Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
BANGUSIN MO AKO/PUSANG
BASA
ITANONGMOKAYKUYAJOBERT PRODUCTION
DIRECTED BY: DARYLL “PTOYTOY” DARIA
AND TIMOTHY “DAMASO” ARTIFICIO
STARRING: JOENEL “PAPA J” DE ASIS,
REINOEL “YU-TEN” RAGMAC,
MEINARD “KAMAO” MORON
PROGRAMMING LANGUAGE
BSCS-2C
Prof. Mina Villafuerte
Structured Data Types
Structured Data Objects and Data Types
-A data object that is constructed as an
aggregate of other data objects, called
components, is termed a structured data object or
data structure. A component may be elementary
or it may be another data structure(e.g., a
component of an array me be a number or it may
be a record, character string, or another array).
Specification of Data Structure Types
The major attributes for specifying data
structures include the ff. :
Number of components. A data structure may
be of fixed size if the number if components is
invariant during its lifetime or of variable size.
Variable-sized data structure types usually define
operations that insert and delete components from
structures.
Arrays and records are common examples of
fixed-size data structure types; stacks, lists, sets,
tables and files are examples of variable-size types.
Type of each components. A data structure is
homogeneous if all its components are of the same
type. It is heterogeneous if its components are of
different types.
Ex. Arrays, sets and files are usually
homogeneous, whereas records and lists are usually
heterogeneous.
A data structure type need a selection
mechanism for identifying individual components of
the data structure.
Maximum number of components.
FOR A VARIABLE SIZE DATA STRUCTURES SUCH A
STACKS.
Organization of the component.The most
common organization is a simple linear sequence
component. Multidimensional array, records whose
components are records, and lists whose
components are lists. These extended forms may
treated as separate types or simply as the basic
sequential type in which the components are data
structures of similar type.
The names to be used in components
Operations on Data Structures
Specification of the domain and range of
operations on data structure types may be given in
much the same manner as for elementary types.
Some new classes of operations are of particular
importance:
Component selection operations. Processing
of data structures often proceeds by retrieving each
component of the structure. Two types of selection
operations access components of a data structure
and make them available for processing by other
operations: random selection, in which an arbitrary
component of the data structure is accessed, and
sequential selection, in which components are
selected in a predetermined order.
Whole-data structure operations. Operations
may take entire data structures as arguments and
produce new data structures as results. Most
languages provide limited set of such whole-data
structure operations (e.g., addition of two arrays,
assignment of one record to another, or a union
operation on sets).
Insertion/deletion of components.
Operations that change the number of components in a
data structure to have a major impact on storage
representations and storage management for data
structures.
Creation/destruction of data structures.
Operations that create and destroy data structures also
have a major impact on storage management for data
structures.
Implementation of Data Structure Types
Implementation considerations for data structure
types include the same issues as for elementary types.
In addition, two new issues develop that strongly affect
the choice of storage
representations : efficient selection of components
from a data structure, and efficient overall storage
management for the language implementation.
Storage Representations. The storage
representation for a data structure includes (1)
storage for the components of the structure, and
(2) an optional descriptor that stores some or all of
the attributes of the structure. The two basic
representations are the ff. :
Component
Component
Component
Component
Component
Component
Component
Component
Component
Sequential
Linked
Sequential representation, in which the data
structure is stored in a single contiguous block of
storage that includes both descriptor and components.
Linked representation, in which the data
structure is stored in several noncontiguous blocks of
storage, with the blocks linked together through
pointers.
Implementation of Operations on Data
Structures
Sequential representation. Random selection of a
component often involves a base-address-plusoffset calculation using an accessing formula. The
relative location of the entire block is the base
address. The accessing formula, given the name or
subscript of the desired component (e.g., the
integer subscripts of an array component), specifies
how to compute the offset of the component.
Linked representation. Random selection of a
component from a linked structure involves
following a chain pointers from the first block of
storage in the structure to the desired component.
Selection of a sequence of components proceeds by
selecting the first component and then following the
link pointer from the current component to the next
component for each subsequent selection.
Storage Management and Data Structures
The lifetime of any data objects begins when the binding
of the object to a particular storage location is made
(i.e., when a block [or blocks] of storage is allocated and
the storage representation for the data object is
initialized). The lifetime ends when the binding of object
to storage block is dissolved.
At the time that a data object is created (i.e., at the start
of its lifetime), an access path to the data must also be
created so that the data object can be accessed by
operations in the program.
Creation of an access path is accomplished either
through association of the data object with an identifier,
its name, in some referencing environment or through
storage of a pointer to the structure in some other
exiting, already accessible structure.
During the lifetime of a data object, additional access
paths to it may be created (i.e., by passing it as an
argument to a subprogram or creating new pointers to
it). Access paths may also be destroyed in various ways
(e.g., by assigning a new value to a pointer variable or by
return from a subprogram), with the consequent loss of
its referencing environment.
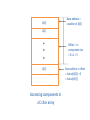
A[0]
Base address =
Location of A[0]
A[1]
Offset = i x
component size
=5x1=5
A[5]
Accessing components in
a C char array
Base address + offset
= lvalue(A[0]) + 5
= lvalue(A[5])
Two central problems in a storage management
arise because of the interplay between the lifetime of a
data object and the access paths to it that exist:
1.) Garbage. When all access paths to a data object are
destroyed but the data object continues to exist, the
data object is said to be garbage. The data object can no
longer be accessed from other parts of the program, so
it is of no further use.
2.) Dangling references. A dangling reference is an
access path that continues to exist after the lifetime of
the associated data object. An access path ordinarily
lead to the location a data object (i.e., to the beginning
of the block of storage for the object).
Declaration and Type Checking for Data
Structures
The basic concepts and concerns surrounding
declarations and type checking for data structures
are similar to those discussed for elementary data
objects. However , structures are ordinarily more
complex because there are more attributes to
specify or component selection operations must be
taken into account. These are two main problems:
1.) Existence of a selected component. The
arguments to a selection operation may be of the
right types, but the component designated may not
exist in the data structures.
2.) Type of a selected component. A selection
sequence may define a complex path through a data
structure to the desired component.
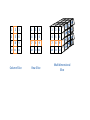
Vector and Arrays
A vector is a data structure composed of a fixed
number of components of the same type organized as a
simple linear sequence.
A component of a vector is selected by giving its
subscript, an integer (or enumeration value) indicating
the position of the components in the sequence. A
vector is also termed a one-dimensional array or linear
array. A two-dimensional array, or matrix , has its
components organized into a rectangular grid of rows
and columns. Both a row subscript and a column
subscript are needed to select a component of a matrix.
Multidimensional arrays of three or more dimensions
are defined in a similar manner.
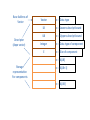
Base Address of
Vector
Descriptor
(dope vector)
Vector
Data type
LB
Lower subscript bound
UB
Upper subscript bound
Integer
E
Data type of component
Size of component
A[LB]
Storage
representation
For components
A[LB+1]
A[UB]
1
2
3
1
2
3
1
2
3
4
5
6
4
5
6
4
5
6
7
8
9
7
8
9
7
8
9
10
11 12
10
11 12
10
11 12
Column Slice
Row Slice
Multidimensional
Slice
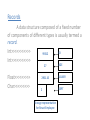
Records
A data structure composed of a fixed number
of components of different types is usually termed a
record.
Int>>>>>>>>>>>
ID
99312
Int>>>>>>>>>>>
27
Float>>>>>>>>>
Char>>>>>>>>>
AGE
2901.10
SALARY
Z
DEPT
Storage representation
for Struct Employee
Implementation of vectors.
The homogeneity of components and fixed size of vector
make storage and accessing of individual components
straightforward.
Packed and unpacked storage representation. A packed
storage representation is one in which components of a
vector are packed into storage sequentially without regard
for placing a component at the beginning of an addressable
word or byte of storage.
Storage Implementation of records.
lvalue (R.I) = alpha + Ki when alpha is the base address
and the Ki is the ith component.
struct EmployeeType{
int ID
}
LISTS
A data structure composed of an ordered
sequence of data structure is usually termed as list.
(a b c)
list
atom
a
list
atom
Bb
list
atom
c
Representation of storage for
lists
SETS
A set is a data object containing an
unordered collection of distinct values. In contrast,
a list is an ordered collection of values, some of
which may be repeated.
In Programming Languages, the term set is
sometimes applied to a data structure representing
an ordered set. An ordered set is actually a list with
duplicate values removed; it requires no special
consideration. The unordered set, however, admits
two specialized storage representations that merit
attention.
Bit-string representation of sets. The bit string
storage representation is appropriate where the size
of the underlying universe of values (the values that
may appear in set data objects) is known to be
small.
Hash-coded representation of sets. A common
alternative representation for a set is based on the
technique of hash coding or scatter storage. This
method may be used when the underlying universe
of possible values is large (e.g., when the set
contains numbers or character strings).
Executable Data Objects
in most languages, especially compiled languages
like C and Ada, executable source programs and the data
objects they manipulate are separate structures.
However, this is not necessarily always true. In
languages like LISP and Prolog, executable statements
may be data that are accessible by the program, and
that may be manipulated by it. For example, LISP stores
all of its data in lists. The scheme expression
(define myfunction(cons(a b c) (d e f)))
Simply defines the function name myfunction to be the
cons operation defined earlier. This is stored as a linked
list much like any other list structures.
Group : WANDEYSERBIS..
Members
Daria, Daryll Louis
Artificio, Timothy
Ragmac, Reinoel
De Asis, Joenel
Moron, John Meinard







































![java.util.Vector.copyInto(Object[] anArray) Method](http://s1.studyres.com/store/data/006018135_1-cbf286e09e917cba174628ed9a7acd15-150x150.png)

