Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Lecture notes 5: sampling distributions and the central limit theorem Highlights: • The law of large numbers • The central limit theorem • Sampling distributions • Formalizing the central limit theorem • Calculating probabilities associated with sample means Two important results in inferential statistics • Two results that are important in establishing the basis for inferential statistics are the law of large numbers (LLN) and the central limit theorem (CLT). • Both of these results have to do with sample size, and the kinds of behaviors we can expect from statistics which are calculated using “large” samples rather than “small” samples. • We will first consider the LLN, and then the CLT. The law of large numbers • The law of large numbers tells us what tends to happen to a sample mean as the sample size gets bigger. • It says that, as our sample size increases, the average of our sample will tend to get closer and closer to the true average of the population from which we are sampling. • Here is a simple example: if you flip a coin twice, you may well get two heads. In this case, you will have flipped heads, on average, 100% of the time. • You may also get two tails. In this case, you will have flipped heads, on average, 0% of the time. • You may also get one tail and one head, which would give you the “correct” average of 50%, but there is a very good chance that your average will be very far off from the true average. • If you flip a coin 10 times, chances are still pretty good that the average number of heads will be far away from 5. • Now let’s say you flip a coin 1,000,000 times. Again, you are unlikely to flip heads exactly 50% of the time. However, rate at which you flip heads will almost certainly be very close to 50%. • Here is a visual example of how the proportion of coin flips that are heads approaches 50% as the number of flips increases: • Likewise with rolling dice. Here is an image showing the behavior of the average of the rolls of multiple dice as the # of dice (or “trials”, as the horizontal axis is labeled) increases: Note that the “population” average is (1 2 3 4 5 6) 3.5 6 • The law of large numbers would also apply to estimating human height using a sample. • The average height of adult American women is 64 inches (or 5ft, 4”). • If you take a sample of two adult American women, you might happen to pick to who are taller than average, or two who are shorter than average. • If you sample 200 adult American women, these differences will mostly cancel out, and the average from your sample should be very close to 64”. (The average for women in our class is 64.51”.) • The law of large numbers also tells us why casinos don’t have to worry about going out of business due to a bunch of lucky gamblers. • Casino games are always designed so that the casino has an advantage, in the sense that over the long run they will tend to make money and gamblers will tend to lose money. • So, even though an individual gambler may do very well at a casino, if you combine the winnings and losing thousands upon thousands of gamblers, the house will on average make money. • To use the dice example: I wouldn’t bet $1,000 that, on a single roll of a die, the number that comes up will be less than five, even though there is a 4/6 chance of this happening and I would have the advantage. • However I would bet $1,000 that on 10 rolls of a die, the average of all the rolls would be less than five. This is because I know that, by the law of large numbers, the average of the rolls will be close to 3.5. • Just how unlikely is it that the average of 10 rolls will be 5 or greater? We will find the answer to this using the central limit theorem. The Central Limit Theorem • The Central Limit Theorem tells us that any distribution (no matter how skewed or strange) will produce a normal distribution of sample means if you take large enough samples from it. • Furthermore, the larger the sample sizes, the less spread out this distribution of means becomes. • This is of great importance in statistics. It allows us to use the properties of a normal distribution when analyzing data, even when the data we are analyzing is not normal. • This is nice, because we rarely work with normally distributed data, and we are often interested in means. • Here is how it works: take any distribution you like; for instance, this heavily positively skewed distribution: • Now take a random sample from this distribution. I used software to take a sample of size n=2. > sample1=sample(x,2) [1] 11 9 > mean(sample1) [1] 10 • So, we took a random sample, and got the numbers 11 and 9. Their mean is 10. • We can keep doing this over and over again, and recording the mean of each sample. • Here are the results I got from doing this 20 more times. Remember, for each sample, I draw two random numbers from our skewed distribution, and then I find their average. So these are all sample means, from samples of size n=2: 22.0 4.0 17.5 14.0 16.5 6.5 14.0 19.5 33.0 10.0 16.0 9.5 32.0 9.5 19.5 6.5 6.5 8.5 12.0 7.5 • Here is a histogram of the 20 sample means from the previous slide, along with that of the original data: • Notice that this new histogram looks much closer to a normal distribution than the original. All we did was take repeated samples of size n=2, and then graphed their averages. • Let’s see what happens when we increase the sample size. Sample size: n=10 Sample size: n=30 Despite being skewed, it didn’t take very large samples for this dataset to quickly “turn normal”. Also notice that, as the sample size increases, the distribution of means becomes less spread out. • How large the sample size must be before we can be confident that the distribution of sample means will be normal depends upon how far from (or close to) normal the underlying distribution is. • Extremely skewed distributions require larger sample sizes. Distributions that are already normal will always have normally distributed sample means. • As a very loose, general rule of thumb, n=30 is a “safe” sample size under which we can assume the distribution of sample means is normal. If the underlying distribution is already close to normal, the sample size can be much smaller. If the underlying distribution is extremely skewed, the sample size needs to be much larger. Sampling distributions • All of the histograms we just looked at are examples of sampling distributions. • A sampling distribution is the distribution of a statistic “under repeated sampling”. In other words, it tell us the values that a statistic takes on, and how often it takes them on. • Note again how these sampling distributions were created: in these examples, we kept taking new samples from the same population over and over again, and each time we recorded the sample mean. • Each histogram we created displayed a sampling distribution of means. Sampling distributions • The central limit theorem tells us about the behavior of the sampling distribution of a mean. • All statistics have associated sampling distributions. • Any time we calculate a statistic from a random sample, we can treat it as having come from a sampling distribution of possible values for that statistic that we could have had our sample been different. • This concept is the basis for all of the inferential procedures we will look at. Sir Francis Galton on the Central Limit Theorem: “I know of scarcely anything so apt to impress the imagination as the wonderful form of cosmic order expressed by the law of frequency of error. The law would have been personified by the Greeks if they had known of it. It reigns with serenity and complete selfeffacement amidst the wildest confusion. The larger the mob, the greater the apparent anarchy, the more perfect its sway. It is the supreme law of unreason. Whenever a large sample of chaotic elements are taken in hand and marshaled in the order of their magnitude, an unsuspected and most beautiful form of regularity proves to have been latent all along.” Formalizing the Central Limit Theorem The Central Limit Theorem can be stated formally: For any distribution with mean μ and standard deviation σ, the distribution of sample means converges to a normal distribution with mean μ and standard deviation , as n goes to infinity. Here, “as n goes to infinity” can just be thought of as “as n gets larger and larger”. And the distribution of the sample means can be written as: Formalizing the Central Limit Theorem • This reads as “X-bar is distributed normally with mean mu and variance sigma squared over n.” • Note that if the variance is deviation will be . • We can also use this notation to describe the standard normal distribution: • i.e. “z is distributed normally with mean 0 and variance 1” , the standard Formalizing the Central Limit Theorem Since we know that the sampling distribution of a sample mean will converge to a normal with mean μ and standard deviation , we can convert any sample mean to a z-score and find probabilities associated with it, using a slightly modified z formula: Note that, in order to use this formula, μ and σ must be either known or assumed. Calculating probabilities associated with sample means • Here is the example we introduced earlier: the 6 numbers on a die have a mean of 3.5 and a standard deviation of 1.87. What is the probability that the average of 10 rolls will be less than 5? • Formally, this can be written as: • To convert x to z, we use this new z formula: Which gives us: Calculating probabilities associated with sample means Another example: we know that the heights of adult women in the U.S. are normally distributed with a mean of 64 inches and a standard deviation of 3 inches. What is the probability that a sample of 20 women will yield a mean height between 63 and 65 inches? Formally, we can write this as: Using our z formula gives us: Calculating probabilities associated with sample means To get a feel for how the distribution of the sample mean differs from the distribution of the original variable itself, let’s find the probability that one randomly selected women’s height will be between 63 and 65 inches: P (63 x 65) Calculating probabilities associated with sample means Note that this probability is much smaller than the one we calculated for a sample mean. Visually, we can draw how the distribution of height itself differs from the distribution of mean height when the sample size is n=20: Putting the LLN and CLT together • The central limit theorem can also be understood in terms of the law of large numbers. • The law of large numbers tells us that, as our sample size increases, the mean of our sample is more and more likely to be close to the true mean. • If we take lots of samples from a population (i.e. if we obtain a sampling distribution), then each sample mean is more likely to be close to the true mean if the sample size is large rather than if it is small. Putting the LLN and CLT together • So, if we have a sampling distribution of means taken from a population, then the larger each sample was, the less spread out around the true population mean this distribution will be. • This agrees with what we know from the central limit theorem: that, as our sample size gets larger, sampling distribution of the mean becomes both more “normal” and less spread out, since the standard deviation of these means gets smaller. Remember the sampling distribution! • In the next set of notes, we will begin discussing formal statistical inferential procedures. • In these procedures, we will be computing special kinds of statistics from sample data, called “test statistics”. • These test statistics will be treated as having come from a known sampling distribution, which will double as a probability distribution. • This will allow us to compute probabilities associated these statistics, which in turn will help us answer scientific questions – which is the reason we collect data in the first place!




















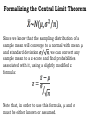









![z[i]=mean(sample(c(0:9),10,replace=T))](http://s1.studyres.com/store/data/008530004_1-3344053a8298b21c308045f6d361efc1-150x150.png)








