Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Mining Approximate Frequent
Itemsets in the Presence of Noise
By- J. Liu, S. Paulsen, X. Sun, W. Wang, A. Nobel and J. Prins
Presentation by- Apurv Awasthi
Title Statement
This paper introduces an approach to
implement noise tolerant frequent itemset
mining of the binary matrix representation
of the database
Index
Introduction to Frequent Itemset Mining
• Frequent Itemset Mining
• Binary Matrix Representation Model
• Problems
Motivation
Proposed Model
Proposed Algorithm
AFI Mining vs. Exact Frequent Itemset Mining
Related Works
Experimental Results
Discussion
Conclusion
Introduction to Frequent Itemset Mining
Frequent pattern: a pattern (a set of items,
subsequences, substructures, etc.) that occurs
frequently in a data set
Originally developed to discover association rules
Applications
• Bio-molecular applications:
oDNA sequence analysis, protein structure
analysis
• Business applications:
oMarket basket analysis, sale campaign analysis
The Binary Matrix Representation Model
Model for representing relational databases
Rows correspond to objects
Columns correspond to attributes of the objects
• ‘1’ indicates presence
• ‘0’ indicates absence
• Frequent Itemset mining is a key
technique for analyzing such data
Apply Apriori algorithm
Item -->
I1
I2
I3
I4
I5
T1
1
0
1
1
0
T2
0
1
1
0
1
T3
1
1
1
0
1
T4
0
1
0
0
1
T5
1
0
0
0
0
Transaction
Problem with Frequent Itemset Mining
•
•
The traditional model for mining
frequent itemsets requires that every
item must occur in each supporting
transaction
NOT a practical assumption!
• Real data is typically subject to noise
• Reasons for noise
o
o
o
o
Human error
Measurement error
Vagaries of human behavior
Stochastic nature of studied biological behavior
Effect of Noise
Fragmentation of Patterns by Noise
• Discover multiple small fragments of the true itemset
• Miss the true itemset itself!
Example
• Exact frequent itemset
mining algorithm will miss
the main itemset ‘A’
• Observe three fragmented
itemsets – Itemset 1,2 and
3
• Fragmented itemsets may
not satisfy the minimum
support criteria and will
therefore be discarded
Mathematical Proof of Fragmentation
From: Significance and Recovery of block structures in binary matrices with noise by X. Sun & A.B. Nobel
With probability 1,
M(Y) <= 2logan− 2loga(logan)
when n is sufficiently large
i.e. in the presence of noise, only a fraction
of the initial block of 1s can be recovered
Where –
Matrix X: contains actual values recorded in the absence of any noise
Matrix Z: binary noise matrix whose entries are independent Bernoulli’s random
variable such that Z ~ Bern(p) for 0<=p<=0.5
M(Y): is the largest k such that Y contains k transactions having k common items
Y = X xor Z, a = (1 − p)−1
Motivation
The failure of classical frequent itemset mining to
detect simple patterns in the presence of random
errors (i.e. noise) compromises the ability of these
algorithms to detect association, cluster items or
build classifiers when such errors are present
Possible Solutions
Let the matrix contain a small fraction of 0s
DRAWBACK:
“Free riders” like column h
(for matrix C) and row 6
(for matrix B)
SOLUTION: Limit the number of 0s in each row and column
Proposed Model
1.
Use Approximate Frequent Itemset (AFI)
AFI characteristics
• Sub-matrix contains large fraction of 1s
• Supporting transaction should contain most of the items
i.e. number of 0s in every row must fall below user defined
threshold (єr)
• Supporting item should occur in most of the transaction
i.e. number of 0s in every column must fall below user defined
threshold (єc)
• Number of rows > minimum support
AFI
Mathematical definition
• For a given binary matrix D having I0 items and T0 transactions,
an itemset I c I0 is an approximate frequent itemset AFI(єr,єc) if
there exists a set of transactions T c T0 with |T| ≥ |T0|.minsup
such that
• Similarly, define weak AFI(є)
AFI example
A, B and C are weak AFI (0.25)
A: valid AFI(0.25,0.25)
B: weak AFI(*,0.25)
C: weak AFI(0.25,*)
Drawback of AFI
AFI criteria violates the Apriori property!
Apriori Property: all sub-itemsets of
a frequent itemset must be
frequent
But, sub-itemset of an AFI need not
be AFI e.g. A is a valid AFI for
minSupport = 4, but {b,c,e}, {b,c,d}
etc are not valid AFIs
• PROBLEM – now minimum support can not be used as a
pruning technique
• SOLUTION – a generalization of Apriori properties for
noisy conditions (called Noise Tolerant Support Pruning)
Proposed Model
1.
2.
3.
Use Approximate Frequent Itemset (AFI)
Noise Tolerant Support Pruning – to prune and
generate candidate itemsets
0/1 Extension - to count the support of a noise tolerant itemset based on the support set of its
sub-itemsets
Noise Tolerant Support Pruning
For a given єr, єc and minsup the noise tolerant
pruning support for a length-k itemset is-
Proof
0/1 Extensions
Starting from singleton itemsets, generate (k+1) itemsets
from k itemsets in sequential manner
The number of 0s allowed in the itemset grows with the
length of the itemset in a discrete manner
1 Extension
If
then the transaction set of
a (k+1) itemset I is the intersection of the transaction
sets of its length k subsets
0 Extension
If
then the transaction set of
a (k+1) itemset I is the union of the transaction sets of its
length k subsets
Proof
Proposed Algorithm
AFI vs. Exact Frequent Itemset
єr, єc = 1/3; n=8; minsup =1
AFI Mining
AFI vs. Exact Frequent Itemset
Exact Frequent
Itemset Mining
Transaction Item
T1
a,b,c
T2
a,b
T3
a,c
T4
b,c
T5
a,b,c,d
T6
d
T7
b,d
T8
a
1-candidates
Itemset Support
a
5
b
5
c
4
d
3
Freq 1-itemsets
2-candidates
Itemset Support
Freq 2-itemsets
Itemset Support
a
5
ab
3
b
5
ac
3
c
4
bc
3
MinSup = 0.5 i.e. 4 transactions
n=8
Itemset
Null
AFI vs. Exact Frequent Itemset Result
Approximate Frequent Itemset
Exact Frequent Itemset
Generates the frequent
itemset {a,b,c}
Can not generate any
frequent itemset in the
presence of noise for the
given minimum support
value
Related Works
Yang et al. (2001) proposed two error-tolerant models, termed weak
error-tolerant itemsets or weak ETI [which is equivalent to weak AFI]
and strong ETI which is [equivalent to AFI(єr,*)]
DRAWBACK
No efficient pruning technique – rely on heuristics and sampling
techniques
Do not preclude columns of 0
Steinbach et al. (2004) proposed a “support envelope” which is a tool
for exploration and visualization of the high-level structures of
association patterns. A symmetric ETI model is proposed such that the
same fraction of errors are allowed in both rows and columns.
DRAWBACK
Implements same error co-efficient for rows and columns i.e. єr= єc
Admits only a fixed number of 0s in the itemset. Fraction of noise does
not vary with size of itemset sub-matrix
Related Works
Seppänen and Mannila (2004) proposed to mine the dense itemsets in
the presence of noise where the dense itemsets are the itemsets with a
sufficiently large sub-matrix that exceeds a given density threshold of
attributes present.
DRAWBACK
Enforces the constraint that all sub-itemsets of a dense itemset must be
frequent – will fail to identify larger itemsets that have sufficient
support because all sub-itemsets might not have enough support
Requires repeated scans of the database
Experimental Results - Scalability
Scalability
• Database of 10,000
transactions and 100
items
• Run time increases as
noise tolerance
increases
• Reducing item wise
error constraint leads
to greater reduction in
run time as compared
to transaction wise
error constraint
Experimental Results – Synthetic Data
Quality Testing for
single cluster
• Create data with an
embedded pattern
• Add noise by flipping
each entry with
probability p where
0.01 ≤ p ≤ 0.2
Experimental Results – Synthetic Data
Quality Testing for
multiple clusters
• Create data with
multiple embedded
pattern
• Add noise by flipping
each entry with
probability p where
0.01 ≤ p ≤ 0.2
Experimental Results – Real World Data
Zoo Data Set
• Database contained 101 instances and 18 attribute
• All the instances are classified into 7 classes e.g. Mammals, fish etc
Exact
Generated subsets of
animal in each class
Then found subsets of their
common features
ETI (єr)
Identified "fins" and
"domestic" as common
features
NOT necessarily true
AFI (єr,єc)
Only AFI was able to
recover 3 classes with 100%
accuracy
Discussion
Advantages
• Flexibility of placing constraints independently along rows
and columns
• Generalized Apriori technique for pruning
• Avoids repeated scans of database by using 0/1 extension
Summary
The paper outlines an algorithm for mining
approximate frequent itemsets from noisy data
It introduces
• an AFI model
• Generalized Apriori property for pruning
The proposed algorithm generates more useful
itemsets compared to existing algorithms and is also
computationally more efficient
Thank You!
Extra Slides for
Questionnaire
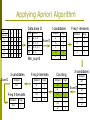
Applying Apriori Algorithm
Data base D
Item -->
Transaction
T1
T2
T3
T4
T5
a
b
c
d
e
1
0
0
1
1
1
1
0
0
1
1
0
0
1
1
0
1
0
0
0
0
0
1
1
0
TID
T1
T2
T3
T4
Items
a, c, d
b, c, e
a, b, c, e
b, e
1-candidates
Scan D
Min_sup=2
3-candidates
Scan D
Itemset
bce
Freq 3-itemsets
Itemset
bce
Sup
2
Freq 2-itemsets
Itemset
ac
bc
be
ce
Sup
2
2
3
2
Itemset
a
b
c
d
e
Sup
2
3
3
1
3
Counting
Itemset
ab
ac
ae
bc
be
ce
Sup
1
2
1
2
3
2
Freq 1-itemsets
Itemset
a
b
c
e
Sup
2
3
3
3
2-candidates
Itemset
ab
ac
Scan D
ae
bc
be
ce
Noise Tolerant Support Pruning - Proof
0/1 Extensions Proof
Number of zeroes allowed in an itemset grows with the length of
the itemset