQL database.
Yes
schema
Name of the schema in the database.
No
authenticationType
Type of authentication used to
connect to the MySQL database.
Possible values are: Basic .
Yes
username
Specify user name to connect to the
MySQL database.
Yes
password
Specify password for the user account
you specified.
Yes
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the on-premises MySQL database.
Yes
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type RelationalTable (which includes
MySQL dataset) has the following properties
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the MySQL
Database instance that linked service
refers to.
No (if query of RelationalSource is
specified)
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, are policies are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
When source in copy activity is of type RelationalSource (which includes MySQL), the following properties
are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable.
No (if tableName of
dataset is specified)
JSON example: Copy data from MySQL to Azure Blob
This example provides sample JSON definitions that you can use to create a pipeline by using Azure portal or
Visual Studio or Azure PowerShell. It shows how to copy data from an on-premises MySQL database to an
Azure Blob Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in
Azure Data Factory.
IMPORTANT
This sample provides JSON snippets. It does not include step-by-step instructions for creating the data factory. See
moving data between on-premises locations and cloud article for step-by-step instructions.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesMySql.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from a query result in MySQL database to a blob hourly. The JSON properties used in
these samples are described in sections following the samples.
As a first step, setup the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
MySQL linked service:
{
"name": "OnPremMySqlLinkedService",
"properties": {
"type": "OnPremisesMySql",
"typeProperties": {
"server": "<server name>",
"database": "<database name>",
"schema": "<schema name>",
"authenticationType": "<authentication type>",
"userName": "<user name>",
"password": "<password>",
"gatewayName": "<gateway>"
}
}
}
Azure Storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
MySQL input dataset:
The sample assumes you have created a table “MyTable” in MySQL and it contains a column called
“timestampcolumn” for time series data.
Setting “external”: ”true” informs the Data Factory service that the table is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "MySqlDataSet",
"properties": {
"published": false,
"type": "RelationalTable",
"linkedServiceName": "OnPremMySqlLinkedService",
"typeProperties": {},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobMySqlDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/mysql/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is set
to BlobSink. The SQL query specified for the query property selects the data in the past hour to copy.
{
"name": "CopyMySqlToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "$$Text.Format('select * from MyTable where timestamp >= \\'{0:yyyyMM-ddTHH:mm:ss}\\' AND timestamp < \\'{1:yyyy-MM-ddTHH:mm:ss}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "MySqlDataSet"
}
],
"outputs": [
{
"name": "AzureBlobMySqlDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "MySqlToBlob"
}
],
"start": "2014-06-01T18:00:00Z",
"end": "2014-06-01T19:00:00Z"
}
}
Type mapping for MySQL
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following two-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to MySQL, the following mappings are used from MySQL types to .NET types.
MYSQL DATABASE TYPE
.NET FRAMEWORK TYPE
bigint unsigned
Decimal
bigint
Int64
bit
Decimal
MYSQL DATABASE TYPE
.NET FRAMEWORK TYPE
blob
Byte[]
bool
Boolean
char
String
date
Datetime
datetime
Datetime
decimal
Decimal
double precision
Double
double
Double
enum
String
float
Single
int unsigned
Int64
int
Int32
integer unsigned
Int64
integer
Int32
long varbinary
Byte[]
long varchar
String
longblob
Byte[]
longtext
String
mediumblob
Byte[]
mediumint unsigned
Int64
mediumint
Int32
mediumtext
String
numeric
Decimal
real
Double
set
String
MYSQL DATABASE TYPE
.NET FRAMEWORK TYPE
smallint unsigned
Int32
smallint
Int16
text
String
time
TimeSpan
timestamp
Datetime
tinyblob
Byte[]
tinyint unsigned
Int16
tinyint
Int16
tinytext
String
varchar
String
year
Int
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data From a OData source using Azure Data
Factory
6/5/2017 • 9 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an OData source. It
builds on the Data Movement Activities article, which presents a general overview of data movement with the
copy activity.
You can copy data from an OData source to any supported sink data store. For a list of data stores supported as
sinks by the copy activity, see the Supported data stores table. Data factory currently supports only moving
data from an OData source to other data stores, but not for moving data from other data stores to an OData
source.
Supported versions and authentication types
This OData connector support OData version 3.0 and 4.0, and you can copy data from both cloud OData and
on-premises OData sources. For the latter, you need to install the Data Management Gateway. See Move data
between on-premises and cloud article for details about Data Management Gateway.
Below authentication types are supported:
To access cloud OData feed, you can use anonymous, basic (user name and password), or Azure Active
Directory based OAuth authentication.
To access on-premises OData feed, you can use anonymous, basic (user name and password), or Windows
authentication.
Getting started
You can create a pipeline with a copy activity that moves data from an OData source by using different
tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an OData source, see JSON example: Copy data from OData source to Azure Blob
section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to OData source:
Linked Service properties
The following table provides description for JSON elements specific to OData linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OData
Yes
url
Url of the OData service.
Yes
authenticationType
Type of authentication used to
connect to the OData source.
Yes
For cloud OData, possible values are
Anonymous, Basic, and OAuth (note
Azure Data Factory currently only
support Azure Active Directory based
OAuth).
For on-premises OData, possible
values are Anonymous, Basic, and
Windows.
username
Specify user name if you are using
Basic authentication.
Yes (only if you are using Basic
authentication)
password
Specify password for the user account
you specified for the username.
Yes (only if you are using Basic
authentication)
authorizedCredential
If you are using OAuth, click
Authorize button in the Data Factory
Copy Wizard or Editor and enter your
credential, then the value of this
property will be auto-generated.
Yes (only if you are using OAuth
authentication)
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the on-premises OData service.
Specify only if you are copying data
from on-prem OData source.
No
Using Basic authentication
{
"name": "inputLinkedService",
"properties":
{
"type": "OData",
"typeProperties":
{
"url": "http://services.odata.org/OData/OData.svc",
"authenticationType": "Basic",
"username": "username",
"password": "password"
}
}
}
Using Anonymous authentication
{
"name": "ODataLinkedService",
"properties":
{
"type": "OData",
"typeProperties":
{
"url": "http://services.odata.org/OData/OData.svc",
"authenticationType": "Anonymous"
}
}
}
Using Windows authentication accessing on-premises OData source
{
"name": "inputLinkedService",
"properties":
{
"type": "OData",
"typeProperties":
{
"url": "<endpoint of on-premises OData source e.g. Dynamics CRM>",
"authenticationType": "Windows",
"username": "domain\\user",
"password": "password",
"gatewayName": "mygateway"
}
}
}
Using OAuth authentication accessing cloud OData source
{
"name": "inputLinkedService",
"properties":
{
"type": "OData",
"typeProperties":
{
"url": "<endpoint of cloud OData source e.g.
https://<tenant>.crm.dynamics.com/XRMServices/2011/OrganizationData.svc>",
"authenticationType": "OAuth",
"authorizedCredential": "<auto generated by clicking the Authorize button on UI>"
}
}
}
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type ODataResource (which includes
OData dataset) has the following properties
PROPERTY
DESCRIPTION
REQUIRED
path
Path to the OData resource
No
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of activities.
Properties available in the typeProperties section of the activity on the other hand vary with each activity type.
For Copy activity, they vary depending on the types of sources and sinks.
When source is of type RelationalSource (which includes OData) the following properties are available in
typeProperties section:
PROPERTY
DESCRIPTION
EXAMPLE
REQUIRED
query
Use the custom query to
read data.
"?$select=Name,
Description&$top=5"
No
Type Mapping for OData
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following two-step approach.
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data from OData, the following mappings are used from OData types to .NET type.
ODATA DATA TYPE
.NET TYPE
Edm.Binary
Byte[]
Edm.Boolean
Bool
Edm.Byte
Byte[]
Edm.DateTime
DateTime
Edm.Decimal
Decimal
Edm.Double
Double
Edm.Single
Single
Edm.Guid
Guid
Edm.Int16
Int16
Edm.Int32
Int32
Edm.Int64
Int64
Edm.SByte
Int16
Edm.String
String
Edm.Time
TimeSpan
Edm.DateTimeOffset
DateTimeOffset
NOTE
OData complex data types e.g. Object are not supported.
JSON example: Copy data from OData source to Azure Blob
This example provides sample JSON definitions that you can use to create a pipeline by using Azure portal or
Visual Studio or Azure PowerShell. They show how to copy data from an OData source to an Azure Blob
Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data
Factory. The sample has the following Data Factory entities:
1.
2.
3.
4.
5.
A linked service of type OData.
A linked service of type AzureStorage.
An input dataset of type ODataResource.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from querying against an OData source to an Azure blob every hour. The JSON
properties used in these samples are described in sections following the samples.
OData linked service: This example uses the Anonymous authentication. See OData linked service section for
different types of authentication you can use.
{
"name": "ODataLinkedService",
"properties":
{
"type": "OData",
"typeProperties":
{
"url": "http://services.odata.org/OData/OData.svc",
"authenticationType": "Anonymous"
}
}
}
Azure Storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
OData input dataset:
Setting “external”: ”true” informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "ODataDataset",
"properties":
{
"type": "ODataResource",
"typeProperties":
{
"path": "Products"
},
"linkedServiceName": "ODataLinkedService",
"structure": [],
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
Specifying path in the dataset definition is optional.
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobODataDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/odata/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with OData source and Blob sink:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled to
run every hour. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is set
to BlobSink. The SQL query specified for the query property selects the latest (newest) data from the OData
source.
{
"name": "CopyODataToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "?$select=Name, Description&$top=5",
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "ODataDataSet"
}
],
"outputs": [
{
"name": "AzureBlobODataDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "ODataToBlob"
}
],
"start": "2017-02-01T18:00:00Z",
"end": "2017-02-03T19:00:00Z"
}
}
Specifying query in the pipeline definition is optional. The URL that the Data Factory service uses to retrieve
data is: URL specified in the linked service (required) + path specified in the dataset (optional) + query in the
pipeline (optional).
Type mapping for OData
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data from OData data stores, OData data types are mapped to .NET types.
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data From ODBC data stores using Azure
Data Factory
5/16/2017 • 10 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
ODBC data store. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
You can copy data from an ODBC data store to any supported sink data store. For a list of data stores
supported as sinks by the copy activity, see the Supported data stores table. Data factory currently supports
only moving data from an ODBC data store to other data stores, but not for moving data from other data
stores to an ODBC data store.
Enabling connectivity
Data Factory service supports connecting to on-premises ODBC sources using the Data Management Gateway.
See moving data between on-premises locations and cloud article to learn about Data Management Gateway
and step-by-step instructions on setting up the gateway. Use the gateway to connect to an ODBC data store
even if it is hosted in an Azure IaaS VM.
You can install the gateway on the same on-premises machine or the Azure VM as the ODBC data store.
However, we recommend that you install the gateway on a separate machine/Azure IaaS VM to avoid resource
contention and for better performance. When you install the gateway on a separate machine, the machine
should be able to access the machine with the ODBC data store.
Apart from the Data Management Gateway, you also need to install the ODBC driver for the data store on the
gateway machine.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Getting started
You can create a pipeline with a copy activity that moves data from an ODBC data store by using different
tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an ODBC data store, see JSON example: Copy data from ODBC data store to Azure Blob
section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to ODBC data store:
Linked service properties
The following table provides description for JSON elements specific to ODBC linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesOdbc
Yes
connectionString
The non-access credential portion of
the connection string and an optional
encrypted credential. See examples in
the following sections.
Yes
credential
The access credential portion of the
connection string specified in driverspecific property-value format.
Example:
“Uid=;Pwd=;RefreshToken=;”.
No
authenticationType
Type of authentication used to
connect to the ODBC data store.
Possible values are: Anonymous and
Basic.
Yes
username
Specify user name if you are using
Basic authentication.
No
password
Specify password for the user account
you specified for the username.
No
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the ODBC data store.
Yes
Using Basic authentication
{
"name": "odbc",
"properties":
{
"type": "OnPremisesOdbc",
"typeProperties":
{
"authenticationType": "Basic",
"connectionString": "Driver={SQL Server};Server=Server.database.windows.net;
Database=TestDatabase;",
"userName": "username",
"password": "password",
"gatewayName": "mygateway"
}
}
}
Using Basic authentication with encrypted credentials
You can encrypt the credentials using the New-AzureRMDataFactoryEncryptValue (1.0 version of Azure
PowerShell) cmdlet or New-AzureDataFactoryEncryptValue (0.9 or earlier version of the Azure PowerShell).
{
"name": "odbc",
"properties":
{
"type": "OnPremisesOdbc",
"typeProperties":
{
"authenticationType": "Basic",
"connectionString": "Driver={SQL Server};Server=myserver.database.windows.net;
Database=TestDatabase;;EncryptedCredential=eyJDb25uZWN0...........................",
"gatewayName": "mygateway"
}
}
}
Using Anonymous authentication
{
"name": "odbc",
"properties":
{
"type": "OnPremisesOdbc",
"typeProperties":
{
"authenticationType": "Anonymous",
"connectionString": "Driver={SQL Server};Server={servername}.database.windows.net;
Database=TestDatabase;",
"credential": "UID={uid};PWD={pwd}",
"gatewayName": "mygateway"
}
}
}
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type RelationalTable (which includes
ODBC dataset) has the following properties
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the ODBC data
store.
Yes
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policies are available for all types of
activities.
Properties available in the typeProperties section of the activity on the other hand vary with each activity type.
For Copy activity, they vary depending on the types of sources and sinks.
In copy activity, when source is of type RelationalSource (which includes ODBC), the following properties are
available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable.
Yes
JSON example: Copy data from ODBC data store to Azure Blob
This example provides JSON definitions that you can use to create a pipeline by using Azure portal or Visual
Studio or Azure PowerShell. It shows how to copy data from an ODBC source to an Azure Blob Storage.
However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data Factory.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesOdbc.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from a query result in an ODBC data store to a blob every hour. The JSON properties
used in these samples are described in sections following the samples.
As a first step, set up the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
ODBC linked service This example uses the Basic authentication. See ODBC linked service section for different
types of authentication you can use.
{
"name": "OnPremOdbcLinkedService",
"properties":
{
"type": "OnPremisesOdbc",
"typeProperties":
{
"authenticationType": "Basic",
"connectionString": "Driver={SQL Server};Server=Server.database.windows.net;
Database=TestDatabase;",
"userName": "username",
"password": "password",
"gatewayName": "mygateway"
}
}
}
Azure Storage linked service
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
ODBC input dataset
The sample assumes you have created a table “MyTable” in an ODBC database and it contains a column called
“timestampcolumn” for time series data.
Setting “external”: ”true” informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "ODBCDataSet",
"properties": {
"published": false,
"type": "RelationalTable",
"linkedServiceName": "OnPremOdbcLinkedService",
"typeProperties": {},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOdbcDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/odbc/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity in a pipeline with ODBC source (RelationalSource) and Blob sink (BlobSink)
The pipeline contains a Copy Activity that is configured to use these input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is
set to BlobSink. The SQL query specified for the query property selects the data in the past hour to copy.
{
"name": "CopyODBCToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "$$Text.Format('select * from MyTable where timestamp >= \\'{0:yyyy-MMddTHH:mm:ss}\\' AND timestamp < \\'{1:yyyy-MM-ddTHH:mm:ss}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "OdbcDataSet"
}
],
"outputs": [
{
"name": "AzureBlobOdbcDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "OdbcToBlob"
}
],
"start": "2016-06-01T18:00:00Z",
"end": "2016-06-01T19:00:00Z"
}
}
Type mapping for ODBC
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following two-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data from ODBC data stores, ODBC data types are mapped to .NET types as mentioned in the
ODBC Data Type Mappings topic.
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
GE Historian store
You create an ODBC linked service to link a GE Proficy Historian (now GE Historian) data store to an Azure data
factory as shown in the following example:
{
"name": "HistorianLinkedService",
"properties":
{
"type": "OnPremisesOdbc",
"typeProperties":
{
"connectionString": "DSN=<name of the GE Historian store>",
"gatewayName": "<gateway name>",
"authenticationType": "Basic",
"userName": "<user name>",
"password": "<password>"
}
}
}
Install Data Management Gateway on an on-premises machine and register the gateway with the portal. The
gateway installed on your on-premises computer uses the ODBC driver for GE Historian to connect to the GE
Historian data store. Therefore, install the driver if it is not already installed on the gateway machine. See
Enabling connectivity section for details.
Before you use the GE Historian store in a Data Factory solution, verify whether the gateway can connect to the
data store using instructions in the next section.
Read the article from the beginning for a detailed overview of using ODBC data stores as source data stores in
a copy operation.
Troubleshoot connectivity issues
To troubleshoot connection issues, use the Diagnostics tab of Data Management Gateway Configuration
Manager.
1. Launch Data Management Gateway Configuration Manager. You can either run "C:\Program
Files\Microsoft Data Management Gateway\1.0\Shared\ConfigManager.exe" directly (or) search for
Gateway to find a link to Microsoft Data Management Gateway application as shown in the
following image.
2. Switch to the Diagnostics tab.
3. Select the type of data store (linked service).
4. Specify authentication and enter credentials (or) enter connection string that is used to connect to the
data store.
5. Click Test connection to test the connection to the data store.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Copy data to/from on-premises Oracle using
Azure Data Factory
6/9/2017 • 15 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data to/from an on-premises
Oracle database. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
Supported scenarios
You can copy data from an Oracle database to the following data stores:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Data Lake Store
Azure Cosmos DB (DocumentDB API)
Azure SQL Database
Azure SQL Data Warehouse
Azure Search Index
Azure Table storage
Databases
SQL Server
Oracle
File
File system
You can copy data from the following data stores to an Oracle database:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Cosmos DB (DocumentDB API)
Azure Data Lake Store
Azure SQL Database
Azure SQL Data Warehouse
Azure Table storage
Databases
Amazon Redshift
DB2
MySQL
Oracle
PostgreSQL
SAP Business Warehouse
SAP HANA
SQL Server
Sybase
Teradata
NoSQL
Cassandra
MongoDB
CATEGORY
DATA STORE
File
Amazon S3
File System
FTP
HDFS
SFTP
Others
Generic HTTP
Generic OData
Generic ODBC
Salesforce
Web Table (table from HTML)
GE Historian
Prerequisites
Data Factory supports connecting to on-premises Oracle sources using the Data Management Gateway. See
Data Management Gateway article to learn about Data Management Gateway and Move data from onpremises to cloud article for step-by-step instructions on setting up the gateway a data pipeline to move data.
Gateway is required even if the Oracle is hosted in an Azure IaaS VM. You can install the gateway on the same
IaaS VM as the data store or on a different VM as long as the gateway can connect to the database.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Supported versions and installation
This Oracle connector support two versions of drivers:
Microsoft driver for Oracle (recommended): starting from Data Management Gateway version 2.7, a
Microsoft driver for Oracle is automatically installed along with the gateway, so you don't need to
additionally handle the driver in order to establish connectivity to Oracle, and you can also experience
better copy performance using this driver. Below versions of Oracle databases are supported:
Oracle 12c R1 (12.1)
Oracle 11g R1, R2 (11.1, 11.2)
Oracle 10g R1, R2 (10.1, 10.2)
Oracle 9i R1, R2 (9.0.1, 9.2)
Oracle 8i R3 (8.1.7)
IMPORTANT
Currently Microsoft driver for Oracle only supports copying data from Oracle but not writing to Oracle. And note the
test connection capability in Data Management Gateway Diagnostics tab does not support this driver. Alternatively,
you can use the copy wizard to validate the connectivity.
Oracle Data Provider for .NET: you can also choose to use Oracle Data Provider to copy data from/to
Oracle. This component is included in Oracle Data Access Components for Windows. Install the
appropriate version (32/64 bit) on the machine where the gateway is installed. Oracle Data Provider
.NET 12.1 can access to Oracle Database 10g Release 2 or later.
If you choose “XCopy Installation”, follow steps in the readme.htm. We recommend you choose the
installer with UI (non-XCopy one).
After installing the provider, restart the Data Management Gateway host service on your machine
using Services applet (or) Data Management Gateway Configuration Manager.
If you use copy wizard to author the copy pipeline, the driver type will be auto-determined. Microsoft driver
will be used by default, unless your gateway version is lower than 2.7 or you choose Oracle as sink.
Getting started
You can create a pipeline with a copy activity that moves data to/from an on-premises Oracle database by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create a data factory. A data factory may contain one or more pipelines.
2. Create linked services to link input and output data stores to your data factory. For example, if you are
copying data from an Oralce database to an Azure blob storage, you create two linked services to link your
Oracle database and Azure storage account to your data factory. For linked service properties that are
specific to Oracle, see linked service properties section.
3. Create datasets to represent input and output data for the copy operation. In the example mentioned in
the last step, you create a dataset to specify the table in your Oracle database that contains the input data.
And, you create another dataset to specify the blob container and the folder that holds the data copied
from the Oracle database. For dataset properties that are specific to Oracle, see dataset properties section.
4. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output. In the
example mentioned earlier, you use OracleSource as a source and BlobSink as a sink for the copy activity.
Similarly, if you are copying from Azure Blob Storage to Oracle Database, you use BlobSource and
OracleSink in the copy activity. For copy activity properties that are specific to Oracle database, see copy
activity properties section. For details on how to use a data store as a source or a sink, click the link in the
previous section for your data store.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that
are used to copy data to/from an on-premises Oracle database, see JSON examples section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities:
Linked service properties
The following table provides description for JSON elements specific to Oracle linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesOracle
Yes
PROPERTY
DESCRIPTION
REQUIRED
driverType
Specify which driver to use to copy
data from/to Oracle Database.
Allowed values are Microsoft or ODP
(default). See Supported version and
installation section on driver details.
No
connectionString
Specify information needed to
connect to the Oracle Database
instance for the connectionString
property.
Yes
gatewayName
Name of the gateway that that is
used to connect to the on-premises
Oracle server
Yes
Example: using Microsoft driver:
{
"name": "OnPremisesOracleLinkedService",
"properties": {
"type": "OnPremisesOracle",
"typeProperties": {
"driverType": "Microsoft",
"connectionString":"Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=
<password>;",
"gatewayName": "<gateway name>"
}
}
}
Example: using ODP driver
Refer to this site for the allowed formats.
{
"name": "OnPremisesOracleLinkedService",
"properties": {
"type": "OnPremisesOracle",
"typeProperties": {
"connectionString": "Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=<hostname>)(PORT=
<port number>))(CONNECT_DATA=(SERVICE_NAME=<SID>)));
User Id=<username>;Password=<password>;",
"gatewayName": "<gateway name>"
}
}
}
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Oracle, Azure blob,
Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for the dataset of type OracleTable has the following
properties:
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the Oracle
Database that the linked service refers
to.
No (if oracleReaderQuery of
OracleSource is specified)
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of
activities.
NOTE
The Copy Activity takes only one input and produces only one output.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
OracleSource
In Copy activity, when the source is of type OracleSource the following properties are available in
typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
oracleReaderQuery
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable
No (if tableName of
dataset is specified)
If not specified, the SQL
statement that is executed:
select * from MyTable
OracleSink
OracleSink supports the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
writeBatchTimeout
Wait time for the batch
insert operation to
complete before it times
out.
timespan
No
writeBatchSize
Inserts data into the SQL
table when the buffer size
reaches writeBatchSize.
Integer (number of rows)
No (default: 100)
sqlWriterCleanupScript
Specify a query for Copy
Activity to execute such
that data of a specific slice
is cleaned up.
A query statement.
No
Example: 00:30:00 (30
minutes).
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
sliceIdentifierColumnName
Specify column name for
Copy Activity to fill with
auto generated slice
identifier, which is used to
clean up data of a specific
slice when rerun.
Column name of a column
with data type of
binary(32).
No
JSON examples for copying data to and from Oracle database
The following example provides sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data from/to an Oracle database to/from
Azure Blob Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in
Azure Data Factory.
Example: Copy data from Oracle to Azure Blob
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesOracle.
A linked service of type AzureStorage.
An input dataset of type OracleTable.
An output dataset of type AzureBlob.
A pipeline with Copy activity that uses OracleSource as source and BlobSink as sink.
The sample copies data from a table in an on-premises Oracle database to a blob hourly. For more
information on various properties used in the sample, see documentation in sections following the samples.
Oracle linked service:
{
"name": "OnPremisesOracleLinkedService",
"properties": {
"type": "OnPremisesOracle",
"typeProperties": {
"driverType": "Microsoft",
"connectionString":"Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=
<password>;",
"gatewayName": "<gateway name>"
}
}
}
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<account name>;AccountKey=
<Account key>"
}
}
}
Oracle input dataset:
The sample assumes you have created a table “MyTable” in Oracle and it contains a column called
“timestampcolumn” for time series data.
Setting “external”: ”true” informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "OracleInput",
"properties": {
"type": "OracleTable",
"linkedServiceName": "OnPremisesOracleLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"offset": "01:00:00",
"interval": "1",
"anchorDateTime": "2014-02-27T12:00:00",
"frequency": "Hour"
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path and file name for the
blob are dynamically evaluated based on the start time of the slice that is being processed. The folder path
uses year, month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run hourly. In the pipeline JSON definition, the source type is set to OracleSource and sink type is set to
BlobSink. The SQL query specified with oracleReaderQuery property selects the data in the past hour to
copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "OracletoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": " OracleInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "OracleSource",
"oracleReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn
>= \\'{0:yyyy-MM-dd HH:mm}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Example: Copy data from Azure Blob to Oracle
This sample shows how to copy data from an Azure Blob Storage to an on-premises Oracle database.
However, data can be copied directly from any of the sources stated here using the Copy Activity in Azure
Data Factory.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesOracle.
A linked service of type AzureStorage.
An input dataset of type AzureBlob.
An output dataset of type OracleTable.
A pipeline with Copy activity that uses BlobSource as source OracleSink as sink.
The sample copies data from a blob to a table in an on-premises Oracle database every hour. For more
information on various properties used in the sample, see documentation in sections following the samples.
Oracle linked service:
{
"name": "OnPremisesOracleLinkedService",
"properties": {
"type": "OnPremisesOracle",
"typeProperties": {
"connectionString": "Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=<hostname>)(PORT=
<port number>))(CONNECT_DATA=(SERVICE_NAME=<SID>)));
User Id=<username>;Password=<password>;",
"gatewayName": "<gateway name>"
}
}
}
Azure Blob storage linked service:
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<account name>;AccountKey=
<Account key>"
}
}
}
Azure Blob input dataset
Data is picked up from a new blob every hour (frequency: hour, interval: 1). The folder path and file name for
the blob are dynamically evaluated based on the start time of the slice that is being processed. The folder path
uses year, month, and day part of the start time and file name uses the hour part of the start time. “external”:
“true” setting informs the Data Factory service that this table is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
}
},
"external": true,
"availability": {
"frequency": "Day",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Oracle output dataset:
The sample assumes you have created a table “MyTable” in Oracle. Create the table in Oracle with the same
number of columns as you expect the Blob CSV file to contain. New rows are added to the table every hour.
{
"name": "OracleOutput",
"properties": {
"type": "OracleTable",
"linkedServiceName": "OnPremisesOracleLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"availability": {
"frequency": "Day",
"interval": "1"
}
}
}
Pipeline with Copy activity:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to BlobSource and the sink type is
set to OracleSink.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-05T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "AzureBlobtoOracle",
"description": "Copy Activity",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "OracleOutput"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "OracleSink"
}
},
"scheduler": {
"frequency": "Day",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Troubleshooting tips
Problem 1: .NET Framework Data Provider
You see the following error message:
Copy activity met invalid parameters: 'UnknownParameterName', Detailed message: Unable to find the
requested .Net Framework Data Provider. It may not be installed”.
Possible causes:
1. The .NET Framework Data Provider for Oracle was not installed.
2. The .NET Framework Data Provider for Oracle was installed to .NET Framework 2.0 and is not found in the
.NET Framework 4.0 folders.
Resolution/Workaround:
1. If you haven't installed the .NET Provider for Oracle, install it and retry the scenario.
2. If you get the error message even after installing the provider, do the following steps:
a. Open machine config of .NET 2.0 from the folder:
:\Windows\Microsoft.NET\Framework64\v2.0.50727\CONFIG\machine.config.
b. Search for Oracle Data Provider for .NET, and you should be able to find an entry as shown in the
following sample under system.data -> DbProviderFactories: “”
3. Copy this entry to the machine.config file in the following v4.0 folder:
:\Windows\Microsoft.NET\Framework64\v4.0.30319\Config\machine.config, and change the version to
4.xxx.x.x.
4. Install “\11.2.0\client_1\odp.net\bin\4\Oracle.DataAccess.dll” into the global assembly cache (GAC) by
running gacutil /i [provider path] .## Troubleshooting tips
Problem 2: datetime formatting
You see the following error message:
Message=Operation failed in Oracle Database with the following error: 'ORA-01861: literal does not match
format string'.,Source=,''Type=Oracle.DataAccess.Client.OracleException,Message=ORA-01861: literal does
not match format string,Source=Oracle Data Provider for .NET,'.
Resolution/Workaround:
You may need to adjust the query string in your copy activity based on how dates are configured in your
Oracle database, as shown in the following sample (using the to_date function):
"oracleReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >= to_date(\\'{0:MM-ddyyyy HH:mm}\\',\\'MM/DD/YYYY HH24:MI\\') AND timestampcolumn < to_date(\\'{1:MM-dd-yyyy
HH:mm}\\',\\'MM/DD/YYYY HH24:MI\\') ', WindowStart, WindowEnd)"
Type mapping for Oracle
As mentioned in the data movement activities article Copy activity performs automatic type conversions from
source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data from Oracle, the following mappings are used from Oracle data type to .NET type and vice
versa.
ORACLE DATA TYPE
.NET FRAMEWORK DATA TYPE
BFILE
Byte[]
BLOB
Byte[]
CHAR
String
CLOB
String
DATE
DateTime
FLOAT
Decimal, String (if precision > 28)
INTEGER
Decimal, String (if precision > 28)
INTERVAL YEAR TO MONTH
Int32
INTERVAL DAY TO SECOND
TimeSpan
LONG
String
LONG RAW
Byte[]
NCHAR
String
NCLOB
String
NUMBER
Decimal, String (if precision > 28)
NVARCHAR2
String
RAW
Byte[]
ROWID
String
TIMESTAMP
DateTime
TIMESTAMP WITH LOCAL TIME ZONE
DateTime
TIMESTAMP WITH TIME ZONE
DateTime
UNSIGNED INTEGER
Number
VARCHAR2
String
XML
String
NOTE
Data type INTERVAL YEAR TO MONTH and INTERVAL DAY TO SECOND are not supported when using Microsoft
driver.
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns
in Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from PostgreSQL using Azure Data
Factory
6/6/2017 • 8 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
PostgreSQL database. It builds on the Data Movement Activities article, which presents a general overview of
data movement with the copy activity.
You can copy data from an on-premises PostgreSQL data store to any supported sink data store. For a list of
data stores supported as sinks by the copy activity, see supported data stores. Data factory currently supports
moving data from a PostgreSQL database to other data stores, but not for moving data from other data stores
to an PostgreSQL database.
prerequisites
Data Factory service supports connecting to on-premises PostgreSQL sources using the Data Management
Gateway. See moving data between on-premises locations and cloud article to learn about Data Management
Gateway and step-by-step instructions on setting up the gateway.
Gateway is required even if the PostgreSQL database is hosted in an Azure IaaS VM. You can install gateway on
the same IaaS VM as the data store or on a different VM as long as the gateway can connect to the database.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Supported versions and installation
For Data Management Gateway to connect to the PostgreSQL Database, install the Ngpsql data provider for
PostgreSQL 2.0.12 or above on the same system as the Data Management Gateway. PostgreSQL version 7.4
and above is supported.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises PostgreSQL data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline:
Azure portal
Visual Studio
Azure PowerShell
Azure Resource Manager template
.NET API
REST API
See Copy activity tutorial for step-by-step instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises PostgreSQL data store, see JSON example: Copy data from PostgreSQL
to Azure Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to a PostgreSQL data store:
Linked service properties
The following table provides description for JSON elements specific to PostgreSQL linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesPostgreSql
Yes
server
Name of the PostgreSQL server.
Yes
database
Name of the PostgreSQL database.
Yes
schema
Name of the schema in the database.
The schema name is case-sensitive.
No
authenticationType
Type of authentication used to
connect to the PostgreSQL database.
Possible values are: Anonymous, Basic,
and Windows.
Yes
username
Specify user name if you are using
Basic or Windows authentication.
No
password
Specify password for the user account
you specified for the username.
No
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the on-premises PostgreSQL
database.
Yes
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types.
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type RelationalTable (which includes
PostgreSQL dataset) has the following properties:
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the PostgreSQL
Database instance that linked service
refers to. The tableName is casesensitive.
No (if query of RelationalSource is
specified)
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For Copy
activity, they vary depending on the types of sources and sinks.
When source is of type RelationalSource (which includes PostgreSQL), the following properties are available
in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL query string. For
example: "query": "select *
from
\"MySchema\".\"MyTable\"".
No (if tableName of
dataset is specified)
NOTE
Schema and table names are case-sensitive. Enclose them in
""
(double quotes) in the query.
Example:
"query": "select * from \"MySchema\".\"MyTable\""
JSON example: Copy data from PostgreSQL to Azure Blob
This example provides sample JSON definitions that you can use to create a pipeline by using Azure portal or
Visual Studio or Azure PowerShell. They show how to copy data from PostgreSQL database to Azure Blob
Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data
Factory.
IMPORTANT
This sample provides JSON snippets. It does not include step-by-step instructions for creating the data factory. See
moving data between on-premises locations and cloud article for step-by-step instructions.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesPostgreSql.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
The pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from a query result in PostgreSQL database to a blob every hour. The JSON properties
used in these samples are described in sections following the samples.
As a first step, setup the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
PostgreSQL linked service:
{
"name": "OnPremPostgreSqlLinkedService",
"properties": {
"type": "OnPremisesPostgreSql",
"typeProperties": {
"server": "<server>",
"database": "<database>",
"schema": "<schema>",
"authenticationType": "<authentication type>",
"username": "<username>",
"password": "<password>",
"gatewayName": "<gatewayName>"
}
}
}
Azure Blob storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<AccountName>;AccountKey=
<AccountKey>"
}
}
}
PostgreSQL input dataset:
The sample assumes you have created a table “MyTable” in PostgreSQL and it contains a column called
“timestamp” for time series data.
Setting "external": true informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "PostgreSqlDataSet",
"properties": {
"type": "RelationalTable",
"linkedServiceName": "OnPremPostgreSqlLinkedService",
"typeProperties": {},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path and file name for the
blob are dynamically evaluated based on the start time of the slice that is being processed. The folder path uses
year, month, day, and hours parts of the start time.
{
"name": "AzureBlobPostgreSqlDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/postgresql/yearno={Year}/monthno={Month}/dayno={Day}/hourno=
{Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run hourly. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is set
to BlobSink. The SQL query specified for the query property selects the data from the public.usstates table in
the PostgreSQL database.
{
"name": "CopyPostgreSqlToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "select * from \"public\".\"usstates\""
},
"sink": {
"type": "BlobSink"
}
},
"inputs": [
{
"name": "PostgreSqlDataSet"
}
],
"outputs": [
{
"name": "AzureBlobPostgreSqlDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "PostgreSqlToBlob"
}
],
"start": "2014-06-01T18:00:00Z",
"end": "2014-06-01T19:00:00Z"
}
}
Type mapping for PostgreSQL
As mentioned in the data movement activities article Copy activity performs automatic type conversions from
source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to PostgreSQL, the following mappings are used from PostgreSQL type to .NET type.
POSTGRESQL DATABASE TYPE
POSTGRESSQL ALIASES
abstime
.NET FRAMEWORK TYPE
Datetime
bigint
int8
Int64
bigserial
serial8
Int64
bit [ (n) ]
Byte[], String
POSTGRESQL DATABASE TYPE
POSTGRESSQL ALIASES
.NET FRAMEWORK TYPE
bit varying [ (n) ]
varbit
Byte[], String
boolean
bool
Boolean
box
Byte[], String
bytea
Byte[], String
character [ (n) ]
char [ (n) ]
String
character varying [ (n) ]
varchar [ (n) ]
String
cid
String
cidr
String
circle
Byte[], String
date
Datetime
daterange
String
double precision
float8
Double
inet
Byte[], String
intarry
String
int4range
String
int8range
String
integer
int, int4
Int32
interval [ fields ] [ (p) ]
Timespan
json
String
jsonb
Byte[]
line
Byte[], String
lseg
Byte[], String
macaddr
Byte[], String
money
Decimal
numeric [ (p, s) ]
decimal [ (p, s) ]
Decimal
POSTGRESQL DATABASE TYPE
POSTGRESSQL ALIASES
.NET FRAMEWORK TYPE
numrange
String
oid
Int32
path
Byte[], String
pg_lsn
Int64
point
Byte[], String
polygon
Byte[], String
real
float4
Single
smallint
int2
Int16
smallserial
serial2
Int16
serial
serial4
Int32
text
String
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from Salesforce by using Azure Data
Factory
6/5/2017 • 10 min to read • Edit Online
This article outlines how you can use Copy Activity in an Azure data factory to copy data from Salesforce to any
data store that is listed under the Sink column in the supported sources and sinks table. This article builds on
the data movement activities article, which presents a general overview of data movement with Copy Activity
and supported data store combinations.
Azure Data Factory currently supports only moving data from Salesforce to supported sink data stores, but
does not support moving data from other data stores to Salesforce.
Supported versions
This connector supports the following editions of Salesforce: Developer Edition, Professional Edition, Enterprise
Edition, or Unlimited Edition. And it supports copying from Salesforce production, sandbox and custom
domain.
Prerequisites
API permission must be enabled. See How do I enable API access in Salesforce by permission set?
To copy data from Salesforce to on-premises data stores, you must have at least Data Management
Gateway 2.0 installed in your on-premises environment.
Salesforce request limits
Salesforce has limits for both total API requests and concurrent API requests. Note the following points:
If the number of concurrent requests exceeds the limit, throttling occurs and you will see random failures.
If the total number of requests exceeds the limit, the Salesforce account will be blocked for 24 hours.
You might also receive the “REQUEST_LIMIT_EXCEEDED“ error in both scenarios. See the "API Request Limits"
section in the Salesforce Developer Limits article for details.
Getting started
You can create a pipeline with a copy activity that moves data from Salesforce by using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from Salesforce, see JSON example: Copy data from Salesforce to Azure Blob section of this
article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to Salesforce:
Linked service properties
The following table provides descriptions for JSON elements that are specific to the Salesforce linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
Salesforce.
Yes
environmentUrl
Specify the URL of Salesforce instance.
No
- Default is
"https://login.salesforce.com".
- To copy data from sandbox, specify
"https://test.salesforce.com".
- To copy data from custom domain,
specify, for example,
"https://[domain].my.salesforce.com".
username
Specify a user name for the user
account.
Yes
password
Specify a password for the user
account.
Yes
securityToken
Specify a security token for the user
account. See Get security token for
instructions on how to reset/get a
security token. To learn about security
tokens in general, see Security and the
API.
Yes
Dataset properties
For a full list of sections and properties that are available for defining datasets, see the Creating datasets article.
Sections such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL,
Azure blob, Azure table, and so on).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for a dataset of the type RelationalTable has the
following properties:
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in Salesforce.
No (if a query of RelationalSource is
specified)
IMPORTANT
The "__c" part of the API Name is needed for any custom object.
Copy activity properties
For a full list of sections and properties that are available for defining activities, see the Creating pipelines
article. Properties like name, description, input and output tables, and various policies are available for all types
of activities.
The properties that are available in the typeProperties section of the activity, on the other hand, vary with each
activity type. For Copy Activity, they vary depending on the types of sources and sinks.
In copy activity, when the source is of the type RelationalSource (which includes Salesforce), the following
properties are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
A SQL-92 query or
Salesforce Object Query
Language (SOQL) query.
For example:
No (if the tableName of
the dataset is specified)
select * from
MyTable__c
.
IMPORTANT
The "__c" part of the API Name is needed for any custom object.
Query tips
Retrieving data using where clause on DateTime column
When specify the SOQL or SQL query, pay attention to the DateTime format difference. For example:
SOQL sample:
$$Text.Format('SELECT Id, Name, BillingCity FROM Account WHERE LastModifiedDate >= {0:yyyy-MMddTHH:mm:ssZ} AND LastModifiedDate < {1:yyyy-MM-ddTHH:mm:ssZ}', WindowStart, WindowEnd)
SQL sample:
Using copy wizard to specify the query:
$$Text.Format('SELECT * FROM Account WHERE LastModifiedDate >= {{ts\'{0:yyyy-MM-dd HH:mm:ss}\'}}
AND LastModifiedDate < {{ts\'{1:yyyy-MM-dd HH:mm:ss}\'}}', WindowStart, WindowEnd)
Using JSON editing to specify the query (escape char properly):
$$Text.Format('SELECT * FROM Account WHERE LastModifiedDate >= {{ts\\'{0:yyyy-MM-dd HH:mm:ss}\\'}}
AND LastModifiedDate < {{ts\\'{1:yyyy-MM-dd HH:mm:ss}\\'}}', WindowStart, WindowEnd)
Retrieving data from Salesforce Report
You can retrieve data from Salesforce reports by specifying query as
"query": "{call \"TestReport\"}" .
{call "<report name>"}
,for example,.
Retrieving deleted records from Salesforce Recycle Bin
To query the soft deleted records from Salesforce Recycle Bin, you can specify "IsDeleted = 1" in your query.
For example,
To query only the deleted records, specify "select * from MyTable__c where IsDeleted= 1"
To query all the records including the existing and the deleted, specify "select * from MyTable__c where
IsDeleted = 0 or IsDeleted = 1"
JSON example: Copy data from Salesforce to Azure Blob
The following example provides sample JSON definitions that you can use to create a pipeline by using the
Azure portal, Visual Studio, or Azure PowerShell. They show how to copy data from Salesforce to Azure Blob
Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data
Factory.
Here are the Data Factory artifacts that you'll need to create to implement the scenario. The sections that follow
the list provide details about these steps.
A linked service of the type Salesforce
A linked service of the type AzureStorage
An input dataset of the type RelationalTable
An output dataset of the type AzureBlob
A pipeline with Copy Activity that uses RelationalSource and BlobSink
Salesforce linked service
This example uses the Salesforce linked service. See the Salesforce linked service section for the properties
that are supported by this linked service. See Get security token for instructions on how to reset/get the
security token.
{
"name": "SalesforceLinkedService",
"properties":
{
"type": "Salesforce",
"typeProperties":
{
"username": "<user name>",
"password": "<password>",
"securityToken": "<security token>"
}
}
}
Azure Storage linked service
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Salesforce input dataset
{
"name": "SalesforceInput",
"properties": {
"linkedServiceName": "SalesforceLinkedService",
"type": "RelationalTable",
"typeProperties": {
"tableName": "AllDataType__c"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Setting external to true informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
IMPORTANT
The "__c" part of the API Name is needed for any custom object.
Azure blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1).
{
"name": "AzureBlobOutput",
"properties":
{
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties":
{
"folderPath": "adfgetstarted/alltypes_c"
},
"availability":
{
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy Activity
The pipeline contains Copy Activity, which is configured to use the input and output datasets, and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to RelationalSource, and the sink
type is set to BlobSink.
See RelationalSource type properties for the list of properties that are supported by the RelationalSource.
{
"name":"SamplePipeline",
"properties":{
"start":"2016-06-01T18:00:00",
"end":"2016-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "SalesforceToAzureBlob",
"description": "Copy from Salesforce to an Azure blob",
"type": "Copy",
"inputs": [
{
"name": "SalesforceInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "SELECT Id, Col_AutoNumber__c, Col_Checkbox__c, Col_Currency__c, Col_Date__c,
Col_DateTime__c, Col_Email__c, Col_Number__c, Col_Percent__c, Col_Phone__c, Col_Picklist__c,
Col_Picklist_MultiSelect__c, Col_Text__c, Col_Text_Area__c, Col_Text_AreaLong__c, Col_Text_AreaRich__c,
Col_URL__c, Col_Text_Encrypt__c, Col_Lookup__c FROM AllDataType__c"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
IMPORTANT
The "__c" part of the API Name is needed for any custom object.
Type mapping for Salesforce
SALESFORCE TYPE
.NET-BASED TYPE
Auto Number
String
Checkbox
Boolean
Currency
Double
Date
DateTime
Date/Time
DateTime
Email
String
Id
String
Lookup Relationship
String
Multi-Select Picklist
String
Number
Double
Percent
Double
Phone
String
Picklist
String
Text
String
Text Area
String
Text Area (Long)
String
Text Area (Rich)
String
Text (Encrypted)
String
URL
String
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data
Factory.
Specifying structure definition for rectangular datasets
The structure section in the datasets JSON is an optional section for rectangular tables (with rows & columns)
and contains a collection of columns for the table. You will use the structure section for either providing type
information for type conversions or doing column mappings. The following sections describe these features in
detail.
Each column contains the following properties:
PROPERTY
DESCRIPTION
REQUIRED
name
Name of the column.
Yes
type
Data type of the column. See type
conversions section below for more
details regarding when should you
specify type information
No
culture
.NET based culture to be used when
type is specified and is .NET type
Datetime or Datetimeoffset. Default is
“en-us”.
No
format
Format string to be used when type is
specified and is .NET type Datetime or
Datetimeoffset.
No
The following sample shows the structure section JSON for a table that has three columns userid, name, and
lastlogindate.
"structure":
[
{ "name": "userid"},
{ "name": "name"},
{ "name": "lastlogindate"}
],
Please use the following guidelines for when to include “structure” information and what to include in the
structure section.
For structured data sources that store data schema and type information along with the data itself
(sources like SQL Server, Oracle, Azure table etc.), you should specify the “structure” section only if you
want do column mapping of specific source columns to specific columns in sink and their names are not
the same (see details in column mapping section below).
As mentioned above, the type information is optional in “structure” section. For structured sources, type
information is already available as part of dataset definition in the data store, so you should not include
type information when you do include the “structure” section.
For schema on read data sources (specifically Azure blob) you can choose to store data without
storing any schema or type information with the data. For these types of data sources you should include
“structure” in the following 2 cases:
You want to do column mapping.
When the dataset is a source in a Copy activity, you can provide type information in “structure” and
data factory will use this type information for conversion to native types for the sink. See Move data
to and from Azure Blob article for more information.
Supported .NET -based types
Data factory supports the following CLS compliant .NET based type values for providing type information in
“structure” for schema on read data sources like Azure blob.
Int16
Int32
Int64
Single
Double
Decimal
Byte[]
Bool
String
Guid
Datetime
Datetimeoffset
Timespan
For Datetime & Datetimeoffset you can also optionally specify “culture” & “format” string to facilitate parsing
of your custom Datetime string. See sample for type conversion below.
Performance and tuning
See the Copy Activity performance and tuning guide to learn about key factors that impact performance of
data movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data From SAP Business Warehouse using
Azure Data Factory
5/16/2017 • 9 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises SAP
Business Warehouse (BW). It builds on the Data Movement Activities article, which presents a general overview
of data movement with the copy activity.
You can copy data from an on-premises SAP Business Warehouse data store to any supported sink data store.
For a list of data stores supported as sinks by the copy activity, see the Supported data stores table. Data
factory currently supports only moving data from an SAP Business Warehouse to other data stores, but not for
moving data from other data stores to an SAP Business Warehouse.
Supported versions and installation
This connector supports SAP Business Warehouse version 7.x. It supports copying data from InfoCubes and
QueryCubes (including BEx queries) using MDX queries.
To enable the connectivity to the SAP BW instance, install the following components:
Data Management Gateway: Data Factory service supports connecting to on-premises data stores
(including SAP Business Warehouse) using a component called Data Management Gateway. To learn about
Data Management Gateway and step-by-step instructions for setting up the gateway, see Moving data
between on-premises data store to cloud data store article. Gateway is required even if the SAP Business
Warehouse is hosted in an Azure IaaS virtual machine (VM). You can install the gateway on the same VM as
the data store or on a different VM as long as the gateway can connect to the database.
SAP NetWeaver library on the gateway machine. You can get the SAP Netweaver library from your SAP
administrator, or directly from the SAP Software Download Center. Search for the SAP Note #1025361 to
get the download location for the most recent version. Make sure that the architecture for the SAP
NetWeaver library (32-bit or 64-bit) matches your gateway installation. Then install all files included in the
SAP NetWeaver RFC SDK according to the SAP Note. The SAP NetWeaver library is also included in the SAP
Client Tools installation.
TIP
Put the dlls extracted from the NetWeaver RFC SDK into system32 folder.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises Cassandra data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises SAP Business Warehouse, see JSON example: Copy data from SAP
Business Warehouse to Azure Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to an SAP BW data store:
Linked service properties
The following table provides description for JSON elements specific to SAP Business Warehouse (BW) linked
service.
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
server
Name of the server on
which the SAP BW instance
resides.
string
Yes
systemNumber
System number of the SAP
BW system.
Two-digit decimal number
represented as a string.
Yes
clientId
Client ID of the client in the
SAP W system.
Three-digit decimal number
represented as a string.
Yes
username
Name of the user who has
access to the SAP server
string
Yes
password
Password for the user.
string
Yes
gatewayName
Name of the gateway that
the Data Factory service
should use to connect to
the on-premises SAP BW
instance.
string
Yes
encryptedCredential
The encrypted credential
string.
string
No
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. There are no type-specific properties supported for the SAP BW dataset of type
RelationalTable.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, are policies are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
When source in copy activity is of type RelationalSource (which includes SAP BW), the following properties
are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Specifies the MDX query to
read data from the SAP BW
instance.
MDX query.
Yes
JSON example: Copy data from SAP Business Warehouse to Azure
Blob
The following example provides sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. This sample shows how to copy data from an on-premises SAP
Business Warehouse to an Azure Blob Storage. However, data can be copied directly to any of the sinks stated
here using the Copy Activity in Azure Data Factory.
IMPORTANT
This sample provides JSON snippets. It does not include step-by-step instructions for creating the data factory. See
moving data between on-premises locations and cloud article for step-by-step instructions.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type SapBw.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from an SAP Business Warehouse instance to an Azure blob hourly. The JSON
properties used in these samples are described in sections following the samples.
As a first step, setup the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
SAP Business Warehouse linked service
This linked service links your SAP BW instance to the data factory. The type property is set to SapBw. The
typeProperties section provides connection information for the SAP BW instance.
{
"name": "SapBwLinkedService",
"properties":
{
"type": "SapBw",
"typeProperties":
{
"server": "<server name>",
"systemNumber": "<system number>",
"clientId": "<client id>",
"username": "<SAP user>",
"password": "<Password for SAP user>",
"gatewayName": "<gateway name>"
}
}
}
Azure Storage linked service
This linked service links your Azure Storage account to the data factory. The type property is set to
AzureStorage. The typeProperties section provides connection information for the Azure Storage account.
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
SAP BW input dataset
This dataset defines the SAP Business Warehouse dataset. You set the type of the Data Factory dataset to
RelationalTable. Currently, you do not specify any type-specific properties for an SAP BW dataset. The query
in the Copy Activity definition specifies what data to read from the SAP BW instance.
Setting external property to true informs the Data Factory service that the table is external to the data factory
and is not produced by an activity in the data factory.
Frequency and interval properties defines the schedule. In this case, the data is read from the SAP BW instance
hourly.
{
"name": "SapBwDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": "SapBwLinkedService",
"typeProperties": {},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Azure Blob output dataset
This dataset defines the output Azure Blob dataset. The type property is set to AzureBlob. The typeProperties
section provides where the data copied from the SAP BW instance is stored. The data is written to a new blob
every hour (frequency: hour, interval: 1). The folder path for the blob is dynamically evaluated based on the
start time of the slice that is being processed. The folder path uses year, month, day, and hours parts of the
start time.
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/sapbw/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to RelationalSource (for SAP BW
source) and sink type is set to BlobSink. The query specified for the query property selects the data in the
past hour to copy.
{
"name": "CopySapBwToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "<MDX query for SAP BW>"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "SapBwDataset"
}
],
"outputs": [
{
"name": "AzureBlobDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "SapBwToBlob"
}
],
"start": "2017-03-01T18:00:00Z",
"end": "2017-03-01T19:00:00Z"
}
}
Type mapping for SAP BW
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following two-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data from SAP BW, the following mappings are used from SAP BW types to .NET types.
DATA TYPE IN THE ABAP DICTIONARY
.NET DATA TYPE
ACCP
Int
CHAR
String
CLNT
String
DATA TYPE IN THE ABAP DICTIONARY
.NET DATA TYPE
CURR
Decimal
CUKY
String
DEC
Decimal
FLTP
Double
INT1
Byte
INT2
Int16
INT4
Int
LANG
String
LCHR
String
LRAW
Byte[]
PREC
Int16
QUAN
Decimal
RAW
Byte[]
RAWSTRING
Byte[]
STRING
String
UNIT
String
DATS
String
NUMC
String
TIMS
String
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data
Factory.
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data From SAP HANA using Azure Data
Factory
6/5/2017 • 9 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises SAP
HANA. It builds on the Data Movement Activities article, which presents a general overview of data movement
with the copy activity.
You can copy data from an on-premises SAP HANA data store to any supported sink data store. For a list of
data stores supported as sinks by the copy activity, see the Supported data stores table. Data factory currently
supports only moving data from an SAP HANA to other data stores, but not for moving data from other data
stores to an SAP HANA.
Supported versions and installation
This connector supports any version of SAP HANA database. It supports copying data from HANA information
models (such as Analytic and Calculation views) and Row/Column tables using SQL queries.
To enable the connectivity to the SAP HANA instance, install the following components:
Data Management Gateway: Data Factory service supports connecting to on-premises data stores
(including SAP HANA) using a component called Data Management Gateway. To learn about Data
Management Gateway and step-by-step instructions for setting up the gateway, see Moving data between
on-premises data store to cloud data store article. Gateway is required even if the SAP HANA is hosted in an
Azure IaaS virtual machine (VM). You can install the gateway on the same VM as the data store or on a
different VM as long as the gateway can connect to the database.
SAP HANA ODBC driver on the gateway machine. You can download the SAP HANA ODBC driver from
the SAP Software Download Center. Search with the keyword SAP HANA CLIENT for Windows.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises Cassandra data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises SAP HANA, see JSON example: Copy data from SAP HANA to Azure
Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to an SAP HANA data store:
Linked service properties
The following table provides description for JSON elements specific to SAP HANA linked service.
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
server
Name of the server on
which the SAP HANA
instance resides. If your
server is using a
customized port, specify
server:port .
string
Yes
authenticationType
Type of authentication.
string. "Basic" or "Windows"
Yes
username
Name of the user who has
access to the SAP server
string
Yes
password
Password for the user.
string
Yes
gatewayName
Name of the gateway that
the Data Factory service
should use to connect to
the on-premises SAP HANA
instance.
string
Yes
encryptedCredential
The encrypted credential
string.
string
No
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. There are no type-specific properties supported for the SAP HANA dataset of type
RelationalTable.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, are policies are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
When source in copy activity is of type RelationalSource (which includes SAP HANA), the following properties
are available in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Specifies the SQL query to
read data from the SAP
HANA instance.
SQL query.
Yes
JSON example: Copy data from SAP HANA to Azure Blob
The following sample provides sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. This sample shows how to copy data from an on-premises SAP
HANA to an Azure Blob Storage. However, data can be copied directly to any of the sinks listed here using the
Copy Activity in Azure Data Factory.
IMPORTANT
This sample provides JSON snippets. It does not include step-by-step instructions for creating the data factory. See
moving data between on-premises locations and cloud article for step-by-step instructions.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type SapHana.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from an SAP HANA instance to an Azure blob hourly. The JSON properties used in
these samples are described in sections following the samples.
As a first step, setup the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
SAP HANA linked service
This linked service links your SAP HANA instance to the data factory. The type property is set to SapHana. The
typeProperties section provides connection information for the SAP HANA instance.
{
"name": "SapHanaLinkedService",
"properties":
{
"type": "SapHana",
"typeProperties":
{
"server": "<server name>",
"authenticationType": "<Basic, or Windows>",
"username": "<SAP user>",
"password": "<Password for SAP user>",
"gatewayName": "<gateway name>"
}
}
}
Azure Storage linked service
This linked service links your Azure Storage account to the data factory. The type property is set to
AzureStorage. The typeProperties section provides connection information for the Azure Storage account.
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
SAP HANA input dataset
This dataset defines the SAP HANA dataset. You set the type of the Data Factory dataset to RelationalTable.
Currently, you do not specify any type-specific properties for an SAP HANA dataset. The query in the Copy
Activity definition specifies what data to read from the SAP HANA instance.
Setting external property to true informs the Data Factory service that the table is external to the data factory
and is not produced by an activity in the data factory.
Frequency and interval properties defines the schedule. In this case, the data is read from the SAP HANA
instance hourly.
{
"name": "SapHanaDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": "SapHanaLinkedService",
"typeProperties": {},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true
}
}
Azure Blob output dataset
This dataset defines the output Azure Blob dataset. The type property is set to AzureBlob. The typeProperties
section provides where the data copied from the SAP HANA instance is stored. The data is written to a new
blob every hour (frequency: hour, interval: 1). The folder path for the blob is dynamically evaluated based on
the start time of the slice that is being processed. The folder path uses year, month, day, and hours parts of the
start time.
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/saphana/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to RelationalSource (for SAP HANA
source) and sink type is set to BlobSink. The SQL query specified for the query property selects the data in
the past hour to copy.
{
"name": "CopySapHanaToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "<SQL Query for HANA>"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "SapHanaDataset"
}
],
"outputs": [
{
"name": "AzureBlobDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "SapHanaToBlob"
}
],
"start": "2017-03-01T18:00:00Z",
"end": "2017-03-01T19:00:00Z"
}
}
Type mapping for SAP HANA
As mentioned in the data movement activities article, Copy activity performs automatic type conversions from
source types to sink types with the following two-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data from SAP HANA, the following mappings are used from SAP HANA types to .NET types.
SAP HANA TYPE
.NET BASED TYPE
TINYINT
Byte
SMALLINT
Int16
INT
Int32
SAP HANA TYPE
.NET BASED TYPE
BIGINT
Int64
REAL
Single
DOUBLE
Single
DECIMAL
Decimal
BOOLEAN
Byte
VARCHAR
String
NVARCHAR
String
CLOB
Byte[]
ALPHANUM
String
BLOB
Byte[]
DATE
DateTime
TIME
TimeSpan
TIMESTAMP
DateTime
SECONDDATE
DateTime
Known limitations
There are a few known limitations when copying data from SAP HANA:
NVARCHAR strings are truncated to maximum length of 4000 Unicode characters
SMALLDECIMAL is not supported
VARBINARY is not supported
Valid Dates are between 1899/12/30 and 9999/12/31
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from an SFTP server using Azure Data
Factory
6/5/2017 • 11 min to read • Edit Online
This article outlines how to use the Copy Activity in Azure Data Factory to move data from an onpremises/cloud SFTP server to a supported sink data store. This article builds on the data movement activities
article that presents a general overview of data movement with copy activity and the list of data stores
supported as sources/sinks.
Data factory currently supports only moving data from an SFTP server to other data stores, but not for moving
data from other data stores to an SFTP server. It supports both on-premises and cloud SFTP servers.
NOTE
Copy Activity does not delete the source file after it is successfully copied to the destination. If you need to delete the
source file after a successful copy, create a custom activity to delete the file and use the activity in the pipeline.
Supported scenarios and authentication types
You can use this SFTP connector to copy data from both cloud SFTP servers and on-premises SFTP servers.
Basic and SshPublicKey authentication types are supported when connecting to the SFTP server.
When copying data from an on-premises SFTP server, you need install a Data Management Gateway in the onpremises environment/Azure VM. See Data Management Gateway for details on the gateway. See moving data
between on-premises locations and cloud article for step-by-step instructions on setting up the gateway and
using it.
Getting started
You can create a pipeline with a copy activity that moves data from an SFTP source by using different
tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using
Copy Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure
PowerShell, Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial
for step-by-step instructions to create a pipeline with a copy activity. For JSON samples to copy data
from SFTP server to Azure Blob Storage, see JSON Example: Copy data from SFTP server to Azure blob
section of this article.
Linked service properties
The following table provides description for JSON elements specific to FTP linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to
Sftp .
Yes
PROPERTY
DESCRIPTION
REQUIRED
host
Name or IP address of the SFTP
server.
Yes
port
Port on which the SFTP server is
listening. The default value is: 21
No
authenticationType
Specify authentication type. Allowed
values: Basic, SshPublicKey.
Yes
Refer to Using basic authentication
and Using SSH public key
authentication sections on more
properties and JSON samples
respectively.
skipHostKeyValidation
Specify whether to skip host key
validation.
No. The default value: false
hostKeyFingerprint
Specify the finger print of the host
key.
Yes if the skipHostKeyValidation is
set to false.
gatewayName
Name of the Data Management
Gateway to connect to an onpremises SFTP server.
Yes if copying data from an onpremises SFTP server.
encryptedCredential
Encrypted credential to access the
SFTP server. Auto-generated when
you specify basic authentication
(username + password) or
SshPublicKey authentication
(username + private key path or
content) in copy wizard or the
ClickOnce popup dialog.
No. Apply only when copying data
from an on-premises SFTP server.
Using basic authentication
To use basic authentication, set authenticationType as Basic , and specify the following properties besides the
SFTP connector generic ones introduced in the last section:
PROPERTY
DESCRIPTION
REQUIRED
username
User who has access to the SFTP
server.
Yes
password
Password for the user (username).
Yes
Example: Basic authentication
{
"name": "SftpLinkedService",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "mysftpserver",
"port": 22,
"authenticationType": "Basic",
"username": "xxx",
"password": "xxx",
"skipHostKeyValidation": false,
"hostKeyFingerPrint": "ssh-rsa 2048 xx:00:00:00:xx:00:x0:0x:0x:0x:0x:00:00:x0:x0:00",
"gatewayName": "mygateway"
}
}
}
Example: Basic authentication with encrypted credential
{
"name": "SftpLinkedService",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "mysftpserver",
"port": 22,
"authenticationType": "Basic",
"username": "xxx",
"encryptedCredential": "xxxxxxxxxxxxxxxxx",
"skipHostKeyValidation": false,
"hostKeyFingerPrint": "ssh-rsa 2048 xx:00:00:00:xx:00:x0:0x:0x:0x:0x:00:00:x0:x0:00",
"gatewayName": "mygateway"
}
}
}
Using SSH public key authentication
To use SSH public key authentication, set authenticationType as SshPublicKey , and specify the following
properties besides the SFTP connector generic ones introduced in the last section:
PROPERTY
DESCRIPTION
REQUIRED
username
User who has access to the SFTP
server
Yes
privateKeyPath
Specify absolute path to the private
key file that gateway can access.
Specify either the
privateKeyPath
privateKeyContent
or
.
Apply only when copying data from
an on-premises SFTP server.
privateKeyContent
A serialized string of the private key
content. The Copy Wizard can read
the private key file and extract the
private key content automatically. If
you are using any other tool/SDK, use
the privateKeyPath property instead.
Specify either the
privateKeyPath
privateKeyContent
.
or
PROPERTY
DESCRIPTION
REQUIRED
passPhrase
Specify the pass phrase/password to
decrypt the private key if the key file is
protected by a pass phrase.
Yes if the private key file is protected
by a pass phrase.
NOTE
SFTP connector only support OpenSSH key. Make sure your key file is in the proper format. You can use Putty tool to
convert from .ppk to OpenSSH format.
Example: SshPublicKey authentication using private key filePath
{
"name": "SftpLinkedServiceWithPrivateKeyPath",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "mysftpserver",
"port": 22,
"authenticationType": "SshPublicKey",
"username": "xxx",
"privateKeyPath": "D:\\privatekey_openssh",
"passPhrase": "xxx",
"skipHostKeyValidation": true,
"gatewayName": "mygateway"
}
}
}
Example: SshPublicKey authentication using private key content
{
"name": "SftpLinkedServiceWithPrivateKeyContent",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "mysftpserver.westus.cloudapp.azure.com",
"port": 22,
"authenticationType": "SshPublicKey",
"username": "xxx",
"privateKeyContent": "<base64 string of the private key content>",
"passPhrase": "xxx",
"skipHostKeyValidation": true
}
}
}
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types.
The typeProperties section is different for each type of dataset. It provides information that is specific to the
dataset type. The typeProperties section for a dataset of type FileShare dataset has the following properties:
PROPERTY
DESCRIPTION
REQUIRED
folderPath
Sub path to the folder. Use escape
character ‘ \ ’ for special characters in
the string. See Sample linked service
and dataset definitions for examples.
Yes
You can combine this property with
partitionBy to have folder paths
based on slice start/end date-times.
fileName
Specify the name of the file in the
folderPath if you want the table to
refer to a specific file in the folder. If
you do not specify any value for this
property, the table points to all files in
the folder.
No
When fileName is not specified for an
output dataset, the name of the
generated file would be in the
following this format:
Data..txt (Example: Data.0a405f8a93ff-4c6f-b3be-f69616f1df7a.txt
fileFilter
Specify a filter to be used to select a
subset of files in the folderPath rather
than all files.
No
Allowed values are: * (multiple
characters) and ? (single character).
Examples 1:
Example 2:
"fileFilter": "*.log"
"fileFilter": 2014-1-?.txt"
fileFilter is applicable for an input
FileShare dataset. This property is not
supported with HDFS.
partitionedBy
partitionedBy can be used to specify a
dynamic folderPath, filename for time
series data. For example, folderPath
parameterized for every hour of data.
No
format
The following format types are
supported: TextFormat, JsonFormat,
AvroFormat, OrcFormat,
ParquetFormat. Set the type
property under format to one of these
values. For more information, see Text
Format, Json Format, Avro Format,
Orc Format, and Parquet Format
sections.
No
If you want to copy files as-is
between file-based stores (binary
copy), skip the format section in both
input and output dataset definitions.
PROPERTY
DESCRIPTION
REQUIRED
compression
Specify the type and level of
compression for the data. Supported
types are: GZip, Deflate, BZip2, and
ZipDeflate. Supported levels are:
Optimal and Fastest. For more
information, see File and compression
formats in Azure Data Factory.
No
useBinaryTransfer
Specify whether use Binary transfer
mode. True for binary mode and false
ASCII. Default value: True. This
property can only be used when
associated linked service type is of
type: FtpServer.
No
NOTE
filename and fileFilter cannot be used simultaneously.
Using partionedBy property
As mentioned in the previous section, you can specify a dynamic folderPath, filename for time series data with
partitionedBy. You can do so with the Data Factory macros and the system variable SliceStart, SliceEnd that
indicate the logical time period for a given data slice.
To learn about time series datasets, scheduling, and slices, See Creating Datasets, Scheduling & Execution, and
Creating Pipelines articles.
Sample 1:
"folderPath": "wikidatagateway/wikisampledataout/{Slice}",
"partitionedBy":
[
{ "name": "Slice", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyyMMddHH" } },
],
In this example {Slice} is replaced with the value of Data Factory system variable SliceStart in the format
(YYYYMMDDHH) specified. The SliceStart refers to start time of the slice. The folderPath is different for each
slice. Example: wikidatagateway/wikisampledataout/2014100103 or
wikidatagateway/wikisampledataout/2014100104.
Sample 2:
"folderPath": "wikidatagateway/wikisampledataout/{Year}/{Month}/{Day}",
"fileName": "{Hour}.csv",
"partitionedBy":
[
{ "name": "Year", "value": { "type": "DateTime", "date": "SliceStart", "format": "yyyy" } },
{ "name": "Month", "value": { "type": "DateTime", "date": "SliceStart", "format": "MM" } },
{ "name": "Day", "value": { "type": "DateTime", "date": "SliceStart", "format": "dd" } },
{ "name": "Hour", "value": { "type": "DateTime", "date": "SliceStart", "format": "hh" } }
],
In this example, year, month, day, and time of SliceStart are extracted into separate variables that are used by
folderPath and fileName properties.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policies are available for all types of
activities.
Whereas, the properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, the type properties vary depending on the types of sources and sinks.
In Copy Activity, when source is of type FileSystemSource, the following properties are available in
typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
recursive
Indicates whether the data
is read recursively from the
sub folders or only from
the specified folder.
True, False (default)
No
Supported file and compression formats
See File and compression formats in Azure Data Factory article on details.
JSON Example: Copy data from SFTP server to Azure blob
The following example provides sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data from SFTP source to Azure Blob
Storage. However, data can be copied directly from any of sources to any of the sinks stated here using the
Copy Activity in Azure Data Factory.
IMPORTANT
This sample provides JSON snippets. It does not include step-by-step instructions for creating the data factory. See
moving data between on-premises locations and cloud article for step-by-step instructions.
The sample has the following data factory entities:
A linked service of type sftp.
A linked service of type AzureStorage.
An input dataset of type FileShare.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses FileSystemSource and BlobSink.
The sample copies data from an SFTP server to an Azure blob every hour. The JSON properties used in these
samples are described in sections following the samples.
SFTP linked service
This example uses the basic authentication with user name and password in plain text. You can also use one of
the following ways:
Basic authentication with encrypted credentials
SSH public key authentication
See FTP linked service section for different types of authentication you can use.
{
"name": "SftpLinkedService",
"properties": {
"type": "Sftp",
"typeProperties": {
"host": "mysftpserver",
"port": 22,
"authenticationType": "Basic",
"username": "myuser",
"password": "mypassword",
"skipHostKeyValidation": false,
"hostKeyFingerPrint": "ssh-rsa 2048 xx:00:00:00:xx:00:x0:0x:0x:0x:0x:00:00:x0:x0:00",
"gatewayName": "mygateway"
}
}
}
Azure Storage linked service
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
SFTP input dataset
This dataset refers to the SFTP folder
destination.
mysharedfolder
and file
test.csv
. The pipeline copies the file to the
Setting "external": "true" informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "SFTPFileInput",
"properties": {
"type": "FileShare",
"linkedServiceName": "SftpLinkedService",
"typeProperties": {
"folderPath": "mysharedfolder",
"fileName": "test.csv"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Azure Blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/sftp/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to FileSystemSource and sink type is
set to BlobSink.
{
"name": "pipeline",
"properties": {
"activities": [{
"name": "SFTPToBlobCopy",
"inputs": [{
"name": "SFTPFileInput"
}],
"outputs": [{
"name": "AzureBlobOutput"
}],
"type": "Copy",
"typeProperties": {
"source": {
"type": "FileSystemSource"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 1,
"timeout": "00:05:00"
}
}],
"start": "2017-02-20T18:00:00Z",
"end": "2017-02-20T19:00:00Z"
}
}
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Next Steps
See the following articles:
Copy Activity tutorial for step-by-step instructions for creating a pipeline with a Copy Activity.
Move data to and from SQL Server on-premises
or on IaaS (Azure VM) using Azure Data Factory
6/9/2017 • 18 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data to/from an on-premises
SQL Server database. It builds on the Data Movement Activities article, which presents a general overview of
data movement with the copy activity.
Supported scenarios
You can copy data from a SQL Server database to the following data stores:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Data Lake Store
Azure Cosmos DB (DocumentDB API)
Azure SQL Database
Azure SQL Data Warehouse
Azure Search Index
Azure Table storage
Databases
SQL Server
Oracle
File
File system
You can copy data from the following data stores to a SQL Server database:
CATEGORY
DATA STORE
Azure
Azure Blob storage
Azure Cosmos DB (DocumentDB API)
Azure Data Lake Store
Azure SQL Database
Azure SQL Data Warehouse
Azure Table storage
Databases
Amazon Redshift
DB2
MySQL
Oracle
PostgreSQL
SAP Business Warehouse
SAP HANA
SQL Server
Sybase
Teradata
NoSQL
Cassandra
MongoDB
CATEGORY
DATA STORE
File
Amazon S3
File System
FTP
HDFS
SFTP
Others
Generic HTTP
Generic OData
Generic ODBC
Salesforce
Web Table (table from HTML)
GE Historian
Supported SQL Server versions
This SQL Server connector support copying data from/to the following versions of instance hosted onpremises or in Azure IaaS using both SQL authentication and Windows authentication: SQL Server 2016, SQL
Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
Enabling connectivity
The concepts and steps needed for connecting with SQL Server hosted on-premises or in Azure IaaS
(Infrastructure-as-a-Service) VMs are the same. In both cases, you need to use Data Management Gateway
for connectivity.
See moving data between on-premises locations and cloud article to learn about Data Management Gateway
and step-by-step instructions on setting up the gateway. Setting up a gateway instance is a pre-requisite for
connecting with SQL Server.
While you can install gateway on the same on-premises machine or cloud VM instance as the SQL Server for
better performance, we recommended that you install them on separate machines. Having the gateway and
SQL Server on separate machines reduces resource contention.
Getting started
You can create a pipeline with a copy activity that moves data to/from an on-premises SQL Server database
by using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from
a source data store to a sink data store:
1. Create a data factory. A data factory may contain one or more pipelines.
2. Create linked services to link input and output data stores to your data factory. For example, if you are
copying data from a SQL Server database to an Azure blob storage, you create two linked services to link
your SQL Server database and Azure storage account to your data factory. For linked service properties
that are specific to SQL Server database, see linked service properties section.
3. Create datasets to represent input and output data for the copy operation. In the example mentioned in
the last step, you create a dataset to specify the SQL table in your SQL Server database that contains the
input data. And, you create another dataset to specify the blob container and the folder that holds the data
copied from the SQL Server database. For dataset properties that are specific to SQL Server database, see
dataset properties section.
4. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output. In the
example mentioned earlier, you use SqlSource as a source and BlobSink as a sink for the copy activity.
Similarly, if you are copying from Azure Blob Storage to SQL Server Database, you use BlobSource and
SqlSink in the copy activity. For copy activity properties that are specific to SQL Server Database, see copy
activity properties section. For details on how to use a data store as a source or a sink, click the link in the
previous section for your data store.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For samples with JSON definitions for Data Factory entities that
are used to copy data to/from an on-premises SQL Server database, see JSON examples section of this
article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to SQL Server:
Linked service properties
You create a linked service of type OnPremisesSqlServer to link an on-premises SQL Server database to a
data factory. The following table provides description for JSON elements specific to on-premises SQL Server
linked service.
The following table provides description for JSON elements specific to SQL Server linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property should be set to:
OnPremisesSqlServer.
Yes
connectionString
Specify connectionString information
needed to connect to the onpremises SQL Server database using
either SQL authentication or
Windows authentication.
Yes
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the on-premises SQL Server
database.
Yes
username
Specify user name if you are using
Windows Authentication. Example:
domainname\username.
No
password
Specify password for the user account
you specified for the username.
No
You can encrypt credentials using the New-AzureRmDataFactoryEncryptValue cmdlet and use them in
the connection string as shown in the following example (EncryptedCredential property):
"connectionString": "Data Source=<servername>;Initial Catalog=<databasename>;Integrated
Security=True;EncryptedCredential=<encrypted credential>",
Samples
JSON for using SQL Authentication
{
"name": "MyOnPremisesSQLDB",
"properties":
{
"type": "OnPremisesSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>;Initial Catalog=MarketingCampaigns;Integrated
Security=False;User ID=<username>;Password=<password>;",
"gatewayName": "<gateway name>"
}
}
}
JSON for using Windows Authentication
Data Management Gateway will impersonate the specified user account to connect to the on-premises SQL
Server database.
{
"Name": " MyOnPremisesSQLDB",
"Properties":
{
"type": "OnPremisesSqlServer",
"typeProperties": {
"ConnectionString": "Data Source=<servername>;Initial Catalog=MarketingCampaigns;Integrated
Security=True;",
"username": "<domain\\username>",
"password": "<password>",
"gatewayName": "<gateway name>"
}
}
}
Dataset properties
In the samples, you have used a dataset of type SqlServerTable to represent a table in a SQL Server
database.
For a full list of sections & properties available for defining datasets, see the Creating datasets article.
Sections such as structure, availability, and policy of a dataset JSON are similar for all dataset types (SQL
Server, Azure blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for the dataset of type SqlServerTable has the
following properties:
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table or view in the SQL
Server Database instance that linked
service refers to.
Yes
Copy activity properties
If you are moving data from a SQL Server database, you set the source type in the copy activity to SqlSource.
Similarly, if you are moving data to a SQL Server database, you set the sink type in the copy activity to
SqlSink. This section provides a list of properties supported by SqlSource and SqlSink.
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policies are available for all types of
activities.
NOTE
The Copy Activity takes only one input and produces only one output.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For
Copy activity, they vary depending on the types of sources and sinks.
SqlSource
When source in a copy activity is of type SqlSource, the following properties are available in typeProperties
section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
sqlReaderQuery
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable. May reference
multiple tables from the
database referenced by the
input dataset. If not
specified, the SQL
statement that is executed:
select from MyTable.
No
sqlReaderStoredProcedure
Name
Name of the stored
procedure that reads data
from the source table.
Name of the stored
procedure. The last SQL
statement must be a
SELECT statement in the
stored procedure.
No
storedProcedureParameter
s
Parameters for the stored
procedure.
Name/value pairs. Names
and casing of parameters
must match the names
and casing of the stored
procedure parameters.
No
If the sqlReaderQuery is specified for the SqlSource, the Copy Activity runs this query against the SQL
Server Database source to get the data.
Alternatively, you can specify a stored procedure by specifying the sqlReaderStoredProcedureName and
storedProcedureParameters (if the stored procedure takes parameters).
If you do not specify either sqlReaderQuery or sqlReaderStoredProcedureName, the columns defined in the
structure section are used to build a select query to run against the SQL Server Database. If the dataset
definition does not have the structure, all columns are selected from the table.
NOTE
When you use sqlReaderStoredProcedureName, you still need to specify a value for the tableName property in
the dataset JSON. There are no validations performed against this table though.
SqlSink
SqlSink supports the following properties:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
writeBatchTimeout
Wait time for the batch
insert operation to
complete before it times
out.
timespan
No
writeBatchSize
Inserts data into the SQL
table when the buffer size
reaches writeBatchSize.
Integer (number of rows)
No (default: 10000)
sqlWriterCleanupScript
Specify query for Copy
Activity to execute such
that data of a specific slice
is cleaned up. For more
information, see repeatable
copy section.
A query statement.
No
sliceIdentifierColumnName
Specify column name for
Copy Activity to fill with
auto generated slice
identifier, which is used to
clean up data of a specific
slice when rerun. For more
information, see repeatable
copy section.
Column name of a column
with data type of
binary(32).
No
sqlWriterStoredProcedureN
ame
Name of the stored
procedure that upserts
(updates/inserts) data into
the target table.
Name of the stored
procedure.
No
storedProcedureParameter
s
Parameters for the stored
procedure.
Name/value pairs. Names
and casing of parameters
must match the names
and casing of the stored
procedure parameters.
No
sqlWriterTableType
Specify table type name to
be used in the stored
procedure. Copy activity
makes the data being
moved available in a temp
table with this table type.
Stored procedure code can
then merge the data being
copied with existing data.
A table type name.
No
Example: “00:30:00” (30
minutes).
JSON examples for copying data from and to SQL Server
The following examples provide sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. The following samples show how to copy data to and from SQL
Server and Azure Blob Storage. However, data can be copied directly from any of sources to any of the sinks
stated here using the Copy Activity in Azure Data Factory.
Example: Copy data from SQL Server to Azure Blob
The following sample shows:
1.
2.
3.
4.
5.
A linked service of type OnPremisesSqlServer.
A linked service of type AzureStorage.
An input dataset of type SqlServerTable.
An output dataset of type AzureBlob.
The pipeline with Copy activity that uses SqlSource and BlobSink.
The sample copies time-series data from a SQL Server table to an Azure blob every hour. The JSON
properties used in these samples are described in sections following the samples.
As a first step, setup the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
SQL Server linked service
{
"Name": "SqlServerLinkedService",
"properties": {
"type": "OnPremisesSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>;Initial Catalog=<databasename>;Integrated
Security=False;User ID=<username>;Password=<password>;",
"gatewayName": "<gatewayname>"
}
}
}
Azure Blob storage linked service
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
SQL Server input dataset
The sample assumes you have created a table “MyTable” in SQL Server and it contains a column called
“timestampcolumn” for time series data. You can query over multiple tables within the same database using
a single dataset, but a single table must be used for the dataset's tableName typeProperty.
Setting “external”: ”true” informs Data Factory service that the dataset is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "SqlServerInput",
"properties": {
"type": "SqlServerTable",
"linkedServiceName": "SqlServerLinkedService",
"typeProperties": {
"tableName": "MyTable"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobOutput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": "\t",
"rowDelimiter": "\n"
}
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity
The pipeline contains a Copy Activity that is configured to use these input and output datasets and is
scheduled to run every hour. In the pipeline JSON definition, the source type is set to SqlSource and sink
type is set to BlobSink. The SQL query specified for the SqlReaderQuery property selects the data in the
past hour to copy.
{
"name":"SamplePipeline",
"properties":{
"start":"2016-06-01T18:00:00",
"end":"2016-06-01T19:00:00",
"description":"pipeline for copy activity",
"activities":[
{
"name": "SqlServertoBlob",
"description": "copy activity",
"type": "Copy",
"inputs": [
{
"name": " SqlServerInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"SqlReaderQuery": "$$Text.Format('select * from MyTable where timestampcolumn >= \\'{0:yyyyMM-dd HH:mm}\\' AND timestampcolumn < \\'{1:yyyy-MM-dd HH:mm}\\'', WindowStart, WindowEnd)"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
In this example, sqlReaderQuery is specified for the SqlSource. The Copy Activity runs this query against the
SQL Server Database source to get the data. Alternatively, you can specify a stored procedure by specifying
the sqlReaderStoredProcedureName and storedProcedureParameters (if the stored procedure takes
parameters). The sqlReaderQuery can reference multiple tables within the database referenced by the input
dataset. It is not limited to only the table set as the dataset's tableName typeProperty.
If you do not specify sqlReaderQuery or sqlReaderStoredProcedureName, the columns defined in the
structure section are used to build a select query to run against the SQL Server Database. If the dataset
definition does not have the structure, all columns are selected from the table.
See the Sql Source section and BlobSink for the list of properties supported by SqlSource and BlobSink.
Example: Copy data from Azure Blob to SQL Server
The following sample shows:
1. The linked service of type OnPremisesSqlServer.
2.
3.
4.
5.
The linked service of type AzureStorage.
An input dataset of type AzureBlob.
An output dataset of type SqlServerTable.
The pipeline with Copy activity that uses BlobSource and SqlSink.
The sample copies time-series data from an Azure blob to a SQL Server table every hour. The JSON
properties used in these samples are described in sections following the samples.
SQL Server linked service
{
"Name": "SqlServerLinkedService",
"properties": {
"type": "OnPremisesSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>;Initial Catalog=<databasename>;Integrated
Security=False;User ID=<username>;Password=<password>;",
"gatewayName": "<gatewayname>"
}
}
}
Azure Blob storage linked service
{
"name": "StorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
Azure Blob input dataset
Data is picked up from a new blob every hour (frequency: hour, interval: 1). The folder path and file name for
the blob are dynamically evaluated based on the start time of the slice that is being processed. The folder
path uses year, month, and day part of the start time and file name uses the hour part of the start time.
“external”: “true” setting informs the Data Factory service that the dataset is external to the data factory and is
not produced by an activity in the data factory.
{
"name": "AzureBlobInput",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "StorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/myfolder/yearno={Year}/monthno={Month}/dayno={Day}",
"fileName": "{Hour}.csv",
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
}
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
SQL Server output dataset
The sample copies data to a table named “MyTable” in SQL Server. Create the table in SQL Server with the
same number of columns as you expect the Blob CSV file to contain. New rows are added to the table every
hour.
{
"name": "SqlServerOutput",
"properties": {
"type": "SqlServerTable",
"linkedServiceName": "SqlServerLinkedService",
"typeProperties": {
"tableName": "MyOutputTable"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity
The pipeline contains a Copy Activity that is configured to use these input and output datasets and is
scheduled to run every hour. In the pipeline JSON definition, the source type is set to BlobSource and sink
type is set to SqlSink.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "AzureBlobtoSQL",
"description": "Copy Activity",
"type": "Copy",
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": " SqlServerOutput "
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"blobColumnSeparators": ","
},
"sink": {
"type": "SqlSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Troubleshooting connection issues
1. Configure your SQL Server to accept remote connections. Launch SQL Server Management Studio,
right-click server, and click Properties. Select Connections from the list and check Allow remote
connections to the server.
See Configure the remote access Server Configuration Option for detailed steps.
2. Launch SQL Server Configuration Manager. Expand SQL Server Network Configuration for the
instance you want, and select Protocols for MSSQLSERVER. You should see protocols in the rightpane. Enable TCP/IP by right-clicking TCP/IP and clicking Enable.
See Enable or Disable a Server Network Protocol for details and alternate ways of enabling TCP/IP
protocol.
3. In the same window, double-click TCP/IP to launch TCP/IP Properties window.
4. Switch to the IP Addresses tab. Scroll down to see IPAll section. Note down the TCP Port **(default is
**1433).
5. Create a rule for the Windows Firewall on the machine to allow incoming traffic through this port.
6. Verify connection: To connect to the SQL Server using fully qualified name, use SQL Server
Management Studio from a different machine. For example: "..corp..com,1433."
IMPORTANT
See Move data between on-premises sources and the cloud with Data Management Gateway for detailed
information.
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Identity columns in the target database
This section provides an example that copies data from a source table with no identity column to a
destination table with an identity column.
Source table:
create table dbo.SourceTbl
(
name varchar(100),
age int
)
Destination table:
create table dbo.TargetTbl
(
identifier int identity(1,1),
name varchar(100),
age int
)
Notice that the target table has an identity column.
Source dataset JSON definition
{
"name": "SampleSource",
"properties": {
"published": false,
"type": " SqlServerTable",
"linkedServiceName": "TestIdentitySQL",
"typeProperties": {
"tableName": "SourceTbl"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {}
}
}
Destination dataset JSON definition
{
"name": "SampleTarget",
"properties": {
"structure": [
{ "name": "name" },
{ "name": "age" }
],
"published": false,
"type": "AzureSqlTable",
"linkedServiceName": "TestIdentitySQLSource",
"typeProperties": {
"tableName": "TargetTbl"
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": false,
"policy": {}
}
}
Notice that as your source and target table have different schema (target has an additional column with
identity). In this scenario, you need to specify structure property in the target dataset definition, which
doesn’t include the identity column.
Invoke stored procedure from SQL sink
See Invoke stored procedure for SQL sink in copy activity article for an example of invoking a stored
procedure from SQL sink in a copy activity of a pipeline.
Type mapping for SQL server
As mentioned in the data movement activities article, the Copy activity performs automatic type conversions
from source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to & from SQL server, the following mappings are used from SQL type to .NET type and
vice versa.
The mapping is same as the SQL Server Data Type Mapping for ADO.NET.
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
bigint
Int64
binary
Byte[]
bit
Boolean
char
String, Char[]
date
DateTime
Datetime
DateTime
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
datetime2
DateTime
Datetimeoffset
DateTimeOffset
Decimal
Decimal
FILESTREAM attribute (varbinary(max))
Byte[]
Float
Double
image
Byte[]
int
Int32
money
Decimal
nchar
String, Char[]
ntext
String, Char[]
numeric
Decimal
nvarchar
String, Char[]
real
Single
rowversion
Byte[]
smalldatetime
DateTime
smallint
Int16
smallmoney
Decimal
sql_variant
Object *
text
String, Char[]
time
TimeSpan
timestamp
Byte[]
tinyint
Byte
uniqueidentifier
Guid
varbinary
Byte[]
varchar
String, Char[]
SQL SERVER DATABASE ENGINE TYPE
.NET FRAMEWORK TYPE
xml
Xml
Mapping source to sink columns
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure
Data Factory.
Repeatable copy
When copying data to SQL Server Database, the copy activity appends data to the sink table by default. To
perform an UPSERT instead, See Repeatable write to SqlSink article.
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from Sybase using Azure Data Factory
4/12/2017 • 8 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
Sybase database. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
You can copy data from an on-premises Sybase data store to any supported sink data store. For a list of data
stores supported as sinks by the copy activity, see the Supported data stores table. Data factory currently
supports only moving data from a Sybase data store to other data stores, but not for moving data from other
data stores to a Sybase data store.
Prerequisites
Data Factory service supports connecting to on-premises Sybase sources using the Data Management
Gateway. See moving data between on-premises locations and cloud article to learn about Data Management
Gateway and step-by-step instructions on setting up the gateway.
Gateway is required even if the Sybase database is hosted in an Azure IaaS VM. You can install the gateway on
the same IaaS VM as the data store or on a different VM as long as the gateway can connect to the database.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Supported versions and installation
For Data Management Gateway to connect to the Sybase Database, you need to install the data provider for
Sybase iAnywhere.Data.SQLAnywhere 16 or above on the same system as the Data Management Gateway.
Sybase version 16 and above is supported.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises Cassandra data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises Sybase data store, see JSON example: Copy data from Sybase to Azure
Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to a Sybase data store:
Linked service properties
The following table provides description for JSON elements specific to Sybase linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesSybase
Yes
server
Name of the Sybase server.
Yes
database
Name of the Sybase database.
Yes
schema
Name of the schema in the database.
No
authenticationType
Type of authentication used to
connect to the Sybase database.
Possible values are: Anonymous, Basic,
and Windows.
Yes
username
Specify user name if you are using
Basic or Windows authentication.
No
password
Specify password for the user account
you specified for the username.
No
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the on-premises Sybase database.
Yes
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. The typeProperties section for dataset of type RelationalTable (which includes
Sybase dataset) has the following properties:
PROPERTY
DESCRIPTION
REQUIRED
tableName
Name of the table in the Sybase
Database instance that linked service
refers to.
No (if query of RelationalSource is
specified)
Copy activity properties
For a full list of sections & properties available for defining activities, see Creating Pipelines article. Properties
such as name, description, input and output tables, and policy are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For Copy
activity, they vary depending on the types of sources and sinks.
When the source is of type RelationalSource (which includes Sybase), the following properties are available
in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable.
No (if tableName of
dataset is specified)
JSON example: Copy data from Sybase to Azure Blob
The following example provides sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data from Sybase database to Azure Blob
Storage. However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data
Factory.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesSybase.
A liked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
The pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from a query result in Sybase database to a blob every hour. The JSON properties used
in these samples are described in sections following the samples.
As a first step, setup the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
Sybase linked service:
{
"name": "OnPremSybaseLinkedService",
"properties": {
"type": "OnPremisesSybase",
"typeProperties": {
"server": "<server>",
"database": "<database>",
"schema": "<schema>",
"authenticationType": "<authentication type>",
"username": "<username>",
"password": "<password>",
"gatewayName": "<gatewayName>"
}
}
}
Azure Blob storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorageLinkedService",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<AccountName>;AccountKey=
<AccountKey>"
}
}
}
Sybase input dataset:
The sample assumes you have created a table “MyTable” in Sybase and it contains a column called
“timestamp” for time series data.
Setting “external”: true informs the Data Factory service that this dataset is external to the data factory and is
not produced by an activity in the data factory. Notice that the type of the linked service is set to:
RelationalTable.
{
"name": "SybaseDataSet",
"properties": {
"type": "RelationalTable",
"linkedServiceName": "OnPremSybaseLinkedService",
"typeProperties": {},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobSybaseDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"folderPath": "mycontainer/sybase/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
]
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run hourly. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is set
to BlobSink. The SQL query specified for the query property selects the data from the DBA.Orders table in the
database.
{
"name": "CopySybaseToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "select * from DBA.Orders"
},
"sink": {
"type": "BlobSink"
}
},
"inputs": [
{
"name": "SybaseDataSet"
}
],
"outputs": [
{
"name": "AzureBlobSybaseDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "SybaseToBlob"
}
],
"start": "2014-06-01T18:00:00Z",
"end": "2014-06-01T19:00:00Z"
}
}
Type mapping for Sybase
As mentioned in the Data Movement Activities article, the Copy activity performs automatic type conversions
from source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
Sybase supports T-SQL and T-SQL types. For a mapping table from sql types to .NET type, see Azure SQL
Connector article.
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from Teradata using Azure Data Factory
4/12/2017 • 8 min to read • Edit Online
This article explains how to use the Copy Activity in Azure Data Factory to move data from an on-premises
Teradata database. It builds on the Data Movement Activities article, which presents a general overview of data
movement with the copy activity.
You can copy data from an on-premises Teradata data store to any supported sink data store. For a list of data
stores supported as sinks by the copy activity, see the Supported data stores table. Data factory currently
supports only moving data from a Teradata data store to other data stores, but not for moving data from other
data stores to a Teradata data store.
Prerequisites
Data factory supports connecting to on-premises Teradata sources via the Data Management Gateway. See
moving data between on-premises locations and cloud article to learn about Data Management Gateway and
step-by-step instructions on setting up the gateway.
Gateway is required even if the Teradata is hosted in an Azure IaaS VM. You can install the gateway on the
same IaaS VM as the data store or on a different VM as long as the gateway can connect to the database.
NOTE
See Troubleshoot gateway issues for tips on troubleshooting connection/gateway related issues.
Supported versions and installation
For Data Management Gateway to connect to the Teradata Database, you need to install the .NET Data Provider
for Teradata version 14 or above on the same system as the Data Management Gateway. Teradata version 12
and above is supported.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises Cassandra data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from an on-premises Teradata data store, see JSON example: Copy data from Teradata to
Azure Blob section of this article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to a Teradata data store:
Linked service properties
The following table provides description for JSON elements specific to Teradata linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
OnPremisesTeradata
Yes
server
Name of the Teradata server.
Yes
authenticationType
Type of authentication used to
connect to the Teradata database.
Possible values are: Anonymous, Basic,
and Windows.
Yes
username
Specify user name if you are using
Basic or Windows authentication.
No
password
Specify password for the user account
you specified for the username.
No
gatewayName
Name of the gateway that the Data
Factory service should use to connect
to the on-premises Teradata database.
Yes
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location of
the data in the data store. Currently, there are no type properties supported for the Teradata dataset.
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policies are available for all types of
activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For Copy
activity, they vary depending on the types of sources and sinks.
When the source is of type RelationalSource (which includes Teradata), the following properties are available
in typeProperties section:
PROPERTY
DESCRIPTION
ALLOWED VALUES
REQUIRED
query
Use the custom query to
read data.
SQL query string. For
example: select * from
MyTable.
Yes
JSON example: Copy data from Teradata to Azure Blob
The following example provides sample JSON definitions that you can use to create a pipeline by using Azure
portal or Visual Studio or Azure PowerShell. They show how to copy data from Teradata to Azure Blob Storage.
However, data can be copied to any of the sinks stated here using the Copy Activity in Azure Data Factory.
The sample has the following data factory entities:
1.
2.
3.
4.
5.
A linked service of type OnPremisesTeradata.
A linked service of type AzureStorage.
An input dataset of type RelationalTable.
An output dataset of type AzureBlob.
The pipeline with Copy Activity that uses RelationalSource and BlobSink.
The sample copies data from a query result in Teradata database to a blob every hour. The JSON properties
used in these samples are described in sections following the samples.
As a first step, setup the data management gateway. The instructions are in the moving data between onpremises locations and cloud article.
Teradata linked service:
{
"name": "OnPremTeradataLinkedService",
"properties": {
"type": "OnPremisesTeradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<authentication type>",
"username": "<username>",
"password": "<password>",
"gatewayName": "<gatewayName>"
}
}
}
Azure Blob storage linked service:
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorageLinkedService",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<AccountName>;AccountKey=
<AccountKey>"
}
}
}
Teradata input dataset:
The sample assumes you have created a table “MyTable” in Teradata and it contains a column called
“timestamp” for time series data.
Setting “external”: true informs the Data Factory service that the table is external to the data factory and is not
produced by an activity in the data factory.
{
"name": "TeradataDataSet",
"properties": {
"published": false,
"type": "RelationalTable",
"linkedServiceName": "OnPremTeradataLinkedService",
"typeProperties": {
},
"availability": {
"frequency": "Hour",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}
Azure Blob output dataset:
Data is written to a new blob every hour (frequency: hour, interval: 1). The folder path for the blob is
dynamically evaluated based on the start time of the slice that is being processed. The folder path uses year,
month, day, and hours parts of the start time.
{
"name": "AzureBlobTeradataDataSet",
"properties": {
"published": false,
"location": {
"type": "AzureBlobLocation",
"folderPath": "mycontainer/teradata/yearno={Year}/monthno={Month}/dayno={Day}/hourno={Hour}",
"format": {
"type": "TextFormat",
"rowDelimiter": "\n",
"columnDelimiter": "\t"
},
"partitionedBy": [
{
"name": "Year",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy"
}
},
{
"name": "Month",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "MM"
}
},
{
"name": "Day",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "dd"
}
},
{
"name": "Hour",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "HH"
}
}
],
"linkedServiceName": "AzureStorageLinkedService"
},
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity:
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run hourly. In the pipeline JSON definition, the source type is set to RelationalSource and sink type is set
to BlobSink. The SQL query specified for the query property selects the data in the past hour to copy.
{
"name": "CopyTeradataToBlob",
"properties": {
"description": "pipeline for copy activity",
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "RelationalSource",
"query": "$$Text.Format('select * from MyTable where timestamp >= \\'{0:yyyy-MMddTHH:mm:ss}\\' AND timestamp < \\'{1:yyyy-MM-ddTHH:mm:ss}\\'', SliceStart, SliceEnd)"
},
"sink": {
"type": "BlobSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
}
},
"inputs": [
{
"name": "TeradataDataSet"
}
],
"outputs": [
{
"name": "AzureBlobTeradataDataSet"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "TeradataToBlob"
}
],
"start": "2014-06-01T18:00:00Z",
"end": "2014-06-01T19:00:00Z",
"isPaused": false
}
}
Type mapping for Teradata
As mentioned in the data movement activities article, the Copy activity performs automatic type conversions
from source types to sink types with the following 2-step approach:
1. Convert from native source types to .NET type
2. Convert from .NET type to native sink type
When moving data to Teradata, the following mappings are used from Teradata type to .NET type.
TERADATA DATABASE TYPE
.NET FRAMEWORK TYPE
Char
String
Clob
String
TERADATA DATABASE TYPE
.NET FRAMEWORK TYPE
Graphic
String
VarChar
String
VarGraphic
String
Blob
Byte[]
Byte
Byte[]
VarByte
Byte[]
BigInt
Int64
ByteInt
Int16
Decimal
Decimal
Double
Double
Integer
Int32
Number
Double
SmallInt
Int16
Date
DateTime
Time
TimeSpan
Time With Time Zone
String
Timestamp
DateTime
Timestamp With Time Zone
DateTimeOffset
Interval Day
TimeSpan
Interval Day To Hour
TimeSpan
Interval Day To Minute
TimeSpan
Interval Day To Second
TimeSpan
Interval Hour
TimeSpan
Interval Hour To Minute
TimeSpan
Interval Hour To Second
TimeSpan
TERADATA DATABASE TYPE
.NET FRAMEWORK TYPE
Interval Minute
TimeSpan
Interval Minute To Second
TimeSpan
Interval Second
TimeSpan
Interval Year
String
Interval Year To Month
String
Interval Month
String
Period(Date)
String
Period(Time)
String
Period(Time With Time Zone)
String
Period(Timestamp)
String
Period(Timestamp With Time Zone)
String
Xml
String
Map source to sink columns
To learn about mapping columns in source dataset to columns in sink dataset, see Mapping dataset columns in
Azure Data Factory.
Repeatable read from relational sources
When copying data from relational data stores, keep repeatability in mind to avoid unintended outcomes. In
Azure Data Factory, you can rerun a slice manually. You can also configure retry policy for a dataset so that a
slice is rerun when a failure occurs. When a slice is rerun in either way, you need to make sure that the same
data is read no matter how many times a slice is run. See Repeatable read from relational sources.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Move data from a Web table source using Azure
Data Factory
4/12/2017 • 6 min to read • Edit Online
This article outlines how to use the Copy Activity in Azure Data Factory to move data from a table in a Web
page to a supported sink data store. This article builds on the data movement activities article that presents a
general overview of data movement with copy activity and the list of data stores supported as sources/sinks.
Data factory currently supports only moving data from a Web table to other data stores, but not moving data
from other data stores to a Web table destination.
IMPORTANT
This Web connector currently supports only extracting table content from an HTML page. To retrieve data from a
HTTP/s endpoint, use HTTP connector instead.
Getting started
You can create a pipeline with a copy activity that moves data from an on-premises Cassandra data store by
using different tools/APIs.
The easiest way to create a pipeline is to use the Copy Wizard. See Tutorial: Create a pipeline using Copy
Wizard for a quick walkthrough on creating a pipeline using the Copy data wizard.
You can also use the following tools to create a pipeline: Azure portal, Visual Studio, Azure PowerShell,
Azure Resource Manager template, .NET API, and REST API. See Copy activity tutorial for step-by-step
instructions to create a pipeline with a copy activity.
Whether you use the tools or APIs, you perform the following steps to create a pipeline that moves data from a
source data store to a sink data store:
1. Create linked services to link input and output data stores to your data factory.
2. Create datasets to represent input and output data for the copy operation.
3. Create a pipeline with a copy activity that takes a dataset as an input and a dataset as an output.
When you use the wizard, JSON definitions for these Data Factory entities (linked services, datasets, and the
pipeline) are automatically created for you. When you use tools/APIs (except .NET API), you define these Data
Factory entities by using the JSON format. For a sample with JSON definitions for Data Factory entities that are
used to copy data from a web table, see JSON example: Copy data from Web table to Azure Blob section of this
article.
The following sections provide details about JSON properties that are used to define Data Factory entities
specific to a Web table:
Linked service properties
The following table provides description for JSON elements specific to Web linked service.
PROPERTY
DESCRIPTION
REQUIRED
type
The type property must be set to:
Web
Yes
Url
URL to the Web source
Yes
authenticationType
Anonymous.
Yes
Using Anonymous authentication
{
"name": "web",
"properties":
{
"type": "Web",
"typeProperties":
{
"authenticationType": "Anonymous",
"url" : "https://en.wikipedia.org/wiki/"
}
}
}
Dataset properties
For a full list of sections & properties available for defining datasets, see the Creating datasets article. Sections
such as structure, availability, and policy of a dataset JSON are similar for all dataset types (Azure SQL, Azure
blob, Azure table, etc.).
The typeProperties section is different for each type of dataset and provides information about the location
of the data in the data store. The typeProperties section for dataset of type WebTable has the following
properties
PROPERTY
DESCRIPTION
REQUIRED
type
type of the dataset. must be set to
WebTable
Yes
path
A relative URL to the resource that
contains the table.
No. When path is not specified, only
the URL specified in the linked service
definition is used.
index
The index of the table in the resource.
See Get index of a table in an HTML
page section for steps to getting index
of a table in an HTML page.
Yes
Example:
{
"name": "WebTableInput",
"properties": {
"type": "WebTable",
"linkedServiceName": "WebLinkedService",
"typeProperties": {
"index": 1,
"path": "AFI's_100_Years...100_Movies"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Copy activity properties
For a full list of sections & properties available for defining activities, see the Creating Pipelines article.
Properties such as name, description, input and output tables, and policy are available for all types of activities.
Whereas, properties available in the typeProperties section of the activity vary with each activity type. For Copy
activity, they vary depending on the types of sources and sinks.
Currently, when the source in copy activity is of type WebSource, no additional properties are supported.
JSON example: Copy data from Web table to Azure Blob
The following sample shows:
1.
2.
3.
4.
5.
A linked service of type Web.
A linked service of type AzureStorage.
An input dataset of type WebTable.
An output dataset of type AzureBlob.
A pipeline with Copy Activity that uses WebSource and BlobSink.
The sample copies data from a Web table to an Azure blob every hour. The JSON properties used in these
samples are described in sections following the samples.
The following sample shows how to copy data from a Web table to an Azure blob. However, data can be
copied directly to any of the sinks stated in the Data Movement Activities article by using the Copy Activity in
Azure Data Factory.
Web linked service This example uses the Web linked service with anonymous authentication. See Web
linked service section for different types of authentication you can use.
{
"name": "WebLinkedService",
"properties":
{
"type": "Web",
"typeProperties":
{
"authenticationType": "Anonymous",
"url" : "https://en.wikipedia.org/wiki/"
}
}
}
Azure Storage linked service
{
"name": "AzureStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=
<accountkey>"
}
}
}
WebTable input dataset Setting external to true informs the Data Factory service that the dataset is
external to the data factory and is not produced by an activity in the data factory.
NOTE
See Get index of a table in an HTML page section for steps to getting index of a table in an HTML page.
{
"name": "WebTableInput",
"properties": {
"type": "WebTable",
"linkedServiceName": "WebLinkedService",
"typeProperties": {
"index": 1,
"path": "AFI's_100_Years...100_Movies"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 1
}
}
}
Azure Blob output dataset
Data is written to a new blob every hour (frequency: hour, interval: 1).
{
"name": "AzureBlobOutput",
"properties":
{
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties":
{
"folderPath": "adfgetstarted/Movies"
},
"availability":
{
"frequency": "Hour",
"interval": 1
}
}
}
Pipeline with Copy activity
The pipeline contains a Copy Activity that is configured to use the input and output datasets and is scheduled
to run every hour. In the pipeline JSON definition, the source type is set to WebSource and sink type is set to
BlobSink.
See WebSource type properties for the list of properties supported by the WebSource.
{
"name":"SamplePipeline",
"properties":{
"start":"2014-06-01T18:00:00",
"end":"2014-06-01T19:00:00",
"description":"pipeline with copy activity",
"activities":[
{
"name": "WebTableToAzureBlob",
"description": "Copy from a Web table to an Azure blob",
"type": "Copy",
"inputs": [
{
"name": "WebTableInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"typeProperties": {
"source": {
"type": "WebSource"
},
"sink": {
"type": "BlobSink"
}
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"policy": {
"concurrency": 1,
"executionPriorityOrder": "OldestFirst",
"retry": 0,
"timeout": "01:00:00"
}
}
]
}
}
Get index of a table in an HTML page
1. Launch Excel 2016 and switch to the Data tab.
2. Click New Query on the toolbar, point to From Other Sources and click From Web.
3. In the From Web dialog box, enter URL that you would use in linked service JSON (for example:
https://en.wikipedia.org/wiki/) along with path you would specify for the dataset (for example:
AFI%27s_100_Years...100_Movies), and click OK.
URL used in this example: https://en.wikipedia.org/wiki/AFI%27s_100_Years...100_Movies
4. If you see Access Web content dialog box, select the right URL, authentication, and click Connect.
5. Click a table item in the tree view to see content from the table and then click Edit button at the
bottom.
6. In the Query Editor window, click Advanced Editor button on the toolbar.
7. In the Advanced Editor dialog box, the number next to "Source" is the index.
If you are using Excel 2013, use Microsoft Power Query for Excel to get the index. See Connect to a web page
article for details. The steps are similar if you are using Microsoft Power BI for Desktop.
NOTE
To map columns from source dataset to columns from sink dataset, see Mapping dataset columns in Azure Data
Factory.
Performance and Tuning
See Copy Activity Performance & Tuning Guide to learn about key factors that impact performance of data
movement (Copy Activity) in Azure Data Factory and various ways to optimize it.
Data Management Gateway
5/8/2017 • 21 min to read • Edit Online
The Data Management Gateway is a client agent that you must install in your on-premises environment to
copy data between cloud and on-premises data stores. The on-premises data stores supported by Data
Factory are listed in the Supported data sources section.
NOTE
Currently, gateway supports only the copy activity and stored procedure activity in Data Factory. It is not possible to
use the gateway from a custom activity to access on-premises data sources.
This article complements the walkthrough in the Move data between on-premises and cloud data stores
article. In the walkthrough, you create a pipeline that uses the gateway to move data from an on-premises
SQL Server database to an Azure blob. This article provides detailed in-depth information about the Data
Management Gateway.
Overview
Capabilities of Data Management gateway
Data Management Gateway provides the following capabilities:
Model on-premises data sources and cloud data sources within the same data factory and move data.
Have a single pane of glass for monitoring and management with visibility into gateway status from the
Data Factory blade.
Manage access to on-premises data sources securely.
No changes required to corporate firewall. Gateway only makes outbound HTTP-based connections
to open internet.
Encrypt credentials for your on-premises data stores with your certificate.
Move data efficiently – data is transferred in parallel, resilient to intermittent network issues with auto
retry logic.
Command flow and data flow
When you use a copy activity to copy data between on-premises and cloud, the activity uses a gateway to
transfer data from on-premises data source to cloud and vice versa.
Here high-level data flow for and summary of steps for copy with data gateway:
1. Data developer creates a gateway for an Azure Data Factory using either the Azure portal or PowerShell
Cmdlet.
2. Data developer creates a linked service for an on-premises data store by specifying the gateway. As part of
setting up the linked service, data developer uses the Setting Credentials application to specify
authentication types and credentials. The Setting Credentials application dialog communicates with the
data store to test connection and the gateway to save credentials.
3. Gateway encrypts the credentials with the certificate associated with the gateway (supplied by data
developer), before saving the credentials in the cloud.
4. Data Factory service communicates with the gateway for scheduling & management of jobs via a control
channel that uses a shared Azure service bus queue. When a copy activity job needs to be kicked off, Data
Factory queues the request along with credential information. Gateway kicks off the job after polling the
queue.
5. The gateway decrypts the credentials with the same certificate and then connects to the on-premises data
store with proper authentication type and credentials.
6. The gateway copies data from an on-premises store to a cloud storage, or vice versa depending on how
the Copy Activity is configured in the data pipeline. For this step, the gateway directly communicates with
cloud-based storage services such as Azure Blob Storage over a secure (HTTPS) channel.
Considerations for using gateway
A single instance of Data Management Gateway can be used for multiple on-premises data sources.
However, a single gateway instance is tied to only one Azure data factory and cannot be shared
with another data factory.
You can have only one instance of Data Management Gateway installed on a single machine.
Suppose, you have two data factories that need to access on-premises data sources, you need to install
gateways on two on-premises computers. In other words, a gateway is tied to a specific data factory
The gateway does not need to be on the same machine as the data source. However, having
gateway closer to the data source reduces the time for the gateway to connect to the data source. We
recommend that you install the gateway on a machine that is different from the one that hosts onpremises data source. When the gateway and data source are on different machines, the gateway does not
compete for resources with data source.
You can have multiple gateways on different machines connecting to the same on-premises data
source. For example, you may have two gateways serving two data factories but the same on-premises
data source is registered with both the data factories.
If you already have a gateway installed on your computer serving a Power BI scenario, install a separate
gateway for Azure Data Factory on another machine.
Gateway must be used even when you use ExpressRoute.
Treat your data source as an on-premises data source (that is behind a firewall) even when you use
ExpressRoute. Use the gateway to establish connectivity between the service and the data source.
You must use the gateway even if the data store is in the cloud on an Azure IaaS VM.
Installation
Prerequisites
The supported Operating System versions are Windows 7, Windows 8/8.1, Windows 10, Windows
Server 2008 R2, Windows Server 2012, Windows Server 2012 R2. Installation of the Data Management
Gateway on a domain controller is currently not supported.
.NET Framework 4.5.1 or above is required. If you are installing gateway on a Windows 7 machine, install
.NET Framework 4.5 or later. See .NET Framework System Requirements for details.
The recommended configuration for the gateway machine is at least 2 GHz, 4 cores, 8-GB RAM, and 80GB disk.
If the host machine hibernates, the gateway does not respond to data requests. Therefore, configure an
appropriate power plan on the computer before installing the gateway. If the machine is configured to
hibernate, the gateway installation prompts a message.
You must be an administrator on the machine to install and configure the Data Management Gateway
successfully. You can add additional users to the Data Management Gateway Users local Windows
group. The members of this group are able to use the Data Management Gateway Configuration Manager
tool to configure the gateway.
As copy activity runs happen on a specific frequency, the resource usage (CPU, memory) on the machine also
follows the same pattern with peak and idle times. Resource utilization also depends heavily on the amount
of data being moved. When multiple copy jobs are in progress, you see resource usage go up during peak
times.
Installation options
Data Management Gateway can be installed in the following ways:
By downloading an MSI setup package from the Microsoft Download Center. The MSI can also be used to
upgrade existing Data Management Gateway to the latest version, with all settings preserved.
By clicking Download and install data gateway link under MANUAL SETUP or Install directly on this
computer under EXPRESS SETUP. See Move data between on-premises and cloud article for step-by-step
instructions on using express setup. The manual step takes you to the download center. The instructions
for downloading and installing the gateway from download center are in the next section.
Installation best practices:
1. Configure power plan on the host machine for the gateway so that the machine does not hibernate. If the
host machine hibernates, the gateway does not respond to data requests.
2. Back up the certificate associated with the gateway.
Install gateway from download center
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
Navigate to Microsoft Data Management Gateway download page.
Click Download, select the appropriate version (32-bit vs. 64-bit), and click Next.
Run the MSI directly or save it to your hard disk and run.
On the Welcome page, select a language click Next.
Accept the End-User License Agreement and click Next.
Select folder to install the gateway and click Next.
On the Ready to install page, click Install.
Click Finish to complete installation.
Get the key from the Azure portal. See the next section for step-by-step instructions.
On the Register gateway page of Data Management Gateway Configuration Manager running on
your machine, do the following steps:
a. Paste the key in the text.
b. Optionally, click Show gateway key to see the key text.
c. Click Register.
Register gateway using key
If you haven't already created a logical gateway in the portal
To create a gateway in the portal and get the key from the Configure blade, Follow steps from walkthrough
in the Move data between on-premises and cloud article.
If you have already created the logical gateway in the portal
1. In Azure portal, navigate to the Data Factory blade, and click Linked Services tile.
2. In the Linked Services blade, select the logical gateway you created in the portal.
3. In the Data Gateway blade, click Download and install data gateway.
4. In the Configure blade, click Recreate key. Click Yes on the warning message after reading it
carefully.
5. Click Copy button next to the key. The key is copied to the clipboard.
System tray icons/ notifications
The following image shows some of the tray icons that you see.
If you move cursor over the system tray icon/notification message, you see details about the state of the
gateway/update operation in a popup window.
Ports and firewall
There are two firewalls you need to consider: corporate firewall running on the central router of the
organization, and Windows firewall configured as a daemon on the local machine where the gateway is
installed.
At corporate firewall level, you need configure the following domains and outbound ports:
DOMAIN NAMES
PORTS
DESCRIPTION
*.servicebus.windows.net
443, 80
Used for communication with Data
Movement Service backend
*.core.windows.net
443
Used for Staged copy using Azure
Blob (if configured)
*.frontend.clouddatahub.net
443
Used for communication with Data
Movement Service backend
At windows firewall level, these outbound ports are normally enabled. If not, you can configure the domains
and ports accordingly on gateway machine.
NOTE
1. Based on your source/ sinks, you may have to whitelist additional domains and outbound ports in your corporate/
windows firewall.
2. For some Cloud Databases (eg. SQL Azure Database, Azure Data Lake, etc.), you may need to whitelist IP address of
Gateway machine on there firewall configuration.
Copy data from a source data store to a sink data store
Ensure that the firewall rules are enabled properly on the corporate firewall, Windows firewall on the gateway
machine, and the data store itself. Enabling these rules allows the gateway to connect to both source and sink
successfully. Enable rules for each data store that is involved in the copy operation.
For example, to copy from an on-premises data store to an Azure SQL Database sink or an Azure SQL
Data Warehouse sink, do the following steps:
Allow outbound TCP communication on port 1433 for both Windows firewall and corporate firewall.
Configure the firewall settings of Azure SQL server to add the IP address of the gateway machine to the
list of allowed IP addresses.
NOTE
If your firewall does not allow outbound port 1433, Gateway will not be able to access Azure SQL directly. In this case
you may use Staged Copy to SQL Azure Database/ SQL Azure DW. In this scenario you would only require HTTPS (port
443) for the data movement.
Proxy server considerations
If your corporate network environment uses a proxy server to access the internet, configure Data
Management Gateway to use appropriate proxy settings. You can set the proxy during the initial registration
phase.
Gateway uses the proxy server to connect to the cloud service. Click Change link during initial setup. You see
the proxy setting dialog.
There are three configuration options:
Do not use proxy: Gateway does not explicitly use any proxy to connect to cloud services.
Use system proxy: Gateway uses the proxy setting that is configured in diahost.exe.config and
diawp.exe.config. If no proxy is configured in diahost.exe.config and diawp.exe.config, gateway connects to
cloud service directly without going through proxy.
Use custom proxy: Configure the HTTP proxy setting to use for gateway, instead of using configurations
in diahost.exe.config and diawp.exe.config. Address and Port are required. User Name and Password are
optional depending on your proxy’s authentication setting. All settings are encrypted with the credential
certificate of the gateway and stored locally on the gateway host machine.
The Data Management Gateway Host Service restarts automatically after you save the updated proxy settings.
After gateway has been successfully registered, if you want to view or update proxy settings, use Data
Management Gateway Configuration Manager.
1.
2.
3.
4.
Launch Data Management Gateway Configuration Manager.
Switch to the Settings tab.
Click Change link in HTTP Proxy section to launch the Set HTTP Proxy dialog.
After you click the Next button, you see a warning dialog asking for your permission to save the proxy
setting and restart the Gateway Host Service.
You can view and update HTTP proxy by using Configuration Manager tool.
NOTE
If you set up a proxy server with NTLM authentication, Gateway Host Service runs under the domain account. If you
change the password for the domain account later, remember to update configuration settings for the service and
restart it accordingly. Due to this requirement, we suggest you use a dedicated domain account to access the proxy
server that does not require you to update the password frequently.
Configure proxy server settings
If you select Use system proxy setting for the HTTP proxy, gateway uses the proxy setting in
diahost.exe.config and diawp.exe.config. If no proxy is specified in diahost.exe.config and diawp.exe.config,
gateway connects to cloud service directly without going through proxy. The following procedure provides
instructions for updating the diahost.exe.config file.
1. In File Explorer, make a safe copy of C:\Program Files\Microsoft Data Management
Gateway\2.0\Shared\diahost.exe.config to back up the original file.
2. Launch Notepad.exe running as administrator, and open text file “C:\Program Files\Microsoft Data
Management Gateway\2.0\Shared\diahost.exe.config. You find the default tag for system.net as shown
in the following code:
<system.net>
<defaultProxy useDefaultCredentials="true" />
</system.net>
You can then add proxy server details as shown in the following example:
<system.net>
<defaultProxy enabled="true">
<proxy bypassonlocal="true" proxyaddress="http://proxy.domain.org:8888/" />
</defaultProxy>
</system.net>
Additional properties are allowed inside the proxy tag to specify the required settings like
scriptLocation. Refer to proxy Element (Network Settings) on syntax.
<proxy autoDetect="true|false|unspecified" bypassonlocal="true|false|unspecified"
proxyaddress="uriString" scriptLocation="uriString" usesystemdefault="true|false|unspecified "/>
3. Save the configuration file into the original location, then restart the Data Management Gateway Host
service, which picks up the changes. To restart the service: use services applet from the control panel, or
from the Data Management Gateway Configuration Manager > click the Stop Service button, then
click the Start Service. If the service does not start, it is likely that an incorrect XML tag syntax has been
added into the application configuration file that was edited.
IMPORTANT
Do not forget to update both diahost.exe.config and diawp.exe.config.
In addition to these points, you also need to make sure Microsoft Azure is in your company’s whitelist. The list
of valid Microsoft Azure IP addresses can be downloaded from the Microsoft Download Center.
Possible symptoms for firewall and proxy server-related issues
If you encounter errors similar to the following ones, it is likely due to improper configuration of the firewall
or proxy server, which blocks gateway from connecting to Data Factory to authenticate itself. Refer to
previous section to ensure your firewall and proxy server are properly configured.
1. When you try to register the gateway, you receive the following error: "Failed to register the gateway key.
Before trying to register the gateway key again, confirm that the Data Management Gateway is in a
connected state and the Data Management Gateway Host Service is Started."
2. When you open Configuration Manager, you see status as “Disconnected” or “Connecting.” When viewing
Windows event logs, under “Event Viewer” > “Application and Services Logs” > “Data Management
Gateway”, you see error messages such as the following error: Unable to connect to the remote server
A component of Data Management Gateway has become unresponsive and restarts automatically. Component
name: Gateway.
Open port 8050 for credential encryption
The Setting Credentials application uses the inbound port 8050 to relay credentials to the gateway when
you set up an on-premises linked service in the Azure portal. During gateway setup, by default, the Data
Management Gateway installation opens it on the gateway machine.
If you are using a third-party firewall, you can manually open the port 8050. If you run into firewall issue
during gateway setup, you can try using the following command to install the gateway without configuring
the firewall.
msiexec /q /i DataManagementGateway.msi NOFIREWALL=1
If you choose not to open the port 8050 on the gateway machine, use mechanisms other than using the
Setting Credentials application to configure data store credentials. For example, you could use NewAzureRmDataFactoryEncryptValue PowerShell cmdlet. See Setting Credentials and Security section on how
data store credentials can be set.
Update
By default, Data Management Gateway is automatically updated when a newer version of the gateway is
available. The gateway is not updated until all the scheduled tasks are done. No further tasks are processed by
the gateway until the update operation is completed. If the update fails, gateway is rolled back to the old
version.
You see the scheduled update time in the following places:
The gateway properties blade in the Azure portal.
Home page of the Data Management Gateway Configuration Manager
System tray notification message.
The Home tab of the Data Management Gateway Configuration Manager displays the update schedule and
the last time the gateway was installed/updated.
You can install the update right away or wait for the gateway to be automatically updated at the scheduled
time. For example, the following image shows you the notification message shown in the Gateway
Configuration Manager along with the Update button that you can click to install it immediately.
The notification message in the system tray would look as shown in the following image:
You see the status of update operation (manual or automatic) in the system tray. When you launch Gateway
Configuration Manager next time, you see a message on the notification bar that the gateway has been
updated along with a link to what's new topic.
To disable/enable auto -update feature
You can disable/enable the auto-update feature by doing the following steps:
1. Launch Windows PowerShell on the gateway machine.
2. Switch to the C:\Program Files\Microsoft Data Management Gateway\2.0\PowerShellScript folder.
3. Run the following command to turn the auto-update feature OFF (disable).
.\GatewayAutoUpdateToggle.ps1 -off
4. To turn it back on:
.\GatewayAutoUpdateToggle.ps1 -on
Configuration Manager
Once you install the gateway, you can launch Data Management Gateway Configuration Manager in
one of the following ways:
In the Search window, type Data Management Gateway to access this utility.
Run the executable ConfigManager.exe in the folder: C:\Program Files\Microsoft Data Management
Gateway\2.0\Shared
Home page
The Home page allows you to do the following actions:
View status of the gateway (connected to the cloud service etc.).
Register using a key from the portal.
Stop and start the Data Management Gateway Host service on the gateway machine.
Schedule updates at a specific time of the days.
View the date when the gateway was last updated.
Settings page
The Settings page allows you to do the following actions:
View, change, and export certificate used by the gateway. This certificate is used to encrypt data source
credentials.
Change HTTPS port for the endpoint. The gateway opens a port for setting the data source credentials.
Status of the endpoint
View SSL certificate is used for SSL communication between portal and the gateway to set credentials for
data sources.
Diagnostics page
The Diagnostics page allows you to do the following actions:
Enable verbose logging, view logs in event viewer, and send logs to Microsoft if there was a failure.
Test connection to a data source.
Help page
The Help page displays the following information:
Brief description of the gateway
Version number
Links to online help, privacy statement, and license agreement.
Troubleshooting gateway issues
See Troubleshooting gateway issues article for information/tips for troubleshooting issues with using the
Data Management Gateway.
Move gateway from a machine to another
This section provides steps for moving gateway client from one machine to another machine.
1. In the portal, navigate to the Data Factory home page, and click the Linked Services tile.
2. Select your gateway in the DATA GATEWAYS section of the Linked Services blade.
3. In the Data gateway blade, click Download and install data gateway.
4. In the Configure blade, click Download and install data gateway, and follow instructions to install
the data gateway on the machine.
5. Keep the Microsoft Data Management Gateway Configuration Manager open.
6. In the Configure blade in the portal, click Recreate key on the command bar, and click Yes for the
warning message. Click copy button next to key text that copies the key to the clipboard. The gateway
on the old machine stops functioning as soon you recreate the key.
7. Paste the key into text box in the Register Gateway page of the Data Management Gateway
Configuration Manager on your machine. (optional) Click Show gateway key check box to see the
key text.
8. Click Register to register the gateway with the cloud service.
9. On the Settings tab, click Change to select the same certificate that was used with the old gateway,
enter the password, and click Finish.
You can export a certificate from the old gateway by doing the following steps: launch Data
Management Gateway Configuration Manager on the old machine, switch to the Certificate tab, click
Export button and follow the instructions.
10. After successful registration of the gateway, you should see the Registration set to Registered and
Status set to Started on the Home page of the Gateway Configuration Manager.
Encrypting credentials
To encrypt credentials in the Data Factory Editor, do the following steps:
1. Launch web browser on the gateway machine, navigate to Azure portal. Search for your data factory if
needed, open data factory in the DATA FACTORY blade and then click Author & Deploy to launch Data
Factory Editor.
2. Click an existing linked service in the tree view to see its JSON definition or create a linked service that
requires a Data Management Gateway (for example: SQL Server or Oracle).
3. In the JSON editor, for the gatewayName property, enter the name of the gateway.
4. Enter server name for the Data Source property in the connectionString.
5. Enter database name for the Initial Catalog property in the connectionString.
6. Click Encrypt button on the command bar that launches the click-once Credential Manager application.
You should see the Setting Credentials dialog box.
7. In the Setting Credentials dialog box, do the following steps:
a. Select authentication that you want the Data Factory service to use to connect to the database.
b. Enter name of the user who has access to the database for the USERNAME setting.
c. Enter password for the user for the PASSWORD setting.
d. Click OK to encrypt credentials and close the dialog box.
8. You should see a encryptedCredential property in the connectionString now.
{
"name": "SqlServerLinkedService",
"properties": {
"type": "OnPremisesSqlServer",
"description": "",
"typeProperties": {
"connectionString": "data source=myserver;initial catalog=mydatabase;Integrated
Security=False;EncryptedCredential=eyJDb25uZWN0aW9uU3R",
"gatewayName": "adftutorialgateway"
}
}
}
If you access the portal from a machine that is different from the gateway machine, you must make
sure that the Credentials Manager application can connect to the gateway machine. If the application
cannot reach the gateway machine, it does not allow you to set credentials for the data source and to
test connection to the data source.
When you use the Setting Credentials application, the portal encrypts the credentials with the certificate
specified in the Certificate tab of the Gateway Configuration Manager on the gateway machine.
If you are looking for an API-based approach for encrypting the credentials, you can use the NewAzureRmDataFactoryEncryptValue PowerShell cmdlet to encrypt credentials. The cmdlet uses the certificate
that gateway is configured to use to encrypt the credentials. You add encrypted credentials to the
EncryptedCredential element of the connectionString in the JSON. You use the JSON with the NewAzureRmDataFactoryLinkedService cmdlet or in the Data Factory Editor.
"connectionString": "Data Source=<servername>;Initial Catalog=<databasename>;Integrated
Security=True;EncryptedCredential=<encrypted credential>",
There is one more approach for setting credentials using Data Factory Editor. If you create a SQL Server
linked service by using the editor and you enter credentials in plain text, the credentials are encrypted using a
certificate that the Data Factory service owns. It does NOT use the certificate that gateway is configured to
use. While this approach might be a little faster in some cases, it is less secure. Therefore, we recommend that
you follow this approach only for development/testing purposes.
PowerShell cmdlets
This section describes how to create and register a gateway using Azure PowerShell cmdlets.
1. Launch Azure PowerShell in administrator mode.
2. Log in to your Azure account by running the following command and entering your Azure credentials.
Login-AzureRmAccount
3. Use the New-AzureRmDataFactoryGateway cmdlet to create a logical gateway as follows:
$MyDMG = New-AzureRmDataFactoryGateway -Name <gatewayName> -DataFactoryName <dataFactoryName> ResourceGroupName ADF –Description <desc>
Example command and output:
PS C:\> $MyDMG = New-AzureRmDataFactoryGateway -Name MyGateway -DataFactoryName $df ResourceGroupName ADF –Description “gateway for walkthrough”
Name
: MyGateway
Description
: gateway for walkthrough
Version
:
Status
: NeedRegistration
VersionStatus
: None
CreateTime
: 9/28/2014 10:58:22
RegisterTime
:
LastConnectTime :
ExpiryTime
:
ProvisioningState : Succeeded
Key
: ADF#00000000-0000-4fb8-a867-947877aef6cb@fda06d87-f446-43b1-948578af26b8bab0@4707262b-dc25-4fe5-881c-c8a7c3c569fe@wu#nfU4aBlq/heRyYFZ2Xt/CD+7i73PEO521Sj2AFOCmiI
4. In Azure PowerShell, switch to the folder: C:\Program Files\Microsoft Data Management
Gateway\2.0\PowerShellScript\. Run RegisterGateway.ps1 associated with the local variable $Key
as shown in the following command. This script registers the client agent installed on your machine
with the logical gateway you create earlier.
PS C:\> .\RegisterGateway.ps1 $MyDMG.Key
Agent registration is successful!
You can register the gateway on a remote machine by using the IsRegisterOnRemoteMachine
parameter. Example:
.\RegisterGateway.ps1 $MyDMG.Key -IsRegisterOnRemoteMachine true
5. You can use the Get-AzureRmDataFactoryGateway cmdlet to get the list of Gateways in your data
factory. When the Status shows online, it means your gateway is ready to use.
Get-AzureRmDataFactoryGateway -DataFactoryName <dataFactoryName> -ResourceGroupName ADF
You can remove a gateway using the Remove-AzureRmDataFactoryGateway cmdlet and update
description for a gateway using the Set-AzureRmDataFactoryGateway cmdlets. For syntax and
other details about these cmdlets, see Data Factory Cmdlet Reference.
List gateways using PowerShell
Get-AzureRmDataFactoryGateway -DataFactoryName jasoncopyusingstoredprocedure -ResourceGroupName
ADF_ResourceGroup
Remove gateway using PowerShell
Remove-AzureRmDataFactoryGateway -Name JasonHDMG_byPSRemote -ResourceGroupName ADF_ResourceGroup DataFactoryName jasoncopyusingstoredprocedure -Force
Next Steps
See Move data between on-premises and cloud data stores article. In the walkthrough, you create a
pipeline that uses the gateway to move data from an on-premises SQL Server database to an Azure blob.
Transform data in Azure Data Factory
5/16/2017 • 3 min to read • Edit Online
Overview
This article explains data transformation activities in Azure Data Factory that you can use to transform and
processes your raw data into predictions and insights. A transformation activity executes in a computing
environment such as Azure HDInsight cluster or an Azure Batch. It provides links to articles with detailed
information on each transformation activity.
Data Factory supports the following data transformation activities that can be added to pipelines either
individually or chained with another activity.
NOTE
For a walkthrough with step-by-step instructions, see Create a pipeline with Hive transformation article.
HDInsight Hive activity
The HDInsight Hive activity in a Data Factory pipeline executes Hive queries on your own or on-demand
Windows/Linux-based HDInsight cluster. See Hive Activity article for details about this activity.
HDInsight Pig activity
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand
Windows/Linux-based HDInsight cluster. See Pig Activity article for details about this activity.
HDInsight MapReduce activity
The HDInsight MapReduce activity in a Data Factory pipeline executes MapReduce programs on your own or
on-demand Windows/Linux-based HDInsight cluster. See MapReduce Activity article for details about this
activity.
HDInsight Streaming activity
The HDInsight Streaming Activity in a Data Factory pipeline executes Hadoop Streaming programs on your
own or on-demand Windows/Linux-based HDInsight cluster. See HDInsight Streaming activity for details about
this activity.
HDInsight Spark Activity
The HDInsight Spark activity in a Data Factory pipeline executes Spark programs on your own HDInsight
cluster. For details, see Invoke Spark programs from Azure Data Factory.
Machine Learning activities
Azure Data Factory enables you to easily create pipelines that use a published Azure Machine Learning web
service for predictive analytics. Using the Batch Execution Activity in an Azure Data Factory pipeline, you can
invoke a Machine Learning web service to make predictions on the data in batch.
Over time, the predictive models in the Machine Learning scoring experiments need to be retrained using new
input datasets. After you are done with retraining, you want to update the scoring web service with the
retrained Machine Learning model. You can use the Update Resource Activity to update the web service with
the newly trained model.
See Use Machine Learning activities for details about these Machine Learning activities.
Stored procedure activity
You can use the SQL Server Stored Procedure activity in a Data Factory pipeline to invoke a stored procedure in
one of the following data stores: Azure SQL Database, Azure SQL Data Warehouse, SQL Server Database in
your enterprise or an Azure VM. See Stored Procedure Activity article for details.
Data Lake Analytics U-SQL activity
Data Lake Analytics U-SQL Activity runs a U-SQL script on an Azure Data Lake Analytics cluster. See Data
Analytics U-SQL Activity article for details.
.NET custom activity
If you need to transform data in a way that is not supported by Data Factory, you can create a custom activity
with your own data processing logic and use the activity in the pipeline. You can configure the custom .NET
activity to run using either an Azure Batch service or an Azure HDInsight cluster. See Use custom activities
article for details.
You can create a custom activity to run R scripts on your HDInsight cluster with R installed. See Run R Script
using Azure Data Factory.
Compute environments
You create a linked service for the compute environment and then use the linked service when defining a
transformation activity. There are two types of compute environments supported by Data Factory.
1. On-Demand: In this case, the computing environment is fully managed by Data Factory. It is automatically
created by the Data Factory service before a job is submitted to process data and removed when the job is
completed. You can configure and control granular settings of the on-demand compute environment for job
execution, cluster management, and bootstrapping actions.
2. Bring Your Own: In this case, you can register your own computing environment (for example HDInsight
cluster) as a linked service in Data Factory. The computing environment is managed by you and the Data
Factory service uses it to execute the activities.
See Compute Linked Services article to learn about compute services supported by Data Factory.
Summary
Azure Data Factory supports the following data transformation activities and the compute environments for the
activities. The transformation activities can be added to pipelines either individually or chained with another
activity.
DATA TRANSFORMATION ACTIVITY
COMPUTE ENVIRONMENT
Hive
HDInsight [Hadoop]
Pig
HDInsight [Hadoop]
DATA TRANSFORMATION ACTIVITY
COMPUTE ENVIRONMENT
MapReduce
HDInsight [Hadoop]
Hadoop Streaming
HDInsight [Hadoop]
Machine Learning activities: Batch Execution and Update
Resource
Azure VM
Stored Procedure
Azure SQL, Azure SQL Data Warehouse, or SQL Server
Data Lake Analytics U-SQL
Azure Data Lake Analytics
DotNet
HDInsight [Hadoop] or Azure Batch
Transform data using Hive Activity in Azure Data
Factory
5/22/2017 • 4 min to read • Edit Online
The HDInsight Hive activity in a Data Factory pipeline executes Hive queries on your own or on-demand
Windows/Linux-based HDInsight cluster. This article builds on the data transformation activities article, which
presents a general overview of data transformation and the supported transformation activities.
Syntax
{
"name": "Hive Activity",
"description": "description",
"type": "HDInsightHive",
"inputs": [
{
"name": "input tables"
}
],
"outputs": [
{
"name": "output tables"
}
],
"linkedServiceName": "MyHDInsightLinkedService",
"typeProperties": {
"script": "Hive script",
"scriptPath": "<pathtotheHivescriptfileinAzureblobstorage>",
"defines": {
"param1": "param1Value"
}
},
"scheduler": {
"frequency": "Day",
"interval": 1
}
}
Syntax details
PROPERTY
DESCRIPTION
REQUIRED
name
Name of the activity
Yes
description
Text describing what the activity is
used for
No
type
HDinsightHive
Yes
inputs
Inputs consumed by the Hive activity
No
outputs
Outputs produced by the Hive activity
Yes
PROPERTY
DESCRIPTION
REQUIRED
linkedServiceName
Reference to the HDInsight cluster
registered as a linked service in Data
Factory
Yes
script
Specify the Hive script inline
No
script path
Store the Hive script in an Azure blob
storage and provide the path to the
file. Use 'script' or 'scriptPath'
property. Both cannot be used
together. The file name is casesensitive.
No
defines
Specify parameters as key/value pairs
for referencing within the Hive script
using 'hiveconf'
No
Example
Let’s consider an example of game logs analytics where you want to identify the time spent by users playing
games launched by your company.
The following log is a sample game log, which is comma ( , ) separated and contains the following fields –
ProfileID, SessionStart, Duration, SrcIPAddress, and GameType.
1809,2014-05-04
1703,2014-05-04
1703,2014-05-04
1809,2014-05-04
.....
12:04:25.3470000,14,221.117.223.75,CaptureFlag
06:05:06.0090000,16,12.49.178.247,KingHill
10:21:57.3290000,10,199.118.18.179,CaptureFlag
05:24:22.2100000,23,192.84.66.141,KingHill
The Hive script to process this data:
DROP TABLE IF EXISTS HiveSampleIn;
CREATE EXTERNAL TABLE HiveSampleIn
(
ProfileID
string,
SessionStart
string,
Duration
int,
SrcIPAddress
string,
GameType
string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '10' STORED AS TEXTFILE LOCATION
'wasb://adfwalkthrough@<storageaccount>.blob.core.windows.net/samplein/';
DROP TABLE IF EXISTS HiveSampleOut;
CREATE EXTERNAL TABLE HiveSampleOut
(
ProfileID
string,
Duration
int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '10' STORED AS TEXTFILE LOCATION
'wasb://adfwalkthrough@<storageaccount>.blob.core.windows.net/sampleout/';
INSERT OVERWRITE TABLE HiveSampleOut
Select
ProfileID,
SUM(Duration)
FROM HiveSampleIn Group by ProfileID
To execute this Hive script in a Data Factory pipeline, you need to do the following
1. Create a linked service to register your own HDInsight compute cluster or configure on-demand HDInsight
compute cluster. Let’s call this linked service “HDInsightLinkedService”.
2. Create a linked service to configure the connection to Azure Blob storage hosting the data. Let’s call this
linked service “StorageLinkedService”
3. Create datasets pointing to the input and the output data. Let’s call the input dataset “HiveSampleIn” and
the output dataset “HiveSampleOut”
4. Copy the Hive query as a file to Azure Blob Storage configured in step #2. if the storage for hosting the
data is different from the one hosting this query file, create a separate Azure Storage linked service and
refer to it in the activity. Use scriptPath **to specify the path to hive query file and
**scriptLinkedService to specify the Azure storage that contains the script file.
NOTE
You can also provide the Hive script inline in the activity definition by using the script property. We do not
recommend this approach as all special characters in the script within the JSON document needs to be escaped
and may cause debugging issues. The best practice is to follow step #4.
5. Create a pipeline with the HDInsightHive activity. The activity processes/transforms the data.
{
"name": "HiveActivitySamplePipeline",
"properties": {
"activities": [
{
"name": "HiveActivitySample",
"type": "HDInsightHive",
"inputs": [
{
"name": "HiveSampleIn"
}
],
"outputs": [
{
"name": "HiveSampleOut"
}
],
"linkedServiceName": "HDInsightLinkedService",
"typeproperties": {
"scriptPath": "adfwalkthrough\\scripts\\samplehive.hql",
"scriptLinkedService": "StorageLinkedService"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
}
}
]
}
}
6. Deploy the pipeline. See Creating pipelines article for details.
7. Monitor the pipeline using the data factory monitoring and management views. See Monitoring and
manage Data Factory pipelines article for details.
Specifying parameters for a Hive script
In this example, game logs are ingested daily into Azure Blob Storage and are stored in a folder partitioned
with date and time. You want to parameterize the Hive script and pass the input folder location dynamically
during runtime and also produce the output partitioned with date and time.
To use parameterized Hive script, do the following
Define the parameters in defines.
{
"name": "HiveActivitySamplePipeline",
"properties": {
"activities": [
{
"name": "HiveActivitySample",
"type": "HDInsightHive",
"inputs": [
{
"name": "HiveSampleIn"
}
],
"outputs": [
{
"name": "HiveSampleOut"
}
],
"linkedServiceName": "HDInsightLinkedService",
"typeproperties": {
"scriptPath": "adfwalkthrough\\scripts\\samplehive.hql",
"scriptLinkedService": "StorageLinkedService",
"defines": {
"Input":
"$$Text.Format('wasb://adfwalkthrough@<storageaccountname>.blob.core.windows.net/samplein/yearno=
{0:yyyy}/monthno={0:MM}/dayno={0:dd}/', SliceStart)",
"Output":
"$$Text.Format('wasb://adfwalkthrough@<storageaccountname>.blob.core.windows.net/sampleout/yearno=
{0:yyyy}/monthno={0:MM}/dayno={0:dd}/', SliceStart)"
},
"scheduler": {
"frequency": "Hour",
"interval": 1
}
}
}
]
}
}
In the Hive Script, refer to the parameter using ${hiveconf:parameterName}.
DROP TABLE IF EXISTS HiveSampleIn;
CREATE EXTERNAL TABLE HiveSampleIn
(
ProfileID
string,
SessionStart
string,
Duration
int,
SrcIPAddress
string,
GameType
string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '10' STORED AS TEXTFILE
LOCATION '${hiveconf:Input}';
DROP TABLE IF EXISTS HiveSampleOut;
CREATE EXTERNAL TABLE HiveSampleOut
(
ProfileID
string,
Duration
int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '10' STORED AS TEXTFILE
LOCATION '${hiveconf:Output}';
INSERT OVERWRITE TABLE HiveSampleOut
Select
ProfileID,
SUM(Duration)
FROM HiveSampleIn Group by ProfileID
See Also
Pig Activity
MapReduce Activity
Hadoop Streaming Activity
Invoke Spark programs
Invoke R scripts
Transform data using Pig Activity in Azure Data
Factory
5/22/2017 • 3 min to read • Edit Online
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand
Windows/Linux-based HDInsight cluster. This article builds on the data transformation activities article, which
presents a general overview of data transformation and the supported transformation activities.
Syntax
{
"name": "HiveActivitySamplePipeline",
"properties": {
"activities": [
{
"name": "Pig Activity",
"description": "description",
"type": "HDInsightPig",
"inputs": [
{
"name": "input tables"
}
],
"outputs": [
{
"name": "output tables"
}
],
"linkedServiceName": "MyHDInsightLinkedService",
"typeProperties": {
"script": "Pig script",
"scriptPath": "<pathtothePigscriptfileinAzureblobstorage>",
"defines": {
"param1": "param1Value"
}
},
"scheduler": {
"frequency": "Day",
"interval": 1
}
}
]
}
}
Syntax details
PROPERTY
DESCRIPTION
REQUIRED
name
Name of the activity
Yes
description
Text describing what the activity is
used for
No
PROPERTY
DESCRIPTION
REQUIRED
type
HDinsightPig
Yes
inputs
One or more inputs consumed by the
Pig activity
No
outputs
One or more outputs produced by the
Pig activity
Yes
linkedServiceName
Reference to the HDInsight cluster
registered as a linked service in Data
Factory
Yes
script
Specify the Pig script inline
No
script path
Store the Pig script in an Azure blob
storage and provide the path to the
file. Use 'script' or 'scriptPath'
property. Both cannot be used
together. The file name is casesensitive.
No
defines
Specify parameters as key/value pairs
for referencing within the Pig script
No
Example
Let’s consider an example of game logs analytics where you want to identify the time spent by players playing
games launched by your company.
The following sample game log is a comma (,) separated file. It contains the following fields – ProfileID,
SessionStart, Duration, SrcIPAddress, and GameType.
1809,2014-05-04
1703,2014-05-04
1703,2014-05-04
1809,2014-05-04
.....
12:04:25.3470000,14,221.117.223.75,CaptureFlag
06:05:06.0090000,16,12.49.178.247,KingHill
10:21:57.3290000,10,199.118.18.179,CaptureFlag
05:24:22.2100000,23,192.84.66.141,KingHill
The Pig script to process this data:
PigSampleIn = LOAD 'wasb://[email protected]/samplein/' USING PigStorage(',')
AS (ProfileID:chararray, SessionStart:chararray, Duration:int, SrcIPAddress:chararray, GameType:chararray);
GroupProfile = Group PigSampleIn all;
PigSampleOut = Foreach GroupProfile Generate PigSampleIn.ProfileID, SUM(PigSampleIn.Duration);
Store PigSampleOut into 'wasb://[email protected]/sampleoutpig/' USING
PigStorage (',');
To execute this Pig script in a Data Factory pipeline, do the following:
1. Create a linked service to register your own HDInsight compute cluster or configure on-demand HDInsight
compute cluster. Let’s call this linked service HDInsightLinkedService.
2. Create a linked service to configure the connection to Azure Blob storage hosting the data. Let’s call this
linked service StorageLinkedService.
3. Create datasets pointing to the input and the output data. Let’s call the input dataset PigSampleIn and the
output dataset PigSampleOut.
4. Copy the Pig query in a file the Azure Blob Storage configured in step #2. If the Azure storage that hosts
the data is different from the one that hosts the query file, create a separate Azure Storage linked service.
Refer to the linked service in the activity configuration. Use scriptPath **to specify the path to pig
script file and **scriptLinkedService.
NOTE
You can also provide the Pig script inline in the activity definition by using the script property. However, we do
not recommend this approach as all special characters in the script needs to be escaped and may cause
debugging issues. The best practice is to follow step #4.
5. Create the pipeline with the HDInsightPig activity. This activity processes the input data by running Pig
script on HDInsight cluster.
{
"name": "PigActivitySamplePipeline",
"properties": {
"activities": [
{
"name": "PigActivitySample",
"type": "HDInsightPig",
"inputs": [
{
"name": "PigSampleIn"
}
],
"outputs": [
{
"name": "PigSampleOut"
}
],
"linkedServiceName": "HDInsightLinkedService",
"typeproperties": {
"scriptPath": "adfwalkthrough\\scripts\\enrichlogs.pig",
"scriptLinkedService": "StorageLinkedService"
},
"scheduler": {
"frequency": "Day",
"interval": 1
}
}
]
}
}
6. Deploy the pipeline. See Creating pipelines article for details.
7. Monitor the pipeline using the data factory monitoring and management views. See Monitoring and
manage Data Factory pipelines article for details.
Specifying parameters for a Pig script
Consider the following example: game logs are ingested daily into Azure Blob Storage and stored in a folder
partitioned based on date and time. You want to parameterize the Pig script and pass the input folder location
dynamically during runtime and also produce the output partitioned with date and time.
To use parameterized Pig script, do the following:
Define the parameters in defines.
{
"name": "PigActivitySamplePipeline",
"properties": {
"activities": [
{
"name": "PigActivitySample",
"type": "HDInsightPig",
"inputs": [
{
"name": "PigSampleIn"
}
],
"outputs": [
{
"name": "PigSampleOut"
}
],
"linkedServiceName": "HDInsightLinkedService",
"typeproperties": {
"scriptPath": "adfwalkthrough\\scripts\\samplepig.hql",
"scriptLinkedService": "StorageLinkedService",
"defines": {
"Input": "$$Text.Format('wasb:
//adfwalkthrough@<storageaccountname>.blob.core.windows.net/samplein/yearno={0: yyyy}/monthno=
{0:MM}/dayno={0: dd}/',SliceStart)",
"Output":
"$$Text.Format('wasb://adfwalkthrough@<storageaccountname>.blob.core.windows.net/sampleout/yearno=
{0:yyyy}/monthno={0:MM}/dayno={0:dd}/', SliceStart)"
}
},
"scheduler": {
"frequency": "Day",
"interval": 1
}
}
]
}
}
In the Pig Script, refer to the parameters using '$parameterName' as shown in the following example:
PigSampleIn = LOAD '$Input' USING PigStorage(',') AS (ProfileID:chararray, SessionStart:chararray,
Duration:int, SrcIPAddress:chararray, GameType:chararray);
GroupProfile = Group PigSampleIn all;
PigSampleOut = Foreach GroupProfile Generate PigSampleIn.ProfileID, SUM(PigSampleIn.Duration);
Store PigSampleOut into '$Output' USING PigStorage (',');
See Also
Hive Activity
MapReduce Activity
Hadoop Streaming Activity
Invoke Spark programs
Invoke R scripts
Invoke MapReduce Programs from Data Factory
3/13/2017 • 4 min to read • Edit Online
The HDInsight MapReduce activity in a Data Factory pipeline executes MapReduce programs on your own or
on-demand Windows/Linux-based HDInsight cluster. This article builds on the data transformation activities
article, which presents a general overview of data transformation and the supported transformation activities.
Introduction
A pipeline in an Azure data factory processes data in linked storage services by using linked compute services.
It contains a sequence of activities where each activity performs a specific processing operation. This article
describes using the HDInsight MapReduce Activity.
See Pig and Hive for details about running Pig/Hive scripts on a Windows/Linux-based HDInsight cluster from
a pipeline by using HDInsight Pig and Hive activities.
JSON for HDInsight MapReduce Activity
In the JSON definition for the HDInsight Activity:
1.
2.
3.
4.
Set the type of the activity to HDInsight.
Specify the name of the class for className property.
Specify the path to the JAR file including the file name for jarFilePath property.
Specify the linked service that refers to the Azure Blob Storage that contains the JAR file for
jarLinkedService property.
5. Specify any arguments for the MapReduce program in the arguments section. At runtime, you see a
few extra arguments (for example: mapreduce.job.tags) from the MapReduce framework. To
differentiate your arguments with the MapReduce arguments, consider using both option and value as
arguments as shown in the following example (-s, --input, --output etc., are options immediately
followed by their values).
{
"name": "MahoutMapReduceSamplePipeline",
"properties": {
"description": "Sample Pipeline to Run a Mahout Custom Map Reduce Jar. This job calcuates an
Item Similarity Matrix to determine the similarity between 2 items",
"activities": [
{
"type": "HDInsightMapReduce",
"typeProperties": {
"className":
"org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"jarLinkedService": "StorageLinkedService",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://[email protected]/Mahout/input",
"--output",
"wasb://[email protected]/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://[email protected]/Mahout/temp/mahout"
]
},
"inputs": [
{
"name": "MahoutInput"
}
],
"outputs": [
{
"name": "MahoutOutput"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Hour",
"interval": 1
},
"name": "MahoutActivity",
"description": "Custom Map Reduce to generate Mahout result",
"linkedServiceName": "HDInsightLinkedService"
}
],
"start": "2017-01-03T00:00:00Z",
"end": "2017-01-04T00:00:00Z"
}
}
You can use the HDInsight MapReduce Activity to run any MapReduce jar file on an HDInsight cluster. In
the following sample JSON definition of a pipeline, the HDInsight Activity is configured to run a Mahout
JAR file.
Sample on GitHub
You can download a sample for using the HDInsight MapReduce Activity from: Data Factory Samples on
GitHub.
Running the Word Count program
The pipeline in this example runs the Word Count Map/Reduce program on your Azure HDInsight cluster.
Linked Services
First, you create a linked service to link the Azure Storage that is used by the Azure HDInsight cluster to the
Azure data factory. If you copy/paste the following code, do not forget to replace account name and account
key with the name and key of your Azure Storage.
Azure Storage linked service
{